1. Introduction
Fog-related low-visibility events are extreme situations that can be extremely dangerous for road transportation and aviation [
1,
2]. The accurate prediction of fog-related events has become an important task in the forecasting literature in the last decades. There are different methods devoted to low-visibility forecasting, including numerical weather prediction (NWP) based on the use of mesoscale (or high-resolution) NWP models to accurately forecast fog events [
3,
4,
5,
6]; additionally, data-driven and statistical approaches are based on the processing of measured or simulated meteorological variables [
7].
As part of data-driven approaches, machine learning (ML) and deep learning (DL) approaches have become an attractive tool to tackle the prediction of low-visibility events, obtaining a level of accuracy not seen before. Many of these approaches were, in fact, proposed in the frame of transportation safety, and many of them were tested with airports [
8] or roads data. For example, in [
9], artificial neural networks (ANNs) were used to provide accurate forecasts at Canberra International Airport, employing a 44-year database of standard meteorological observations. In [
10], different ML regression approaches were tested in the problem of low-visibility events prediction due to radiation fog at Valladolid airport, Spain. In [
11], a multiobjective evolutionary neural network was applied to the same problem, obtaining improvements over alternative ML algorithms. In [
12], a hybrid prediction model for daily low-visibility events at Valladolid Airport, which combines fixed-size and dynamic windows and adapts its size according to the dynamics of the time series, was proposed, using ordinal classifiers as the prediction model. In [
13], tree-based statistical models based on highly resolved meteorological observations were applied to forecast low visibility at airports. In [
14], different ML models (tree-based ensemble, feedforward neural network, and generalized linear methods) were applied in the problem of horizontal visibility prediction, using hourly observed data at 36 synoptic land stations over the northern part of Morocco. In [
15], shallow ML classification and regression algorithms were used to forecast the orographic fog in the A-8 motor-road. In [
16], a fog forecast system at Poprad-Tatry Airport using ML algorithms such as SVMs, decision trees, and k-nearest neighbors was proposed. The forecast models made use of information on visibility obtained through remote camera observations. In [
17,
18], ML techniques were applied to classify low-visibility events in Chengdu (China) and Florida (USA), respectively, with applications to road safety. Very recently, alternative approaches to low-visibility events prediction based on tree-based ML algorithms were discussed in [
19]. In [
20], ML approaches were proposed to estimate visibility in Seoul, South Korea, one of the most polluted cities in Asia.Input data considered were meteorological variables (temperature, relative humidity, and precipitation) and particulate matter (PM10 and PM2.5) which were acquired from an automatic weather station. Observational data were considered as targets. In [
17], six different ML approaches were tested in the problem of atmospheric visibility prediction, from ground observation target data at Chengdu, China. As input data, ERA5 reanalysis from the ECMWF was considered. A principal component analysis was applied to the data as a preprocesing step. The results obtained showed that neural networks obtained the best results among all ML methods tested in this particular problem. In [
21], different ML methods (support vector machine (SVM), k-nearest neighbor, and random forest), as well as several deep learning methods, were tested in a visibility forecasting problem in China. The input data considered were the main factors related to visibility, such as wind speed, wind direction, temperature, and humidity, among others.
Alternative works applied DL methodologies to low-visibility forecasting problems: for example, a novel framework consisting of an long short-term memory (LSTM) network and fully connected layer was recently proposed in [
22]. In [
23], deep neural networks (DNNs) were applied to forecast airport visibility. In [
24], several DL methods were applied using climatological data for visibility forecasting. Convolutional neural networks (CNNs) have been applied to atmospheric visibility prediction, for example, in [
25], where a new approach based on deep integrated CNNs was proposed for the estimation of visibility distances from camera imagery. In [
26], fog visibility categories were forecasted using a 3D-CNN, with thresholds below 1600 m, 3200 m, and 6400 m, using numerical weather prediction models and satellite measurements as input data. In a further study with similar data [
27], the performance of different CNN architectures in the prediction of coastal fog was investigated. Autoregressive recurrent neural networks (ARRNNs) have also been applied to visibility prediction problems, such as in [
28], where an ARRNN was applied to the problem of atmospheric visibility prediction at Dulles International Airport, Virginia (USA), using variables such as precipitation, temperature, wind speed, humidity, smoke, fog, mist, and particulate matter (PM) concentrations in the atmosphere. The ARRNN showed better performance than alternative DL approaches such as LSTM or recursive neural networks in this particular problem. In [
29], a RNN was applied to the problem of visibility prediction in Eastern China. This work showed that the RNN was able to improve the results from a CNN in the same problem. In [
30], a deep learning model based on principal component analysis and a deep belief network (DBN) was proposed to solve the problem of atmospheric visibility in short- and long-term sequences. In [
31], a multimodal learning method based on a CNN and a gated recurrent unit (GRU) model was proposed. Input data and features from closed-circuit television images and multivariate time series data collected at Daesan Port (South Korea) were used to feed the DL prediction system. This system shows a better performance in the prediction of sea fog and visibility than alternatives that only consider temporal information or spatial information. In [
32], the combination of two CNN models (VGG-16 and Xception) was evaluated in the problem of low-visibility events from airports images. The work also discussed the relationship between runway visual range at the airport and surface meteorological conditions using the deep networks as basic elements.
All these previous approaches based on ML and DL techniques yielded accurate results in different fog-related low-visibility events prediction problems, but in the majority of cases, the explicability of the results is not easy to obtain, due to the complexity and extremely nonlinear characteristic of the ML and DL algorithms. In the last few years, explicableartificial intelligence (XAI) [
33] has been acknowledged as a crucial feature of AI or ML algorithms when applied to science and engineering problems, and specially in geoscience- and atmospheric-related problems [
34]. XAI is based on the fact that, when developing an ML model to solve a given problem, the consideration of interpretability is an extremely important additional design driver, especially in some fields in which the physics of the problem plays a principal role, such as in geoscience and Earth observation problems [
35]. This leads to the development of ML models in which the interpretation of the system is a primary objective, in such a way that the models provide either an understanding of the model mechanisms or give the reason why some predictions are obtained. The interest in physics-awareness and XAI in atmospheric-related problems in the last years has produced revisiting classical methods which promote the interpretation of results, such as those based on inductive decision rules.
There have been different attempts to apply inductive decision rules to problems related to fog and visibility prediction. In [
36], a C4.5 decision tree was used to generate induction rules for marine fog forecasting at different buoys off the California coast. In [
37], a multirule-based method was developed, where threshold values of multiple variables were employed to define fog conditions in the forecast. The objective was to forecast low-visibility episodes due to radiation fog in Abu Dhabi, in the United Arab Emirates. Fuzzy-logic-based rules systems have also been developed in fog prediction, for example, in [
38]. In [
39], a fuzzy-rules-based system was proposed to predict fog in Lahore, India. In [
40], an objective fuzzy logic fog forecasting model based on outputs from a high-resolution operational NWP model was proposed, where the fuzzy logic was employed to deal with the inaccuracy of NWP prediction and uncertainties associated with relationships between fog predictors and fog occurrence. This methodology was tested at Perth Airport, with good results.
In this paper, we focus on events of extreme low-visibility, and how they can be accurately forecasted using rule induction and rule evolution methods. In this case, explicability of the rules is in the core of the proposal, in addition to obtaining accurate results in extreme low-visibility events. Two different methodologies were satisfactorily applied. In the first one, both induced and evolved rules and boxes of rules were used as a simpler alternative to ML/DL classifiers, offering, in some cases, some advantages with respect to those ones: (1) Rule-based classification models provide a direct physical explainability of the outcomes, which can be very helpful in the implementation of these models in real applications; (2) the complexity of these models is substantially lower than the ML/DL classification methods in many cases, thereby considerably reducing the computational cost, as well as the training time and the complexities of the system deployment; and (3) the performance of rule-based classifiers for the prediction of extreme low-visibility events are competitive with respect to far more complex ML/DL models, although this much depends on the specific problem at hand. The second approach focused on the integration of the information provided by the induced/evolved rules in order to enrich the complex ML/DL models. Specifically, the idea is to add to the original database, composed of meteorological variables measurements, a Boolean extra variable, which provides information related to the fulfillment of the rules or boxes of rules. This leads to a significant improvement of the classification models’ performance for the three prediction time horizons assessed.
The rest of the paper is structured in the following way: the next section describes the algorithms used in this work for rule induction construction, the PRIM, and an evolutionary approach (CRO-SL), together with the ML and DL classification methods employed. Then,
Section 3 describes the specific problem of extreme low-visibility events forecasting and description, and gives details on the atmospheric variables involved in the problem.
Section 4 presents the experimental section, where the results obtained in this problem are presented and discussed for the two approaches implemented. Finally,
Section 5 closes the paper with some concluding remarks on the research carried out.
3. Data and Problem Description
Visibility data measured at the Mondoñedo weather station, Galicia, Spain (43.38 N, 7.37 W), from 1 January 2018 to 30 November 2019 with a sampling frequency of 30 min were used in this paper, accounting for a total of 33,015 samples. This station measures visibility in the A8 motor-road in Lugo, where orographic (hill) fog usually occurs, forcing the closure of the motor-road in cases of extreme low-visibility events. Note that orographic fog is formed when moist air moves up a hill, resulting in expansion and cooling of the air to its dew point, and producing intense episodes of low visibility. The Mondoñedo area is known to experience frequent low-visibility events caused by orographic fog due to winds coming from the Cantabrian Sea.
The data were acquired with a Biral WS-100 visibility sensor, which operates between 0 to 2000 m. The location of Mondoñedo is 140 m above sea level, and the distance to the sea is around 20 km; all the variables were acquired at 2 m height from the ground.
