1. Introduction
1.1. Background
The monitoring of land use and land cover (LULC) is among the most fundamental environmental survey efforts required to support policy development and effective landscape management. There are many national, European and international policies which target the environment and aim for the comprehensive, ambitious and long-term protection of nature and sustainable land management. Information on LULC plays a key role in a large number of European environmental directives and regulations, such as the Birds Directive, Habitats Directive, Water Framework Directive, Common Agriculture Policy (CAP) and Biodiversity Strategy for 2030 [
1]. More recently, the Nature Restoration Law, which has set binding targets for EU member states to restore degraded ecosystems, was adopted in June 2024 and will require LULC information for the submission of National Restoration Plans [
2]. All these policies hope to reverse the degradation of ecosystems and the alarming loss of natural capital that undermine our wellbeing and prosperity; however, without sufficient, reliable, regular and interoperable land surface information, they will be ineffective.
Many current environmental issues are directly related to land surface properties and processes, such as habitats, biodiversity, phenology, soil condition, the distribution of plant species and ecosystem services. They are also impacted by external issues related to population growth, land take, resource extraction and climate change. Human existential activities and behaviour (living, working, production, education, supplying, recreation, mobility and communication, socialising) also have significant impacts on the environment through the occupation of the land surface by settlements, transportation and industrial infrastructure, agriculture, forestry, the exploitation of natural resources and tourism. The land surface, the negative change of state of which can only—if at all—be reversed with huge efforts, is therefore a crucial ecological factor, an essential economic resource and a key societal determinant for all spatially relevant basic functions of human existence and, not least, nations’ sense of identity. Land thus plays a central role in all three factors of sustainable development: ecology, economy and society [
3], and its variability and complexity are difficult, if not impossible, to capture in a simple fashion.
1.2. Current Practice
To be able to manage the land in a sustainable manner and provide fundamental information for evidence-based land-related decisions, it is crucial to understand the status, condition and change processes on the Earth’s surface. Over time, a huge number and variety of methods have been developed to measure the land and monitor the environment for land management, policy implementation or taxation [
4]. Given its ability to provide regular, consistent, global, synoptic and fine-spatial-resolution measurements, Earth Observation (EO) has become a key data source for producing LULC information. The EO-based LULC products to date have tended to be produced independently of each other at the global, European, national and subnational levels, as well as across different disciplines and sectors, each of them focusing on a fairly similar end product but with different emphases on thematic content and depth, spatial detail and temporal reference. This independent and uncoordinated production can be explained and justified by the large variation in the objectives and requirements of these products, but it leads to reduced interoperability and sometimes also to the duplication of work and, thereby, the inefficient use of resources (Nedd, Light, Owens, James, Johnson & Anandhi [
5]).
Conventionally, land monitoring has relied on the classification approach, meaning the association of a single label from a predefined legend with each feature being mapped. Classification embodies a structured method of organising data into categories based on predefined, specific criteria. Each classification system is bound to the purposes it was designed for and consequently incorporates the generalisation of the complex and variable real world. It is used to facilitate analysis and comparison, which work only within the scope of the chosen nomenclature. The categorisation of land into different classes is based on expert judgement and subjective assumptions, and often both the initial capture and later re-extraction of information are dependent on interpreting the data. The broad needs of land monitoring systems have led to the development of numerous and non-compatible kinds of classification systems and nomenclatures (for example, the Land Utilisation Survey of Great Britain (Environment Agency [
6]), the United States Geological Survey (Anderson, Hardy, Roach, Witmer [
7]) and the Land Cover Classification System (Di Gregorio, Jansen [
8])) to feed the multitude of applications with LULC data (Di Gregorio & O’Brien [
9]). Most of these nomenclatures contain an intimate mixture of land cover and land use information and are likely to result in different subdivisions between classes and differing levels of thematic granularity. Each application emphasises particular aspects of land cover and land use related to specific end user requirements and purposes. Additionally, the thematic coverage of a nomenclature is often controlled by the landscape situations in the geographic regions it is designed to represent. For instance, the European CORINE Land Cover (Büttner [
10]) nomenclature does not include tropical forests and mangroves as specific classes, whereas global nomenclatures focus more on them due to their global importance. Finally, nomenclatures can and should evolve over time, where the initial class structures and definitions need to adapt to and align with the capabilities of the satellite sensors used, but this must be handled carefully.
1.3. Problem Setting
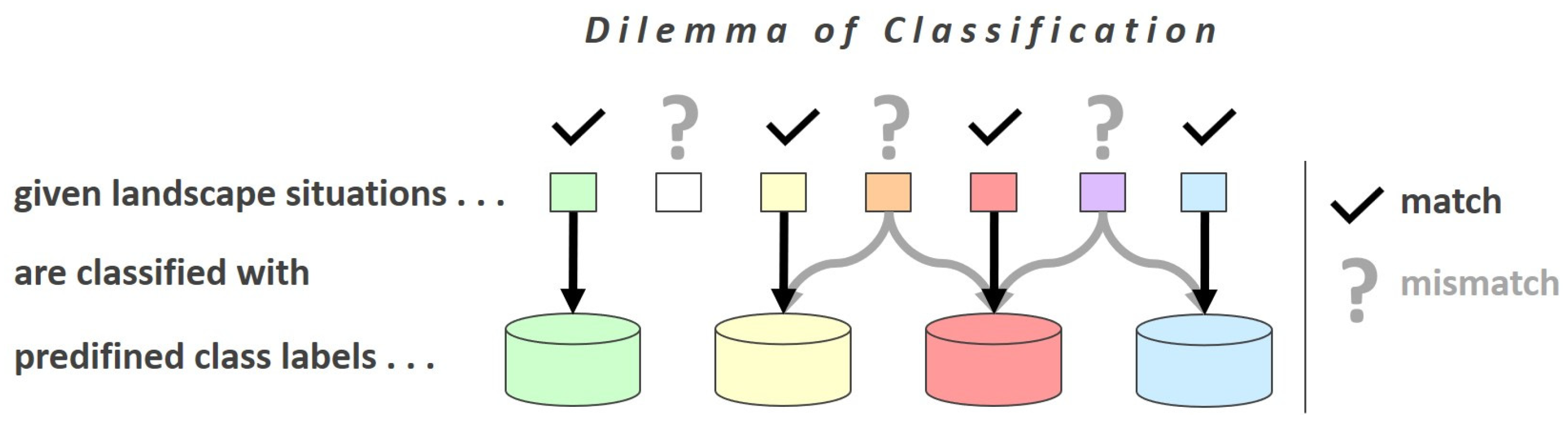
Due to the tailoring-to-purpose approaches adopted by classification/product system designers, it is often difficult or even impossible to compare or transfer information between different classification systems because they do not match each other’s purposes (e.g., between a crop type map and an urban planning map). Also, certain specific landscape situations which are not consistently covered by any of the predefined classes have to be somehow classified with the limited available set of labels, even though none of the predefined class labels really match the specific landscape reality (see
Figure 1).
As a result, the different data collection methods, different spatial scales, tailored-to-purpose definitions and lack of completeness within nomenclatures hamper the data transfer from one application/classification system to another and thus form an obstacle for data reuse and cross-border and interdisciplinary data integration. Also, the variation in the products among them and over time limits the reliability of the changes detected between instances.
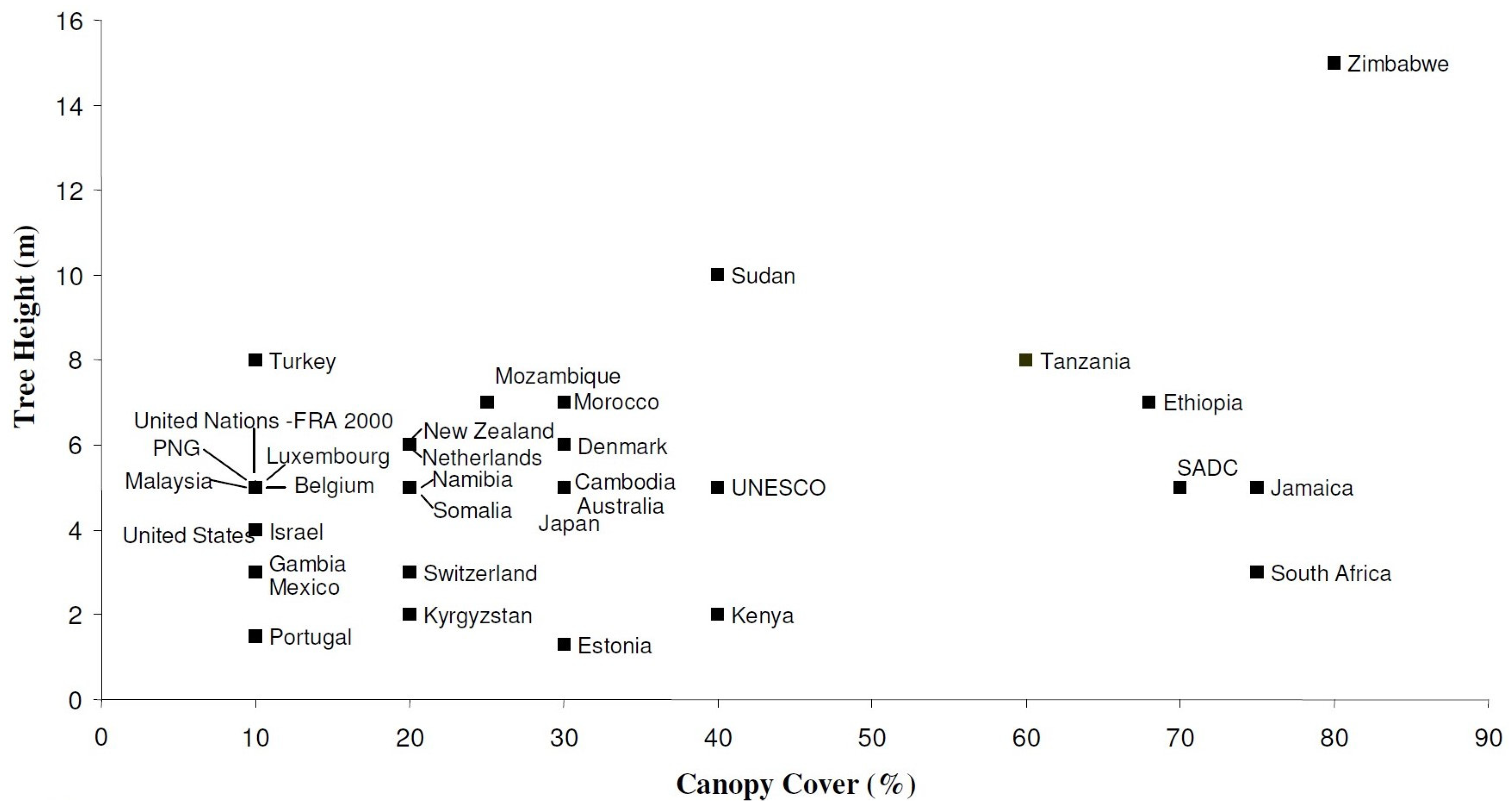
A good example of this problem and the differences in class definitions was identified and described by Comber, Fisher and Wadsworth [
11] when they considered the question “what is land cover?”. By examining the definitions of “forest”, a commonly used land cover (and land use) term across different countries, it turned out that the same label could have a range of meanings when looking at the combination of tree height and canopy cover (see
Figure 2). The same label can therefore represent very different landscape situations, even in neighbouring countries and when the region is covered by the same environmental policies. In consequence, the use of these labels without fully understanding their meanings has dramatic impacts on downstream applications, on statistical accounting and, finally, on local, regional and especially global decision making. For instance, efforts to curtail deforestation require reliable assessments of the current forest area, yet the definitions for what a forest exactly means differ significantly across countries, institutions and epistemic communities (Côte, Wartmann & Purves [
12]).
