Abstract
In this paper, a new filter nonmonotone adaptive trust region with fixed step length for unconstrained optimization is proposed. The trust region radius adopts a new adaptive strategy to overcome additional computational costs at each iteration. A new nonmonotone trust region ratio is introduced. When a trial step is not successful, a multidimensional filter is employed to increase the possibility of the trial step being accepted. If the trial step is still not accepted by the filter set, it is possible to find a new iteration point along the trial step and the step length is computed by a fixed formula. The positive definite symmetric matrix of the approximate Hessian matrix is updated using the MBFGS method. The global convergence and superlinear convergence of the proposed algorithm is proven by some classical assumptions. The efficiency of the algorithm is tested by numerical results.
1. Introduction
Consider the following unconstrained optimization problem:
where : is a twice continuously differentiable function. The trust region method is one of the prominent classes of iterative methods. At the iteration point , the trial step is obtained by the following quadratic subproblem:
where is the Euclidean norm, , , , is a symmetric approximation of , and is a trust region radius. The most ordinary ratio is defined as follows:
Generally, the numerator is referred to as the actual reduction and the denominator is known as the predicted reduction.
The disadvantage of the traditional trust region method is that the subproblem needs to be solved many times to achieve an acceptable trial step in one iteration. To overcome this drawback, Mo et al. [1] first proposed a nonmonotone trust region algorithm with a fixed step length. When the trial step is not acceptable, we use a fixed step length to find a new iteration point instead of resolving the subproblem. Based on this advantage, Ou, Hang, and Wang have proposed a trust region algorithm with fixed step length in [2,3,4], respectively. The fixed step length is computed by
It is well known that the strategy of selecting a trust region radius has a significant impact on the performance of the trust region methods. In 1997, Sartenaer [5] presented a strategy which can automatically determine an initial trust region radius. This fact leads to an increase in the number of subproblems to be solved in some problems, thereby reducing the efficiency of these methods. In 2002, Zhang et al. [6] provided another scheme to reduce the number of subproblems that need to be solved, where the trust region radius uses: , , where . Zhang’s strategy requires an estimation of the inverse of the matrixes and in each iteration; however, Li [4] has suggested another practically efficient adaptive trust region radius that uses . The strategy requires not only the gradient value but also the function value. Inspired by these facts, some modified versions of adaptive trust region methods have been proposed in [7,8,9,10].
As we all know, monotone techniques may slow down the rate of convergence, especially in the presence of the narrow curved valley. The monotone techniques require the value of the function to be decreased at each iteration. In order to overcome these disadvantages, Deng et al. [11] proposed a nonmonotone trust region algorithm in 1993. The general nonmonotone term is defined by
where , , and is an integer. Deng et al. [11] modified the ratio (3) which evaluates the consistency between the quadratic model and the objective function in trust region methods. The most common nonmonotone ratio is defined as follows:
The general nonmonotone term suffers from various drawbacks, such as the fact that numerical performance is highly dependent on the choice of . In order to introduce a more suitable nonmonotone strategy, Ahookhosh et al. [12] proposed a new nonmonotone ratio as follows.
where
in which , with , and . We recommend that interested readers refer to [13,14] for more details and progress on the nonmonotone trust region algorithm.
In order to overcome the difficulties associated with using the penalty function, especially the adjustment of the penalty parameter. The filter methods were recently presented by Fletcher and Leyffer [15] for constrained nonlinear optimization. More recently, Gould et al. [16] explored a new nonmonotone trust region algorithm for the unconstrained optimization problems with the multidimensional filter technique in [17]. Compared with the standard nonmonotone algorithm, the new algorithm dynamically determines iterations based on filter elements and increases the possibility of the trial step being accepted. Therefore, this topic has received great attention in recent years (see [18,19,20,21]).
The remainder of this paper is organized as follows. In Section 2, we describe a new trust region method. The global convergence is investigated in Section 3. In Section 4, we prove the superlinear convergence of the algorithm. Numerical results are shown in Section 5. Finally, the paper ends with some conclusions in Section 6.
2. The New Algorithm
In this section, we propose a trust region method by combining a new trust region radius and the modified trust region ratio to effectively solve unconstrained optimization problems. In each iteration, a trial step is generated by solving an adaptive trust region subproblem,
where and is an adjustment parameter. Prompted by the adaptive technique, the proposed method has the following effective properties: it is not necessary to calculate the matrix of the inverse and the value of each iteration point, and the algorithm also reduces the related workload and calculation time.
