Maximum-Entropy-Model-Enabled Complexity Reduction Algorithm in Modern Video Coding Standards

Abstract
1. Introduction
- A fast CU size decision algorithm is proposed to reduce the complexity of the modern video encoder, which consists of CU termination, skip, and normal decisions. The maximum-entropy-model-enabled CU size decision approach is formulated to maximize the condition of entropy. Moreover, the improved iterative scaling (IIS) algorithm is proposed to solve this optimization problem.
- The rate–distortion (RD) cost, coded block flag (CBF), and depth information of neighboring CUs are as featured as parameters which do not bring in additional calculations. Moreover, the online method is proposed to learn the model parameters.
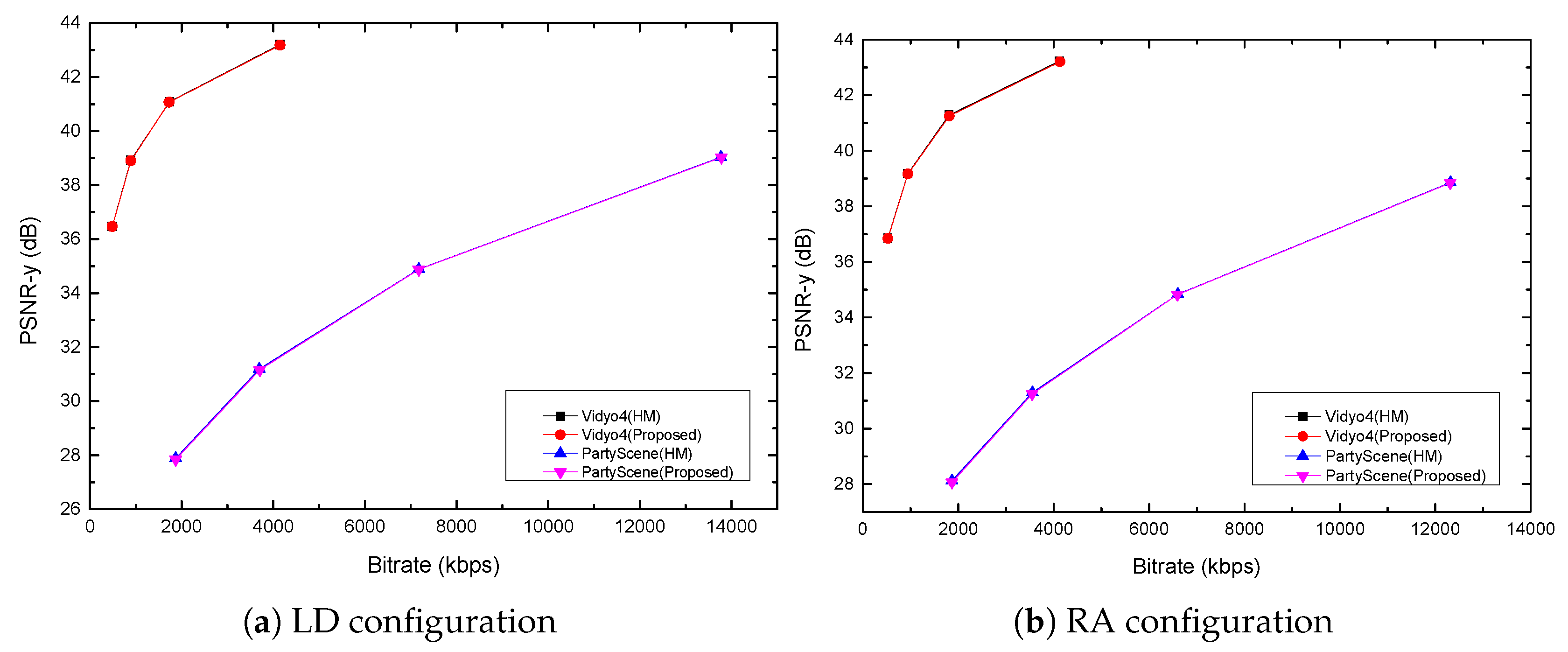
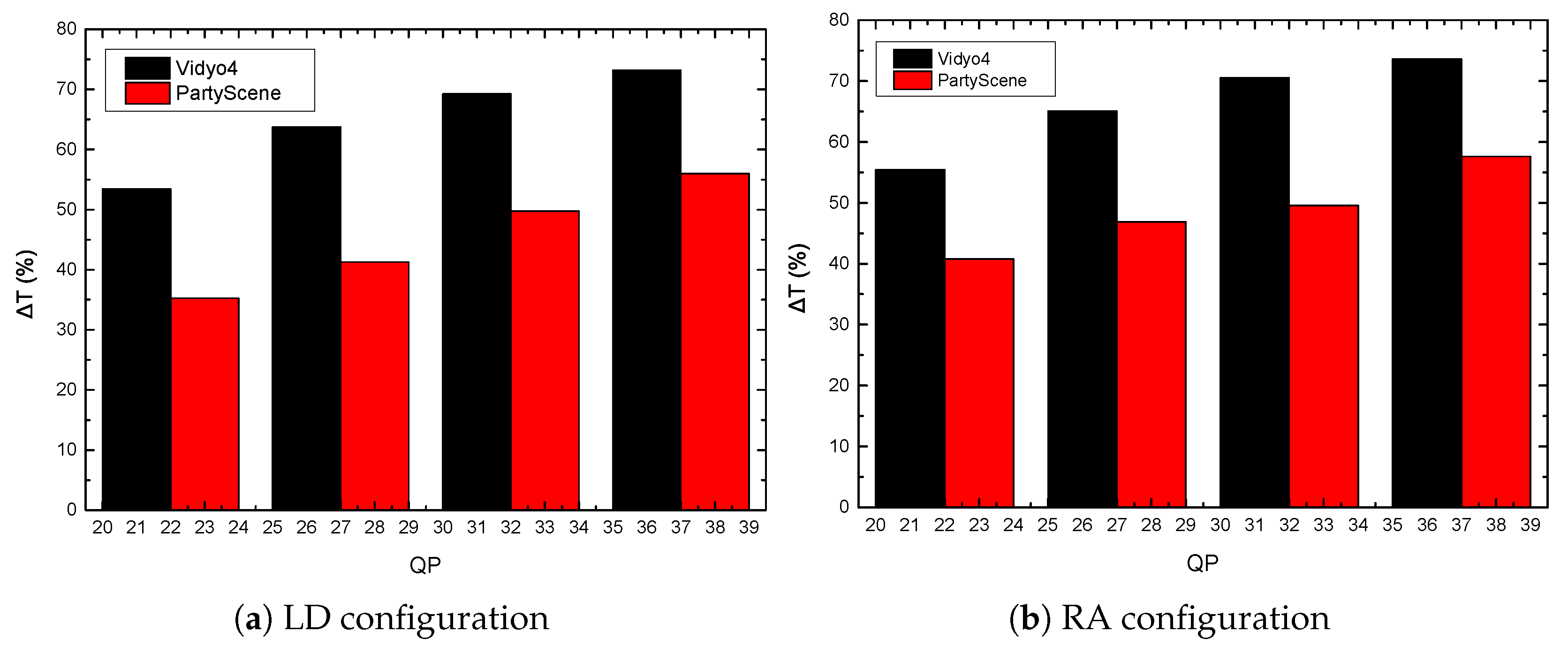
- Based on H.265/HEVC standards, the proposed method reduces the computational complexity significantly. The simulation results demonstrate that the proposed algorithm reduces the average encoding time by 53.27% and 