Large-Scale Traffic Congestion Prediction Based on the Symmetric Extreme Learning Machine Cluster Fast Learning Method


Abstract
1. Introduction
2. Methodology
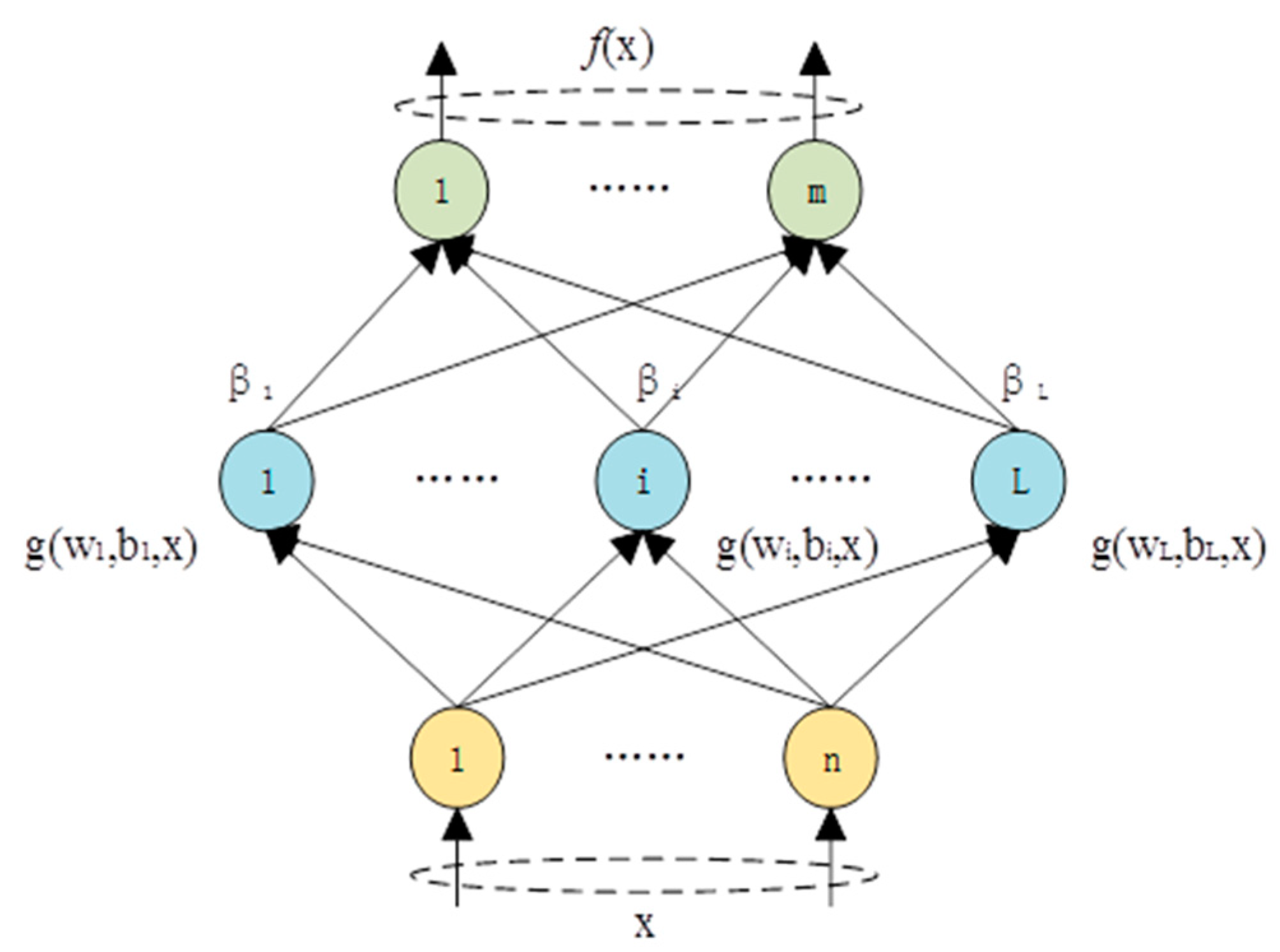
2.1. Extreme Learning Machine
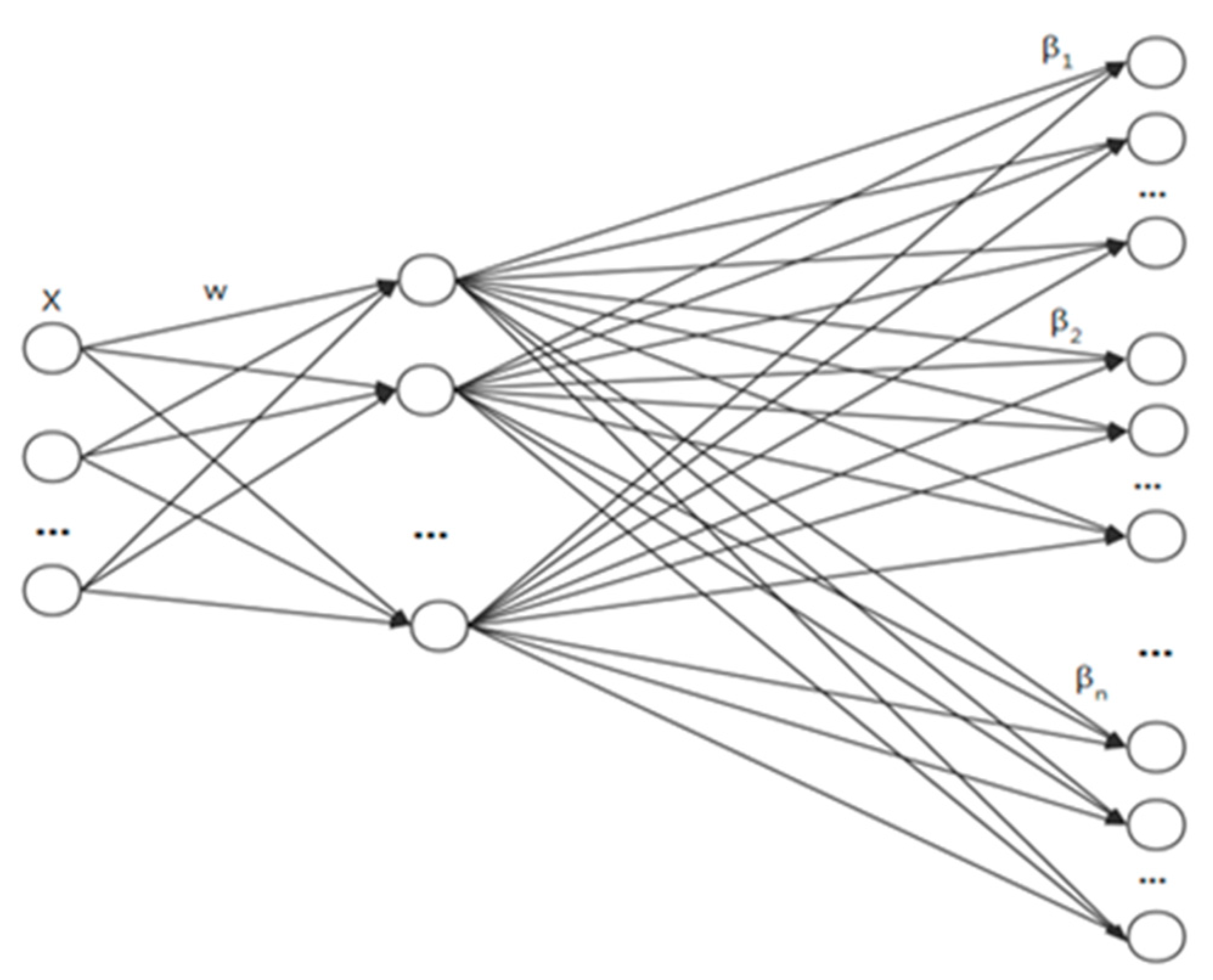
2.2. Symmetric Extreme Learning Machine Algorithm
2.3. Proposed Symmetric Extreme Learning Machine Cluster Algorithm
| Algorithm 1. S-ELM-Cluster fast learning |
