1. Introduction
Fine particulate matter (PM
2.5) refers to particles in ambient air with an aerodynamic equivalent diameter of 2.5 μm or less. PM
2.5 affects the environment and climate [
1] and is also extremely hazardous to human health [
2,
3]. Based on micro-level studies on PM
2.5 formation mechanisms, an increasing number of studies have confirmed that, as an atmospheric pollutant, PM
2.5 has obvious regional transport characteristics [
4,
5]. The distribution of PM
2.5 is more influenced by macro-level factors, and scholars have explored the effects of land use, transportation, and meteorological conditions on PM
2.5 [
6,
7,
8,
9]. Land is closely related to PM
2.5. On the one hand, different land use types are sources or sinks of PM
2.5 [
10,
11]. The artificial surfaces not only carry many pollution emission sites such as factory emissions and traffic emissions, but also have difficulty in blocking and adsorbing dust, making regional PM
2.5 concentrations prone to increase. Vegetation cover such as forestland has a strong adsorption effect on air pollutants, which helps to reduce regional PM
2.5 concentrations. On the other hand, regional land use patterns also influence local climate and thus have an indirect effect on PM
2.5 [
12,
13]. Studying the influence of land use on PM
2.5 means understanding the formation mechanism of this pollutant from a systemic perspective, to guide the rational development, use, and protection of territorial space. In addition, it can also predict and simulate the spatial distribution based on the quantitative study of the relationship between land use and PM
2.5 [
14,
15,
16].
Based on the relationship between PM
2.5 and related factors, the regression relationship between station monitoring data and elements such as land use can be analyzed, and a regression model of PM
2.5 and these factors can be developed to simulate concentrations within the region. This method has been applied in the Small Area Variations in Air Quality and Health (SAVIAH) project in Europe, where scholars have mapped air pollution distribution based on regression methods, using land use, traffic, and other relevant factors as explanatory variables [
17]. The method came to be known as the land use regression (LUR) model. Instead of pursuing complex physicochemical processes, LUR models are based on the analysis of the relationship between air pollutant concentrations and relevant factors, and can make predictions according to measured data [
18,
19,
20]. Currently, the LUR model begins to be applied to the study of environmental issues besides atmospheric pollutants [
21]. In addition, the development of the LUR model presents an in-depth trend from different angles. Scholars have conducted extended research from different perspectives. Firstly, the data used for modeling have been further enriched. Landscape pattern indicators, aerosol optical depth, point of interest (POI), and three-dimensional (3D) data are introduced into the model to help improve the accuracy and the spatio-temporal resolution of the simulation [
22,
23,
24]. Secondly, the spatio-temporal scale of the study has been expanded. LUR was first used to simulate mean concentrations at urban spatial scales and over long periods. However, now there are studies on the distribution of pollutants at different points over 24 h, spanning across provinces, urban clusters, and countries [
25,
26,
27]. Lastly, and most importantly, LUR modeling methods have developed significantly. Nonlinear regression, geographically weighted regression (GWR), generalized summation models, and machine learning have effectively improved the models [
28,
29,
30]. Therefore, here we take Zhejiang Province as the study area and estimate PM
2.5 concentrations using LUR, GWR, and random forest (RF). In previous studies, applying LUR at province-level administrative units in China [
22,
23,
31,
32], Liu et al. used land use, population density, road networks, and distance to the ocean data to simulate the spatial distribution of PM
2.5 concentrations in Shanghai [
31], but ignored POI, meteorological, and socio-economic factors. Wu et al. used land use, population density, road length, and POI data to estimate spatial variations in PM
2.5 in Beijing [
22], but did not consider meteorological and socio-economic factors. We used more comprehensive predictor variables, including land use data, road data, POI data, meteorological data, and socio-economic data. Moreover, in studies predicting PM
2.5 concentrations in China, few studies compared the spatial distribution results and model accuracy of LUR, GWR, and RF, while we provide a comparative analysis of the models.
