SIAT: A Distributed Video Analytics Framework for Intelligent Video Surveillance


Abstract
:1. Introduction
- We propose and develop a novel layered framework for intelligent video surveillance which has the ability to process both real-time streaming videos and offline batch processing in a scalable manner. The SIAT framework can be used as the reference architecture for distributed video analytics.
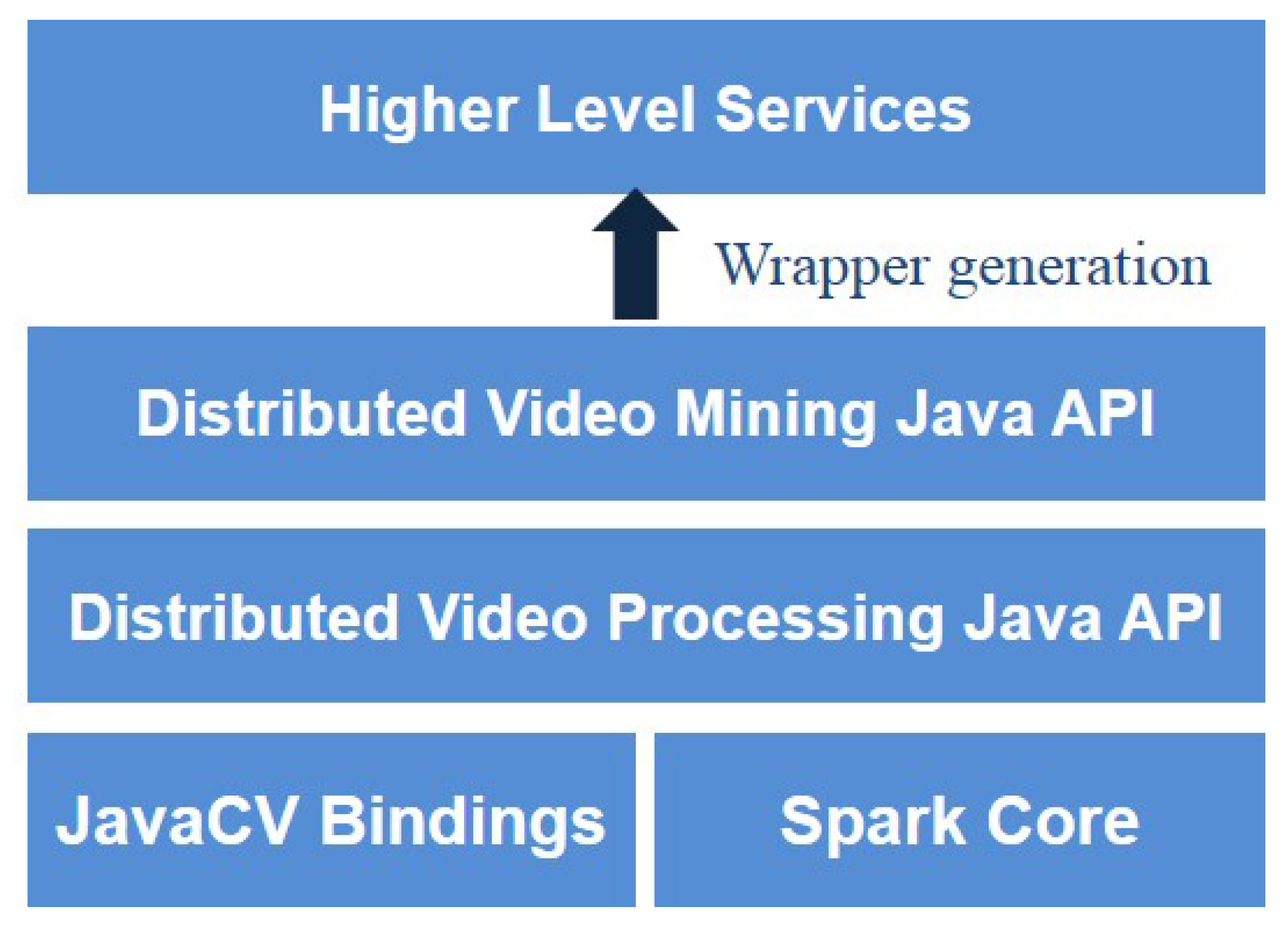
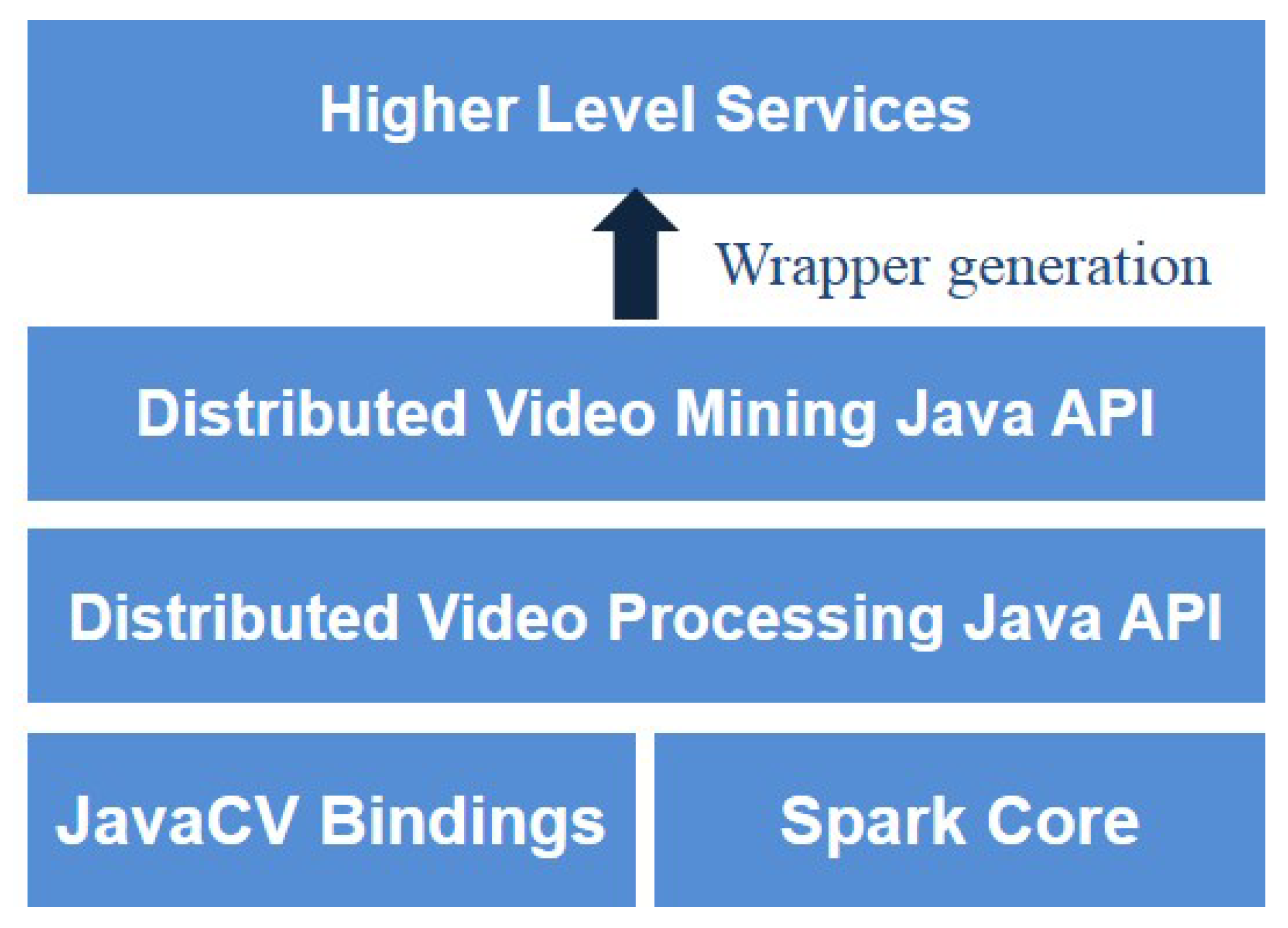
- We introduce a distributed video processing library that provides video processing on top of Spark. Our work is not only limited to providing basic distributed video processing APIs but it also provides distributed dynamic feature extraction