1. Introduction
In industry and life, many application systems monitor real-time data. When an abnormal change in data is detected, several abnormal data are combined to make decisions. Such systems include oil drilling early warning systems [
1], industrial sensor systems [
2], internet data stream [
3], medical surveillance systems [
4], gas turbine fuel systems [
5], the Internet of Things [
6], and wind turbines [
7]. A general decision system flowchart is shown in
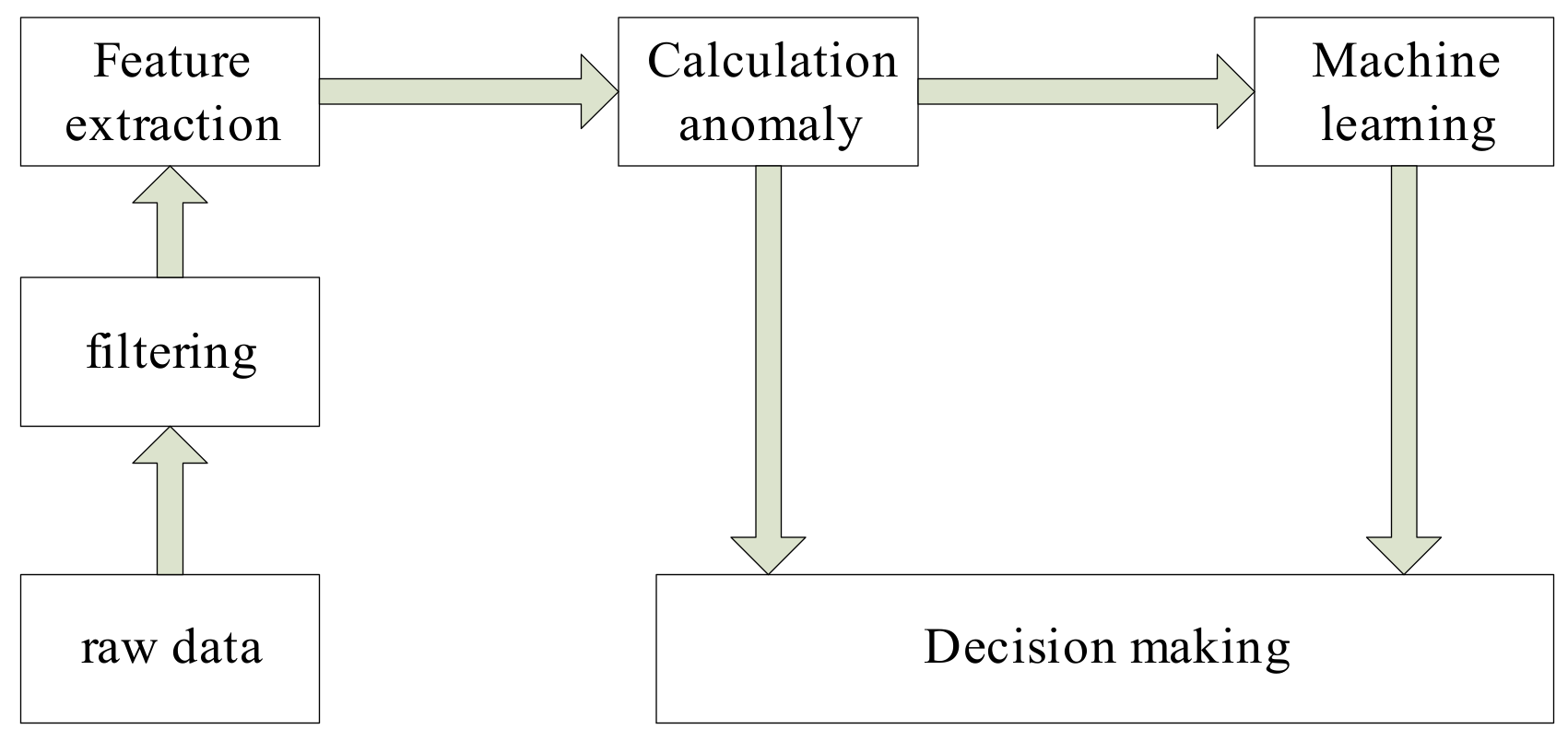
Figure 1, as follows:
As shown in
Figure 1, machine learning can obtain the decision model by mining the rule of abnormal change of the parameters. When the combined parameters with the same abnormal changes are obtained, the decision model is achieved. We can see that many decision-making systems must know which parameters are abnormal before making decisions, must know the degree of abnormality, and must make corresponding decisions based on these abnormal parameters and the degree of their abnormalities.
The common features of these systems are listed as follows:
The amount of data is practically infinite, pouring in as time goes on.
Each piece of data has its own time stamp.
There is concept drift, and there is no regular data distribution.
Affected by various conditions, such as the sensor’s operating environment and its installation location, some data are distorted or ineffective and are of low quality.
