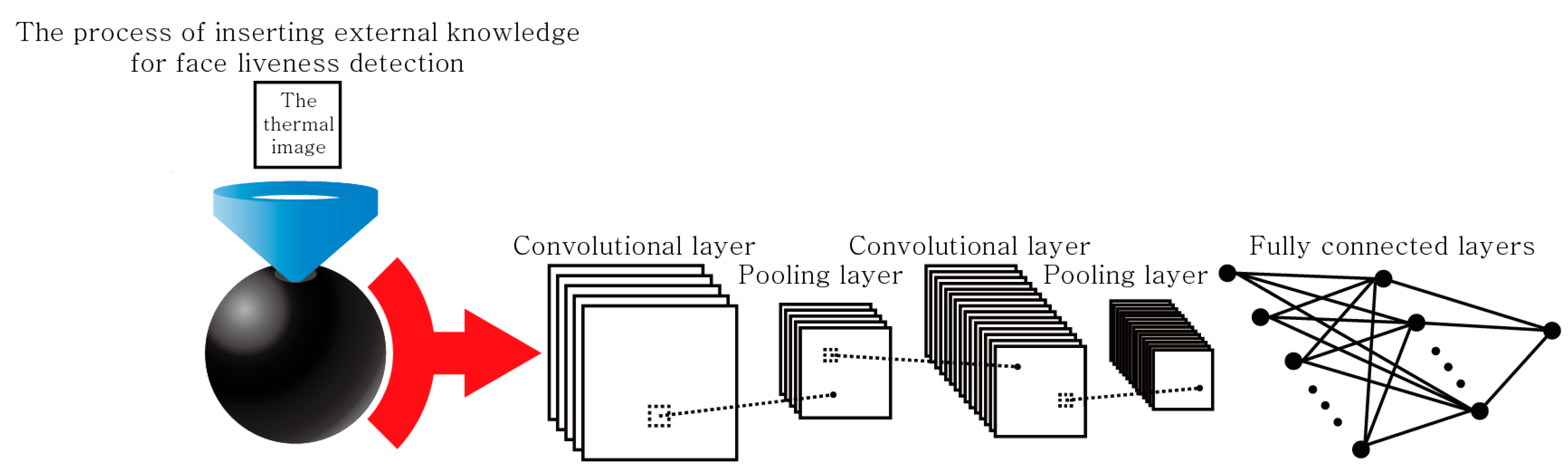
4.1. Data Collection and Experimental Environment Construction
The Flir C3 was used as the camera for collecting data. The camera has two lenses on the front: an RGB lens to obtain RGB images of 640 × 480 pixels and an infrared lens to obtain thermal images of 80 × 60 pixels. The information on the Flir C3 can be found at a website listed in
Supplementary Materials at the end of this paper. We collected one RGB image and one thermal image in each scene to find suitable data for face liveness detection. Since a thermal image is better than an RGB image at night, we took images in indoor residential environments with visible light for accurate performance comparison. There were no conditions for the distance of the object. The faces in the dataset were used with and without a variety of accessories, such as glasses. No matter what, the face is covered by any object, which can cover anything except the eyes, nose, and mouth. We used the function of the Flir C3 that allows for the simultaneous operation of the two lenses. A total of 844 scenes were taken. The actual data used were 844 Excel files with temperature information collected from infrared lens and 2532 Excel files with R, G, and B information collected from RGB lens. In
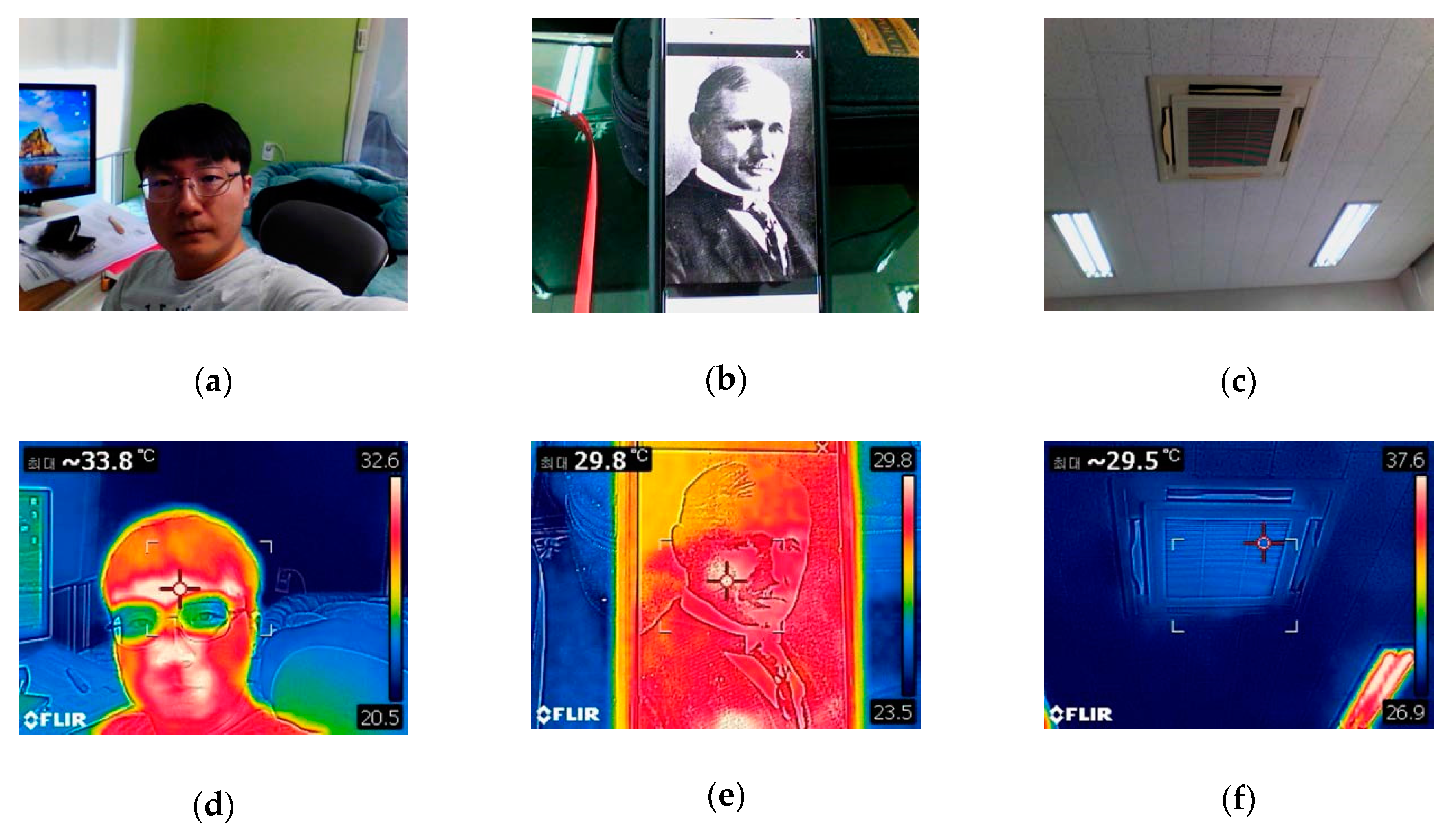
Figure 3, the images in the top row are RGB images, while the images in the bottom row are thermal images.
Figure 3a,d are RGB and thermal images with a real face present, respectively.
