

A Robust Tomato Counting Framework for Greenhouse Inspection Robots Using YOLOv8 and Inter-Frame Prediction


Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Data Acquisition and Preparation
3.2. Inspection Robot and Sensor System
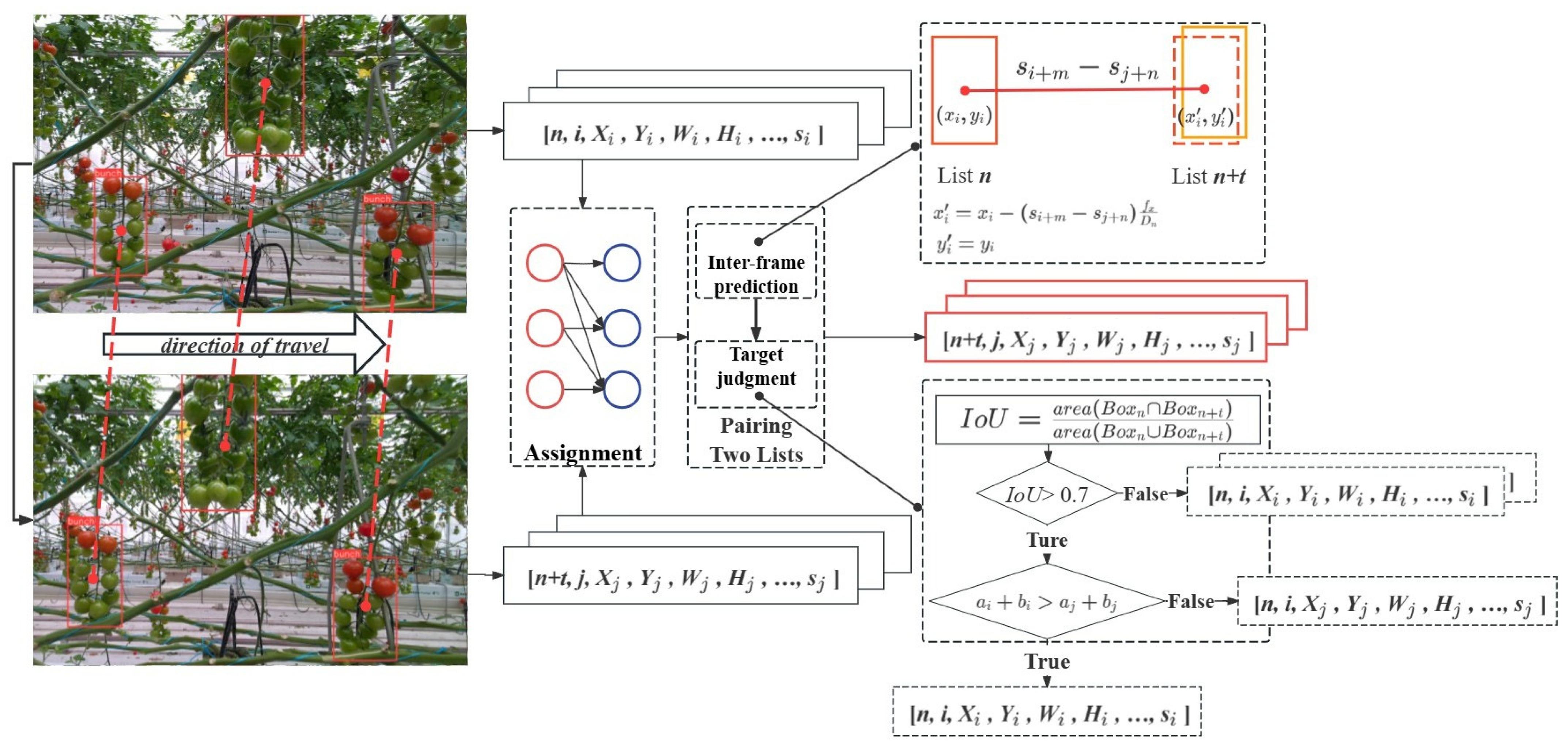
3.3. Algorithms
3.3.1. Spatiotemporal Tuple
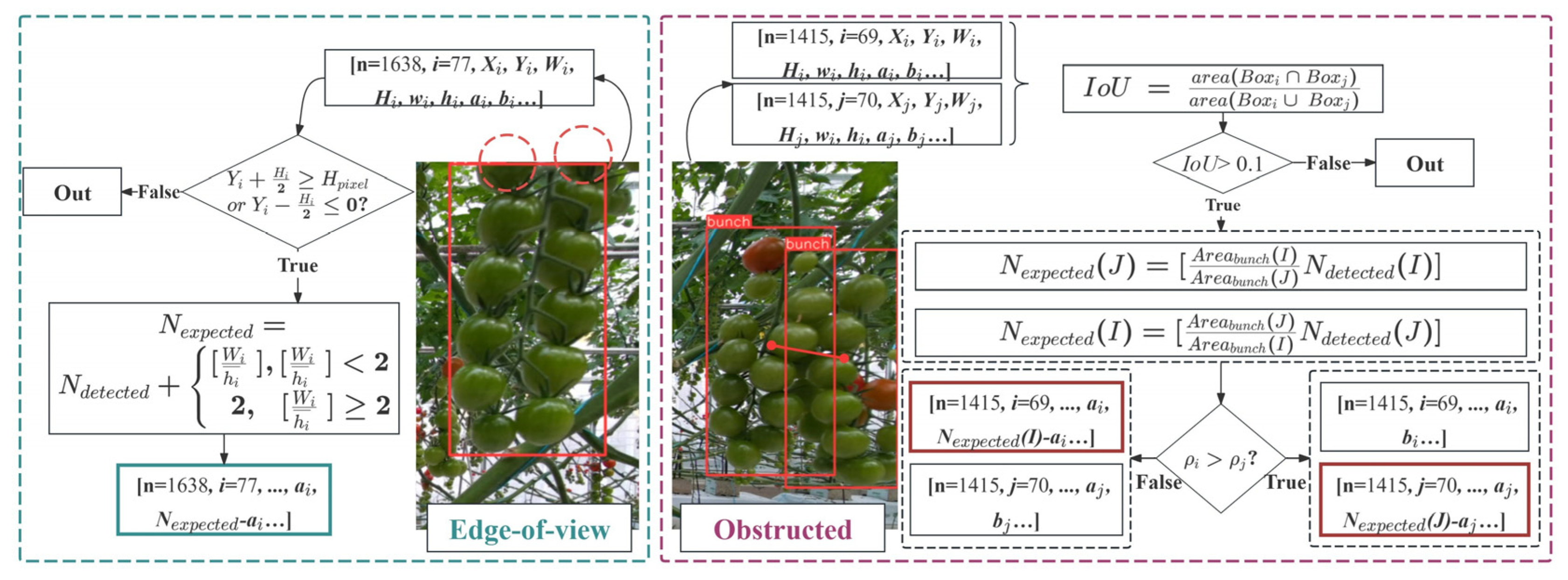
3.3.2. Tracking and Counting Tomatoes with Sensor Fusion
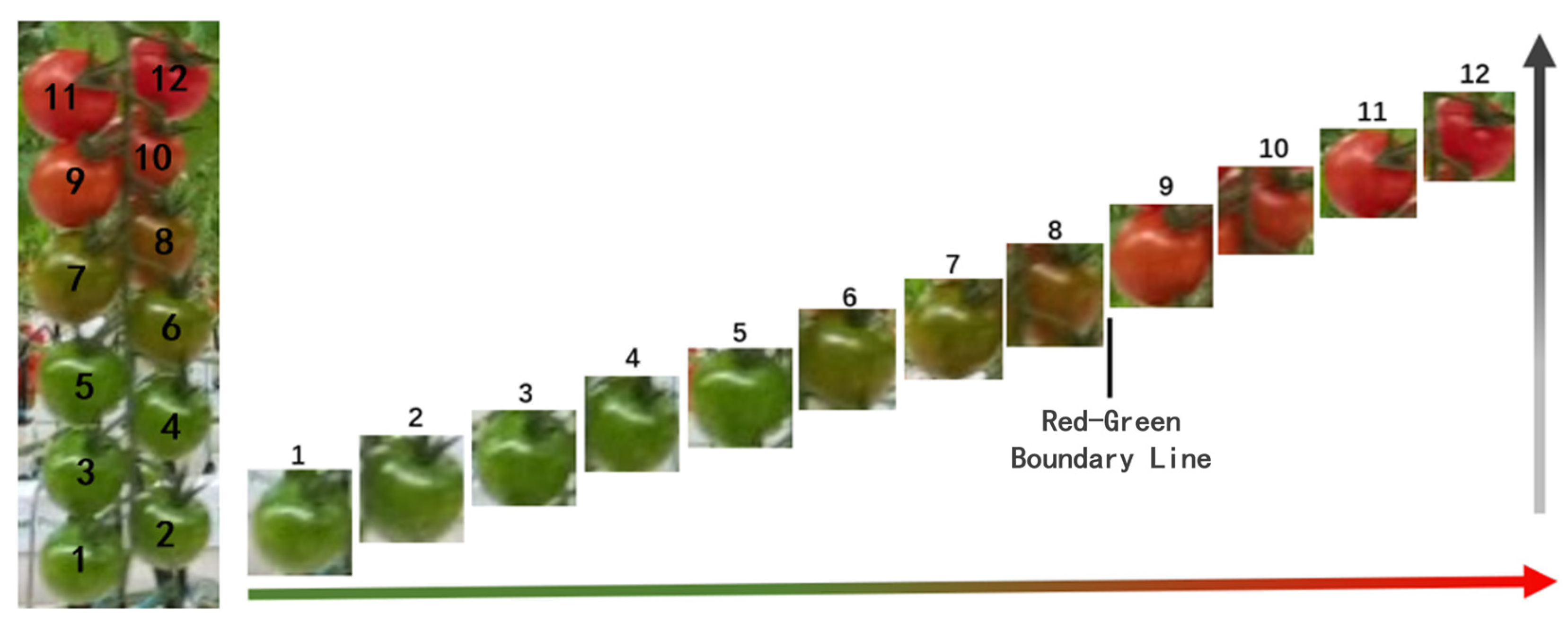
3.3.3. Ripeness Determination
4. Results
- Comparison of our counting method with the YOLOv8 + DeepSORT method;
- Comparison of our counting method with the tomato counting method for density estimation;
- Analysis of the compensation processing steps and their impact on tomato detection results;
- Evaluation of the current ripeness detection method.
4.1. Experimental Setup
4.2. Comparison with Other Approaches
Evaluation Indicators
- Metrics for Tomato Cluster Counting:
- Metrics for Single Fruit Counting:
4.3. Tomato Counting Based on Density Estimation
4.4. Tomato Counting Based on YOLOv8 and DeepSORT
4.5. Impact of Post-Processing
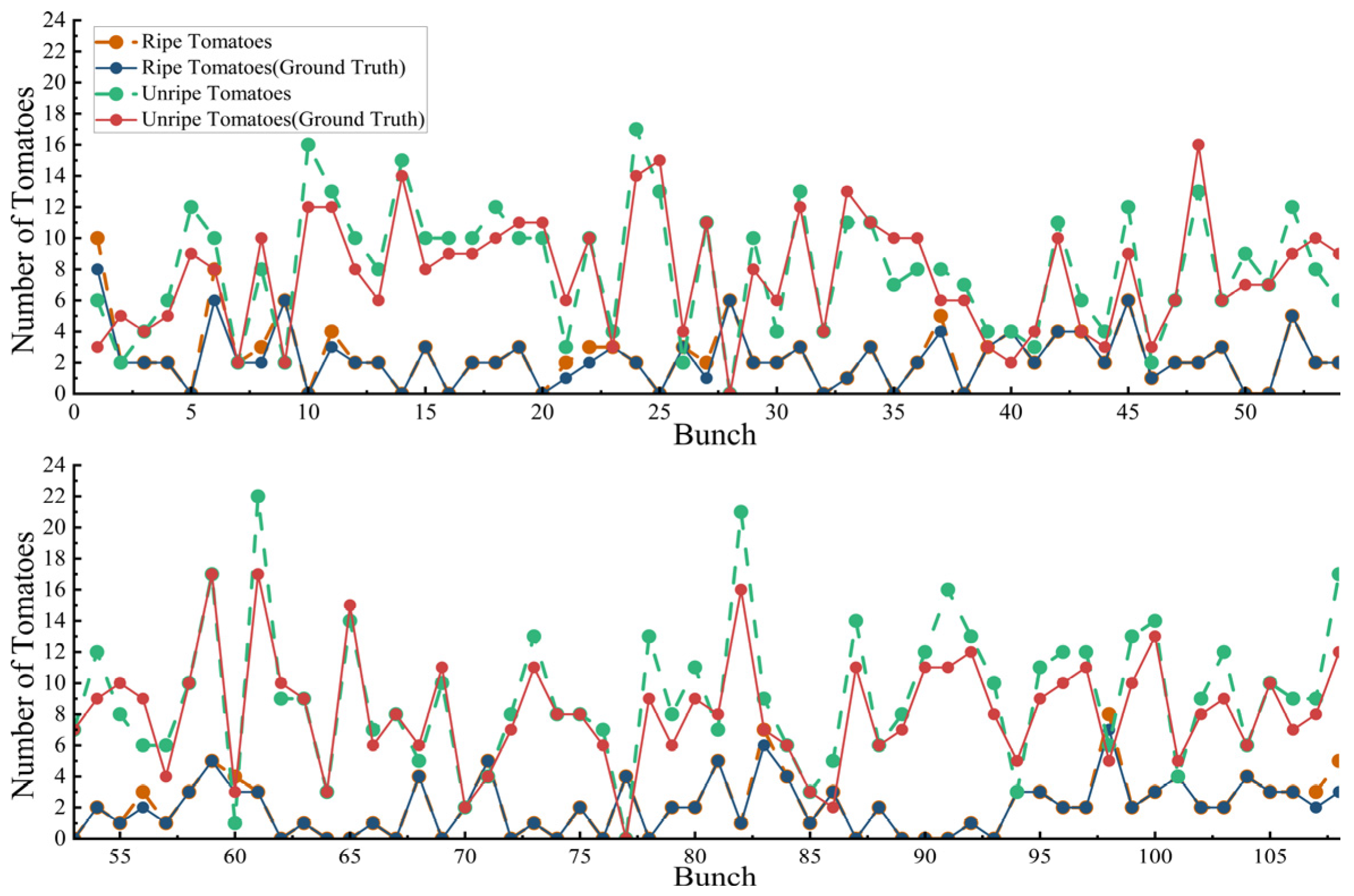
4.6. Accuracy of Mature and Immature Fruit Counting
4.7. Visualization Results of the Tomato Inspections
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Su, T.L.; Zuo, M. CropDeep: The crop vision dataset for deep-learning-based classification and detection in precision agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed]
