2.3.1. Land Surface Temperature Retrieval
To enhance the correlation between surface temperature and air temperature, this study utilizes high-accuracy Landsat series data. Starting in January 2024, NASA will discontinue the provision of atmospheric transmittance queries and will instead provide processed data directly. Consequently, the previously commonly used single-window algorithm is no longer applicable. By consulting the guidelines from the U.S. Geological Survey regarding the processing of Landsat Level-2 scientific products, which includes specifications for the scaling factors and offsets for each band, the following algorithm can be used to scale the ST-B6 (thermal infrared) band in remote sensing images:
where
represents the surface temperature in degrees Celsius, and
denotes the band digital number.
However, due to sensor malfunctions on the Landsat 7 satellite, some remote sensing images have missing data. There are four locations where missing images overlap with study sites, so this research employs MODIS series images as supplements [
27].
First, read the remote sensing data in ENVI (version 4.2), obtaining the thermal infrared dataset’s bands 31 and 32. The radiance calibration coefficients for each band are extracted and scaled using the following formulas:
where
is the radiance of each band, and
is the displayed value of the band. Then, the reflectance dataset included in the remote sensing data is located, selecting spatial and spectral subsets near Wuhan, and performing geometric correction on the reflectance data. After the correction is completed, the split-window algorithm’s calculations are performed. The formula is as follows:
In this equation,
refers to the surface temperature, while
and
are the brightness temperatures of MODIS’s 31st and 32nd bands, respectively. The parameters
,
, and
of the split-window algorithm are defined as follows:
Intermediate parameters in these formulas are defined as follows:
where
is the atmospheric transmittance at angle ɵ, and
is the surface emissivity for band i. Additional values for atmospheric transmittance, surface emissivity, and brightness temperature are required to perform surface temperature retrieval.
The atmospheric transmittance
is a fundamental parameter for calculating surface temperature, indicating the ability of the atmosphere to transmit electromagnetic waves (such as light, infrared radiation, etc.). It represents the proportion of incident radiation energy that can pass through the atmosphere to reach the surface or a specific level, typically calculated based on atmospheric water vapor content. In this study, MODIS bands 2 and 19 are used to retrieve atmospheric moisture content, which is then used to obtain atmospheric transmittance. The atmospheric moisture content of any pixel in the MODIS image can be calculated using the following formula:
Here,
is the atmospheric moisture content (g/cm
2), while
and
are constants set at 0.02 and 0.6321, respectively.
and
are the ground reflectance values for bands 2 and 19. The simulated equations are utilized as follows:
Thus, atmospheric transmittance can be obtained.
Surface emissivity refers to the ability of surface materials to emit radiation relative to a black body (an ideal radiator) at the same temperature. Its value typically ranges between 0 and 1, where 1 signifies perfect radiation (black body) and 0 signifies no radiation. Surface emissivity depends on factors such as material, surface roughness, temperature, and wavelength, meaning it is influenced by the land-use status of the region. The study area is divided into three categories: water surface, urban areas, and natural surfaces. A mixed pixel decomposition method is utilized to calculate the emissivity for natural surfaces and urban areas based on vegetation coverage, which is calculated as follows:
First, the Normalized Difference Vegetation Index (NDVI) must be obtained. This is a widely used remote sensing metric primarily used to assess the health, density, and growth of vegetation coverage. NDVI quantifies greenness and biomass by combining data from red and near-infrared bands. NDVI values typically range from −1 to 1, with higher values indicating healthier and denser vegetation. Values between 0 and 1 represent areas with sparse or dense vegetation. Values close to 0 typically indicate no vegetation and may include bare soil, water bodies, or urbanized areas, while negative values indicate non-vegetative surface features such as water bodies, clouds, snow, or ice. The calculation is as follows:
where
is the reflectance value for the near-infrared band, and
is the reflectance value for the red band; both are obtainable from remote sensing data. After obtaining the NDVI, the vegetation coverage (
) can be calculated. This value measures the coverage rate of surface vegetation, with higher values indicating more abundant vegetation. The calculation is as follows:
where
represents the minimum NDVI within the study area, generally indicating bare land or built-up areas, and
represents the maximum NDVI within the study area, usually indicating dense vegetation. After that, surface emissivity
can be obtained. For vegetated and arable areas, the following formula applies:
For built-up areas, the formula is
For water bodies, since their radiative properties are almost equivalent to a black body, constants are directly used: ε31 = 0.996, ε32 = 0.992.