APIs which extracts prominent information from the video data.
- We also develop application scenarios for both online and offline distributed video data processing services.
- Extensive experiments are performed to ensure scalability, fault-tolerance and effectiveness.
2. Related Work
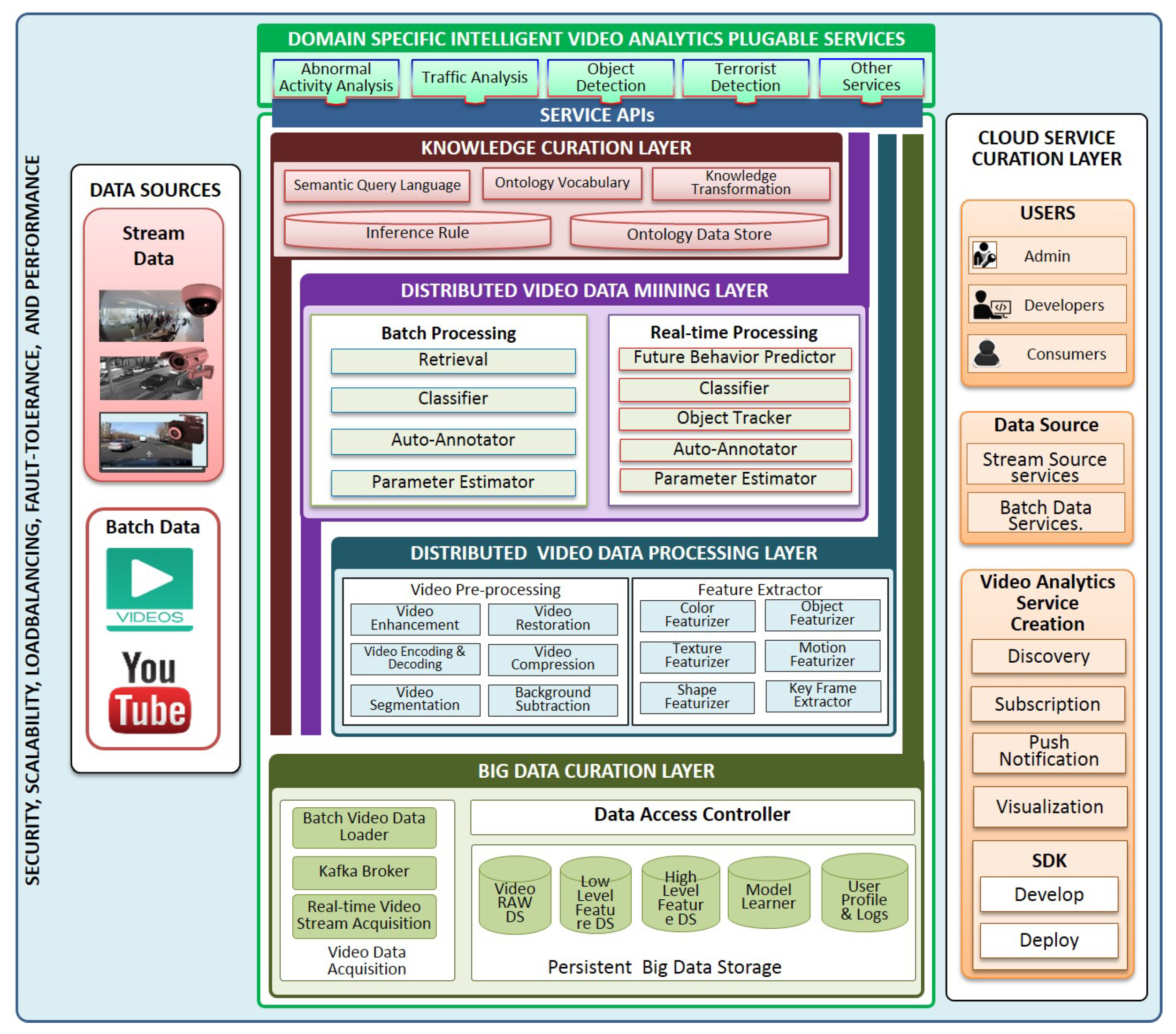
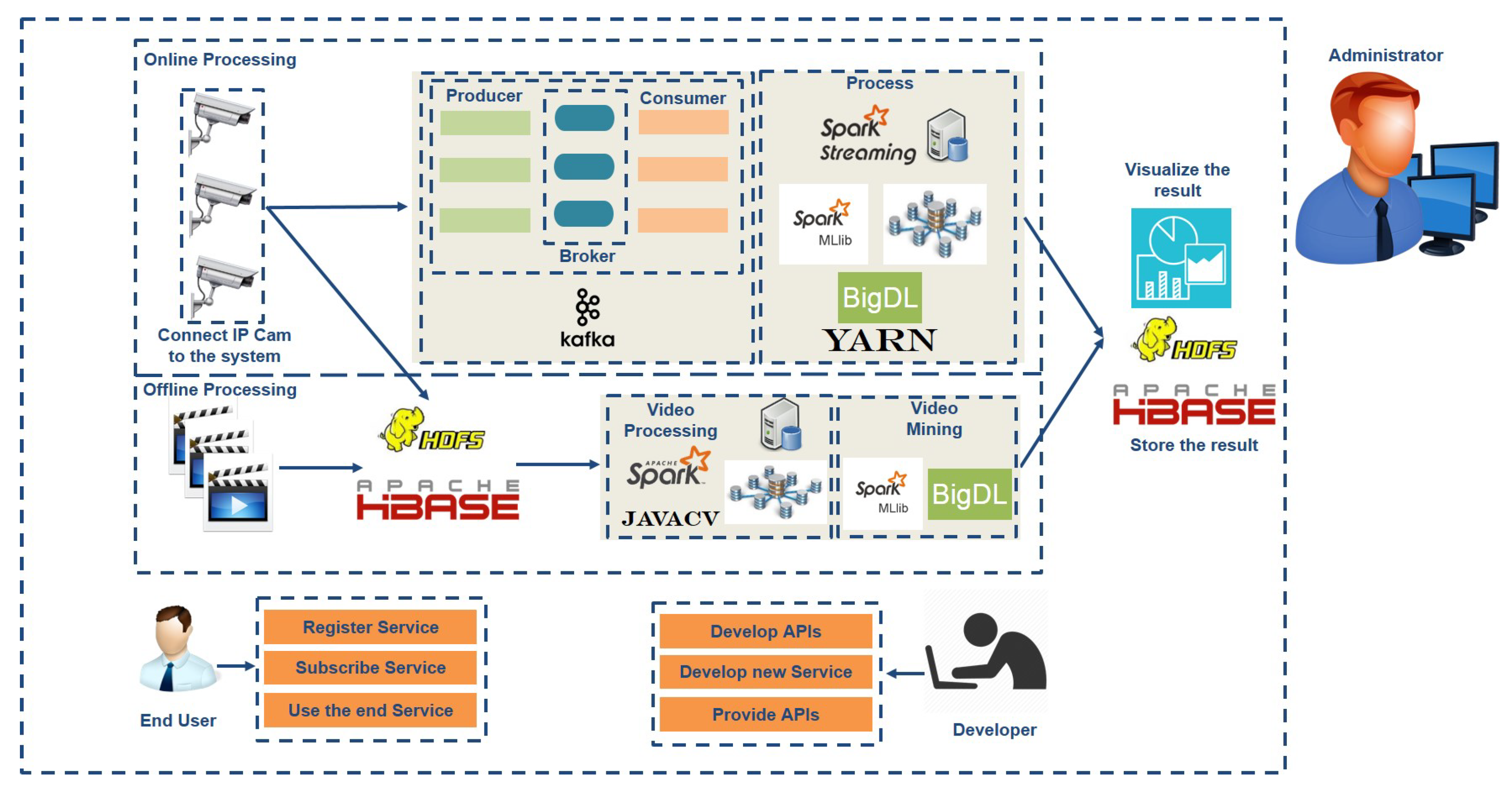
