
A Proposed Framework for Secure Data Storage in a Big Data Environment Based on Blockchain and Mobile Agent

 ,
,  ,
,
Abstract
:1. Introduction
- Designing an architecture that provides secure data storage and sharing using the Blockchain and Mobile Agent for Big Data applications. Proposed architecture related to Blockchain is based on two layers with two private Blockchains; to protect data, a data storage system by leveraging IPFS technology was adopted;
- Proposing a trustability check mechanism for the new joint requests to the Big Data system to ensure the basic level of security of the new device;
- Employing a two-level manager that deals with data fragmentation and storage to ensure data protection and preventing any illegal data retrieval;
- Developing the proposed solution to effectively and securely operate on local storage instead of cloud ones to gain a high level of data privacy;
- Designing a lightweight and generic solution that can be applied to various Big Data environments;
- Realizing a performance evaluation of the proposed framework based on metrics such as throughput and latency for read and write operations but also by making a security analysis and assessment of the developed prototype by comparison with other similar approaches existing in the literature.
2. Background and Related Work
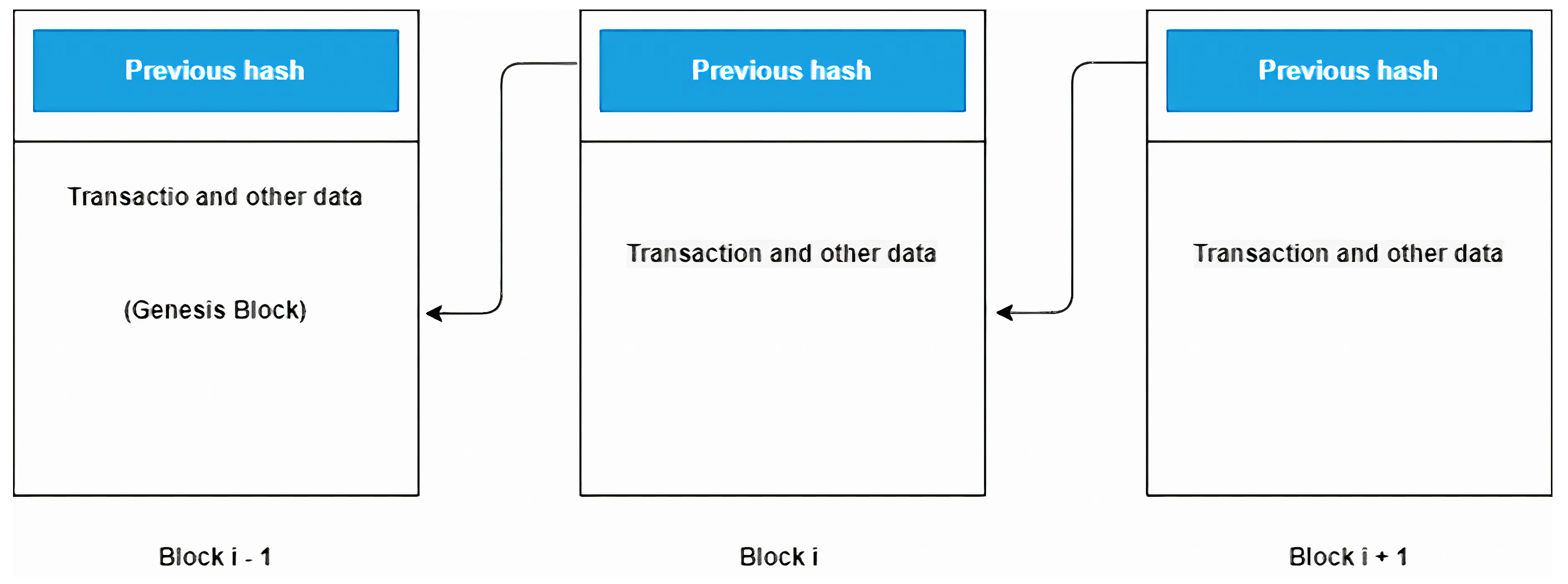
2.1. Blockchain
2.2. Ethereum
2.3. Smart Contract
2.4. Mobile Agent
- They enable the cost-effective and efficient use of communication networks with high latency and low bandwidth.
- They make it possible to utilize portable, low-cost personal communications devices to accomplish sophisticated activities even when they are disconnected from the network.
- They allow true decentralization and asynchronous operations.
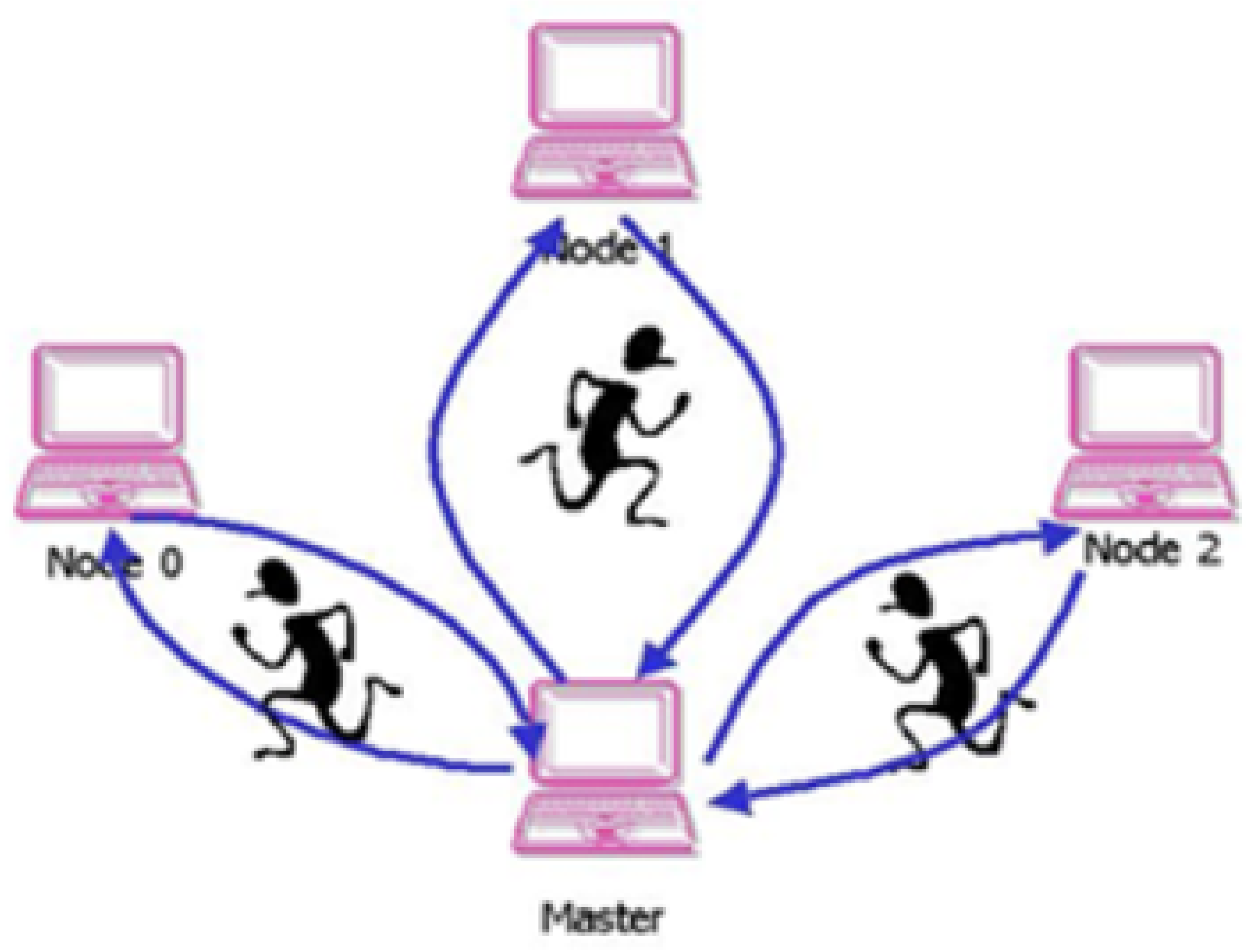
