Weather During Key Growth Stages Explains Grain Quality and Yield of Maize


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Compilation
2.2. Correlation and Principal Component Analyses
2.3. Stepwise Linear Regression and Remedial Measures
2.4. Cluster Analyses and Imputation Methods
3. Results and Discussion
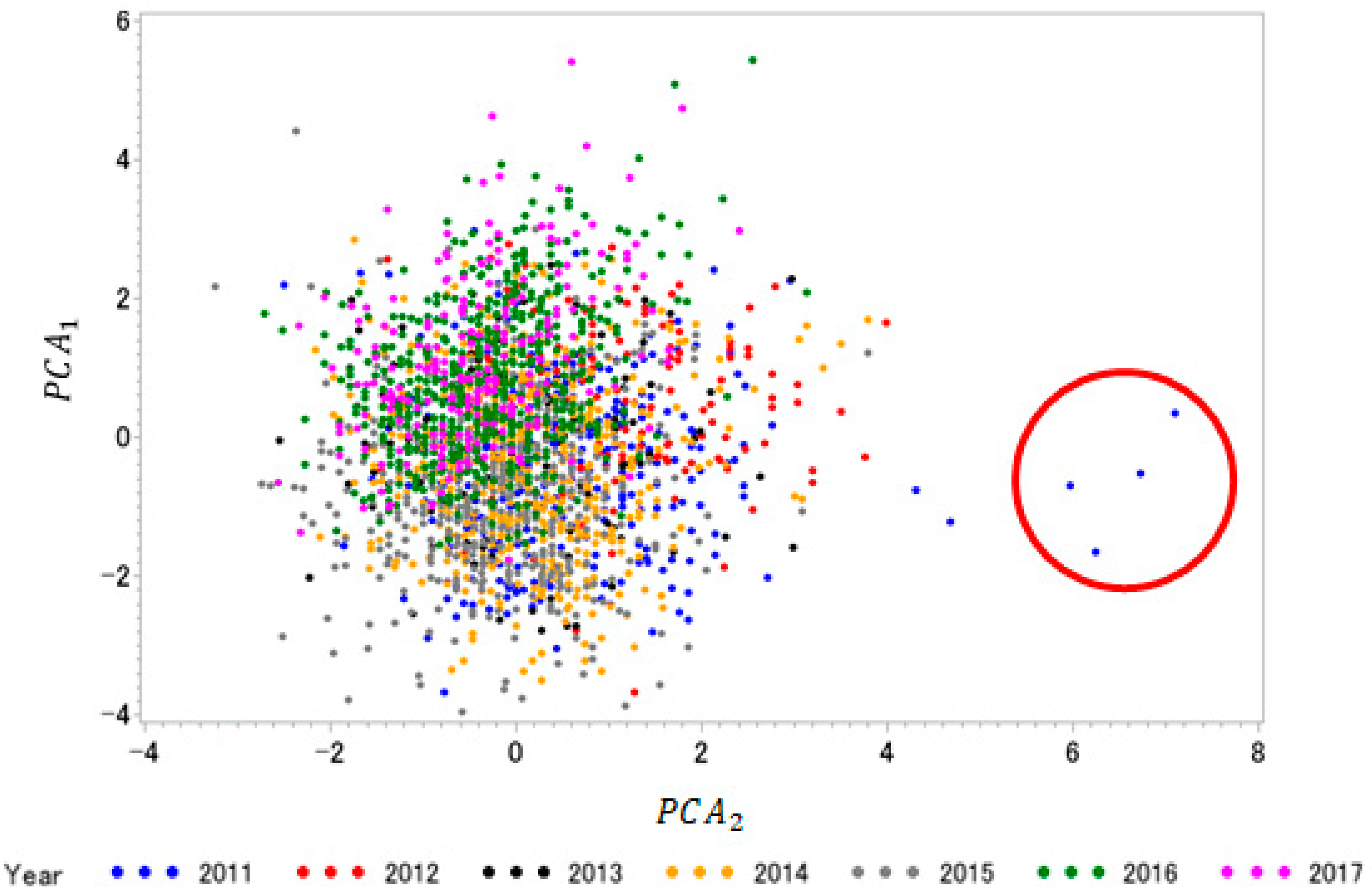
3.1. Correlation and Principal Component Analysis
3.2. Stepwise Regression with Weather and Climatic Variables
