Multiple-Attribute Decision-Making Method Using Similarity Measures of Hesitant Linguistic Neutrosophic Numbers Regarding Least Common Multiple Cardinality


Abstract
1. Introduction
2. Linguistic Neutrosophic Numbers (LNNs)
- (1)
- If S(ϑα) < S(ϑβ), then ϑα < ϑβ;
- (2)
- If S(ϑα) > S(ϑβ), then ϑα > ϑβ;
- (3)
- If S(ϑα) = S(ϑβ) and V(ϑα) < V(ϑβ), then ϑα < ϑβ;
- (4)
- If S(ϑα) = S(ϑβ) and V(ϑα) > V(ϑβ), then ϑα > ϑβ;
- (5)
- If S(ϑα) = S(ϑβ) and V(ϑα) = V(ϑβ), then ϑα = ϑβ.
3. Hesitant Linguistic Neutrosophic Numbers (HLNNs) and HLNN Set
4. LCMC-Based Distance and Similarity Measures of HLNNs
- (HP1)
- ;
- (HP2)
- if and only if;
- (HP3)
- ;
- (HP4)
- Letbe a HLNN set, thenandif.
- (HP1)
- ;
- (HP2)
- if and only if;
- (HP3)
- ;
- (HP4)
- Letbe a HLNN set, then there areandif.
5. MADM Method Using the Similarity Measure of HLNNs
6. Actual Example
7. Discussion and Analysis
7.1. Resolution Analysis
7.2. Sensitivity Analysis of Weights
8. Conclusions
- (1)
- The proposed HLNN provides a new effective way to express more decision information than existing LNNs by considering the hesitancy of DMs.
- (2)
- The proposed MADM method of HLNNs solves the MADM problems with HLNN information for the first time, as well as the gap of existing linguistic decision-making methods.
- (3)
Author Contributions
Funding
Conflicts of Interest
References
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning Part I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. A model of consensus in group decision making under linguistic assessments. Fuzzy Set Syst. 1996, 78, 73–87. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E. Linguistic decision analysis: Steps for solving decision problems under linguistic information. Fuzzy Set Syst. 2000, 115, 67–82. [Google Scholar] [CrossRef]
- Xu, Z.S. A method based on linguistic aggregation operators for group decision making with linguistic preference relations. Inf. Sci. 2004, 166, 19–30. [Google Scholar] [CrossRef]
- Xu, Z.S. Uncertain linguistic aggregation operators based approach to multiple attribute group decision making under uncertain linguistic environment. Inf. Sci. 2004, 168, 171–184. [Google Scholar] [CrossRef]
- Xu, Z.S. Induced uncertain linguistic OWA operators applied to group decision making. Inf. Sci. 2006, 7, 231–238. [Google Scholar] [CrossRef]