2.5. Security and Privacy Requirement in Big Data Frameworks
2.5.1. The Trustability of New Nodes Connected to the Big Data Environment
2.5.2. Access Control Enforcement
2.5.3. Integrity and Security of Data during Transfer and Storage
2.5.4. Policy Protection
2.5.5. Data Privacy
- We propose a mechanism that checks the basic level of security for any new device that needs to connect to the system. Hence, we ensure the trustability of the device;
- We propose a two-level manager that deals with data fragmentation and storage. Therefore, data passes through two levels of fragmentation which makes data retrieval complicated for intruders and malicious requests, as detailed in Section 3.1.2. Furthermore, the two-level manager prevents and direct connection between users and data as discussed in Section 3.1.2;
- We implement a private Blockchain with a smart contract in each level of the manager to store the meta-data and policies related to each level. Consequently, data tampering and malicious access are prevented;
- We develop our system to be deployed in local storage to ensure a high level of data privacy, unlike most existing studies that rely on cloud storage.
3. Materials and Methods
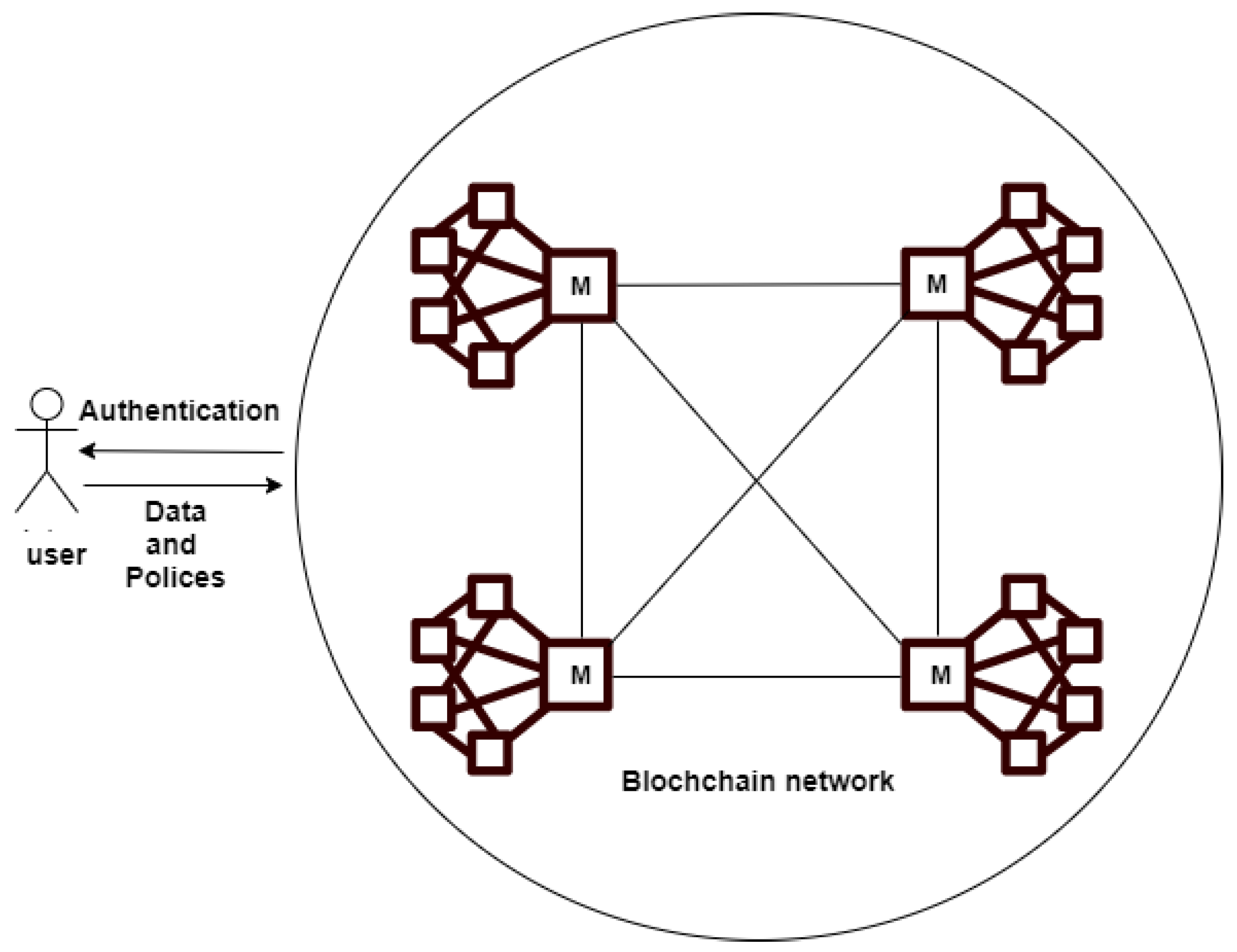
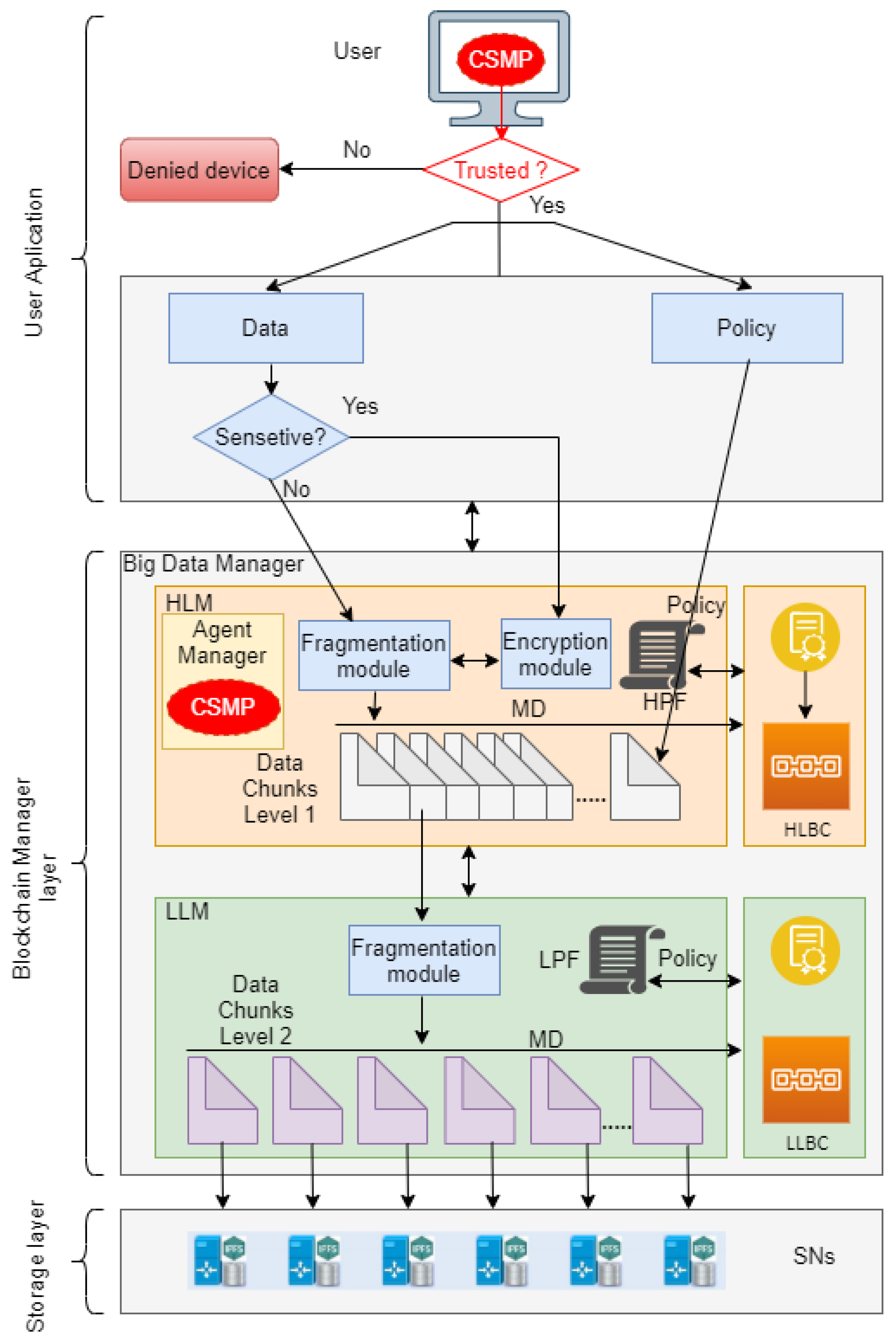
3.1. System Design and Architecture
3.1.1. User Application Layer
3.1.2. Blockchain Manager Layer
- 1.
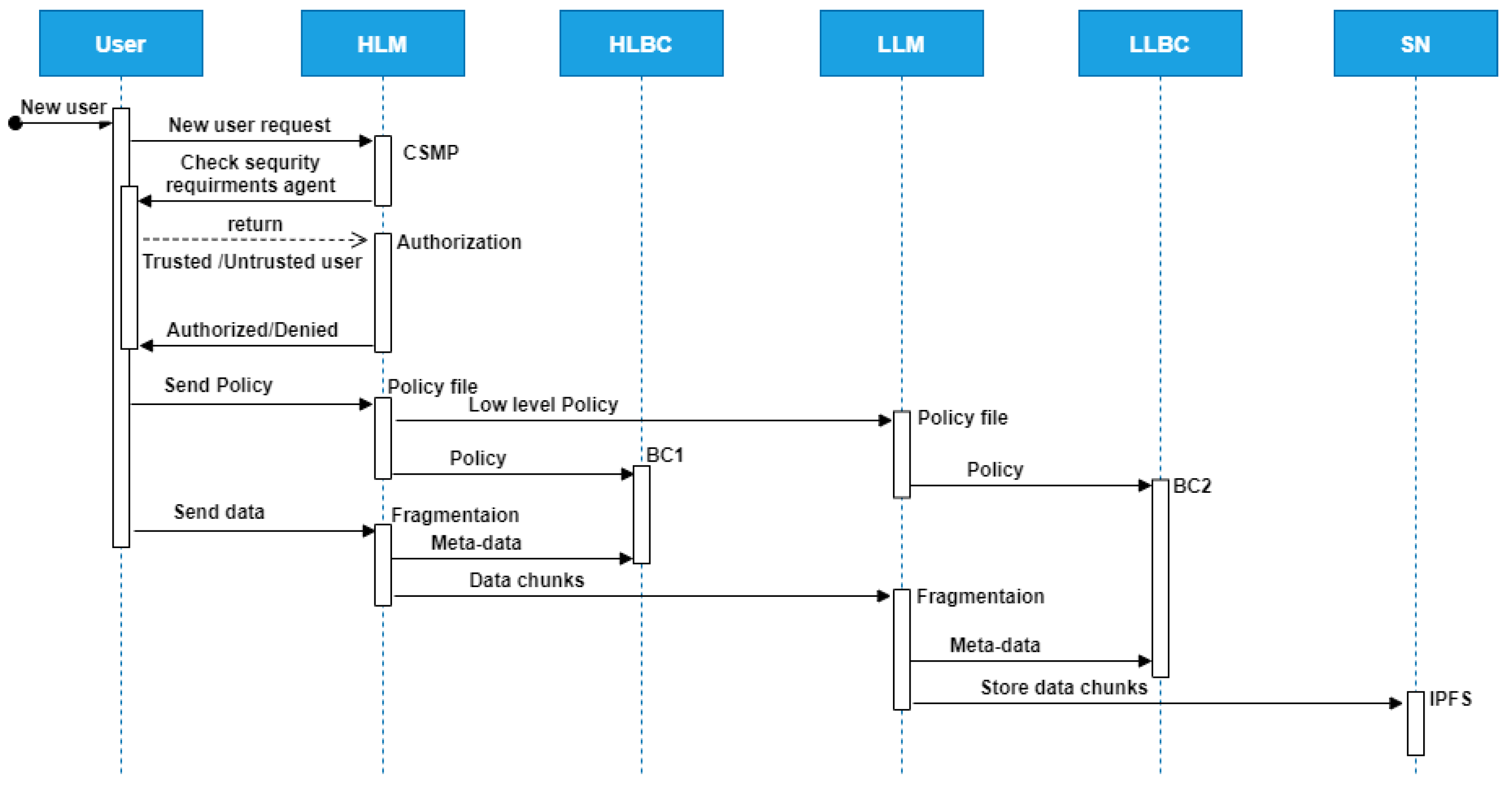
- High-level manager (HLM): The high-level manager deals with users requests. Therefore, this layer receives any new joint request and verifies the trustability of the requesting device using a mobile agent. Moreover, the HLM keeps meta-data of all clusters to easily and securely manages the clusters connections. Therefore, any untrusted or malicious cluster will not be able to join