Moving Object Detection Based on Background Compensation and Deep Learning


Abstract
:1. Introduction
2. Related Work
2.1. Moving Object Detection Methods
2.2. Object Detection Methods
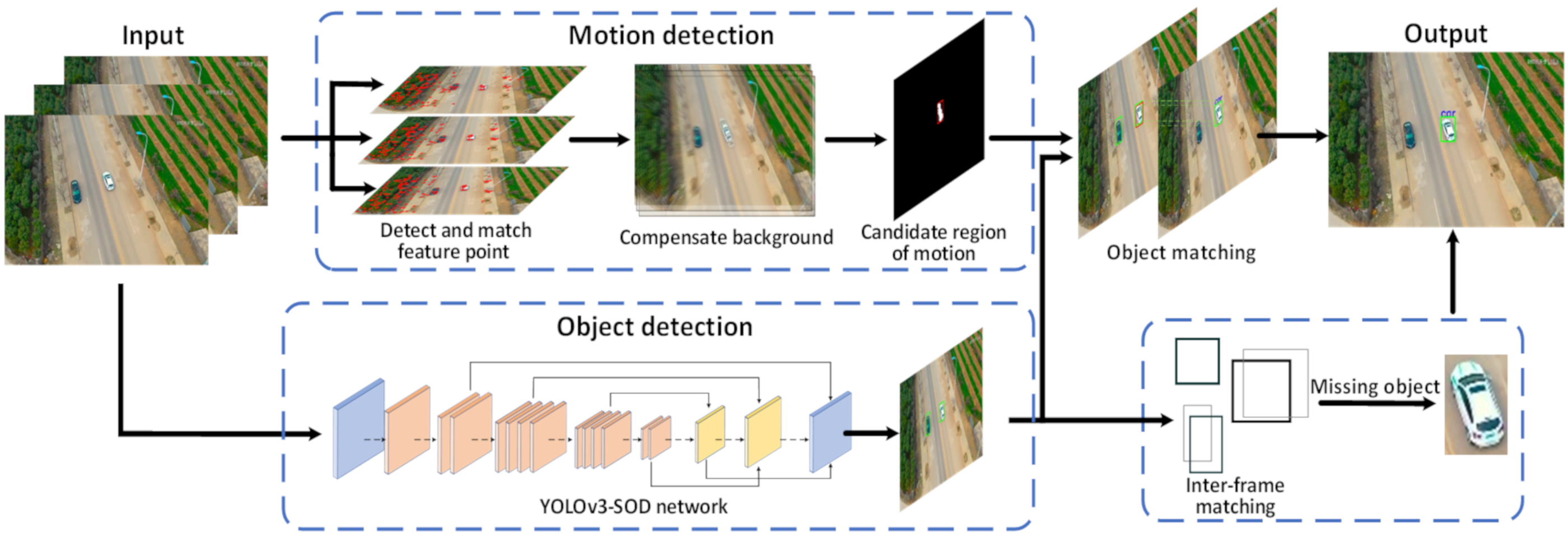
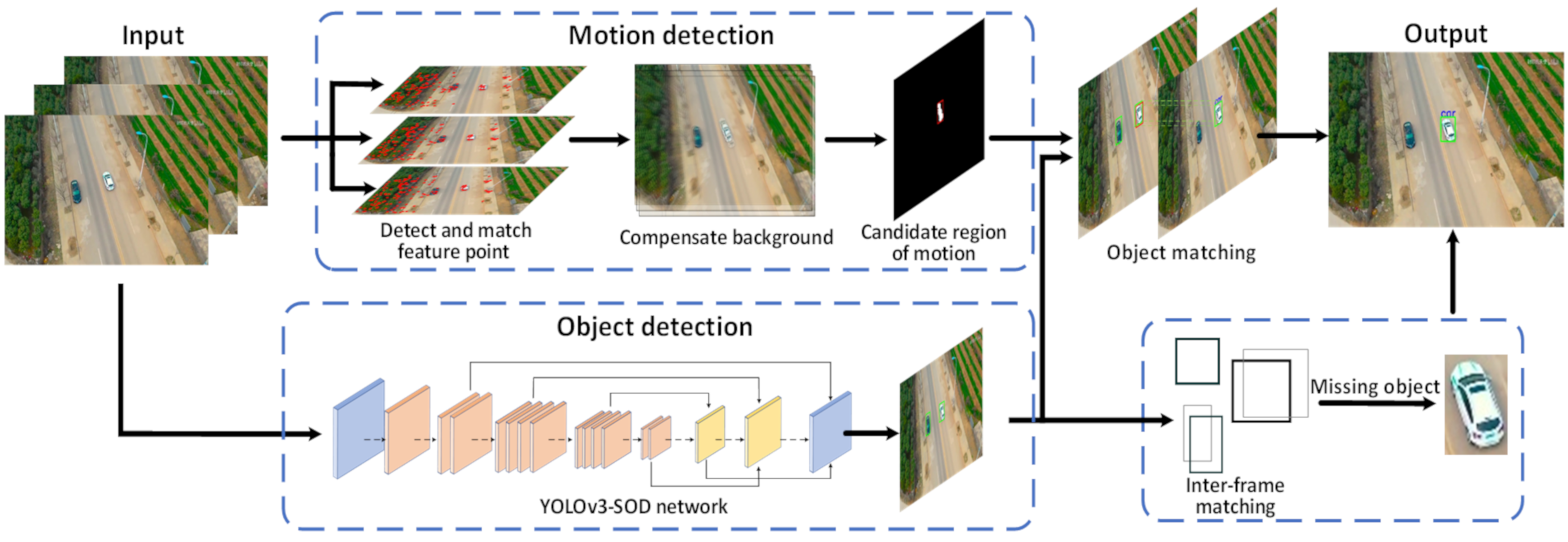
3. Proposed Method
3.1. Motion Detection
- When the intensity of the feature points is greater, they are less likely to be lost;
- An excessive number of feature points can result in too many calculations when matching features;
- An excessive concentration of feature points can lead to large errors for the motion parameters. Thus, a reasonable distribution for the feature points should be broad and average, and not include outer points.
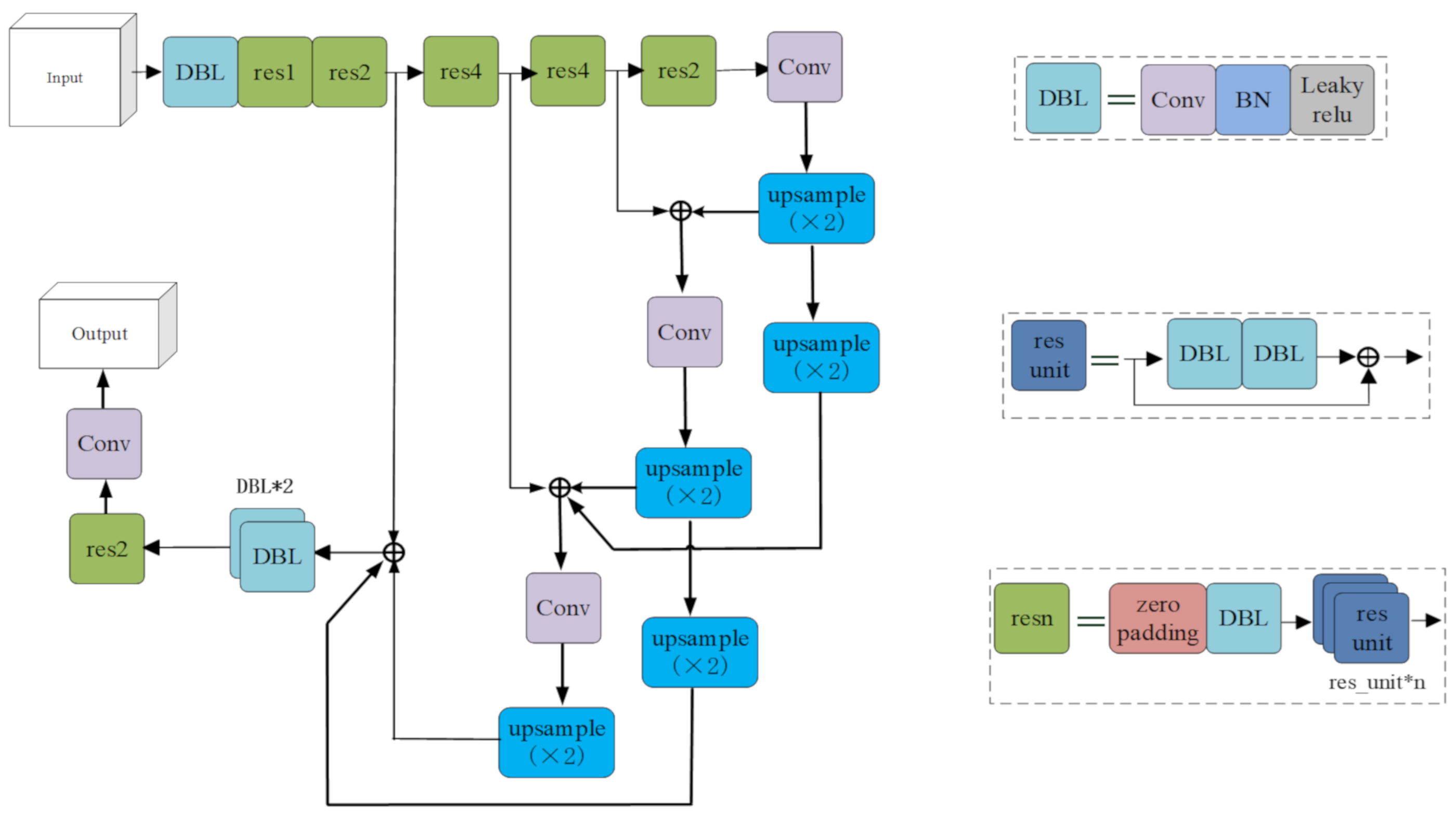
3.2. Object Detection
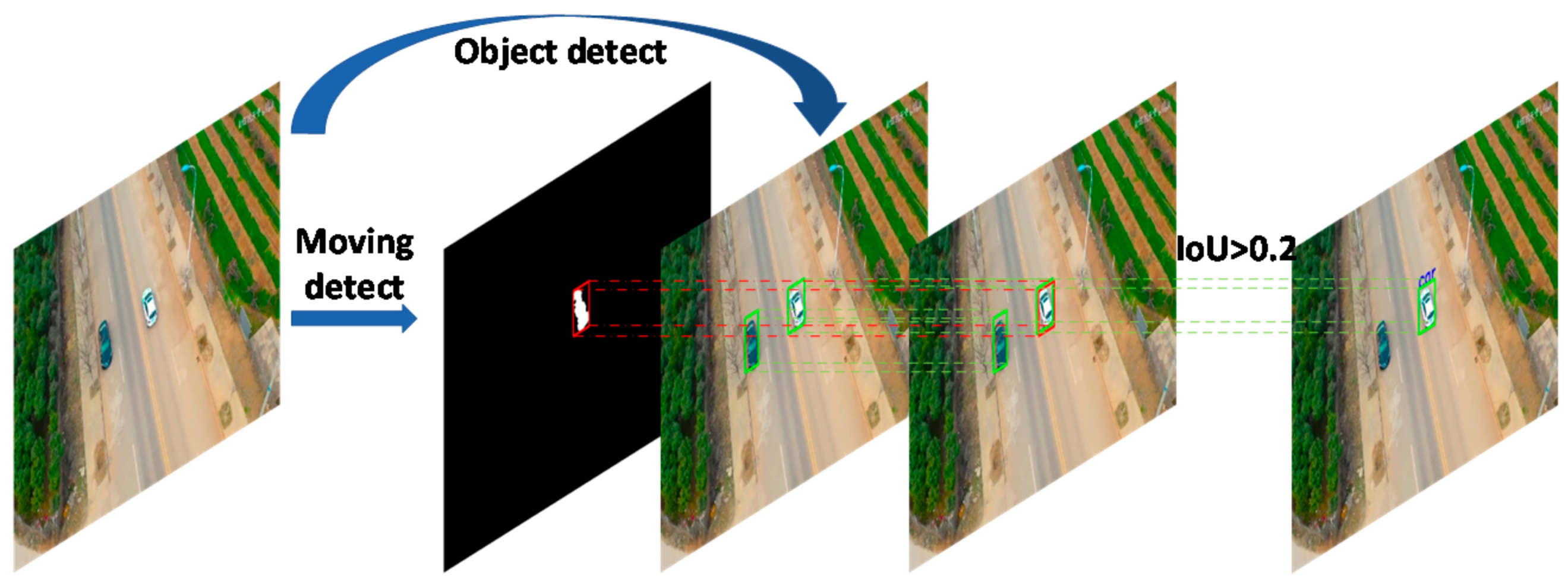
3.3. Object Matching
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Results and Comparisons
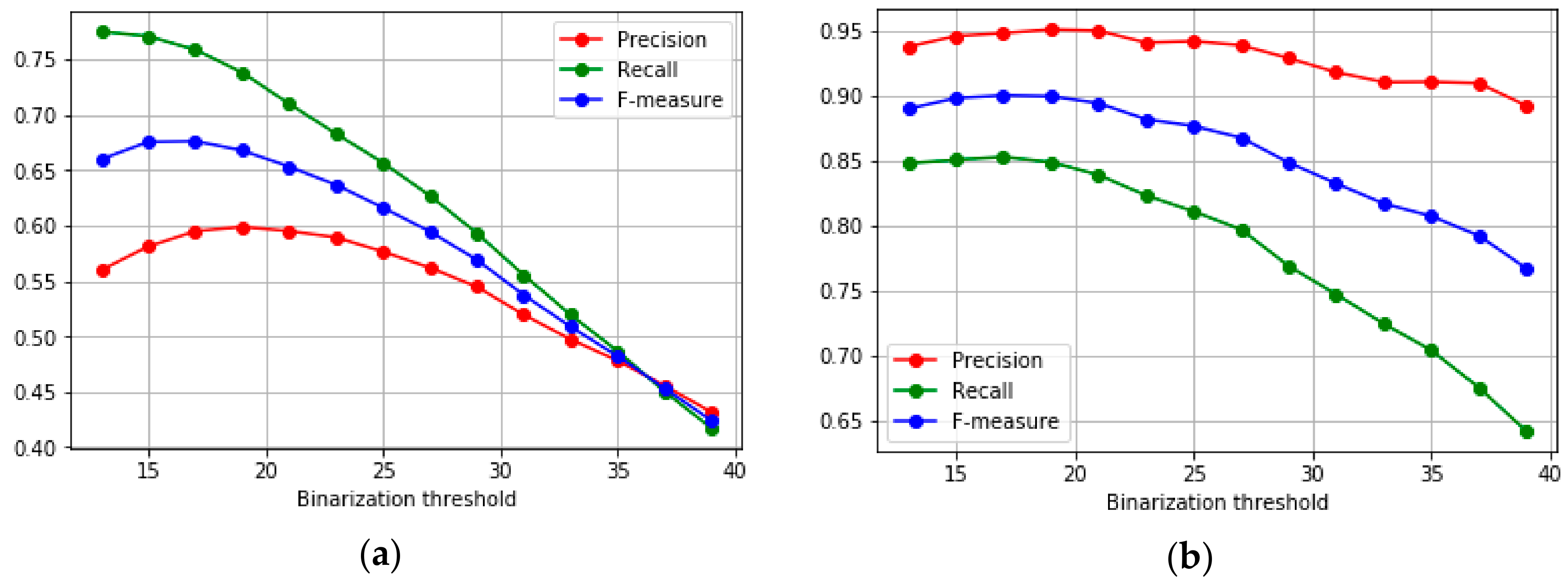
4.3.1. Results on Motion Detection Module
4.3.2. Results on Object Detection Module
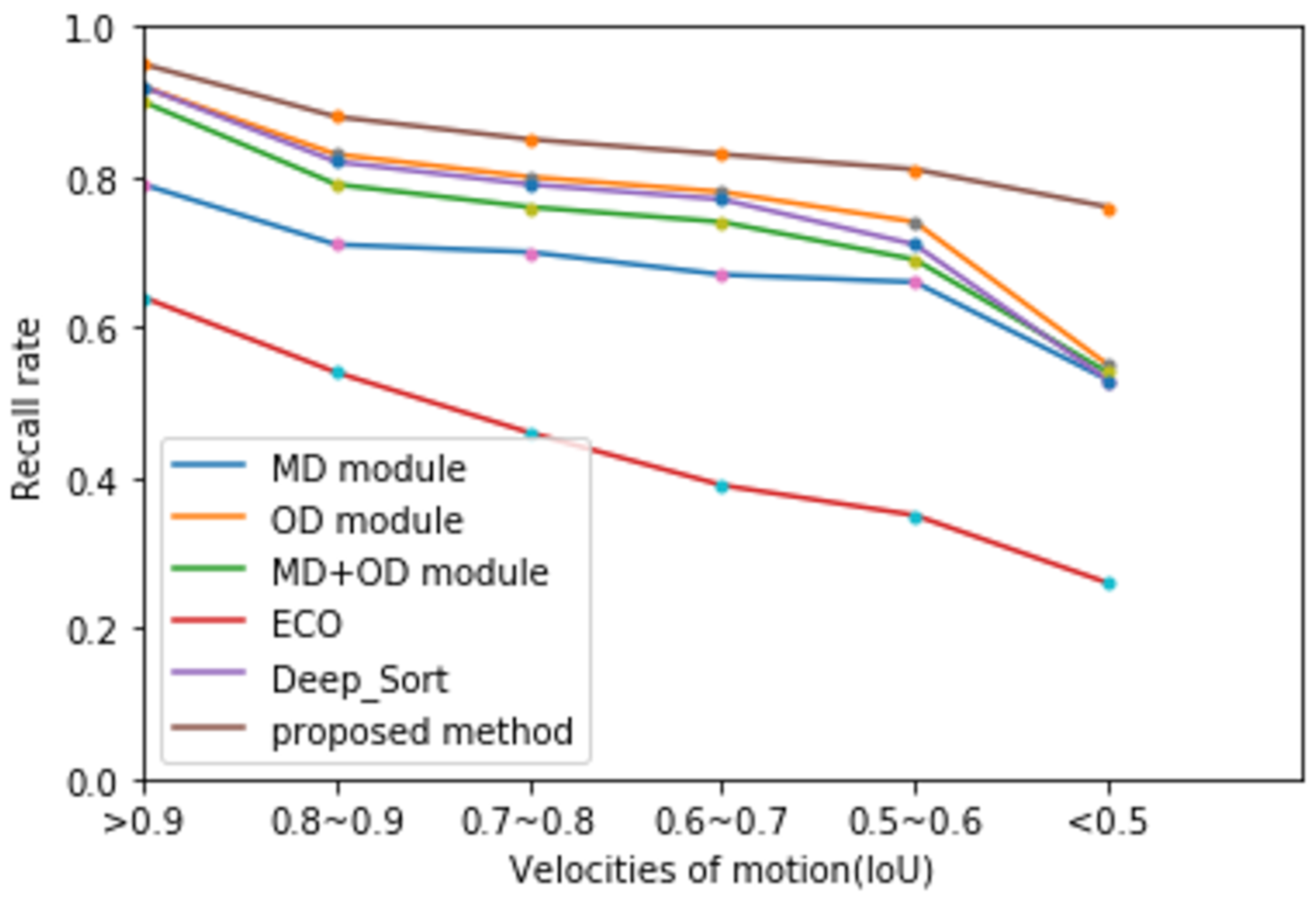
4.3.3. Comparison Results on the MDR105 Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lee, S.H.; Kwon, S.C.; Shim, J.W.; Lim, J.E.; Yoo, J. WisenetMD: Motion Detection Using Dynamic Background Region Analysis. Symmetry 2019, 11, 621. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi, M.; Ouarda, W.; Alimi, A.M. Efficient and Fast Objects Detection Technique for Intelligent Video Surveillance Using Transfer Learning and Fine-Tuning. Arab. J. Sci. Eng. 2020, 45, 1421–1433. [Google Scholar] [CrossRef]
- Genci, C. A vision-based approach for intelligent robot navigation. Int. J. Intell. Syst. Technol. Appl. 2010, 9, 97–107. [Google Scholar]
- Tsai, D.M.; Tseng, T.H. A template reconstruction scheme for moving object detection from a mobile robot. Ind. Robot 2013, 40, 559–573. [Google Scholar] [CrossRef]
- Yin, G.; Li, Y.; Zhang, J. The Research of Video Tracking System Based on Virtual Reality. In Proceedings of the 2008 International Conference on Internet Computing in Science and Engineering, Harbin, China, 28–29 January 2008; pp. 122–127. [Google Scholar]
- Singh, A.; Dutta, M.K. Imperceptible watermarking for security of fundus images in tele-ophthalmology applications and computer-aided diagnosis of retina diseases. Int. J. Med. Inform. 2017, 108, 110–124. [Google Scholar] [CrossRef] [PubMed]
- Cho, J.; Jung, Y.; Kim, D.; Lee, S.; Jung, Y. Design of Moving Object Detector Based on Modified GMM Algorithm for UAV Collision Avoidance. J. Semicond. Technol. Sci. 2018, 18, 491–499. [Google Scholar] [CrossRef]