Figure 3b,e are RGB and thermal images with a face on a display, respectively.
Figure 3c,f shows images taken of a ceiling air conditioner with no face. In the thermal images, the color is obtained by the software in the thermal camera itself so that the measured temperature can be intuitively grasped visually. In
Figure 3a,b,d,e, it can be seen that the outline of the heat distribution and the heat on the face from the display differ from those of the real face. The RGB face liveness detection dataset jongwoo (RFLDDJ) we created and the thermal face liveness detection dataset jongwoo (TFLDDJ) we created are available on the internet. In NUAA [
8], the whole picture is completely filled with faces. However, in the RGB dataset we created, people and objects were shot in indoor living environments in order to increase the level of difficulty. In other words, multiple objects coexist in a single image in the datasets we made. The data are more difficult because a more general situation is assumed. The information of the datasets can be found at websites listed in the
Supplementary Materials at the end of this paper.
The numbers of pixels differ between the two lenses. The RGB lens has 640 pixels horizontally and 480 pixels vertically, for a total of 307,200 pixels on an image. By contrast, the infrared lens has 80 pixels horizontally and 60 pixels vertically, for a total of 4800 pixels on an image. The numbers of pixels in images obtained by the two lenses differ by 64 times. However, the range of actually measured scenes is not much different.