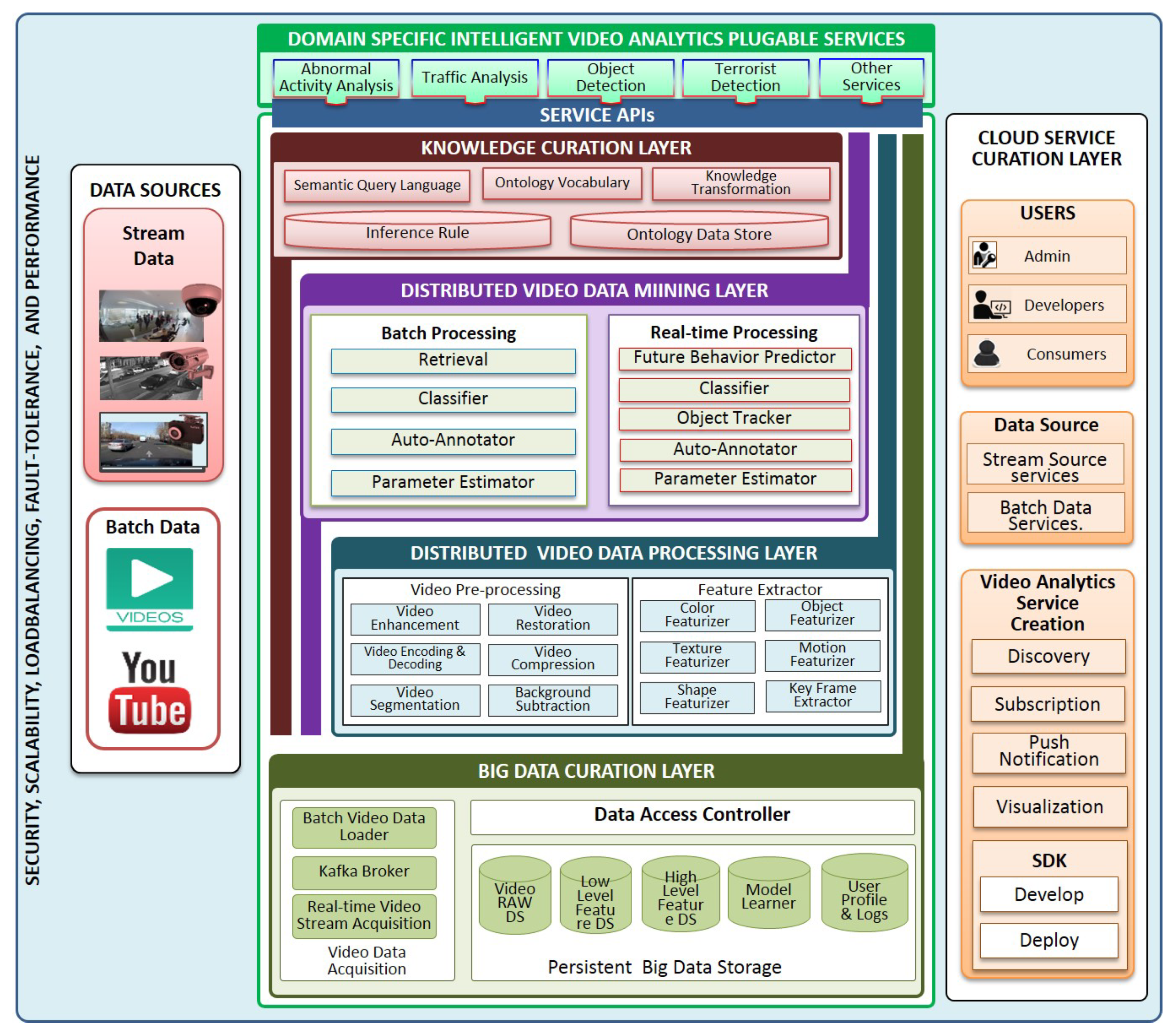
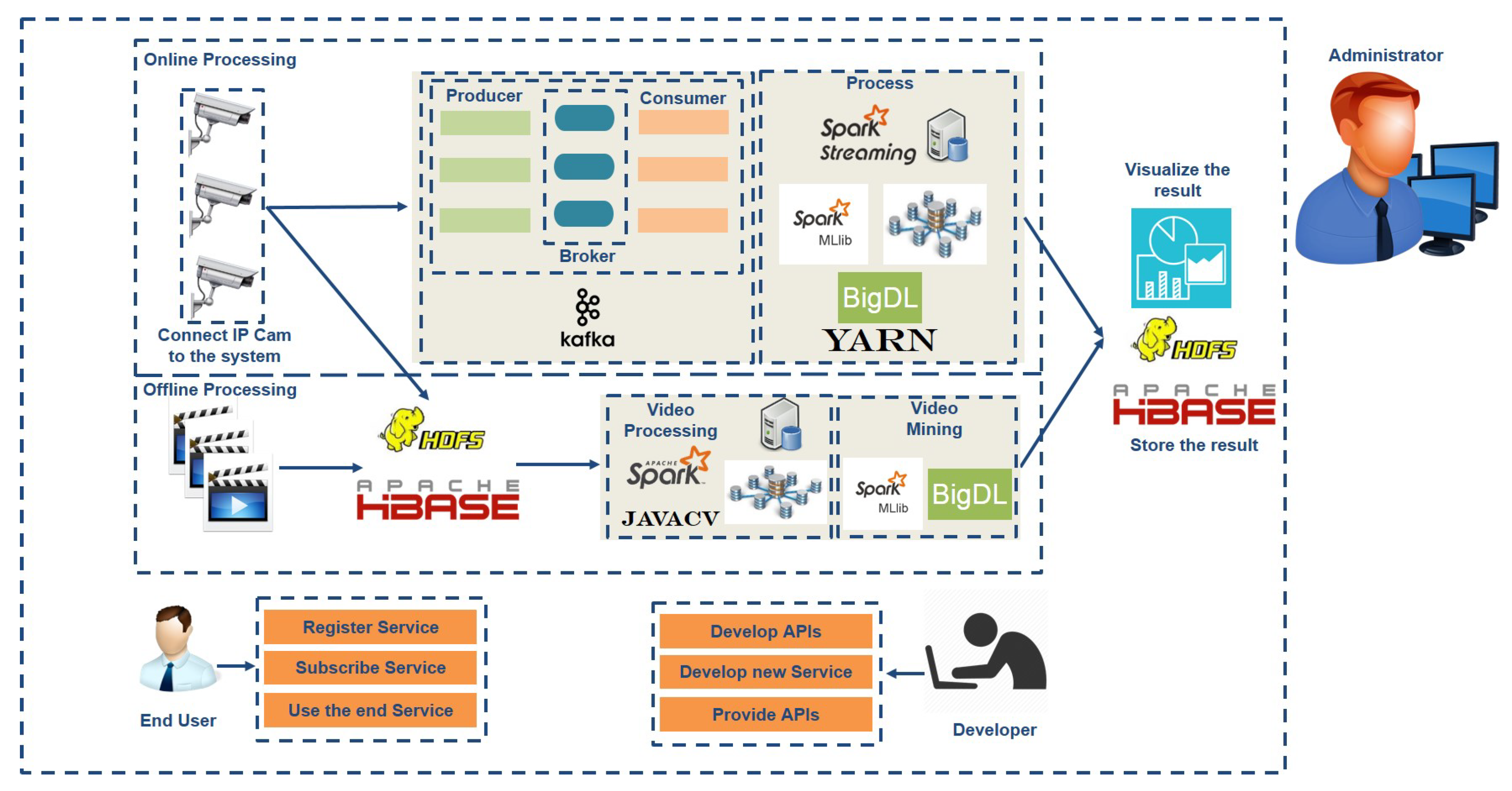
3. SIAT Framework
3.1. Big Data Curation Layer
3.1.1. Real-Time Video Stream Acquisition
3.1.2. Big Data Persistence
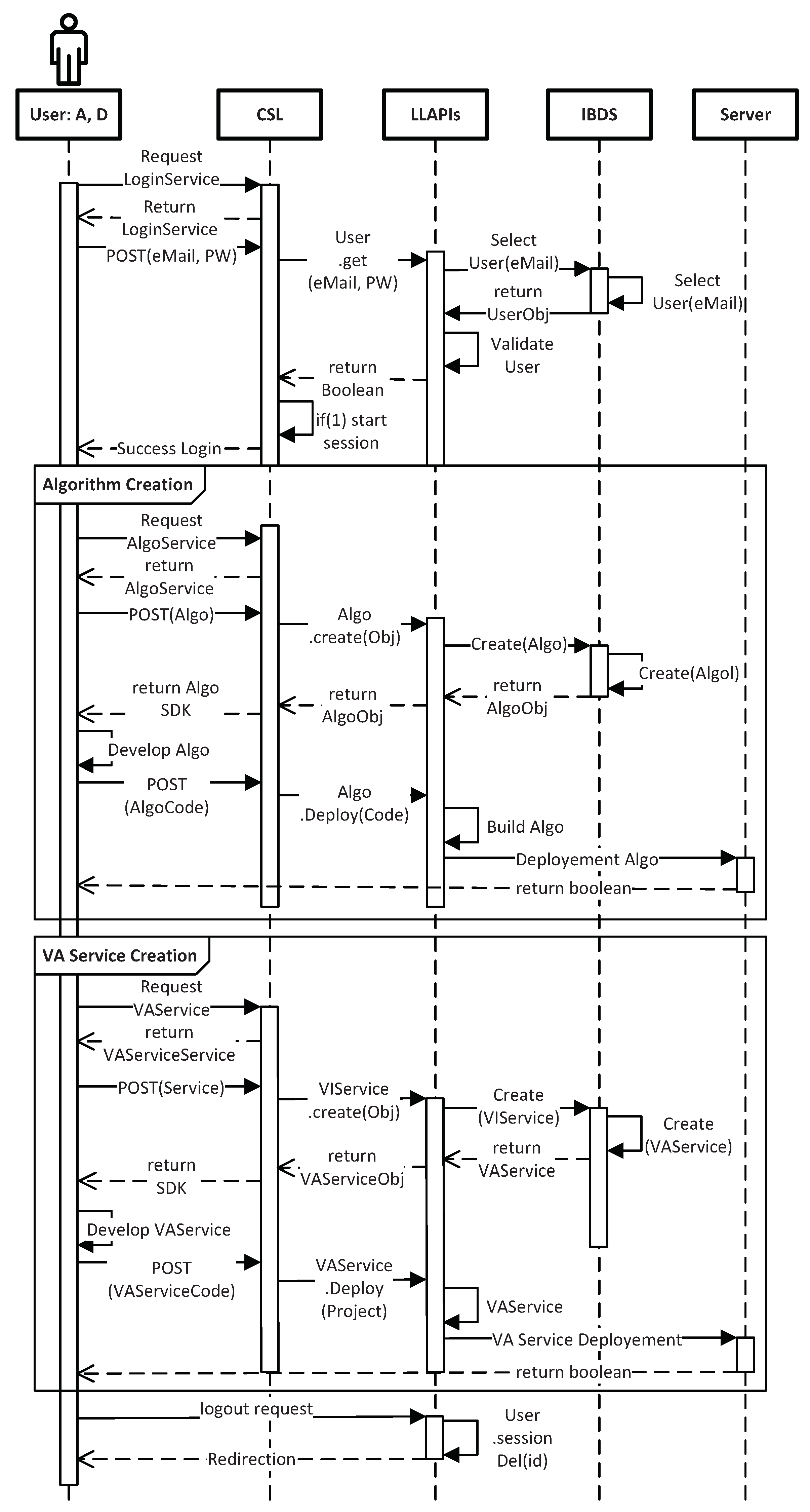
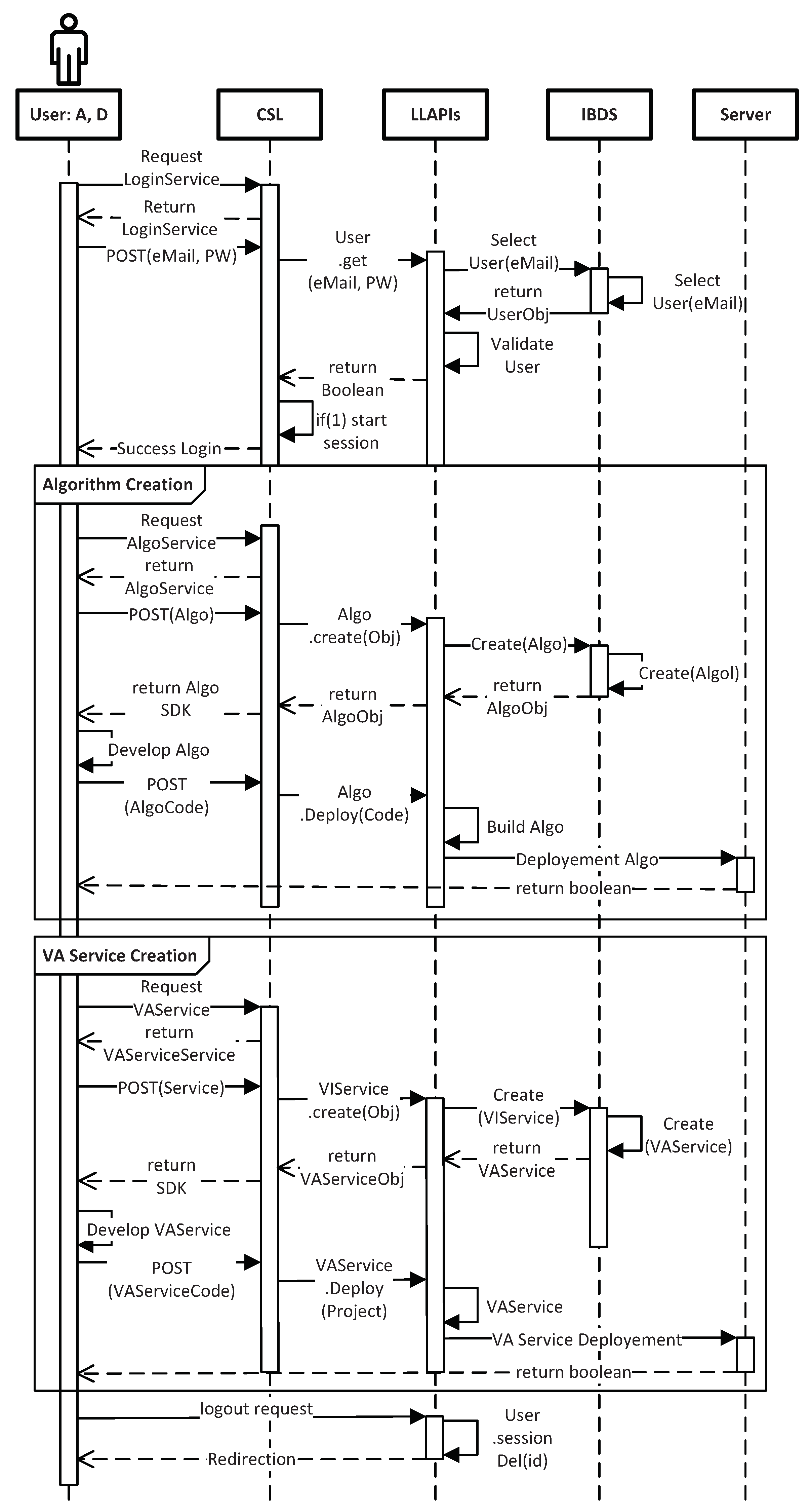
3.2. Service Curation Layer
3.3. Distributed Video Data Processing Layer
