Iterative Group Decomposition for Refining Microaggregation Solutions



Abstract
1. Introduction
2. Microaggregation Problem
3. Related Work
3.1. Microaggregation Approaches
3.2. Refining Approaches
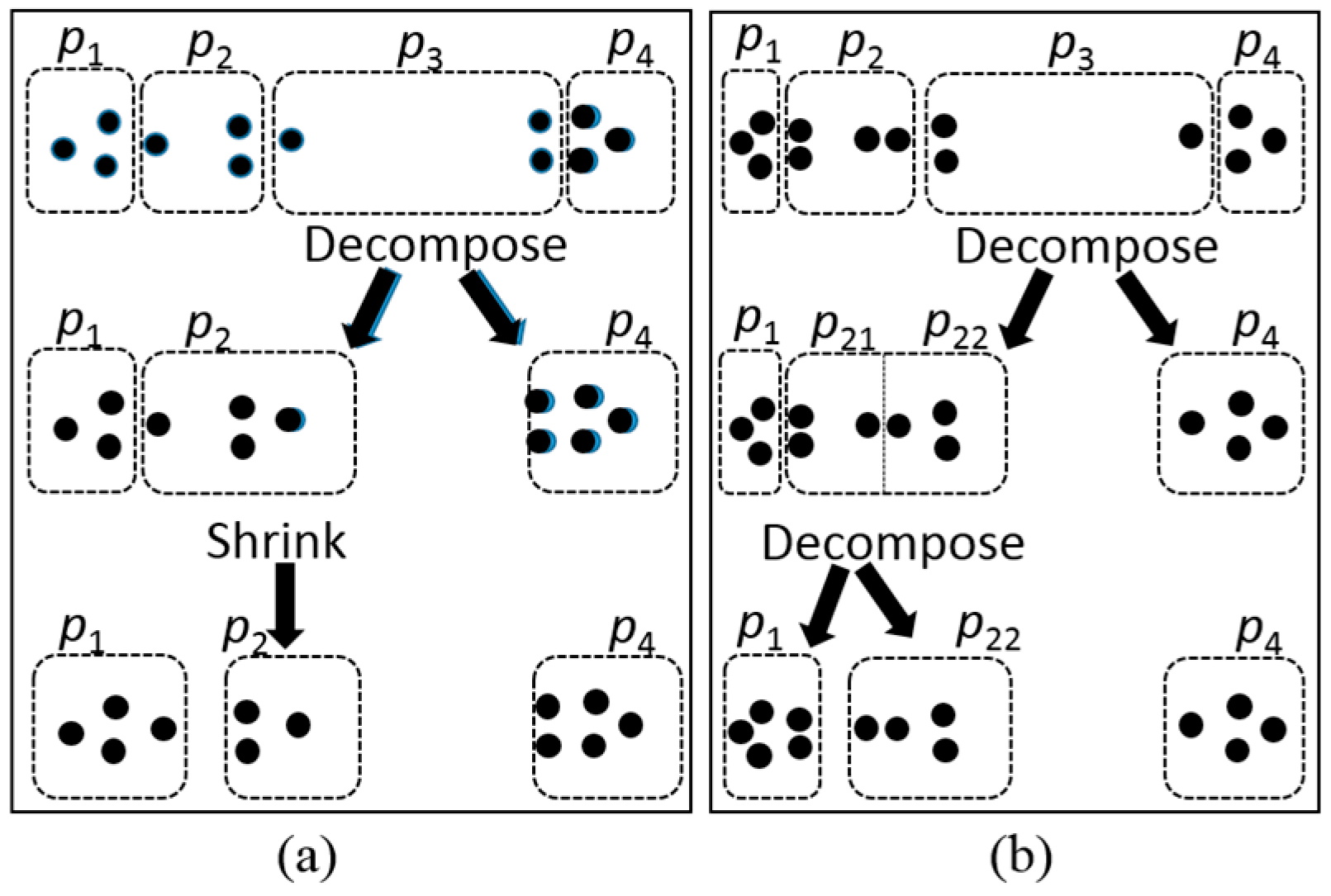
4. Proposed Algorithm
5. Experiment
5.1. Datasets
5.2. Experimental Settings
5.3. Experimental Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Domingo-Ferrer, J.; Torra, V. Privacy in data mining. Data Min. Knowl. Discov. 2005, 11, 117–119. [Google Scholar] [CrossRef]
- Willenborg, L.; Waal, T.D. Data Analytic Impact of SDC Techniques on Microdata. In Elements of Statistical Disclosure Control; Springer: New York, NY, USA, 2000. [Google Scholar]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Hansen, S.L.; Mukherjee, S. A polynomial algorithm for optimal univariate microaggregation. IEEE Trans. Knowl. Data Eng. 2003, 15, 1043–1044. [Google Scholar] [CrossRef]
- Oganian, A.; Domingo-Ferrer, J. On the complexity of optimal microaggregation for statistical disclosure control. Stat. J. U. N. Econ. Comm. Eur. 2001, 18, 345–353. [Google Scholar]
- Domingo-Ferrer, J.; Torra, V. Ordinal, continuous and heterogeneous k-anonymity through microaggregation. Data Min. Knowl. Discov. 2005, 11, 195–212. [Google Scholar] [CrossRef]
- Laszlo, M.; Mukherjee, S. Minimum spanning tree partitioning algorithm for microaggregation. IEEE Trans. Knowl. Data Eng. 2005, 17, 902–911. [Google Scholar] [CrossRef]
- Chang, C.C.; Li, Y.C.; Huang, W.H. TFRP: An efficient microaggregation algorithm for statistical disclosure control. J. Syst. Softw. 2007, 80, 1866–1878. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Martinez-Balleste, A.; Mateo-Sanz, J.M.; Sebe, F. Efficient multivariate data-oriented microaggregation. Int. J. Large Data Bases 2006, 15, 355–369. [Google Scholar] [CrossRef]
- Lin, J.L.; Wen, T.H.; Hsieh, J.C.; Chang, P.C. Density-based microaggregation for statistical disclosure control. Expert Syst. Appl. 2010, 37, 3256–3263. [Google Scholar] [CrossRef]
- Panagiotakis, C.; Tziritas, G. Successive group selection for microaggregation. IEEE Trans. Knowl. Data Eng. 2013, 25, 1191–1195. [Google Scholar] [CrossRef]
- Mortazavi, R.; Jalili, S. Fast data-oriented microaggregation algorithm for large numerical datasets. Knowl. Based Syst. 2014, 67, 195–205. [Google Scholar] [CrossRef]
- Aloise, D.; Araújo, A. A derivative-free algorithm for refining numerical microaggregation solutions. Int. Trans. Oper. Res. 2015, 22, 693–712. [Google Scholar] [CrossRef]
