Emotion Classification Using a Tensorflow Generative Adversarial Network Implementation



Abstract
1. Introduction
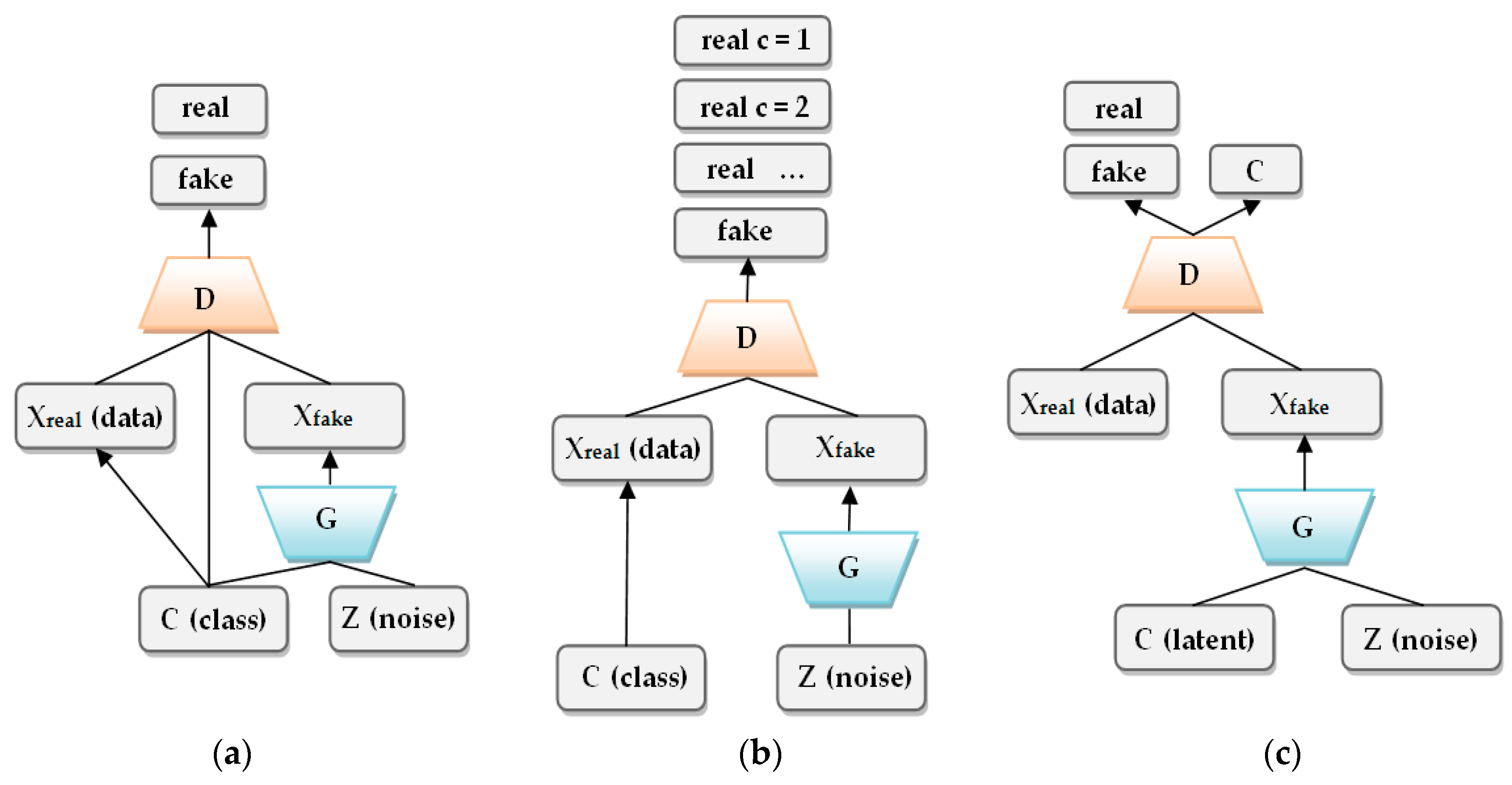
- Class conditional models: condition the G to produce an image in a specific class and use the D to assert whether the image is fake or real (two output classes)
- N-output classes [27]: Use the D to classify the input image in various classes; ideally, the generated images should have a low level of confidence for the output class. The semi-supervised learning approach almost leads to the best performance in classifying images containing numbers or different objects. Unfortunately, the unsupervised approach has proven a weak accuracy in multiple-class classification.
- N+1-output classes [29,30,31]: Use the N-classes approach but also have a distinct class for generated images. The semi-supervised trained classifier in Reference [29] is a more data-efficient version of the regular GAN, delivering higher quality and requiring less training time. The research has been conducted on the MNIST database (Modified National Institute of Standards and Technology database). The same conclusion was also reached in References [30] and [31] by the creators of the original GAN, but with an expanded dataset containing images of different objects, animals and plants.