Zhejiang Province’s strong internal linkages in economic and social activities, rapid economic growth, rising population, and increasing urban scale have put enormous pressure on the regional atmospheric environment. As one of the major provinces in the Yangtze River Delta region, the duration and influence of hazy days in Zhejiang Province has been increasing since the 1970s, especially since 2000 [
33]. A previous study shows that from January 2015 to April 2018, the change in air quality in northern Zhejiang was worse than that in southern Zhejiang. For example, the air quality in Hangzhou, the capital of Zhejiang Province, decreased by 6.69%. In contrast, the air quality in Lishui and Zhoushan in southern Zhejiang improved by 8.04% and 4.67%, respectively [
34]. As the industrial structure continues to be optimized, and as the Air Pollution Prevention and Control Action Plan is implemented in full, PM
2.5 pollution in Zhejiang Province has improved significantly in recent years. The Department of Ecology and Environment of Zhejiang Province has issued a range of PM
2.5 concentrations of 15–28 µg/m
3 for the 11 cities in 2021. Further studies are needed to track its changing characteristics. Based on the mechanism and characteristics between PM
2.5 and land use, the LUR model can be better applied to PM
2.5 spatial distribution simulation, which helps us study the PM
2.5 distribution characteristics in Zhejiang Province. It also helps us understand the causes of pollution to a certain extent, and to explore the inner formation mechanism of the influence of land use structure and other factors on PM
2.5. The main objectives of the study are: (1) exploring the correlation between PM
2.5 and the explanatory variables in the study area; (2) establishing a basic LUR model and improved LUR models based on GWR and RF methods for more accurate regional PM
2.5 simulation; and (3) providing a comparative analysis of the LUR, GWR, and RF.
3. Results
3.1. The Basic Land Use Regression Model
In the multiple stepwise linear regression, the variable Y in the regression model is the average PM2.5 concentration in 2020 at each station. The most significant explanatory variable was gradually added to the regression equation. Based on the regression coefficients and statistics, the variables that were not significant or could not improve the fitting effect were removed until there were no variables that needed to be removed or no variables that could be introduced. Moreover, as samples with absolute values of standardized residuals greater than 2.5 affect the normal distribution of residuals, these samples need to be excluded. Therefore, the final model was constructed based on 48 samples.
The multiple stepwise linear regression model contains three explanatory variables, namely the area of artificial surfaces within a 10 km buffer zone radius, the area of forestland within a 10 km buffer zone radius, and the wind speed.
Table 2 shows the multiple stepwise linear regression model parameters. The model was better fitted with an adjusted R
2 of 0.645. The root mean squared error (RMSE) was 2.46, with good accuracy. The standardized coefficients of artificial surfaces, forest land, and wind speed were 0.416, −0.446, and −0.525, respectively. In addition to reflecting the direction of each factor’s contribution to PM
2.5, it also indicates that wind speed plays a relatively more important role in reducing PM
2.5 pollution when the land use type is similar. In summary, the equation for the multiple stepwise linear regression is shown below:
