Deep Learning as a Tool for Automatic Segmentation of Corneal Endothelium Images


Abstract
1. Introduction
2. Materials and Methods
2.1. Endothelial Images
2.2. Training Set Preparation
- Cell border class finds pixel which corresponds to cell border and then cuts the sample assuring that this pixel is placed as a central point of the patch.
- Cell center class for each cell finds its mass-center and these coordinates are used to choose an appropriate pixel as a central point of the sample.
- Cell body is an additional class, which assumes to describe data which are far from cell center but are not a border. In order to create the sample, which belongs to this set, a cell border was sampled, and points laying 5 pixels from it in a horizontal or vertical direction (chosen randomly) were denoted as a central point of a sample.
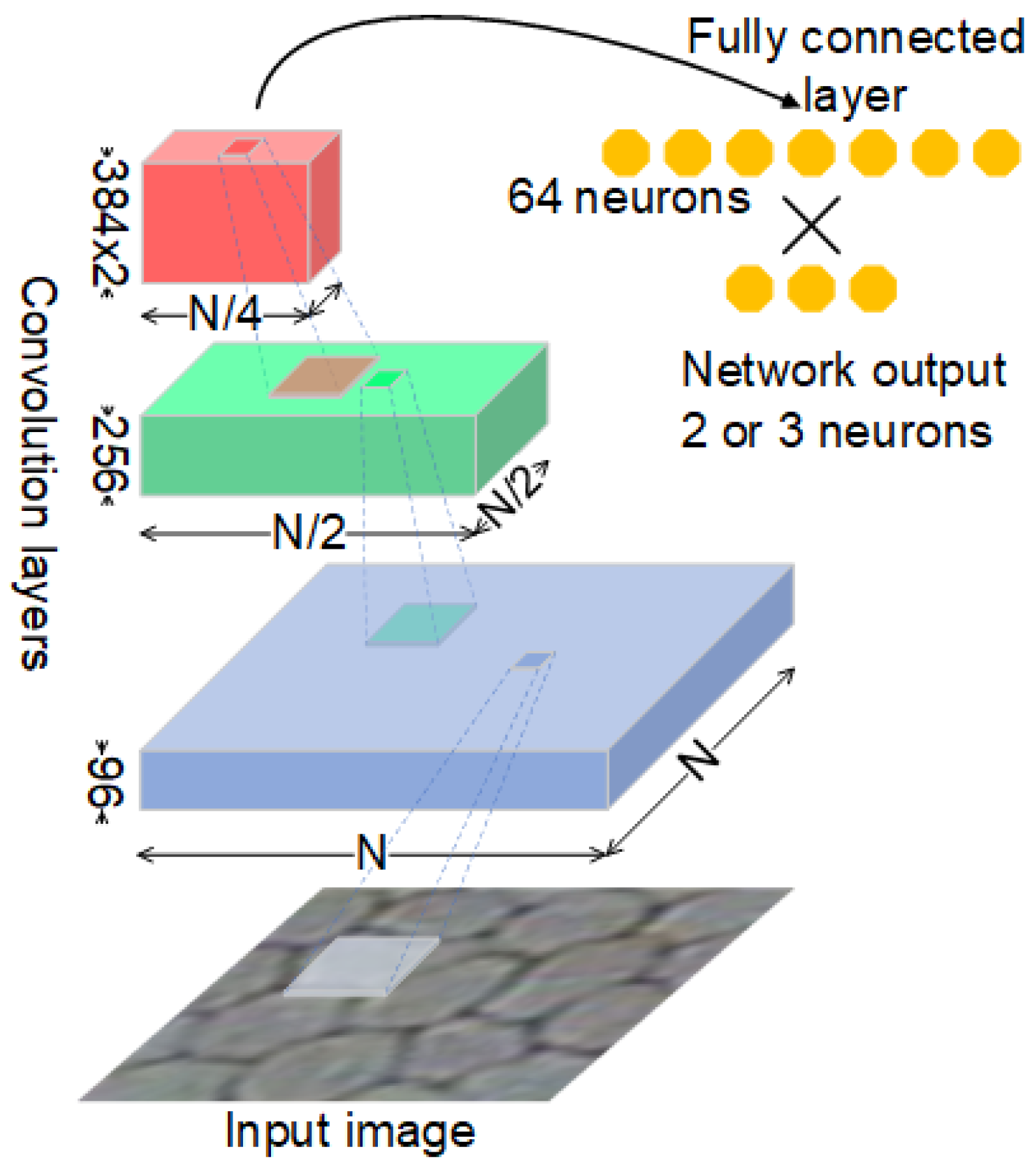
2.3. Convolutional Neural Network
2.4. Segmentation Approaches
2.5. Cell Splitting
2.6. Border Skeletonization
3. Results and Discussion
3.1. CNN for Two-Class Problem
3.2. CNN for Three-Class Problem
3.3. Splitting Merged Cells
3.4. Segmentation Accuracy
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Agarwal, S.; Agarwal, A.; Apple, D.; Buratto, L. Textbook of Ophthalmology; Jaypee Brothers, Medical Publishers Ltd.: New Dehli, India, 2002. [Google Scholar]
- Meyer, L.; Ubels, J.; Edelhauser, H. Corneal endothelial morphology in the rat. Investig. Ophthalmol. Vis. Sci. 1988, 29, 940–949. [Google Scholar]
- Rao, G.N.; Lohman, L.; Aquavella, J. Cell size-shape relationships in corneal endothelium. Investig. Ophthalmol. Vis. Sci. 1982, 22, 271–274. [Google Scholar]
- Doughty, M. The ambiguous coefficient of variation: Polymegethism of the corneal endothelium and central corneal thickness. Int. Contact Lens Clin. 1990, 17, 240–248. [Google Scholar] [CrossRef]
- Doughty, M. Concerning the symmetry of the hexagonal cells of the corneal endothelium. Exp. Eye Res. 1992, 55, 145–154. [Google Scholar] [CrossRef]
- Mazurek, P. Cell structures modeling using fractal generator and torus geometry. In Proceedings of the 2016 21st International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 29 August–1 September 2016; pp. 750–755. [Google Scholar]
- Nurzynska, K.; Piorkowski, A. The correlation analysis of the shape parameters for endothelial image characterisation. Image Anal. Stereol. 2016, 35, 149–158. [Google Scholar] [CrossRef][Green Version]
- Nurzynska, K.; Kubo, M.; Muramoto, K.i. Shape parameters for automatic classification of snow particles into snowflake and graupel. Meteorol. Appl. 2013, 20, 257–265. [Google Scholar] [CrossRef]
