
Reconstruction of Urban Rainfall Measurements to Estimate the Spatiotemporal Variability of Extreme Rainfall


Abstract
1. Introduction
- To reconstruct the sub-daily rainfall time series for an urban rain-gauge network using a machine learning algorithm.
- To investigate the spatiotemporal changes in extreme rainfall for Bangalore, India, with an additional focus on the intracity variations.
2. Data and Study Area
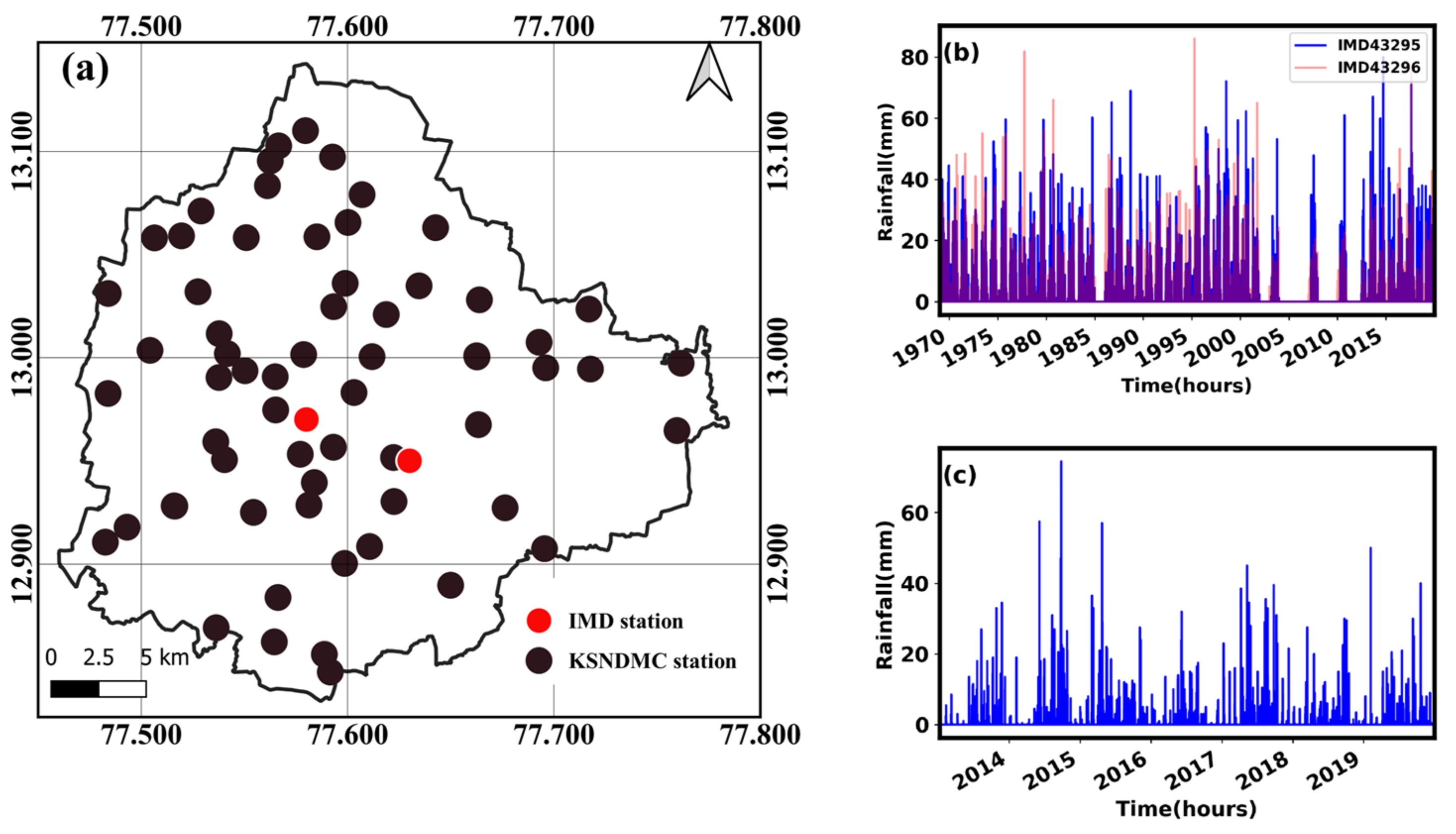
2.1. IMD and KSNDMC Station Data
2.2. Study Area: Bangalore
3. Methodology
3.1. Rainfall Reconstruction Using Random Forest Regression
3.2. Spatiotemporal Analysis of the Reconstructed Rainfall
3.3. Computation of ARF
4. Results
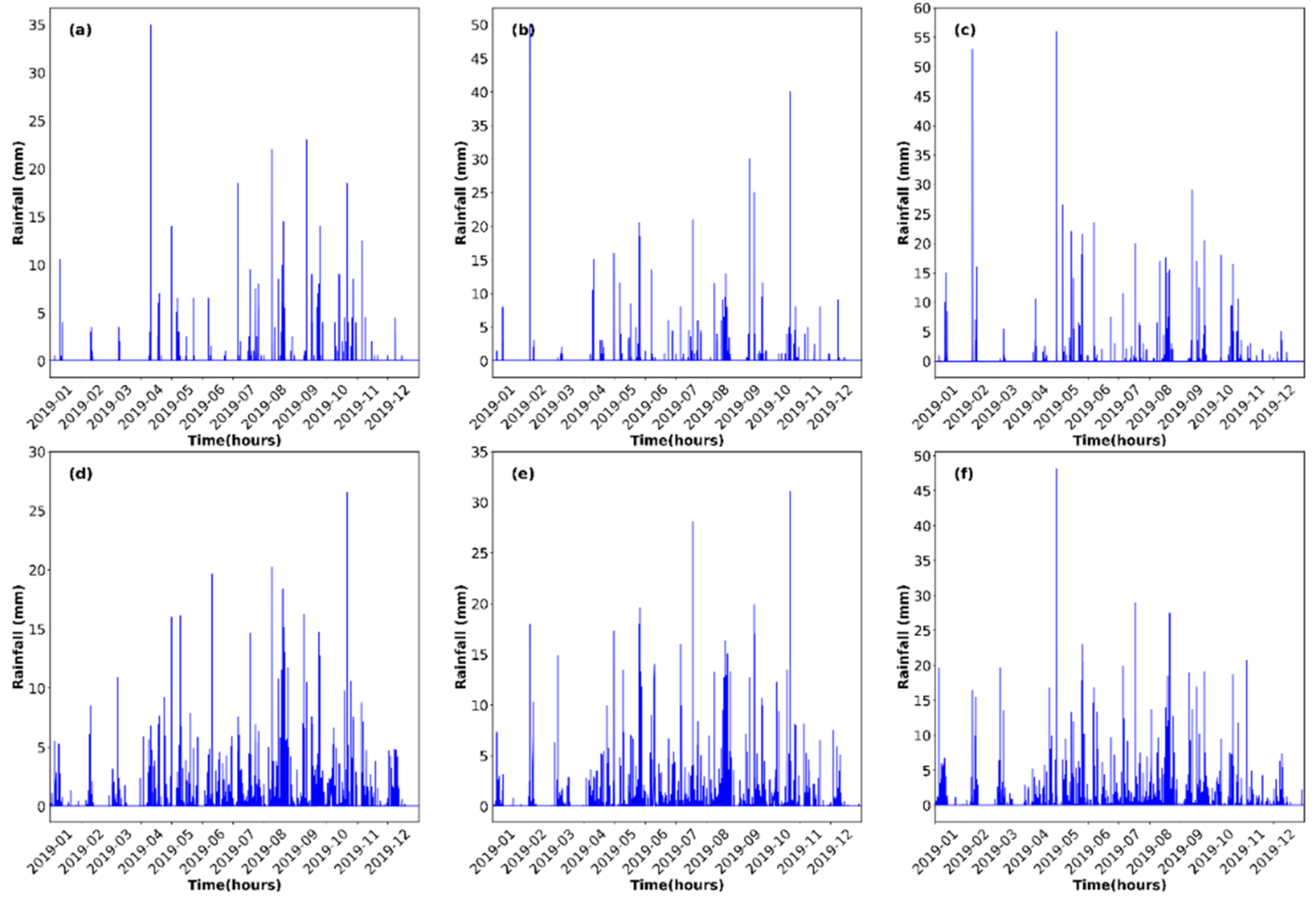
4.1. Reconstruction of Historic Rainfall
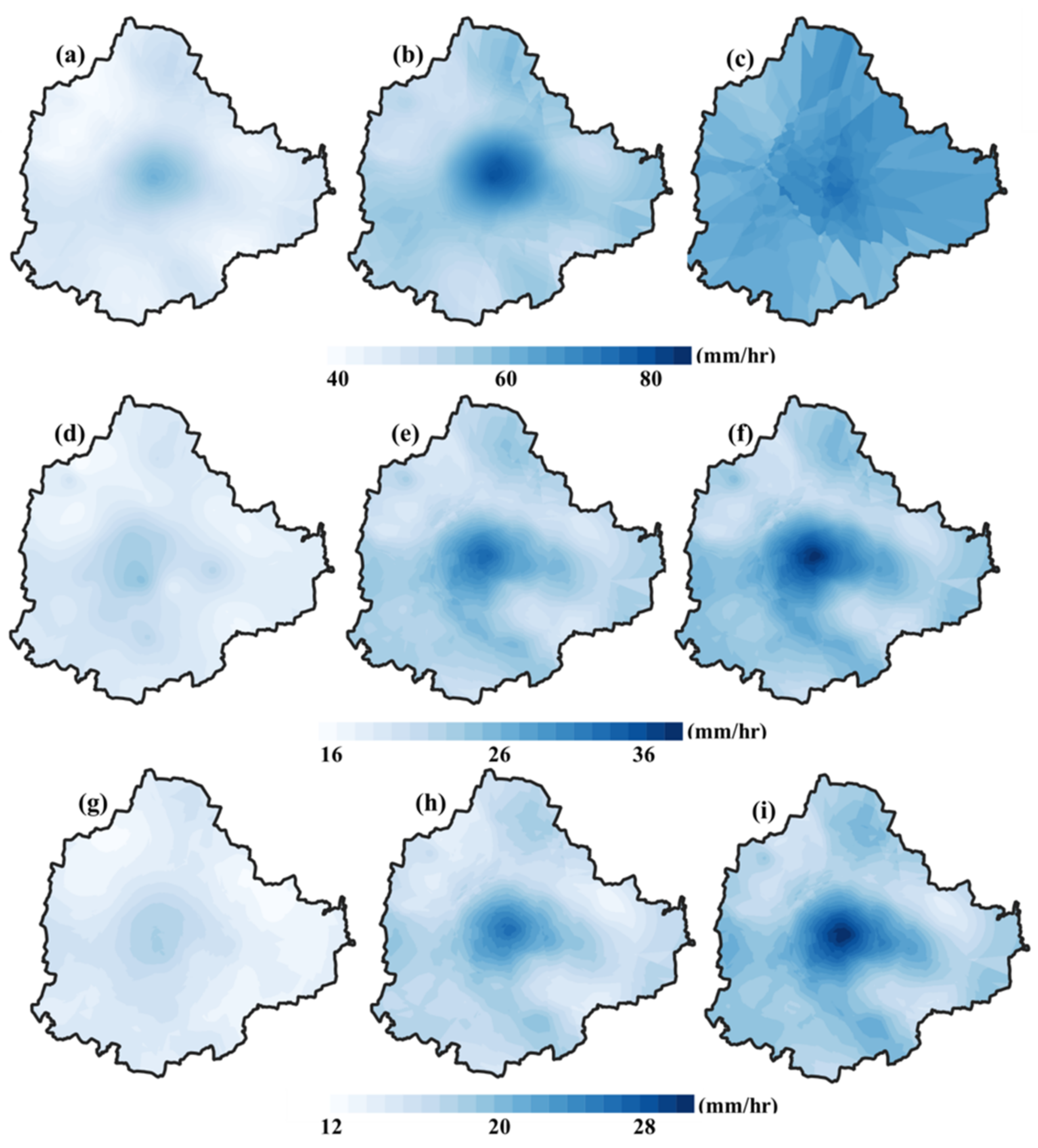
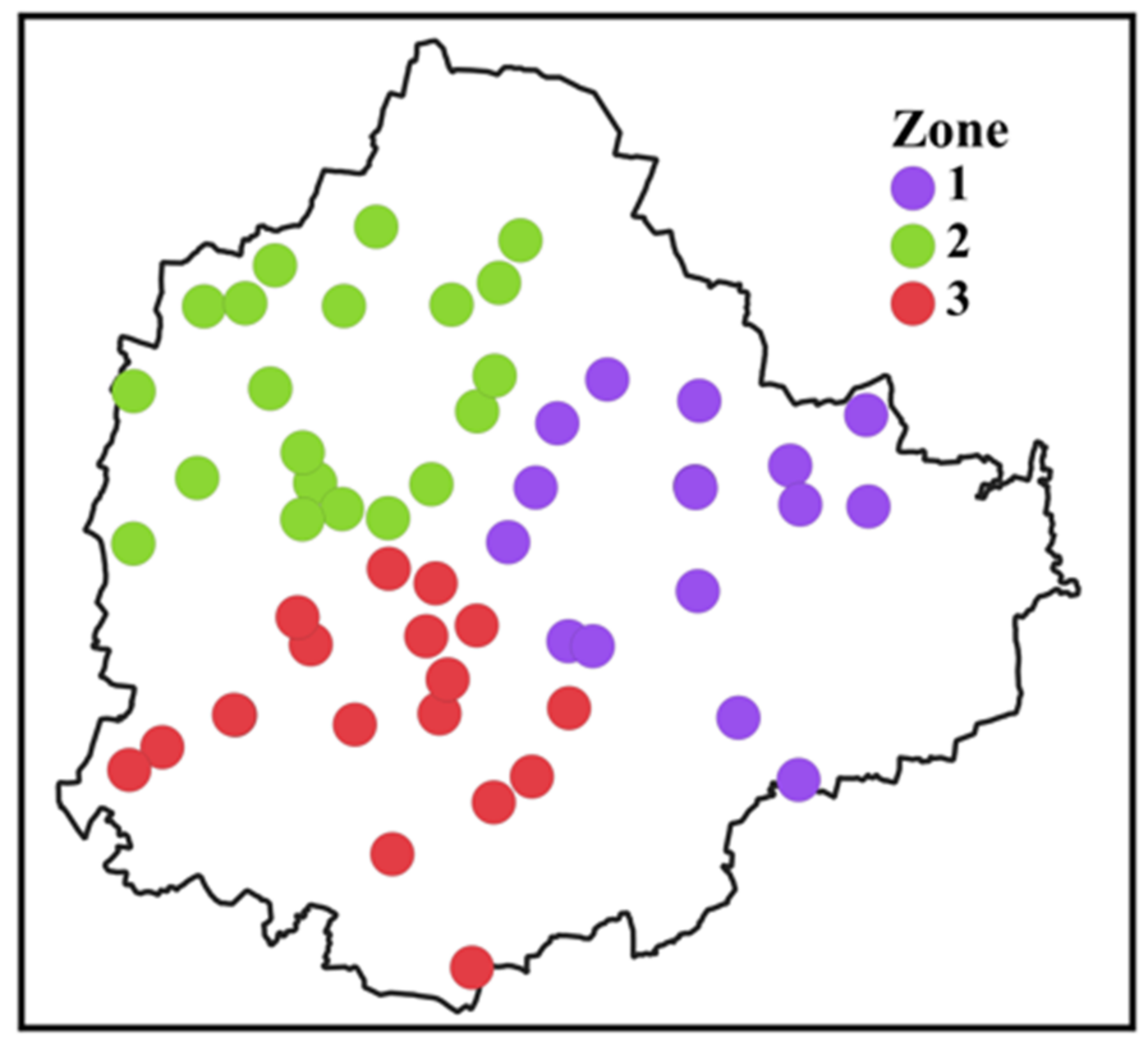
4.2. Spatiotemporal Analysis of the Extremes
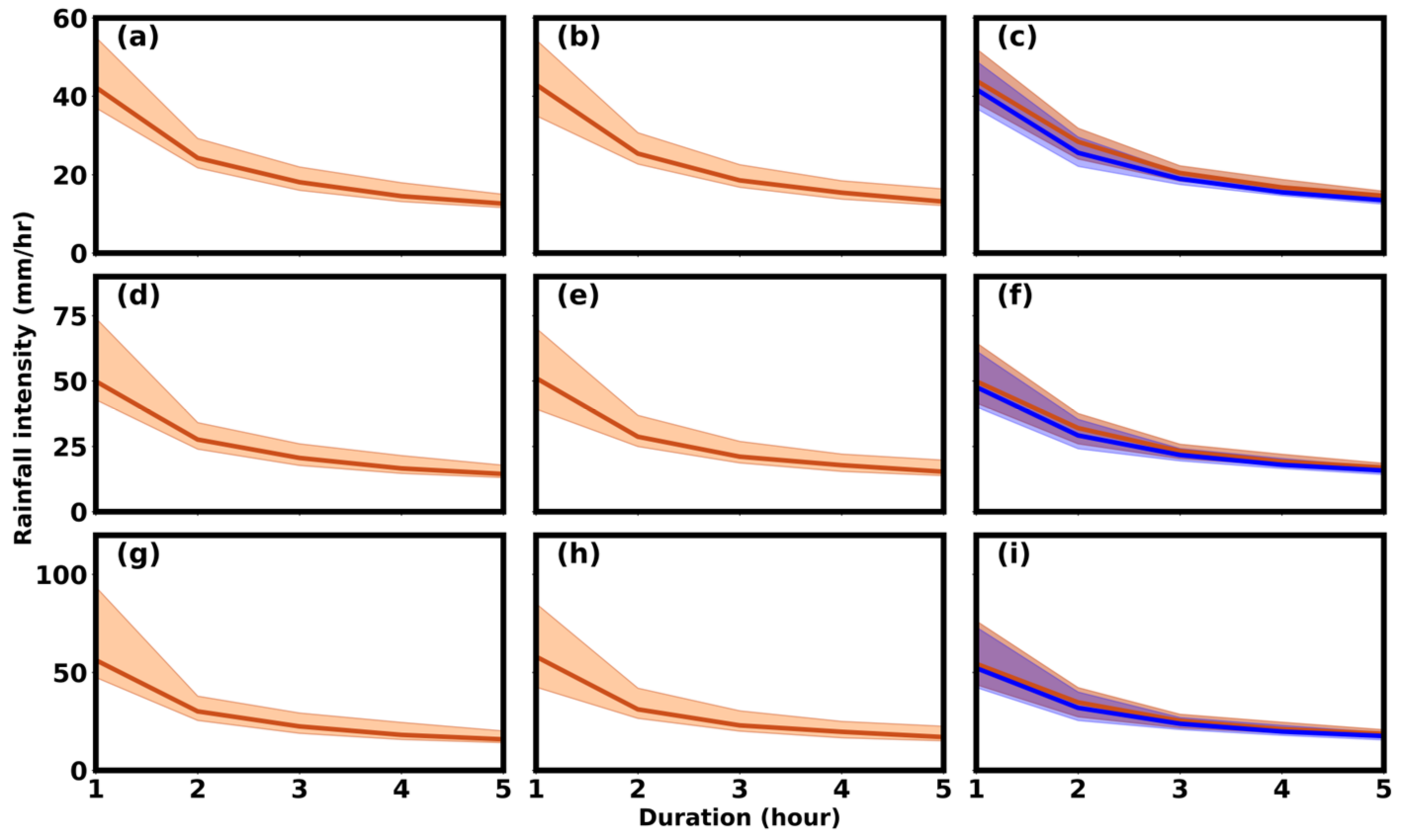
4.3. Areal Reduction Factor
5. Summary and Discussion
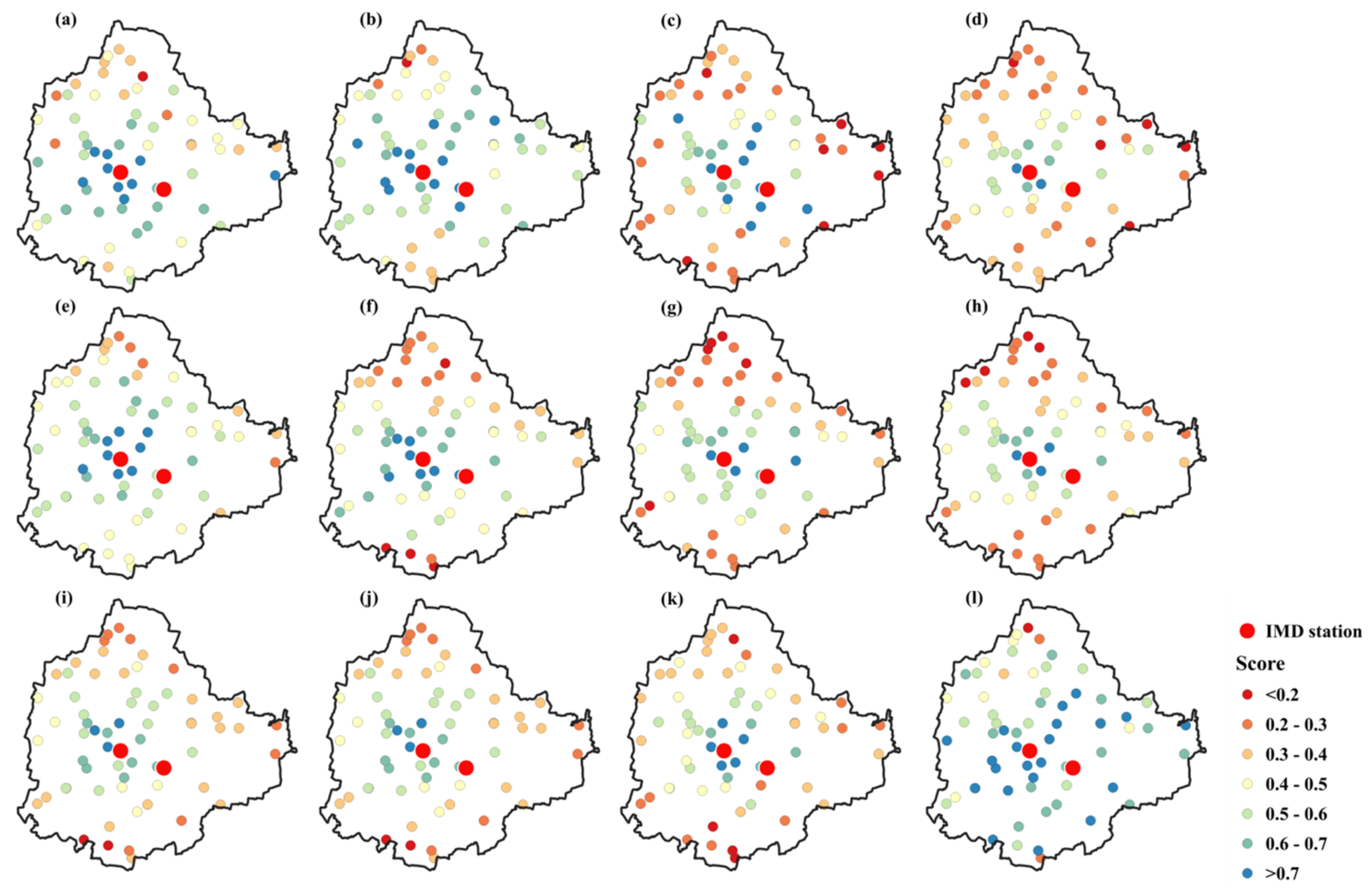
- A random forest model can efficiently reconstruct hourly rainfall time series. KSNDMC stations located near IMD stations showed higher coefficient of determination values as compared to those located farther from the IMD stations.
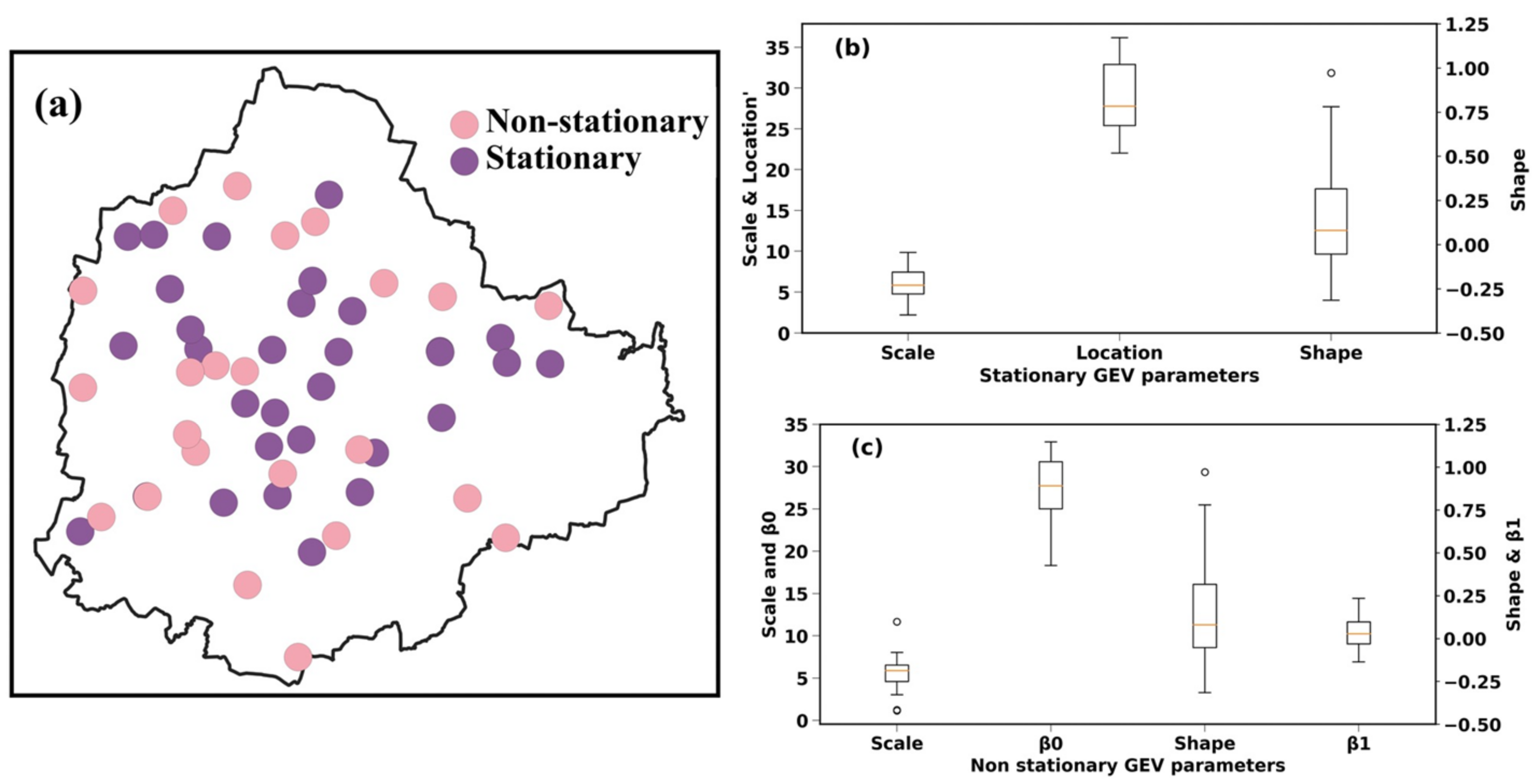
- Almost half of the KSNDMC stations exhibited non-stationarity in their AMR series, indicating that a stationary GEV model would not be sufficient to model the AMR at these stations. Additionally, non-stationarity in AMR series also implies that the IDF relationships for these stations are a function of time. We found that a non-stationary extreme value distribution with a trend component in the location parameter can efficiently model the AMR data.
