Reusing Source Task Knowledge via Transfer Approximator in Reinforcement Transfer Learning




Abstract
:1. Introduction
- The concept of the transfer approximator is proposed. By taking the state from the target task as the input and predicting the quality of actions in the target task, the transfer approximator does not need the action mappings across the two tasks. As for the state mapping in the inter-task mapping, it is replaced by the state feature mapping rules that are different from the state mapping of the inter-task mapping to some extent.
- Two mapping rules called full mapping and group mapping are designed. The mapping rule is used in the transfer approximator for mapping each state feature of the target task into a set of features in the source task. With such feature mapping rules, much more related feature information can be used. Differently from the state mapping of the inter-task mapping, the full mapping rule is totally task independent and human-free. However, it is hard for the group mapping rule to be task independent, but it can have relatively less human involvement depending on the grouping method used. For example, there will be nearly no human involvement if the grouping is done by certain machine learning methods.
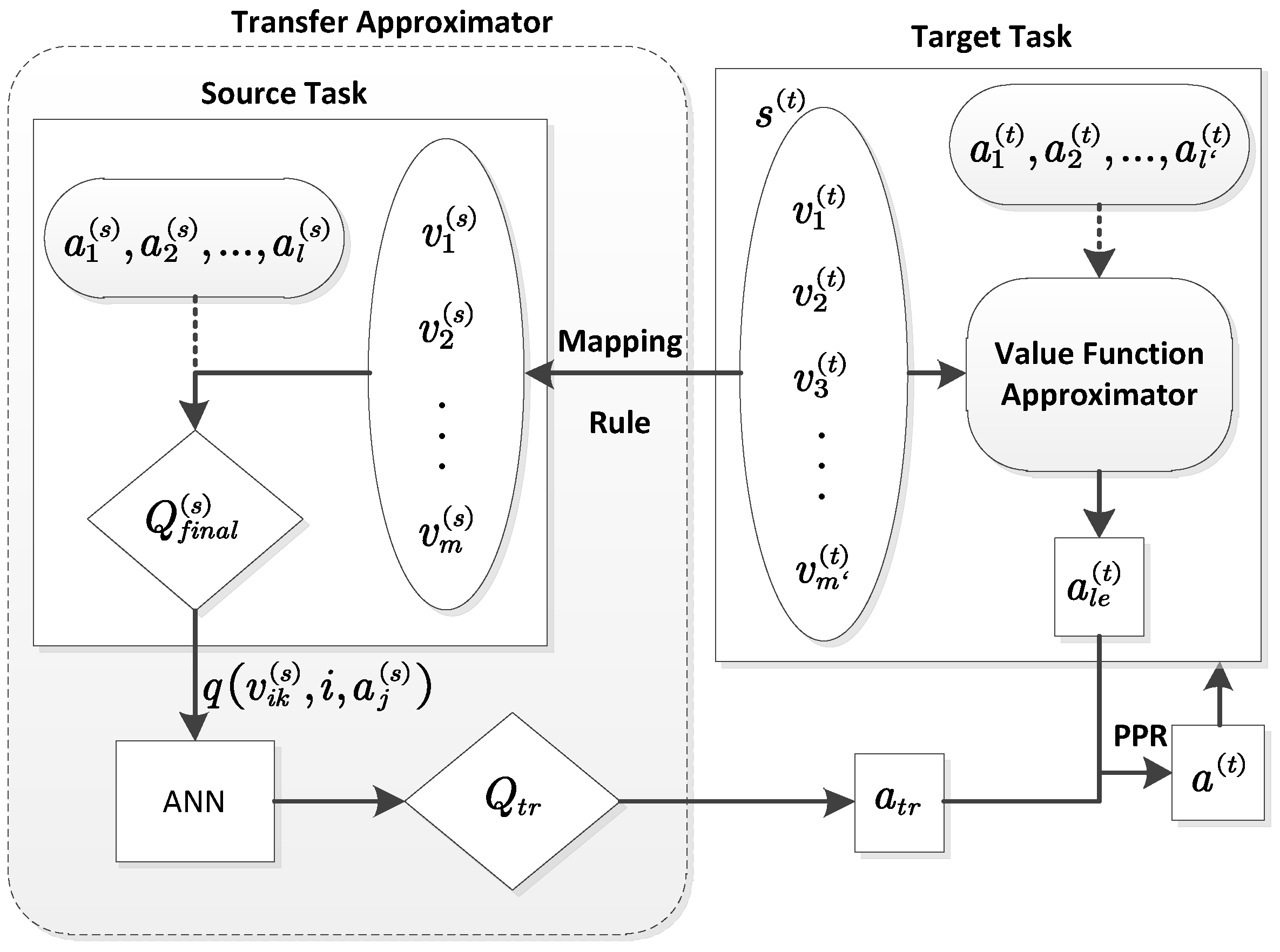
- A new transfer learning framework, called Transfer Learning via Artificial Neural Network Approximator (TL-ANNA), is proposed. It builds an Artificial Neural Network (ANN) transfer approximator to transfer the related knowledge from the source task to the target task and reuses the transferred knowledge based on the PPR scheme. The ANNs are used to predict the quality of actions in the target task, which allows certain errors in collecting source knowledge and increases the robustness of transfer learning. The result from the transfer approximator is combined with the PPR scheme. Without extra parameter training during the RL of the target task, the PPR scheme provides easy integration between transferred knowledge and learned knowledge.
