Are MCDA Methods Benchmarkable? A Comparative Study of TOPSIS, VIKOR, COPRAS, and PROMETHEE II Methods



Abstract
1. Introduction
2. Literature Review
2.1. MCDA State of the Art
2.1.1. MCDA Foundations
2.1.2. Operational Point of View and Preference Aggregation Techniques
- The use of a single synthesized criterion: In this approach, the result of the variants’ comparisons is determined for each criterion separately. Then the results are synthesized into a global assessment. The full order of variants is obtained here [65];
- The synthesis of the criteria based on the relation of outranking: Due to the occurrence of incomparability relations, this approach allows for obtaining the partial order of variants [65];
2.1.3. American School-Based MCDA Methods
2.1.4. European School-Based MCDA Methods
2.1.5. Mixed and Rule-Based Methods
2.2. MCDA Methods Selection and Benchmarking Problem
3. Preliminaries
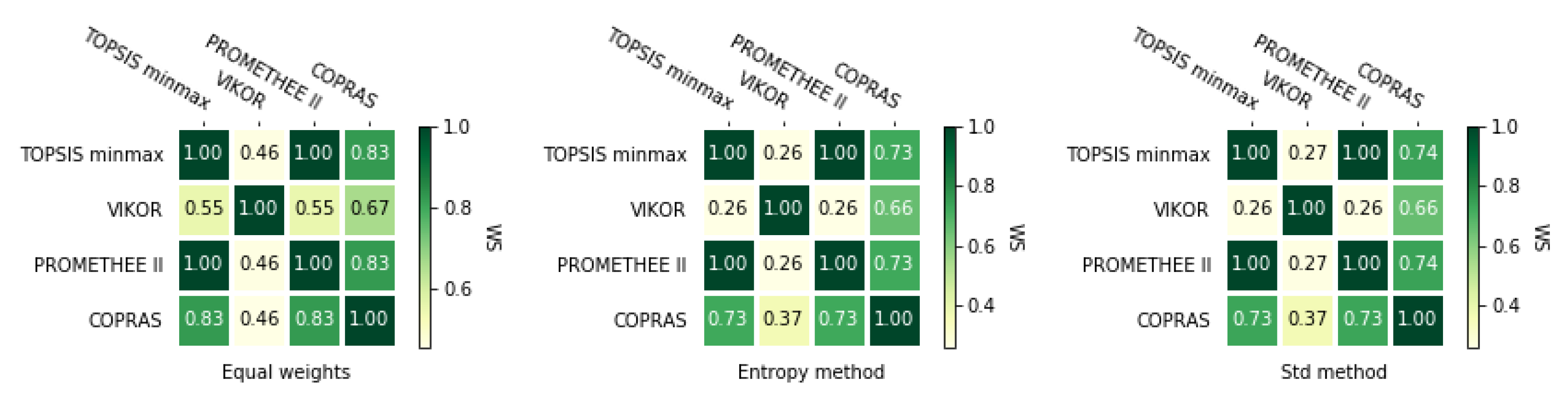
3.1. MCDA Methods
3.1.1. TOPSIS
3.1.2. VIKOR
3.1.3. COPRAS
3.1.4. PROMETHEE II
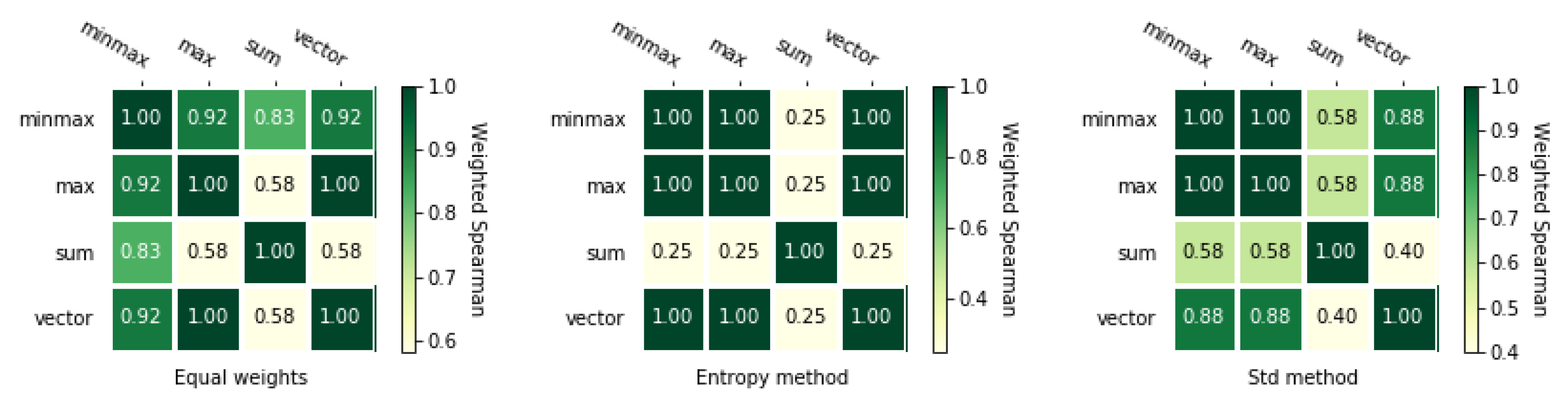
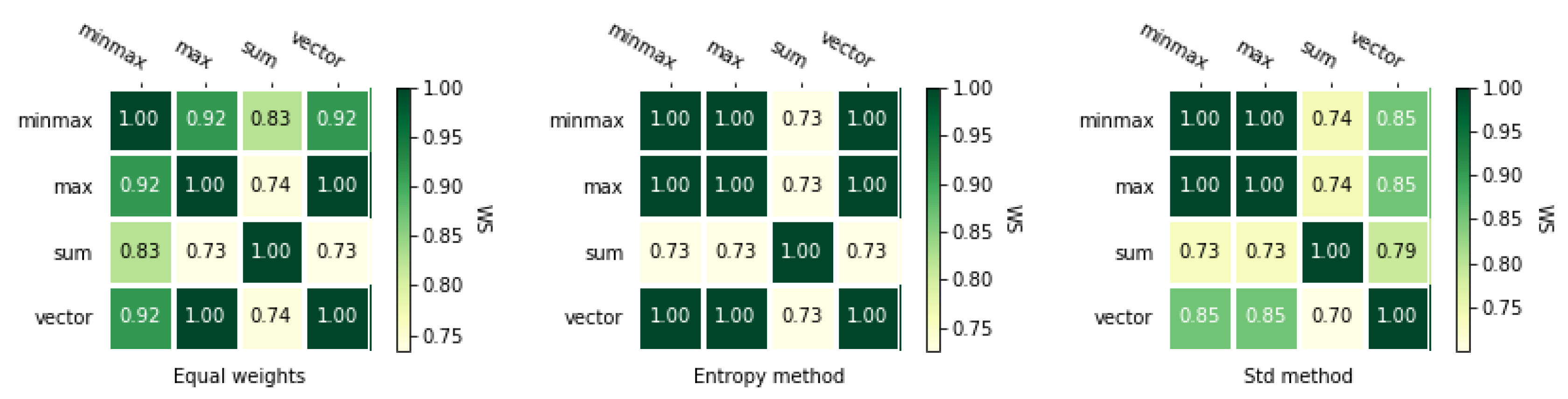
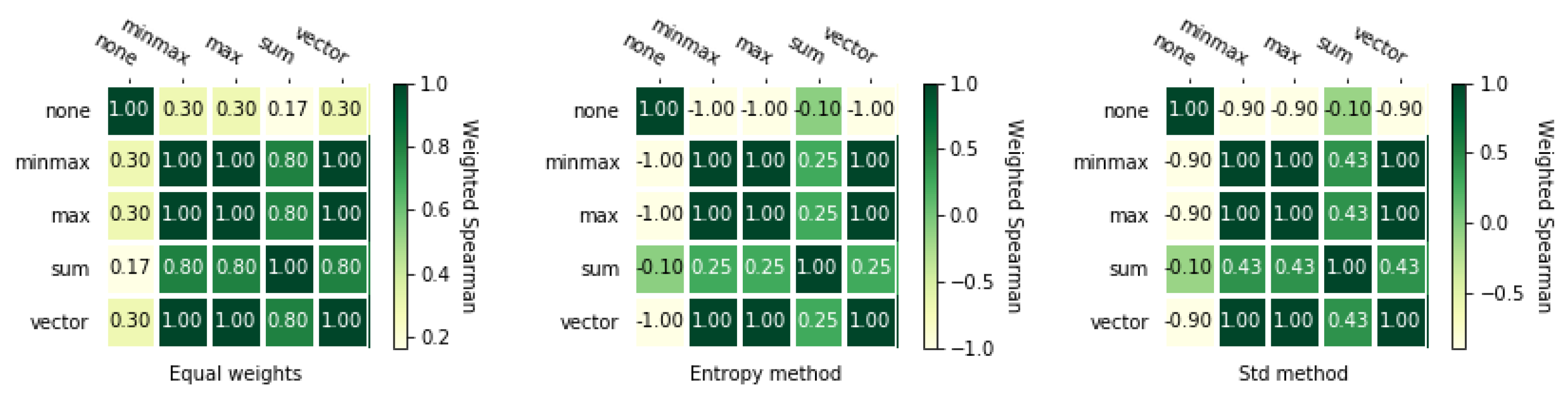
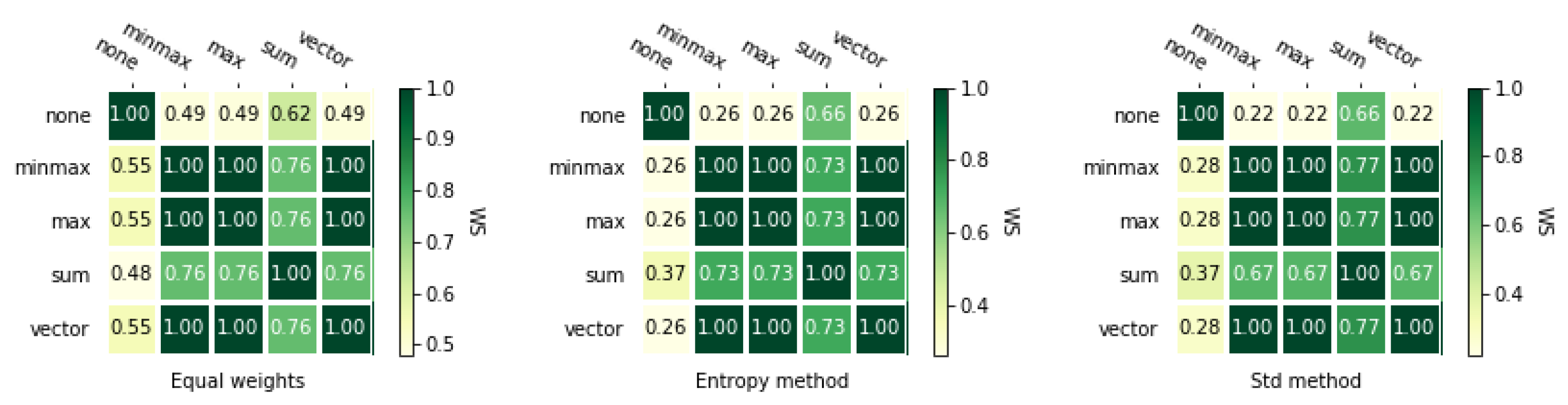
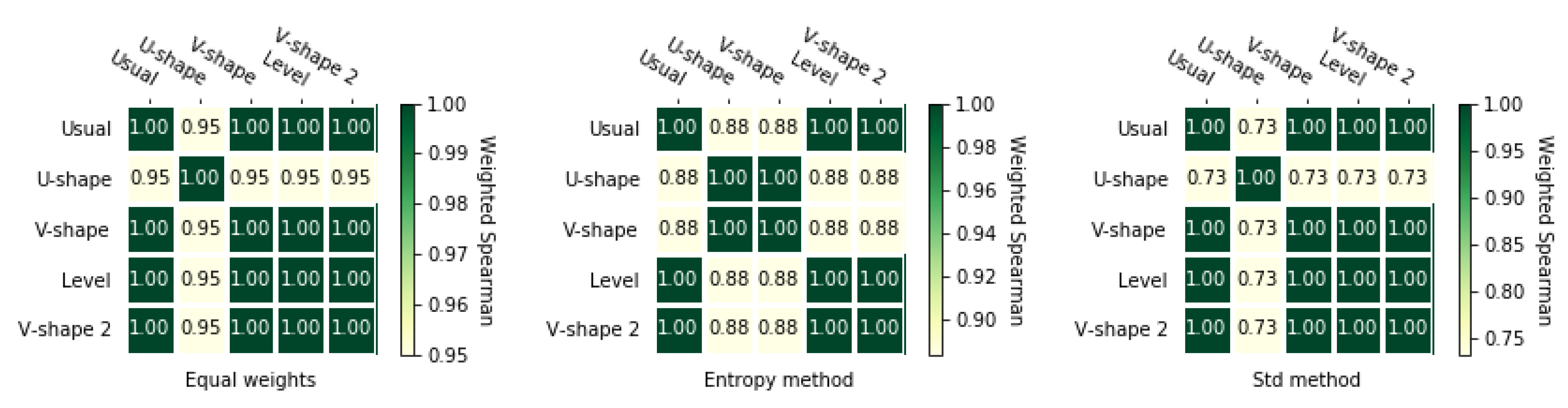
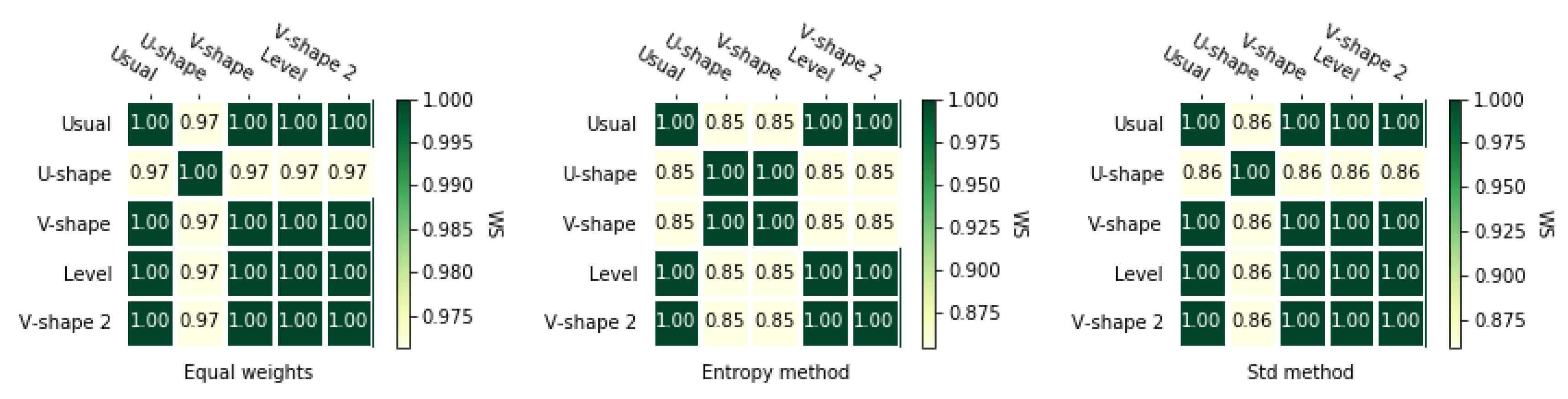
3.2. Normalization Methods
3.3. Weighting Methods
3.3.1. Equal Weights
3.3.2. Entropy Method
3.3.3. Standard Deviation Method
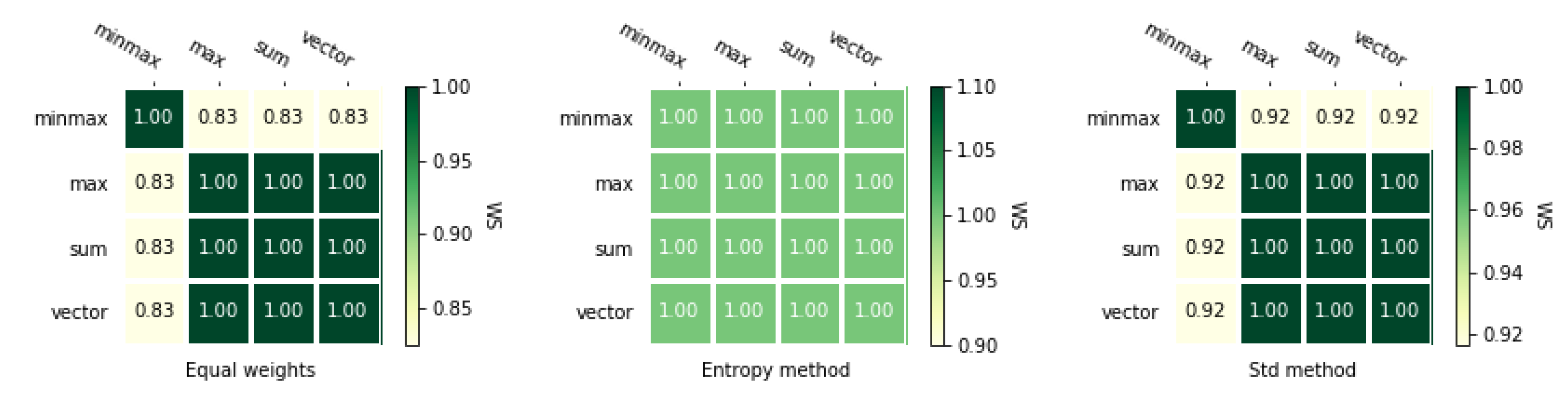
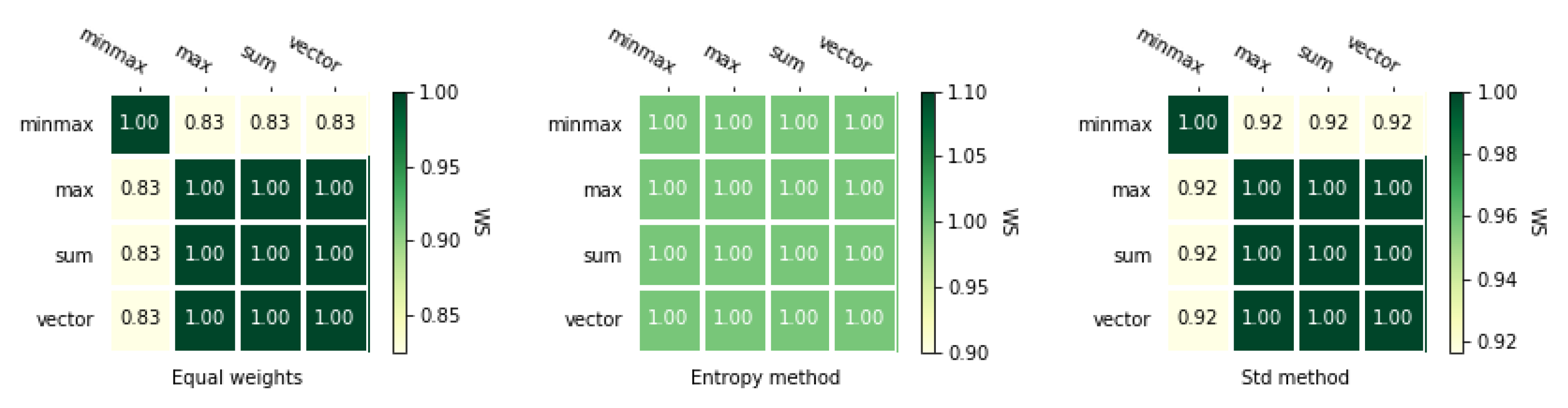
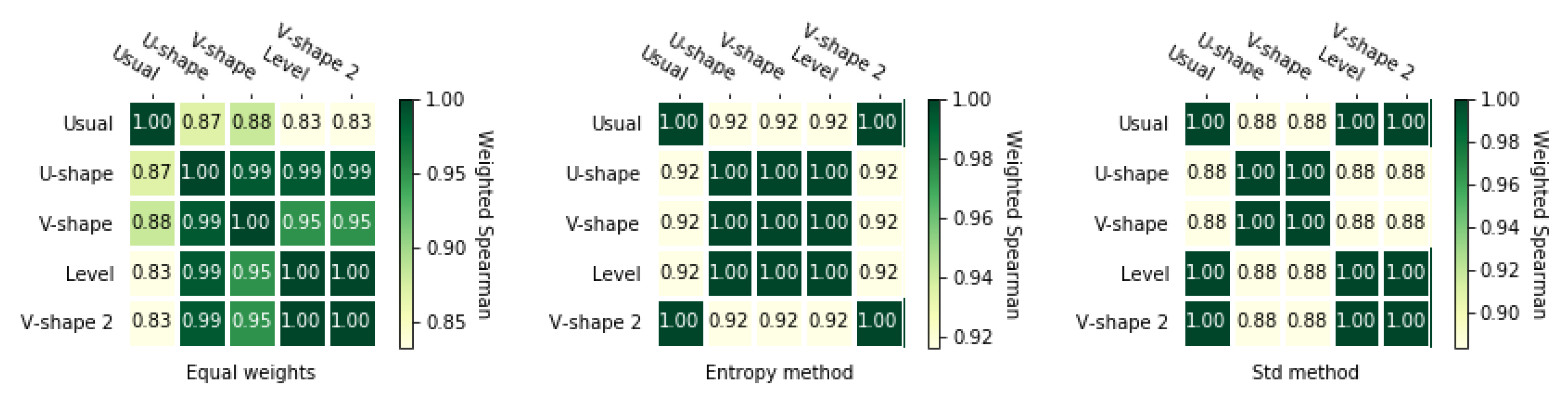
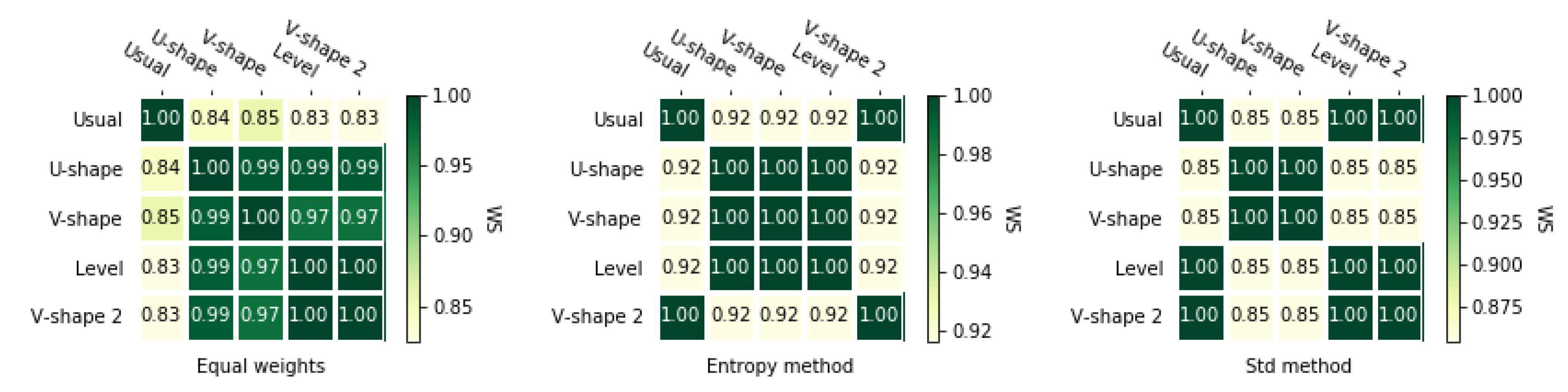
3.4. Correlation Coefficients
3.4.1. Spearman’s Rank Correlation Coefficient
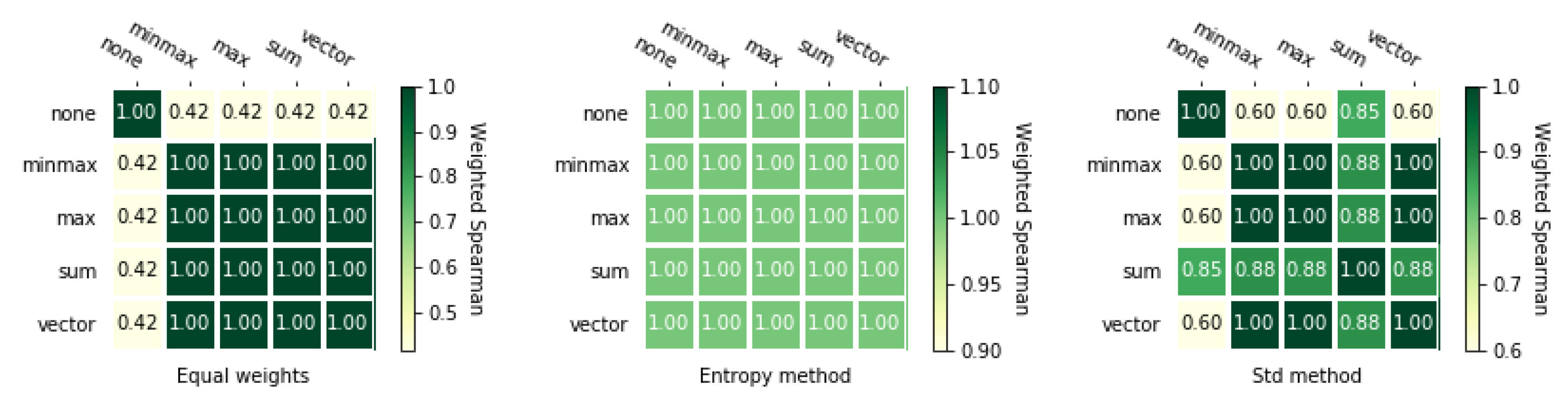
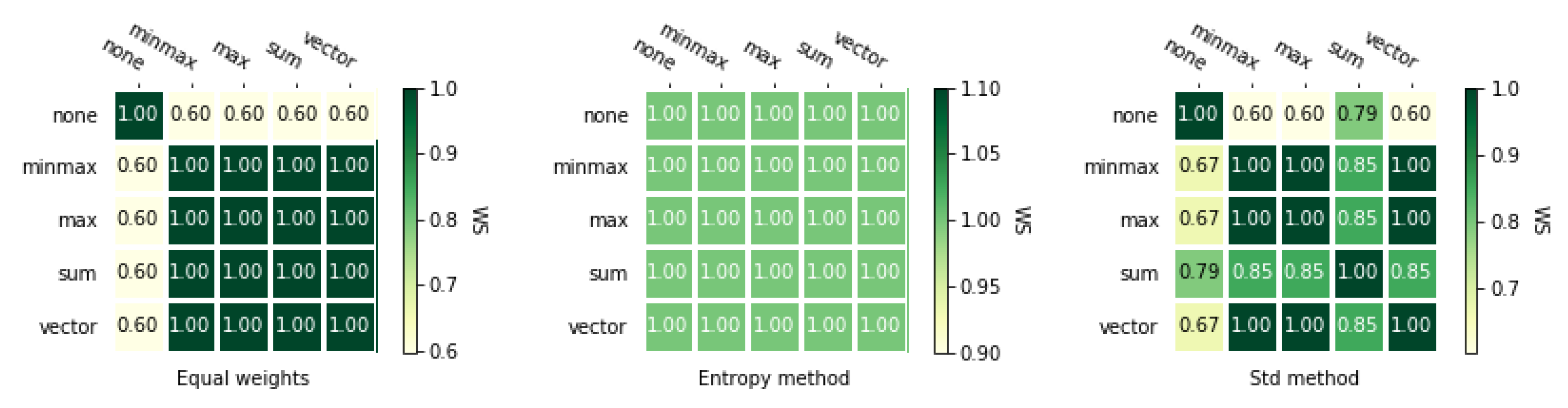
3.4.2. Weighted Spearman’s Rank Correlation Coefficient
3.4.3. Rank Similarity Coefficient
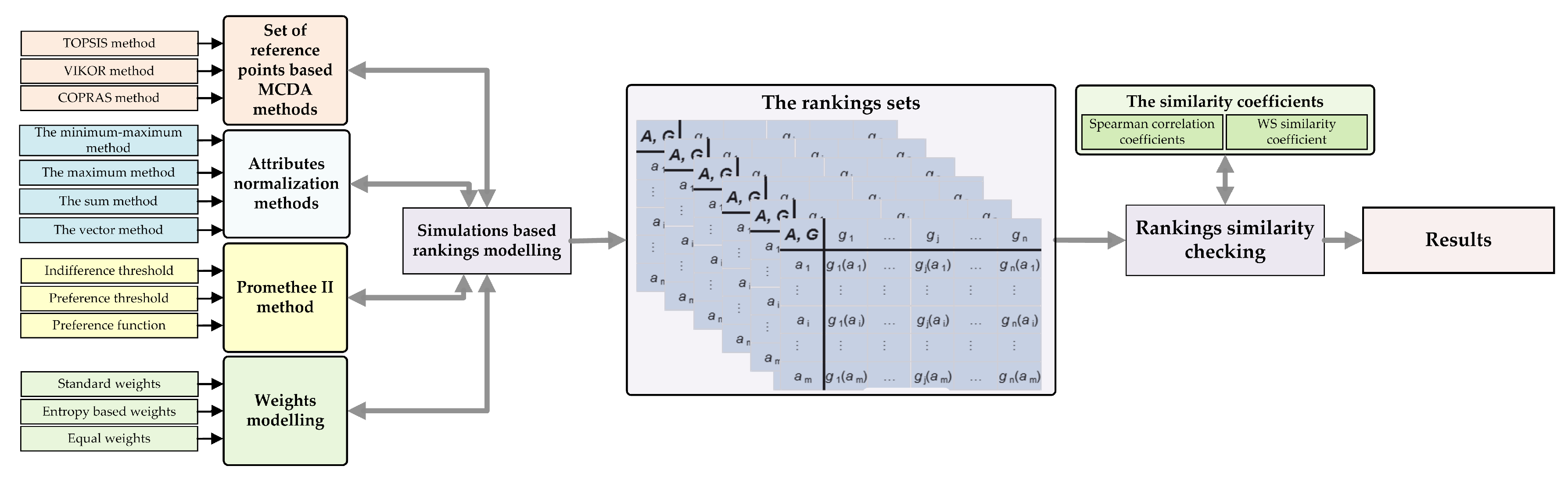
4. Study Case and Numerical Examples
- Step 1.
