1. Introduction
Heavy-duty diesel vehicles are one of the main tools for long-distance cargo transportation around the world, which have the advantages of flexible, convenient and low-cost transportation and play an important role in the national economy. However, due to their high fuel consumption, long mileage and high ownership, heavy-duty diesel vehicles have become an important source of nitrogen oxide emissions from motor vehicles. According to the “
China Mobile Source Environmental Management Annual Report (2021) [
1]”, diesel vehicle emissions of carbon monoxide (CO), hydrocarbons (HC), nitrogen oxides (NOx) and particulate matter (PM) accounted for 9.9%, 18.7%, 57.3% and 77.8% of national vehicle emissions in 2020, respectively. Therefore, the NOx emission control is the difficulty and focus of the current pollution reduction in heavy-duty diesel vehicles, but the effectiveness of standard control measures for heavy-duty diesel vehicles needs to quantitatively be evaluated based on accurate diesel vehicle transient emission models. The formulation of the current emission limit standard is based on the emission factor model under the laboratory cycle conditions, and the vehicle emissions are calculated by establishing the correlation between the emission characteristics of the motor vehicle and various influencing factors of the motor vehicle. The emission factor model serves as the basis for the emission inventory accounting and the formulation of emission reduction policies.
The current vehicle emission models are different in terms of computational requirements and the experimental physical input data. Some emission factor models, such as the MOBILE model [
2] developed by the U.S. Environmental Protection Agency (U.S. EPA), the EMFAC model [
3] developed by the California Air Resources Board (CARB) and the COPERT model [
4] developed by the European Commission, calculate the emissions based on the average speed of specific driving cycles. These models are usually used to estimate or predict macro-level traffic emissions in a specific area (regional area or city scale) for a specific time period of total pollution emissions (usually a quarter or a year), while ignoring the dynamic driving conditions. Another kind of emission model incorporate the instantaneous speed, acceleration/deceleration and other vehicle driving characteristic data to accurately reflect the emissions under different vehicle operating modes such as idle, steady-state cruise and various acceleration/deceleration levels, which are suitable for analyzing the emission of a single vehicle or a number of specific roads emissions calculation tasks. These models mainly include the IVE model [
5] and the CMEM model [
6] developed by the University of California, Riverside (UCR). The MOVES is a comprehensive model [
7] developed by the EPA, which can estimate emissions based on average velocity as well as operating conditions. It can be appropriate for both micro, meso and macro emission estimation. Due to the lack of basic data, the domestic research on emission factor models started late, and the foreign default values were directly used to evaluate local vehicle pollution emissions, resulting in large estimation errors.
In the last few years, there have been significant advancements in the field of vehicle emission modeling, driven by the widespread adoption of technologies such as Portable Emission Measurement System (PEMS) [
8] and OBD remote online monitoring [
9]. These technologies have enabled researchers to obtain actual road emission factors, which can be used to refine and improve emission models used in developed countries. Quirama et al. [
10] utilized PEMS to develop a methodology based on energy consumption analysis at a micro-trip level. This mode facilitated the assessment of real-world energy consumption and emissions for a fleet operating within a defined geographical region. Tsinghua University and other domestic institutions have developed the Beijing Vehicle Emission Factor Model (EMBEV) based on established emission models from foreign sources [
11]. Wang et al. [
12] employed a computational approach based on decision optimization to estimate road segment speeds using low-frequency GPS trajectory data. They combined this with a micro-emission model to estimate carbon dioxide emissions. Kumar et al. [
13] used 6 years of air pollution data from 23 Indian cities, selected relevant features through correlation analysis, solved the data imbalance problem by using resampling techniques and, finally, identified key pollutants directly affecting the Air Quality Index (AQI) using a machine learning approach. Wang et al. [
14] considered the influence of historical vehicle operating states and developed a microscopic emission model based on a BP neural network using short-term driving conditions. Xu et al. [
15] proposed a deep learning-based approach for exhaust gas telemetry data using COPERT emission factors. This approach involved constructing a three-layer self-encoder network to extract features from heterogeneous data sources such as meteorological data, road network data, traffic flow data and urban functional areas, thereby correcting the COPERT emission model. Yang et al. [
16] analyzed the actual CO
2 and NOx emissions of National IV buses using remote on-board diagnostic (OBD) data. They established a calculation method for CO
2 and NOx emissions based on OBD data. In light of the swift progress in artificial intelligence technology, there has been a notable emergence of innovative theoretical perspectives and sophisticated technical approaches. These advancements have brought about substantial changes in the landscape of research and analysis across traditional industries. Recently, there has been a surge in scholarly research focusing on the online monitoring of OBD vehicle networks. Xu et al. [
17] proposed a transfer learning-based approach for predicting mobile source pollution in the context of OBD pollution monitoring, specifically focusing on the impact of multiple external factors. The study utilized diesel vehicles as a case study and successfully achieved knowledge transfer across different vehicle models. Molina [
18] employed random forest to determine the most influential driver variables based on the best attributes of the training model using OBD II data. Rivera-Campoverde et al. [
19] addressed the challenge of estimating vehicle pollutant emission levels in the absence of an accurate model and limited measurement campaigns. They proposed a novel method for pollutant emission estimation by utilizing vehicle driving variables such as vehicle gear, engine speed and gas pedal position as inputs to a neural network model. The results of their approach closely aligned with those obtained from the IVE model and real driving emissions (RDE) test results. Wang et al. [
20] proposed a coherent methodology that utilizes the OBD system to collect operational data from heavy-duty diesel vehicles. Subsequently, an artificial neural network is constructed to develop an emission prediction model. This approach enables real-time monitoring of the vehicle’s emission status, providing valuable insights for environmental protection and vehicle management purposes. Chen et al. [
21] presented a methodology for gathering vehicle parameters, including speed, RPM, throttle position, engine load, etc., through the OBD interface. Subsequently, they employed the AdaBoost algorithm to classify driving behaviors, achieving an impressive accuracy rate of 99.8% across various driving scenarios.