| Train Input: Training sample X, sample marker T, number of hidden layer neurons L, regularization coefficient C, excitation function . Output: All enumerated types , hidden layer output weights group , shared hidden layer network .
|
3. Short-Term Congestion Prediction Based on the Symmetric Extreme Learning Machine Cluster Algorithm
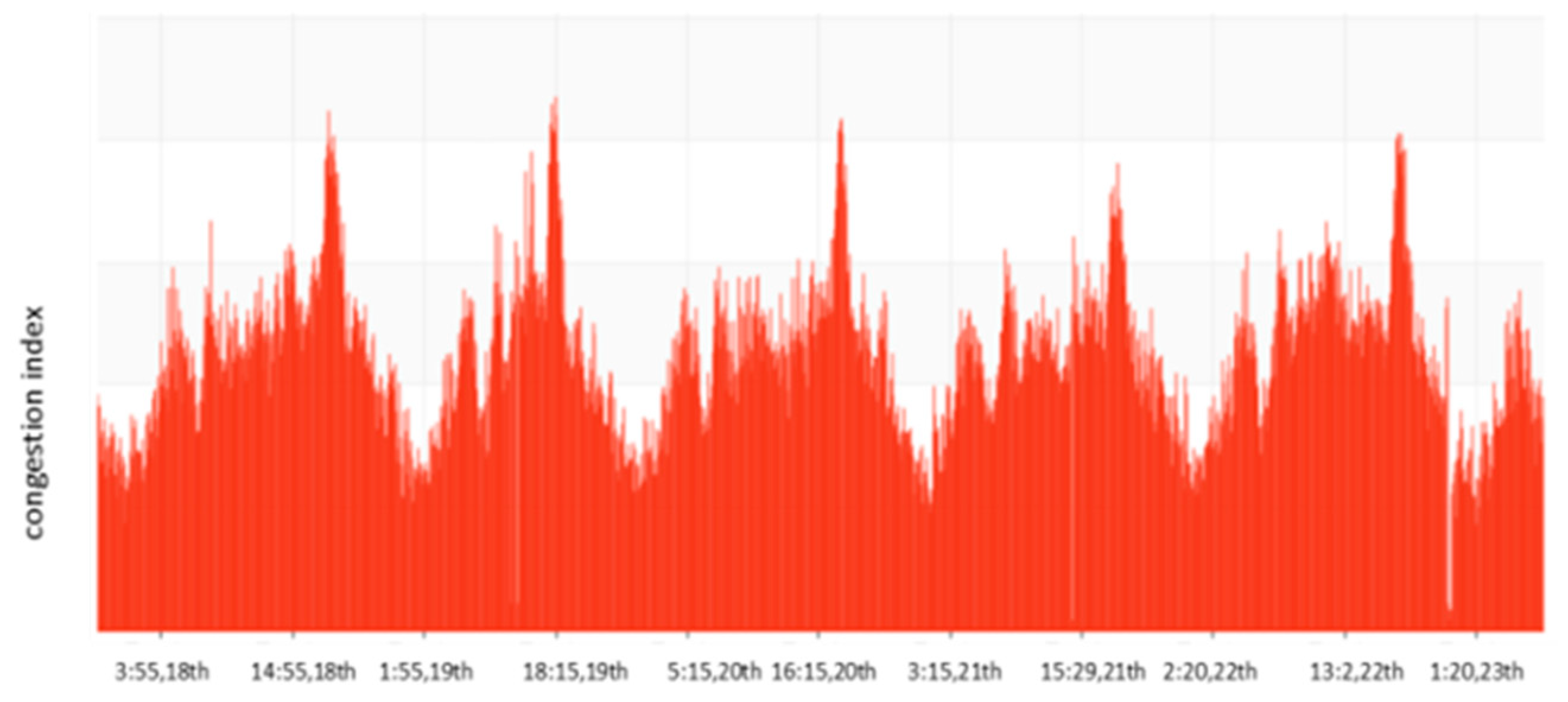
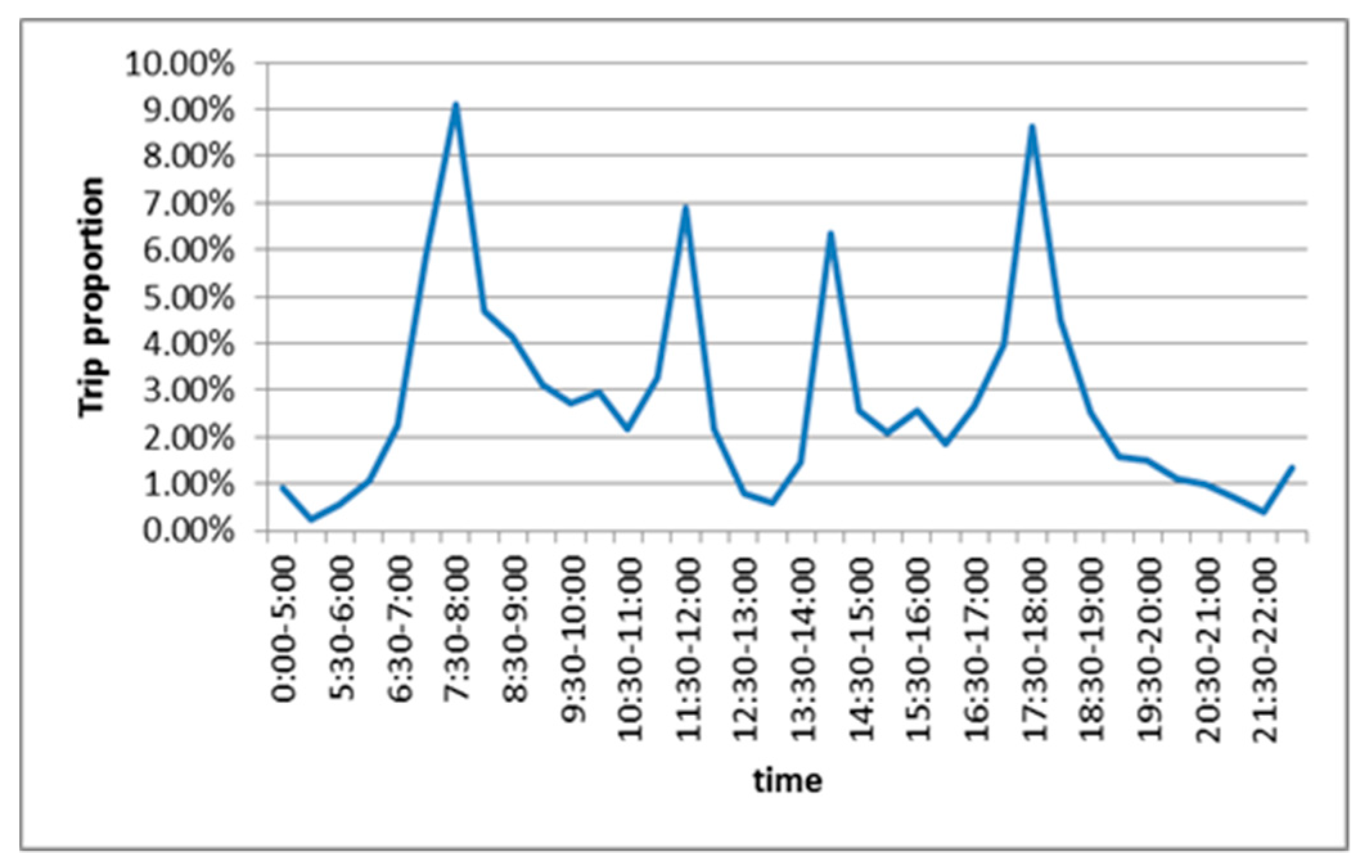
3.1. Time Series Analysis of Traffic Flow
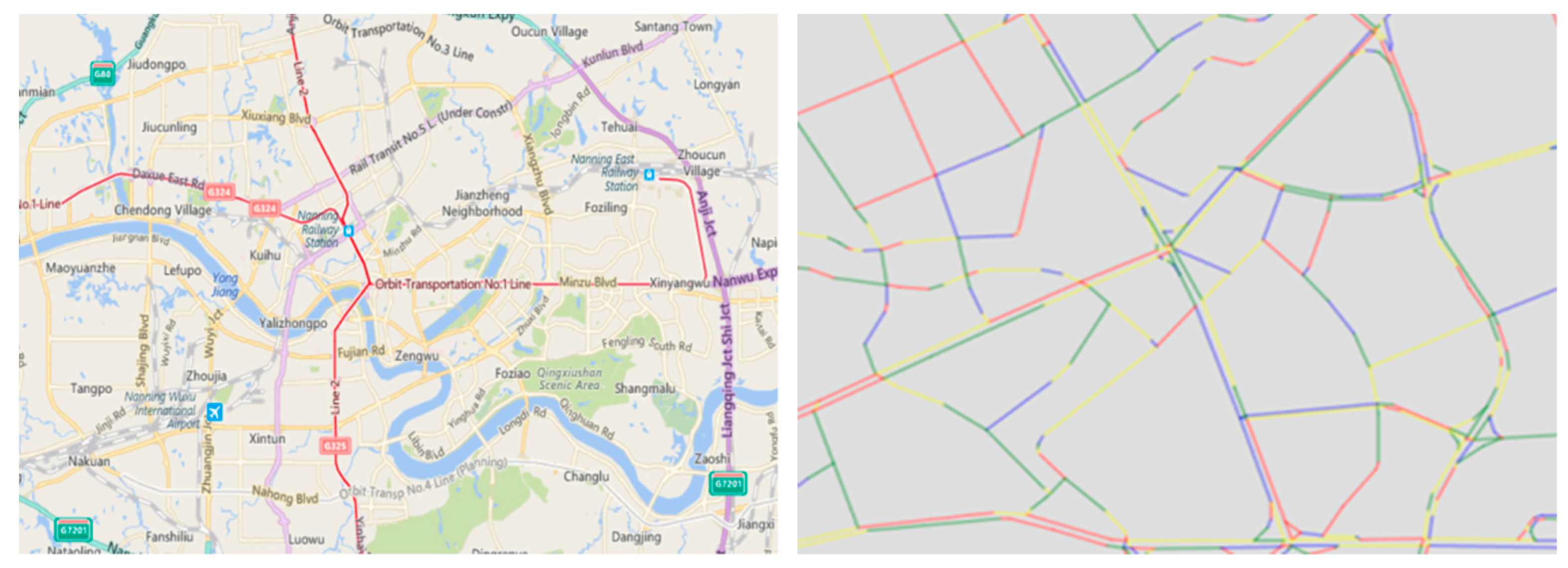
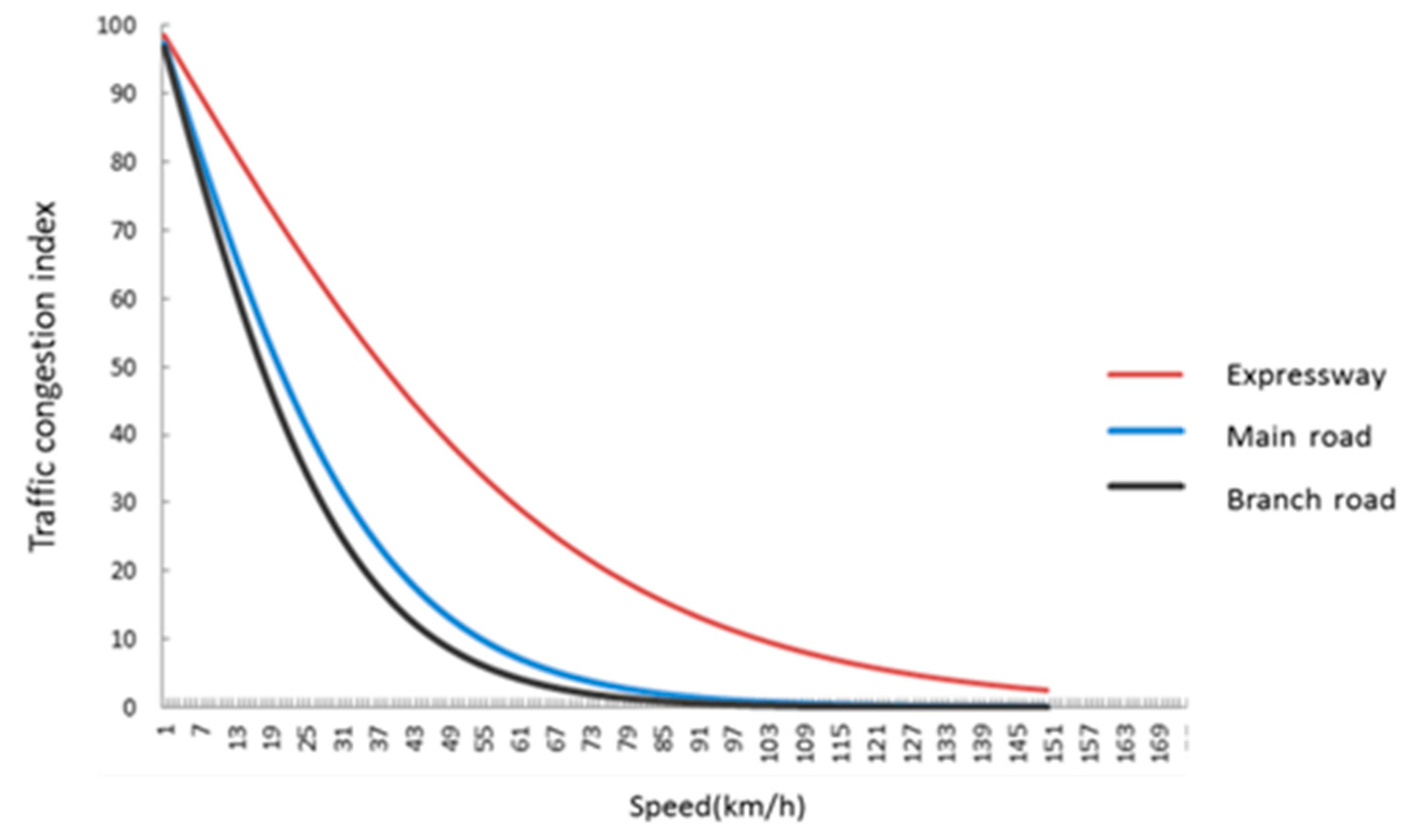
3.2. Traffic Congestion Index
3.3. Feature Extraction and Modelling
3.3.1. Section Clustering
3.3.2. Feature Extraction
- Road factors: These include the road level, lane number, road traffic light distribution, road intersection distribution, and road related inherent features.
- Environmental factors: These include the urban functional areas on which roads are located, and whether there are schools, large public places or other factors that affect the traffic flow.
- Sudden factors: These include uncertain factors such as weather changes, traffic accidents, traffic control, and other key activities.
- Road clusters, discrete features, 1, 2, 3, 4, …, 50, a total of 50 kinds of values.
- The current time, discrete characteristics, 06:05, 06:15, 21:55, a total of 191 values.
- The congestion values in the past eight historical periods: A continuous feature with a range of 0–100, wherein each historical period is ten minutes.
- Road level: Highways, expressways, main roads, secondary roads and branches.