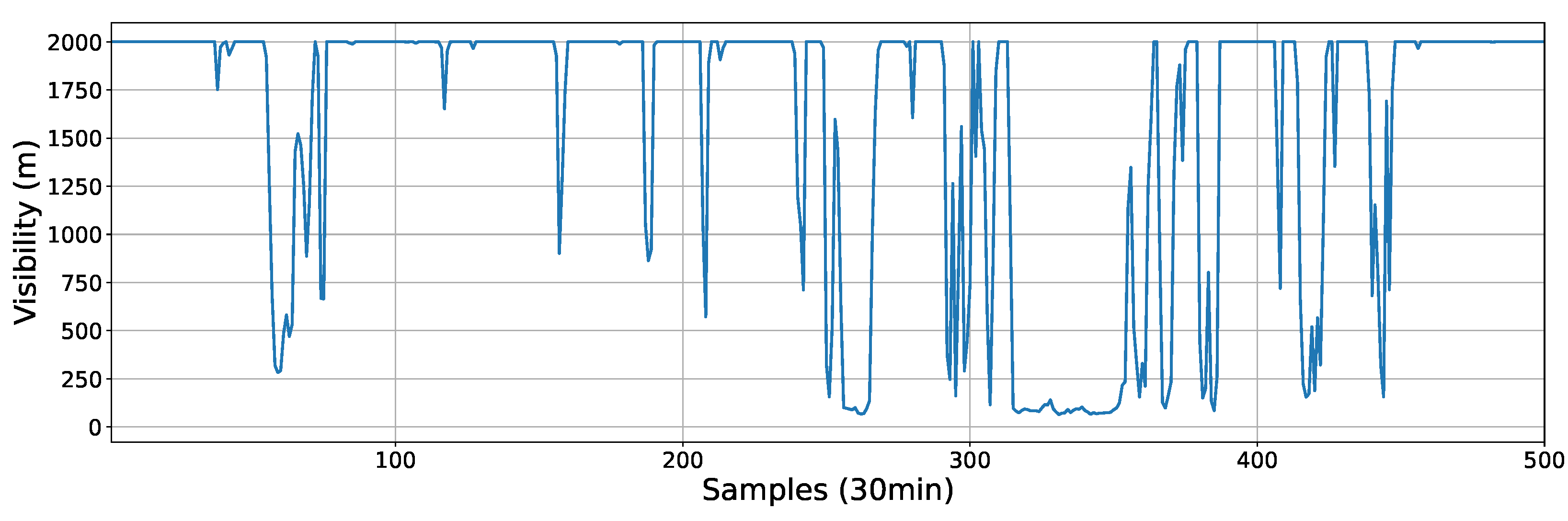
Figure 5 illustrates the first 500 samples of the visibility time series, where the tendency of the data to remain close to 2000 or to 0 can be observed, while there are few data in intermediate ranges. This is further illustrated by plotting the density function of the data (
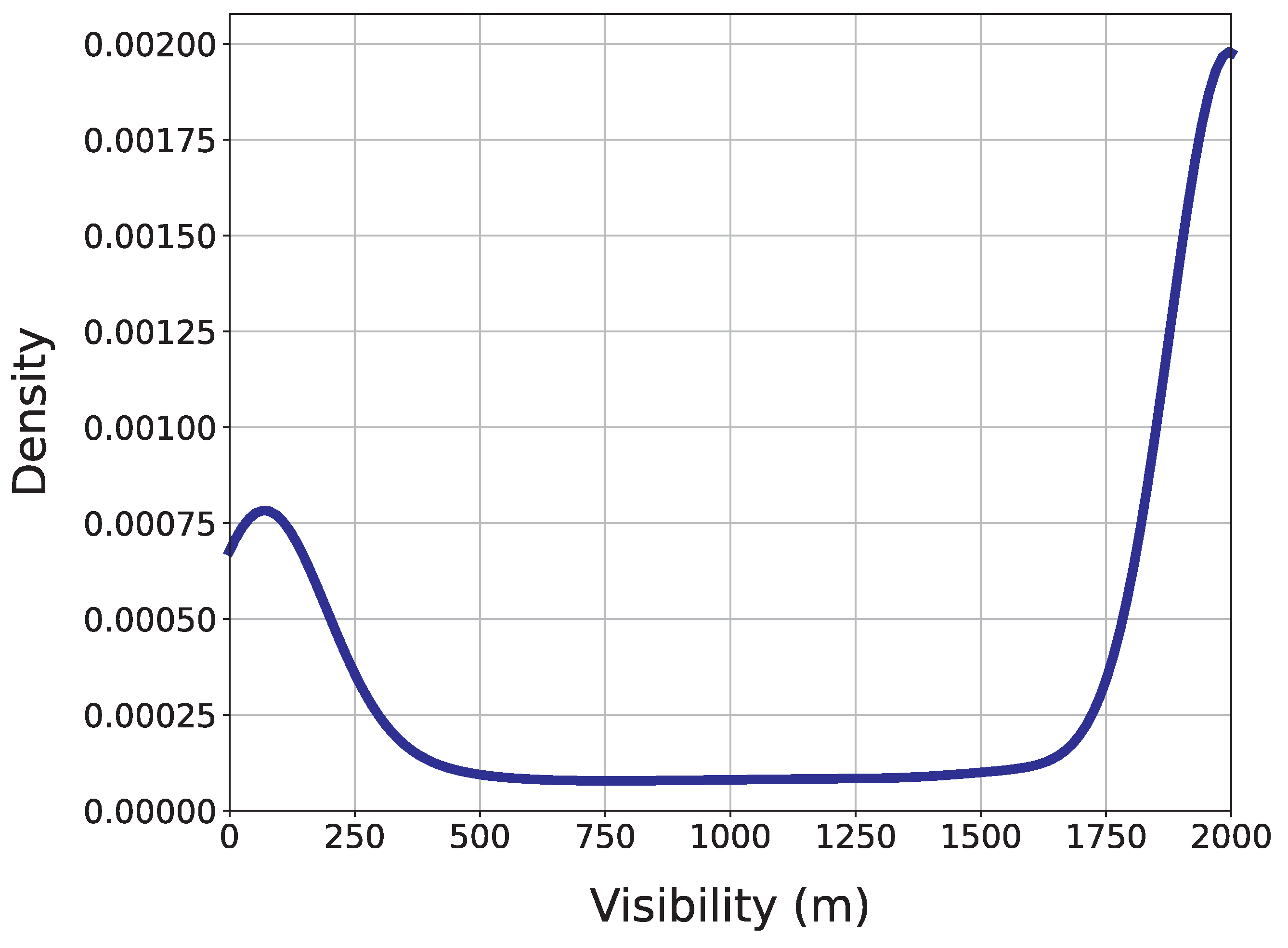
Figure 6), where two peaks may be found: one near 0 m, corresponding to very low visibility levels, and a much more prominent peak near 2000 m, corresponding to events where visibility is very good.
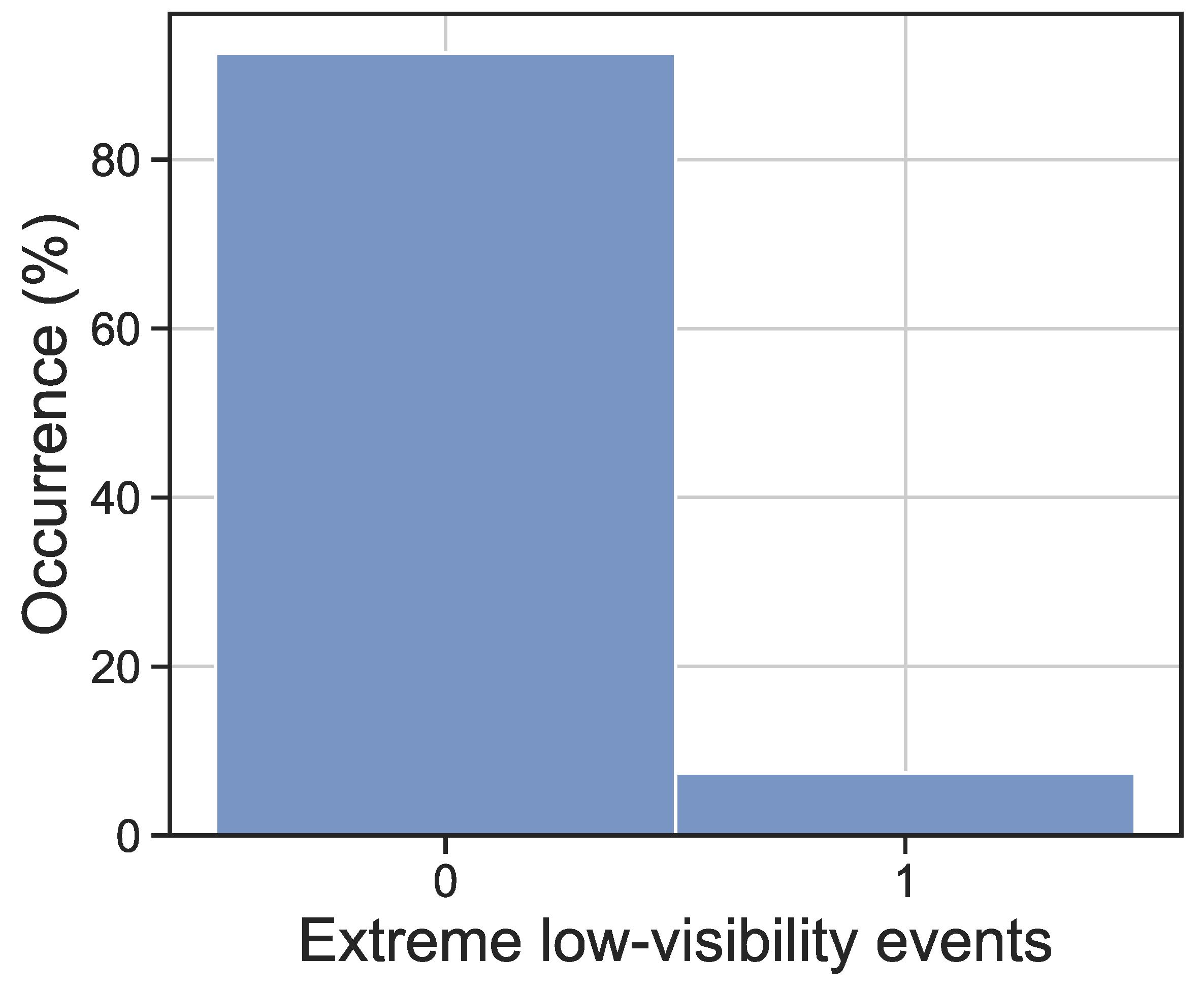
This work is focused on extreme low-visibility events, i.e., those fog events leading to visibility values below 40 m, which are those affecting the normal motor-road circulation the most. Since the problem is approached as a binary classification problem,
Figure 7 shows the distribution of samples for each class, where extreme low-visibility events (class 1) account for 7.41% of the total number of samples. Thus, we focus on developing inductive and evolutionary rules for detecting and describing these specific events. The predictive variables used in this study for dealing with extreme low-visibility events consist of 11 exogenous meteorological variables registered by the same weather station at Mondoñedo (
Table 1). A brief discussion on the predictive variables is worthy here. Note that we used all the variables available (measured) in the Mondoñedo weather station; we did not carry out a previous step of feature selection, so we trust that the proposed algorithms are able to deal with possible redundancy between predicted variables, extracting the useful information from them in terms of their contribution to the visibility prediction. In addition, note that some of them are not related to visibility, but they are measured for other reasons, such as for the care of the road. For example, salinity of water in air is a variable related to corrosion of elements in the road, but it does not seem to be fully related to orographic fog. Similarly, accumulated precipitation (during the last hour) and ground temperature do not have much relation with the fog formation mechanism, but they can be involved in its persistence. The time horizons of the visibility forecast were established in +3 h, +5 h, and +10 h; therefore, measured variables acquired from
(or ranging from
to
in the case of DL methods) are used as predictors to forecast visibility at
,
, and
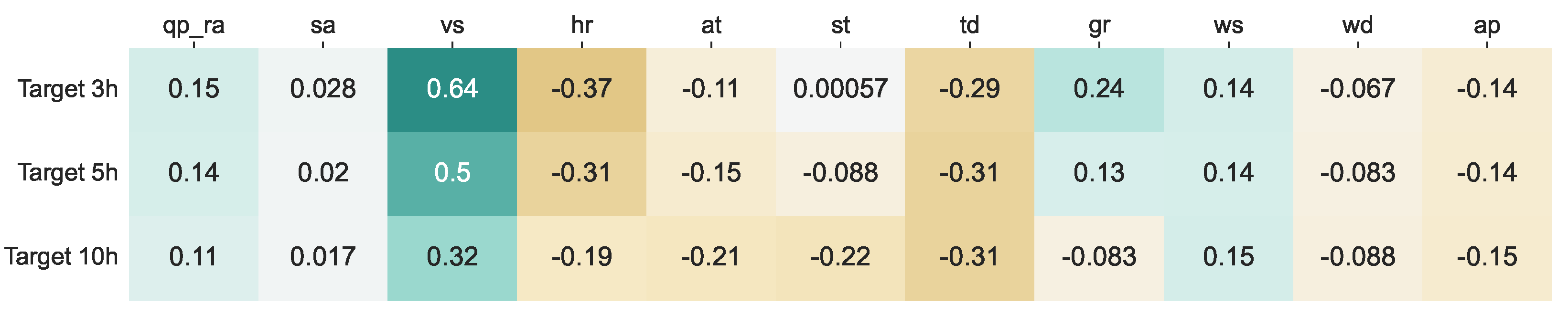
. In order to obtain an idea of the importance of the predictive variables, the Pearson correlation coefficient among the predictive variables and the target variable (prior to its binarization) is presented in
Figure 8 for the three prediction time horizons considered. It can be seen how for some variables (qp_ra, sa, td, ws, ap) the correlation remains constant as the prediction horizon increases, while for others (vs, hr, at, st, gr, wd) the correlation varies. The variables showing the highest correlation are visibility in previous hours, the relative humidity, and the dew temperature. On the contrary, there are some other variables, such as salinity of water in air or ground temperature, which do not have, as expected, a high correlation with visibility prediction.
