Exploration with Multiple Random ε-Buffers in Off-Policy Deep Reinforcement Learning


Abstract
:1. Introduction
2. Background
| Algorithm 1 Deep Q-learning with Experience Replay |
| Initialize replay memory D to capacity N Initialize action-value function Q with random weights for episode = 1, M do Initialize sequence s1 = {x1} and preprocessed sequenced ϕ1 = ϕ (s1) for t = 1, T do With probability ε, select a random action αt Otherwise select αt = maxαQ*(ϕ(st),α;θ) Execute action αt in emulator and observe reward rt and image xt+1 Set st+1 = st, αt, xt+1 and preprocess ϕt+1 = ϕ(st+1) Store transition (ϕt, αt, rt, ϕt+1) in D Sample random mini-batch of transitions (ϕj, αj, rj, ϕj+1) from D Set yj = rj for terminal ϕj+1 Or yj = rj + γmaxα’Q *(ϕj+1,α’;θ) for non-terminal ϕj+1 Perform a gradient descent step on (yj − Q(ϕj, αj |θ))2 end for end for |
| Algorithm 2 Deep Deterministic Policy Gradient |
| Randomly initialize critic Q(s, a|θQ) and actor μ(s|θμ) with weights θQ and θμ Initialize target Q’ and μ’ with weights θQ’← θQ, θμ’ ← θμ Initialize replay memory R for episode = 1, M do Initialize a random process N for action exploration Receive initial observation state s1 for t = 1, T do Select action αt = μ(st|θμ) + Ɲt according to the current policy and exploration noise Execute action αt and