The radiance temperature must be calculated using the Planck function, which describes the spectral distribution of black-body radiation, expressing the relationship between the radiation intensity emitted by a black body at a specific temperature and wavelength. The Planck function can explain how the radiation intensity emitted by an object varies across different wavelengths; in this study, it takes the following forms:
At this point, all parameters in Formula (4) have been obtained. By substituting these parameters and handling any outliers, the surface temperature can be derived.
To account for errors arising from the mixed use of different remote sensing data, we also employ the method developed by Huanfeng Shen et al. [
28]. to calibrate remotely sensed images of varying resolutions. The principle of this method is that the error values for different-resolution images at any given location are the same. Before calibration, it is essential that all data from different sensors is re-projected and sampled onto a common spatial grid. Thus, we defined a common coordinate system (WGS1984) for both Landsat and MODIS data within ArcGIS. The equation for calibration is as follows:
where
is the temperature corresponding to the missing moment of the high-resolution satellite,
is the known temperature at another moment, and
and
are the temperatures from the medium-resolution satellite at two different times. Therefore, this research retrieves images from the Landsat 7 satellite prior to its malfunction and compares them with MODIS images from the same period to determine the discrepancies, subsequently calibrating the MODIS images during the research period to estimate the air temperature values corresponding to the missing points in the Landsat 7 images.
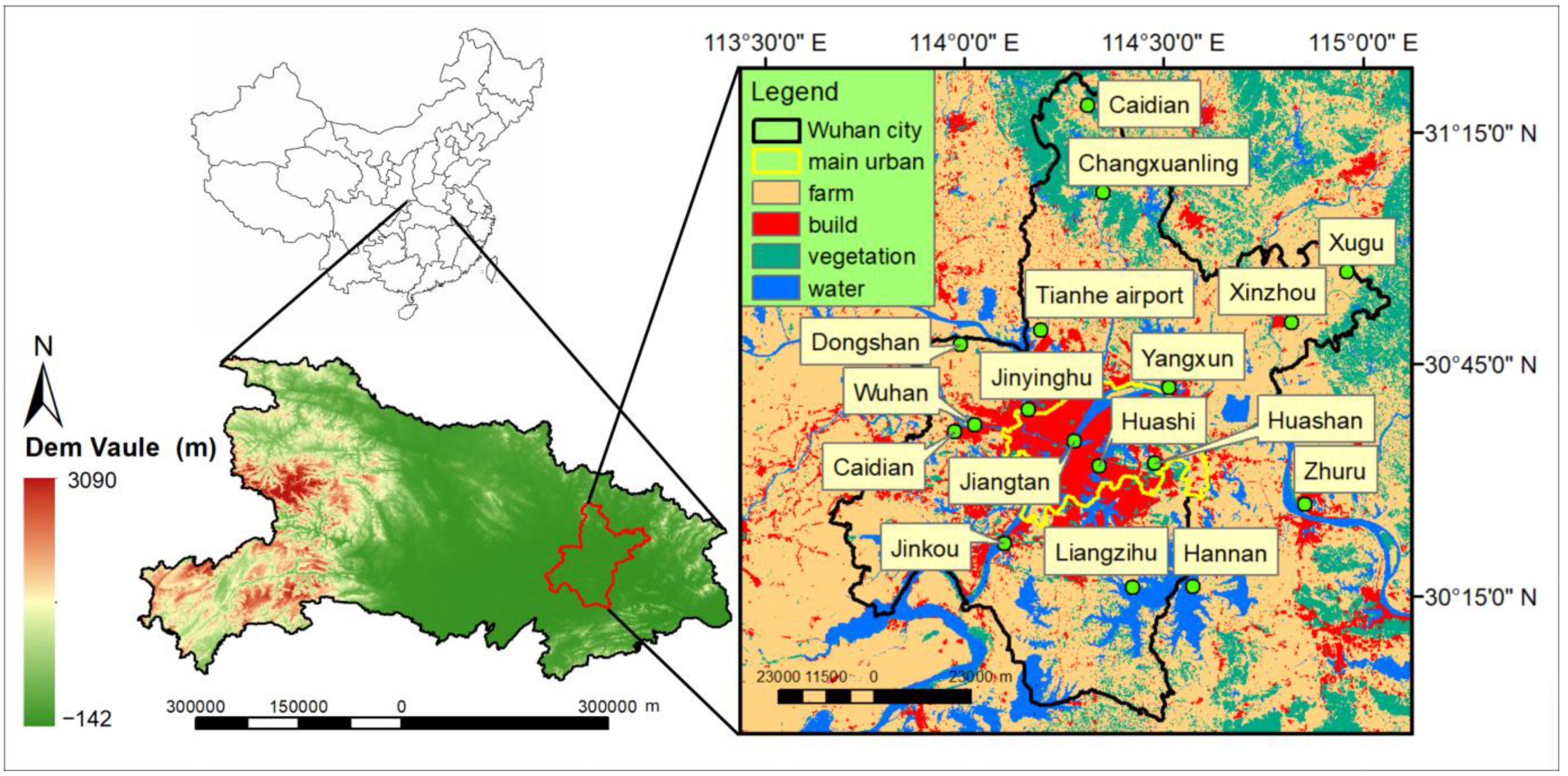