2. Literature Review
3. Reinforcement Transfer Learning
3.1. Reinforcement Learning
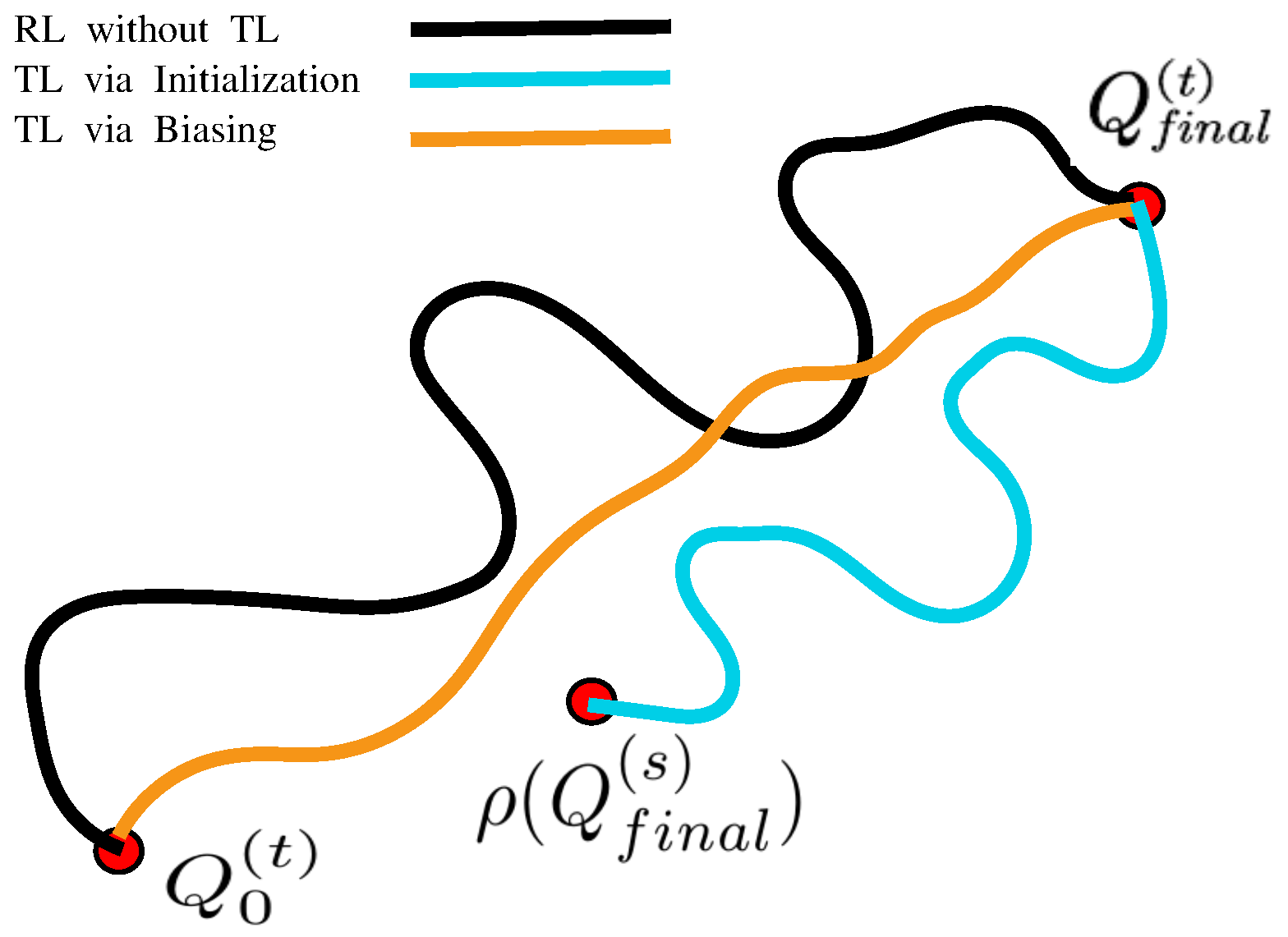
3.2. Transfer Learning
4. Transfer Learning via ANN Approximator
| Algorithm 1 The process in an ANN transfer approximator |
| Input: Output: 1: for each feature in do 2: Map into a set of features () in the source task 3: for each feature and each action do 4: Activate related source knowledge (q-value function from ) 5: end for 6: end for 7: Use all the q-value functions obtained as the inputs of the ANNs 8: Predict the quality of the target task actions (denoted by ) with ANNs 9: |
- With the use of the transfer approximator, TL-ANNA removes the need of the action mapping in the inter-task mapping. The state feature mapping rule in the transfer approximator can make a better use of the related knowledge in the source task than the typical one-to-one state mapping from a inter-task mapping does. Certain state feature mapping rules in the transfer approximator can even eliminate the human involvement.