In fact, the matrix is usually obtained by approximation, and the subproblems are only solved roughly. In this case, it may be more reasonable to adjust the next trust radius , not only according to , but also by considering the use of . To improve the efficiency of the nonmonotone trust region methods, we can define the modified ratio formula based on (7) as follows:
where is a positive integer and is the weight of , such that .
More exactly, can be used to determine whether the trial step is acceptable. Adjusting the next radius depends on (11), thus is updated by
In what follows, we refer to by . When an component of is needed, we denote it using . Based on this filter, we say that an iterate point dominates if, and only if
A multidimensional filter is a list of -tuples of the form , such that
where , belong to .
For all , a new trial point is acceptable if there exists , such that
If the iterate point is acceptable, we add to the filter. Meanwhile, we remove all the points which are dominated by from the filter. In the general filter trust region algorithm, for the trial point satisfying , we verify whether it is accepted by filter . In our algorithm, it is the trial point that satisfies , and verifies whether or not it is accepted by the filter .
Our discussion can be summarized as the following Algorithm 1.
| Algorithm 1. A new filter nonmonotone adaptive trust region method. |
| Step 0. (Initialization) An initial point and a symmetric matrix are given. The constants , , , , , and are also given. Step 1. If , then stop. Step 2. Solve the subproblem (2) to find the trial step . Step 3. Choose , which satisfies . Compute , , and , respectively. Step 4. Test the trial step. If , then set . Otherwise compute ; if is acceptable by the filter , then , add into the filter . Otherwise, find the step length satisfying (4), set . end(if) end(If) Step 5. Update the trust region radius by , where is updated by (12). Step 6. Compute the new Hessian approximation by a modified BFGS method formula. Set , and return to Step 1. |
In order to obtain convergence results, we use the following notation:
, , . Then, we have . When , we have .
3. Convergence Analysis
To establish the convergence of Algorithm 1, we make the following common assumption.
Assumption 1.
H1.The level set,whereis boundedis continuously differentiable on the level set.
H2. The matrixis uniformly bounded, i.e., there exists a constantsuch that.
H3. There exists constantsuch that, for all.
Remark 1.
In order to analyze the convergence of the new algorithm, it should be seen to that the trial stepsatisfies the following conditions:
where the constant.
Remark 2.
Ifis a twice continuously differentiable function, then H1 means that there is a positive constantsuch that
Lemma 1.
For all, we can obtain that
Proof.
The proof is given by using Taylor’s expansion and H3. □
Lemma 2.
Suppose that H1-H3 hold, the sequenceis generated by Algorithm 1. Moreover, assume that there exists a constantsuch that, for all. Then, for every, there exists a nonnegative integer, so thatis a successful iteration point, i.e.,.
Proof.
We are able to prove this by using contradiction; we assume that there exists an iteration , and that is an unsuccessful iteration point for all nonnegative integer , i.e.,
It follows from (11) that . Thus, using (10) and (12), we show
As a matter of fact, in the unsuccessful iterations, we have . Thus, according to and (21), we have
Now, using Lemma 1 and (16) we get
According to the definition of , we get . Thus, for sufficiently large we have,
which contradicts (20). This completes the proof of Lemma 2. □
Lemma 3.
Suppose that H1–H3 hold and the sequenceis generated by Algorithm 1. Set. For, we have
Proof.
According to the definition of , for all , we have . Using the differential mean value theorem, we get
where . For and (18), we obtain
Note that (4) and (16) imply that for all. Setting means that . According to (17), (25), and (26), we can conclude that (24) holds. □
Lemma 4.
Suppose that the sequenceis generated by Algorithm 1. Then, we have.
Proof.
We can proceed by induction. When , apparently .
Assuming that holds, we would obtain . Then, we can prove that .
(a) When , consider two cases:
Case 1: . According to (7) and (16), we obtain . Thus, we have . Following the definition of and , we obtain
The above two inequalities show that
Case 2: . According to , we have . Thus, we get .
(b) When . Using Lemma 3 and (27), we obtain .
Now, we can conclude that . □
Lemma 5.
Suppose that H1–H3 hold, and the sequenceis generated by Algorithm 1. This would mean thatis a not a monotonically increasing sequence, nor is it convergent.
Proof.
Now, we can prove that the sequence is not a monotonically increasing sequence. Thus, we consider two cases:
Case 1: For , it is clear that . Since, for any , we have . Thus, we get .
