2.1. Experimental Tasks and Subjects
The EEG database used for testing the proposed algorithm was built in our previous work [
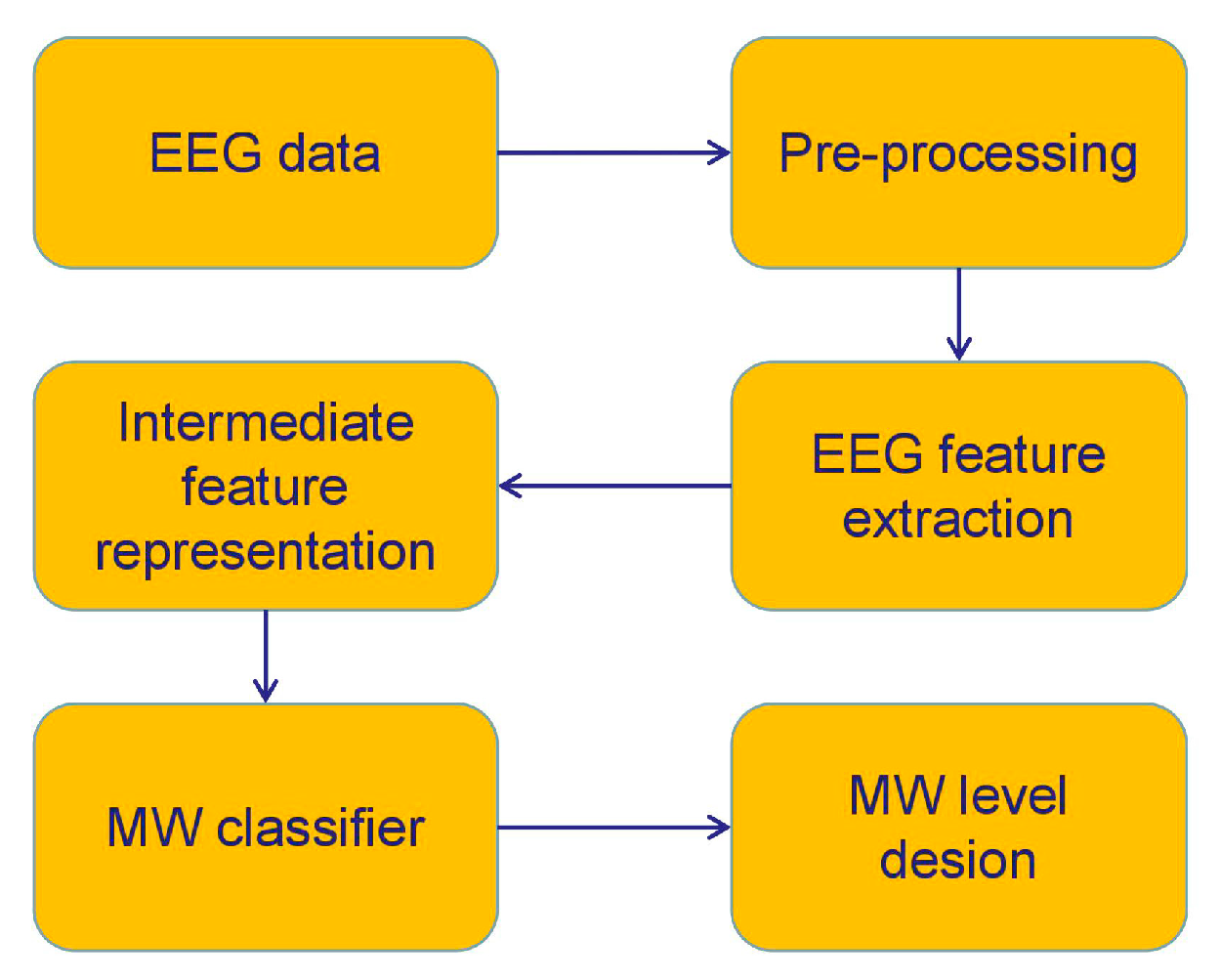
33]. The framework of MW level assessment is described in
Figure 1. We simulated the HM collaboration environment via a software platform termed as automation-enhanced cabin air management systems (ACAMS) [
7,
34,
35]. This experiment used a simplified version of automation-enhanced cabin air management systems (ACAMS) and consisted of loading and unloading phases. ACAMS consisted of four subsystems: Air pressure, temperature, carbon dioxide concentration and oxygen concentration. The function of ACAMS is to observe and control the air quality in the closed space of the spacecraft. This software platform is used to simulate a safety-critical human–machine collaboration environment. Subjects need to concentrate on the operation because the trajectory can easily exceed the target range. Under the ACAMS, the ongoing physiological data of operators corresponding to different task complexities were acquired and used for modeling their transient MW level. The operation of the tasks was related to the maintenance of the air quality in a virtual spacecraft via human-computer interaction.
