
“Location, Location, Location”: Fluctuations in Real Estate Market Values after COVID-19 and the War in Ukraine Based on Econometric and Spatial Analysis, Random Forest, and Multivariate Regression




Abstract
1. Introduction
1.1. Fixed Effects and Market Value
1.2. Choosing the Econometric Model among the Multi-Parametric Value Assessment Methods
2. Purpose and Materials and Methods
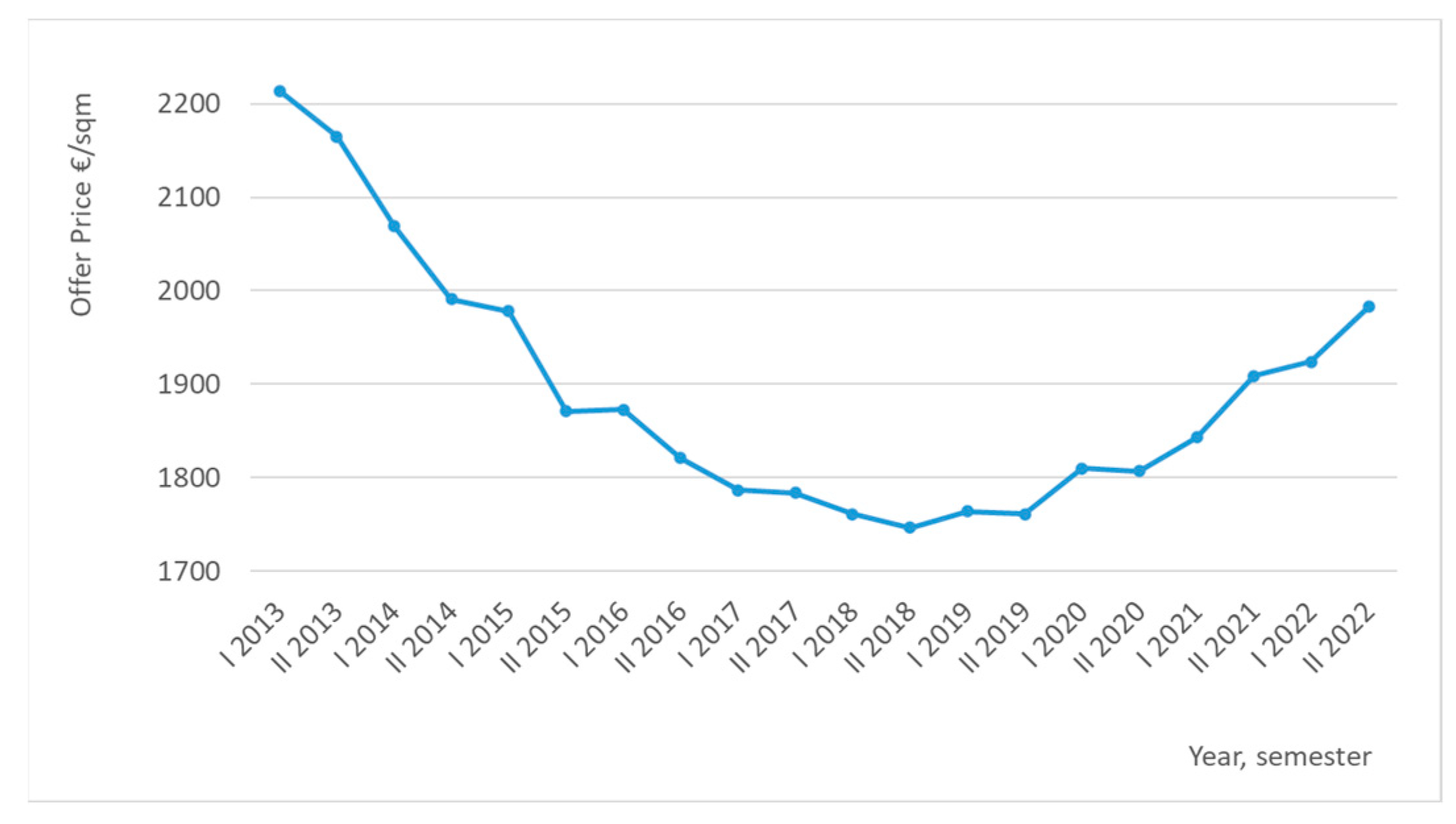
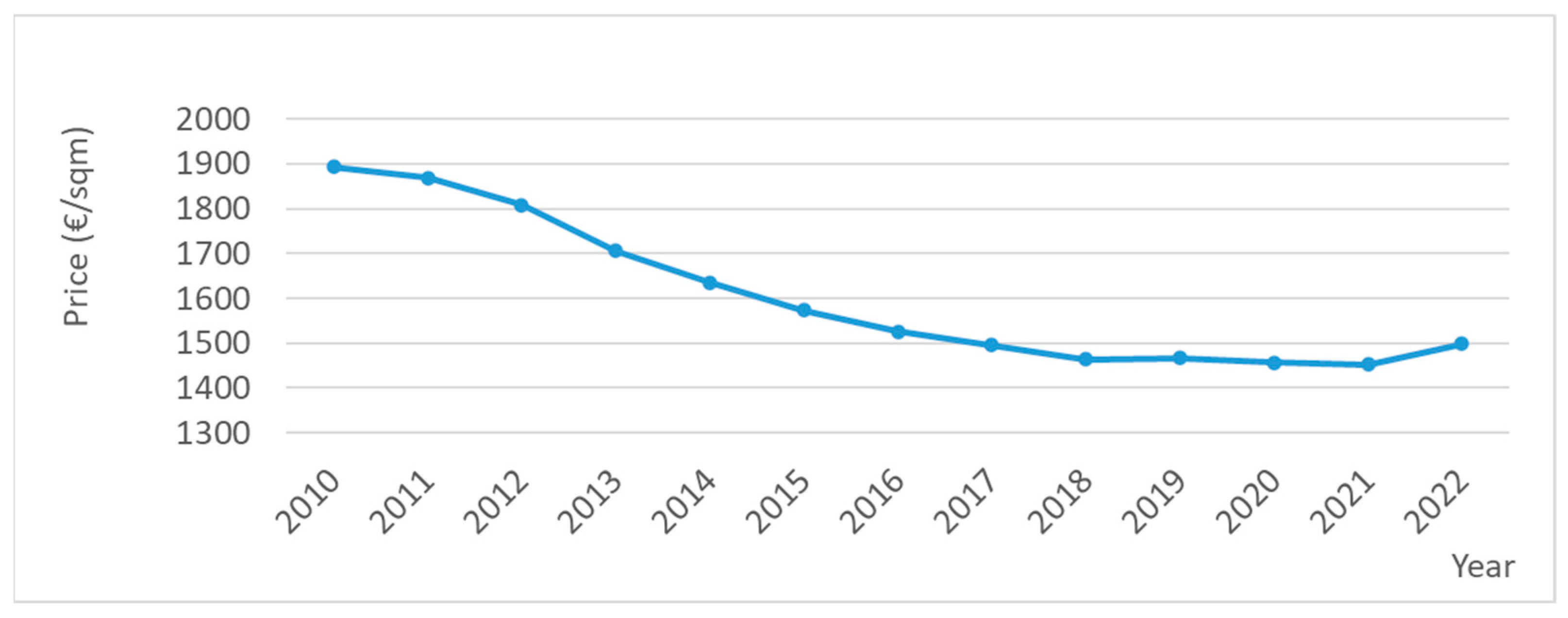
2.1. A Diachronic Analysis Related to Major Anomalous Events
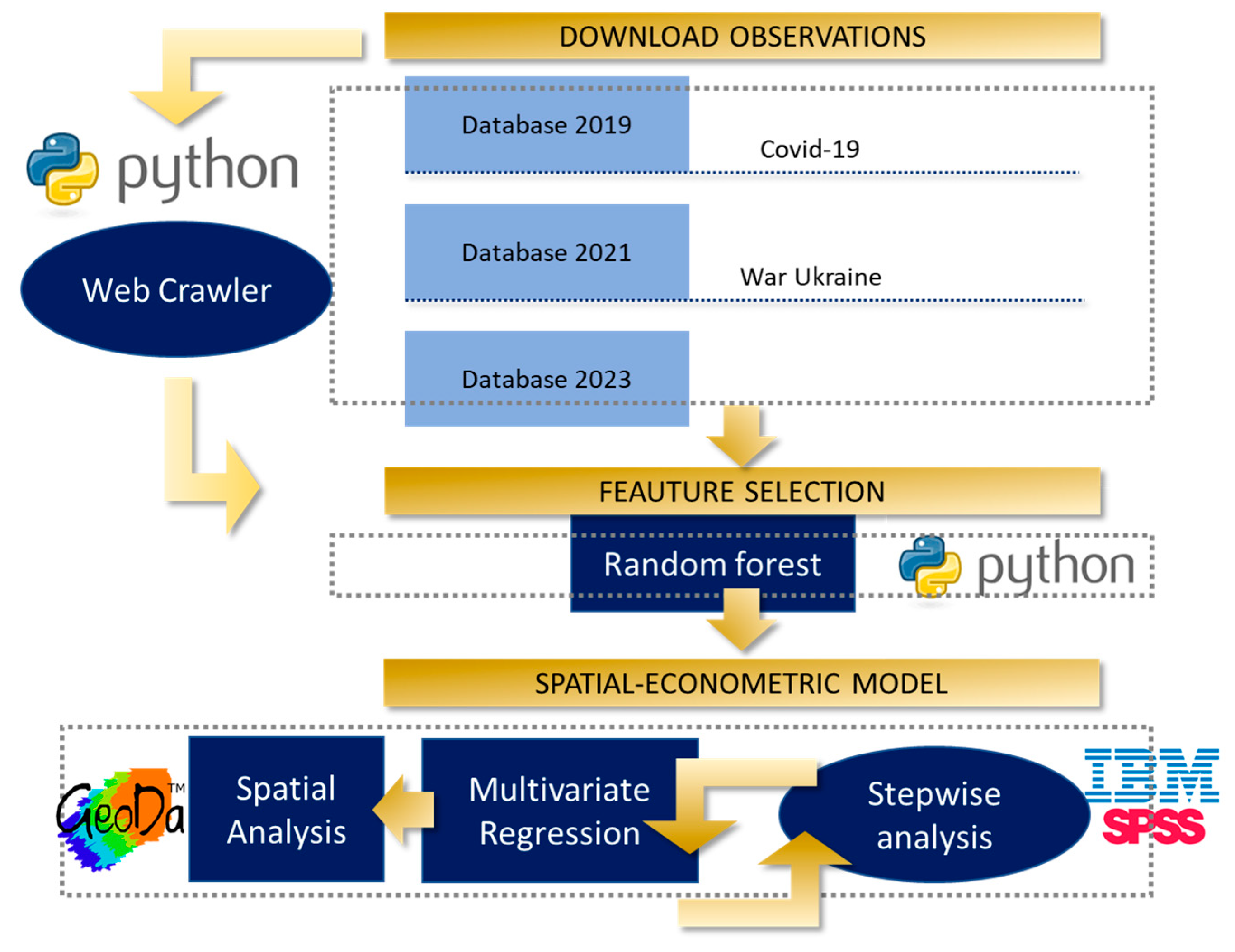
2.2. Methodological Approach and Workflow
- In STEP 1, the exemplary case study is defined, i.e., the real estate market in Padova. The case study is described based on three databases (DBs) collected at different times. The first database is dated 2019, II semester, representing the pre-COVID-19 situation. It is named DB2019 for the sake of simplicity. The second database is dated 2021, II semester, portraying the market two years after the first COVID-19 alert but before the outbreak of the War. It is called DB2021. The third database is dated 2023, I semester, depicting the market changes one year after the outbreak of the War in Ukraine. This last database is named DB2023.
- As far as STEP 2 is concerned, a set of construction and neighbourhood descriptive features of the buildings are selected and discussed as the independent regressors in the econometric models. In contrast, the market value of the property is the dependent variable.
- In STEP 3, the authors develop an automated procedure to download data and information about the buildings for sale in Padova. This step is carried out in Python® computer language, producing a web-crawling software to browse and extract information from web pages according to a predefined path. The web crawler has been used three times (2019, II semester; 2021, II semester; 2023, I semester) to read and download information from specific Italian selling websites regarding properties for sale, monitoring market changes in asking prices over time.
- Before producing the regression models, in STEP 4, a feature selection process is conducted to understand how each predictor variable influences the response variable and eliminate the less significant regressors. The feature selection procedure helps to simplify the model outcome, reduces computational time, and overcomes the overfitting problem. The Random Forest (RF) regressor is used to test the variable importance, leading to exclude some predictors from the regression models. The RF procedure is again conducted in Python code.
- STEP 5 produces the spatial-econometric models as Multivariate Regressions (MRs). The econometric model MR2019 is developed based on the dataset DB2019, the MR2021 refers to the dataset DB2019, and the MR2023 corresponds to DB2023. The spatial analyses are conducted using the GeoDa® software, while the stepwise analysis produced to define the MRs is developed with the help of the IBM SPSS 29® software.