observe reward rt and new state st+1 Store transition (st, αt, rt, st+1) in R Sample random mini-batch of transitions (sj, αj, rj, sj+1) from R Set yj = rj + γQ’(sj+1, μ’(sj+1|θμ’)|θQ’) Update critic by minimizing the loss: L = (yj − Q(sj, αj|θQ))2 Update the actor policy using the sampled policy gradient: ∇θμI≈ ∇αQ(s,α|θQ)|s = sj, α = α μ(sj)∇θμμ(s|θμ)|sj Update the target: θQ’← τθQ+(1−τ) θQ’ θμ’← τθμ+(1−τ) θμ’ end for end for |
3. Multiple Random ε-Buffers
3.1. Proposed Off-Policy Algorithm
| Algorithm 3 Deep Q-learning with multiple random ε-buffers |
| Initialize replay memory R1 and R2 Initialize Q-function with random weights for episode = 1, M do Initialize sequence s1 and ϕ1 = ϕ (s1) for t = 1, T do With probability ε, select a random action αt Or select αt = maxαQ *((st), α;θ) Execute action αt in emulator and observe reward rt Set st+1 = st, αt and ϕt+1 = ϕ (st+1) Store transition (ϕt, αt, rt, ϕt+1) in R1 //standard experience buffer Store transition (ϕt, αt, rt, ϕt+1) in R2 //second experience buffer Sample random mini-batch of transitions (ϕj, αj, rj, ϕj+1) from either R1 or R2 Set yj = rj Or yj = rj + γmaxα’Q*(ϕj+1, α’|θ) Perform a gradient descent step on (yj − Q(ϕj, αj|θ))2 end for Sample random mini-batch of transitions from either R1 or R2 end for |
3.2. Algorithm Description