Operators were required to manually monitor and maintain four variables (O2 concentration, air pressure, CO2 concentration, temperature) to their respective ranges according to given instructions. That is, when any of the subsystems’ program runs incorrectly, operators manually control the task until the systems error is fixed. Simultaneously, the current EEG signals were recorded. The complexity for performing control tasks is measured by the number of manually controlled subsystems (NOS). According to different value of NOS, the complexity and demand of the manual control tasks is gradually changing, which can induce a variation of the MW.
Eight male participants (22–24 years) were engaged and coded by S1, S2, S3, S4, S5, S6, S7, and S8. All participants were volunteer graduate students from the East China University of Science and Technology. All participants have been trained in ACAMS operations for more than 10 h before the start of the formal experiment. As can be seen from our previous work [
36], the average task performance was analyzed and its mean value of all subjects in the first control condition was not significantly varied compared with the last control condition (i.e., from 0.957 to 0.936). Moreover, all subjects cannot perfectly operate the ACAMS of high task complexity in both sessions (with average task performance of 0.783). Since the task demands in the high difficulty conditions were the same across two sessions, the habituation effect of subjects was properly controlled. The reason behind this is that each participant was trained for more than 10 h before the formal experiment and their task performance properly converged.
To rule out the effects of the circadian rhythm, each subject conducted the experiment from 2:00 p.m. to 5:00 p.m. for different sessions. The participants were required to perform two identical sessions of experiments. Each session consisted of eight control task load conditions. After the starting 5-min baseline condition under NOS with the value of 0, there were six 15-min conditions followed by the last 5-min baseline condition again. The duration of each session was 100 min (100 = 6 × 15 + 2 × 5). The operator’s cognitive demand for manual tasks were gradually increased and then reduced within 100 min in one session. We selected the EEG data from six, 15-min conditions in each session. A total of 16 (2 × 8) physiological datasets were built. Under conditions #1, #2, #3, #4, #5, and #6, the participants needed to manually operate ACAMS under NOS with the value of 2, 3, 4, 4, 3, and 2. The subjective rating analysis was omitted and can be found in our previous work [
33].
2.2. EEG Feature Extraction
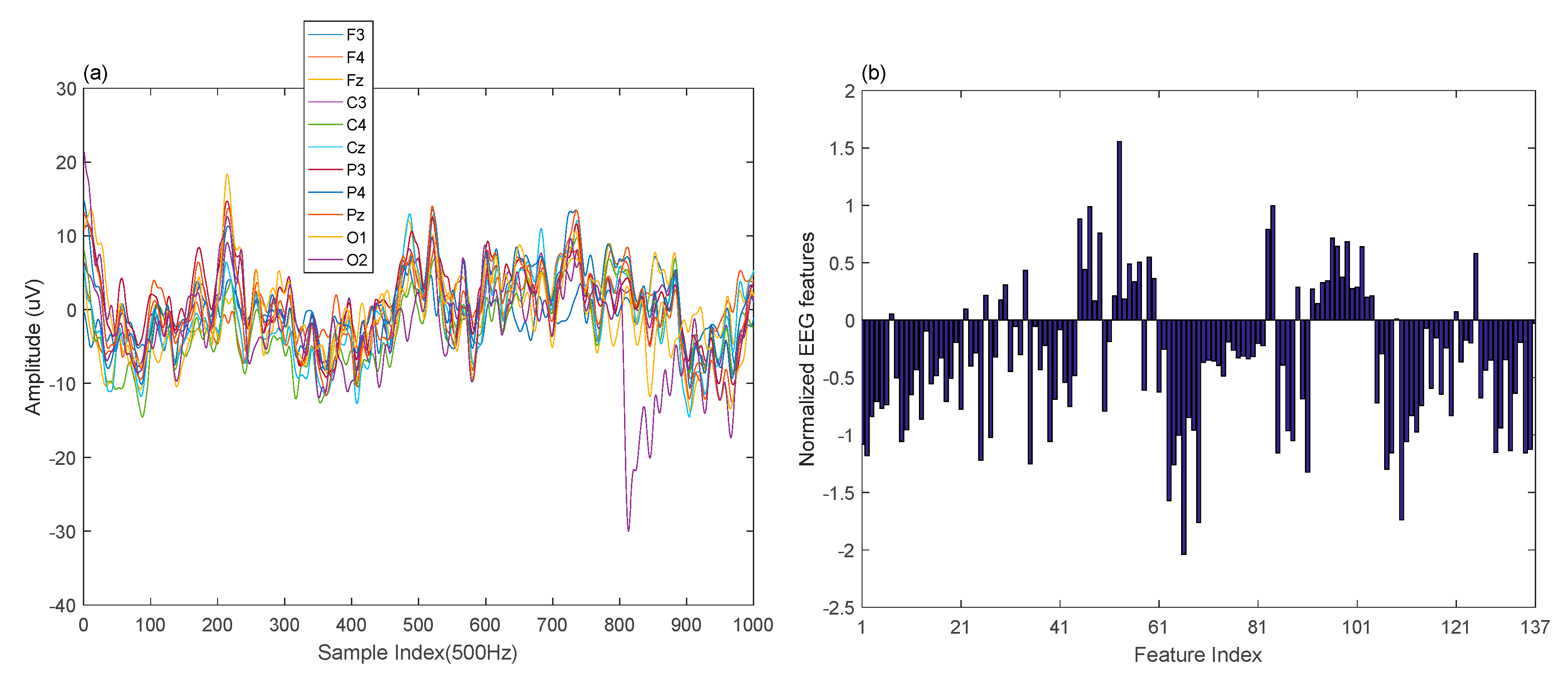
The raw EEG signals and the extracted EEG features are depicted in