56.36% under low delay and random access configurations, while Bjontegaard Delta Bit Rates (BD-BRs) are 0.72% and 0.93% on average.
2. Related Work
3. Background
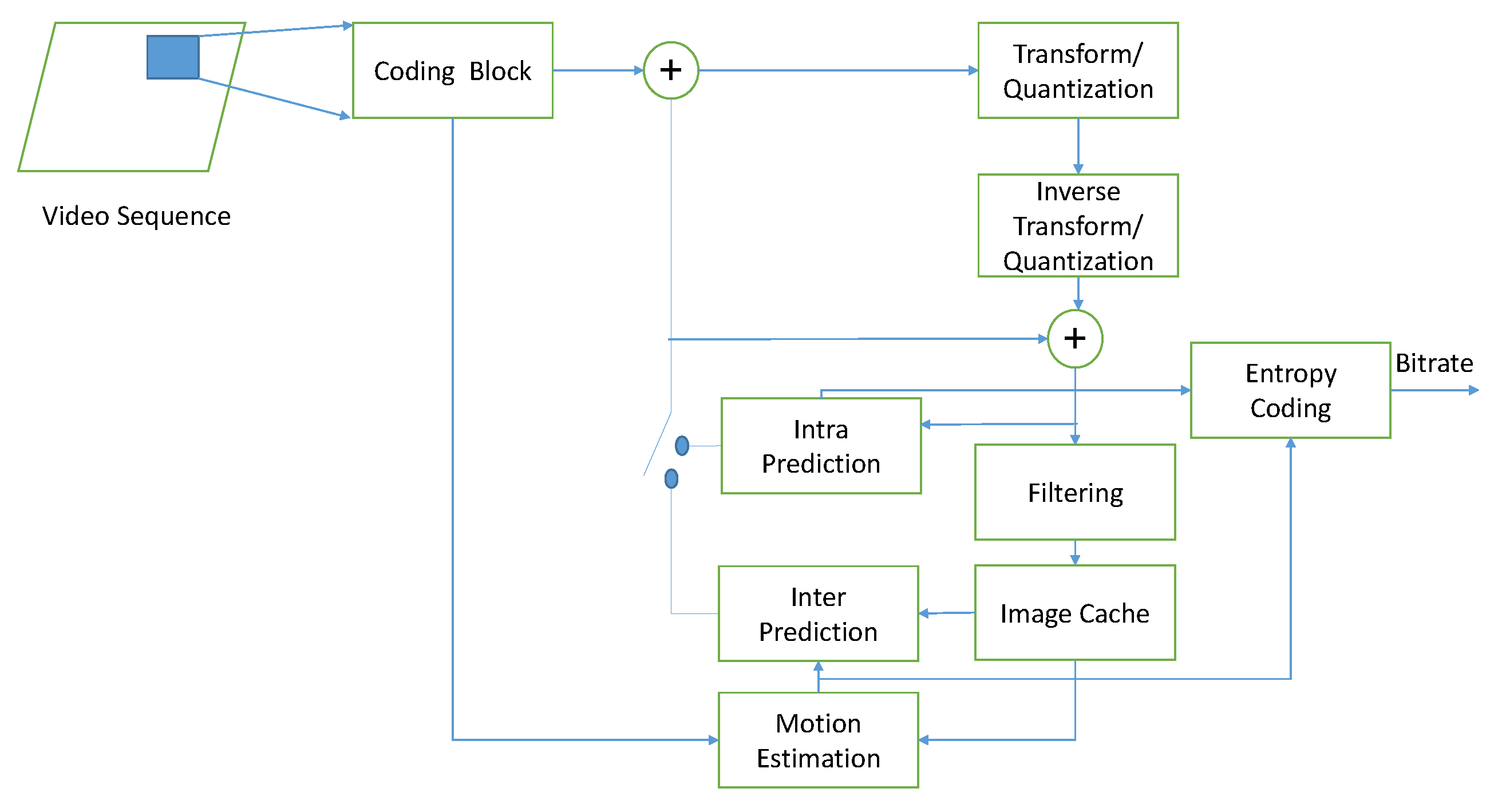
3.1. High-Efficiency Video Coding Standard
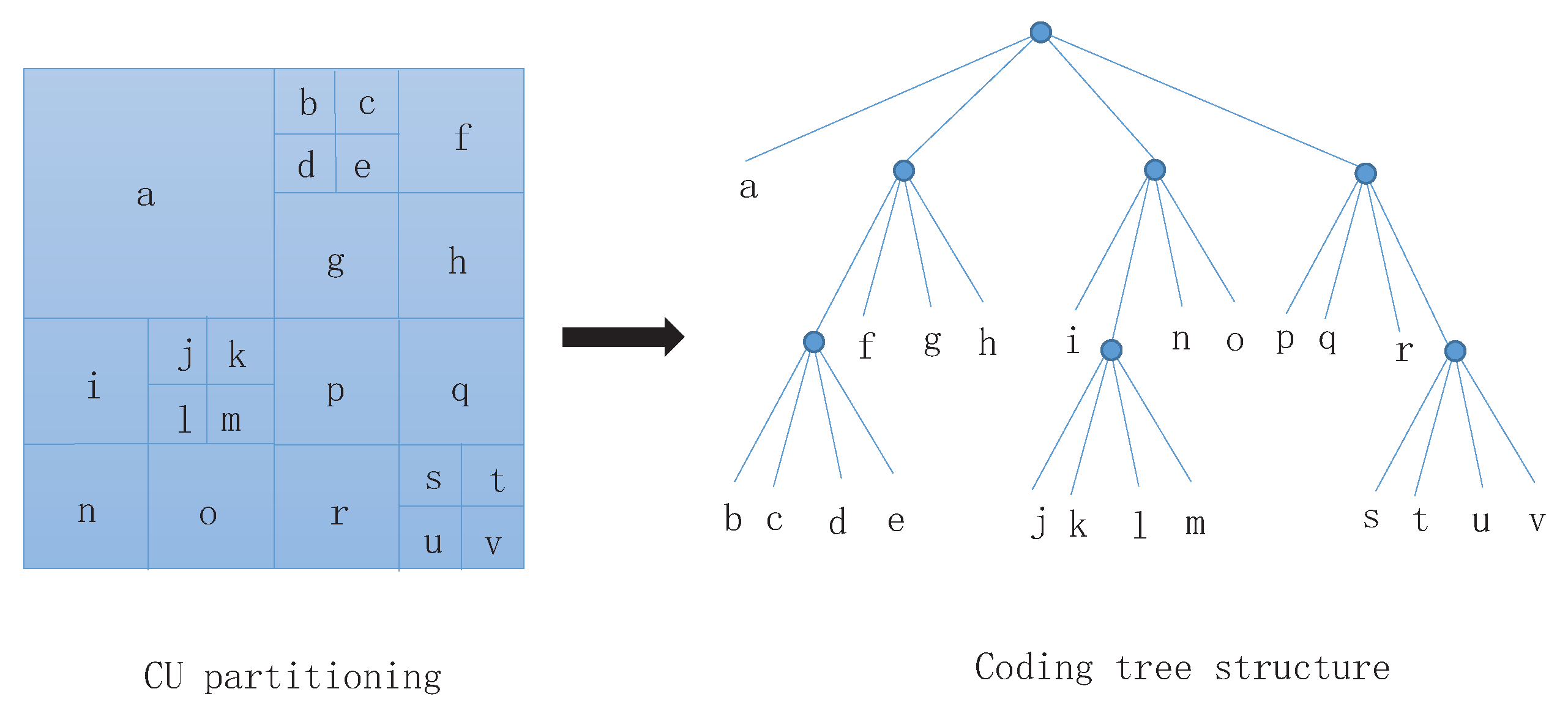
- The size of the CU block in H.265/HEVC is larger than the macroblock size in H.264/AVC. For relatively flat images, a large CU block can be selected, which can save the number of code stream bits and improve coding effectiveness.
