1. Introduction
Image processing using RGB-D video extends the conventional RGB video by using various information related to the distance of objects. Image processing using RGB-D video is actively studied in the fields of the face detection [
1,
2,
3,
4], object detection and tracking [
5,
6,
7], SLAM (Simultaneous Localization and Mapping) [
8,
9], and so on. As application through the RGB-D videos increases, the need for depth video encoding will also be increased. The depth video encoding method can be categorized as point cloud encoding [
10,
11,
12,
13,
14,
15], mesh structure [
16,
17,
18,
19,
20,
21], and the conventional encoding method such as adopted by H.264/AVC [
22,
23,
24,
25,
26,
27,
28]. The point cloud compression algorithms focus on the static scanned point cloud, and cannot handle the replicate geometry information contained in depth frames. In the mesh-based depth schemes, extracting the mesh from each raw depth frame costs additional computing and accordingly coding complexity increases. However, the depth pixel has a high dynamic range that is different from the 8-bit pixel in the traditional RGB picture. The coding schemes designed for 8-bit video component signal encoding may not be directly applicable to the depth picture compression.
Video can be efficiently compressed by reducing the spatial redundancy in a picture, which is that adjacent pixels in same object have similar pixel values. The spatial redundancy can be reduced by encoding the difference between the value predicted by the neighboring pixels and original value. The video encoding standards such as H.264/AVC and H.265/HEVC provide intra-picture prediction modes such as direction modes and DC mode for reducing the spatial redundancy. However, it is hard to apply conventional intra prediction methods for the color picture to the depth picture because the depth picture has different characteristics from the color picture such as distribution change of pixels according to surface type. Therefore, the intra prediction methods for the depth picture have been studied. Liu [