- Wei, G.W. Uncertain linguistic hybrid geometric mean operator and its application to group decision making under uncertain linguistic environment. Int. J. Uncertain. Fuzziness 2009, 17, 251–267. [Google Scholar] [CrossRef]
- Peng, B.; Ye, C.; Zeng, S. Uncertain pure linguistic hybrid harmonic averaging operator and generalized interval aggregation operator based approach to group decision making. Knowl.-Based Syst. 2012, 36, 175–181. [Google Scholar] [CrossRef]
- Chen, Z.C.; Liu, P.H.; Pei, Z. An approach to multiple attribute group decision making based on linguistic intuitionistic fuzzy numbers. Int. J. Comput. Intell. Syst. 2015, 8, 747–760. [Google Scholar] [CrossRef]
- Liu, P.D.; Liu, J.L.; Merigó, J.M. Partitioned Heronian means based on linguistic intuitionistic fuzzy numbers for dealing with multi-attribute group decision making. Appl. Soft Comput. 2018, 62, 395–422. [Google Scholar] [CrossRef]
- Peng, X.; Liu, C. Algorithms for neutrosophic soft decision making based on EDAS, new similarity measure and level soft set. J. Intell. Fuzzy Syst. 2017, 32, 955–968. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Bausys, R.; Juodagalviene, B.; Garnyte-Sapranaviciene, I. Model for residential house element and material selection by neutrosophic MULTIMOORA method. Eng. Appl. Artif. Intell. 2017, 64, 315–324. [Google Scholar] [CrossRef]
- Bausys, R.; Juodagalviene, B. Garage location selection for residential house by WASPAS-SVNS method. J. Civ. Eng. Manag. 2017, 23, 421–429. [Google Scholar] [CrossRef]
- Fang, Z.B.; Ye, J. Multiple attribute group decision-making method based on linguistic neutrosophic numbers. Symmetry 2017, 9, 111. [Google Scholar] [CrossRef]
- Liu, P.D.; Mahmood, T.; Khan, Q. Group decision making based on power Heronian aggregation operators under linguistic neutrosophic environment. Int. J. Fuzzy Syst. 2018, 20, 970–985. [Google Scholar] [CrossRef]
- Torra, V.; Narukawa, Y. On hesitant fuzzy sets and decision. In Proceedings of the 18th IEEE International Conference on Fuzzy Systems, Jeju Island, Korea, 20–24 August 2009; pp. 1378–1382. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. Hesitant Fuzzy Linguistic Term Sets for Decision Making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; MartíNez, L.; Herrera, F. A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets. Inf. Sci. 2013, 241, 28–42. [Google Scholar] [CrossRef]