3. The Case Study
4. A Discussion of Construction and Neighbourhood Variables
4.1. Construction Parameters
4.2. Neighbourhood Parameters
5. A Web Crawler to Download Data
5.1. Developing the Web Crawler
5.2. Measuring the Observations
6. The Random Forest as Feature Importance
6.1. Analysis of the Databases
6.2. Feature Importance Analysis
7. A Spatial and Econometric Analysis
7.1. The Multivariate Regressions
- Y is the dependent variable (i.e., the market value measured in €/sqm);
- a0 is the constant;
- βr are the coefficients of the regressors Xr, 1 ≤ r ≤ R;
- Xr are the dependent variables 1 ≤ r ≤ R (i.e., the characteristics of the buildings);
- R is the total number of dependent variables (Xr);
- 𝜑 is the error.
- X1 = Building internal services (Ʃ 0/1 of lift, private garden, private garage, shared parking space, cellar, terrace, building automation, central heating, photovoltaic system, MCV, air conditioning, optical fibre, and fireplace);
- X2 = Floor area (sqm);
- X3 = Energy class (from 10 to 1, where 10 represents the highest class A4, and 1 the lowest, i.e., class G);
- X4 = City centre straight line distance (km);
- X5 = Urban amenities and leisure (total n. of services in 1 km ring buffer of cultural facilities, museums, art galleries, theatres, cinemas, and libraries);
- X6 = Commercial services (total n. of services in 1 km ring buffer of big shopping malls, big commercial facilities, and small supermarkets);
- X7 = Bus and tram stop (total n. of services in the Ped shed of bus stop and tram stop).
- 1 ≤ i ≤ N
- 1 ≤ j ≤ N
- −1 ≤ I ≤ 1
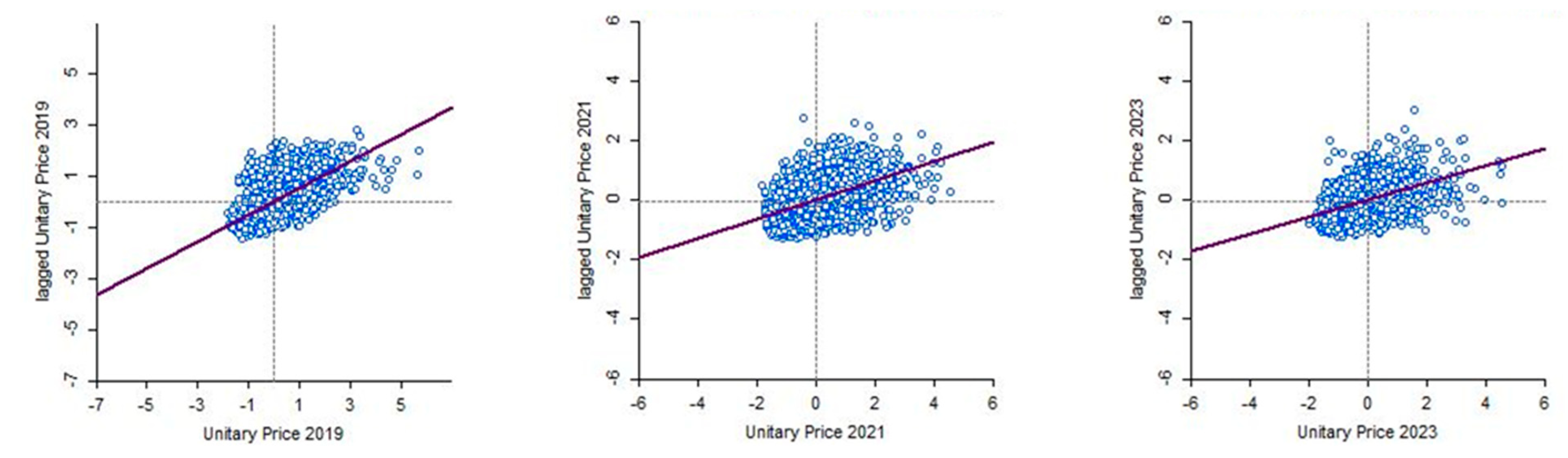
7.2. Discussing Fluctuations in Market Preferences
8. Discussion and Conclusions
- Before the first COVID-19 pandemic alert;
- Two years after the first COVID-19 alert but before the outbreak of the War in Ukraine;
- One year after the outbreak of the War in Ukraine.
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| ao | constant (intercept of the regression) |
| DB | database |
| DB2019 | database dated 2019, II semester |
| DB2021 | database dated 2021, II semester |
| DB2023 | database dated 2023, I semester |
| DBs | databases |
| GIS | geographic information system |
| I | Univariate Moran I index |
| I2019 | Moran I index developed on DB2019 |
| I2021 | Moran I index developed on DB2021 |
| I2023 | Moran I index developed on DB2023 |
| MR | Multivariate Regression |
| MR2019 | Multivariate Regression developed on DB2019 |
| MR2021 | Multivariate Regression developed on DB2021 |
| MR2023 | Multivariate Regression developed on DB2023 |
| MRs | Multivariate Regressions |
| N | number of observations |
| POI | Point of Interest |
| POIs | Points of Interest |
| R | total number of predictors |
| RF | Random Forest |
| U.o.M. | unit of measure |
| Wij | the weights matrix |
| Xi | the variable that describe the phenomena |
| Xmed | the sample mean |
| Xr | dependent variables 1 ≤ r ≤ R (i.e., the characteristics of the buildings) |
| Y | dependent variable (i.e., the market value) |
| Y2019 | dependent variable (i.e., the market value 2019) |
| Y2021 | dependent variable (i.e., the market value 2021) |
| Y2023 | dependent variable (i.e., the market value 2023) |
| βr | coefficients of the regressors Xr, 1 ≤ r ≤ R |
| 𝜑 | error |
References
- Safire, W. Location, Location, Location. Available online: https://www.nytimes.com/2009/06/28/magazine/28FOB-onlanguage-t.html (accessed on 30 April 2023).
- Wang, A.; Xu, Y. Multiple linear regression analysis of real estate price. In Proceedings of the International Conference on Robots and Intelligent System, ICRIS 2018, Changsha, China, 26–27 May 2018; IEEE: Piscataway, NJ, USA; pp. 564–568. [Google Scholar]
- Feng, J.; Zhu, J. Nonlinear regression model and option analysis of real estate price. Dalian Ligong Daxue Xuebao/J. Dalian Univ. Technol. 2017, 57, 545–550. [Google Scholar] [CrossRef]
- Bertazzon, S. L’ Analisi Spaziale. La Geografia Che … Conta; FrancoAngeli: Milan, Italy, 2022; ISBN 9788835139461. [Google Scholar]
- Simonotti, M. Metodi di Stima Immobiliare; Flaccovio: Palermo, Italy, 2006. [Google Scholar]
- Shen, K. Application of market comparison approach in land price appraisal. In Proceedings of the Geology Resource Management and Sustainable Development—Academic Conference Proceedings of 2009 Geology Resource Management and Sustainable Development, CGRMSD 2009, Lushan, China, 30 November 2009; pp. 225–230. [Google Scholar]
- Salvo, F.; Tavano, D.; De Ruggiero, M. Hedonic price of the built-up area appraisal in the market comparison approach. Smart Innov. Syst. Technol. 2021, 2, 696–704. [Google Scholar]
- D’Amato, M.; Cvorovich, V.; Amoruso, P. Short tab market comparison approach. An application to the residential real estate market in Bari. Stud. Syst. Decis. Control 2017, 86, 401–410. [Google Scholar]
- Valier, A. Who performs better? AVMs vs. hedonic models. J. Prop. Investig. Financ. 2020, 38, 213–225. [Google Scholar] [CrossRef]
- IAAO Standard on Mass Appraisal of Real Property; International Association of Assessing Officers: Kansas City, MO, USA, 2017.