3.2.1. PCA1—High Grain Protein and Oil
3.2.2. PCA2—High Grain Protein Over Oil
3.2.3. Yield
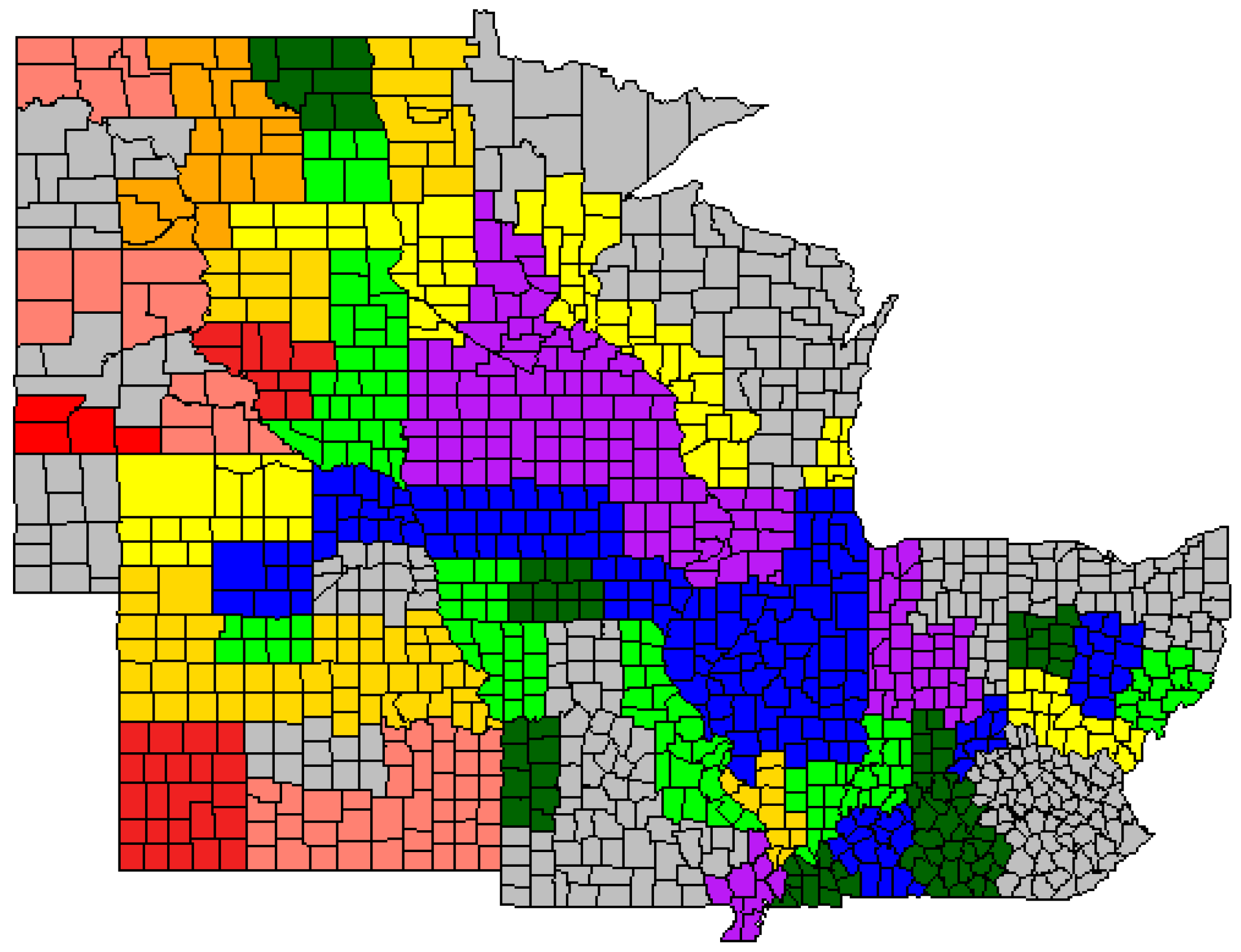
3.3. Multivariate Clustering Analysis by ASD
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- U.S. Census Bureau. U.S. Exports to World Total by 5-Digit End-Use Code. Available online: https://www.census.gov/foreign-trade/statistics/product/enduse/exports/c0000.html (accessed on 20 August 2018).