- Tian, H.; Wang, T.; Liu, Y.; Qiao, X.; Li, Y. Computer vision technology in agricultural automation—A review. Inf. Process. Agric. 2020, 7, 1–19. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. intelligence 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [PubMed]
- Suo, R.; Gao, F.; Zhou, Z.; Fu, L.; Song, Z.; Dhupia, J.; Li, R.; Cui, Y. Improved multi-classes kiwifruit detection in orchard to avoid collisions during robotic picking. Comput. Electron. Agric. 2021, 182, 106052. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Afonso, M.; Fonteijn, H.; Fiorentin, F.S.; Lensink, D.; Mooij, M.; Faber, N.; Polder, G.; Wehrens, R. Tomato fruit detection and counting in greenhouses using deep learning. Front. Plant Sci. 2020, 11, 571299. [Google Scholar] [CrossRef] [PubMed]
- Pei, Y.; Liu, H.; Bei, Q. Collision-Line Counting Method Using DeepSORT to Count Pedestrian Flow Density and Hungary Algorithm. In Proceedings of the 2021 IEEE 3rd International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Changsha, China, 20–22 October 2021; pp. 621–626. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Rong, J.C.; Zhou, H.; Zhang, F.; Yuan, T.; Wang, P.B. Tomato cluster detection and counting using improved YOLOv5 based on RGB-D fusion. Comput. Electron. Agric. 2023, 207, 107741. [Google Scholar] [CrossRef]
- Qi, Z.X.; Zhang, W.Q.; Yuan, T.; Rong, J.; Hua, W.; Zhang, Z.; Deng, X.; Zhang, J.; Li, W. An improved framework based on tracking-by-detection for simultaneous estimation of yield and maturity level in cherry tomatoes. Measurement 2024, 226, 114117. [Google Scholar] [CrossRef]