29] introduced the new intra coding mode that is to reconstruct depth pixels with sparse representations of each depth block to intra prediction. Fu [
22] proposed improvement of efficiency of the intra-picture encoding for filtering the noise by using error model of depth value. Lan [
30] introduced the context-based spatial domain intra mode. For its intra prediction mode, only the neighboring already predicted pixels belonging to the same object can be used to make prediction. Shen [
31] proposed the edge-aware intra prediction in H.264/AVC that predicts by determining a predictors based on edge locations in a macroblock. However, conventional methods of intra prediction for the depth picture are dependent on location information of objects in the picture.
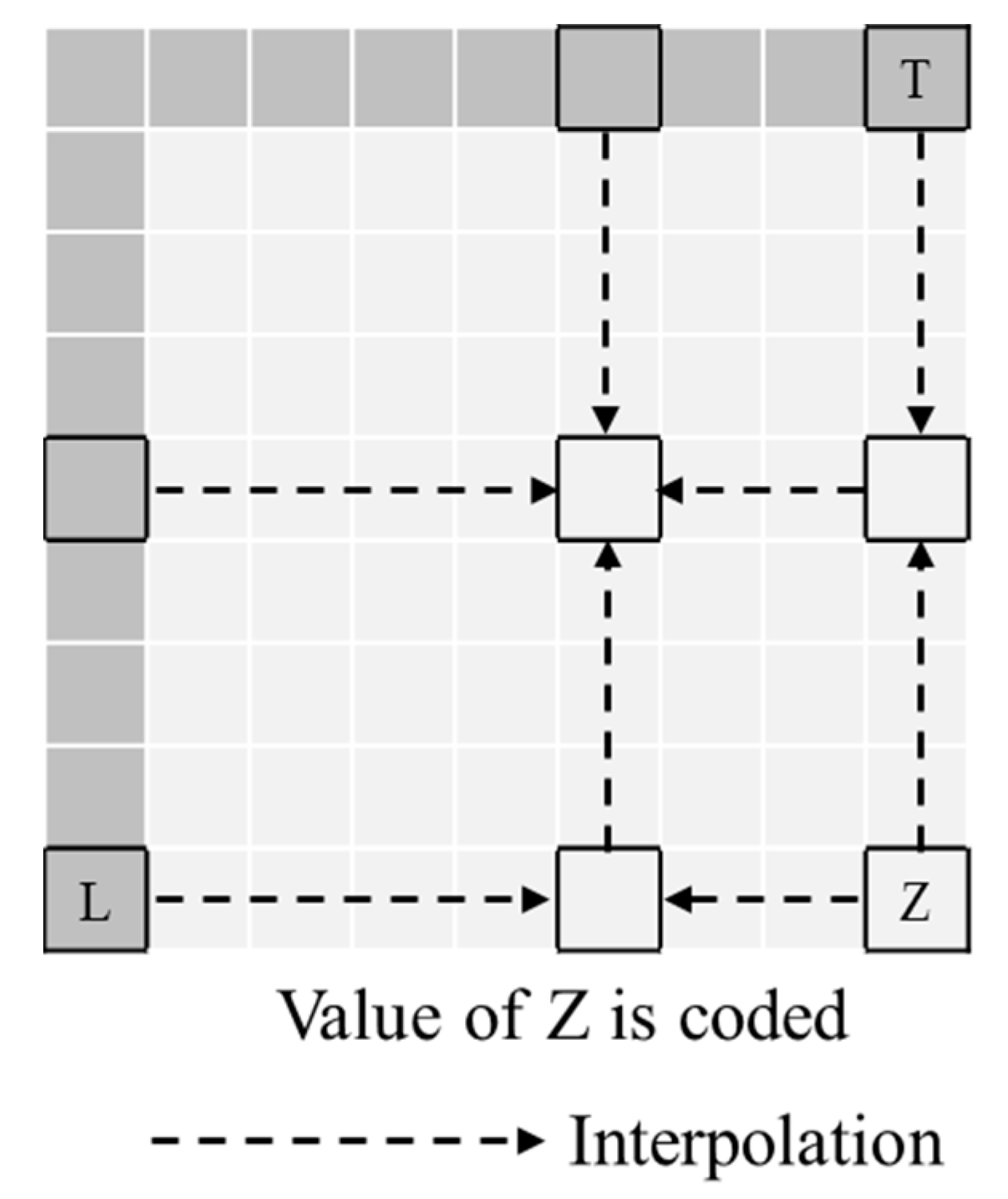
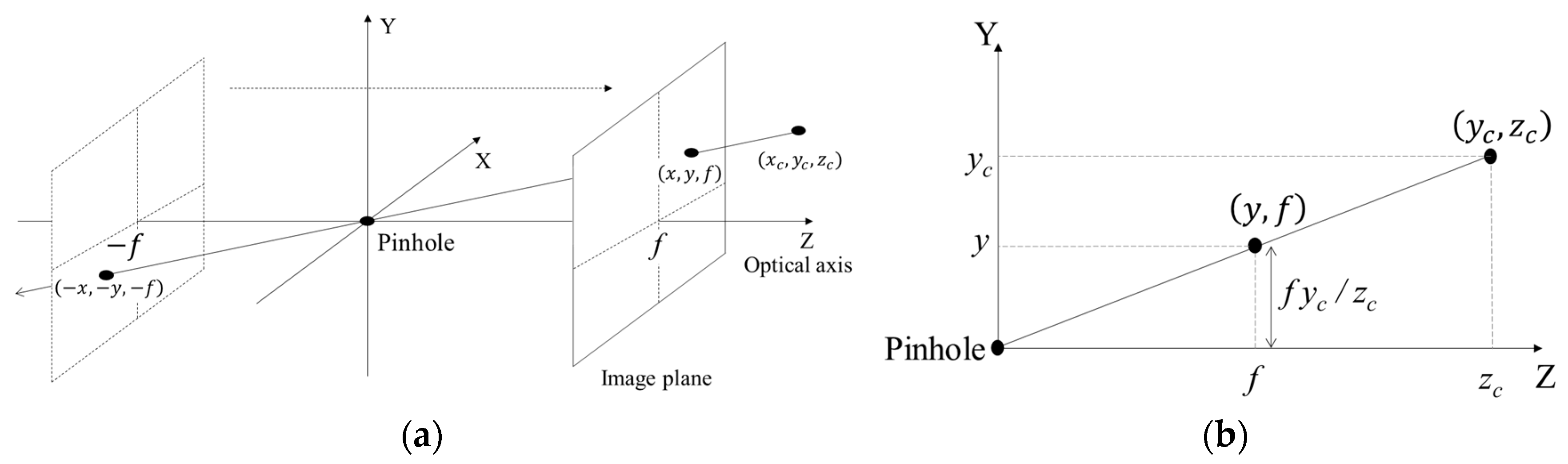
In this paper, we propose the non-direction mode in the intra prediction for the depth picture. The conventional non-direction mode for the intra prediction such as the plane mode in H.264/AVC or the planar mode in H.265/HEVC predicts the macroblock through the linear function whose parameters are computed using reference samples. In contrast, the proposed intra-prediction mode assumes that the macroblock is composed of a plane surface. The plane surface in the macroblock is estimated by modeling the plane through the depth values. The proposed mode can be applied using the variable-size block. We compare the proposed mode with the conventional intra prediction modes and show that the proposed method is more efficient for depth picture than the conventional intra prediction methods.
