Hierarchical Intrusion Detection Using Machine Learning and Knowledge Model



Abstract
1. Introduction
2. Related Work
3. Hierarchical Intrusion Detection
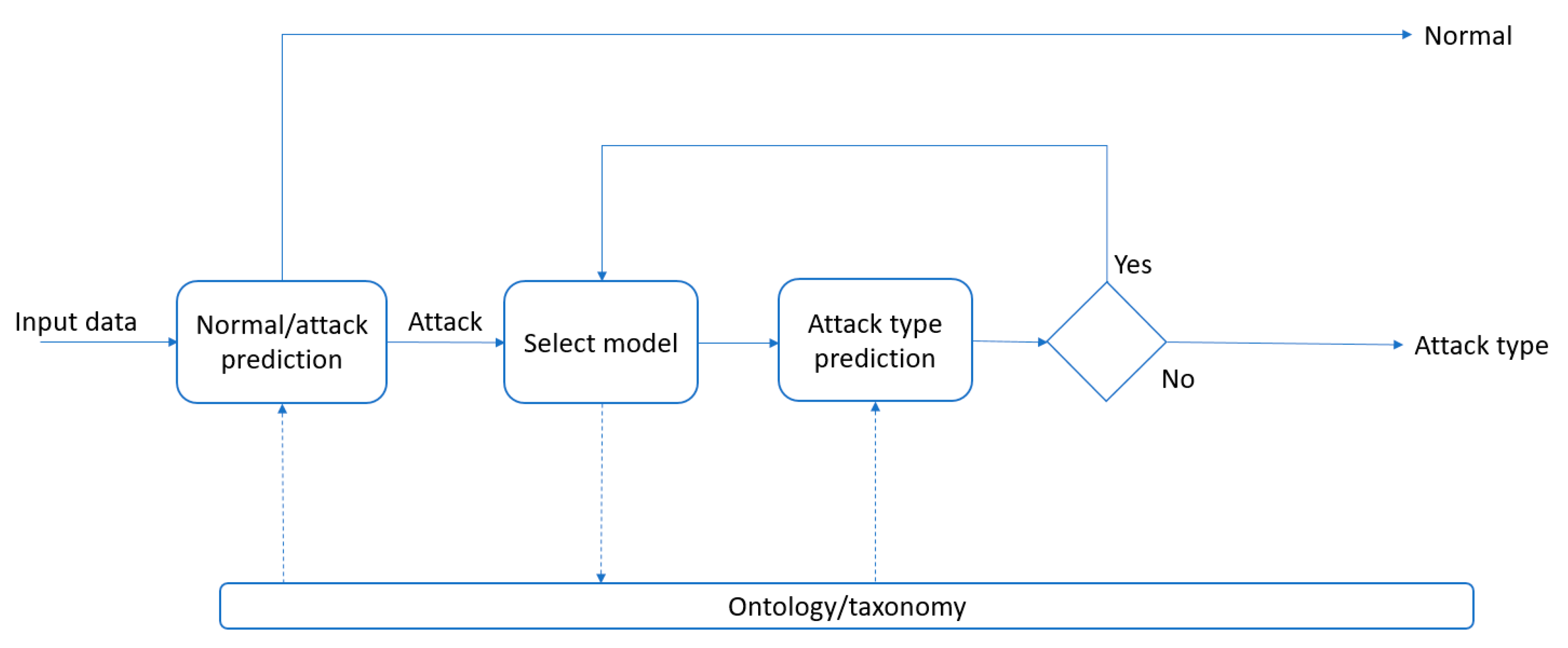
3.1. The Overall Architecture of the Proposed System
- Normal/Attack separation—the first phase is a binary classification task. The classifier used in this phase is used to distinguish normal traffic and attacks. If a connection is labelled as a normal one, then an alarm is not raised. Otherwise, the suspicious connection is processed by a set of models to determine the class of attack during the phase 2.
- Attack class and type prediction—this phase is guided by the taxonomy of the attacks from the knowledge model. The system hierarchically processes the taxonomy and selects the appropriate model to classify the instance on a particular level of a class hierarchy.
- When a class of attack is predicted, ontology is queried for all relevant sub-types of the attack type and to retrieve the suitable model to predict the particular sub-type. Knowledge model can also be used to extract specific domain-related information as a new attribute, which could be used either to improve the classifier’s performance or to provide context, domain-specific information which could complement the predictive model.
