Applying Educational Data Mining to Explore Students’ Learning Patterns in the Flipped Learning Approach for Coding Education


Abstract
1. Introduction
- In the blended learning environment, can we use the data generated in the learning process to forecast learners’ performances?
- Can we apply the generated model to predict the data of the other class?
- Can we find a specific learning model from the learner’s learning behavior? How can the learning group be defined and which variables should they be based on?
2. Literature Review
2.1. Blending Learning Environment
2.2. Educational Data Mining
2.3. Visual Analysis
3. Method
3.1. Participants
3.2. Data Collection
- (1)
- The source of the students’ asynchronous online learning behavior was obtained from the learning management system log file.
- (2)
- The source of the students’ synchronous learning behavior was from the Facebook live platform.
- (3)
- The source of the students’ course evaluation was from the learner questionnaire.
3.3. Research Tools
- (1)
- Learning Management System
- (2)
- Facebook Live Platform, Facebook Graph API
- (3)
- Final learner questionnaire
3.4. Data Analysis
4. Results
4.1. Mid-Term Forecast
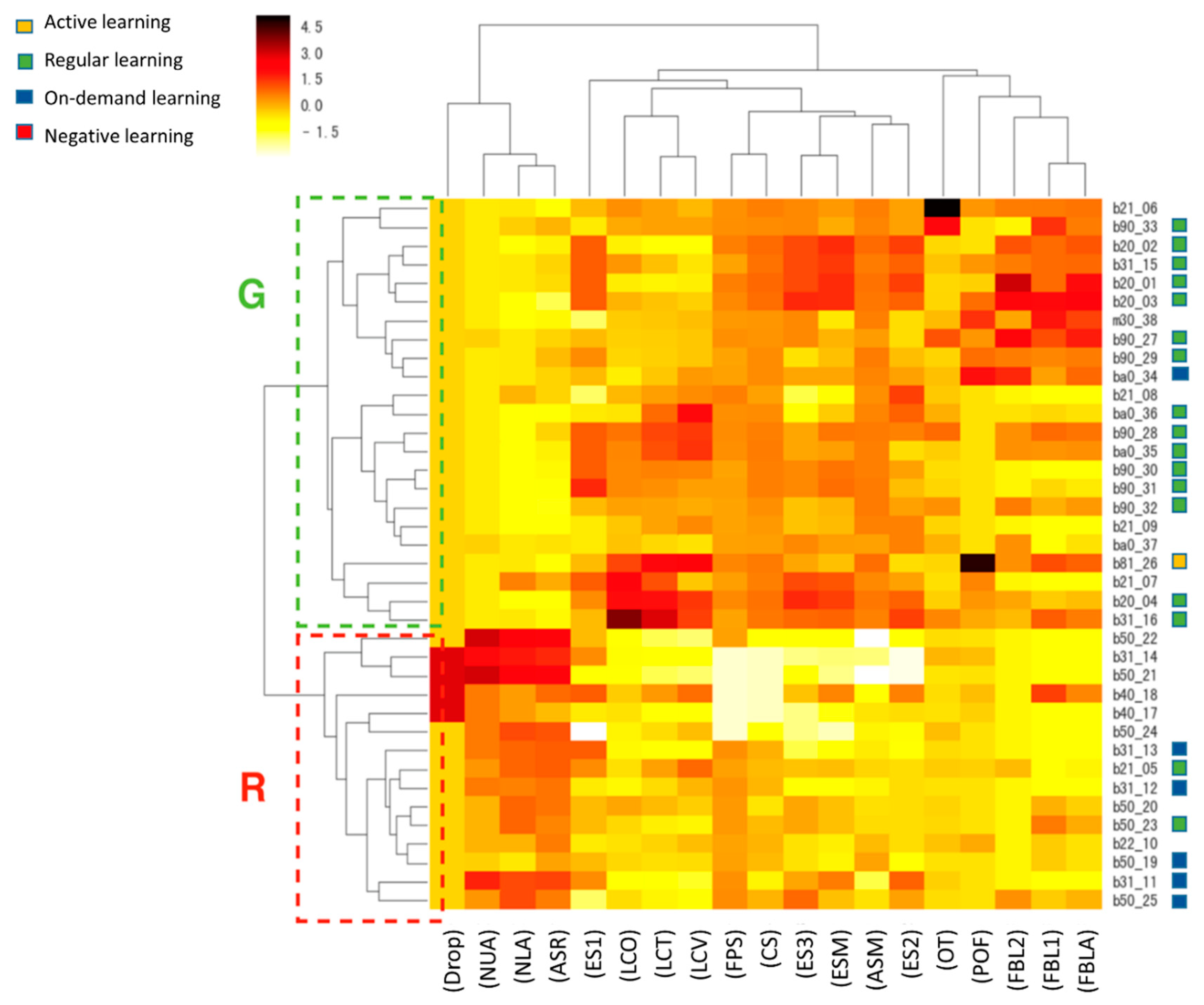
4.2. Learning Behavior Grouping
4.3. Discussion on Conscious Learning Attitude
5. Conclusions and Discussion
5.1. Explore the Impact of Overall Learning Behavior on Learning Performance in a Mixed Learning Environment
- (1)
- Synchronous/non-synchronized participants have better learning performance.