- By combining the PPR scheme with the transfer approximator, TL-ANNA can integrate the source knowledge during the RL process, not just before the RL process.
4.1. State Feature Mapping Rules
4.1.1. Full Mapping
4.1.2. Group Mapping
4.2. Construction of the ANNs
| Algorithm 2 The process for obtaining the ANNs of transfer approximator |
| 1: 2: Run the target task 3: for each step t do 4: if then 5: record the tuples 6: else 7: stop the target task 8: end if 9: end for 10: Generate the input samples of the training data 11: Generate the corresponding output samples of the training data 12: Train the ANNs |
4.2.1. Generating Input Samples
4.2.2. Generating Output Samples
4.3. Biasing the Action Selection with PPR Scheme
| Algorithm 3 Biasing Action Selection with PPR Scheme |
| 1: 2: Load source task knowledge 3: for each episode do 4: Initialize the start state with 5: 6: if then 7: random action 8: else 9: if then 10: send to the transfer approximator 11: obtain from the transfer approximator 12: 13: else 14: 15: 16: end if 17: end if 18: 19: Execute action 20: Observe new state and reward 21: for each step of the episode do 22: 23: Repeat line 6 to line 17 24: 25: Use Sarsa and to update 26: Execute action 27: Observe new state and reward 28: , , , 29: end for 30: 31: end for |
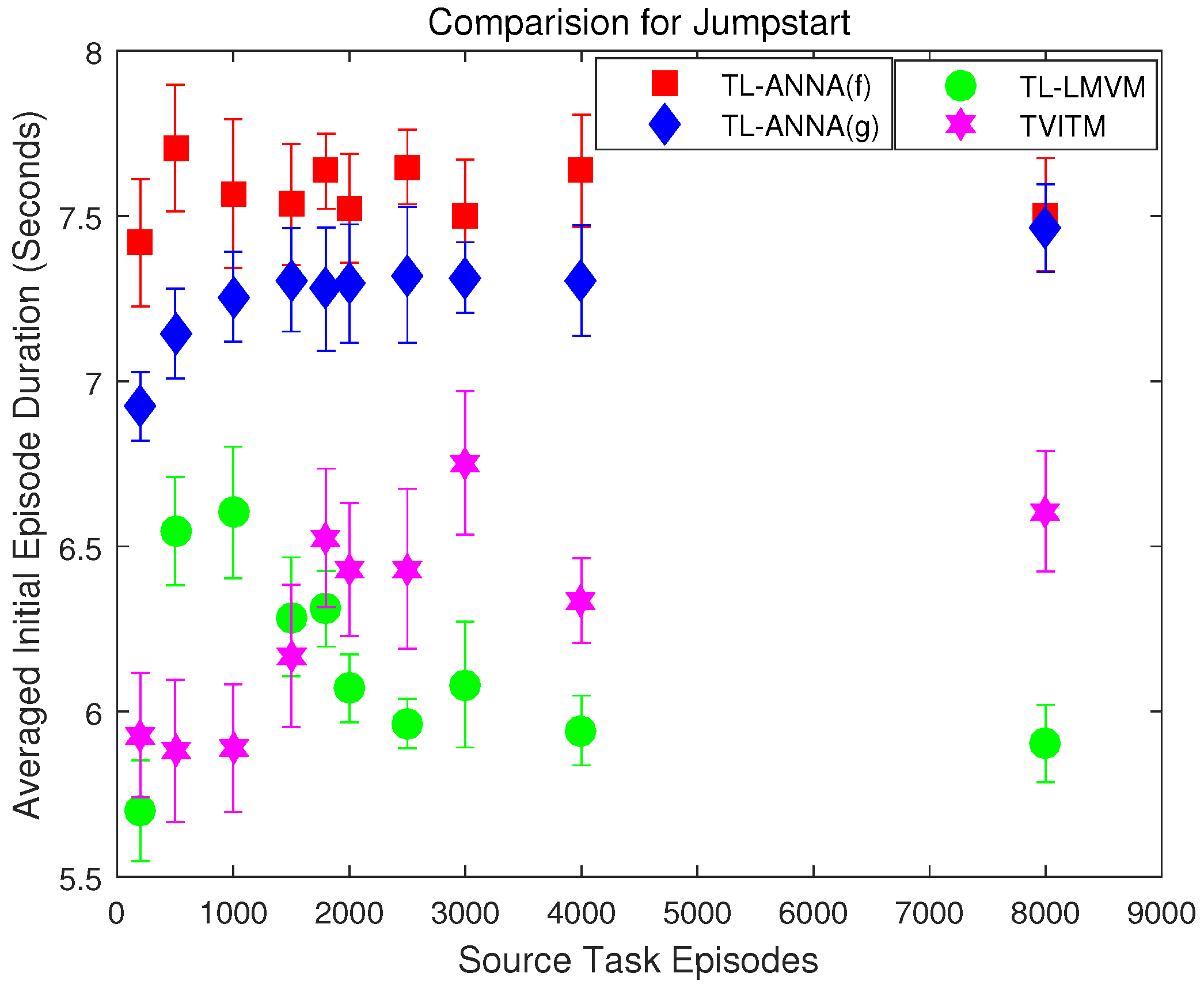
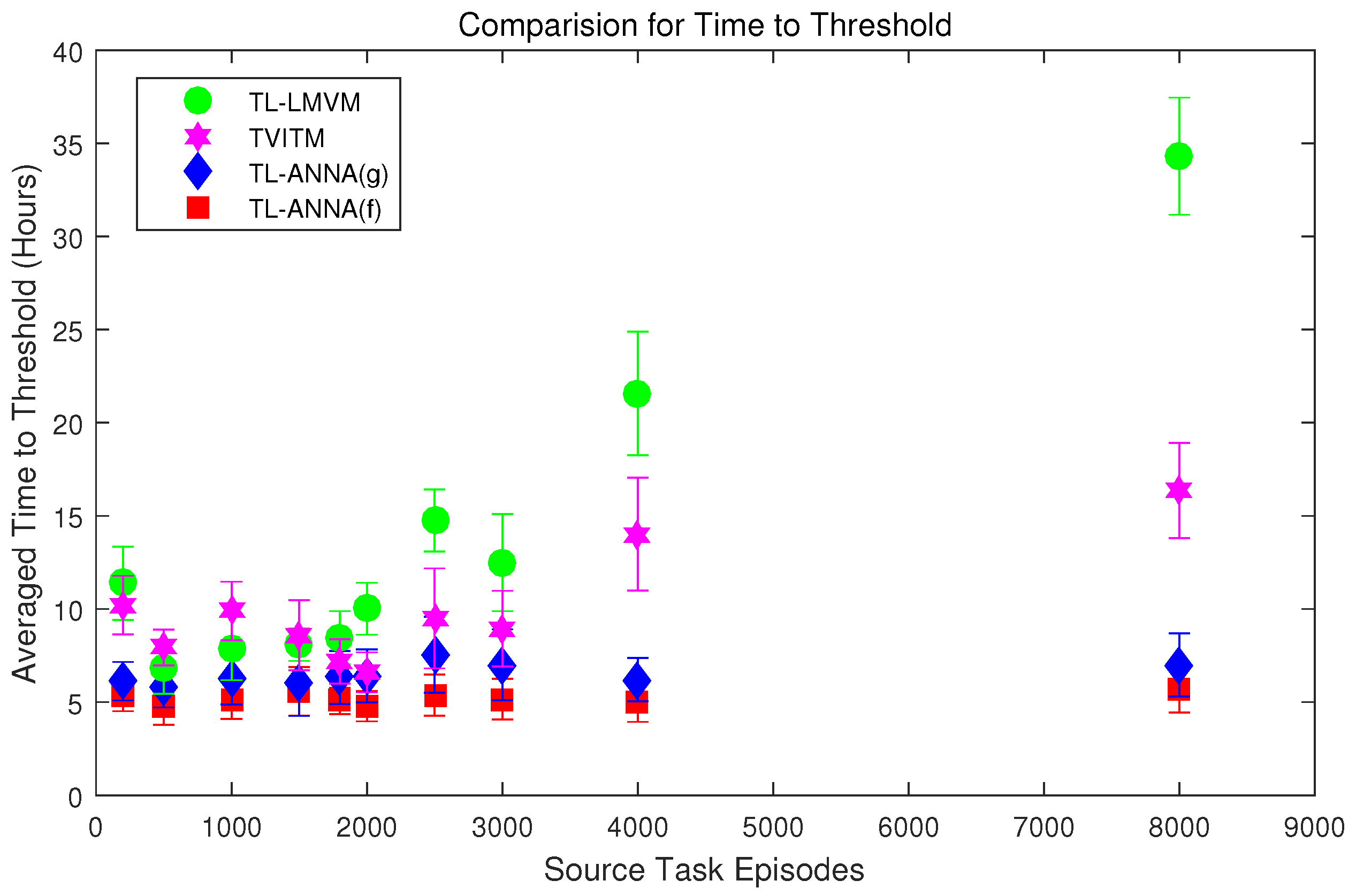
5. Experiments and Results
5.1. Keepaway Task
5.2. TL-ANNA in Keepaway
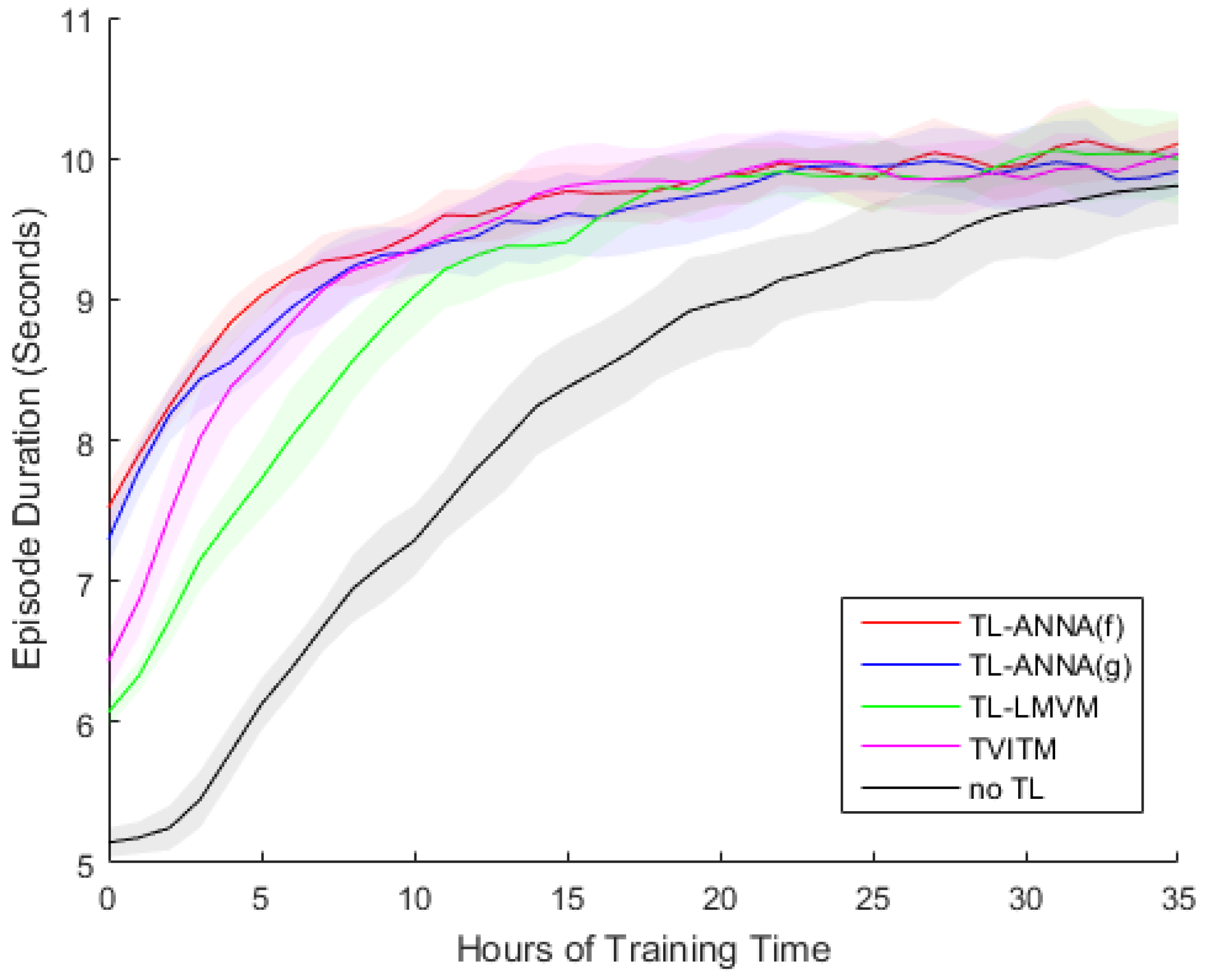
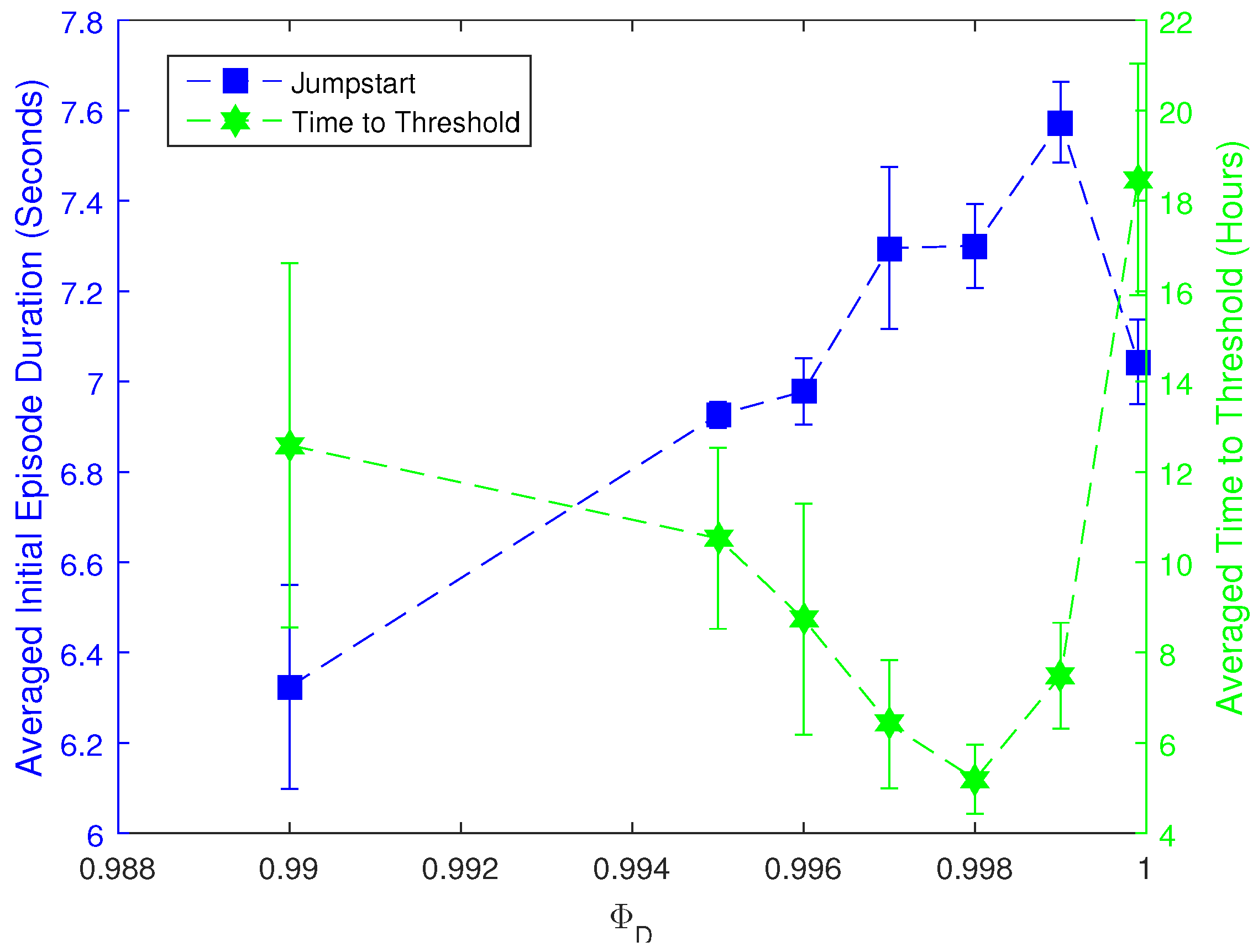
5.3. Experiment Settings and Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Taylor, M.E.; Stone, P.; Liu, Y. Transfer learning via inter-task mappings for temporal difference learning. J. Mach. Learn. Res. 2007, 8, 2125–2167. [Google Scholar]