4. Simulation Results
In order to measure the performance of the intra prediction, we use depth videos with various objects by Kinect and Kinect v2. The focal length of device for simulation, which is used as
f in Equation (9), is specified as shown in
Table 1. Depth videos are obtained from [
41,
42,
43].
Table 2 shows the picture resolutions for each source.
Figure 10 shows the pictures for each source.
We measure the prediction accuracy of proposed mode according to block size
N. In this simulation, we regard the blocks that MSE is over than 1000 as non-plane blocks and exclude these blocks from this simulation.
Table 3 shows the simulation results. The pixel value is predicted more accurately as
N is smaller.
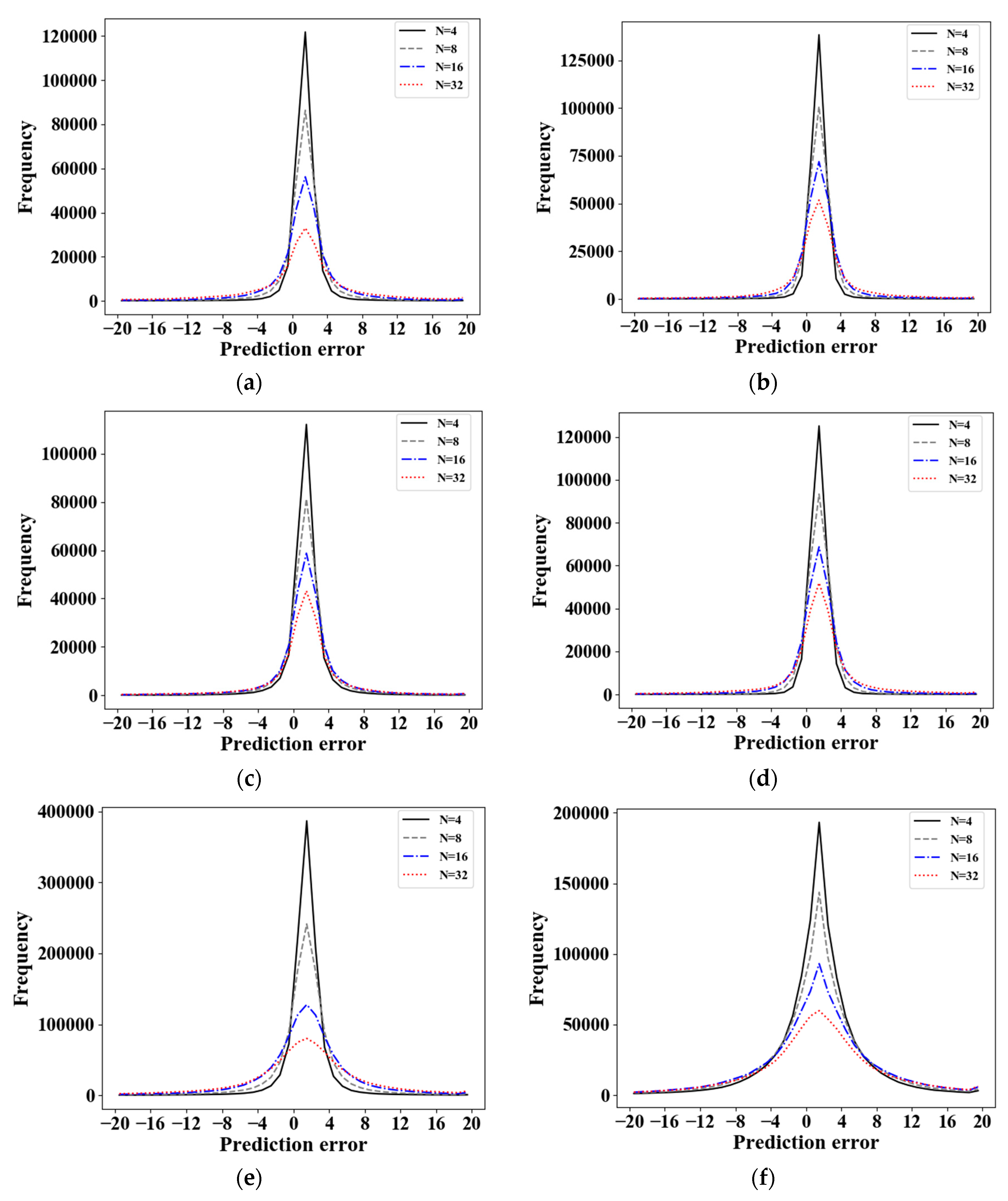
We measure distributions of the prediction error in the proposed mode. The prediction errors are distributed in the range of [−107, 105], [−226, 217], [−344, 434], and [−842, 949] in the cases of
N = 4, 8, 16, and 32, respectively, as shown in
Table 4.