However, the current emission model uses artificially designed parameters such as vehicle speed and acceleration to characterize the relationship between vehicle driving conditions and pollution emissions, where only the time domain information of vehicle driving conditions data came from multiple sensors is used to construct the emission model, without considering the frequency domain representation information of the vehicle engine states. The current emission models are mainly based on the traditional regression learning method, in which it is difficult to ensure the accuracy of the model representation and comprehensively describe the mapping relationship between the vehicle driving state and emissions under different working conditions.
The representative models are shown in
Table 1 (where VSP represents the instantaneous output power per unit mass of a motor vehicle). The data of these models come from bench tests and on-board tests and it is difficult to obtain accurate emission factors directly using these models on OBD data. Under the circumstance that it is difficult to fully verify the results of most emission models in China, the process application should be an important indicator of emission model selection. When calculating emissions, it is not necessary to choose the latest model. Different models are suitable for different regional situations and development stages Although the emission model based on operating conditions can better reflect the relationship between actual driving conditions and emissions, vehicle pollution control is still in the early stage in most cities in China, and there is a lack of statistical data on vehicle ownership and in-vehicle driving conditions. When the model input parameters are difficult to obtain and the accuracy cannot be guaranteed, it will not help even if there is a model that is fully applicable to the local area. The purpose of this work is to revise the emission model, and the primary consideration is the availability of model parameters for model selection, and the ease of building an a priori emission model. Considering the congruence between the emission standards and vehicular control technologies employed in China and Europe, coupled with the accessibility of the requisite parameters for the European-developed COPERT model, it is not surprising that COPERT has found extensive application in research related to pollution emissions from on-road mobile sources within China [
22,
23,
24,
25]. In light of these factors, this study has elected to utilize COPERT as the emission model of choice, subjecting it to amend for the purpose of calculating NOx emission factors within the OBD dataset.
Vehicle driving conditions play a pivotal role in determining emissions. When modeling on-road mobile source emissions, the focus is typically on establishing the relationship between the operational status of the mobile source and the level of pollutant emissions. The accuracy and validity of the model rely on the precise representation of the on-road mobile source’s operational status. Therefore, in order to modify the COPERT model to achieve the application of COPERT model on the OBD dataset, it is necessary to accurately represent the on-road mobile source operation state. However, the mobile source driving state is complicated and variable due to the influence of driving behavior, external environment and other factors, and it is not enough to accurately represent the mobile source driving state by only relying on the monitoring data at a certain moment. Therefore, considering the influence of historical information on the calculation of emission factors at the current moment is the key to our modification of the COPERT model.
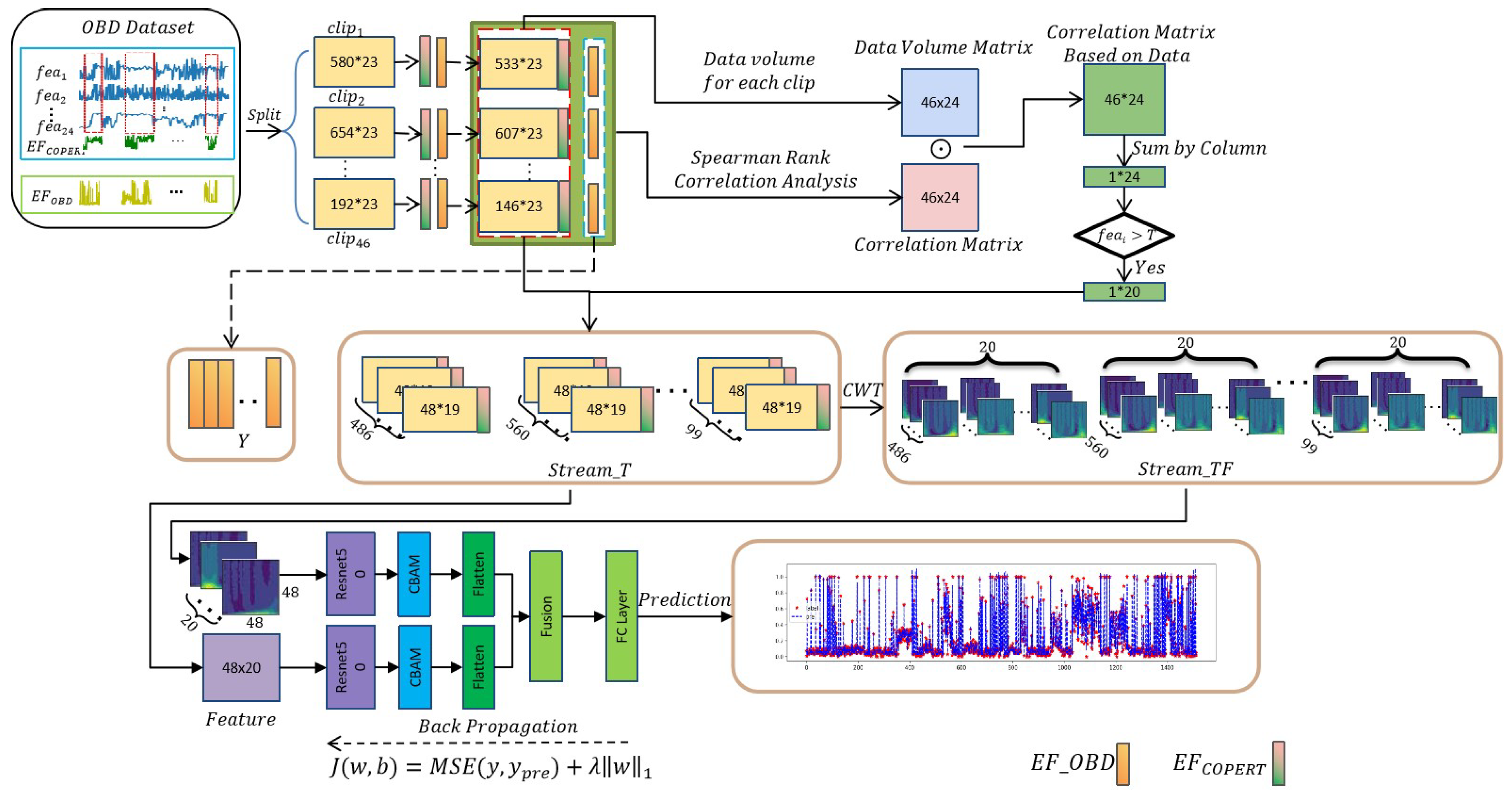
To address the aforementioned challenges in emission model construction, we propose a two-stream modification model based on the fusion of time-series and time-frequency features with historical information (HI_TTFTS). First, the actual emission factors of the OBD, using Spearman rank correlation analysis, are used to extract the correlation factors from the data volume for the measured data of the OBD, which are presented as not strictly continuous. Then, by utilizing the NOx emission factors alongside the corresponding attributes at the same time point, the historical information matrix is constructed. Subsequently, the continuous wavelet transform (CWT) is applied to obtain a multi-channel time-frequency matrix representation of the historical information. Finally, the two-stream model, consisting of ResNet and the convolutional block attention module (CBAM), is employed to incorporate both the time series matrix and the time-frequency matrix for model refinement. To assess the effectiveness of the proposed model, a comprehensive set of experiments was conducted. The results obtained from these experiments demonstrate the significant potential of our approach in accurately estimating NOx emission factors using online monitoring data from OBD vehicle networks. This innovative approach opens up new avenues for future research in this field.