- Mortazavi, R.; Jalili, S.; Gohargazi, H. Multivariate microaggregation by iterative optimization. Appl. Intell. 2013, 39, 529–544. [Google Scholar] [CrossRef]
- Laszlo, M.; Mukherjee, S. Iterated local search for microaggregation. J. Syst. Softw. 2015, 100, 15–26. [Google Scholar] [CrossRef]
- Mortazavi, R.; Jalili, S. A novel local search method for microaggregation. ISC Int. J. Inf. Secur. 2015, 7, 15–26. [Google Scholar]
- Domingo-Ferrer, J.; Mateo-Sanz, J.M. Practical data-oriented microaggregation for statistical disclosure control. IEEE Trans. Knowl. Data Eng. 2002, 14, 189–201. [Google Scholar] [CrossRef]
- Kabir, M.E.; Mahmood, A.N.; Wang, H.; Mustafa, A. Microaggregation sorting framework for K-anonymity statistical disclosure control in cloud computing. IEEE Trans. Cloud Comput. 2015. Available online: http://doi.ieeecomputersociety.org/10.1109/TCC.2015.2469649 (accessed on 1 June 2018). [CrossRef]
- Kabir, M.E.; Wang, H.; Zhang, Y. A pairwise-systematic microaggregation for statistical disclosure control. In Proceedings of the IEEE 10th International Conference on Data Mining (ICDM), Sydney, NSW, Australia, 13–17 December 2010; pp. 266–273. [Google Scholar]
- Kabir, M.E.; Wang, H. Systematic clustering-based microaggregation for statistical disclosure control. In Proceedings of the 2010 Fourth International Conference on Network and System Security, Melbourne, VIC, Australia, 1–3 September 2010; pp. 435–441. [Google Scholar]
- Sun, X.; Wang, H.; Li, J.; Zhang, Y. An approximate microaggregation approach for microdata protection. Expert Syst. Appl. 2012, 39, 2211–2219. [Google Scholar] [CrossRef]
- Panagiotakis, C.; Tziritas, G. A minimum spanning tree equipartition algorithm for microaggregation. J. Appl. Stat. 2015, 42, 846–865. [Google Scholar] [CrossRef]
- Zahn, C.T. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Trans. Comput. 1971, C-20, 68–86. [Google Scholar] [CrossRef]
- Ward, J.H. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. l-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar]
- Sun, X.; Wang, H.; Li, J.; Zhang, Y. Satisfying privacy requirements before data anonymization. Comput. J. 2012, 55, 422–437. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Soria-Comas, J. Steered microaggregation: A unified primitive for anonymization of data sets and data streams. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 995–1002. [Google Scholar]
- Domingo-Ferrer, J.; Sebe, F.; Solanas, A. A polynomial-time approximation to optimal multivariate microaggregation. Comput. Math. Appl. 2008, 55, 714–732. [Google Scholar] [CrossRef]