Figure 2. The EEG data were measured via the 10–20 international electrode system on 11 positions of the scalp (i.e., F3, F4, Fz, C3, C4, Cz, P3, P4, Pz, O1, and O2) at the frequency of 500 Hz. Frontal theta power and the parietal alpha were used for MW variation detection. In addition, we also noticed that the EEG power of the alpha frequency band in the central scalp region degreases along with the increase of the MW according to [
37,
38,
39]. In [
40], the EEG power of the occipital channels was shown to be related to the stress and fatigue. Therefore, in order to improve the diversity of the possible EEG features that were salient to workload variation, the central and occipital electrodes were also employed in the experiment. To cope with the electromyography (EMG) noise, the independent component analysis (ICA) was employed to filter the raw EEG data. The independent component associated with the muscular activity was identified by careful visual inspection and was eliminated before extracting EEG features. Moreover, the ACAMS operations were not heavily depended on the sensory motor functionality of the cortex. If such noise exists, the possible EEG clues could be allocated with small weight values since the supervised machine learning algorithm only adopted MW levels as target classes. Therefore, the irrelevant EEG indicators can be well controlled.
The preprocessing steps of the acquired EEG signals are shown as follows:
- (1)
All EEG signals were filtered through a three-order low-pass IIR filter with a cutoff frequency of 40 Hz. The related works [
41,
42,
43] indicated that removing EOG artifacts can improve the EEG classification rate, the blink artifacts in EEG signals were eliminated by the coherence method in this study. According to our previous work [
33], the blink artifact was removed by the following equation
In the equation, the EEG signal and the synchronized EOG signal at the time instant
are denoted by
and
, respectively. The transfer coefficient
is defined by
where
denotes the number of samples in an EEG segment,
and
are the means of EEG signal and synchronized EOG signal in a channel, respectively.
- (2)
The filtered EEG was divided into 2-s segments and processed with a high-pass IIR filter (cutoff frequency of 1 Hz) to remove respiratory artifacts.
- (3)
Fast Fourier transform was adopted to compute the power spectral density (PSD) features of the EEG signals. For each channel, four features were obtained by the calculated PSD within theta (4–8 Hz), alpha (8–13 Hz), beta (14–30 Hz), and gamma (31–40 Hz) frequency bands. Based on the PSD features from F3, F4, C3, C4, P3, P4, O1, and O2, we further computed sixteen power differences between the right and left hemispheres of the scalp. That is, 60 frequency domain features were extracted. Then, 77-time domain features were elicited via mean, variance, zero crossing rate, Shannon entropy, spectral entropy, kurtosis, and skewness of 11 channels. The indices and notations of 137 EEG features are shown in
Table 1.
