A Hybrid Deep Learning Model to Forecast Particulate Matter Concentration Levels in Seoul, South Korea



Abstract
1. Introduction
2. Materials
2.1 Observation Stations
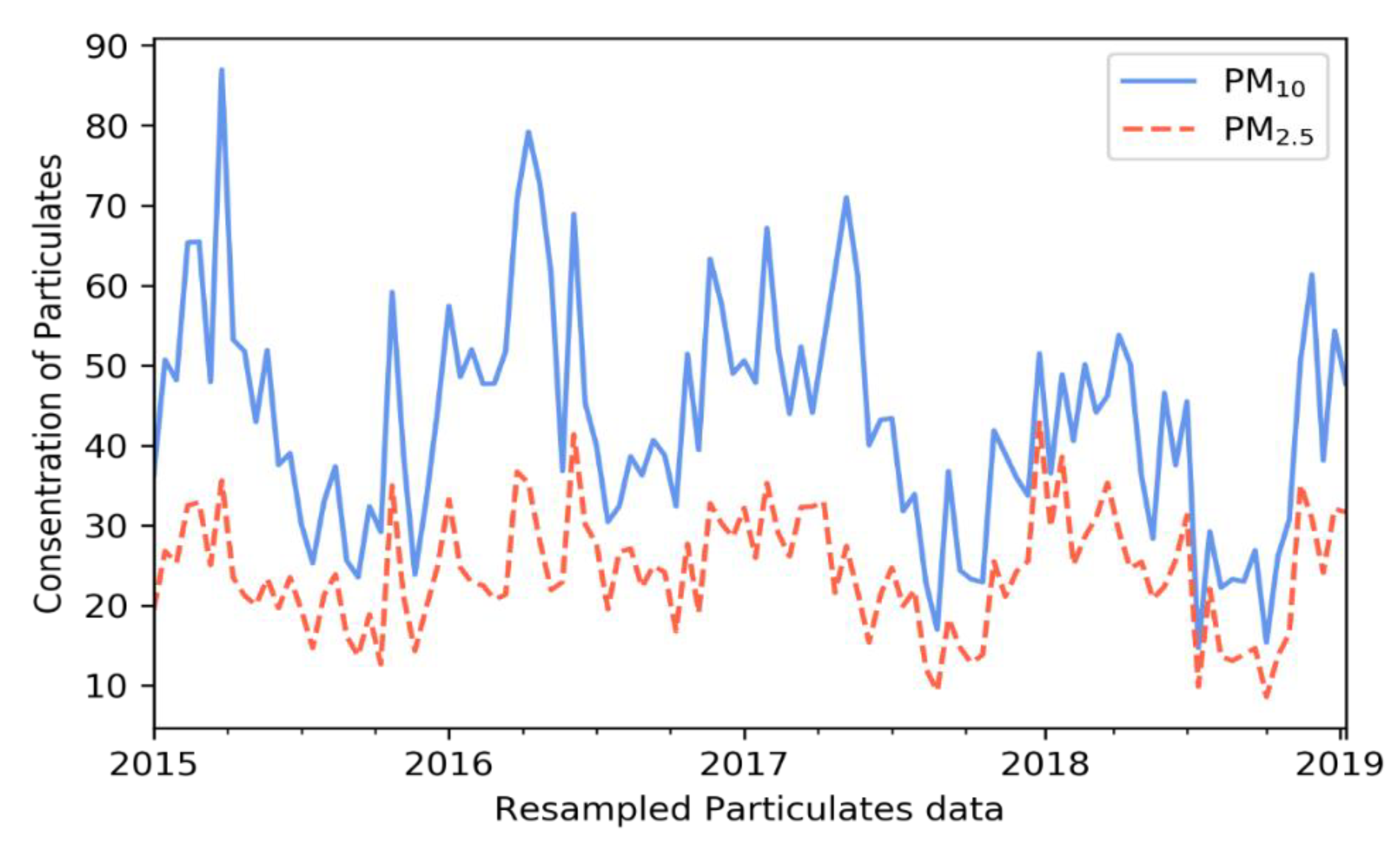
2.2 Data Description
3. Methodology
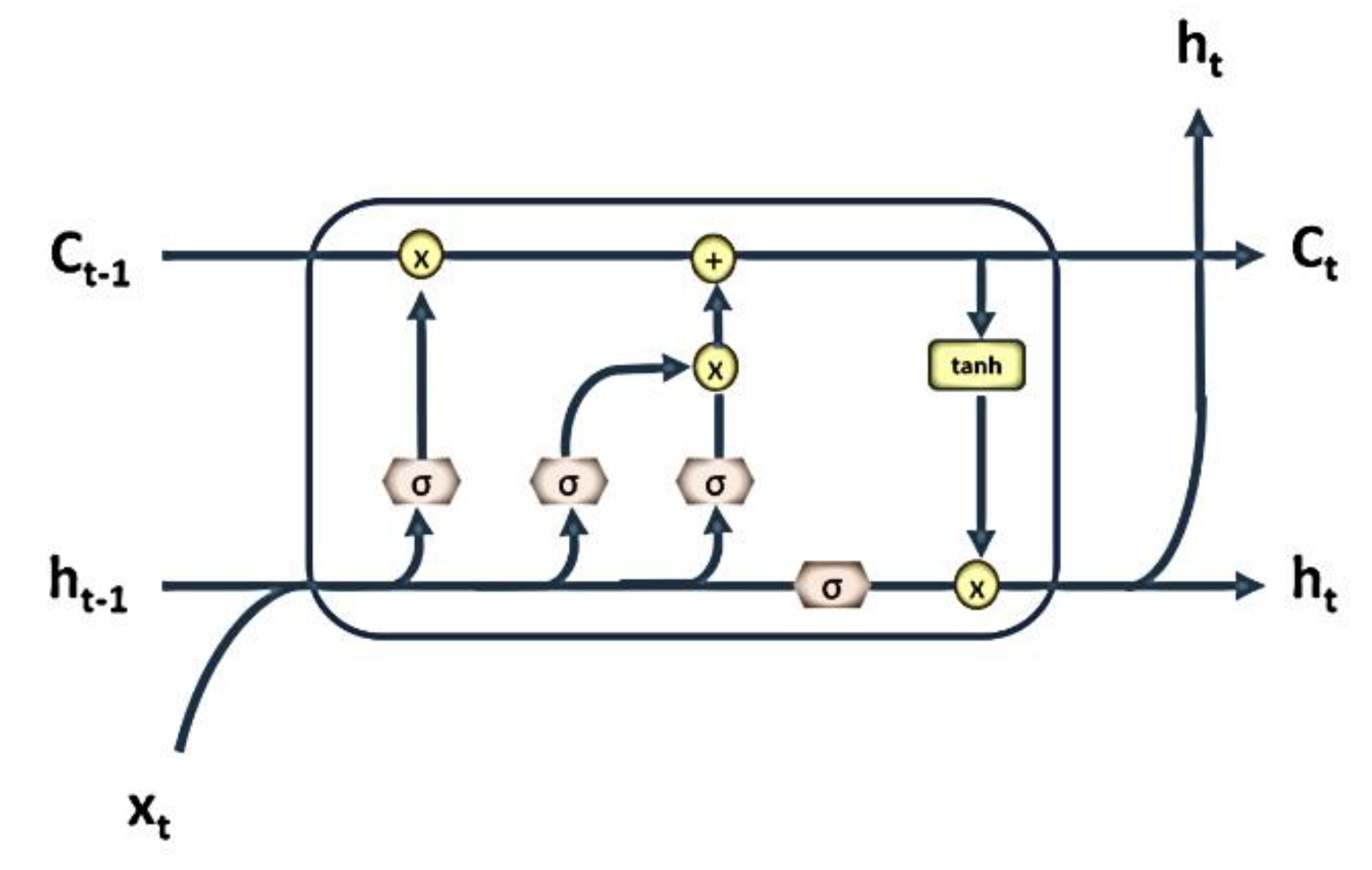
3.1 The Long Short-Term Recurrent Unit
3.2. The Gated Recurrent Unit
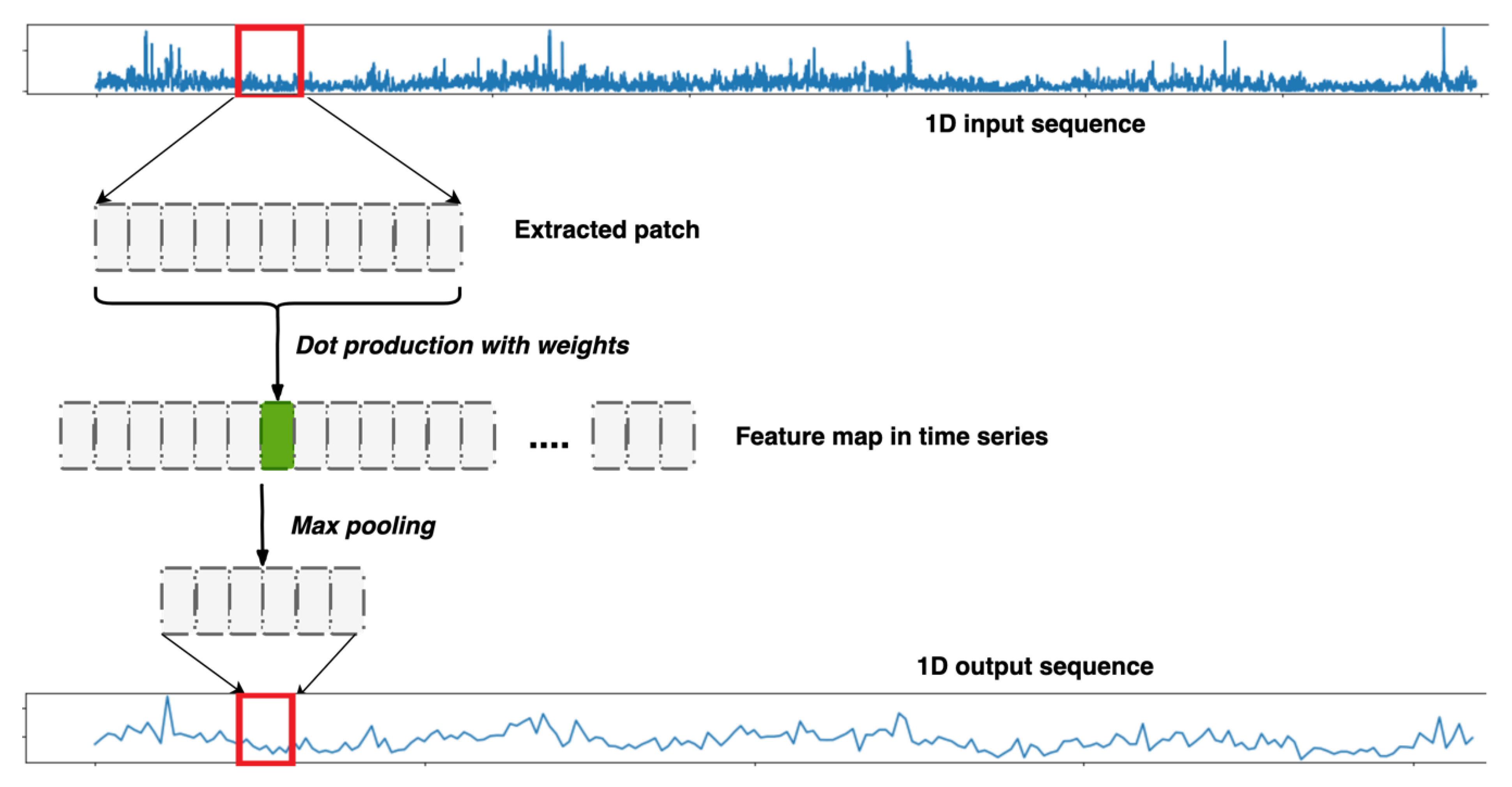
3.3. Convolutional Layers
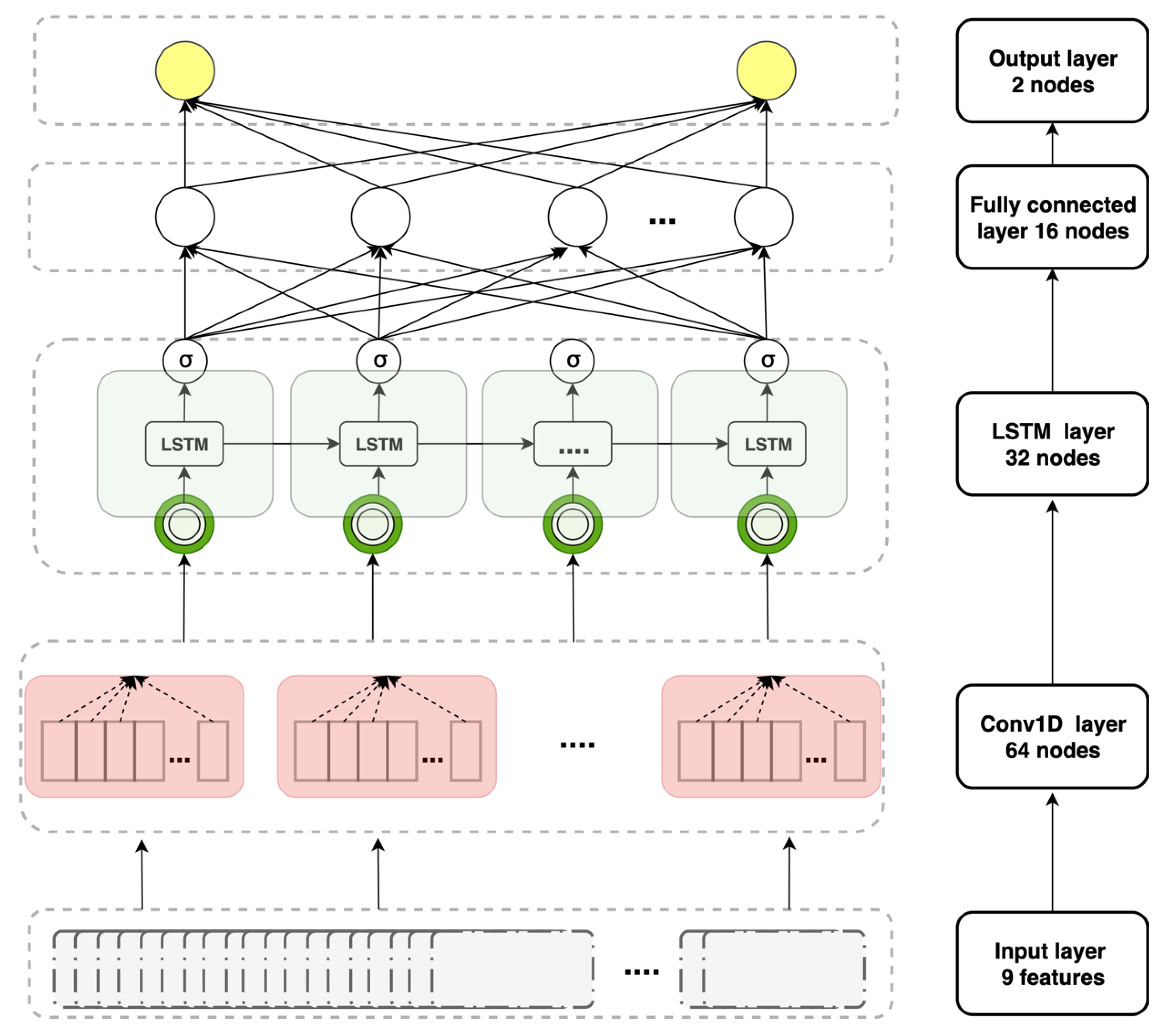
3.4. Hybrid Models
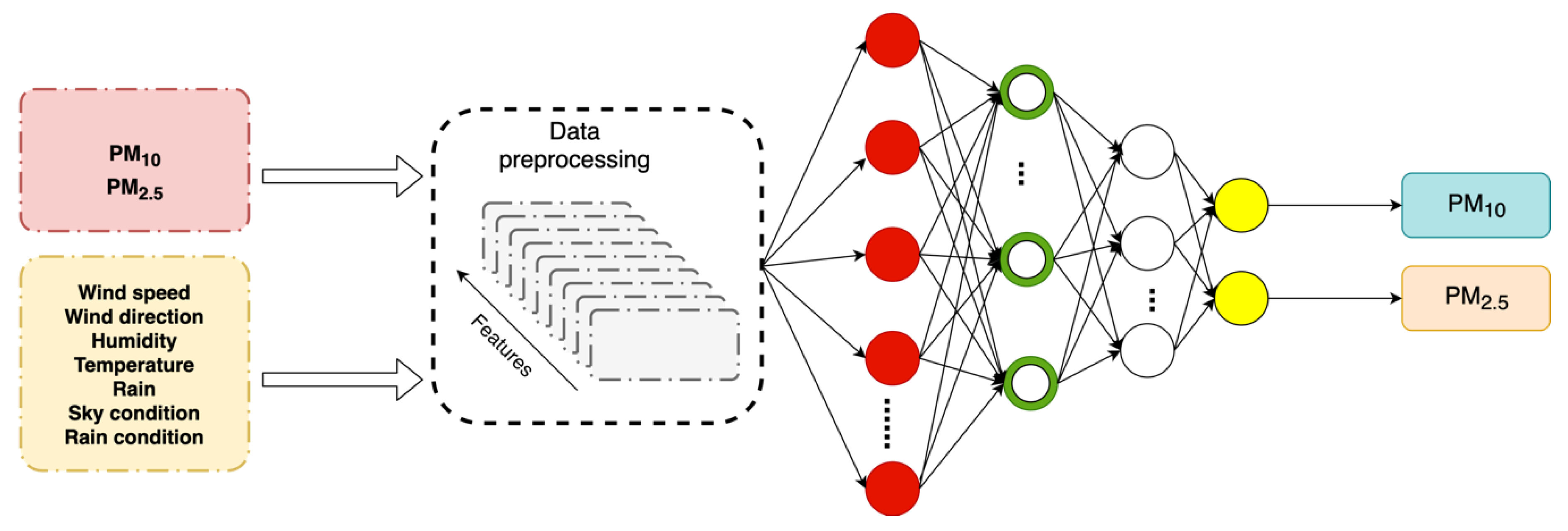
3.5. General Workflow
- Data choice. Good-quality training data are essential. For each specific model, the data type and attributes must be chosen carefully. The authors used pollution data and meteorological data to train models, combining several training factors (hourly particulates concentrations and meteorological data) into one dataset, aligning the different types of data at the same time points.
- Data preprocessing. The researchers used various data preprocessed via different methods to generate inputs to the NNs. The specific preprocessing methods used met the requirements of the training models. For example, the first layer of (the input to) the LSTM model was an LSTM layer.
- Model training. The models use input data to learn hidden features. The training model structures differ. For the LSTM model, the green layer with recurrent units is an LSTM layer, the white layer is fully connected, and the last layer is the output layer. Training requires tuning of the various hyperparameters that affect training and model performance.
- Hyperparameter tuning. During model training, many hyperparameters must be defined or modified to optimize predictions. Model hyperparameters differ, and all models were optimized before comparison.
- Output generation. After training, the best model was identified, and the success of training was evaluated by inputting test data. Both the PM10 and PM2.5 concentrations served as outputs. Thus, the output layers featured two neurons.
- Model comparison. All models were trained to generate predictions. The authors used all models to predict air pollution concentrations in the same area and then identified the most suitable model.