- Aloise, D.; Hansen, P.; Rocha, C.; Santi, É. Column generation bounds for numerical microaggregation. J. Glob. Optim. 2014, 60, 165–182. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tested Method | Heuristic for Selecting the 1st Record of Each Group | Heuristic for Growing a Group to Size k | Method for Refining a Solution |
|---|---|---|---|
| CBFS-NN | CBFS | Nearest Neighbors to 1st record | None |
| CBFS-NN2 | CBFS | Nearest Neighbors to 1st record | TFRP2 |
| CBFS-NN3 | CBFS | Nearest Neighbors to 1st record | Our method in Figure 1 |
| CBFS-NC | CBFS | Nearest to group’s Centroid | None |
| CBFS-NC2 | CBFS | Nearest to group’s Centroid | TFRP2 |
| CBFS-NC3 | CBFS | Nearest to group’s Centroid | Our method in Figure 1 |
| MDAV-NN | MDAV | Nearest Neighbors to 1st record | None |
| MDAV-NN2 | MDAV | Nearest Neighbors to 1st record | TFRP2 |
| MDAV-NN3 | MDAV | Nearest Neighbors to 1st record | Our method in Figure 1 |
| MDAV-NC | MDAV | Nearest to group’s Centroid | None |
| MDAV-NC2 | MDAV | Nearest to group’s Centroid | TFRP2 |
| MDAV-NC3 | MDAV | Nearest to group’s Centroid | Our method in Figure 1 |
| TFRP-NN | TFRP | Nearest Neighbors to 1st record | None |
| TFRP-NN2 | TFRP | Nearest Neighbors to 1st record | TFRP2 |
| TFRP-NN3 | TFRP | Nearest Neighbors to 1st record | Our method in Figure 1 |
| TFRP-NC | TFRP | Nearest to group’s Centroid | None |
| TFRP-NC2 | TFRP | Nearest to group’s Centroid | TFRP2 |
| TFRP-NC3 | TFRP | Nearest to group’s Centroid | Our method in Figure 1 |
| GSMS-NN | GSMS | Nearest Neighbors to 1st record | None |
| GSMS-NN2 | GSMS | Nearest Neighbors to 1st record | TFRP2 |
| GSMS-NN3 | GSMS | Nearest Neighbors to 1st record | Our method in Figure 1 |
| Method/k | 3 | 4 | 5 | 10 | 20 | 30 |
|---|---|---|---|---|---|---|
| CBFS-NN | 16.966 | 19.730 | 22.819 | 33.215 | 42.955 | 49.489 |
| CBFS-NN2 | 16.966 | 19.227 | 22.588 | 33.211 | 42.944 | 49.481 |
| CBFS-NN3 | 16.966 | 18.651 | 22.268 | 33.173 | 42.872 | 49.404 |
| CBFS-NC | 15.617 | 19.230 | 22.609 | 37.105 | 47.685 | 56.042 |
| CBFS-NC2 | 15.617 | 19.210 | 22.150 | 36.892 | 46.415 | 53.212 |
| CBFS-NC3 | 15.617 | 19.172 | 21.434 | 36.290 | 41.848 | 47.231 |
| MDAV-NN | 16.9326 | 19.546 | 22.4613 | 33.192 | 43.195 | 49.483 |
| MDAV-NN2 | 16.9324 | 19.029 | 22.4613 | 33.192 | 43.099 | 49.460 |
| MDAV-NN3 | 16.9320 | 18.434 | 22.4612 | 33.184 | 42.771 | 49.261 |
| MDAV-NC | 15.631 | 19.176 | 22.712 | 36.992 | 47.705 | 56.370 |
| MDAV-NC2 | 15.617 | 19.140 | 22.284 | 36.955 | 46.167 | 52.705 |
| MDAV-NC3 | 15.598 | 19.068 | 21.409 | 36.389 | 41.122 | 47.297 |
| TFRP-NN | 17.112 | 19.995 | 23.412 | 33.557 | 43.416 | 50.187 |