- Calculate 3 vectors of weights, using equations described in Section 3.3;
- Step 2.
- Split criteria into profit and cost criteria: Assuming we have n criteria, first are considered to be profit criteria and the rest ones are considered to be cost;
- Step 3.
- Compute 3 rankings using MCDA methods listed in Section 3.1 and three different weighting vectors.
| Algorithm 1 Research algorithm |
|
4.1. Decision Matrices
4.2. TOPSIS
4.3. VIKOR
4.4. PROMETHEE II
4.5. Different Methods
4.6. Summary
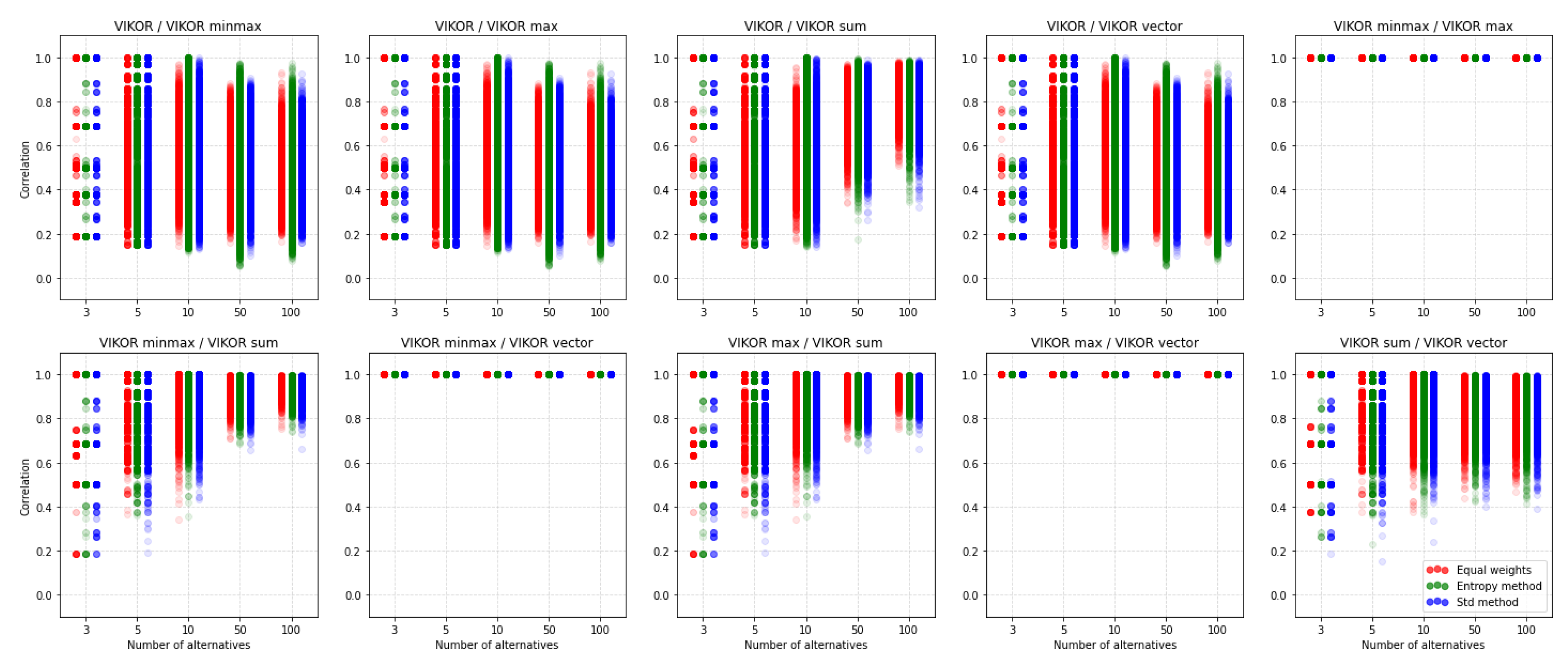
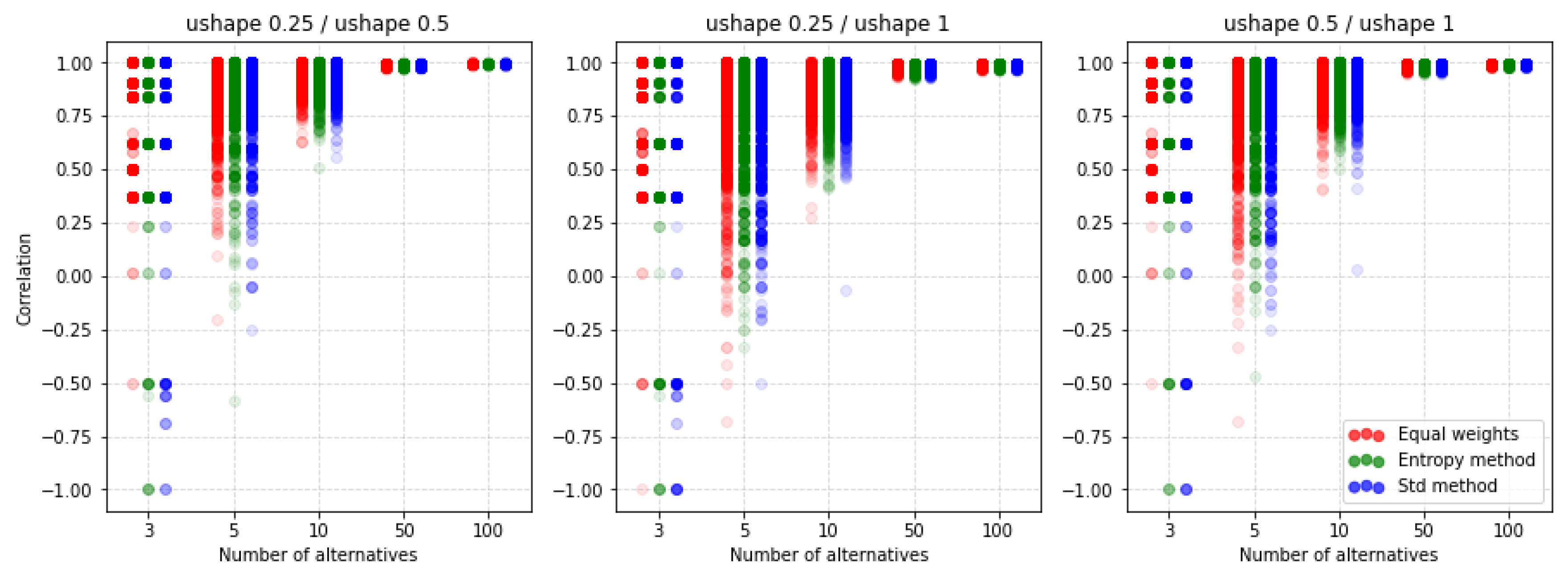
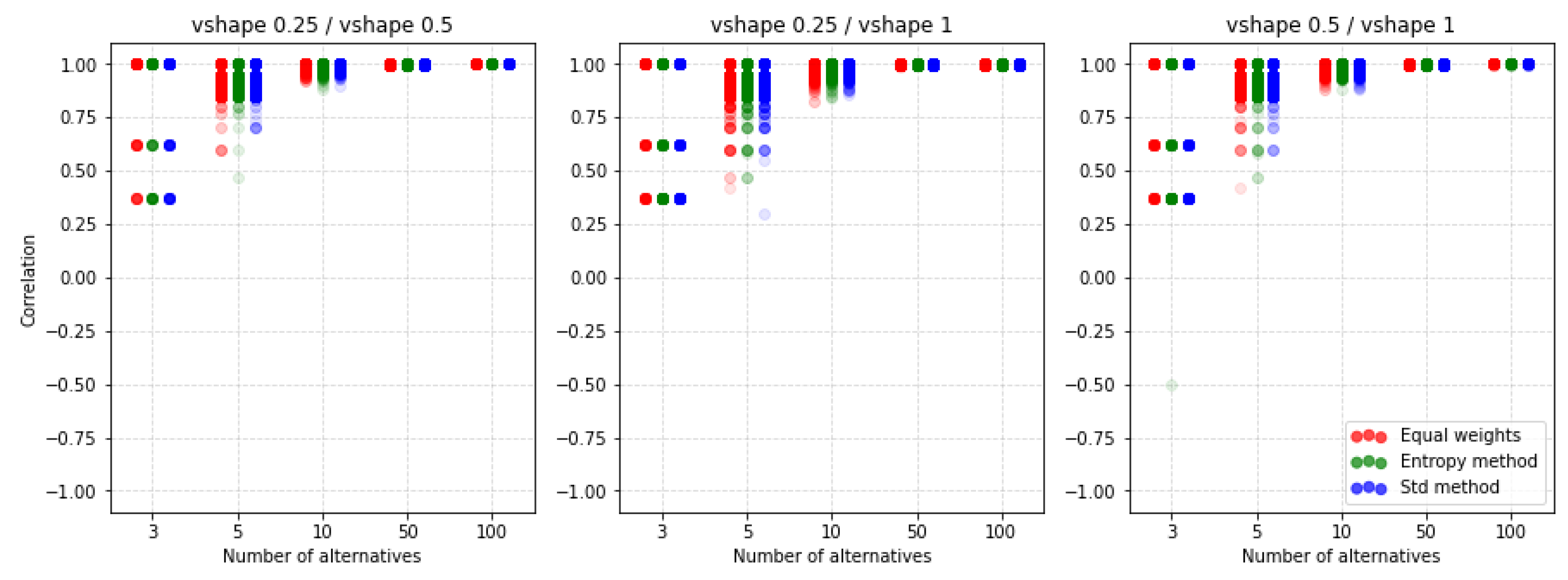
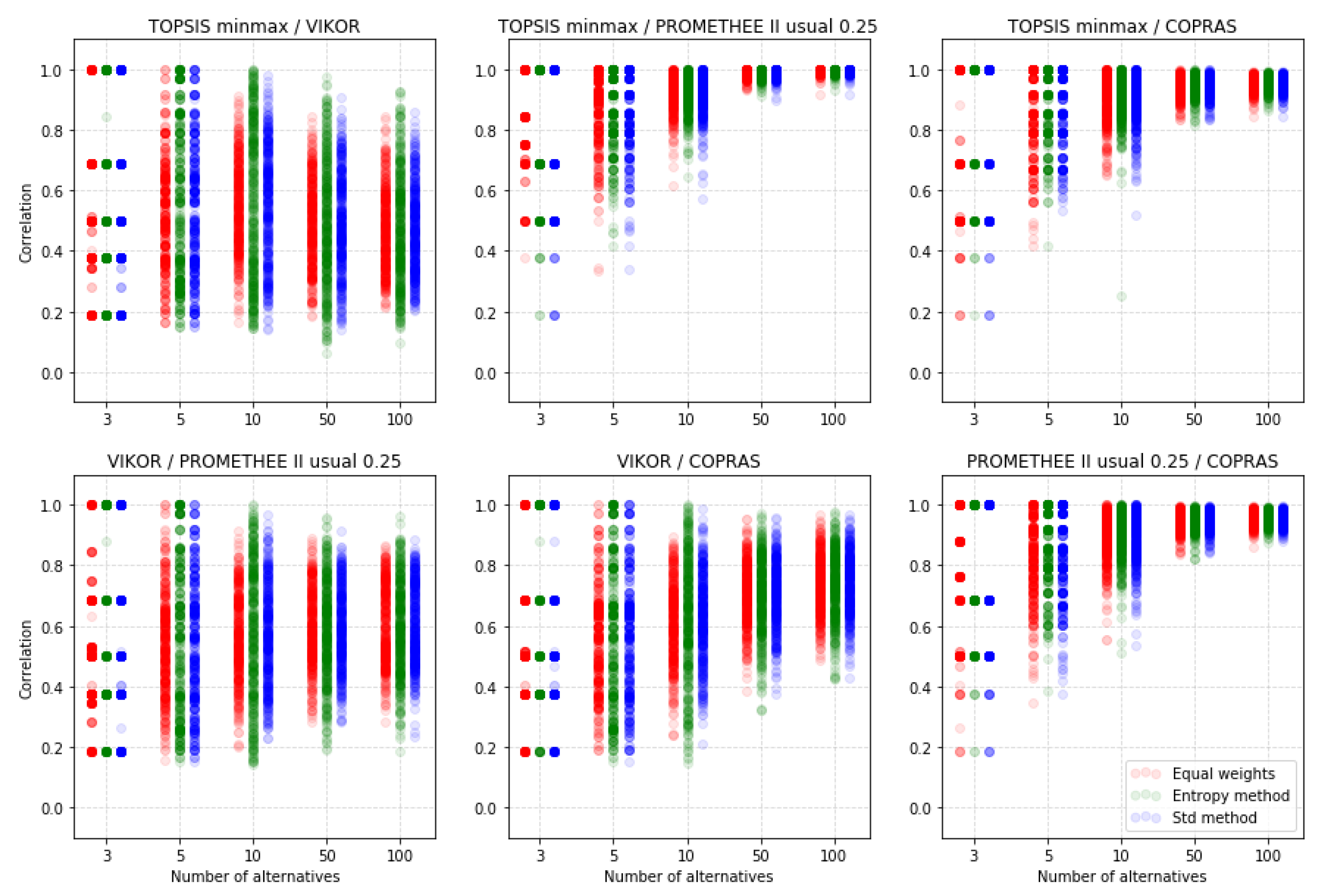
5. Results and Discussion
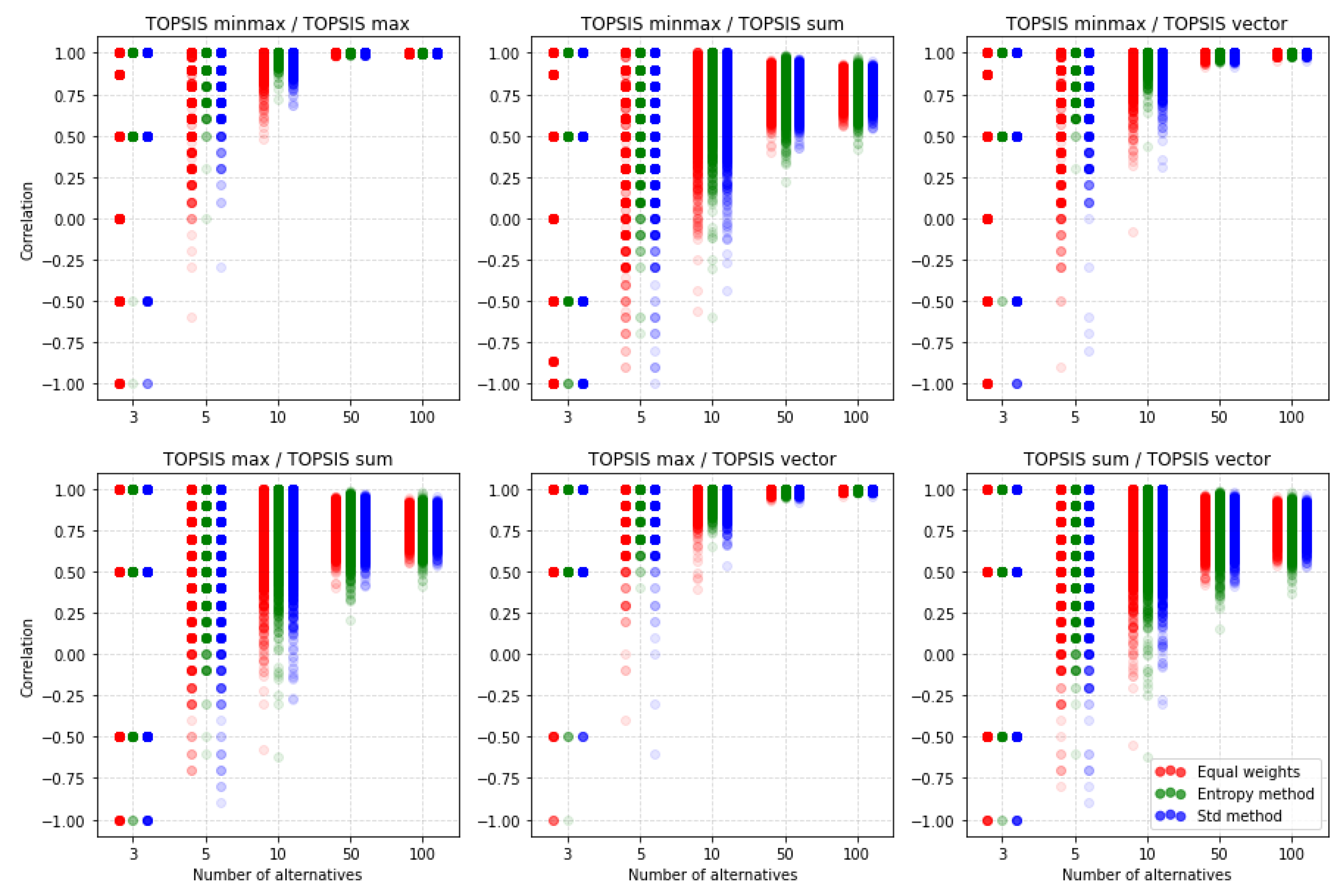
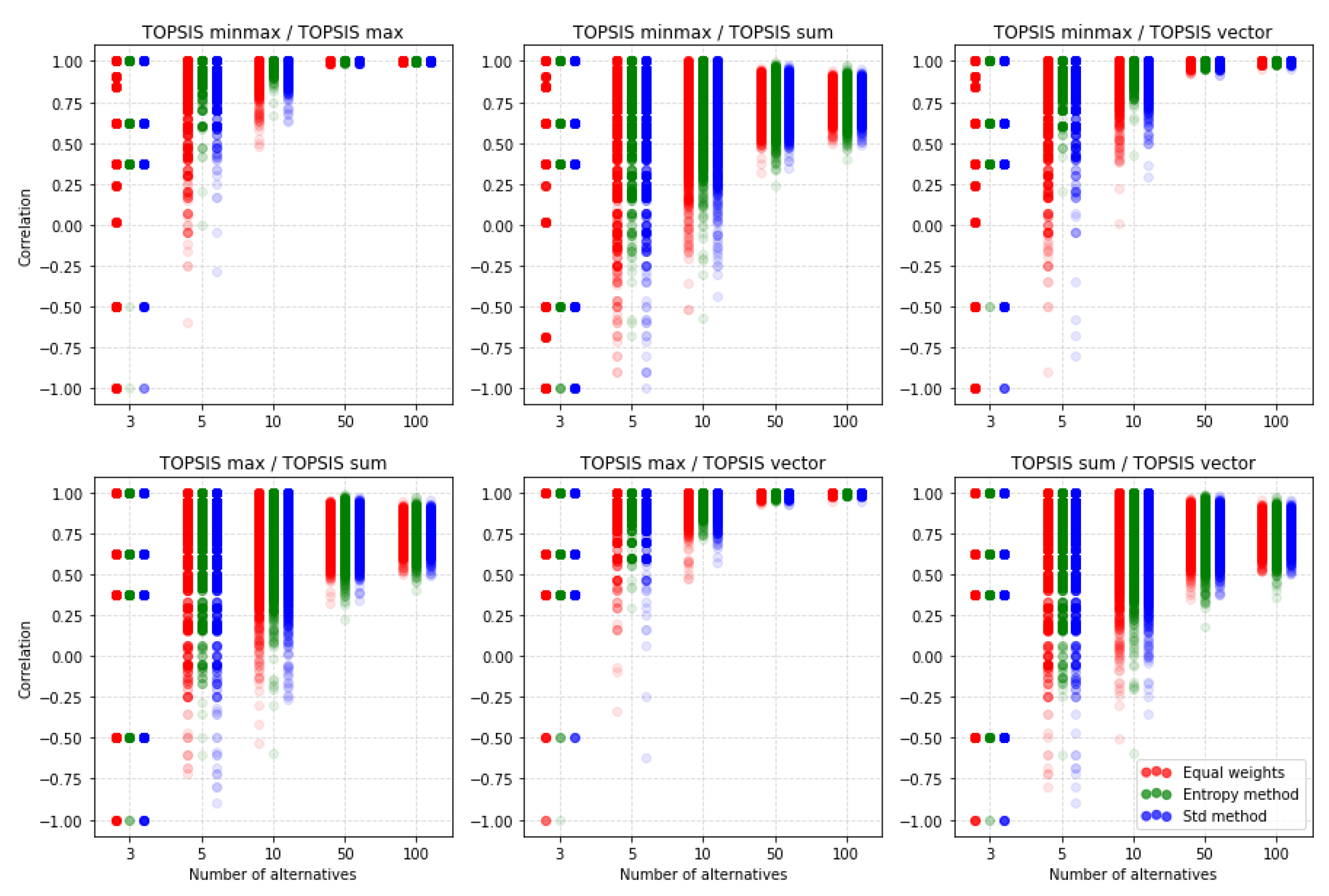
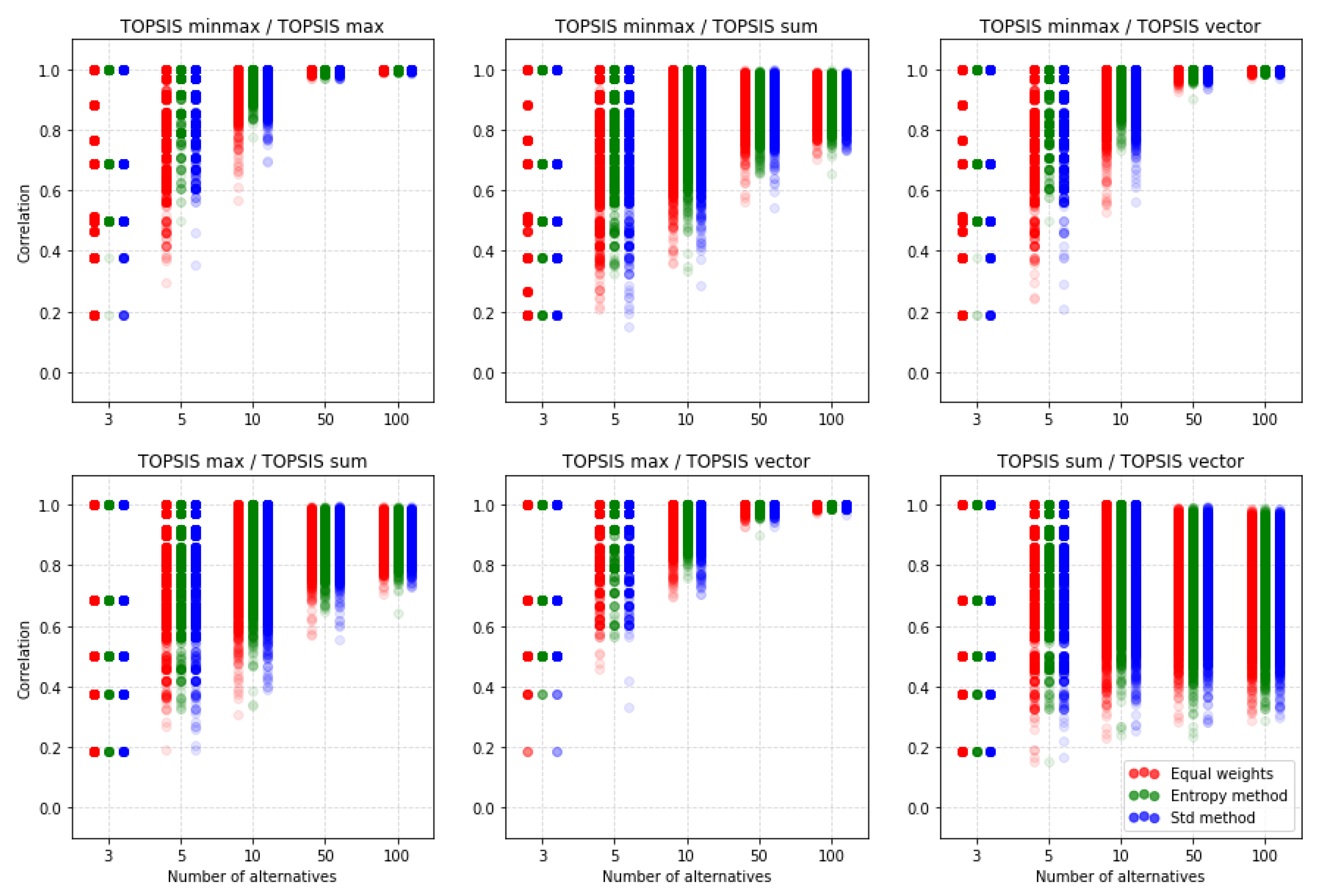
5.1. TOPSIS
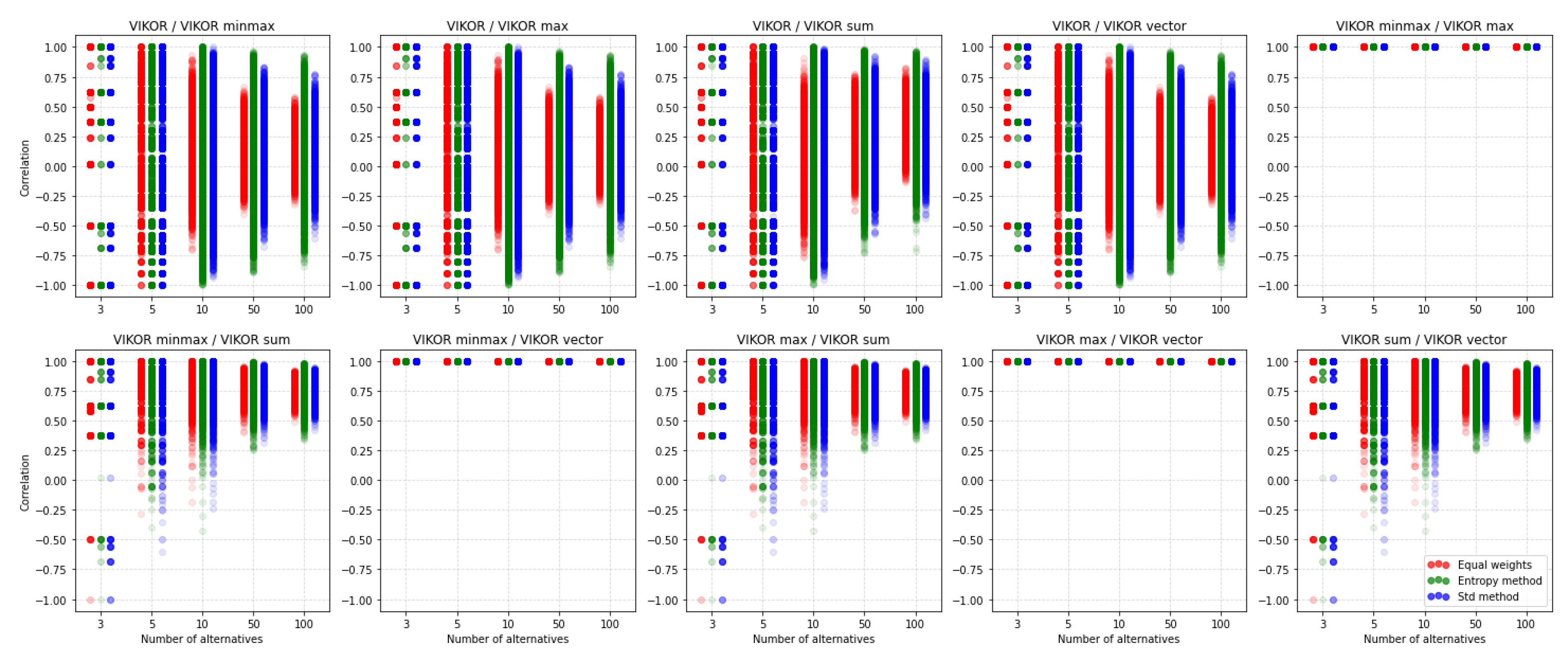
5.2. VIKOR
5.3. PROMETHEE II
5.4. Comparison of the MCDA Methods
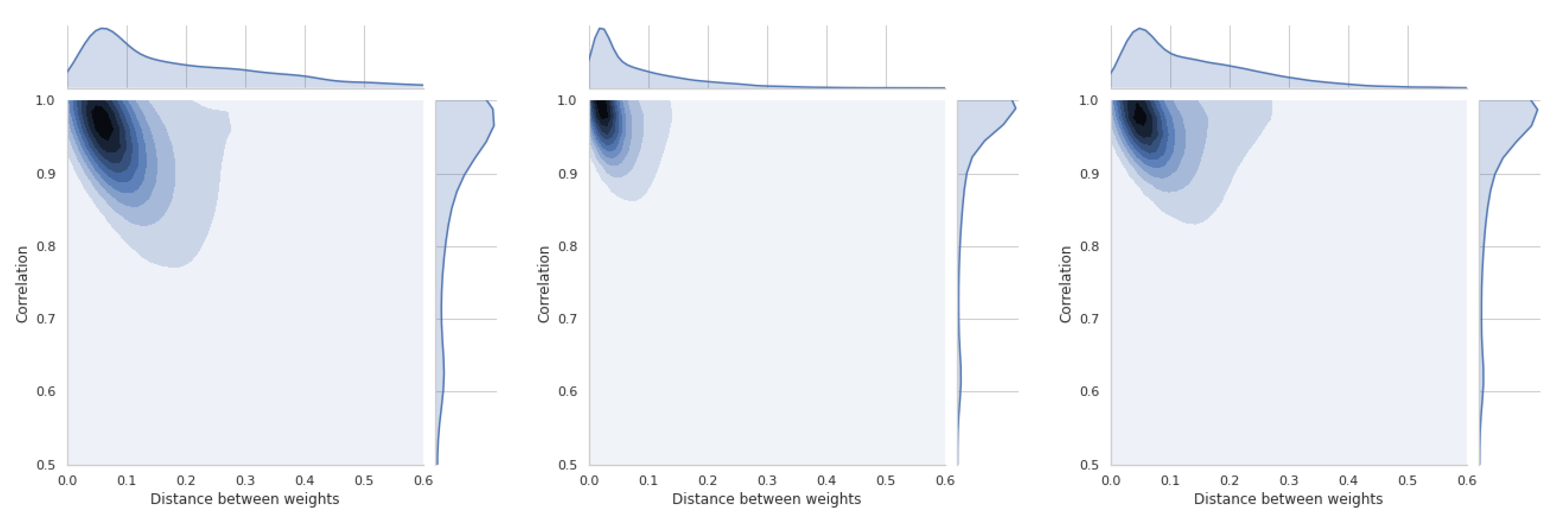
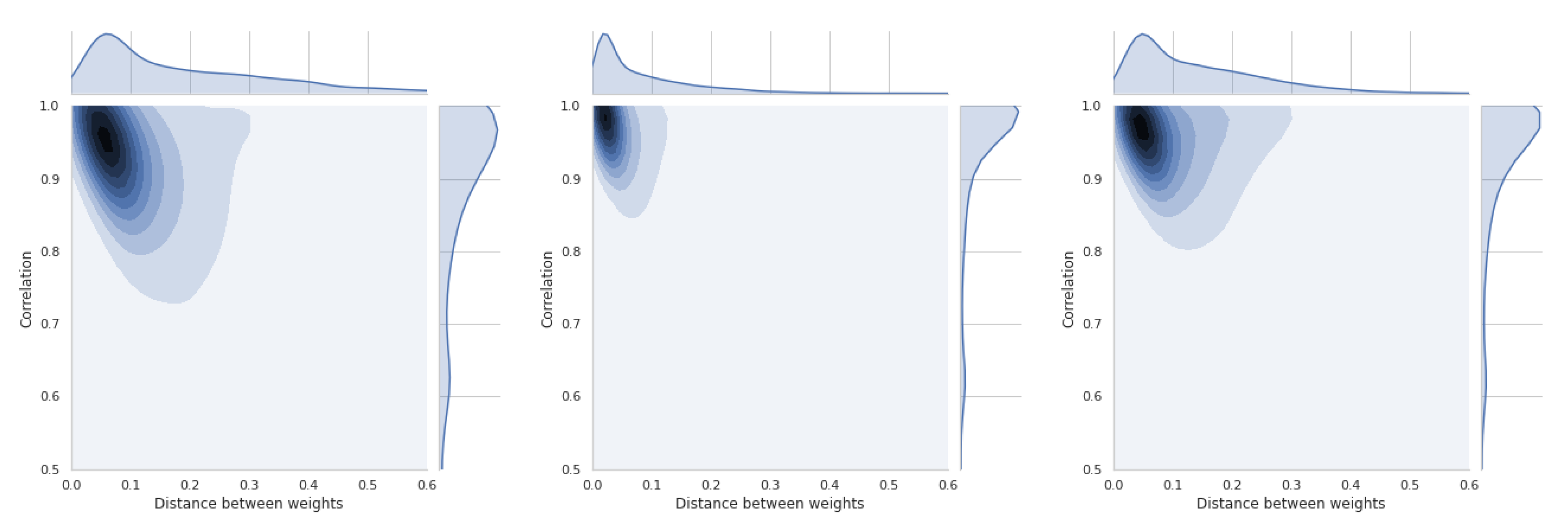
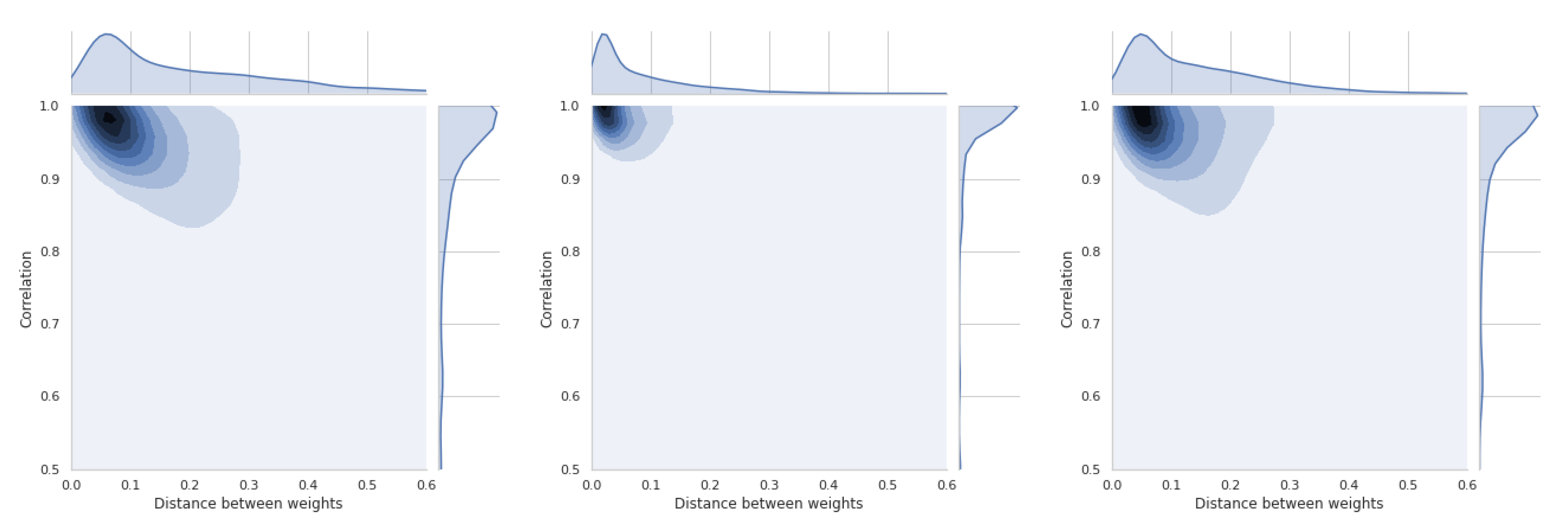
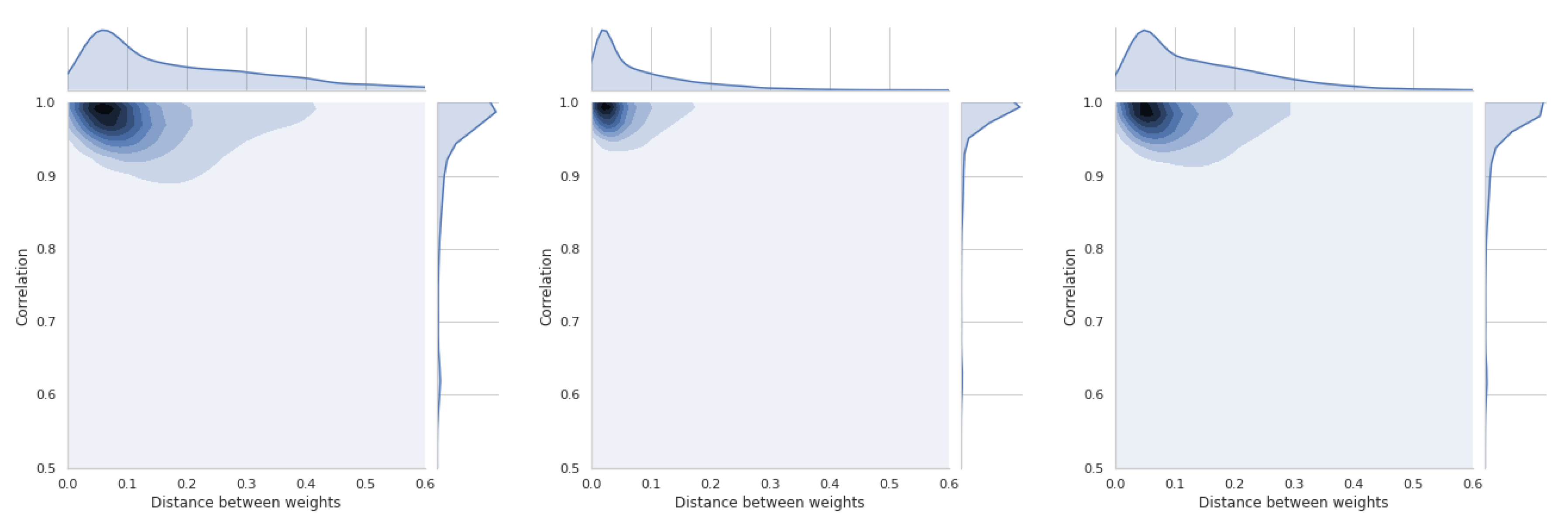
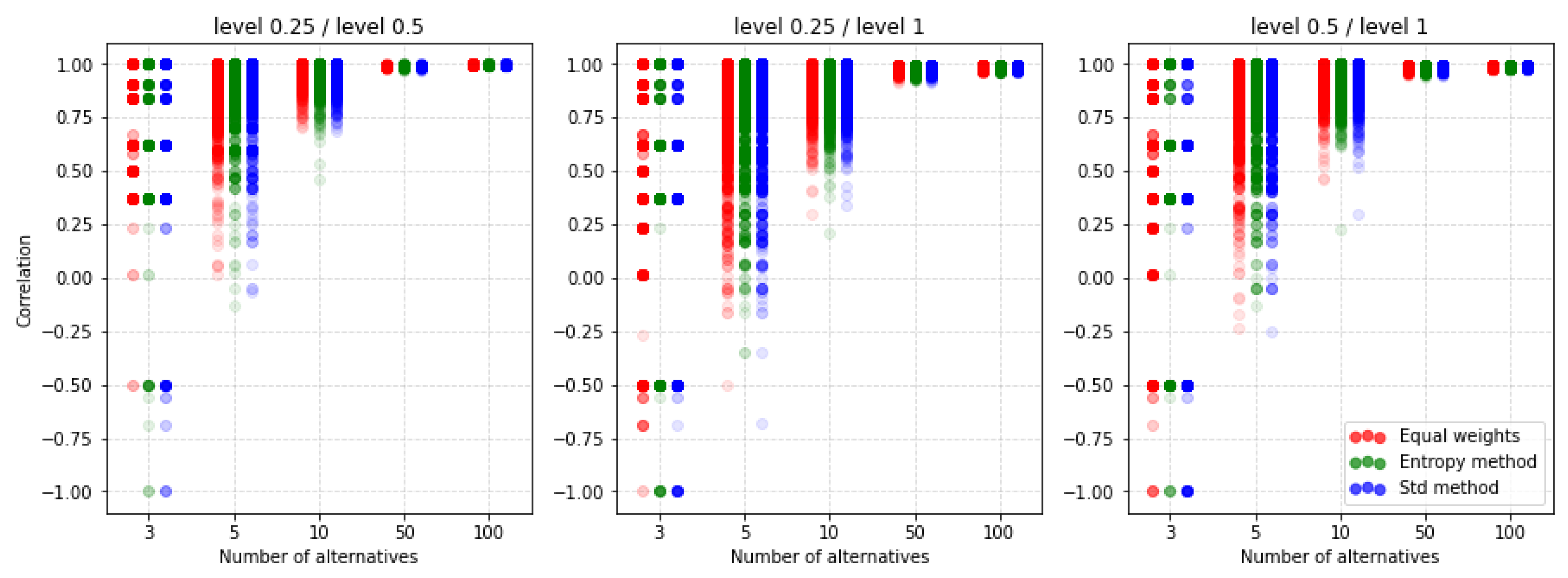
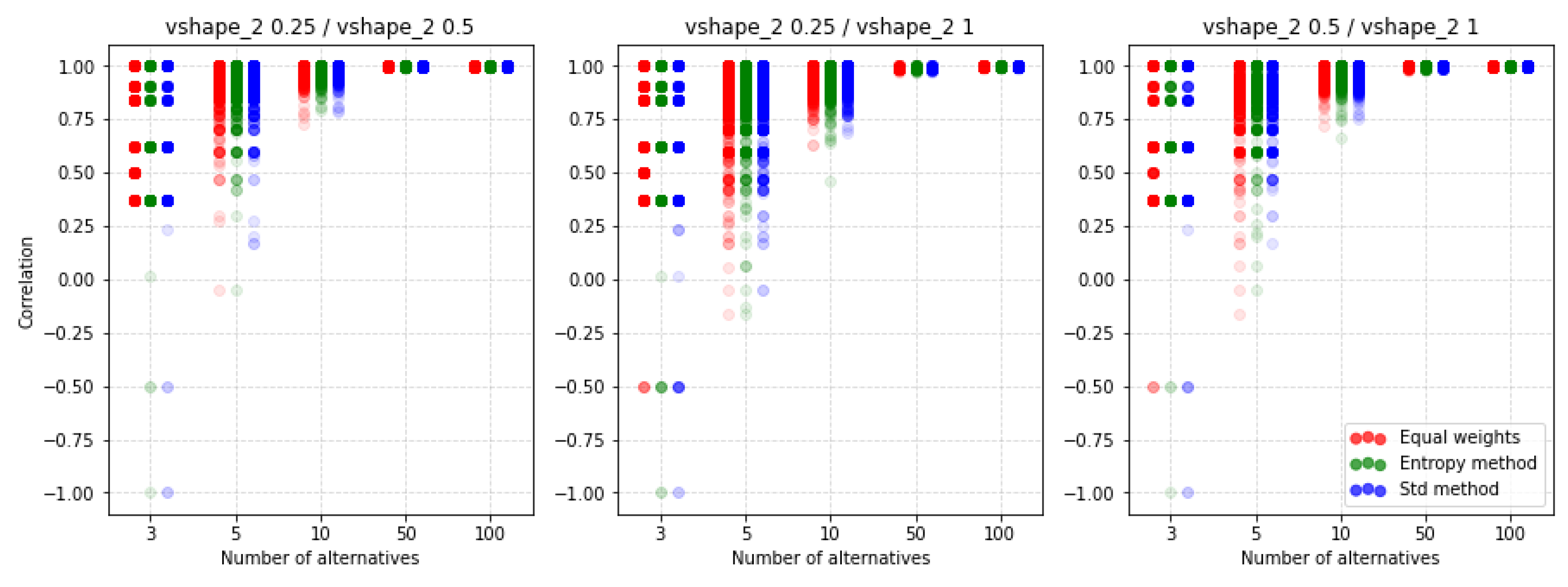
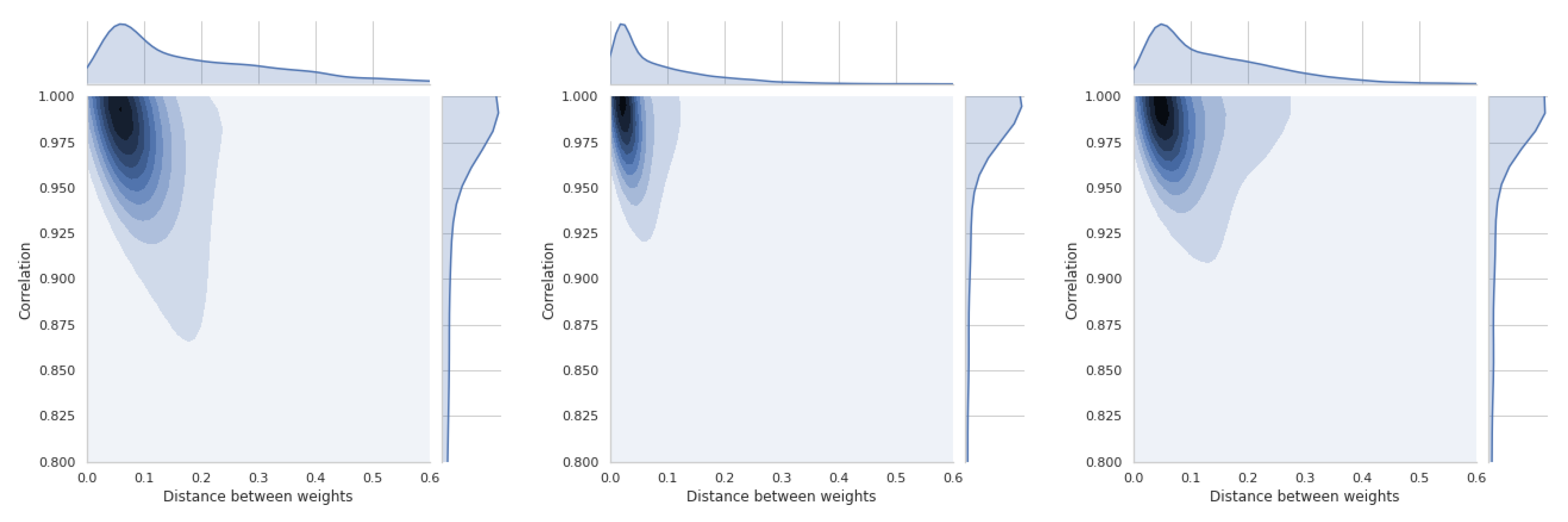
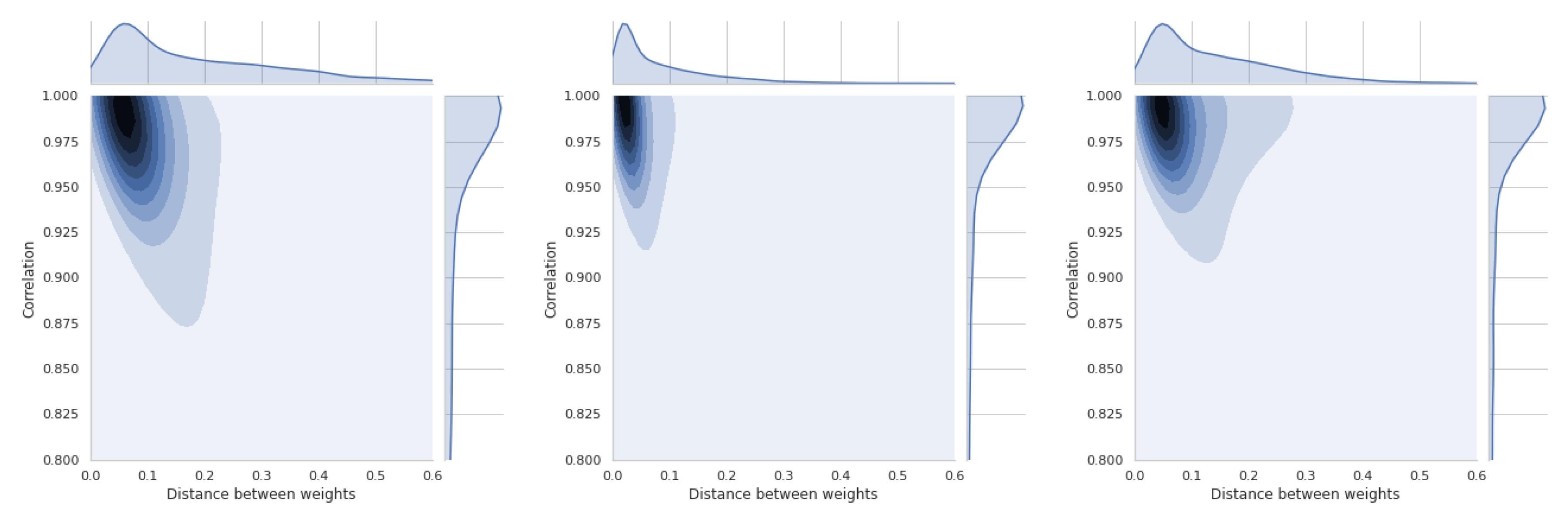
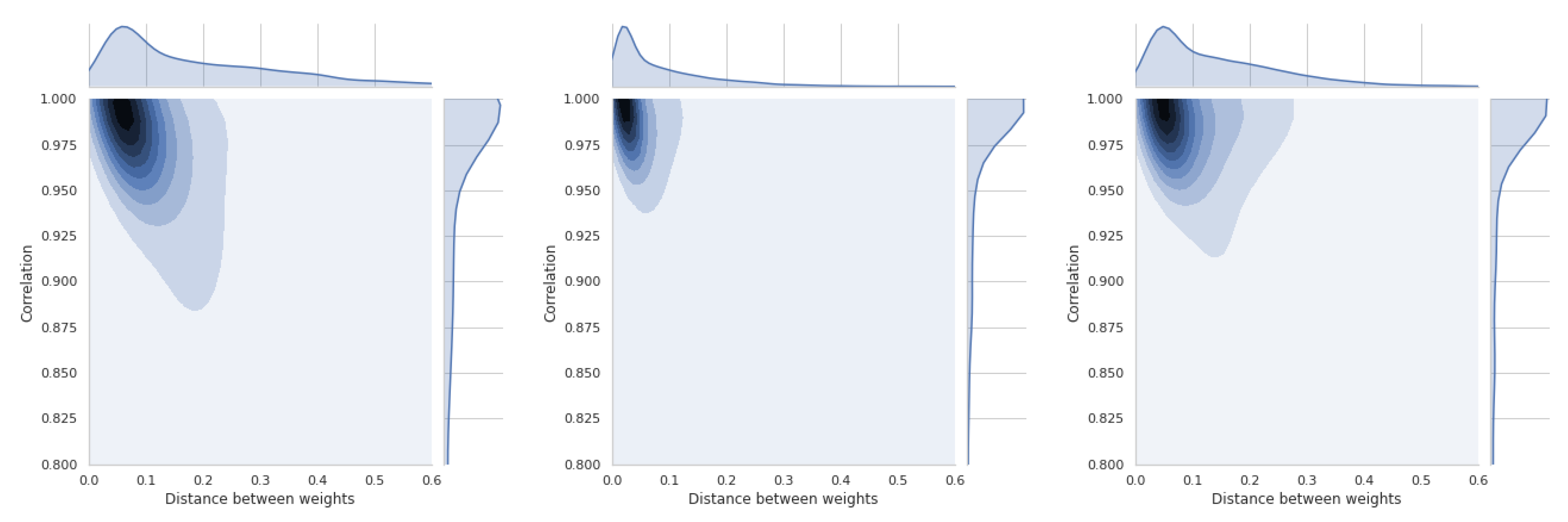
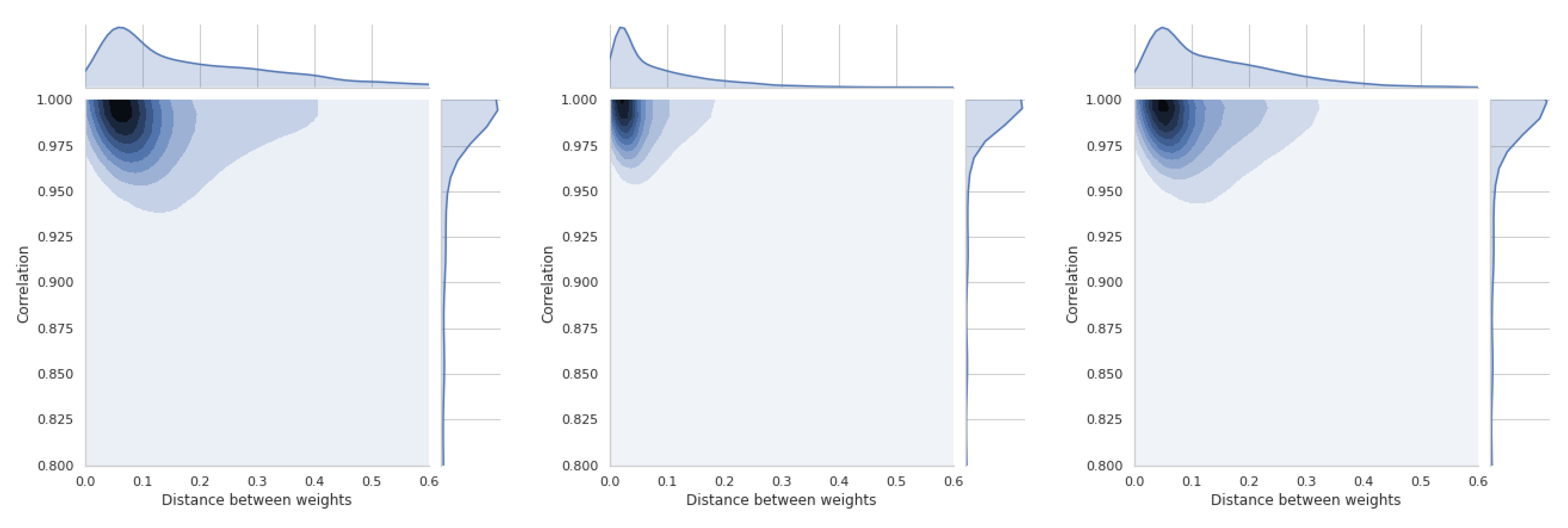
5.5. Dependence of Ranking Similarity Coefficients on the Distance between Weight Vectors
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| TOPSIS | Technique for Order of Preference by Similarity to Ideal Solution |
| VIKOR | VlseKriterijumska Optimizacija I Kompromisno Resenje (Serbian) |
| COPRAS | Complex Proportional Assessment |
| PROMETHEE | Preference Ranking Organization Method for Enrichment of Evaluation |
| MCDA | Multi Criteria Decision Analysis |
| MCDM | Multi Criteria Decision Making |
| PIS | Positive Ideal Solution |
| NIS | Negative ideal Solution |
| SD | Standard Deviation |
Appendix A. Figures


















Appendix B. Tables

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.947 | 0.957 | 0.275 | |
| 0.018 | 0.631 | 0.581 | |
| 0.565 | 0.295 | 0.701 | |
| 0.423 | 0.602 | 0.509 | |
| 0.664 | 0.637 | 0.786 | |
| 0.333 | 0.333 | 0.333 | |
| 0.678 | 0.172 | 0.151 | |
| 0.442 | 0.303 | 0.255 |
| Minmax | Max | Sum | Vector | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | ||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | ||||
| 5 | 3 | 4 | 4 | 3 | 3 | 4 | 3 | 3 | 4 | 3 | 3 | ||||
| 2 | 4 | 3 | 3 | 4 | 4 | 3 | 4 | 4 | 3 | 4 | 4 | ||||
| 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | ||||
| None | Minmax | Max | Sum | Vector | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | |||||
| 3 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| 5 | 5 | 5 | 4 | 5 | 5 | 4 | 5 | 5 | 4 | 5 | 5 | 4 | 5 | 5 | |||||
| 4 | 3 | 4 | 5 | 3 | 4 | 5 | 3 | 4 | 5 | 3 | 4 | 5 | 3 | 4 | |||||
| 2 | 4 | 3 | 2 | 4 | 2 | 2 | 4 | 2 | 2 | 4 | 3 | 2 | 4 | 2 | |||||
| 1 | 2 | 1 | 3 | 2 | 3 | 3 | 2 | 3 | 3 | 2 | 2 | 3 | 2 | 3 | |||||
| Usual | U-Shape | V-Shape | Level | V-Shape 2 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | |||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| 4 | 5 | 5 | 4 | 5 | 5 | 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | |||||
| 5 | 3 | 4 | 4 | 4 | 4 | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 3 | 4 | |||||
| 3 | 4 | 3 | 2 | 3 | 2 | 2 | 3 | 2 | 2 | 3 | 3 | 2 | 4 | 3 | |||||
| 2 | 2 | 2 | 3 | 2 | 3 | 3 | 2 | 3 | 3 | 2 | 2 | 3 | 2 | 2 | |||||
| TOPSIS | VIKOR | PROM. II | COPRAS | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | ||||
| 1 | 1 | 1 | 3 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| 4 | 5 | 5 | 5 | 5 | 5 | 4 | 5 | 5 | 5 | 5 | 5 | ||||
| 5 | 3 | 4 | 4 | 3 | 4 | 5 | 3 | 4 | 4 | 3 | 4 | ||||
| 2 | 4 | 3 | 2 | 4 | 3 | 3 | 4 | 3 | 3 | 4 | 3 | ||||
| 3 | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | ||||
| Norm | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | ||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | ||
| (a) | equal | 0.828 | 0.923 | 0.977 | 0.999 | 1.000 | 0.755 | 0.897 | 0.966 | 0.999 | 1.000 | 0.744 | 0.887 | 0.966 | 0.998 | 1.000 | 0.735 | 0.871 | 0.964 | 0.998 | 1.000 |
| entropy | 0.979 | 0.986 | 0.991 | 0.999 | 1.000 | 0.973 | 0.980 | 0.989 | 0.999 | 1.000 | 0.977 | 0.974 | 0.989 | 0.999 | 1.000 | 0.973 | 0.973 | 0.988 | 0.999 | 1.000 | |
| std | 0.916 | 0.960 | 0.985 | 0.999 | 1.000 | 0.913 | 0.949 | 0.977 | 0.999 | 1.000 | 0.904 | 0.938 | 0.976 | 0.998 | 1.000 | 0.897 | 0.933 | 0.974 | 0.998 | 1.000 | |
| (b) | equal | 0.740 | 0.808 | 0.821 | 0.815 | 0.807 | 0.651 | 0.754 | 0.805 | 0.825 | 0.821 | 0.596 | 0.679 | 0.714 | 0.733 | 0.735 | 0.571 | 0.658 | 0.702 | 0.742 | 0.748 |
| entropy | 0.916 | 0.895 | 0.851 | 0.812 | 0.804 | 0.905 | 0.878 | 0.847 | 0.826 | 0.820 | 0.878 | 0.796 | 0.755 | 0.731 | 0.733 | 0.865 | 0.796 | 0.766 | 0.742 | 0.745 | |
| std | 0.836 | 0.844 | 0.832 | 0.813 | 0.805 | 0.823 | 0.815 | 0.819 | 0.824 | 0.820 | 0.783 | 0.735 | 0.727 | 0.732 | 0.734 | 0.762 | 0.722 | 0.720 | 0.741 | 0.747 | |
| (c) | equal | 0.803 | 0.900 | 0.957 | 0.994 | 0.997 | 0.703 | 0.856 | 0.934 | 0.991 | 0.996 | 0.696 | 0.839 | 0.929 | 0.989 | 0.995 | 0.701 | 0.818 | 0.922 | 0.989 | 0.995 |
| entropy | 0.972 | 0.977 | 0.984 | 0.996 | 0.998 | 0.961 | 0.969 | 0.976 | 0.993 | 0.997 | 0.963 | 0.959 | 0.973 | 0.992 | 0.996 | 0.960 | 0.958 | 0.967 | 0.991 | 0.996 | |
| std | 0.899 | 0.942 | 0.970 | 0.994 | 0.997 | 0.890 | 0.921 | 0.951 | 0.991 | 0.996 | 0.875 | 0.903 | 0.947 | 0.990 | 0.996 | 0.874 | 0.893 | 0.938 | 0.989 | 0.995 | |
| (d) | equal | 0.870 | 0.849 | 0.827 | 0.813 | 0.806 | 0.842 | 0.829 | 0.821 | 0.824 | 0.821 | 0.785 | 0.747 | 0.732 | 0.732 | 0.733 | 0.782 | 0.741 | 0.723 | 0.741 | 0.747 |
| entropy | 0.925 | 0.895 | 0.850 | 0.810 | 0.802 | 0.913 | 0.882 | 0.847 | 0.824 | 0.819 | 0.883 | 0.802 | 0.756 | 0.729 | 0.732 | 0.873 | 0.802 | 0.769 | 0.740 | 0.744 | |
| std | 0.895 | 0.864 | 0.833 | 0.811 | 0.804 | 0.880 | 0.850 | 0.827 | 0.822 | 0.819 | 0.833 | 0.763 | 0.734 | 0.731 | 0.733 | 0.839 | 0.763 | 0.731 | 0.739 | 0.746 | |
| (e) | equal | 0.966 | 0.971 | 0.980 | 0.995 | 0.998 | 0.926 | 0.950 | 0.965 | 0.992 | 0.996 | 0.917 | 0.941 | 0.960 | 0.991 | 0.996 | 0.923 | 0.934 | 0.956 | 0.990 | 0.995 |
| entropy | 0.986 | 0.986 | 0.989 | 0.996 | 0.998 | 0.976 | 0.980 | 0.983 | 0.994 | 0.997 | 0.974 | 0.972 | 0.977 | 0.993 | 0.996 | 0.970 | 0.964 | 0.972 | 0.992 | 0.996 | |
| std | 0.975 | 0.979 | 0.983 | 0.995 | 0.998 | 0.970 | 0.963 | 0.971 | 0.992 | 0.996 | 0.954 | 0.952 | 0.966 | 0.991 | 0.996 | 0.947 | 0.943 | 0.960 | 0.990 | 0.996 | |
| (f) | equal | 0.868 | 0.850 | 0.829 | 0.812 | 0.806 | 0.861 | 0.846 | 0.833 | 0.826 | 0.822 | 0.788 | 0.750 | 0.729 | 0.732 | 0.733 | 0.795 | 0.751 | 0.731 | 0.742 | 0.748 |
| entropy | 0.922 | 0.897 | 0.849 | 0.808 | 0.801 | 0.925 | 0.890 | 0.852 | 0.824 | 0.819 | 0.886 | 0.803 | 0.755 | 0.727 | 0.730 | 0.874 | 0.808 | 0.771 | 0.740 | 0.744 | |
| std | 0.899 | 0.870 | 0.835 | 0.811 | 0.804 | 0.888 | 0.859 | 0.837 | 0.825 | 0.821 | 0.830 | 0.767 | 0.734 | 0.731 | 0.733 | 0.848 | 0.764 | 0.736 | 0.741 | 0.747 | |
| Norm | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | ||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | ||
| (a) | equal | 0.864 | 0.931 | 0.980 | 0.999 | 1.000 | 0.837 | 0.910 | 0.967 | 0.999 | 1.000 | 0.826 | 0.900 | 0.966 | 0.999 | 1.000 | 0.821 | 0.886 | 0.962 | 0.998 | 1.000 |
| entropy | 0.983 | 0.986 | 0.988 | 0.999 | 1.000 | 0.978 | 0.979 | 0.987 | 0.999 | 1.000 | 0.982 | 0.973 | 0.985 | 0.999 | 1.000 | 0.979 | 0.972 | 0.984 | 0.999 | 1.000 | |
| std | 0.939 | 0.961 | 0.985 | 0.999 | 1.000 | 0.934 | 0.946 | 0.974 | 0.999 | 1.000 | 0.925 | 0.940 | 0.974 | 0.999 | 1.000 | 0.921 | 0.936 | 0.971 | 0.999 | 1.000 | |
| (b) | equal | 0.812 | 0.842 | 0.865 | 0.926 | 0.944 | 0.774 | 0.813 | 0.857 | 0.915 | 0.932 | 0.748 | 0.776 | 0.810 | 0.868 | 0.885 | 0.740 | 0.767 | 0.809 | 0.869 | 0.886 |
| entropy | 0.936 | 0.908 | 0.889 | 0.927 | 0.945 | 0.928 | 0.898 | 0.887 | 0.917 | 0.932 | 0.908 | 0.843 | 0.836 | 0.873 | 0.887 | 0.897 | 0.841 | 0.838 | 0.873 | 0.889 | |
| std | 0.889 | 0.871 | 0.874 | 0.926 | 0.944 | 0.878 | 0.852 | 0.865 | 0.916 | 0.932 | 0.852 | 0.805 | 0.816 | 0.869 | 0.886 | 0.840 | 0.801 | 0.815 | 0.870 | 0.886 | |
| (c) | equal | 0.847 | 0.912 | 0.964 | 0.998 | 0.999 | 0.805 | 0.881 | 0.945 | 0.996 | 0.999 | 0.800 | 0.868 | 0.939 | 0.995 | 0.998 | 0.803 | 0.852 | 0.932 | 0.993 | 0.998 |
| entropy | 0.977 | 0.976 | 0.981 | 0.998 | 0.999 | 0.969 | 0.969 | 0.975 | 0.996 | 0.999 | 0.970 | 0.957 | 0.970 | 0.995 | 0.998 | 0.968 | 0.957 | 0.965 | 0.995 | 0.998 | |