- Lin, C.Y.; Muchtar, K.; Lin, W.Y.; Jian, Z.Y. Moving Object Detection Through Image Bit-Planes Representation Without Thresholding. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1404–1414. [Google Scholar] [CrossRef]
- Shin, J.; Kim, S.; Kang, S.; Lee, S.W.; Paik, J.; Abidi, B.; Abidi, M. Optical flow-based real-time object tracking using non-prior training active feature model. Real-Time Imaging 2005, 11, 204–218. [Google Scholar] [CrossRef]
- Fan, X.; Cheng, Y.; Qiang, F. Moving Target Detection Algorithm Based on Susan Edge Detection and Frame Difference. In Proceedings of the International Conference on Information Science and Control Engineering, Shanghai, China, 24–26 April 2015; pp. 323–326. [Google Scholar]
- Jarraya, S.K.; Hammami, M.; Hanêne, B.-A. Accurate Background Modeling for Moving Object Detection in a Dynamic Scene. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications, Sydney, Australia, 1–3 December 2010; pp. 52–57. [Google Scholar]
- Wang, P.; Yang, J.; Mao, Z.; Zhang, C.; Zhang, G. Object Detection Based on Motion Vector Compensation in Dynamic Background. Ordnance Ind. Autom. 2019, 38, 6–10. [Google Scholar]
- Rodriguez, P.; Wohlberg, B. Translational and rotational jitter invariant incremental principal component pursuit for video background modeling. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 537–541. [Google Scholar]