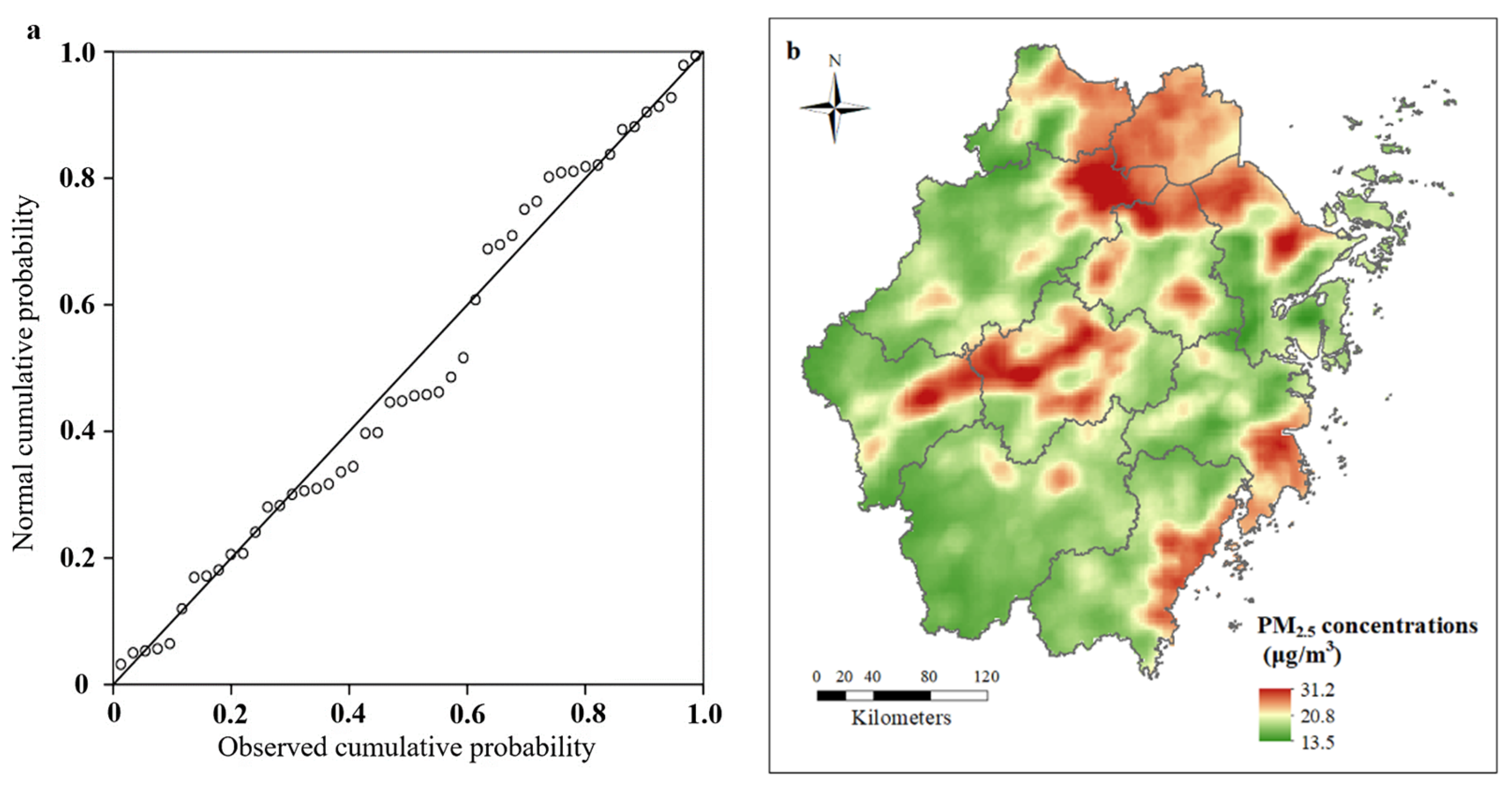
The constructed regression equation was subjected to residual analysis to verify the reasonableness of the hypothesis and the reliability of the data. The significance of the Kolmogorov–Smirnov (K-S) test was 0.200 and the significance of the Shapiro–Wilk (S-W) test was 0.505, and the residuals were consistent with a normal distribution.
Figure 3a shows the probability–probability (P-P) plot of the standardized residuals. The scatter was distributed around the straight line y = x, indicating that the standardized residuals conform to a standard normal distribution, verifying that the regression hypothesis holds and that the data are reliable. The accuracy of the constructed model was then tested using the leave-one-out cross-validation method, and the RMSE was 2.56. Based on a 2 km × 2 km fishnet, Zhejiang Province was divided into a total of 26,329 grids, and each grid’s area of artificial surfaces within a buffer zone of 10 km radius, the area of forestland within a buffer zone of 10 km radius, and the annual average wind speed were extracted. The values of the explanatory variables were substituted into the obtained model and the gridded PM
2.5 concentration values were calculated to simulate the spatial distribution of PM
2.5 concentrations, as shown in
Figure 3b.
3.2. Improved LUR Model Based on Geographically Weighted Regression
Since only a few variables were ultimately included in the regression equation, some variables that affect PM2.5 concentrations were ignored. In particular, there were differences between regions in socio-economic and natural environment, which may cause the relationship or structure between the explanatory variables and PM2.5 to change spatially. Therefore, this study considered the spatial heterogeneity and further analyzed the effect of the relevant factors in different regions based on the GWR method.
To avoid global multicollinearity between variables in the GWR, three factors, the area of artificial surfaces within a 10 km buffer zone radius, the area of forestland within a 10 km buffer zone radius, and the wind speed, were used as explanatory variables for the analysis.
Figure 4 shows the coefficient of the three variables in the GWR. The results show that the area of artificial surfaces has a positive effect on the increase in PM
2.5 concentration. This is attributed to the rapid expansion of artificial surfaces as urbanization progresses, gathering a large number of industrial activities, energy emissions, etc., which directly contributes to the increase in PM
2.5 concentrations [
11]. The coefficient of artificial surfaces gradually increases from northeast to southwest. This indicates that the area of artificial surfaces in southwest Zhejiang has a stronger positive effect on the increase in the PM
2.5 concentration than that in northeast Zhejiang. The area of forestland has a negative effect on the increase in PM
2.5 concentration. This is due to the dust-blocking effect of the vegetation leaves and absorption effect of the stem surfaces to weaken the PM
2.5 concentrations [
43]. The absolute value of the coefficient of forestland gradually increases from southwest to northeast. This indicates that forestland in northeast Zhejiang has a stronger negative effect on PM
2.5 than in the southwest region. The coefficient of wind speed shows a trend that is higher in the east and lower in the west. As in the case of the annual mean wind speed, the effect on decreasing PM
2.5 concentration may be enhanced as the wind speed increases.