- Štubňová, M.; Urbaníková, M.; Hudáková, J.; Papcunová, V. Estimation of residential property market price: Comparison of artificial neural networks and hedonic pricing model. Emerg. Sci. J. 2020, 4, 530–538. [Google Scholar] [CrossRef]
- Amrutphale, J.; Rathore, P.; Malviya, V. A Novel Approach for Stock Market Price Prediction Based on Polynomial Linear Regression. Lect. Notes Netw. Syst. 2020, 100, 161–171. [Google Scholar] [CrossRef]
- Pérez-Rave, J.I.; Correa-Morales, J.C.; González-Echavarría, F. A machine learning approach to big data regression analysis of real estate prices for inferential and predictive purposes. J. Prop. Res. 2019, 36, 59–96. [Google Scholar] [CrossRef]
- Baldominos, A.; Blanco, I.; Moreno, A.J.; Iturrarte, R.; Bernárdez, Ó.; Afonso, C. Identifying real estate opportunities using machine learning. Appl. Sci. 2018, 8, 2321. [Google Scholar] [CrossRef]
- Gabrielli, L.; Ruggeri, A.G. Developing a model for energy retrofit in large building portfolios: Energy assessment, optimization and uncertainty. Energy Build. 2019, 202, 109356. [Google Scholar] [CrossRef]
- Gabrielli, L.; Ruggeri, A.G. Optimal design in energy retrofit interventions on building stocks: A decision support system. Green Energy Technol. 2021, 231–248. [Google Scholar]
- Pittarello, M.; Scarpa, M.; Ruggeri, A.G.; Gabrielli, L.; Schibuola, L. Artificial neural networks to optimize zero energy building (Zeb) projects from the early design stages. Appl. Sci. 2021, 11, 5377. [Google Scholar] [CrossRef]
- Gabrielli, L.; Ruggeri, A.G.; Scarpa, M. Automatic energy demand assessment in low-carbon investments: A neural network approach for building portfolios. J. Eur. Real Estate Res. 2020, 13, 357–385. [Google Scholar] [CrossRef]
- Rosen, S. Hedonic prices and implicit markets: Product differentiation in pure competition. J. Polit. Econ. 1974, 82, 34–55. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P.; Torrieri, F.; Pagliara, F.; Nijkamp, P. Estimo e Valutazione Economica dei Progetti: Profili Metodologici ed Applicazioni al Settore Immobiliare; SCIENZE REGIONALI; Il Mulino: Bologna, Italy, 2022; ISBN 9788899306038. [Google Scholar]
- Gabrielli, L.; Ruggeri, A.G.; Scarpa, M. How COVID-19 Pandemic Has Affected the Market Value According to Multi-parametric Methods. Lect. Notes Networks Syst. 2022, 482, 1018–1027. [Google Scholar]
- Gabrielli, L.; Ruggeri, A.G.; Scarpa, M. Using Artificial Neural Networks to Uncover Real Estate Market Transparency: The Market Value. In Proceedings of the Lecture Notes in Computer Science; Gervasi, O., Murgante, B., Misra, S., Garau, C., Blečić, I., Taniar, D., Apduhan, B.O., Rocha, A.M.A.C., Tarantino, E., Torre, C.M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 12954 LNCS, pp. 183–192. [Google Scholar]
- World Health Organization. Available online: https://www.who.int/ (accessed on 15 October 2021).
- Nicola, M.; Alsafi, Z.; Sohrabi, C.; Kerwan, A.; Al-Jabir, A.; Iosifidis, C.; Agha, M.; Agha, R. The socio-economic implications of the coronavirus pandemic (COVID-19): A review. Int. J. Surg. 2020, 78, 185–193. [Google Scholar] [CrossRef]
- ANSA Ucraina: La Cronaca, Dall’attacco Alla Chiamata Alle Armi. Alle 4:13 la Notizia di Esplosioni a Kiev, Poi in Rapida Sequenza in Altre Città. Available online: https://www.ansa.it/sito/notizie/mondo/2022/02/24/ucraina-la-cronaca-dallattacco-alla-grande-fuga_3bba3244-a42c-4210-8d41-83c584236fa8.html (accessed on 30 March 2023).