- Ge, Y.; Lin, S.; Zhang, Y.; Li, Z.; Cheng, H.; Dong, J.; Shao, S.; Zhang, J.; Qi, X.; Wu, Z. Tracking and counting of tomato at different growth period using an improving YOLO-deepsort network for inspection robot. Machines 2022, 10, 489. [Google Scholar] [CrossRef]
- Wang, Z.; Ling, Y.M.; Wang, X.L.; Meng, D.; Nie, L.; An, G.; Wang, X. An improved Faster R-CNN model for multi-object tomato maturity detection in complex scenarios. Ecol. Inform. 2022, 72, 101886. [Google Scholar] [CrossRef]
- Parico, A.I.B.; Ahamed, T. Real time pear fruit detection and counting using YOLOv4 models and deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef] [PubMed]
- Zheng, T.X.; Jiang, M.Z.; Li, Y.F.; Feng, M. Research on tomato detection in natural environment based on RC-YOLOv4. Comput. Electron. Agric. 2022, 198, 107029. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, P.; Dai, G.; Yan, J.; Yang, Z. Tomato fruit maturity detection method based on YOLOV4 and statistical color model. In Proceedings of the 2021 IEEE 11th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Jiaxing, China, 27–31 July 2021; pp. 904–908. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Maheswari, P.; Raja, P.; Apolo-Apolo, O.E.; Pérez-Ruiz, M. Intelligent fruit yield estimation for orchards using deep learning based semantic segmentation techniques—A review. Front. Plant Sci. 2021, 12, 684328. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Specification |
|---|---|
| Dimensions | 1.4 × 0.86 × 2.2 m |
| Weight | 200 kg |
| Max Speed | 0.3 m/s |
| Operating Time | 6 h |
| Camera | RealSense D435i |
| Resolution | 1080 × 720 pixels |
