1. Introduction
With the expansion of the competitive environment, optimal supply chain (SC) design has become one of the fundamental issues business communities are facing [
1]. This has affected all of the organization’s activities to produce products, improve quality, reduce costs and provide the required services. On the other hand, with increasing greenhouse gas emissions and pollutants, managers of organizations and researchers are planning to set up networks that, in addition to considering economic optimization, have a special focus on environmental factors and the reduction of pollutants in all sectors [
2].
The reverse logistics network, as part of the SC, means the accurate, correct and timely transmission of materials and the kinds of goods that are usable and unusable from the endpoint (last consumer or end-user) through the SC to the appropriate plant. In other words, reverse logistics is the process of moving and transferring goods and products that can be returned through the SC [
3]. In this regard, the most important factor that is recognized in technical and economic studies of supply chains is the demand parameter, which should be considered in the design of forward or reverse supply chain networks (SCNs) [
4,
5,
6,
7].
Moreover, many countries have an increasing interest in protecting the environment and applying environmental laws. Hence, industry owners and manufacturers have turned their attention to the design and development of the SC, taking into account environmental factors [
8,
9,
10,
11,
12]. Green SC Design, integrating SC management with environmental requirements at all stages of product design, the selection and delivery of raw materials, production and manufacturing, distribution and transfer processes, delivery to the customer, and the management of recycling and reuse after consumption to maximize energy efficiency and the efficient use of resources are associated with improving the performance of the entire SC [
8,
13,
14,
15,
16,
17,
18,
19,
20].
Several reasons justify the notion of reverse logistics and using recycled material in a reverse supply chain. The steel industry, with more than 2.5 trillion dollars worth of products, is important [
21]. Usually, different economic, cost reduction, governmental regulatory, and social responsibility motivations encourage organizations to follow reverse logistic notions. Generally, the steel industry supply chain includes several stages of mining, processing, distributing and recycling. The concern of sustainability is very important in this industry. For instance, directly producing reduced iron instead of scrap requires 1120 cubic meters of water, 300,000 cubic meters of natural gas and 130,000 kilowatt-hours of electricity. This potential amount of saving has led to the introduction of a reverse logistic supply chain in the steel industry.
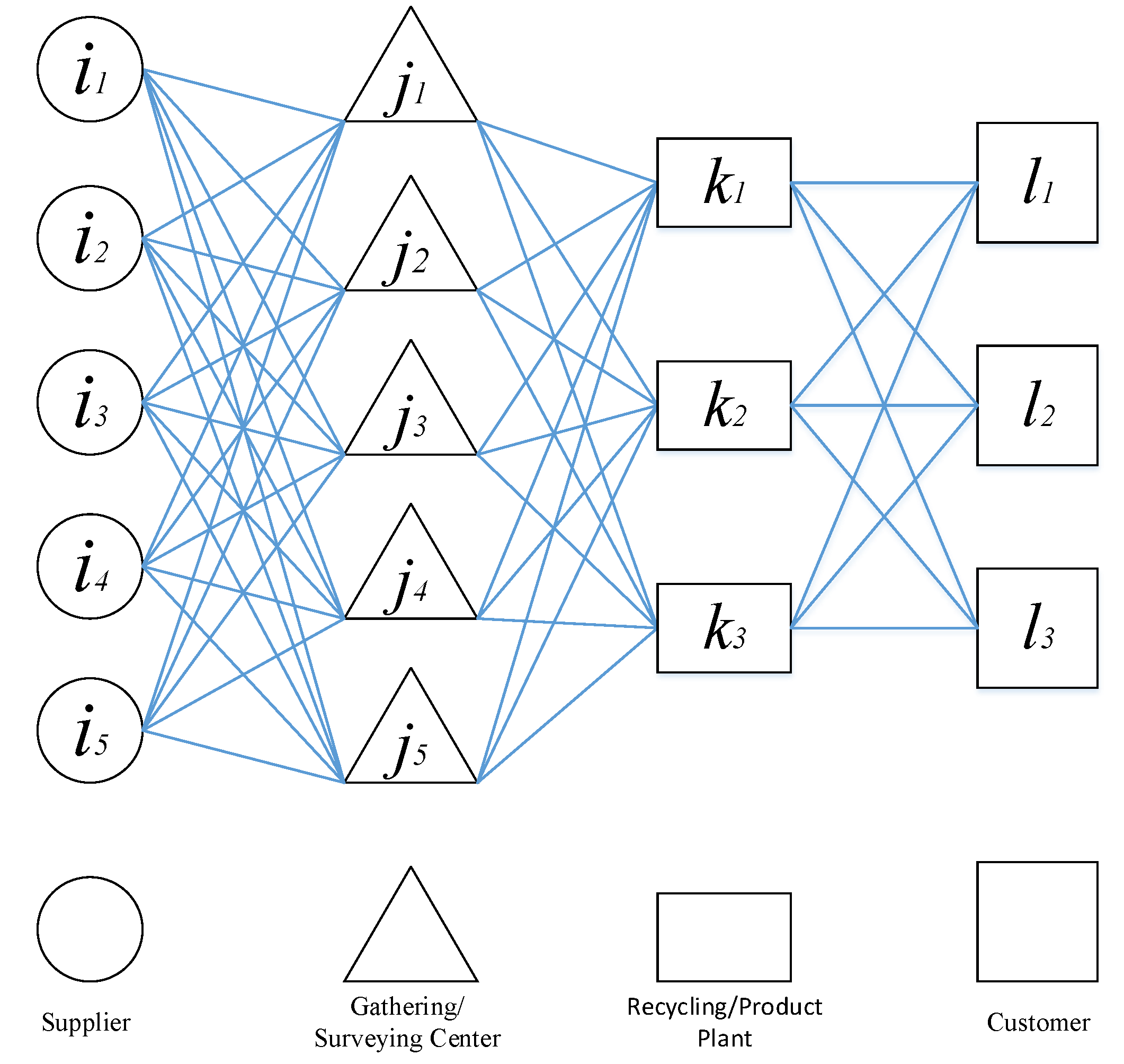
In this research, scenario planning was used to deal with uncertainty in the demand parameter due to unpredictable changes that have occurred during the research period in the studied case. To realize the economic, environmental and social effects of the reverse SCN and to optimize the model, three objectives were laid out, including maximizing operating profit, minimizing adverse environmental impacts and maximizing the level of service to suppliers and customers. To consider uncertainty, the multi-echelon supply chain, reverse logistics, and green supply design, the logistics network presented in this study consisted of four levels. The first level was the waste providers, considered as returning product suppliers, which could be the customers of previous periods who have returned their remaining products or can be new suppliers of scrap supplies. The second level was the gathering centers of the returned products, being responsible for supplying the scrap from the first-level suppliers of the chain, and in particular, being responsible for supplying the returned product, inspection, sorting, storage, and transferring the product to the recycling plants (product factories). The third level was the recycling plants for the production of new products, based on the received scrap from the gathering centers, which were responsible for producing new products. Finally, the fourth level was the customers. According to the given explanation, the proposed network is shown as a framework in
Figure 1.