3.2.1. DQN with Multiple Random ε-Buffers
- Initialize replay memories of both R1 and R2 and Q(s,a), and initiate the process from a random state, s.
- Initialize the sequence with the start state, s.
- The agent learns the policy maxαQ*((st,a);θ) with greed and follows another policy with probability ε.
- For exploration, an experience composed of a tuple, such as (state s, action a, reward r, new state s’), is in both R1 and R2.
- Sample a random mini-batch of transitions from either R1 or R2.
- The weights for performing the gradient descent (rj + γmaxα’Q*(ϕj+1, α’|) − Q(ϕj, αj|θ)) for a target DQN with multiple random ε-buffers.
- Steps 3–6 are repeated for training.
- For the next episode, sample a random mini-batch of transitions from either R1 or R2.
- Steps 2–8 are repeated for training.
3.2.2. DDPG with Multiple Random ε-Buffers
- Initialize critic deep network Q(s, a|θQ) and actor deep network μ(s|θμ).
- Initialize replay memories in both R1 and R2.
- The agent selects the action according to the current policy, αt = μ(st|θμ) + Ɲt.
- For exploration, an experience composed of a tuple, such as (state s, action a, reward r, new state s’), is in both R1 and R2.
- A mini-batch of transitions is randomly sampled from either R1 or R2.
- The critic network is updated by the loss function L = 1/n∑j(rj + γQ’(sj+1, μ’(sj+1|θμ’)|θQ’) − Q(sj, αj |θQ))2.