| std | 0.927 | 0.946 | 0.972 | 0.998 | 0.999 | 0.919 | 0.923 | 0.955 | 0.996 | 0.999 | 0.906 | 0.910 | 0.949 | 0.995 | 0.998 | 0.909 | 0.905 | 0.944 | 0.994 | 0.998 | |
| (d) | equal | 0.909 | 0.871 | 0.868 | 0.925 | 0.944 | 0.889 | 0.865 | 0.865 | 0.915 | 0.932 | 0.853 | 0.809 | 0.818 | 0.867 | 0.885 | 0.852 | 0.812 | 0.816 | 0.869 | 0.886 |
| entropy | 0.943 | 0.909 | 0.891 | 0.927 | 0.945 | 0.936 | 0.902 | 0.890 | 0.917 | 0.932 | 0.913 | 0.847 | 0.839 | 0.873 | 0.887 | 0.906 | 0.844 | 0.840 | 0.873 | 0.889 | |
| std | 0.924 | 0.884 | 0.875 | 0.926 | 0.944 | 0.914 | 0.878 | 0.871 | 0.916 | 0.932 | 0.883 | 0.823 | 0.821 | 0.868 | 0.886 | 0.890 | 0.824 | 0.821 | 0.869 | 0.886 | |
| (e) | equal | 0.972 | 0.969 | 0.980 | 0.998 | 0.999 | 0.945 | 0.951 | 0.967 | 0.997 | 0.999 | 0.939 | 0.943 | 0.960 | 0.995 | 0.998 | 0.943 | 0.937 | 0.956 | 0.994 | 0.998 |
| entropy | 0.989 | 0.984 | 0.987 | 0.998 | 0.999 | 0.983 | 0.979 | 0.981 | 0.997 | 0.999 | 0.979 | 0.969 | 0.976 | 0.996 | 0.998 | 0.978 | 0.963 | 0.971 | 0.995 | 0.998 | |
| std | 0.980 | 0.978 | 0.983 | 0.998 | 0.999 | 0.977 | 0.963 | 0.971 | 0.996 | 0.999 | 0.964 | 0.950 | 0.963 | 0.996 | 0.999 | 0.960 | 0.945 | 0.960 | 0.994 | 0.998 | |
| (f) | equal | 0.906 | 0.870 | 0.848 | 0.825 | 0.821 | 0.897 | 0.866 | 0.839 | 0.791 | 0.773 | 0.857 | 0.800 | 0.774 | 0.745 | 0.734 | 0.852 | 0.801 | 0.770 | 0.730 | 0.724 |
| entropy | 0.942 | 0.909 | 0.872 | 0.821 | 0.816 | 0.942 | 0.904 | 0.865 | 0.781 | 0.769 | 0.913 | 0.841 | 0.802 | 0.740 | 0.731 | 0.905 | 0.843 | 0.802 | 0.725 | 0.721 | |
| std | 0.926 | 0.885 | 0.854 | 0.823 | 0.821 | 0.917 | 0.879 | 0.846 | 0.788 | 0.774 | 0.881 | 0.817 | 0.782 | 0.744 | 0.733 | 0.891 | 0.813 | 0.774 | 0.730 | 0.722 | |
| Norm | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | ||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | ||
| (a) | equal | 0.083 | −0.003 | −0.029 | −0.028 | −0.030 | 0.237 | 0.317 | 0.313 | 0.344 | 0.338 | 0.043 | 0.058 | 0.066 | 0.067 | 0.069 | 0.162 | 0.223 | 0.238 | 0.255 | 0.255 |
| entropy | 0.010 | −0.030 | −0.036 | −0.016 | −0.026 | 0.310 | 0.345 | 0.336 | 0.361 | 0.330 | 0.031 | 0.006 | 0.037 | 0.053 | 0.066 | 0.211 | 0.192 | 0.260 | 0.236 | 0.233 | |
| std | 0.022 | −0.033 | −0.040 | −0.027 | −0.032 | 0.270 | 0.329 | 0.304 | 0.345 | 0.329 | 0.038 | 0.014 | 0.033 | 0.057 | 0.065 | 0.199 | 0.175 | 0.226 | 0.237 | 0.246 | |
| (b) | equal | 0.083 | −0.003 | −0.029 | −0.028 | −0.030 | 0.237 | 0.317 | 0.313 | 0.344 | 0.338 | 0.043 | 0.058 | 0.066 | 0.067 | 0.069 | 0.162 | 0.223 | 0.238 | 0.255 | 0.255 |
| entropy | 0.010 | −0.030 | −0.036 | −0.016 | −0.026 | 0.310 | 0.345 | 0.336 | 0.361 | 0.330 | 0.031 | 0.006 | 0.037 | 0.053 | 0.066 | 0.211 | 0.192 | 0.260 | 0.236 | 0.233 | |
| std | 0.022 | −0.033 | −0.040 | −0.027 | −0.032 | 0.270 | 0.329 | 0.304 | 0.345 | 0.329 | 0.038 | 0.014 | 0.033 | 0.057 | 0.065 | 0.199 | 0.175 | 0.226 | 0.237 | 0.246 | |
| (c) | equal | 0.088 | −0.033 | −0.020 | 0.222 | 0.358 | 0.250 | 0.265 | 0.231 | 0.377 | 0.468 | 0.055 | 0.018 | −0.029 | 0.121 | 0.235 | 0.159 | 0.210 | 0.129 | 0.237 | 0.335 |
| entropy | 0.022 | 0.003 | 0.046 | 0.277 | 0.386 | 0.315 | 0.356 | 0.370 | 0.499 | 0.532 | 0.026 | −0.006 | 0.048 | 0.173 | 0.248 | 0.194 | 0.181 | 0.240 | 0.305 | 0.356 | |
| std | 0.017 | −0.014 | 0.014 | 0.242 | 0.367 | 0.266 | 0.305 | 0.290 | 0.426 | 0.487 | −0.002 | −0.044 | −0.025 | 0.094 | 0.186 | 0.164 | 0.108 | 0.141 | 0.220 | 0.290 | |
| (d) | equal | 0.083 | −0.003 | −0.029 | −0.028 | −0.030 | 0.237 | 0.317 | 0.313 | 0.344 | 0.338 | 0.043 | 0.058 | 0.066 | 0.067 | 0.069 | 0.162 | 0.223 | 0.238 | 0.255 | 0.255 |
| entropy | 0.010 | −0.030 | −0.036 | −0.016 | −0.026 | 0.310 | 0.345 | 0.336 | 0.361 | 0.330 | 0.031 | 0.006 | 0.037 | 0.053 | 0.066 | 0.211 | 0.192 | 0.260 | 0.236 | 0.233 | |
| std | 0.022 | −0.033 | −0.040 | −0.027 | −0.032 | 0.270 | 0.329 | 0.304 | 0.345 | 0.329 | 0.038 | 0.014 | 0.033 | 0.057 | 0.065 | 0.199 | 0.175 | 0.226 | 0.237 | 0.246 | |
| (e) | equal | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| entropy | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| std | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| (f) | equal | 0.950 | 0.889 | 0.851 | 0.791 | 0.760 | 0.964 | 0.915 | 0.865 | 0.826 | 0.812 | 0.925 | 0.903 | 0.843 | 0.793 | 0.778 | 0.925 | 0.918 | 0.852 | 0.805 | 0.795 |
| entropy | 0.938 | 0.901 | 0.865 | 0.795 | 0.759 | 0.937 | 0.909 | 0.884 | 0.846 | 0.821 | 0.892 | 0.846 | 0.813 | 0.767 | 0.748 | 0.909 | 0.857 | 0.849 | 0.793 | 0.772 | |
| std | 0.917 | 0.880 | 0.847 | 0.791 | 0.758 | 0.922 | 0.901 | 0.867 | 0.833 | 0.814 | 0.873 | 0.839 | 0.806 | 0.765 | 0.749 | 0.896 | 0.849 | 0.836 | 0.784 | 0.769 | |
| (g) | equal | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| entropy | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| std | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| (h) | equal | 0.950 | 0.889 | 0.851 | 0.791 | 0.760 | 0.964 | 0.915 | 0.865 | 0.826 | 0.812 | 0.925 | 0.903 | 0.843 | 0.793 | 0.778 | 0.925 | 0.918 | 0.852 | 0.805 | 0.795 |
| entropy | 0.938 | 0.901 | 0.865 | 0.795 | 0.759 | 0.937 | 0.909 | 0.884 | 0.846 | 0.821 | 0.892 | 0.846 | 0.813 | 0.767 | 0.748 | 0.909 | 0.857 | 0.849 | 0.793 | 0.772 | |
| std | 0.917 | 0.880 | 0.847 | 0.791 | 0.758 | 0.922 | 0.901 | 0.867 | 0.833 | 0.814 | 0.873 | 0.839 | 0.806 | 0.765 | 0.749 | 0.896 | 0.849 | 0.836 | 0.784 | 0.769 | |
| (i) | equal | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| entropy | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| std | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| (j) | equal | 0.950 | 0.889 | 0.851 | 0.791 | 0.760 | 0.964 | 0.915 | 0.865 | 0.826 | 0.812 | 0.925 | 0.903 | 0.843 | 0.793 | 0.778 | 0.925 | 0.918 | 0.852 | 0.805 | 0.795 |
| entropy | 0.938 | 0.901 | 0.865 | 0.795 | 0.759 | 0.937 | 0.909 | 0.884 | 0.846 | 0.821 | 0.892 | 0.846 | 0.813 | 0.767 | 0.748 | 0.909 | 0.857 | 0.849 | 0.793 | 0.772 | |
| std | 0.917 | 0.880 | 0.847 | 0.791 | 0.758 | 0.922 | 0.901 | 0.867 | 0.833 | 0.814 | 0.873 | 0.839 | 0.806 | 0.765 | 0.749 | 0.896 | 0.849 | 0.836 | 0.784 | 0.769 | |
| Norm | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | ||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | ||
| (a) | equal | 0.458 | 0.487 | 0.475 | 0.369 | 0.340 | 0.570 | 0.596 | 0.621 | 0.601 | 0.567 | 0.537 | 0.521 | 0.533 | 0.468 | 0.441 | 0.570 | 0.582 | 0.610 | 0.592 | 0.575 |
| entropy | 0.599 | 0.526 | 0.489 | 0.392 | 0.355 | 0.686 | 0.662 | 0.643 | 0.613 | 0.570 | 0.570 | 0.528 | 0.519 | 0.457 | 0.435 | 0.623 | 0.590 | 0.613 | 0.570 | 0.554 | |
| std | 0.549 | 0.493 | 0.474 | 0.374 | 0.343 | 0.622 | 0.624 | 0.621 | 0.605 | 0.567 | 0.540 | 0.511 | 0.520 | 0.463 | 0.441 | 0.593 | 0.571 | 0.599 | 0.584 | 0.571 | |
| (b) | equal | 0.458 | 0.487 | 0.475 | 0.369 | 0.340 | 0.570 | 0.596 | 0.621 | 0.601 | 0.567 | 0.537 | 0.521 | 0.533 | 0.468 | 0.441 | 0.570 | 0.582 | 0.610 | 0.592 | 0.575 |
| entropy | 0.599 | 0.526 | 0.489 | 0.392 | 0.355 | 0.686 | 0.662 | 0.643 | 0.613 | 0.570 | 0.570 | 0.528 | 0.519 | 0.457 | 0.435 | 0.623 | 0.590 | 0.613 | 0.570 | 0.554 | |
| std | 0.549 | 0.493 | 0.474 | 0.374 | 0.343 | 0.622 | 0.624 | 0.621 | 0.605 | 0.567 | 0.540 | 0.511 | 0.520 | 0.463 | 0.441 | 0.593 | 0.571 | 0.599 | 0.584 | 0.571 | |
| (c) | equal | 0.470 | 0.507 | 0.564 | 0.747 | 0.829 | 0.571 | 0.588 | 0.644 | 0.814 | 0.878 | 0.540 | 0.514 | 0.542 | 0.700 | 0.790 | 0.566 | 0.580 | 0.595 | 0.746 | 0.823 |
| entropy | 0.607 | 0.560 | 0.593 | 0.763 | 0.836 | 0.691 | 0.686 | 0.712 | 0.844 | 0.891 | 0.580 | 0.550 | 0.580 | 0.710 | 0.780 | 0.628 | 0.614 | 0.650 | 0.761 | 0.818 | |
| std | 0.558 | 0.531 | 0.580 | 0.754 | 0.832 | 0.627 | 0.639 | 0.675 | 0.828 | 0.883 | 0.533 | 0.515 | 0.549 | 0.675 | 0.755 | 0.588 | 0.564 | 0.606 | 0.726 | 0.789 | |
| (d) | equal | 0.458 | 0.487 | 0.475 | 0.369 | 0.340 | 0.570 | 0.596 | 0.621 | 0.601 | 0.567 | 0.537 | 0.521 | 0.533 | 0.468 | 0.441 | 0.570 | 0.582 | 0.610 | 0.592 | 0.575 |
| entropy | 0.599 | 0.526 | 0.489 | 0.392 | 0.355 | 0.686 | 0.662 | 0.643 | 0.613 | 0.570 | 0.570 | 0.528 | 0.519 | 0.457 | 0.435 | 0.623 | 0.590 | 0.613 | 0.570 | 0.554 | |
| std | 0.549 | 0.493 | 0.474 | 0.374 | 0.343 | 0.622 | 0.624 | 0.621 | 0.605 | 0.567 | 0.540 | 0.511 | 0.520 | 0.463 | 0.441 | 0.593 | 0.571 | 0.599 | 0.584 | 0.571 | |