The overall aim of this study was to design a sustainable reverse logistics integrated model in conditions of demand uncertainty, to optimize the flow of materials throughout the SC, and to determine the number and location of facilities and the planning of SC transportation. In this regard, the following objectives were considered in this research:
Identifying and categorizing the necessary processes to implement the reverse logistics network of the steel industry;
Maximizing the operating profit of the SC so as to meet economic requirements;
Minimizing the adverse environmental impacts to meet environmental requirements;
Maximizing the satisfaction of suppliers and customers to meet social requirements.
This study presents a multi-objective mathematical model for reverse SC design. The proposed model allows the NSGA-II algorithm to plan the recycling of products in the Iranian steel industry based on the modified approach of Feito Cespon et al. (2017) with their model. The proposed model has the following features [
22]:
Using a robust optimization approach and NSGA-II algorithm for the multi-objective modeling of the reverse SCN, including the flows of materials and transportation planning in conditions of uncertain demand;
Evaluating environmental indicators based on CO2 emissions as one of the most important greenhouse gas emissions in the environment;
Evaluating customer service levels (CSLs) based on maximizing the received products returned from suppliers/previous customers and selling new products to customers;
Defining different scenarios for dealing with uncertainty of demand and quantifying them according to expert opinion.
A reverse logistics network as part of the SC means the accurate, correct and timely transmission of materials and the types of goods that are usable and unusable from the endpoint (last consumer or end-user) through the SC to the appropriate plant. In this regard, many types of research have been previously illustrated.
Table 1 compares the illustrated pieces of research with the proposed method, from different perspectives.
According to previous research, although many studies and articles have focused on the issue of sustainable SCN, there are some knowledge gaps in this area that are briefly summarized as follows:
Most research focuses on the design of a new SC, and there exists a shortage of network redesign;
The impact of the number and location of facilities on the environment is not considered;
There are very few models that consider reconstructing reverse SC with a simultaneous analysis of social, economic, and environmental goals;
Uncertainty about the number of resources and demand for recycled products, along with the management of diverse materials, are issues that require investigation in the future.
Based on the above-mentioned gaps, the present study expresses a multi-objective mathematical model for redesigning the reverse SC network. The proposed model allows the use of a robustness approach to recycling multiple products. The proposed model has the following features:
The use of a robust optimization approach for redesigning a recycling SC network, including multiple flows of materials and uncertainties regarding the waste products used as raw materials, and the final demand for recycled products;
The structure of the expected functional index for evaluating a configuration for a new SC considering the economic and environmental objectives in different scenarios.
3. Results
This proposed model is based upon the work of Feito Cespon et al. 2017 [
22] by using a different objective function and case study and different solving approaches to compare the results. This is due to the main model (real-world case study) not being solvable with mathematical programming methods. At first, a smaller scale research model with fewer data called the “Initial Model” can be solved by an augmented epsilon constraint method, and subsequently, it is solved by the NSGA-II algorithm [
46,
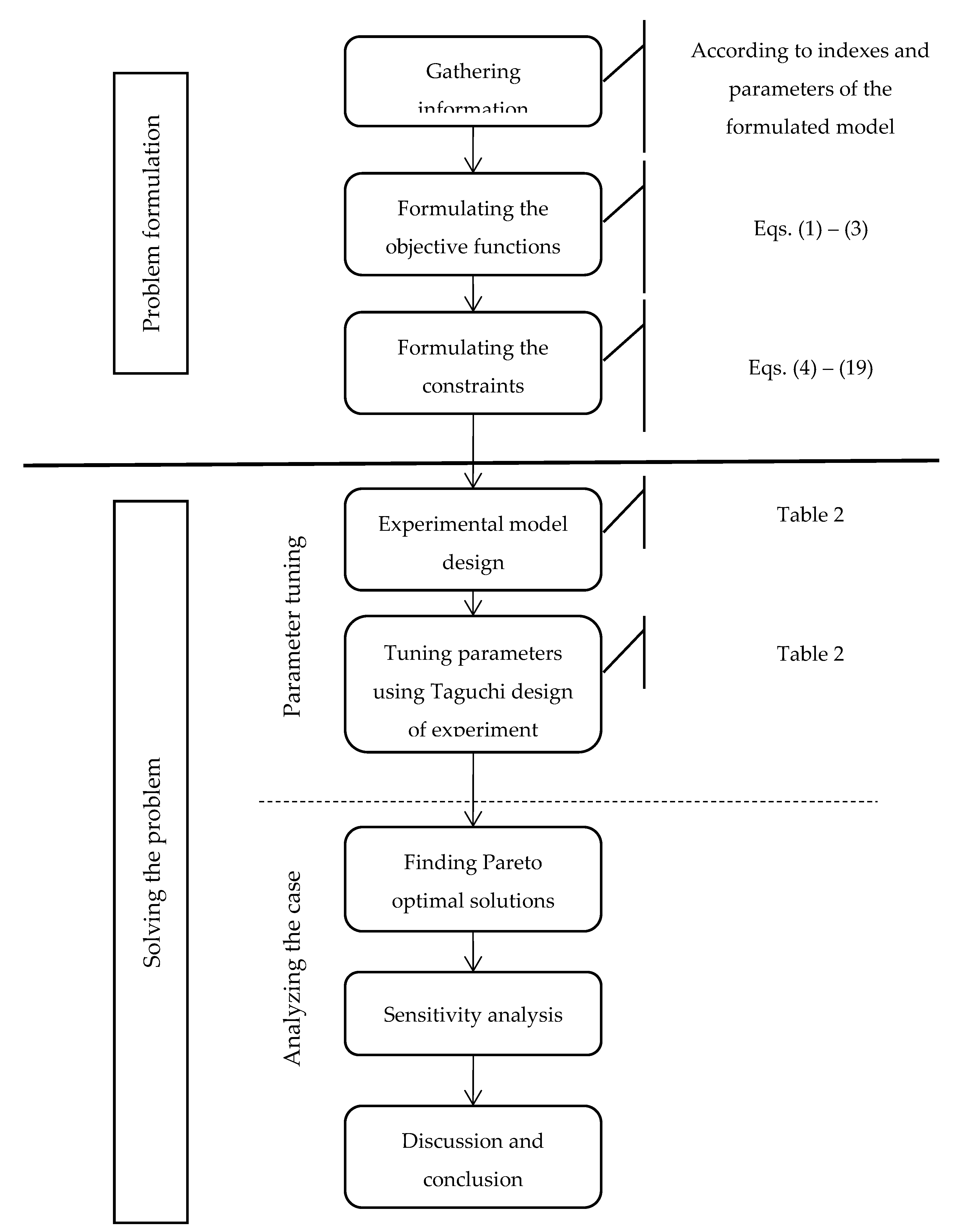
47]. Furthermore, the performance of the NSGA-II algorithm is evaluated by solving several examples in the proposed research model, and the corresponding criteria are calculated. Afterwards, with the confidence of the model’s validity, and since the main problem is Np-hard, the model of the real-world case study called “Main Model” is solved by the NSGA-II algorithm and will be analyzed at the end. Note that sensitivity analysis will be implemented on the initial model. Before solving the model, the method for determining the chromosome in the NSGA-II algorithm is presented. The algorithmic scheme of this section is illustrated in
Figure 2.