2. Related Work
3. Materials and Methods
3.1. Training and Evaluation Phase
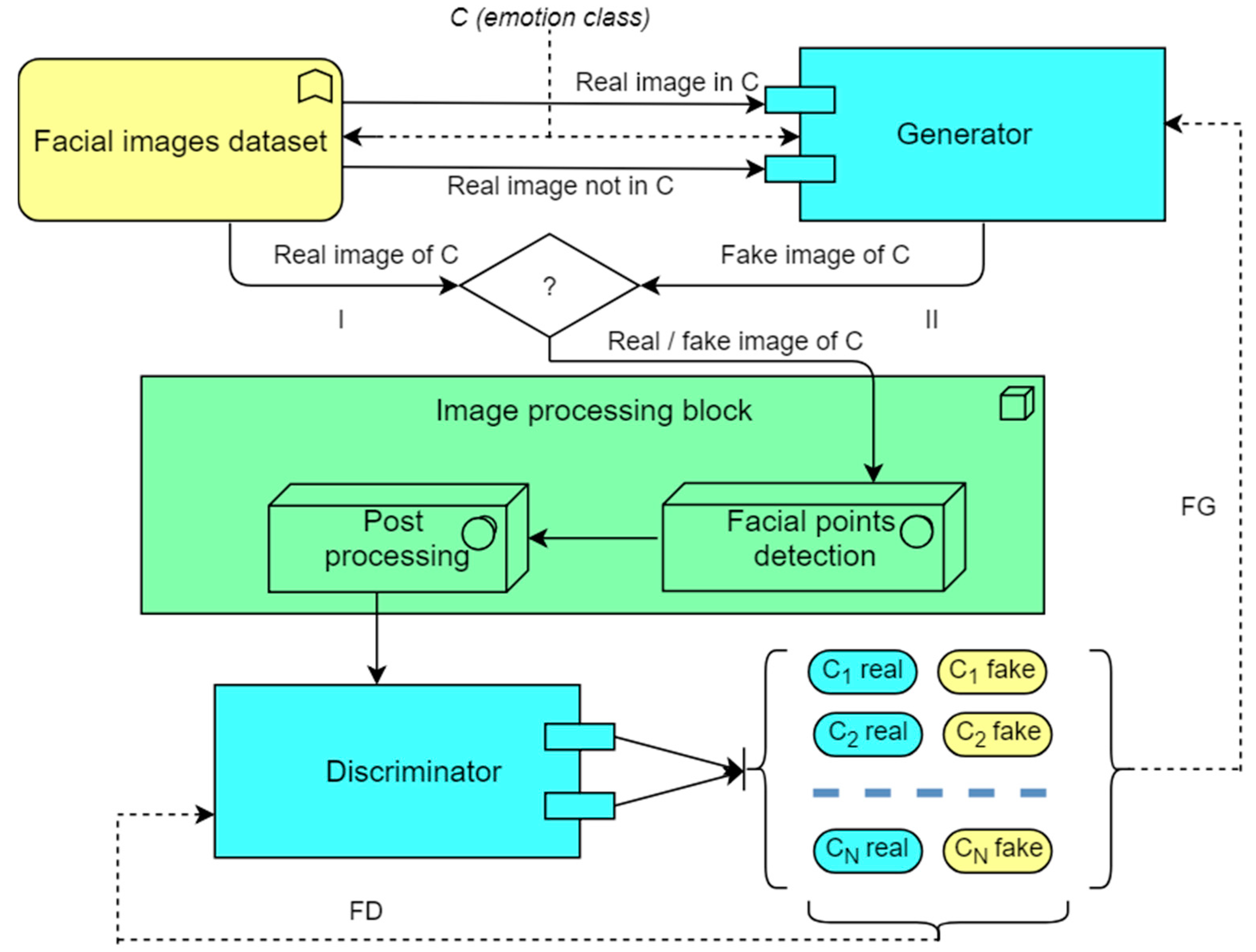
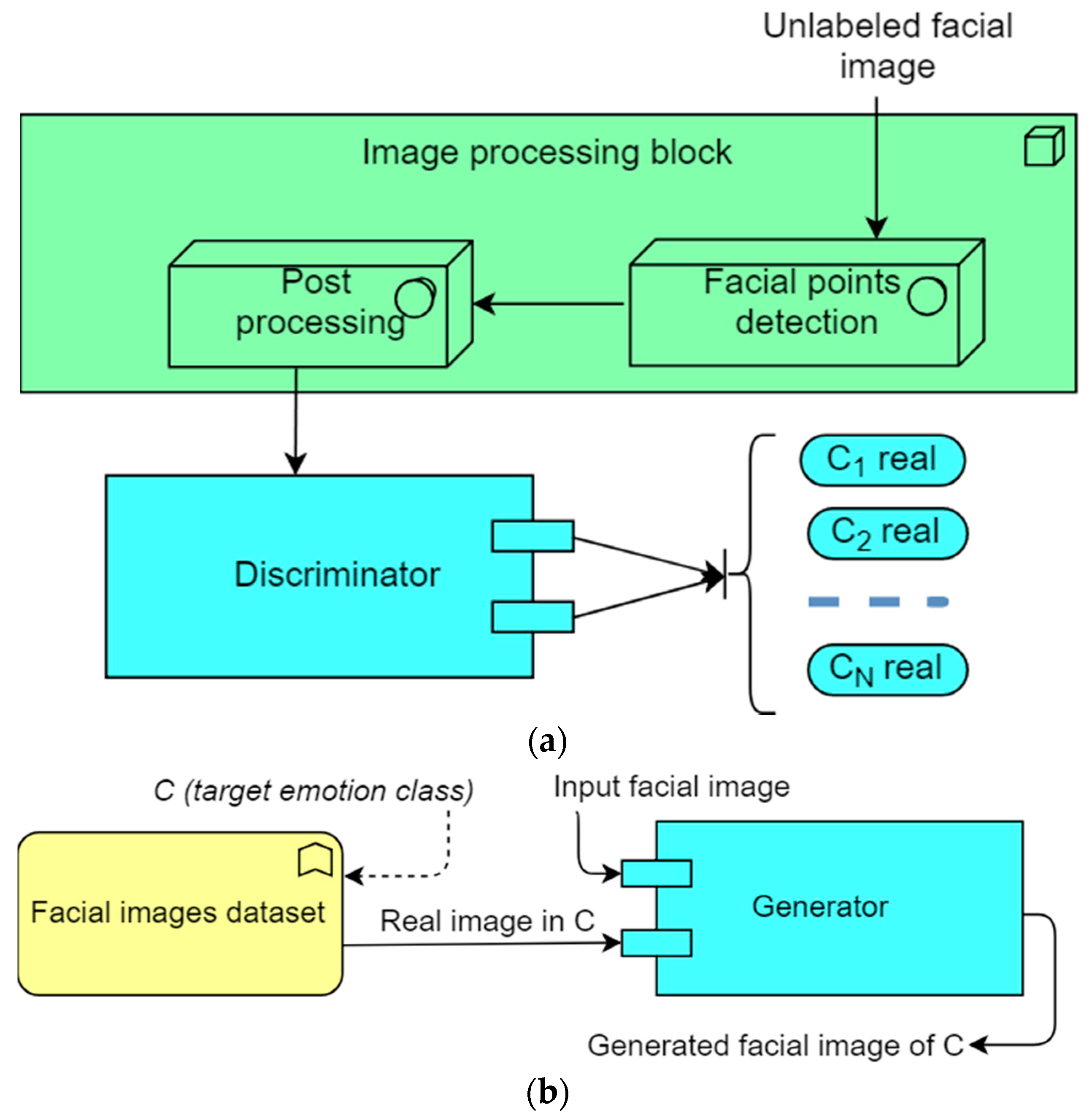
3.1.1. System Architecture
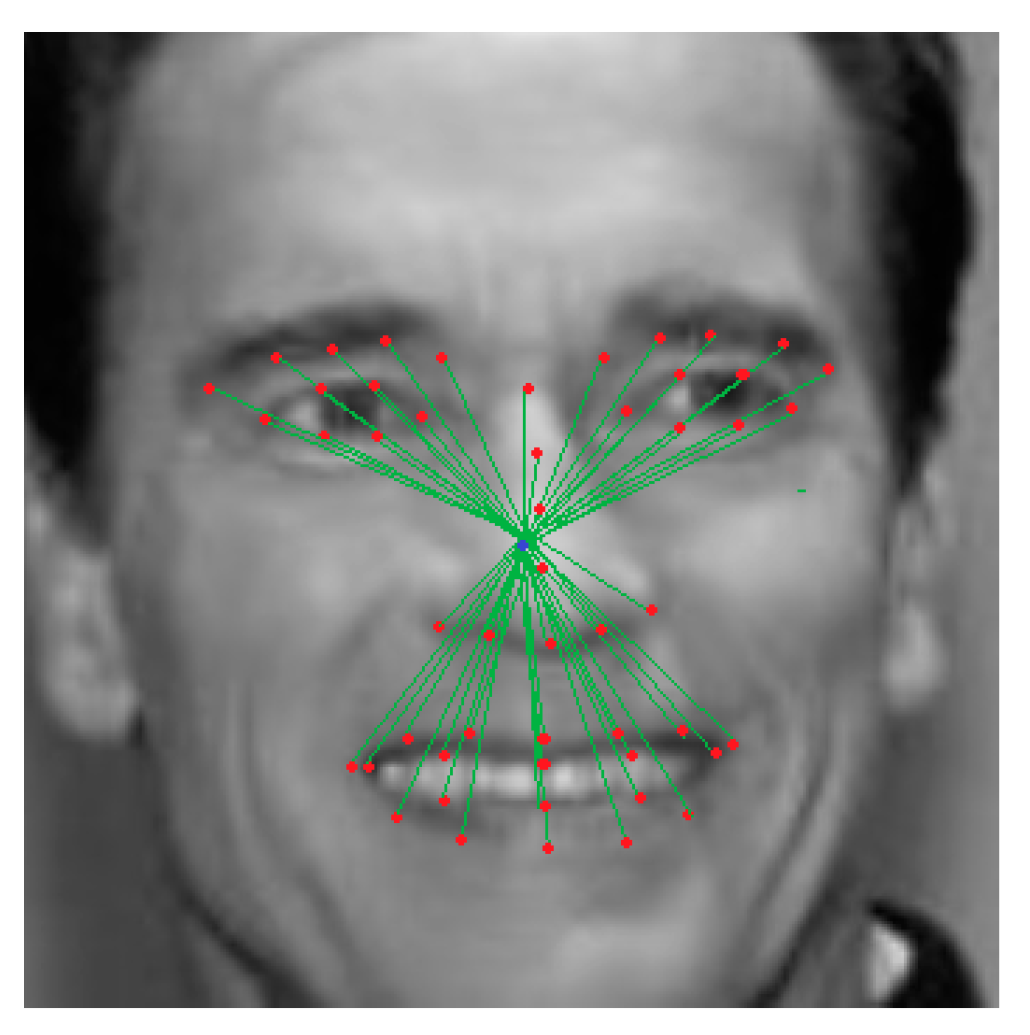
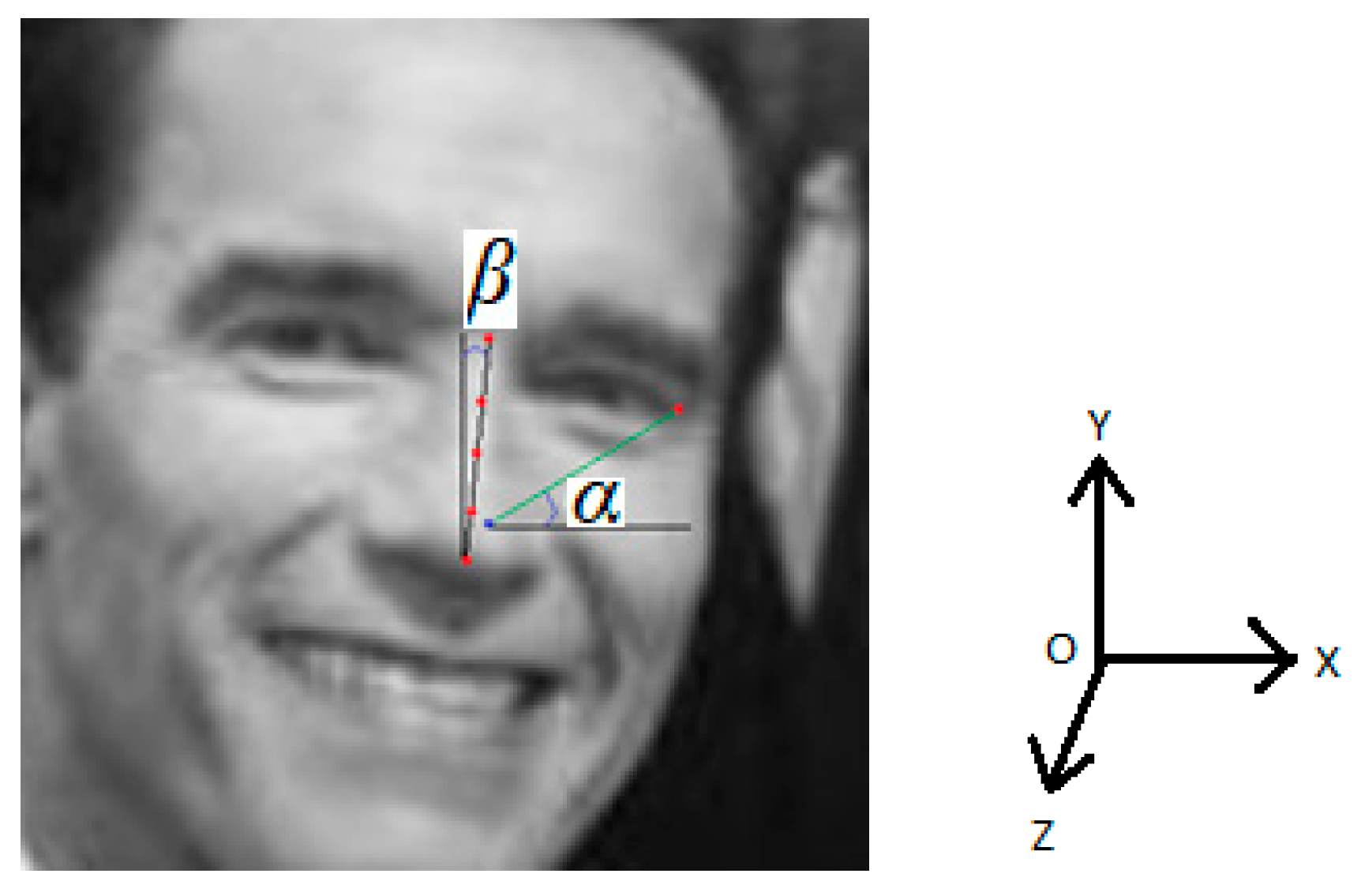
3.1.2. Image Processing Block
- Right eyebrow—points 18, 19, 20, 21 and 22;
- Left eyebrow—points 23, 24, 25, 26 and 27;
- Right eye—points 37, 38, 39, 40, 41 and 42;
- Left eye—points 43, 44, 45,46, 47 and 48;
- Nose—points 28, 29, 30, 31, 32, 33, 34, 35 and 36;
- Mouth:
- ○
- Upper outer lip—points 49, 50, 51, 52, 53, 54, and 55;
- ○
- Upper inner lip—points 61, 62, 63, 64, and 65;
- ○
- Lower inner lip—points 61, 65, 66, 67, and 68;
- ○
- Lower outer lip—points 49, 55, 56, 57, 58, 59, and 60.