4. Experiments and Results
4.1. Evaluation Methods
4.2. Model Tuning
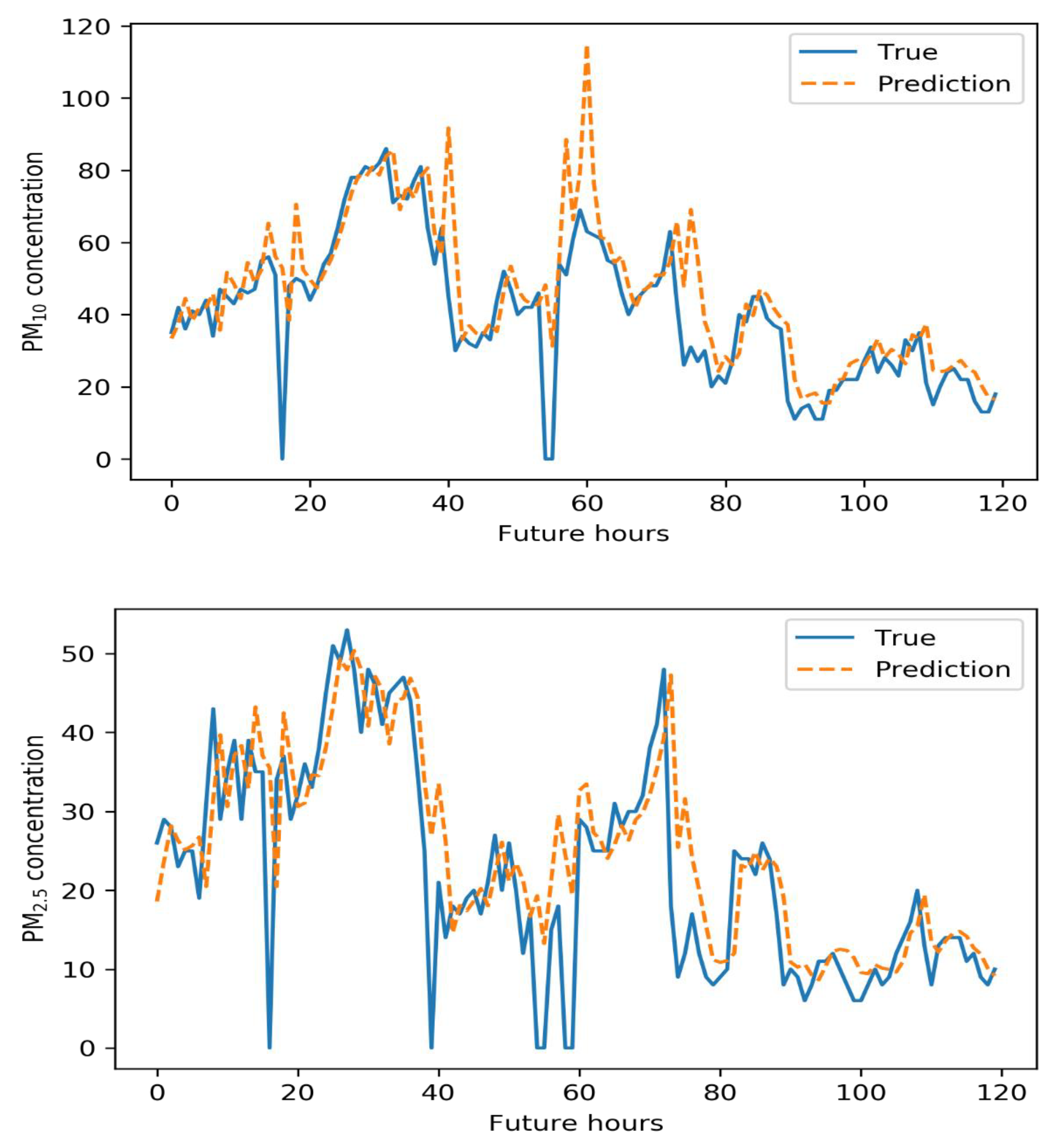
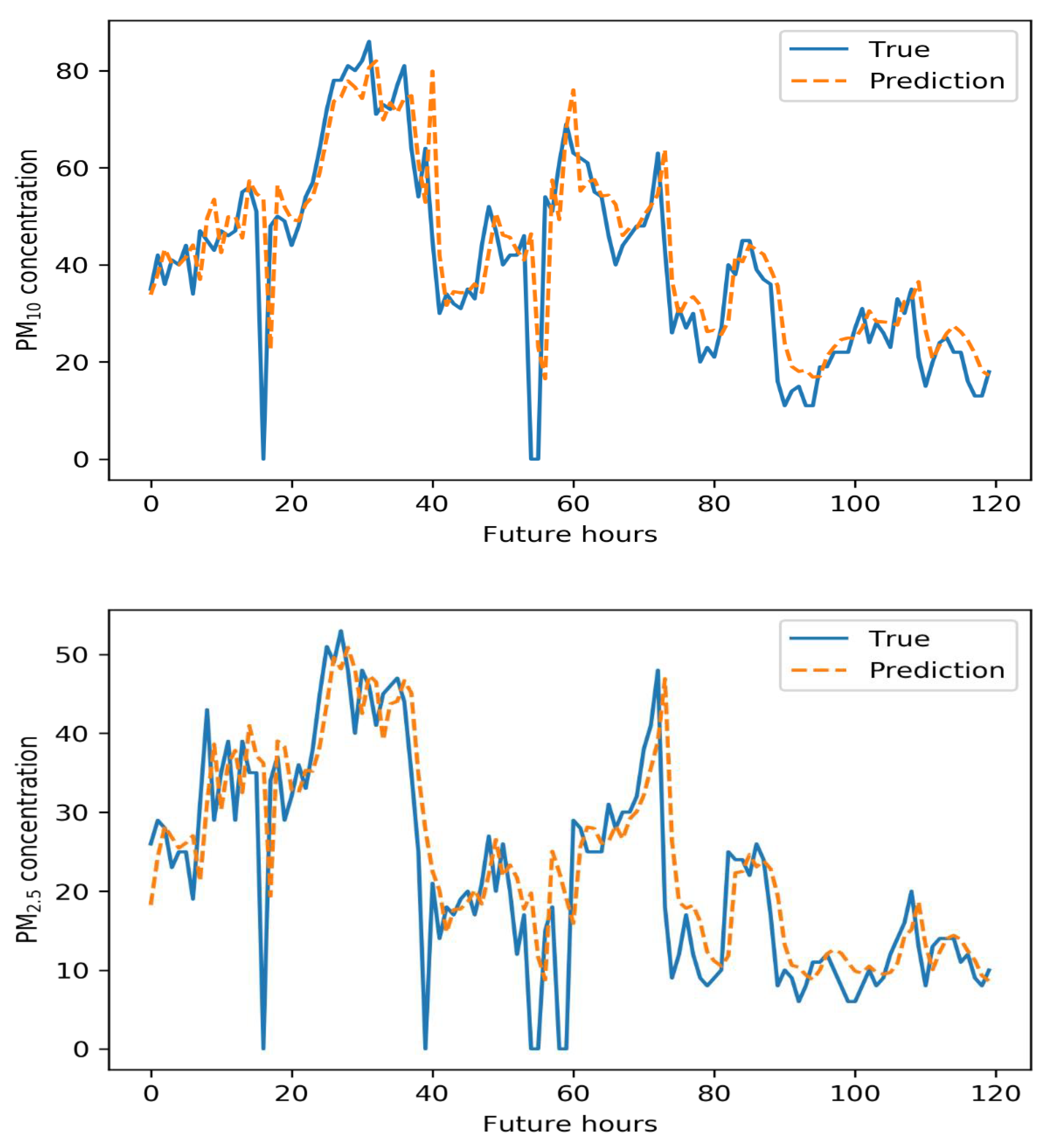
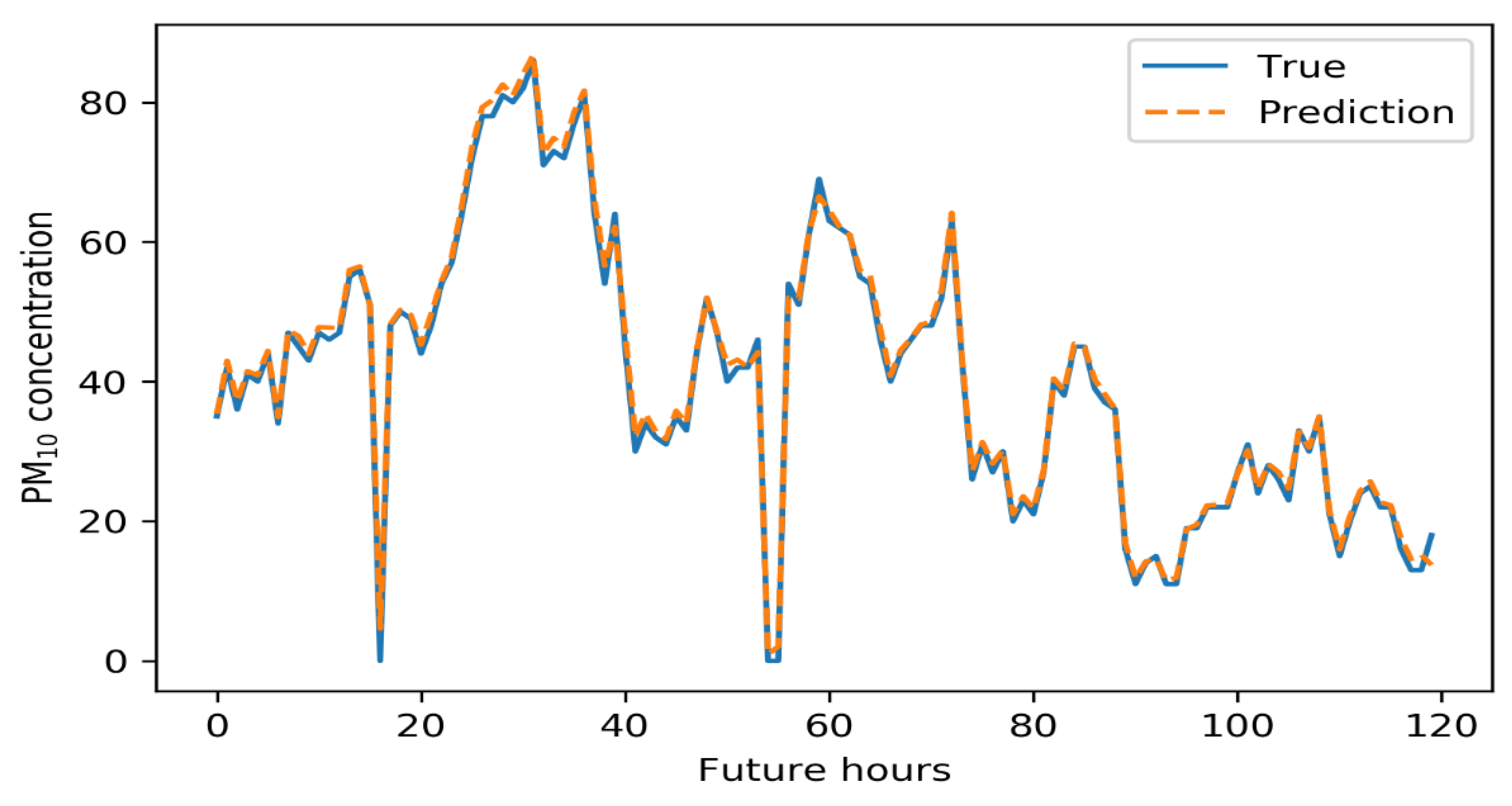
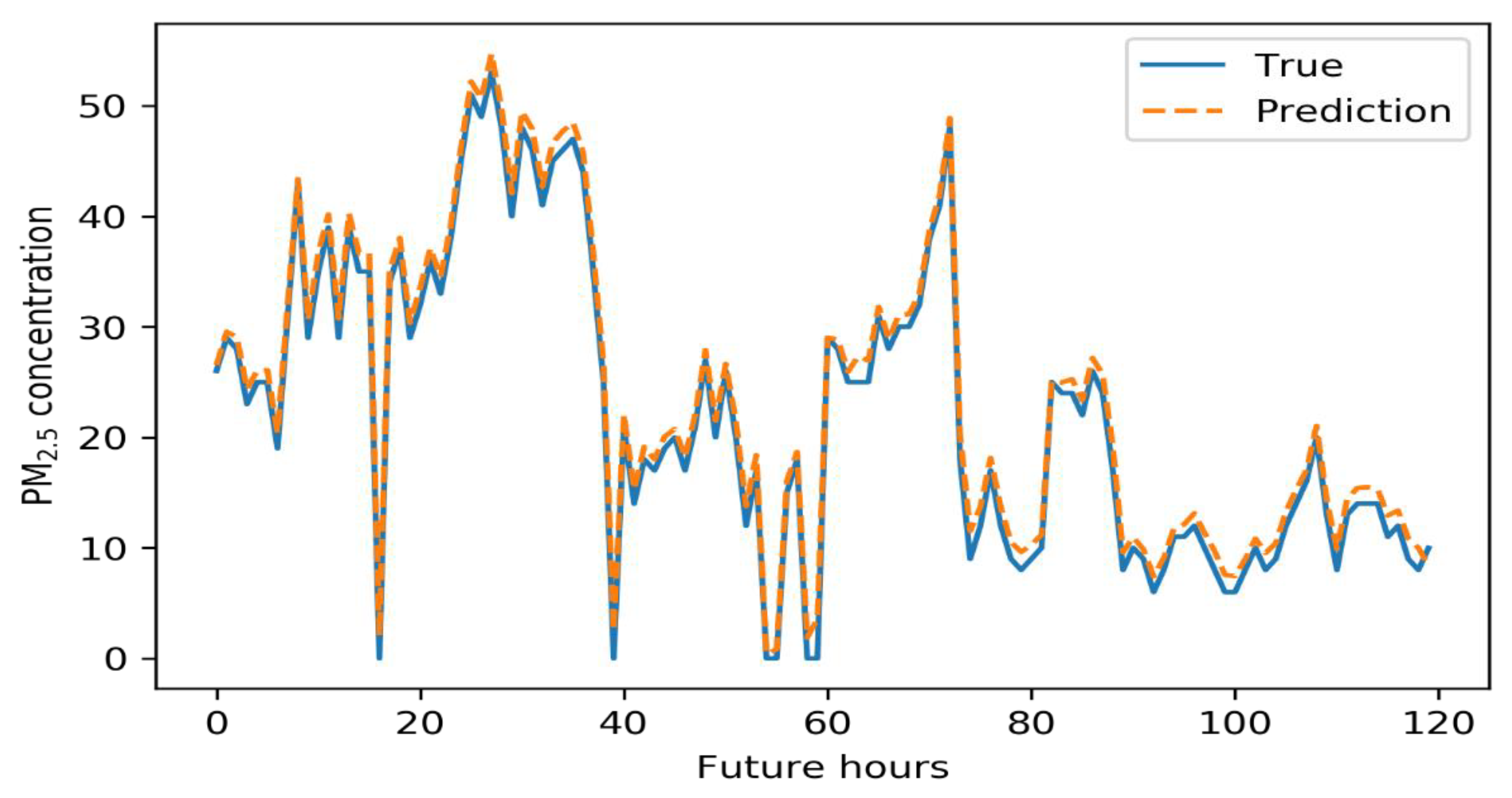
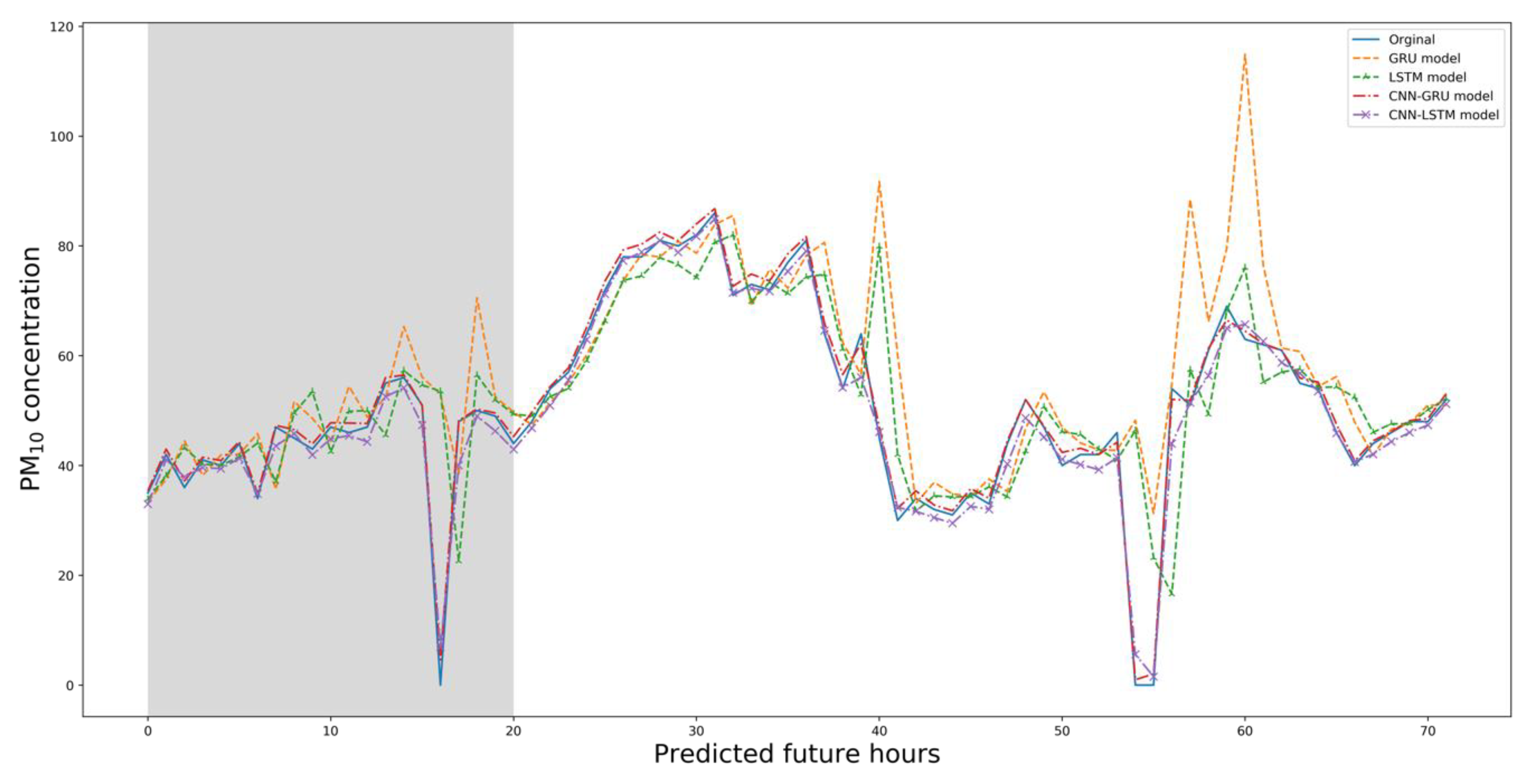
5. Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- United States Environmental Protection Agency (EPA). Particulate Matter (PM) Basics. Available online: https://www.epa.gov/pm-pollution/particulate-matter-pm-basics#PM (accessed on 5 October 2019).
- Lu, F.; Xu, D.; Cheng, Y.; Dong, S.; Guo, C.; Jiang, X.; Zheng, X. Systematic review and meta-analysis of the adverse health effects of ambient PM2.5 and PM10 pollution in the Chinese population. Environ. Res. 2015, 136, 196–204. [Google Scholar] [CrossRef]