Real-time decision-making requires the real-time monitoring of operating status; decisions can thus be made in real time. Based on the above, the anomaly detection algorithm applied to data streams requires a high detection accuracy and low complexity, and only one scan and one detection are allowed. The first two features are opposites (regarding accuracy and complexity), as algorithms with high detection accuracy are often more complex. For example, traditional machine learning algorithms aim toward static data classification, but their long calculation time cannot be applied to the data stream at all and therefore cannot satisfy the real-time system. Due to real-time requirements, algorithms with low complexity generally hardly achieve data stream anomaly detection accuracy. Data stream anomaly detection, including conceptual drift detection [
8] and conceptual drift anomaly detection [
9], can be regarded as a further analysis operation of multi-class machine learning. Based on papers published in international top conferences and international authoritative journals in the field of machine learning, data stream anomaly detection [
10] research has increasingly been given academic attention for the past few years. Data streams, which exists extensively in work and life, have provided a wide range of application fields. Due to the characteristics of the data stream analyzed above, data stream machine learning has brought about great challenges. Therefore, data stream anomaly detection has transformed from single methods to cross-integration methods, such as the sliding window model [
11,
12], control charts [
13], evolutionary calculation [
14], transfer learning [
15], and clustering [
16]. Traditional analysis methods, such as feature selection [
17], ensemble learning [
18], and various pattern classification theories [
19], have been transformed into data stream anomaly detection methods through combinations with sliding windows. Sliding windows and ensemble learning have been combined with data stream anomaly classification [
20]; sliding windows and evolutionary algorithms have been combined with data stream anomaly detection classification [
21]; and singular spectrum analysis and control charts have been combined with a real-time cardiac anomaly detection algorithm [
22]. The combination of these algorithms will inevitably lead to an increase in the algorithm complexity, but with the advancement of computer technology, greater computing capability can already support the application of data stream anomaly detection algorithms in reality. The contributions of this article are the following: (1) we use nested sliding windows to enhance the trend analysis of the current point and historical data, (2) we reduce the impact weight of the current point by calculating the mean difference twice, (3) we integrate the above two points using the cumulative sum (CUSUM) algorithm, and (4) we increase the outbound rate parameter and perform real-time data stream detection.
The data stream is affected by concept drift [
23]. The concept drift of machine learning represents the phenomenon that the statistical characteristics of the target variable change in an unpredictable manner over time. The data trend in the data stream changes in real time, and the current point data change is the starting point of the real concept drift or the interference point, which is a problem that the data stream machine learning algorithm needs to solve.
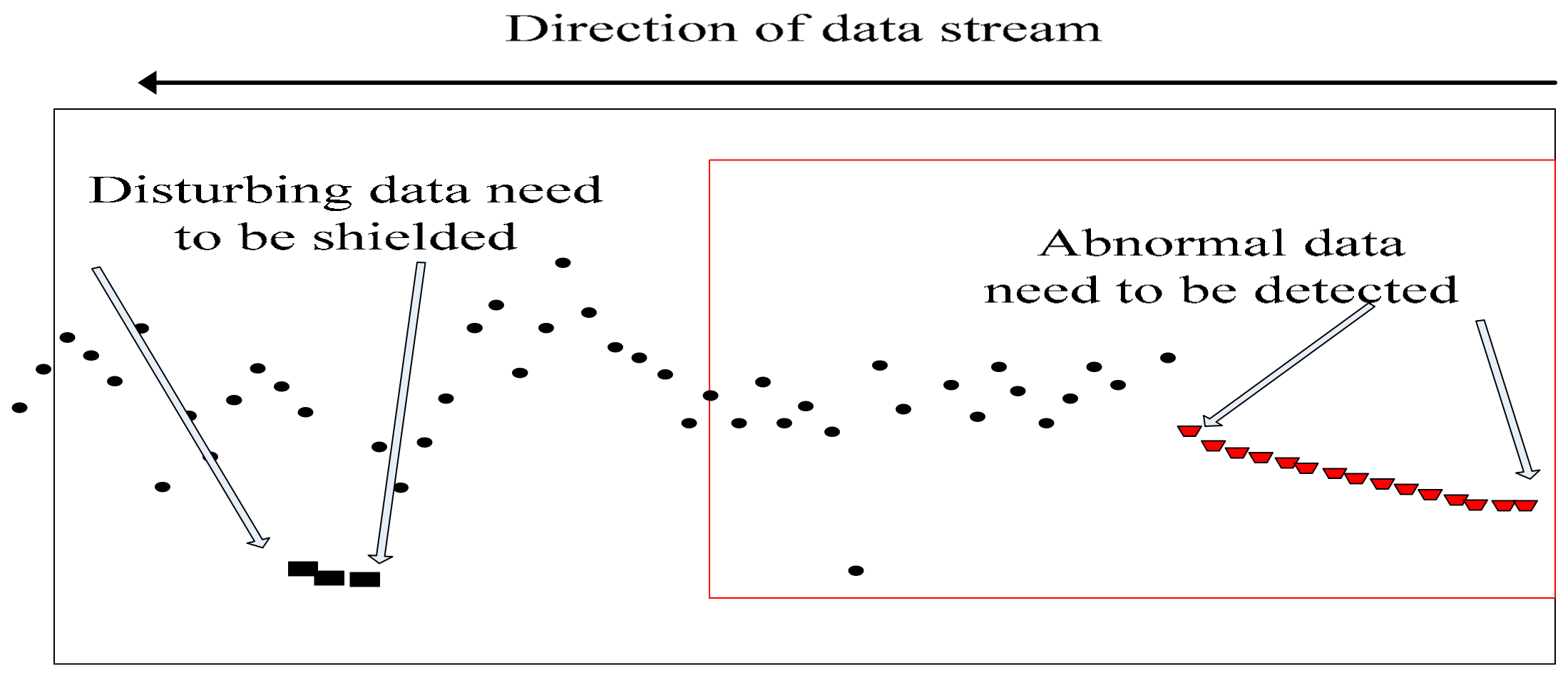
As shown in
Figure 2, several data deviate from the normal trend at the back end, but no trend deviates continuously and quickly returns to the overall trend. Therefore, these data are disturbance data and should not be considered as abnormal data that enter into the decision model, as it will otherwise lead to late mistaken decisions. The front-end data continuously deviate from the overall trend, so it is regarded as abnormal data. Abnormal point detection and abnormality detection are required, and several abnormal parameters need to be used in the later stage to make decisions. The former abnormal data drop is the real one caused by real internal causes, which is our focus and target of detection, because the change is caused by the internal environment, the abnormal changes of these data are consistent with the goals of our decision-making. It is necessary to correctly classify this data and detect the degree of abnormality. Therefore, reducing the misclassification caused by the interference data, increasing the trend judgment, and improving the accuracy of forecasting are research directions in the field of data stream machine learning.