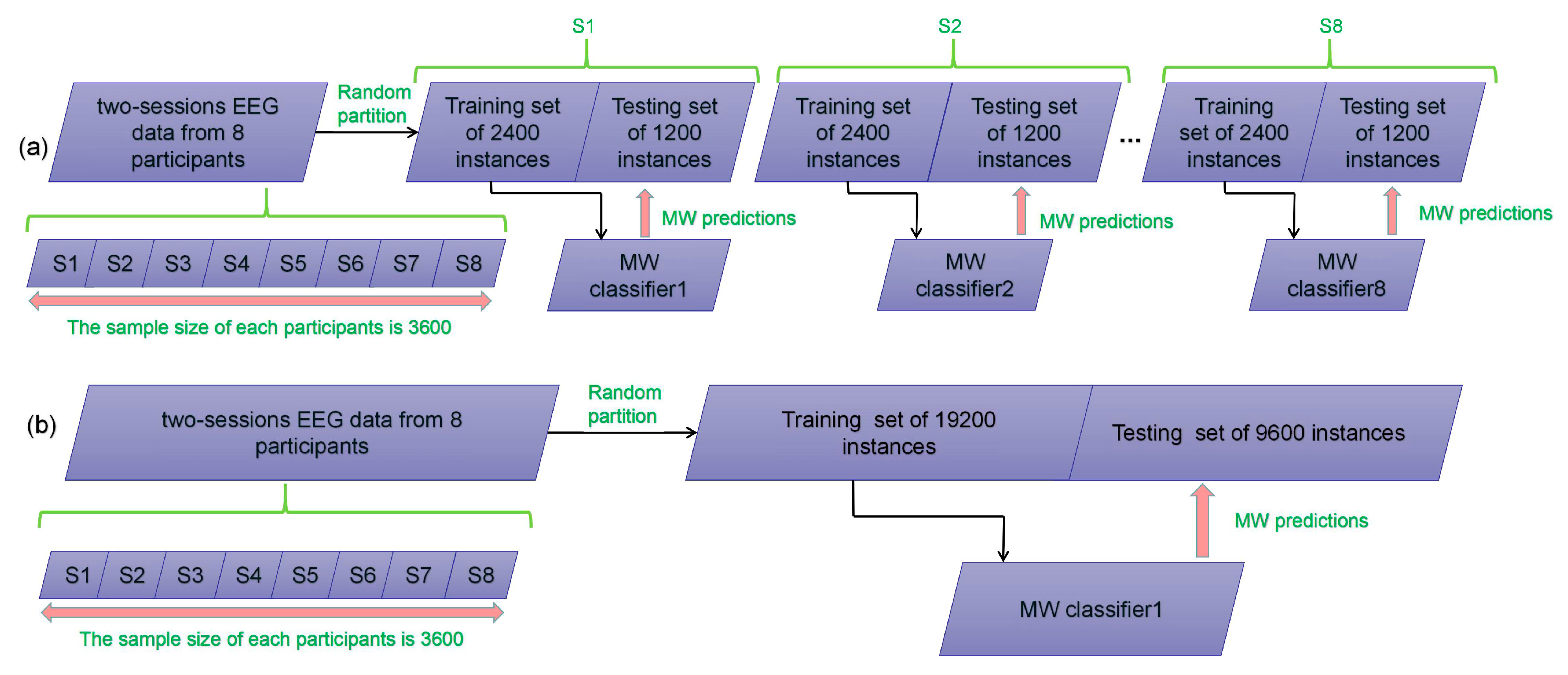
Finally, there were 8 subjects in the experiment, and each subject had two feature sets. Each feature set is a matrix of the same size. The number of rows of the matrix is 1800 for the number of data points, and the number of columns of the matrix is 137 for the number of features. That is, 28,800 data points are available in total. Each feature was normalized into the time course of zero mean and one standard deviation. The EEG vectors were assigned the MW labels of low and high classes and quantified as and , respectively. Note that the first and the last 450 EEG instances in each feature matrix represent a low MW level and the remaining 900 points correspond to high MW levels.
2.3. Extreme Learning Machine
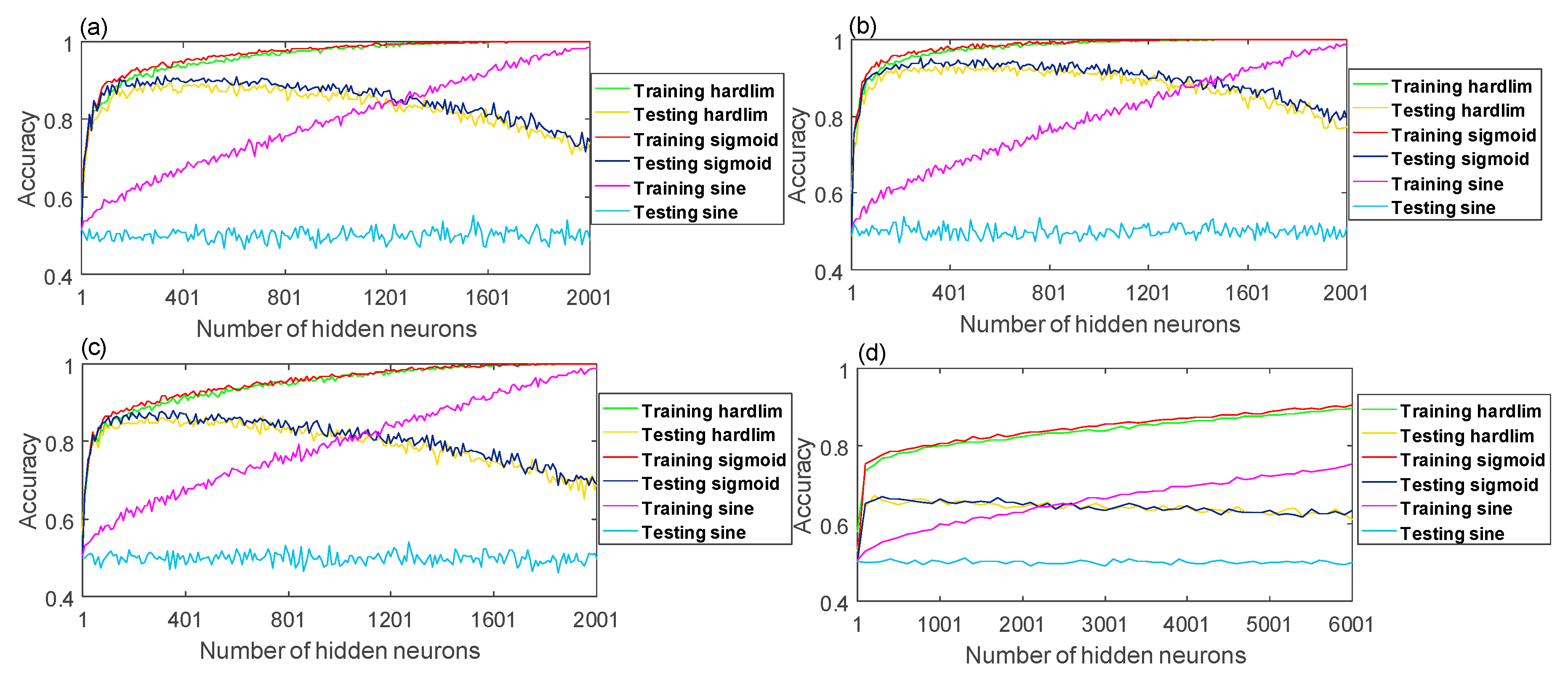
ELM is a fast-training modeling approach based on SLFN [
44,
45].
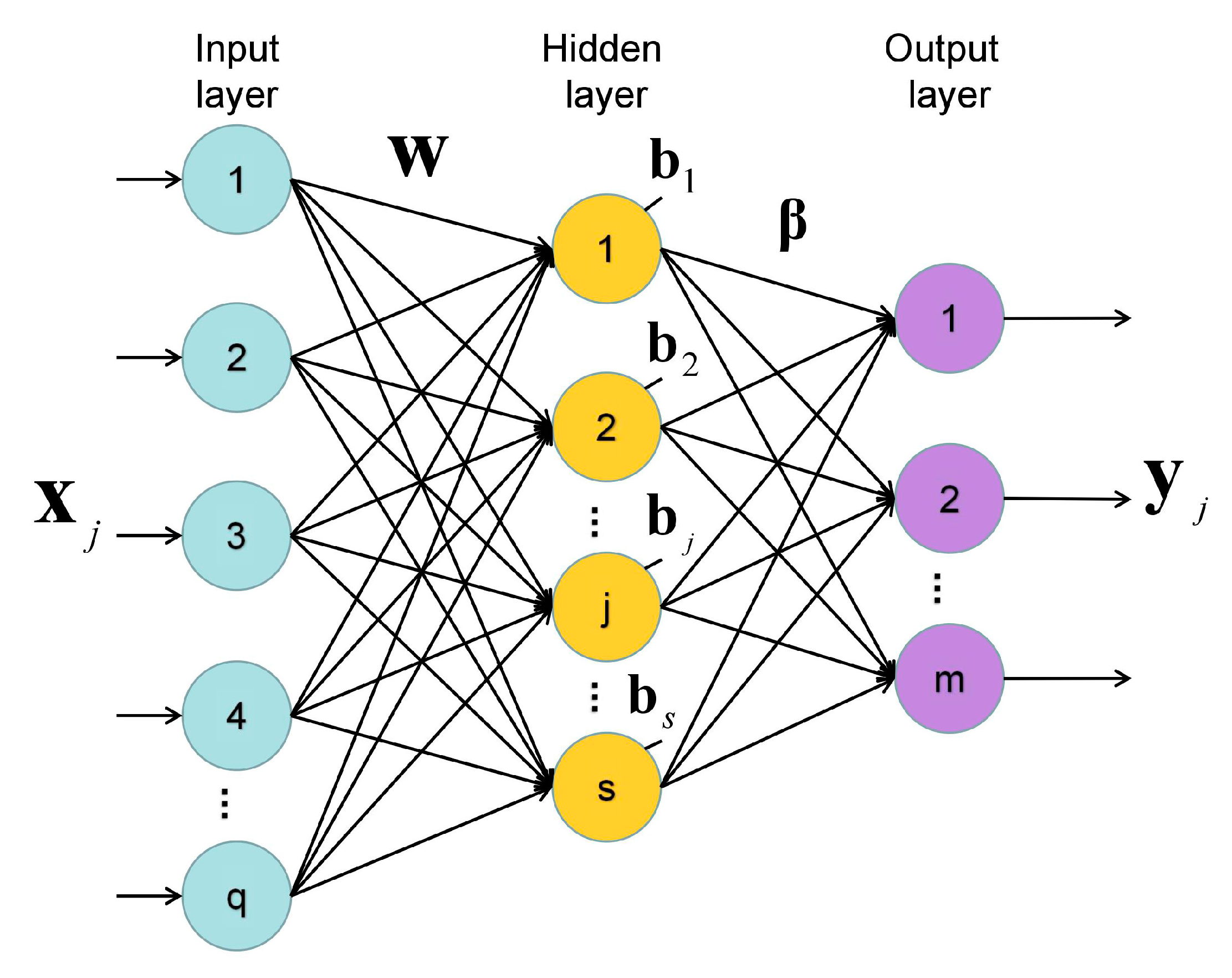
Figure 3 shows a typical SLFN-based ELM architecture, where
is the input sample array and the corresponding output label array is
. Let denote the input weights, output weights, and bias of the hidden neuron as
,
, and
, respectively. Training a SLFN as an ELM is equivalent to minimizing the output error between the target output
and model output
regarding to the parameters,
,
and
, i.e.,
In Equation (3), is the number of EEG samples, is the activation function. The number of the input, output and hidden neurons are defined as , , and , respectively. The training cost function is formulated in a least squared term,
