Cloud Detection for Satellite Imagery Using Attention-Based U-Net Convolutional Neural Network


Abstract
1. Introduction
2. Methodology
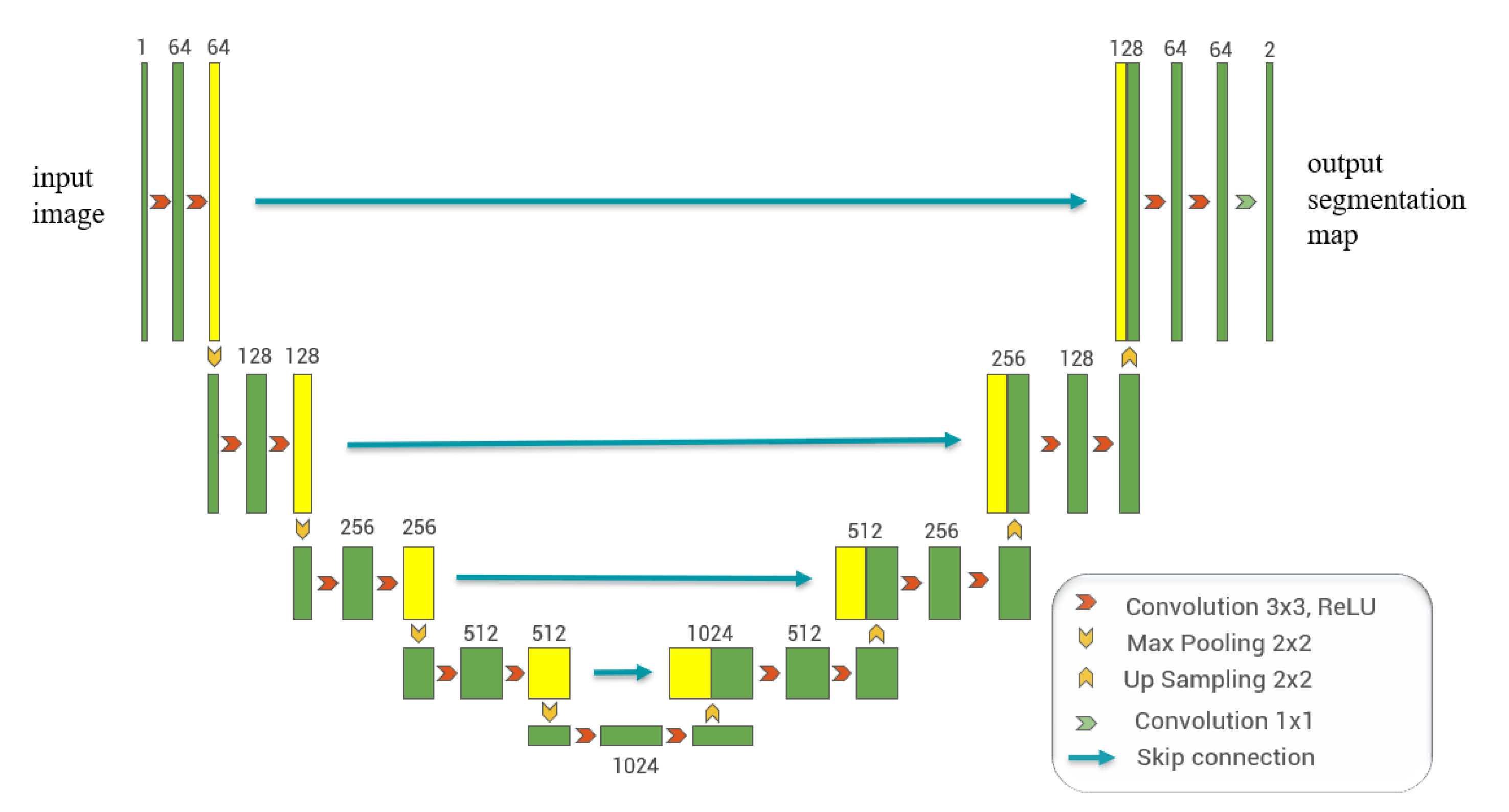
2.1. U-Net Architecture
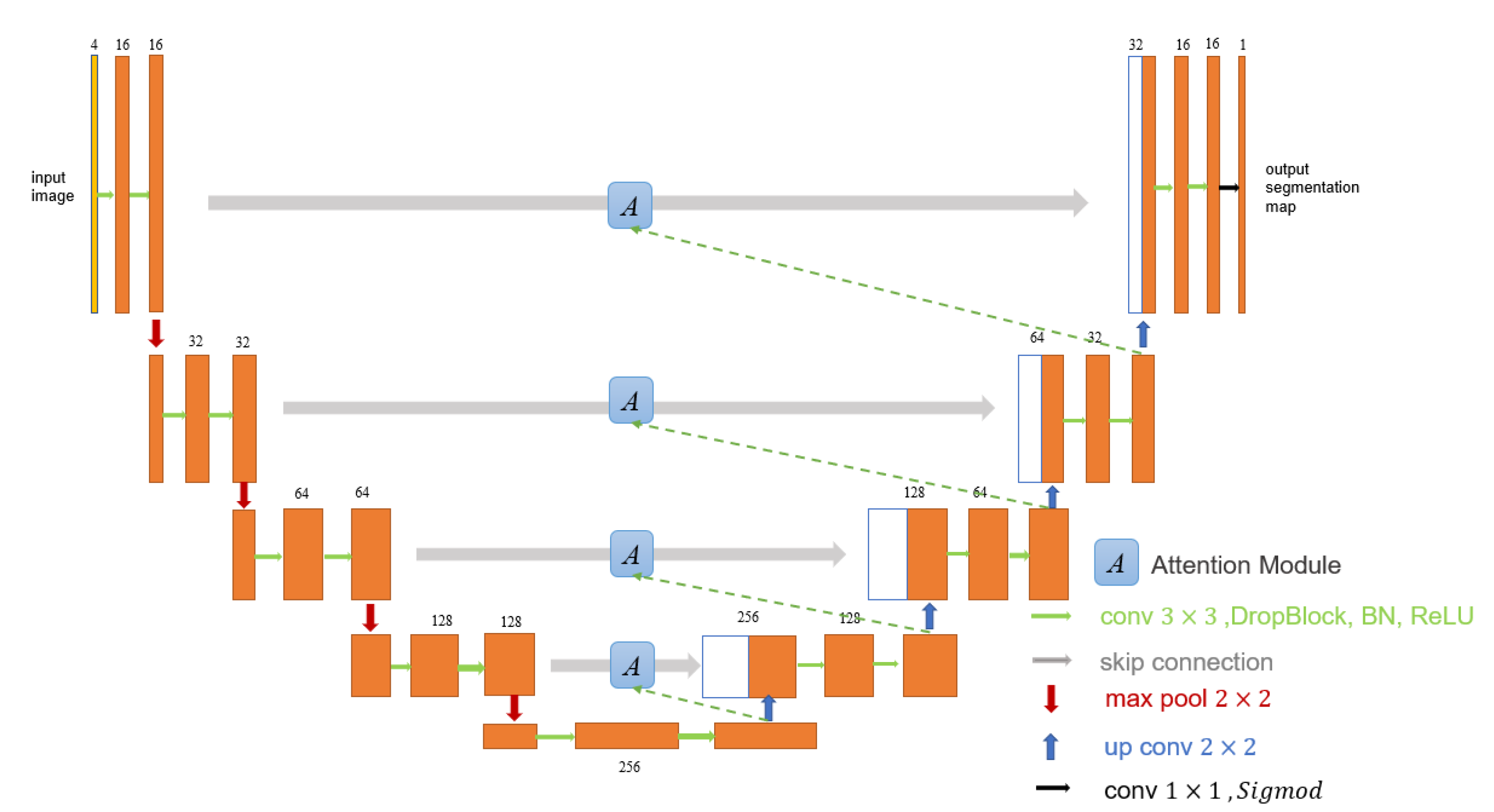
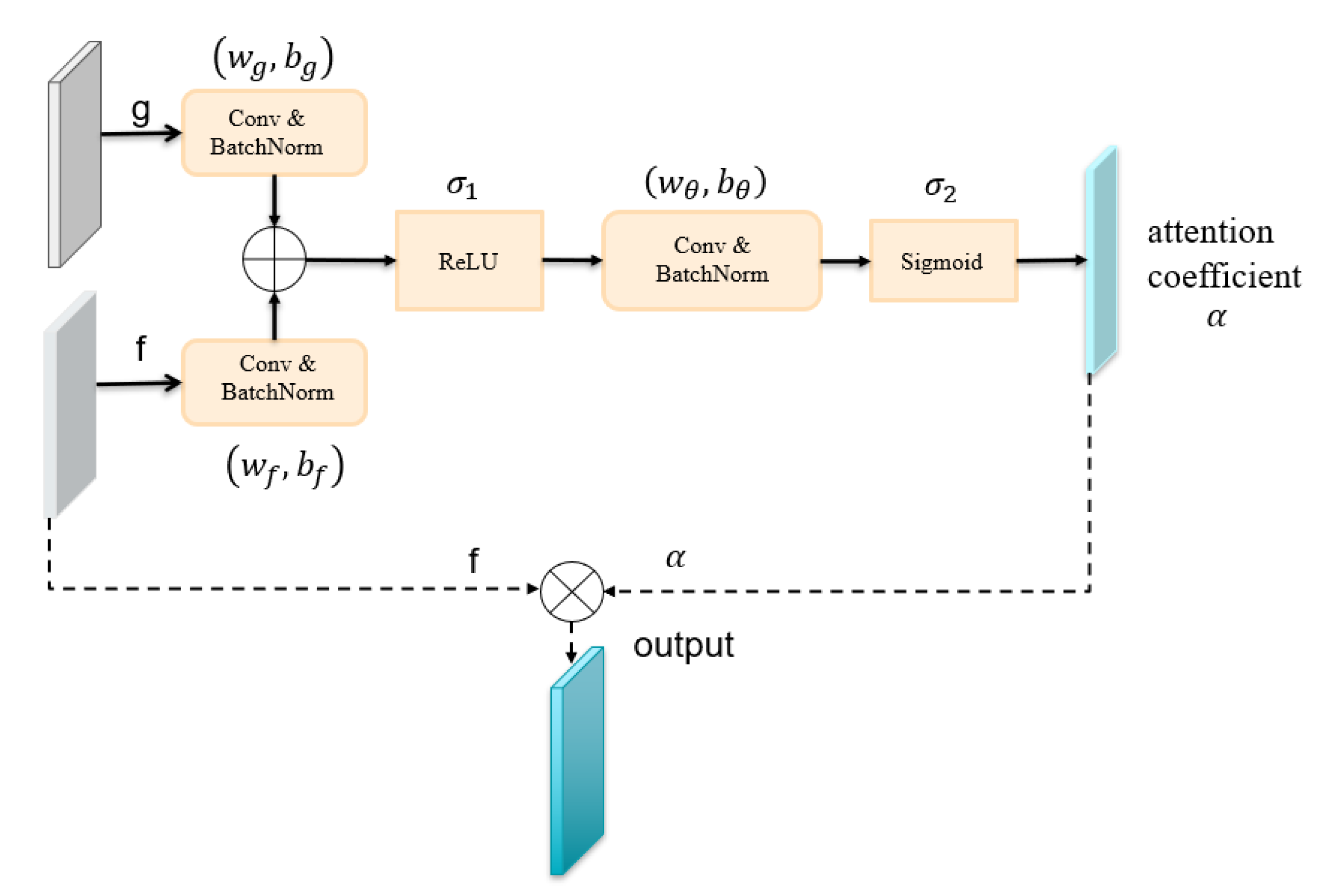