the Big Data system or communicate with other clusters. In addition, the high-level manager fragments received data into multiple chunks to be assigned to multiple clusters. Besides, HLM encrypts received sensitive data before the fragmentation. A high-level manager consists of six components that work cooperatively as demonstrated below:
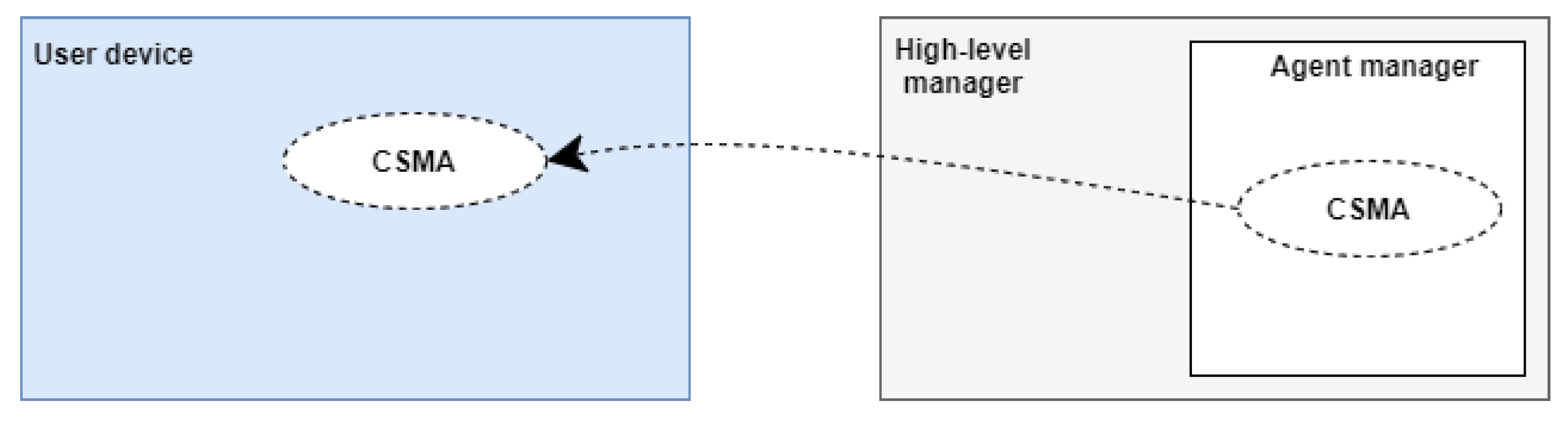
- Mobile agent named check security requirements agent. This agent is generated by the agent manager in high-level manager to migrate to any new node that wants to connect to the big data system as shown in Figure 6. This mobile agent checks to see if new nodes are trusted by detecting whether they meet security policy requirements, such as updated antivirus software. In general, this agent will determine if the node can connect to a Big Data system or not.
- A high fragmentation module, which divides the data into chunks to distribute them on clusters.
- A high-level policy file, which contains information about clusters in the system and a set of rules established by the data owner that determines who can access their data.
- A high-level Blockchain, which stores the high-level meta-data and high-level policy and all transactions performed in the high-level manager.
- Smart contract named HighMasterNode. This smart contract performs many functions, the most important of which are:
- −
- Creating a high-level policy file and storing it in high-level Blockchain.
- −
- Storing meta-data that were created after data fragmentation by the high-level manager in the high-level Blockchain.
- Encryption module: this module encrypts any received sensitive data using Advanced Encryption Standard.
- 2.