The technical circumstances of land monitoring and the ability to generate LULC information have developed significantly over recent years. The quality and repetitive provision of affordable satellite imagery, the cost of computing power, the availability of data storage capacities and the range of methodologies have evolved rapidly, which now opens new approaches to the extraction of land information from remote sensing data (Zhang & Li [
13]). In parallel, thematic requirements and political reporting obligations have also evolved and have required a higher level of detail and greater urgency. Quick and robust responses need to be found to address climate change and other environmental challenges caused by local actions with global consequences. Therefore, a common understanding of LULC information associated with local phenomena and characteristics within the global context is crucial to provide the fundamental basis for monitoring and decision-making processes.
Two strong constraints in knowledge creation can therefore be identified: one is access to data, and the other is the understanding of data for the subsequent extraction of actionable information. Once a decision maker or citizen has gained access to spatial information from one or more data sources relevant to their needs and duties, the issue of product compatibility and interoperability still remains.
1.4. Problem Solving
To address the first constraint, Copernicus, the EO component of the European Union’s Space programme, offers data and information services that are built on satellite EO and in situ sources. The Sentinel constellation of EO satellites provides unprecedented amounts of image data suitable for producing LULC information. The European Environment Agency (EEA) has been delegated as the Entrusted Entity for the implementation of the pan-European and local components of the Copernicus Land Monitoring Service (CLMS) to produce such products. In parallel, NASA has opened the Landsat archive, and the commercial sector has also developed EO systems that complement the acquisitions by publicly owned systems. Thus, the constraints of data and information paucity and access have now been largely removed.
The second challenge, to develop the standards and specifications to allow the interoperability of land information and maximise the exploitation of the derived products, still remains and is the focus of this paper.
The EEA has been responsible for organising the production of the CORINE Land Cover (CLC) map (Ferenac, Soukup, Hazeu & Jaffrain [
14]), a de facto standard for European land monitoring, for over three decades, providing LULC status and change information at 6-year intervals. More recently, the European Environment Information and Observation Network (Eionet) [
15] has supported the harmonisation of national monitoring at the EU level and improved synergies with pan-European land cover activities. In this regard, since 2008, the EAGLE Group [
16] has been developing a solution and proof of concept to support a semantic and technical framework for a European harmonised information management capacity for land monitoring. The targeted strategy aims to step out of the situation of being trapped in circling around the search for the one perfect compromise nomenclature that fits multiple requirements and dismantle the dilemma of classification.
The work of the EAGLE Group has resulted in the “EAGLE concept”, which directly addresses the issues which have been described above. Initially, the idea was just to enhance the existing classification system of the CLC map to make it more flexible and precise, but soon after starting the work, the potential for more use cases beyond the CLC map arose, offering a new general approach to land description and the harmonisation of nomenclatures.
The work of the EAGLE Group fits into the evolving realisation that fixed legends/nomenclatures and hard classifications were a limiting factor in the development of land monitoring. In the early 2000s, the National Land Use Database (NLUD) (Harrison [
17]) was developed in the U.K. to support the sustainable development of land resources in both urban and rural contexts and inform the development of policies across all areas of human activity. The NLUD split the description of features into distinct land cover and land use components with internal hierarchical structures. In the late 2000s, the European Commission’s INSPIRE (Infrastructure for Spatial Information in the European Community) directive (European Parliament [
18]) and the Land Use and Cover Area Frame Survey (LUCAS) (EuroStat [
19]) followed a similar approach when defining their themes for spatial data. The EAGLE Group continued this conceptual development, which manifested in a data model to address many of the issues around LULC mapping (Arnold, Kosztra, Banko, Smith, Hazeu, Bock & Valcarcel Sanz [
20]; Arnold, Smith, Hazeu, Kosztra, Perger, Banko, Soukup, Strand, Valcarcel Sanz & Bock [
21]; Arnold [
22]). This then began to be seen as part of a road map for harmonised European land monitoring during the mid-2010s (Kleeschulte, Soukup, Hazeu, Smith, Arnold & Kosztra [
23]; Arnold, Hazeu & Valcarcel Sanz [
24]). Once the basic idea to clearly and comprehensively distinguish between the themes LC and LU within semantic systems was established, other stakeholders and initiatives, like ISO standards 19144-2 (Land Cover Meta Language—LCML [
25]) (Mosca, Di Gregorio, Henry, Jalal & Blonda [
26]) and 19144-3 (Land Use Meta Language—LUML [
27]), continued the trend.
This paper therefore builds on the earlier EAGLE Group work and provides the current status of the concept. It has evolved over time and, since the most recent round of upgrades, has now reached a relatively stable version which can be deployed widely and consistently. It has been adopted over recent years by the EEA to support the specification of some of the CLMS products, and a number of European, national and subnational initiatives have adopted its concepts to deliver more powerful, flexible and multi-use products. It is therefore becoming the cornerstone of European land monitoring within the Copernicus programme. This paper will therefore describe (i) the concepts set out in the EAGLE data model, (ii) recent updates, (iii) its wall-to-wall implementation with the CLMS and (iv) its specialised regional downstream uses. It will conclude by describing how the EAGLE concept fits into wider LULC standard initiatives, the unique strengths it brings to the table and opportunities for its future extension and evolution.
To complete this introduction, it should be noted that this paper is not a conventional report on setting and testing a scientific hypothesis against empirical or statistical samples but is rather a report on the concept’s state of play and on collected experiences from applied use cases.
2. Characterisation with the EAGLE Approach
The EAGLE approach is a paradigm shift away from a “paper map”-based world where features are given a single label from a fixed nomenclature to one where features have a rich characterisation which describes them more completely. This approach is more flexible and powerful, as it allows the description of a feature to be extended if new data or requirements emerge, and it allows detailed questions to be asked about a specific aspect of a feature. It also allows each of the individual characteristics to be dynamic so that a feature may only change part of its description during an update. For instance, a forested area can be felled, and its land cover becomes bare ground, but its land use may remain as forestry if it is intended to be replanted. Also, features may have multiple and complementary characteristics, such as a forest with multiple uses for timber production and recreation or a field with multiple land covers during a crop-growing cycle.
This section will present the EAGLE approach by describing the two technical manifestations of the concept: the EAGLE matrix (an Excel sheet) and the EAGLE data model (in UML format). These two variants are tools to move from the classification towards the characterisation of landscape features and phenomena. This section also includes a description of the key tools for semantic analysis and design and lists some of the latest upgrades to the model.
The list of EAGLE model elements has evolved since the first drafts in 2009 to become a comprehensive representation of characteristics not restricted to only EO data as the input source of information. To populate some of these elements, data sources beyond EO data are needed, such as in situ measurements or observations. This means that the design of the concept is purely semantic and is not bound or restricted to a particular type of input data source.
This paper will focus on the description of land units as areal objects, leaving aside point and linear features, in terms of the elements of the EAGLE data model. The elements are, in the main, organised in a hierarchical pattern of increasing thematic granularity with the coarsest levels of detail designated as thematic blocks.
The latest versions of the EAGLE matrix and UML data model, including textual documentation, can be found in the CLMS EAGLE document archive [
28].