2.2. Proposed Network Architecture
3. Experiments and Results
3.1. Datasets and Preparation
3.2. Training Methodology
3.3. Evaluation Metrics
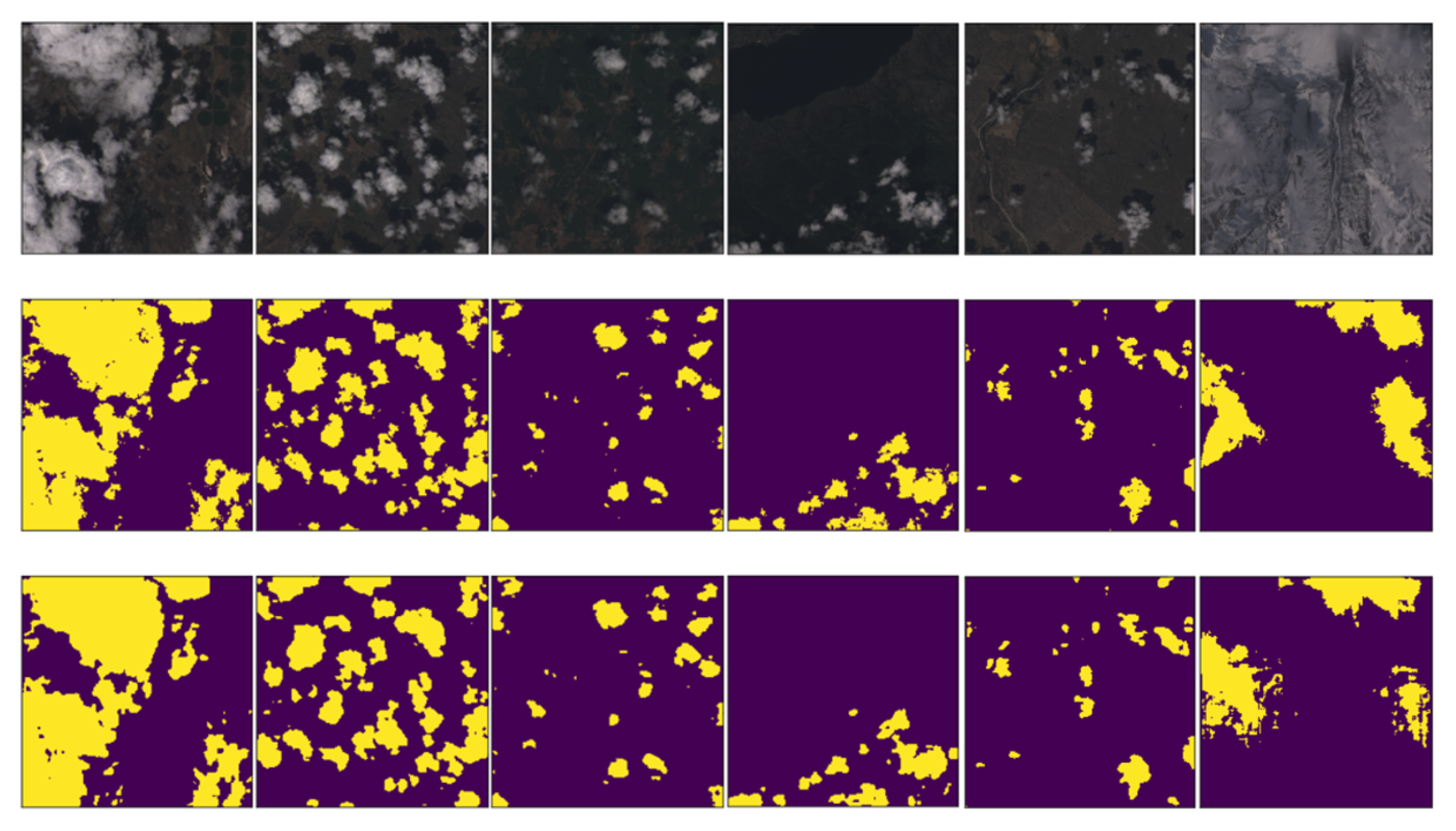
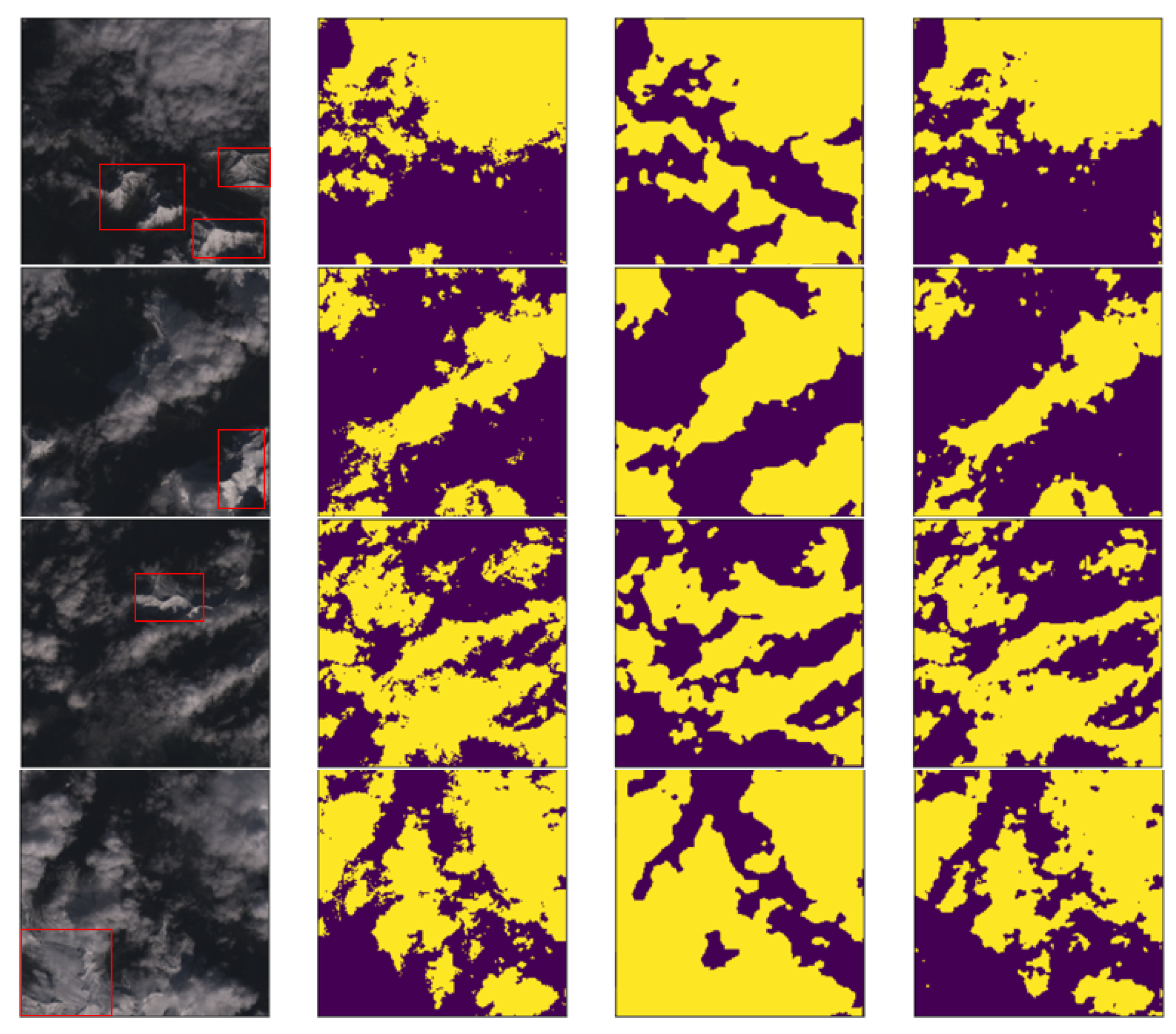
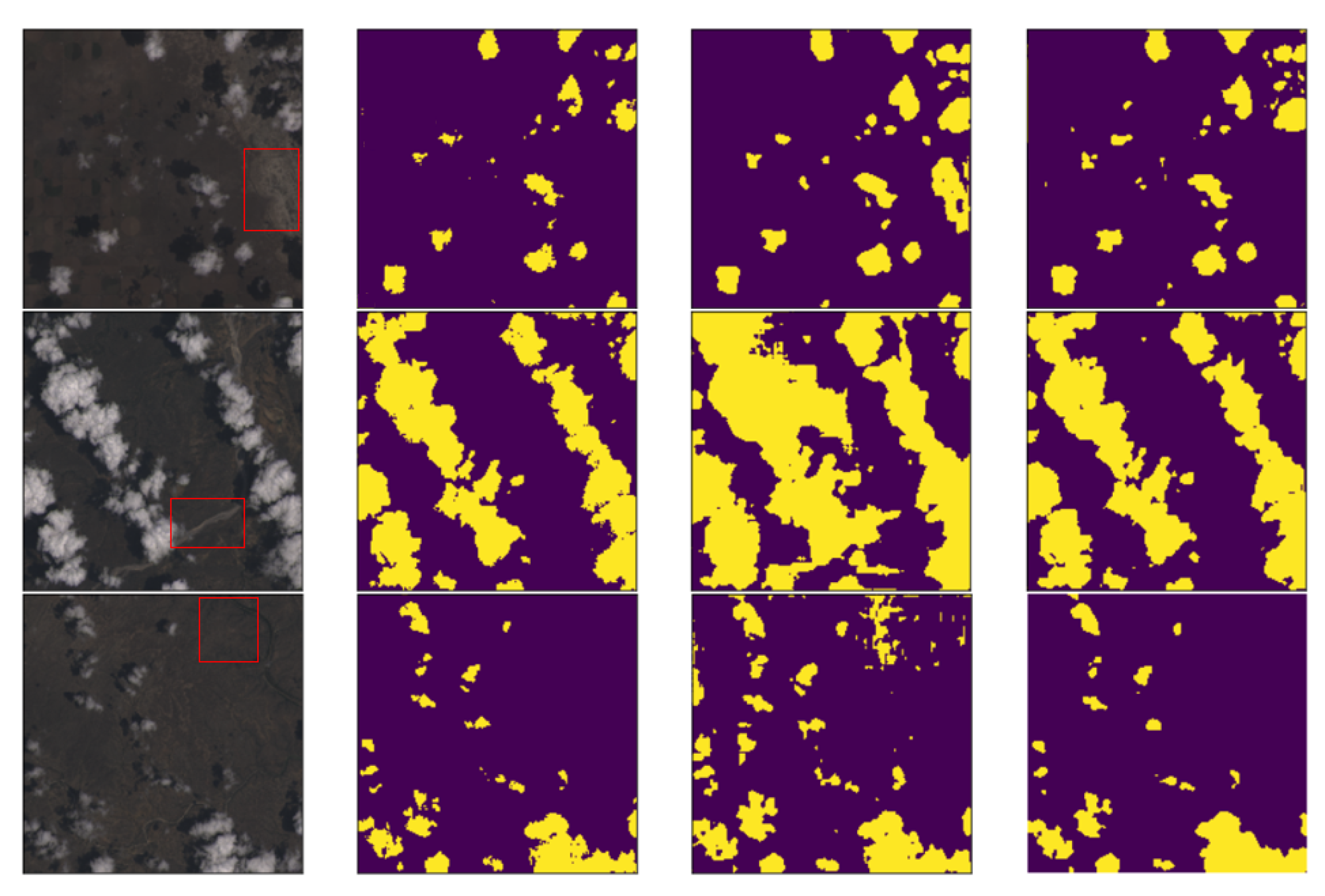
3.4. Experimental Results
4. Discussions
- (1)
- From the experimental results, we can find that the U-Net network, the Cloud-Net network and Cloud-AttU network based on the U-Net architecture are significantly better than Fmask. The U-Net network adopts the symmetric Encoder-Decoder structure, which achieves the fusion of high-level features and low-level features through the skip-connection operation, making the output results contain richer multi-scale information. This symmetrical network structure is concise and stable, significantly enhancing the effect of image segmentation. The results of this study demonstrate the good performance of the U-Net architecture in cloud detection tasks, indicating that this symmetrical network architecture, which fuses multi-scale information, has great potential for applications in satellite image processing and deserves further research.