- Low-level manager (LLM): The low-level manager keeps the meta-data of storage nodes of the corresponding cluster. Thus, communication between storage nodes is handled through the LLM. As a result, untrusted or malicious nodes are not able to join the cluster. Additionally, the LLM fragments received data from the HLM into multiple smaller chunks and stores them in multiple storage nodes. The low-level manager is made up of four components as described below:
- A low fragmentation module, which divides the chunk into smaller chunks and distributes them among storage nodes in the cluster.
- A low-level policy file, which contains information about the nodes in the clusters and includes rules that specify whether data can be transferred from one node to another.
- A low-level Blockchain, which stores the low-level meta-data and low policy file and all transactions performed in the low-level manager.
- Smart contract named LowMasterNode. This smart contract performs many functions, the most important of which are:
- −
- Creating low-level policy file and storing it in low-level Blockchain.
- −
- Storing meta data that was created after data fragmentation by the low-level manager in low-level Blockchain.
3.1.3. Storage Layer
3.2. Workflow of the Proposed Solution
- Step 1: Initialization (executed by the user device):The user can create an account on the metamask after it has been ensured that their device meets the security requirements. These requirements can include having an active antivirus program, having the latest operating system update, and so on. These requirements can be checked through the check security requirements agent. The user’s account address is fetched in the application through web3.js from the metamask. The user can upload data files and policies to the high-level manager. Sensitive data are encrypted using symmetric-key encryption and transfer, while the transfer of normal data is done without encryption.