Figure 4 shows its example.
As shown in
Figure 4, the number of pixels has a difference of 64 times, but there is not much difference in the area to be taken. In addition, because the RGB lens and the infrared lens have different pixel sizes, and because there is a slight difference in the position of each lens on the camera, it is not clear how many pixels from the horizontal, vertical, top, and bottom sides should be cut for the same range of the scene. Therefore, it is impossible to capture the same extent of the range of the scene. For the correct experiment, if the real face is in a scene that the infrared lens cannot capture as an image, this image was removed from the experiment.
We use Adam [
33], Dropout [
34], and ReLu [
35] to improve learning abilities when learning CNN and Thermal Face-CNN. The Adam algorithm reduces error by learning the weights existing in the artificial neural network. It is easier to execute than the back-propagation algorithm [
36]. It is also more efficient and requires less memory [
33]. Dropout prevents overfitting by allowing each node not to participate in the calculation randomly during the learning process [
34]. Sigmoid [
37] was used as an activation function in the output layer of all artificial neural networks used in the experiments except for C-SVM, and ReLu was used as an activation function of the hidden layer. As the pooling layer, the max pooling layer [
32] is used. In addition, the probability of dropping each node is 10%. An intel core i7-7820X CPU was used as the hardware in the experiment, and the memory was DDR4 32G. The experiment was carried out using the Tensorflow [
38] library, which has artificial neural network code. In the case of C-SVM, the sklearn.svm.svc library was used to carry out the experiment. The information of the library can be found at a website listed in the
Supplementary Materials at the end of this paper.
Accuracy [
4], recall [
4], and precision [
4] were mainly used as evaluation indices in the experiment. In this study, accuracy refers to how the actual value and predicted value are matched, regardless of the presence or absence of a real face. Recall is an index of how many images having the real face are judged to have the real face. Precision is also an index of how many images have the real face among those predicted to have the real face.
4.2. The Comparison of Face Liveness Detection between the RGB Image and Thermal Image
Before examining the performance of the proposed Thermal Face-CNN, we obtained accuracy, recall, and precision for each RGB image and thermal image dataset in order to identify the appropriate dataset for face liveness detection. For the comparison, we used CNN, MLP, and C-SVM. The left side of
Table 1 shows the parameters of CNN applied to the RGB image dataset, and the right side of
Table 1 shows the parameters of CNN applied to the thermal image dataset. We empirically sought the values of the parameters that would make the error of the artificial neural network converge to zero.
In
Table 1,
nodes refers to the number of nodes in the corresponding layer. Further, con_ means convolutional layer and pool_ means pooling layer. input_, hidden_, and output_ mean input layer, hidden layer, and output layer, respectively. The rest of the parameters are the same as those described in
Section 3. In
Table 1, the values in parentheses represent two values for the width and length of the kernel and pooling sequentially.
The parameter values for C-SVM used in the thermal image dataset are shown in
Table 2.
In
Table 2,
c is an
error penalty parameter, and we changed
c when we experimented. RBF [
39] or polynomial (POLY) [
39] is used as
kernel.
gamma is the coefficient of
kernel. In addition,
n_features means the number of features and
tolerance means stopping criterion.
degree means the degree of the polynomial kernel function.
The parameters of the MLP used to learn the thermal images are shown in
Table 3.
A total of 599 images in the RGB image dataset and thermal image dataset from image 1 to image 599 were used as training data, and the remaining 245 images were used for test data. There are 338 images of 844 images with the real face, and 506 images without the real face. In the training set are 225 images with the real face, and 113 images with the real face are in test set. In the training set were 374 images without the real face, and 132 images without the real face are in the test set.
Table 4 shows the experimental results of CNN in the RGB image dataset and the thermal image dataset.
Table 5 and
Table 6 show the experimental results of MLP and C-SVM in the thermal image dataset. The figures in the following tables, including
Table 4,
Table 5 and
Table 6, were rounded to the fourth decimal place. Figures expressed as percentages in the following tables were rounded to the second decimal place.