4. Experiments and Results
This section reports the results obtained in this work. In the first place,
Section 4.2 analyzes the rules obtained by the induction and discovery algorithms. Next,
Section 4.3 presents and discusses the results obtained for the first proposed methodology, consisting of the use of decision rules as a possible alternative to classification algorithms. Finally, results for the second approach are provided in
Section 4.4, where information related to decision rules is incorporated into the ML/DL classifiers as an additional input feature.
4.1. Experimental Setup
The experimental setup, along with the parameters set for the different ML and DL methods, are detailed in this section. First, a preliminary dataset preparation is carried out. The steps of this preprocessing are: (1) Splitting the dataset into training and test (75–25%) subsets, ensuring that no test instance was seen by the classification methods during the training. Due to dealing with timed series data, instead of randomly splitting the datasets, the last 25% of the data were separated as test data. (2) Scaling of the features, which is important to ensure the upper and lower limits of data in the given predefined range. Feature standardization was performed, causing data to have zero mean and a unit variance (Equation (
25)), where
x is the original feature vector,
denotes the feature mean, and
its standard deviation.
Table 2 shows the parameters used for the benchmark methods considered. All of the simulations were run on an Intel(R) Core(TM) i7-10700 CPU with 2.90 GHz and 16 GB RAM using the Python libraries sklearn, tensorflow, prim, and scipy.
In addition, we performed a previous optimization of the DPCRO-SL hyperparameters before using it for rule evolution. For this purpose, a genetic algorithm (GA) was used. There are many examples in the literature of successful uses of a GA for optimizing hyperparameters of, for example, neural networks [
74]. That is why we opted for this option.
The search space includes several ranges for the hyperparameters values indicated in
Table 2, and a list of possible operators for the DPCRO-SL. Specifically, this includes 2-point crossover (2Px), 3-point crossover (3Px), multipoint crossover (MPx), differential evolution DE/rand/1, differential evolution DE/best/1, component-wise swapping (CS), Gaussian mutation (GM), and Cauchy mutation (CM).
As a result of this process of optimization and selection of hyperparameters, we obtained the values specified in
Table 2, as well as the operators defined in
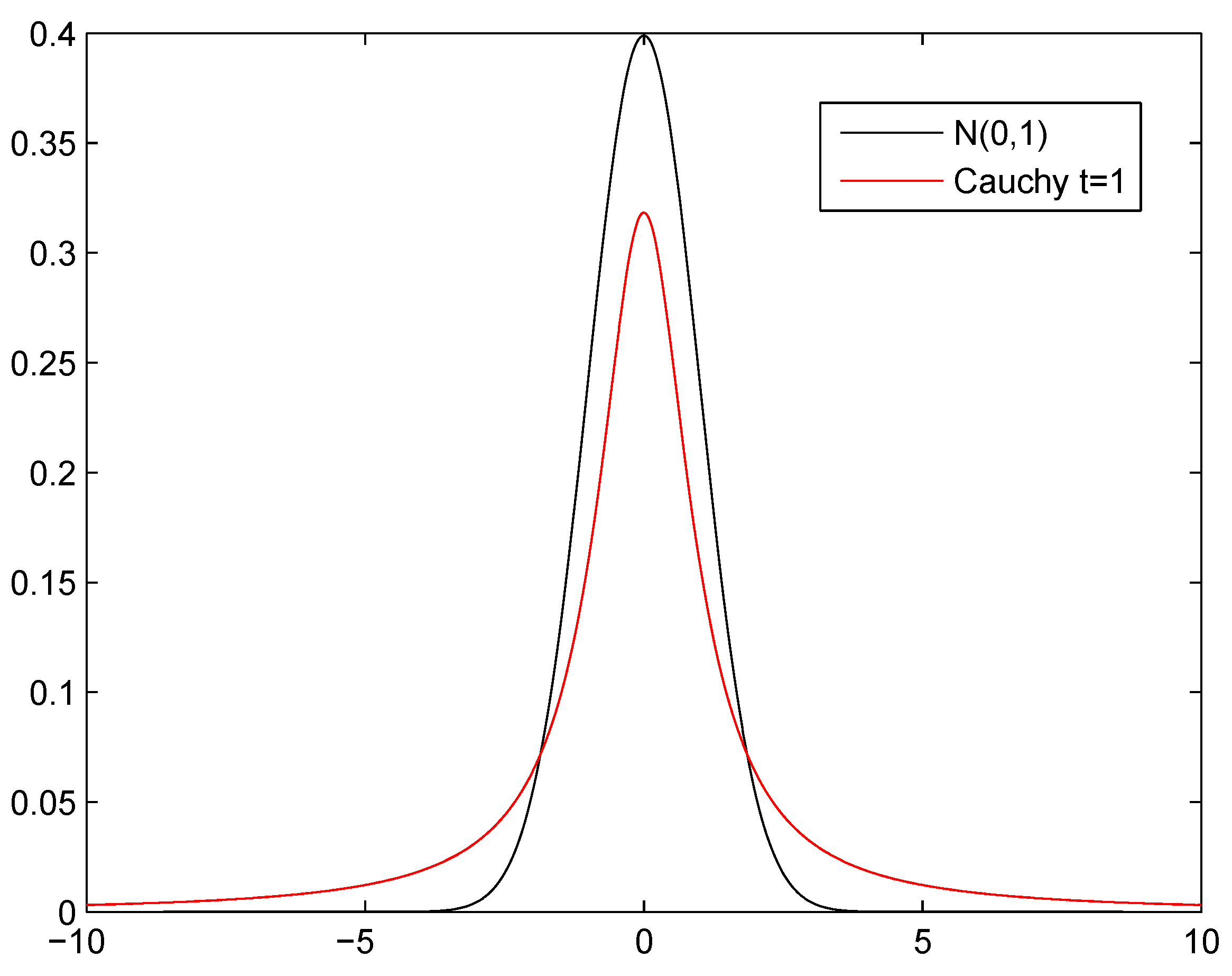
Section 2.1.2.3. It should be discussed why these operators perform better than others, i.e., DE/rand/1 instead of DE/best/1 and Cauchy mutation instead of Gaussian mutation. The reason in both cases is similar: the PRIM rules are already very good themselves, and we are unlikely to find an improvement in their neighborhood. Therefore, a mutation with greater variance such as the Cauchy (see
Figure 2) facilitates a higher exploration than the Gaussian. Furthermore, DPCRO-SL itself is responsible for modifying the significance and quantity of the population with which each operator works at all times. This may explain why a 3Px crossover is not necessary. With 2Px already available to cross in blocks of components and MPx to cross several (or all) components, an intermediate operator between the two does not seem necessary, as the algorithm itself will combine MPx and 2Px to obtain the desired crossover. Eventually, the CS operator can offer a fine granularity level to modify the latest details close to the good solutions.
4.2. Analysis of the Extracted Decision Rules
We start this section by analyzing the heuristics defined in
Section 2.1.2.2. For the WeSum objective function, we set 0.01, 0.1, 0.2, 0.3, 0.6, 0.7, and 0.9 as values of
. With this experiment, it is possible to verify whether it is better to penalize precision or support. Each heuristic is used 10 times to evolve and generate the best possible set of rules, i.e., 10 sets of rules (or boxes) are generated with each heuristic.
Then, we establish a threshold for minimum support size and precision for each box, namely, a minimum of 100 individuals (0.61% support) and a minimum of 40% precision. In this way we can measure how many boxes generated by each heuristic satisfy the threshold for each predictive horizon.