- The number of adjacent roads at the road entrance: This continuous feature is 0, 1, 2, 3.
- The number of adjacent road connections at the road section: Continuous characteristics, with a value of 0, 1, 2, 3, ….
4. Implementation and Experimental Results
4.1. Data
4.2. S-ELM-Cluster Model Tuning Test
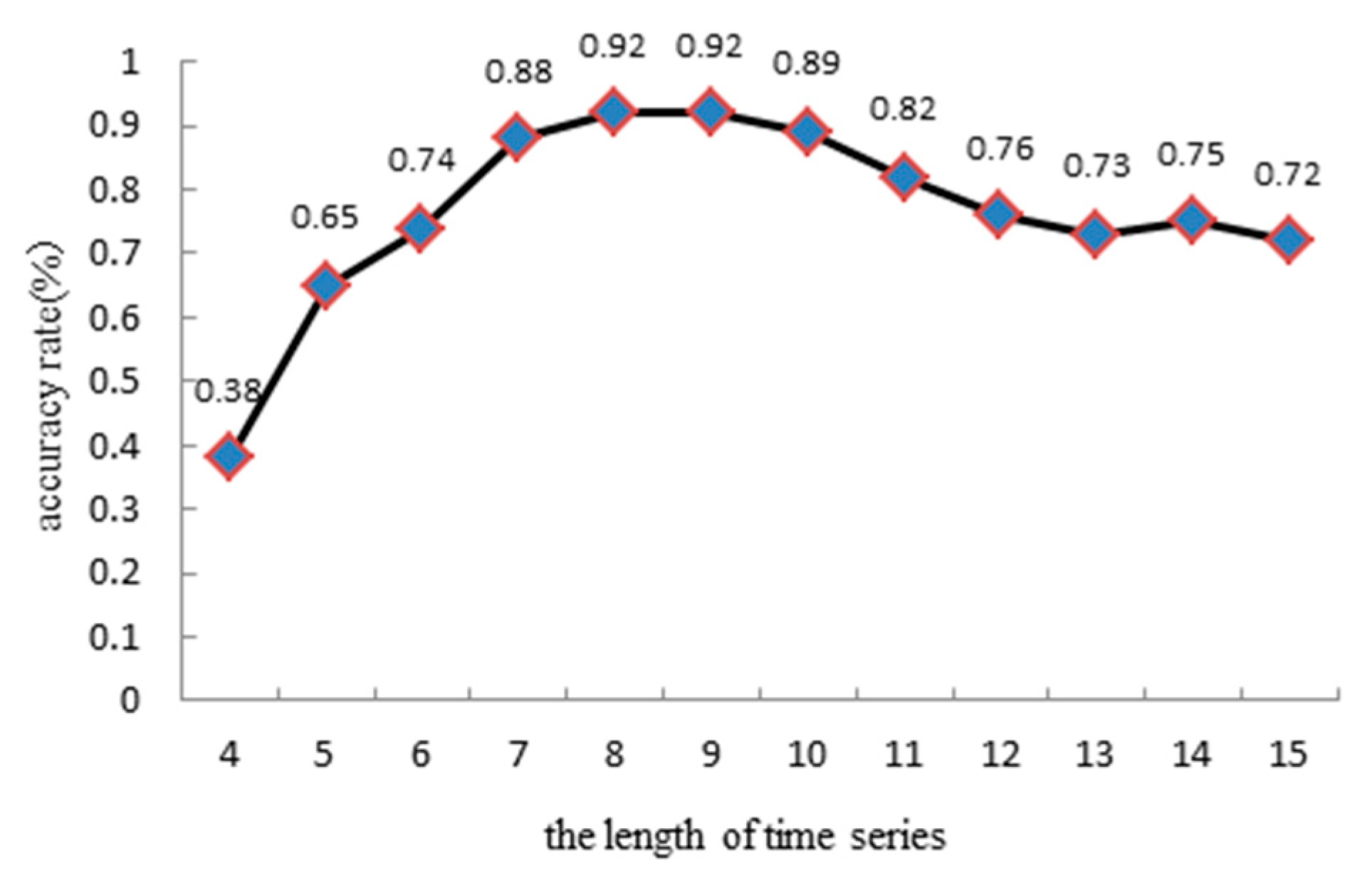
4.2.1. The Length of Time Series
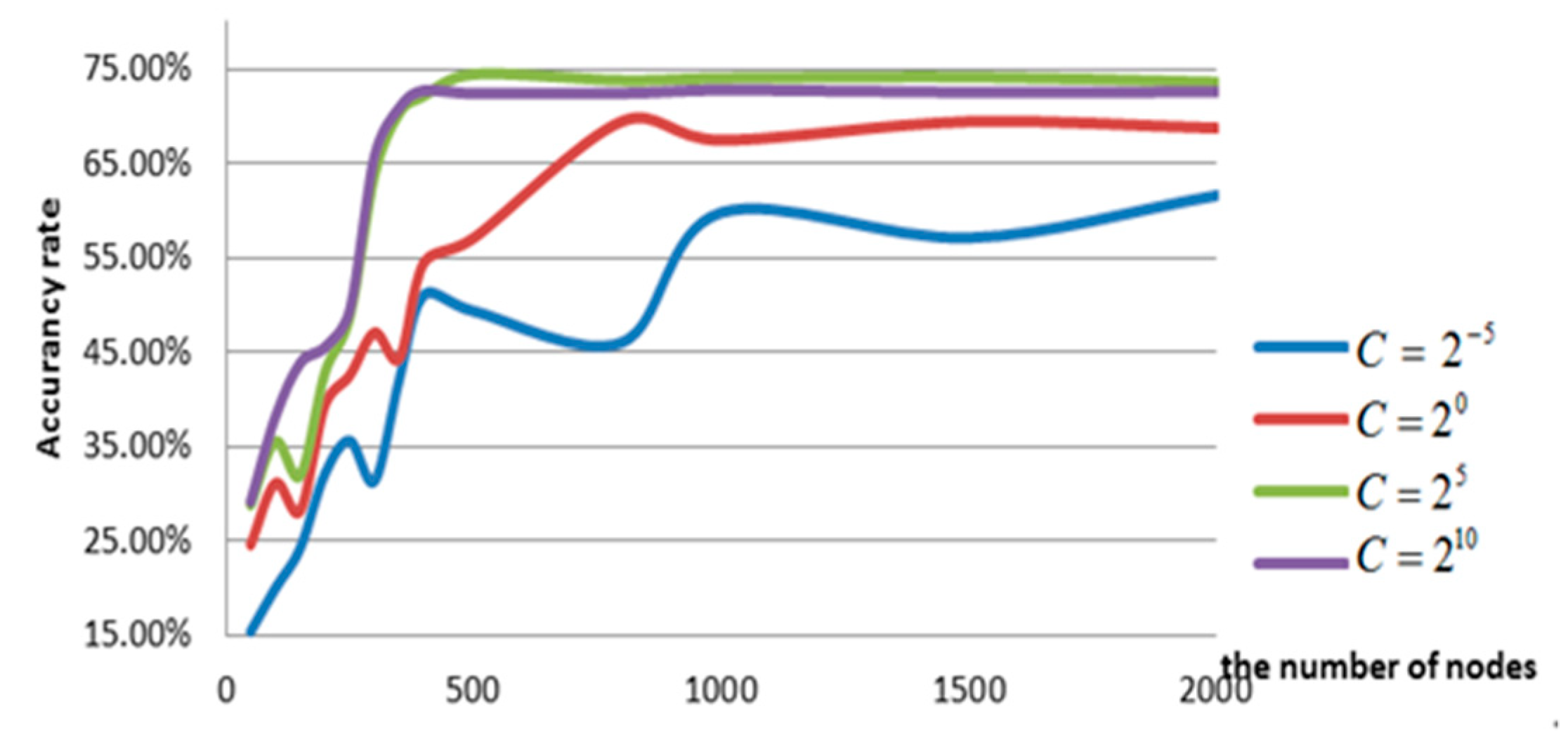
4.2.2. The Regularization Coefficient C and the Number of Hidden Layer Nodes L
4.3. Comparison Test of the S-ELM-Cluster and ELM
4.4. Comparison of the S-ELM-Cluster and Other Algorithms
4.5. Prediction Results Evaluation
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Ghosh, B.; Basu, B.; O’Mahony, M. Bayesian Time-Series Model for Short-Term Traffic Flow Forecasting. J. Transp. Eng. 2007, 133, 180–189. [Google Scholar] [CrossRef]
- Guo, J.; Huang, W.; Williams, B.M. Adaptive Kalman filter approach for stochastic short-term traffic flow rate prediction and uncertainty quantification. Transp. Res. Part C 2014, 43, 50–64. [Google Scholar] [CrossRef]
- Yu, G.; Zhang, C. Switching ARIMA model based forecasting for traffic flow. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Brighton, UK, 12–17 May 2004; Volume 2, pp. 429–432. [Google Scholar]
- Zhang, Y.; Ye, Z. Short-Term Traffic Flow Forecasting Using Fuzzy Logic System Methods. J. Intell. Transp. Syst. 2008, 12, 102–112. [Google Scholar] [CrossRef]
- Xue, J.; Shi, Z. Short-Time Traffic Flow Prediction Based on Chaos Time Series Theory. J. Transp. Syst. Eng. Inf. Technol. 2008, 8, 68–72. [Google Scholar] [CrossRef]
- Cetin, M.; Comert, G. Short-Term Traffic Flow Prediction with Regime Switching Models. J. Transp. Res. Board 2006, 1965, 23–31. [Google Scholar] [CrossRef]
- Abdulhai, B.; Porwal, H.; Recker, W. Short-Term Traffic Flow Prediction Using Neuro-Genetic Algorithms. ITS J. Intell. Transp. Syst. 2002, 7, 3–41. [Google Scholar] [CrossRef]