The remaining parts of this paper are arranged as follows. We clarify the COPERT model and relevant deep learning models in
Section 2. In
Section 3, we present the details of the proposed time-frequency two-stream network model. The experiments and result analysis are presented in
Section 4. Finally, we conclude the paper and discuss the future possible extending work in
Section 5.
3. Methodology
In this section, we focus on the specific introduction of the model. Refer to
Figure 3, where we present a two-stream network model based on the fusion of time-series and time-frequency features of historical information to modify the COPERT model. Firstly, in view of the fact that the OBD data actually monitored are not strictly continuous in temporal terms, we divide the whole dataset into driving segments to obtain multiple continuous driving segments; Then, based on the amount of data in each driving segment, we use Spearman rank correlation analysis to select the correlation attributes with the emission factors of NOx obtained from the OBD data. Finally, the selected relevant attributes are used to construct the historical information matrix, and the corresponding historical information matrix is converted into a time-frequency matrix using CWT, and the historical information matrix and the time-frequency matrix are used as inputs in two parallel structures combined by ResNet50 and CBAM to complete the correction of the COPERT model and achieve the emission factor of NOx using the COPERT model on the OBD dataset.
3.1. Data Description
In this paper, the experiment uses the actual travel OBD data of a diesel vehicle collected in Hefei in 2020, the engine attributes and sampling standard of this diesel vehicle are shown in
Table 4.
In the data preprocessing phase, the collected raw data underwent several steps. Initially, irrelevant attributes were removed, followed by anomalous records with values of 0 for vehicle speed, NOx concentration and instantaneous engine fuel consumption rate.
Table 5 provides an overview of the attributes and their corresponding symbols in each dataset after the completion of the preprocessing stage.
3.2. Data Processing
In the actual correction phase of the COPERT model, we need data that are as continuous as possible in time series with complete labeling of each record. However, the OBD data collected for the actual road driving cannot be collected directly due to their inherent non-strict continuity in time series and the to be corrected and the as a label. We need to divide the pre-processed dataset into continuous driving segments and obtain the emission factors for NOx. The data processing methods in this paper are Driving Segment Division and Get Emission factor of NOx.
3.2.1. Driving Segment Division
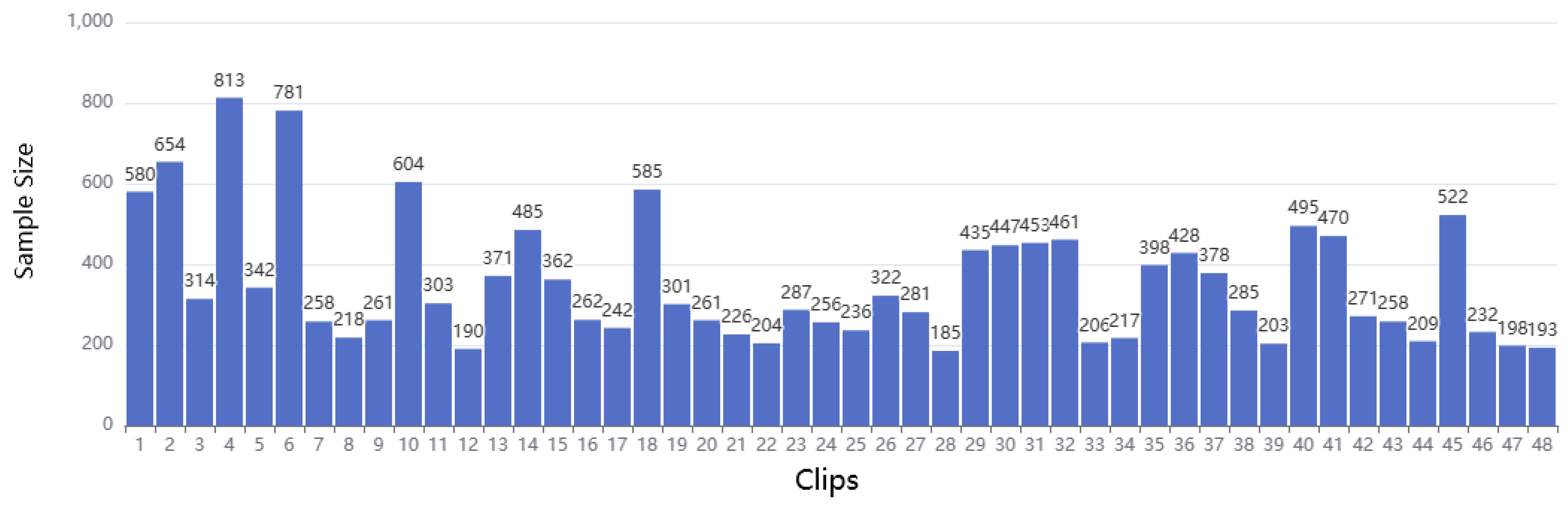
Considering that the dataset consists of real-world driving data from a diesel vehicle collected across several days, it contains consecutive driving segments, resulting in a presentation of the data that is not strictly continuous. During preprocessing, irrelevant records were removed, causing a division in the continuous driving segments and further division in the already non-strictly continuous records. However, it is important to note that the records without delay preceding and following the removed erroneous records are still regarded as continuous. Therefore, It is essential to determine an optimal upper limit for the continuous time interval when partitioning the dataset into driving segments. This ensures that the impact of removing invalid data during preprocessing is minimized.