- (2)
- Learners with stable pace have better learning performance.
5.2. Use Machine Learning to Establish an Interim Warning System to Predict High-risk Group Learners
- (1)
- Using a mixed education environment to generate data can accurately predict high-risk group learners during the period
- (2)
- The model trained in this study can be extrapolated and applied to other courses to predict learner performance.
5.3. Model Analysis Definitions for Learner Learning Behavior
- (1)
- Using the clustering method can explore the fixed learning mode for the learner’s learning behavior.
- (2)
- Using hierarchical clustering and heat map can further define learning mode grouping from multi-dimensional user data variables.
5.4. Limitations of This Study
Author Contributions
Funding
Conflicts of Interest
References
- Ni, A.Y. Comparing the effectiveness of classroom and online learning: Teaching research methods. J. Public Aff. Educ. 2013, 19, 199–215. [Google Scholar] [CrossRef]
- Graham, C.R.; Woodfield, W.; Harrison, J.B. A framework for institutional adoption and implementation of blended learning in higher education. Internet High. Educ. 2013, 18, 4–14. [Google Scholar] [CrossRef]
- Wang, Q.Y. A generic model for guiding the integration of ICT into teaching and learning. Innov. Educ. Teach. Int. 2008, 45, 411–419. [Google Scholar] [CrossRef]
- He, W. Examining students’ online interaction in a live video streaming environment using data mining and text mining. Comput. Hum. Behav. 2013, 29, 90–102. [Google Scholar] [CrossRef]
- Romero, C.; López, M.-I.; Luna, J.-M.; Ventura, S. Predicting students’ final performance from participation in on-line discussion forums. Comput. Educ. 2013, 68, 458–472. [Google Scholar] [CrossRef]
- Garrison, D.R.; Kanuka, H. Blended learning: Uncovering its transformative potential in higher education. Internet High. Educ. 2004, 7, 95–105. [Google Scholar] [CrossRef]
- Park, Y.; Yu, J.H.; Jo, I.H. Clustering blended learning courses by online behavior data case study in a Korean higher education institute. Internet High. Educ 2016, 29, 1–11. [Google Scholar] [CrossRef]
- Francis, R.; Raftery, J. Blended learning landscapes. Brookes Ejournal Learn. Teach. 2005, 1, 1–5. [Google Scholar]
- Halverson, L.R.; Graham, C.R.; Spring, K.J.; Drysdale, J.S.; Henrie, C.R. A thematic analysis of the most highly cited scholarship in the first decade of blended learning research. Internet High. Educ. 2014, 20, 20–34. [Google Scholar] [CrossRef]
- Sikder, S.; Herold, H.; Meinel, G.; Lorenzen-Zabel, A. Blessings of open data and technology: E-learning examples on land use monitoring and e-mobility. In Proceeding of the STS Conference, Graz, Austria, 6–7 May 2019. [Google Scholar]
- Keržič, D.; Tomaževič, N.; Aristovnik, A.; Umek, L. Exploring critical factors of the perceived usefulness of blended learning for higher education students. PLoS ONE 2019, 14, e0223767. [Google Scholar] [CrossRef] [PubMed]
- Baker, R.; Yacef, K. The State of educational data mining in 2009: A review and future visions. J. Educ. Data Min. 2009, 1, 3–17. [Google Scholar] [CrossRef]
- Baker, R. Data Mining for Education. In International Encyclopedia of Education, 3rd ed.; Peterson, P., Baker, E., Mcgaw, B., Eds.; Elsevier: Oxford, UK, 2012; pp. 112–118. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. ManCybern. Part C Appl. Rev. 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Araque, F.; Roldan, C.; Salguero, A. Factors influencing university drop out rates. Comput. Educ. 2019, 53, 563–574. [Google Scholar] [CrossRef]
- Hämäläinen, W.; Vinni, M. Classifiers for Educational Data Mining; Chapman & Hall/CRC: London, UK, 2011. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S.; Garcia, E. Data mining in course management systems: Moodle case study and tutorial. Comput. Educ. 2008, 51, 368–384. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Data mining in education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 12–27. [Google Scholar] [CrossRef]