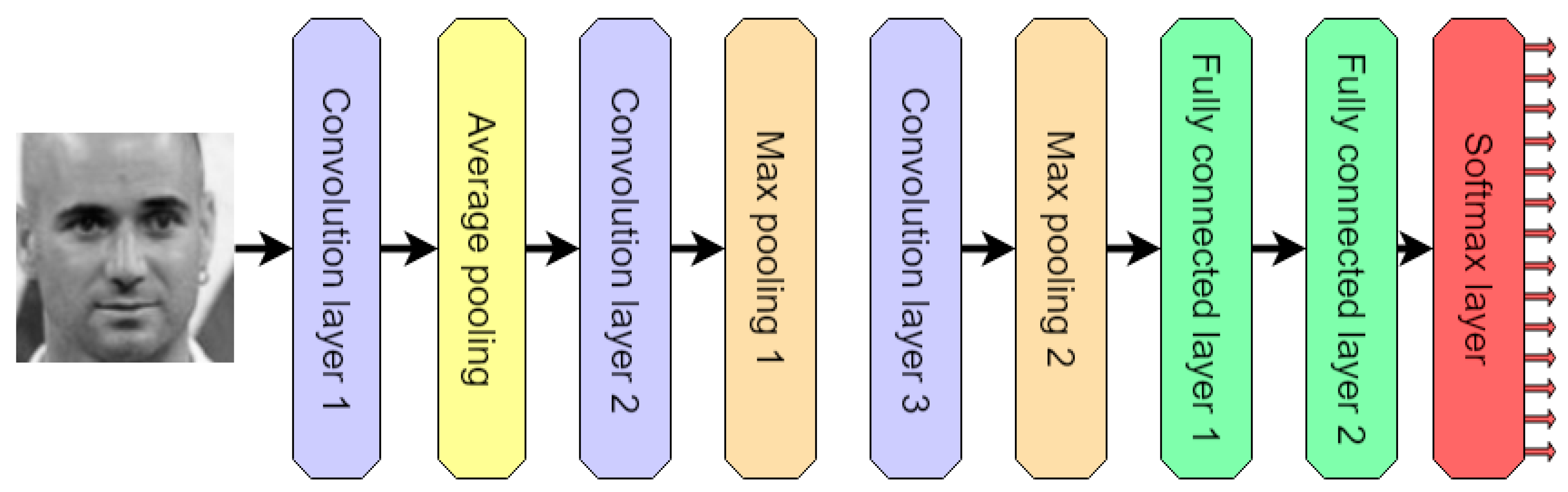
3.1.3. Discriminator
3.1.4. Generator
- Convolutional layers (1a–4a, 1b–4b)
- ○
- 5 × 5 filter functions, stride 1, padding 2 (0-padding)
- ○
- Layers 1 and 2–128 neurons, Layers 3 and 4–256 neurons
- Max pooling layers (1a–4a, 1b–4b) with stride 2 × 2
- Fully connected layers
- ○
- 256 neurons for the encoders, 512 for the decoder
- Deconvolutional (transposed convolution) layers (1–4)
- ○
- 5 × 5 filter functions, stride 1, padding 2 (0-padding)
- ○
- Layers 1 and 2–128 neurons, Layers 3 and 4–256 neurons
- Upsampling layers (1–4) with stride 2 × 2
- Leaky ReLU as activation function—gradient 0.15
3.2. Operational Phase
4. Experimental Results
- TP–Number of true positives, positive correctly classified as positive
- TN–Number of true negatives, negative correctly classified as negative
- FP–Number of false positives, negative classified as positive
- FN–Number of false negatives, positive classified as negative
- Only real images of the class considered as positive (R)
- Only fake images of the class considered as positives (F)
- All images of the class (both real and fake) considered as positive (R + F)
- Real/fake differentiation (real images are positive, fake images are negative, regardless of the class) (R/F)
5. Discussion
6. Conclusions and Further Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wiskott, L.; Kruger, N.; Von Der Malsburg, C. Face recognition by elastic bunch graph matching. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 775–779. [Google Scholar] [CrossRef]
- Face Recognition Market by Component, Technology, Use Case, End-User, and Region–Global Forecast to 2022. Available online: https://www.marketsandmarkets.com/Market-Reports/facial-recognition-market-995.html (accessed on 21 March 2018).
- Yang, M.H.; Kriegman, D.J.; Ahuja, N. Detecting Faces in Images: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 19, 775–779. [Google Scholar]
- Gupta, V.; Sharma, D. A study of various face detection methods. Int. J. Adv. Res. Comput. Commun. Eng. 2014, 3, 6694–6697. [Google Scholar]
- Hiyam, H.; Beiji, Z.; Majeed, R. A survey of feature base methods for human face detection. Int. J. Control Autom. 2015, 8, 61–77. [Google Scholar]
- Smrti, T.; Nitin, M. Detection, segmentation and recognition of face and its features using neural network. J. Biosens. Bioelectron. 2016, 7. [Google Scholar] [CrossRef]
- Le, T.H. Applying Artificial Neural Networks for Face Recognition. Adv. Artif. Neural Syst. 2011. [Google Scholar] [CrossRef]
- Farfade, S.S.; Saberian, M.; Li, L.J. Multiview face detection using deep convolutional neural networks. In Proceedings of the 5th International Conference on Multimedia Retrieval (ICMR), Shanghai, China, 23–26 June 2015. [Google Scholar]
- Martinez-Gonzalez, A.N.; Ayala-Ramirez, V. Real time face detection using neural networks. In Proceedings of the 10th Mexican International Conference on Artificial Intelligence, Puebla, Mexico, 26 November–4 December 2011. [Google Scholar]
- Kasar, M.M.; Bhattacharyya, D.; Kim, T.H. Face recognition using neural network: A review. Int. J. Secur. Appl. 2016, 10, 81–100. [Google Scholar] [CrossRef]
- Al-Allaf, O.N. Review of face detection systems based artificial neural networks algorithms. Int. J. Multimed. Appl. 2014, 6. [Google Scholar] [CrossRef]
- Prihasto, B.; Choirunnisa, S.; Nurdiansyah, M.I.; Mathulapragsan, S.; Chu, V.C.; Chen, S.H.; Wang, J.C. A survey of deep face recognition in the wild. In Proceedings of the 2016 International Conference on Orange Technologies, Melbourne, Australia, 17–20 December 2016. [Google Scholar] [CrossRef]
- Fu, Z.P.; Zhang, Y.N.; Hou, H.Y. Survey of deep learning in face recognition. In Proceedings of the 2014 International Conference on Orange Technologies, Xi’an, China, 20–23 September 2014. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep face recognition: A survey. arXiv, 2018; arXiv:1804.06655. [Google Scholar]
- Kim, Y.G.; Lee, W.O.; Kim, K.W.; Hong, H.G.; Park, K.R. Performance enhancement of face recognition in smart TV using symmetrical fuzzy-based quality assessment. Symmetry 2015, 7, 1475–1518. [Google Scholar] [CrossRef]
- Hong, H.G.; Lee, W.O.; Kim, Y.G.; Kim, K.W.; Nguyen, D.T.; Park, K.R. Fuzzy system-based face detection robust to in-plane rotation based on symmetrical characteristics of a face. Symmetry 2016, 8, 75. [Google Scholar] [CrossRef]
- Sharifi, O.; Eskandari, M. Cosmetic Detection framework for face and iris biometrics. Symmetry 2018, 10, 122. [Google Scholar] [CrossRef]