- USDA ERS. Corn and Other Feedgrains: Background. Available online: https://www.ers.usda.gov/topics/crops/corn-and-other-feedgrains/background/ (accessed on 20 August 2018).
- U.S. Grains Council. Corn Reports. Available online: https://grains.org/corn_report/ (accessed on 31 July 2018).
- Wilhelm, E.P.; Mullen, R.E.; Keeling, P.L.; Singletary, G.W. Heat stress during grain filling in maize: Effects on kernel growth and metabolism. Crop Sci. 1999, 39, 1733–1741. [Google Scholar] [CrossRef]
- Peng, B.; Guan, K.; Pan, M.; Li, Y. Benefits of seasonal climate prediction and satellite data for forecasting US maize yield. Geophys. Res. Lett. 2018, 45, 9662–9671. [Google Scholar] [CrossRef]
- Lecerf, R.; Ceglar, A.; López-Lozano, R.; Van Der Velde, M.; Bauruth, B. Assessing the information in crop model and meteorological indicators to forecast crop yield over Europe. Agric. Syst. 2019, 168, 191–202. [Google Scholar] [CrossRef]
- Warren, F.B. Forecasting corn ear weights from daily weather data. In Proceedings of the Conference Applied Statistics in Agriculture, Manhattan, KS, USA, 30 April–2 May 1989. [Google Scholar] [CrossRef]
- Alexander, D.E. Breeding special nutritional and industrial types. In Corn and Corn Improvement, 3rd ed.; Sprague, G., Dudley, J., Eds.; ASA-CSSA-SSSA: Madison, WI, USA, 1988. [Google Scholar]
- Thomison, P.R.; Geyer, A.B.; Lotz, L.D.; Siegrist, H.J.; Dobbels, T.L. Topcross high oil corn production: Select grain quality attributes. Agron. J. 2003, 95, 147–154. [Google Scholar] [CrossRef]
- Uribelarrea, M.; Below, F.E.; Moose, S.P. Grain composition and productivity of maize hybrids derived from the Illinois Protein Strains in response to variable nitrogen supply. Crop Sci. 2004, 44, 1593–1600. [Google Scholar] [CrossRef]
- USDA ERS. Corn and Other Feedgrains: Trade. Available online: https://www.ers.usda.gov/topics/crops/corn-and-other-feedgrains/trade/ (accessed on 20 August 2018).
- Butts-Wilmsmeyer, C.J.; Mumm, R.H.; Bohn, M.O. Concentration of beneficial phytochemicals in harvested grain of US yellow dent maize (Zea mays L.) germplasm. J. Agric. Food Chem. 2017, 65, 8311–8318. [Google Scholar] [CrossRef] [PubMed]
- Cook, J.P.; McMullen, M.D.; Holland, J.B.; Tian, F.; Bradbury, P.; Ross-Ibarra, J.; Buckler, E.S.; Flint-Garcia, S.A. Genetic architecture of maize kernel composition in the nested association mapping and inbred association panels. Plant Physiol. 2012, 158, 824–834. [Google Scholar] [CrossRef] [PubMed]
- Lejeune, P.; Bernier, G. Effect of environment on the early steps of ear initiation in maize (Zea mays L.). Plant Cell Environ. 1996, 19, 217–224. [Google Scholar] [CrossRef]
- Cantarero, M.G.; Cirilo, A.G.; Andrade, F.H. Night temperature at silking affects kernel set in maize. Crop Sci. 1999, 39, 703–710. [Google Scholar] [CrossRef]
- Edreira, J.I.R.; Carpici, E.B.; Sammarro, D.; Otegui, M.E. Heat stress effects around flowering on kernel set of temperate and tropical maize hybrids. Field Crops Res. 2011, 123, 62–73. [Google Scholar] [CrossRef]