| IMU | HWT901B |
| Computer | NVIDIA Jetson Nano |
| Actual Tomato Production by Ridge | Ridge 1 | Ridge 2 | Ridge 3 |
|---|---|---|---|
| Number of tomato clusters | 98 | 105 | 108 |
| Number of mature fruits | 232 | 258 | 251 |
| Number of immature fruits | 778 | 797 | 926 |
| Total | 1010 | 1055 | 1177 |
| Metric | YOLOv8 + DeepSORT | Density Estimation | Our Method |
|---|---|---|---|
| Principle | Computer vision-based detection and tracking | Manual sampling and density-based extrapolation | Detection and IMU-based tracking |
| Tracking performance | Medium (0.569) | - | High (0.954) |
| Accuracy | Medium (82.20%) | Medium (80.17%) | High (97.30%) |
| Advantages | Efficient, repeatable | Simple implementation, hardware_free | Efficient, repeatable, higher accuracy |
| Limitations | IMU-free, Medium accuracy | Inconsistent errors with low reproducibility, low accuracy | Requires high-precision IMU |
| Speed | High (20.90) | - | High (28.72) |
| Scalability | Strong | Weak | Strong |
| YOLOv8 + DeepSORT | Our Method | |||||
|---|---|---|---|---|---|---|
| Ridge 1 | Ridge 2 | Ridge 3 | Ridge 1 | Ridge 2 | Ridge 3 | |
| Sum of frames | 2272 | 2254 | 2297 | 2251 | 2191 | 2236 |
| GT | 98 | 105 | 108 | 98 | 105 | 108 |
| FN | 2 | 3 | 2 | 2 | 4 | 3 |
| FP | 29 | 34 | 31 | 0 | 0 | 1 |
| IDSW | 10 | 13 | 9 | 0 | 0 | 1 |
| MOTA | 0.582 | 0.524 | 0.600 | 0.980 | 0.952 | 0.954 |
| Our Method | YOLOv8 + DeepSORT | Density Estimation | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 1st | 2nd | 3rd | 1st | 2nd | 3rd | |