Figure 11 shows the distributions of prediction errors within the range of [−20,20] according to
N. The variance of prediction error increases as
N increases.
Next, the prediction accuracy and the entropy power are investigated when the proposed prediction mode is included. The conventional prediction modes are applied to all of the modes of H.264/AVC and the planar mode of H.265/HEVC. Including proposed mode means adding the proposed mode to the conventional modes. The entropy power is defined as the output of white noise with the same frequency of all signals in an environment. The entropy power is calculated as follows:
where
fi is the probability of a signal
i. In the results shown by
Table 5 and
Table 6, prediction accuracy and entropy power are improved in the including proposed mode. These results show that the depth video can be effectively compressed by the proposed mode.
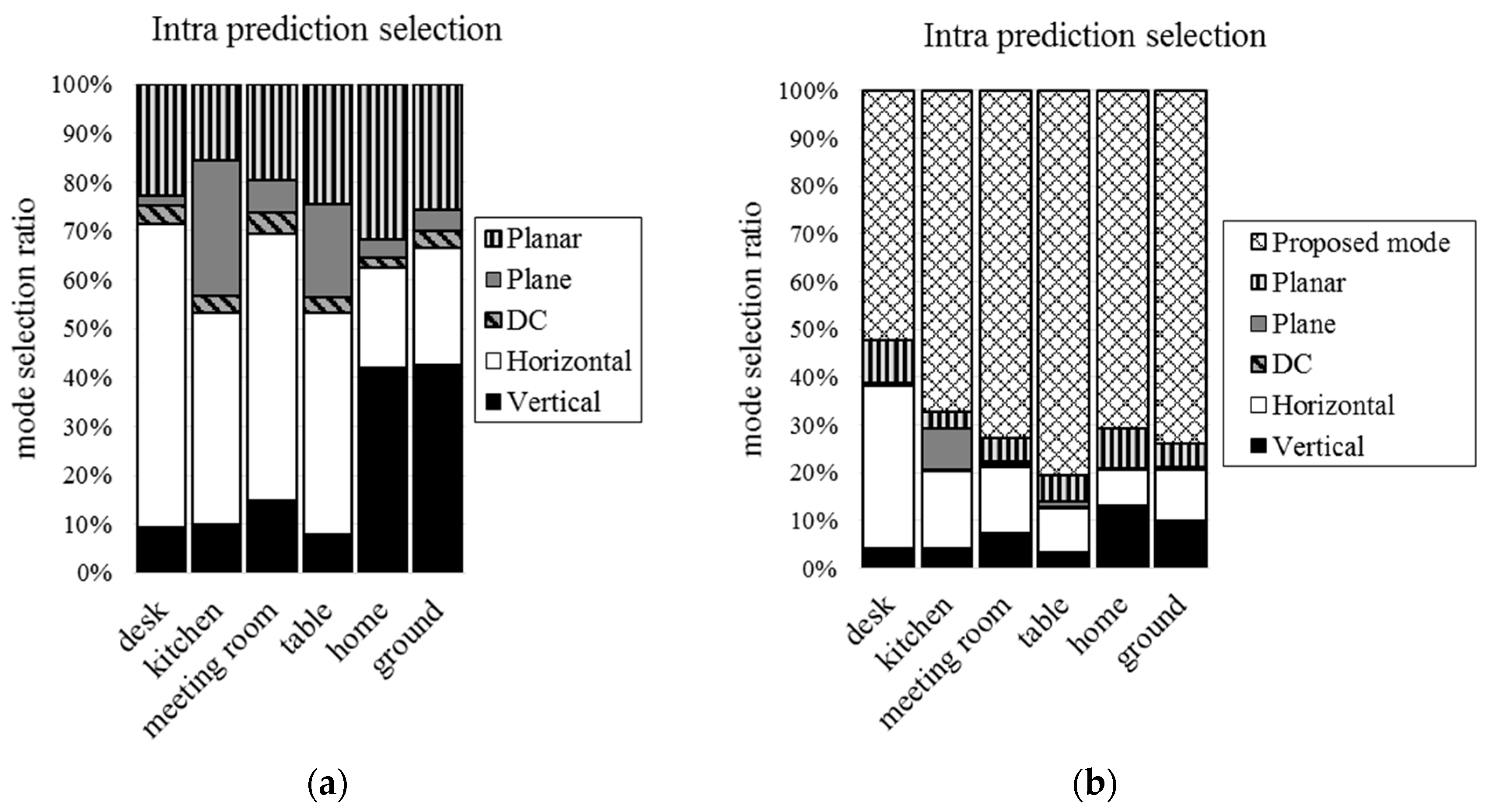
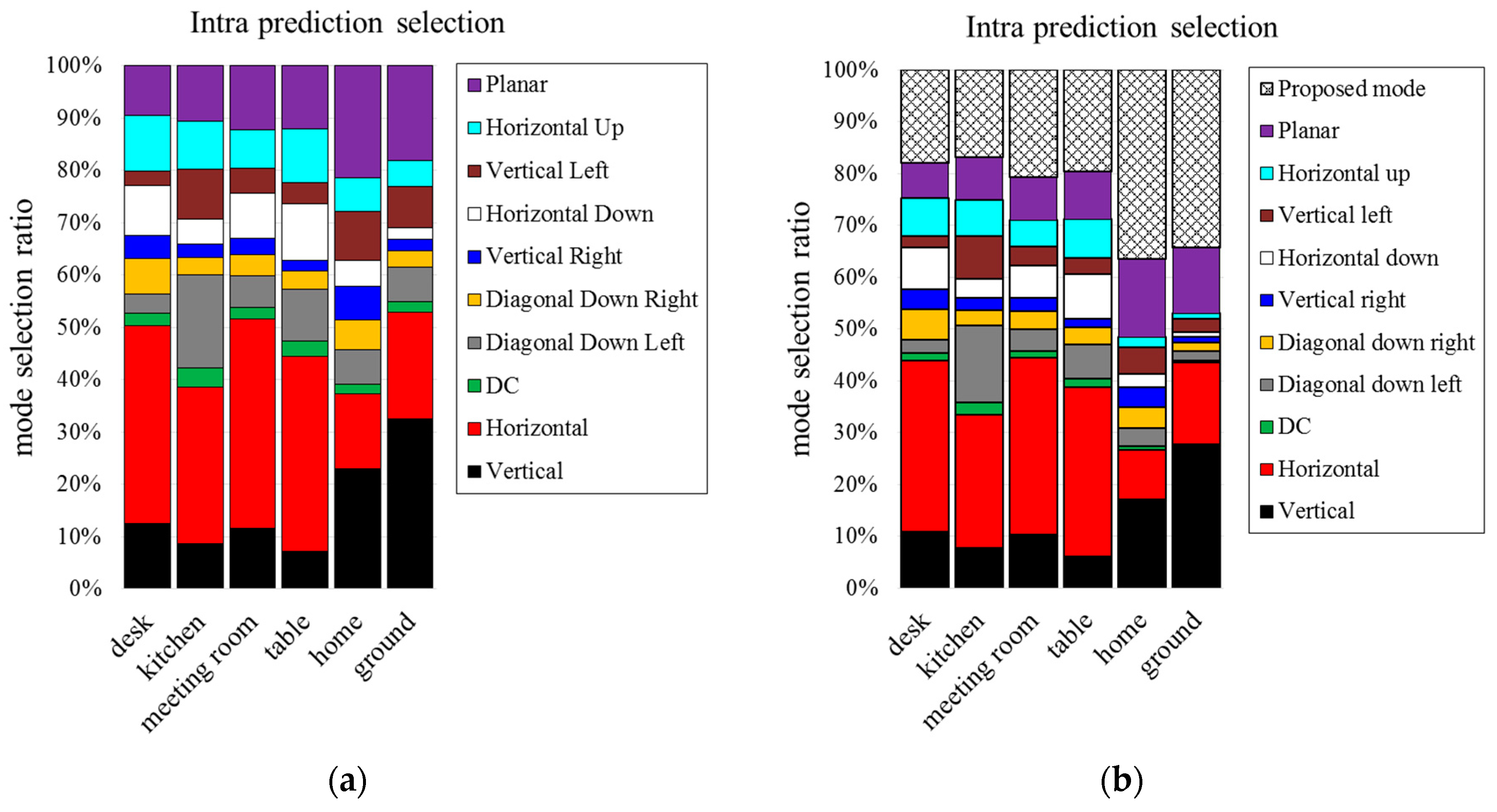
Figure 12 and
Figure 13 show the mode selection frequency of intra prediction when the block sizes are 16 × 16 and 4 × 4. In the case of including the proposed mode, the proposed mode is selected by more than 50% when block size is 16 × 16. More than 20% is selected when block size is 4 × 4. We can see that the proposed mode is more efficient than conventional intra prediction modes. The proposed mode in 16 × 16 block size is selected more than 4 × 4 block size.