- Suhr, J.K.; Jung, H.G.; Li, G.; Noh, S.I.; Kim, J. Background Compensation for Pan-Tilt-Zoom Cameras Using 1-D Feature Matching and Outlier Rejection. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 371–377. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, X.; Wang, B.; Li, W.; Liu, Y.; Zhang, M. Background Subtraction for Moving Cameras based on trajectory-controlled segmentation and Label Inference. KSII Trans. Internet Inf. Syst. 2015, 9, 4092–4107. [Google Scholar]
- Brox, T.; Malik, J. Object Segmentation by Long Term Analysis of Point Trajectories. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 282–295. [Google Scholar]
- Singh, S.; Arora, C.; Jawahar, C.V. Trajectory Aligned Features For First Person Action Recognition. Pattern Recognit. 2017, 62, 45–55. [Google Scholar] [CrossRef] [Green Version]
- Comaniciu, D.; Ramesh, V.; Meer, P. Kernel-based object tracking. Pattern Anal. Mach. Intell. 2003, 25, 564–575. [Google Scholar] [CrossRef] [Green Version]
- Hyeonseob, N.; Bohyung, H. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Martin, D.; Goutam, B.; Fahad, S.K.; Michael, F. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Raychaudhuri, A.; Maity, S.; Chakrabarti, A.; Bhattacharjee, D. Detection of Moving Objects in Video Using Block-Based Approach. In Proceedings of the International Conference on Computational Intelligence, Communications, and Business Analytics, Kolkata, India, 24 March 2017; pp. 151–167. [Google Scholar]