- Fernández, F.; Veloso, M. Probabilistic Policy Reuse in a Reinforcement Learning Agent. In Proceedings of the Fifth International Joint Conference on Autonomous Agents and Multiagent Systems, Hakodate, Japan, 8–12 May 2006. [Google Scholar]
- Taylor, M.E.; Suay, H.B.; Chernova, S. Integrating reinforcement learning with human demonstrations of varying ability. In Proceedings of the 10th International Conference on Autonomous Agents and Multiagent Systems, Taipei, Taiwan, 2–6 May 2011; pp. 617–624. [Google Scholar]
- Cheng, Q.; Wang, X.; Shen, L. Transfer learning via linear multi-variable mapping under reinforcement learning framework. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 8795–8799. [Google Scholar]
- Taylor, M.E.; Kuhlmann, G.; Stone, P. Autonomous transfer for reinforcement learning. In Proceedings of the Seventh International Joint Conference on Autonomous Agents and Multiagent Systems, Estoril, Portugal, 12–16 May 2008. [Google Scholar]
- da Silva, F.L.; Costa, A.H.R. Towards Zero-Shot Autonomous Inter-Task Mapping through Object-Oriented Task Description. In Proceedings of the Transfer in Reinforcement Learning Workshop (TiRL) in AAMAS 2017, São Paulo, Brazil, 8–12 May 2017; pp. 1–10. [Google Scholar]
- Cheng, Q.; Wang, X.; Shen, L. An Autonomous Inter-task Mapping Learning Method via Artificial Neural Network for Transfer Learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Biomimetics, Macao, China, 5–8 December 2017; pp. 768–773. [Google Scholar]
- Wang, Z.; Taylor, M.E. Effective Transfer via Demonstrations in Reinforcement Learning: A Preliminary Study. In Proceedings of the 2016 AAAI Spring Symposium Series, Palo Alto, CA, USA, 21–23 March 2016; The AAAI Press: Palo Alto, CA, USA, 2016. [Google Scholar]