- The actor network is updated by the policy gradient descent ∇θμI ≈ 1/n∑j∇αQ(s|θQ)|s = sj, α = α μ(sj) ∇θμμ(s|θμ)|sj for a target DDPG with multiple random ε-buffers.
- Update the target network θQ’ ← τθQ + (1 − τ) θQ’ and θμ’ ← τθμ + (1 − τ) θμ’.
- Steps 3–8 are repeated for training.
- For the next episode, a mini-batch of transitions is randomly sampled from either R1 or R2.
- Steps 2–10 are repeated for training.
| Algorithm 4 Deep Deterministic Policy Gradient with multiple random ε-buffers |
| Initialize critic Q(s, a|θQ) and actor μ(s|θμ) with weights θQ and θμ Initialize target Q’ and μ’ with weights θQ’← θQ, θμ’ ← θμ Initialize replay memory R1 and R2 for episode = 1, M do Initialize observation s1 and a random process N for action exploration for t = 1, T do Select action αt = μ(st|θμ) + Ɲt by the current policy and exploration noise Execute action αt and observe reward rt and new state st+1 Store transition (st, αt, rt, st+1) in R1 //standard experience buffer Store transition (st, αt, rt, st+1) in R2 //second experience buffer Sample a random mini-batch of transitions (sj, αj, rj, sj+1) from either R1 or R2 Set yj = rj + γQ’(sj+1, μ’(sj+1|θμ’)|θ Q’) Update critic by minimizing the loss: L = (yj − Q(sj, αj|θQ))2 Update the actor