- Nozari, A.; Hoseini, S.M. Recognition of Moving Objects in Videos of Moving Camera with Harris Attributes. In Proceedings of the 2015 Fourteenth Mexican International Conference on Artificial Intelligence (MICAI), Cuernavaca, Mexico, 25–31 October 2015; pp. 42–45. [Google Scholar]
- Guang, L.I.; Yan, F. Moving object detection based on SIFT features matching and K-means clustering. J. Comput. Appl. 2012, 32, 2824–2826. [Google Scholar]
- Luo; Hao, W. A Moving Object Detection Algorithm Based on ORB under Dynamic Scene. Appl. Mech. Mater. 2014, 602–605, 1638–1641. [Google Scholar] [CrossRef]
- Hafiane, A.; Palaniappan, K.; Seetharaman, G. UAV-Video Registration Using Block-Based Features. In Proceedings of the 2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; pp. 1104–1107. [Google Scholar]
- Setyawan, F.A.; Tan, J.K.; Kim, H.; Ishikawa, S. Detection of Moving Objects in a Video Captured by a Moving Camera Using Error Reduction. In Proceedings of the SICE Annual Conference, Hokaido University, Sapporo, Japan, 9–12 September 2014; pp. 347–352. [Google Scholar]
- Nicolai, W.; Alex, B.; Dietrich, P. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Number of Feature Points | Time (s) |
|---|---|---|
| FAST [34] | 108 | 0.000180 |
| Harris [25] | 245 | 0.037304 |