Case 2: For , we obtain . Thus, using the definition of and (5), we observe that
is not a monotonically increasing sequence. This fact, along with H1, implies that
This shows that the sequence is convergent. □
Lemma 6.
Suppose that H1–H3 hold, and there existssuch that, for all. Then, there is a constant, and we have
where.
Proof.
Set . We proceed by induction; set
When , we can see that . Then, assume that (31) holds for . Note that is an increasing sequence. Thus, we prove that
(a) When , i.e., . Using (11) and (7), we deduce that . From (12), we get , where is a constant. Thus, the inequality implies that .
(b) When , i.e., . Supposing that , we have
Then, assuming that , we have
Thus,
Using Taylor’s formula and H1–H3, it is easy to show that
where . When combining (35) with (36), we discover that
Moreover, the inequality (16), together with , imply that
Multiply the two sides of inequality (38) by , such that
On the other hand, from H3, (37), and (39), we have
If , we have . Otherwise, we obtain . Now, following (40) we obtain
Thus,
The proof is completed. □
Based on the analyses and lemmas above, we obtain the global convergence of Algorithm 1 as follows:
Theorem 1.
(Global Convergence) Suppose that H1–H3 hold, and the sequenceis generated by Algorithm 1. Then,
Proof.
Consider the following two cases:
Case 1: The number of successful iterations and many filter iterations are infinite, e.g., , .
We proceed from this proof with a contradiction. Suppose that (42) is not true, then there exists a positive constant such that . From H1, we can see that is bounded. Set in the index of set is the sequence . Thus, there exists a subsequence , which satisfies , , and we have
Using (43), as is sufficiently large, we have
As this is a contradiction, the proof is completed.
Case 2: The number of successful iterations is infinite, and the number of filter iterations is finite, e.g., , .
Assume for a moment that there exists an integer constant , such that . This implies that , and we therefore have . Hence, from (16) and (27), we find that
We proceed from this proof with a contradiction. Suppose that there exist constants and , such that , . Based on Lemma 6 and (45), we write
Set , thus,
According to (47) and , this is an increasing sequence, as we have
We then take the maximum value of both sides of (48), along with Lemma 5, to imply that
According to (5), we have
Thus, we get
Now, using (51), we deduce that
which contradicts . This completes the proof of Theorem 1. □
4. Local Convergence
In this section, we will demonstrate the superlinear convergence of Algorithm 1 under appropriate conditions.
Theorem 2.
(Superlinear Convergence) Suppose that H1–H3 hold, and the sequencegenerated by Algorithm 1 converges to. Moreover, assume thatis a positive definite, andis Lipschitz continuous in a neighborhood of. If, where, and
Then, the sequenceconverges tosuperlinearly, that is,
Proof.
Following Lemmas 1 and 2, it is obvious that for sufficiently large . This shows that Algorithm 1 has been simplified to the superlinear convergence standard quasi-Newton methods [22]. Thus, the superlinear convergence of this algorithm can be proven to be similar to Theorem 5.5.1 in [22]. We omit it for convenience. □
5. Preliminary Numerical Experiments
In this section, we perform numerical experiments on Algorithm 1, and compare it with Mo [1] and Hang [4]. A set of unconstrained test problems (of variable dimension) are selected from [23]. The simulation experiment uses MATLAB 9.4 and the processor uses Intel (R) Core (TM), 2.00 GHz, 6 GB RAM. Take exactly the same value for the public parameters of these algorithms: , , , , . In our experiments, algorithms are being stopped when or the number of iterations exceeds 10,000. We denote the running time via CPU. and denoted the total number of gradient evaluations, and the total number of function evaluations, respectively. The matrix is updated using a MBFGS formula [24]:
where , , , .
To facilitate this, we used the following notations to represent the algorithms:
ANTRFS: A Nonmonotone Trust Region Method with Fixed Step length [1];
FSNATR: On a Fixed Step length Nonmonotone Adaptive Trust Region Method [4];
From Table 1, there are some variable dimension problems, which select the dimension in the range [4,1000]. We know that the new algorithm is generally better than NTRFS and FSNATR in terms of the total number of gradient evaluations and function evaluations. The new algorithm solves all the test functions in Table 1. The performance profiles given by Dolan and Moré [25] are used to compare the efficiency of the three algorithms. Figure 1, Figure 2 and Figure 3 give the performance profiles of the three algorithms for running time, the number of gradient evaluations, and the number of function evaluations, respectively. The figures show that Algorithm 1 performs well when compared with the other algorithms, at least on the test problems considered, which are mostly of small dimension. It can be observed that Algorithm 1 increases faster than the other algorithms, especially in contrast to NTRFS. Therefore, we can deduce that the new algorithm is more efficient and robust than the other considered trust region algorithms for solving small and medium-scale unconstrained optimization problems.