- Substantial spatiotemporal variations exist in the IDF relationships over the KSNDMC stations and for the three city-regions. Rainfall intensity is highest at the center of Bangalore for any rainfall duration and frequency, indicating the impact of severe urbanization on the spatiotemporal characteristics of extreme rainfall. The results confirm that the IDF relationships for non-stationary grid points have been changing over the years.
- The ARFs for different durations are close to 0.8 until the circular area is less than 450 km2. As the area increases beyond that, the ARF decreases to 0.4. The ARF results indicate that the areal average rainfall estimated from point rainfall estimates decreases as the area increases if a rain-gauge network is considered. An ARF value between 0.4 and 0.8 indicates an overestimation in design floods if the areal average rainfall is considered directly in design flood calculation without applying the ARF.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. The Random Forest Regression Algorithm
Appendix B. Augmented Dickey–Fuller Test
Appendix C. K-Means Clustering
Appendix D. Areal Reduction Factor
- k = number of stations in the area.
- n = number of years.
- = annual maximum point rainfall for year j at station i = max (,…).
- d = number of specific durations in the year.
- = specific duration of point precipitation at station i in year j on day u.
- = annual maximum areal rainfall for year j = max (,…)
- = specific duration of areal precipitation at specific time u for year j.
References
- Douglas, I.; Alam, K.; Maghenda, M.; Mcdonnell, Y.; McLean, L.; Campbell, J. Unjust Waters: Climate Change, Flooding and the Urban Poor in Africa. Environ. Urban. 2008, 20, 187–205. [Google Scholar] [CrossRef]
- Hettiarachchi, S.; Wasko, C.; Sharma, A. Increase in flood risk resulting from climate change in a developed urban watershed–the role of storm temporal patterns. Hydrol. Earth Syst. Sci. 2018, 22, 2041–2056. [Google Scholar] [CrossRef]
- Huang, J.; Fatichi, S.; Mascaro, G.; Manoli, G.; Peleg, N. Intensification of Sub-Daily Rainfall Extremes in a Low-Rise Urban Area. Urban Clim. 2022, 42, 101124. [Google Scholar] [CrossRef]
- Shastri, H.; Paul, S.; Ghosh, S.; Karmakar, S. Impacts of Urbanization on Indian Summer Monsoon Rainfall Extremes. J. Geophys. Res. Atmos. 2015, 120, 496–516. [Google Scholar] [CrossRef]
- Baghel, A. Causes of Urban Floods in India: Study of Mumbai in 2006 and Chennai in 2015. In Proceedings of the International Conference on Disaster and Risk Management: AGORA 2016, Sohna, India, 11 November 2016. [Google Scholar]
- De, U.S.; Singh, G.P.; Rase, D.M. Urban Flooding in Recent Decades in Four Mega Cities of India. J. Ind. Geophys. Union 2013, 17, 153–165. [Google Scholar]
- Gupta, K. Challenges in Developing Urban Flood Resilience in India. Philos. Trans. R. Soc. A 2020, 378, 20190211. [Google Scholar] [CrossRef]
- Ekström, M.; Jones, P.D. Impact of Rainfall Estimation Uncertainty on Streamflow Estimations for Catchments Wye and Tyne in the United Kingdom. Int. J. Climatol. 2009, 29, 79–86. [Google Scholar] [CrossRef]