The difficulty of data stream anomaly detection lies in concept drift. The future distribution of a data stream is unknown. It is difficult to classify only the current data or several neighboring data. If the current data undergo a conceptual drift, subsequent data will continue and can then be regarded as true abnormal data. This type of concept drift may be caused by some kind of intrinsic mechanism. It is data that need special attention and continuous analysis. However, it is normal to return to general trends in the short term. Designing an algorithm that detects when concept drift of a data stream occurs and correctly classifies and shields interference data is difficult, and it is difficult to calculate statistics of data stream distribution. To solve such problems, the clustered data stream classification method [
23] and the data stream decomposition method [
24] have been proposed. Although the above methods can detect data stream anomalies while satisfying the concept drift of the data stream, there is no analysis of interference data or the real concept drift data. This paper proposes a dual mean value cumulative sum DCUSUM data stream anomaly detection method based on sliding nest window chart anomaly detection based on data streams (SNWCAD-DS). Anomaly detection is achieved using the method of control charts. This method not only can detect the concept drift of the data stream, but also can shield the influence of the interference point. Compared with the traditional data stream machine, this method improves classification accuracy, which can meet the practical needs of field engineering.
This paper first introduces the related work, then introduces the control chart algorithm of two mean calculations, simulates and compares the performance of algorithm, and finally summarizes the contribution of the paper.
3. DCUSUM-DS Algorithm
When the data stream is affected by the environment and accompanied by interference and noise, the machine learning classification is even worse. The traditional classification method has a certain time delay. In summary, the characteristics of the data stream determine that data stream machine learning cannot be classified by a single method. Combining multiple methods to classify data streams must also take into account the constraints of the algorithm complexity [
28,
29], which can meet the requirement of real-time online operation.
As shown in
Figure 5, it is difficult to classify real time because of concept drift. Therefore, the sliding window strategy is adopted. Secondly, the window of nesting is used to reduce the sensitivity of the current data.
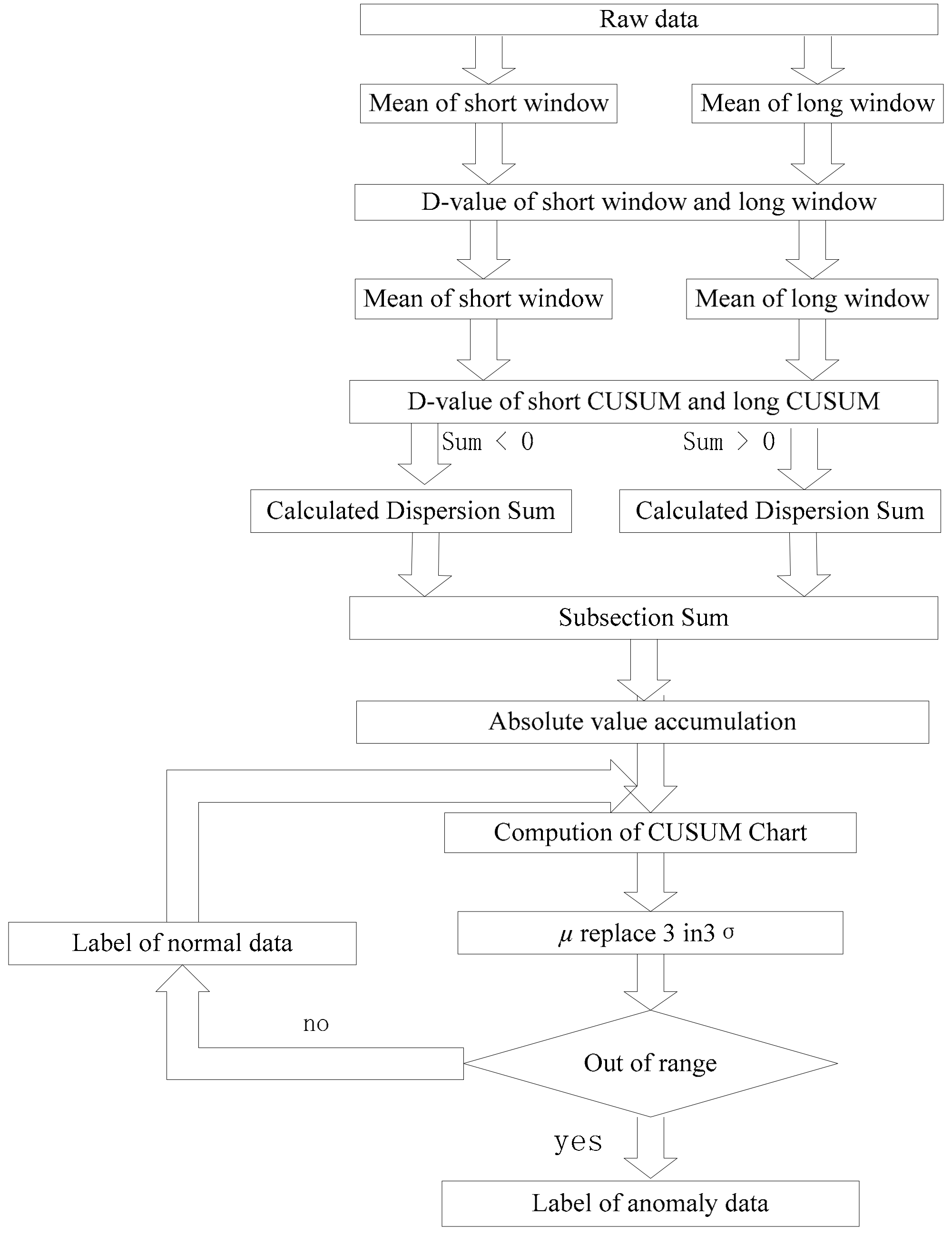
Two mean deviation methods are used to extract the feature quantity, and the misclassification problem caused by a few points deviating from the normal trend is masked. Finally, DCUSUM-DS are adopted. The DCUSUM-DS algorithm is summarized in Algorithm 2 as follows:
| Algorithm 2 DCUSUM-DS |
1. DCUSUM-DS: initialize , , T,
2. Compute: , , ,
3.