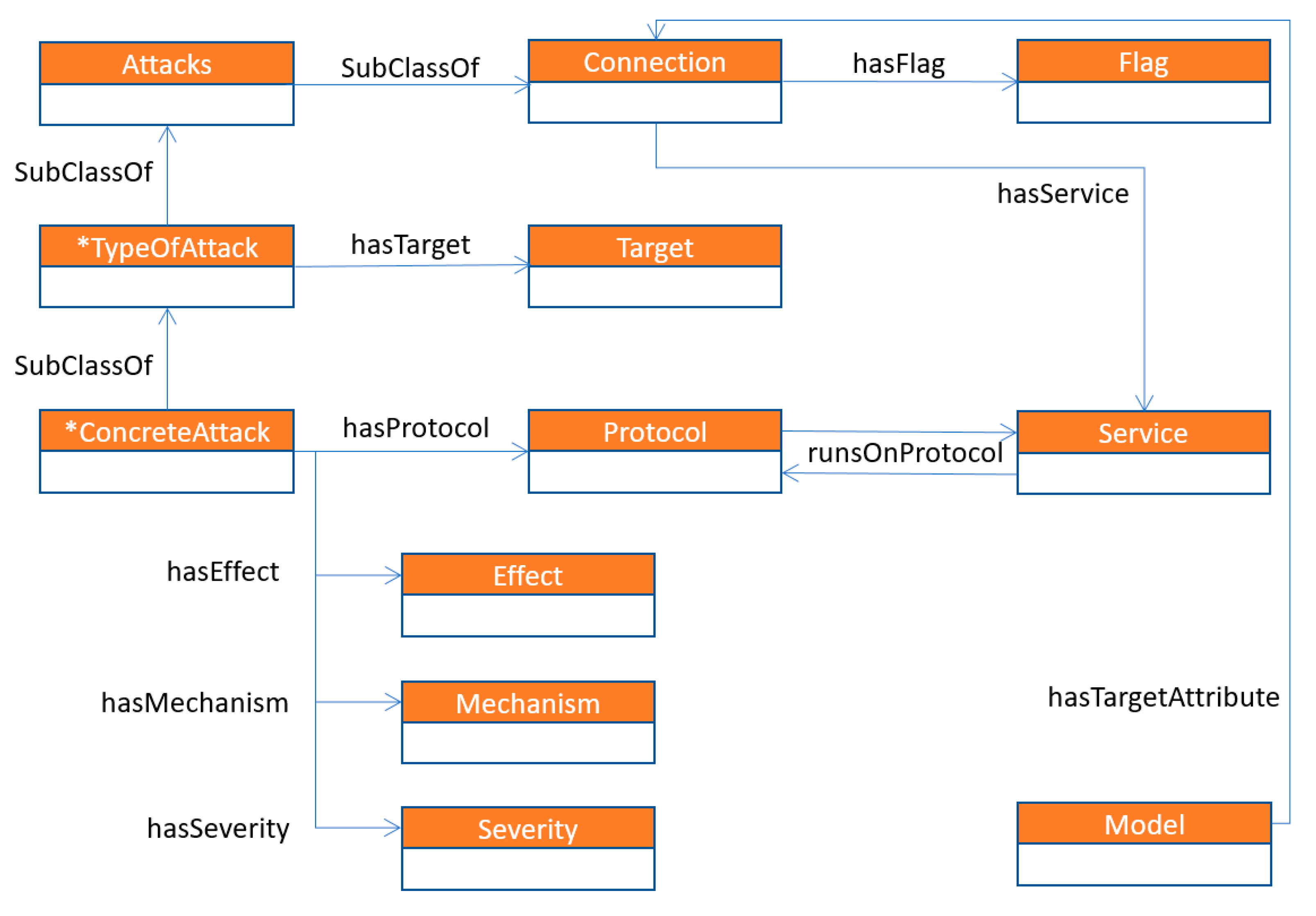
3.2. Network Intrusion Knowledge Model
- Connection class represents particular connections, whether normal ones or attacks. The class forms a class hierarchy when a sub-class Attacks represents the attack. Attack sub-classes (TypeOfAttack) represent the classes of the attacks (e.g., DoS, r2l, etc.); concrete attacks types are modelled as a sub-class of the ConcreteAttack type classes (e.g., back, land, etc.).