- Chutsagulprom, N.; Chaisee, K.; Wongsaijai, B.; Inkeaw, P.; Oonariya, C. Spatial Interpolation Methods for Estimating Monthly Rainfall Distribution in Thailand. Theor. Appl. Climatol. 2021, 148, 317–328. [Google Scholar] [CrossRef]
- Khouider, B.; Sabeerali, C.T.; Ajayamohan, R.S.; Praveen, V.; Majda, A.J.; Pai, D.S.; Rajeevan, M. A Novel Method for Interpolating Daily Station Rainfall Data Using a Stochastic Lattice Model. J. Hydrometeorol. 2020, 21, 909–933. [Google Scholar] [CrossRef]
- Te Chow, V. Applied Hydrology; Tata McGraw-Hill Education: New York, NY, USA, 2010; ISBN 007070242X. [Google Scholar]
- Salleh, N.S.A.; Aziz, M.K.B.M.; Adzhar, N. Optimal Design of a Rain Gauge Network Models. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2019; Volume 1366, p. 12072. [Google Scholar]
- Maier, R.; Krebs, G.; Pichler, M.; Muschalla, D.; Gruber, G. Spatial Rainfall Variability in Urban Environments—High-Density Precipitation Measurements on a City-Scale. Water 2020, 12, 1157. [Google Scholar] [CrossRef]
- Berne, A.; Delrieu, G.; Creutin, J.-D.; Obled, C. Temporal and Spatial Resolution of Rainfall Measurements Required for Urban Hydrology. J. Hydrol. 2004, 299, 166–179. [Google Scholar] [CrossRef]
- Zeleňáková, M.; Purcz, P.; Hlavatá, H.; Blišťan, P. Climate Change in Urban versus Rural Areas. Procedia Eng. 2015, 119, 1171–1180. [Google Scholar] [CrossRef]
- Singh, J.; Karmakar, S.; PaiMazumder, D.; Ghosh, S.; Niyogi, D. Urbanization Alters Rainfall Extremes over the Contiguous United States. Environ. Res. Lett. 2020, 15, 74033. [Google Scholar] [CrossRef]
- Liu, J.; Niyogi, D. Identification of Linkages between Urban Heat Island Magnitude and Urban Rainfall Modification by Use of Causal Discovery Algorithms. Urban Clim. 2020, 33, 100659. [Google Scholar] [CrossRef]