| SURF [35] | 242 | 0.162658 |
| SIFT [26] | 532 | 0.037742 |
| Class Name | Image Number | Object Number | Object Size (Pixel) | ||
|---|---|---|---|---|---|
| Max | Min | Average | |||
| person | 11836 | 13393 | 225 | 18 | 70 |
| car | 17714 | 21530 | 201 | 16 | 58 |
| aeroplane | 11520 | 12827 | 406 | 16 | 97 |
| Method | P | R | F1 | AP (%) | mAP (%) | FPS | Size (MB) | ||
|---|---|---|---|---|---|---|---|---|---|
| Aeroplane | Car | Person | |||||||
| TinyYOLOv3 | 0.97 | 0.44 | 0.70 | 85 | 58 | 51 | 65 | 42 | 33 |
| YOLOv3 | 0.96 | 0.82 | 0.89 | 90 | 90 | 87 | 90 | 24 | 235 |
| SSD | 0.96 | 0.58 | 0.77 | 90 | 80 | 70 | 80 | 60 | 162 |
| FPN | 0.65 | 0.74 | 0.69 | 82 | 83 | 69 | 78 | 2 | 460 |
| YOLOv3-SOD | 0.96 | 0.86 | 0.91 | 91 | 91 | 89 | 91 | 27 | 98 |
| Method | <25 | 25~50 | 50~75 | 75~100 | >100 |
|---|---|---|---|---|---|
| TinyYOLOV3 | 0.00 | 0.31 | 0.82 | 0.77 | 0.89 |
| YOLOV3 | 0.86 | 0.90 | 0.85 | 0.87 | 0.89 |
| SSD | 0.10 | 0.53 | 0.83 | 0.91 | 0.89 |
| FPN | 0.76 | 0.84 | 0.82 | 0.68 | 0.49 |
| YOLOV3-SOD | 0.89 | 0.90 | 0.89 | 0.80 | 0.66 |
| Method | P | R | F1 | |||
|---|---|---|---|---|---|---|
| MD Module | OD Module | OM Module | ||||
| Proposed method | ✓ | 0.60 | 0.75 | 0.66 | ||
| ✓ | 0.81 | 0.86 | 0.83 | |||
| ✓ | ✓ | 0.95 | 0.80 | 0.86 | ||
| ✓ | ✓ | ✓ | 0.96 | 0.85 | 0.90 | |
| ECO | 0.86 | 0.73 | 0.79 | |||