- The size and depth of the CU in H.265/HEVC can be selected according to the characteristics of the image, so that the performance of the encoder can be greatly improved.
- There are macroblocks and sub-macroblocks in H.264/AVC. There are only CU blocks in H.265/HEVC, and the structure is simple.
3.2. Maximum Entropy Principle
4. The Proposed Approach
- (1)
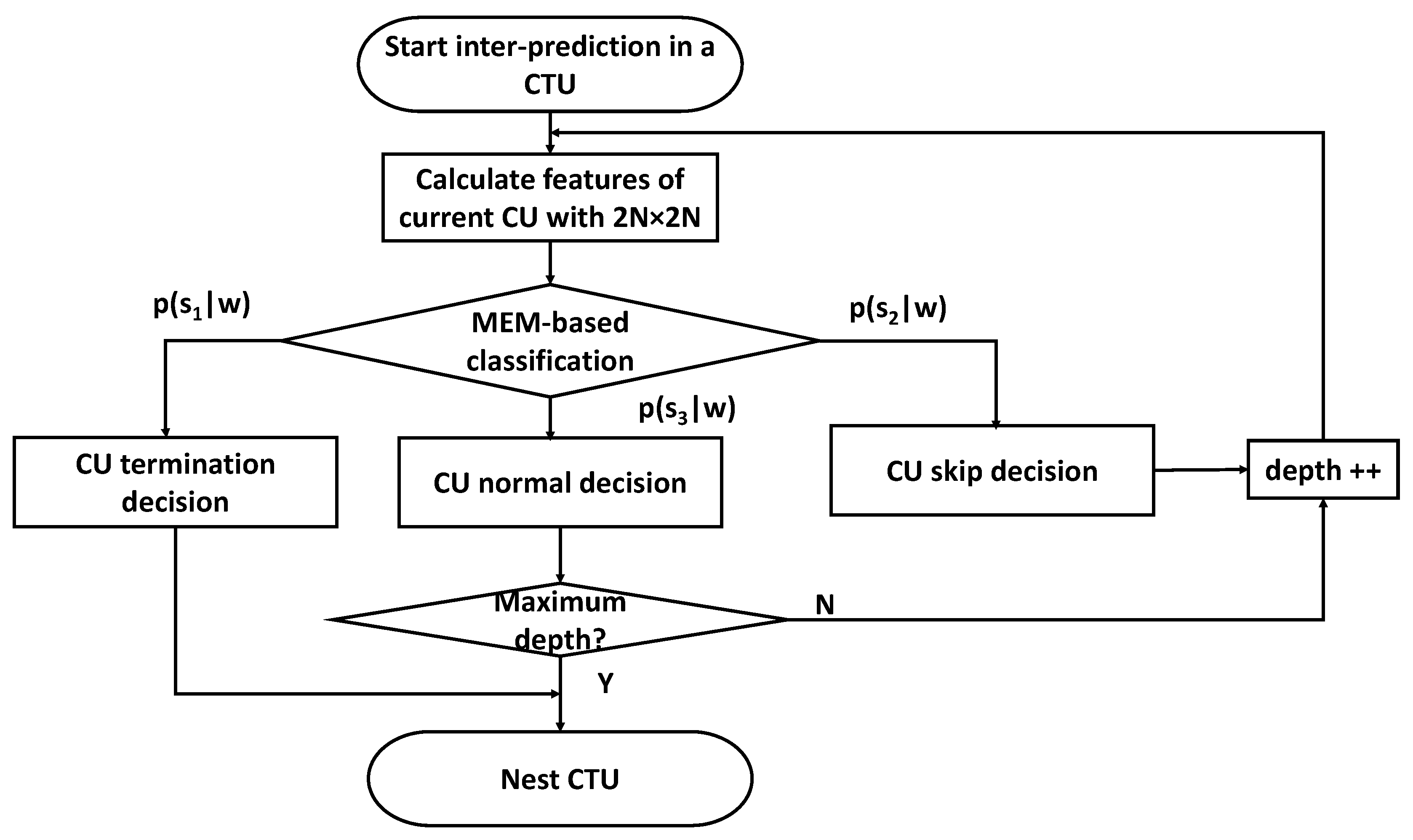
- Firstly, model parameter values are imported from the LUT. Then, inter-prediction is started in a CTU by using the proposed method.