- Li, Y.; Song, L.; He, R.; Tan, T. Anti-Makeup: Learning a bi-level adversarial network for makeup-invariant face verification. arXiv, 2018; arXiv:1709.03654. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversial Nets. arXiv, 2014; arXiv:1406.2661. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. arXiv, 2016; arXiv:1610.09585. [Google Scholar]
- Gauthier, J. Conditional Generative Adversarial Nets for Convolutional Face Generation. 2015. Available online: http://cs231n.stanford.edu/reports/2015/pdfs/jgauthie_final_report.pdf (accessed on 15 April 2018).
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. arXiv, 2017; arXiv:1702.01983. [Google Scholar]
- Huang, E.; Zhang, S.; Li, T.; He, R. Beyond face rotation: Global and local perception gan for photorealistic and identity preserving frontal view synthesis. arXiv, 2017; arXiv:1704.04086. [Google Scholar]
- Li, Z.; Luo, Y. Generate identity-preserving faces by generative adversarial networks. arXiv, 2017; arXiv:1706.03227. [Google Scholar]
- Zhou, H.; Sun, J.; Yacoob, Y.; Jacobs, D.W. Label Denoising Adversarial Network (LDAN) for Inverse Lighting of Face Images. arXiv, 2017; arXiv:1709.01993. [Google Scholar]
- Zhang, W.; Shu, Z.; Samaras, D.; Chen, L. Improving heterogeneous face recognition with conditional adversial networks. arXiv, 2017; arXiv:1709.02848. [Google Scholar]
- Springenberg, J.T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv, 2015; arXiv:1511.06390. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Odena, A. Semi-supervised learning with generative adversarial networks. arXiv, 2016; arXiv:1606.01583. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training Gans. arXiv, 2016; arXiv:1606.03498. [Google Scholar]
- Papernot, N.; Abadi, M.; Erlingsson, U.; Goodfellow, I.; Talwar, K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv, 2016; arXiv:1610.05755. [Google Scholar]
- Fredrickson, B.L. Cultivating positive emotions to optimize health and well-being. Prev. Treat. 2003, 3. [Google Scholar] [CrossRef]
- Fredrickson, B.L.; Levenson, R.W. Positive emotions speed recovery from the cardiovascular sequelae of negative emotions. Cogn. Emot. 1998, 12, 191–220. [Google Scholar] [CrossRef] [PubMed]
- Gallo, L.C.; Matthews, K.A. Understanding the association between socioeconomic status and physical health: Do negative emotions play a role? Psychol. Bull. 2003, 129, 10–51. [Google Scholar] [CrossRef] [PubMed]
- Todaro, J.F.; Shen, B.J.; Niura, R.; Sprio, A.; Ward, K.D. Effect of negative emotions on frequency of coronary heart disease (The Normative Aging Study). Am. J. Cardiol. 2003, 92, 901–906. [Google Scholar] [CrossRef]
- Huang, Y.; Khan, S.M. DyadGAN: Generating facial expressions in dyadic interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Zhou, Y.; Shi, B.E. Photorealistic facial expression synthesis by the conditional difference adversarial autoencoder. arXiv, 2017; arXiv:1708.09126. [Google Scholar]
- Lu, Y.; Tai, Y.W.; Tang, C.K. Conditional CycleGAN for attribute guided face image generation. arXiv, 2017; arXiv:1705.09966. [Google Scholar]
- Ding, H.; Sricharan, K.; Chellappa, R. ExprGAN: Facial expression editing with controllable expression intensity. arXiv, 2017; arXiv:1709.03842. [Google Scholar]
- Xu, R.; Zhou, Z.; Zhang, W.; Yu, Y. Face transfer with generative adversarial network. arXiv, 2017; arXiv:1710.06090. [Google Scholar]
- Nojavanasghari, B.; Huang, Y.; Khan, S.M. Interactive generative adversarial networks for facial expression generation in dyadic interactions. arXiv, 2018; arXiv:1801.09092. [Google Scholar]
- Tian, Y.L.; Kanage, T.; Cohn, J. Robust Lip Tracking by Combining Shape, Color and Motion. In Proceedings of the 4th Asian Conference on Computer Vision, Taipei, Taiwan, 8–11 January 2000. [Google Scholar]
- Agarwal, M.; Krohn-Grimberghe, A.; Vyas, R. Facial key points detection using deep convolutional neural network—Naimishnet. arXiv, 2017; arXiv:1710.00977. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Suh, K.H.; Kim, Y.; Lee, E.C. Facial feature movements caused by various emotions: Differences according to sex. Symmetry 2016, 8, 86. [Google Scholar] [CrossRef]
- Dachapally, P.R. Facial emotion detection using convolutional neural networks and representational autoencoder units. arXiv, 2017; arXiv:1706.01509. [Google Scholar]
- Lyons, M.J.; Kamachi, M.; Gyoba, J. Japanese Female Facial Expressions (JAFFE). Database of Digital Images. 1997. Available online: http://www.kasrl.org/jaffe.html (accessed on 15 April 2018).