In this way, we obtained surface temperature and air temperature data for 17 sites on 13 cloudless days between 2013 and 2019. By combining this with the land-use distribution map, we matched the land use, surface temperature, and air temperature for each site, filtering out values with significant discrepancies. Ultimately, we obtained 233 data sets, with 84 sets from arable land, 77 from urban areas, 25 from vegetation, and 22 from water bodies. The land-use types and sample sizes for each site are detailed below (
Table 3).
2.3.2. Prediction Methods for Land Surface Temperature and Air Temperature
To improve model accuracy, different LST–AT relationships were established for each land-use type using various modeling approaches.
According to Agnieszka et al., the linearity of the LST–AT relationship depends on the built-up index [
11]. Polynomial and exponential fitting methods were used, with models defined as follows:
where
,
,
, and
are regression coefficients, AT is air temperature, and LST is land surface temperature. In traditional fitting, regression coefficients are determined by minimizing the sum of squared errors (SSE) between predicted and actual values using the least squares method.
- 2.
Random Forest (RF)
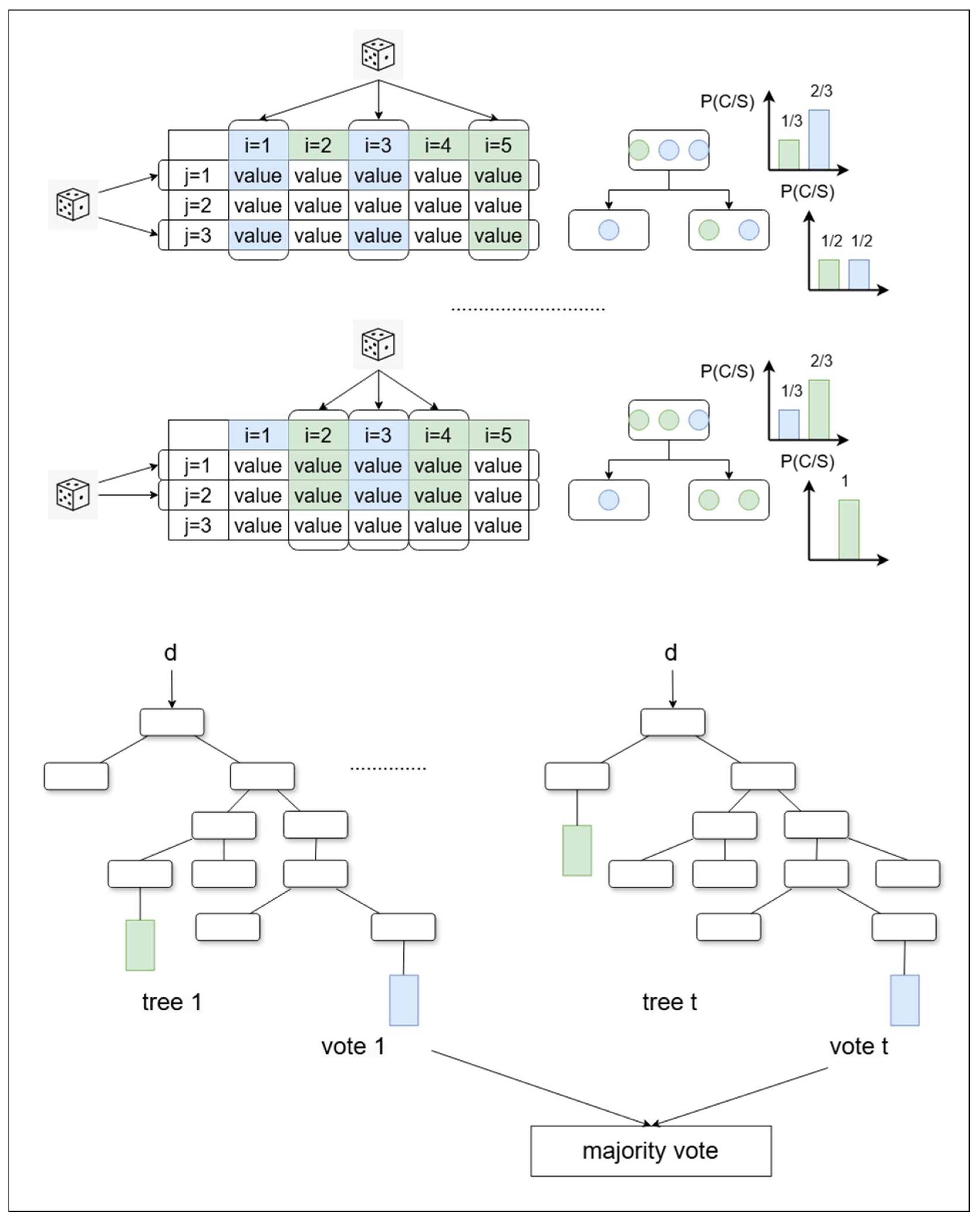
The Random Forest algorithm is an ensemble learning method primarily used for classification and regression tasks. It consists of multiple decision trees, improving model accuracy and robustness through ensemble learning. The steps of the Random Forest algorithm are as follows (
Figure 5):
Initially, the Bootstrap Sampling method is employed to randomly extract multiple subsets (sample sets) from the original training dataset. Each subset is typically the same size as the original dataset, but sampling allows for duplicates. By providing different training data for each tree, the diversity of the model is increased, thereby enhancing the overall performance of the ensemble model.