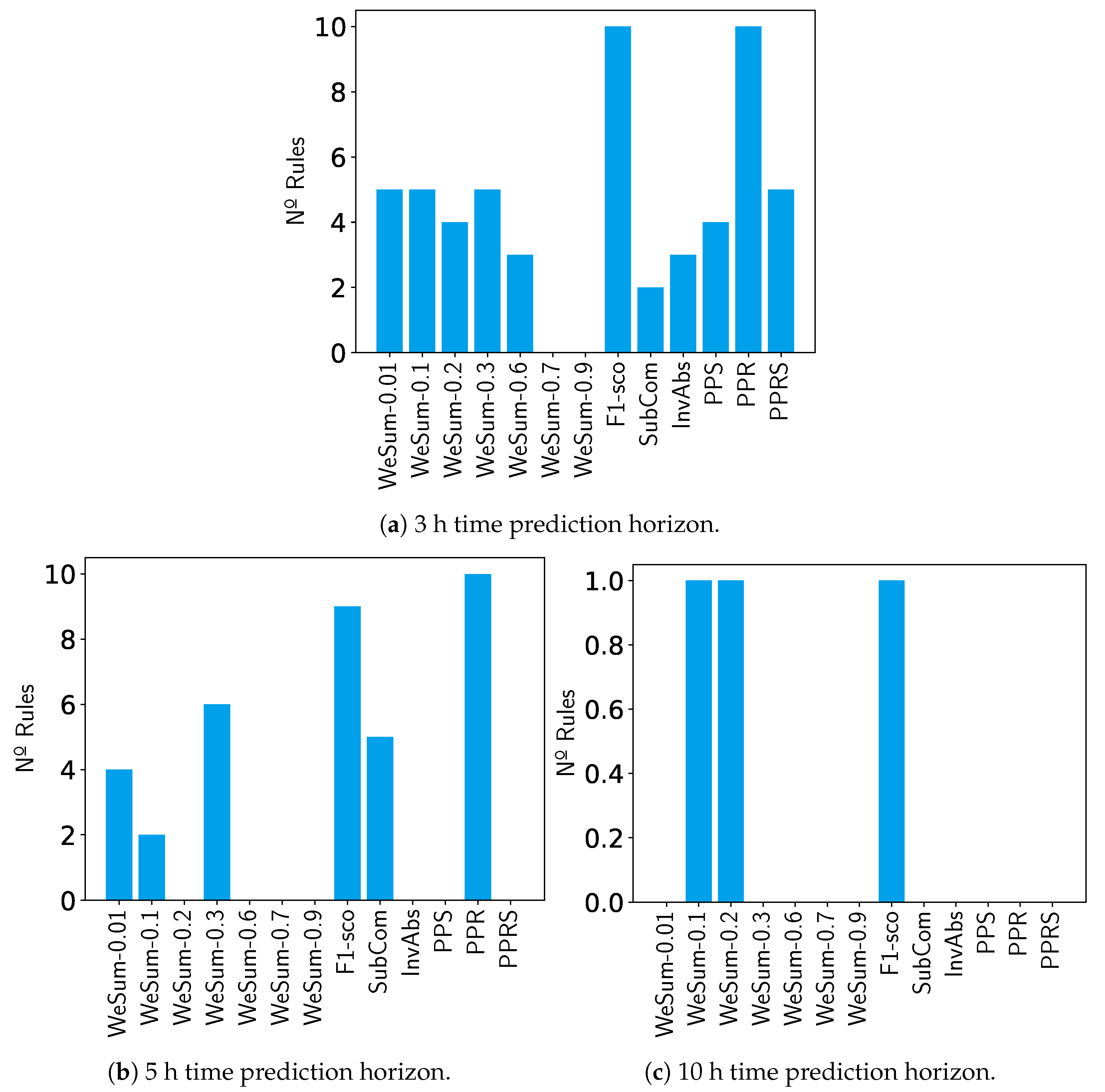
Figure 9 shows the number of rule sets that fulfill the threshold on each time prediction horizon considered.
For the 3 h case (
Figure 9a), the F1-score and PPR heuristics stand out from the others. As for WeSum, it seems that the low
values are better. Regarding the other heuristics, none of them can be said to work poorly for this time horizon, because they generate valid boxes. However, it can be seen that there are better heuristics within them.
In the 5 h horizon (
Figure 9b), the heuristics F1-score and PPR continue to dominate, so that all (or almost all) the boxes generated outstrip the threshold. It also proves that WeSum is substantially better with small
values. Compared to other heuristics, only SubCom survives.
Finally, note that in the 10 h case (
Figure 9c), only the F1-score and WeSum heuristics with small values of
fulfill the threshold.
With all these results in mind, we can draw several conclusions: first, we showed that alpha values between are the better option for WeSum heuristics. On the other hand, the best of all heuristics is undoubtedly F1-score. This is present in all time steps, producing very good sets of rules. It should also be mentioned that PPR performs well overall.
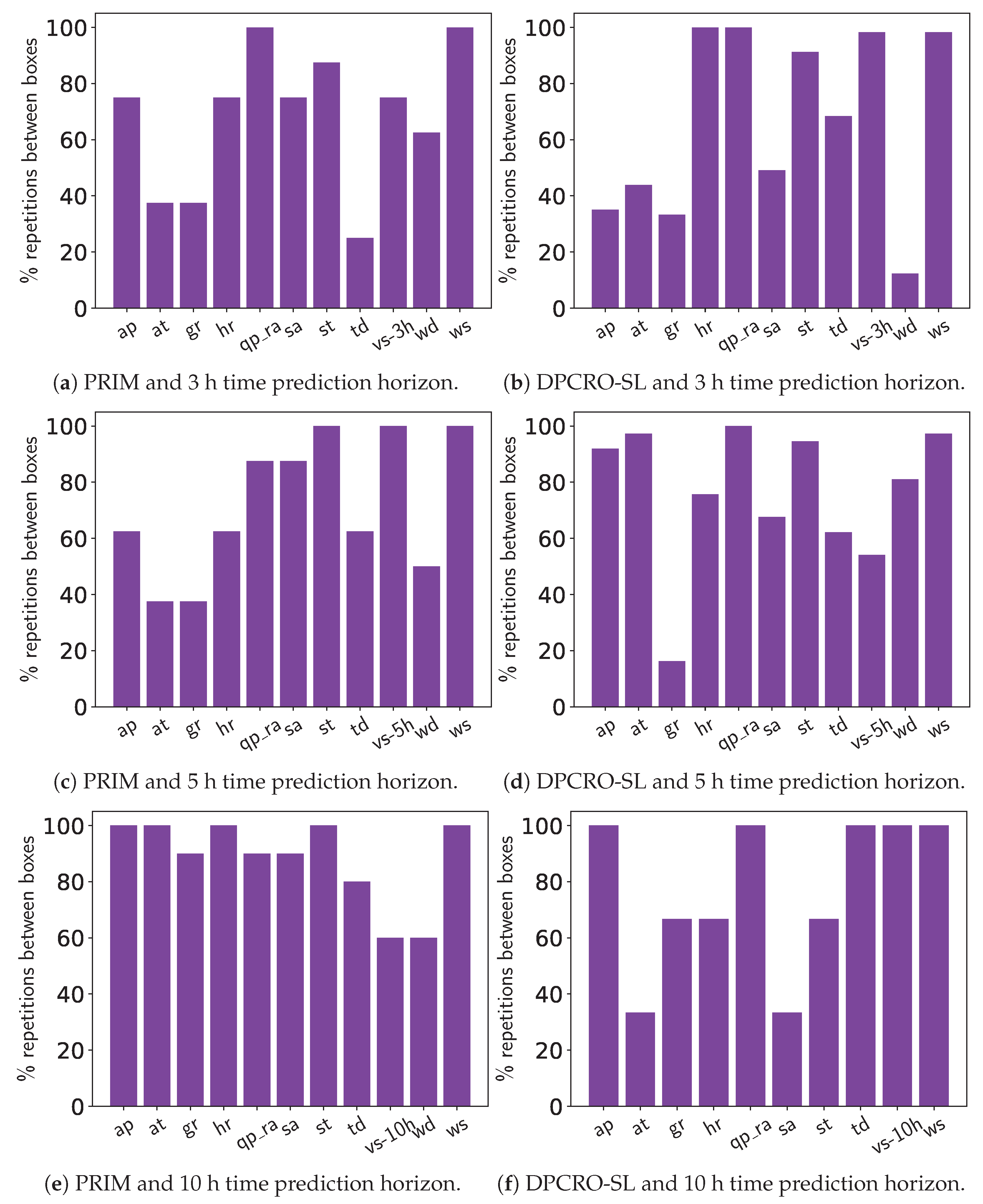
Afterwards, it is possible to observe in
Figure 10 how many times each variable is repeated between the different boxes for each time horizon, both for the boxes of PRIM and those obtained by the DPCRO-SL. This helps us to analyze the importance of each variable over time, and the impact that each one of them can have on short- and long-term predictions. We consider the average behavior between PRIM and DPCRO-SL, remembering that the number of boxes that overtake the threshold is decreasing as the prediction horizon increases.
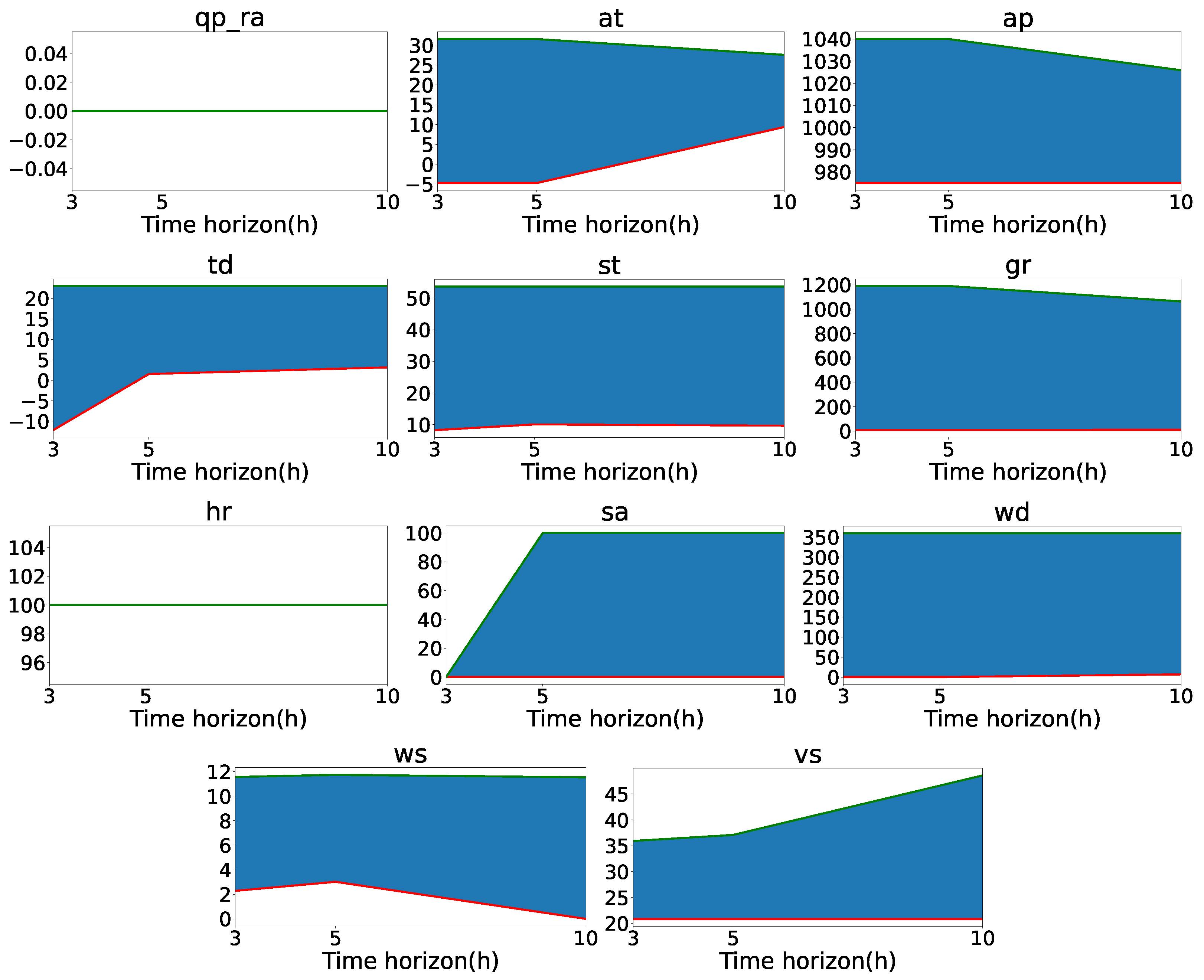
Instead, in
Figure 11 we find the rules associated with each variable in the most restrictive box that was generated from each horizon. As mentioned in Section
2, these rules are expressed by a range of values to be taken by the variable, i.e., the lower limit (minimum) and upper limit (maximum) between which it has to be set. This means that if the range of values specified by the rules covers all possible values, the variable is not very important for the prediction; however, if the range is very small, the variable has great relevance. These figures allow us to reinforce the conclusions that can be obtained from the repetitions between boxes by time horizons.