| TFRP-NN2 | 17.070 | 19.715 | 23.136 | 33.405 | 43.343 | 49.965 |
| TFRP-NN3 | 16.954 | 19.275 | 22.408 | 32.866 | 42.652 | 48.512 |
| TFRP-NC | 17.629 | 19.511 | 23.222 | 35.645 | 47.654 | 55.604 |
| TFRP-NC2 | 16.702 | 19.374 | 23.171 | 35.400 | 46.317 | 53.050 |
| TFRP-NC3 | 16.021 | 19.233 | 22.839 | 34.909 | 41.358 | 47.034 |
| GSMS-NN | 16.610 | 19.050 | 21.948 | 33.234 | 43.023 | 49.433 |
| GSMS-NN2 | 16.610 | 19.046 | 21.723 | 33.230 | 43.008 | 49.429 |
| GSMS-NN3 | 16.610 | 19.039 | 21.311 | 33.208 | 42.932 | 49.395 |
| Method/k | 3 | 4 | 5 | 10 | 20 | 30 |
|---|---|---|---|---|---|---|
| CBFS-NN | 5.654 | 7.441 | 8.884 | 14.001 | 19.469 | 23.881 |
| CBFS-NN2 | 5.648 | 7.439 | 8.848 | 13.902 | 19.384 | 23.651 |
| CBFS-NN3 | 5.644 | 7.406 | 8.554 | 12.809 | 17.938 | 21.509 |
| CBFS-NC | 5.348 | 7.173 | 8.685 | 14.341 | 21.390 | 26.505 |
| CBFS-NC2 | 5.337 | 7.165 | 8.656 | 14.117 | 20.470 | 24.848 |
| CBFS-NC3 | 5.325 | 7.139 | 8.575 | 12.672 | 17.365 | 20.326 |
| MDAV-NN | 5.692 | 7.495 | 9.088 | 14.156 | 19.578 | 23.407 |
| MDAV-NN2 | 5.683 | 7.434 | 9.054 | 14.017 | 19.492 | 23.289 |
| MDAV-NN3 | 5.660 | 7.218 | 8.950 | 12.809 | 18.129 | 21.201 |
| MDAV-NC | 5.343 | 7.290 | 8.945 | 14.361 | 21.364 | 25.123 |
| MDAV-NC2 | 5.335 | 7.265 | 8.898 | 14.043 | 20.091 | 23.686 |
| MDAV-NC3 | 5.334 | 7.222 | 8.698 | 12.648 | 17.481 | 20.647 |
| TFRP-NN | 5.864 | 7.965 | 9.252 | 14.369 | 20.167 | 23.607 |
| TFRP-NN2 | 5.805 | 7.831 | 9.039 | 14.042 | 19.817 | 23.063 |
| TFRP-NN3 | 5.735 | 7.428 | 8.408 | 13.024 | 18.211 | 21.112 |
| TFRP-NC | 5.645 | 7.636 | 9.301 | 14.834 | 21.719 | 26.725 |
| TFRP-NC2 | 5.546 | 7.496 | 9.037 | 14.265 | 20.555 | 25.031 |
| TFRP-NC3 | 5.466 | 7.382 | 8.796 | 12.963 | 17.973 | 20.892 |
| GSMS-NN | 5.564 | 7.254 | 8.686 | 13.549 | 18.792 | 22.432 |
| GSMS-NN2 | 5.545 | 7.251 | 8.597 | 13.452 | 18.451 | 22.354 |
| GSMS-NN3 | 5.535 | 7.240 | 8.367 | 13.085 | 17.230 | 21.089 |
| Method/k | 3 | 4 | 5 | 10 | 20 | 30 |
|---|---|---|---|---|---|---|
| CBFS-NN | 0.478 | 0.671 | 1.740 | 3.512 | 7.053 | 10.919 |
| CBFS-NN2 | 0.416 | 0.614 | 0.960 | 2.644 | 6.981 | 10.854 |
| CBFS-NN3 | 0.402 | 0.587 | 0.803 | 2.036 | 6.823 | 10.605 |
| CBFS-NC | 0.470 | 0.672 | 1.533 | 3.276 | 7.628 | 10.084 |
| CBFS-NC2 | 0.426 | 0.612 | 0.891 | 2.552 | 7.410 | 10.046 |
| CBFS-NC3 | 0.415 | 0.574 | 0.762 | 2.282 | 7.110 | 10.038 |
| MDAV-NN | 0.483 | 0.671 | 1.667 | 3.840 | 7.095 | 10.273 |
| MDAV-NN2 | 0.417 | 0.614 | 0.969 | 2.931 | 7.010 | 10.192 |
| MDAV-NN3 | 0.401 | 0.587 | 0.802 | 2.022 | 6.806 | 9.873 |