4. Compute: , , ,
5.
6. Compute: , , ,
7. If
8. Compute:
9. If
10. Compute:
11. Compute: CUSUM()
12. Box(CUSUM())
13. If
14. Compute: n = n + 1(initialize n = 0)
15. If n >
16. Output: Label
17. If
18. Compute:
19. Compute:
20. CUSUM()
21. Box(CUSUM())If
22. Compute: n = n + 1(initialize n = 0)
23. If n >
24. Output: label |
is the length of the long window. is the length of the short window. T is the threshold value. is the output rate. is the average value of the original value in the short window. is the variance of the original value in the short window. is the mean value of the long window. is the variance of the long window. is the mean of the short window mean value. is the mean of the long window mean value. is the variance of the short window. is the variance of the long window. is the short window average of quadratic variables. is the long window average of quadratic variables. is the quadratic variable variance of the short window. is the quadratic variable variance of the long window. is the label of data. The calculation of the above parameters is a procedure of the derived parameters, which is used to generate the final feature . First, the algorithm uses a sliding window to truncate the data stream, analyzes the current data and historical data changes, and uses a nested window to smooth the current point and to reduce the current point sensitivity. Second, to mask the problem of misjudgment caused by a few consecutive data deviations from normal trends the algorithm uses two mean value methods. The resulting feature quantities are entered into the CUSUM method for analysis. The results are presented in a box diagram to allow for the determination of parameter abnormality. The final result of the algorithm is the classification flag of the parameter. If there is an abnormal parameter, the abnormality of the parameter can be analyzed.
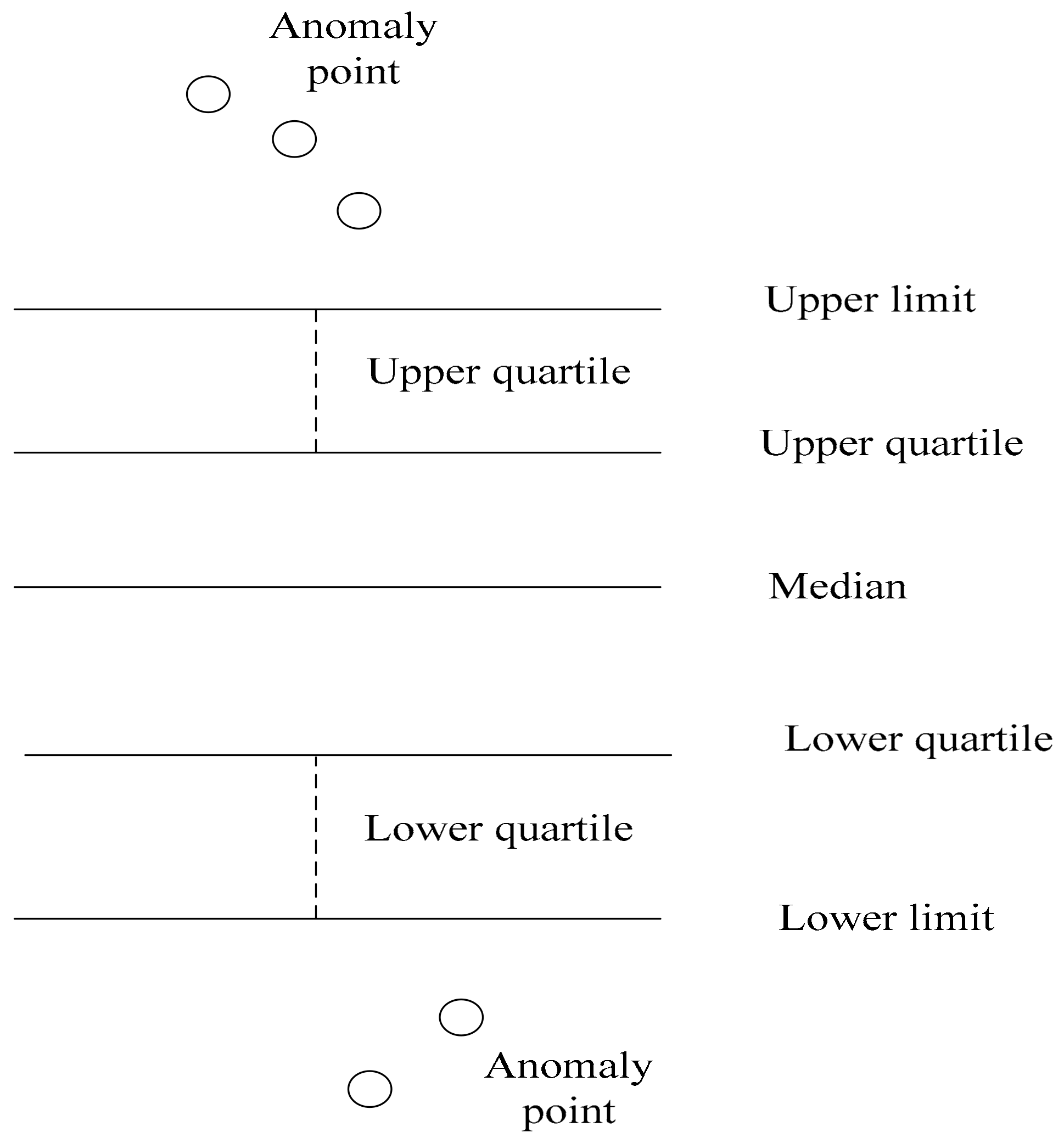
As shown in
Figure 6, the box diagram is a method for determining the final result. The upper and lower abnormal boundary values are continuously monitored online, and the data are labeled as abnormal by focusing on the data exceeding the upper limit and lower limit curves. The advantage of this analysis method is that it can increase the judgment margin.