- (2)
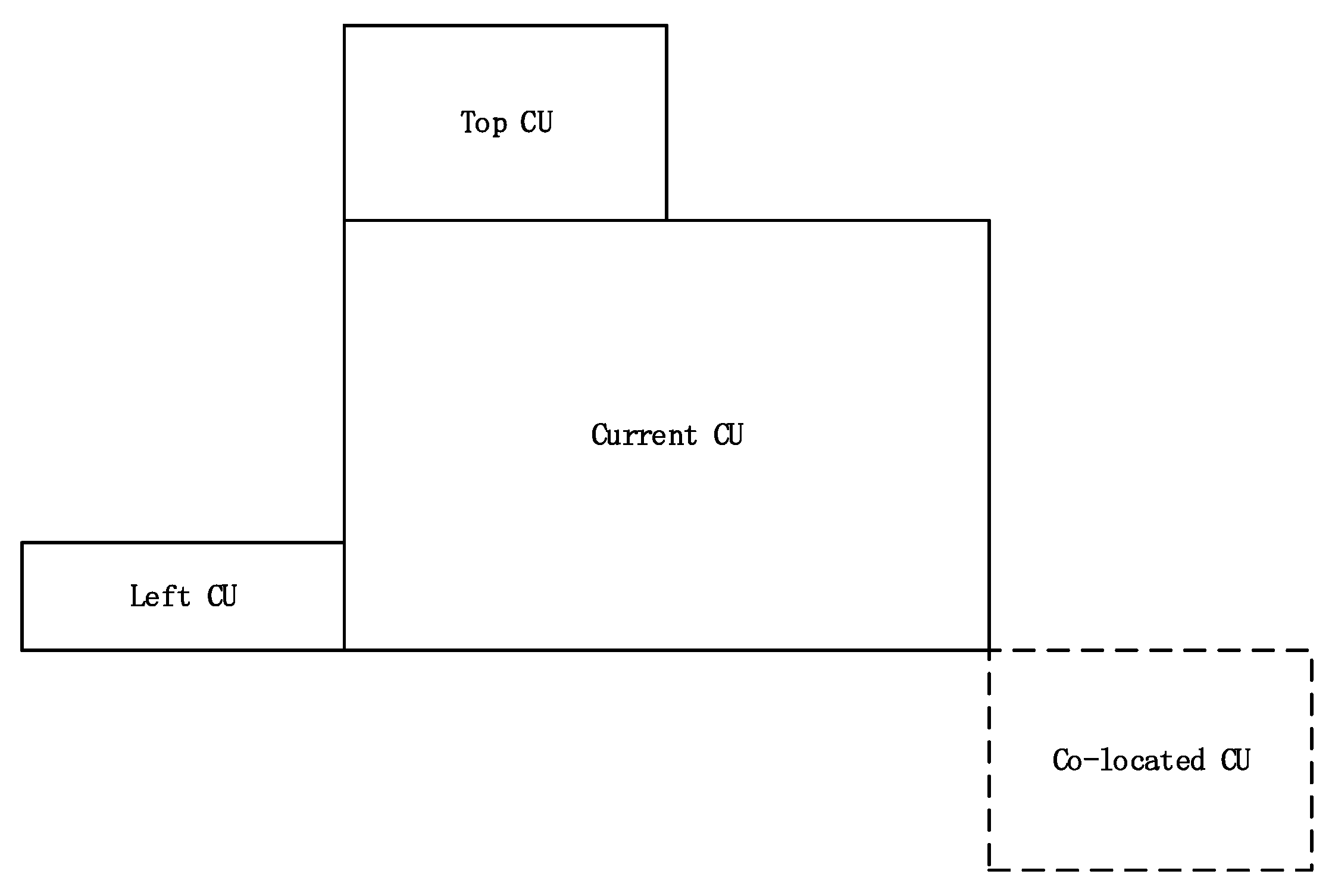
- Secondly, spatial and temporal features—including the RD cost, CBF value, depth information of top, left, and co-located CUs of PU with the 2N × 2N mode—are calculated. The feature set is expressed as w.