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Workshop on Faces in ’RealLife’ Images: Detection, Alignment, and Recognition: Marseille, France, 2008. [Google Scholar]
- Zhu, X.; Liu, Y.; Qin, Z.; Li, J. Data augmentation in emotion classification using generative adversarial networks. arXiv, 2017; arXiv:1711.00648. [Google Scholar]
- Facial Expression Recognition (FER2013) Dataset. Available online: https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data (accessed on 19 October 2017).
- Lee, K.W.; Hong, H.G.; Park, K.R. Fuzzy system-based fear estimation based on the symmetrical characteristics of face and facial feature points. Symmetry 2017, 9, 102. [Google Scholar] [CrossRef]
- Al-Shabi, M.; Cheah, W.P.; Connie, T. Facial expression recognition using a hybrid CNN-SIFT aggregator. arXiv, 2016; arXiv:1608.02833. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+); A Complete Dataset for Action Unit and Emotion-Specified Expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Dhal, A.; Goecke, R.; Luvey, S.; Gedeon, T. Static facial expressions in tough; data, evaluation protocol and benchmark. In Proceedings of the IEEE International Conference on Computer Vision ICCV2011, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Mishra, S.; Prasada, G.R.B.; Kumar, R.K.; Sanyal, G. Emotion Recognition through facila gestures—A deep learning approach. In Proceedings of the Fifth International Conference on Mining Intelligence and Knowledge Exploration (MIKE), Hyderabad, India, 13–15 December 2017; pp. 11–21. [Google Scholar]
- Quinn, M.A.; Sivesind, G.; Reis, G. Real-Time Emotion Recognition from Facial Expressions. 2017. Available online: http://cs229.stanford.edu/proj2017/final-reports/5243420.pdf (accessed on 15 April 2018).
- Plutschik, R. The nature of emotions. Am. Sci. 2001, 89, 344. [Google Scholar] [CrossRef]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv, 2016; arXiv:1606.03657. [Google Scholar]
- Dlib Library. Available online: http://blog.dlib.net/2014/08/real-time-face-pose-estimation.html (accessed on 12 November 2017).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Happiness (H) | Sadness (SA) | Anger (A) | Fear (FE) | Disgust (D) | Surprise (SU) | Neutral (N) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | F | R | F | R | F | R | F | R | F | R | F | R | F | ||
| H | R | 911 | 37 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 7 | 21 | 5 |
| F | 27 | 923 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 18 | 7 | 23 | |
| SA | R | 6 | 0 | 704 | 62 | 19 | 3 | 9 | 0 | 55 | 9 | 3 | 0 | 97 | 33 |
| F | 0 | 3 | 57 | 705 | 2 | 11 | 0 | 4 | 7 | 63 | 0 | 1 | 37 | 110 | |
| A | R | 2 | 0 | 5 | 0 | 765 | 65 | 23 | 6 | 54 | 14 | 39 | 15 | 12 | 0 |
| F | 0 | 1 | 0 | 2 | 92 | 771 | 5 | 17 | 12 | 50 | 14 | 25 | 2 | 9 | |
| FE | R | 3 | 0 | 14 | 3 | 21 | 5 | 715 | 83 | 13 | 4 | 62 | 21 | 44 | 12 |
| F | 0 | 0 | 4 | 10 | 5 | 10 | 89 | 719 | 2 | 7 | 19 | 61 | 13 | 51 | |
| D | R | 2 | 0 | 15 | 4 | 67 | 20 | 15 | 4 | 753 | 82 | 9 | 3 | 21 | 5 |
| F | 0 | 0 | 1 | 14 | 19 | 65 | 3 | 18 | 78 | 767 | 3 | 11 | 3 | 18 | |
| SU | R | 78 | 28 | 0 | 0 | 3 | 0 | 58 | 15 | 13 | 3 | 712 | 85 | 5 | 0 |
| F | 22 | 77 | 0 | 0 | 0 | 7 | 18 | 61 | 2 | 17 | 88 | 705 | 1 | 2 | |
| N | R | 74 | 22 | 63 | 15 | 14 | 1 | 17 | 3 | 22 | 3 | 22 | 1 | 683 | 60 |
| F | 12 | 76 | 10 | 52 | 0 | 12 | 1 | 18 | 4 | 21 | 2 | 32 | 64 | 696 | |
| True positive rate (TPR)/sensitivity | False positive rate (FPR) | ||