- Markus, S. Long-term business implications of Russia’s war in Ukraine. Asian Bus. Manag. 2022, 21, 483–487. [Google Scholar] [CrossRef]
- Zahra, S.A. Institutional Change and International Entrepreneurship after the War in Ukraine. Br. J. Manag. 2022, 33, 1689–1693. [Google Scholar] [CrossRef]
- Wang, Y.; Bouri, E.; Fareed, Z.; Dai, Y. Geopolitical risk and the systemic risk in the commodity markets under the war in Ukraine. Financ. Res. Lett. 2022, 49, 103066. [Google Scholar] [CrossRef]
- Steffen, B.; Patt, A. A historical turning point? Early evidence on how the Russia-Ukraine war changes public support for clean energy policies. Energy Res. Soc. Sci. 2022, 91, 102758. [Google Scholar] [CrossRef]
- Rawtani, D.; Gupta, G.; Khatri, N.; Rao, P.K.; Hussain, C.M. Environmental damages due to war in Ukraine: A perspective. Sci. Total Environ. 2022, 850, 157932. [Google Scholar] [CrossRef]
- Zhou, X.-Y.; Lu, G.; Xu, Z.; Yan, X.; Khu, S.-T.; Yang, J.; Zhao, J. Influence of Russia-Ukraine War on the Global Energy and Food Security. Resour. Conserv. Recycl. 2023, 188, 106657. [Google Scholar] [CrossRef]
- Piech, K. Health Care Financing and Economic Performance during the Coronavirus Pandemic, the War in Ukraine and the Energy Transition Attempt. Sustainability 2022, 14, 10601. [Google Scholar] [CrossRef]
- Elvevåg, B.; DeLisi, L.E. The mental health consequences on children of the war in Ukraine: A commentary. Psychiatry Res. 2022, 317, 114798. [Google Scholar] [CrossRef] [PubMed]
- Kalaitzaki, A.E.; Tamiolaki, A. Russia-Ukraine War: Jeopardizing the mental health gains already been obtained globally. Asian J. Psychiatr. 2022, 78, 103285. [Google Scholar] [CrossRef]
- Quaglio, C.; Todella, E.; Lami, I.M. Adequate Housing and COVID-19: Assessing the Potential for Value Creation through the Project. Sustainability 2021, 13, 10563. [Google Scholar] [CrossRef]
- Tokazhanov, G.; Tleuken, A.; Guney, M.; Turkyilmaz, A.; Karaca, F. How is COVID-19 Experience Transforming Sustainability Requirements of Residential Buildings? A Review. Sustainability 2020, 12, 8732. [Google Scholar] [CrossRef]
- Tucci, F. Pandemia e Green City. Le necessità di un confronto per una riflessione sul futuro del nostro Abitare. In Pandemia e Alcune Sfide Green del Nostro Tempo; Fondazione Sviluppo Sostenibile: Rome, Italy, 2020. [Google Scholar]
- De Toro, P.; Nocca, F.; Buglione, F. Real Estate Market Responses to the COVID-19 Crisis: Which Prospects for the Metropolitan Area of Naples (Italy)? Urban Sci. 2021, 5, 23. [Google Scholar] [CrossRef]
- Martinho, V.J.P.D. Impacts of the COVID-19 Pandemic and the Russia–Ukraine Conflict on Land Use across the World. Land 2022, 11, 1614. [Google Scholar] [CrossRef]
- Trojanek, R.; Gluszak, M. Short-run impact of the Ukrainian refugee crisis on the housing market in Poland. Financ. Res. Lett. 2022, 50, 103236. [Google Scholar] [CrossRef]
- Belasen, A.R.; Polachek, S.W. How disasters affect local labor markets: The effects of hurricanes in Florida. J. Hum. Resour. 2009, 44, 251–276. [Google Scholar] [CrossRef]
- Boustan, L.P.; Kahn, M.E.; Rhode, P.W.; Yanguas, M.L. The effect of natural disasters on economic activity in US counties: A century of data. J. Urban Econ. 2020, 118, 103257. [Google Scholar] [CrossRef]
- Yakub, A.A.; Hishamuddin, M.A.; Kamalahasan, A.; Abdul Jalil, R.B.; Salawu, A.O. An Integrated Approach Based on Artificial Intelligence Using Anfis and Ann for Multiple Criteria Real Estate Price Prediction. Plan. Malays. 2021, 19, 270–282. [Google Scholar] [CrossRef]
- Kalliola, J.; Kapočiūte-Dzikiene, J.; Damaševičius, R. Neural network hyperparameter optimization for prediction of real estate prices in Helsinki. PeerJ Comput. Sci. 2021, 7, e444. [Google Scholar] [CrossRef] [PubMed]
- Quotazioni Immobiliari nel Comune di Padova. Available online: https://www.immobiliare.it/mercato-immobiliare/veneto/padova/ (accessed on 30 March 2023).
- Nomisma Spa—Servizi di Analisi e Valutazioni Immobiliari. Available online: https://www.nomisma.it/servizi/osservatori/osservatori-di-mercato/osservatorio-immobiliare/ (accessed on 30 March 2023).
- Agenzia delle Entrate—Osservatorio del Mercato Immobiliare. Available online: https://www.pd.camcom.it/gestisci-impresa/studi-informazione-economica/quotazioni-immobili-1 (accessed on 30 March 2023).
- Sirmans, G.S.; Macpherson, A.D.; Zietz, N.E. The Composition of Hedonic Pricing Models. J. Real Estate Lit. 2005, 13, 3–43. [Google Scholar] [CrossRef]
- Mora-Garcia, R.T.; Cespedes-Lopez, M.F.; Perez-Sanchez, V.R.; Marti, P.; Perez-Sanchez, J.C. Determinants of the price of housing in the province of Alicante (Spain): Analysis using quantile regression. Sustainability 2019, 11, 437. [Google Scholar] [CrossRef]
- Wolf, L.; Murray, A. Spatial Analysis. In International Encyclopedia of Geography. People, the Earth, Environment and Technology; Wiley: New York, NY, USA, 2016. [Google Scholar]
- Brueckner, J.K.; Thisse, J.F.; Zenou, Y. Why is central Paris rich and downtown Detroit poor? An amenity-based theory. Eur. Econ. Rev. 1999, 43, 91–107. [Google Scholar] [CrossRef]
- Dubé, J.; Thériault, M.; Des Rosiers, F. Commuter rail accessibility and house values: The case of the Montreal South Shore, Canada, 1992–2009. Transp. Res. Part A Policy Pract. 2013, 54, 49–66. [Google Scholar] [CrossRef]
- Lin, J.J.; Hwang, C.H. Analysis of property prices before and after the opening of the Taipei subway system. Ann. Reg. Sci. 2004, 38, 687–704. [Google Scholar] [CrossRef]
- Zhang, B.; Li, W.; Lownes, N.; Zhang, C. Estimating the impacts of proximity to public transportation on residential property values: An empirical analysis for hartford and stamford areas, connecticut. ISPRS Int. J. Geo-Inf. 2021, 10, 44. [Google Scholar] [CrossRef]
- Lin, C.W.; Wang, J.C.; Zhong, B.Y.; Jiang, J.A.; Wu, Y.F.; Leu, S.W.; Nee, T.E. Lie symmetry analysis of the effects of urban infrastructures on residential property values. PLoS ONE 2021, 16, e0255233. [Google Scholar] [CrossRef]
- Filippova, O.; Sheng, M. Impact of bus rapid transit on residential property prices in Auckland, New Zealand. J. Transp. Geogr. 2020, 86, 102780. [Google Scholar] [CrossRef]