- Brys, T.; Harutyunyan, A.; Taylor, M.E.; Nowé, A. Policy transfer using reward shaping. In Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems, Istanbul, Turkey, 4–8 May 2015; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2015; pp. 181–188. [Google Scholar]
- Du, Z.; Wang, C.; Sun, Y.; Wu, G. Context-Aware Indoor VLC/RF Heterogeneous Network Selection: Reinforcement Learning with Knowledge Transfer. IEEE Access 2018, 6, 33275–33284. [Google Scholar] [CrossRef]
- Zhan, Y.; Taylor, M.E. Online transfer learning in reinforcement learning domains. arXiv, 2015; arXiv:1507.00436. [Google Scholar]
- Koga, M.L.; Freire, V.; Costa, A.H. Stochastic abstract policies: Generalizing knowledge to improve reinforcement learning. IEEE Trans. Cybern. 2015, 45, 77–88. [Google Scholar] [CrossRef] [PubMed]
- Laflamme, S. Transfer in Reinforcement Learning: An Empirical Comparison of Methods in Mario AI. Master’s Thesis, McGill University Libraries, Montreal, QC, Canada, 2017. [Google Scholar]
- Laroche, R.; Barlier, M. Transfer Reinforcement Learning with Shared Dynamics. In Proceedings of the AAAI-17—Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 2147–2153. [Google Scholar]
- Wang, Y.; Meng, Q.; Cheng, W.; Liug, Y.; Ma, Z.M.; Liu, T.Y. Target Transfer Q-Learning and Its Convergence Analysis. arXiv, 2018; arXiv:1809.08923. [Google Scholar]
- Faudzi, A.A.M.; Takano, H.; Murata, J. Transfer Learning Through Policy Abstraction Using Learning Vector Quantization. J. Telecommun. Electron. Comput. Eng. 2018, 10, 163–168. [Google Scholar]