Traditional neural network training approaches are mostly based on gradient descent optimization via BP algorithm. On the contrary, in the process of the ELM modeling the input weights and hidden layer bias are randomly determined while all output weights of hidden layer are computed via the norm minimization-based approach. To this end, it is unnecessary to tune the input weights and hidden layer bias in the training process.
Based on the input weights and bias that are randomly selected, the model fitting error in Equation (4) can be derived via a linear equation systems, , where is the output matrix of the hidden layer. The entry of is denoted as follows
In Equation (5), the induced local field, , is computed via the function signal below
Thus, the output weight
can be elicited by the generalized inverse matrix operation
where
denotes the Moore-Penrose generalized inverse of matrix
[
27]. Singular value decomposition can be implemented to compute
. The pseudo codes of the ELM training algorithm are summarized in
Table 2 [
46]. In the pseudo code, the training set, activation function, the number of hidden nodes, and the output weights are defined as
,
,
and
, respectively. The remaining parameters are consistent with the above.
2.4. Adaboost Based ELM Ensemble Classifier
To improve the classification accuracy of MW on EEG datasets, we introduced the ELM classifier ensemble to find different individual personalities existing in EEG features. The framework of the ELM ensemble is designed based on the adaptive boosting algorithm (Adaboost) [
47]. In the classical boosting algorithm [
48], each training instance is given with an initial weight before the training procedure begins while the value of the weight is automatically adjusted during each iteration. In particular, the Adaboost algorithm adds a new classifier in each training iteration and additionally constructs several weak classifiers on the same sample pool. A strong classifier can thus be integrated via those weak classifiers.
To implement the Adaboost method into the ELM ensemble, we first initialized the weights of each training data of training instances with , . That is, the initial weights of the sample are . Then, we ran () iterations to select a basic classifier possessing the highest classification precision. The error rate of the selected classifier on the is computed by
In Equation (8), denotes the input sample array, corresponds to output label array, represents statistics that is wrongly classified. If is correctly (or incorrectly) classified, or () exists. The weight of in the final strong classifier is computed by the following equation
According to [
47], the weight distribution of the training sample is updated via
The output of the strong classifier is integrated from the weak classifiers through the weight as follows
In Equation (11),
is the final output of the classifier. The pseudo codes of the Adaboost ELM is presented in
Table 3 [
46], where the maximum number of iterations is
, the weight of each weak classifier is
and the output of the strong classifier is
. The remaining parameters are consistent with the above.