- Ryan, S. Property values and transportation facilities: Finding the transportation-land use connection. J. Plan. Lit. 1999, 13, 412–427. [Google Scholar] [CrossRef]
- Zhang, D.; Jiao, J. How does urban rail transit influence residential property values? Evidence from an emerging Chinese megacity. Sustainability 2019, 11, 534. [Google Scholar] [CrossRef]
- Cavallaro, F.; Bruzzone, F.; Nocera, S. Spatial and social equity implications for High-Speed Railway lines in Northern Italy. Transp. Res. Part A Policy Pract. 2020, 135, 327–340. [Google Scholar] [CrossRef]
- Beenstock, M.; Feldman, D.; Felsenstein, D. Hedonic pricing when housing is endogenous: The value of access to the trans-Israel highway. J. Reg. Sci. 2016, 56, 134–155. [Google Scholar] [CrossRef]
- Cordera, R.; Coppola, P.; dell’Olio, L.; Ibeas, Á. The impact of accessibility by public transport on real estate values: A comparison between the cities of Rome and Santander. Transp. Res. Part A Policy Pract. 2019, 125, 308–319. [Google Scholar] [CrossRef]
- Pan, H.; Zhang, M. Rail transit impacts on land use: Evidence from Shanghai, China. Transp. Res. Rec. 2008, 2048, 16–25. [Google Scholar] [CrossRef]
- Boshoff, D.G.B. The influence of rapid rail systems on office values: A case study on South Africa. Pac. Rim Prop. Res. J. 2017, 23, 267–302. [Google Scholar] [CrossRef]
- Zhong, H.; Li, W. Rail transit investment and property values: An old tale retold. Transp. Policy 2016, 51, 33–48. [Google Scholar] [CrossRef]
- Ibeas, Á.; Cordera, R.; Dell’Olio, L.; Coppola, P.; Dominguez, A. Modelling transport and real-estate values interactions in urban systems. J. Transp. Geogr. 2012, 24, 370–382. [Google Scholar] [CrossRef]
- Bohman, H.; Nilsson, D. The impact of regional commuter trains on property values: Price segments and income. J. Transp. Geogr. 2016, 56, 102–109. [Google Scholar] [CrossRef]
- Bollinger, C.R.; Ihlanfeldt, K.R.; Bowes, D.R. Spatial Variation in Office Rents within the Atlanta Region. Urban Stud. 1998, 35, 1097–1118. [Google Scholar] [CrossRef]
- Landis, J. BART Access and Office Building Performance; University of California: Berkeley, CA, USA, 1995. [Google Scholar]
- Zhou, Z.; Chen, H.; Han, L.; Zhang, A. The Effect of a Subway on House Prices: Evidence from Shanghai. Real Estate Econ. 2021, 49, 199–234. [Google Scholar] [CrossRef]
- Weinstein, B.L.; Clower, T.L. An Assessment of the DART LRT on Taxable Property Valuations and Transit Oriented Development; University of North Texas: Denton, TX, USA, 2002. [Google Scholar]
- Li, S.; Chen, L.; Zhao, P. The impact of metro services on housing prices: A case study from Beijing. Transportation 2017, 46, 1291–1317. [Google Scholar] [CrossRef]
- Dai, X.; Bai, X.; Xu, M. The influence of Beijing rail transfer stations on surrounding housing prices. Habitat Int. 2016, 55, 79–88. [Google Scholar] [CrossRef]
- Shen, Q.; Xu, S.; Lin, J. Effects of bus transit-oriented development (BTOD) on single-family property value in Seattle metropolitan area. Urban Stud. 2018, 55, 2960–2979. [Google Scholar] [CrossRef]
- Lieske, S.N.; van den Nouwelant, R.; Han, J.H.; Pettit, C. A novel hedonic price modelling approach for estimating the impact of transportation infrastructure on property prices. Urban Stud. 2021, 58, 182–202. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, T.; Mao, C. Does the difference in urban public facility allocation cause spatial inequality in housing prices? Evidence from Chongqing, China. Sustainability 2019, 11, 6096. [Google Scholar] [CrossRef]
- Tatwani, S.; Kumar, E. Parametric comparison of various feature selection techniques. J. Adv. Res. Dyn. Control Syst. 2019, 11, 1180–1190. [Google Scholar] [CrossRef]
- Ghosh, M.; Guha, R.; Sarkar, R.; Abraham, A. A wrapper-filter feature selection technique based on ant colony optimization. Neural Comput. Appl. 2020, 32, 7839–7857. [Google Scholar] [CrossRef]
- Suresh, S.M.S.; Narayanan, A. Improving Classification Accuracy Using Combined Filter+Wrapper Feature Selection Technique. In Proceedings of the 2019 3rd IEEE International Conference on Electrical, Computer and Communication Technologies, ICECCT 2019, Tamil Nadu, India, 20–22 February 2019; Department of Computer Science and Engineering, Amrita School of Engineering, Amrita Vishwa Vidyapeetham: Amritapuri, India, 2019. [Google Scholar]
- Yassi, M.; Moattar, M.H. Robust and stable feature selection by integrating ranking methods and wrapper technique in genetic data classification. Biochem. Biophys. Res. Commun. 2014, 446, 850–856. [Google Scholar] [CrossRef] [PubMed]
- Siham, A.; Sara, S.; Abdellah, A. Feature selection based on machine learning for credit scoring: An evaluation of filter and embedded methods. In Proceedings of the 2021 International Conference on INnovations in Intelligent SysTems and Applications, INISTA 2021—Proceedings, Kocaeli, Turkey, 17 May 2021; Hassan II University of Casablanca, Networks, Telecoms and Multimedia LIM@II-FSTM: Mohammedia, Morocco, 2021. [Google Scholar]
- Ugolini, M. Metodologie di Apprendimento Automatico Applicate Alla Generazione di Dati 3D; University of Bologna: Bologna, Italy, 2014; pp. 1–49. [Google Scholar]
- Green, S.B. How Many Subjects Does It Take To Do A Regression Analysis. Multivariate Behav. Res. 1991, 26, 499–510. [Google Scholar] [CrossRef] [PubMed]
- Anselin, L. Spatial Econometric. Methods and Models; Springer: New York, NY, USA, 1988. [Google Scholar]
- Getis, A. Reflections on Spatial Autocorrelation. Reg. Sci. Urban Econ. 2007, 37, 491–496. [Google Scholar] [CrossRef]
- Diggle, P.J. On Parameter Estimation and Goodness-of-Fit Testing for Spatial Point Patterns. Biometrics 1979, 35, 87–101. [Google Scholar] [CrossRef]
- Tajani, F.; Morano, P.; Di Liddo, F.; Guarini, M.R.; Ranieri, R. The Effects of COVID-19 Pandemic on the Housing Market: A Case Study in Rome (Italy). Lect. Notes Comput. Sci. 2021, 12954, 50–62. [Google Scholar]
- Superbonus 110%. Available online: https://www.governo.it/superbonus (accessed on 17 December 2021).