The first variable to evaluate is atmospheric pressure. It is observed that with a forecast horizon of +3 h, this variable appears in approximately 75% of PRIM boxes and 35% of DPCRO-SL boxes. In the next horizon, it is present in 60% and 90% of the boxes, respectively. Finally, for the 10 h horizon, the atmospheric pressure is found in all generated boxes. The most restrictive box value ranges emphasizes this point, showing that for 3 h and 5 h, the atmospheric pressure is irrelevant, while for the 10 h case it has a more significant role. In summary, these results show that atmospheric pressure can have effects on extreme low-visibility events in the long-term.
Something similar happens with air temperature. For a time horizon of 3 h, it appears in 40% of PRIM boxes and 45% of DPCRO-SL boxes. For 5 h it is found at 40% and 95%, respectively, while for 10 h, it is found at 100% and 35%. Even more accentuated is the case of global solar radiation, with 40% and 35% for 3 h, 40% and 15% for 5 h, and 90% and 70% for 10 h.
Figure 11 reinforces this because it is seen that for the most restrictive box, air temperature and global solar radiation acquire importance at 10h. This means that, similar to atmospheric pressure, air temperature and global solar radiation can influence the long-term prediction of the thick fog at Mondoñedo station.
Accumulated precipitation and relative humidity seem to be very important variables for the prediction, for the time prediction horizon of 3 h are found in 75% and 100% of PRIM boxes, respectively, and 100% of DPCRO-SL boxes in both cases. In the other horizons, they maintain a presence equal to or greater than 70% in the different boxes. The ranges of these variables for the most restrictive box are very small for all horizons. In particular, it is important for fog formation that the value of accumulated precipitation oscillates around 0 and the value of relative humidity is as close as possible to 100%.
Visibility and wind speed seem to be closely related. Both variables maintain a presence greater than 80% (and almost always close to or equal to 100%) in the boxes of PRIM and DPCRO-SL for all prediction time horizons, except for 10 h. In that case, the visibility is in 60% of the boxes. In the evolution of the value ranges we can see that both variables have a very considerable influence in the short and medium term, but not in the long-term prediction. Remembering that the 10 h horizon boxes are much less numerous, there is no contradiction in that the variables are in most 10 h boxes, as long as the rules associated with these variables select all (or almost all) the range of possible values.
Dew temperature is found in only 30% of PRIM boxes and 70% of DPCRO-SL boxes for 3 h. In 5 h and 10 h, their presence increases above 60% in all cases. This means that it is a variable whose influence is only appreciable in the medium–long term. The opposite is true of salinity. It is a variable that has a large presence in the boxes of 3 h (75% and 50%), but whose presence in 10 h is somewhat reduced, reaching 30% for DPCRO-SL. Since its range of values is increasing over time horizons, it is a variable with relevance only in the short-term prediction time horizon.
Finally, the variables floor temperature and wind direction are irrelevant in the prediction of thick fog, although for different reasons. The floor temperature is present in most boxes, both for PRIM and DPCRO-SL in different time steps. Its lowest presence is 60% in 10 h, remaining in other cases close to 90% or 100%. While this is true,
Figure 11 shows us that rules associated with floor temperature, although always present, select the full (or nearly full) range of possible values. This can set a floor temperature minimum to 12, but with negligible importance. In the case of wind speed, even though we can see that the range of values always covers the totality, it is a variable that is not even present in most boxes. Except for the case of 80% in the boxes of DPCRO-SL in 5 h, in the other boxes, it is always below 60%, reaching 10% for DPCRO-SL in 3 h and 0% for DPCRO-SL in 5 h.
4.3. Use of Induced Rules to Anticipate the Presence of Thick Fog
Initially, the induced rules were used as a classification technique in order to anticipate the presence or absence of thick fog (
Figure 12). For this purpose, two different approaches were tested. In the first one, given a test sample, each induced rule was assessed individually on the predictive variables and, if the rule was fulfilled, the prediction of that rule implied the presence of thick fog. Therefore, a different output was generated for each rule. In order to select the best performing rule, the performance of the forecasted values was also assessed individually on the training data, selecting the rules with the best scores for the three evaluated metrics, and computing those performances again on the test data.
The second approach consists of the evaluation of boxes of induced rules instead of just individual rules. Therefore, the outcome of the prediction for each box was considered to be positive (meaning that the presence of fog was forecasted) in the case that all the individual rules were fulfilled. Again, as the number of boxes is significant, the performance of each box is measured on train data, selecting the best performers for each metric and then assessing their values on the test data.
Test error metrics for these experiments are further displayed in
Appendix A.
Table A1 shows the test error metrics for the +3 h prediction time horizon of all the classifiers evaluated. Here, it can be seen how the GB is the most reliable ML method, remaining the most balanced performing method in the three metrics measured. Regarding the DL methods, the four classifiers yield similar performance, though slightly worse than the GB.
Moving on to the evaluation of rule boxes, it may be observed that, by prioritizing the recall metric among others, a superior result is obtained compared to the model with the highest recall of the benchmark methods, GNB, which obtains a 98% of detection of severe fog, albeit with a very low precision of 18%. Instead, the best PRIM box achieves a 90% of positive detection rate with a precision of almost 30%, and the best CRO box yields 86% of detection with a 34% of precision. When evaluating the more balanced boxes, the ones with better F1-score, it can be seen that, although they achieve quite good results, especially with the CRO-evolved boxes with a score of 0.61, they do not improve the results achieved by the GB (0.66).
Regarding the performance of the individual induced rules used as a classification method, it is observed that for both cases, PRIM and CRO-evolved rules, the ones with the higher recall values reach a 100% of thick fog detection rate, although the use of these rules as classifiers lacks practical interest due to the low accuracy rate achieved (9.45% for both cases). Nevertheless, the rules with the best F1-score present very competitive results for both cases, even surpassing the best ML classifier for the case of the CRO-evolved rule. Thus, the use of this rule constitutes a simpler, faster, and computationally cheaper alternative to the use of the ML/DL classification techniques.
Figure 13 displays the F1-score distribution for all the classification methods evaluated, showing a clear difference in error distribution shapes between the individual induced rules and the rule boxes: while the former reach higher maximum values than the latter, the average for the boxes remains higher. This is explained by the fact that boxes, as combinations of individual rules, take both strong and weak rules and combine them to produce more consistent results than the individual rules. However, in order to solve the prediction problem tackled in this paper, simply taking the best performing individual rule is more appealing, ensuring that it will lead to better results.
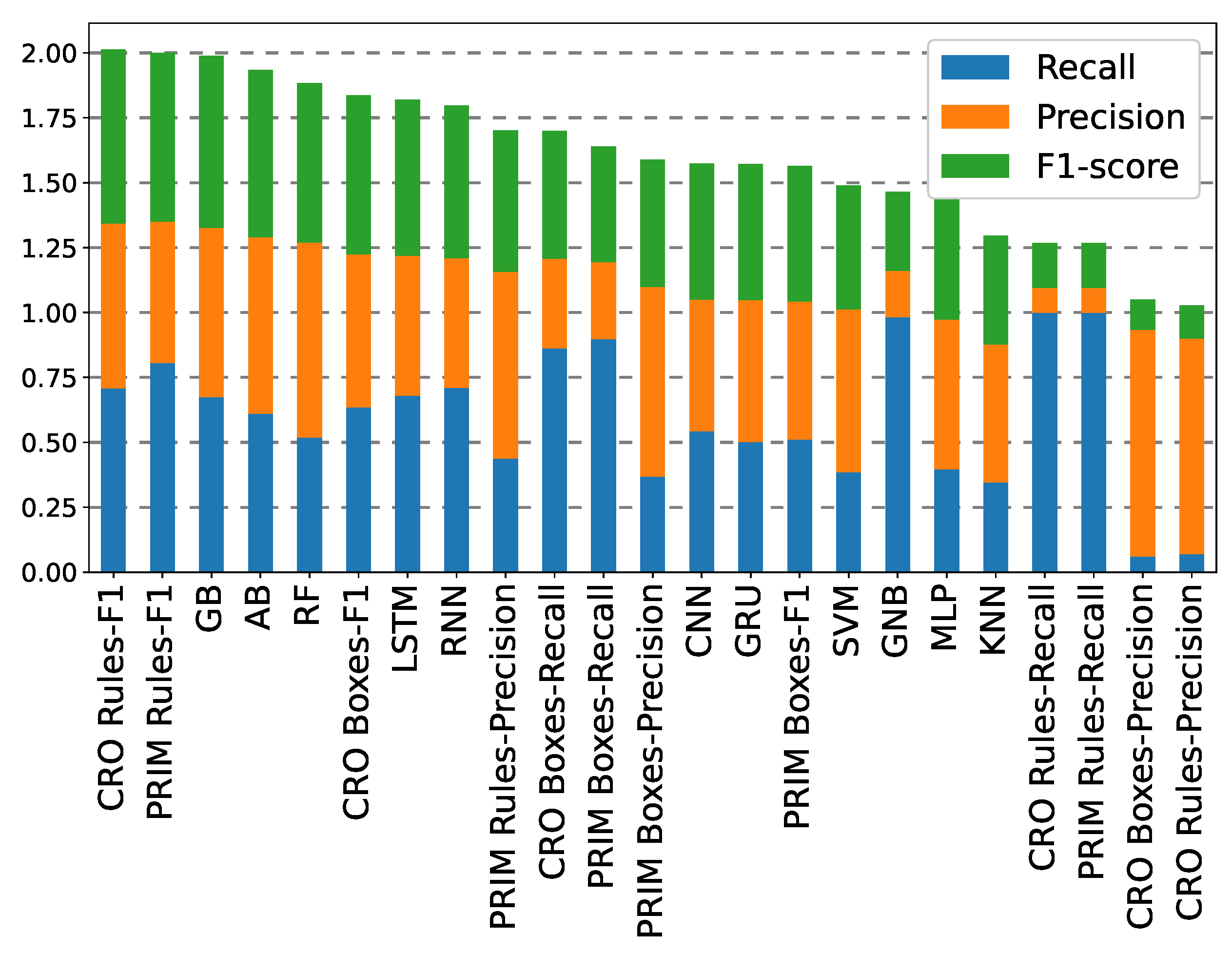
Finally,
Figure 14 shows the comparison of all the classification methods tested in the +3 h prediction case, sorted from best to worst performance, and considering the sum of the three error metrics assessed. It is observed that the individual rules, both PRIM-induced and CRO-evolved, outperform the other methods used, representing the most optimal options for predicting thick fog events.