- Prasad, P.V.V.; Bheemanahalli, R.; Jagadish, S.V.K. Field crops and the fear of heat stress-opportunities, challenges and future directions. Field Crops Res. 2017, 200, 114–121. [Google Scholar] [CrossRef]
- Jones, R.J.; Gengenbach, B.G.; Cardwell, V.B. Temperature effects on in vitro kernel development of maize. Crop Sci. 1981, 21, 761–766. [Google Scholar] [CrossRef]
- Seebauer, J.R.; Singletary, G.W.; Krumpelman, P.M.; Ruffo, M.L.; Below, F.E. Relationship of source and sink in determining kernel composition of maize. J. Exp. Bot. 2010, 61, 511–519. [Google Scholar] [CrossRef] [PubMed]
- Singletary, G.W.; Banisadr, R.; Keeling, P.L. Heat-stress during grain filling in maize—effects on carbohydrate storage and metabolism. Aust. J. Plant Physiol. 1994, 21, 829–841. [Google Scholar] [CrossRef]
- Abe, A.; Menkir, A.; Moose, S.P.; Adetimirin, V.O.; Olaniyan, A.B. Genetic variation for nitrogen-use efficiency among selected tropical maize hybrids differing in grain yield potential. J. Crop Improv. 2013, 27, 31–52. [Google Scholar] [CrossRef]
- Blackmer, A.M.; Pottker, D.; Cerrato, M.E.; Webb, J. Correlations between soil nitrate concentrations in late spring and corn yields in Iowa. J. Prod. Agric. 1989, 2, 103–109. [Google Scholar] [CrossRef]
- Jeong, H.; Bhattarai, R. Exploring the effects of nitrogen fertilization management alternatives on nitrate loss and crop yields in tile-drained fields in Illinois. J. Environ. Manag. 2018, 213, 341–352. [Google Scholar] [CrossRef]
- Mastrodomenico, A.T.; Hendrix, C.C.; Below, F.E. Nitrogen use efficiency and the genetic variation of maize expired plant variety protection germplasm. Agriculture 2018, 8, 3. [Google Scholar] [CrossRef]
- Seebauer, J.R.; Moose, S.P.; Fabbri, B.J.; Crossland, L.D.; Below, F.E. Amino acid metabolism in maize earshoots. Implications for assimilate preconditioning and nitrogen signaling. Plant Physiol. 2004, 136, 4326–4334. [Google Scholar] [CrossRef]
- Archontoulis, S.V.; Miguez, F.E.; Moore, K.J. Evaluating APSIM maize, soil water, soil nitrogen, manure, and soil temperature modules in the midwestern United States. Agron. J. 2014, 106, 1025–1040. [Google Scholar] [CrossRef]
- Yang, X.L.; Lu, Y.L.; Tong, Y.A.; Yin, X.F. A 5-year lysimeter monitoring of nitrate leaching from wheat-maize rotation system: Comparison between optimum N fertilization and conventional farmer N fertilization. Agric. Ecosyst. Environ. 2015, 199, 34–42. [Google Scholar] [CrossRef]
- Troyer, A.F. Adaptedness and heterosis in corn and mule hybrids. Crop Sci. 2006, 46, 528–543. [Google Scholar] [CrossRef]
- Illinois Crop Improvement Association. Grain Laboratory Services. Available online: https://www.ilcrop.com/labservices/grainservices (accessed on 20 January 2018).
- USDA NASS. Quick Stats. Available online: https://quickstats.nass.usda.gov/ (accessed on 1 August 2018).
- Becker, R.A.; Wilks, A.R.; Brownrigg, R.; Minka, T.P.; Deckmyn, A. Maps: Draw Geographical Maps. R Package Version 3.3.0. Available online: https://CRAN.R-project.org/package=maps (accessed on 15 August 2018).
- Chapman, K.; McGuire, J. NutrientStar TED Framework Tool. Available online: http://nutrientstar.org/ted-framework/ (accessed on 31 July 2018).