- Step 2: Uploading data to the Blockchain manager (executed by the high-level manager):The high-level manager receives the data and divides it using the high fragmentation module into equal n chunks. Then, every chunk is sent to a specific cluster after meta-data of this chunk are created. The meta-data and policy are stored in the high-level Blockchain manager through a smart contract. The high-level manager receives the policies and stores them in the high policy file.
- Step 3: Uploading data to storage nodes (executed by the low-level manager):The low-level manager receives the chunk of data sent to this cluster and divides it using the low fragmentation module into equal n chunks. Every chunk is stored in the IPFS in a corresponding storage node in this cluster after its meta-data have been created. The meta-data are stored in the low-level Blockchain manager through a smart contract.
| Algorithm 1 General workflow |
|
| Algorithm 2 Data fragmentation |
|
4. Results and Discussion
4.1. Implementation Details
- GanacheGanache is a type of software that provides virtual accounts to execute smart contracts based on the Blockchain. It is a Blockchain-based simulator used to deploy smart contracts and execute several tests and commands. Ganache stores a unique address for each account and performs mining [36].
- MetamaskMetamask is one of the most secure ways to connect to Blockchain-based applications. The user uses the Metamask interface to connect to the Ethereum Wallet [37].
- Node.jsNode.js is a back-end JavaScript run-time environment and cross-platform that executes JavaScript code [38].
- Truffle FrameworkThe Truffle framework is an Ethereum-like Blockchain simulation platform used for building, testing, and deploying applications. It is used to compile and deploy smart contracts in this system [39].
- IPFSThe IPFS is the Interplanetary File System, a protocol used to store and share Big Data in peer-to-peer networks in a distributed file system. We used the IPFS to store data files to allow flexible and reliable decentralized data storage in a corresponding storage node.
4.2. Performance Evaluation
4.2.1. Performance Evaluation Settings