On the basis of satisfying the concept drift, it can adapt to the change of parameters in real time, track the dynamic trend of the data stream, and, also in real time, monitor and classify the data in the sliding window. On the basis of satisfying the data stream, it meets the analysis requirements of sliding window technology.
4. Simulation and Comparison
The data selected in this paper is the drilling data of the Tarim oilfield. The oil drilling data is a typical industrial data stream. There are dozens of sensors at the drilling site, and the parameters, including the derived parameters, are between 100 and 300 parameters. Affected by the sensor installation position, performance, and working environment, data stream data are often interrupted and lost. The sampling frequency of these data streams is generally 1 or 0.2 Hz. The sampling frequency chosen in this paper is 1 Hz. The analysis parameter is the total cell volume. The comparison algorithms are the automatic outlier detection for data streams (A-ODDS) [
30,
31] and SNWCAD-DS algorithms. The adopted standard is the area under the curve (AUC) and the Jaccard similarity coefficient. The specific object of analysis consists of 1413 total pool volume data, which is firstly tagged with expert experience, and then, supervised classification methods are applied to these tagged data. The accuracy and false positive rate are tested by comparing different algorithms, and the quality of the algorithm is thus determined. The complexity of the algorithm is based on the same data analysis length comparison. The algorithm comparison formula is as follows:
If a positive class tag is predicted to be negative, it is called false negative (FN); if the negative class tag is predicted to be negative, it is called true negative (TN); if the negative class tag is predicted to be positive, it is called false positive (FP); and, if a positive class tag is predicted to be positive, it is called true positive (TP). In addition, the AUC is calculated by changing the threshold, so is considered as a threshold. True positive rate (TPR) is the accuracy rate, and false positive rate (FPR) is the false alarm rate.
Jaccard’s coefficient is expressed as follows:
The higher Jaccard’s coefficient (JC), the higher the similarity. The receiver operating characteristic (ROC) comprises two categories: anomaly data and normal data. In the anomaly data, we not only identify abnormal rises but also identify abnormal declines. Therefore, it considers three categories in total.
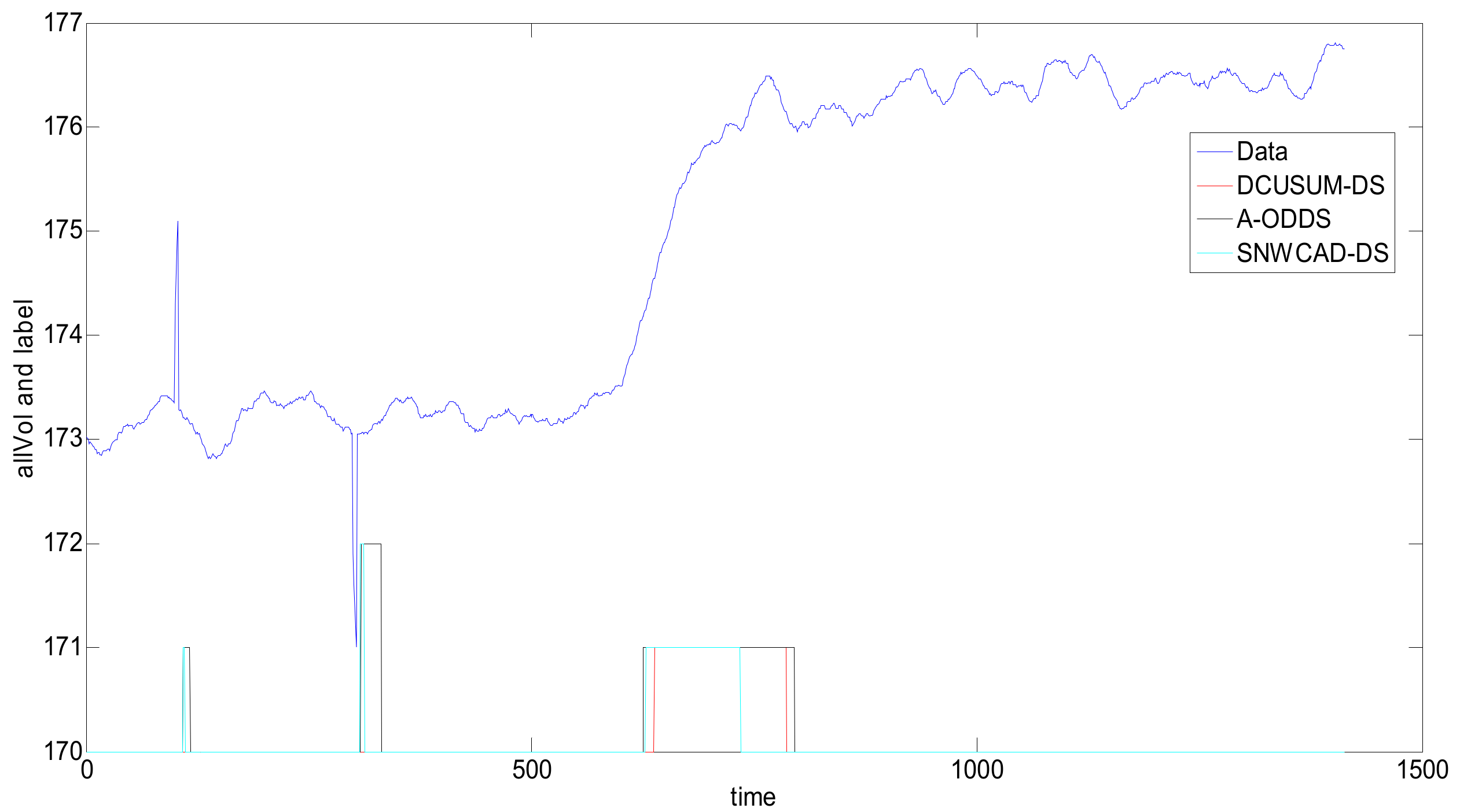
As shown in
Figure 7, there are four points that show an upward trend and that deviate from the normal trend at 100, and five points that have a downward trend and that deviate from the normal trend at 300.