- USDA NASS. County Data Frequently Asked Questions. Available online: https://www.nass.usda.gov/Data_and_Statistics/County_Data_Files/Frequently_Asked_Questions/index.php# (accessed on 20 July 2018).
- USDA NASS. Charts and Maps. Available online: https://www.nass.usda.gov/Charts_and_Maps/Crops_County/boundary_maps/indexgif.php (accessed on 20 July 2018).
- Midwestern Regional Climate Center. Cli-Mate: Daily County Data between Two Dates. Available online: https://mrcc.illinois.edu/CLIMATE/ (accessed on 20 July 2018).
- Johnson, D.E. Principal component analysis. In Applied Multivariate Methods for Data Analysts; Brooks/Cole Publishing Company: Pacific Grove, CA, USA, 1998; pp. 110–111. [Google Scholar]
- Butts-Wilmsmeyer, C.J.; Mumm, R.H.; Rausch, K.; Kandhola, G.; Yana, N.A.; Happ, M.M.; Ostezan, A.; Wasmund, M.; Bohn, M.O. Changes in phenolic acid content in maize during food product processing. J. Agric. Food Chem. 2018, 66, 3378–3385. [Google Scholar] [CrossRef] [PubMed]
- Labate, J.A.; Lamkey, K.R.; Mitchell, S.E.; Kresovich, S.; Sullivan, H.; Smith, J.S.C. Molecular and historical aspects of corn belt dent diversity. Crop Sci. 2003, 43, 80–91. [Google Scholar] [CrossRef]
- Li, P.X.P.; Hardacre, A.K.; Campanella, O.H.; Kirkpatrick, K.J. Determination of endosperm characteristics of 38 corn hybrids using the Stenvert Hardness test. Cereal Chem. 1996, 73, 466–471. [Google Scholar]
- Brown, W.L.; Zuber, M.S.; Darrah, L.L.; Glover, D.V. Origin, adaptation, and types of corn. In National Corn Handbook; Cooperative Extension Service, Iowa State Univ.: Ames, IA, USA, 1985; pp. 1–6. [Google Scholar]
- Gayral, M.; Gaillard, C.; Bakan, B.; Dalgalarrondo, M.; Elmorjani, K.; Delluc, C.; Brunet, S.; Linossier, L.; Morel, M.H.; Marion, D. Transition from vitreous to floury endosperm in maize (Zea mays L.) kernels is related to protein and starch gradients. J. Cereal Sci. 2016, 68, 148–154. [Google Scholar] [CrossRef]
- Kereliuk, G.R.; Sosulski, F.W. Properties of corn samples varying in percentage of dent and flint kernels. Food Sci. Technol. Leb.-Wiss. Technol. 1995, 28, 589–597. [Google Scholar] [CrossRef]
- Kutner, M.H.; Nachtsheim, C.J.; Neter, J.; Li, W. Applied linear statistical models. In Applied Linear Statistical Models, 5 ed.; Gordon, B., Hercher, R.T., Eds.; McGraw-Hill: New York, NY, USA, 2005. [Google Scholar]
- Dinnes, D.L.; Karlen, D.L.; Jaynes, D.B.; Kaspar, T.C.; Hatfield, J.L.; Colvin, T.S.; Cambardella, C.A. Nitrogen management strategies to reduce nitrate leaching in tile-drained midwestern soils. Agron. J. 2002, 94, 153–171. [Google Scholar] [CrossRef]
- Dwyer, L.M.; Stewart, D.W.; Tollenaar, M. Analysis of maize leaf photosynthesis under drought stress. Can. J. Plant Sci. 1992, 72, 477–481. [Google Scholar] [CrossRef]
- Lobell, D.B.; Field, C.B. Global scale climate—Crop yield relationships and the impacts of recent warming. Environ. Res. Lett. 2007, 2, 014002. [Google Scholar] [CrossRef]
- Nielson, B.L. Warm Nights & High Yields of Corn: Oil & Water? Available online: https://www.agry.purdue.edu/ext/corn/news/timeless/WarmNights.html (accessed on 22 August 2018).