- (3)
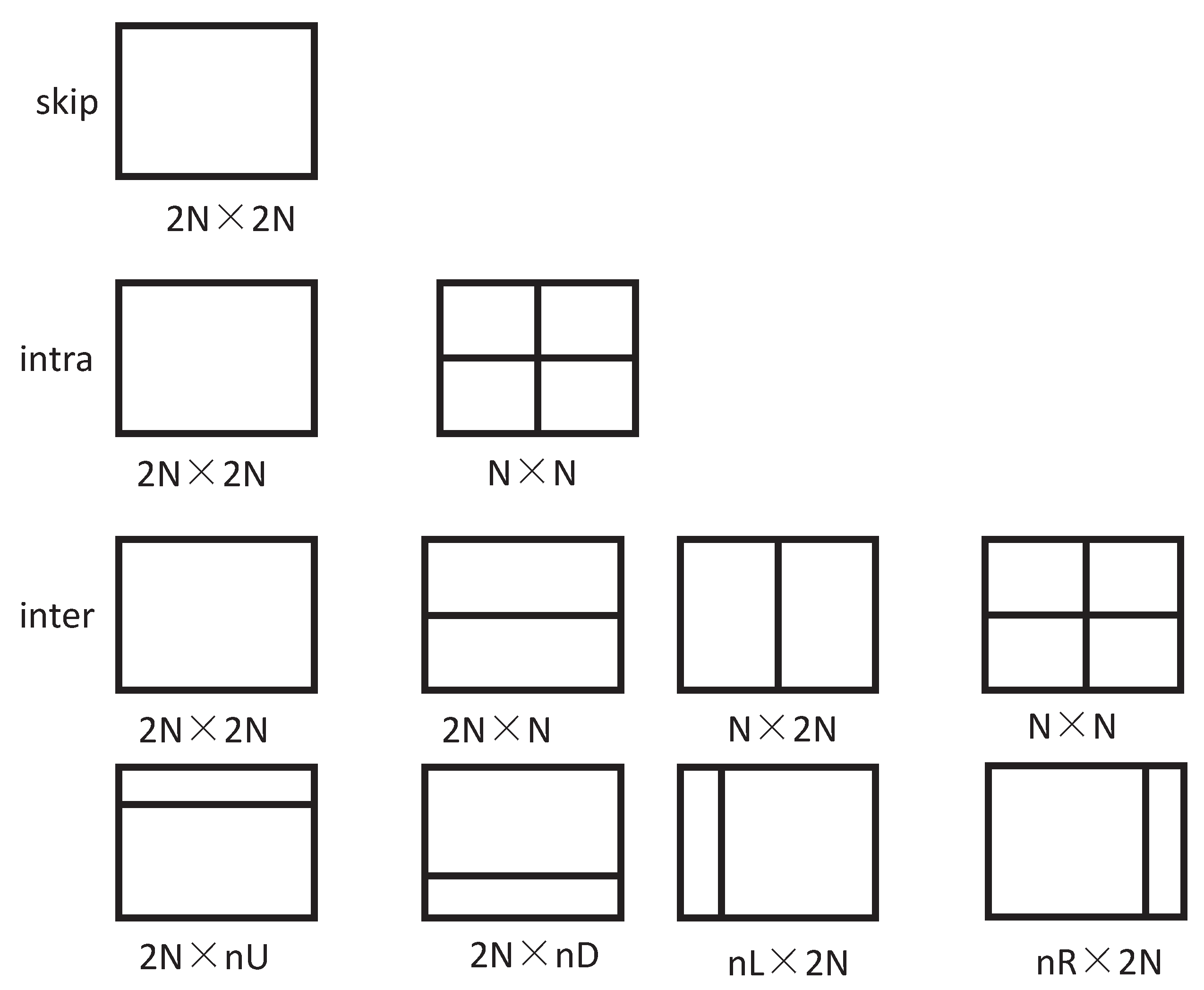
- Then, based on parameter values , the model is calculated. If , the CU termination decision is processed. In this case, the splitting of the CU terminates in the current depth. Otherwise, if , the CU skip decision is made. In this case, the PU mode is determined at the earliest stage and RDO technology is processed in the next depth. Otherwise, the CU normal decision is made.
- (4)
- Finally, when the current depth of CU is less than the maximum depth, the steps (2) and (3) are repeated. Otherwise, the next CTU is checked.
5. Simulation Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Ramezanpour, M.; Zargari, F. Fast CU size and prediction mode decision method for HEVC encoder based on spatial features. Signal Image Video Process. 2016, 10, 1233–1240. [Google Scholar] [CrossRef]
- Tohidypour, H.R.; Pourazad, M.T.; Nasiopoulos, P. Probabilistic approach for predicting the size of coding units in the quad-tree structure of the quality and spatial scalable HEVC. IEEE Trans. Multimed. 2016, 18, 182–195. [Google Scholar] [CrossRef]
- Zhong, G.; He, X.; Qing, L.; Li, Y. A fast inter-prediction algorithm for HEVC based on temporal and spatial correlation. Multimed. Tools Appl. 2015, 74, 11023–11043. [Google Scholar] [CrossRef]
- Shen, L.; Zhang, Z.; Liu, Z. Adaptive inter-mode decision for HEVC jointly utilizing inter-level and spatiotemporal correlations. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1709–1722. [Google Scholar] [CrossRef]
- Majid, M.; Owais, M.; Anwar, S.M. Visual saliency based redundancy allocation in HEVC compatible multiple description video coding. Multimed. Tools Appl. 2017, 77, 20955–20977. [Google Scholar] [CrossRef]
- Chen, M.J.; Wu, Y.D.; Yeh, C.H.; Lin, K.M.; Lin, S.D. Efficient CU and PU decision based on motion information for interprediction of HEVC. IEEE Trans. Ind. Inform. 2018, 14, 4735–4745. [Google Scholar] [CrossRef]
- Shen, L.; Li, K.; Feng, G.; An, P.; Liu, Z. Efficient intra mode selection for depth-map coding utilizing spatiotemporal, inter-component and inter-view correlations in 3D-HEVC. IEEE Trans. Image Process. 2018, 27, 4195–4206. [Google Scholar] [CrossRef]
- Jiang, X.; Feng, J.; Song, T.; Katayama, T. Low-complexity and hardware-friendly H. 265/HEVC encoder for vehicular ad-hoc networks. Sensors 2019, 19, 1927. [Google Scholar] [CrossRef]
- Zhang, J.; Kwong, S.; Wang, X. Two-stage fast inter CU decision for HEVC based on bayesian method and conditional random fields. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3223–3235. [Google Scholar] [CrossRef]
- Jiang, X.; Song, T.; Shimamoto, T.; Shi, W.; Wang, L. Spatio-temporal prediction based algorithm for parallel improvement of HEVC. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2015, 98, 2229–2237. [Google Scholar] [CrossRef]
- Bae, J.H.; Sunwoo, M.H. Adaptive early termination algorithm using coding unit depth history in HEVC. J. Signal Process. Syst. 2019, 91, 863–873. [Google Scholar] [CrossRef]
- Cebrian-Marquez, G.; Martínez, J.L.; Cuenca, P. Adaptive inter CU partitioning based on a look-ahead stage for HEVC. Signal Process. Image Commun. 2019, 76, 97–108. [Google Scholar] [CrossRef]
- Liao, Y.W.; Chen, M.J.; Yeh, C.H.; Lin, J.R.; Chen, C.W. Efficient inter-prediction depth coding algorithm based on depth map segmentation for 3D-HEVC. Multimed. Tools Appl. 2019, 78, 10181–10205. [Google Scholar] [CrossRef]