2.5. Heterogeneous Ensemble ELM
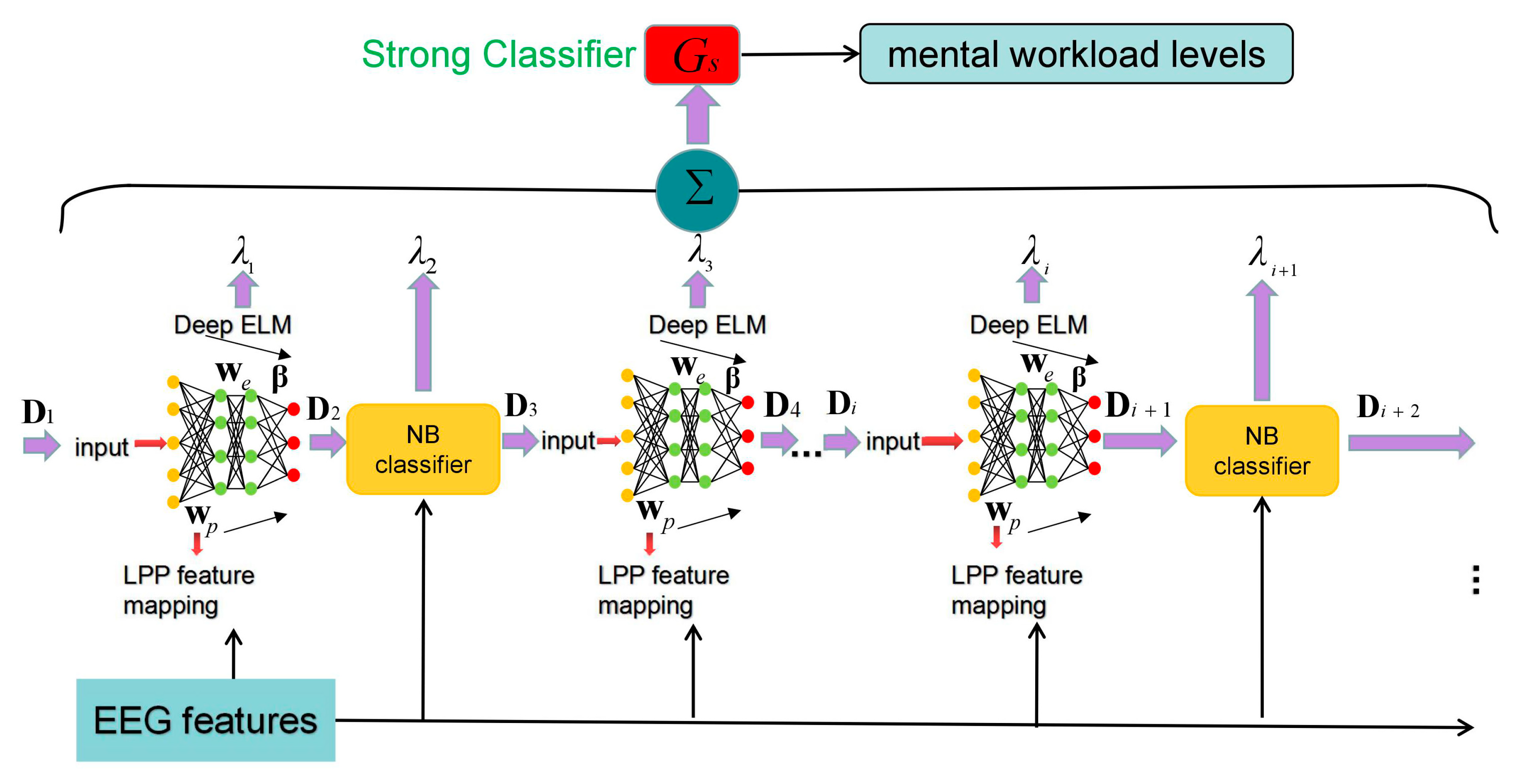
To further improve the generalization capability of the Adaboost ELM classifier on a specific participant, we adopted heterogeneous weak classifiers and the deep learning principle. The architecture of the proposed method termed as heterogeneous ensemble ELM (HE-ELM) is illustrated in
Figure 4.
On one hand, the Naive Bayesian (NB) model was used as alternative weak classifiers to improve the diversity of the ensemble committee. The motivation behind this lies in two aspects: (1) The input weights of all member ELMs are randomly determined from a uniform distribution and it may lead to similar hidden-neuron properties across two weak classifiers; (2) the mechanism of the inference functionality for the Bayesian model is inherently different from the classical ELM and thus facilitates a heterogeneous classifier ensemble.
By setting different values of the class prior probability, we obtained diverse Bayesian models. For ELMs, we implemented different activation functions and hidden neuron numbers. To this end, Bayesian and ELM models with different hyper-parameters can produce a group of dissimilar decision boundaries. The overall error of the strong classifier can be reduced after integrating all heterogeneous models.
By denoting the maximum number of the iteration as , the whole ensemble process builds weak classifiers, where the classifiers consist of NB models (denoted by ) and ELMs (denoted by ) with . According to Equation (3), the output of each ELM can be expressed as
The prediction of the NB model is computed as
In Equation (13),
and
denote the input instance and the label of class
with
, respectively. By incorporating
in Equation (11), the classification accuracy of the strong classifier
generated in each iteration is defined as
where
represents the function for measuring the number of misclassification EEG data points in all
instances. Then, the member classifier
in the
iteration is selected by
In addition, a deep network structure was applied in each member ELM and NB model aimed at finding high-level EEG feature representations. We add a new abstraction layer to the member classifier in which the network weights are trained by using local preserving projection (LPP) that preserves the local geometrical properties of the EEG data distribution [
49,
50]. Let denote the input weight as a transformation matrix
to map EEG feature vectors
to a feature abstraction vector
, i.e.,
By creating an adjacent graph between and , the entry of edge matrix is computed by using the Gaussian kernel with the width parameter ,
The input weight
of the deep ELM network can be trained by solving the following linear equation system,
where
,
, and
are the input sample array, the diagonal matrix computed from
, and the Laplacian matrix, respectively. By denoting the solution of Equation (18) as column vectors
, the input weight of a deep ELM is
.