- Matsubara, T.; Norinaga, Y.; Ozawa, Y.; Cui, Y. Policy Transfer from Simulations to Real World by Transfer Component Analysis. In Proceedings of the 14th IEEE International Conference on Automation Science and Engineering, Munich, Germany, 20–24 August 2018. [Google Scholar]
- Schwab, D.; Zhu, Y.; Veloso, M. Zero Shot Transfer Learning for Robot Soccer. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, Stockholm, Sweden, 10–15 July 2018; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2018; pp. 2070–2072. [Google Scholar]
- Gupta, A.; Devin, C.; Liu, Y.; Abbeel, P.; Levine, S. Learning invariant feature spaces to transfer skills with reinforcement learning. arXiv, 2017; arXiv:1703.02949. [Google Scholar]
- Lehnert, L.; Tellex, S.; Littman, M.L. Advantages and Limitations of using Successor Features for Transfer in Reinforcement Learning. arXiv, 2017; arXiv:1708.00102. [Google Scholar]
- Shoeleh, F.; Asadpour, M. Graph based skill acquisition and transfer learning for continuous reinforcement learning domains. Pattern Recognit. Lett. 2017, 87, 104–116. [Google Scholar] [CrossRef]
- Joshi, G.; Chowdhary, G. Cross-Domain Transfer in Reinforcement Learning using Target Apprentice. arXiv, 2018; arXiv:1801.06920. [Google Scholar]
- Kelly, S.; Heywood, M.I. Knowledge Transfer from Keepaway Soccer to Half-field Offense through Program Symbiosis: Building Simple Programs for a Complex Task. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation, Madrid, Spain, 11–15 July 2015; ACM: New York, NY, USA, 2015; pp. 1143–1150. [Google Scholar]
- Didi, S.; Nitschke, G. Multi-agent behavior-based policy transfer. In Proceedings of the 19th European Conference on the Applications of Evolutionary Computation, Porto, Portugal, 30 March–1 April 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 181–197. [Google Scholar]