- Effect class covers all possible effects that an attack affects (e.g., slowing down of the server response, gaining root access for the user, service outage, etc.)
- Mechanism class and its sub-classes describe all possible mechanisms of particular attacks (e.g., poor environment maintenance, incorrect configuration of the components, etc.)
- Flag characterizes the normal or error states of the specific connections (e.g., service not responding, denied the connection, etc.)
- Protocol represents the protocols used in the connection (e.g., TCP, UDP, etc.)
- Service concept describes service types related to the connection (e.g., http, telnet, etc.)
- Severity describes how severe the possible attack type effects could be (low, medium and high).
- Targets define the possible targets of the particular attack type (e.g., user, network, data, etc.).
- Models concept covers the classification models used to predict the given target attribute
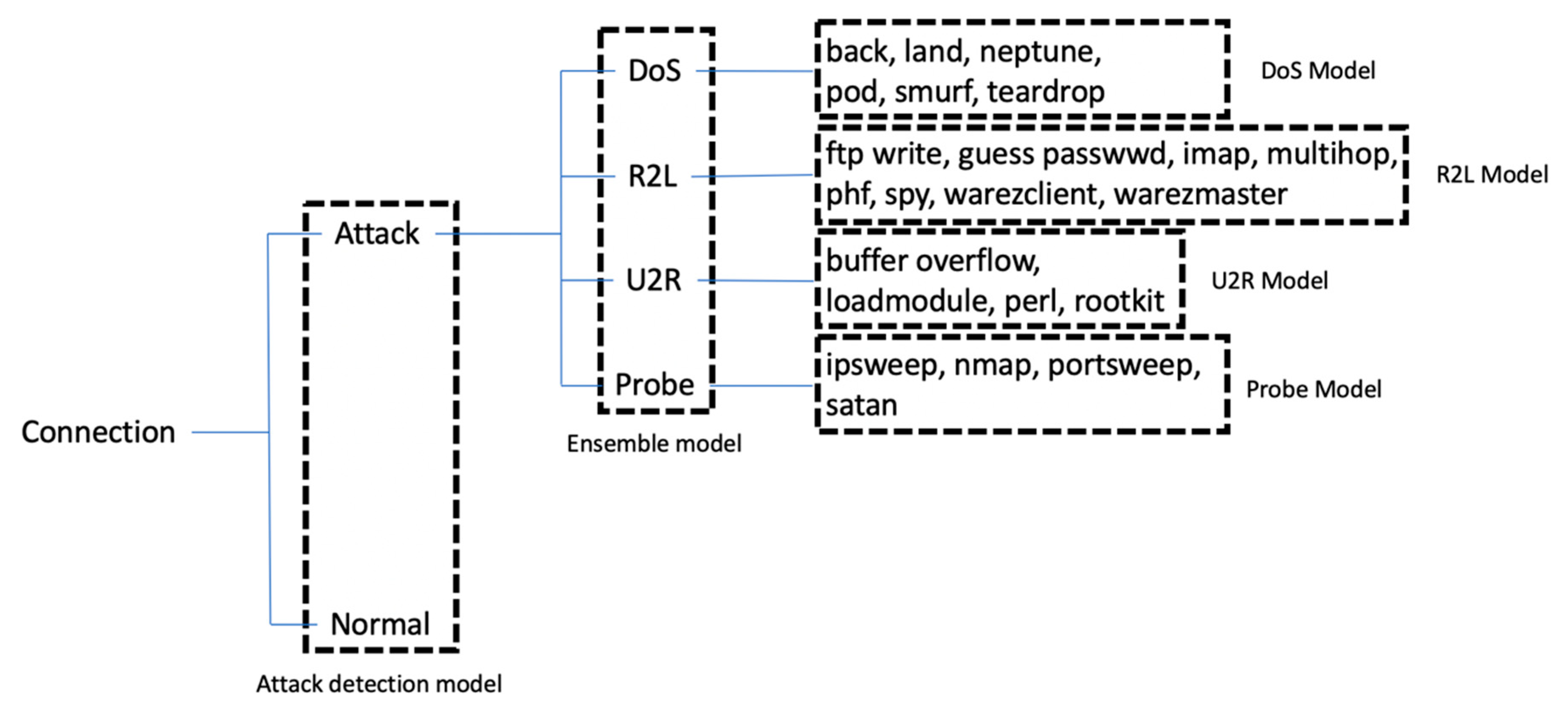
3.3. Machine learning Models for Detection of the Network Attacks on KDD 99 Dataset
3.4. Use of Knowledge Model in Multi-Stage Intrusion Detection
4. Experimental Evaluation
4.1. Performance Metrics
- TP (True Positive): when predicted network attack is in fact an attack,
- TN (True Negative): when predicted normal record is in fact normal record,
- FN (False Negative): when predicted normal record is in fact an attack,
- FP (False Positive): when predicted network attack is in fact a normal record.