The difficulty in data stream anomaly monitoring is that the data stream is infinitely accumulating. When the current point deviating from the normal trend enters the sliding window, it is necessary to refer to not only the data value of the current moment, but also the values of several data that are close and that have also deviated from normal trends in the past few moments. As shown in the above figure, at the interference points at 100 and 300 on the time axis, the traditional data stream machine learning is often misclassified. The interference on the time axis 100 are abnormally rising, and the interference on the time axis 300 are abnormally low; these phenomena are ubiquitous in engineering. In this case, such classification is wrong because, at these two moments, there are no associated accidents or targets. The cause of this data change may be environmental interference or the sensor installation location. The purpose of the newly designed DCUSUM-DS algorithm is to detect the abnormal upward trend of the data stream after 600, to mark 600–700 data points as rising labels, to shield the interference of some points deviations, and to label the interference data as normal.
As shown in
Table 1, in order to improve the fairness and credibility of each algorithm’s detection accuracy, the false alarm rate, and the algorithm complexity, the same parameters are set for each algorithm. The long window is uniformly set to 140, the short window is set to 25, the threshold is set to 0.5, and the outbound rate is set to 8. The following simulation, in addition to the data listed in
Table 2, uses the parameter settings in
Table 1 and compares the advantages and disadvantages of each algorithm by comparing the TPR, FPR, the AUC area, and the algorithm calculation time.
As shown in
Figure 8, the abnormal rising flag is 1, and the abnormal falling flag is 2. Through the simulation comparison of the three methods, we can see that the DCUSUM-DS can not only detect the abnormal increase of the data stream at 600–700 points but can also shield the interference of a few data at 100 and 300, achieving the purpose of the design and meeting the actual needs of the site. Although the A-ODDS and SNWCAD-DS algorithms can detect the abnormal increase of data streams at 600–700, 100 and 300 interference data cannot be masked. Therefore, the new proposed algorithm DCUSUM-DS achieves its purpose.
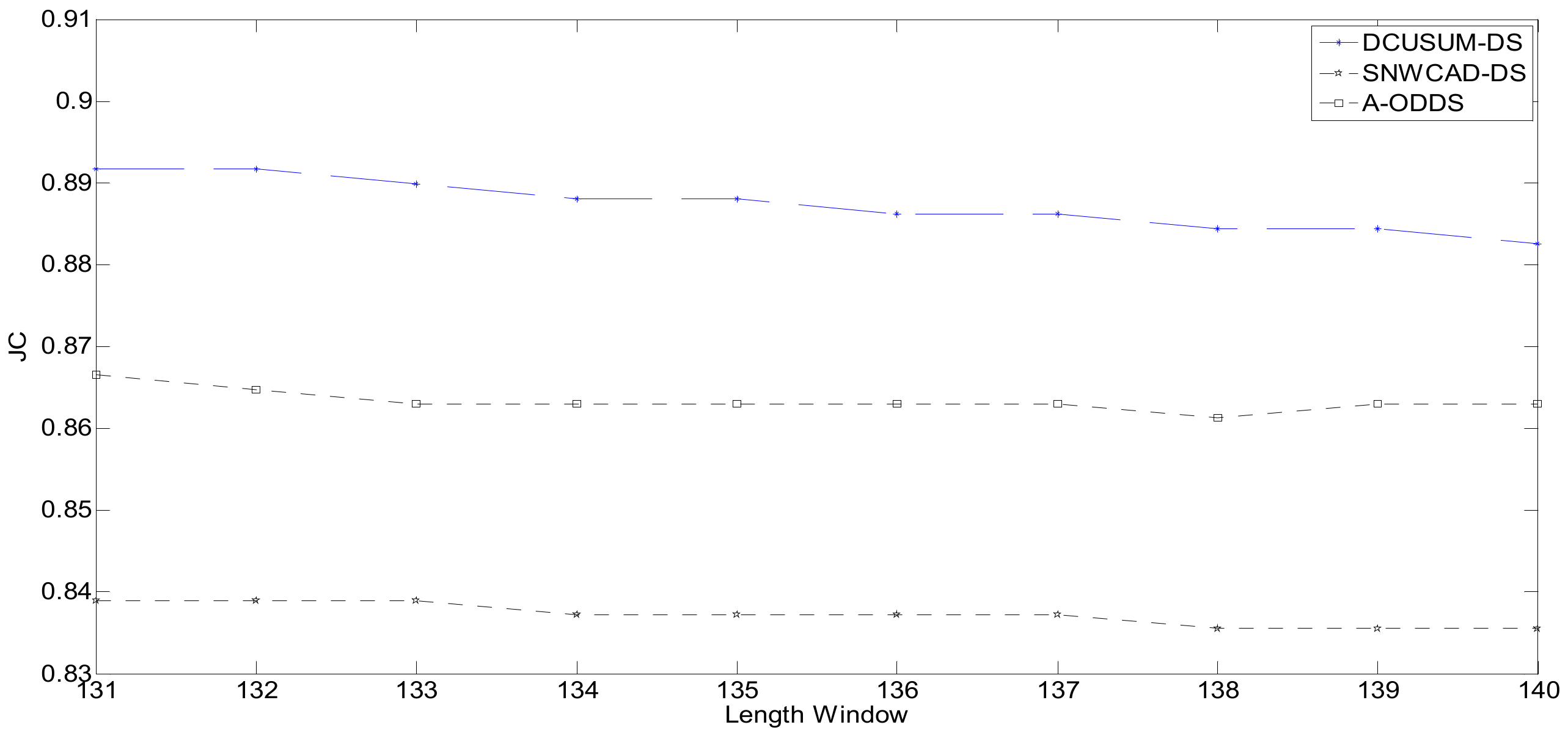
Figure 9 shows the distribution of Jaccard’s coefficient. The abscissa is the length of the long window. The meaning of this expression is to obtain different Jaccard’s coefficients by setting different lengths of the window and to obtain Jaccard’s coefficient through different window lengths to analyze and compare the quality of the algorithm. Jaccard’s coefficient represents a similarity measure of the online stream classification algorithm for data stream machine learning.