To this end, the output of each deep ELM classifier can be formulized as
For the NB model, the dimensionality of the EEG feature vectors have been reduced and its output is computed as
It is noted the final strong classifiers are generated in the last iteration of each ensemble learning process on the training set from a single participant, i.e., participant-dependent classifiers are built for MW recognition.
Table 4 lists the pseudo codes for the proposed HE-ELM algorithm [
46], where the dimension required to reduce the dimension of the matrix is
, the prior probability of the NB model is
, the output of the strong classifier is
and the dimensionally reduced input matrix is
. It is noted in the initial iteration that the weak classifier
was constructed by an ELM model. If the performance of the newly-added classifier, i.e., another ELM
, in the second iteration is lower than the current strong classifier, we rebuild
and compare it against a weak NB model according to Equation (20). In the case that the highest performance of
is achieved, the next iteration is carried out. Each subsequent iteration repeats such a computational process until the final strong classifier is generated.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
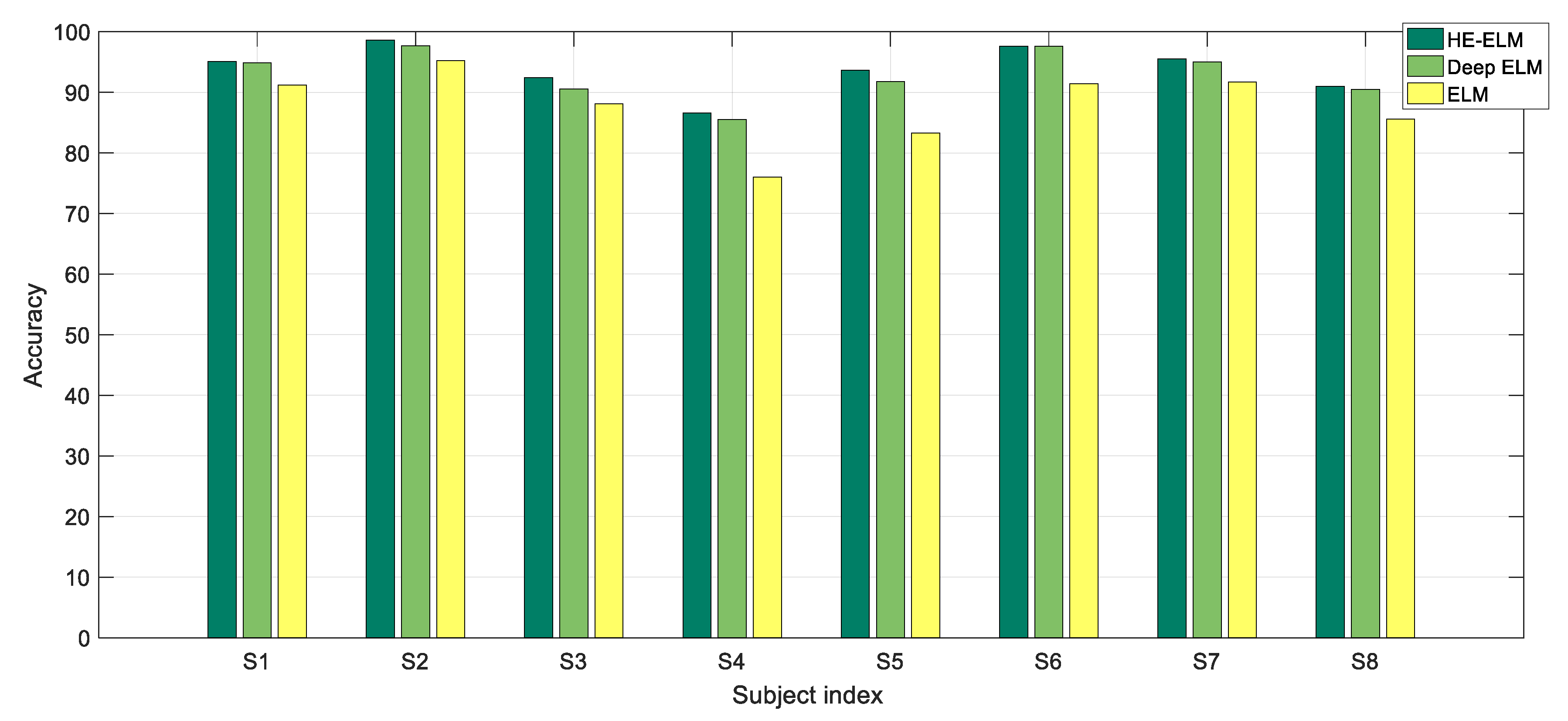{kind=link}
{kind=link}
{kind=link}
{kind=link}