- Vincent, L.M.; Masters, B.R. Morphological image processing and network analysis of cornea endothelial cell images. In Proceedings of the International Society for Optics and Photonics, San Diego, CA, USA, 1 June 1992; Volume 1769, pp. 212–226. [Google Scholar]
- Caetano, C.A.C.; Entura, L.; Sousa, S.J.; Tufo, R.E.A. Identification and segmentation of cells in images of donated corneas using mathematical morphology. In Proceedings of the XIII Brazilian Symposium on Computer Graphics and Image Processing, Gramado, Brazil, 17–20 October 2000; p. 344. [Google Scholar]
- Malmberg, F.; Selig, B.; Luengo Hendriks, C. Exact Evaluation of Stochastic Watersheds: From Trees to General Graphs. In Discrete Geometry for Computer Imagery; Lecture Notes in Computer Science; Barcucci, E., Frosini, A., Rinaldi, S., Eds.; Springer International Publishing: Berlin, Germany, 2014; Volume 8668, pp. 309–319. [Google Scholar]
- Bernander, K.B.; Gustavsson, K.; Selig, B.; Sintorn, I.M.; Luengo Hendriks, C.L. Improving the Stochastic Watershed. Pattern Recognit. Lett. 2013, 34, 993–1000. [Google Scholar] [CrossRef]
- Selig, B.; Malmberg, F.; Luengo Hendriks, C.L. Fast evaluation of the robust stochastic watershed. In Proceedings of the 12th International Syposium on Mathematical Morphology Mathematical Morphology and Its Applications to Signal and Image Processing, Lecture Notes in Computer Science, Reykjavik, Iceland, 27–29 May 2015; Volume 9082, pp. 705–716. [Google Scholar]
- Selig, B.; Vermeer, K.A.; Rieger, B.; Hillenaar, T.; Hendriks, C.L.L. Fully automatic evaluation of the corneal endothelium from in vivo confocal microscopy. BMC Med. Imaging 2015, 15. [Google Scholar] [CrossRef] [PubMed]
- Mahzoun, M.; Okazaki, K.; Mitsumoto, H.; Kawai, H.; Sato, Y.; Tamura, S.; Kani, K. Detection and complement of hexagonal borders in corneal endothelial cell image. Med. Imaging Technol. 1996, 14, 56–69. [Google Scholar]
- Serra, J.; Mlynarczuk, M. Morphological merging of multidimensional data. In Proceedings of the STERMAT 2000, Krakow, Poland, 20–23 September 2000; pp. 385–390. [Google Scholar]
- Foracchia, M.; Ruggeri, A. Corneal endothelium analysis by means of Bayesian shape modeling. In Proceedings of the 25th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Cancun, Mexico, 17–21 September 2003; pp. 794–797. [Google Scholar]
- Foracchia, M.; Ruggeri, A. Corneal Endothelium Cell Field Analysis by means of Interacting Bayesian Shape Models. In Proceedings of the 29th Annual International Conference of the Engineering in Medicine and Biology Society, Lyon, France, 22–26 Auguest 2007; pp. 6035–6038. [Google Scholar]