- (2)
- From the experimental results, it was found that U-Net with the attention mechanism can achieve better cloud detection results than the original U-Net. This performance boost should benefit from the attention gate. In the attention module, the output is obtained by multiplying the feature map by the attention coefficient in the attention gate. The attention coefficients tend to get larger values in the clouded region and smaller values in the cloudless region. This mechanism makes the value of the cloudless region of the feature map smaller and the value of the target region of the feature map larger, thus improving the performance of cloud detection.
- (3)
- From the experimental results, it can be concluded that Cloud-AttU with the attention mechanism has a stronger cloud detection capability compared to Cloud-Net and single U-Net. Cloud-AttU can better resist the interference of snow and ice, and has a stronger identification ability. It is well known that satellite remote sensing data are susceptible to interference from various noises, so data processing methods that are resistant to interference are highly desirable for satellite data. Attentional mechanisms have a clear advantage in recognizing and resisting noise interference, and thus hold great potential and research promise in numerous areas of satellite data processing.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| FCN | full convolution network |
| AG | attention gate |
| FMask | Function of mask |
| BN | Batch Normalization |
| ReLU | Rectified Linear Unit |
| NASA | National Aeronautics and Space Administration |
| OLI | operational land imager |
| TIRS | Thermal Infrared Sensor |
| GF4 | GaoFen-4 |
| FY-4 | FengYun-4 |
| MCNNs | Multiple Convolutional Neural Networks |
| Adam | Adaptive Moment Optimization |
References
- Leprince, S.; Barbot, S.; Ayoub, F.; Avouac, J. Automatic and Precise Orthorectification, Coregistration, and Subpixel Correlation of Satellite Images, Application to Ground Deformation Measurements. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1529–1558. [Google Scholar] [CrossRef]
- Leitloff, J.; Hinz, S.; Stilla, U. Vehicle Detection in Very High Resolution Satellite Images of City Areas. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2795–2806. [Google Scholar] [CrossRef]
- Wei, J.; Li, Z.; Peng, Y.; Sun, L. MODIS Collection 6.1 aerosol optical depth products over land and ocean: Validation and comparison. Atmos. Environ. 2019, 201, 428–440. [Google Scholar] [CrossRef]
- Xie, F.; Shi, M.; Shi, Z.; Yin, J.; Zhao, D. Multilevel Cloud Detection in Remote Sensing Images Based on Deep Learning. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3631–3640. [Google Scholar] [CrossRef]
- Shi, M.; Xie, F.; Zi, Y.; Yin, J. Cloud detection of remote sensing images by deep learning. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 701–704. [Google Scholar]
- Shen, X.; Li, Q.; Tian, Y.; Shen, L. An uneven illumination correction algorithm for optical remote sensing images covered with thin clouds. Remote Sens. 2015, 7, 11848–11862. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Cheng, Q.; Wu, P.; Gan, W.; Fang, L. Cloud removal in remote sensing images using nonnegative matrix factorization and error correction. ISPRS J. Photogramm. Remote Sens. 2019, 148, 103–113. [Google Scholar] [CrossRef]
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and temporal distribution of clouds observed by MODIS onboard the Terra and Aqua satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Sun, L.; Yang, X.; Jia, S.; Jia, C.; Wang, Q.; Liu, X.; Wei, J.; Zhou, X. Satellite data cloud detection using deep learning supported by hyperspectral data. Int. J. Remote Sens. 2020, 41, 1349–1371. [Google Scholar] [CrossRef]
- Ceppi, P.; Brient, F.; Zelinka, M.D.; Hartmann, D.L. Cloud feedback mechanisms and their representation in global climate models. WIREs Clim. Chang. 2017, 8, e465. [Google Scholar] [CrossRef]