- Rajendran, J.; Prasanna, P.; Ravindran, B.; Khapra, M. Adaapt: A deep architecture for adaptive policy transfer from multiple sources. arXiv, 2015; arXiv:1510.02879. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Albus, J.S. Brains, Behaviour, and Robotics; Byte Books: Perterborough, NH, USA, 1981. [Google Scholar]
- Chung, I.H.; Sainath, T.N.; Ramabhadran, B.; Picheny, M.; Gunnels, J.; Austel, V.; Chauhari, U.; Kingsbury, B. Parallel deep neural network training for big data on blue gene/q. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1703–1714. [Google Scholar] [CrossRef]
- Połap, D.; Woźniak, M.; Wei, W.; Damaševičius, R. Multi-threaded learning control mechanism for neural networks. Future Gener. Comput. Syst. 2018, 87, 16–34. [Google Scholar] [CrossRef]
- Fernández, F.; García, J.; Veloso, M. Probabilistic policy reuse for inter-task transfer learning. Robot. Auton. Syst. 2010, 58, 866–871. [Google Scholar] [CrossRef]
- Shi, H.; Lin, Z.; Hwang, K.S.; Yang, S.; Chen, J. An Adaptive Strategy Selection Method With Reinforcement Learning for Robotic Soccer Games. IEEE Access 2018, 6, 8376–8386. [Google Scholar] [CrossRef]
- Stone, P.; Kuhlmann, G.; Taylor, M.E.; Liu, Y. Keepaway soccer: From machine learning testbed to benchmark. In Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2005; pp. 93–105. [Google Scholar]
- Taylor, M.E.; Stone, P. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group # | Meaning | Total Number | Range | Type |
|---|---|---|---|---|
| 1 | distance from a keeper to the center | x | distance | |
| 2 | distance from a taker to the center | y | distance | |
| 3 | distance from a keeper to the keeper | distance | ||