by the sampled policy gradient: ∇θμI≈ ∇αQ(s,α|θQ)|s = sj, α = α μ(sj)∇θμμ(s|θμ)|sj Update the target: θ Q’← τθQ+(1−τ) θ Q’ θ μ’← τθμ+(1−τ) θ μ’ end for Sample a random mini-batch of transitions from either R1 or R2 end for |
4. Evaluation and Results
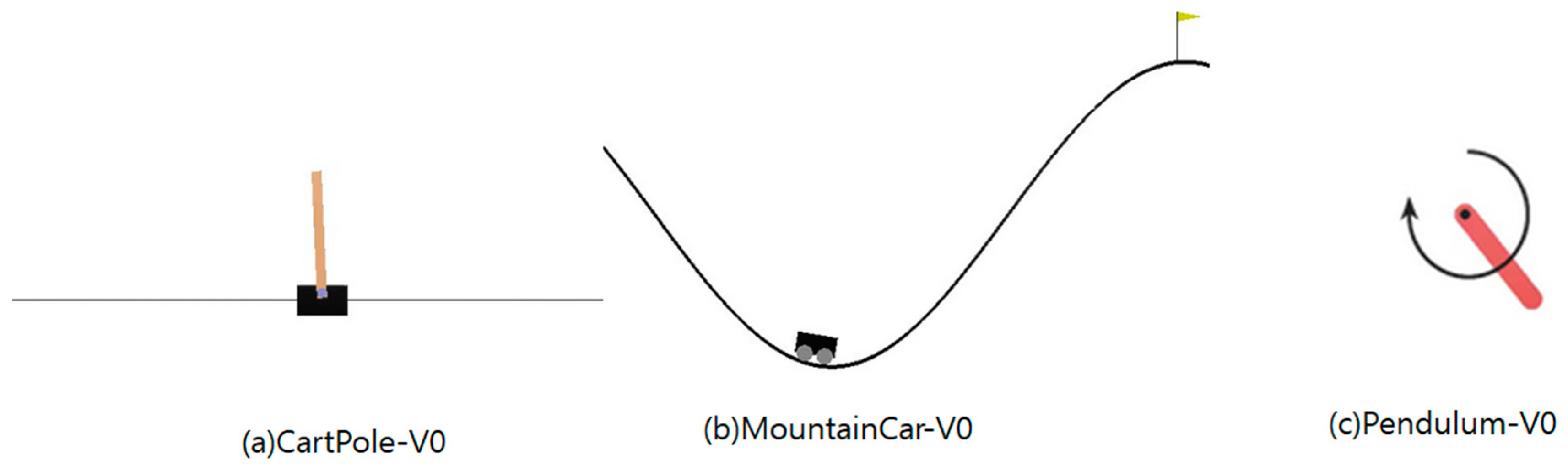
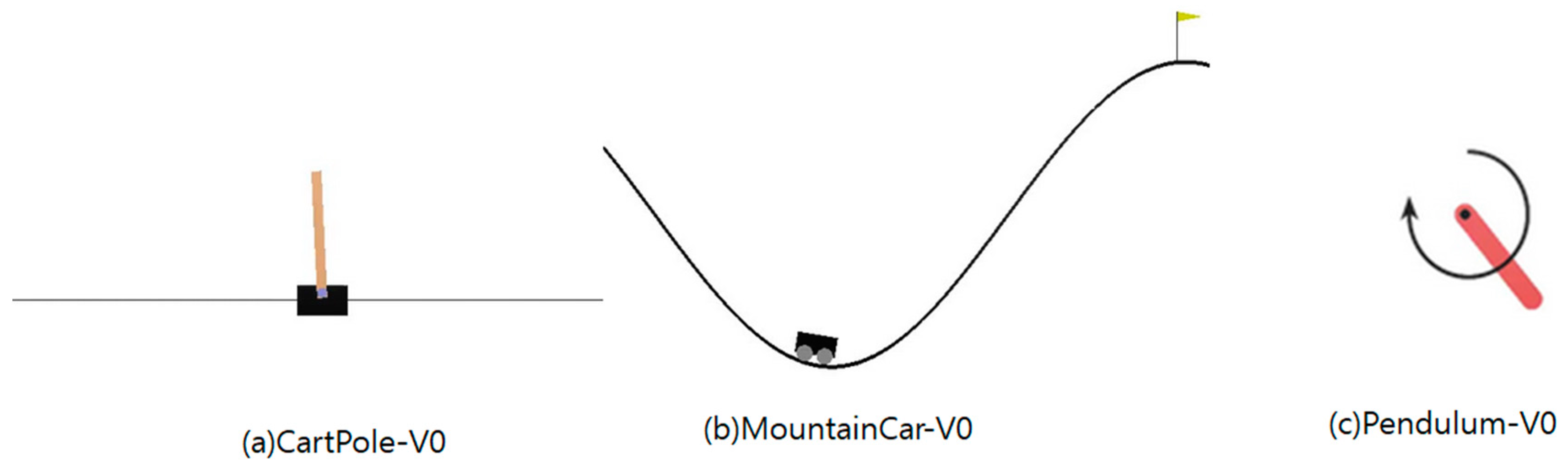
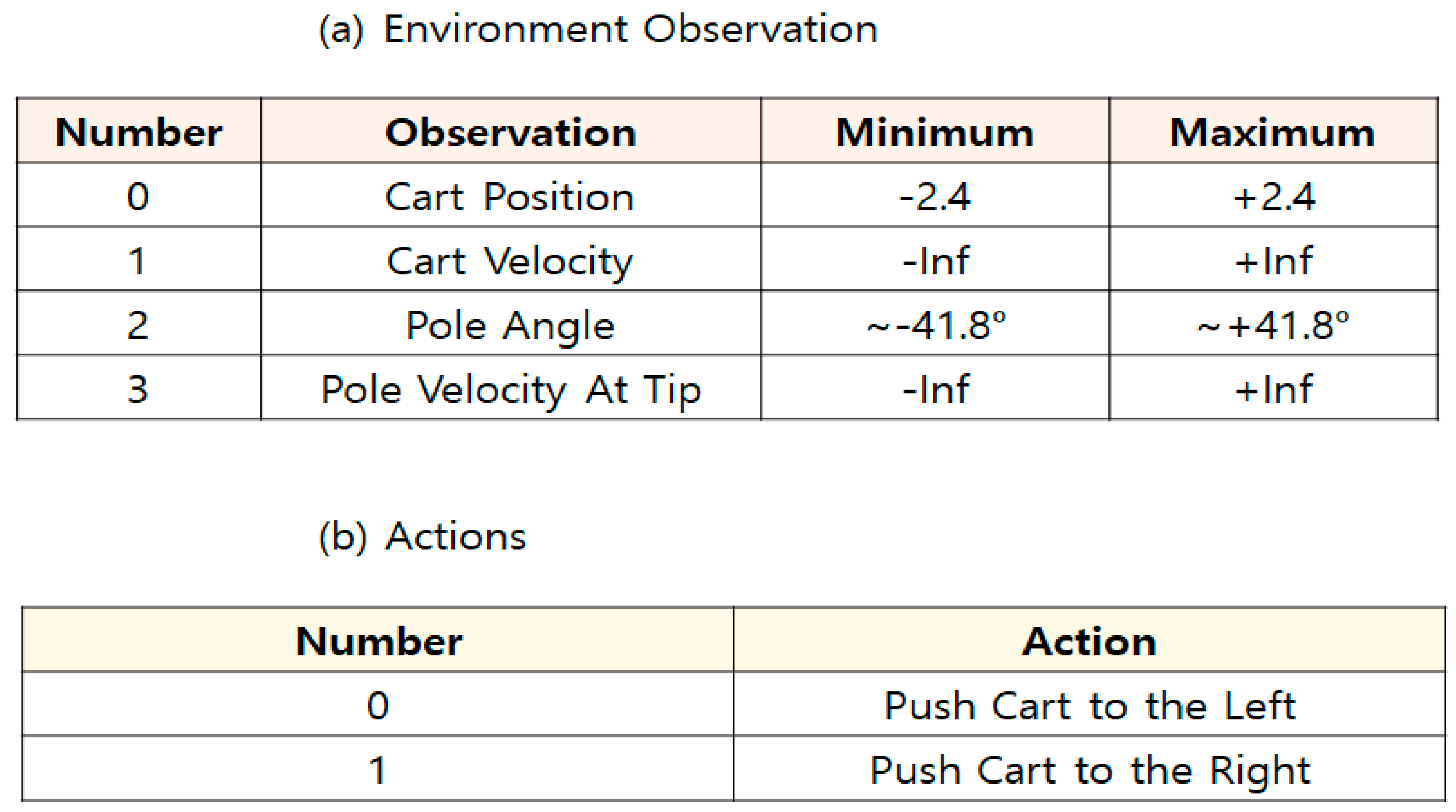
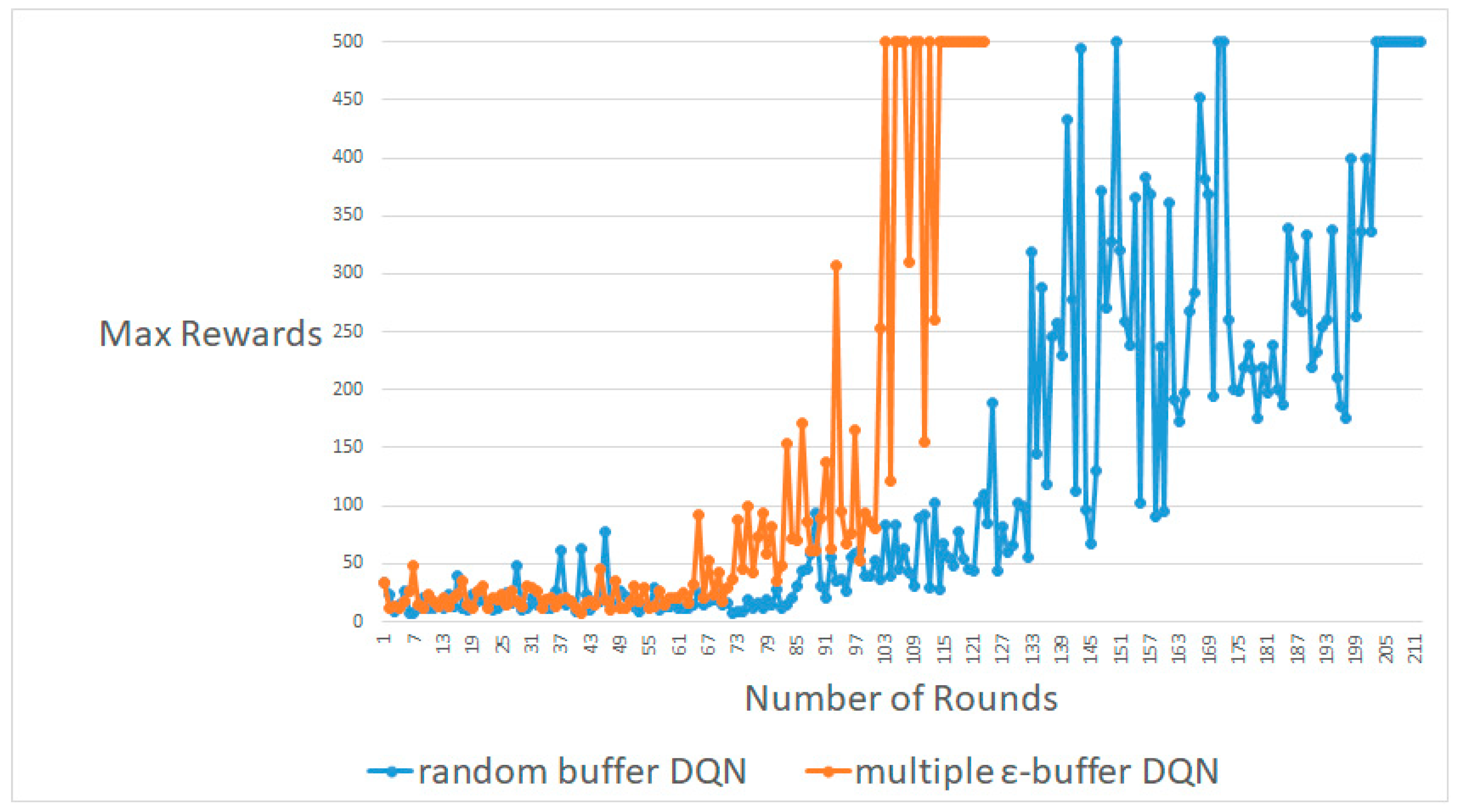
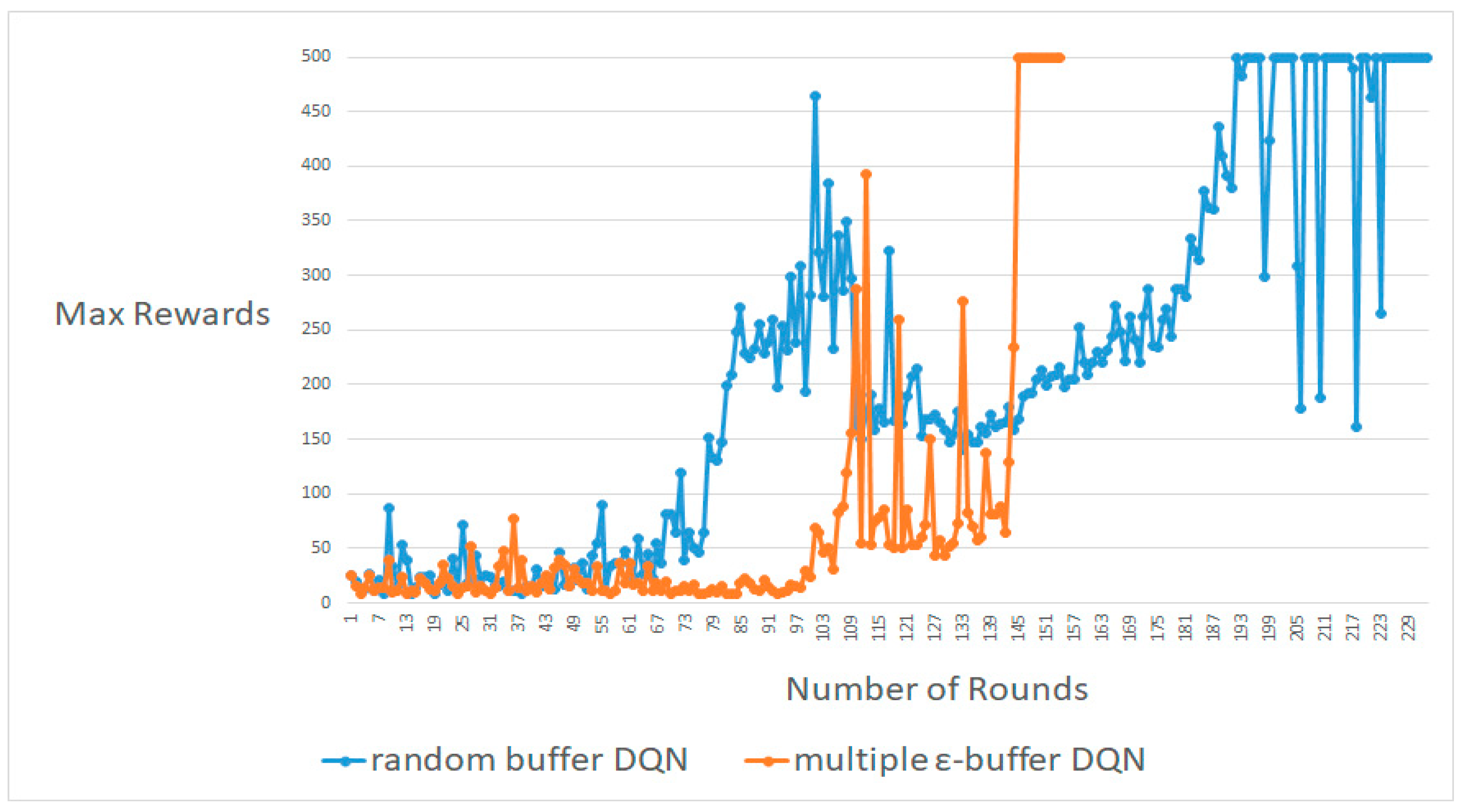
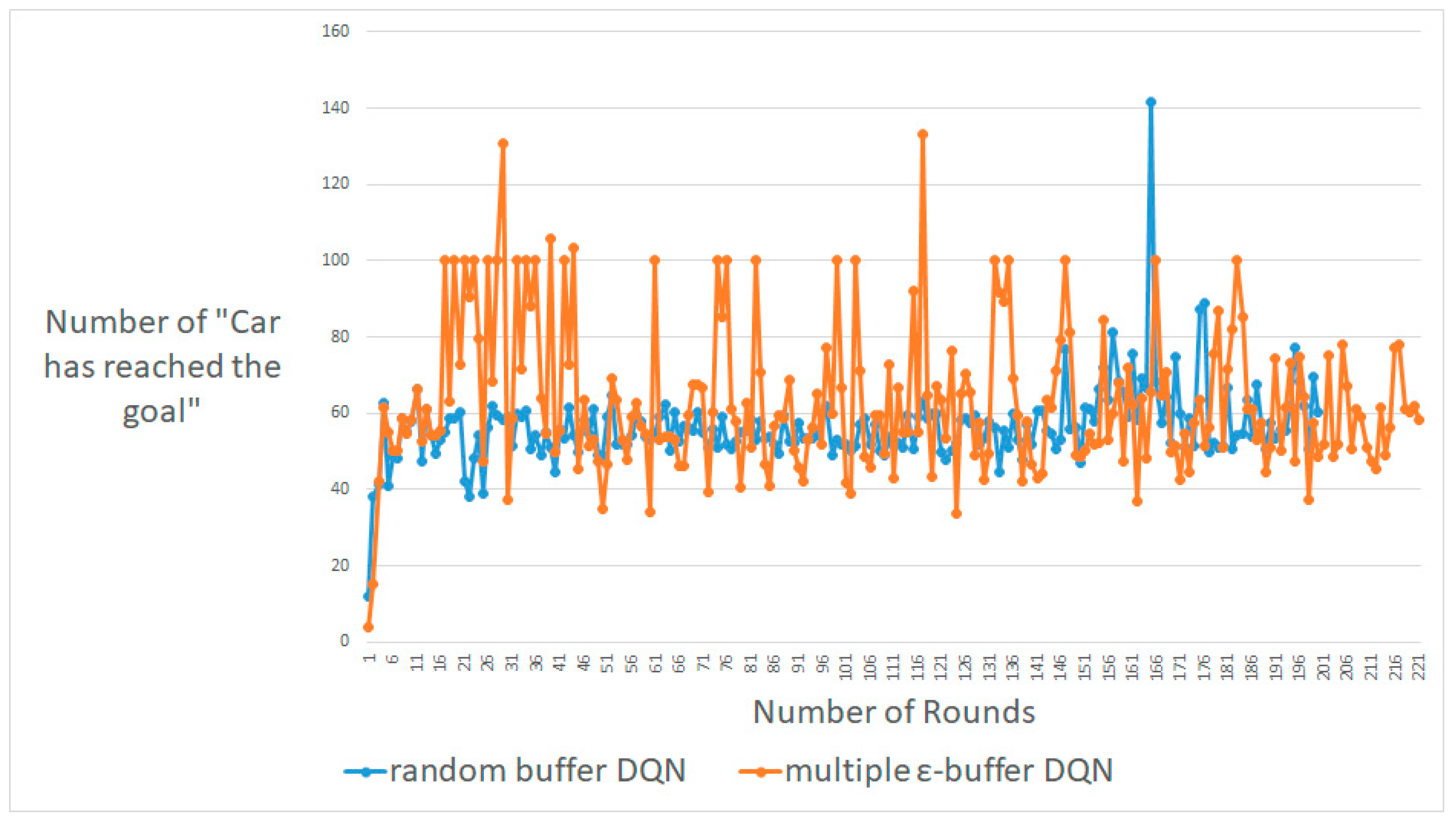
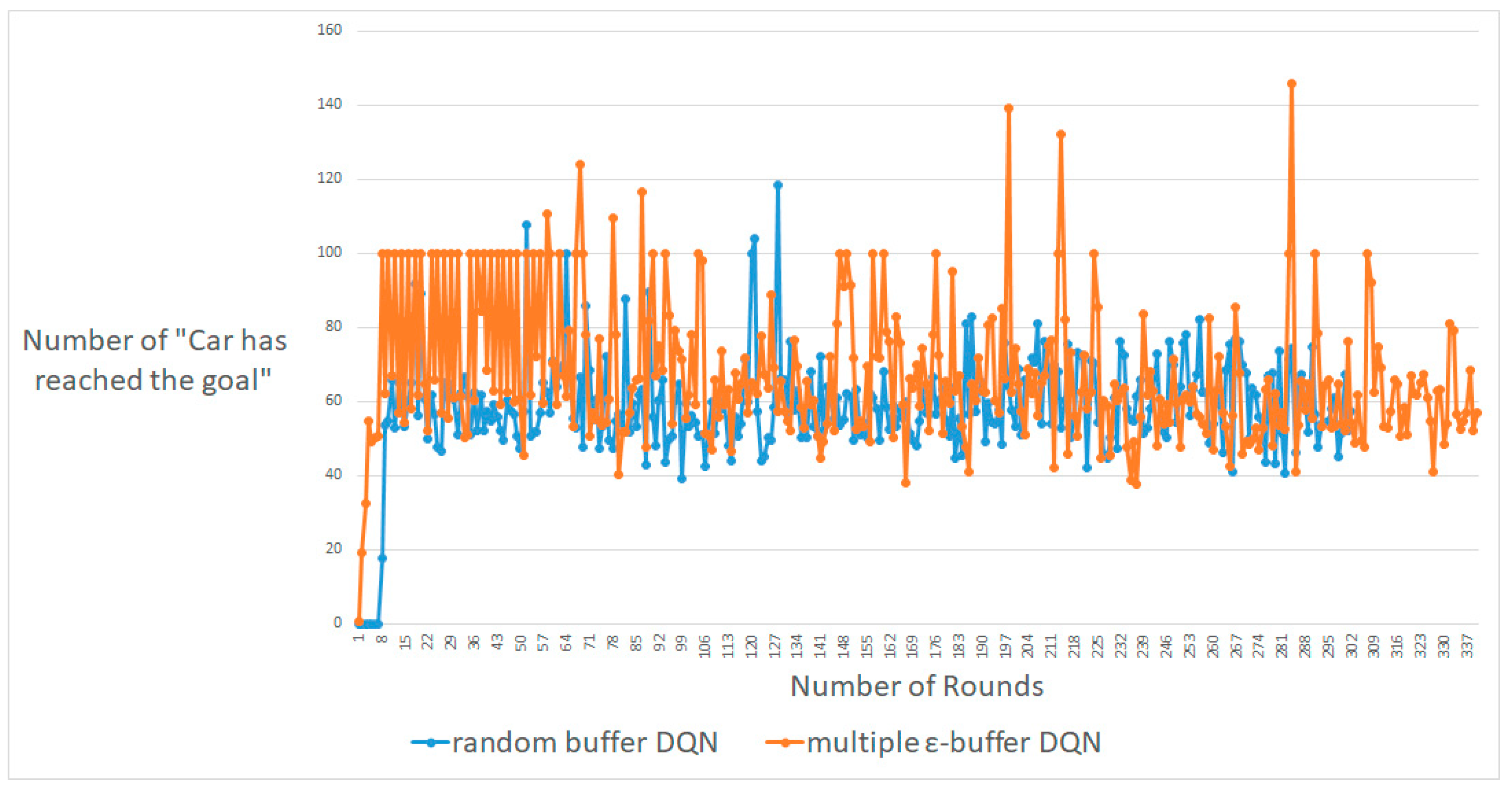
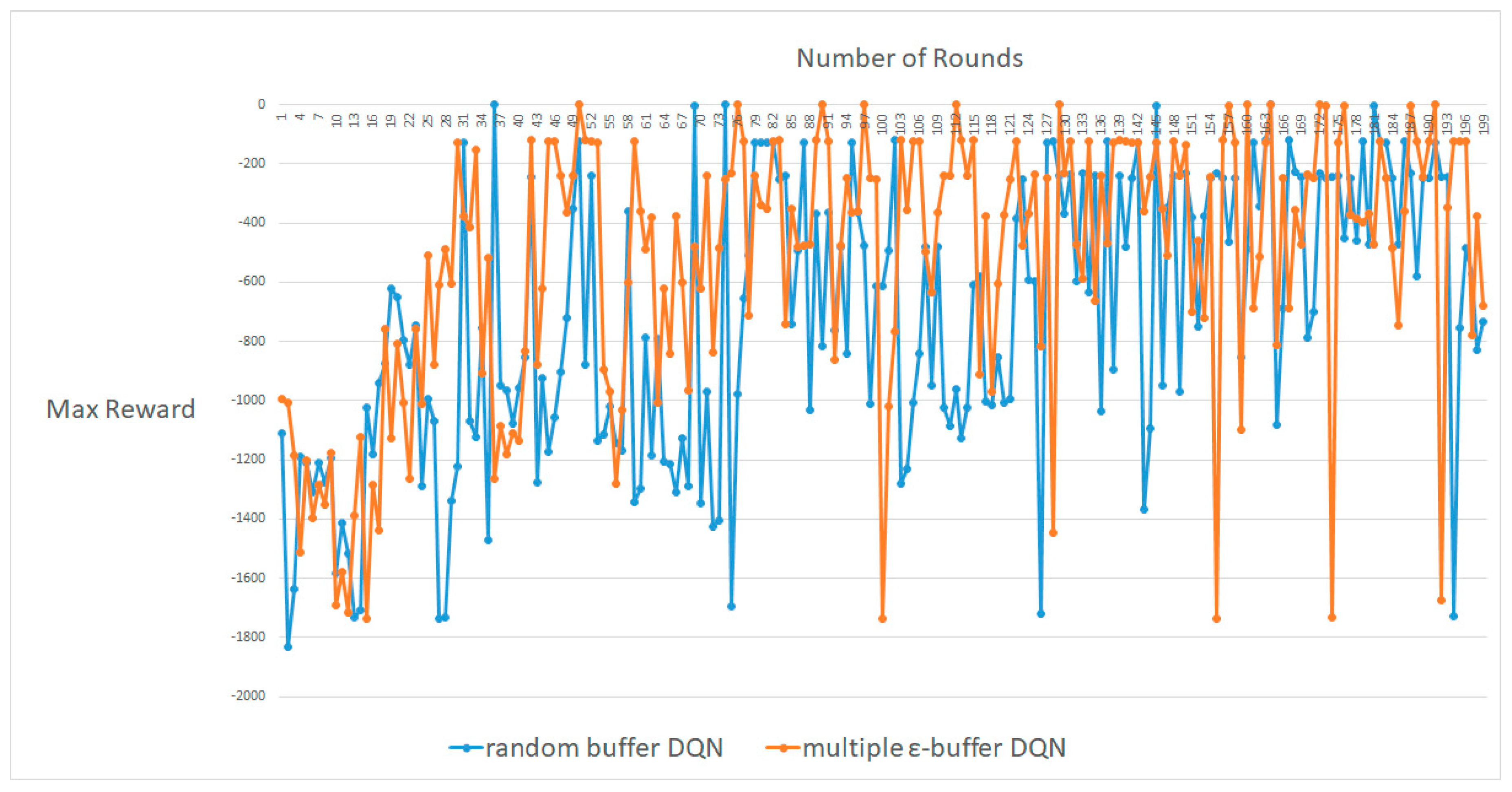
4.1. CartPole-V0
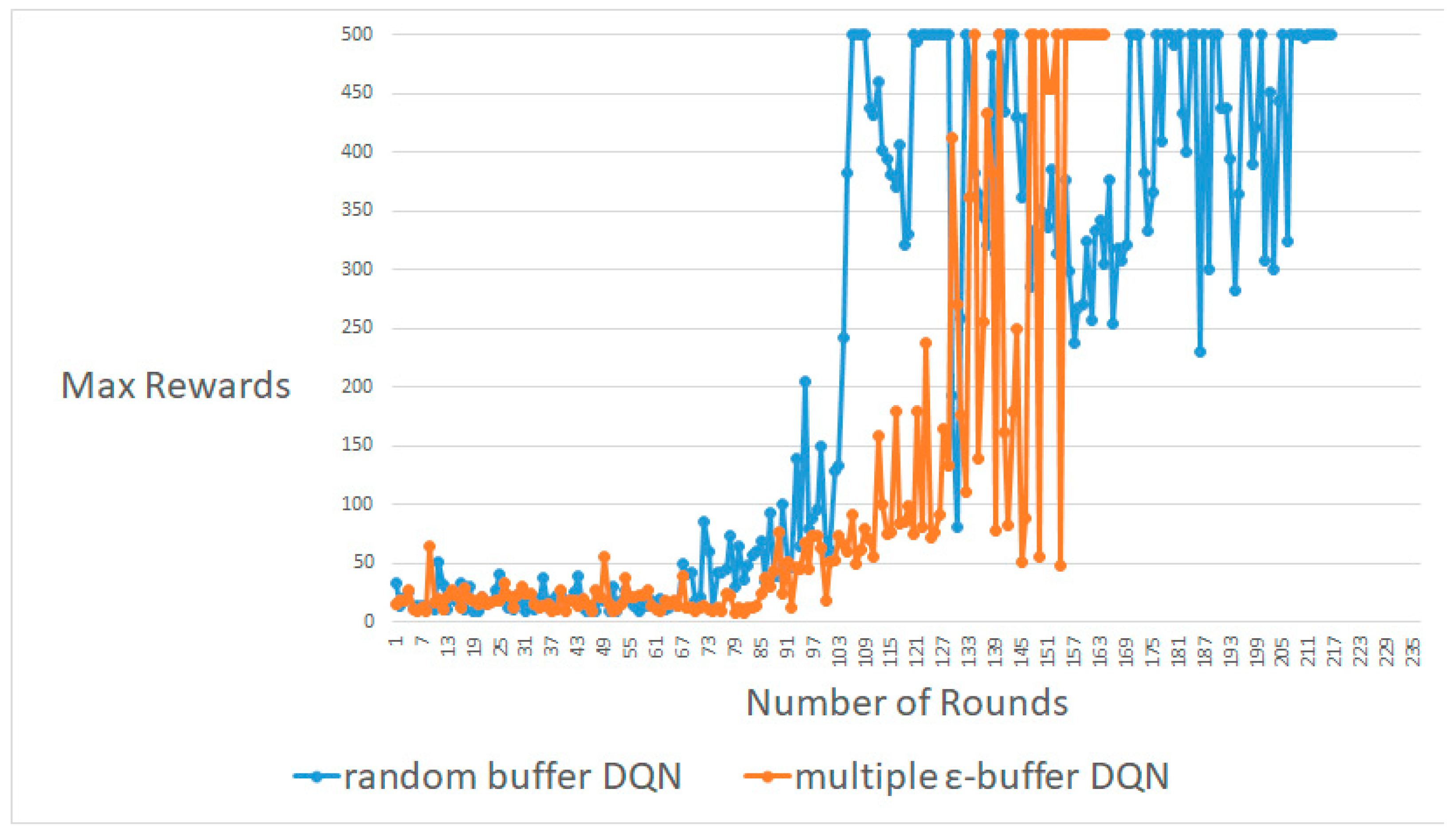
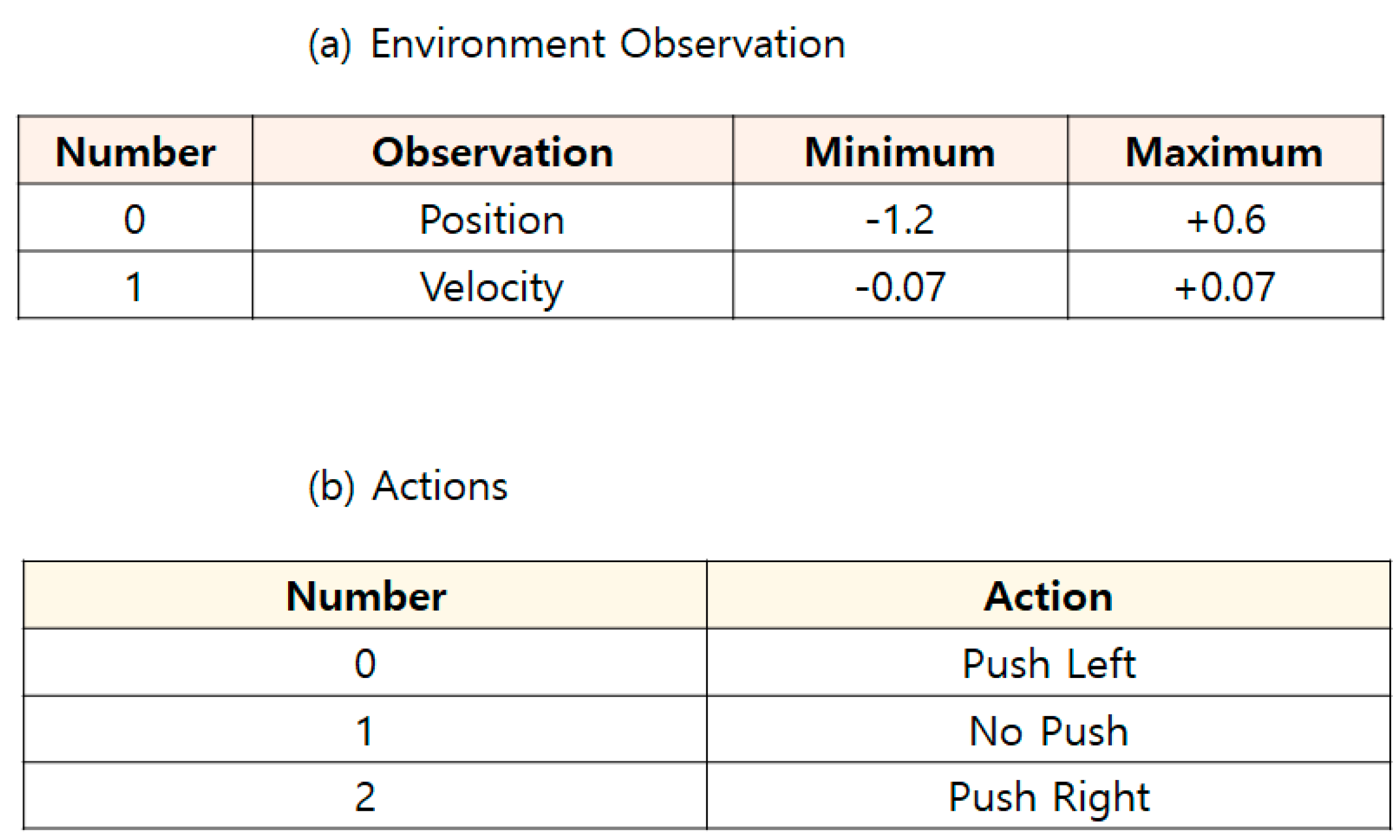
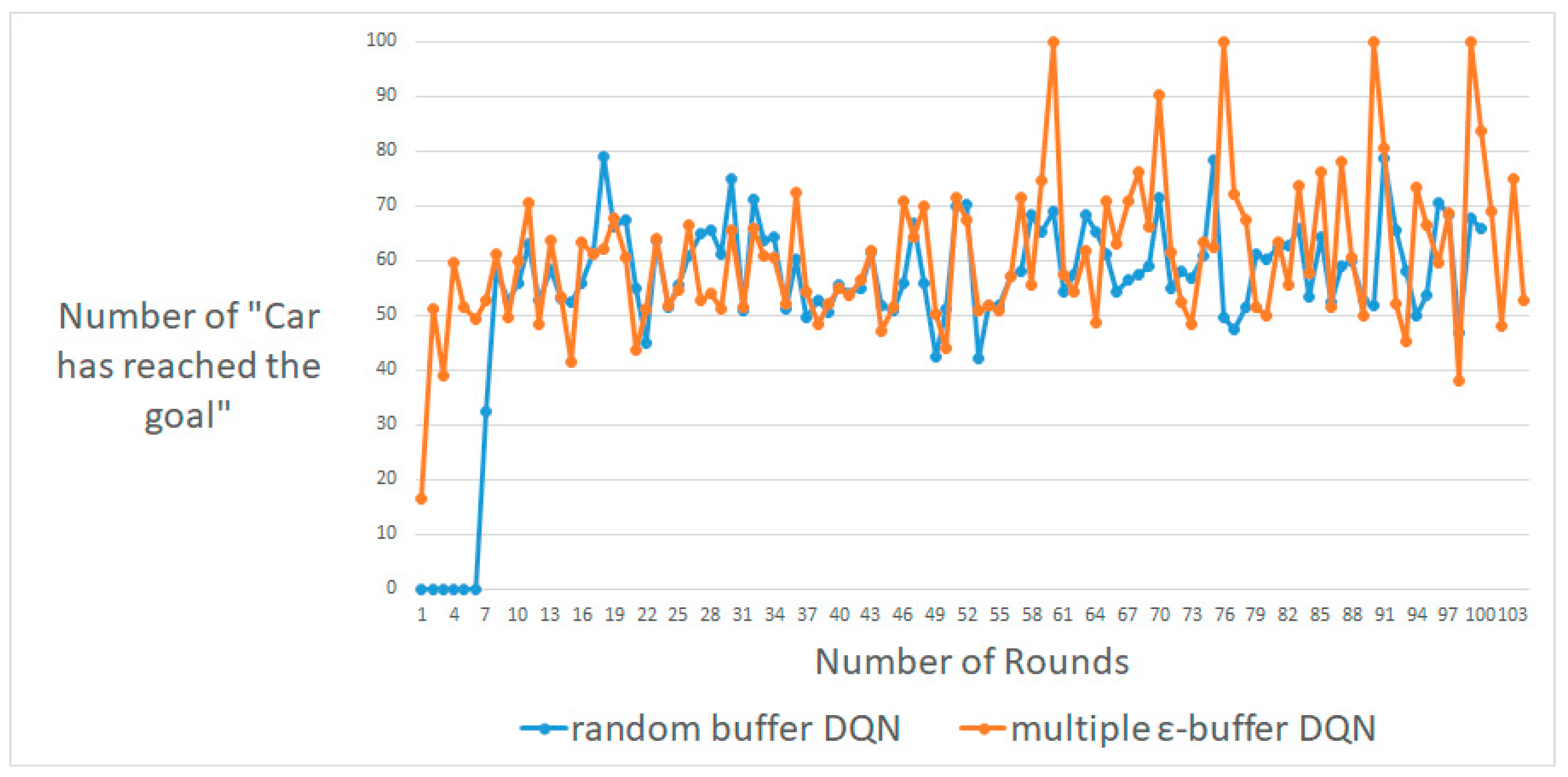
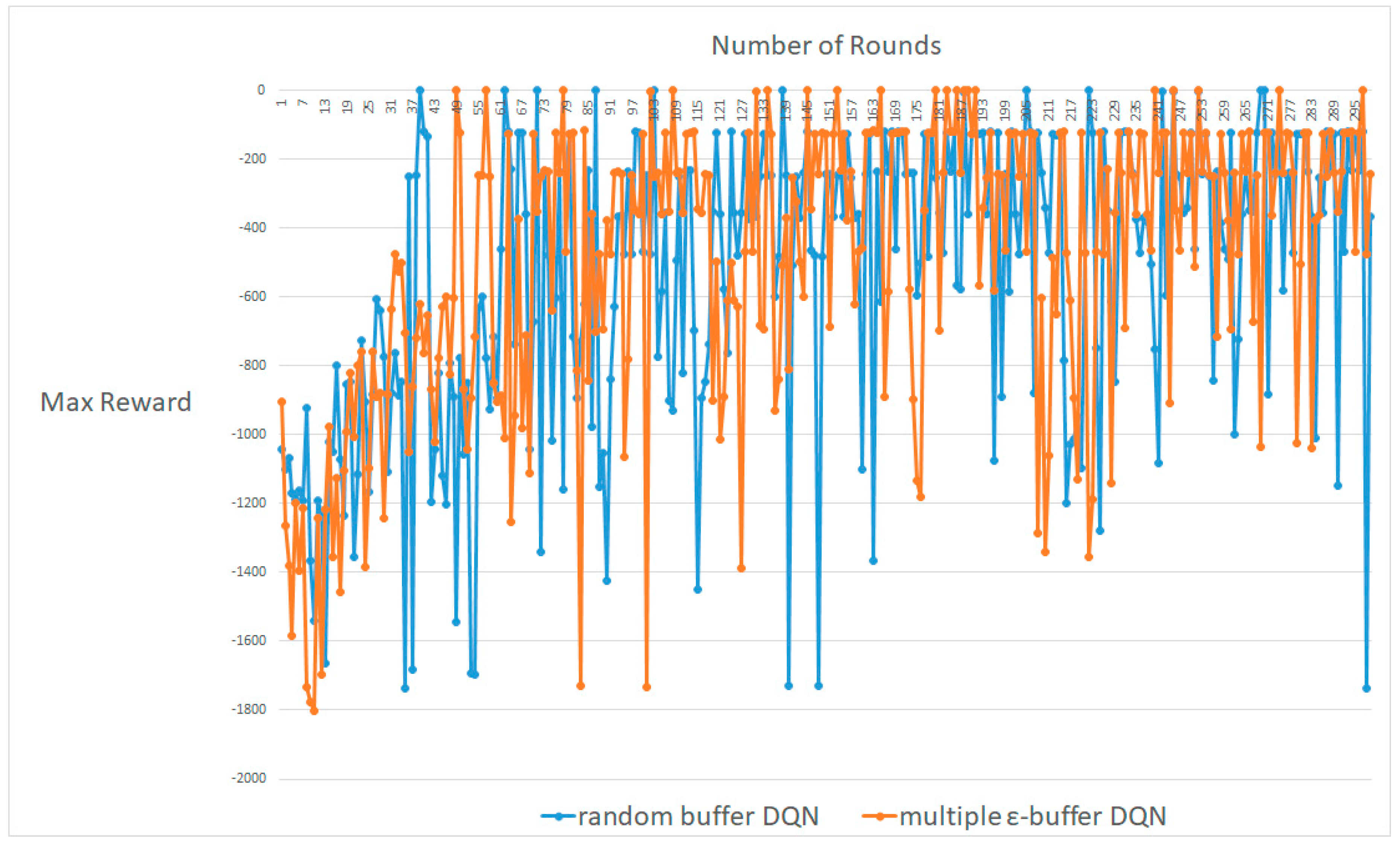
4.2. MountainCar-V0
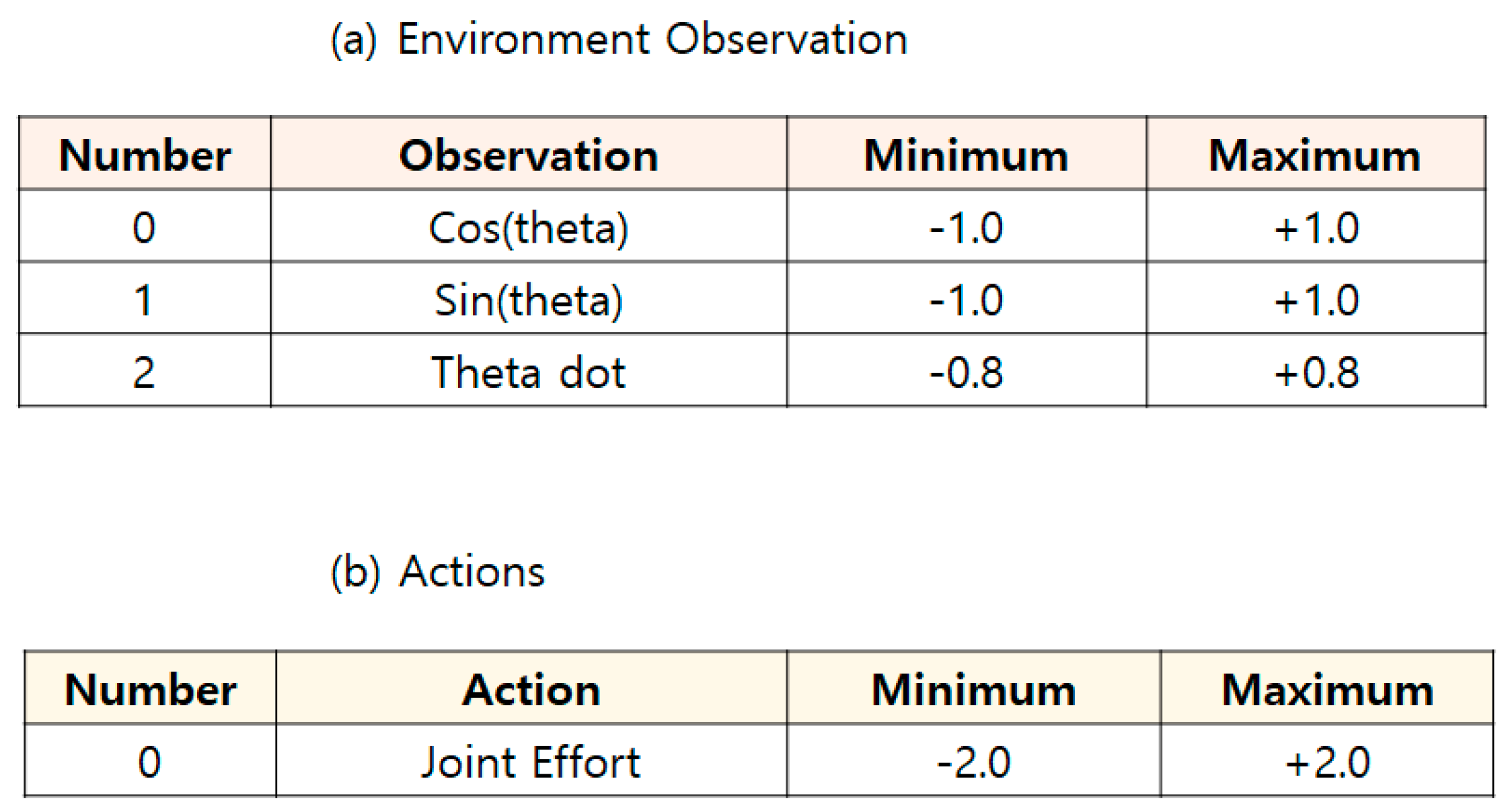
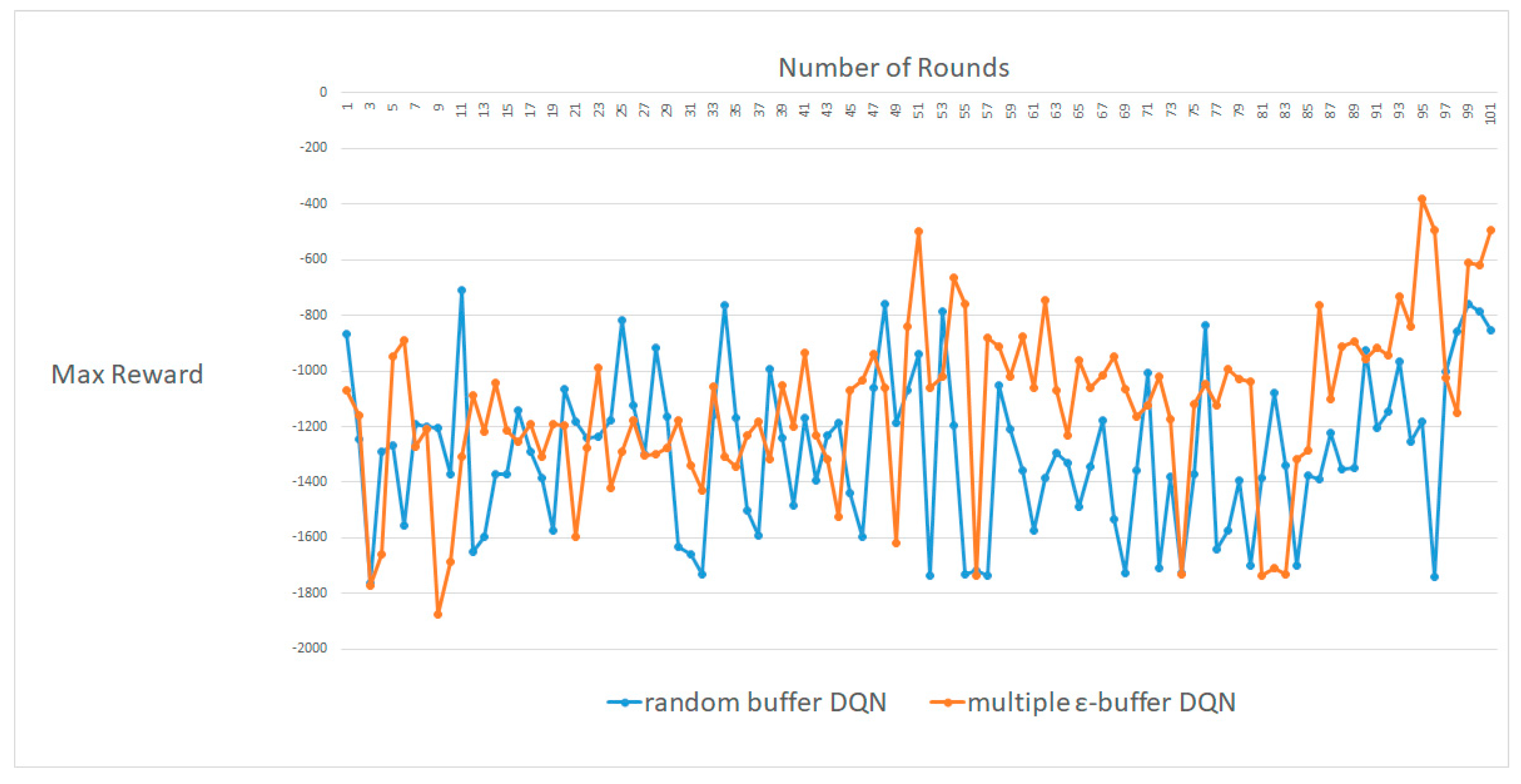
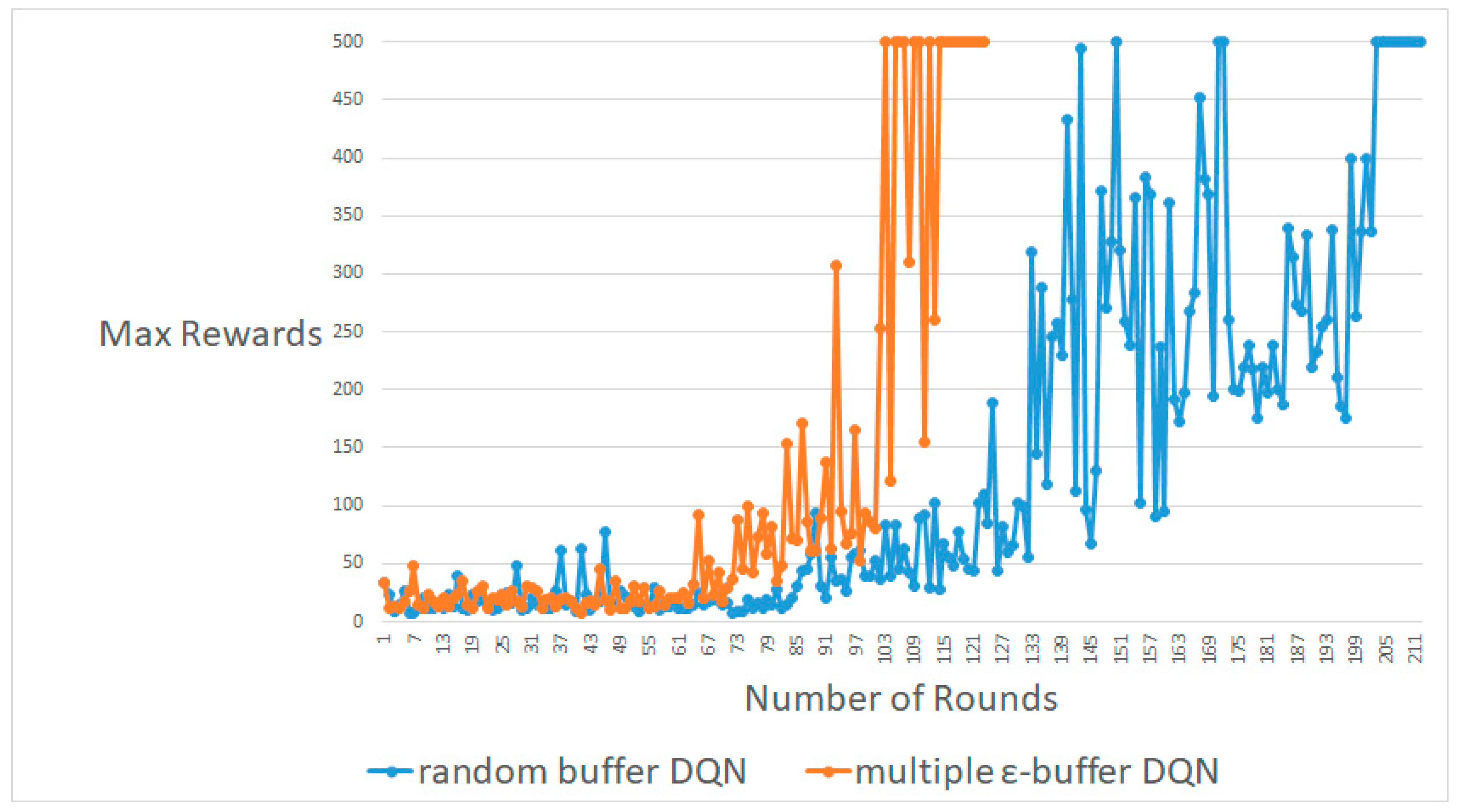
4.3. Pendulum-V0
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 1. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Kim, C.; Park, J. Designing online network intrusion detection using deep auto-encoder Q-learning. Comput. Electr. Eng. 2019, 79, 106460. [Google Scholar] [CrossRef]
- Park, J.; Salim, M.M.; Jo, J.; Sicato, J.C.S.; Rathore, S.; Park, J.H. CIoT-Net: A scalable cognitive IoT based smart city network architecture. Hum. Cent. Comput. Inf. Sci. 2019, 9, 29. [Google Scholar] [CrossRef]