- Testing environmentWe conducted experiments using the following configurations to test the performance of the proposed framework:We used four virtual machines (VMs) running on Google Cloud to provide the infrastructure for the private Blockchain. Each VM had a 2 GHz and 4-core Intel i7 CPU. Additionally, we used Hyperledger Besu v2.21.2, an open-source Ethereum client that provides a permissioned private Blockchain to build the private Blockchain [40]. In terms of a Peer-to-Peer network, we used one validator node, three peer nodes, and the Clique Consensus Protocol. We use Hyperledger Caliper v0.3.1 which is a benchmark tool used to evaluate the performance of the Blockchain system [41]. The Caliper tool provides a performance report containing several performance indicators, such as resource utilization, transaction latency, transaction throughput, read throughput, read latency, etc. The programming language is JavaScript and solidity.
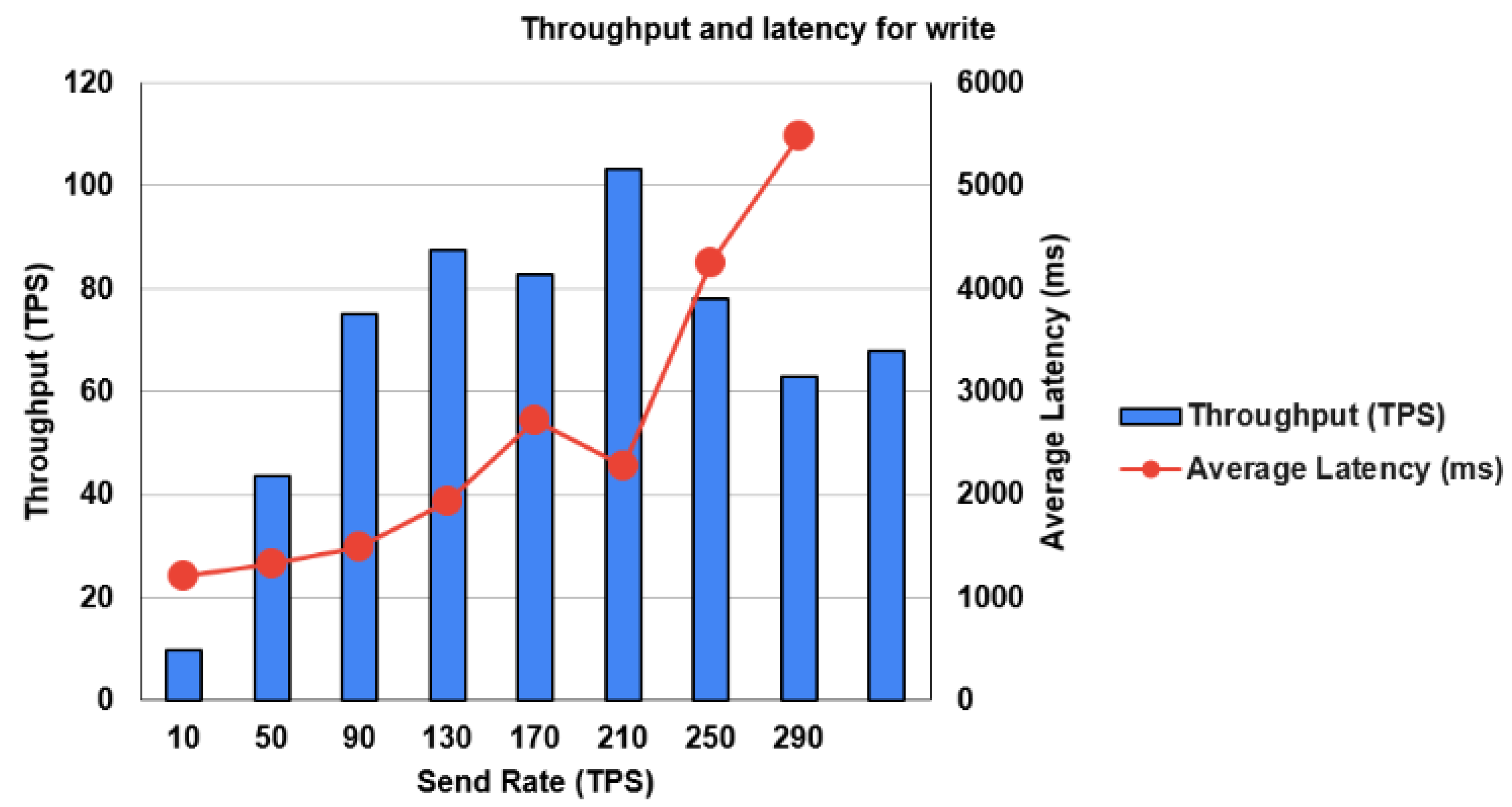
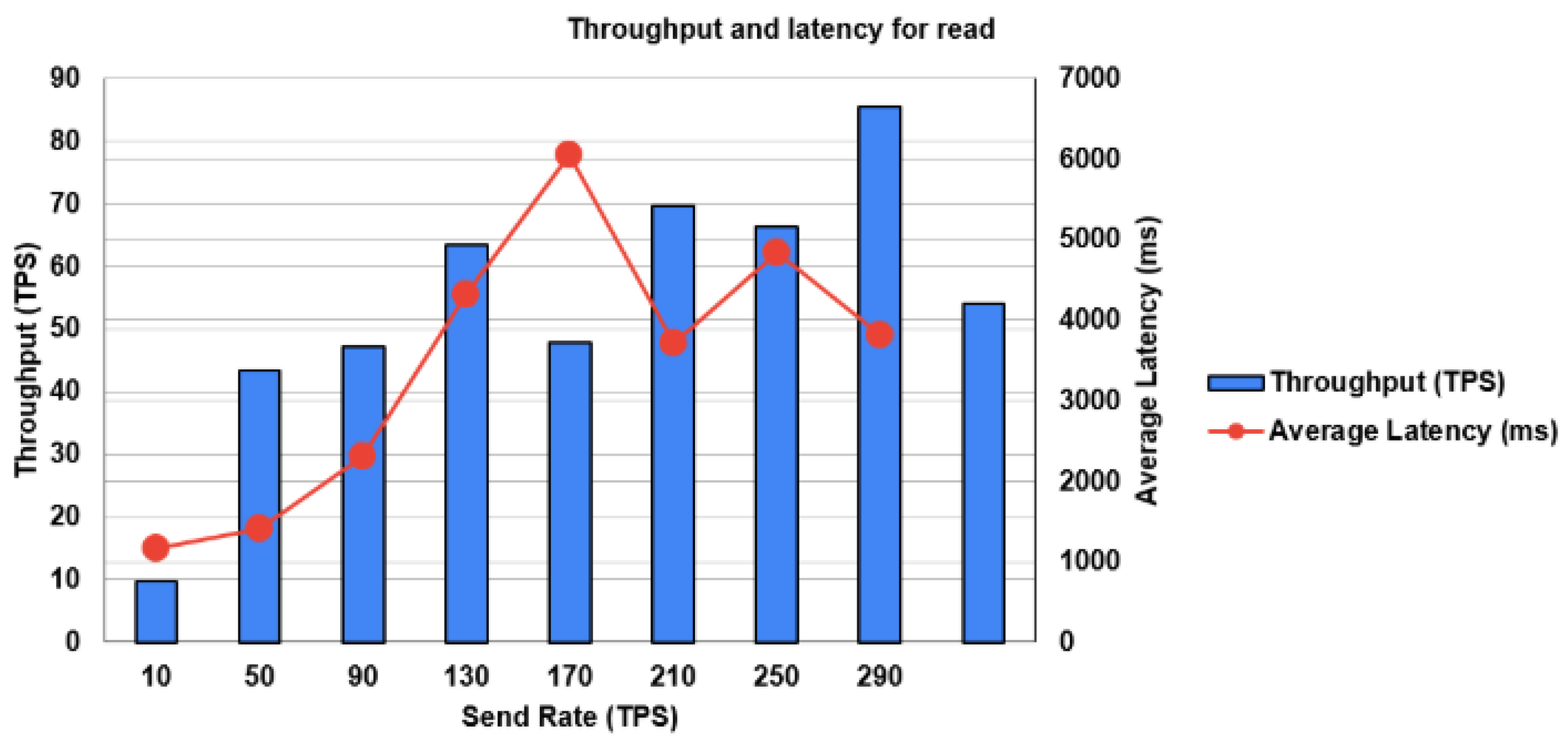
- Experimental settingsFor the write operation, we used the following settings:The number of test rounds was 8 rounds with 500 transactions per round. The type of control rate was fixed-rate. Finally, the used send rates were 10 tps, 50 tps, 90 tps, 130 tps, 170 tps, 210 tps, 250 tps, and 290 tps. The same setting was used for read operations.
4.2.2. Performance Evaluation Metrics
4.3. Performance Assessment
4.4. Security Analysis of the Proposed Framework
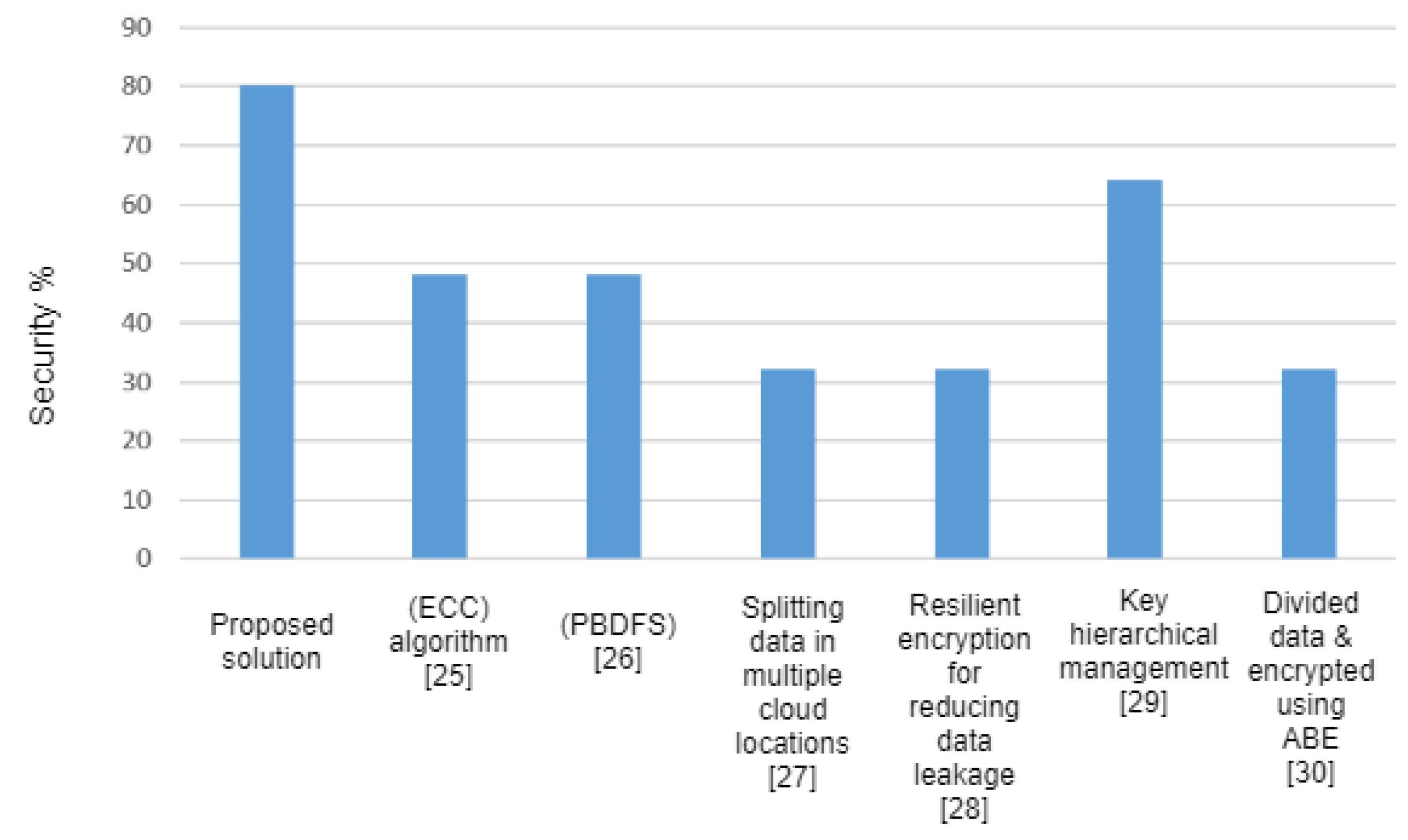
4.5. Comparison of the Proposed Framework with Related Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baig, M.I.; Shuib, L.; Yadegaridehkordi, E. Big data adoption: State of the art and research challenges. Inf. Process. Manag. 2019, 56, 102095. [Google Scholar] [CrossRef]
- Samsudeen, S.N.; Haleem, A. Impacts and challenges of big data: A review. Int. J. Psychosoc. Rehabil. 2020, 7, 479–487. [Google Scholar]
- Bao, R.; Chen, Z.; Obaidat, M.S. Challenges and techniques in Big data security and privacy: A review. Secur. Priv. 2018, 1, e13. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Xiong, N.; Ren, J. Data security and privacy protection for cloud storage: A survey. IEEE Access 2020, 8, 131723–131740. [Google Scholar] [CrossRef]
- Alex, W. Global DataSphere to Hit 175 Zettabytes by 2025, IDC Says. Datanami 2018, 17, 13237–13244. [Google Scholar]
- Subbalakshmi, S.; Madhavi, K. Security challenges of Big Data storage in Cloud environment: A Survey. Int. J. Appl. Eng. Res. 2018, 13, 13237–13244. [Google Scholar]
- Venkatraman, S.; Venkatraman, R. Big data security challenges and strategies. AIMS Math. 2019, 4, 860–879. [Google Scholar] [CrossRef]
- Prajapati, P.; Shah, P. A review on secure data deduplication: Cloud storage security issue. J. King Saud-Univ. Comput. Inf. Sci. 2020, in press. [Google Scholar] [CrossRef]