- Romero, C.; Espejo, P.; Romero, R.; Ventura, S. Web usage mining for predicting final marks of students that use Moodle courses. Comput. Appl. Eng. 2013, 21, 135–146. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S.; Espejo, P.; Hervás, C. Data mining algorithms to classify students. In Proceedings of the Educational Data Mining, Montréal, QC, Canada, 20–21 June 2008; pp. 20–21. [Google Scholar]
- Kulkarni, V.Y.; Sinha, P.K. Pruning of random forest classifiers: A survey and future directions. In Proceedings of the 2012 International Conference on Data Science & Engineering (ICDSE 2012), Cochin, Kerala, India, 18–20 July 2012; pp. 64–68. [Google Scholar]
- Osmanbegović, E.; Suljic, M.; Agić, H. Determing dominant factors for students performance prediction by using data mining classification algorithms. Tranzicija 2015, 16, 147–158. [Google Scholar]
- Hou, H.-T. Computers in human behavior integrating cluster and sequential analysis to explore learners’ flow and behavioral patterns in a simulation game with situated-learning context for science courses: A video-based process exploration. Comput. Hum. Behav. 2015, 48, 424–435. [Google Scholar] [CrossRef]
- Friendly, M. A Brief History of Data Visualization. In Handbook of Data Visualization; Springer Handbooks Comp. Statistics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef]
- Tufte, E.R. The visual display of quantitative information. Am. J. Phys. 1986, 53, 1117. [Google Scholar] [CrossRef]
- Kochevar, P. Database Management for Data Visualization. In Database Issues for Data Visualization; Lee, J.P., Grinstein, G.G., Eds.; Springer Lecture Notes in Computer Science: Berlin/Heidelberg, Germany, 1994; Volume 871. [Google Scholar] [CrossRef]
- Gitelman, L.; Jackson, V. Introduction. In Raw data. Is an Oxymoron; Gitelman, L., Ed.; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Beer, D. Popular Culture and New Media: The Politics of Circulation; Palgrave: London, UK, 2013. [Google Scholar]
- Garrison, D.; Anderson, R.T.; Archer, W. Critical inquiry in a text-based environment: Computer conferencing in higher education. Internet High. Educ. 2000, 2, 87–105. [Google Scholar] [CrossRef]
- Shaw, R.S. A study of the relationships among learning styles, participation types, and performance in programming language learning supported by online forums. Comput. Educ. 2012, 58, 111–120. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Label | Logistic Regression | Decision Tree | Random Forest | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| 0/Fail | 0.33 | 0.50 | 0.40 | 0.33 | 0.50 | 0.40 | 0.53 | 0.50 | 0.50 |
| 1/Pass | 0.89 | 0.80 | 0.84 | 0.89 | 0.80 | 0.84 | 0.90 | 0.90 | 0.90 |
| Avg/Total | 0.80 | 0.75 | 0.77 | 0.80 | 0.75 | 0.77 | 0.83 | 0.83 | 0.83 |
| Data Label | Precision | Recall | F1-Score |
|---|---|---|---|
| 0/Fail | 0.33 | 0.50 | 0.40 |
| 1/Pass | 0.89 | 0.80 | 0.84 |
| Avg/Total | 0.80 | 0.75 | 0.77 |
| Question | Active Learning | Regular Learning | On-Demand Learning | Negative Learning |
|---|---|---|---|---|
| I think my learning mode for this course | 1 (4%) | 19 (73%) | 6 (23%) | 0 (0%) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, H.-C.; Liu, I.-F.; Liang, C.-T.; Su, Y.-S. Applying Educational Data Mining to Explore Students’ Learning Patterns in the Flipped Learning Approach for Coding Education. Symmetry 2020, 12, 213. https://doi.org/10.3390/sym12020213
Hung H-C, Liu I-F, Liang C-T, Su Y-S. Applying Educational Data Mining to Explore Students’ Learning Patterns in the Flipped Learning Approach for Coding Education. Symmetry. 2020; 12(2):213. https://doi.org/10.3390/sym12020213
Chicago/Turabian StyleHung, Hui-Chun, I-Fan Liu, Che-Tien Liang, and Yu-Sheng Su. 2020. "Applying Educational Data Mining to Explore Students’ Learning Patterns in the Flipped Learning Approach for Coding Education" Symmetry 12, no. 2: 213. https://doi.org/10.3390/sym12020213
APA StyleHung, H.-C., Liu, I.-F., Liang, C.-T., & Su, Y.-S. (2020). Applying Educational Data Mining to Explore Students’ Learning Patterns in the Flipped Learning Approach for Coding Education. Symmetry, 12(2), 213. https://doi.org/10.3390/sym12020213