- Sheppard, S.C.; Oehler, K.; Benjamin, B.; Kessler, A. Culture and Revitalization: The Economic Effects of MASS MoCA on Its Community; Williams College: Williamstown, MA, USA, 2006. [Google Scholar]
- Moro, M.; Mayor, K.; Lyons, S. Does the housing market reflect cultural heritage? A case study of Greater Dublin. Environ. Plan. A 2013, 45, 2884–2903. [Google Scholar] [CrossRef]
- Ahlfeldt, G.M.; Maennig, W. Substitutability and complementarity of urban amenities: External effects of built heritage in Berlin. Real Estate Econ. 2010, 38, 285–323. [Google Scholar] [CrossRef]
- Moreno Gil, S.; Ritchie, J.R.B. Understanding the museum image formation process: A comparison of residents and tourists. J. Travel Res. 2009, 47, 480–493. [Google Scholar] [CrossRef]
- Adair, A.; McGreal, S.; Smyth, A.; Cooper, J.; Ryley, T. House prices and accessibility: The testing of relationships within the Belfast Urban Area. Hous. Stud. 2000, 15, 699–716. [Google Scholar] [CrossRef]
- Rivas, R.; Patil, D.; Hristidis, V.; Barr, J.R.; Srinivasan, N. The impact of colleges and hospitals to local real estate markets. J. Big Data 2019, 6, 7. [Google Scholar] [CrossRef]
- Tian, G.; Wei, Y.D.; Li, H. Effects of accessibility and environmental health risk on housing prices: A case of Salt Lake County, Utah. Appl. Geogr. 2017, 89, 12–21. [Google Scholar] [CrossRef]
- Waddell, P.; Shukla, V. Employment Dynamics, Spatial Restructuring, and the Business Cycle. Geogr. Anal. 1993, 25, 35–52. [Google Scholar] [CrossRef]
- Yuan, F.; Wei, Y.D.; Wu, J. Amenity effects of urban facilities on housing prices in China: Accessibility, scarcity, and urban spaces. Cities 2020, 96, 102433. [Google Scholar] [CrossRef]
- Gibbons, S.; Machin, S. Paying for Primary Schools: Admission Constraints, School Popularity or Congestion? Econ. J. 2006, 116, 77–92. [Google Scholar] [CrossRef]
- Gibbons, S.; Machin, S. Valuing English primary schools. J. Urban Econ. 2003, 53, 197–219. [Google Scholar] [CrossRef]
- Wen, H.; Xiao, Y.; Hui, E.C.M.; Zhang, L. Education quality, accessibility, and housing price: Does spatial heterogeneity exist in education capitalization? Habitat Int. 2018, 78, 68–82. [Google Scholar] [CrossRef]
- Fack, G.; Grenet, J. When do better schools raise housing prices? Evidence from Paris public and private schools. J. Public Econ. 2010, 94, 59–77. [Google Scholar] [CrossRef]
- Owusu-Edusei, K.; Espey, M.; Lin, H. Does Close Count? School Proximity, School Quality, and Residential Property Values. J. Agric. Appl. Econ. 2007, 39, 211–221. [Google Scholar] [CrossRef]
- Feng, X.; Humphreys, B.R. The impact of professional sports facilities on housing values: Evidence from census block group data. City Cult. Soc. 2012, 3, 189–200. [Google Scholar] [CrossRef]
- Ahlfeldt, G.M.; Kavetsos, G. Form or function? The effect of new sports stadia on property prices in London. J. R. Stat. Soc. Ser. A Stat. Soc. 2014, 177, 169–190. [Google Scholar] [CrossRef]
- Ahlfeldt, G.M.; Maennig, W. Impact of sports arenas on land values: Evidence from Berlin. Ann. Reg. Sci. 2010, 44, 205–227. [Google Scholar] [CrossRef]
- Tu, C.C. How Does a New Sports Stadium Affect Housing Values? The Case of FedEx Field. Land Econ. 2005, 81, 379–395. [Google Scholar] [CrossRef]
- Nicholls, S.; Crompton, J.L. The impact of greenways on property values: Evidence from Austin, Texas. J. Leis. Res. 2005, 37, 321–341. [Google Scholar] [CrossRef]
- Smith, D. Valuing Housing and Green Spaces: Understanding Local Amenities, the Built Environment and House Prices in London; University College London: London, UK, 2010; ISBN 9781847813909. [Google Scholar]
- Van Fossen, W. The Effect of Supermarket Entrance on Nearby Residential Property Values in the United States from 1997 to 2015; Yale University: New Haven, CT, USA, 2017. [Google Scholar]
- Kole, K. Grocery Stores Raise Property Values: Evidence from FRESH; University of California: Irvine, CA, USA, 2021; pp. 1–27. [Google Scholar]
- Neill, P.O. Homes Close to a Supermarket Can Boost House Prices by More than £21,000; mpamag: Washington, DC, USA, 2018. [Google Scholar]
- Bomberg, M. The Value of Food: The impact of supermarket proximity on home values in Oakland. Policy Matters J. 2012, 5–12. [Google Scholar]
- Yang, L.; Wang, B.; Zhou, J.; Wang, X. Walking accessibility and property prices. Transp. Res. Part D Transp. Environ. 2018, 62, 551–562. [Google Scholar] [CrossRef]
- Tiemann, L. The Effect of Grocery Store Openings on Residential Property Prices: Evidence from Morrisons Stores in England; University of Groningen: Groningen, The Netherlands, 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transaction Prices in PADOVA (€/sqm) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Semester, Year | Maintenance Conditions | Prestigious Areas | Centre | Semi-Centre | Suburbs | ||||
| Min | Max | Min | Max | Min | Max | Min | Max | ||
| I 2022 | New constructions | 3532 | 4290 | 2964 | 3659 | 1910 | 2254 | 1214 | 1547 |
| Good maintenance conditions | 2655 | 3221 | 2119 | 2579 | 1322 | 1739 | 945 | 1212 | |
| Poor maintenance conditions | 1632 | 2160 | 1462 | 1790 | 858 | 1180 | 623 | 851 | |
| I 2021 | New constructions | 3482 | 4209 | 2793 | 3518 | 1846 | 2159 | 1192 | 1496 |
| Good maintenance conditions | 2583 | 3038 | 2041 | 2496 | 1273 | 1685 | 925 | 1197 | |
| Poor maintenance conditions | 1573 | 2062 | 1442 | 1707 | 835 | 1140 | 608 | 824 | |
| I 2020 | New constructions | 3520 | 4323 | 2761 | 3440 | 1857 | 2168 | 1201 | 1507 |
| Good maintenance conditions | 2612 | 3170 | 2075 | 2524 | 1285 | 1664 | 901 | 1183 | |
| Poor maintenance conditions | 1571 | 2155 | 1440 | 1718 | 847 | 1154 | 603 | 835 | |
| I 2019 | New constructions | 3451 | 4226 | 2745 | 3485 | 1848 | 2175 | 1212 | 1542 |
| Good maintenance conditions | 2571 | 3108 | 2042 | 2583 | 1307 | 1672 | 919 | 1194 | |
| Poor maintenance conditions | 1577 | 2142 | 1483 | 1788 | 855 | 1147 | 618 | 841 | |
| INTRINSIC FEATURES: Construction Characteristics | ||
|---|---|---|
| Building construction characteristics | Terrace Area | Energy Class |