- Janssen, N.; Fischer, P.; Marra, M.; Ameling, C.; Cassee, F.R. Short-term effects of PM2.5, PM10 and PM2.5–10 on daily mortality in the Netherlands. Sci. Total Environ. 2013, 463, 20–26. [Google Scholar] [CrossRef]
- Scapellato, M.L.; Canova, C.; De Simone, A.; Carrieri, M.; Maestrelli, P.; Simonato, L.; Bartolucci, G.B. Personal PM10 exposure in asthmatic adults in Padova, Italy: Seasonal variability and factors affecting individual concentrations of particulate matter. Int. J. Hyg. Environ. Health 2009, 212, 626–636. [Google Scholar] [CrossRef]
- Wu, S.; Deng, F.; Hao, Y.; Wang, X.; Zheng, C.; Lv, H.; Lu, X.; Wei, H.; Huang, J.; Qin, Y.; et al. Fine particulate matter, temperature, and lung function in healthy adults: Findings from the HVNR study. Chemosphere 2014, 108, 168–174. [Google Scholar] [CrossRef]
- Turner, M.C.; Krewski, D.; Pope, C.A., III; Chen, Y.; Gapstur, S.M.; Thun, M.J. Long-term ambient fine particulate matter air pollution and lung cancer in a large cohort of never-smokers. Am. J. Respir. Crit. Care Med. 2011, 184, 1374–1381. [Google Scholar] [CrossRef]
- Lin, Y.-S.; Chang, Y.-H.; Chang, Y.-S. Constructing PM2.5 map based on mobile PM2.5 sensor and cloud platform. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology (CIT), Nadi, Fiji, 8–10 December 2016; pp. 702–707. [Google Scholar]
- Korea M.O.E.S. Air Quality Standards. Available online: http://www.me.go.kr/mamo/web/index.do?menuId=586 (accessed on 14 January 2019).