- Sun, P.J. Privacy protection and data security in cloud computing: A survey, challenges, and solutions. IEEE Access 2019, 7, 147420–147452. [Google Scholar] [CrossRef]
- Big Data Working Group, Expanded Top Ten Big Data Security and Privacy Challenges. Available online: https://downloads.cloudsecurityalliance.org/initiatives/bdwg/Expanded_Top_Ten_Big_Data_Security_and_Privacy_Challenges.pdf (accessed on 27 February 2016).
- Wright, C.S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://ssrn.com/abstract=3440802 (accessed on 21 June 2021).
- Conoscenti, M.; Vetro, A.; De Martin, J.C. Blockchain for the Internet of Things: A systematic literature review. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Zahid, J.I.; Ferworn, A.; Hussain, F. Blockchain: A Technical Overview; IEEE Internet Policy Newsletter; IEEE: Piscataway, NJ, USA, 2018; pp. 1–3. [Google Scholar]
- Dai, H.N.; Zheng, Z.; Zhang, Y. Blockchain for Internet of Things: A survey. IEEE Internet Things J. 2019, 6, 8076–8094. [Google Scholar] [CrossRef] [Green Version]
- Aujla, G.S.; Chaudhary, R.; Kumar, N.; Das, A.K.; Rodrigues, J.J. SecSVA: Secure storage, verification, and auditing of big data in the cloud environment. IEEE Commun. Mag. 2018, 56, 78–85. [Google Scholar] [CrossRef]
- Dinh, T.T.A.; Wang, J.; Chen, G.; Liu, R.; Ooi, B.C.; Tan, K.L. Blockbench: A framework for analyzing private blockchains. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1085–1100. [Google Scholar] [CrossRef]
- Lei, K.; Zhang, Q.; Xu, L.; Qi, Z. Reputation-based byzantine fault-tolerance for consortium blockchain. In Proceedings of the 2018 IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS), Singapore, 11–13 December 2018; pp. 604–611. [Google Scholar] [CrossRef]
- Shahnaz, A.; Qamar, U.; Khalid, A. Using blockchain for electronic health records. IEEE Access 2019, 7, 147782–147795. [Google Scholar] [CrossRef]
- Mohanta, B.K.; Panda, S.S.; Jena, D. An overview of smart contract and use cases in blockchain technology. In Proceedings of the 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Bahga, A.; Madisetti, V.K. Blockchain platform for industrial internet of things. J. Softw. Eng. Appl. 2016, 9, 533–546. [Google Scholar] [CrossRef] [Green Version]
- Krupansky, J. What Is a Software Agent. 2015. Available online: https://medium.com/@jackkrupansky/what-is-a-software-agent-6089dfe8f99 (accessed on 5 July 2021).
- Mobile Agent Framework. 2013. Available online: http://maf.sourceforge.net/ (accessed on 5 July 2021).