- Below, F.E.; Cazetta, J.O.; Seebauer, J.R. Carbon/nitrogen interactions during ear and kernel development of maize. In Physiology and Modeling Kernel Set in Maize; Westgate, M., Boote, K., Eds.; Crop Science Society of America and American Society of Agronomy: Madison, WI, USA, 2000; pp. 15–24. [Google Scholar] [CrossRef]
- Mayer, L.I.; Edreira, J.I.R.; Maddonni, G.A. Oil yield components of maize crops exposed to heat stress during early and late grain-filling stages. Crop Sci. 2014, 54, 2236–2250. [Google Scholar] [CrossRef]
- Carter, E.K.; Melkonian, J.; Riha, S.J.; Shaw, S.B. Separating heat stress from moisture stress: Analyzing yield response to high temperature in irrigated maize. Environ. Res. Lett. 2016, 11, 094012. [Google Scholar] [CrossRef]
- Glelck, P.; Heberger, M. American Rivers: A Graphic. Available online: http://pacinst.org/american-rivers-a-graphic/ (accessed on 24 October 2018).



{kind=link}
{kind=link}
| Xik | Acronym | General Description | Models Where Included | ||
|---|---|---|---|---|---|
| PCA1 | PCA2 | Yield | |||
| Xi1 | EGP | The total precipitation during the early vegetative growth stage in inches | Y | N | Y |
| Xi2 | EGT | The average daily temperature during the early vegetative growth stage in °F | N | N | N |
| Xi3 | FP | The total precipitation during the flowering growth stage in inches | N | Y | Y |
| Xi4 | FT | The average daily temperature during flowering in °F | Y | Y | Y |
| Xi5 | GFP | The total precipitation during grain fill in inches | Y | N | Y |
| Xi6 | GFT | The average daily temperature during grain fill in °F | Y | Y | Y |
| Xi7 | GFMT | The average minimum daily temperature during grain fill in °F | N | Y | Y |
| Xi8 | SWS | Soil water storage, more positive values indicate a greater soil water storage capacity | N | Y | Y |
| Xi9 | AI | The aridity index, smaller values indicate a more arid environment as a function of average annual precipitation and rate of evapotranspiration | Y | Y | Y |
| Xi10 | GDD | The average growing degree days for an area | N | N | N |
| Xi11 | D | A qualitative covariate accounting for the greater protein content typical of hybrids grown in the Dakotas. This variable was assigned a value of 0 if the sample in question came from either ND or SD and a value of 1 otherwise. | Y | Y | Y |
| EGP † | EGT | FP | FT | GFP | GFT | GFMT | SWS | GDD | AI | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.132 | −0.175 | −0.110 | −0.019 | −0.243 | −0.193 | 0.006 | −0.025 | −0.004 | EGP | |
| −0.260 | 0.169 | −0.058 | 0.221 | 0.213 | −0.086 | 0.520 | 0.442 | EGT | ||
| 0.019 | 0.153 | 0.150 | 0.237 | −0.060 | −0.003 | 0.099 | FP | |||
| −0.175 | 0.496 | 0.420 | 0.098 | 0.373 | 0.004 | FT | ||||
| 0.084 | 0.203 | 0.024 | 0.049 | 0.207 | GFP | |||||
| 0.953 | 0.029 | 0.701 | 0.261 | GFT | ||||||
| 0.001 | 0.693 | 0.346 | GFMT | |||||||
| 0.011 | −0.178 | SWS | ||||||||
| 0.479 | GDD |