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef]
- Díaz-Robles, L.A.; Ortega, J.C.; Fu, J.S.; Reed, G.D.; Chow, J.C.; Watson, J.G.; Moncada-Herrera, J.A. A hybrid ARIMA and artificial neural networks model to forecast particulate matter in urban areas: The case of Temuco, Chile. Atmos. Environ. 2008, 42, 8331–8340. [Google Scholar] [CrossRef]
- Nieto, P.G.; Combarro, E.F.; del Coz Díaz, J.; Montañés, E. A SVM-based regression model to study the air quality at local scale in Oviedo urban area (Northern Spain): A case study. Appl. Math. Comput. 2013, 219, 8923–8937. [Google Scholar]
- Li, C.; Hsu, N.C.; Tsay, S.-C. A study on the potential applications of satellite data in air quality monitoring and forecasting. Atmos. Environ. 2011, 45, 3663–3675. [Google Scholar] [CrossRef]
- Chakraborty, K.; Mehrotra, K.; Mohan, C.K.; Ranka, S. Forecasting the behavior of multivariate time series using neural networks. Neural Netw. 1992, 5, 961–970. [Google Scholar] [CrossRef]
- Paschalidou, A.K.; Karakitsios, S.; Kleanthous, S.; Kassomenos, P.A. Forecasting hourly PM 10 concentration in Cyprus through artificial neural networks and multiple regression models: Implications to local environmental management. Environ. Sci. Pollut. Res. Vol. 2011, 18, 316–327. [Google Scholar] [CrossRef]
- Lu, W.; Wang, W.; Fan, H.; Leung, A.; Xu, Z.; Lo, S.; Wong, J.C.K. Prediction of pollutant levels in causeway bay area of Hong Kong using an improved neural network model. J. Environ. Eng. 2002, 128, 1146–1157. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Petneházi, G. Recurrent neural networks for time series forecasting. arXiv 2019, arXiv:1901.00069. [Google Scholar]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. arXiv 2019, arXiv:1909.00590. [Google Scholar]
- Schäfer, A.M.; Zimmermann, H.G. Recurrent neural networks are universal approximators. In Proceedings of the International Conference on Artificial Neural Networks, Athens, Greece, 10–14 September 2006; Volume 4131, pp. 632–640. [Google Scholar]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bianchi, F.M.; Maiorino, E.; Kampffmeyer, M.C.; Rizzi, A.; Jenssen, R. An overview and comparative analysis of recurrent neural networks for short term load forecasting. Neural Evol. Comput. 2017. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.0127. [Google Scholar]
- Mittelman, R. Time-series modeling with undecimated fully convolutional neural networks. arXiv 2015, arXiv:1508.00317. [Google Scholar]
- Chen, Y.; Kang, Y.; Chen, Y.; Wang, Z. Probabilistic forecasting with temporal convolutional neural network. Neurocomputing 2019, in press. [Google Scholar] [CrossRef]
- Papanastasiou, D.; Melas, D.; Kioutsioukis, I. Development and assessment of neural network and multiple regression models in order to predict PM10 levels in a medium-sized Mediterranean city. Water Air Soil Pollut. 2007, 182, 325–334. [Google Scholar] [CrossRef]
- Tai, A.P.; Mickley, L.J.; Jacob, D.J. Correlations between fine particulate matter (PM2.5) and meteorological variables in the United States: Implications for the sensitivity of PM2.5 to climate change. Atmos. Environ. 2010, 44, 3976–3984. [Google Scholar] [CrossRef]
- Sayegh, A.S.; Munir, S.; Habeebullah, T.M. Comparing the performance of statistical models for predicting PM10 concentrations. Aerosol Air Qual. Res. 2014, 14, 653–665. [Google Scholar] [CrossRef]
- Grivas, G.; Chaloulakou, A. Artificial neural network models for prediction of PM10 hourly concentrations, in the Greater Area of Athens, Greece. Atmos. Environ. 2006, 40, 1216–1229. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J.J.A.E. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Smyl, S.; Kuber, K. Data preprocessing and augmentation for multiple short time series forecasting with recurrent neural networks. In Proceedings of the 36th International Symposium on Forecasting, Santander, Spain, 19–22 June 2016. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Station | Site Code | Location | Latitude | Longitude |
|---|---|---|---|---|---|
| Urban | Gangnam-gu | 111261 | 426, Hakdong-ro | N 37.5181 | E 127.0472 |
| Urban | Gwangjin-gu | 111141 | 571, Gwangnaru-ro | N 37.5441 | E 127.0930 |
| Urban | Dobong-gu | 111171 | 34, Sirubong-ro 2-gil | N 37.6627 | E 127.0269 |
| Urban | Gangdong-gu | 111274 | 59, Gucheonmyeon-ro 42-gil | N 37.5431 | E 127.1255 |
| Urban | Gangseo-gu | 111212 | 71, Gangseo-ro 45da-gil | N 37.5446 | E 126.8350 |
| Roadside | Seoul Station | 111122 | 405, Hangang-daero | N 37.5544 | E 126.9717 |
| Roadside | Jongno | 111125 | 169, Jong-ro, Jongno-gu | N 37.5708 | E 126.9965 |
| Roadside | Gonghangro | 111213 | 727–1091, Magok-dong | N 37.5678 | E 126.8348 |
| Roadside | Cheonho-daero | 111275 | 1151, Cheonho-daero | N 37.5341 | E 127.1510 |
| Roadside | Yangjaedong | 111264 | 201, Gangnam-daero | N 37.4820 | E 127.0362 |
| PM10 | PM2.5 | Temperature | Sky Condition | Rain | Humidity | Rain Condition | Wind_x | Wind_y | |
|---|---|---|---|---|---|---|---|---|---|
| PM10 | 1.0000 | 0.7763 | −0.1637 | −0.0537 | −0.0509 | −0.0809 | −0.0355 | −0.0031 | 0.0049 |