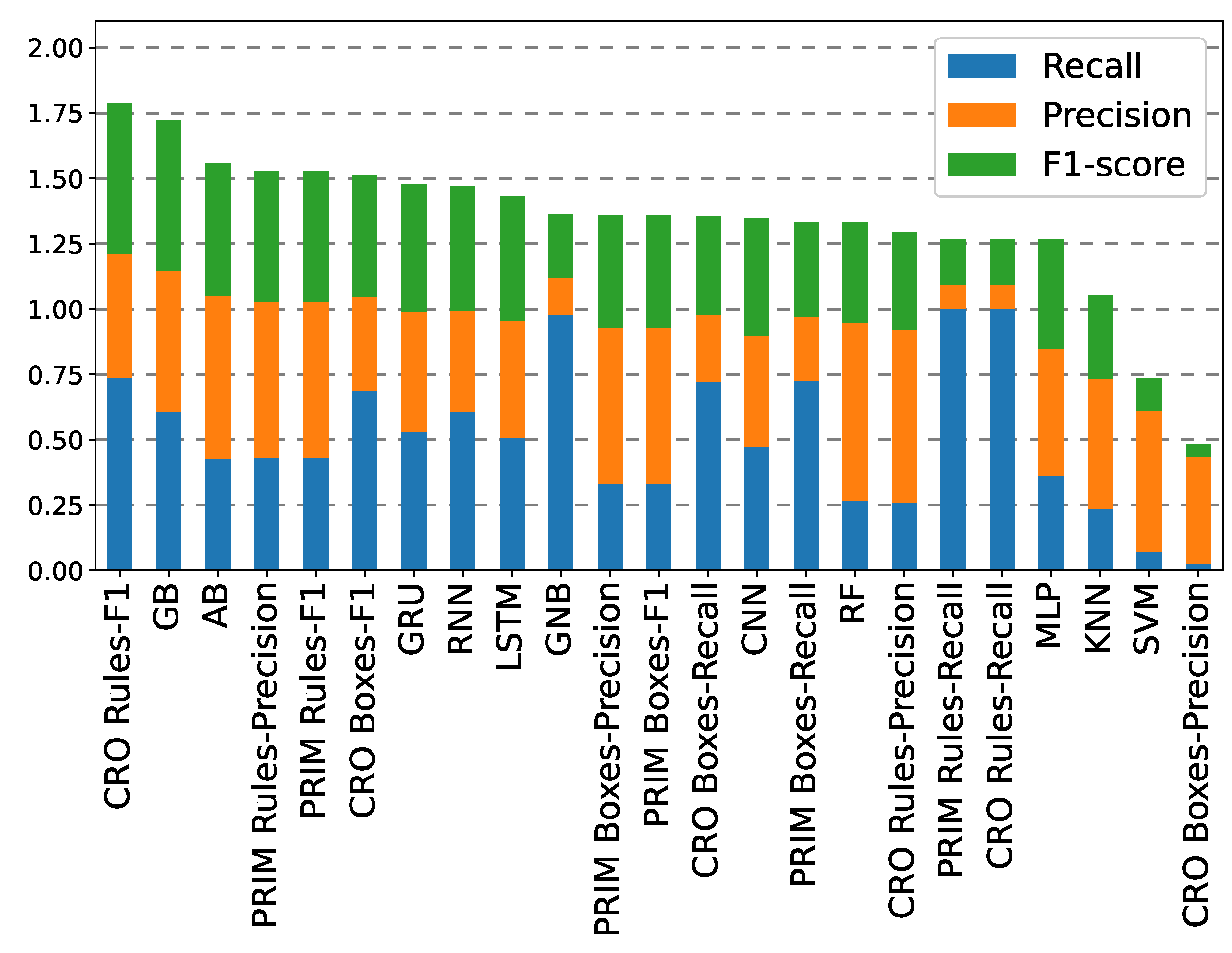
Regarding the performance of the employed methods for a 5 h prediction time horizon,
Table A2 shows the error metrics for each of the classification techniques. Here, it can be noted how the previously drawn conclusions for the preceding time horizon are maintained. GB remains as the ML/DL method with the best F1-score, but this result is surpassed by the best individual rule evolved with CRO. Regarding the rule boxes, it is shown how in terms of F1-score neither PRIM nor CRO boxes outperform the best individual rules, with detection rates of above 72% with precision around 25%.
Figure 15 shows the sorted comparison of the methods’ performances, headed by the best (in terms of F1-score) individual rule evolved by CRO. Then, the two boosting ML methods, GB and AB, are the next-best performers, followed by the individual rules induced by PRIM.
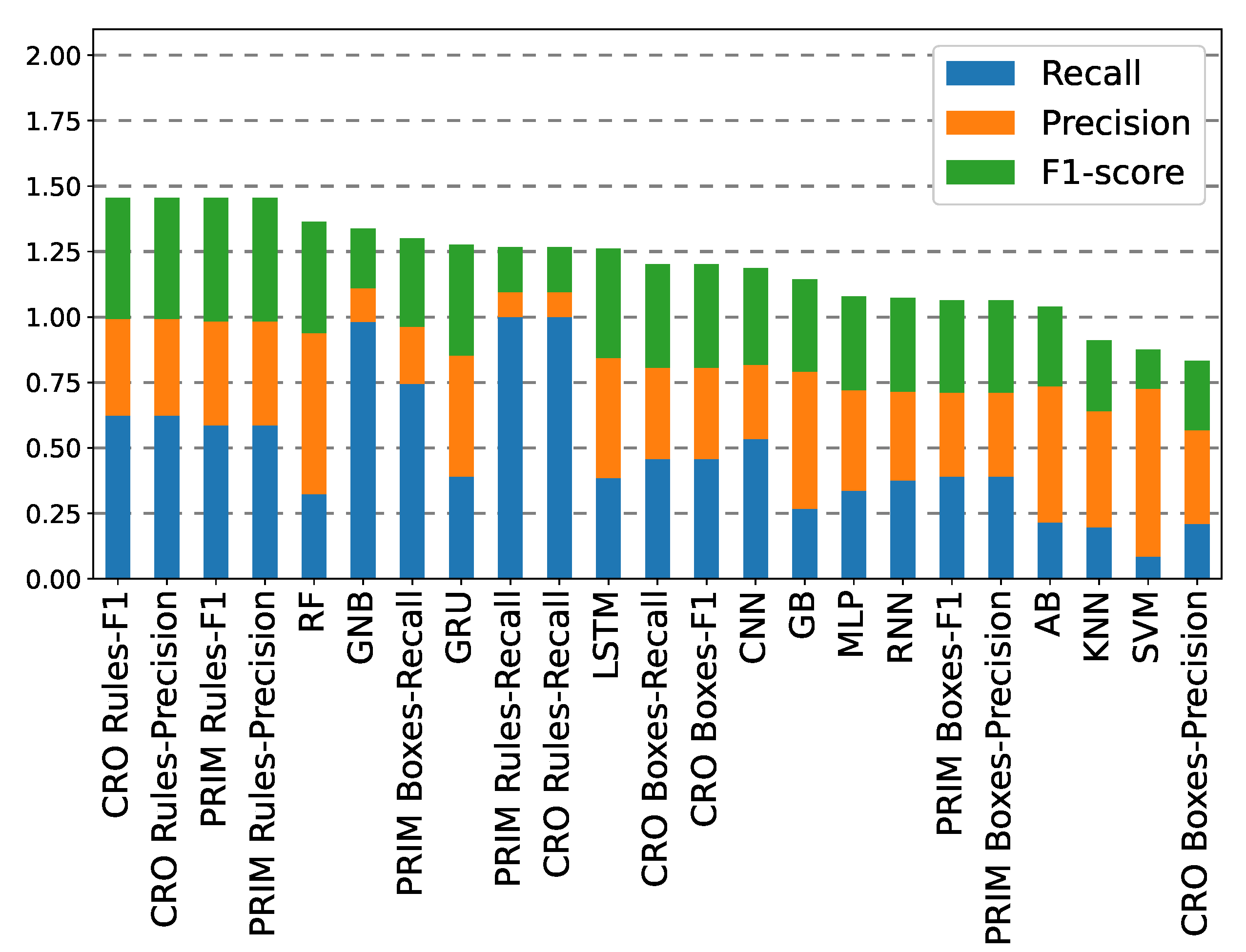
Finally,
Table A3 displays the test results for the time prediction horizon at +10 h. In this case, the conclusions drawn are slightly different from the previous scenarios: first, RF becomes the best performing ML classifier instead of GB. Moreover, DL methods outperform ML models in this long-term prediction, with the RNN model being the one with the higher F1-score. Differences are also observed in the performance analysis of the individual rules, where, in this case, it is the PRIM-induced rules that offer the best overall performance in terms of F1-score, with a significant increase of 6% with respect to the best ML/DL model.
Figure 16 shows the test performance of all the methods sorted according to the sum of the three error metrics assessed. In this case, both the CRO-evolved and the PRIM-induced individual rules remain as the most reliable and robust classifiers, outperforming the ML/DL models.