In this study, we have defined a maximum time interval of 180 s. Any records with intervals exceeding this threshold are considered as separate driving segments. After the initial screening, each piece of the drive contains a varying number of records. To ascertain that each selected driving segment is of sufficient length for calculating emission factors based on historical information, we have set the minimum number of records per segment to 180, which is equivalent to a duration of 15 min. The data volume for each segment is presented in
Figure 4.
3.2.2. Obtaining NOx Emission Factors
In the process of obtaining emission factors, the emission factor for the
k-th record is determined by considering the collective data from the first record to the
kth record. The specific criteria for selecting
k will be explained in more detail in
Section 4. As we encounter the challenge of computing the NOx emission factor for the initial
k-1 records within each driving segment during emission factor calculation, we initiate the process for each driving segment from the
kth record onwards and align the computed emission factors
and
with the corresponding timestamps. Furthermore, our dataset lacks the measurement of the engine fuel volume flow rate
, thus we derive
using the following formula.
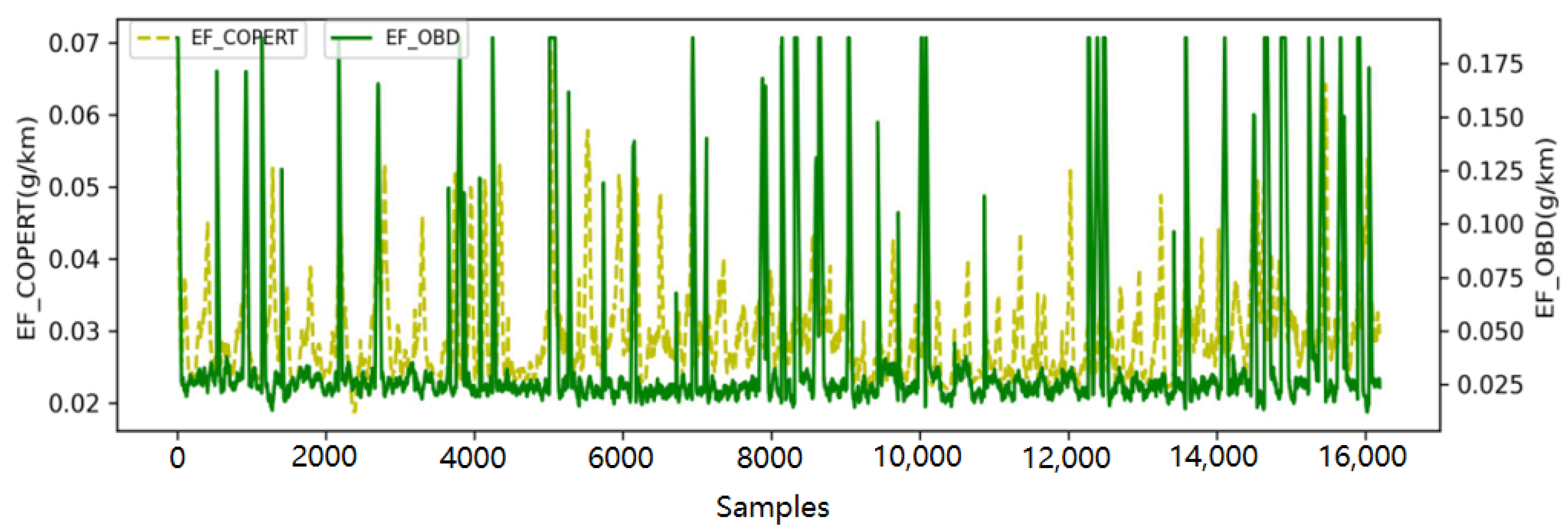
By using Equations (1)–(3),
and
were computed. The results are shown in
Figure 5 (taking
k = 48 as an example). The figure illustrates that, in the majority of data records, the peaks of
are lower than those of
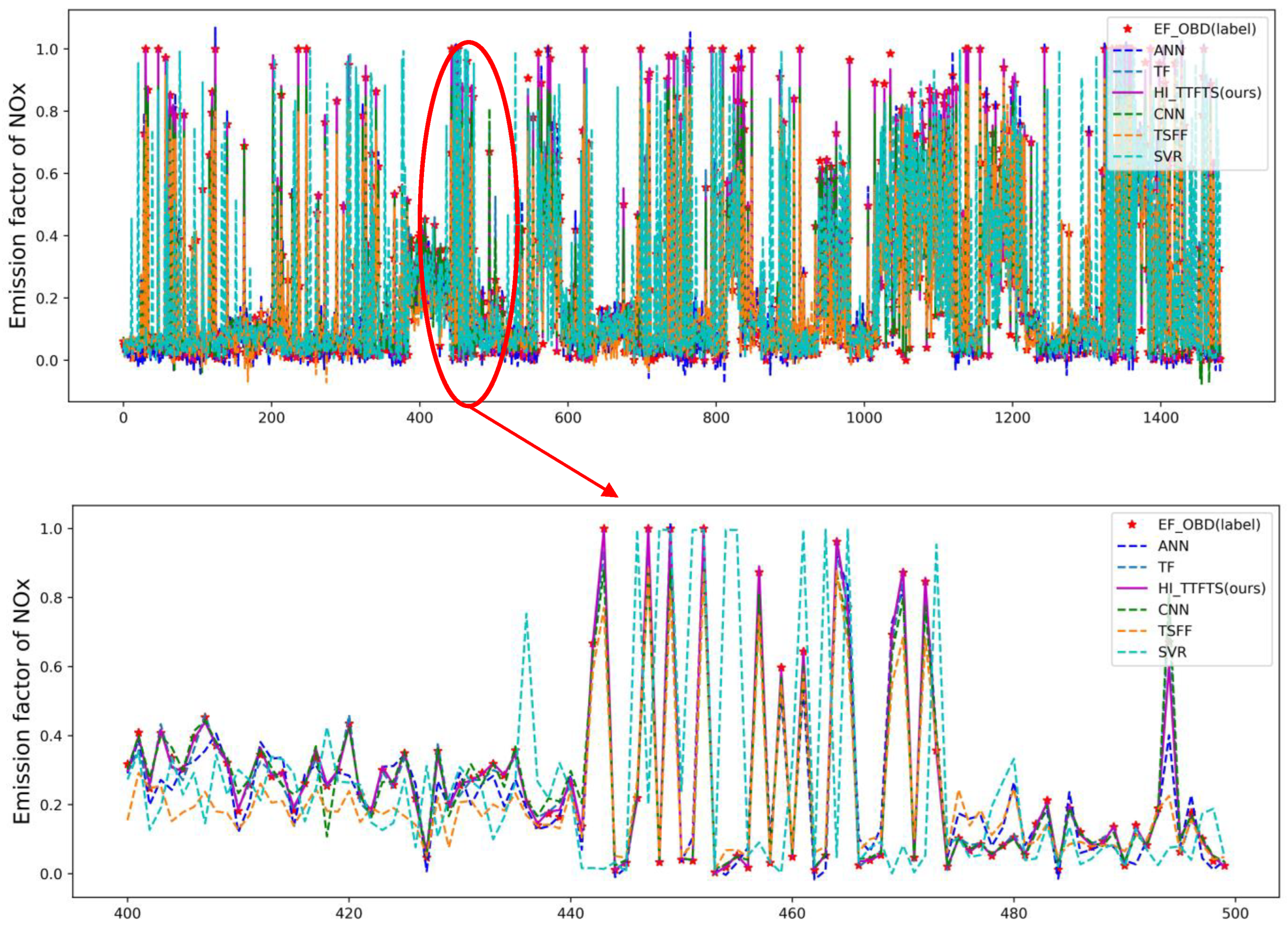
, while the troughs are higher. Directly observing common characteristics of the two trends is challenging. This indicates a substantial disparity in the NOx emission factors calculated by the COPERT and OBD models. Simply deriving emission factors from the COPERT model and adjusting them to fit the OBD data using specific mathematical formulas is difficult.
3.3. Screening of Correlation Factors
The impact of each attribute derived from OBD data on the calculation of emission factors varies. Attributes with low correlations have minimal influence during the training of the model. This not only hampers the enhancement of model performance but also increases the number of model parameters. Thus, it is essential to choose factors that demonstrate strong correlations with before initiating model training.
In our work, Spearman correlation analysis is used by us to select the attributes that have high correlation with . Using Spearman correlation analysis for a continuous dataset, we can easily derive correlations among attributes using the t-value test; however, our data are multiple continuous driving segments and there are differences in data volume. Therefore, we propose a correlation factor screening based on the amount of data for each model.