2.1. EAGLE Matrix
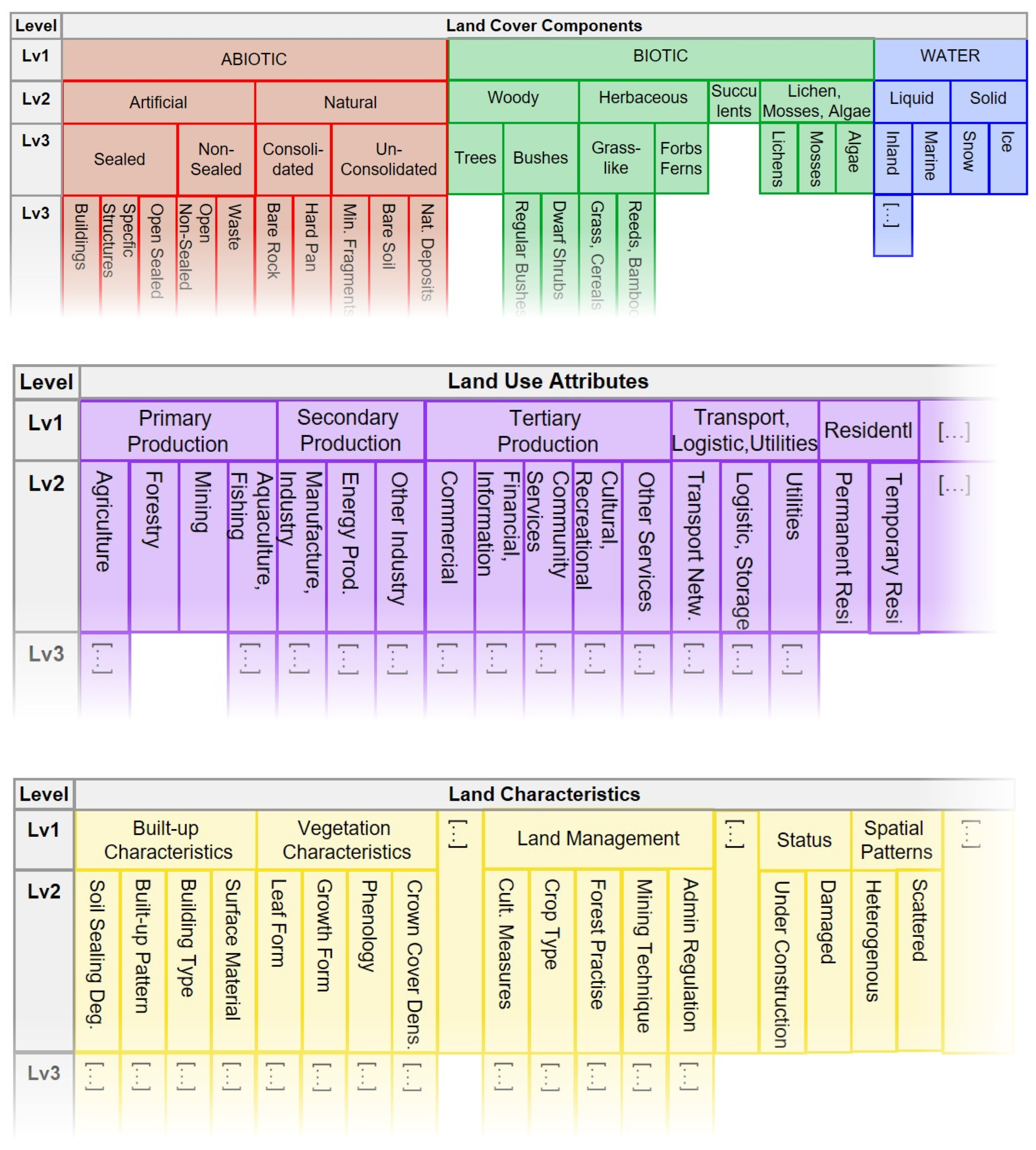
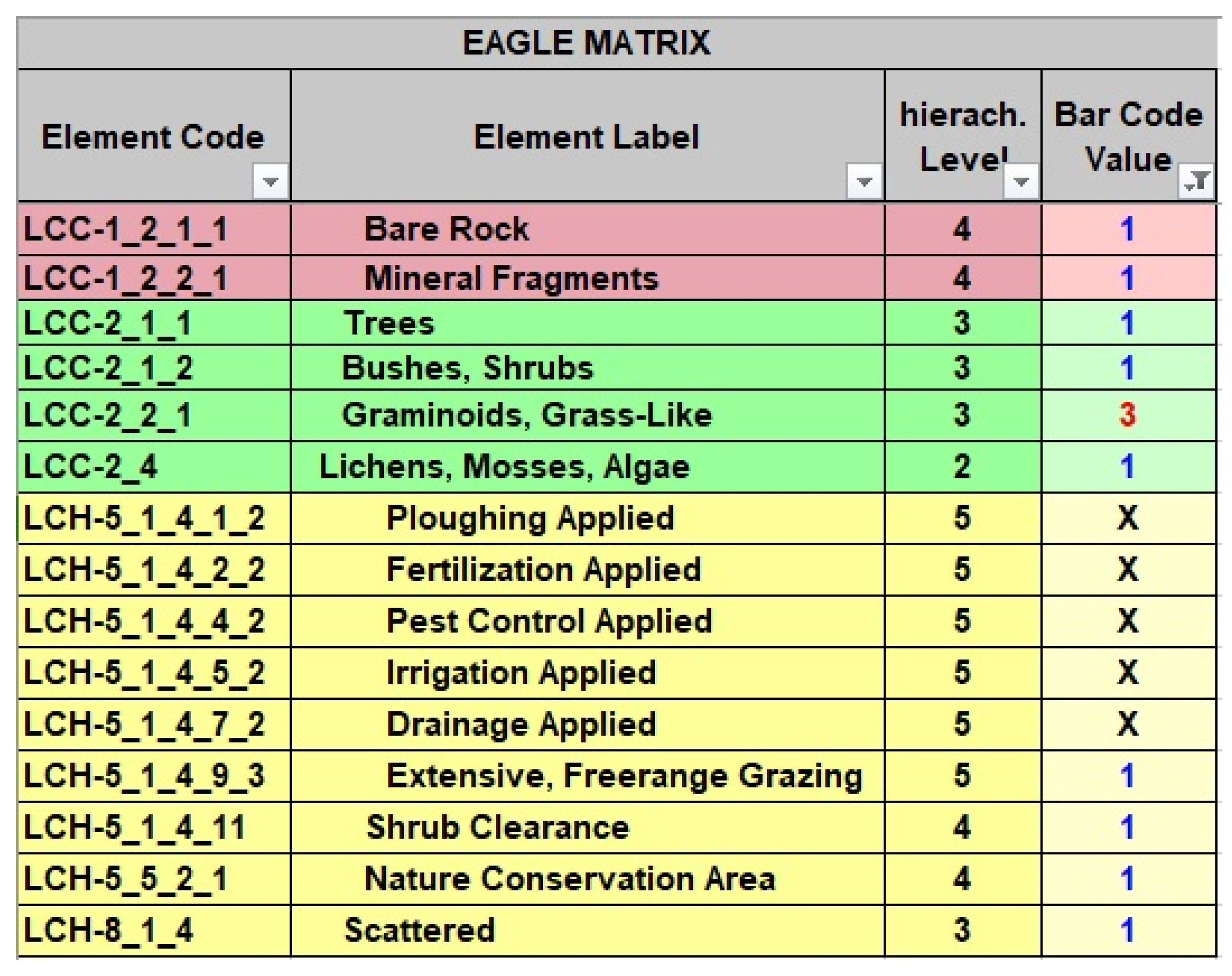
The matrix consists of three blocks of EAGLE elements. The first two blocks enforce the principle of a clear separation between the two main themes of land cover and land use. These two blocks are therefore referred to as the land cover components (LCCs) and land use attributes (LUAs). A third block represents a broad range of land characteristics (LCHs), adding further details either related to the land cover and land use information held in the first two blocks or about an independent property related to the land unit. All three blocks are designed according to a hierarchical structure, with parent (higher-level) elements and child (subordinated) elements (
Figure 3 and
Figure 4).
The LCC block contains a rather limited but comprehensive set of elements and is relatively stable over time and between version releases. In theory, the concept is able to assign any unit of the Earth’s surface to one or more of these land cover components.
The LUA block also aims to be comprehensive in the sense that any land use can be assigned to one of the elements in the block. However, if not listed explicitly as a land use attribute, it should at least be possible to locate an appropriate land use under a parent element.
All entries on all levels in the LCC and LUA blocks can be used as descriptive elements for a feature or class.
The LCH block is also structured hierarchically, but here the upper levels are mostly headings or subheadings, and only the lowest level (apart from a few exceptions) contains the descriptive elements (as the information carrier) of the actual land characteristics. For example, “Built-up characteristics” and “Built-up pattern” cannot in themselves be descriptive elements, but one of the end points, such as “Single Blocks, Discontinuous”, can be an element. One exception is the module LCH Crop Types, where there are also groups of crops like “Cereals” (as an intermediate category, with for example “arable crops” above and “wheat” below) which can also be used as descriptive elements. The difference between a heading and a descriptive element is like speaking about “colour” as the heading and “blue” as the element that carries the distinct information itself.
To find a common language when speaking about the EAGLE matrix, a few expressions are used to address specific parts of the matrix. This is helpful when working on the matrix or when communicating about the matrix among users and developers:
Matrix blocks: The three main blocks of the matrix are the LCC, LUA and LCH elements. These are the first entry points into the content of the matrix structure.
Matrix module: The matrix module is a collection of matrix elements that refers to a certain topic or phenomenon (e.g., Water Characteristics), main land cover component (e.g., Biotic/Vegetation Characteristics) or land use type (e.g., Agricultural Land Management).
Matrix segment: The matrix segment is the section of the matrix module that contains a coherent group of elements under a thematic heading (e.g., Water Regime under the module Water Characteristics, or Cultivation Practice under the module Agricultural Land Management). The segments may be subdivided into sub-segments (subheadings).
Matrix elements: This is a neutral term to address all entries (LCCs, LUAs, LCHs) in the entire matrix (and model) as elements. Matrix elements are all of the lowest and most important levels of the LCH matrix block, where the single values are listed to store the characteristic information of a feature in particular, plus all entries of the LCC and LUA blocks throughout the hierarchical levels.
There are two variants of the matrix, a horizontal form and a vertical form, which are both identical in terms of content. The horizontally arranged matrix (illustrated in the figures above) more intuitively shows the hierarchical structure of the elements. However, handling the matrix and applying the bar-coding method (see below) is easier with the vertical form of the matrix.
2.2. EAGLE Data Model
The EAGLE concept also exists as a data model written in the UML (Unified Modelling Language). Content-wise, it mirrors the EAGLE matrix with all the elements of the three LCC, LUA and LCH matrix blocks included.