In
Table 4 and
Table 5, “The best” refers to the highest values. “Average” means the average value. In order to obtain the information shown in
Table 4, five CNNs in the RGB image dataset and 20 CNNs in the thermal image dataset were implemented with the same parameters. Because the combinations of weights obtained when the neural network is learned with the same parameters are always different and show different performances, we repeated the experiment 20 times in order to obtain the average performance of the general accuracy, recall, and precision values. However, in the RGB image dataset, the number of pixels contained in each image was 907,200, which required a substantial amount of computation. Therefore, 20 CNNs were learned in the thermal image dataset, but only five CNNs were learned in the RGB image dataset. To obtain
Table 5, five MLPs were learned because MLP requires a large amount of computation. To evaluate C-SVM’s performance in
Table 6, we obtained one C-SVM on each parameter setting. The values of accuracy, recall, and precision shown in
Table 4, which were obtained using the thermal image dataset, are higher than those of the RGB image dataset. It can be seen from the above that, on CNN, the thermal image is more suitable than the RGB image.
In the case of MLP, since there is 907,200-pixel information per RGB image, the number of nodes in the input layer should also be 907,200. We tried to implement an MLP with about 900,000 nodes in the input layer, but the hardware limitations made it impossible to calculate. Further, the C-SVM was learned using the parameters shown in
Table 2, but it was determined that there was no real face for all the test data, because it was not learned properly. However, as shown in
Table 5 and
Table 6, MLP and C-SVM can be learned because of the small number of pixels in a thermal image data. Through comparing
Table 4,
Table 5 and
Table 6, it can be seen that good performance can be obtained by the thermal image data.
4.3. Performance Comparison of CNN, C-SVM, and Thermal Face-CNN
Section 4.2 showed that the thermal image is better than the RGB image. In
Section 4.3, we applied the Thermal Face-CNN proposed in this paper to the thermal image with superior performance for face liveness detection than the RGB image, and we compared its performance with those of the other algorithms. We used the same parameters of CNN on the thermal image dataset for Thermal Face-CNN. We also constructed 20 Thermal Face-CNNs with the same parameter setting as used in the experiment on 20 CNNs, shown in
Table 4. The accuracy, recall, and precision values of Thermal Face-CNNs are shown in
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12. Parenthetical values in these tables indicate
knowledge value,
up limit, and
down limit values, sequentially.