The data correlation analysis for multiple driving segments is shown in
Figure 3. We computed the direct Spearman correlation coefficients between
and other factors (including
) in all driving segments separately and chose
t = 1.645 for hypothesis testing to determine whether
is strongly correlated with other attributes in that form segment. Based on this, we extracted all other driving segment attributes that were correlated with
and constructed a correlation matrix
C. Each row in
C represents the correlation of each attribute in the driving segment with
and
, where 1 represents a strong correlation and 0 represents a weak correlation, and each column in
C represented a specific attribute type. To accommodate variations in data volume across different driving segments, we generated a data volume matrix
D. Each row in
D corresponded to a specific driving segment, and the values in each column represented the data volume of that driving segment. We then computed the Hadamard product of matrices
C and
D (with
C being the element-wise matrix of
D). The values in the resulting matrix represent the correlation of each driving segment attribute with respect to
based on the current amount of data. Finally, the summation of each column in this matrix yielded the correlation data volume matrix
, which is visually depicted as illustrated below.
Within the equation, denotes the data quantity linked to for the i-th attribute, represents the data quantity associated with versus , and ⊙ signifies the Hadamard product. The data quantity for each attribute in is compared against the predefined threshold of correlation data . An attribute is considered strong correlation if . The final correlation attributes obtained are then combined with to obtain the final dataset.
3.4. Two-Stream Model Based on Historical Information
As shown above, we have constructed an input matrix based on the NOx emission factor about k-1 segment history information under multiple external factors. Briefly, each column of the input matrix represents one-dimensional time-series information of a certain attribute, which indicates that the whole matrix is from the time domain and is a time-series matrix containing multidimensional time-series information. To convert the one-dimensional temporal signal into a two-dimensional time-frequency matrix for each column of the input matrix, the Continuous Wavelet Transform (CWT) can be utilized. This transformed time-frequency matrix can represent both the time and frequency domain information of the information collected from heavy-duty diesel vehicles. It offers a clear representation of the correlation between signal frequency and temporal transformation.