- Lin, R.; Zhao, X.F.; Wei, G.W. Models for selecting an ERP system with hesitant fuzzy linguistic information. J. Intell. Fuzzy Syst. 2014, 26, 2155–2165. [Google Scholar] [CrossRef]
- Wang, J.Q.; Wu, J.T.; Wang, J.; Zhang, H.; Chen, X. Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Inf. Sci. 2014, 288, 55–72. [Google Scholar] [CrossRef]
- Ye, J. Multiple Attribute Decision-Making Methods Based on the Expected Value and the Similarity Measure of Hesitant Neutrosophic Linguistic Numbers. Cogn. Comput. 2018, 10, 454–463. [Google Scholar] [CrossRef]
- Zhu, B.; Xu, Z. Consistency Measures for Hesitant Fuzzy Linguistic Preference Relations. IEEE Trans. Fuzzy Syst. 2014, 22, 35–45. [Google Scholar] [CrossRef]
- Liao, H.; Xu, Z.; Zeng, X.J.; Merigó, J.M. Qualitative decision making with correlation coefficients of hesitant fuzzy linguistic term sets. Knowl.-Based Syst. 2015, 76, 127–138. [Google Scholar] [CrossRef]
- Ye, J. Multiple-attribute Decision-Making Method under a Single-Valued Neutrosophic Hesitant Fuzzy Environment. J. Intell. Syst. 2014, 24, 23–36. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
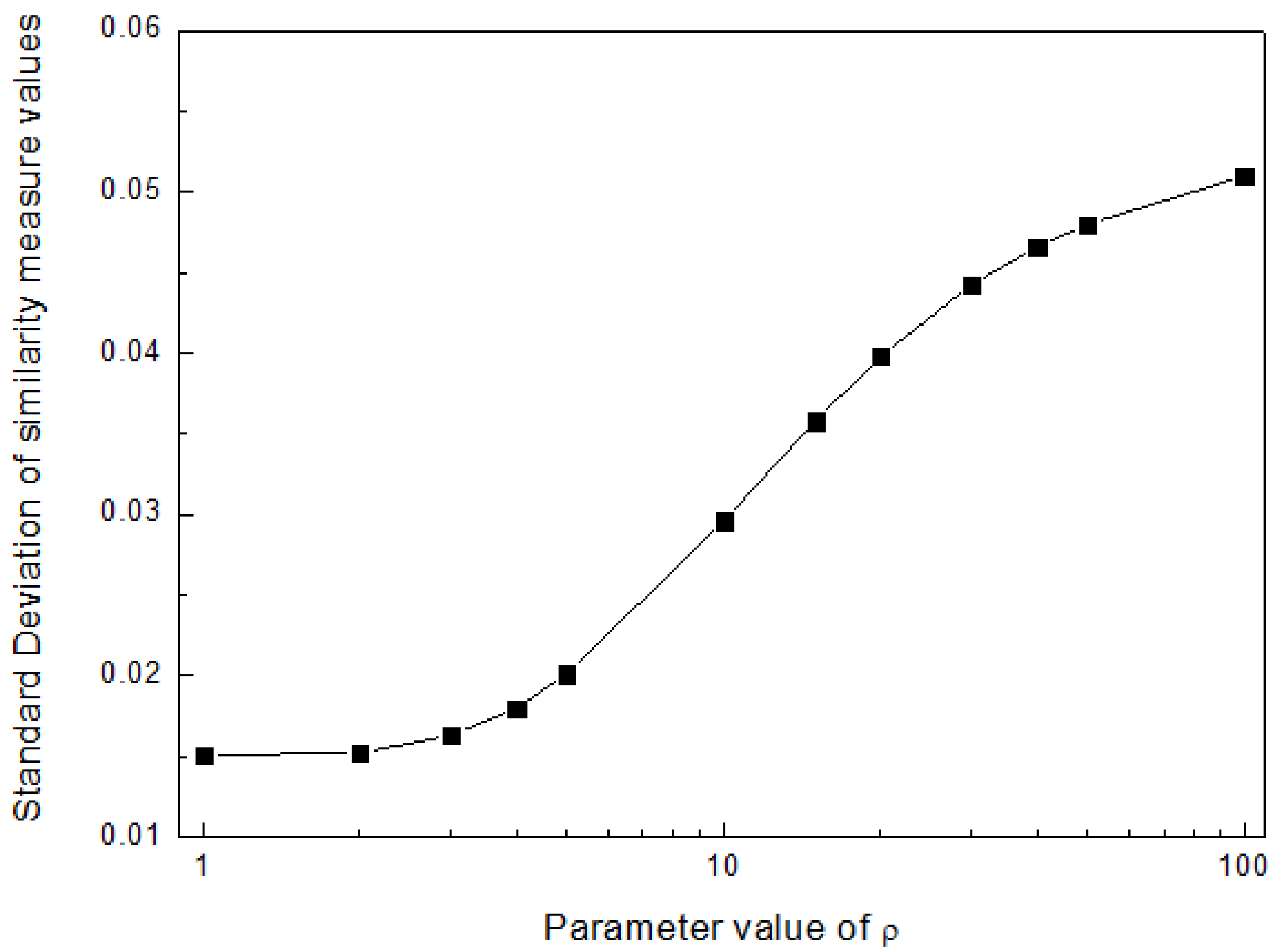
| ρ1 | Sw(g1, g*), Sw(g2, g*), Sw(g3, g*), Sw(g4, g*) 2 | Ranking Order | AV 3 | SD 4 | Best Alternative |
|---|---|---|---|---|---|
| 1 | 0.7354, 0.7493, 0.7406, 0.7747 | g4 > g2 > g3 > g1 | 0.7500 | 0.0151 | g4 |
| 2 | 0.7121, 0.7224, 0.7217, 0.7525 | g4 > g2 > g3 > g1 | 0.7272 | 0.0152 | g4 |
| 3 | 0.6905, 0.6985, 0.7037, 0.7335 | g4 > g3 > g2 > g1 | 0.7066 | 0.0163 | g4 |
| 4 | 0.6710, 0.6781, 0.6867, 0.7182 | g4 > g3 > g2 > g1 | 0.6885 | 0.018 | g4 |
| 5 | 0.6539, 0.6608, 0.6710, 0.7061 | g4 > g3 > g2 > g1 | 0.6730 | 0.0201 | g4 |
| 10 | 0.5972, 0.6047, 0.6133, 0.6722 | g4 > g3 > g2 > g1 | 0.6219 | 0.0296 | g4 |
| 15 | 0.5690, 0.5754, 0.5817, 0.6575 | g4 > g3 > g2 > g1 | 0.5959 | 0.0358 | g4 |
| 20 | 0.5531, 0.5582, 0.5631, 0.6497 | g4 > g3 > g2 > g1 | 0.5810 | 0.0398 | g4 |
| 30 | 0.5361, 0.5397, 0.5432, 0.6417 | g4 > g3 > g2 > g1 | 0.5652 | 0.0443 | g4 |
| 40 | 0.5273, 0.5301, 0.5327, 0.6376 | g4 > g3 > g2 > g1 | 0.5569 | 0.0466 | g4 |