The factors affecting Jaccard’s coefficient include not only the correct rate of the classification result, the error rate, and the missing report rate, but also the setting of the window length and the outbound rate. Due to the delay, the higher Jaccard’s coefficient, the higher the accuracy; the lower Jaccard’s coefficient, the lower the accuracy. The operating environment involves the Central Processing Unit (CPU) dual-core 2.1GHz, Win7 Sp1 x86, and memory 2G. The running time is shown in
Table 2.
Table 2 is a further interpretation of
Figure 9. The table shows the time of each single-step analysis for different lengths of the long window and objectively evaluates the complexity of the algorithm by averaging the time. The calculated operating environment is as follows: Win7 Sp1 x86, a CPU dual-core 2.1 GHz, 2G memory. According to the sampling frequency of 1 Hz, the proposed new algorithm can be calculated within 0.2 s in a 1 s interval, which fully meets the actual operating requirements of the site.
As shown in
Figure 10, the data in the normal range are enveloped in the upper and lower threshold lines. When there is an abnormal rise or an abnormal drop, the feature value will exceed the threshold line. The anomaly detection algorithm deals with the current point and several nearby data. After the cumulative number of deviation data exceeds the set demarcation rate, the anomaly detection algorithm reaches the classification criteria. Afterward, the abnormal points that continue this trend are labeled as abnormal data, and the previous abnormal points are labeled as normal data.
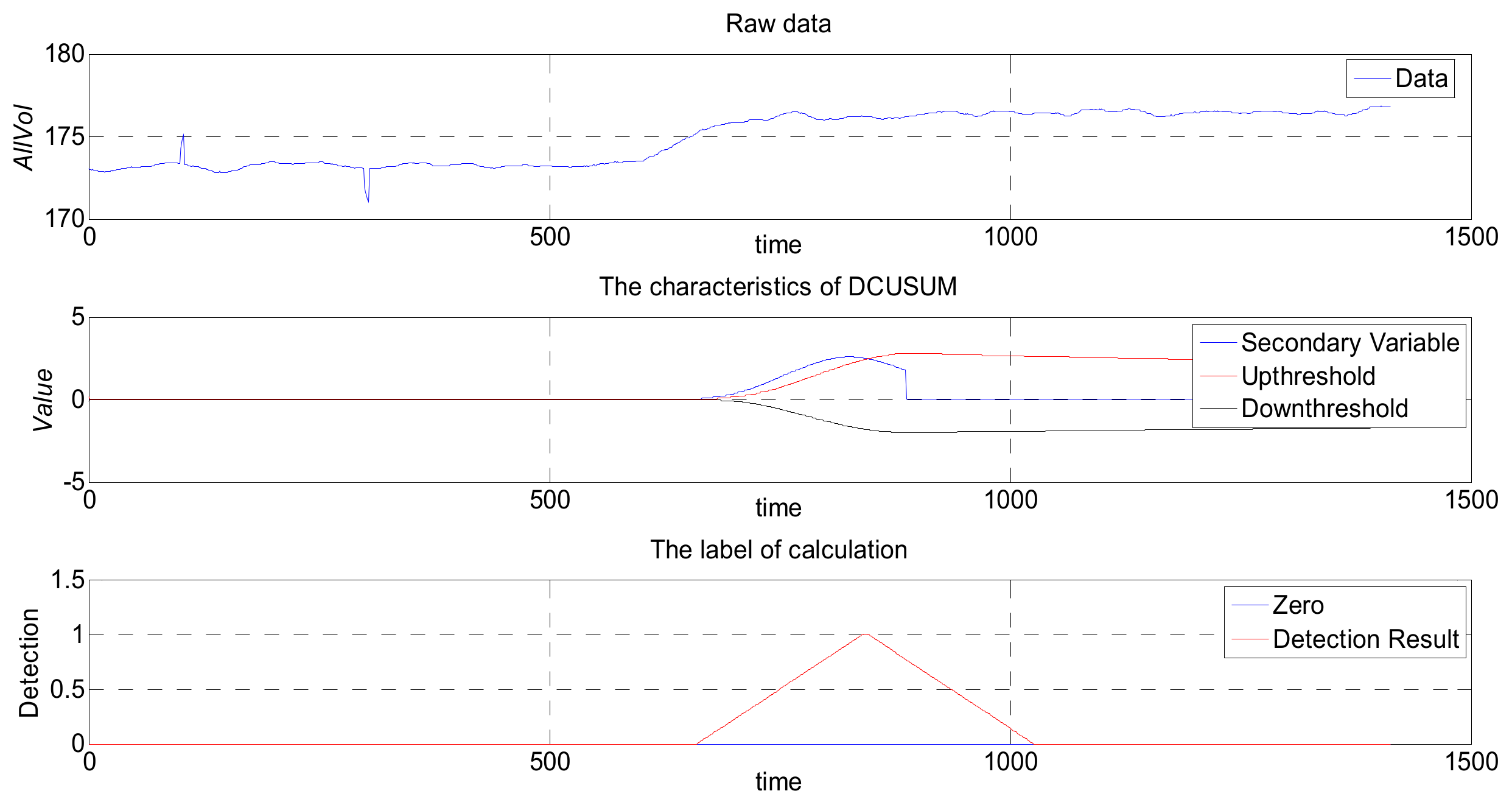
Figure 11 maps the original values of the DCUSUM-DS space. The top graph is drawn from the original data, the middle graph is the feature quantity graph after data conversion, and the bottom graph is the tagged data graph. It can be clearly seen from the middle graph that the feature amount obviously exceeds the upper threshold line. The bottom graph clearly shows that the original data have a significant anomaly, while the other two interference points are not displayed, which is consistent with the original intention of the algorithm design.