4.2. Performance Evaluation
4.2.1. Model Training and Evaluation
4.2.2. Overall Approach Performance
4.2.3. Attack Severity Prediction
5. Discussion and Future Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Park, J. Advances in Future Internet and the Industrial Internet of Things. Symmetry 2019, 11, 244. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (formerly BIONETICS), New York, NY, USA, 3–5 December 2016. [Google Scholar]
- Khan, M.A.; Karim, M.d.R.; Kim, Y. A Scalable and Hybrid Intrusion Detection System Based on the Convolutional-LSTM Network. Symmetry 2019, 11, 583. [Google Scholar] [CrossRef]
- Ahmim, A.; Ghoualmi Zine, N. A new hierarchical intrusion detection system based on a binary tree of classifiers. Inf. Comput. Secur. 2015, 23, 31–57. [Google Scholar] [CrossRef]
- Ahmim, A.; Ghoualmi-Zine, N. A New Fast and High Performance Intrusion Detection System. Int. J. Secur. Appl. 2013, 7, 67–80. [Google Scholar] [CrossRef]
- Kevric, J.; Jukic, S.; Subasi, A. An effective combining classifier approach using tree algorithms for network intrusion detection. Neural Comput. Appl. 2017, 28, 1051–1058. [Google Scholar] [CrossRef]
- Srivastav, N.; Challa, R.K. Novel intrusion detection system integrating layered framework with neural network. In Proceedings of the 2013 3rd IEEE International Advance Computing Conference (IACC), Ghaziabad, India, 22–23 February 2013; pp. 682–689. [Google Scholar]
- Aljawarneh, S.; Aldwairi, M.; Yassein, M.B. Anomaly-based intrusion detection system through feature selection analysis and building hybrid efficient model. J. Comput. Sci. 2018, 25, 152–160. [Google Scholar] [CrossRef]
- Samrin, R.; Vasumathi, D. Review on anomaly based network intrusion detection system. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, 15–16 December 2017; pp. 141–147. [Google Scholar]
- Arunadevi, M.; Perumal, S.K. Ontology based approach for network security. In Proceedings of the 2016 International Conference on Advanced Communication Control and Computing Technologies (ICACCCT), Ramanathapuram, India, 25–27 May 2016; pp. 573–578. [Google Scholar]
- Salahi, A.; Ansarinia, M. Predicting network attacks using ontology-driven inference. arXiv 2013, arXiv:13040913. [Google Scholar]
- Ahmim, A.; Maglaras, L.; Ferrag, M.A.; Derdour, M.; Janicke, H. A novel hierarchical intrusion detection system based on decision tree and rules-based models. arXiv 2018, arXiv:181209059. [Google Scholar]
- Sharma, N.; Mukherjee, S. A Novel Multi-Classifier Layered Approach to Improve Minority Attack Detection in IDS. Procedia Technol. 2012, 6, 913–921. [Google Scholar] [CrossRef]
- Ibrahim, H.E.; Badr, S.M.; Shaheen, M.A. Adaptive layered approach using machine learning techniques with gain ratio for intrusion detection systems. arXiv 2012, arXiv:12107650. [Google Scholar]
- Gupta, K.K.; Nath, B.; Kotagiri, R. Layered Approach Using Conditional Random Fields for Intrusion Detection. IEEE Trans. Dependable Secur. Comput. 2010, 7, 35–49. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, G.; Jiang, S.; Dai, M. An efficient intrusion detection system based on feature selection and ensemble classifier. arXiv 2019, arXiv:190401352. [Google Scholar]
- Abdoli, F.; Meibody, N.; Bazoubandi, R. An Attacks Ontology for computer and networks attack. In Innovations and Advances in Computer Sciences and Engineering; Sobh, T., Ed.; Springer: Dordrecht, The Netherlands, 2010; pp. 473–476. ISBN 978-90-481-3657-5. [Google Scholar]