- Shahrban, M.; Walker, J.P.; Wang, Q.J.; Seed, A.; Steinle, P. An Evaluation of Numerical Weather Prediction Based Rainfall Forecasts. Hydrol. Sci. J. 2016, 61, 2704–2717. [Google Scholar] [CrossRef]
- Hussein, K.A.; Alsumaiti, T.S.; Ghebreyesus, D.T.; Sharif, H.O.; Abdalati, W. High-Resolution Spatiotemporal Trend Analysis of Precipitation Using Satellite-Based Products over the United Arab Emirates. Water 2021, 13, 2376. [Google Scholar] [CrossRef]
- Berner, J.; Ha, S.-Y.; Hacker, J.P.; Fournier, A.; Snyder, C. Model Uncertainty in a Mesoscale Ensemble Prediction System: Stochastic versus Multiphysics Representations. Mon. Weather Rev. 2011, 139, 1972–1995. [Google Scholar] [CrossRef]
- Clark, A.; Kain, J.; Stensrud, D.; Xue, M.; Kong, F.; Coniglio, M.; Thomas, K.; Wang, Y.; Brewster, K.; Gao, J.; et al. Probabilistic Precipitation Forecast Skill as a Function of Ensemble Size and Spatial Scale in a Convection-Allowing Ensemble. Mon. Weather Rev. 2011, 139, 1410–1418. [Google Scholar] [CrossRef]
- Lachniet, M.S.; Bernal, J.P.; Asmerom, Y.; Polyak, V.; Piperno, D. A 2400 Yr Mesoamerican Rainfall Reconstruction Links Climate and Cultural Change. Geology 2012, 40, 259–262. [Google Scholar] [CrossRef]
- Oberhuber, W.; Kofler, W. Dendroclimatological Spring Rainfall Reconstruction for an Inner Alpine Dry Valley. Theor. Appl. Climatol. 2002, 71, 97–106. [Google Scholar] [CrossRef]
- Sansanwal, K.; Shrivastava, G.; Anand, R.; Sharma, K. Big Data Analysis and Compression for Indoor Air Quality. In Handbook of IoT and Big Data; CRC Press: Boca Raton, FL, USA, 2019; pp. 1–21. ISBN 0429053290. [Google Scholar]