3.4. Distributed Video Data Mining Layer
3.4.1. Video Data Mining Based on Spark MLlib
3.4.2. Video Data Mining Based on Deep Learning Techniques
3.5. Knowledge Curation Layer
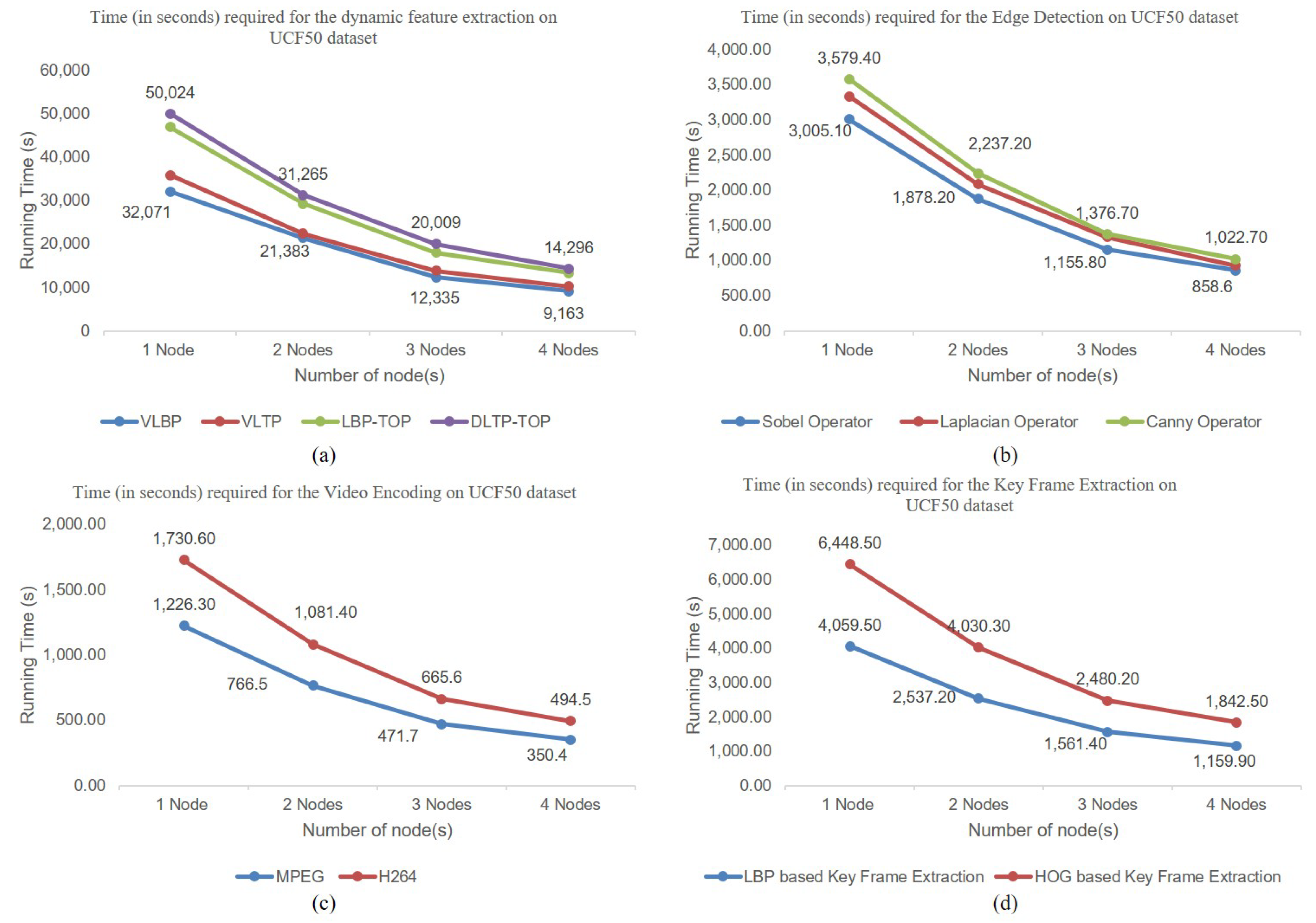
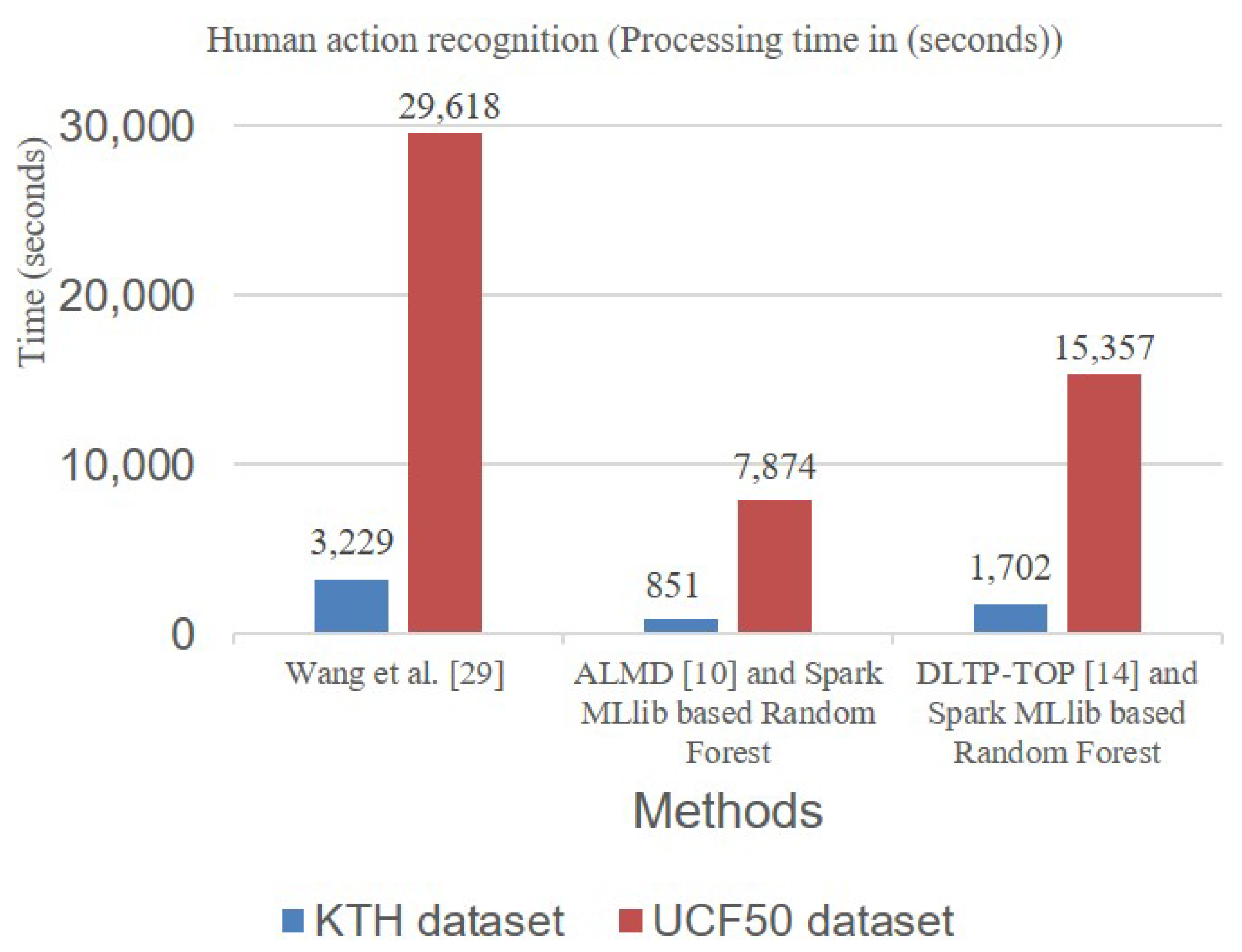
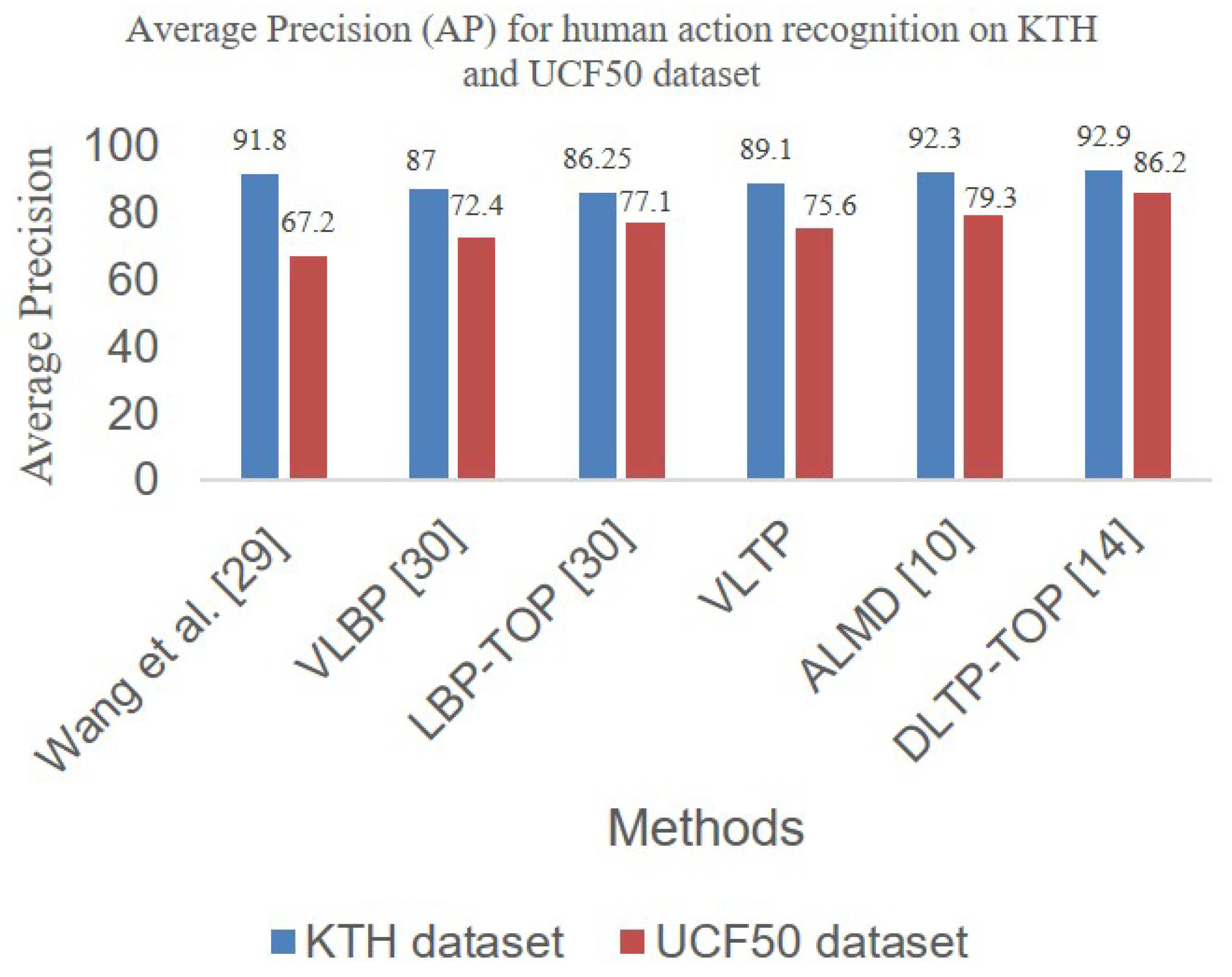
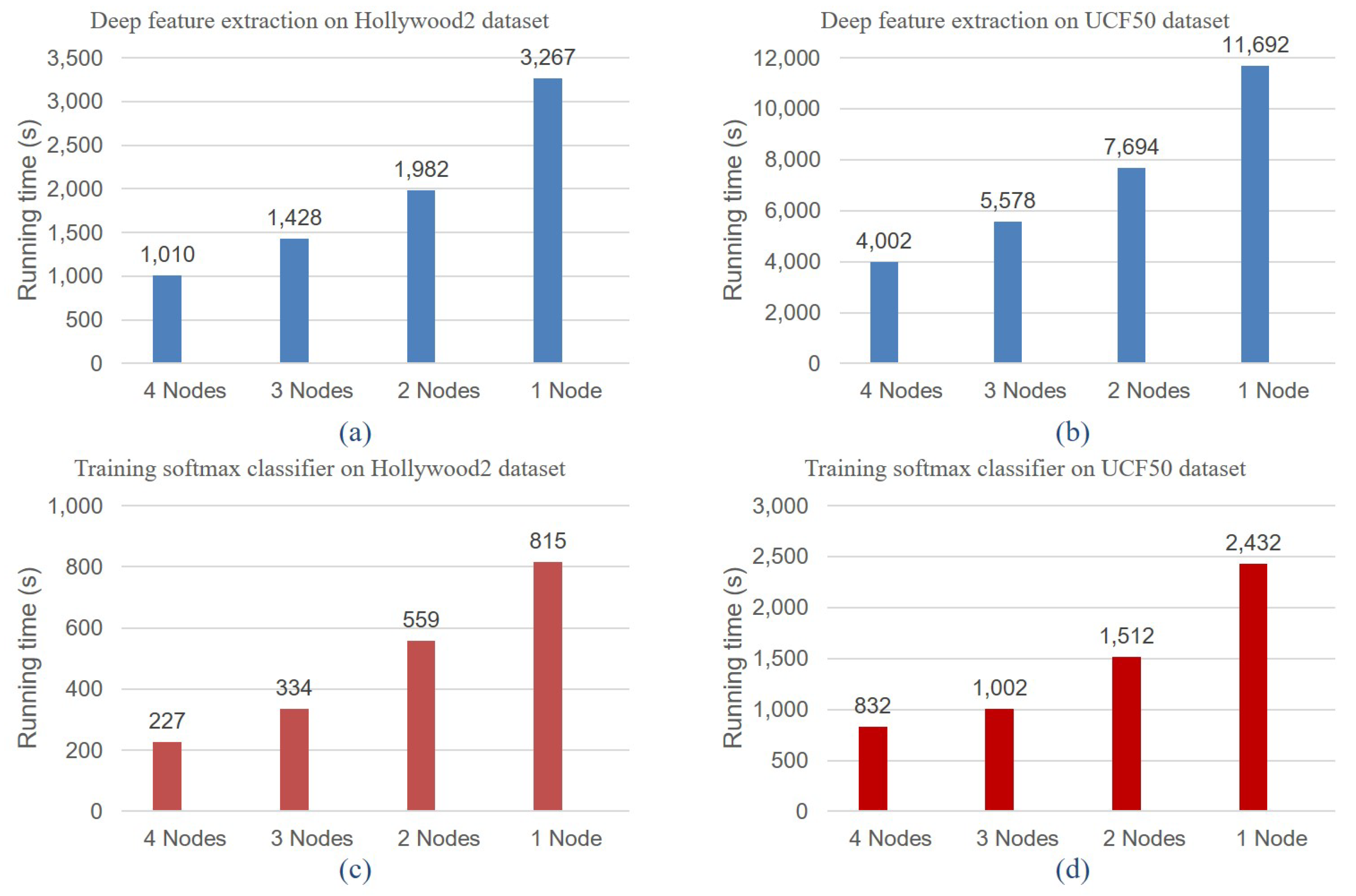
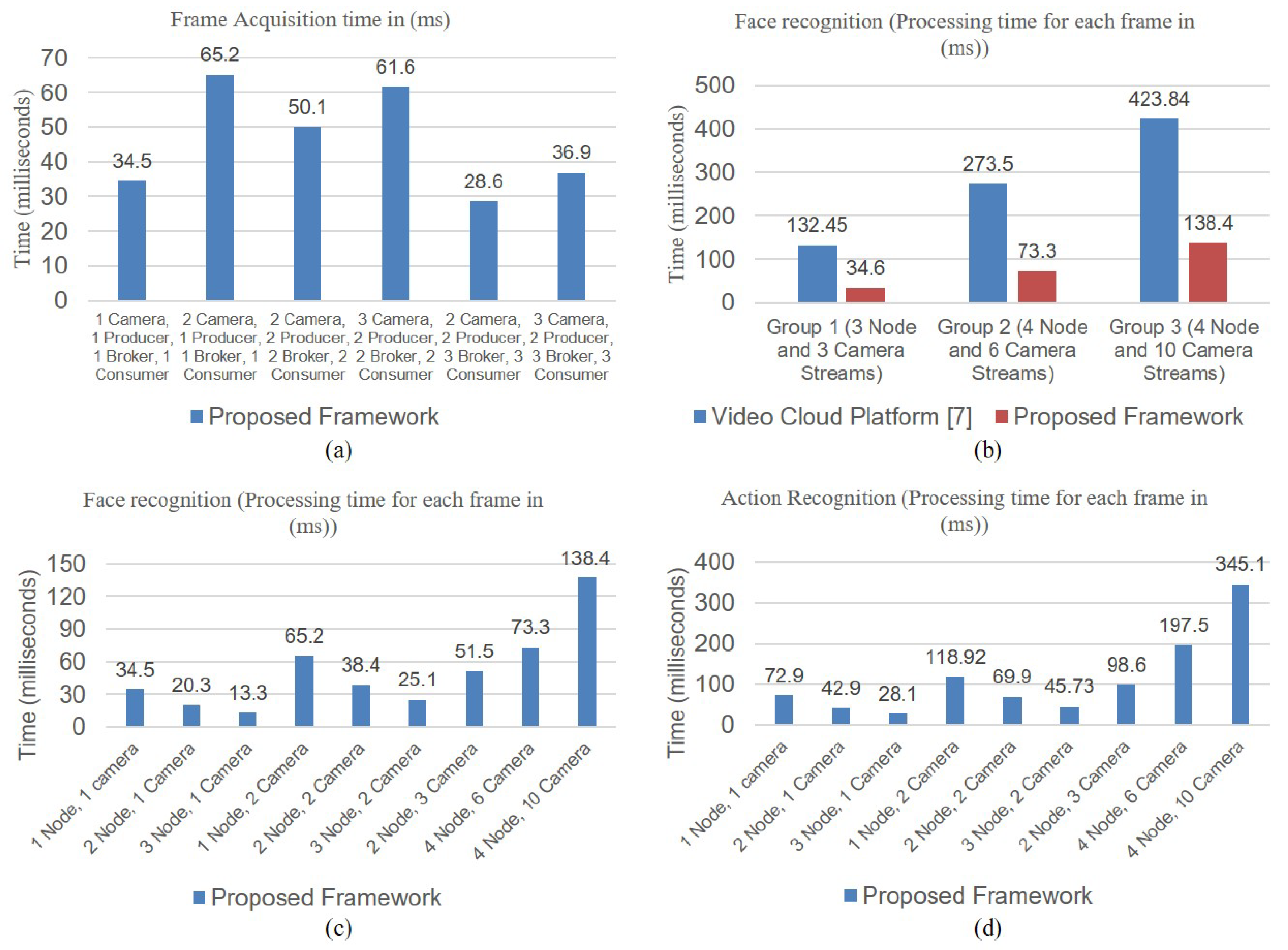