“The best” and “Average” in
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12 mean the highest value and average value, respectively. In
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12, A_im (%) means how much the average value is improved in comparison with CNN, and M_im (%) means how much the maximum value is improved in comparison with CNN. For example, A_im (%) and M_im (%) are obtained by average and the best values in the right side of
Table 4 and
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12. The information on all the experimental results can be found at websites listed in the
Supplementary Materials found at the end of this paper.
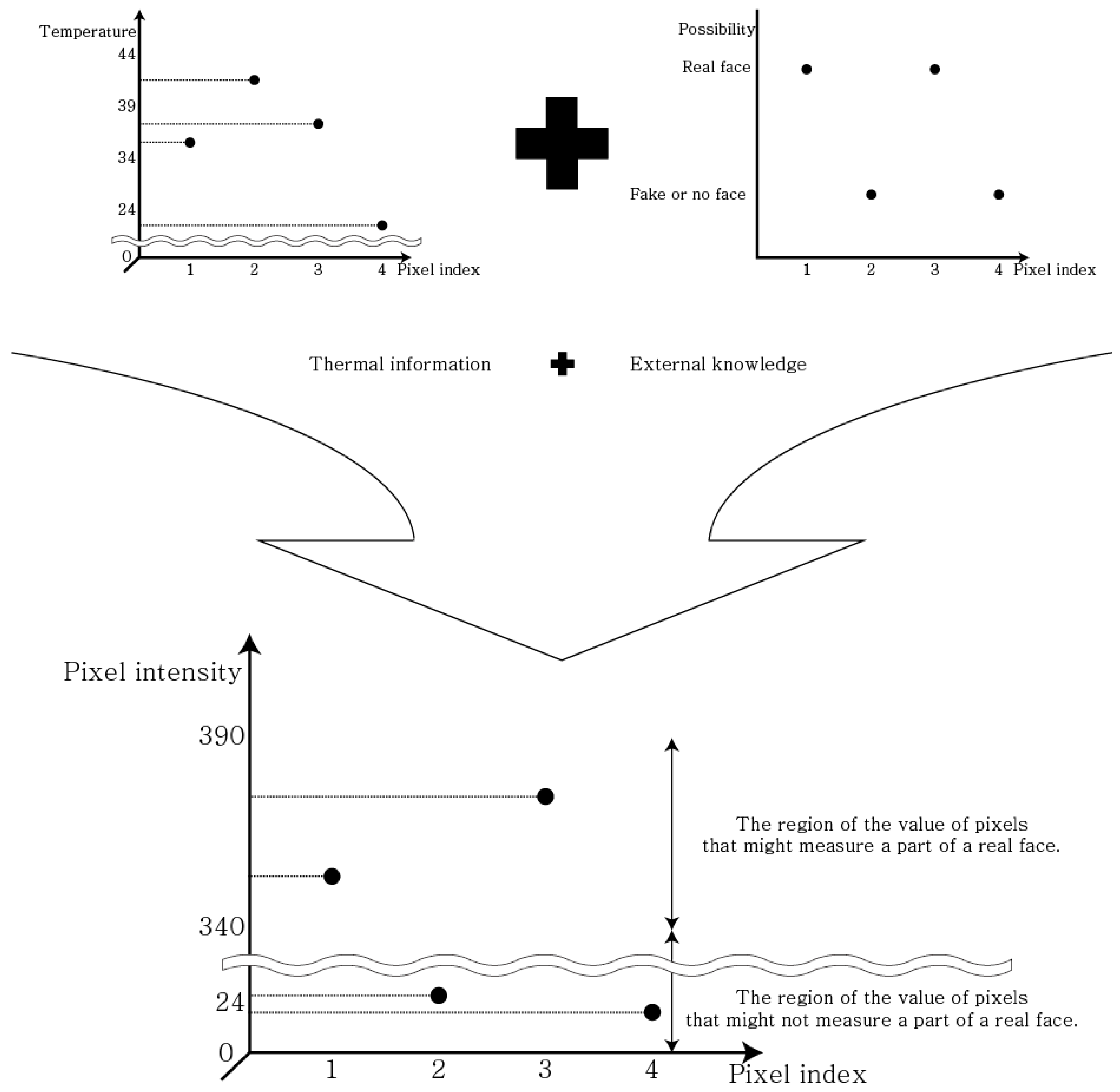
When the
knowledge value is 10 in the Thermal Face-CNNs described in
Table 7 and
Table 8 and the left side of
Table 9, the values of accuracy, recall, and precision are obtained as changes occur to the values of the
up limit and
down limit. When the
up limit and
down limit are 39 and 33, respectively, the average recall value has the greatest increase, by 12.39%. When the
up limit and
down limit values are 39 and 34, respectively, the average recall value is increased by 10.44%. When the
up limit and
down limit are 40 and 34, respectively, the average recall value is increased by 7.97%, and the average precision value is decreased slightly by −1.53%. In addition, when the
up limit and
down limit are 41 and 34, respectively, the average recall is increased by 6.61%, and the precision is decreased by −2.18%. When the values of the
up limit and
down limit are 39 and 35, respectively, the amount of the increment of recall is reduced the best.
The Thermal Face-CNNs described on the left side of
Table 7 and the right side of
Table 9 and
Table 10,
Table 11 and
Table 12 show the amount by which the performance changed when the
up limit and
down limit are 39 and 34, respectively, and when the
knowledge value is changed.
Table 12 shows that much lower performance can be achieved with Thermal Face-CNN than with CNN. The Thermal Face-CNN used to obtain the data in
Table 12 has the same parameters as the Thermal Face-CNNs used to obtain the data in the left side of
Table 7, except for the fact that the
knowledge value is 1,000. Therefore, a huge
knowledge value shows that performance can be rather reduced. The best performance was obtained by increasing the average recall value by 13.72% when the
knowledge value was −5, and the second-best average recall value was increased by 11.47% when the
knowledge value was −10. In addition, when the
knowledge value was 10, the third-best performance was obtained by increasing the average recall value by 10.44%. When the
knowledge value was −100, the average recall value was increased by 10.43%, which was the fourth-best performance.