- Barbieri, F.; Rajakaruna, S.; Ghosh, A. Very short-term photovoltaic power forecasting with cloud modeling: A review. Renew. Sustain. Energy Rev. 2017, 75, 242–263. [Google Scholar] [CrossRef]
- Chen, P.Y.; Srinivasan, R.; Fedosejevs, G.; Narasimhan, B. An automated cloud detection method for daily NOAA-14 AVHRR data for Texas, USA. Int. J. Remote Sens. 2002, 23, 2939–2950. [Google Scholar] [CrossRef]
- Kostornaya, A.A.; Saprykin, E.I.; Zakhvatov, M.G.; Tokareva, Y.V. A method of cloud detection from satellite data. Russ. Meteorol. Hydrol. 2017, 42, 753–758. [Google Scholar] [CrossRef]
- Tang, H.; Yu, K.; Hagolle, O.; Jiang, K.; Geng, X.; Zhao, Y. A cloud detection method based on a time series of MODIS surface reflectance images. Int. J. Digit. Earth 2013, 6, 157–171. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, L.; Zhang, Z.; Wang, C.; Xiao, B. Automatic cloud detection for all-sky images using superpixel segmentation. IEEE Geosci. Remote Sens. Lett. 2014, 12, 354–358. [Google Scholar]
- Long-fei, L.; Yun-hao, C.; Jing, L. Texture analysis methods used in remote sensing images. Remote Sens. Technol. Appl. 2011, 18, 441–447. [Google Scholar]
- Ioannidou, A.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. Deep Learning Advances in Computer Vision with 3D Data: A Survey. ACM Comput. Surv. 2017, 50. [Google Scholar] [CrossRef]
- Villalba-Diez, J.; Schmidt, D.; Gevers, R.; Ordieres-Meré, J.; Buchwitz, M.; Wellbrock, W. Deep Learning for Industrial Computer Vision Quality Control in the Printing Industry 4.0. Sensors 2019, 19, 3987. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep learning based oil palm tree detection and counting for high-resolution remote sensing images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.; Bilal, M.; Yang, X.; Wang, J.; Li, W. Multilevel cloud detection for high-resolution remote sensing imagery using multiple convolutional neural networks. ISPRS Int. J. Geo-Inf. 2018, 7, 181. [Google Scholar] [CrossRef]
- Segal-Rozenhaimer, M.; Li, A.; Das, K.; Chirayath, V. Cloud detection algorithm for multi-modal satellite imagery using convolutional neural-networks (CNN). Remote Sens. Environ. 2020, 237, 111446. [Google Scholar] [CrossRef]
- Ozkan, S.; Efendioglu, M.; Demirpolat, C. Cloud detection from RGB color remote sensing images with deep pyramid networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 6939–6942. [Google Scholar]
- Francis, A.; Sidiropoulos, P.; Muller, J.P. CloudFCN: Accurate and Robust Cloud Detection for Satellite Imagery with Deep Learning. Remote Sens. 2019, 11, 2312. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water body extraction from very high-resolution remote sensing imagery using deep U-Net and a superpixel-based conditional random field model. IEEE Geosci. Remote Sens. Lett. 2018, 16, 618–622. [Google Scholar] [CrossRef]
- Wei, S.; Zhang, H.; Wang, C.; Wang, Y.; Xu, L. Multi-temporal SAR data large-scale crop mapping based on U-Net model. Remote Sens. 2019, 11, 68. [Google Scholar] [CrossRef]
- Cao, K.; Zhang, X. An Improved Res-UNet Model for Tree Species Classification Using Airborne High-Resolution Images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef]
- Cui, B.; Zhang, Y.; Li, X.; Wu, J.; Lu, Y. WetlandNet: Semantic Segmentation for Remote Sensing Images of Coastal Wetlands via Improved UNet with Deconvolution. In Genetic and Evolutionary Computing; Springer: Singapore, 2020; pp. 281–292. [Google Scholar]
- Soni, A.; Koner, R.; Villuri, V.G.K. M-UNet: Modified U-Net Segmentation Framework with Satellite Imagery. In Proceedings of the Global AI Congress, Kolkata, India, 12–14 September 2019; Springer: Singapore, 3 April 2020; pp. 47–59. [Google Scholar]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Lian, S.; Luo, Z.; Zhong, Z.; Lin, X.; Su, S.; Li, S. Attention guided U-Net for accurate iris segmentation. J. Vis. Commun. Image Represent. 2018, 56, 296–304. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Plaza, A. Hybrid first and second order attention Unet for building segmentation in remote sensing images. Inf. Sci. 2020, 63, 140305. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description generation for remote sensing images using attribute attention mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef]