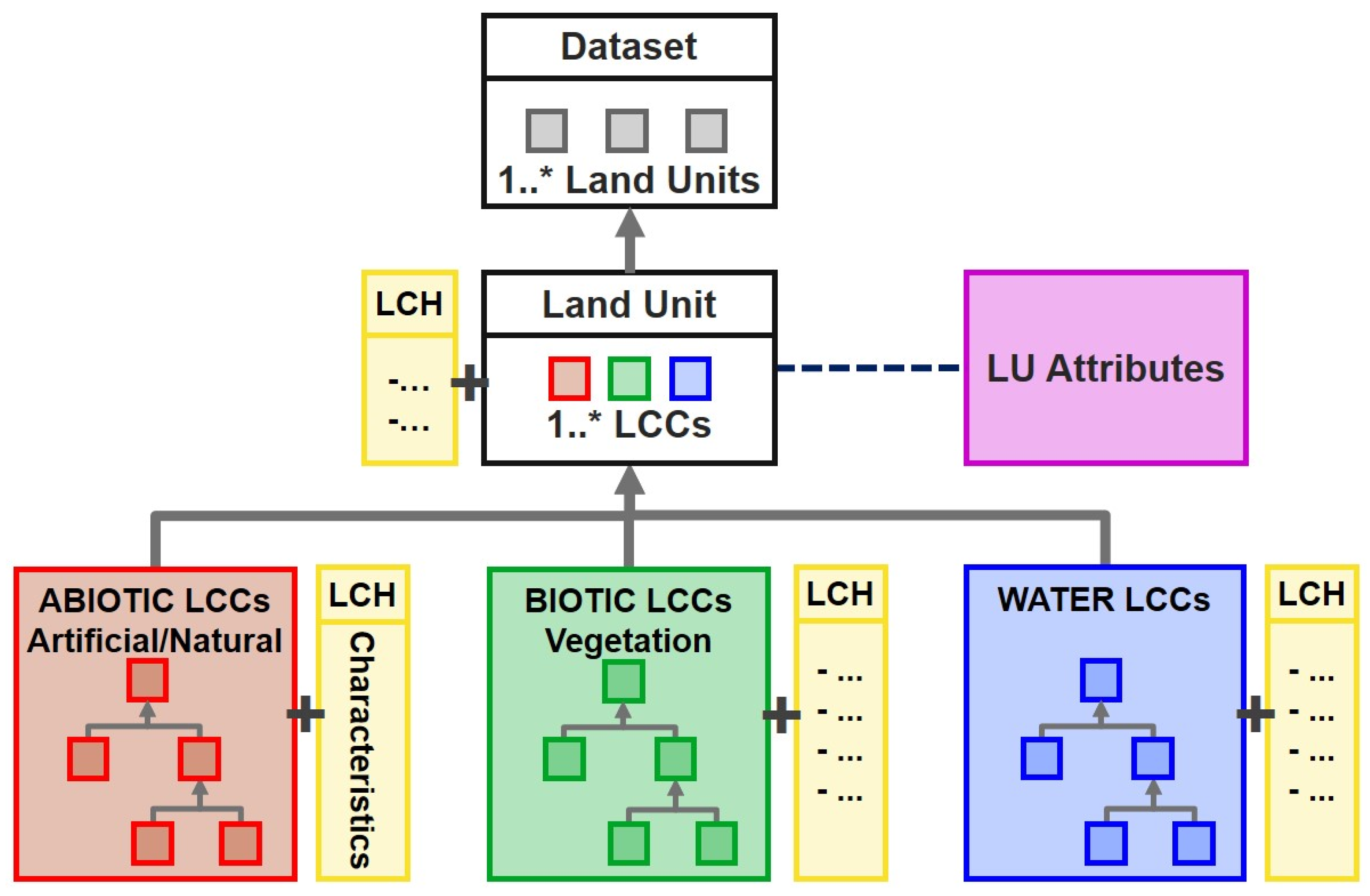
One of the main uses of the EAGLE approach is to describe and document classification systems. In this case, the feature addressed by the EAGLE data model is thus the individual class within a classification system which initially was used to label mapped objects (land units). In the EAGLE approach, the class is then described content-wise by one LCC or a combination of several LCCs to list the land cover aspect of the class. In addition to the LCCs, the description can be enriched by LUAs to recognise the associated land uses. Each selected LCC, as well as the entire class, can be further described with the addition of LCHs (
Figure 5).
Although intended for use as a metalanguage and a tool to describe, document and transform various existing (and future) classification systems, the EAGLE approach can obviously also be used as the basis for a classification system in its own right. In this case, the features addressed by the model are the land units themselves, and the EAGLE matrix is used to populate the individual units with relevant land information.
The data model has a hierarchical structure that is based on the LCCs. Underneath the main land unit is a hierarchical tree with all the LCCs as UML classes. The LCHs are embedded as UML attributes (formed of codelists and codelist values) within each LCC model class, where relevant and on an appropriate hierarchical level, from where they are inherited.
2.3. EAGLE Bar Coding
The bar-coding approach is a way of using the EAGLE matrix for the semantic analysis and design of classes by allocating EAGLE elements and then scoring them appropriately, where the numbers called “Bar Code Values” give the chosen elements a certain role in the characterisation.
2.3.1. Semantic Analysis
The main intended application area for the EAGLE model is the semantic analysis of existing nomenclatures and their classes by decomposing them into EAGLE elements. This step is vital to examine the comparability of different nomenclatures and to allow datasets to be combined, such as in bottom-up integration or change detection. This analysis also allows ambiguities and gaps (e.g., missing land cover and land use types) within nomenclatures to be identified.
To formalise the description of classes, the “bar-coding” method was developed, which aims to transfer the information content of textual class definitions from a given nomenclature to a standardised ontological expression in terms of the EAGLE matrix. The elements of the EAGLE matrix allow class definitions to be semantically composed and decomposed. Practically speaking, the bar coding is performed by screening the textual definitions of a given class, identifying all the relevant land cover, land use and characteristic aspects of the class, recording these elements in the EAGLE matrix and marking their corresponding values. In doing so, many matrix elements will remain blank except the ones that matter for expressing the semantically decomposed class into the EAGLE taxonomy. When entered into a database, the bar-coding results are also machine-readable, making them far more useful.
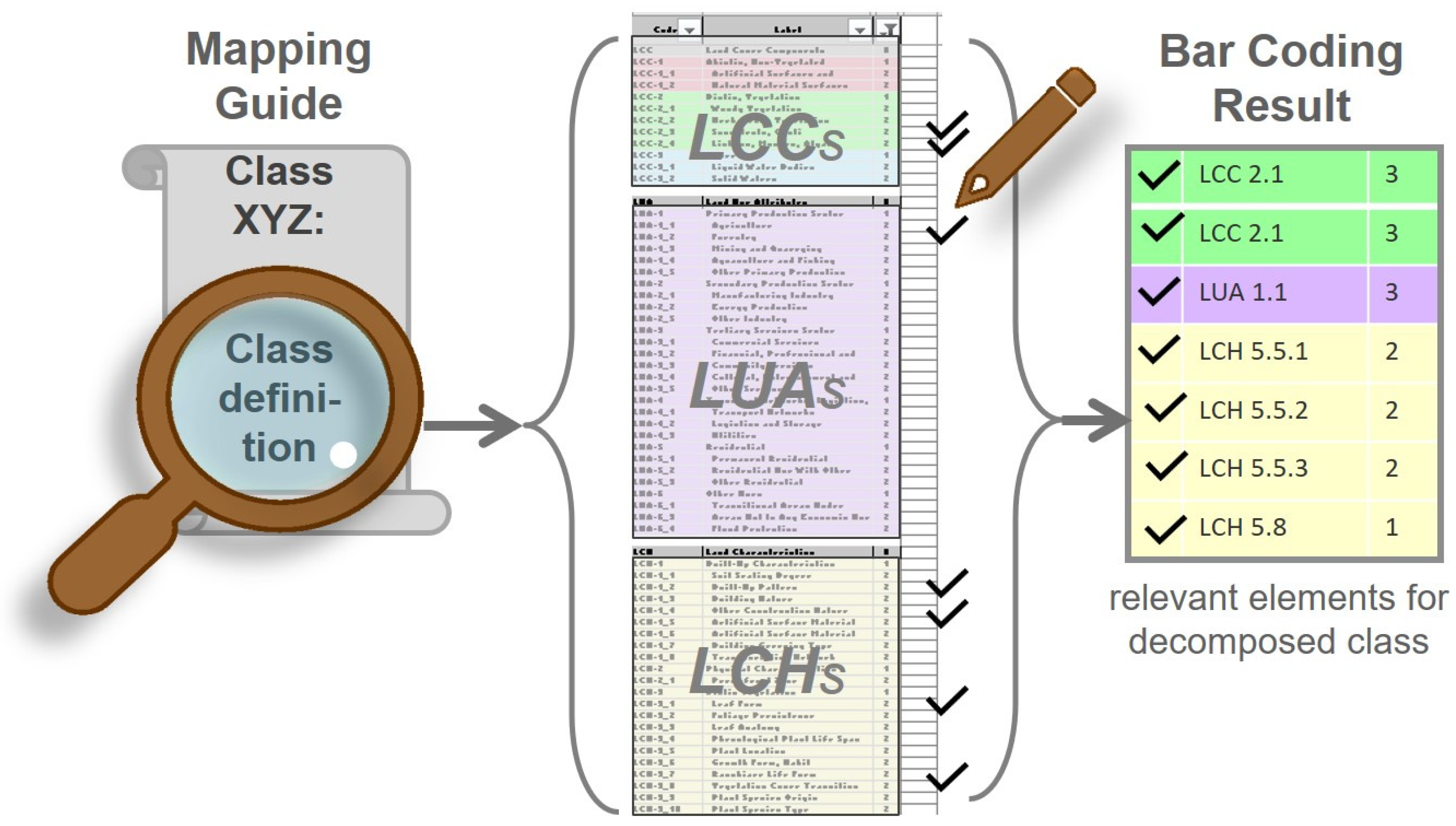
In more detail,
Figure 6 shows an example of the textual definition of a CLC class which has been decomposed into the relevant EAGLE matrix blocks within which the descriptor statements can be assigned to EAGLE elements.