| True negative rate (TNR)/specificity | False negative rate (FNR) | ||
| Positive prediction value (PPV)/precision | False discovery rate (FDR) | ||
| Negative prediction value (NPV) | Accuracy (ACC) |
| TPR | TNR | PPV | NPV | FPR | FNR | FDR | ACC | ||
|---|---|---|---|---|---|---|---|---|---|
| H | R | 0.911 | 0.982 | 0.801 | 0.993 | 0.018 | 0.089 | 0.199 | 0.977 |
| F | 0.923 | 0.981 | 0.791 | 0.994 | 0.019 | 0.077 | 0.209 | 0.977 | |
| R + F | 0.917 | 0.982 | 0.796 | 0.985 | 0.018 | 0.083 | 0.204 | 0.954 | |
| R/F | 0.951 | 0.964 | 0.963 | 0.951 | 0.036 | 0.049 | 0.037 | 0.9575 | |
| SA | R | 0.704 | 0.987 | 0.806 | 0.977 | 0.013 | 0.296 | 0.194 | 0.966 |
| F | 0.705 | 0.987 | 0.813 | 0.977 | 0.013 | 0.295 | 0.187 | 0.967 | |
| R + F | 0.704 | 0.987 | 0.809 | 0.951 | 0.013 | 0.296 | 0.191 | 0.934 | |
| R/F | 0.893 | 0.897 | 0.896 | 0.893 | 0.103 | 0.107 | 0.104 | 0.895 | |
| A | R | 0.765 | 0.981 | 0.759 | 0.982 | 0.019 | 0.235 | 0.241 | 0.965 |
| F | 0.771 | 0.984 | 0.794 | 0.982 | 0.016 | 0.229 | 0.206 | 0.969 | |
| R + F | 0.768 | 0.983 | 0.776 | 0.961 | 0.017 | 0.232 | 0.224 | 0.933 | |
| R/F | 0.900 | 0.875 | 0.878 | 0.897 | 0.125 | 0.100 | 0.122 | 0.887 | |
| FE | R | 0.715 | 0.982 | 0.750 | 0.978 | 0.018 | 0.285 | 0.250 | 0.962 |
| F | 0.719 | 0.982 | 0.758 | 0.978 | 0.018 | 0.281 | 0.242 | 0.963 | |
| R + F | 0.717 | 0.982 | 0.754 | 0.953 | 0.018 | 0.283 | 0.246 | 0.926 | |
| R/F | 0.872 | 0.869 | 0.868 | 0.87 | 0.131 | 0.128 | 0.132 | 0.865 | |
| D | R | 0.753 | 0.980 | 0.741 | 0.980 | 0.020 | 0.247 | 0.259 | 0.963 |
| F | 0.767 | 0.979 | 0.737 | 0.982 | 0.021 | 0.233 | 0.263 | 0.963 | |
| R + F | 0.760 | 0.979 | 0.739 | 0.958 | 0.021 | 0.240 | 0.261 | 0.927 | |
| R/F | 0.882 | 0.893 | 0.891 | 0.883 | 0.107 | 0.118 | 0.109 | 0.887 | |
| SU | R | 0.712 | 0.978 | 0.716 | 0.977 | 0.022 | 0.288 | 0.284 | 0.959 |
| F | 0.705 | 0.979 | 0.715 | 0.977 | 0.021 | 0.295 | 0.285 | 0.958 | |
| R + F | 0.709 | 0.978 | 0.716 | 0.951 | 0.022 | 0.291 | 0.284 | 0.918 | |
| R/F | 0.869 | 0.869 | 0.869 | 0.869 | 0.131 | 0.131 | 0.131 | 0.869 | |
| N | R | 0.683 | 0.975 | 0.676 | 0.975 | 0.025 | 0.317 | 0.324 | 0.954 |
| F | 0.696 | 0.975 | 0.679 | 0.976 | 0.025 | 0.304 | 0.321 | 0.954 | |
| R + F | 0.690 | 0.975 | 0.678 | 0.948 | 0.025 | 0.310 | 0.322 | 0.908 | |
| R/F | 0.895 | 0.907 | 0.905 | 0.896 | 0.093 | 0.105 | 0.095 | 0.901 | |
| Total | R | 0.749 | 0.981 | 0.750 | 0.980 | 0.019 | 0.251 | 0.250 | 0.749 |
| F | 0.755 | 0.981 | 0.754 | 0.981 | 0.019 | 0.245 | 0.246 | 0.755 | |
| R + F | 0.752 | 0.981 | 0.752 | 0.958 | 0.019 | 0.248 | 0.248 | 0.752 | |
| R/F | 0.894 | 0.896 | 0.895 | 0.894 | 0.104 | 0.106 | 0.105 | 0.829 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caramihale, T.; Popescu, D.; Ichim, L. Emotion Classification Using a Tensorflow Generative Adversarial Network Implementation. Symmetry 2018, 10, 414. https://doi.org/10.3390/sym10090414
Caramihale T, Popescu D, Ichim L. Emotion Classification Using a Tensorflow Generative Adversarial Network Implementation. Symmetry. 2018; 10(9):414. https://doi.org/10.3390/sym10090414
Chicago/Turabian StyleCaramihale, Traian, Dan Popescu, and Loretta Ichim. 2018. "Emotion Classification Using a Tensorflow Generative Adversarial Network Implementation" Symmetry 10, no. 9: 414. https://doi.org/10.3390/sym10090414
APA StyleCaramihale, T., Popescu, D., & Ichim, L. (2018). Emotion Classification Using a Tensorflow Generative Adversarial Network Implementation. Symmetry, 10(9), 414. https://doi.org/10.3390/sym10090414