| Deep_Sort | 0.82 | 0.87 | 0.85 | |||
| Method | Recall at Different Size of Bounding Box | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| MD | OD | OM | <25 | 25~50 | 50~75 | 75~100 | 100~125 | >125 | |
| Proposed method | ✓ | 0.44 | 0.80 | 0.85 | 0.72 | 0.84 | 0.86 | ||
| ✓ | 0.93 | 0.91 | 0.87 | 0.90 | 0.95 | 0.88 | |||
| ✓ | ✓ | 0.77 | 0.85 | 0.89 | 0.84 | 0.75 | 0.72 | ||
| ✓ | ✓ | ✓ | 0.79 | 0.85 | 0.91 | 0.88 | 0.87 | 0.83 | |
| ECO | 0.44 | 0.61 | 0.57 | 0.51 | 0.32 | 0.36 | |||
| Deep_Sort | 0.86 | 0.86 | 0.82 | 0.86 | 0.92 | 0.86 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Wang, Z.; Wang, S.; Chen, S. Moving Object Detection Based on Background Compensation and Deep Learning. Symmetry 2020, 12, 1965. https://doi.org/10.3390/sym12121965
Zhu J, Wang Z, Wang S, Chen S. Moving Object Detection Based on Background Compensation and Deep Learning. Symmetry. 2020; 12(12):1965. https://doi.org/10.3390/sym12121965
Chicago/Turabian StyleZhu, Juncai, Zhizhong Wang, Songwei Wang, and Shuli Chen. 2020. "Moving Object Detection Based on Background Compensation and Deep Learning" Symmetry 12, no. 12: 1965. https://doi.org/10.3390/sym12121965
APA StyleZhu, J., Wang, Z., Wang, S., & Chen, S. (2020). Moving Object Detection Based on Background Compensation and Deep Learning. Symmetry, 12(12), 1965. https://doi.org/10.3390/sym12121965