- Smith, B.L.; Demetsky, M.J. Short-Term Traffic Flow Prediction: Neural Network Approach Transportation Research Record. Transp. Res. Board 1994, 98–104. [Google Scholar]
- Zhao, L.; Wang, F.Y. Short-term traffic flow prediction based on ratio-median lengths of intervals two-factors high-order fuzzy time series. In Proceedings of the Vehicular Electronics and Safety, Beijing, China, 13–15 December 2007; pp. 1–7. [Google Scholar]
- Xu, Q.; Ding, Z. Bi discipline. A real-time prediction method of traffic flow based on dynamic recurrent neural network. J. Huaihai Inst. Technol. Nat. Sci. Edit. 2004, 12, 14–17. [Google Scholar]
- Yang, Q.; Zhang, B.; Gao, P. Based on improved dynamic recurrent neural network for short time prediction of traffic volume. J. Jilin Univ. Eng. Edit. 2012, 4, 887–891. [Google Scholar]
- Jiao, G.T.; Xu, J.; Ma, Y. Traffic volume prediction method based on QPSO-RBF. Traffic Inf. Saf. 2008, 26, 128–131. [Google Scholar]
- Çetiner, B.G.; Sari, M.; Borat, O.A. Neural Network Based Traffic-Flow Prediction Model. Math. Comput. Appl. 2010, 15, 269–278. [Google Scholar] [CrossRef]
- Mussone, L. A review of feedforward neural networks in transportation research. E I Elektrotech. Informationstech. 1999, 116, 360–365. [Google Scholar] [CrossRef]
- Bing, Q.; Gong, B.; Yang, Z.; Shang, Q.; Zhou, X. A short-term traffic flow local prediction method of combined kernel function relevance vector machine. J. Harbin Inst. Technol. 2017, 49, 144–149. [Google Scholar]
- Shang, Q.; Lin, C.; Yang, Z.; Bing, Q.; Zhou, X. Short-term traffic flow prediction model using particle swarm optimization–based combined kernel function-least squares support vector machine combined with chaos theory. Adv. Mech. Eng. 2016, 8, 1–12. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Aguirre, L.; Lopes, R.; Amaral, G.; Letellier, C. Constraining the topology of neural networks to ensure dynamics with symmetry properties. Phys. Rev. E 2004, 69, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Wolfgang, A.; Harris, C.; Hanzo, L. Symmetric RBF classifier for nonlinear detection in multiple-antenna-aided systems. Trans. Neural Netw. 2008, 19, 737–745. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Hong, X.; Harris, C. Grey-box radial basis function modelling. Neurocomputing 2011, 74, 1564–1571. [Google Scholar] [CrossRef]
- Espinoza, M.; Suykens, J.; Moor, B. Imposing symmetry in least squares support vector machines regression. In Proceedings of the 44th IEEE conference on decision and control, Seville, Spain, 12–15 December 2005; pp. 5716–5721. [Google Scholar]
- McNames, J.; Suykens, J.A.K.; Vandewalle, J. Winning entry of the K. U. Leuven time series prediction competition. Int. J. Bifurc. Chaos 1999, 9, 1485–1500. [Google Scholar] [CrossRef]
- Liu, X.; Li, P.; Gao, C. Symmetric extreme learning machine. Neural Comput. Appl. 2013, 22, 551–558. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th Edition. J. Oper. Res. Soc. 2015, 22, 199–201. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples; Springer: Berlin, Germany, 2017. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Anděl, J.; Perez, M.G.; Negrao, A.I. Estimating the dimension of a linear model. Kybern.-Praha 1981, 17, 514–525. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
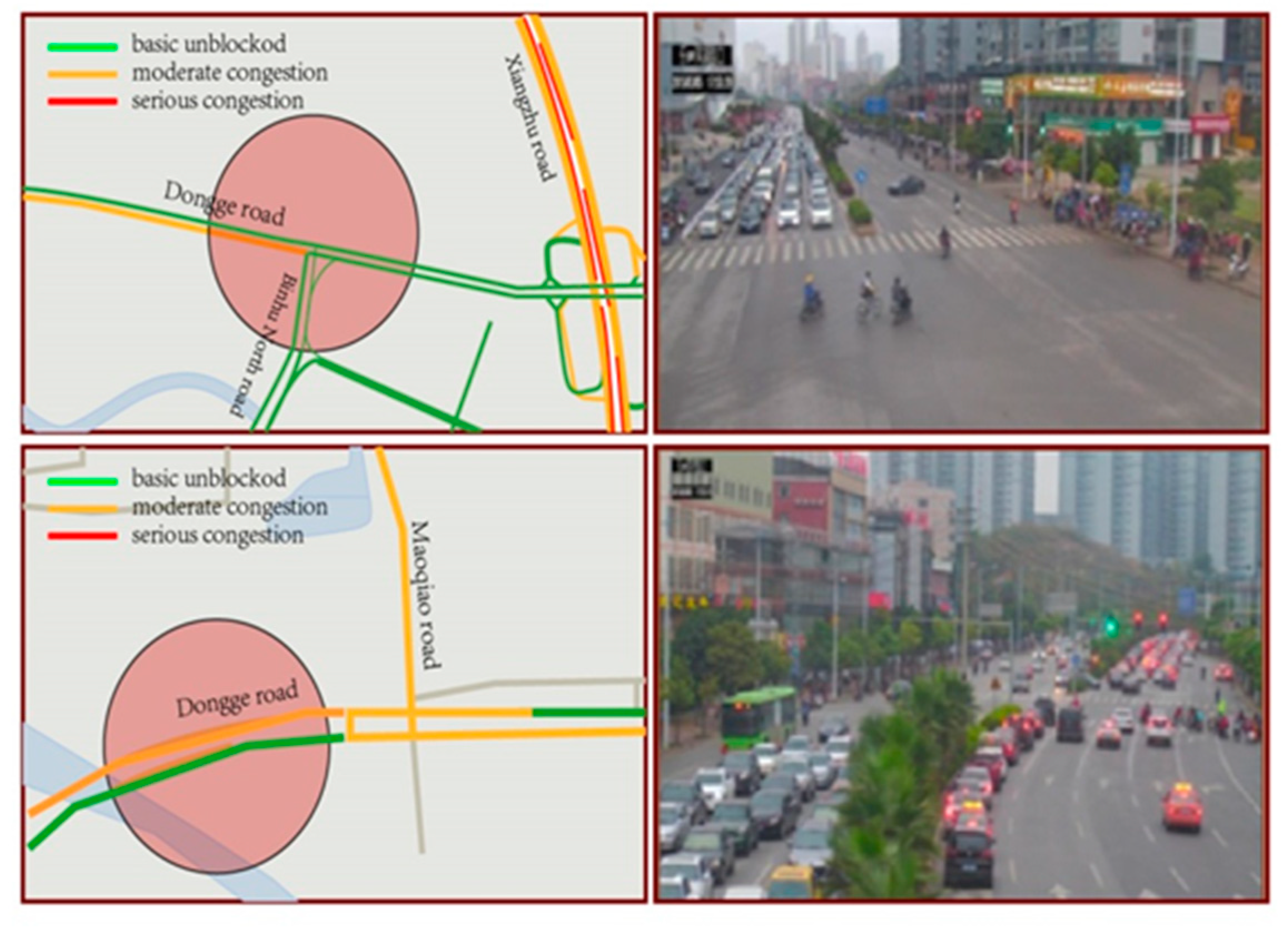{kind=link}
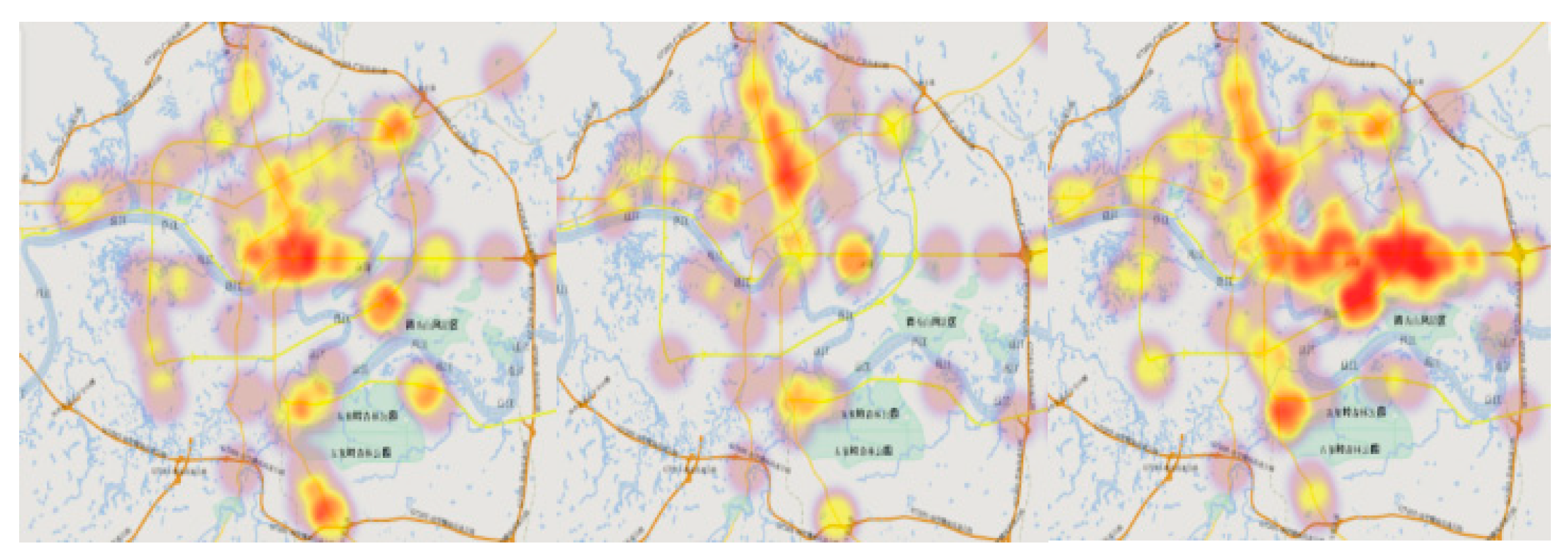{kind=link}
| Unblocked | Basic Unblocked | Mild Congestion | Moderate Congestion | Serious Congestion | ||
|---|---|---|---|---|---|---|
| Speed interval (km/h) | Highways, expressways | (65,∞) | (50,65] | (35,50] | (20,35] | [0,20] |
| Main road | (40,∞) | (30,40] | (20,30] | (15,20] | [0,15] | |
| Secondary roads, branches | (35,∞) | (25,35] | (15,25] | (10,15] | [0,10] | |
| Congestion value | (0,20) | [20,40) | [40,60) | [60,80) | [80,100] | |
| Map show color | Light green | Green | Yellow | Red | Deep red | |
| Highways, Expressways | Main Roads | Secondary Roads, Branches |
|---|---|---|
| 0.028 | 0.052 | 0.065 |