Except for
Table 12, the average recall values of the Thermal Face-CNN having external knowledge about the temperature of the real face in
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11 show that the average recall value and the best recall value are better than the CNN shown in the right side of
Table 4. An increase of the recall value means that the Thermal Face-CNN has detected more data having the real face than CNN. It can be seen that CNN and Thermal Face-CNN are not significantly different in terms of accuracy and precision when we compare the values in the right sides of
Table 4 and
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11. Looking at the performance of Thermal Face-CNN that obtained the best performance, in the left side of
Table 10, we can see that Thermal Face-CNN was not reduced at all. Therefore, Thermal Face-CNN is superior to CNN in all indices.
The performance obtained by Thermal Face-CNN must be compared with the accuracy, recall, and precision values recorded in
Table 5 and
Table 6 quantitatively.
Table 10 shows that the method with the highest accuracy is 0.8367 on Thermal Face-CNN. In addition, the results in
Table 6 show that C-SVM is the method with the highest recall. Further,
Table 5 shows that MLP is the method with the highest precision. However, MLP is a relatively bad way to detect the real face because the recall value is too small. Thermal Face-CNN has the best accuracy and more balance between recall and precision than MLP and C-SVM. For accurate performance evaluation, F-measure [
40] is used. F-measure is a widely used index that quantitatively evaluates performance by simultaneously considering recall and precision. F-measure is shown in Equation (2).
β is a positive real number or zero. Also
precision,
recall, and
F-measure are the values of precision, recall, and F-measure, respectively. A larger F_measure value means a better algorithm. When
β is one, the most frequently used F-measure formula appears in Equation (3).
F-measure_1 in Equation (3) means the value of F-measure when
β is one. As shown in Equation (4),
difference denotes the difference value of F-measures of the Thermal Face-CNN and C-SVM; Thermal Face-CNN obtained 0.8327 accuracy, 0.8407 recall, 0.8051 precision, and C-SVM obtained 0.8245 accuracy, 0.9381 recall, 0.7465 precision corresponding to
Table 6.
When the
difference is zero, the
β value is 0.8885, meaning that the two
f-measure values are the same. When
β is greater than or equal to 0 and less than 0.8885, then Thermal Face-CNN is better. By contrast, when
β is greater than 0.8885, C-SVM is better. You can find the corresponding conditions by obtaining equations in the same way for several Thermal Face-CNNs. It is trivial to find
β that makes