- Tiwari, S.; Jha, S.K.; Sivakumar, B. Reconstruction of Daily Rainfall Data Using the Concepts of Networks: Accounting for Spatial Connections in Neighborhood Selection. J. Hydrol. 2019, 579, 124185. [Google Scholar] [CrossRef]
- Rupa, C.; Mujumdar, P.P. Quantification of Uncertainty in Spatial Return Levels of Urban Precipitation Extremes. J. Hydrol. Eng. 2018, 23, 4017053. [Google Scholar] [CrossRef]
- Beck, H.E.; Zimmermann, N.E.; McVicar, T.R.; Vergopolan, N.; Berg, A.; Wood, E.F. Present and Future Köppen-Geiger Climate Classification Maps at 1-Km Resolution. Sci. Data 2018, 5, 180214. [Google Scholar] [CrossRef] [PubMed]
- Rajashekara, S. Monthly and Annual Variation of Temperature in Urban Habitats of the Bengaluru Region, India. Trans. Sci. Technol. 2020, 7, 29–34. [Google Scholar]
- Schonlau, M.; Zou, R.Y. The Random Forest Algorithm for Statistical Learning. Stata J. 2020, 20, 3–29. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model Evaluation Guidelines for Systematic Quantification of Accuracy in Watershed Simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Feitoza Silva, D.; Simonovic, S.P.; Schardong, A.; Avruch Goldenfum, J. Introducing Non-Stationarity into the Development of Intensity-Duration-Frequency Curves under a Changing Climate. Water 2021, 13, 1008. [Google Scholar] [CrossRef]
- Doni, A.F.; Negera, Y.D.P.; Maria, O.A.H. K-Means Clustering Algorithm for Determination of Clustering of Bangkalan Regional Development Potential. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1569, p. 22078. [Google Scholar]
- De Michele, C.; Kottegoda, N.T.; Rosso, R. The Derivation of Areal Reduction Factor of Storm Rainfall from Its Scaling Properties. Water Resour. Res. 2001, 37, 3247–3252. [Google Scholar] [CrossRef]