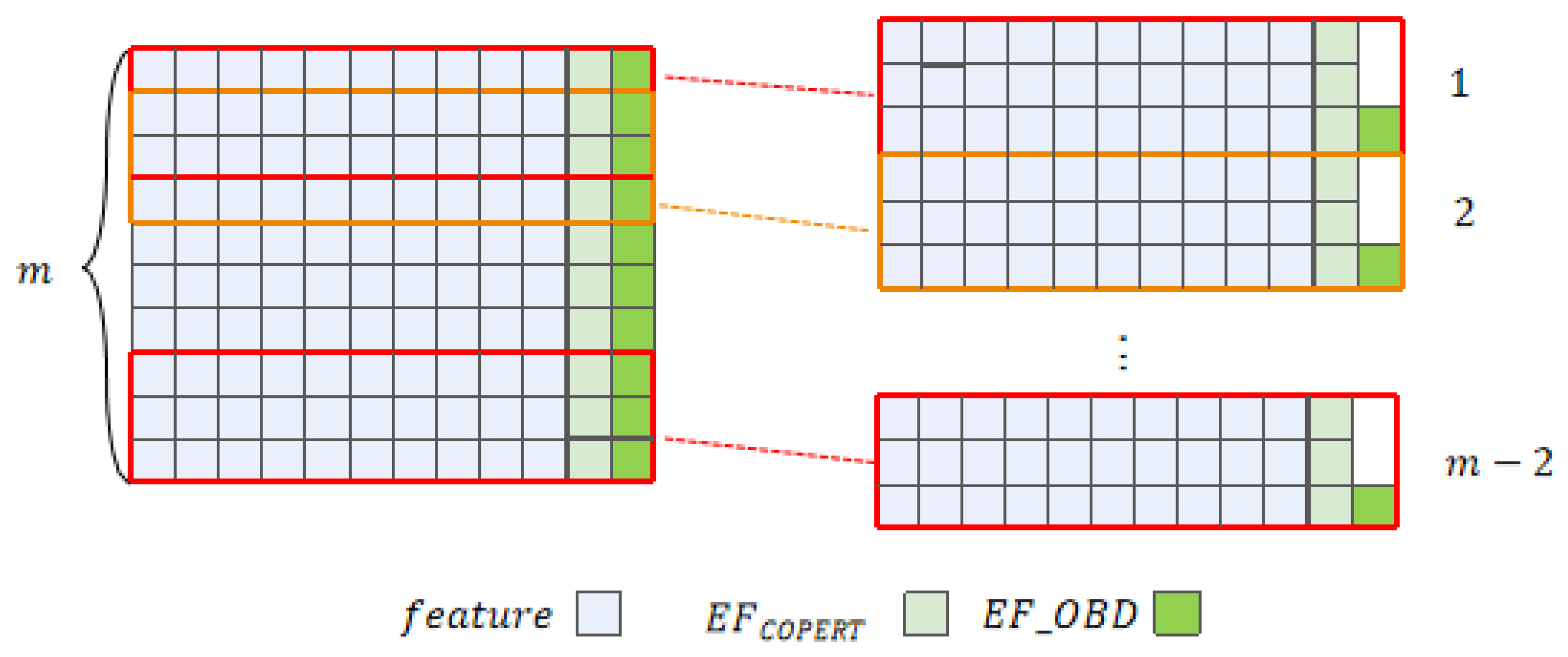
3.4.1. Historical Information Matrix Construction
After the above series of operations, we get the driving segments that combine emission factors and keep only the attributes strongly related to
. For each driving segment, with
k as a step and
as the label, In order to construct a historical information matrix, we take the driving segment with
k = 3 and length m as a representative example. Within each matrix, the first two records represent the historical information, while the third record represents the current information. The corresponding
value for the current information is used as the label. This procedure yields a total of
m − 2 matrices, as shown in
Figure 6.
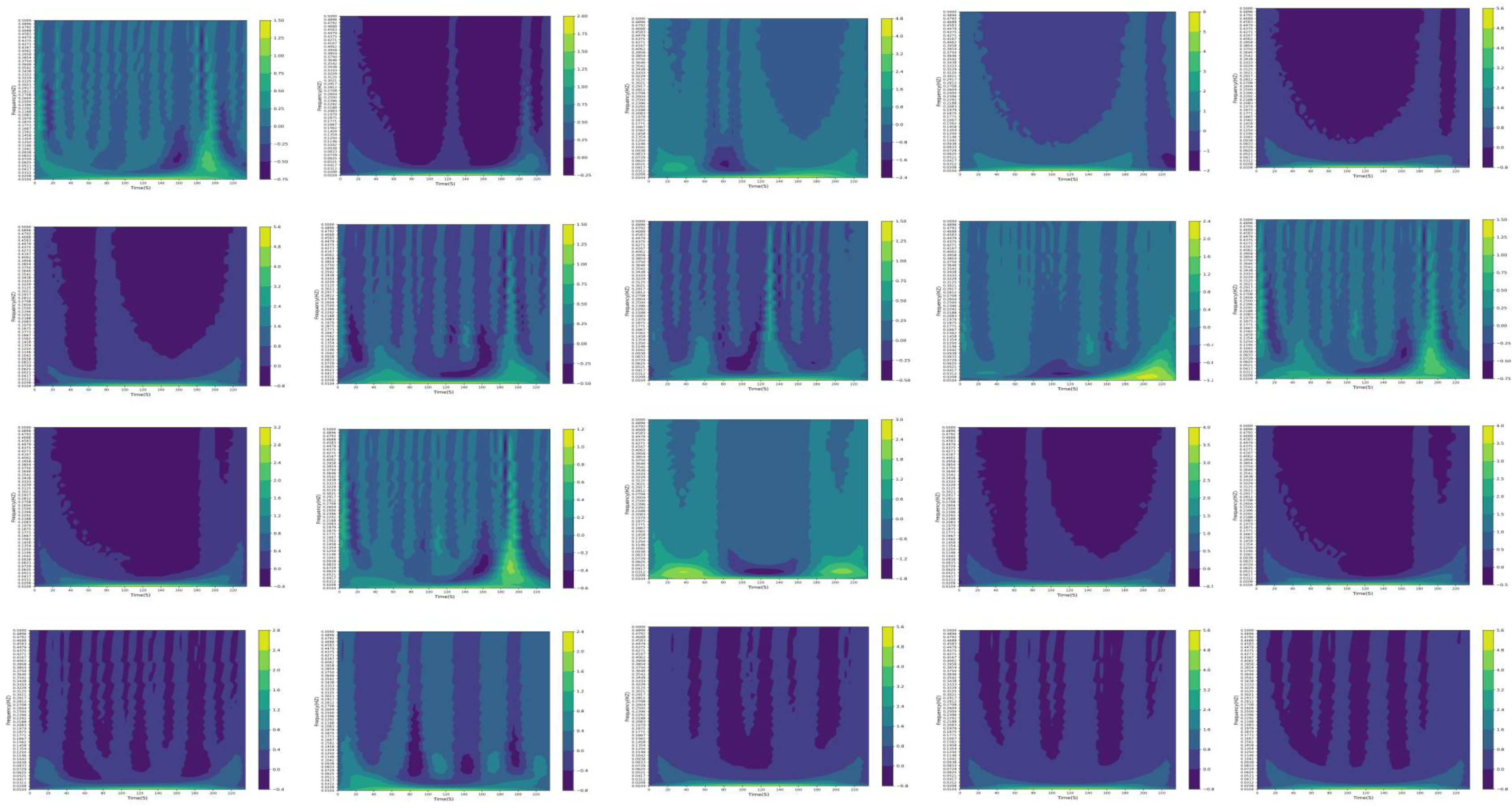
3.4.2. CWT
For each column in the historical information matrix, the application of the continuous wavelet transform allows for the conversion of the one-dimensional time-series signal into a two-dimensional time-frequency matrix. This transformation facilitates the visualization of the emission attribute signals from the mobile source, revealing their characteristics in both the time and frequency domains. It provides a clear depiction of the relationship between signal frequency transformation and time. CWT is performed on a historical information matrix (
k = 48,
= Q2), and the resulting time-frequency matrix is visualized as shown in
Figure 7.