3.1. Definition of Chromosomes in the NSGA-II Algorithm
The matrix of the answer in the model has two sections, called allocation and assignment. The allocation section has two parts, the first part of which is the location of the gathering centers (J), and the second part is the location of the recycling plants (K). The cells of the matrix are filled with numbers 0 or 1, for example, if J = 5 and K = 3; an example of this matrix is given in
Table 2.
According to
Table 2, gathering center No. 5 has been constructed, and gathering centers No. 1, 2, 3 and 4 have not been constructed. Moreover, the recycling plant No.1 has been constructed and the recycling centers No. 2 and 3 have not been constructed. Each set is the answer that is called a chromosome. The assignment section shows the flow rate from the waste supplier to the gathering centers, from the gathering centers to the recycling plants and from the recycling plants to the customers. In
Table 3, the assignment section is shown. As a case in point, in the first part of the following table, which is a K ∗ L dimensional matrix, the flow rates from the recycling plants (k) to the customer (l) for the transportation mode (m), that is m = 1, p = 1 and s = 1, are shown.
Based on
Table 3, it is obvious that the flow rate of product 1 from the recycling plant 1 to customer 1 by transportation mode 1 in scenario 1 is 3. In this regard, each answer set is called a chromosome, and each cell is a gene.
3.2. NSGA-II Operator Selection
Achieving a high performance of genetic algorithms is highly dependent on the performance of the genetic operators. One of the main operators in genetic algorithms is crossover. The crossover operator is used to generate a new chromosome by crossing over two selected chromosomes. Different crossover operators are represented in previous studies. Here in this paper, the single point crossover is used. The next important operator is a mutation to assure diversity. Beyond the mutation probability that is tuned in
Section 3.6, in this study, the reverse and replace operators are used randomly to mutate the selected chromosomes. In reverse mutation, two genes are selected in the considered chromosome, and the values of remaining genes between these two selected genes are reversed from right to left. In the replacement mutation, two genes are selected, and their positions are swapped with one another’s.
3.3. Initial Model Solving Results
Table 4 indicates SC characteristics in the initial model. Furthermore, the probability of the occurrence of each scenario is obtained using the analytical hierarchical process (hereafter AHP) method, which for scenarios 1 to 2, is 52.4% and 47.6%, respectively. Moreover, in the initial model, a big M value is 10,000.
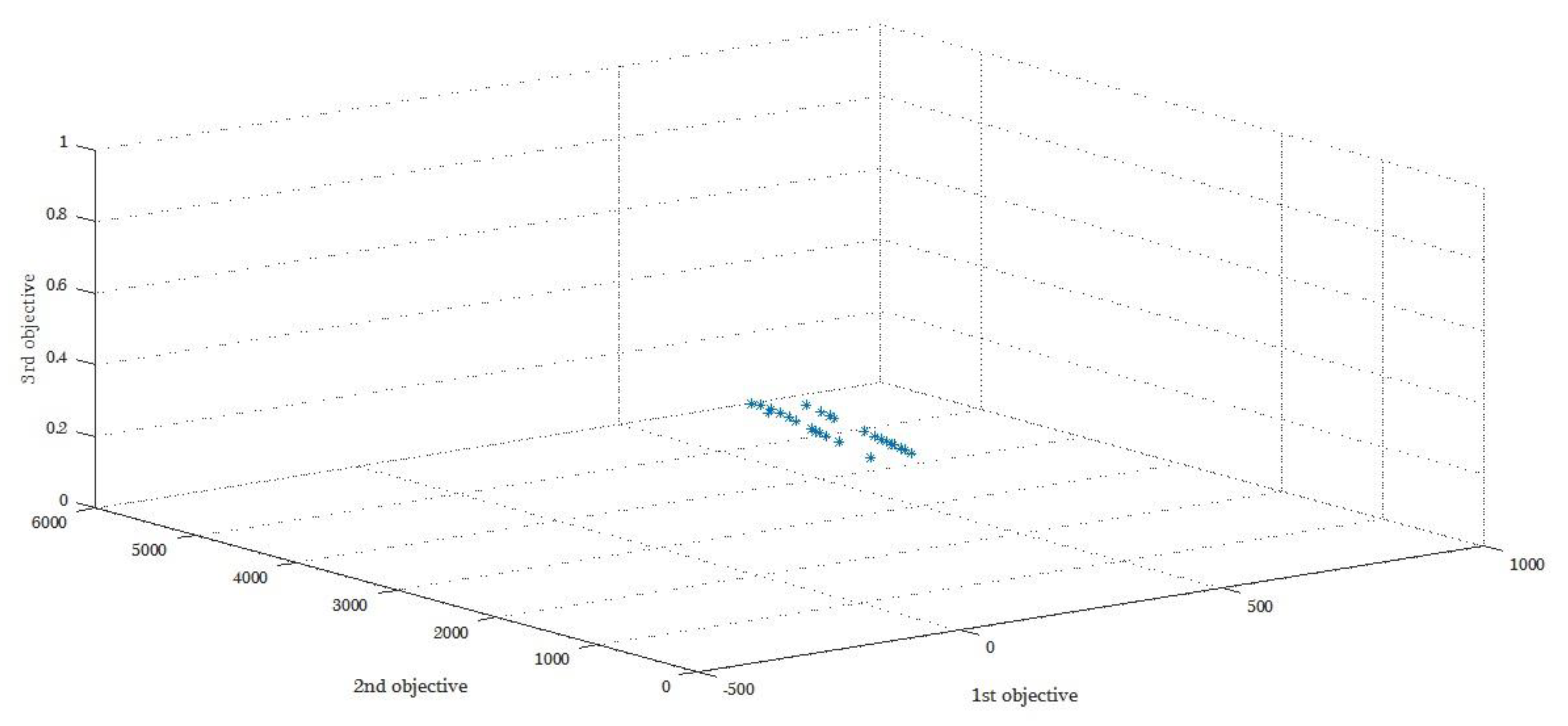
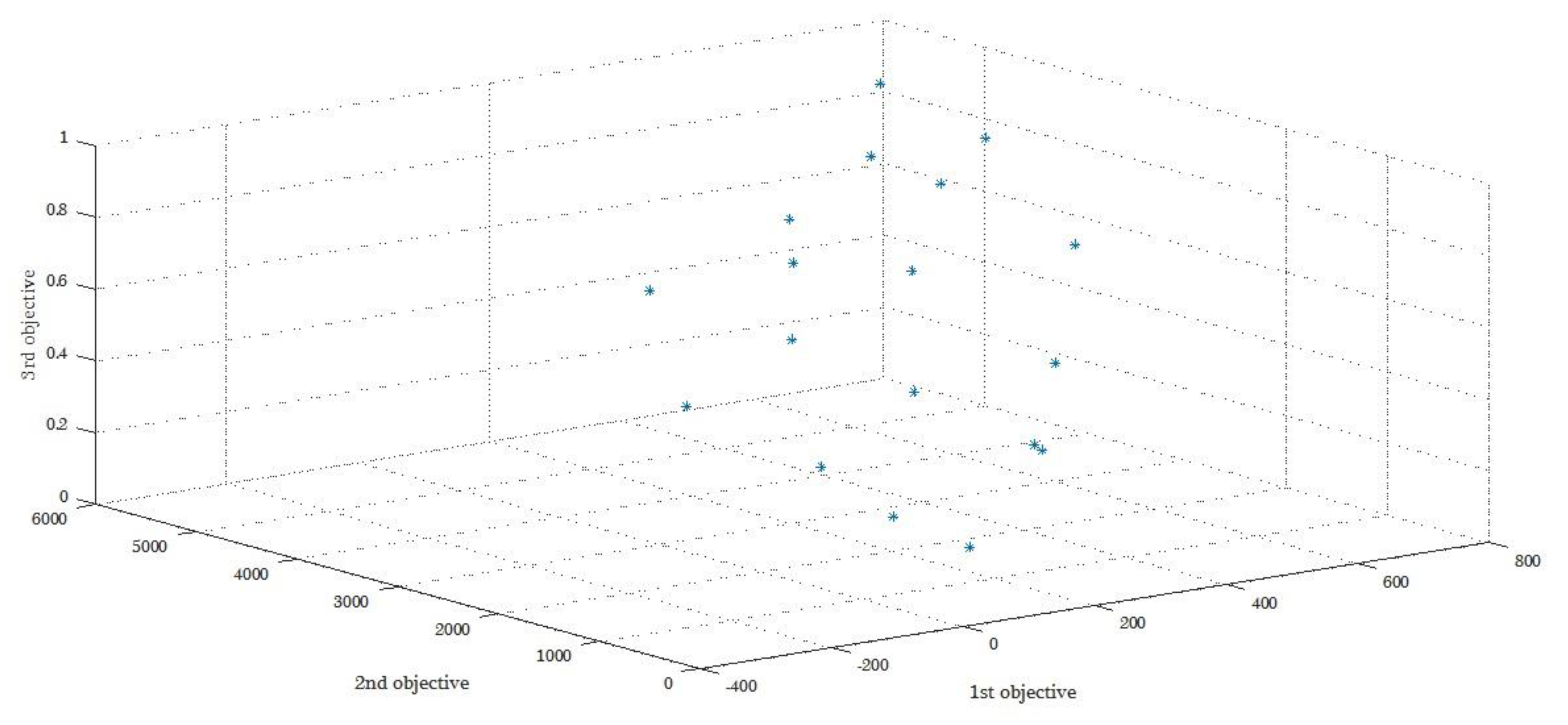
The Pareto result according to the GAMS and NSGA-II algorithm of five sets of answers derived from the initial model solving is shown in
Table 5 and
Table 6.
Figure 3 and
Figure 4 show these Pareto points. It is conceivable that the results obtained for the small scale problems by GAMS will outperform the NSGA-II results, as this can be seen in similar studies [
48,
49,
50]; however, as it is illustrated in the next sections, the main advantage of NSGA-II is in its ability to solve large scale and real-world problems. The time of the GAMS solving in this model, although the problem dimensions are low, is 326 seconds, which is increased sharply by increasing the dimensions of the problem.
Figure 3 and
Figure 4 show that when the values of the first objective function deteriorate, the values of the other objectives function do not. In other words, these values remain either constant or close to their optimal values, which is the expected process that the multi-objective models suggest.
3.4. Model Validation