4.4. Use of Rules as Additional Predictive Variables in ML/DL
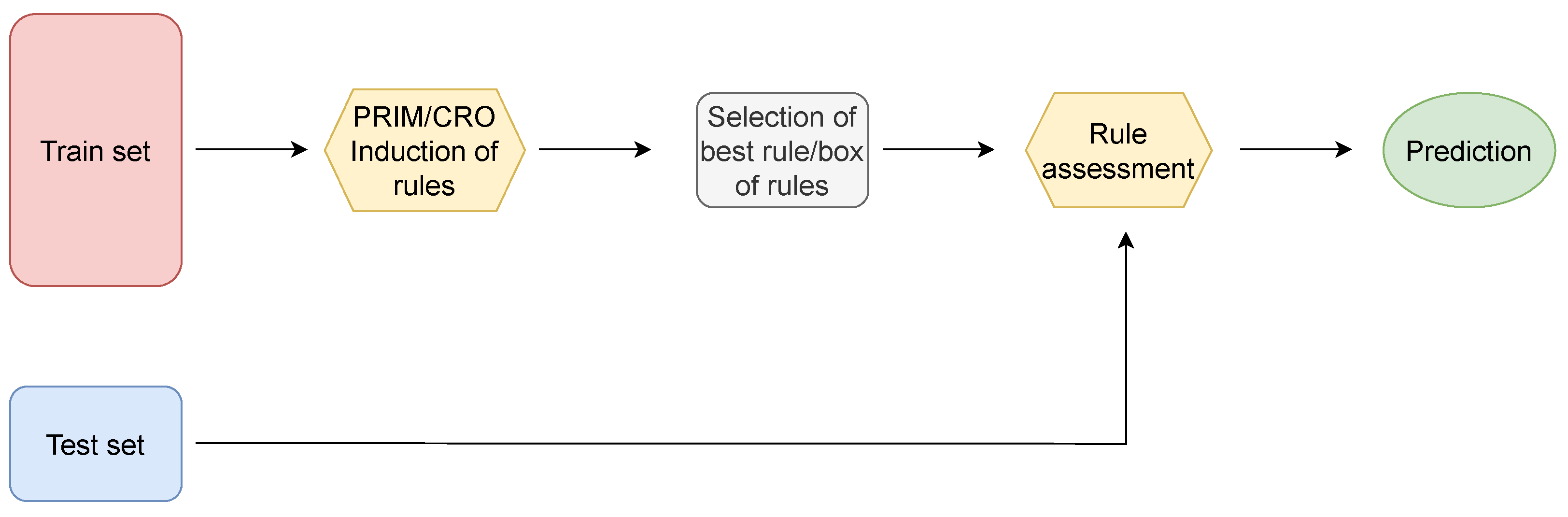
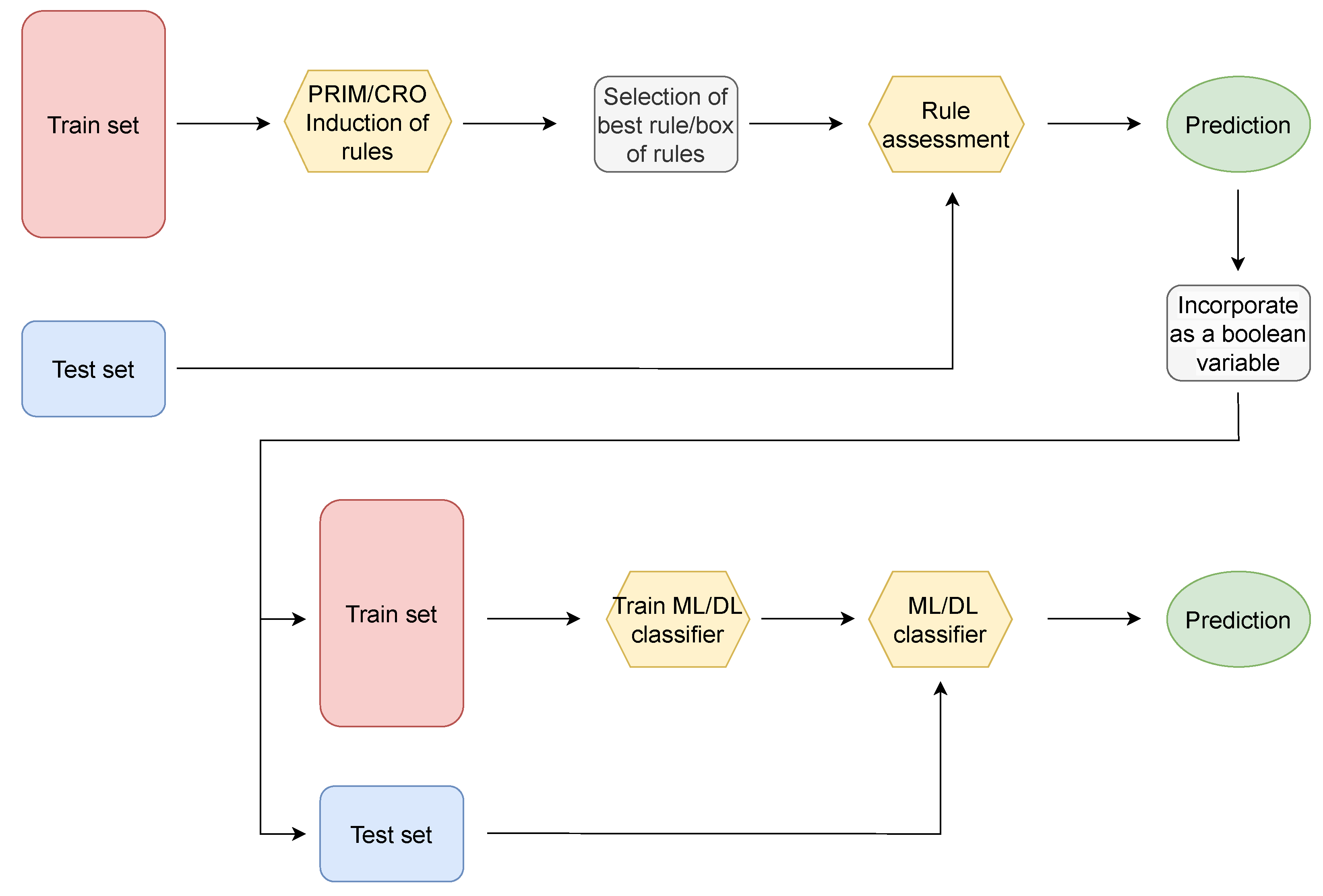
The second methodology implemented in this paper involves the use of the induced rules as an additional predictive Boolean variable in the ML/DL classification models. In this way, once the inducted rules have been assessed both on the train and test samples, a Boolean variable is created according to whether the rule (or box of rules) is fulfilled or not. This additional variable is then inserted in addition to the meteorological variables that form the train and test data. Subsequently, the ML and DL classification models are trained using the new training set, and their test predictions are further evaluated.
Figure 17 illustrates the flow diagram of the followed methodology.
Five different strategies were studied for selecting the additional variables to be introduced into the system, which are shown in
Table 3. The first and second cases consist of the selection of the best box of rules, corresponding with the one presenting the highest F1-score in the training data, both the PRIM-induced best box (Case 1) and the CRO-evolved best box (Case 2). The same approach was repeated using the best individual rules instead of sets of rules in Cases 3 (best rule induced by PRIM) and 4 (best CRO-evolved rule). Finally, Case 5 adds the four preceding cases’ variables to the database.
Next, the results obtained for the three prediction time horizons evaluated (+3 h,+5 h, and +10 h) are presented and discussed. Test error metrics for these experiments are further displayed in
Appendix B.
Table A4 displays the results for the +3 h prediction, revealing the substantial improvement in the three evaluated error metrics compared tothe classifiers experiment when introducing as predictive variables the information related to the different rules or sets of rules, both induced and evolved. It is noteworthy that the only models that maintain identical results are those with a boosting architecture (AB and GB), and it becomes apparent that the added variables do not contribute towards the ensembles that form these methods.
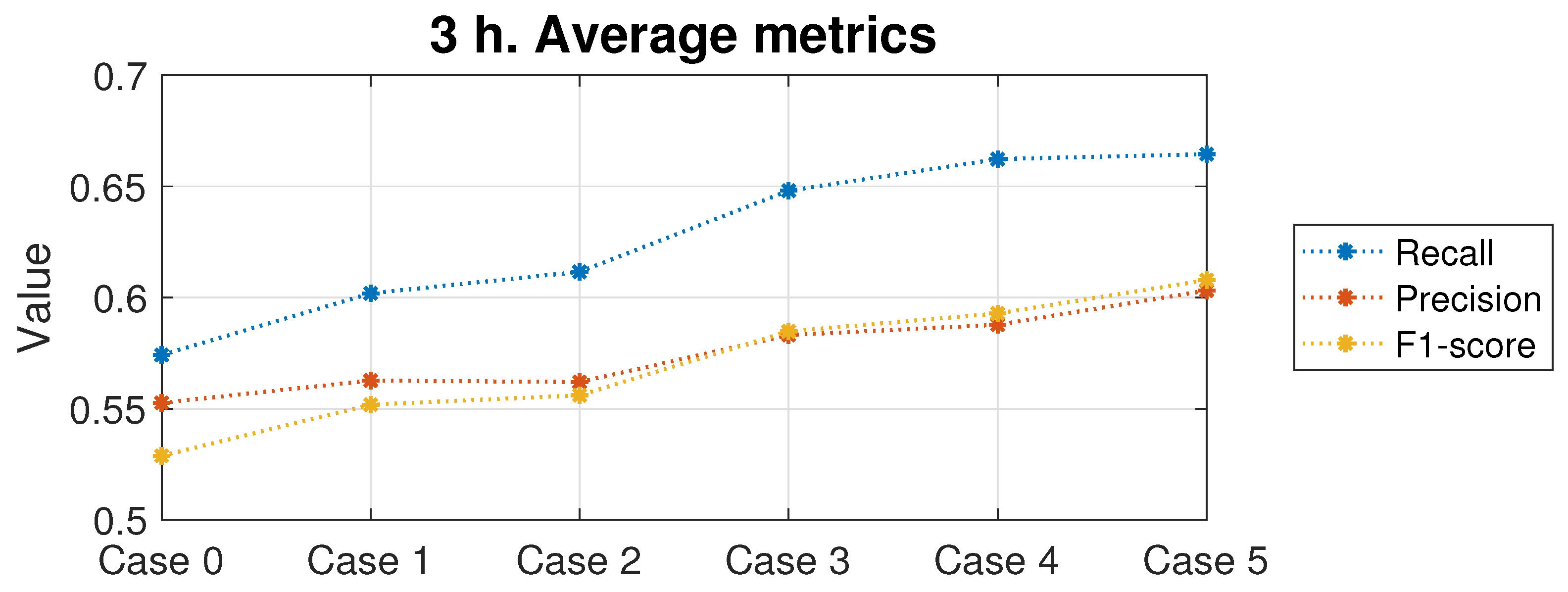
When comparing the different cases studied regarding which rules are introduced as additional variables, by observing the average of the error metrics from all classifiers, it can be noticed that Case 5 (which includes the four variables studied) is the one that achieves better results, improving the recall metric by 15.8% over the initial results, the precision by 9.1%, and the F1-score by 15.10%. For the sake of clarity, the average metrics of all classifiers for the six cases evaluated are represented in
Figure 18. Three conclusions can be drawn from this Figure: (1) the best performing case is clearly Case 5, the one adding the four additional variables into the system, meaning that the models perform better when handling all the possible information they can have; (2) Case 2 performs better than Case 1, and Case 4 performs better than Case 3, indicating that in both situations, whether dealing with individual rules or with sets of rules, it yields better results to work with CRO-evolved rules than with those induced by PRIM; and (3) Cases 3 and 4 perform far better than Cases 1 and 2, suggesting that dealing with a single rule is more efficient than working with a complete set of rules.