For CWT, the choice of wavelet basis functions has a large impact on the effect of wavelet transform. To evaluate the conversion effect of CWT, for a variety of wavelet basis functions, we consider the converted time-frequency matrix as a gray-scale map, and based on the amount of data, we construct a quality index (
) index using information entropy (IE) and Laplacian gradient (LG) to evaluate its converted time-frequency map, where IE is used to measure the uncertainty of the information source and LG is used to evaluate the clarity of the gray-scale map. The formulaic description of the quality index (
) is as follows:
In the provided equation, represents the number of features, while denotes the cardinality of the combined training and validation datasets. The expression is utilized to quantify the relative frequency of grayscale values with pixel value i in an image of dimensions mn, where the grayscale range spans from 0 to 255. In this context, signifies the occurrence count of pixel value i within the image. The symbol represents the convolution operation involving the Laplacian operator at the pixel coordinate (x, y), and Laplacian operator .
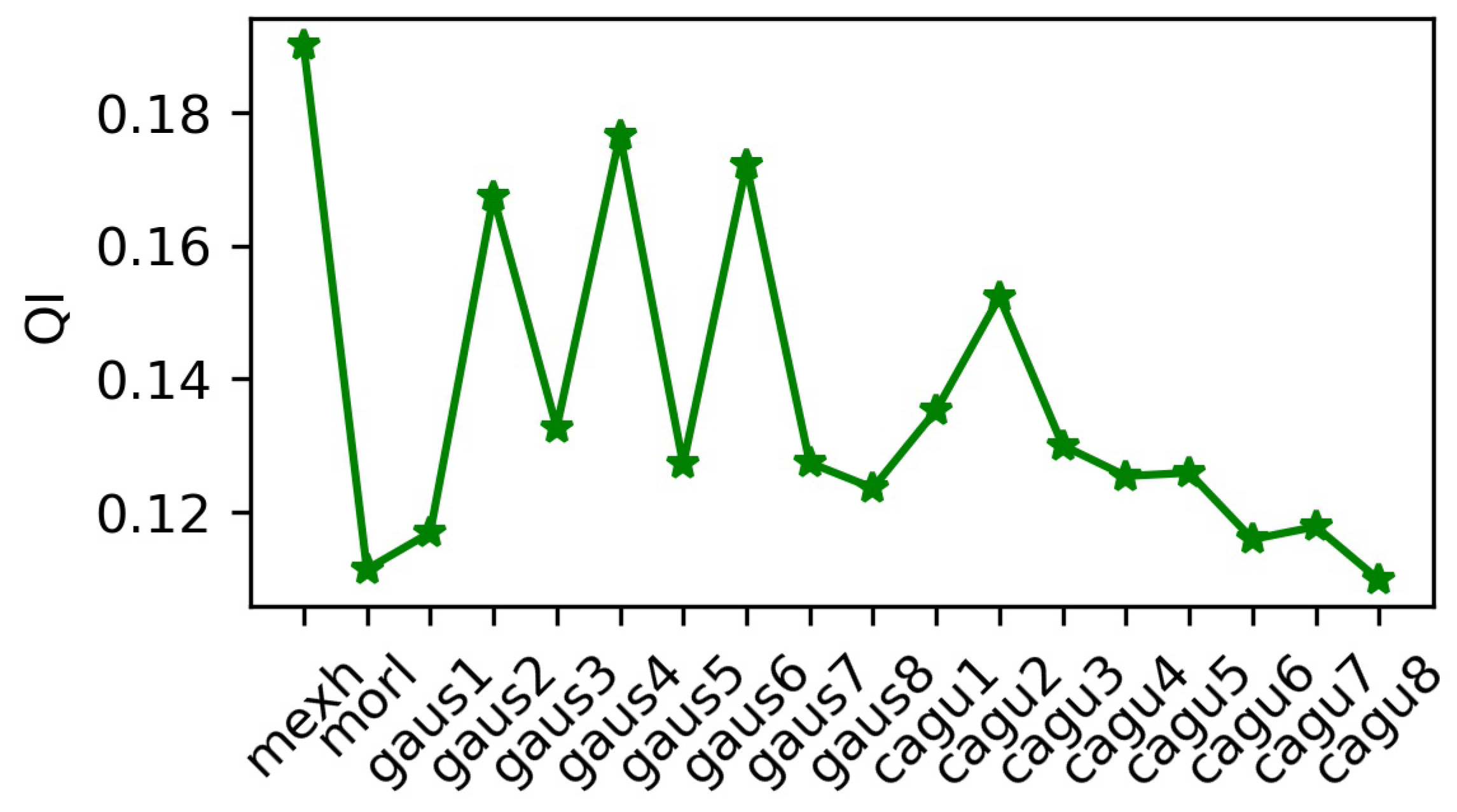
By using the
indicator, the quality of each wavelet basis function is shown
Figure 8 (
k = 48), where the mexh wavelet basis function has the largest
value and the best conversion. Therefore, the
function will be used for the continuous wavelet transform in the subsequent experiments of this paper. After CWT, the time-frequency matrix obtained for each relevant attribute and
is superimposed into a multi-channel matrix as the final time-frequency stream input.