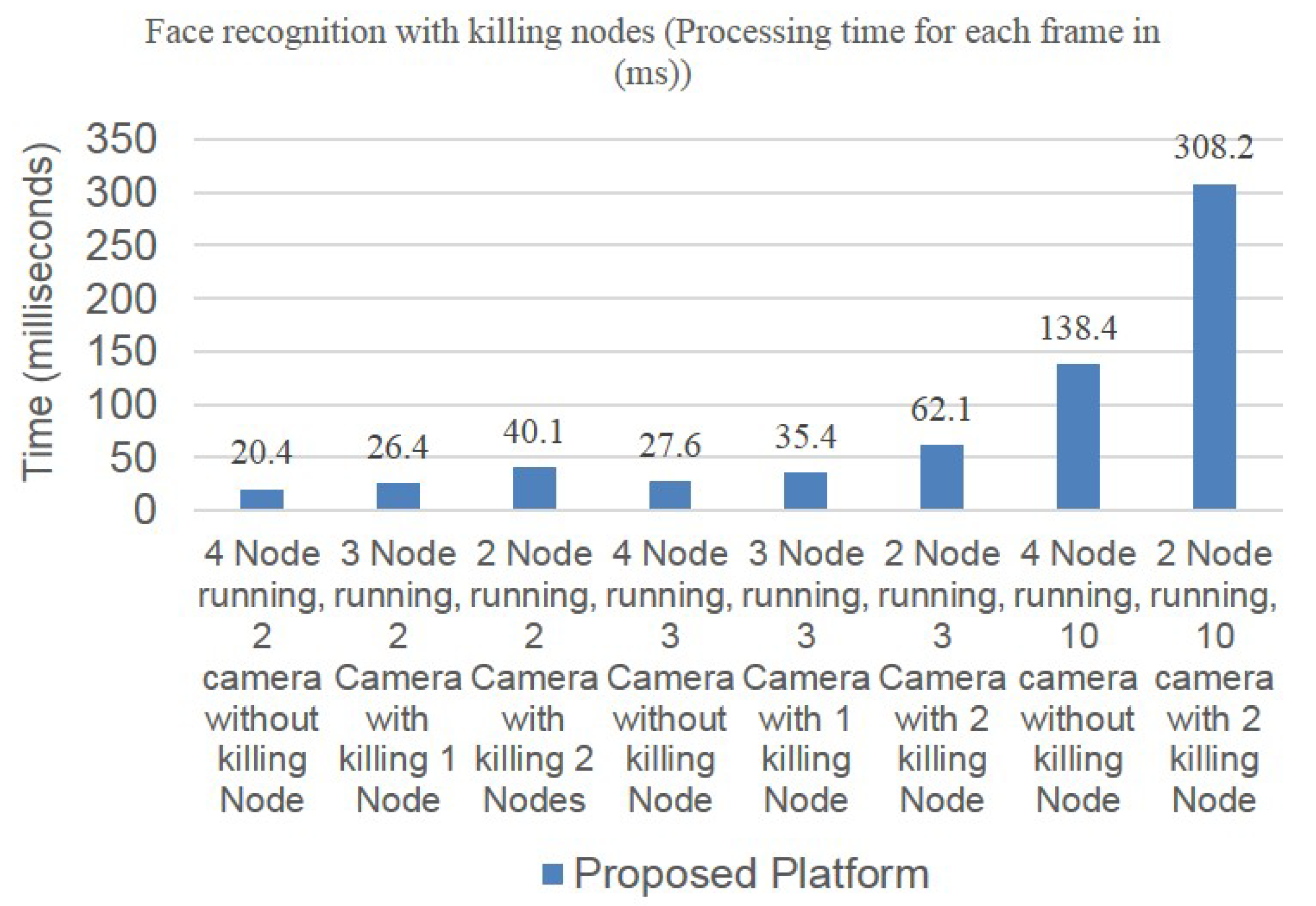
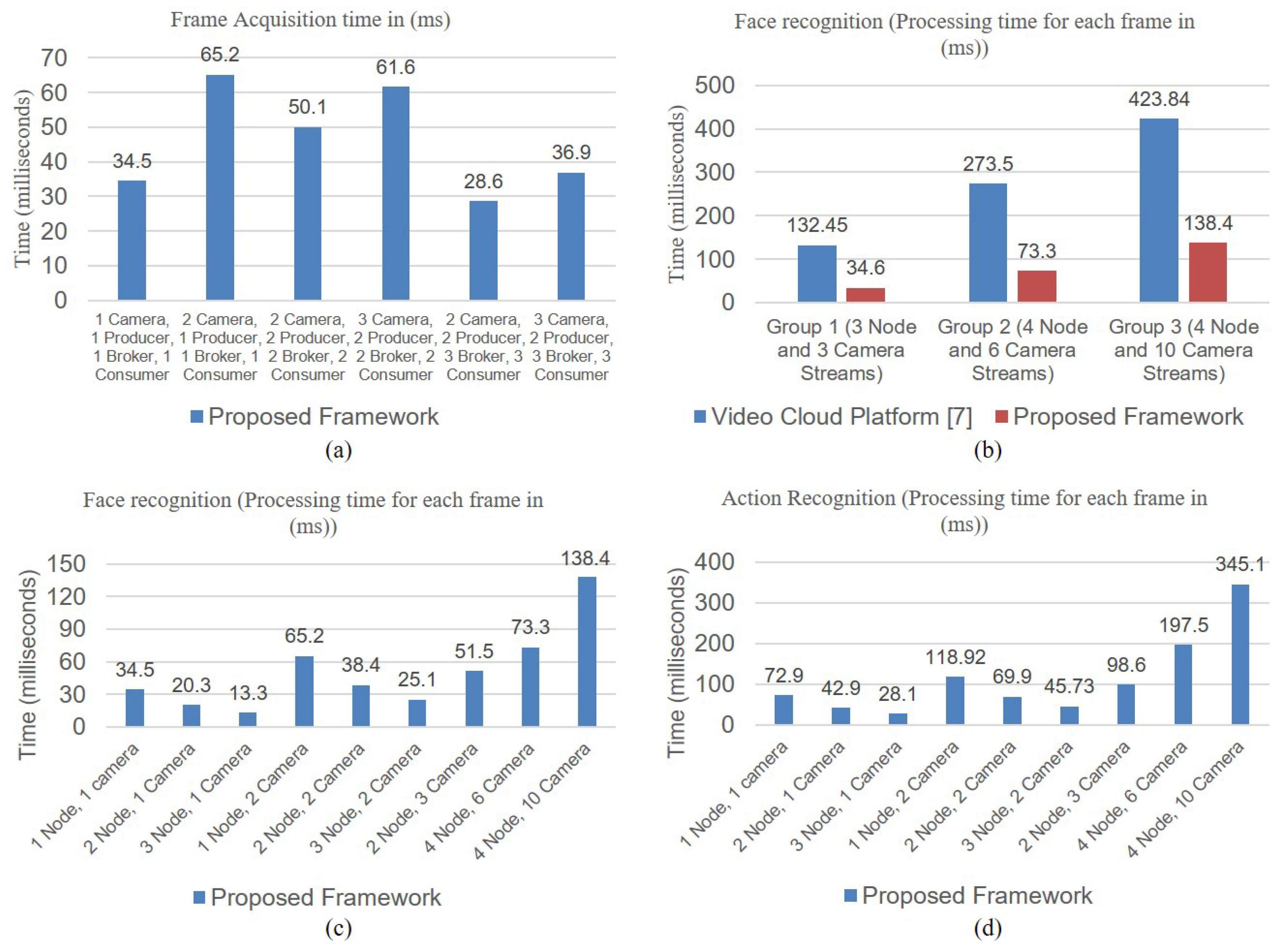
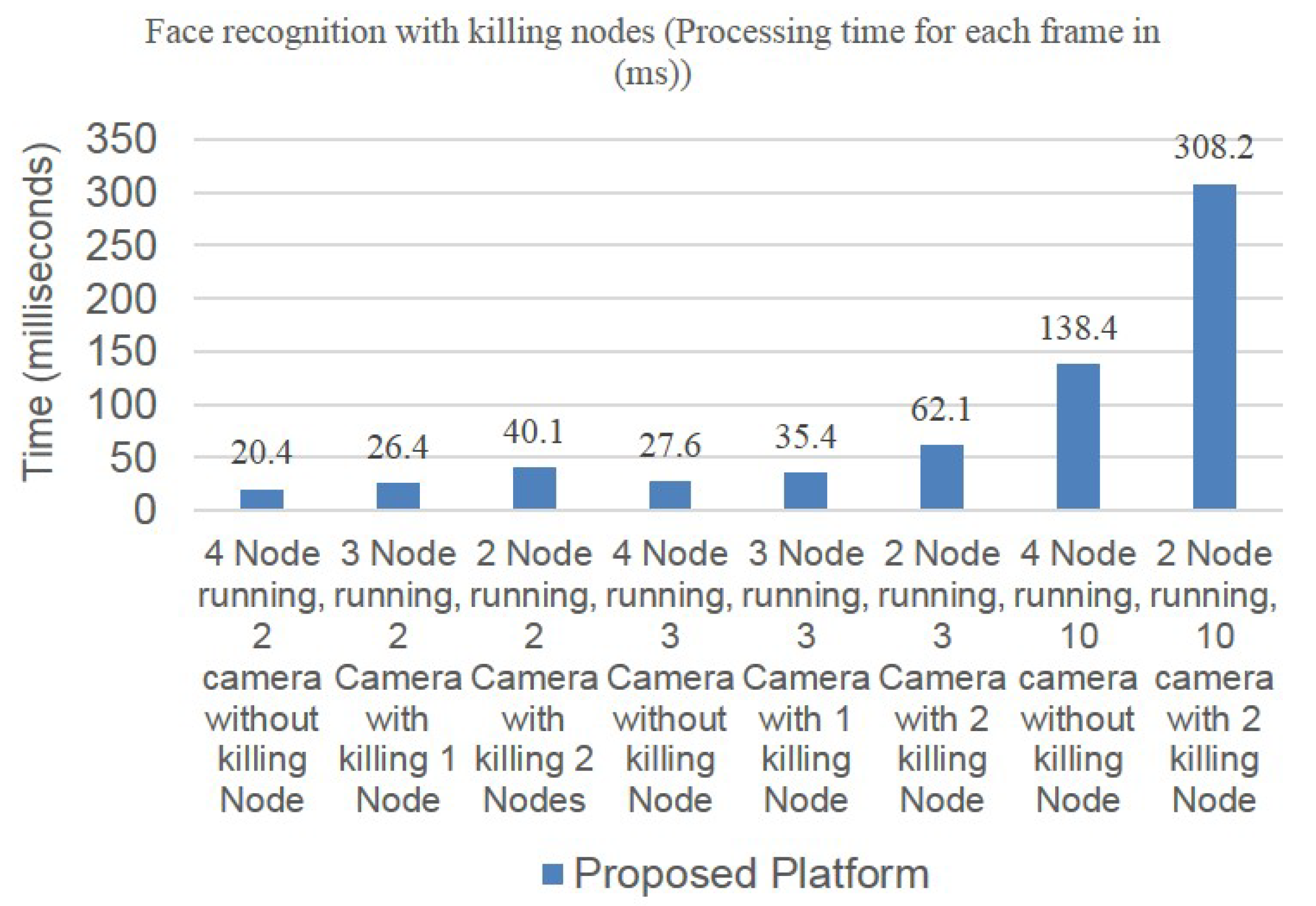
4. Experimental Analysis
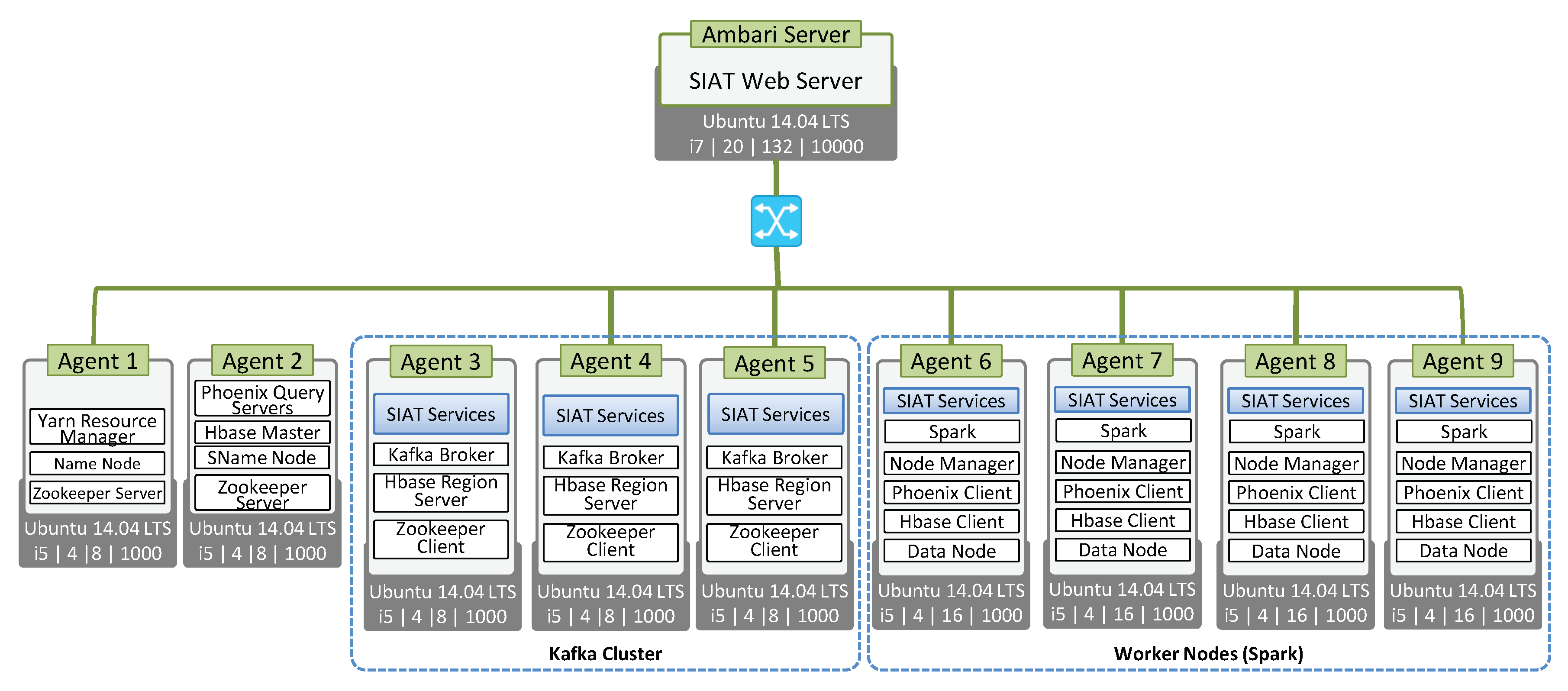
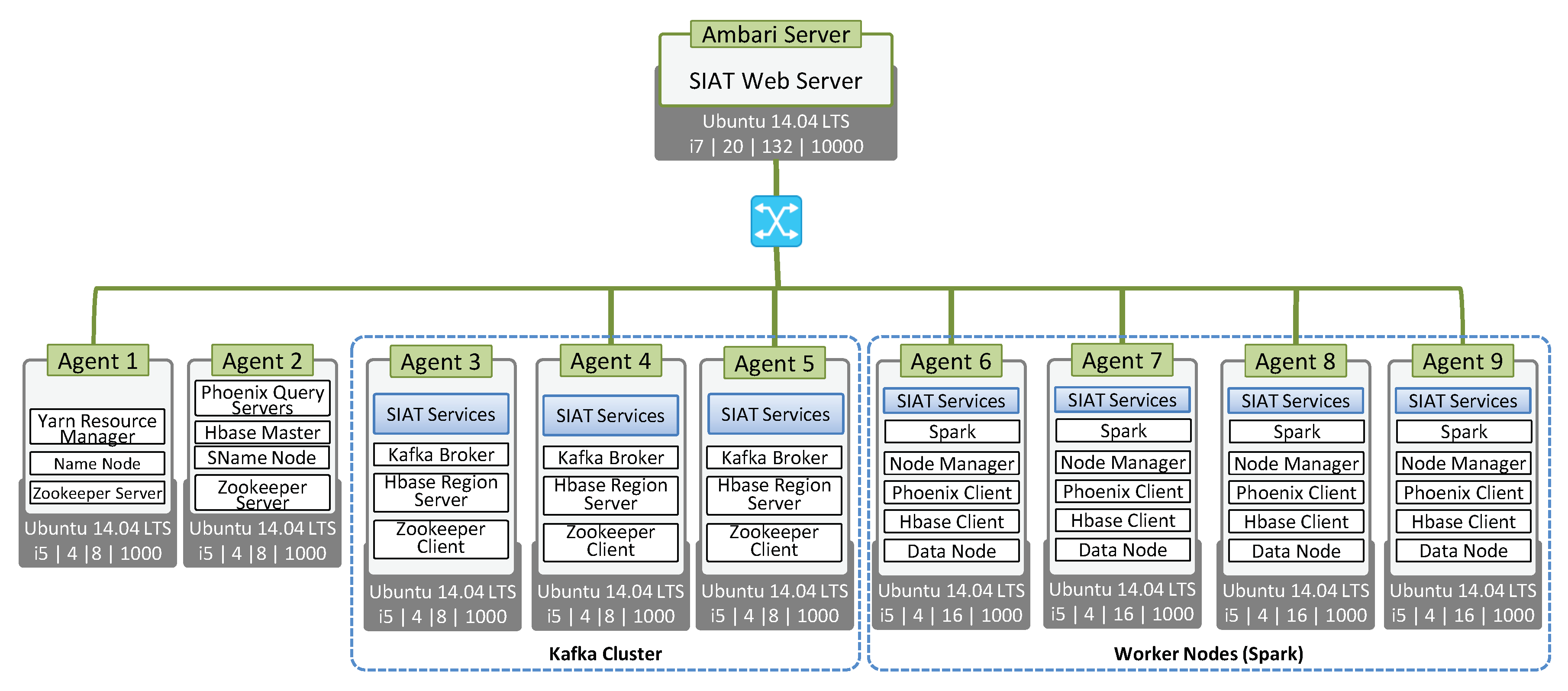
4.1. Experimental Setup
4.2. Application Scenarios
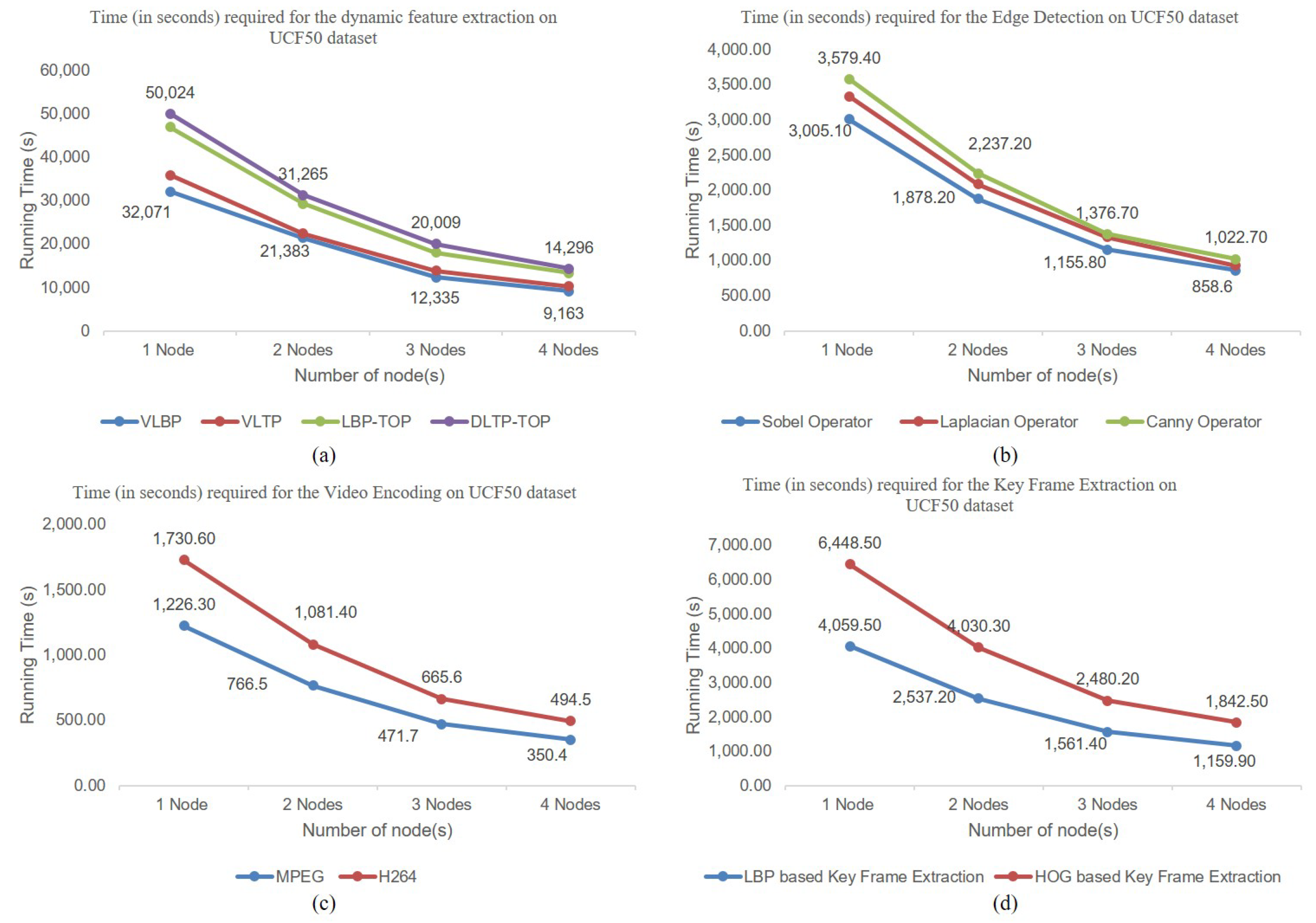
4.2.1. Offline Service Scenario Applications