The bar coding then selects and assigns values to all the relevant LCC, LUA and LCH elements from the matrix that describe the specific class.
The available bar-coding values (BCVs) associated with each element are as follows:
The value 0 means that the element is absent from or irrelevant to the definition of the class;
The value 1 means that the element typically and/or occasionally appears in the class definition;
The value 2 means that one or more of these elements must be present (i.e., selective mandatory) in the class definition;
The value 3 means that all of these elements must be present (i.e., cumulative mandatory) in the class definition;
The value 4 means that at least two of these elements must be present in the class definition;
The value 5 means that only this single element is relevant to the class definition (i.e., the EAGLE element and the class definition are identical);
The value X means that the element must not occur or is excluded by the class definition.
The bar-coding exercise results in a standardised and concise representation of a semantically decomposed class definition using a sequence of BCV codes (from where the inspiration for the term “bar code” was derived). The bar-coded example in
Figure 7 is the next step in the process of decomposing the illustrated class definition example in
Figure 6. In this case, the “CLC 321 Natural Grassland” class is made up of a set of LCC and LCH elements. It must contain Graminoids (BCV of 3) and may potentially contain other land cover components (BCV of 1), but it also must exclude certain land management practices (BCV of X).
This bar-coding approach therefore streamlines the process of representing complex information about different classes, making it easier to handle visually and to compare them with similar classes from other classification systems.
Figure 8 summarises the action of screening the textual definitions of a class within a nomenclature for terms that relate to land cover, land use or other characteristic information. More detail can be found in the online nomenclature description of the analysed class in
Figure 7 [
29].
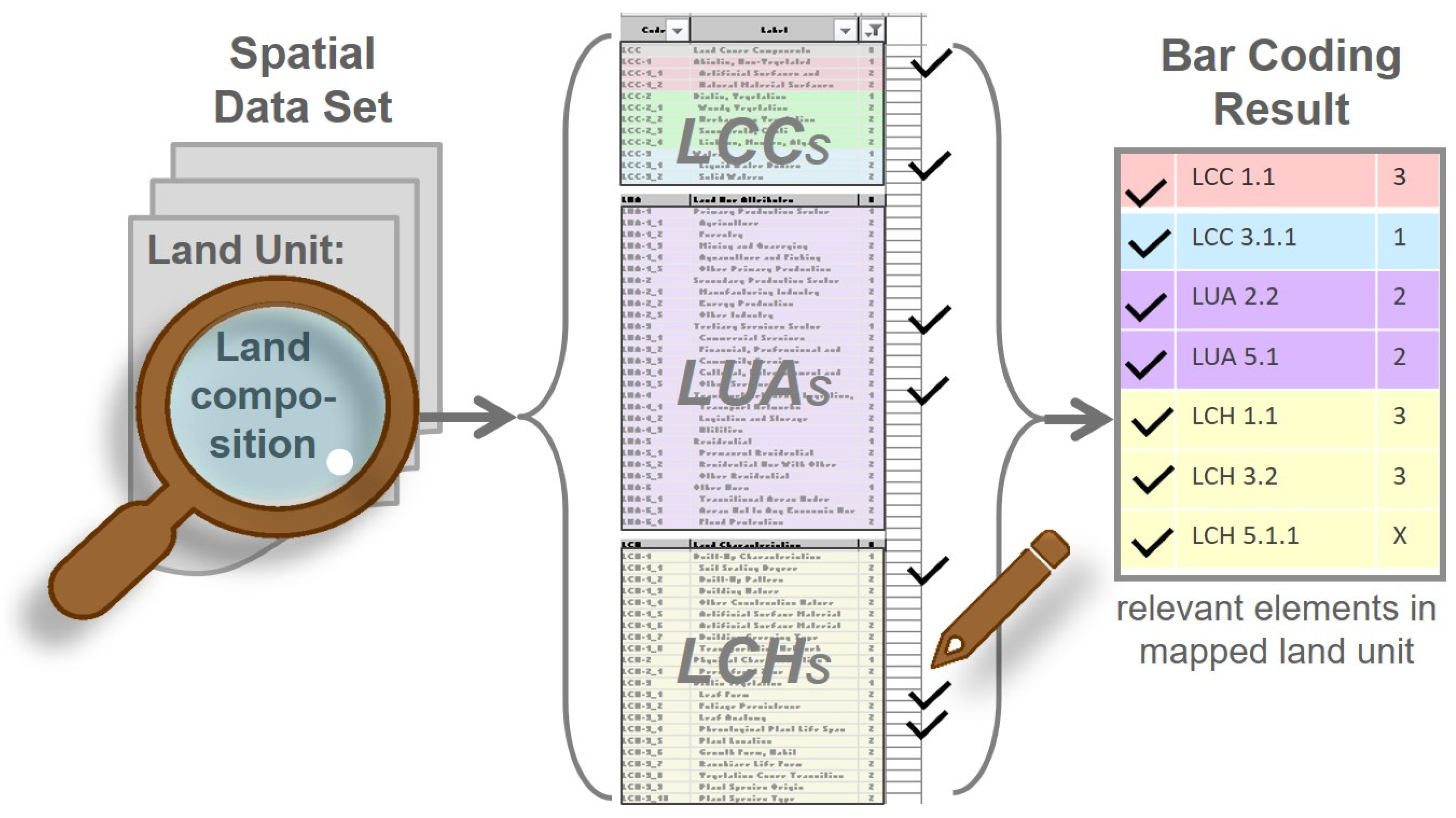
2.3.2. Semantic Design
The converse process to “bar coding” a class from a nomenclature can also be performed with the EAGLE concept when designing a new classification system. In this case, the user can select a collection of matrix elements (that they consider mandatory/optional/typical/excluded by definition) for a new class which the user wishes to define in a nomenclature. By reviewing the bar codes, the user can determine whether there are any ambiguities between each of the proposed classes and whether all of the required landscape characteristics, represented by the EAGLE elements, are being mapped. Once the bar codes for the classes have been agreed upon, the selected EAGLE elements can be used to prepare textual definitions and support the development of mapping guides.
Figure 9 illustrates the action of preparing a required land composition by searching for terms that relate to land cover, land use or other characteristic information of the proposed class.
2.3.3. Direct Description of Land Units
A third application of the EAGLE matrix/model is the description of the actual spatial units within the landscape by choosing the model elements to represent the features which can be identified in the field or from other geospatial data sources. The information about spatial units can be stored in a database, e.g., through a mapping campaign, using the EAGLE data model. It is a more individualised approach that can be applied for single features or groups of them, compared to the more systematic approach of semantically analysing a nomenclature which embraces an entire dataset.
2.4. Recent EAGLE Developments
The latest version of the EAGLE concept at the time of writing this paper is v3.2 (the EAGLE document archive with a link to the latest EAGLE version plus documentation [
28]). Since the first published version, the matrix and model have evolved in terms of their thematic extent and have gained more complexity and versatility. Here, a selection of new elements and changes are highlighted, comparing them to the previous distribution version (v3.1.2). The changes between the two versions focus on the adding, renaming, replacing or deletion of matrix elements. Most of the changes have been made in the LCH block, and only a limited number were made in the LCC and LUA blocks.
A major focus of the changes has been the matrix module of the LCH “Agricultural Land Management”. The revision of crop types was required to untangle the subdividing criteria (e.g., cultivation purpose, harvest method, etc.) in the previous version that were oriented around a crop nomenclature used at the European level to administer the agricultural subsidies paid to the farmers under the CAP. These revisions have made the EAGLE matrix semantically more independent from policy changes. The new crop types focus on the form of the crop and the part of the plant which is harvested considering botanical aspects. The previously interwoven aspects of cultivation purposes have now been given their own matrix segment independent from the crop types. In response to the new CLMS product HRL Vegetated Land Cover Characteristics (VLCCs), the crop season (winter, summer, year-round) became important, which now has its own short segment within the matrix. Matrix segments for crop rotation and cultivation were added, and the segment for grazing was extended to provide a richer description of livestock management. A list of the most common forest tree species was also added, under the existing segment “Forest Land Management”.
Beyond the Land Management part in the matrix, other minor but not less important changes have been made. In particular, the LCC was extended to be more aligned with the CLMS HRL VLCC Grassland Layers. Also, some LUAs were simplified to disentangle a historical land cover association which can actually be covered by LCCs. LCH additions were also made related to groundwater, mining practices, climate zones and terrain characteristics.
Some more general issues were addressed related to the structure of the EAGLE matrix. Each EAGLE matrix element has three identifiers: the URI (Uniform Resource Identifier), the label code and the label name. When starting to build downstream services based on the EAGLE ontology, it was decided that the URI should be the stable identifier which shall not change. Label codes and label names, however, can be changed when useful or necessary, without jeopardising the ontology of the established system. The user of any service normally only sees the label code and label name, while the URI is used as a unique identifier by the software system in the background. The EAGLE URIs are now listed and maintained permanently within the Eionet Data Dictionary (Eionet [
30]).
2.5. Comparison of the EAGLE Matrix and Model: Advantages and Disadvantages
The EAGLE matrix and model are two different technical manifestations of the same concept, and both forms have their own advantages and drawbacks.
The advantages of the matrix are the ease of access to the technical representation in the form of a tabular sheet (Excel). The user does not need any sophisticated software tools or skills to engage with the concept. Further, the matrix gives a well-structured overview of the entire inventory of EAGLE matrix elements in a hierarchical order for each of the three matrix blocks. With the EAGLE matrix, the bar-coding method (see
Section 2.3.1. above) can be applied easily.