3.4.3. Two Stream
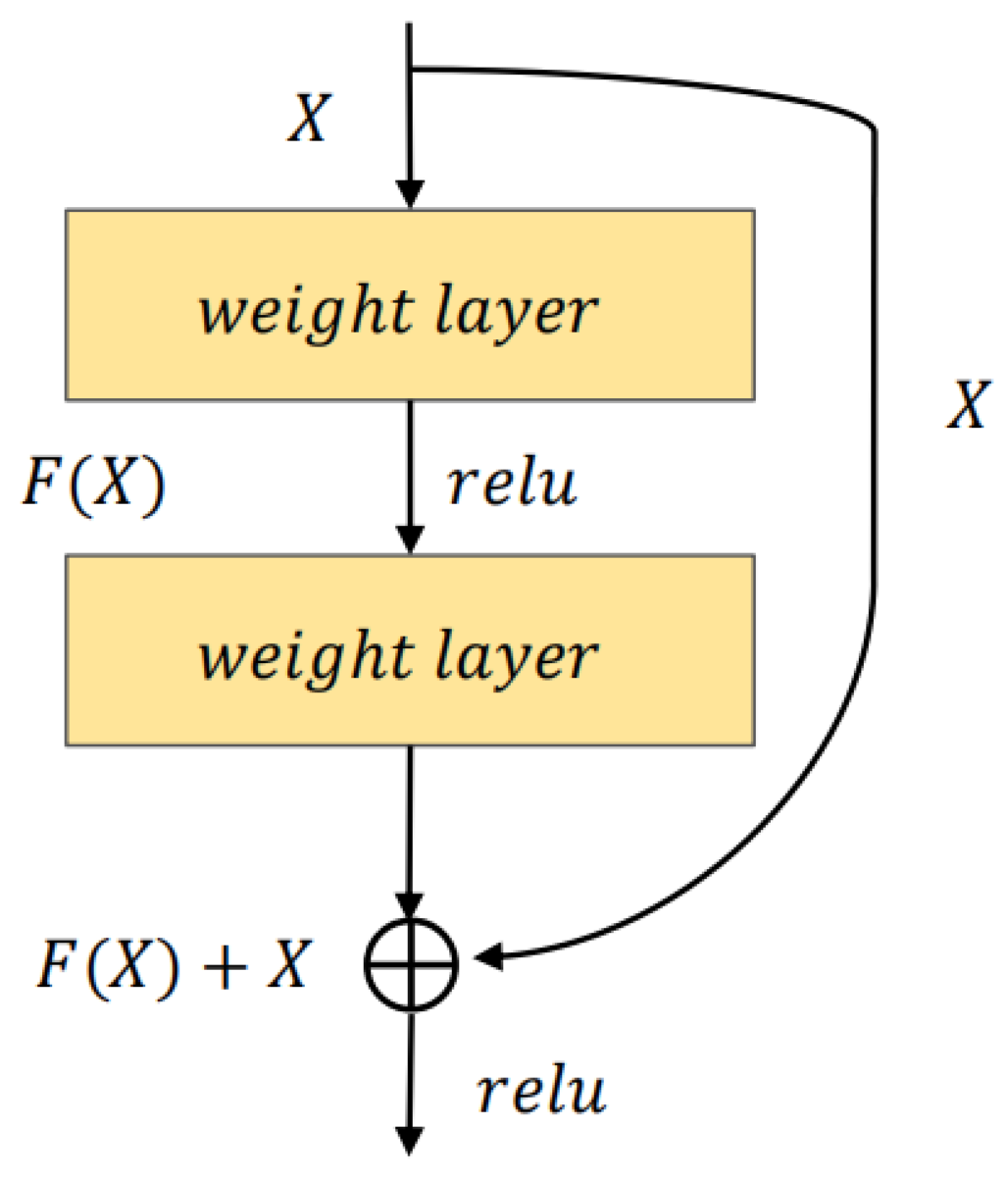
In this paper, we use a combination of ResNet50 and CBAM to extract historical features. The CBAM module is added after the stage four output.
The two stream models use a combination of two parallel Resnet50 and CBAM, and after averaging the pooling layers, the output size of the two stream models is
, which is reshaped to
, and then the reshaped features are fused. Feature fusion is a mid-level fusion between data fusion and decision fusion [
44]. It can eliminate redundant information due to correlation between different feature sets. The features extracted from the time-series stream and the time-frequency stream are fused and the strategy is defined as follows.
where
b represents the bath sequence number,
T is the temporal flow characteristics and
is the time-frequency flow characteristics.
After passing through the feature fusion layer, the model can obtain a more comprehensive and accurate evaluation structure. Finally, the fused feature vectors are fed into the FC layer to achieve one regression prediction. The loss function is as follows, where the first term MSE is used to ensure the prediction performance in training and the second term
norm is used to prevent overfitting.
where
,
w is the weight,
b is the bias,
y is the label and
is the model prediction.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}