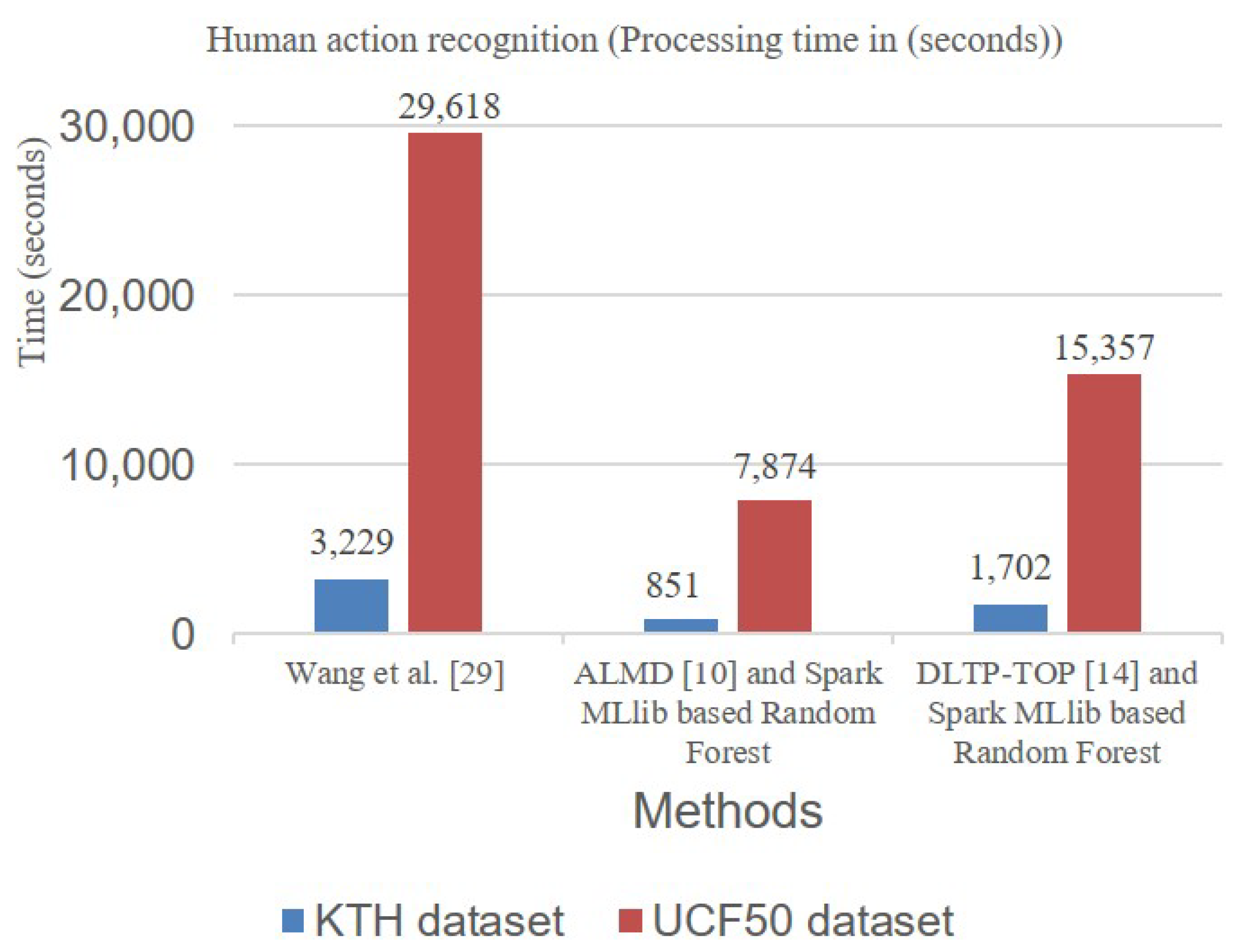
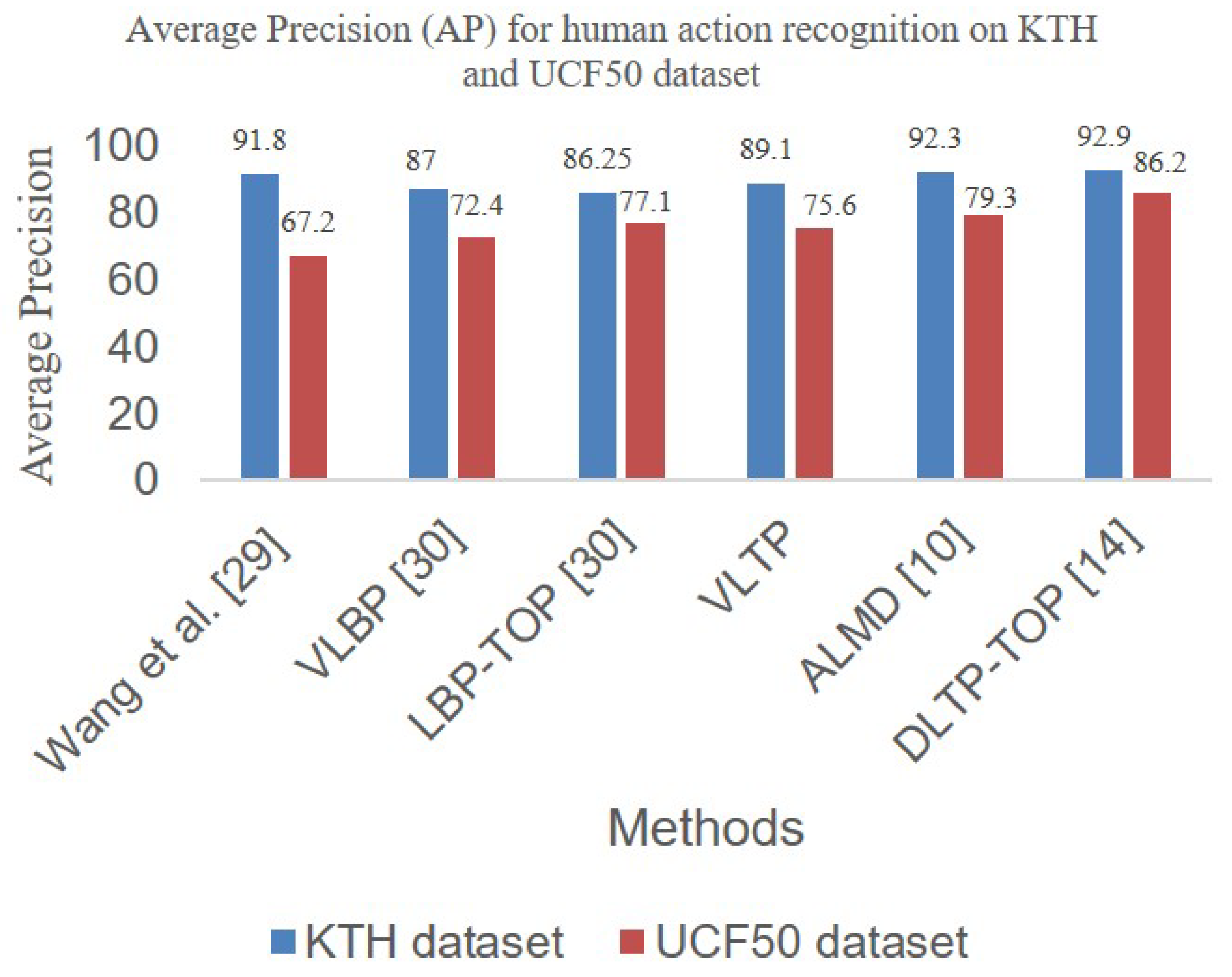
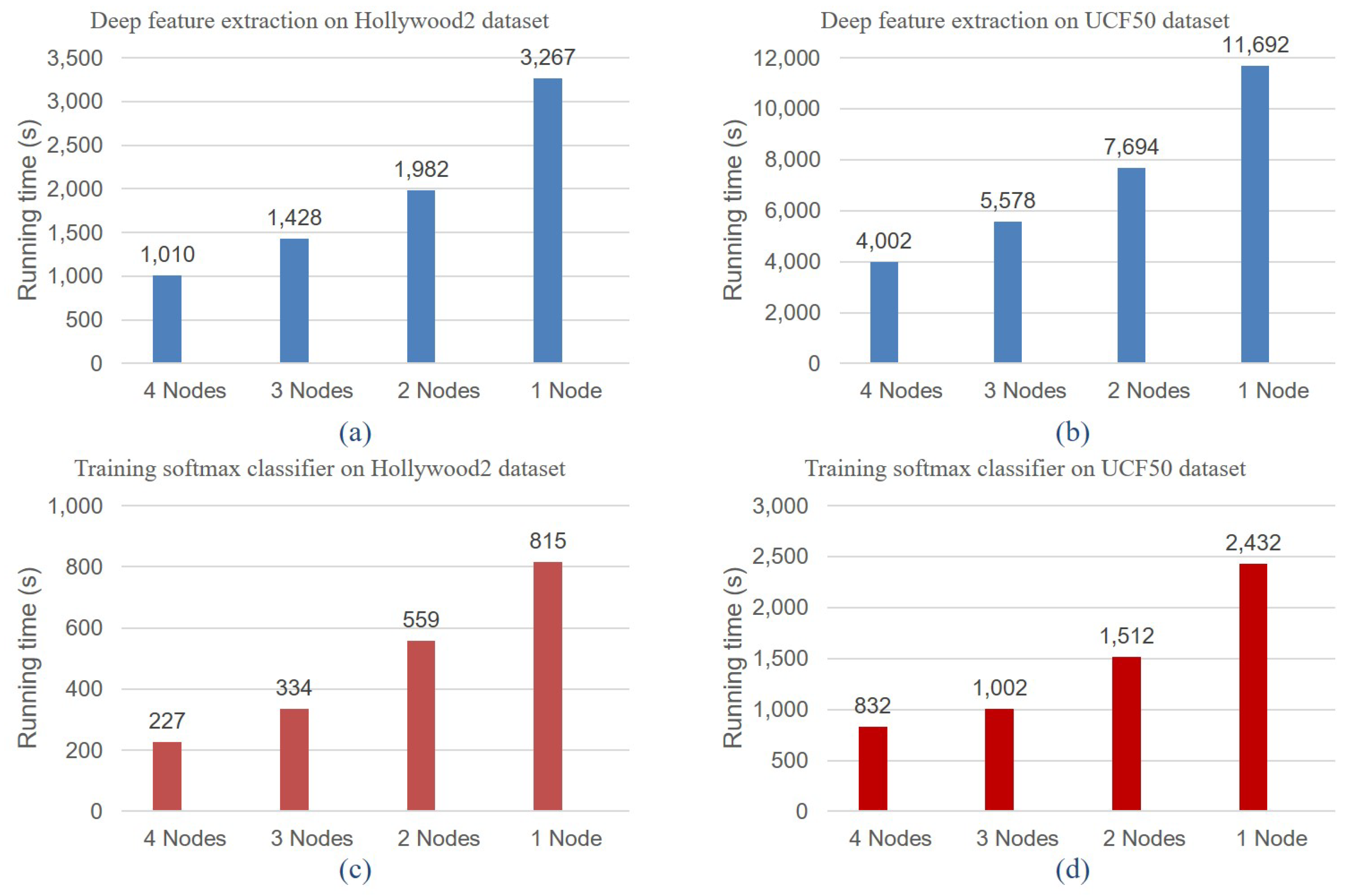
4.2.2. Online Service Scenario Applications
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- 37 Mind Blowing Youtube Facts, Figures and Statistics. Available online: https://merchdope.com/youtube-stats/ (accessed on 5 November 2018).