| (e) | equal | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| entropy | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| std | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| (f) | equal | 0.959 | 0.897 | 0.890 | 0.946 | 0.962 | 0.970 | 0.916 | 0.884 | 0.937 | 0.957 | 0.942 | 0.909 | 0.874 | 0.931 | 0.952 | 0.944 | 0.923 | 0.876 | 0.923 | 0.949 |
| entropy | 0.950 | 0.914 | 0.903 | 0.948 | 0.963 | 0.951 | 0.924 | 0.909 | 0.945 | 0.960 | 0.917 | 0.875 | 0.868 | 0.911 | 0.930 | 0.929 | 0.882 | 0.883 | 0.915 | 0.933 | |
| std | 0.933 | 0.896 | 0.889 | 0.946 | 0.962 | 0.944 | 0.909 | 0.890 | 0.940 | 0.958 | 0.907 | 0.863 | 0.858 | 0.914 | 0.935 | 0.926 | 0.871 | 0.867 | 0.912 | 0.933 | |
| (g) | equal | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| entropy | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| std | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| (h) | equal | 0.959 | 0.897 | 0.890 | 0.946 | 0.962 | 0.970 | 0.916 | 0.884 | 0.937 | 0.957 | 0.942 | 0.909 | 0.874 | 0.931 | 0.952 | 0.944 | 0.923 | 0.876 | 0.923 | 0.949 |
| entropy | 0.950 | 0.914 | 0.903 | 0.948 | 0.963 | 0.951 | 0.924 | 0.909 | 0.945 | 0.960 | 0.917 | 0.875 | 0.868 | 0.911 | 0.930 | 0.929 | 0.882 | 0.883 | 0.915 | 0.933 | |
| std | 0.933 | 0.896 | 0.889 | 0.946 | 0.962 | 0.944 | 0.909 | 0.890 | 0.940 | 0.958 | 0.907 | 0.863 | 0.858 | 0.914 | 0.935 | 0.926 | 0.871 | 0.867 | 0.912 | 0.933 | |
| (i) | equal | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| entropy | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| std | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| (j) | equal | 0.954 | 0.897 | 0.874 | 0.874 | 0.876 | 0.971 | 0.917 | 0.878 | 0.870 | 0.869 | 0.943 | 0.910 | 0.869 | 0.873 | 0.876 | 0.945 | 0.922 | 0.873 | 0.865 | 0.869 |
| entropy | 0.950 | 0.913 | 0.889 | 0.885 | 0.884 | 0.950 | 0.922 | 0.900 | 0.892 | 0.885 | 0.919 | 0.872 | 0.858 | 0.856 | 0.853 | 0.930 | 0.881 | 0.873 | 0.866 | 0.866 | |
| std | 0.934 | 0.894 | 0.872 | 0.877 | 0.878 | 0.944 | 0.908 | 0.882 | 0.879 | 0.875 | 0.906 | 0.863 | 0.849 | 0.862 | 0.865 | 0.928 | 0.869 | 0.865 | 0.866 | 0.865 | |
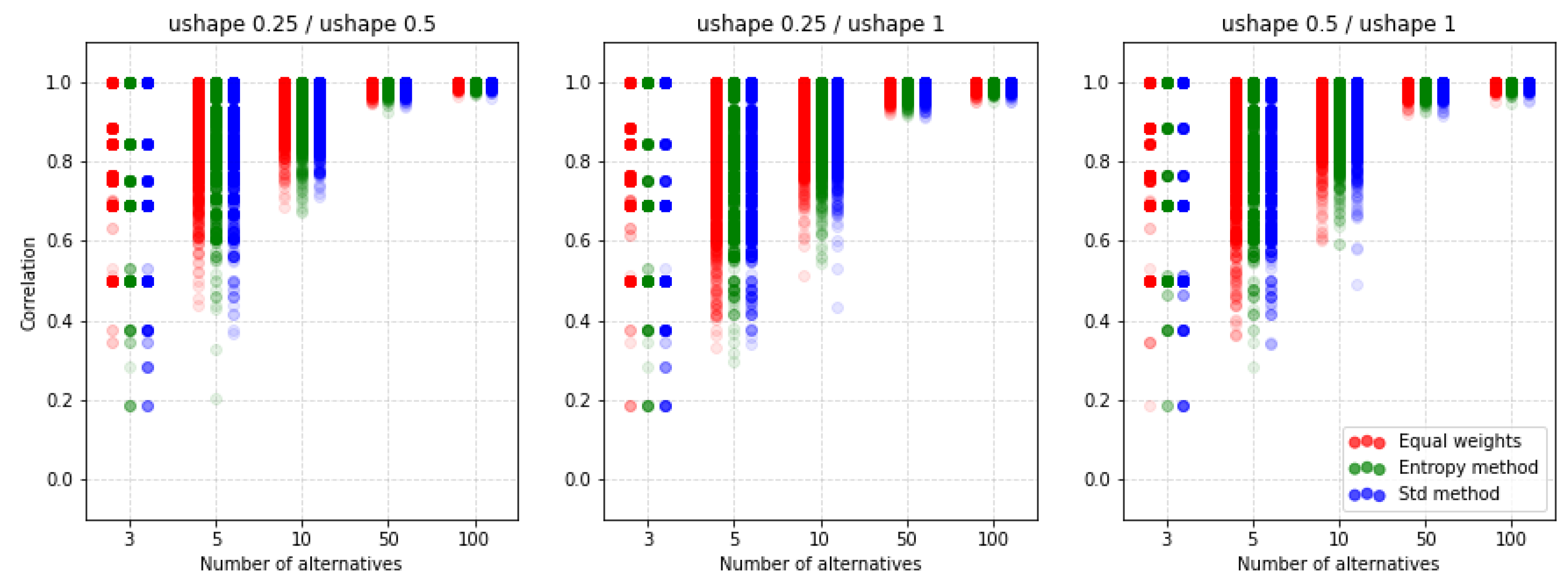
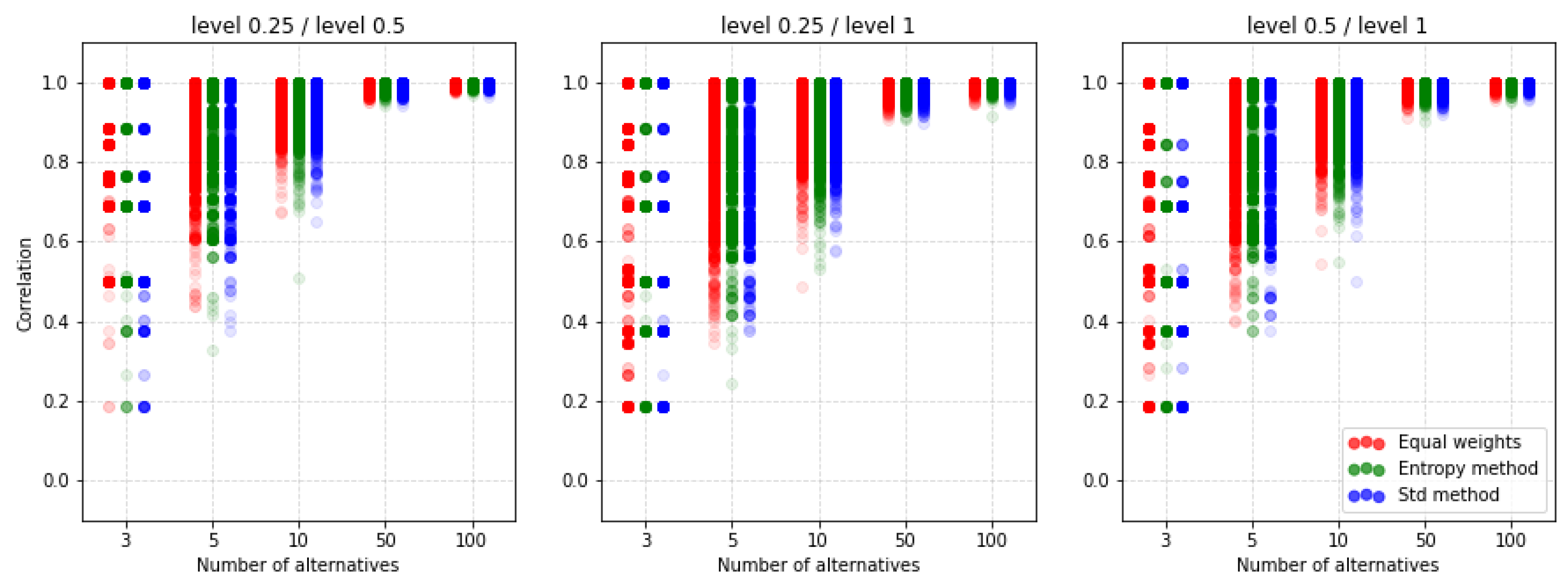
| Type | k | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | |||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | |||
| (a) | 0.25/0.5 | equal | 0.967 | 0.930 | 0.959 | 0.992 | 0.996 | 0.951 | 0.929 | 0.956 | 0.994 | 0.997 | 0.952 | 0.929 | 0.957 | 0.994 | 0.997 | 0.944 | 0.923 | 0.958 | 0.993 | 0.997 |
| entropy | 0.971 | 0.937 | 0.955 | 0.992 | 0.996 | 0.965 | 0.932 | 0.958 | 0.993 | 0.997 | 0.958 | 0.926 | 0.954 | 0.993 | 0.997 | 0.968 | 0.927 | 0.956 | 0.993 | 0.997 | ||
| std | 0.967 | 0.933 | 0.957 | 0.992 | 0.996 | 0.956 | 0.928 | 0.954 | 0.993 | 0.997 | 0.952 | 0.919 | 0.956 | 0.993 | 0.997 | 0.957 | 0.924 | 0.958 | 0.993 | 0.997 | ||
| 0.25/1 | equal | 0.946 | 0.885 | 0.938 | 0.990 | 0.995 | 0.934 | 0.875 | 0.928 | 0.989 | 0.995 | 0.931 | 0.874 | 0.928 | 0.988 | 0.995 | 0.931 | 0.860 | 0.925 | 0.988 | 0.994 | |
| entropy | 0.969 | 0.898 | 0.931 | 0.989 | 0.995 | 0.945 | 0.877 | 0.927 | 0.988 | 0.995 | 0.948 | 0.874 | 0.924 | 0.988 | 0.994 | 0.952 | 0.873 | 0.924 | 0.988 | 0.994 | ||
| std | 0.951 | 0.887 | 0.934 | 0.990 | 0.995 | 0.932 | 0.870 | 0.926 | 0.989 | 0.995 | 0.929 | 0.865 | 0.925 | 0.988 | 0.994 | 0.931 | 0.862 | 0.926 | 0.988 | 0.994 | ||
| 0.5/1 | equal | 0.958 | 0.906 | 0.946 | 0.991 | 0.995 | 0.950 | 0.897 | 0.941 | 0.991 | 0.996 | 0.944 | 0.900 | 0.940 | 0.990 | 0.996 | 0.944 | 0.888 | 0.939 | 0.990 | 0.995 | |
| entropy | 0.973 | 0.915 | 0.943 | 0.991 | 0.995 | 0.952 | 0.902 | 0.941 | 0.990 | 0.996 | 0.956 | 0.899 | 0.935 | 0.990 | 0.995 | 0.961 | 0.894 | 0.939 | 0.990 | 0.995 | ||
| std | 0.964 | 0.906 | 0.945 | 0.991 | 0.995 | 0.944 | 0.892 | 0.941 | 0.991 | 0.996 | 0.949 | 0.889 | 0.937 | 0.990 | 0.996 | 0.946 | 0.889 | 0.939 | 0.991 | 0.995 | ||
| (b) | 0.25/0.5 | equal | 1.000 | 0.991 | 0.994 | 0.999 | 1.000 | 0.996 | 0.990 | 0.994 | 0.999 | 1.000 | 0.997 | 0.992 | 0.994 | 0.999 | 1.000 | 0.993 | 0.985 | 0.994 | 0.999 | 1.000 |
| entropy | 0.996 | 0.993 | 0.995 | 0.999 | 1.000 | 0.997 | 0.992 | 0.995 | 0.999 | 1.000 | 0.997 | 0.992 | 0.994 | 0.999 | 1.000 | 0.994 | 0.991 | 0.994 | 0.999 | 1.000 | ||
| std | 0.995 | 0.991 | 0.995 | 0.999 | 1.000 | 0.996 | 0.991 | 0.994 | 0.999 | 1.000 | 0.994 | 0.990 | 0.994 | 0.999 | 1.000 | 0.995 | 0.990 | 0.994 | 0.999 | 1.000 | ||
| 0.25/1 | equal | 1.000 | 0.980 | 0.989 | 0.998 | 0.999 | 0.995 | 0.980 | 0.984 | 0.998 | 0.999 | 0.992 | 0.980 | 0.985 | 0.998 | 0.999 | 0.987 | 0.977 | 0.986 | 0.998 | 0.999 | |
| entropy | 0.992 | 0.985 | 0.989 | 0.998 | 0.999 | 0.986 | 0.982 | 0.988 | 0.998 | 0.999 | 0.990 | 0.982 | 0.986 | 0.998 | 0.999 | 0.986 | 0.980 | 0.986 | 0.998 | 0.999 | ||
| std | 0.995 | 0.982 | 0.989 | 0.998 | 0.999 | 0.984 | 0.982 | 0.987 | 0.998 | 0.999 | 0.990 | 0.980 | 0.986 | 0.998 | 0.999 | 0.985 | 0.978 | 0.986 | 0.998 | 0.999 | ||
| 0.5/1 | equal | 1.000 | 0.987 | 0.993 | 0.999 | 0.999 | 0.993 | 0.988 | 0.989 | 0.998 | 0.999 | 0.991 | 0.985 | 0.990 | 0.998 | 0.999 | 0.987 | 0.986 | 0.990 | 0.999 | 0.999 | |
| entropy | 0.992 | 0.989 | 0.992 | 0.999 | 0.999 | 0.986 | 0.988 | 0.992 | 0.999 | 0.999 | 0.991 | 0.987 | 0.991 | 0.999 | 0.999 | 0.987 | 0.986 | 0.990 | 0.999 | 0.999 | ||
| std | 0.994 | 0.986 | 0.993 | 0.999 | 1.000 | 0.986 | 0.987 | 0.992 | 0.999 | 0.999 | 0.990 | 0.988 | 0.990 | 0.999 | 0.999 | 0.983 | 0.985 | 0.990 | 0.998 | 0.999 | ||
| (c) | 0.25/0.5 | equal | 0.936 | 0.930 | 0.967 | 0.994 | 0.997 | 0.930 | 0.935 | 0.964 | 0.995 | 0.998 | 0.940 | 0.935 | 0.962 | 0.995 | 0.998 | 0.929 | 0.929 | 0.962 | 0.995 | 0.998 |
| entropy | 0.954 | 0.938 | 0.962 | 0.993 | 0.997 | 0.949 | 0.934 | 0.964 | 0.994 | 0.998 | 0.947 | 0.937 | 0.960 | 0.994 | 0.997 | 0.944 | 0.935 | 0.960 | 0.994 | 0.997 | ||
| std | 0.948 | 0.937 | 0.965 | 0.994 | 0.997 | 0.943 | 0.937 | 0.963 | 0.995 | 0.997 | 0.944 | 0.935 | 0.962 | 0.994 | 0.998 | 0.930 | 0.932 | 0.964 | 0.995 | 0.998 | ||
| 0.25/1 | equal | 0.854 | 0.888 | 0.943 | 0.992 | 0.996 | 0.858 | 0.876 | 0.934 | 0.988 | 0.995 | 0.870 | 0.880 | 0.930 | 0.987 | 0.994 | 0.859 | 0.864 | 0.928 | 0.988 | 0.993 | |
| entropy | 0.942 | 0.898 | 0.935 | 0.991 | 0.996 | 0.917 | 0.886 | 0.931 | 0.988 | 0.996 | 0.901 | 0.878 | 0.924 | 0.987 | 0.993 | 0.900 | 0.873 | 0.926 | 0.987 | 0.993 | ||
| std | 0.904 | 0.889 | 0.939 | 0.991 | 0.996 | 0.871 | 0.877 | 0.930 | 0.988 | 0.995 | 0.873 | 0.876 | 0.929 | 0.987 | 0.994 | 0.867 | 0.868 | 0.928 | 0.987 | 0.993 | ||
| 0.5/1 | equal | 0.862 | 0.909 | 0.952 | 0.993 | 0.996 | 0.876 | 0.899 | 0.946 | 0.991 | 0.996 | 0.879 | 0.903 | 0.945 | 0.990 | 0.995 | 0.874 | 0.891 | 0.941 | 0.990 | 0.995 | |
| entropy | 0.941 | 0.917 | 0.948 | 0.993 | 0.996 | 0.922 | 0.909 | 0.944 | 0.990 | 0.996 | 0.912 | 0.899 | 0.940 | 0.990 | 0.995 | 0.907 | 0.902 | 0.939 | 0.990 | 0.995 | ||
| std | 0.913 | 0.911 | 0.950 | 0.993 | 0.996 | 0.884 | 0.900 | 0.945 | 0.990 | 0.996 | 0.883 | 0.896 | 0.944 | 0.990 | 0.995 | 0.885 | 0.894 | 0.940 | 0.990 | 0.995 | ||
| (d) | 0.25/0.5 | equal | 0.962 | 0.965 | 0.986 | 0.997 | 0.999 | 0.970 | 0.970 | 0.985 | 0.998 | 0.999 | 0.974 | 0.975 | 0.985 | 0.998 | 0.999 | 0.972 | 0.973 | 0.984 | 0.998 | 0.999 |
| entropy | 0.969 | 0.970 | 0.983 | 0.997 | 0.999 | 0.976 | 0.970 | 0.985 | 0.998 | 0.999 | 0.977 | 0.975 | 0.983 | 0.998 | 0.999 | 0.980 | 0.973 | 0.985 | 0.998 | 0.999 | ||
| std | 0.973 | 0.971 | 0.986 | 0.997 | 0.999 | 0.979 | 0.974 | 0.986 | 0.998 | 0.999 | 0.974 | 0.979 | 0.986 | 0.998 | 0.999 | 0.973 | 0.973 | 0.987 | 0.998 | 0.999 | ||
| 0.25/1 | equal | 0.922 | 0.933 | 0.973 | 0.995 | 0.998 | 0.932 | 0.937 | 0.968 | 0.995 | 0.998 | 0.948 | 0.941 | 0.967 | 0.995 | 0.997 | 0.936 | 0.938 | 0.965 | 0.995 | 0.997 | |
| entropy | 0.939 | 0.942 | 0.966 | 0.995 | 0.998 | 0.946 | 0.935 | 0.968 | 0.995 | 0.998 | 0.943 | 0.944 | 0.964 | 0.994 | 0.997 | 0.951 | 0.940 | 0.966 | 0.994 | 0.997 | ||
| std | 0.940 | 0.940 | 0.972 | 0.995 | 0.998 | 0.946 | 0.936 | 0.968 | 0.995 | 0.998 | 0.942 | 0.945 | 0.966 | 0.995 | 0.997 | 0.946 | 0.938 | 0.966 | 0.995 | 0.997 | ||
| 0.5/1 | equal | 0.937 | 0.957 | 0.983 | 0.997 | 0.999 | 0.948 | 0.958 | 0.978 | 0.997 | 0.999 | 0.960 | 0.959 | 0.978 | 0.996 | 0.998 | 0.956 | 0.953 | 0.977 | 0.996 | 0.998 | |
| entropy | 0.963 | 0.964 | 0.978 | 0.997 | 0.999 | 0.964 | 0.956 | 0.978 | 0.997 | 0.999 | 0.962 | 0.959 | 0.976 | 0.996 | 0.998 | 0.968 | 0.960 | 0.976 | 0.996 | 0.998 | ||
| std | 0.961 | 0.961 | 0.980 | 0.997 | 0.999 | 0.960 | 0.956 | 0.977 | 0.997 | 0.998 | 0.961 | 0.960 | 0.977 | 0.996 | 0.998 | 0.964 | 0.958 | 0.976 | 0.996 | 0.998 | ||
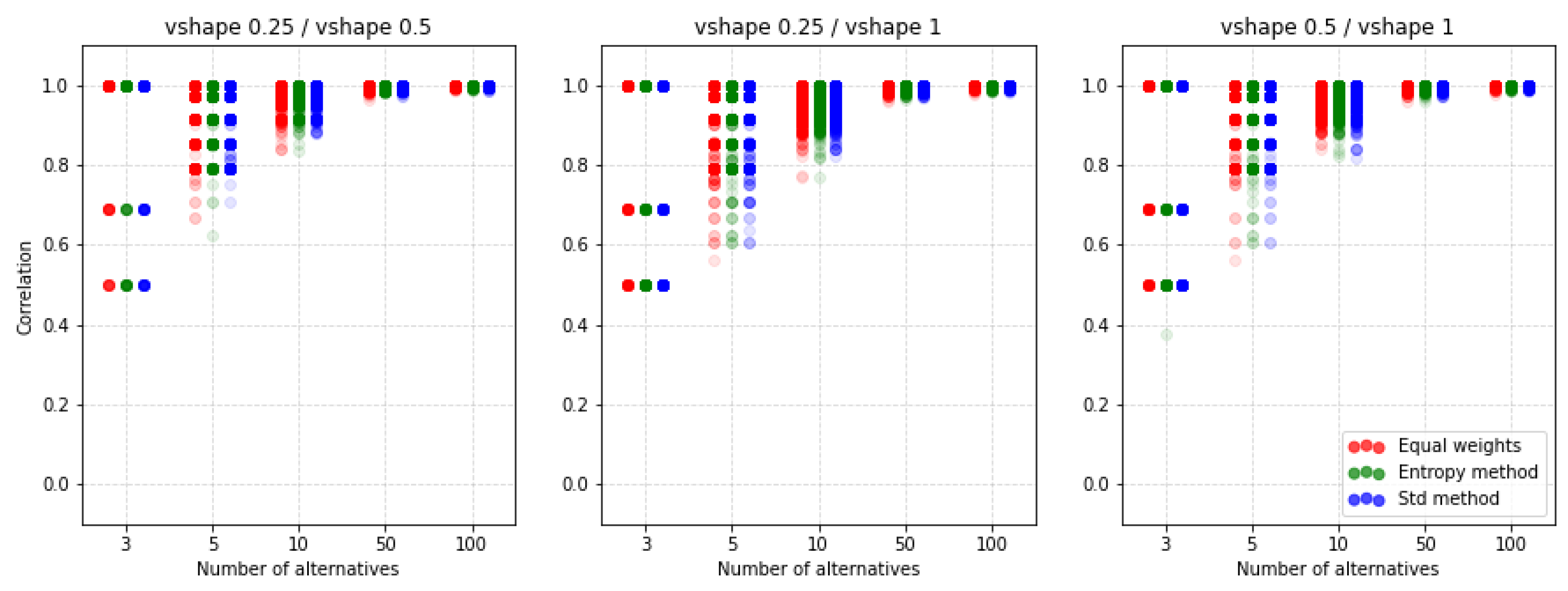
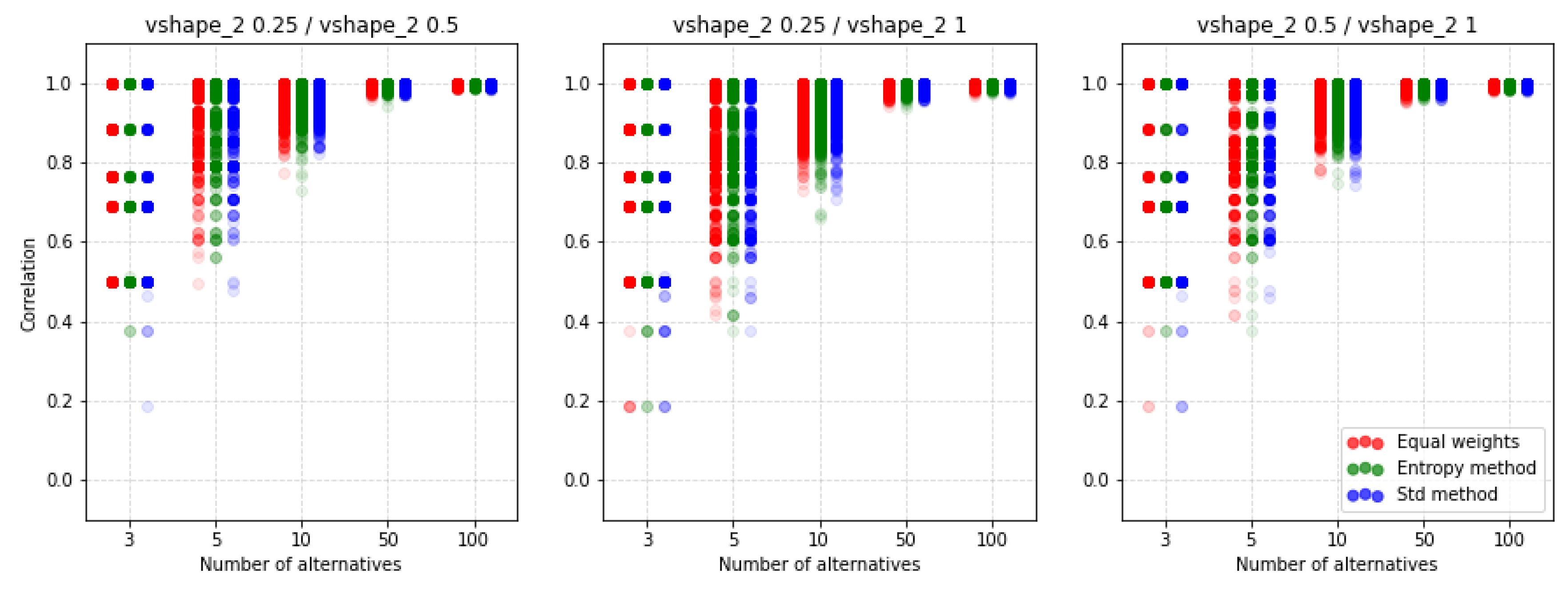