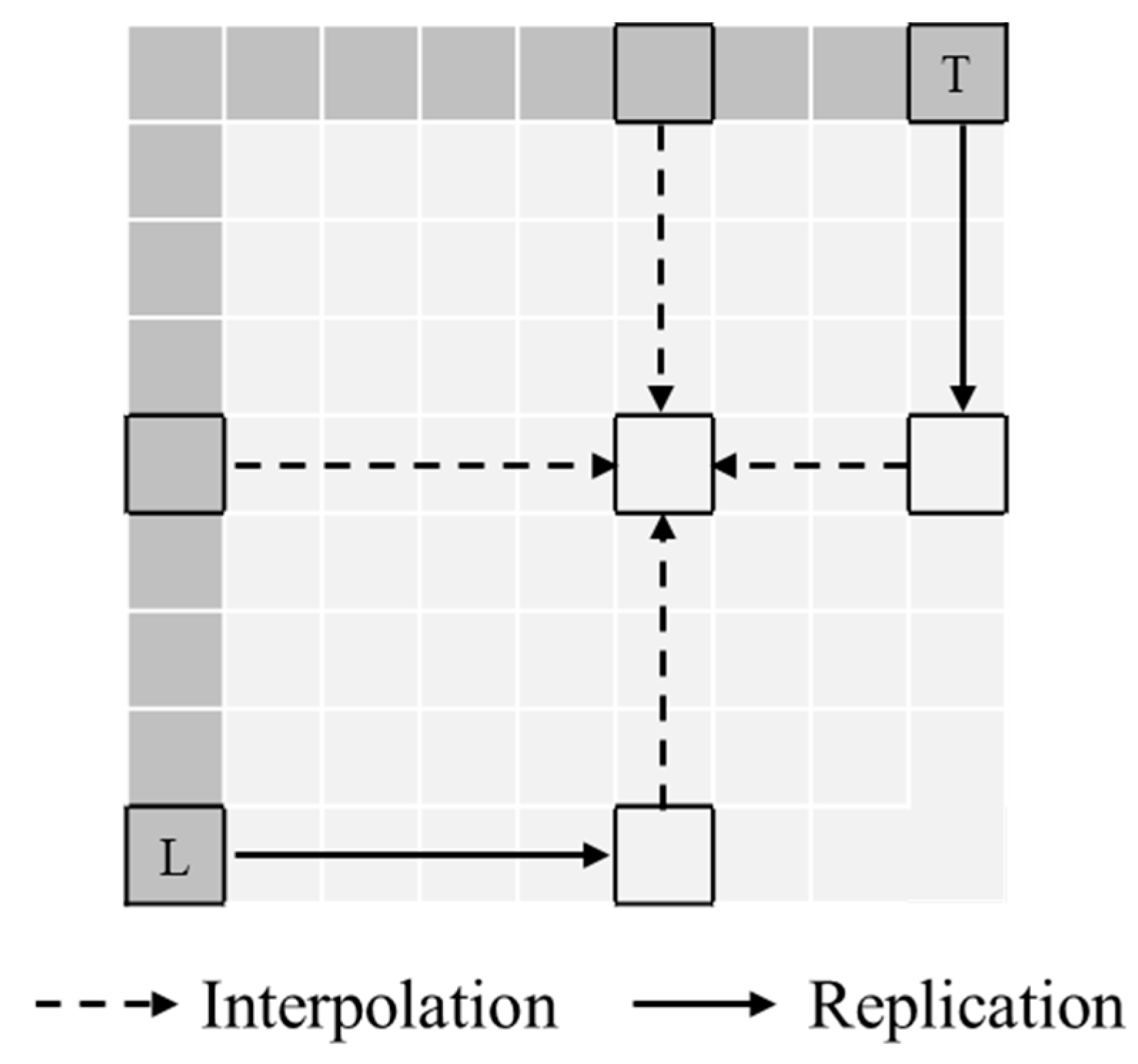
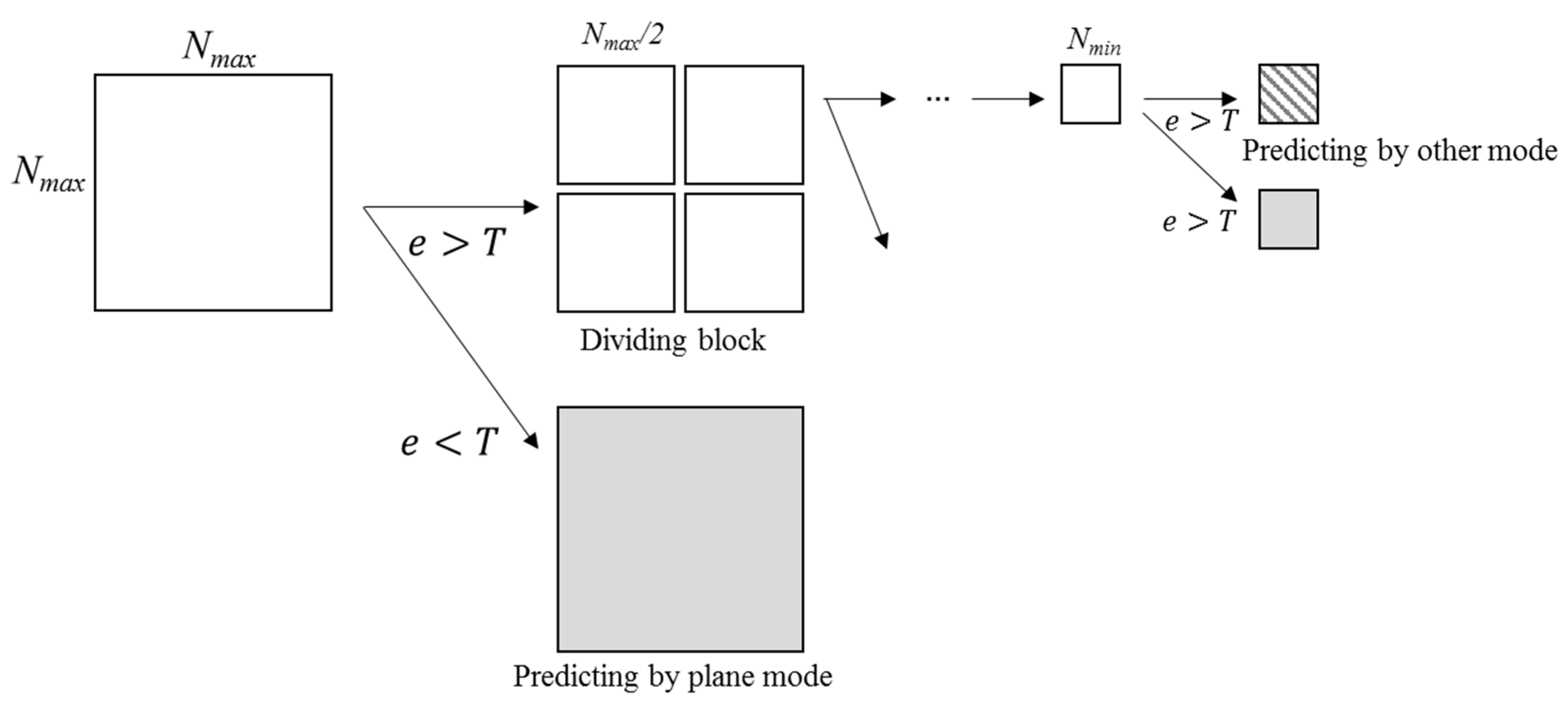
Then, the prediction accuracy is simulated for variable-size block. In this simulation, the minimum block size is set to 4 × 4 and the maximum block size to 32 × 32.
Table 7 shows the number of blocks divided by variable-size and MSE according to threshold
T. The prediction accuracy is improved as the
T is lower, but the number of blocks increases as the
T is lower.
Table 8,
Table 9,
Table 10 and
Table 11 show the number of blocks according to the block size when the threshold
T is 200, 400, 600, and 800, respectively. As
T is larger, the number of blocks which are selected to the maximum block size increases and the number of blocks which are selected to others block sizes decreases.