| Training Data Set | Training Sample Source | Number of Training Samples | Test Sample Source | Number of Test Samples |
|---|---|---|---|---|
| Working day | 20–24 March 2017 | 4,961,698 | 27 March 2017 | 1,036,785 |
| Weekend | Saturdays and Sundays, March 2017 | 5,023,698 | 26 March 2017 | 968,254 |
| Major festival | Ching Ming Festival and May Day in 2017 | 5,069,547 | 2 May 2017 | 1,187,234 |
| Algorithm | Training Time (s) | Accuracy |
|---|---|---|
| ELM | 116 | 64.28% |
| S-ELM | 67 | 65.77% |
| S-ELM-Cluster (single process) | 134 | 92.99% |
| S-ELM-Cluster (20 processes) | 9.2 | 93.12% |
| S-ELM-Cluster (40 processes) | 5.1 | 93.04% |
| Algorithm | Training Time (s) | Accuracy |
|---|---|---|
| S-ELM-Cluster (40 processes) | 24.63 | 92.08% |
| GBDT | 4501.16 | 92.10% |
| Ridge | 893.23 | 89.49% |
| Lasso | 9.34 | 86.79% |
| LR | 7.69 | 74.15% |
| Algorithm | Training Time (s) | Accuracy |
|---|---|---|
| S-ELM-Cluster (single process) | 10.57 | 90.91% |
| SVM | 686.85 | 87.87% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, Y.; Ban, X.; Liu, X.; Shen, Q. Large-Scale Traffic Congestion Prediction Based on the Symmetric Extreme Learning Machine Cluster Fast Learning Method. Symmetry 2019, 11, 730. https://doi.org/10.3390/sym11060730
Xing Y, Ban X, Liu X, Shen Q. Large-Scale Traffic Congestion Prediction Based on the Symmetric Extreme Learning Machine Cluster Fast Learning Method. Symmetry. 2019; 11(6):730. https://doi.org/10.3390/sym11060730
Chicago/Turabian StyleXing, Yiming, Xiaojuan Ban, Xu Liu, and Qing Shen. 2019. "Large-Scale Traffic Congestion Prediction Based on the Symmetric Extreme Learning Machine Cluster Fast Learning Method" Symmetry 11, no. 6: 730. https://doi.org/10.3390/sym11060730
APA StyleXing, Y., Ban, X., Liu, X., & Shen, Q. (2019). Large-Scale Traffic Congestion Prediction Based on the Symmetric Extreme Learning Machine Cluster Fast Learning Method. Symmetry, 11(6), 730. https://doi.org/10.3390/sym11060730