| Type | k | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | |||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | |||
| (a) | 0.25/0.5 | equal | 0.969 | 0.942 | 0.967 | 0.994 | 0.997 | 0.952 | 0.940 | 0.965 | 0.993 | 0.997 | 0.961 | 0.940 | 0.965 | 0.993 | 0.997 | 0.944 | 0.928 | 0.962 | 0.993 | 0.996 |
| entropy | 0.970 | 0.940 | 0.963 | 0.993 | 0.997 | 0.955 | 0.929 | 0.961 | 0.993 | 0.996 | 0.944 | 0.923 | 0.958 | 0.993 | 0.996 | 0.957 | 0.923 | 0.957 | 0.993 | 0.996 | ||
| std | 0.958 | 0.934 | 0.961 | 0.994 | 0.997 | 0.942 | 0.927 | 0.957 | 0.993 | 0.997 | 0.935 | 0.915 | 0.958 | 0.993 | 0.996 | 0.942 | 0.916 | 0.959 | 0.993 | 0.996 | ||
| 0.25/1 | equal | 0.939 | 0.892 | 0.937 | 0.986 | 0.992 | 0.924 | 0.871 | 0.923 | 0.982 | 0.990 | 0.926 | 0.871 | 0.925 | 0.982 | 0.989 | 0.924 | 0.842 | 0.919 | 0.982 | 0.989 | |
| entropy | 0.965 | 0.895 | 0.929 | 0.985 | 0.991 | 0.925 | 0.864 | 0.918 | 0.982 | 0.989 | 0.929 | 0.852 | 0.915 | 0.981 | 0.989 | 0.938 | 0.849 | 0.909 | 0.981 | 0.989 | ||
| std | 0.940 | 0.881 | 0.930 | 0.985 | 0.991 | 0.907 | 0.852 | 0.917 | 0.982 | 0.990 | 0.900 | 0.842 | 0.917 | 0.981 | 0.989 | 0.905 | 0.833 | 0.914 | 0.981 | 0.989 | ||
| 0.5/1 | equal | 0.954 | 0.916 | 0.952 | 0.989 | 0.994 | 0.945 | 0.902 | 0.943 | 0.988 | 0.993 | 0.943 | 0.902 | 0.943 | 0.987 | 0.993 | 0.939 | 0.885 | 0.942 | 0.987 | 0.993 | |
| entropy | 0.968 | 0.918 | 0.946 | 0.989 | 0.994 | 0.938 | 0.899 | 0.938 | 0.987 | 0.993 | 0.941 | 0.884 | 0.935 | 0.987 | 0.993 | 0.947 | 0.879 | 0.933 | 0.987 | 0.993 | ||
| std | 0.955 | 0.906 | 0.946 | 0.989 | 0.994 | 0.925 | 0.883 | 0.939 | 0.987 | 0.993 | 0.928 | 0.876 | 0.937 | 0.987 | 0.993 | 0.927 | 0.875 | 0.936 | 0.987 | 0.993 | ||
| (b) | 0.25/0.5 | equal | 1.000 | 0.992 | 0.996 | 1.000 | 1.000 | 0.995 | 0.991 | 0.996 | 1.000 | 1.000 | 0.997 | 0.993 | 0.996 | 0.999 | 1.000 | 0.992 | 0.987 | 0.996 | 0.999 | 1.000 |
| entropy | 0.995 | 0.994 | 0.997 | 1.000 | 1.000 | 0.996 | 0.993 | 0.996 | 0.999 | 1.000 | 0.997 | 0.993 | 0.996 | 0.999 | 1.000 | 0.993 | 0.992 | 0.996 | 0.999 | 1.000 | ||
| std | 0.994 | 0.992 | 0.996 | 1.000 | 1.000 | 0.995 | 0.992 | 0.996 | 0.999 | 1.000 | 0.993 | 0.991 | 0.996 | 1.000 | 1.000 | 0.994 | 0.991 | 0.996 | 0.999 | 1.000 | ||
| 0.25/1 | equal | 1.000 | 0.982 | 0.991 | 0.999 | 1.000 | 0.994 | 0.982 | 0.989 | 0.999 | 0.999 | 0.990 | 0.981 | 0.990 | 0.999 | 0.999 | 0.984 | 0.979 | 0.989 | 0.999 | 0.999 | |
| entropy | 0.991 | 0.987 | 0.993 | 0.999 | 1.000 | 0.983 | 0.983 | 0.991 | 0.999 | 0.999 | 0.988 | 0.983 | 0.990 | 0.999 | 0.999 | 0.983 | 0.981 | 0.989 | 0.999 | 0.999 | ||
| std | 0.994 | 0.984 | 0.991 | 0.999 | 1.000 | 0.981 | 0.984 | 0.991 | 0.999 | 0.999 | 0.988 | 0.981 | 0.990 | 0.999 | 0.999 | 0.981 | 0.981 | 0.990 | 0.999 | 0.999 | ||
| 0.5/1 | equal | 1.000 | 0.989 | 0.995 | 0.999 | 1.000 | 0.992 | 0.989 | 0.993 | 0.999 | 1.000 | 0.990 | 0.987 | 0.994 | 0.999 | 1.000 | 0.984 | 0.987 | 0.993 | 0.999 | 1.000 | |
| entropy | 0.990 | 0.990 | 0.995 | 0.999 | 1.000 | 0.983 | 0.989 | 0.994 | 0.999 | 1.000 | 0.989 | 0.988 | 0.994 | 0.999 | 1.000 | 0.983 | 0.988 | 0.993 | 0.999 | 1.000 | ||
| std | 0.992 | 0.988 | 0.995 | 0.999 | 1.000 | 0.982 | 0.989 | 0.994 | 0.999 | 1.000 | 0.987 | 0.989 | 0.993 | 0.999 | 1.000 | 0.979 | 0.987 | 0.993 | 0.999 | 1.000 | ||
| (c) | 0.25/0.5 | equal | 0.940 | 0.941 | 0.974 | 0.995 | 0.998 | 0.930 | 0.943 | 0.971 | 0.995 | 0.997 | 0.944 | 0.945 | 0.970 | 0.995 | 0.997 | 0.926 | 0.935 | 0.968 | 0.995 | 0.997 |
| entropy | 0.947 | 0.941 | 0.969 | 0.995 | 0.997 | 0.932 | 0.936 | 0.968 | 0.995 | 0.997 | 0.932 | 0.935 | 0.965 | 0.994 | 0.997 | 0.926 | 0.932 | 0.965 | 0.994 | 0.997 | ||
| std | 0.933 | 0.940 | 0.969 | 0.995 | 0.998 | 0.926 | 0.937 | 0.967 | 0.995 | 0.997 | 0.926 | 0.935 | 0.966 | 0.994 | 0.997 | 0.902 | 0.927 | 0.967 | 0.994 | 0.997 | ||
| 0.25/1 | equal | 0.802 | 0.893 | 0.944 | 0.985 | 0.990 | 0.827 | 0.867 | 0.930 | 0.981 | 0.987 | 0.841 | 0.874 | 0.929 | 0.980 | 0.986 | 0.812 | 0.848 | 0.924 | 0.980 | 0.986 | |
| entropy | 0.924 | 0.894 | 0.935 | 0.983 | 0.989 | 0.884 | 0.871 | 0.923 | 0.979 | 0.986 | 0.856 | 0.859 | 0.919 | 0.979 | 0.986 | 0.858 | 0.849 | 0.914 | 0.979 | 0.985 | ||
| std | 0.865 | 0.882 | 0.937 | 0.984 | 0.989 | 0.815 | 0.860 | 0.924 | 0.980 | 0.987 | 0.815 | 0.858 | 0.923 | 0.979 | 0.986 | 0.806 | 0.841 | 0.920 | 0.979 | 0.986 | ||
| 0.5/1 | equal | 0.807 | 0.918 | 0.958 | 0.989 | 0.993 | 0.854 | 0.902 | 0.948 | 0.987 | 0.992 | 0.855 | 0.904 | 0.948 | 0.987 | 0.991 | 0.844 | 0.888 | 0.943 | 0.987 | 0.991 | |
| entropy | 0.921 | 0.918 | 0.951 | 0.988 | 0.993 | 0.893 | 0.902 | 0.944 | 0.986 | 0.991 | 0.877 | 0.888 | 0.940 | 0.986 | 0.991 | 0.873 | 0.889 | 0.937 | 0.986 | 0.991 | ||
| std | 0.876 | 0.908 | 0.952 | 0.988 | 0.993 | 0.834 | 0.895 | 0.945 | 0.987 | 0.991 | 0.831 | 0.887 | 0.944 | 0.986 | 0.991 | 0.830 | 0.881 | 0.940 | 0.986 | 0.991 | ||
| (d) | 0.25/0.5 | equal | 0.966 | 0.970 | 0.988 | 0.999 | 0.999 | 0.971 | 0.973 | 0.988 | 0.998 | 0.999 | 0.973 | 0.978 | 0.988 | 0.998 | 0.999 | 0.968 | 0.976 | 0.988 | 0.998 | 0.999 |
| entropy | 0.965 | 0.974 | 0.988 | 0.999 | 0.999 | 0.970 | 0.973 | 0.989 | 0.998 | 0.999 | 0.972 | 0.977 | 0.988 | 0.998 | 0.999 | 0.975 | 0.976 | 0.989 | 0.998 | 0.999 | ||
| std | 0.972 | 0.974 | 0.989 | 0.999 | 0.999 | 0.975 | 0.976 | 0.989 | 0.999 | 0.999 | 0.967 | 0.981 | 0.988 | 0.998 | 0.999 | 0.966 | 0.975 | 0.990 | 0.998 | 0.999 | ||
| 0.25/1 | equal | 0.924 | 0.935 | 0.976 | 0.996 | 0.998 | 0.924 | 0.937 | 0.972 | 0.995 | 0.997 | 0.941 | 0.942 | 0.970 | 0.995 | 0.997 | 0.921 | 0.938 | 0.970 | 0.995 | 0.997 | |
| entropy | 0.933 | 0.946 | 0.973 | 0.995 | 0.997 | 0.932 | 0.935 | 0.972 | 0.995 | 0.997 | 0.929 | 0.945 | 0.968 | 0.994 | 0.997 | 0.936 | 0.939 | 0.970 | 0.994 | 0.997 | ||
| std | 0.934 | 0.943 | 0.975 | 0.996 | 0.998 | 0.935 | 0.936 | 0.972 | 0.995 | 0.997 | 0.927 | 0.946 | 0.970 | 0.994 | 0.997 | 0.928 | 0.937 | 0.971 | 0.995 | 0.997 | ||
| 0.5/1 | equal | 0.929 | 0.958 | 0.985 | 0.998 | 0.999 | 0.936 | 0.959 | 0.983 | 0.997 | 0.998 | 0.950 | 0.961 | 0.982 | 0.997 | 0.998 | 0.945 | 0.955 | 0.982 | 0.997 | 0.998 | |
| entropy | 0.958 | 0.967 | 0.984 | 0.997 | 0.999 | 0.954 | 0.959 | 0.982 | 0.997 | 0.998 | 0.953 | 0.960 | 0.981 | 0.997 | 0.998 | 0.960 | 0.960 | 0.980 | 0.997 | 0.998 | ||
| std | 0.956 | 0.965 | 0.984 | 0.997 | 0.999 | 0.950 | 0.958 | 0.982 | 0.997 | 0.998 | 0.952 | 0.962 | 0.981 | 0.997 | 0.998 | 0.953 | 0.960 | 0.981 | 0.997 | 0.998 | ||
| Method | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | ||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | ||
| (a) | equal | 0.060 | −0.009 | −0.024 | −0.025 | −0.029 | 0.181 | 0.261 | 0.272 | 0.300 | 0.296 | 0.030 | −0.019 | −0.003 | −0.014 | −0.011 | 0.135 | 0.133 | 0.148 | 0.165 | 0.170 |
| entropy | 0.018 | −0.024 | −0.033 | −0.010 | −0.023 | 0.307 | 0.330 | 0.317 | 0.326 | 0.294 | 0.011 | −0.025 | −0.002 | −0.014 | −0.004 | 0.182 | 0.156 | 0.207 | 0.159 | 0.157 | |
| std | 0.024 | −0.034 | −0.032 | −0.021 | −0.030 | 0.246 | 0.304 | 0.277 | 0.307 | 0.290 | 0.011 | −0.028 | −0.013 | −0.015 | −0.008 | 0.166 | 0.128 | 0.167 | 0.158 | 0.167 | |
| (b) | equal | 0.891 | 0.889 | 0.934 | 0.985 | 0.992 | 0.896 | 0.879 | 0.919 | 0.982 | 0.990 | 0.881 | 0.876 | 0.925 | 0.983 | 0.990 | 0.860 | 0.872 | 0.922 | 0.983 | 0.991 |
| entropy | 0.900 | 0.898 | 0.936 | 0.980 | 0.988 | 0.850 | 0.866 | 0.913 | 0.969 | 0.983 | 0.837 | 0.848 | 0.899 | 0.967 | 0.980 | 0.790 | 0.831 | 0.883 | 0.965 | 0.980 | |
| std | 0.848 | 0.865 | 0.925 | 0.983 | 0.990 | 0.789 | 0.852 | 0.907 | 0.977 | 0.988 | 0.798 | 0.836 | 0.904 | 0.977 | 0.987 | 0.771 | 0.821 | 0.903 | 0.978 | 0.988 | |
| (c) | equal | 0.754 | 0.832 | 0.853 | 0.873 | 0.872 | 0.735 | 0.803 | 0.852 | 0.884 | 0.885 | 0.751 | 0.851 | 0.906 | 0.944 | 0.948 | 0.760 | 0.835 | 0.905 | 0.941 | 0.946 |
| entropy | 0.919 | 0.900 | 0.874 | 0.869 | 0.868 | 0.914 | 0.880 | 0.867 | 0.877 | 0.880 | 0.912 | 0.889 | 0.910 | 0.938 | 0.944 | 0.900 | 0.884 | 0.903 | 0.934 | 0.941 | |
| std | 0.839 | 0.860 | 0.859 | 0.871 | 0.870 | 0.847 | 0.840 | 0.855 | 0.881 | 0.884 | 0.854 | 0.875 | 0.909 | 0.942 | 0.947 | 0.855 | 0.860 | 0.909 | 0.939 | 0.944 | |
| (d) | equal | 0.173 | 0.044 | −0.011 | −0.028 | −0.029 | 0.209 | 0.259 | 0.266 | 0.293 | 0.292 | 0.084 | 0.004 | −0.003 | −0.018 | −0.017 | 0.169 | 0.150 | 0.149 | 0.159 | 0.164 |
| entropy | 0.019 | −0.019 | −0.031 | −0.016 | −0.025 | 0.269 | 0.310 | 0.298 | 0.313 | 0.288 | 0.010 | −0.039 | −0.004 | −0.017 | −0.012 | 0.167 | 0.127 | 0.180 | 0.150 | 0.152 | |