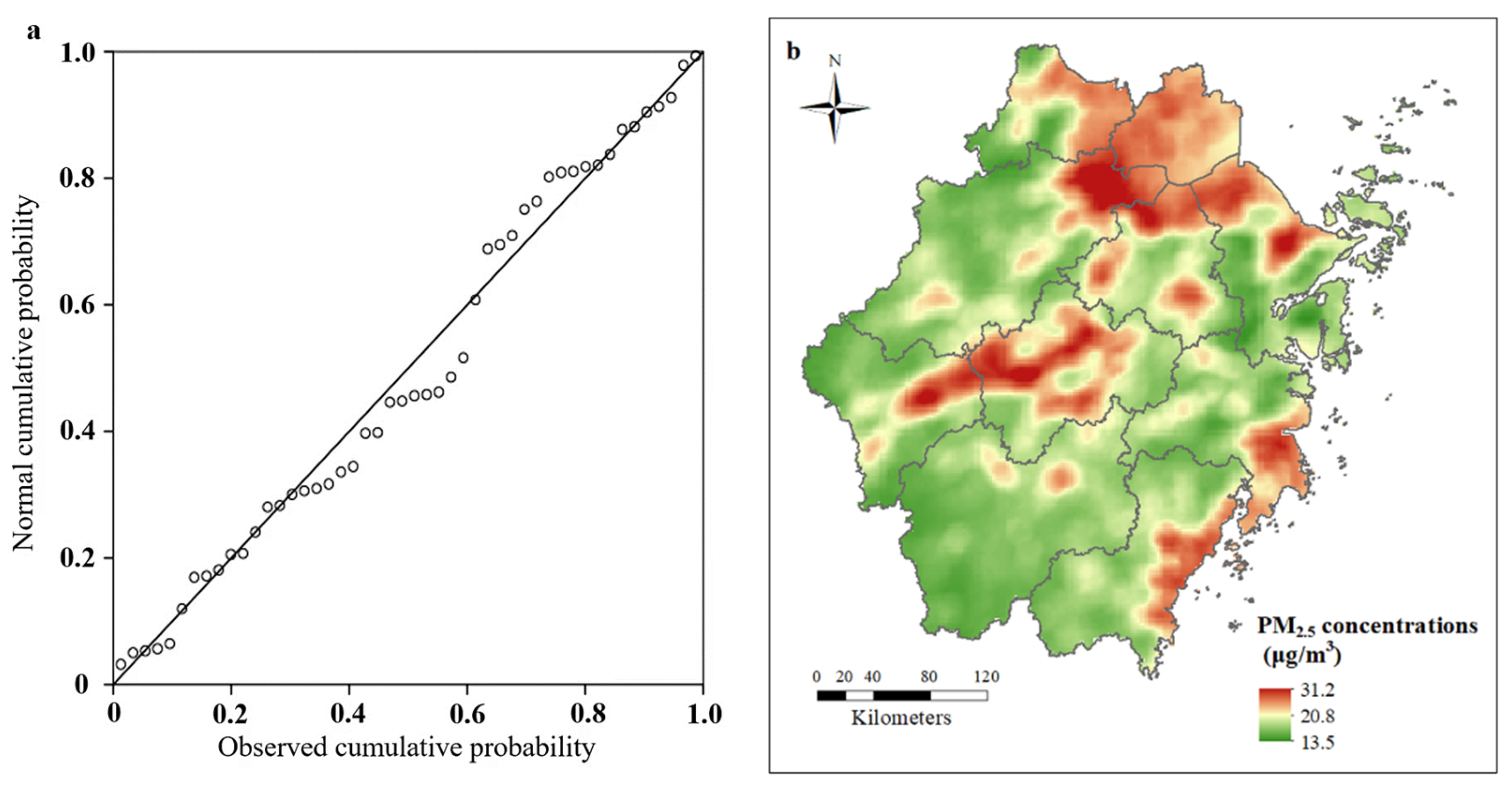
The global adjusted R
2 of the GWR model was 0.767. The local R
2 of the samples ranged from a minimum of 0.53 to a maximum of 0.88, with an average of 0.65. The normality of the standardized residuals of the model was tested and the significance of the Shapiro–Wilk (S-W) test was 0.944, which is much greater than 0.05, indicating that it conforms to a normal distribution. The P-P plot of the standardized residuals is shown in
Figure 5a. In addition, the standardized residuals should also show a random rather than a clustering distribution in terms of geographical distribution. The global Moran index (Moran I) was used for diagnosis and the results showed a global Moran index of −0.15 with a
p-value of 0.23, with no significant clustering trend. The above analysis indicates that the model is reliable. Compared with the basic LUR model, the GWR-based improved LUR model has a higher simulation accuracy with a residual sum of squares of 148.18, an RMSE of 1.757, and an Akaike information criterion (AICc) of 214.73.