- Sun, Y.; Tan, W. A trust-aware task allocation method using deep q-learning for uncertain mobile crowdsourcing. Hum. Cent. Comput. Inf. Sci. 2019, 9, 25. [Google Scholar] [CrossRef] [Green Version]
- Kwon, B.-W.; Sharma, P.K.; Park, J.-H. CCTV-Based Multi-Factor Authentication System. J. Inf. Process. Syst. JIPS 2019, 15, 904–919. [Google Scholar] [CrossRef]
- Srilakshmi, N.; Sangaiah, A.K. Selection of Machine Learning Techniques for Network Lifetime Parameters and Synchronization Issues in Wireless Networks. Inf. Process. Syst. JIPS 2019, 15, 833–852. [Google Scholar] [CrossRef]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, P.; Zaremba, W. Hindsight Experience Replay. arXiv 2017, arXiv:1707.01495. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Driessche, G.V.D.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M. Mastering the game of go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Cobbe, K.; Klimov, O.; Hesse, C.; Kim, T.; Schulman, J. Quantifying Generalization in Reinforcement Learning. arXiv 2019, arXiv:1812.02341. [Google Scholar]
- Liu, R.; Zou, J. The Effects of Memory Replay in Reinforcement Learning. arXiv 2017, arXiv:1710.06574. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2016, arXiv:1511.05952. [Google Scholar]