Table 1.
Numerical comparisons on a subset of test problems.

Figure 1.
CPU performance profile for the three algorithms.
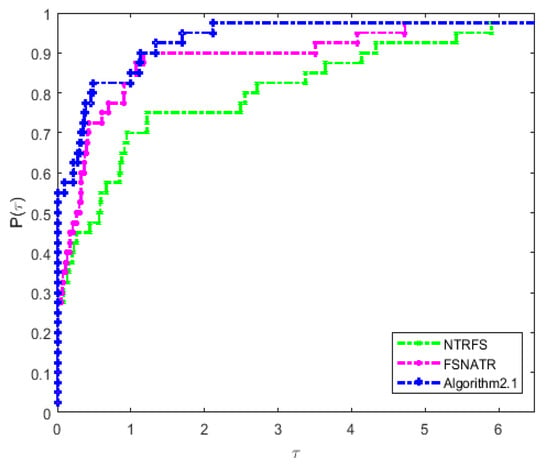
Figure 2.
Performance profile for the number of gradient evaluations ().
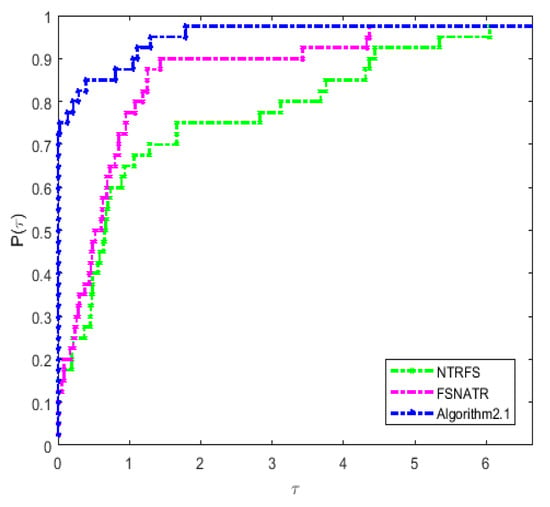
Figure 3.
Performance profile for the number of function evaluations ().
6. Conclusions
In this paper, the authors proposed a new nonmonotone trust region method and also put forward the following innovations:
(1) a new adaptive radius strategy to reduce the number of calculations;
(2) a modified trust region ratio to solve effectively unconstrained optimization problems. The filter technology is also important. Theorems 1 and 2 show that the proposed algorithm can preserve global convergence and superlinear convergence, respectively. According to preliminary numerical experiments, we can conclude that the new algorithm is very effective for unconstrained optimization, and the nonmonotone technology is very helpful for many optimization problems. In the future, we will have more ideas for solving many optimization problems, such as combining the modified conjugate gradient algorithm with a modified trust region method. We can also use the new algorithm for solving constrained optimization problems.