However, the matrix is limited in its machine-readable handling of complex landscape situations or class definitions where several LCCs play a role and each of them is combined with different LUAs or LCHs. In such cases, human intelligence is needed to read the correct and meaningful connections between the bar-coded elements (for example, only trees or bushes can be broadleaved, while buildings cannot).
The advantage of the UML model is that it is possible to connect it to a physical database that contains geometric objects. With combinations of LCCs, LUAs and LCHs as UML classes and attributes, the model can be applied in an object-oriented approach, as well as to describe entire classes in an abstract way. In doing so, complex situations can also be described because the logic connection between a specific LCC or a group of LCCs and its attached LUAs and LCHs can be expressed directly in a machine-readable way, without the need for the human logic interpretation of the connectivity. Where the matrix determines the hierarchical structure of elements, the UML model carries the logic connection between all the LCCs and its possible LUAs and LCHs because the latter are anchored directly within the UML classes as UML attributes. They are placed at the highest possible (parent) level to allow inheritance to the lower (child) levels. Such a model design prevents the user from making illogical connections between LCCs and LCHs because the direct placement of LCHs as UML attributes only allows certain combinations of LCCs and LCHs. Such semantic information can be stored as machine-readable data and can be exchanged and compared with other databases that also use the UML to express taxonomies or ontologies. Also, the UML model is open to the concept of linked data.
The obvious drawback of the UML model is the necessity for high levels of technical knowledge in data modelling required by the user to work with it.
2.6. Proof-of-Concept Use Case for Semantic Nomenclature Analysis
Ideally, a logically and consistently structured nomenclature is designed so that a subdivision feature is applied only at a single hierarchical level for all branches of the nomenclature it affects. Otherwise, there is the risk of overlapping class definitions. In reality, this principle is not always feasible, depending on the content focus and scope of a nomenclature.
In 2019, the EAGLE Group conducted a semantic analysis of the nomenclature for the new CLMS Priority Area Monitoring product “Coastal Zones” (CZs). The report to the EEA has not been published in detail. The aim of this analysis was to examine the internal consistency of this nomenclature with regard to the criteria used for the hierarchical structure, and also its compatibility with other existing Priority Area Monitoring products. With the help of the EAGLE concept, the authors examined which types of criteria and characteristics were used at the four hierarchical levels (Levels 1–4) for the creation and subdivision of classes and how frequently they were used to design and structure the nomenclature. Further, the analysis addressed different categories of issues, such as overlapping definitions, doublets in class naming, hierarchical logic and thematic content.
The analysis came to the following conclusions:
Regarding the number of classes, the version of CZ nomenclature tested had 8 classes on Level 1, 25 on Level 2, 54 on Level 3 and 15 on Level 4. This means that not all the subdivisions reached from Level 1 down to Level 4, but most of them found their bottom line on Level 3; only urban classes and wetlands were subdivided till Level 4.
From a total of 18 different class criteria, 5 of them were applied on Level 1, 12 on Level 2, another 12 on Level 3 (partly the same as in Level 2) and 2 on Level 4. Thus, Level 2 and Level 3 experienced by far the most diverse subdivision in the hierarchical structure. In total, through all the levels, the most frequently used criteria to subdivide classes were land cover (23 times), land use (33), habitat types (12), spatial context (11), cultivation measures (5), forestry practises (6), landforms (6) and spatial patterns (5).
Often, many criteria were used to define or subdivide classes. The subdivision took place based partly on multiple-criterion selection: a total of 77 class definitions were based on a single criterion, 26 subdivisions were based on double criteria and in 2 cases, even triple criteria were used.
Further, in six cases, some sub-classes were flagged as doublets, indicating where a child class has the same or a very similar name as the parent class and does not contain enough differences from the parent class to truly be a sub-class. In addition, three cases of overlapping class names/content were identified.
After handing over the results in the form of a report to the EEA, most of the identified aspects of the CZ nomenclature design were fixed in the final version. However, the general issue of tailoring to purpose remains a critical point when discussing the classification versus characterisation of land surfaces.
3. Implementation of the EAGLE Concept
Over the past decade the EAGLE concept has been adopted in various use cases, either directly or by adapting its main principles, at the regional, national and international levels. The EAGLE concept is flexible enough to be adapted at larger scales, not only at the pan-European level to describe wall-to-wall landscape inventories but also in very specific thematic fields like the hyperspectral detection of urban surface material types or the distinction of crop types in arable land and how they are managed. This section reports on some of these examples, demonstrating variants of how the problems of conventional classification systems were addressed by implementing the characterisation approaches behind the EAGLE concept.
3.1. Copernicus Land Monitoring Service CLCplus Product Suite
The most important and comprehensive use case of the EAGLE concept is implemented within the CORINE Land Cover second-generation (CLCplus) product suite [
31], which is part of the CLMS. As the name suggests, CLCplus is not a replacement for the CLC but is meant to complement and extend the current time series of LULC products. It has been known for some time that the original CLC was not adequate for modern applications due to its coarse spatial resolution and use of a nomenclature which incorporated both land cover and land use properties within the same classes.
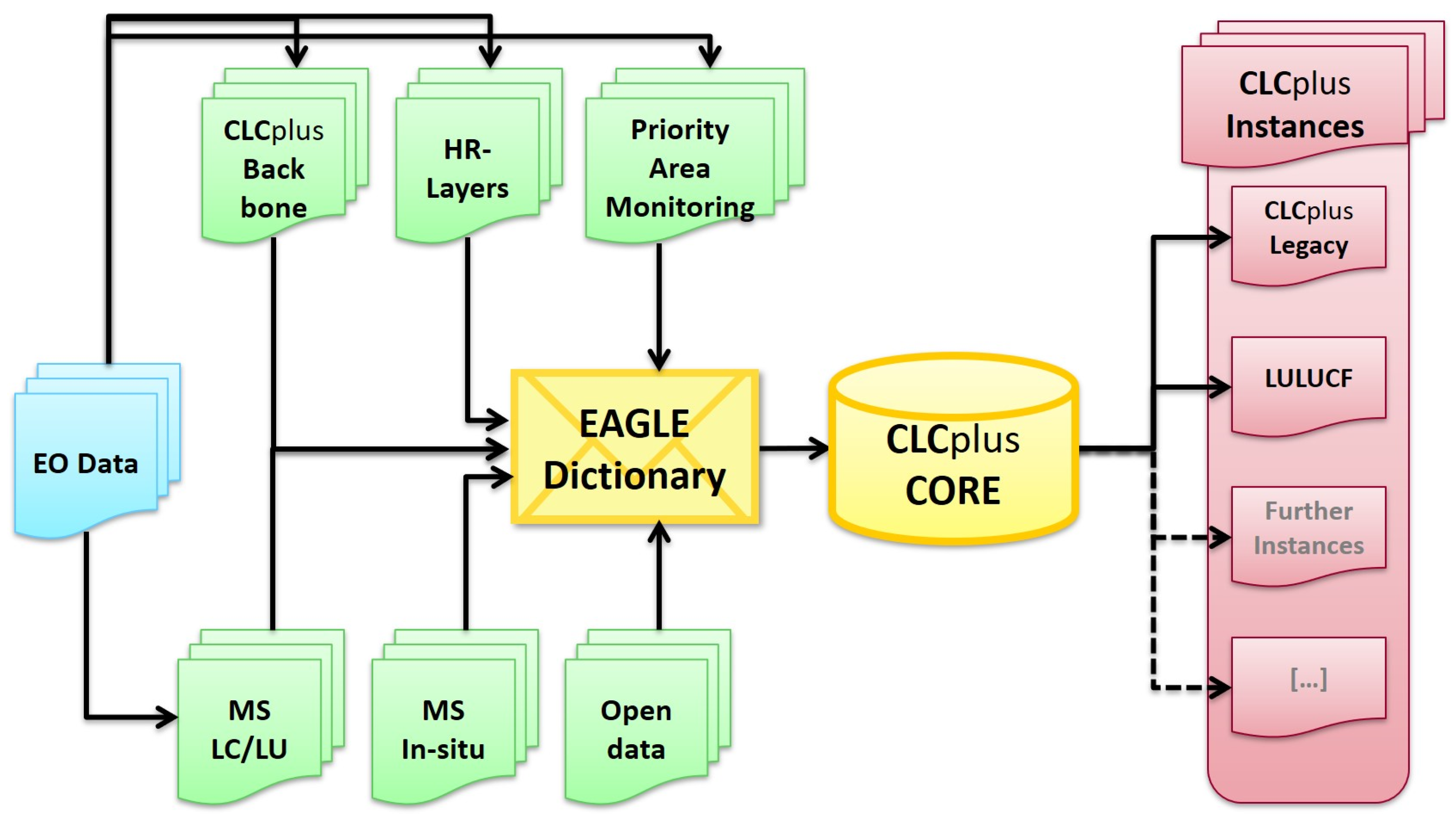
The EEA engaged the EAGLE Group Incoreto develop the overall concept for CLCplus (
Figure 10) and define the following product components, based on the needs of the EEA and rooted in the ideas behind the EAGLE model:
CLCplus Backbone is a spatially detailed, large-scale inventory in 10 m raster format (and vector format, providing a geometric spatial structure attributed with the raster data) for landscape features with limited but robust EO-based land cover information on which to build other products. The thematic detail was derived from the EAGLE LCCs.
CLCplus Core is a consistent multi-use 1 ha grid database repository for environmental land monitoring information populated with a broad range of land cover (including but not limited to CLCplus Backbone), land use and ancillary data from the CLMS and other sources. CLCplus Core forms the information engine to deliver and support tailored thematic information requirements. CLCplus Core represents a complete implementation of the EAGLE data model for each grid cell. The grid approach of CLCplus Core will enable the user to combine various thematic data domains beyond LULC information (e.g., environmental monitoring, habitat types, meteorology, population census data, hazards and risks), which all refer to the standardised and geometrically stable and scalable grid cells.