The simulation results of the spatial distribution of the GWR-based improved LUR model are shown in
Figure 5b, which are generally consistent with the results of the multiple linear regression simulation. The PM
2.5 pollution concentration areas are roughly the same, mainly in the urbanized areas of northern Zhejiang, central Zhejiang, and southeastern Zhejiang.
3.3. Improved LUR Model Based on Random Forest Regression
The improved LUR model based on random forest regression aims to use the screened factors as explanatory variables based on the results from the correlation analysis. Then, the random forest regression was applied for model construction. The training and validation sets were divided in a ratio of 8:2. The optimal parameters were determined using a random search cross-validation method. The number of decision trees in the final model was 600, and the maximum eigenvalue was 3.
The variables, in descending order of contribution to the model, are precipitation, cropland, grassland, forestland, wind speed, population, and artificial surfaces. Unlike the stepwise regression screening results, precipitation and cropland played a greater role in the random forest model.
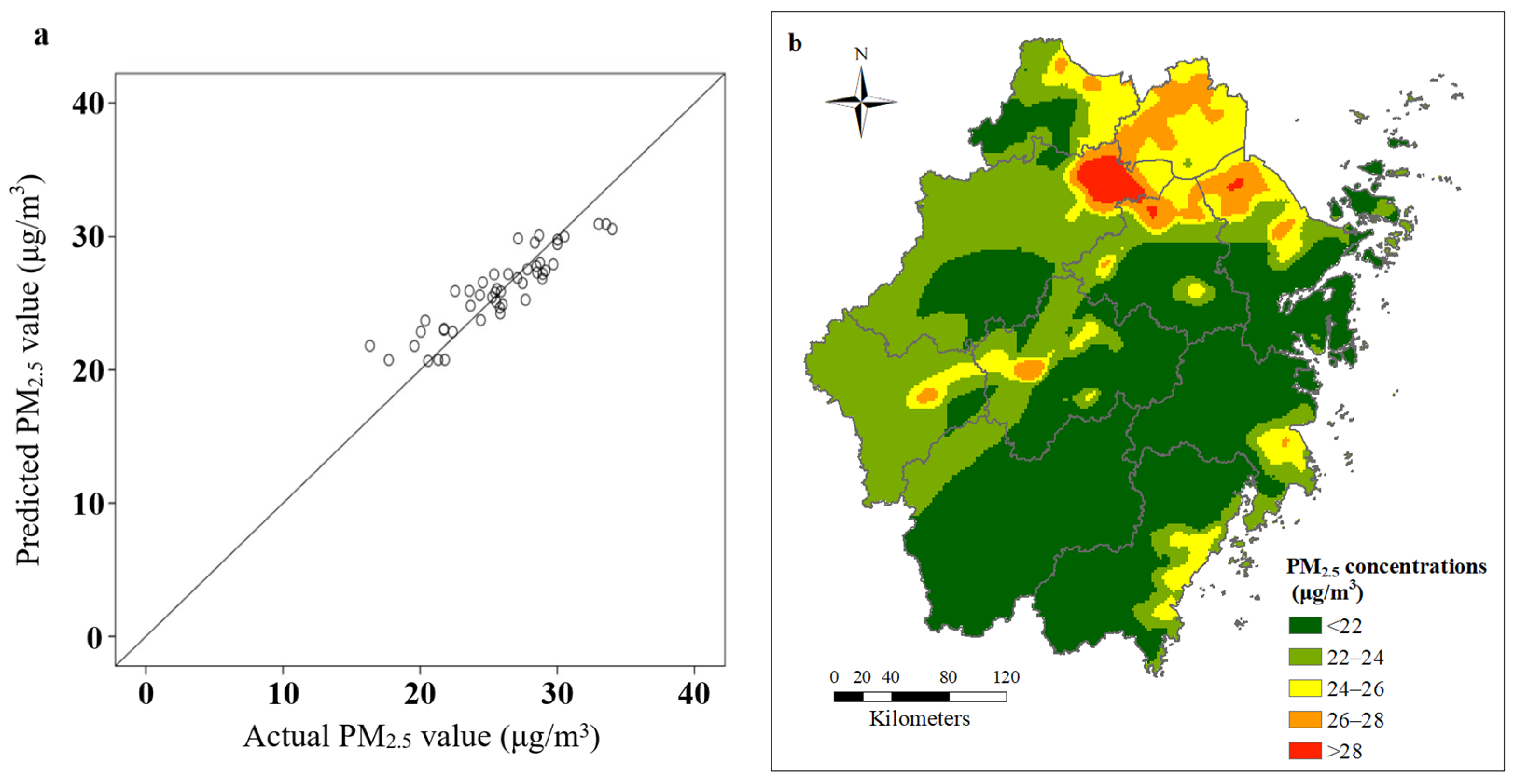
Figure 6a shows the linear fit of the model predictions to the actual values. The predicted values of the model largely matched the actual values, with the scatter concentrated around the diagonal line, indicating a good fit. The adjusted R
2 for the training set of the model was 0.82, with an RMSE of 2.64 and a mean absolute error (MAE) of 1.34. The adjusted R
2 for the validation set was 0.65, with an RMSE of 6.04 and a MAE of 1.90.
The simulation results of spatial distribution based on random forest regression are shown in
Figure 6b, which are significantly different from those of multiple linear regression and GWR simulation, but the judgment of high pollution areas is roughly the same.
3.4. Model Comparisons
The evaluation of the different models on each indicator is shown in
Table 3. To deepen the understanding of the different models, a comparative analysis of the regression models is provided, based on indicators such as MAE, RMSE, adjusted R
2, and modified AICc.
It can be seen that the GWR-based improved LUR model performs better on all four indicators compared to multiple linear regression. The GWR-based improved LUR model shows less deviation between predicted and measured values, better accuracy of model fit, and higher precision. However, it is also noteworthy that the results of multiple stepwise linear regression identify the relevant factors which provide the best fit for GWR. The RF-based LUR model has a much higher adjusted coefficient of determination for the training set and a much smaller MAE, while also performing well in the validation set. However, the RMSE is relatively large, which could be attributed to the limited samples, making the fit results more accidental. It indicates that the accuracy of the model needs to be improved by introducing more samples or selecting more suitable explanatory variables to take advantage of the random forest’s ability to handle a large number of explanatory variables. Similar to previous studies with a small number of monitoring sites [