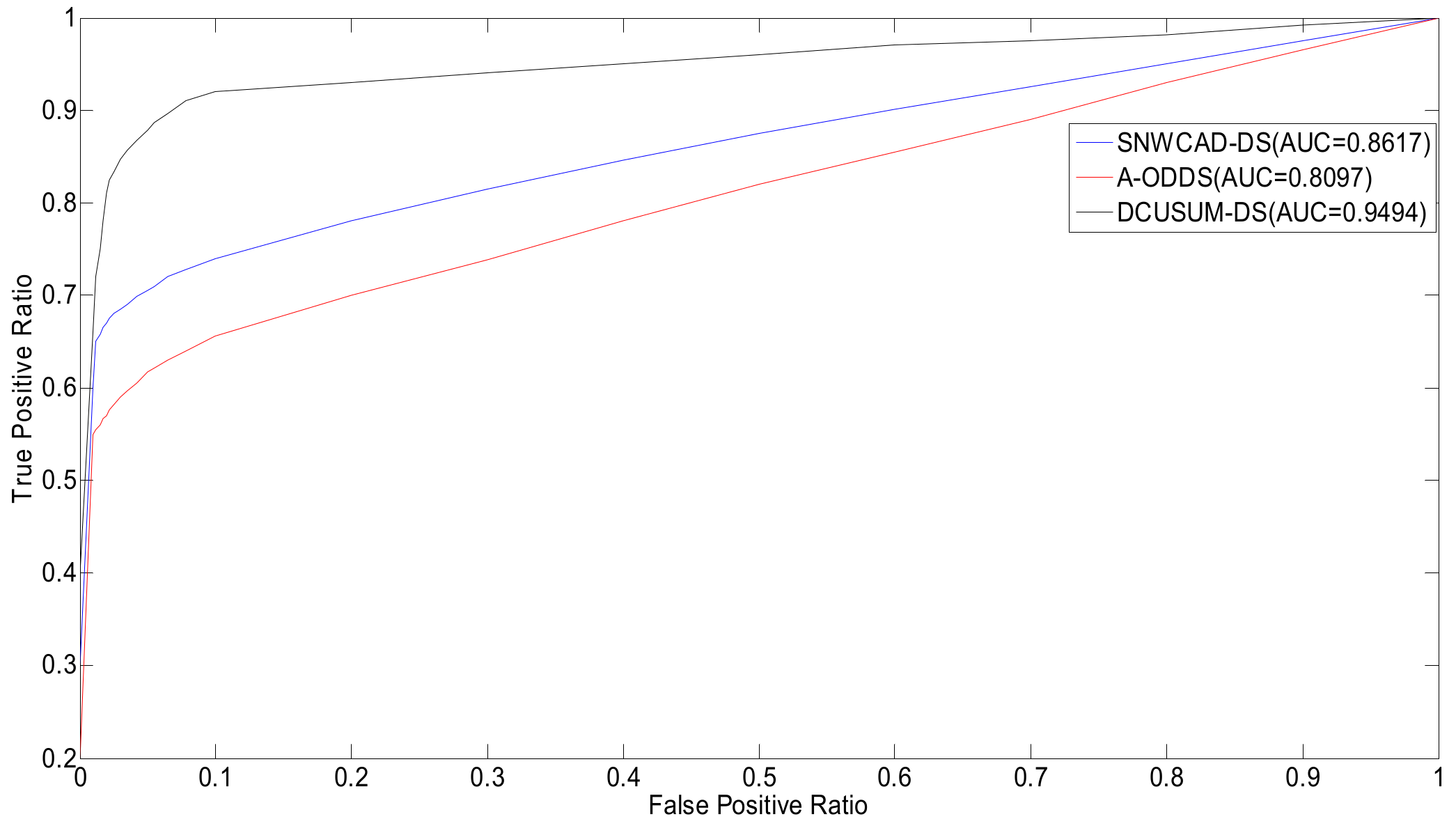
Figure 12 indicates that the proposed new algorithm DCUSUM can increase the TPR and reduce the FPR, compared with SNWCAD-DS and A-ODDS.
Through analysis of
Figure 9,
Figure 12, and
Table 2, we can conclude that the proposed new algorithm DCUSUM-DS improves the accuracy of online classification and reduces the misclassification rate. The influence of the interference data can be masked, real abnormal data can be detected, and the interference data can be filtered out. Computational complexity does not significantly increase, and the algorithm fully meets the relevant working requirements. The laboratory simulation and field application show that the algorithm solves the machine classification problems that arise from poor data quality in industrial data streams, thus improving machine learning classification.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}