- Allen, R.J.; DeGaetano, A.T. Areal Reduction Factors for Two Eastern United States Regions with High Rain-Gauge Density. J. Hydrol. Eng. 2005, 10, 327–335. [Google Scholar] [CrossRef]
- Mohammed, A.; Regonda, S.K.; Kopparthi, N.R. Climatological Features of High Temporal Resolution Rainfall over the Hyderabad City, India. Urban Clim. 2022, 42, 101118. [Google Scholar] [CrossRef]
- Davis, S.; Pentakota, L.; Saptarishy, N.; Mujumdar, P.P. A Flood Forecasting Framework Coupling a High Resolution WRF Ensemble with an Urban Hydrologic Model. Front. Earth Sci. 2022, 10, 883842. [Google Scholar]
- My, L.; Di Bacco, M.; Scorzini, A.R. On the use of gridded data products for trend assessment and aridity classification in a Mediterranean context: The case of the Apulia Region. Water 2022, 14, 2203. [Google Scholar] [CrossRef]
- Bhowmik, R.D.; Sankarasubramanian, A. Limitations of Univariate Statistical Downscaling to Preserve Cross-Correlation between monthly precipitation and temperature. Int. J. Climatol. 2019, 39, 4479–4496. [Google Scholar] [CrossRef]
- Seo, S.; Bhowmik, R.D.; Sankarasubramanian, A.; Mahinthakumar, G.; Kumar, M. The role of cross-correlation between precipitation and temperature on basin-scale simulation of hydrologic variables. J. Hydrol. 2019, 570, 304–314. [Google Scholar] [CrossRef]
- Mehrotra, R.; Sharma, A. An improved standardization procedure to remove systematic low frequency variability biases in GCM simulations. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Bayable, G.; Amare, G.; Alemu, G.; Gashaw, T. Spatiotemporal Variability and Trends of Rainfall and Its Association with Pacific Ocean Sea Surface Temperature in West Harerge Zone, Eastern Ethiopia. Environ. Syst. Res. 2021, 10, 7. [Google Scholar] [CrossRef]