- Razzaq, A.; Anwar, Z.; Ahmad, H.F.; Latif, K.; Munir, F. Ontology for attack detection: An intelligent approach to web application security. Comput. Secur. 2014, 45, 124–146. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, Z.; Xia, G.; Jiang, C. Research on Vulnerability Ontology Model. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 657–661. [Google Scholar]
- Syed, Z.; Padia, A.; Finin, T.; Matthews, L.; Anupam, J. UCO: Unified Cybersecurity Ontology. In Proceedings of the AAAI Workshop on Artificial Intelligence for Cyber Security, Phoenix, Arizona, 12–13 February 2016. [Google Scholar]
- Hung, S.-S.; Liu, D.S.-M. A User-centric Intrusion Detection System by Using Ontology Approach. In Proceedings of the 9th Joint Conference on Information Sciences (JCIS), Kaohsiung, Taiwan, 8–9 October 2006; Atlantis Press: Kaohsiung, Taiwan. [Google Scholar]
- Abdoli, F.; Kahani, M. Ontology-based distributed intrusion detection system. In Proceedings of the 2009 14th International CSI Computer Conference, Tehran, Iran, 20–21 October 2009; pp. 65–70. [Google Scholar]
- Abdoli, F.; Kahani, M. Using Attacks Ontology in Distributed Intrusion Detection System. In Advances in Computer and Information Sciences and Engineering; Sobh, T., Ed.; Springer: Dordrecht, The Netherlands, 2008; pp. 153–158. ISBN 978-1-4020-8740-0. [Google Scholar]
- More, S.; Matthews, M.; Joshi, A.; Finin, T. A Knowledge-Based Approach to Intrusion Detection Modeling. In Proceedings of the 2012 IEEE Symposium on Security and Privacy Workshops, San Francisco, CA, USA, 24–25 May 2012; pp. 75–81. [Google Scholar]
- Karande, H.A.; Gupta, S.S. Ontology based intrusion detection system for web application security. In Proceedings of the 2015 International Conference on Communication Networks (ICCN), Gwalior, India, 19–21 November 2015; pp. 228–232. [Google Scholar]
- Can, Ö.; Ünallır, M.O.; Sezer, E.; Bursa, O.; Erdoğdu, B. A semantic web enabled host intrusion detection system. Int. J. Metadata Semant. Ontol. 2018, 13, 68. [Google Scholar] [CrossRef]
- Divekar, A.; Parekh, M.; Savla, V.; Mishra, R.; Shirole, M. Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives. In Proceedings of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, 25–27 October 2018; pp. 1–8. [Google Scholar]
- Özgür, A.; Erdem, H. A review of KDD99 dataset usage in intrusion detection and machine learning between 2010 and 2015. PeerJ Preprints 2016, 4, e1954v1. [Google Scholar]
- Mavroeidis, V.; Bromander, S. Cyber Threat Intelligence Model: An Evaluation of Taxonomies, Sharing Standards, and Ontologies within Cyber Threat Intelligence. In Proceedings of the 2017 European Intelligence and Security Informatics Conference (EISIC), Athens, Greece, 11–13 September 2017; pp. 91–98. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | Attack Class | Number of Samples |
|---|---|---|
| back | DoS | 2203 |
| land | 21 | |
| neptune | 107,201 | |
| pod | 264 | |
| smurf | 280,790 | |
| teardrop | 979 | |
| satan | Probe | 1589 |
| ipsweep | 1247 | |
| nmap | 231 | |
| portsweep | 1040 | |
| guess_passwd | R2L | 53 |
| ftp_write | 8 | |
| imap | 12 | |
| phf | 4 | |
| multihop | 7 | |
| warezmaster | 20 | |
| warezclient | 1020 | |
| spy | 2 | |
| buffer_overflow | U2R | 30 |