To evaluate the performance of the model and to compare the performance of the NSGA-II algorithm with the augmented epsilon constraint method, five examples with different dimensions randomly compiled on the research model, and the criteria for comparing the efficiency of the multi-objective algorithms, are calculated, the results of which are shown in
Table 7. The results are obtained by running the proposed algorithm in a single trial with a population size of 10,000 and 250 repetitions. As the results indicate, it can be seen that using the NSGA-II algorithm has the necessary validity to solve the main model.
In this table, five measures are reported. Mean Idear Distance (MID) measures the convergence of an algorithm by averaging the distances of solutions from the best feasible solution [
51,
52]. Spacing measures the standard deviation of the distances among the Pareto front solution [
52]. Diversity evaluates the spread of the Pareto front [
52]. The Number of solutions (NoS) is the number of different Pareto solutions [
53,
54]. Time(s) is the time for which the algorithm needs to be run to reach the near-optimal solution [
53,
54].
The lower the index MID, the better the research results. As can be seen, the performance of the Epsilon Constraint (E.C). method in two sets of responses is better than that of the NSGA-II algorithm; however, with increasing dimensions of the problem, the method of E.C. loses its effectiveness. Since this difference is not very high, both indicators have shown good performance.
The lower the index spacing, the better the research results. According to
Table 7, the performance of the NSGA-II algorithm is better than that of the E.C. method. The higher the index (diversity), the better the research results. Based on the results, it can be seen that the proposed E.C method is better than the NSGA-II algorithm.
The higher the index NoS, the better the research results. Based on the results, the NSGA-II algorithm obtained a greater number of Pareto members. It is logical to increase the solution time of the algorithms by increasing the dimensions of the problem.
Therefore, according to the results, the same trend is observed; with an increase in the dimensions of the problems, the time taken to solve by the method of E.C. increases exponentially, and this method loses its efficiency in high-dimensional issues. However, it is almost constant for the NSGA-II algorithm.
3.5. The Parameter Adjustment of the NSGA-II Algorithm
Under the meta-heuristic algorithms that do not guarantee an exact optimal solution, the algorithm may be followed by a different response at any time by solving it. Therefore, a meta-heuristic algorithm is good when used, with almost identical answers each time. The most influential parameters in the NSGA-II algorithm are the number of initial population (nPop), the number of repetitions (MaxIt), the intersection rate (Pc) and the rate of mutation (Pm). With using the Taguchi design of experiments method, the parameters of this algorithm are based on comparative criteria for nine exams that have been determined under the following steps.
3.6. Taguchi Design of Experiment
In the NSGA-II algorithm, the four factors/parameters MaxIt, nPop, Pc, and Pm should be set to optimal levels. For this purpose, at first, for each parameter, three levels of low (1), medium (2) and high (3) are considered, as shown in
Table 8. The proposed Taguchi experiments for four factors at three levels are shown in
Table 9 for nine experiments. These experiments are designed based on Taguchi methods [
55].
Table 8 reveals the levels of the NSGA-II parameters, for each parameter considering three different levels.
Table 9 demonstrates the experiments designed to adjust the parameters of the NSGA-II algorithm. In
Table 10, the results of the NSGA-II algorithm for nine independent experiments are presented.
According to
Table 10, to create an output from each test and for five criteria, using the fuzzy unambiguous technique and the ideal planning approach, all indicators become responses after normalization. The normalization of the results and the calculation of the response variable are shown in
Table 11.