| std | 0.004 | −0.017 | −0.026 | −0.025 | −0.030 | 0.197 | 0.271 | 0.264 | 0.298 | 0.287 | −0.006 | −0.021 | −0.020 | −0.017 | −0.014 | 0.144 | 0.110 | 0.155 | 0.153 | 0.162 | |
| (e) | equal | 0.014 | −0.018 | 0.002 | 0.085 | 0.124 | 0.113 | 0.171 | 0.218 | 0.305 | 0.324 | −0.003 | −0.039 | −0.005 | −0.009 | −0.003 | 0.115 | 0.080 | 0.113 | 0.138 | 0.142 |
| entropy | 0.005 | −0.010 | 0.014 | 0.098 | 0.130 | 0.289 | 0.305 | 0.306 | 0.345 | 0.337 | 0.002 | −0.040 | 0.002 | −0.007 | 0.003 | 0.181 | 0.127 | 0.177 | 0.138 | 0.139 | |
| std | 0.006 | −0.021 | 0.003 | 0.089 | 0.125 | 0.233 | 0.247 | 0.248 | 0.317 | 0.325 | −0.022 | −0.041 | −0.011 | −0.007 | 0.000 | 0.133 | 0.098 | 0.133 | 0.135 | 0.142 | |
| (f) | equal | 0.776 | 0.820 | 0.853 | 0.882 | 0.883 | 0.742 | 0.778 | 0.832 | 0.883 | 0.889 | 0.764 | 0.818 | 0.879 | 0.940 | 0.949 | 0.741 | 0.793 | 0.871 | 0.935 | 0.945 |
| entropy | 0.895 | 0.877 | 0.877 | 0.885 | 0.884 | 0.857 | 0.836 | 0.859 | 0.887 | 0.890 | 0.855 | 0.847 | 0.890 | 0.942 | 0.950 | 0.811 | 0.838 | 0.883 | 0.938 | 0.946 | |
| std | 0.811 | 0.826 | 0.854 | 0.882 | 0.883 | 0.767 | 0.793 | 0.836 | 0.884 | 0.889 | 0.774 | 0.826 | 0.878 | 0.940 | 0.949 | 0.758 | 0.799 | 0.871 | 0.936 | 0.945 | |
| Method | Weighting Method | 2 Criteria | 3 Criteria | 4 Criteria | 5 Criteria | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alternatives | Alternatives | Alternatives | Alternatives | ||||||||||||||||||
| 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | 3 | 5 | 10 | 50 | 100 | ||
| (a) | equal | 0.463 | 0.465 | 0.464 | 0.374 | 0.339 | 0.561 | 0.569 | 0.592 | 0.590 | 0.561 | 0.528 | 0.489 | 0.495 | 0.442 | 0.420 | 0.562 | 0.546 | 0.563 | 0.566 | 0.558 |
| entropy | 0.596 | 0.520 | 0.490 | 0.403 | 0.357 | 0.672 | 0.652 | 0.638 | 0.614 | 0.569 | 0.569 | 0.527 | 0.512 | 0.452 | 0.424 | 0.611 | 0.588 | 0.611 | 0.560 | 0.542 | |
| std | 0.540 | 0.477 | 0.466 | 0.380 | 0.342 | 0.611 | 0.604 | 0.598 | 0.596 | 0.561 | 0.519 | 0.494 | 0.490 | 0.443 | 0.423 | 0.573 | 0.544 | 0.571 | 0.559 | 0.555 | |
| (b) | equal | 0.873 | 0.876 | 0.933 | 0.990 | 0.995 | 0.903 | 0.878 | 0.924 | 0.988 | 0.994 | 0.884 | 0.876 | 0.924 | 0.986 | 0.993 | 0.875 | 0.879 | 0.926 | 0.985 | 0.992 |
| entropy | 0.919 | 0.905 | 0.933 | 0.990 | 0.995 | 0.885 | 0.881 | 0.924 | 0.987 | 0.994 | 0.880 | 0.872 | 0.914 | 0.985 | 0.993 | 0.851 | 0.857 | 0.906 | 0.983 | 0.992 | |
| std | 0.876 | 0.879 | 0.932 | 0.990 | 0.995 | 0.847 | 0.873 | 0.923 | 0.988 | 0.994 | 0.859 | 0.860 | 0.916 | 0.986 | 0.993 | 0.842 | 0.854 | 0.916 | 0.985 | 0.992 | |
| (c) | equal | 0.822 | 0.857 | 0.881 | 0.941 | 0.955 | 0.821 | 0.840 | 0.879 | 0.935 | 0.947 | 0.830 | 0.873 | 0.912 | 0.958 | 0.965 | 0.836 | 0.861 | 0.911 | 0.954 | 0.962 |
| entropy | 0.938 | 0.910 | 0.900 | 0.942 | 0.955 | 0.935 | 0.898 | 0.897 | 0.937 | 0.948 | 0.933 | 0.903 | 0.918 | 0.958 | 0.966 | 0.922 | 0.896 | 0.914 | 0.955 | 0.963 | |
| std | 0.890 | 0.879 | 0.887 | 0.941 | 0.955 | 0.891 | 0.867 | 0.882 | 0.935 | 0.947 | 0.891 | 0.890 | 0.915 | 0.957 | 0.965 | 0.891 | 0.877 | 0.914 | 0.955 | 0.963 | |
| (d) | equal | 0.492 | 0.505 | 0.523 | 0.510 | 0.507 | 0.567 | 0.586 | 0.642 | 0.730 | 0.745 | 0.532 | 0.500 | 0.522 | 0.506 | 0.508 | 0.556 | 0.549 | 0.586 | 0.632 | 0.644 |
| entropy | 0.626 | 0.544 | 0.520 | 0.512 | 0.506 | 0.674 | 0.639 | 0.651 | 0.725 | 0.737 | 0.570 | 0.515 | 0.525 | 0.508 | 0.508 | 0.601 | 0.564 | 0.601 | 0.624 | 0.635 | |
| std | 0.578 | 0.506 | 0.519 | 0.511 | 0.507 | 0.595 | 0.609 | 0.642 | 0.730 | 0.744 | 0.521 | 0.508 | 0.520 | 0.507 | 0.509 | 0.567 | 0.549 | 0.590 | 0.630 | 0.643 | |
| (e) | equal | 0.481 | 0.545 | 0.604 | 0.701 | 0.741 | 0.547 | 0.595 | 0.682 | 0.806 | 0.838 | 0.518 | 0.516 | 0.570 | 0.627 | 0.657 | 0.562 | 0.553 | 0.612 | 0.703 | 0.730 |
| entropy | 0.604 | 0.564 | 0.598 | 0.700 | 0.740 | 0.676 | 0.670 | 0.706 | 0.809 | 0.836 | 0.573 | 0.540 | 0.575 | 0.625 | 0.653 | 0.619 | 0.594 | 0.642 | 0.701 | 0.728 | |
| std | 0.562 | 0.547 | 0.600 | 0.702 | 0.741 | 0.617 | 0.634 | 0.690 | 0.808 | 0.838 | 0.531 | 0.520 | 0.570 | 0.627 | 0.658 | 0.579 | 0.566 | 0.622 | 0.703 | 0.730 | |
| (f) | equal | 0.777 | 0.831 | 0.882 | 0.945 | 0.958 | 0.804 | 0.824 | 0.875 | 0.940 | 0.951 | 0.811 | 0.845 | 0.898 | 0.959 | 0.967 | 0.807 | 0.836 | 0.894 | 0.956 | 0.965 |
| entropy | 0.919 | 0.893 | 0.898 | 0.945 | 0.958 | 0.893 | 0.864 | 0.892 | 0.942 | 0.952 | 0.890 | 0.870 | 0.905 | 0.960 | 0.967 | 0.861 | 0.861 | 0.899 | 0.957 | 0.966 | |
| std | 0.870 | 0.850 | 0.880 | 0.944 | 0.958 | 0.837 | 0.836 | 0.877 | 0.940 | 0.951 | 0.840 | 0.854 | 0.898 | 0.958 | 0.967 | 0.834 | 0.843 | 0.893 | 0.957 | 0.965 | |
References
- Greco, S.; Figueira, J.; Ehrgott, M. Multiple Criteria Decision Analysis; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Roy, B. Multicriteria Methodology for Decision Aiding; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 12. [Google Scholar]
- Kodikara, P.N. Multi-Objective Optimal Operation of Urban Water Supply Systems. Ph.D. Thesis, Victoria University, Footscray, Australia, 2008. [Google Scholar]
- Mulliner, E.; Malys, N.; Maliene, V. Comparative analysis of MCDM methods for the assessment of sustainable housing affordability. Omega 2016, 59, 146–156. [Google Scholar] [CrossRef]
- Tzeng, G.H.; Chiang, C.H.; Li, C.W. Evaluating intertwined effects in e-learning programs: A novel hybrid MCDM model based on factor analysis and DEMATEL. Expert Syst. Appl. 2007, 32, 1028–1044. [Google Scholar] [CrossRef]
- Deveci, M.; Özcan, E.; John, R.; Covrig, C.F.; Pamucar, D. A study on offshore wind farm siting criteria using a novel interval-valued fuzzy-rough based Delphi method. J. Environ. Manag. 2020, 270, 110916. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar] [CrossRef]
- Zopounidis, C.; Doumpos, M. Multicriteria classification and sorting methods: A literature review. Eur. J. Oper. Res. 2002, 138, 229–246. [Google Scholar] [CrossRef]
- Behzadian, M.; Otaghsara, S.K.; Yazdani, M.; Ignatius, J. A state-of the-art survey of TOPSIS applications. Expert Syst. Appl. 2012, 39, 13051–13069. [Google Scholar] [CrossRef]
- Palczewski, K.; Sałabun, W. The fuzzy TOPSIS applications in the last decade. Procedia Comput. Sci. 2019, 159, 2294–2303. [Google Scholar] [CrossRef]
- Sałabun, W. The mean error estimation of TOPSIS method using a fuzzy reference models. J. Theor. Appl. Comput. Sci. 2013, 7, 40–50. [Google Scholar]
- Opricovic, S.; Tzeng, G.H. Extended VIKOR method in comparison with outranking methods. Eur. J. Oper. Res. 2007, 178, 514–529. [Google Scholar] [CrossRef]
- Saaty, T. The Analytic Hierarchy Process; Mcgraw Hill: New York, NY, USA, 1980. [Google Scholar]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Kaklauskas, A.; Peldschus, F.; Turskis, Z. Multi-attribute assessment of road design solutions by using the COPRAS method. Balt. J. Road Bridge Eng. 2007, 2, 195–203. [Google Scholar]
- Govindan, K.; Jepsen, M.B. ELECTRE: A comprehensive literature review on methodologies and applications. Eur. J. Oper. Res. 2016, 250, 1–29. [Google Scholar] [CrossRef]
- Hashemi, S.S.; Hajiagha, S.H.R.; Zavadskas, E.K.; Mahdiraji, H.A. Multicriteria group decision making with ELECTRE III method based on interval-valued intuitionistic fuzzy information. Appl. Math. Model. 2016, 40, 1554–1564. [Google Scholar] [CrossRef]
- Brans, J.P.; Vincke, P.; Mareschal, B. How to select and how to rank projects: The PROMETHEE method. Eur. J. Oper. Res. 1986, 24, 228–238. [Google Scholar] [CrossRef]
- Uhde, B.; Hahn, W.A.; Griess, V.C.; Knoke, T. Hybrid MCDA methods to integrate multiple ecosystem services in forest management planning: A critical review. Environ. Manag. 2015, 56, 373–388. [Google Scholar] [CrossRef] [PubMed]
- Wątróbski, J.; Jankowski, J.; Ziemba, P.; Karczmarczyk, A.; Zioło, M. Generalised framework for multi-criteria method selection: Rule set database and exemplary decision support system implementation blueprints. Data Brief 2019, 22, 639. [Google Scholar] [CrossRef]
- Więckowski, J.; Kizielewicz, B.; Kołodziejczyk, J. Application of Hill Climbing Algorithm in Determining the Characteristic Objects Preferences Based on the Reference Set of Alternatives. In Proceedings of the International Conference on Intelligent Decision Technologies; Springer: Berlin/Heidelberg, Germany, 2020; pp. 341–351. [Google Scholar]
- Wątróbski, J.; Jankowski, J.; Ziemba, P.; Karczmarczyk, A.; Zioło, M. Generalised framework for multi-criteria method selection. Omega 2019, 86, 107–124. [Google Scholar] [CrossRef]