CLCplus Instances are the user-facing end points or final products in the CLCplus product suite. There may potentially be multiple “instances” with different specifications and for different purposes. They will be a derived raster/grid product from the CLCplus Core and will provide LULC monitoring with an improved spatial and thematic performance, relative to the current CLC, for reporting and assessment. The instances can be tailored towards different application domains. For example, CLCplus LULUCF is an important use case for greenhouse gas accounting.
The final element of the conceptual design, although not strictly a new product, is the ability to continue to produce the existing CLC (with an MMU of 25 ha and the current 44 LULC classes), which may be referred to as CLCplus Legacy in the future, which already has a well-established and agreed-upon specification.
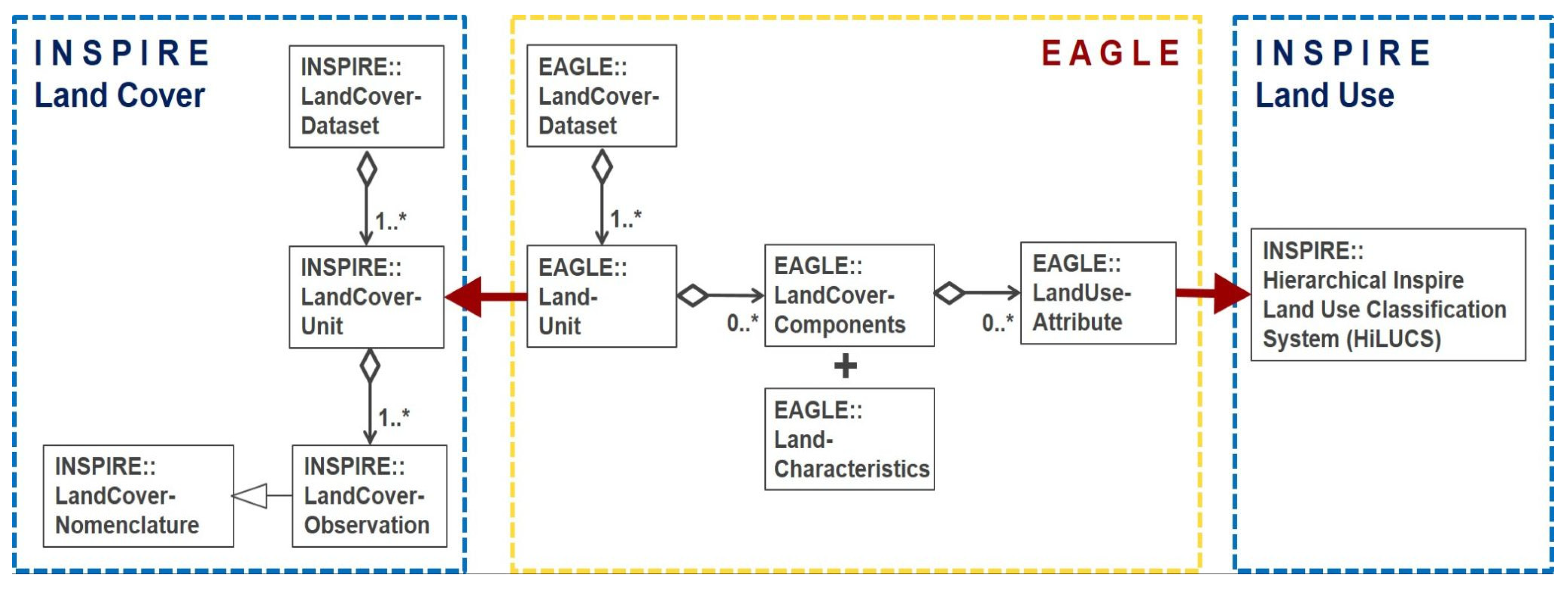
3.2. INSPIRE Data Specification
During the implementation process of the European INSPIRE directive, a connection between the INSPIRE model (INSPIRE geoportal web page [
32]) and the EAGLE model was established. As with the EAGLE, the INSPIRE foresaw the separation of land cover and land use properties. The pure land cover components of the INSPIRE theme land cover strongly (but not completely) relate to the LCCs of the EAGLE model, and the LUAs of the EAGLE are very similar to the Hierarchical INSPIRE Land Use Classification System (HILUCS). The EAGLE UML data model carries an anchor to the UML model from the data specifications on the INSPIRE theme land cover. Both UML models are connected on the level of the LandCoverUnit/LandUnit. The codelist of “Pure Land Cover Components” (INSPIRE PLCC) from these data specifications fall back to and can be mapped with the EAGLE LCCs. The EAGLE LUA data relate to the HILUCS from the data specifications of the INSPIRE theme land use (
Figure 11).
3.3. National Examples
The EAGLE approach is scale-independent and can be applied over any region. This section describes some national examples which highlight how the EAGLE concept has been used as a conceptual basis or semantic tool.
3.3.1. Germany: New LC/LU Feature-Type Catalogue
A semantic analysis using the EAGLE matrix was applied to the feature-type catalogue (GeoInfoDok ATKIS/ALKIS) of the German land surveying authorities (AdV). ATKIS is the topographic–cartographic information system, while ALKIS is the real estate cadastral information system. Both systems use the same application schema but with differences in their minimum mapping units and numbers of mandatory feature types and attributes.
Using the EAGLE bar-coding method, the definitions of all the ATKIS/ALKIS feature types and attributes were semantically checked regarding their thematic content related to land cover and land use. Based on the results, two new separate nomenclatures on LC (“Landbedeckung”) and LU (“Landnutzung”) (AdV [
33,
34]) were designed to:
Disentangle the mixing of these two themes within the current ATKIS/ALKIS nomenclature;
Insert new feature types or attributes to complete the catalogue in terms of missing land cover and land use aspects;
Create a separate nomenclature for each of the two themes: land cover and land use.
The old version of the ALKIS application schema only allowed a land unit to be labelled with one single feature type, while the new nomenclature of “Landnutzung” allows for the assignment of additional land use types to the same land unit. Multi-usage land units can therefore be described closer to reality instead of the previous dilemma of having to choose only one land use type and missing out on others, for example, a central railway station that also contains a shopping mall and a food court, or a parking lot that specifically belongs to an airport. This multiple labelling of land units was also laid out in the EAGLE concept.
3.3.2. France: Occupation of Soil at Large Scale (OCS GE)
In 2017, the EAGLE Group presented the concept to the Institut National de l`Information Géographique et Forestière (IGN) in France, who then initiated a project to create a national land cover/land use product. The IGN has developed a sophisticated product called “Occupation de Sol a Grande Èchelle OCS GE” (Occupation of Soil at Large Scale). Using the EAGLE principle of the clear separation between LCs and LUs, they have implemented two aspects of information named “couverture du sol” and “usage du sol”. The hierarchically structured classes of the French nomenclature are based on the EAGLE LCCs and LUAs (and thus also the INSPIRE HILUCS).
Transport networks like roads, railways and other stable linear features were used to build the geometric framework of the land units in the dataset in a similar way to the approach for the vector version of CLCplus Backbone. A wall-to-wall polygon dataset of France has been produced for the years 2017/2018 and 2021, with updates for 2024 in production. Comprehensive documentation about the data organisation and content definitions can be found online (IGN France [
35]).
3.3.3. Italy: A 2012–2020 Map of Italy
The Italian Institute for Environmental Protection and Research (ISPRA) produces high-spatial- and -thematic-resolution land use and land cover data and maps that can serve as a national reference for conducting analyses of the state of the landscape for studying natural and anthropogenic processes. They are responsible for the production and updating of freely accessible national LULC data derived from a range of different sources (e.g., CLMS products). All ISPRA LU and LC products are defined in compliance with the EAGLE approach.
The methodology (De Fioravante, Strollo, Assennato, Marinosci, Congedo & Munafò [
36]) integrates CLMS and national data for the production of a land cover map capable of supporting applications, such as ecosystem service assessments. Using this process, the final maps were produced from the local and pan-European components of the CLMS: the Priority Are Monitoring Urban Atlas, Riparian Zones and Natura 2000, and the pan-European CLC and HRLs. The input data were reclassified thematically according to an EAGLE-compliant classification system and merged into a 10 m spatial resolution land cover map of Italy. The work used a sixteen-class classification system defined in accordance with the EAGLE and organised into five levels (
Table 1). The classification system was based on previous activities and was improved to maintain the thematic detail offered by the CLMS and national input data. The first three class levels align well with the EAGLE LCCs. The wetland class and the fourth and fifth classification levels of the hierarchy are based on the EAGLE LCHs.
The Italian land cover-, land use- and ecosystem-type maps are therefore a strong example of CLMS integration through the use of the EAGLE data model as an integral centrepiece of land information.
3.4. GENLIB: Developing a Generic Framework for the Library-Based Mapping of Urban Areas
The GENLIB research project proposes the concept of a Generic Urban Spectral Library (GUSL) to address the challenges of urban mapping and to help streamline production. The GUSL is defined as a multi-site collection of richly labelled spectral libraries, equipped with the tools needed to query, transform and apply these libraries for various urban mapping applications.
While the scope of this project covers only urban environments, with a particular focus on artificial land cover types, the authors of the GUSL note that its framework can be extended to serve other remote sensing application domains, like forestry, agriculture and soil science, to detect the plant species types or stress conditions of vegetation cover.
The EAGLE concept was adapted by working with LCC Artificial and its subtypes from the EAGLE matrix and combining them with entries from the Artificial Surface Material Types (under the LCH block). Also, the GENLIB project gave input to insert and extend the EAGLE matrix module of Artificial Surface Material Types to make it even more useable for such applications.
4. Discussion
The EAGLE concept is not another new classification system to be added to the existing long list. Instead, it is a tool to address the ambiguities within nomenclatures and the comparability between them regarding the terms and definitions they apply. The fundamental idea is to have such a tool as a semantic centrepiece within a land monitoring framework, and for it to act as a vehicle to allow for comparisons and translations between different product nomenclatures.