- Video Streaming Now Makes Up 58% of Internet Usage Worldwide. Available online: http://digg.com/2018/streaming-video-worldwide (accessed on 5 November 2018).
- IntelliVision Now Inside 4 Million Smart Cameras—Leader in AI-Based Video Analytics Software. Available online: https://www.intelli-vision.com/news/intellivision-now-inside-4-million-smart-cameras-leader-in-ai-based-video-analytics-software/ (accessed on 5 November 2018).
- Video Analytics Market - Global Forecast to 2023. Available online: https://www.researchandmarkets.com/reports/4530884/videoanalytics-market-by-type-software-and (accessed on 5 November 2018).
- Hossain, M.A. Framework for a Cloud-Based Multimedia Surveillance System. Int. J. Distrib. Sens. Netw. 2014, 10, 135257. [Google Scholar] [CrossRef]
- Nazare, A.C., Jr.; Schwartz, W.R. A scalable and flexible framework for smart video surveillance. Comput. Vis. Image Underst. 2016, 144, 258–275. [Google Scholar] [CrossRef]
- Zhang, W.; Xu, L.; Duan, P.; Gong, W.; Lu, Q.; Yang, S. A video cloud platform combing online and offline cloud computing technologies. Pers. Ubiquitous Comput. 2015, 19, 1099–1110. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the Networked Systems Design and Implementation (NSDI’12), San Jose, CA, USA, 25–27 April 2012; p. 2-2. [Google Scholar]
- Uddin, M.A.; Joolee, J.B.; Alam, A.; Lee, Y.-K. Human action recognition using adaptive local motion descriptor in spark. IEEE Access 2017, 5, 21157–21167. [Google Scholar] [CrossRef]
- Kreps, J.; Narkhede, N.; Rao, J. Kafka: A distributed messaging system for log processing. In Proceedings of the NetDB, Athens, Greece, 12–16 June 2011; pp. 1–7. [Google Scholar]
- Zaharia, M.; Das, T.; Li, H.; Hunter, T.; Shenker, S.; Stoica, I. Discretized Streams: Fault-Tolerant Streaming Computation at Scale. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, Farminton, PA, USA, 3–6 November 2013; pp. 423–438. [Google Scholar]
- Hamilton, M.; Raghunathan, S.; Annavajhala, A.; Kirsanov, D.; Leon, E.d.; Barzilay, E.; Matiach, I.; Davison, J.; Busch, M.; Oprescu, M.; et al. Flexible and scalable deep learning with MMLSpark. In Proceedings of the 4th International Conference on Predictive Applications and APIs, Boston, MA, USA, 24–25 October 2017; pp. 11–22. [Google Scholar]
- Huang, Q.; Ang, P.; Knowles, P.; Nykiel, T.; Tverdokhlib, I.; Yajurvedi, A.; Dapolito, P., IV; Yan, X.; Bykov, M.; Liang, C.; et al. SVE: Distributed Video Processing at Facebook Scale. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 87–103. [Google Scholar]
- Ichinose, A.; Takefusa, A.; Nakada, H.; Oguchi, M. A study of a video analysis framework using Kafka and spark streaming. In Proceedings of the IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017. [Google Scholar]
- Uddin, M.A.; Akhond, M.R.; Lee, Y.-K. Dynamic scene recognition using spatiotemporal based DLTP on spark. IEEE Access 2018, 6, 66123–66133. [Google Scholar] [CrossRef]
- Hu, C.; Xue, G.; Mei, L.; Qi, L.; Shao, J.; Shang, Y.; Wang, J. Building an intelligent video and image analysis evaluation platform for public security. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Chao, W.; Jun, X.M. Multi-agent based distributed video surveillance system over IP. In Proceedings of the International Symposium on Computer Science and Computational Technology, Shanghai, China, 20–22 December 2008; Volume 2, pp. 97–100. [Google Scholar]
- Ostheimer, D.; Lemay, S.; Ghazal, M.; Mayisela, D.; Amer, A.; Dagba, P.F. A modular distributed video surveillance system over IP. In Proceedings of the Canadian Conference on Electrical and Computer Engineering, Ottawa, ON, Canada, 7–10 May 2006; pp. 518–521. [Google Scholar]
- Zhang, H.; Yan, J.; Kou, Y. Efficient online surveillance video processing based on spark framework. In Proceedings of the International Conference on Big Data Computing and Communications, Shenyang, China, 29–31 July 2016; pp. 309–318. [Google Scholar]
- Dai, J.; Wang, Y.; Qiu, X.; Ding, D.; Zhang, Y.; Wang, Y.; Jia, X.; Zhang, C.; Wan, Y.; Li, Z.; et al. BigDL: A Distributed Deep Learning Framework for Big Data. Available online: https://bigdl-project.github.io/master/whitepaper/ (accessed on 5 November 2018).
- Lv, J.; Wu, B.; Yang, S.; Jia, B.; Qiu, P. Efficient large scale near-duplicate video detection base on spark. In Proceedings of the IEEE International Conference on Big Data, Washington, DC, USA, 5–8 December 2016. [Google Scholar]
- Lv, J.; Wu, B.; Liu, C.; Gut, X. PF-Face: A Parallel Framework for Face Classification and Search from Massive Videos Based on Spark. In Proceedings of the IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018. [Google Scholar]
- Huang, L.; Xu, W.; Liu, S.; Pandey, V.; Juri, N.R. Enabling Versatile Analysis of Large Scale Traffic Video Data with Deep Learning and HiveQL. In Proceedings of the IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017. [Google Scholar]
- Yaseen, M.U.; Anjum, A.; Rana, O.; Hill, R. Cloud-based scalable object detection and classification in video streams. Future Gener. Comput. Syst. 2018, 80, 286–298. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, B.; Iqbal, W.; Khan, N.; Mahmood, A.; Erradi, A. Canny edge detection and Hough transform for high resolution video streams using Hadoop and Spark. Clust. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Maini, R.; Aggarwal, H. Study and comparison of various image edge detection techniques. Int. J. Image Process. 2009, 3, 1–11. [Google Scholar]
- Eagle Eye Networks. Available online: https://www.eagleeyenetworks.com/ (accessed on 5 November 2018).
- Intelli-Vision. Available online: https://www.intellivision.com/ (accessed on 5 November 2018).
- Google Vision API. Available online: https://cloud.google.com/video-intelligence/ (accessed on 5 November 2018).
- IBM Intelligent Video Analytics. Available online: https://www.ibm.com/cloud/ (accessed on 5 November 2018).
- Ejsmont, A. Web Scalability for Startup Engineers, 1st ed.; McGraw-Hill Education Group: Boston, MA, USA, 2015. [Google Scholar]
- Snappy. Available online: https://google.github.io/snappy/ (accessed on 5 November 2018).
- George, L. HBase: The Definitive Guide: Random Access to Your Planet-Size Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2011. [Google Scholar]
- Apache Phoenix. Available online: https://phoenix.apache.org/ (accessed on 5 November 2018).
- Wang, H.; Zheng, X.; Xiao, B. Large-scale human action recognition with spark. In Proceedings of the IEEE 17th International Workshop on Multimedia Signal Processing (MMSP), Xiamen, China, 19–21 October 2015. [Google Scholar]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed]
- Chiang, T.; Lee, H.-J.; Pejhan, S.; Sodagar, I.; Zhang, Y.-Q. Demonstration of the mpeg-2, mpeg-4 and h.263 video coding standards. In Proceedings of the First Signal Processing Society Workshop on Multimedia Signal Processing, Princeton, NJ, USA, 23–25 June 1997. [Google Scholar]
- Ejaz, N.; Tariq, T.B.; Baik, S.W. Adaptive key frame extraction for video summarization using an aggregation mechanism. J. Vis. Commun. Image Represent. 2012, 23, 1031–1040. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.B.; Amde, M.; Owen, S.; et al. MLlib: Machine learning in apache spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- Yang, N.C.; Chang, W.H.; Kuo, C.M.; Li, T.H. A fast mpeg-7 dominant color extraction with new similarity measure for image retrieval. J. Vis. Commun. Image Represent. 2008, 19, 92–105. [Google Scholar] [CrossRef]
- Sah, M.; Direkoglu, C. Semantic annotation of surveillance videos for abnormal crowd behaviour search and analysis. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Mediaont. Available online: https://www.w3.org/TR/mediaont-10/ (accessed on 5 November 2018).
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local svm approach. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Reddy, K.K.; Shah, M. Recognizing 50 human action categories of web videos. Mach. Vis. Appl. J. (MVAP) 2012, 24, 971–981. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | APIs | Description |
|---|---|---|
| Background Subtraction | siat. dvdpl. BackgroundSubtractor. MOG (Video Data) | Subtract the background from the foreground of a video. |
| Edge Detection | siat. dvdpl. Edgedetector. SobelOperator (Video Data) | Detect the edge on each frame of the video using the Sobel operator. |
| siat. dvdpl. Edgedetector. LaplacianOperator (Video Data) | Detect the edge on each frame of the video using the Laplacian operator. | |
| siat. dvdpl. Edgedetector. Canny(Video Data) | Detect the edge on each frame of the video using the Canny algorithm. | |
| Video Encoding | siat. dvdpl. VideoEncoder. MPEG ( Video Data) | Encode the video data for video data compression using MPEG algorithm. |
| siat. dvdpl. VideoEncoder. H264 ( Video Data) | Encode the video data for video data compression using H264 algorithm. | |
| Key Frame Extractor | siat. dvdpl. KeyFrameExtractor. LBP (Video Data) | Extract the key frames from each video using frame based feature extractor Local Binary Pattern (LBP). |
| siat. dvdpl. KeyFrameExtractor. HOG ( Video Data) | Extract the key frames from each video using frame based feature extractor Histogram of Oriented Gradient (HOG). | |
| Dynamic Feature Extractor | siat. dvdpl. DynamicFeatureExtractor. VLBP (Video Data) | Extract the dynamic texture feature from each video using Volume Local Binary Pattern (VLBP). |
| siat. dvdpl. DynamicFeatureExtractor. VLTP (Video Data) | Extract the dynamic texture feature from each video using Volume Local Ternary Pattern (VLTP). | |
| siat. dvdpl. DynamicFeatureExtractor. ALMD (Video Data) | Extract the dynamic motion feature from each video using Adaptive Local Motion Descriptor (ALMD). | |
| siat. dvdpl. DynamicFeatureExtractor. LBPTOP (Video Data) | Extract the dynamic texture feature from each video using Local Binary Pattern from Three orthogonal planes (LBP-TOP). | |
| siat. dvdpl. DynamicFeatureExtractor. DLTPTOP (Video Data) | Extract the dynamic texture feature from each video using Directional Local Ternary Pattern from Three orthogonal planes (DLTP-TOP). | |
| Deep Feature Extractor | siat. dvdpl. DeepFeatureExtractor. CNN ( Video Data ) | Extract the deep spatial feature from each video using Convolutional Neural Network (CNN). |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, M.A.; Alam, A.; Tu, N.A.; Islam, M.S.; Lee, Y.-K. SIAT: A Distributed Video Analytics Framework for Intelligent Video Surveillance. Symmetry 2019, 11, 911. https://doi.org/10.3390/sym11070911
Uddin MA, Alam A, Tu NA, Islam MS, Lee Y-K. SIAT: A Distributed Video Analytics Framework for Intelligent Video Surveillance. Symmetry. 2019; 11(7):911. https://doi.org/10.3390/sym11070911
Chicago/Turabian StyleUddin, Md Azher, Aftab Alam, Nguyen Anh Tu, Md Siyamul Islam, and Young-Koo Lee. 2019. "SIAT: A Distributed Video Analytics Framework for Intelligent Video Surveillance" Symmetry 11, no. 7: 911. https://doi.org/10.3390/sym11070911
APA StyleUddin, M. A., Alam, A., Tu, N. A., Islam, M. S., & Lee, Y.-K. (2019). SIAT: A Distributed Video Analytics Framework for Intelligent Video Surveillance. Symmetry, 11(7), 911. https://doi.org/10.3390/sym11070911