difference zero when the parameters are different. Nevertheless, it is important to show that the Thermal Face-CNN is superior by listing the F-measures obtained at commonly used
β values of 0.5 and 2.
Table 13 shows it.
In
Table 13, “Average F-measure” means the F-measure using average recall and average precision in the left side of
Table 10. When
β is 2, F-measure means that F-measure weighs recall higher than precision. When
β is 0.5, F-measure means that F-measure weighs recall lower than precision. Therefore, we can see that Thermal Face-CNN is best when precision has more weight than recall. Precision is more important than recall when the reliability of the algorithm is important. Therefore, Thermal Face-CNN is good for this situation.
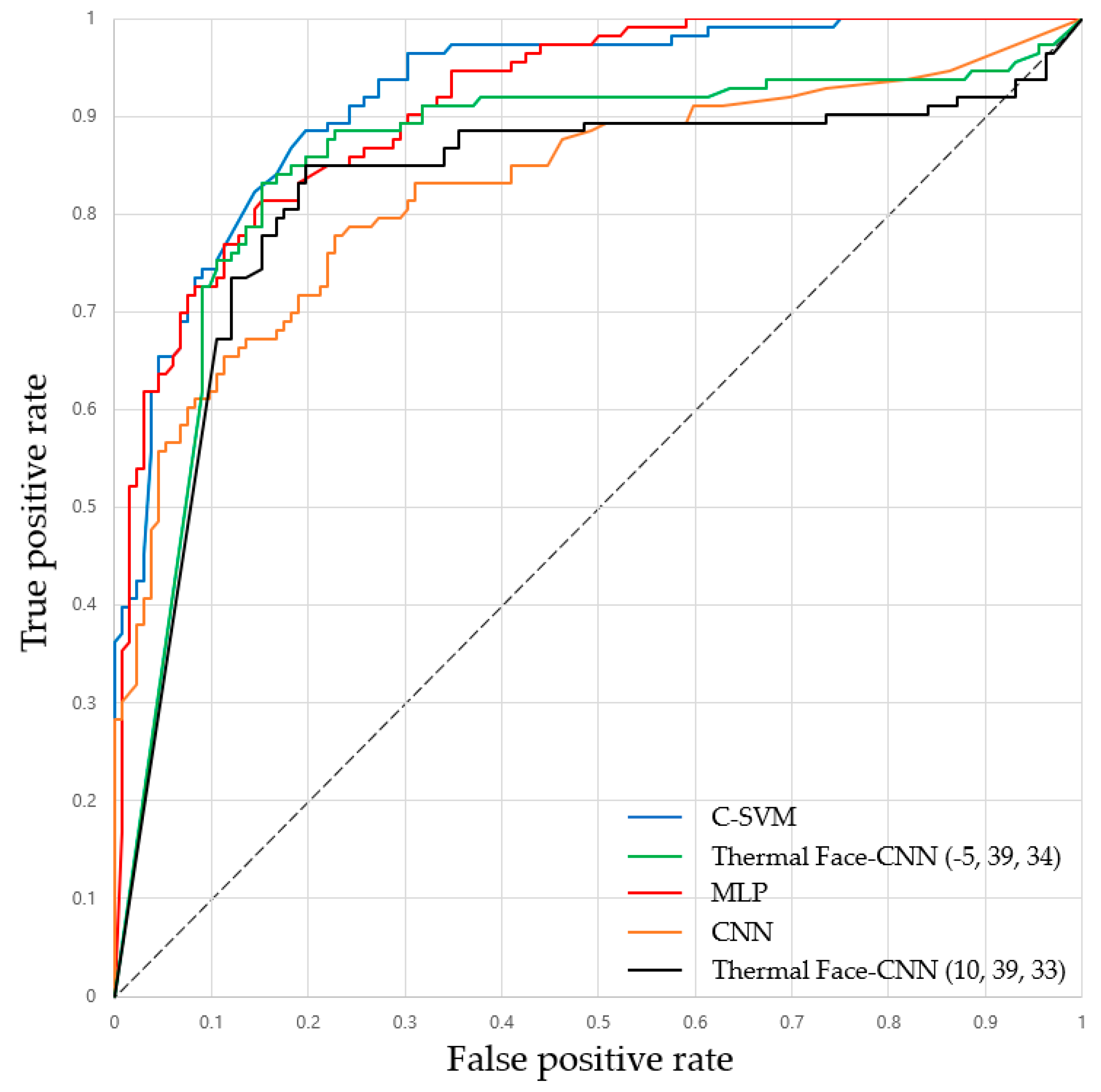
In addition to the comparison based on accuracy, recall, precision, and F-measure, it is shown that the CNN-based proposed algorithm is superior to CNN and has similar performance with the others on receiver operating characteristic (ROC) graph [
41] in
Figure 5. Parenthetical values in
Figure 5 indicate
knowledge value,
up limit, and
down limit values, sequentially.
‘A’ line is better than ‘B’ line if ‘A’ line is closer to the northwest than ‘B’ line in ROC graph. The blue line in
Figure 5 shows the performance of C-SVM, the green and black lines show the performance of Thermal Face-CNN, the red line shows the performance of MLP, and the orange line shows the performance of CNN. To obtain
Figure 5, we used the parameters having the best performance: MLP which has an accuracy of 0.7837, a recall of 0.5664, and a precision of 0.9412 and the CNN which has an accuracy of 0.8367, a recall of 0.7876, and a precision of 0.8476 and the best performance among a
up limit value of 39, and a
down limit value of 34 in Thermal Face-CNN which has an accuracy of 0.8327, a recall of 0.8407, a precision of 0.8051, a
knowledge value value of−5, a
up limit value of 39, and a
down limit value of 34 and the best performance among a
knowledge value of 10 in Thermal Face-CNN which has an accuracy of 0.8245, a recall of 0.8496, a precision of 0.7869, a
knowledge value value of 10, a
up limit value of 39, and a
down limit value of 33 and C-SVM which has a
c value of 1 are used. As shown in
Figure 5, Thermal Face-CNN has the dramatic performance improvement compared to CNN, and the Thermal Face-CNN’s performance is close to that of MLP and C-SVM. In this paper, we argue that Thermal Face-CNN is better when precision is more important than recall. However, ROC graph does not directly consider precision because it uses true positive rate and false positive rate, which are not precision. Nonetheless, the ROC graph shows that Thermal Face-CNN is superior to CNN.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}