- Zhang, M.; Qu, J.; Bai, H. Entropy-based fast largest coding unit partition algorithm in high-efficiency video coding. Entropy 2013, 15, 2277–2287. [Google Scholar] [CrossRef]
- Tai, K.H.; Hsieh, M.Y.; Chen, M.J.; Chen, C.Y.; Yeh, C.H. A fast HEVC encoding method using depth information of collocated CUs and RD cost characteristics of PU modes. IEEE Trans. Broadcast. 2017, 43, 680–692. [Google Scholar] [CrossRef]
- Yao, Y.; Yang, X.; Jia, T.; Jiang, X.; Feng, W. Fast Bayesian decision based block partitioning algorithm for HEVC. Multimed. Tools Appl. 2019, 78, 9129–9147. [Google Scholar] [CrossRef]
- Grellert, M.; Zatt, B.; Bampi, S.; da Silva Cruz, L.A. Fast coding unit partition decision for HEVC using support vector machines. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1741–1753. [Google Scholar] [CrossRef]
- Kim, K.; Ro, W.W. Fast CU depth decision for HEVC using neural networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1462–1473. [Google Scholar] [CrossRef]
- Li, N.; Zhang, Y.; Zhu, L.; Luo, W.; Kwong, S. Reinforcement learning based coding unit early termination algorithm for high efficiency video coding. J. Vis. Commun. Image Represent. 2019, 60, 276–286. [Google Scholar] [CrossRef]
- Goswami, K.; Kim, B.G. A design of fast high-efficiency video coding scheme based on markov chain monte carlo model and Bayesian classifier. IEEE Trans. Ind. Electron. 2018, 65, 8861–8871. [Google Scholar] [CrossRef]
- Kim, K.; Ro, W.W. Contents-aware partitioning algorithm for parallel high efficiency video coding. Multimed. Tools Appl. 2019, 78, 11427–11442. [Google Scholar] [CrossRef]
- Wang, H.; Xiao, B.; Wu, J.; Kwong, S.; Kuo, C.C.J. A collaborative scheduling-based parallel solution for HEVC encoding on multicore platforms. IEEE Trans. Multimed. 2018, 20, 2935–2948. [Google Scholar] [CrossRef]
- Yan, C.; Zhang, Y.; Xu, J.; Dai, F.; Li, L.; Dai, Q.; Wu, F. A highly parallel framework for HEVC coding unit partitioning tree decision on many-core processors. IEEE Signal Process. Lett. 2014, 21, 573–576. [Google Scholar] [CrossRef]
- Clarke, B. Information optimality and Bayesian modelling. J. Econ. 2007, 138, 405–429. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Labs Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- De Garrido, D.P.; Pearlman, W.A. Conditional entropy-constrained vector quantization: high-rate theory and design algorithms. IEEE Trans. Inf. Theory 1995, 41, 901–916. [Google Scholar] [CrossRef]
- Wu, N. An iterative algorithm for power spectrum estimation in the maximum entropy method. IEEE Trans. Acoust. Speech Signal Process 1988, 36, 294–296. [Google Scholar] [CrossRef]
- Palmieri, F.A.N.; Ciuonzo, D. Objective priors from maximum entropy in data classification. Inf. Fusion 2013, 14, 186–198. [Google Scholar] [CrossRef]
- Wu, H.C. The Karush–Kuhn–Tucker optimality conditions in an optimization problem with interval-valued objective function. Eur. J. Oper. Res. 2007, 176, 46–59. [Google Scholar] [CrossRef]
- Berger, A. The Improved Iterative Scaling Algorithm: A Gentle Introduction; Technical Report; CMU: Sayre Highway, Philippines, 1997; pp. 1–4. [Google Scholar]
- Bossen, F. Common Test Conditions and Software Reference Configurations, Joint Collaborative Team on Video Coding (JCT-VC), Document JCTVC-L1110, Geneva, January 2014. Available online: https://www.itu.int/wftp3/av-arch/video-site/0104_Aus/ (accessed on 3 January 2019).