The EAGLE concept embodies a new approach for land monitoring initiatives following an object-oriented approach in landscape modelling. It promotes the paradigm shift from single-value-coded conventional classification techniques, e.g., labels, to a multi-variable descriptive characterisation. Landscape features are then characterised by multiple attributes rather than forced into a single discrete category, which is only partially representative of reality. As data producers move away from traditional, hierarchical classifications towards object-oriented approaches, the tools used for the documentation and transformation of the classification systems must follow suit.
Each landscape feature then contains a set of descriptive attributes not only from which an understanding of the feature can be derived but which can also be exploited to derive thematically detailed feature-specific properties that would be impossible with conventional classification schemes. In this way, it aims at providing a basis for an integrated multi-use framework.
The main tenets of the EAGLE approach are therefore as follows:
A single data model as an integral centrepiece of a land information system providing semantic links between a broad range of products.
A concept that comprises a data model that stores information about land cover components, land use attributes and further characteristics. Elements are defined to be comprehensive and granular enough for multiple uses.
A means of describing features, nomenclatures and their classes in terms of fundamental elements. A class within a nomenclature should be accompanied by a clear and unambiguous definition as part of a mapping guide to support interpretation. The EAGLE concept can be used to review these mapping guides, identify gaps and ambiguities and suggest the need for clarification.
A mechanism for the semantic translation of classes between nomenclatures and a framework for comparing and evaluating nomenclatures, and for comparisons and translations/equivalences among different classification systems. Once the meanings of the labels have been fully described, then the elements they represent can be compared to see if they are similar enough to be combined.
A model that is flexible enough in its structure or hierarchy to allow for the integration of new model elements or modules where possible.
A common basis for designing the specification of future products to make them more interoperable.
An approach which works both bottom-up, i.e., when aggregating individual products into a greater whole, and top-down, i.e., when sharing information produced centrally across multiple subregions.
In general, the EAGLE concept and its data model can be applied in two main ways. Firstly, it can be used as a vehicle to analyse and show the comparability and differences between different LULC classification systems and legends on an abstract semantic level. Secondly, it can be used as a guidance document for LULC mapping programmes to directly capture parameterised information and describe real landscape situations as an instantiated application of the model.
The more flexible and comprehensive object-oriented approach avoids the loss of information about landscape details, which is inevitable when applying a strict classification approach with fixed class definitions or fixed thresholds.
With its thematically neutral approach and enough application flexibility within the architecture, the EAGLE concept addresses many different user communities and working domains. In particular, data modelling architectures, multi-dimensional data cubes and linked data are appropriate approaches to build up a multi-purpose structure for data storage, information analysis and statistical timelines and correlations.
When deploying a real-world implementation of the EAGLE data model, the accuracy and precision of information on the Earth’s surface derived from EO data have to be considered, along with the possible limitations of such data sources. Automated digital image analysis is subject to a certain degree of statistical error, as pixels are classified based on probabilities, and the recognition of objects and their labelling are often subject to generalisation rules. Once such derived information about the Earth’s surface is semantically translated into the EAGLE model, this level of statistical error or geometric generalisation stays with the data and cannot be altered. Different data collection methods have come along with differing statistical errors or varying levels of generalisation. When comparing datasets with different origins that have been through the semantic EAGLE decomposition and are now semantically equalised, they will still carry the bias from the original data interpretation or classification method. This aspect applies not only for EO data but also for any other source of information used to generate spatial data products.
This paper does not aim at proving the usefulness of the EAGLE concept in an empirical manner based on measurable quantitative or statistical figures. Instead, the authors take the selection of the above-mentioned use cases at the national and European levels as proof of its usefulness. Measuring the quantitative effect of the EAGLE concept is a task that has its own charm and legitimacy but cannot be solved within the scope of this paper. The authors therefore encourage other users and scientists to make such studies and assess the usefulness with quantitative criteria, e.g., how increasing the thematic accuracy of a given land monitoring procedure or map can be achieved by aligning it with the EAGLE concept. This paper presents the progress and applicability of the concept itself; other authors are invited to further investigate measurable matters of the concept.
5. Conclusions and Outlook
The EAGLE matrix and data model offer a conceptual framework to support the paradigm shift from classification to the characterisation of land features. The EAGLE matrix in its tabular form provides an easy-to-use tool for the semantic analysis of class definitions and nomenclatures through the bar-coding method, where no special software skills or elaborate training are needed. The EAGLE UML model then provides an advanced solution for the development of database structures to support land characterisations and allow machine-readable instances and onward processing in downstream applications. The content design of the EAGLE concept is purely semantic and is therefore not bound or restricted to a particular domain or input data source.
The innovative aspect of the EAGLE concept is the object-oriented characterisation of the landscape by a componential and attributive description of its features, instead of working with a single, fixed and sometimes poorly defined class label. The concept provides improvements for the storage of information by:
Untangling the mixtures of land cover and land use labels within existing nomenclatures;
Deriving information that is more comparable between systems;
Avoiding the loss of information due to generalisation and cut-off thresholds, which occur when applying conventional class definitions;
Solving the dilemma of when predefined class labels do not match reality and features are forced into the least “wrong” class.
Also, the concept is flexible enough to be adapted to new requirements. When particular landscape characteristics become important and have not yet been represented by model elements, they can be easily integrated under a new model segment without jeopardising the consistent hierarchy of the already existing model segments and blocks.
The use case examples shown here highlight the broad application of the EAGLE concept at different scales and across different application areas. They also show that the EAGLE concept for land characterisation is being adopted as a powerful and flexible tool for the development of mapping products. Having a characterisation approach in the background, even when a product presents a classification result, allows users to drill down into the details of the characteristics if needed, and for products to be reworked for other uses without having to return to the beginning of the mapping process.
The deployment of the EAGLE data model has not been without its challenges, as this is a major paradigm shift and an evolving concept. There have been issues in the early stages of automatically deriving CLCplus Legacy and the development of change products by extraction from the CLCplus Core platform. The EAGLE data model is a more powerful approach, but it has also revealed hidden consequences of the classification process that are now open to scrutiny. Previously, such issues were impossible to consider, as they were baked into the class labels with no opportunity for flexibility. For instance, there can be considerable changes to a landscape feature which a conventional fixed class cannot capture.
A further perspective is to broaden the application of the EAGLE concept to the global level to address challenges such as the monitoring of the UN’s Sustainable Development Goals and the Essential Climate and Biodiversity Variables. Alongside the EAGLE concept, the ISO 19144 standards have been developed, and the ISO technical committee TC 211 has opened a procedure for updating parts of the standards (Mosca, Mushtaq, Munene, Maleh, Mnyanda, Jalal & Ghosh [
37]). This has resulted in three new parts: 19144-2 Land Cover Meta Language (LCML) [
25], 19144-3 Land Use Meta Language (LUML) [
27], similar to the LCCs and LUAs of the EAGLE model, and 19144-4 Registration of Land Cover and Land Use Classification Systems (Not yet published, see Mushtaq, O’Brien, Parslow, Ahlin, Di Gregorio, Latham & Henry [
38]).
The EAGLE concept will continue to evolve as long as it retains backward compatibility to support legacy systems and implementations. Several scenarios are possible, such as extending it into other thematic fields, like soil types, for which a new soil-type module could be inserted into the model. It could also be extended to point objects or point coordinates (beyond areal objects), where certain parameters or indicators are taken from EO data or in situ observations.
With emerging technologies such as artificial intelligence (AI) and machine learning algorithms, data capture methods have the potential to catch up with the versatility and complexity of the EAGLE concept. As remote sensing techniques and GIS analysis are evolving from object delineation to intelligent thematic object recognition, a future branch of the EAGLE concept’s application could be the production of highly differentiated spatial data content directly from satellite imagery into thematic layers. With such new techniques, not only spectral signatures but also the inclusion of the shape, size and temporal aspects (frequency, seasonal appearance), neighbouring context and geographic location of recognised objects will lead to higher thematic accuracy. When envisioning such a scenario, the EAGLE concept would embrace not only its role as a tool for semantic analysis and comparison but also as a sort of elementary inventory for land characterisation. Here, further developments and examinations are necessary to make progress in this area and unlock the potential of automated object-oriented feature recognition and characterisation to feed into new data storage formats like digital twins.
It is clear from the work described here that the EAGLE concept has become established and is exposing the characterisation approach for land monitoring to a broad community of practitioners. The new policy requirements and challenges of the climate and biodiversity crises will demand this type and level of landscape description to produce effective action. The future is positive for the EAGLE concept as part of the environmental toolbox with links to global standards.
6. Acknowledgements
The EAGLE concept and data model have been developed by the authors of this paper with the support of a broader community of land monitoring experts.
The IGN Spain initiated an open discussion about making a move towards object-oriented data modelling for land units with the aim of enhancing the methodology and possibility of storing more descriptive information about a land unit beyond just a single class code.
Soon after, the potential for a future pan-European land monitoring framework led to the establishment of the Eionet Action Group on Land Monitoring in Europe (EAGLE Group). The EAGLE Group is a self-initiated and open group of land monitoring experts from different EEA member countries, mostly—but not only—in their roles as Eionet members.
After the concept reached a certain degree of maturity, the EEA stepped in by financing some technical developments and case studies, and it then funded contracts for the EAGLE Group to be able to continue the work, and especially its the implementation at the pan-European level.
The FP7 HELM (Harmonised European Land Monitoring) project between 2011 and 2013 had a significant impact on the work of the EAGLE Group by bringing together a large circle of national and international land monitoring experts to develop future scenarios for a bottom-up land monitoring approach between member states and the EEA.
The EAGLE concept, as a whole, benefits from different perspectives on European landscape types due to the various and diverse geographic origins of all the EAGLE Group members who contributed to the overall content of the data model, and also from the fact that there was no top-down mandate to follow a predetermined strategy.
The authors would therefore like to thank the EEA for supporting our work, as well as all the land monitoring experts who have contributed at one point or another to the evolution of the EAGLE concept and its testing in real-world situations.




 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}