| MDAV-NC | 0.471 | 0.677 | 1.459 | 3.058 | 7.641 | 9.984 |
| MDAV-NC2 | 0.428 | 0.612 | 0.962 | 2.744 | 7.427 | 9.946 |
| MDAV-NC3 | 0.415 | 0.573 | 0.795 | 2.298 | 7.109 | 9.937 |
| TFRP-NN | 0.513 | 0.680 | 1.768 | 3.543 | 7.087 | 11.116 |
| TFRP-NN2 | 0.419 | 0.613 | 0.969 | 2.669 | 6.977 | 10.993 |
| TFRP-NN3 | 0.405 | 0.585 | 0.8 | 2.04 | 6.771 | 10.491 |
| TFRP-NC | 0.465 | 0.674 | 1.670 | 3.288 | 7.663 | 11.286 |
| TFRP-NC2 | 0.420 | 0.607 | 0.887 | 2.545 | 7.443 | 10.684 |
| TFRP-NC3 | 0.410 | 0.574 | 0.779 | 2.289 | 7.116 | 10.324 |
| GSMS-NN | 0.469 | 0.669 | 1.713 | 3.313 | 6.958 | 11.384 |
| GSMS-NN2 | 0.407 | 0.610 | 0.890 | 2.569 | 6.859 | 10.704 |
| GSMS-NN3 | 0.394 | 0.59 | 0.796 | 2.101 | 6.647 | 9.314 |
| Dataset | k | Best from [11] | Our Best | ||
|---|---|---|---|---|---|
| IL*100 | Method | IL*100 | Method | ||
| Tarragona | 3 | 16.36 | GSMS-T2 | 15.598 | MDAV-NC3 |
| Tarragona | 5 | 21.72 | GSMS-T2 | 21.311 | GSMS-NC3 |
| Tarragona | 10 | 33.18 | MD-MHM | 32.866 | TFRP-NN3 |
| Census | 3 | 5.53 | GSMS-T2 | 5.325 | CBFS-NC3 |
| Census | 5 | 8.58 | GSMS-T2 | 8.367 | GSMS-NN3 |
| Census | 10 | 13.42 | GSMS-T2 | 12.648 | MDAV-NC3 |
| EIA | 3 | 0.401 | GSMS-T2 | 0.394 | GSMS-NN3 |
| EIA | 5 | 0.87 | GSMS-T2 | 0.762 | CBFS-NC3 |
| EIA | 10 | 2.17 | μ-Approx | 2.022 | MDAV-NN3 |
| Method | Tarragona | Census | EIA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| k = 3 | k = 5 | k = 10 | k = 3 | k = 5 | k = 10 | k = 3 | k = 5 | k = 10 | |
| CBFS-NN3 | V | V | V | V | V | ||||
| CBFS-NC3 | V | V | V | V | V | V | |||
| MDAV-NN3 | V | V | V | ||||||
| MDAV-NC3 | V | V | V | V | V | ||||
| TFRP-NN3 | V | V | V | V | V | ||||
| TFRP-NC3 | V | V | V | V | |||||
| GSMS-NN3 | V | V | V | V | V | V | |||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khomnotai, L.; Lin, J.-L.; Peng, Z.-Q.; Santra, A.S. Iterative Group Decomposition for Refining Microaggregation Solutions. Symmetry 2018, 10, 262. https://doi.org/10.3390/sym10070262
Khomnotai L, Lin J-L, Peng Z-Q, Santra AS. Iterative Group Decomposition for Refining Microaggregation Solutions. Symmetry. 2018; 10(7):262. https://doi.org/10.3390/sym10070262
Chicago/Turabian StyleKhomnotai, Laksamee, Jun-Lin Lin, Zhi-Qiang Peng, and Arpita Samanta Santra. 2018. "Iterative Group Decomposition for Refining Microaggregation Solutions" Symmetry 10, no. 7: 262. https://doi.org/10.3390/sym10070262
APA StyleKhomnotai, L., Lin, J.-L., Peng, Z.-Q., & Santra, A. S. (2018). Iterative Group Decomposition for Refining Microaggregation Solutions. Symmetry, 10(7), 262. https://doi.org/10.3390/sym10070262