- Fabijańska, A.; Sankowski, D. Noise adaptive switching median-based filter for impulse noise removal from extremely corrupted images. IET Image Process. 2011, 5, 472–480. [Google Scholar] [CrossRef]
- Habrat, K.; Habrat, M.; Gronkowska-Serafin, J.; Piorkowski, A. Cell detection in corneal endothelial images using directional filters. In Image Processing and Communications Challenges 7; Advances in Intelligent Systems and Computing; Springer: Berlin, Germany, 2016; Volume 389, pp. 113–123. [Google Scholar]
- Dagher, I.; El Tom, K. WaterBalloons: A hybrid watershed Balloon Snake segmentation. Image Vis. Comput. 2008, 26, 905–912. [Google Scholar] [CrossRef]
- Charlampowicz, K.; Reska, D.; Boldak, C. Automatic segmentation of corneal endothelial cells using active contours. Adv. Comput. Sci. Res. 2014, 14, 47–60. [Google Scholar]
- Reska, D.; Jurczuk, K.; Boldak, C.; Kretowski, M. MESA: Complete approach for design and evaluation of segmentation methods using real and simulated tomographic images. Biocybern. Biomed. Eng. 2014, 34, 146–158. [Google Scholar] [CrossRef]
- Zhou, Y. Cell Segmentation Using Level Set Method. Master’s Thesis, Johannes Kepler Universitat, Linz, Austria, 2007. [Google Scholar]
- Khan, M.A.U.; Niazi, M.K.K.; Khan, M.A.; Ibrahim, M.T. Endothelial Cell Image Enhancement using Non-subsampled Image Pyramid. Inf. Technol. J. 2007, 6, 1057–1062. [Google Scholar]
- Brookes, N.H. Morphometry of organ cultured corneal endothelium using Voronoi segmentation. Cell Tissue Bank. 2017, 18, 167–183. [Google Scholar] [CrossRef] [PubMed]
- Piorkowski, A.; Gronkowska-Serafin, J. Towards Automated Cell Segmentation in Corneal Endothelium Images. In Image Processing and Communications Challenges 6; Advances in Intelligent Systems and Computing; Springer: Berlin, Germany, 2015; Volume 313, pp. 179–186. [Google Scholar]
- Piorkowski, A. Best-Fit Segmentation Created Using Flood-Based Iterative Thinning. In Image Processing and Communications Challenges 8. IP&C 2016; Advances in Intelligent Systems and Computing; Choraś, R.S., Ed.; Springer: Berlin, Germany, 2017; Volume 525, pp. 61–68. [Google Scholar]
- Saeed, K.; Tabȩdzki, M.; Rybnik, M.; Adamski, M. K3M: A universal algorithm for image skeletonization and a review of thinning techniques. Int. J. Appl. Math. Comput. Sci. 2010, 20, 317–335. [Google Scholar] [CrossRef]
- Hasegawa, A.; Itoh, K.; Ichioka, Y. Generalization of shift invariant neural networks: image processing of corneal endothelium. Neural Netw. 1996, 9, 345–356. [Google Scholar] [CrossRef]
- Foracchia, M.; Ruggeri, A. Cell contour detection in corneal endothelium in-vivo microscopy. In Proceedings of the 22nd Annual International Conference of the Engineering in Medicine and Biology Society, Chicago, IL, USA, 23–28 July 2000; Volume 2, pp. 1033–1035. [Google Scholar]