Next, when training each decision tree, a random subset of features is selected from all available features. This random feature selection makes the constructed trees less correlated, allowing for more effective use of different features’ information and reducing the risk of overfitting.
Subsequently, decision trees are built using the selected feature subsets and sample sets. The tree construction process follows classic decision tree algorithms (such as CART) by selecting the best partition features to split the dataset into two subsets. This process stops when the subsets can no longer be split, a specific depth is reached, or other stopping criteria are met.
Finally, the Random Forest model is evaluated using metrics such as cross-validation and mean absolute error. Based on the assessment results, model parameters are tuned, including the number of trees, maximum depth, and minimum sample split size, to ensure that the model possesses good generalization capability [
29].
In this study, the model type is first specified as regression. To ensure accuracy, the number of decision trees is set to 100. There are no restrictions on the maximum depth of the decision trees; by default, the trees will continue to grow until stopping conditions are satisfied (the sample count at each leaf node is less than the minimum leaf size), or all samples are completely split. The minimum leaf size is set to 3, requiring at least three samples at each node, which helps reduce model complexity and minimize overfitting risk. The feature function is left at its default setting, such that during each split, the model randomly selects the square root of the number of features for evaluation. The “Out-of-Bag” method is enabled to ascertain the importance of each feature’s contribution to the model.
- 3.