| Floor area | Top Floor | Construction year |
| no. of bathrooms | Fireplace | Typology of the building |
| no. of rooms | Maintenance level | Apartment |
| Floor | Building installations | Apartment in a Villa |
| no. of internal floors | Building Automation | Penthouse |
| Common garden | Central Heating | Farmhouse |
| Private Garden | Photovoltaic System | Loft |
| Private Garden Area | Mechanical Ventilation | Attic |
| Private Garage | Air Conditioning | Multi-storey single-family home |
| Private Garage Area | Optical Fiber | Single-family home |
| Common Parking Space | Lift | Terraced house |
| Basement | Solar Panels | Two-family villa |
| Basement area | Heat Pump | Multi-family villa |
| Terrace | ||
| EXTRINSIC FEATURES: Neighbourhood and Accessibility | ||||
|---|---|---|---|---|
| Point of Interest (POI) | Point of Interest (POI) | |||
| market segment | City Centre | commercial facilities | Shopping malls | |
| central train station | Big commercial areas | |||
| accessibility to trsnsports | minor train stops | Small-supermarkets | ||
| Bus stop | natural amenities | Urban Parks | ||
| Tram stop | Public gardens | |||
| education facilities | nursery | modern amenities | Sport facilities | |
| kindergarten | Hospitals | |||
| primary school | Pharmacies | |||
| INTRINSIC FEATURES: Construction Characteristics | |||||
|---|---|---|---|---|---|
| Variable | Unit | Variable | Unit | Variable | Unit |
| Floor area | sqm | Terrace Area | sqm | Energy Class | 10 ->1 (A4 -> G) |
| no. of bathrooms | number | Top Floor | 0/1 | Construction year | Year (number) |
| no. of rooms | number | Building Automation | 0/1 | Apartment | 0/1 |
| Floor | number | Central Heating | 0/1 | Apartment in a Villa | 0/1 |
| no. of internal floors | number | Photovoltaic System | 0/1 | Penthouse | 0/1 |
| Common garden | 0/1 | Mechanical Ventilation | 0/1 | Farmhouse | 0/1 |
| Private Garden | 0/1 | Air Conditioning | 0/1 | Loft | 0/1 |
| Private Garden Area | sqm | Optical Fiber | 0/1 | Attic | 0/1 |
| Private Garage | 0/1 | Lift | 0/1 | Multi-storey single-family home | 0/1 |
| Private Garage Area | sqm | Solar Panels | 0/1 | Single-family home | 0/1 |
| Common Parking Space | 0/1 | Heat Pump | 0/1 | Terraced house | 0/1 |
| Basement | 0/1 | Fireplace | 0/1 | Two-family villa | 0/1 |
| Basement area | sqm | Maintenance level | 1/2/3/4 | Multi-family villa | 0/2 |
| Terrace | 0/1 | ||||
| EXTRINSIC FEATURES: Localization and Accessibility | ||
|---|---|---|
| Variable | Unit | |
| position | Latitude of the building (observation) | coordinate |
| Longitude of the building (observation) | coordinate | |
| distance | Straight line distance from POI | Km |
| Actual travel distance from POI by car | Km | |
| time | Travel time from POI by car | min |
| Travel time from POI on foot | min | |
| Travel time from POI by public transports | min | |
| proximity | N. of POI in the Ped shed (400 m) | n. |
| N. of POI in a 1 Km ring buffer | n. | |
| INTRINSIC FEATURES: Construction Characteristics | |||||
|---|---|---|---|---|---|
| Variable | Unit | Variable | Unit | Variable | Unit |
| Building construction characteristics | Maintenance level | 1/2/3/4 | Typology of the building | ||
| Floor area | sqm | Energy Class | 10 ->1 (A4 -> G) | Apartment | 0/1 |
| no. of bathrooms | number | Construction year | Year (number) | Apartment in a Villa | 0/1 |
| no. of rooms | number | Building Installations | Penthouse | 0/1 | |
| Floor | number | Building Automation | 0/1 | Farmhouse | 0/1 |
| no. of internal floors | number | Central Heating | 0/1 | Loft | 0/1 |
| Common garden | 0/1 | Photovoltaic System | 0/1 | Attic | 0/1 |
| Private Garden | 0/1 | Mechanical Ventilation | 0/1 | Multi-storey single-family home | 0/1 |
| Private Garage | 0/1 | Air Conditioning | 0/1 | Single-family home | 0/1 |
| Common Parking Space | 0/1 | Optical Fiber | 0/1 | Terraced house | 0/1 |
| Basement | 0/1 | Lift | 0/1 | Two-family villa | 0/1 |
| Terrace | 0/1 | Solar Panels | 0/1 | Multi-family villa | 0/1 |
| Top Floor | 0/1 | Heat Pump | 0/1 | ||
| Class Element or Function | RF Coefficients | ||
|---|---|---|---|
| Intrinsic | 2019 | 2021 | 2022 |
| Typology of the building | 1.24% | 0.94% | 0.80% |
| Building construction characteristics | 31.49% | 38.23% | 74.67% |
| Building installations | 2.13% | 1.53% | 0.42% |
| Extrinsic | 2019 | 2021 | 2022 |
| City centre proximity | 35.70% | 12.88% | 4.81% |
| Transports accessibility | 3.36% | 3.60% | 1.80% |
| Health services proximity | 4.72% | 4.40% | 2.98% |
| Urban amenities and leisure | 11.95% | 28.19% | 8.73% |
| Commercial areas | 3.46% | 4.61% | 2.71% |
| Education facilities proximity | 5.95% | 5.61% | 3.07% |
| 100.00% | 100.00% | 100.00% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gabrielli, L.; Ruggeri, A.G.; Scarpa, M. “Location, Location, Location”: Fluctuations in Real Estate Market Values after COVID-19 and the War in Ukraine Based on Econometric and Spatial Analysis, Random Forest, and Multivariate Regression. Land 2023, 12, 1248. https://doi.org/10.3390/land12061248
Gabrielli L, Ruggeri AG, Scarpa M. “Location, Location, Location”: Fluctuations in Real Estate Market Values after COVID-19 and the War in Ukraine Based on Econometric and Spatial Analysis, Random Forest, and Multivariate Regression. Land. 2023; 12(6):1248. https://doi.org/10.3390/land12061248
Chicago/Turabian StyleGabrielli, Laura, Aurora Greta Ruggeri, and Massimiliano Scarpa. 2023. "“Location, Location, Location”: Fluctuations in Real Estate Market Values after COVID-19 and the War in Ukraine Based on Econometric and Spatial Analysis, Random Forest, and Multivariate Regression" Land 12, no. 6: 1248. https://doi.org/10.3390/land12061248
APA StyleGabrielli, L., Ruggeri, A. G., & Scarpa, M. (2023). “Location, Location, Location”: Fluctuations in Real Estate Market Values after COVID-19 and the War in Ukraine Based on Econometric and Spatial Analysis, Random Forest, and Multivariate Regression. Land, 12(6), 1248. https://doi.org/10.3390/land12061248