- Bjontegaard, G. Calculation of Average PSNR Differences between RD-Curves. In Proceedings of the ITU-T Video Coding Experts Group (VCEG) Thirteenth Meeting, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Jung, J. An excel add-in for computing Bjontegaard metric and its evolution. In Proceedings of the ITU-T Video Coding Experts Group (VCEG) 31st Meeting, Marrakech, MA, USA, 15–16 January 2007. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution | Sequence | BD-BR(%) | BD-PSNR(dB) | T(%) |
|---|---|---|---|---|
| Kinomo | 1.39 | 55.71 | ||
| ParkScene | 0.84 | 54.67 | ||
| Cactus | 0.84 | 50.38 | ||
| BQTerrace | 0.56 | 55.74 | ||
| Average | 0.91 | 54.13 | ||
| BasketballDrill | 0.55 | 46.26 | ||
| BQMall | 0.73 | 49.71 | ||
| PartyScene | 0.46 | 45.57 | ||
| RaceHorses | 0.73 | 48.93 | ||
| Average | 0.62 | 47.62 | ||
| BasketballPass | 0.58 | 52.05 | ||
| BQSquare | 0.06 | 49.52 | ||
| BlowingBubbles | 1.19 | 48.52 | ||
| Average | 0.61 | 49.94 | ||
| Vidyo1 | 0.77 | 62.65 | ||
| Vidyo3 | 0.93 | 61.44 | ||
| Vidyo4 | 0.50 | 64.89 | ||
| Average | 0.73 | 62.99 | ||
| Average | 0.72 | 53.27 |
| Resolution | Sequence | BD-BR(%) | BD-PSNR(dB) | T(%) |
|---|---|---|---|---|
| Kinomo | 1.70 | 56.72 | ||
| ParkScene | 1.02 | 60.89 | ||
| Cactus | 1.18 | 54.27 | ||
| BQTerrace | 0.84 | 57.54 | ||
| Average | 1.19 | 57.36 | ||
| BasketballDrill | 0.54 | 49.51 | ||
| BQMall | 0.96 | 54.52 | ||
| PartyScene | 0.61 | 48.71 | ||
| RaceHorses | 1.23 | 50.26 | ||
| Average | 0.83 | 50.75 | ||
| BasketballPass | 0.89 | 55.32 | ||
| BQSquare | 0.50 | 54.46 | ||
| BlowingBubbles | 1.21 | 52.53 | ||
| Average | 0.87 | 54.10 | ||
| Vidyo1 | 1.00 | 65.51 | ||
| Vidyo3 | 0.57 | 62.66 | ||
| Vidyo4 | 0.74 | 66.16 | ||
| Average | 0.77 | 64.78 | ||
| Average | 0.93 | 56.36 |
| Configuration | Approach | (BD-BR, BD-PSNR, T) |
|---|---|---|
| Low Delay | Our work | (0.72, , 53.27) |
| Tai et al. [16] | (0.75, 37.90) | |
| Grellert et al. [18] | (0.60, , 41.10 ) | |
| Kim et al. [19] | (1.31, , 47.08) | |
| Random Access | Our work | (0.93,, 56.36) |
| Tai et al. [16] | (1.41, , 45.70) | |
| Grellert et al. [18] | (0.48, , 48.00) | |
| Kim et al. [19] | (1.51, , 47.32) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Song, T.; Katayama, T. Maximum-Entropy-Model-Enabled Complexity Reduction Algorithm in Modern Video Coding Standards. Symmetry 2020, 12, 113. https://doi.org/10.3390/sym12010113
Jiang X, Song T, Katayama T. Maximum-Entropy-Model-Enabled Complexity Reduction Algorithm in Modern Video Coding Standards. Symmetry. 2020; 12(1):113. https://doi.org/10.3390/sym12010113
Chicago/Turabian StyleJiang, Xiantao, Tian Song, and Takafumi Katayama. 2020. "Maximum-Entropy-Model-Enabled Complexity Reduction Algorithm in Modern Video Coding Standards" Symmetry 12, no. 1: 113. https://doi.org/10.3390/sym12010113
APA StyleJiang, X., Song, T., & Katayama, T. (2020). Maximum-Entropy-Model-Enabled Complexity Reduction Algorithm in Modern Video Coding Standards. Symmetry, 12(1), 113. https://doi.org/10.3390/sym12010113