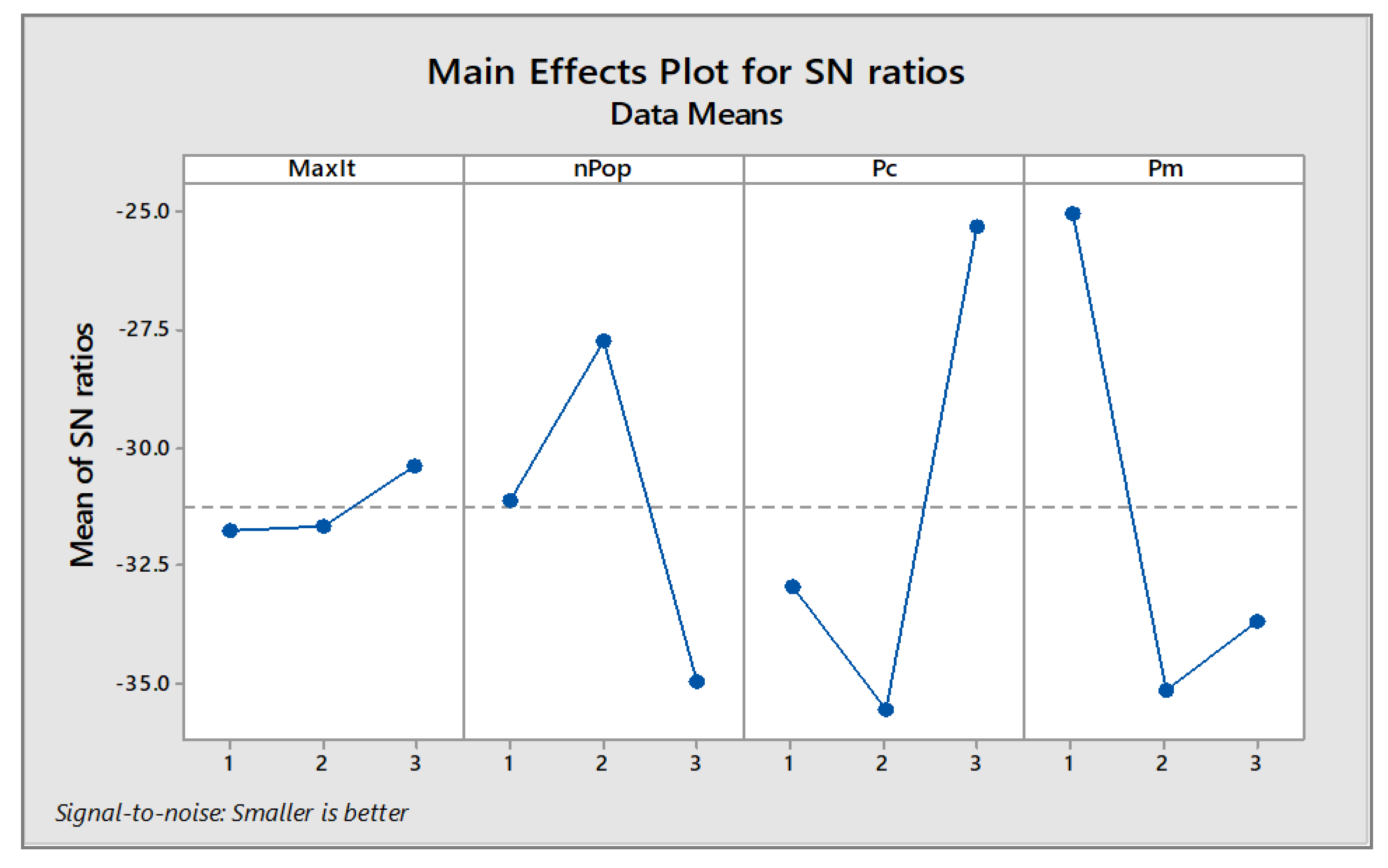
In the last step, based on the calculated response variable in the previous step, the S/N rate is calculated, and the optimal levels of the input parameters are determined. This operation is performed by the MINITAB software, and the results are illustrated in
Figure 5. This figure illustrates the main effect plot of different algorithm parameters. The plots are plotted by fixing parameters at their three levels, and then comparing the means of the S/N ratios against those at different levels.
The optimal levels for the parameters of the algorithm examined according to
Figure 5 and the above tables are shown in
Table 12.
3.7. Results of Solving the Main Model (Case Study)
Table 13 shows the main model of the case study. The case study is related to a steel production company with 8.1 million tons of yearly capacity in Iran. The company produced a set of intermediate and final products. The considered network includes suppliers, recycling plants, transportation modes and gathering centers. Additionally, five types of product are identified to be delivered to three types of customer. The problem parameters are gathered from the company’s databases, which are not presented due to their large magnitude. The problem specification and its parameters are illustrated in
Table 13.
According to the requirements of the considered organization as the case study, five incidental conditions are defined for these conditions, which are considered as a scenario for each mode, providing different data. Moreover, the probabilities of occurrence of each scenario are obtained using the AHP method, which are—for scenarios 1 to 5—16%, 22%, 48%, 9% and 5%, respectively. Furthermore, in the main model, a big M value of 10,000 is considered.
As stated above, since the size of the case study is high and the GAMS software is not able to solve it at an acceptable time, the original model in the MATLAB software is solved based on the NSGA-II algorithm, the Pareto points from which are presented in
Table 14 and
Figure 6.