- Guo, M.; Zhang, D.; Sun, J.; Wu, Y. Symmetry Encoder-Decoder Network with Attention Mechanism for Fast Video Object Segmentation. Symmetry 2019, 11, 1006. [Google Scholar] [CrossRef]
- Xu, R.; Tao, Y.; Lu, Z.; Zhong, Y. Attention-Mechanism-Containing Neural Networks for High-Resolution Remote Sensing Image Classification. Remote Sens. 2018, 10, 1602. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-Branch Multi-Attention Mechanism Network for Hyperspectral Image Classification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef]
- Huang, Y.C.; Chang, J.R.; Chen, L.F.; Chen, Y.S. Deep Neural Network with Attention Mechanism for Classification of Motor Imagery EEG. In Proceedings of the 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1130–1133. [Google Scholar]
- Xiang, X.; Yu, Z.; Lv, N.; Kong, X.; El Saddik, A. Attention-Based Generative Adversarial Network for Semi-supervised Image Classification. Neural Proc. Lett. 2019, 1–14. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An end-to-end cloud detection algorithm for Landsat 8 imagery. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1029–1032. [Google Scholar]
- Mohajerani, S.; Saeedi, P. CPNet: A Context Preserver Convolutional Neural Network for Detecting Shadows in Single RGB Images. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–5. [Google Scholar]
- Mohajerani, S.; Saeedi, P. Shadow Detection in Single RGB Images Using a Context Preserver Convolutional Neural Network Trained by Multiple Adversarial Examples. IEEE Trans. Image Proc. 2019, 28, 4117–4129. [Google Scholar] [CrossRef]
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. Cloud detection algorithm for remote sensing images using fully convolutional neural networks. arXiv 2018, arXiv:1810.05782. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spectral Band | Wavelength (Micrometers) | Resolution (Meters) |
|---|---|---|
| Band 1—Coastal | 0.433–0.453 | 30 |
| Band 2—Blue | 0.450–0.515 | 30 |
| Band 3—Green | 0.525–0.600 | 30 |
| Band 4—Red | 0.630–0.680 | 30 |
| Band 5—Near Infrared (NIR) | 0.845–0.885 | 30 |
| Band 6—Short Wavelength Infrared (SWIR) 1 | 1.560–1.660 | 30 |
| Band 7—Short Wavelength Infrared (SWIR) 2 | 2.100–2.300 | 30 |
| Band 8—Panchromatic | 0.500–0.680 | 15 |
| Band 9—Cirrus | 1.360–1.390 | 30 |
| Model | Jaccard index (%) | Precision (%) | Recall (%) | Specificity (%) | Overall Accuracy (%) |
|---|---|---|---|---|---|
| FCN [51] | 84.90 | 95.17 | 87.65 | 97.10 | 94.91 |
| Fmask [16] | 85.45 | 89.26 | 96.57 | 94.07 | 94.26 |
| Unet | 86.06 | 95.14 | 89.73 | 97.45 | 95.80 |
| Cloud-Net [48] | 87.25 | 96.60 | 90.04 | 98.03 | 96.13 |
| Cloud-AttU | 88.72 | 97.16 | 91.30 | 98.24 | 97.05 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Cao, X.; Liu, B.; Gao, M. Cloud Detection for Satellite Imagery Using Attention-Based U-Net Convolutional Neural Network. Symmetry 2020, 12, 1056. https://doi.org/10.3390/sym12061056
Guo Y, Cao X, Liu B, Gao M. Cloud Detection for Satellite Imagery Using Attention-Based U-Net Convolutional Neural Network. Symmetry. 2020; 12(6):1056. https://doi.org/10.3390/sym12061056
Chicago/Turabian StyleGuo, Yanan, Xiaoqun Cao, Bainian Liu, and Mei Gao. 2020. "Cloud Detection for Satellite Imagery Using Attention-Based U-Net Convolutional Neural Network" Symmetry 12, no. 6: 1056. https://doi.org/10.3390/sym12061056
APA StyleGuo, Y., Cao, X., Liu, B., & Gao, M. (2020). Cloud Detection for Satellite Imagery Using Attention-Based U-Net Convolutional Neural Network. Symmetry, 12(6), 1056. https://doi.org/10.3390/sym12061056