- Guitouni, A.; Martel, J.M. Tentative guidelines to help choosing an appropriate MCDA method. Eur. J. Oper. Res. 1998, 109, 501–521. [Google Scholar] [CrossRef]
- Zanakis, S.H.; Solomon, A.; Wishart, N.; Dublish, S. Multi-attribute decision making: A simulation comparison of select methods. Eur. J. Oper. Res. 1998, 107, 507–529. [Google Scholar] [CrossRef]
- Gershon, M. The role of weights and scales in the application of multiobjective decision making. Eur. J. Oper. Res. 1984, 15, 244–250. [Google Scholar] [CrossRef]
- Cinelli, M.; Kadziński, M.; Gonzalez, M.; Słowiński, R. How to Support the Application of Multiple Criteria Decision Analysis? Let Us Start with a Comprehensive Taxonomy. Omega 2020, 96, 102261. [Google Scholar] [CrossRef]
- Hanne, T. Meta decision problems in multiple criteria decision making. In Multicriteria Decision Making; Springer: Berlin/Heidelberg, Germany, 1999; pp. 147–171. [Google Scholar]
- Wang, X.; Triantaphyllou, E. Ranking irregularities when evaluating alternatives by using some ELECTRE methods. Omega 2008, 36, 45–63. [Google Scholar] [CrossRef]
- Chang, Y.H.; Yeh, C.H.; Chang, Y.W. A new method selection approach for fuzzy group multicriteria decision making. Appl. Soft Comput. 2013, 13, 2179–2187. [Google Scholar] [CrossRef]
- Hajkowicz, S.; Higgins, A. A comparison of multiple criteria analysis techniques for water resource management. Eur. J. Oper. Res. 2008, 184, 255–265. [Google Scholar] [CrossRef]
- Zak, J. The comparison of multiobjective ranking methods applied to solve the mass transit systems’ decision problems. In Proceedings of the 10th Jubilee Meeting of the EURO Working Group on Transportation, Poznan, Poland, 13–16 September 2005; pp. 13–16. [Google Scholar]
- Pamučar, D.; Stević, Ž.; Sremac, S. A new model for determining weight coefficients of criteria in mcdm models: Full consistency method (fucom). Symmetry 2018, 10, 393. [Google Scholar] [CrossRef]
- Zardari, N.H.; Ahmed, K.; Shirazi, S.M.; Yusop, Z.B. Weighting Methods and Their Effects on Multi-Criteria Decision Making Model Outcomes in Water Resources Management; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Wątróbski, J.; Ziemba, E.; Karczmarczyk, A.; Jankowski, J. An index to measure the sustainable information society: The Polish households case. Sustainability 2018, 10, 3223. [Google Scholar] [CrossRef]
- Sałabun, W.; Palczewski, K.; Wątróbski, J. Multicriteria approach to sustainable transport evaluation under incomplete knowledge: Electric bikes case study. Sustainability 2019, 11, 3314. [Google Scholar] [CrossRef]
- Wątróbski, J.; Sałabun, W. Green supplier selection framework based on multi-criteria decision-analysis approach. In Proceedings of the International Conference on Sustainable Design and Manufacturing; Springer: Berlin/Heidelberg, Germany, 2016; pp. 361–371. [Google Scholar]
- Alimardani, M.; Hashemkhani Zolfani, S.; Aghdaie, M.H.; Tamošaitienė, J. A novel hybrid SWARA and VIKOR methodology for supplier selection in an agile environment. Technol. Econ. Dev. Econ. 2013, 19, 533–548. [Google Scholar] [CrossRef]
- Chu, T.C. Selecting plant location via a fuzzy TOPSIS approach. Int. J. Adv. Manuf. Technol. 2002, 20, 859–864. [Google Scholar] [CrossRef]
- Madić, M.; Marković, D.; Petrović, G.; Radovanović, M. Application of COPRAS method for supplier selection. In The Fifth International Conference Transport and Logistics-TIL 2014; Proceedings: Niš, Serbia, 2014; pp. 47–50. [Google Scholar]
- Elevli, B. Logistics freight center locations decision by using Fuzzy-PROMETHEE. Transport 2014, 29, 412–418. [Google Scholar] [CrossRef]
- Stević, Ž.; Pamučar, D.; Puška, A.; Chatterjee, P. Sustainable supplier selection in healthcare industries using a new MCDM method: Measurement of alternatives and ranking according to COmpromise solution (MARCOS). Comput. Ind. Eng. 2020, 140, 106231. [Google Scholar] [CrossRef]
- Ahmadi, A.; Gupta, S.; Karim, R.; Kumar, U. Selection of maintenance strategy for aircraft systems using multi-criteria decision making methodologies. Int. J. Reliab. Qual. Saf. Eng. 2010, 17, 223–243. [Google Scholar] [CrossRef]
- Venkata Rao, R. Evaluating flexible manufacturing systems using a combined multiple attribute decision making method. Int. J. Prod. Res. 2008, 46, 1975–1989. [Google Scholar] [CrossRef]
- Aghdaie, M.H.; Zolfani, S.H.; Zavadskas, E.K. Decision making in machine tool selection: An integrated approach with SWARA and COPRAS-G methods. Eng. Econ. 2013, 24, 5–17. [Google Scholar]
- Hashemi, H.; Bazargan, J.; Mousavi, S.M. A compromise ratio method with an application to water resources management: An intuitionistic fuzzy set. Water Resour. Manag. 2013, 27, 2029–2051. [Google Scholar] [CrossRef]
- Liu, C.; Frazier, P.; Kumar, L.; Macgregor, C.; Blake, N. Catchment-wide wetland assessment and prioritization using the multi-criteria decision-making method TOPSIS. Environ. Manag. 2006, 38, 316–326. [Google Scholar] [CrossRef] [PubMed]
- Roozbahani, A.; Ghased, H.; Hashemy Shahedany, M. Inter-basin water transfer planning with grey COPRAS and fuzzy COPRAS techniques: A case study in Iranian Central Plateau. Sci. Total Environ. 2020, 726, 138499. [Google Scholar] [CrossRef]
- Kapepula, K.M.; Colson, G.; Sabri, K.; Thonart, P. A multiple criteria analysis for household solid waste management in the urban community of Dakar. Waste Manag. 2007, 27, 1690–1705. [Google Scholar] [CrossRef]
- Carnero, M.C. Waste Segregation FMEA Model Integrating Intuitionistic Fuzzy Set and the PAPRIKA Method. Mathematics 2020, 8, 1375. [Google Scholar] [CrossRef]
- Boran, F.; Boran, K.; Menlik, T. The evaluation of renewable energy technologies for electricity generation in Turkey using intuitionistic fuzzy TOPSIS. Energy Sources Part B Econ. Plan. Policy 2012, 7, 81–90. [Google Scholar] [CrossRef]
- Kaya, T.; Kahraman, C. Multicriteria renewable energy planning using an integrated fuzzy VIKOR & AHP methodology: The case of Istanbul. Energy 2010, 35, 2517–2527. [Google Scholar]
- Krishankumar, R.; Ravichandran, K.; Kar, S.; Cavallaro, F.; Zavadskas, E.K.; Mardani, A. Scientific decision framework for evaluation of renewable energy sources under q-rung orthopair fuzzy set with partially known weight information. Sustainability 2019, 11, 4202. [Google Scholar] [CrossRef]
- Rehman, A.U.; Abidi, M.H.; Umer, U.; Usmani, Y.S. Multi-Criteria Decision-Making Approach for Selecting Wind Energy Power Plant Locations. Sustainability 2019, 11, 6112. [Google Scholar] [CrossRef]
- Wątróbski, J.; Ziemba, P.; Wolski, W. Methodological aspects of decision support system for the location of renewable energy sources. In Proceedings of the 2015 Federated Conference on Computer Science and Information Systems (FedCSIS), Lodz, Poland, 13–16 September 2015; pp. 1451–1459. [Google Scholar]
- Riaz, M.; Sałabun, W.; Farid, H.M.A.; Ali, N.; Wątróbski, J. A Robust q-Rung Orthopair Fuzzy Information Aggregation Using Einstein Operations with Application to Sustainable Energy Planning Decision Management. Energies 2020, 13, 2155. [Google Scholar] [CrossRef]
- Tong, L.I.; Chen, C.C.; Wang, C.H. Optimization of multi-response processes using the VIKOR method. Int. J. Adv. Manuf. Technol. 2007, 31, 1049–1057. [Google Scholar] [CrossRef]
- Tong, L.I.; Wang, C.H.; Chen, H.C. Optimization of multiple responses using principal component analysis and technique for order preference by similarity to ideal solution. Int. J. Adv. Manuf. Technol. 2005, 27, 407–414. [Google Scholar] [CrossRef]
- Mlela, M.K.; Xu, H.; Sun, F.; Wang, H.; Madenge, G.D. Material Analysis and Molecular Dynamics Simulation for Cavitation Erosion and Corrosion Suppression in Water Hydraulic Valves. Materials 2020, 13, 453. [Google Scholar] [CrossRef]
- Yazdani, M.; Graeml, F.R. VIKOR and its applications: A state-of-the-art survey. Int. J. Strateg. Decis. Sci. (IJSDS) 2014, 5, 56–83. [Google Scholar] [CrossRef]
- Behzadian, M.; Kazemzadeh, R.; Albadvi, A.; Aghdasi, M. PROMETHEE: A comprehensive literature review on methodologies and applications. Eur. J. Oper. Res. 2010, 200, 198–215. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Turskis, Z. Multiple criteria decision making (MCDM) methods in economics: An overview. Technol. Econ. Dev. Econ. 2011, 17, 397–427. [Google Scholar] [CrossRef]
- Guitouni, A.; Martel, J.M.; Vincke, P.; North, P. A Framework to Choose a Discrete Multicriterion Aggregation Procedure; Defence Research Establishment Valcatier (DREV): Ottawa, ON, Canada, 1998; Available online: https://pdfs.semanticscholar.org/27d5/9c846657268bc840c4df8df98e85de66c562.pdf (accessed on 28 June 2020).