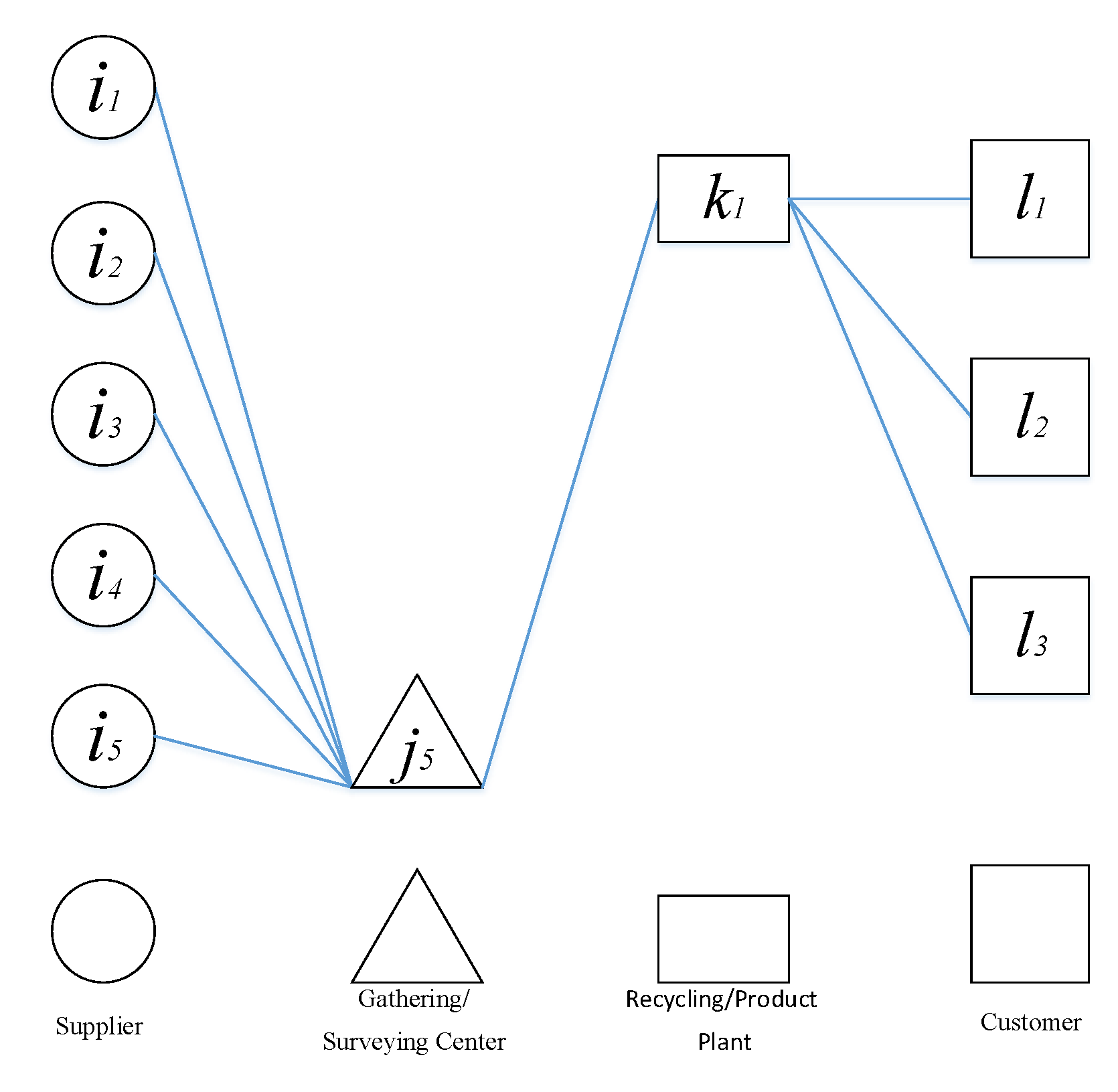
As expected, due to the high cost of constructing facilities in the steel industry, one center (center number 5) of the five candidates was selected, and one factory (factory number 1) of the three nominated recycling/production plants for construction is calculated, and it provides an excellent answer to the case study. In this way, the schematic of the reverse SC model is changed after the solution, as shown in
Figure 6.
Besides, the values of the parameters of the NSGA-II algorithm are described in
Table 15 in the main model.
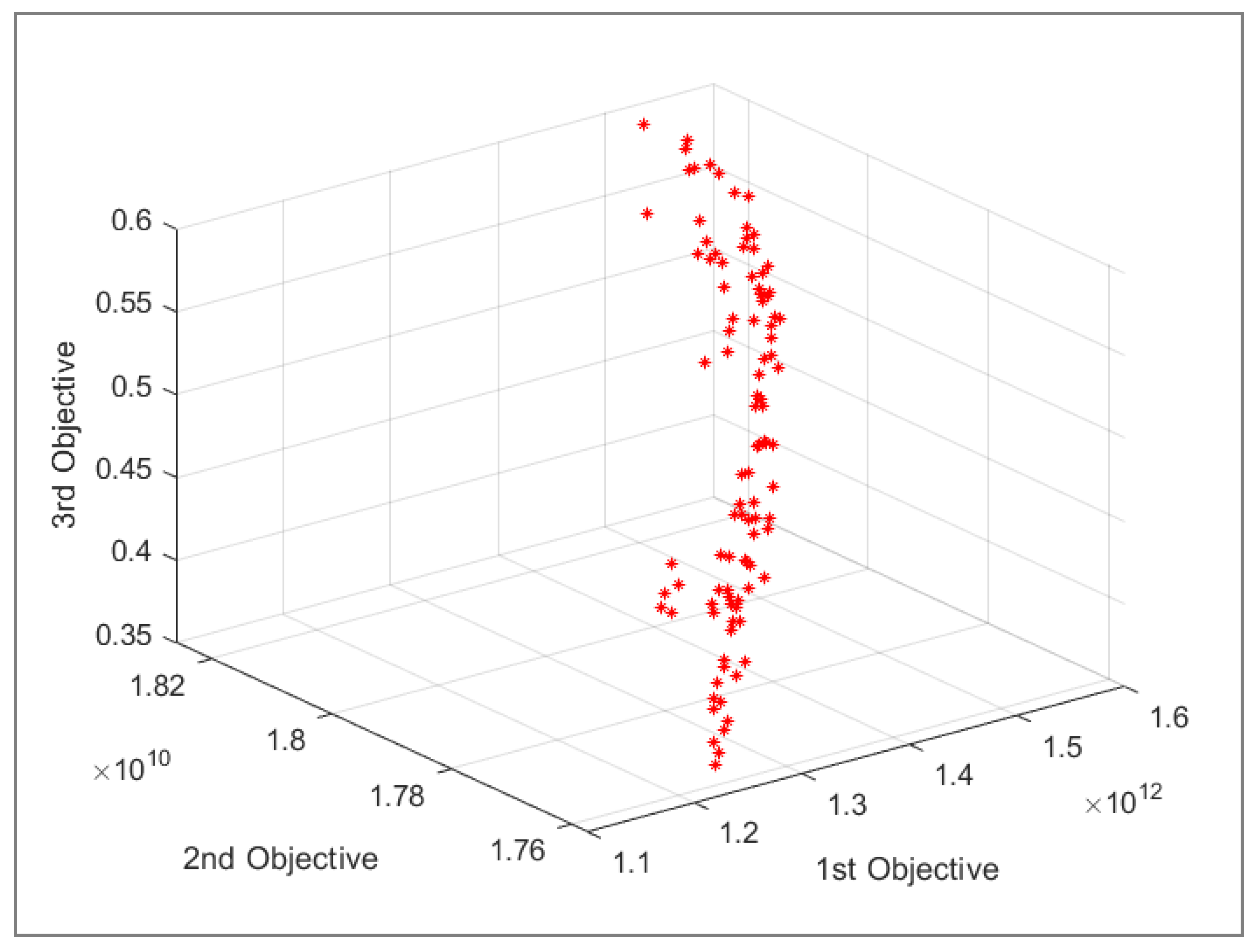
For any Pareto optimal solution, the optimal values of decision variables are obtained(see
Figure 7). For instance, the magnitudes of some decision variables for the first Pareto solution in
Table 14 are represented in
Table 16. According to this table, under the first scenario, a magnitude of 2.4605 of the first product type should be transported from the first supplier to the fifth gathering center. Other values can be interpreted similarly. For each Pareto optimal solution, a similar set of optimal decision variables is obtained.