Author Contributions
Conceptualization, X.W. and Q.Q.; methodology, X.W.; software, X.W.; validation, X.W., Q.Q. and X.D.; formal analysis, X.D.; investigation, Q.Q.; resources, X.D.; data curation, Q.Q.; writing—original draft preparation, X.W.; writing—review and editing, X.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
At the point of finishing this paper, I’d like to express my sincere thanks to all those who have lent me a hand over the course of my writing this paper. First of all, I would like to take this opportunity to show my sincere gratitude to my supervisor, Xianfeng Ding, who has given me so much useful advice on my writing and has tried his best to improve my paper. Secondly, I would like to express my gratitude to my classmates, who offered me references and information on time. Without their help, it would have been much harder for me to finish this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mo, J.T.; Zhang, K.C.; Wei, Z.X. A nonmonotone trust region method for unconstrained optimization. Appl. Math. Comput. 2005, 171, 371–384. [Google Scholar] [CrossRef]
- Ou, Y.G.; Zhou, Q.; Lin, H.C. An ODE-based trust region method for unconstrained optimization problems. J. Comput. Appl. Math. 2009, 232, 318–326. [Google Scholar] [CrossRef]
- Wang, X.Y.; Tong, J. A Nonmonotone Adaptive Trust Region Algorithm with Fixed Stepsize for Unconstrained Optimization Problems. Math. Appl. 2009, 3, 496–500. [Google Scholar]
- Hang, D.; Liu, M. On a Fixed Stepsize Nonmonotonic Self-Adaptive Trust Region Algorithm. J. Southwest China Norm. Univ. 2013, 38. [Google Scholar] [CrossRef]
- Sartenaer, A. Automatic determination of an initial trust region in nonlinear programming. SIAM J. Sci. Comput. 1997, 18, 1788–1803. [Google Scholar] [CrossRef]
- Zhang, X.S.; Zhang, J.L.; Liao, L.Z. An adaptive trust region method and its convergence. Sci. China 2002, 45, 620–631. [Google Scholar] [CrossRef]
- Shi, Z.J.; Guo, J.H. A new trust region methods for unconstrained optimization. Comput. Appl. Math. 2008, 213, 509–520. [Google Scholar] [CrossRef]
- Kimiaei, M. A new class of nonmonotone adaptive trust-region methods for nonlinear equations with box constraints. Calcolo 2017, 54, 769–812. [Google Scholar] [CrossRef]
- Amini, K.; Shiker Mushtak, A.K.; Kimiaei, M. A line search trust-region algorithm with nonmonotone adaptive radius for a system of nonlinear equations. Q. J. Oper. Res. 2016, 4, 132–152. [Google Scholar] [CrossRef]
- Peyghami, M.R.; Tarzanagh, D.A. A relaxed nonmonotone adaptive trust region method for solving unconstrained optimization problems. Comput. Optim. Appl. 2015, 61, 321–341. [Google Scholar] [CrossRef]
- Deng, N.Y.; Xiao, Y.; Zhou, F.J. Nonmonotone Trust Region Algorithm. J. Optim. Theory Appl. 1993, 76, 259–285. [Google Scholar] [CrossRef]
- Ahookhoosh, M.; Amini, K.; Peyghami, M. A nonmonotone trust region line search method for large scale unconstrained optimization. Appl. Math. Model. 2012, 36, 478–487. [Google Scholar] [CrossRef]
- Zhang, H.C.; Hager, W.W. A nonmonotone line search technique and its application to unconstrained optimization. SIAM J. Optim. 2004, 14, 1043–1056. [Google Scholar] [CrossRef]
- Gu, N.Z.; Mo, J.T. Incorporating nonmonotone strategies into the trust region for unconstrained optimization. Comput. Math. Appl. 2008, 55, 2158–2172. [Google Scholar] [CrossRef]
- Fletcher, R.; Leyffer, S. Nonlinear programming without a penalty function. Math. Program. 2002, 91, 239–269. [Google Scholar] [CrossRef]
- Gould, N.I.; Sainvitu, C.; Toint, P.L. A filter-trust-region method for unconstrained optimization. SIAM J. Optim. 2005, 16, 341–357. [Google Scholar] [CrossRef]
- Gould, N.I.; Leyffer, S.; Toint, P.L. A multidimensional filter algorithm for nonlinear equations and nonlinear least-squares. SIAM J. Optim. 2004, 15, 17–38. [Google Scholar] [CrossRef]
- Wächter, A.; Biegler, L.T. Line search filter methods for nonlinear programming and global convergence. SIAM J. Optim. 2005, 16, 1–31. [Google Scholar] [CrossRef]
- Miao, W.H.; Sun, W. A filter trust-region method for unconstrained optimization. Numer. Math. J. Chin. Univ. 2007, 19, 88–96. [Google Scholar]
- Zhang, Y.; Sun, W.; Qi, L. A nonmonotone filter Barzilai-Borwein method for optimization. Asia Pac. J. Oper. Res. 2010, 27, 55–69. [Google Scholar] [CrossRef]
- Fatemi, M.; Mahdavi-Amiri, N. A filter trust-region algorithm for unconstrained optimization with strong global convergence properties. Comput. Optim. Appl. 2012, 52, 239–266. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: New York, NY, USA, 2006. [Google Scholar]
- Andrei, N. An unconstrained optimization test functions collection. Environ. Sci. Technol. 2008, 10, 6552–6558. [Google Scholar]
- Pang, S.; Chen, L. A new family of nonmonotone trust region algorithm. Math. Pract. Theory. 2011, 10, 211–218. [Google Scholar]
- Dolan, E.D.; Moŕe, J.J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).