| 4 | distance from a taker to the keeper | y | distance | |
| 5 | minimal distance from a keeper without ball to takers | distance | ||
| 6 | minimal angle between a keeper and a taker whose vertex is at | angle |
| Group | Target Task Features | Souce Task Features |
|---|---|---|
| 0 | ||
| 1 | ,, | , |
| 2 | ,, | , |
| 3 | ,, | , |
| 4 | ,, | , |
| 5 | ,, | , |
| 6 | ,, | , |
| 3vs.2 Episodes | Training Time (Seconds) | Performance (MSE) | ||
|---|---|---|---|---|
| ANN-g | ANN-f | ANN-g | ANN-f | |
| 200 | 15 | 455 | 0.0502 | 0.0518 |
| 500 | 26 | 425 | 0.0491 | 0.0516 |
| 1000 | 4 | 424 | 0.0503 | 0.0515 |
| 1500 | 33 | 406 | 0.0498 | 0.0515 |
| 1800 | 33 | 390 | 0.0495 | 0.0515 |
| 2000 | 14 | 426 | 0.0493 | 0.0514 |
| 2500 | 14 | 495 | 0.0500 | 0.0513 |
| 3000 | 35 | 434 | 0.0494 | 0.0514 |
| 4000 | 25 | 392 | 0.0495 | 0.0514 |
| 8000 | 4 | 782 | 0.0499 | 0.0514 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Q.; Wang, X.; Niu, Y.; Shen, L. Reusing Source Task Knowledge via Transfer Approximator in Reinforcement Transfer Learning. Symmetry 2019, 11, 25. https://doi.org/10.3390/sym11010025
Cheng Q, Wang X, Niu Y, Shen L. Reusing Source Task Knowledge via Transfer Approximator in Reinforcement Transfer Learning. Symmetry. 2019; 11(1):25. https://doi.org/10.3390/sym11010025
Chicago/Turabian StyleCheng, Qiao, Xiangke Wang, Yifeng Niu, and Lincheng Shen. 2019. "Reusing Source Task Knowledge via Transfer Approximator in Reinforcement Transfer Learning" Symmetry 11, no. 1: 25. https://doi.org/10.3390/sym11010025
APA StyleCheng, Q., Wang, X., Niu, Y., & Shen, L. (2019). Reusing Source Task Knowledge via Transfer Approximator in Reinforcement Transfer Learning. Symmetry, 11(1), 25. https://doi.org/10.3390/sym11010025