BP Neural Network
The backpropagation (BP) neural network is a feedforward neural network training algorithm that adjusts weights by backpropagating errors to minimize output errors. The steps of the BP neural network are outlined as follows (
Figure 6):
First, the network parameters are initialized, determining the number of layers and the number of neurons in each layer. A BP neural network typically consists of an input layer, one or more hidden layers, and an output layer. Each connection’s weights and each neuron’s biases are randomly initialized to small values, ensuring sufficient learning capacity for the network.
Next, forward propagation occurs, where input data is fed into the network through the input layer. Once the input layer receives the data, the input signals are passed to the first hidden layer. Each neuron in the hidden layer calculates a weighted sum and computes its output using an activation function. After processing all hidden layers, the signal reaches the output layer, where the network output is calculated.
Following this, error evaluation occurs, calculating the error between the network output and the actual target values. Common metrics, such as Mean Squared Error (MSE), are used for this calculation. The calculated error is then backpropagated to compute the gradients of the weights concerning the error. Gradient descent algorithms, including Stochastic Gradient Descent (SGD), momentum, RMSProp, and Adam, are commonly used to adjust the weights.
The updated formula is as follows:
where
is the updated weight,
is the original weight,
is the learning rate, and
is the error gradient.
After these steps are completed, forward propagation, error calculation, backpropagation, and weight updating are continuously repeated for each batch or the entire training dataset until the predefined number of training iterations (epochs), error thresholds are reached, or training is stopped based on validation set performance. Finally, independent data is used to validate the network’s generalization ability and prevent overfitting, assessing the model’s real-world application effectiveness [
30].
In this study, the data is first normalized, scaling input and output data to the range of 0 to 1. The training set and test set are then divided in a 19:1 ratio. The hidden layer is set to have four neurons, creating a feedforward neural network. The hidden layer activation function uses the hyperbolic tangent function, while the output layer uses a linear function. The maximum number of iterations is set to 1000, with a learning rate of 0.01 and an error target of 1 × 10−6. Prediction performance metrics such as Root Mean Square Error (RMSE) and Absolute Error are calculated and displayed. Finally, the output data is denormalized to return to its original scale, with standard gradient descent used as the optimization algorithm. Due to the random nature of the path taken during training in the BP neural network, the results of each training session may differ. In this study, the error for this method is taken as the average value of 10 training sessions.