- Ruggeri, A.; Scarpa, F.; De Luca, M.; Meltendorf, C.; Schroeter, J. A system for the automatic estimation of morphometric parameters of corneal endothelium in alizarine red stained images. Br. J. Ophthalmol. 2010, 94, 643–647. [Google Scholar] [CrossRef] [PubMed]
- Katafuchi, S.; Yoshimura, M. Convolution neural network for contour extraction of corneal endothelial cells. In Proceedings of the 13th International Conference on Quality Control by Artificial Vision, Tokyo, Japan, 14 May 2017. [Google Scholar]
- Fabijanska, A. Corneal endothelium image segmentation using feedforward neural network. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems (FedCSIS), Prague, Check Republic, 3–6 September 2017; pp. 629–637. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Piorkowski, A.; Nurzynska, K.; Gronkowska-Serafin, J.; Selig, B.; Boldak, C.; Reska, D. Influence of applied corneal endothelium image segmentation techniques on the clinical parameters. Comput. Med. Imaging Gr. 2017, 55, 13–27. [Google Scholar] [CrossRef] [PubMed]
- Gavet, Y.; Pinoli, J.C. Human visual perception and dissimilarity. Available online: http://spie.org/newsroom/4338-human-visual-perception-and-dissimilarity (accessed on 12 January 2018).
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Dubuisson, M.P.; Jain, A. A modified Hausdorff distance for object matching. In Proceedings of the 12th IAPR International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994; Volume 1, pp. 566–568. [Google Scholar]
- Gavet, Y.; Pinoli, J.C. A Geometric Dissimilarity Criterion Between Jordan Spatial Mosaics. Theoretical Aspects and Application to Segmentation Evaluation. J. Math. Imaging Vis. 2012, 42, 25–49. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | I | II | III |
|---|---|---|---|
| Dice index | |||
| Jaccard coefficient | |||
| MHD | |||
| FOM | |||
| Yasnoff | |||
| Gavet |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nurzynska, K. Deep Learning as a Tool for Automatic Segmentation of Corneal Endothelium Images. Symmetry 2018, 10, 60. https://doi.org/10.3390/sym10030060
Nurzynska K. Deep Learning as a Tool for Automatic Segmentation of Corneal Endothelium Images. Symmetry. 2018; 10(3):60. https://doi.org/10.3390/sym10030060
Chicago/Turabian StyleNurzynska, Karolina. 2018. "Deep Learning as a Tool for Automatic Segmentation of Corneal Endothelium Images" Symmetry 10, no. 3: 60. https://doi.org/10.3390/sym10030060
APA StyleNurzynska, K. (2018). Deep Learning as a Tool for Automatic Segmentation of Corneal Endothelium Images. Symmetry, 10(3), 60. https://doi.org/10.3390/sym10030060