- Alsulbi, K.; Khemakhem, M.; Basuhail, A.; Eassa, F.; Jambi, K.M.; Almarhabi, K. Big Data Security and Privacy: A Taxonomy with Some HPC and Blockchain Perspectives. Int. J. Comput. Sci. Netw. Secur. 2021, 21, 43–55. [Google Scholar]
- Centonze, P. Security and privacy frameworks for access control big data systems. Comput. Mater. Continua 2019, 59, 361–374. [Google Scholar] [CrossRef]
- Gupta, S.; Vashisht, S.; Singh, D. Enhancing Big Data Security Using Elliptic Curve Cryptography. In Proceedings of the 2019 International Conference on Automation, Computational and Technology Management (ICACTM), London, UK, 24–26 May 2019; pp. 348–351. [Google Scholar] [CrossRef]
- Yau, Y.C.; Khethavath, P.; Figueroa, J.A. Secure Pattern-Based Data Sensitivity Framework for Big Data in Healthcare. In Proceedings of the 2019 IEEE International Conference on Big Data, Cloud Computing, Data Science & Engineering (BCD), Honolulu, HI, USA, 29–31 May 2019; pp. 65–70. [Google Scholar] [CrossRef]
- Al-Odat, Z.A.; Al-Qtiemat, E.M.; Khan, S.U. A big data storage scheme based on distributed storage locations and multiple authorizations. In Proceedings of the 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (Big Data Security), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Washington, DC, USA, 27–29 May 2019; pp. 13–18. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, M.; Zheng, D.; Lang, P.; Wu, A.; Chen, C. Efficient and secure big data storage system with leakage resilience in cloud computing. Soft Comput. 2018, 23, 7763–7772. [Google Scholar] [CrossRef]
- Fan, K.; Lou, S.; Su, R.; Li, H.; Yang, Y. Secure and private key management scheme in big data networking. Peer-Peer Netw. Appl. 2018, 11, 992–999. [Google Scholar] [CrossRef]
- Naz, M.; Al-zahrani, F.A.; Khalid, R.; Javaid, N.; Qamar, A.M.; Afzal, M.K.; Shafiq, M. A secure data sharing platform using blockchain and interplanetary file system. Sustainability 2019, 11, 7054. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Li, Y.; Sun, W.; Guan, S. Blockchain Based Big Data Security Protection Scheme. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 574–578. [Google Scholar] [CrossRef]
- Desai, S.; Shelke, R.; Deshmukh, O.; Choudhary, H.; Sambare, S.S. Blockchain based secure data storage and access control system using IPFS. J. Crit. Rev. 2020, 7, 1254–1260. [Google Scholar] [CrossRef]
- Chen, J.; Lv, Z.; Song, H. Design of personnel big data management system based on blockchain. Future Gener. Comput. Syst. 2019, 101, 1122–1129. [Google Scholar] [CrossRef] [Green Version]
- Jung, Y.M.; Jang, W.J. Data management and searching system and method to provide increased security for IoT platform. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 18–20 October 2017; pp. 873–878. [Google Scholar] [CrossRef]
- Javed, M.U.; Rehman, M.; Javaid, N.; Aldegheishem, A.; Alrajeh, N.; Tahir, M. Blockchain-based secure data storage for distributed vehicular networks. Appl. Sci. 2020, 10, 2011. [Google Scholar] [CrossRef] [Green Version]
- Truffle Suite. Available online: Https://truffleframework.com/docs/ganache/overview (accessed on 23 May 2021).
- Metamask. Available online: https://metamask.io/ (accessed on 23 May 2021).
- Node.js. Available online: https://nodejs.org/en/ (accessed on 25 May 2021).
- Truffle Framework. Available online: https://www.trufflesuite.com/truffle (accessed on 25 May 2021).
- Hyperledger Besu. Available online: https://www.hyperledger.org/use/besu (accessed on 19 July 2021).
- Hyperledger Caliper. Available online: https://hyperledger.github.io/caliper/ (accessed on 19 July 2021).
- Performance and Scale Working Group. Hyperledger Blockchain Performance Metrics. Available online: https://www.hyperledger.org/learn/publications/blockchain-performance-metrics (accessed on 19 May 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Meaning |
|---|---|
| M | Manager |
| HLM | High-Level Manager |
| LLM | Low-Level Manager |
| HFM | High Fragmentation Module |
| IPFS | Interplanetary File Storage |
| MD | Meta-Data |
| HLBC | High-Level Blockchain |
| LLBC | Low-Level Blockchain |
| HPF | High Policy File |
| LPF | Low Policy File |
| CSMA | Check Security Mobile Agent |
| LFM | Low Fragmentation Module |
| Paper citation | Trustability of New Nodes Connected to the Big Data Environment | Access Control Enforcement | Security and Integrity of Data During Storage and Transportation | Policy Protection | Data Privacy |
|---|---|---|---|---|---|
| Shubhi [25] | N | Y | Y | N | Y |
| Yiu [26] | N | Y | Y | N | N |
| Zeyad [27] | N | Y | Y | N | N |
| Yinghui [28] | N | Y | Y | N | Y |
| Kai [29] | N | Y | Y | N | Y |
| Aujla [15] | N | Y | Y | Y | Y |
| Proposed framework | Y | Y | Y | Y | Y |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsulbi, K.A.; Khemakhem, M.A.; Basuhail, A.A.; Eassa, F.E.; Jambi, K.M.; Almarhabi, K.A. A Proposed Framework for Secure Data Storage in a Big Data Environment Based on Blockchain and Mobile Agent. Symmetry 2021, 13, 1990. https://doi.org/10.3390/sym13111990
Alsulbi KA, Khemakhem MA, Basuhail AA, Eassa FE, Jambi KM, Almarhabi KA. A Proposed Framework for Secure Data Storage in a Big Data Environment Based on Blockchain and Mobile Agent. Symmetry. 2021; 13(11):1990. https://doi.org/10.3390/sym13111990
Chicago/Turabian StyleAlsulbi, Khalil Ahmad, Maher Ali Khemakhem, Abdullah Ahamd Basuhail, Fathy Eassa Eassa, Kamal Mansur Jambi, and Khalid Ali Almarhabi. 2021. "A Proposed Framework for Secure Data Storage in a Big Data Environment Based on Blockchain and Mobile Agent" Symmetry 13, no. 11: 1990. https://doi.org/10.3390/sym13111990
APA StyleAlsulbi, K. A., Khemakhem, M. A., Basuhail, A. A., Eassa, F. E., Jambi, K. M., & Almarhabi, K. A. (2021). A Proposed Framework for Secure Data Storage in a Big Data Environment Based on Blockchain and Mobile Agent. Symmetry, 13(11), 1990. https://doi.org/10.3390/sym13111990