Subsequently, results for the 5 h time prediction horizon are shown in
Table A5 and
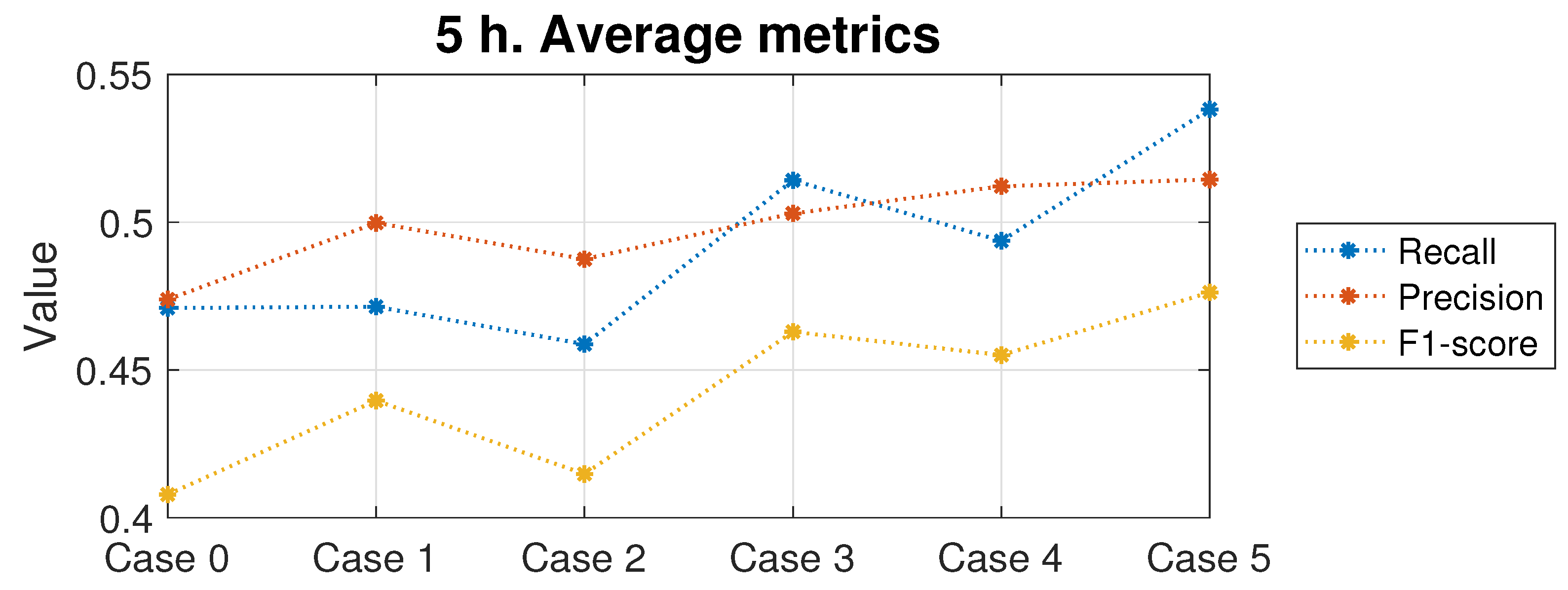
Figure 19. Again, a substantial improvement is observed in the performance of all the classification methods, except for the boosting methods, when adding the induced/evolved rules and boxes of rules as additional predictive features. Specifically, the average improvement shown by these models is 14.9% for the recall metric, 8.5% for the precision, and 17.1% for the F1-score, considering the best performing way of inputting the rule-based information into the systems: adding to the original database the four extra variables (Case 5).
Figure 19 illustrates the differences between the distinct cases evaluated. On this occasion, it is worth mentioning that the use of PRIM-induced rules and rule boxes (Cases 1 and 3) performs better than those evolved with CRO (Cases 2 and 4). However, undoubtedly, the best performing approach continues to be Case 5, with an important enhancement of the three error metrics considered.
Finally,
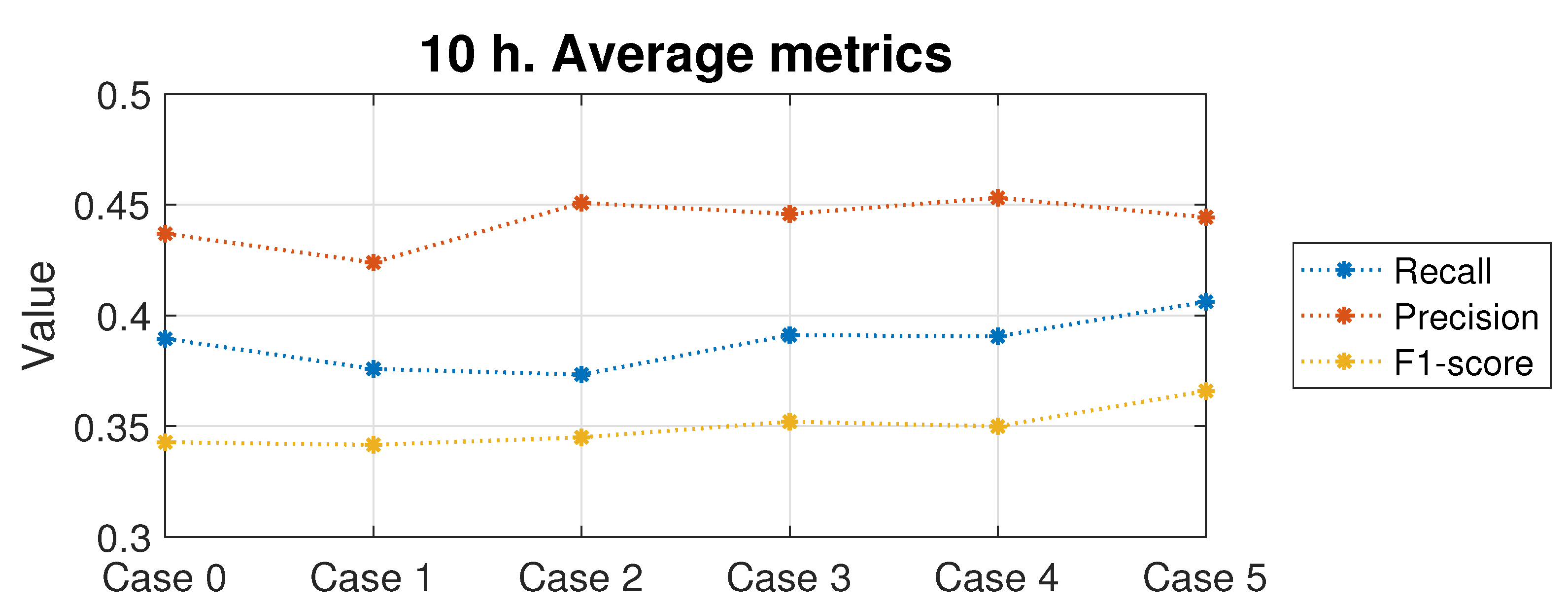
Table A6 displays the results for the 10-hour-ahead forecasting. In this case, with the exception of the SVC and KNN models, it can be observed how the improvements achieved are smaller than in the previous time horizons. Again, the best performing scenario is Case 5, providing an average improvement of 2.6% in the recall metric, keeping the same precision values and improving the F1-score by 8.8%.
Figure 20 illustrates how, in this long-term prediction case, Cases 1 to 4 exhibit very similar performances to the initial database. Only in Case 5, when adding all the supplementary variables to the database, are the recall and F1-score increased, though without any improvement in the precision metric.
5. Conclusions
In this paper, the prediction of extreme low-visibility events due to orographic fog at the A-8 motor-road (Galicia, Northern Spain) was tackled as a binary classification problem for three different prediction time horizons, covering from mid-term to long-term prediction problems (+3, +5, and +10 h). Specifically, the approach pursued in this work focused on the use of explainable classification models based on inductive and evolutionary decision rules. This approach eases the interpretation of the results, thus providing an understanding of the model mechanisms and of the reason why the predictions are obtained. This provides a critical piece of information that is especially relevant in challenging forecasting problems such as long-term predictions (10 h) of extreme low-visibility events, where the low persistence of fog significantly hinders the predictions. In these cases, having a physical explainability of the forecasts can help a committee of experts in decision making at an early stage.
As a preliminary step, a detailed analysis of the rules and sets of rules extracted by the PRIM and CRO algorithms was conducted, concluding that (1) accumulated precipitation and relative humidity are found to be the most important variables, consistently keeping their significance throughout the different time forecasting horizons evaluated; (2) visibility, wind speed, and salinity present a strong influence over the short- and medium-term forecast, but lose relevance in the long term; (3) regarding the medium- and long-term forecasting, the main significant variables arerelated to atmospheric pressure, air temperature, global solar radiation, and dew temperature; and (4) some variables, such as floor temperature and wind direction, are found to remain irrelevant and of no interest for the prediction of thick fog across the different prediction horizons.
The first evaluated methodology consisted of applying PRIM-induced and CRO-evolved rules as a possible simpler alternative to more complex ML/DL classification methods, with a reasonable performance in this particular case. Specifically, a comparison among different strategies of rules-based information application to forecast the presence or absence of thick fog was carried out, demonstrating some performance advantages of these rule-based strategies over conventional ML/DL classifiers, with slight improvements over the best classification model of 1.05% for the 3 h time horizon, 0.63% for the 5 h, and 6.13% for the 10 h (on the F1-score metric). These methods also offer a further strength over the ML/DL models, i.e., their complexity, computational costs, and training time are substantially lower, as they are far simpler models.
The second proposed strategy tested consists of the integration of the information provided by the induced/evolved rules in the ML/DL techniques, as additional predictive features, in order to enrich the complex ML/DL models. Different scenarios were tested to assess the most appropriate way to incorporate the rule-based information into the classification systems. This approach led to a significant enhancement of the classification models’ performances for the three prediction time horizons assessed, and the achieved F1-score improvement ratios attained values of 15.10% for the 3 h time horizon, 17.10% for the 5 h, and 8.80% for the 10 h.
In this work we showed how the use of explainable induced and evolved rules can be of significant interest in the prediction of extreme low-visibility events, providing strong results for complex forecasting problems such as long-term prediction. Note that the proposal in this paper is generalizable to any other location where orographic fog occurs. Future lines of research will consist of improving the way in which rule information is utilized for prediction, by implementing ensembles of rules or rule boxes with a higher level of complexity, combining the individual rules into a fuzzy-based controller to refine the final results obtained, or testing functional regression methods as final outcomes for the system.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