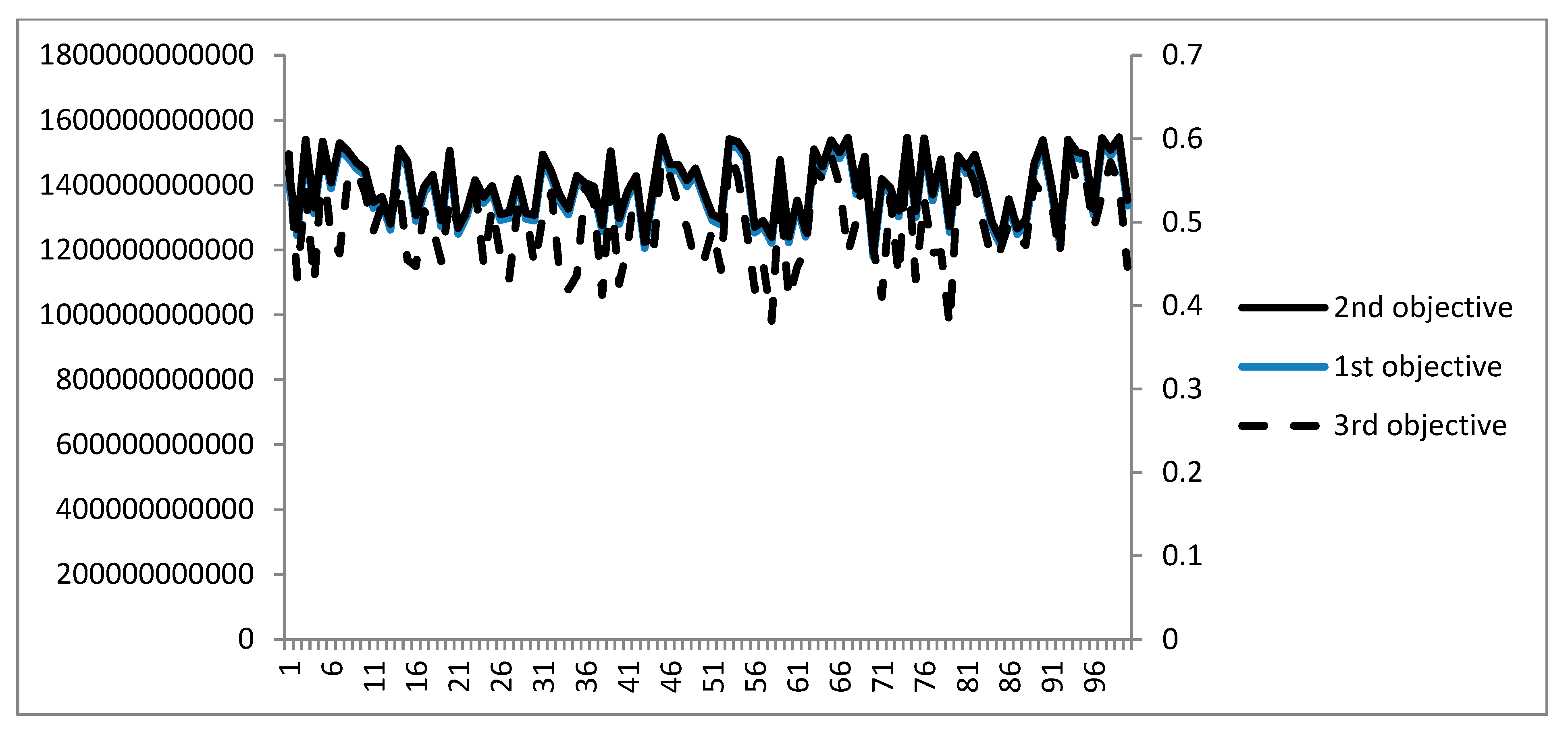
To assure the convergence of the proposed algorithm, with its tuned parameters, the above problem is repetitively solved 100 times.
Figure 8 illustrates the obtained results of the solutions for different objectives. According to this figure, it is clear that the algorithm-proposed solution in all of the objectives represents a controllable variance, and it can be considered as the proposed algorithm reliability. No outlier solutions can be detected in repetitions.
3.8. Sensitivity Analysis
To investigate how the values of the objective functions varied, sensitivity analysis should be performed on some of the parameters. Regarding the multiplicity of the model, two types of analysis are performed. The first type is the change in Pareto’s values relative to the change in one of the parameters. In the present study, this type of analysis—as compared to the change in the demand parameter in the initial model, which decreased by 10%—and the results of this sensitivity analysis are shown in
Table 17 and
Figure 9.
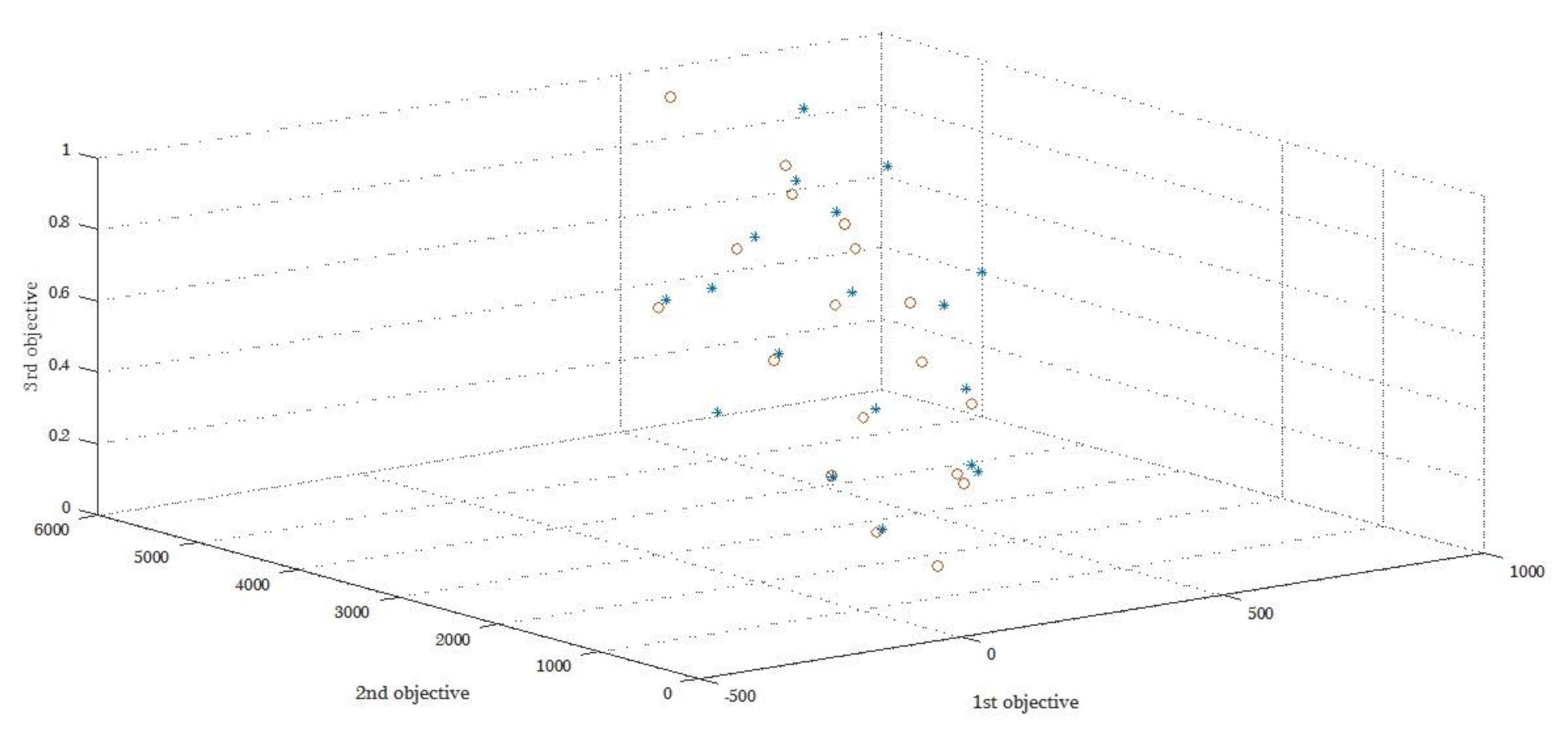
As demonstrated, with the decrease in the average demand, the value of the objective function decreased. By virtue of shipping costs, other items are reduced by decreasing demand. In
Figure 4, the stars represent the Pareto before the change, and the circles represent the Pareto after the change.