The encoding efficiency increases as the number of blocks divided by variable-size decreases. It is necessary to select optimal
T in consideration of the inverse relationship between the prediction accuracy and the encoding efficiency. To find the optimal
T, we define
and
as:
where
is MSE described in (11),
is the number of blocks divided by variable-size according to
T. The optimal
T is determined by finding a solution that satisfies the following equation:
where
λ is a parameter that the weight between the prediction accuracy and the number of blocks divided by variable-size.
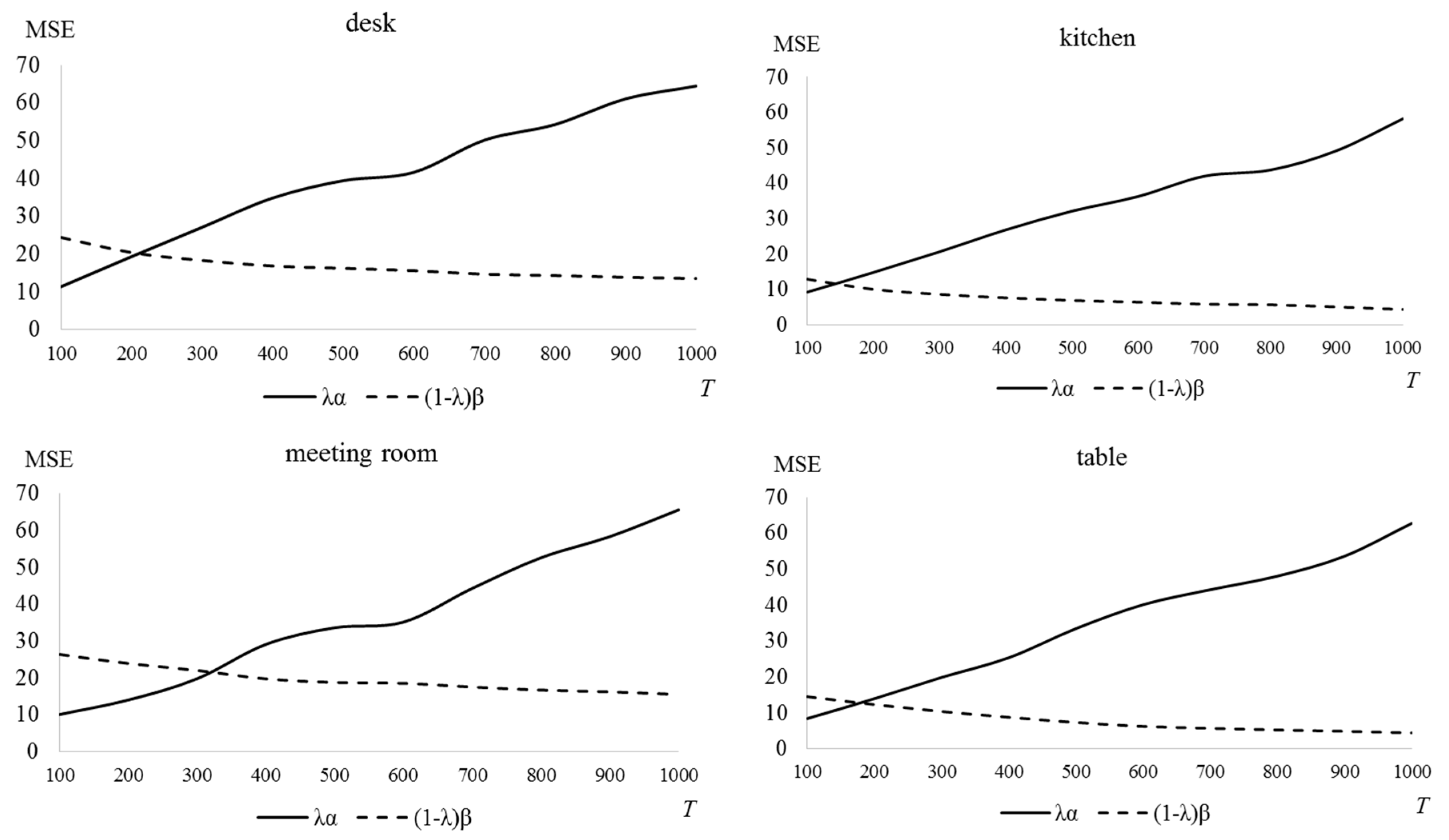
Figure 14 shows finding the optimal
T in each picture when
λ = 0.7. In this case, the optimal
T is determined between 150 and 300.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}