Given the relatively small sample size in this study, full-batch training was utilized. Importing the dataset once facilitates smoother convergence, while a more stable gradient update path may help find better local minima in certain situations, without significantly increasing computation time.
- 4.
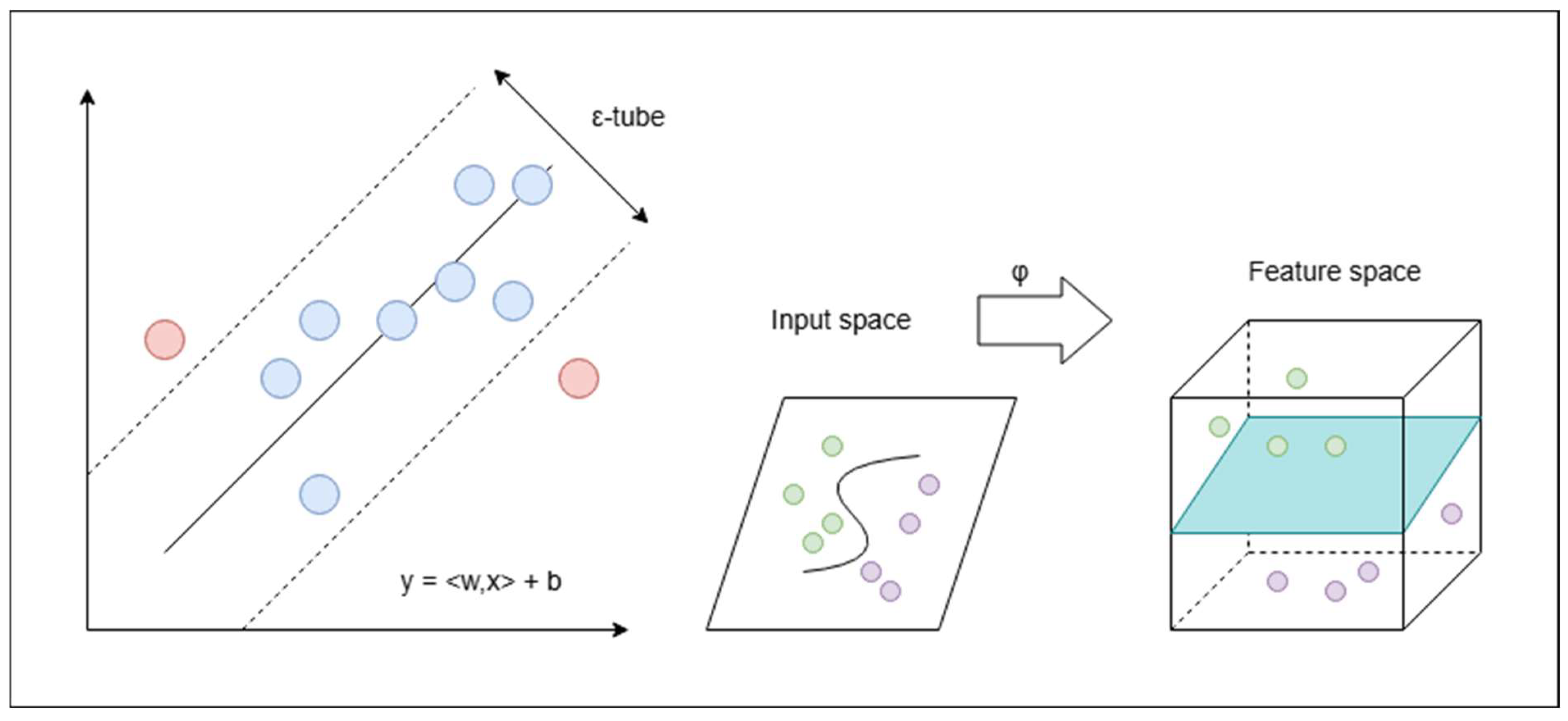
Support Vector Regression (SVR)
Support Vector Regression (SVR), based on Support Vector Machines (SVM), performs regression using a kernel function to enable nonlinear mapping of data [
31]. Support Vector Regression (SVR) is a regression method based on Support Vector Machines (SVM). SVR attempts to find a function that can predict continuous target variables within a desired error range. The steps of SVR are as follows (
Figure 7):
Data preprocessing is the initial step, preparing data for model training and testing, and selecting suitable features for modeling. The features are then scaled to ensure the convergence and stability of the model.
Next, an appropriate kernel function is chosen for the nonlinear mapping of the data. The choice of kernel function significantly impacts SVR’s performance. Common kernel functions include linear kernel, RBF kernel (Radial Basis Function), and polynomial kernel. Once the kernel function is determined, the model penalty parameter and insensitive loss function must be defined. The penalty parameter controls the model’s overfitting on training data and its generalization capability. A smaller increases tolerance for errors, while a larger aims for precise regression of training samples. The insensitive loss function defines a margin, allowing prediction errors less than not to incur penalties, reducing sensitivity to small errors.
The next step involves solving the optimization problem to identify the support vectors. SVR aims to minimize the following objective function by solving its Lagrange dual problem:
where
and
are the slack variables for non-support vectors, and
is the weight vector. This problem can be solved using suitable optimization algorithms, such as Sequential Minimal Optimization.
Finally, the model’s performance on the test set is evaluated using performance metrics such as Mean Squared Error (MSE) and R2 to assess the effectiveness of the SVR model on the test set, thereby determining the model fit. Cross-validation can be employed to further validate the model’s performance and ensure its robustness.
In this study, the Radial Basis Function (RBF) is used as the kernel function. The penalty factor is set to 4.0, imposing stricter penalties on misclassifications, with the goal of reducing training errors. The kernel function parameter is set to 0.8, controlling the function’s width and thus the model’s complexity. The allowable error margin for the model is set at 0.01. After setting all parameters, the optimization is conducted using the Sequential Minimal Optimization algorithm. This algorithm simplifies the optimization problem by selecting two Lagrange multipliers, transforming the optimization issue into smaller sub-problems to be solved progressively, effectively utilizing memory and accelerating convergence. At each step, the algorithm selects two variables while fixing the others, converting the optimization problem into one regarding only these two variables.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}