The second type of sensitivity analysis is employed for one Pareto point (here, for the tenth Pareto point), which is done for the demand parameter. The variability of the value of the objective function concerning demand in the initial model is shown in
Table 18 and
Figure 10.
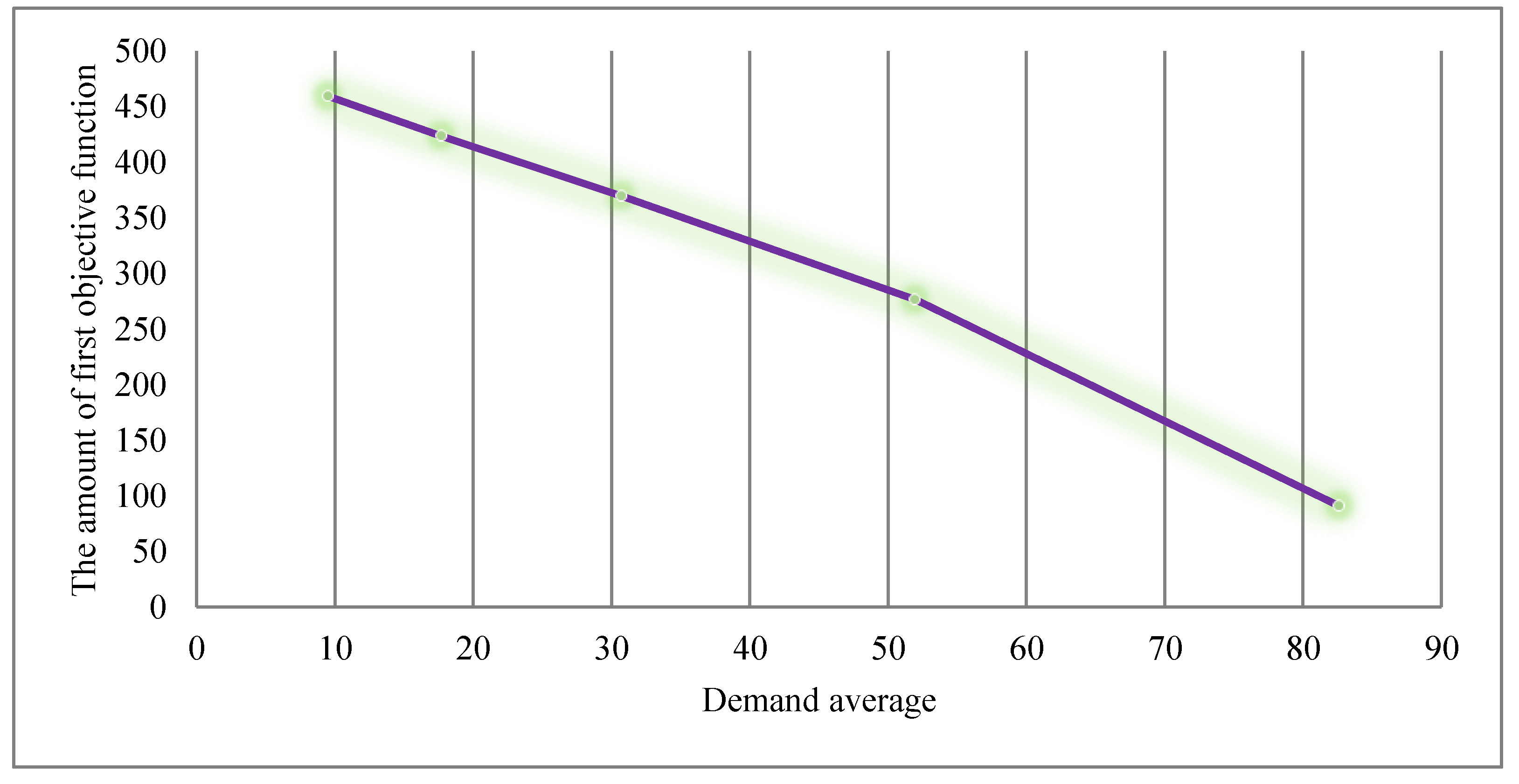
In
Table 18, by assuming that the second and third objective functions are fixed, and that only the changes in the first objective function have been investigated, it is seen that with increasing average demand, the first objective function is reduced. In fact, with increasing demand, the amount of cost is higher than the amount of income.
4. Discussion and Conclusions
In the present study, the model was defined as multi-objective functions based on the conditions of the uncertainty of demand and five scenarios; the model was solved by an augmented epsilon constraint method and the NSGA-II algorithm, and finally analyzed. This proposed model is based upon the work of Feito Cespon et al. 2017 [
22] by using a different objective function and case study and different solving approaches to compare the results. Because the number of levels and actual data of the model would be Np-hard by solving the GAMS, and it would not be able to achieve the optimal response, model validation and sensitivity analysis were done on a smaller scale. The results of the comparative indices showed that solving the model with the NSGA-II algorithm yielded acceptable results, and the main model was solved accordingly. Additionally, the optimal levels of the NSGA-II algorithm parameters were adjusted in the original model, based on the Taguchi design of experiments method. In analyzing the results, as expected, in the locating facility, one gathering center was selected from five candidates, and one recycling plant was selected from three candidate plants. The number of objective functions in different Pareto points has been obtained with a suitable and acceptable dispersion criterion. The model showed that it could be integrated into optimizing the objectives, determining the number and location of necessary facilities and planning the transportation between different levels of the steel industry. Some of the assumptions implied in the current study can be adjusted in future studies. First, there are some general assumptions including the uncertainty of demand parameter, the determinedness of costs, the number and capacity of transportation modes and the number of supply chain levels. These assumptions can be generalized straightforwardly, by considering the uncertainty of other parameters and extending the model into more levels. Additionally, in the current paper, it is assumed that the number of suppliers, customers, gathering centers and recycling plants are determined. However, in some cases, the problem can be formulated to select different markets, suppliers, and gathering and recycling centers in a broader scope. These extensions will not change the structure of the proposed method drastically. However, altering some assumptions requires fundamental changes in the proposed model. Among these assumptions, reference to transshipment among levels (ignoring the sixth assumption) and limiting the capacity of gathering centers and recycling plants can be made. Further research can be done on the above-mentioned problems by changing the current model’s assumptions.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}