| Grain Concentration | Test | |||||
|---|---|---|---|---|---|---|
| Protein | Starch | Oil | Weight | PCA1 | PCA2 | |
| Yield | −0.431 | 0.063 | 0.248 | 0.176 | −0.087 | −0.488 |
| Protein | −0.544 | −0.001 | −0.018 | NA† | NA | |
| Starch | −0.599 | 0.176 | NA | NA | ||
| Oil | −0.070 | NA | NA | |||
| Test Weight | −0.126 | 0.034 | ||||
| PCA1 | 0.000 | |||||
| Grain Concentration | ||||||
|---|---|---|---|---|---|---|
| Year | Protein | Starch | Oil | PCA1 | PCA2 | Yield |
| ————g/kg———— | T/ha | |||||
| All States Included | ||||||
| 2011 | 87.2 | 734.7 | 36.7 | −0.40 | 0.49 | 8.93 |
| 2012 | 94.4 | 731.6 | 37.5 | 0.42 | 1.03 | 7.19 |
| 2013 | 85.8 | 734.1 | 38.5 | −0.17 | 0.03 | 10.00 |
| 2014 | 84.6 | 735.0 | 37.6 | −0.43 | 0.07 | 10.86 |
| 2015 | 81.9 | 736.9 | 37.7 | −0.75 | −0.19 | 10.86 |
| 2016 | 85.7 | 724.7 | 40.4 | 0.84 | −0.32 | 10.97 |
| 2017 | 86.2 | 723.2 | 41.2 | 1.09 | −0.42 | 10.75 |
| Excluding Dakotas | ||||||
| 2011 | 86.8 | 734.8 | 36.8 | −0.41 | 0.43 | 9.41 |
| 2012 | 94.3 | 731.6 | 37.5 | 0.41 | 1.01 | 7.46 |
| 2013 | 85.8 | 734.1 | 38.5 | −0.17 | 0.03 | 10.00 |
| 2014 | 83.8 | 735.6 | 37.9 | −0.50 | −0.05 | 11.51 |
| 2015 | 81.0 | 737.4 | 37.8 | −0.82 | −0.29 | 11.00 |
| 2016 | 84.9 | 725.6 | 40.2 | 0.70 | −0.36 | 11.22 |
| 2017 | 85.9 | 723.6 | 41.1 | 1.04 | −0.43 | 11.45 |
| Cluster | Color | ASD † Count | PCA1 | PCA2 | Yield |
|---|---|---|---|---|---|
| 1 | Purple | 13 | −0.44397 | 0.09525 | 11.214 (178.644) |
| 2 | Blue | 14 | 0.1441 | −0.17026 | 10.840 (172.674) |
| 3 | Green | 12 | 0.19138 | 0.33464 | 9.186 (146.339) |
| 4 | Dark Green | 7 | −0.07588 | −0.10005 | 9.063 (144.381) |
| 5 | Yellow | 9 | −0.73882 | 0.43401 | 10.184 (162.237) |
| 6 | Orange | 8 | 0.72065 | 0.59974 | 8.638 (137.604) |
| 7 | Gold | 3 | 1.52549 | 0.54987 | 6.980 (111.195) |
| 8 | Salmon | 6 | 0.4815 | 0.82565 | 6.564 (104.568) |
| 9 | Brick Red | 3 | 1.30486 | 1.15527 | 9.190 (146.394) |
| 10 | Red | 1 | −1.78707 | 0.90478 | 6.362 (101.340) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Butts-Wilmsmeyer, C.J.; Seebauer, J.R.; Singleton, L.; Below, F.E. Weather During Key Growth Stages Explains Grain Quality and Yield of Maize. Agronomy 2019, 9, 16. https://doi.org/10.3390/agronomy9010016
Butts-Wilmsmeyer CJ, Seebauer JR, Singleton L, Below FE. Weather During Key Growth Stages Explains Grain Quality and Yield of Maize. Agronomy. 2019; 9(1):16. https://doi.org/10.3390/agronomy9010016
Chicago/Turabian StyleButts-Wilmsmeyer, Carrie J., Juliann R. Seebauer, Lee Singleton, and Frederick E. Below. 2019. "Weather During Key Growth Stages Explains Grain Quality and Yield of Maize" Agronomy 9, no. 1: 16. https://doi.org/10.3390/agronomy9010016
APA StyleButts-Wilmsmeyer, C. J., Seebauer, J. R., Singleton, L., & Below, F. E. (2019). Weather During Key Growth Stages Explains Grain Quality and Yield of Maize. Agronomy, 9(1), 16. https://doi.org/10.3390/agronomy9010016