- Plappert, M.; Houthooft, R.; Dhariwal, P.; Sidor, S.; Chen, R.; Chen, X.; Asfour, T.; Abbeel, P.; Andrychowicz, M. Parameter Space Noise for Exploration. arXiv 2018, arXiv:1706.01905. [Google Scholar]
- OpenReview.net. Available online: https://openreview.net/forum?id=ByBAl2eAZ (accessed on 16 February 2018).
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2016, arXiv:1509.02971. [Google Scholar]
- FreeCodeCamp. Available online: https://medium.freecodecamp.org/improvements-in-deep-q-learning-dueling-double-dqn-prioritized-experience-replay-and-fixed-58b130cc5682 (accessed on 5 July 2018).
- RL—DQN Deep Q-network. Available online: https://medium.com/@jonathan_hui/rl-dqn-deep-q-network-e207751f7ae4 (accessed on 17 July 2018).
- OpenAI Gym. Available online: https://gym.openai.com (accessed on 28 May 2016).
- Cart-Pole-V0. Available online: https://github.com/openai/gym/wiki/Cart-Pole-v0 (accessed on 24 June 2019).
- Cart-Pole-DQN. Available online: https://github.com/rlcode/reinforcement-learning-kr/blob/master/2-cartpole/1-dqn/cartpole_dqn.py (accessed on 8 July 2017).
- MountainCar-V0. Available online: https://github.com/openai/gym/wiki/MountainCar-v0 (accessed on 4 May 2019).