| PM2.5 | 0.7763 | 1.0000 | −0.1242 | −0.0110 | −0.0394 | 0.0316 | −0.0197 | 0.0075 | −0.0014 |
| Temperature | −0.1637 | −0.1242 | 1.0000 | 0.2685 | 0.0510 | 0.1477 | −0.0519 | 0.0068 | −0.0113 |
| Sky condition | −0.0537 | −0.0110 | 0.2685 | 1.0000 | 0.1234 | 0.3265 | 0.2314 | −0.0050 | −0.0040 |
| Rain | −0.0509 | −0.0394 | 0.0510 | 0.1234 | 1.0000 | 0.1756 | 0.2625 | 0.0068 | 0.0009 |
| Humidity | −0.0809 | 0.0316 | 0.1477 | 0.3265 | 0.1756 | 1.0000 | 0.2614 | 0.0019 | −0.0061 |
| Rain condition | −0.0355 | −0.0197 | −0.0519 | 0.2314 | 0.2625 | 0.2614 | 1.0000 | 0.0040 | −0.0065 |
| Wind_x | −0.0031 | 0.0075 | 0.0068 | −0.0050 | 0.0068 | 0.0019 | 0.0040 | 1.0000 | −0.0028 |
| Wind_y | 0.0049 | −0.001 | −0.0113 | −0.0040 | 0.0009 | −0.0061 | −0.0065 | −0.0028 | 1.0000 |
| Variable | Measurement Unit | Range |
|---|---|---|
| PM2.5 | µg/m3 | 0~180 |
| PM10 | µg/m3 | 0~400 |
| Temperature | °C | −25~45 |
| Rain | mm | >0 |
| Wind_x | Float | −12~12 |
| Wind_y | Float | −12~12 |
| Humidity | % | 0~100 |
| Rain | Integer | 0, 1, 2, 3 |
| Sky | Integer | 1, 2, 3, 4 |
| Shift Time (h) | PM10 (RMSE) | PM2.5 (RMSE) |
|---|---|---|
| 1 | 11.798 | 7.719 |
| 6 | 26.230 | 12.497 |
| 12 | 26.096 | 13.266 |
| 24 | 11.789 | 6.997 |
| 48 | 16.598 | 9.642 |
| 72 | 21.127 | 10.010 |
| Number of Layers | Results (RMSEs) | Number of Neurons in Each Layer | |||||
|---|---|---|---|---|---|---|---|
| 16 | 32 | 64 | 128 | 256 | 512 | ||
| 3 | PM10 PM2.5 | 14.394 10.323 | 14.313 10.528 | 14.818 10.696 | 14.493 10.667 | 15.408 10.659 | 15.046 10.709 |
| 4 | PM10 PM2.5 | 13.537 9.667 | 14.337 9.914 | 12.516 9.678 | 12.908 9.911 | 13.012 10.334 | 14.589 10.463 |
| 5 | PM10 PM2.5 | 14.124 9.850 | 12.902 9.304 | 13.609 9.963 | 13.956 10.207 | 13.404 9.884 | 14.416 9.980 |
| Model | Attribution | First Layer | Second Layer | Third Layer | Fourth Layer |
|---|---|---|---|---|---|
| GRU | Layer type | GRU | GRU | FC | FC |
| Number of nodes | 64 | 32 | 16 | 2 | |
| Number of parameters | 14,208 | 9312 | 528 | 34 | |
| Activation function | tanh | ReLU | linear | linear | |
| Remarks | Recurrent activation: hard_sigmoid. Return sequences: True. | ||||
| LSTM | Layer type | LSTM | LSTM | FC | FC |
| Number of nodes | 64 | 32 | 16 | 2 | |
| Number of parameters | 18,944 | 12,416 | 528 | 34 | |
| Activation function | tanh | ReLU | linear | linear | |
| Remarks | Recurrent activation: hard_sigmoid. Return sequences: True. | ||||
| CNN–GRU | Layer type | 1DConvNet | GRU | FC | FC |
| Number of nodes | 64 | 32 | 16 | 2 | |
| Number of parameters | 13,888 | 9312 | 528 | 34 | |
| Activation function | ReLU | ReLU | linear | linear | |
| Remarks | Kernel size: 24. Padding: same. | ||||
| CNN–LSTM | Layer type | 1DConvNet | LSTM | FC | FC |
| Number of nodes | 64 | 32 | 16 | 2 | |
| Number of parameters | 13,888 | 12,416 | 528 | 34 | |
| Activation function | ReLU | ReLU | linear | linear | |
| Remarks | Kernel size: 24. Padding: same. | ||||
| Prediction Length (Days) | PM10 (RMSE) | PM10 (MAE) | PM2.5 (RMSE) | PM2.5 (MAE) |
|---|---|---|---|---|
| 1 | 6.547 | 5.210 | 4.707 | 3.889 |
| 3 | 11.450 | 7.089 | 5.074 | 4.046 |
| 7 | 12.010 | 7.212 | 5.546 | 4.096 |
| 15 | 16.096 | 9.314 | 7.260 | 4.633 |
| Area | Evaluation | GRU | LSTM | CNN–GRU | CNN–LSTM |
|---|---|---|---|---|---|
| Gangnam-gu | RMSE MAE | 12.995 7.981 | 11.091 6.901 | 1.688 1.161 | 2.696 1.959 |
| Songpa-gu | RMSE MAE | 15.652 10.124 | 11.322 7.454 | 1.620 1.264 | 2.996 2.259 |
| Seocho-gu | RMSE MAE | 14.010 9.648 | 8.293 6.002 | 1.246 0.942 | 2.507 2.073 |
| Gangseo-gu | RMSE MAE | 8.976 6.143 | 7.727 4.919 | 1.087 0.814 | 2.162 1.681 |
| Geumcheon-gu | RMSE MAE | 9.462 6.777 | 7.616 5.280 | 1.096 0.776 | 1.926 1.495 |
| Area | Evaluation | GRU | LSTM | CNN–GRU | CNN–LSTM |
|---|---|---|---|---|---|
| Gangnam-gu | RMSE MAE | 6.987 4.676 | 6.918 4.603 | 1.558 1.444 | 0.867 0.488 |
| Songpa-gu | RMSE MAE | 6.816 4.636 | 6.097 4.241 | 1.547 1.464 | 0.788 0.509 |
| Seocho-gu | RMSE MAE | 6.058 4.137 | 5.461 3.413 | 1.643 1.587 | 0.608 0.417 |
| Gangseo-gu | RMSE MAE | 4.980 3.523 | 5.387 3.772 | 1.623 1.518 | 0.820 0.548 |
| Geumcheon-gu | RMSE MAE | 4.813 3.617 | 4.872 3.702 | 1.445 1.380 | 0.872 0.633 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, G.; Lee, H.; Lee, G. A Hybrid Deep Learning Model to Forecast Particulate Matter Concentration Levels in Seoul, South Korea. Atmosphere 2020, 11, 348. https://doi.org/10.3390/atmos11040348
Yang G, Lee H, Lee G. A Hybrid Deep Learning Model to Forecast Particulate Matter Concentration Levels in Seoul, South Korea. Atmosphere. 2020; 11(4):348. https://doi.org/10.3390/atmos11040348
Chicago/Turabian StyleYang, Guang, HwaMin Lee, and Giyeol Lee. 2020. "A Hybrid Deep Learning Model to Forecast Particulate Matter Concentration Levels in Seoul, South Korea" Atmosphere 11, no. 4: 348. https://doi.org/10.3390/atmos11040348
APA StyleYang, G., Lee, H., & Lee, G. (2020). A Hybrid Deep Learning Model to Forecast Particulate Matter Concentration Levels in Seoul, South Korea. Atmosphere, 11(4), 348. https://doi.org/10.3390/atmos11040348