- Spronk, J.; Steuer, R.E.; Zopounidis, C. Multicriteria decision aid/analysis in finance. In Multiple Criteria Decision Analysis: State of the Art Surveys; Springer: Berlin/Heidelberg, Germany, 2005; pp. 799–848. [Google Scholar]
- Roy, B. The outranking approach and the foundations of ELECTRE methods. In Readings in Multiple Criteria Decision Aid; Springer: Berlin/Heidelberg, Germany, 1990; pp. 155–183. [Google Scholar]
- Ishizaka, A.; Nemery, P. Multi-Criteria Decision Analysis: Methods and Software; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Stević, Ž.; Pamučar, D.; Subotić, M.; Antuchevičiene, J.; Zavadskas, E.K. The location selection for roundabout construction using Rough BWM-Rough WASPAS approach based on a new Rough Hamy aggregator. Sustainability 2018, 10, 2817. [Google Scholar] [CrossRef]
- Fortemps, P.; Greco, S.; Słowiński, R. Multicriteria choice and ranking using decision rules induced from rough approximation of graded preference relations. In Proceedings of the International Conference on Rough Sets and Current Trends in Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 510–522. [Google Scholar]
- e Costa, C.A.B.; Vincke, P. Multiple criteria decision aid: An overview. In Readings in Multiple Criteria Decision Aid; Springer: Berlin/Heidelberg, Germany, 1990; pp. 3–14. [Google Scholar]
- Wang, J.J.; Yang, D.L. Using a hybrid multi-criteria decision aid method for information systems outsourcing. Comput. Oper. Res. 2007, 34, 3691–3700. [Google Scholar] [CrossRef]
- Figueira, J.; Mousseau, V.; Roy, B. ELECTRE methods. In Multiple Criteria Decision Analysis: State of the Art Surveys; Springer: Berlin/Heidelberg, Germany, 2005; pp. 133–153. [Google Scholar]
- Blin, M.J.; Tsoukiàs, A. Multi-criteria methodology contribution to the software quality evaluation. Softw. Qual. J. 2001, 9, 113–132. [Google Scholar] [CrossRef]
- Edwards, W.; Newman, J.R.; Snapper, K.; Seaver, D. Multiattribute Evaluation; Number 26; Chronicle Books; SAGE Publications: London, UK, 1982. [Google Scholar]
- Jacquet-Lagreze, E.; Siskos, J. Assessing a set of additive utility functions for multicriteria decision-making, the UTA method. Eur. J. Oper. Res. 1982, 10, 151–164. [Google Scholar] [CrossRef]
- e Costa, C.A.B.; Vansnick, J.C. MACBETH—An interactive path towards the construction of cardinal value functions. Int. Trans. Oper. Res. 1994, 1, 489–500. [Google Scholar] [CrossRef]
- Bana E Costa, C.A.; Vansnick, J.C. Applications of the MACBETH approach in the framework of an additive aggregation model. J. Multi-Criteria Decis. Anal. 1997, 6, 107–114. [Google Scholar] [CrossRef]
- Chen, C.T.; Lin, C.T.; Huang, S.F. A fuzzy approach for supplier evaluation and selection in supply chain management. Int. J. Prod. Econ. 2006, 102, 289–301. [Google Scholar] [CrossRef]
- Vahdani, B.; Mousavi, S.M.; Tavakkoli-Moghaddam, R. Group decision making based on novel fuzzy modified TOPSIS method. Appl. Math. Model. 2011, 35, 4257–4269. [Google Scholar] [CrossRef]
- Rashid, T.; Beg, I.; Husnine, S.M. Robot selection by using generalized interval-valued fuzzy numbers with TOPSIS. Appl. Soft Comput. 2014, 21, 462–468. [Google Scholar] [CrossRef]
- Krohling, R.A.; Campanharo, V.C. Fuzzy TOPSIS for group decision making: A case study for accidents with oil spill in the sea. Expert Syst. Appl. 2011, 38, 4190–4197. [Google Scholar] [CrossRef]
- Roy, B. Classement et choix en présence de points de vue multiples. Rev. Française Inform. Rech. Oper. 1968, 2, 57–75. [Google Scholar] [CrossRef]
- Roy, B.; Skalka, J.M. ELECTRE IS: Aspects Méthodologiques et Guide D’utilisation; LAMSADE, Unité Associée au CNRS no 825; Université de Paris Dauphine: Paris, France, 1987. [Google Scholar]
- Roy, B.; Bertier, P.; La méthode ELECTRE, I. Une Application au Media Planning; North Holland: Amsterdam, The Netherlands, 1973. [Google Scholar]
- Roy, B.; Hugonnard, J.C. Ranking of suburban line extension projects on the Paris metro system by a multicriteria method. Transp. Res. Part A Gen. 1982, 16, 301–312. [Google Scholar] [CrossRef]
- Roy, B.; Bouyssou, D. Aide Multicritère à la Décision: Méthodes et Cas; Economica Paris: Paris, France, 1993. [Google Scholar]
- Mareschal, B.; Brans, J.P.; Vincke, P. PROMETHEE: A New Family of Outranking Methods in Multicriteria Analysis; Technical Report; ULB—Universite Libre de: Bruxelles, Belgium, 1984. [Google Scholar]
- Janssens, G.K.; Pangilinan, J.M. Multiple criteria performance analysis of non-dominated sets obtained by multi-objective evolutionary algorithms for optimisation. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Larnaca, Cyprus, 6–7 October 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 94–103. [Google Scholar]
- Chen, T.Y. A PROMETHEE-based outranking method for multiple criteria decision analysis with interval type-2 fuzzy sets. Soft Comput. 2014, 18, 923–940. [Google Scholar] [CrossRef]
- Martinez-Alier, J.; Munda, G.; O’Neill, J. Weak comparability of values as a foundation for ecological economics. Ecol. Econ. 1998, 26, 277–286. [Google Scholar] [CrossRef]
- Munda, G. Cost-benefit analysis in integrated environmental assessment: Some methodological issues. Ecol. Econ. 1996, 19, 157–168. [Google Scholar] [CrossRef]
- Ana, E., Jr.; Bauwens, W.; Broers, O. Quantifying uncertainty using robustness analysis in the application of ORESTE to sewer rehabilitation projects prioritization—Brussels case study. J. Multi-Criteria Decis. Anal. 2009, 16, 111–124. [Google Scholar] [CrossRef]
- Roubens, M. Preference relations on actions and criteria in multicriteria decision making. Eur. J. Oper. Res. 1982, 10, 51–55. [Google Scholar] [CrossRef]
- Hinloopen, E.; Nijkamp, P. Qualitative multiple criteria choice analysis. Qual. Quant. 1990, 24, 37–56. [Google Scholar] [CrossRef]
- Martel, J.M.; Matarazzo, B. Other outranking approaches. In Multiple Criteria Decision Analysis: State of the Art Surveys; Springer: Berlin/Heidelberg, Germany, 2005; pp. 197–259. [Google Scholar]
- Marchant, T. An axiomatic characterization of different majority concepts. Eur. J. Oper. Res. 2007, 179, 160–173. [Google Scholar] [CrossRef][Green Version]
- Bélanger, M.; Martel, J.M. An Automated Explanation Approach for a Decision Support System based on MCDA. ExaCt 2005, 5, 4. [Google Scholar]
- Guitouni, A.; Martel, J.; Bélanger, M.; Hunter, C. Managing a Decision-Making Situation in the Context of the Canadian Airspace Protection; Faculté des Sciences de L’administration de L’Université Laval, Direction de la Recherche: Quebec City, QC, Canada, 1999. [Google Scholar]
- Nijkamp, P.; Rietveld, P.; Voogd, H. Multicriteria Evaluation in Physical Planning; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Vincke, P. Outranking approach. In Multicriteria Decision Making; Springer: Berlin/Heidelberg, Germany, 1999; pp. 305–333. [Google Scholar]
- Paelinck, J.H. Qualitative multiple criteria analysis, environmental protection and multiregional development. In Papers of the Regional Science Association; Springer: Berlin/Heidelberg, Germany, 1976; Volume 36, pp. 59–74. [Google Scholar]
- Matarazzo, B. MAPPAC as a compromise between outranking methods and MAUT. Eur. J. Oper. Res. 1991, 54, 48–65. [Google Scholar] [CrossRef]
- Greco, S. A new pcca method: Idra. Eur. J. Oper. Res. 1997, 98, 587–601. [Google Scholar] [CrossRef]
- Sałabun, W. The Characteristic Objects Method: A New Distance-based Approach to Multicriteria Decision-making Problems. J. Multi-Criteria Decis. Anal. 2015, 22, 37–50. [Google Scholar] [CrossRef]
- Kujawińska, A.; Rogalewicz, M.; Diering, M.; Piłacińska, M.; Hamrol, A.; Kochańskib, A. Assessment of ductile iron casting process with the use of the DRSA method. J. Min. Metall. Sect. B Metall. 2016, 52, 25–34. [Google Scholar] [CrossRef]
- Więckowski, J.; Kizielewicz, B.; Kołodziejczyk, J. Finding an Approximate Global Optimum of Characteristic Objects Preferences by Using Simulated Annealing. In Proceedings of the International Conference on Intelligent Decision Technologies, Split, Croatia, 17–19 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 365–375. [Google Scholar]
- Sałabun, W.; Wątróbski, J.; Piegat, A. Identification of a multi-criteria model of location assessment for renewable energy sources. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 12–16 June 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 321–332. [Google Scholar]
- Sałabun, W.; Karczmarczyk, A.; Wątróbski, J.; Jankowski, J. Handling data uncertainty in decision making with COMET. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1478–1484. [Google Scholar]
- Więckowski, J.; Kizielewicz, B.; Kołodziejczyk, J. The Search of the Optimal Preference Values of the Characteristic Objects by Using Particle Swarm Optimization in the Uncertain Environment. In Proceedings of the International Conference on Intelligent Decision Technologies, Split, Croatia, 17–19 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 353–363. [Google Scholar]
- Inuiguchi, M.; Yoshioka, Y.; Kusunoki, Y. Variable-precision dominance-based rough set approach and attribute reduction. Int. J. Approx. Reason. 2009, 50, 1199–1214. [Google Scholar] [CrossRef]
- Greco, S.; Matarazzo, B.; Slowinski, R. Rough approximation by dominance relations. Int. J. Intell. Syst. 2002, 17, 153–171. [Google Scholar] [CrossRef]
- Słowiński, R.; Greco, S.; Matarazzo, B. Rough-set-based decision support. In Search Methodologies; Springer: Berlin/Heidelberg, Germany, 2014; pp. 557–609. [Google Scholar]
- Al-Shemmeri, T.; Al-Kloub, B.; Pearman, A. Model choice in multicriteria decision aid. Eur. J. Oper. Res. 1997, 97, 550–560. [Google Scholar] [CrossRef]
- Kornyshova, E.; Salinesi, C. MCDM techniques selection approaches: State of the art. In Proceedings of the 2007 IEEE Symposium on Computational Intelligence in Multi-Criteria Decision-Making, Honolulu, HI, USA, 1–5 April 2007; pp. 22–29. [Google Scholar]
- Gershon, M.; Duckstein, L. An algorithm for choosing of a multiobjective technique. In Essays and Surveys on Multiple Criteria Decision Making; Springer: Berlin/Heidelberg, Germany, 1983; pp. 53–62. [Google Scholar]
- Celik, M.; Cicek, K.; Cebi, S. Establishing an international MBA program for shipping executives: Managing OR/MS foundation towards a unique curriculum design. In Proceedings of the 2009 International Conference on Computers & Industrial Engineering, Troyes, France, 6–9 July 2009; pp. 459–463. [Google Scholar]
- Adil, M.; Nunes, M.B.; Peng, G.C. Identifying operational requirements to select suitable decision models for a public sector e-procurement decision support system. JISTEM J. Inf. Syst. Technol. Manag. 2014, 11, 211–228. [Google Scholar] [CrossRef]
- Moghaddam, N.B.; Nasiri, M.; Mousavi, S. An appropriate multiple criteria decision making method for solving electricity planning problems, addressing sustainability issue. Int. J. Environ. Sci. Technol. 2011, 8, 605–620. [Google Scholar] [CrossRef]
- Salinesi, C.; Kornyshova, E. Choosing a Prioritization Method-Case of IS Security Improvement. CAiSE Forum. 2006. Available online: https://pdfs.semanticscholar.org/ef7b/3d0658d0176aee128562b8a9a4c0bb278354.pdf (accessed on 10 July 2020).
- De Montis, A.; De Toro, P.; Droste-Franke, B.; Omann, I.; Stagl, S. Assessing the quality of different MCDA methods. Altern. Environ. Valuat. 2004, 4, 99–133. [Google Scholar]
- Cinelli, M.; Coles, S.R.; Kirwan, K. Analysis of the potentials of multi criteria decision analysis methods to conduct sustainability assessment. Ecol. Indic. 2014, 46, 138–148. [Google Scholar] [CrossRef]
- Wątróbski, J. Outline of multicriteria decision-making in green logistics. Transp. Res. Procedia 2016, 16, 537–552. [Google Scholar] [CrossRef]
- Wątróbski, J.; Jankowski, J. Knowledge management in MCDA domain. In Proceedings of the 2015 Federated Conference on Computer Science and Information Systems (FedCSIS), Lodz, Poland, 13–16 September 2015; pp. 1445–1450. [Google Scholar]
- Wątróbski, J.; Jankowski, J. Guideline for MCDA method selection in production management area. In New Frontiers in Information and Production Systems Modelling and Analysis; Springer: Berlin/Heidelberg, Germany, 2016; pp. 119–138. [Google Scholar]
- Ulengin, F.; Topcu, Y.I.; Sahin, S.O. An artificial neural network approach to multicriteria model selection. In Multiple Criteria Decision Making in the New Millennium; Springer: Berlin/Heidelberg, Germany, 2001; pp. 101–110. [Google Scholar]
- Moffett, A.; Sarkar, S. Incorporating multiple criteria into the design of conservation area networks: A minireview with recommendations. Divers. Distrib. 2006, 12, 125–137. [Google Scholar] [CrossRef]
- Hwang, C.L.; Yoon, K. Methods for multiple attribute decision making. In Multiple Attribute Decision Making; Springer: Berlin/Heidelberg, Germany, 1981; pp. 58–191. [Google Scholar]
- Celik, M.; Topcu, Y.I. Analytical modelling of shipping business processes based on MCDM methods. Marit. Policy Manag. 2009, 36, 469–479. [Google Scholar] [CrossRef]
- Cicek, K.; Celik, M.; Topcu, Y.I. An integrated decision aid extension to material selection problem. Mater. Des. 2010, 31, 4398–4402. [Google Scholar] [CrossRef]
- Kokaraki, N.; Hopfe, C.J.; Robinson, E.; Nikolaidou, E. Testing the reliability of deterministic multi-criteria decision-making methods using building performance simulation. Renew. Sustain. Energy Rev. 2019, 112, 991–1007. [Google Scholar] [CrossRef]
- Kolios, A.; Mytilinou, V.; Lozano-Minguez, E.; Salonitis, K. A comparative study of multiple-criteria decision-making methods under stochastic inputs. Energies 2016, 9, 566. [Google Scholar] [CrossRef]
- Ceballos, B.; Lamata, M.T.; Pelta, D.A. A comparative analysis of multi-criteria decision-making methods. Prog. Artif. Intell. 2016, 5, 315–322. [Google Scholar] [CrossRef]
- Sarraf, R.; McGuire, M.P. Integration and comparison of multi-criteria decision making methods in safe route planner. Expert Syst. Appl. 2020, 154, 113399. [Google Scholar] [CrossRef]
- Garre, A.; Boué, G.; Fernández, P.S.; Membré, J.M.; Egea, J.A. Evaluation of Multicriteria Decision Analysis Algorithms in Food Safety: A Case Study on Emerging Zoonoses Prioritization. Risk Anal. 2020, 40, 336–351. [Google Scholar] [CrossRef]
- Chakraborty, S.; Yeh, C.H. A simulation comparison of normalization procedures for TOPSIS. In Proceedings of the 2009 International Conference on Computers & Industrial Engineering, Troyes, France, 6–9 July 2009; pp. 1815–1820. [Google Scholar]
- Papathanasiou, J.; Ploskas, N. Multiple Criteria Decision Aid; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Opricovic, S. Multicriteria optimization of civil engineering systems. Fac. Civ. Eng. Belgrade 1998, 2, 5–21. [Google Scholar]
- Opricovic, S.; Tzeng, G.H. Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. Eur. J. Oper. Res. 2004, 156, 445–455. [Google Scholar] [CrossRef]
- Zavadskas, E.; Kaklauskas, A. Determination of an efficient contractor by using the new method of multicriteria assessment. In Proceedings of the International Symposium for “The Organization and Management of Construction”. Shaping Theory and Practice, Glasgow, UK, 28 August–3 September 1996; Taylor & Francis: Oxfordshire, UK, 1996; Volume 2, pp. 94–104. [Google Scholar]
- Zavadskas, E.K.; Kaklauskas, A.; Sarka, V. The new method of multicriteria complex proportional assessment of projects. Technol. Econ. Dev. Econ. 1994, 1, 131–139. [Google Scholar]
- Pamučar, D.; Božanić, D.; Lukovac, V.; Komazec, N. Normalized weighted geometric bonferroni mean operator of interval rough numbers—Application in interval rough dematel-copras model. Facta Univ. Ser. Mech. Eng. 2018, 16, 171–191. [Google Scholar]
- Stanojković, J.; Radovanović, M. Selection of drill for drilling with high pressure coolant using entropy and copras MCDM method. UPB Sci. Bull. Ser. D Mech. Eng. 2017, 79, 199–204. [Google Scholar]
- Brans, J.P.; De Smet, Y. PROMETHEE methods. In Multiple Criteria Decision Analysis; Springer: Berlin/Heidelberg, Germany, 2016; pp. 187–219. [Google Scholar]
- Ranjan, R.; Chatterjee, P.; Panchal, D.; Pamucar, D. Performance Evaluation of Sustainable Smart Cities in India: An Adaptation of Cartography in PROMETHEE-GIS Approach. In Advanced Multi-Criteria Decision Making for Addressing Complex Sustainability Issues; IGI Global: Hershey, PA, USA, 2019; pp. 14–40. [Google Scholar]
- Podviezko, A. Distortions introduced by normalisation of values of criteria in multiple criteria methods of evaluation. LMD Darb 2014, 55, 51–56. [Google Scholar] [CrossRef]
- Sałabun, W.; Urbaniak, K. A new coefficient of rankings similarity in decision-making problems. In Proceedings of the International Conference on Computational Science, Amsterdam, The Netherlands, 3–5 June 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]






















| a | ⋯ | |||
| ⋯ | ||||
| ⋯ | ||||
| ⋯ | ||||
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ |
| ⋯ |
| Generalized Criterion | Definition | Parameters to Fix |
|---|---|---|
 | – | |
 | q | |
 | p | |
 | ||
 |
| 0.619 | 0.449 | 0.447 | |
| 0.862 | 0.466 | 0.006 | |
| 0.458 | 0.698 | 0.771 | |
| 0.777 | 0.631 | 0.491 | |
| 0.567 | 0.992 | 0.968 | |
| 0.333 | 0.333 | 0.333 | |
| 0.075 | 0.134 | 0.791 | |
| 0.217 | 0.294 | 0.488 |
| Minmax | Max | Sum | Vector | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | ||||
| 4 | 2 | 3 | 3 | 2 | 3 | 5 | 5 | 5 | 3 | 2 | 2 | ||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| 5 | 4 | 5 | 5 | 4 | 5 | 4 | 4 | 4 | 5 | 4 | 5 | ||||
| 2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 | 3 | 2 | 3 | 3 | ||||
| 3 | 5 | 4 | 4 | 5 | 4 | 2 | 2 | 2 | 4 | 5 | 4 | ||||
| None | Minmax | Max | Sum | Vector | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | |||||
| 5 | 4 | 4 | 4 | 2 | 3 | 4 | 2 | 3 | 5 | 5 | 5 | 4 | 2 | 3 | |||||
| 4 | 5 | 5 | 2 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | |||||
| 3 | 2 | 2 | 5 | 4 | 4 | 5 | 4 | 4 | 4 | 4 | 4 | 5 | 4 | 4 | |||||
| 2 | 3 | 3 | 1 | 3 | 2 | 1 | 3 | 2 | 2 | 3 | 3 | 1 | 3 | 2 | |||||
| 1 | 1 | 1 | 3 | 5 | 5 | 3 | 5 | 5 | 3 | 2 | 2 | 3 | 5 | 5 | |||||
| Usual | U-Shape | V-Shape | Level | V-Shape 2 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | |||||
| 4 | 2 | 3 | 5 | 3 | 5 | 4 | 3 | 3 | 4 | 2 | 3 | 4 | 2 | 3 | |||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| 5 | 4 | 5 | 4 | 4 | 3 | 5 | 4 | 5 | 5 | 4 | 5 | 5 | 4 | 5 | |||||
| 2 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 2 | 2 | 3 | 2 | |||||
| 3 | 5 | 4 | 3 | 5 | 4 | 3 | 5 | 4 | 3 | 5 | 4 | 3 | 5 | 4 | |||||
| TOPSIS | VIKOR | PROM. II | COPRAS | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | (a) | (b) | (c) | ||||
| 4 | 2 | 3 | 5 | 4 | 4 | 4 | 2 | 3 | 5 | 5 | 5 | ||||
| 1 | 1 | 1 | 4 | 5 | 5 | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| 5 | 4 | 5 | 3 | 2 | 2 | 5 | 4 | 5 | 4 | 4 | 4 | ||||
| 2 | 3 | 2 | 2 | 3 | 3 | 2 | 3 | 2 | 3 | 3 | 3 | ||||
| 3 | 5 | 4 | 1 | 1 | 1 | 3 | 5 | 4 | 2 | 2 | 2 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sałabun, W.; Wątróbski, J.; Shekhovtsov, A. Are MCDA Methods Benchmarkable? A Comparative Study of TOPSIS, VIKOR, COPRAS, and PROMETHEE II Methods. Symmetry 2020, 12, 1549. https://doi.org/10.3390/sym12091549
Sałabun W, Wątróbski J, Shekhovtsov A. Are MCDA Methods Benchmarkable? A Comparative Study of TOPSIS, VIKOR, COPRAS, and PROMETHEE II Methods. Symmetry. 2020; 12(9):1549. https://doi.org/10.3390/sym12091549
Chicago/Turabian StyleSałabun, Wojciech, Jarosław Wątróbski, and Andrii Shekhovtsov. 2020. "Are MCDA Methods Benchmarkable? A Comparative Study of TOPSIS, VIKOR, COPRAS, and PROMETHEE II Methods" Symmetry 12, no. 9: 1549. https://doi.org/10.3390/sym12091549
APA StyleSałabun, W., Wątróbski, J., & Shekhovtsov, A. (2020). Are MCDA Methods Benchmarkable? A Comparative Study of TOPSIS, VIKOR, COPRAS, and PROMETHEE II Methods. Symmetry, 12(9), 1549. https://doi.org/10.3390/sym12091549