- MountainCar-V0-DQN. Available online: https://github.com/shivaverma/OpenAIGym/blob/master/mountain-car/MountainCar-v0.py (accessed on 2 April 2019).
- Pendulum-V0. Available online: https://github.com/openai/gym/wiki/Pendulum-v0 (accessed on 31 May 2019).
- Pendulum-V0-DDPG. Available online: https://github.com/openai/gym/blob/master/gym/envs/classic_control/pendulum.py (accessed on 26 October 2019).
- Tensorflow. Available online: https://github.com/tensorflow/tensorflow (accessed on 31 October 2019).
- Keras Documentation. Available online: https://keras.io/ (accessed on 14 October 2019).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, C.; Park, J. Exploration with Multiple Random ε-Buffers in Off-Policy Deep Reinforcement Learning. Symmetry 2019, 11, 1352. https://doi.org/10.3390/sym11111352
Kim C, Park J. Exploration with Multiple Random ε-Buffers in Off-Policy Deep Reinforcement Learning. Symmetry. 2019; 11(11):1352. https://doi.org/10.3390/sym11111352
Chicago/Turabian StyleKim, Chayoung, and JiSu Park. 2019. "Exploration with Multiple Random ε-Buffers in Off-Policy Deep Reinforcement Learning" Symmetry 11, no. 11: 1352. https://doi.org/10.3390/sym11111352
APA StyleKim, C., & Park, J. (2019). Exploration with Multiple Random ε-Buffers in Off-Policy Deep Reinforcement Learning. Symmetry, 11(11), 1352. https://doi.org/10.3390/sym11111352