| EC | 302 | 300 | 300 | 368 | 371 | 353 | 253 (E) * | 231 (E) | 277 (E) |
| ACC | 97.73% | 97.09% | 97.09% | 80.91% | 79.94% | 85.76% | 81.81% | 74.80% | 83.90% |
| FPS | 28.84 | 28.66 | 28.67 | 20.74 | 21.09 | 20.87 | - | - | - |
| Our Method | Density Estimation | |||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 1st | 2nd | 3rd | |
| Measured value (mature) | 234 | 231 | 231 | 195 (E) * | 161 (E) | 201 (E) |
| Measured value (mature) | 857 | 850 | 831 | 672 (E) | 728 (E) | 714 (E) |
| ACC (mature) | 93.22% | 92.03% | 92.03% | 77.70% | 64.14% | 80.08% |
| ACC (immature) | 92.55% | 91.79% | 89.74% | 72.57% | 78.62% | 77.10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Dai, G.; Hu, M.; Wang, P. A Robust Tomato Counting Framework for Greenhouse Inspection Robots Using YOLOv8 and Inter-Frame Prediction. Agronomy 2025, 15, 1135. https://doi.org/10.3390/agronomy15051135
Zheng W, Dai G, Hu M, Wang P. A Robust Tomato Counting Framework for Greenhouse Inspection Robots Using YOLOv8 and Inter-Frame Prediction. Agronomy. 2025; 15(5):1135. https://doi.org/10.3390/agronomy15051135
Chicago/Turabian StyleZheng, Wanli, Guanglin Dai, Miao Hu, and Pengbo Wang. 2025. "A Robust Tomato Counting Framework for Greenhouse Inspection Robots Using YOLOv8 and Inter-Frame Prediction" Agronomy 15, no. 5: 1135. https://doi.org/10.3390/agronomy15051135
APA StyleZheng, W., Dai, G., Hu, M., & Wang, P. (2025). A Robust Tomato Counting Framework for Greenhouse Inspection Robots Using YOLOv8 and Inter-Frame Prediction. Agronomy, 15(5), 1135. https://doi.org/10.3390/agronomy15051135