| loadmodule | 9 | |
| perl | 3 | |
| rootkit | 10 | |
| normal | Normal | 97,227 |
| Weighting Scheme | Class 1 | Class 2 | Class 3 | Class 4 |
|---|---|---|---|---|
| model 1 | w1,1 | w1,2 | w1,3 | w1,4 |
| model 2 | w2,1 | w2,2 | w2,3 | w2,4 |
| model 3 | w3,1 | w3,2 | w3,3 | w3,4 |
| ... | ... | ... | ... | ... |
| Attack Detection Model | Normal | Attack | Precision | Recall |
|---|---|---|---|---|
| Normal | 29,095 | 11 | 0.999 | 0.999 |
| Attack | 35 | 119,066 |
| Ensemble Model | Probe | U2R | DoS | R2L | Precision | Recall |
|---|---|---|---|---|---|---|
| Probe | 1279 | 0 | 1 | 0 | 0.992 | 0.992 |
| U2R | 0 | 15 | 0 | 0 | 1 | 0.882 |
| DoS | 6 | 0 | 117,385 | 0 | 0.999 | 0.999 |
| R2L | 4 | 2 | 0 | 331 | 0.982 | 1 |
| Probe | U2R | DoS | R2L | |
|---|---|---|---|---|
| Overall accuracy | 0.991 | 0.937 | 0.999 | 0.989 |
| Precision | 0.989 | 0.927 | 0.999 | 0.879 |
| Recall | 0.989 | 0.875 | 0.999 | 0.833 |
| SPARQL | Action |
|---|---|
| SELECT ?lname WHERE { ?inst a onto:Connections. ?inst onto:hasModel ?lname | Retrieve the classifier able to predict the attack at the Connection level (decide if the connection is an attack or not) |
| SELECT ?lname WHERE { ?inst a onto:Attacks. ?inst onto:hasModel ?lname | Select the model for prediction of the attack type |
| Classifier | Accuracy | Precision | F-measure | FAR |
|---|---|---|---|---|
| C4.5 | 0.969 | 0.947 | 0.970 | 0.005 |
| Random Forests | 0.964 | 0.998 | 0.986 | 0.025 |
| ForestPA | 0.975 | 0.998 | 0.998 | 0.002 |
| Ensemble model | 0.976 | 0.998 | 0.998 | 0.001 |
| Our approach | 0.998 | 0.998 | 0.998 | 0.001 |
| Ensemble Model | Probe | U2R | DoS | R2L | Normal | Precision | Recall |
|---|---|---|---|---|---|---|---|
| Probe | 1176 | 0 | 5 | 0 | 7 | 0.998 | 0.999 |
| U2R | 0 | 15 | 0 | 0 | 5 | 0.750 | 0.937 |
| DoS | 4 | 0 | 117,547 | 0 | 1 | 0.999 | 0.999 |
| R2L | 3 | 1 | 0 | 346 | 7 | 0.969 | 0.997 |
| Normal | 1 | 0 | 3 | 1 | 48,454 | 0.999 | 0.999 |
| Attack Type | Severity Level |
|---|---|
| ftp_write | low |
| guess_passwd | low |
| spy | low |
| warezclient | low |
| warezmaster | low |
| buffer_overflow | medium |
| loadmodule | medium |
| perl | medium |
| rootkit | medium |
| phf | medium |
| imap | medium |
| multihop | medium |
| ipsweep | medium |
| portsweep | medium |
| nmap | medium |
| satan | high |
| back | high |
| land | high |
| neptune | high |
| pod | high |
| smurf | high |
| teardrop | high |
| High | Low | Medium | Precision | Recall | |
|---|---|---|---|---|---|
| DoS | 117,695 | 0 | 0 | 0.999 | |
| Probe | 443 | 0 | 779 | 0.999 | |
| R2L | 0 | 346 | 6 | ||
| U2R | 0 | 0 | 20 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarnovsky, M.; Paralic, J. Hierarchical Intrusion Detection Using Machine Learning and Knowledge Model. Symmetry 2020, 12, 203. https://doi.org/10.3390/sym12020203
Sarnovsky M, Paralic J. Hierarchical Intrusion Detection Using Machine Learning and Knowledge Model. Symmetry. 2020; 12(2):203. https://doi.org/10.3390/sym12020203
Chicago/Turabian StyleSarnovsky, Martin, and Jan Paralic. 2020. "Hierarchical Intrusion Detection Using Machine Learning and Knowledge Model" Symmetry 12, no. 2: 203. https://doi.org/10.3390/sym12020203
APA StyleSarnovsky, M., & Paralic, J. (2020). Hierarchical Intrusion Detection Using Machine Learning and Knowledge Model. Symmetry, 12(2), 203. https://doi.org/10.3390/sym12020203