- Uvo, C.B.; Foster, K.; Olsson, J. The Spatio-Temporal Influence of Atmospheric Teleconnection Patterns on Hydrology in Sweden. J. Hydrol. Reg. Stud. 2021, 34, 100782. [Google Scholar] [CrossRef]
- Biau, G. Analysis of a Random Forests Model. J. Mach. Learn. Res. 2012, 13, 1063–1095. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SI. No. | Station Name | Index No. | Latitude | Longitude | Elevation |
|---|---|---|---|---|---|
| 1 | City | 43295 | 12.97° N | 77.58° E | 911 m |
| 2 | HAL | 43296 | 12.95° N | 77.63° E | 899 m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joseph, R.; Mujumdar, P.P.; Das Bhowmik, R. Reconstruction of Urban Rainfall Measurements to Estimate the Spatiotemporal Variability of Extreme Rainfall. Water 2022, 14, 3900. https://doi.org/10.3390/w14233900
Joseph R, Mujumdar PP, Das Bhowmik R. Reconstruction of Urban Rainfall Measurements to Estimate the Spatiotemporal Variability of Extreme Rainfall. Water. 2022; 14(23):3900. https://doi.org/10.3390/w14233900
Chicago/Turabian StyleJoseph, Risma, P. P. Mujumdar, and Rajarshi Das Bhowmik. 2022. "Reconstruction of Urban Rainfall Measurements to Estimate the Spatiotemporal Variability of Extreme Rainfall" Water 14, no. 23: 3900. https://doi.org/10.3390/w14233900
APA StyleJoseph, R., Mujumdar, P. P., & Das Bhowmik, R. (2022). Reconstruction of Urban Rainfall Measurements to Estimate the Spatiotemporal Variability of Extreme Rainfall. Water, 14(23), 3900. https://doi.org/10.3390/w14233900