| 50 | 0.5220, 0.5242, 0.5264, 0.6351 | g4 > g3 > g2 > g1 | 0.5519 | 0.048 | g4 |
| 100 | 0.5111, 0.5123, 0.5134, 0.6301 | g4 > g3 > g2 > g1 | 0.5417 | 0.051 | g4 |
| ρ | Sw(g1, g*), Sw(g2, g*), Sw(g3, g*), Sw(g4, g*) | Ranking Order | AV | SD | Best Alternative |
|---|---|---|---|---|---|
| 1 | 0.7431, 0.7546, 0.7500, 0.7755 | g4 > g2 > g3 > g1 | 0.7558 | 0.0121 | g4 |
| 2 | 0.7189, 0.7278, 0.7300, 0.7529 | g4 > g3 > g2 > g1 | 0.7324 | 0.0125 | g4 |
| 3 | 0.6968, 0.7039, 0.7112, 0.7336 | g4 > g3 > g2 > g1 | 0.7114 | 0.0138 | g4 |
| 4 | 0.6769, 0.6833, 0.6938, 0.7180 | g4 > g3 > g2 > g1 | 0.693 | 0.0156 | g4 |
| 5 | 0.6596, 0.6659, 0.6779, 0.7057 | g4 > g3 > g2 > g1 | 0.6773 | 0.0177 | g4 |
| 10 | 0.6019, 0.6088, 0.6193, 0.6717 | g4 > g3 > g2 > g1 | 0.6254 | 0.0274 | g4 |
| 15 | 0.5727, 0.5786, 0.5865, 0.6572 | g4 > g3 > g2 > g1 | 0.5988 | 0.0341 | g4 |
| 20 | 0.556, 0.5608, 0.5671, 0.6495 | g4 > g3 > g2 > g1 | 0.5834 | 0.0384 | g4 |
| 30 | 0.5381, 0.5415, 0.5459, 0.6415 | g4 > g3 > g2 > g1 | 0.5668 | 0.0432 | g4 |
| 40 | 0.5289, 0.5315, 0.5349, 0.6374 | g4 > g3 > g2 > g1 | 0.5582 | 0.0458 | g4 |
| 50 | 0.5232, 0.5254, 0.5281, 0.6350 | g4 > g3 > g2 > g1 | 0.5529 | 0.0474 | g4 |
| 100 | 0.5118, 0.5128, 0.5142, 0.6300 | g4 > g3 > g2 > g1 | 0.5422 | 0.0507 | g4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, W.; Ye, J. Multiple-Attribute Decision-Making Method Using Similarity Measures of Hesitant Linguistic Neutrosophic Numbers Regarding Least Common Multiple Cardinality. Symmetry 2018, 10, 330. https://doi.org/10.3390/sym10080330
Cui W, Ye J. Multiple-Attribute Decision-Making Method Using Similarity Measures of Hesitant Linguistic Neutrosophic Numbers Regarding Least Common Multiple Cardinality. Symmetry. 2018; 10(8):330. https://doi.org/10.3390/sym10080330
Chicago/Turabian StyleCui, Wenhua, and Jun Ye. 2018. "Multiple-Attribute Decision-Making Method Using Similarity Measures of Hesitant Linguistic Neutrosophic Numbers Regarding Least Common Multiple Cardinality" Symmetry 10, no. 8: 330. https://doi.org/10.3390/sym10080330
APA StyleCui, W., & Ye, J. (2018). Multiple-Attribute Decision-Making Method Using Similarity Measures of Hesitant Linguistic Neutrosophic Numbers Regarding Least Common Multiple Cardinality. Symmetry, 10(8), 330. https://doi.org/10.3390/sym10080330