44,
45], here we achieved the spatial distribution of PM
2.5 concentrations based on 49 monitoring sites, but the issue of distribution and the number of monitoring sites still needs to be addressed in the future. More monitoring sites could increase the precision of PM
2.5 concentration estimation [
46]. Furthermore, although an improved LUR model with acceptable accuracy was developed using GWR and RF, the accuracy of this model could be further improved by introducing more predictors under a spatially uniform distribution of monitoring stations.
The average PM
2.5 concentrations obtained by different methods for each city in 2020 were compared and analyzed, and the results are shown in
Table 4. The values in the three models were derived from the zonal statistics of the raster simulation results. The overall trend of PM
2.5 spatial distribution in Zhejiang Province obtained by different methods is similar, but the average PM
2.5 concentrations in prefecture-level cities obtained from different models are quite different. First, the average PM
2.5 concentrations obtained based on the national control air quality monitoring sites are generally larger. This is because apart from the control points, the vast majority of stations are arranged within the urban area of the city. As analyzed in the previous section, urban areas are where PM
2.5 pollution sources are concentrated, and land use patterns are not conducive to PM
2.5 dispersion. Therefore, the average value based on monitoring stations mainly reflects the pollution situation in the urban area. However, the zonal statistics results obtained through the models reflect the city-wide pollution concentration.
Due to the different underlying logic and methodology, the results based on the regression model simulations differ significantly from those based on the monitoring sites; (the simulated average PM2.5 concentrations are relatively low), while the differences between the different regression models are relatively small. Geographically weighted regression simulations yielded the lowest mean PM2.5 concentrations for each city in the zonal statistics. It is also worth noting the relatively high estimate of pollution for Jiaxing at 26.35 μg/m³. Due to the inclusion of more explanatory variables and a different model structure, the random forest regression simulation results give different PM2.5 pollution emissions for each city compared to the other two regression models. The simulation results of the RF-based improved LUR show a small difference between the upper and lower limits.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}