
Prediction of Water Stress Episodes in Fruit Trees Based on Soil and Weather Time Series Data

 ,
,  , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Site and Irrigation Treatments
2.2. Crop Water Status Measurement
2.3. Soil Water and Meteorological Variables Measurement
2.4. Dataset Arrangement
2.5. Modeling Approaches
2.5.1. Binary Supervised Classification of Tree Water Status
- By directly applying a ML classification technique, i.e., without taking into account the problem of imbalanced classes.
- By previously applying an oversampling technique to compensate for the sample size of both classes. Specifically, we applied MWMOTE (Majority Weighted Minority Oversampling Technique for imbalance dataset learning) [28], which is included in the R ‘imbalance’ package [29]. MWMOTE is a modification of the SMOTE technique [30], which overcomes some of its limitations when there are noisy instances, in which case SMOTE would generate additional noisy instances from them.
2.5.2. Ψstem Estimation with Regression Techniques
2.6. Summary of Data Configurations Analyzed in the Study
3. Results and Discussion
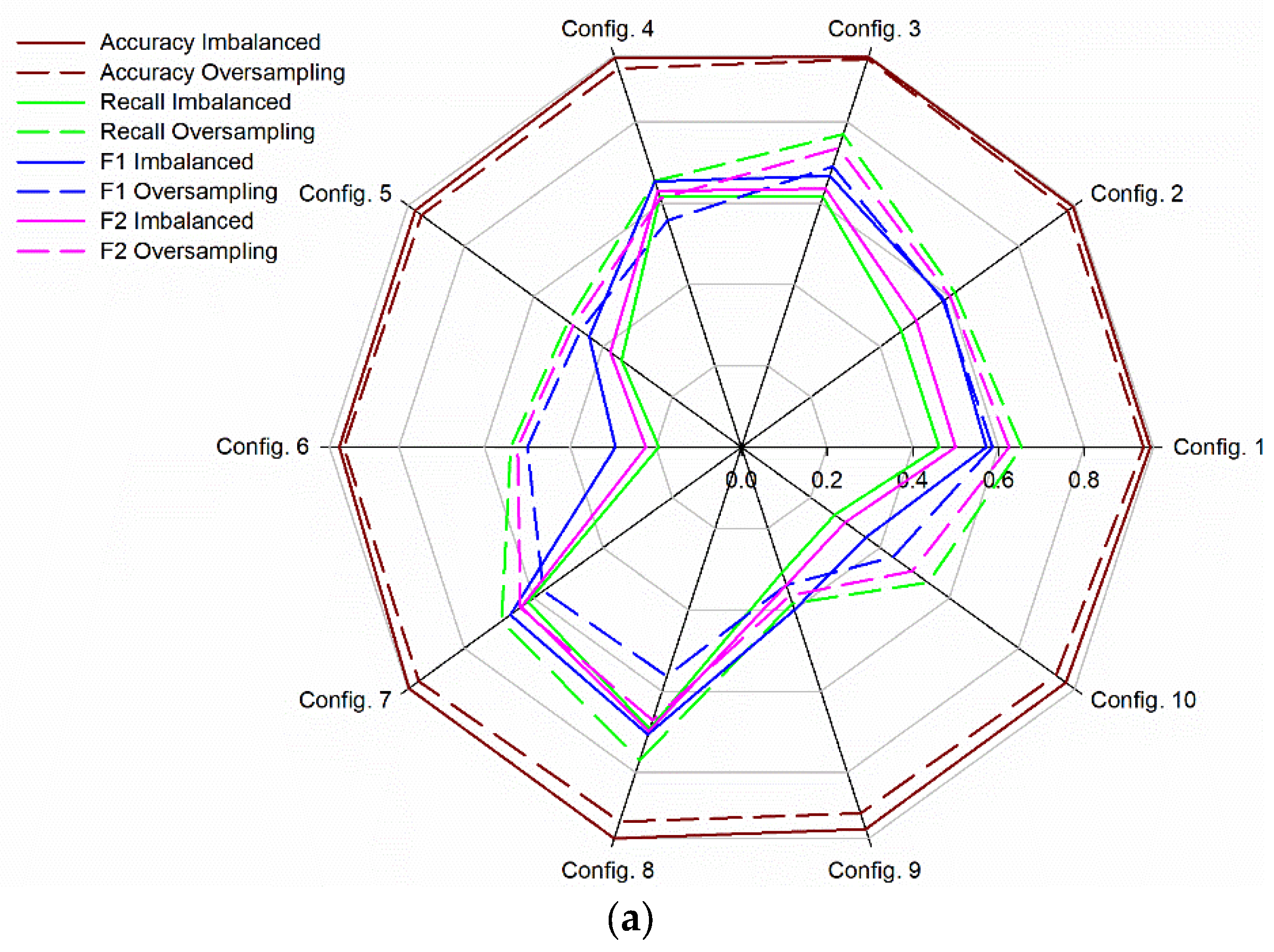
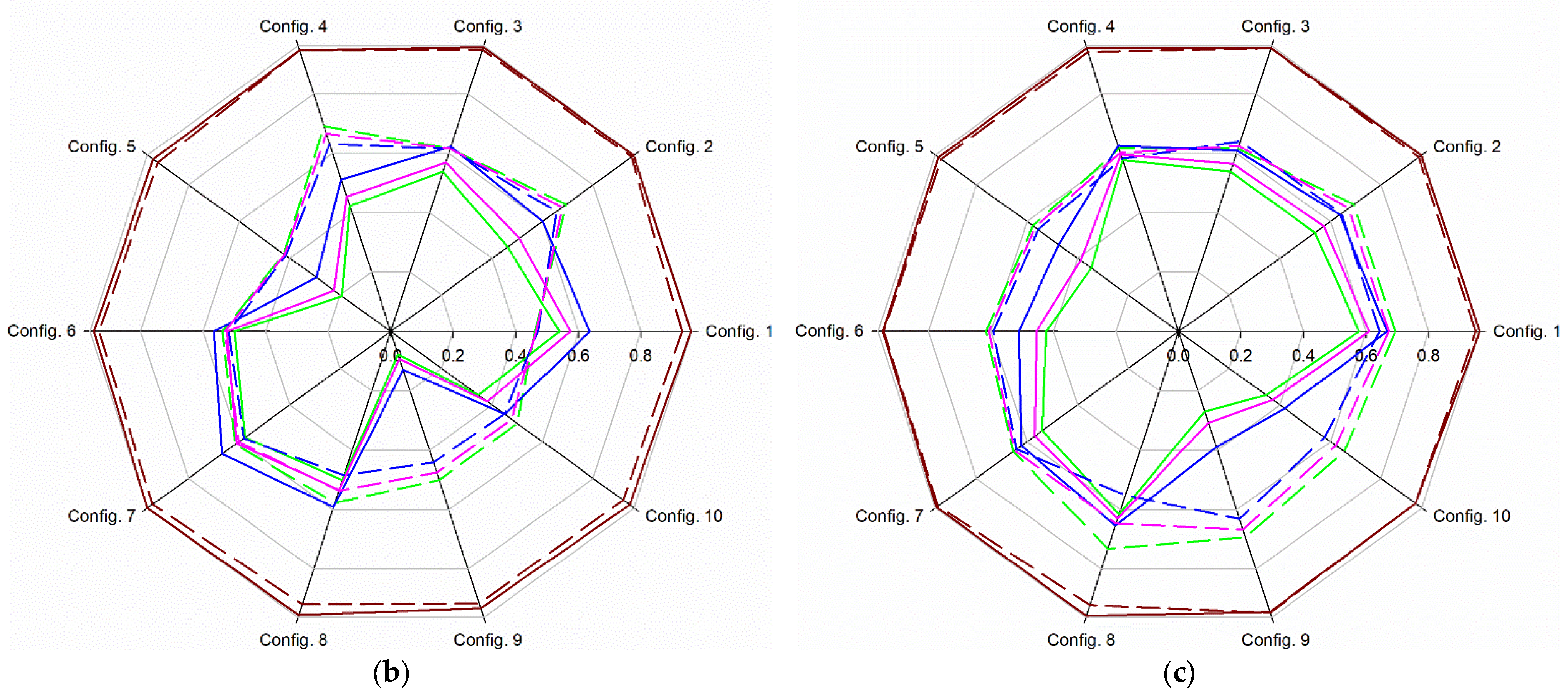
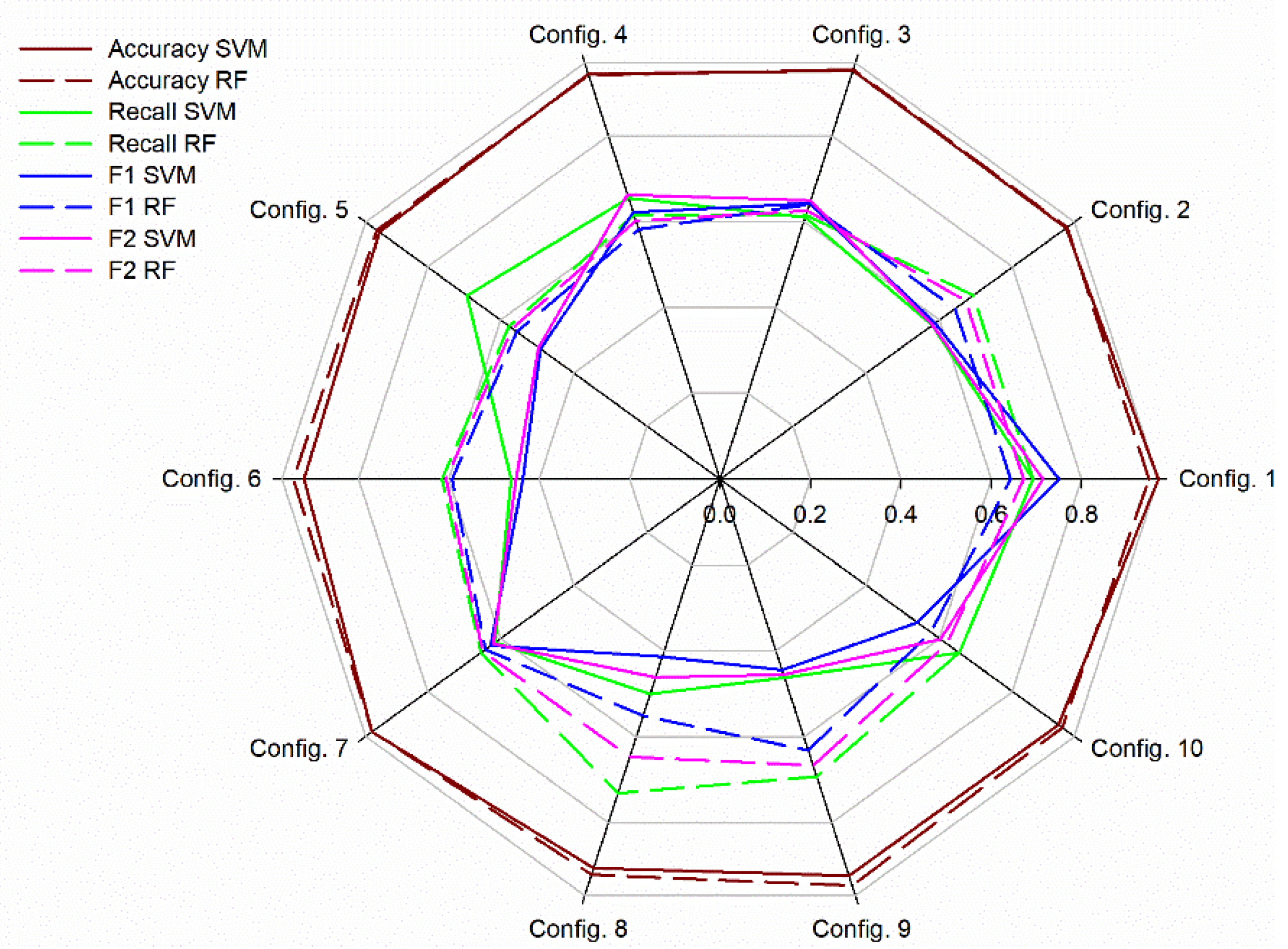
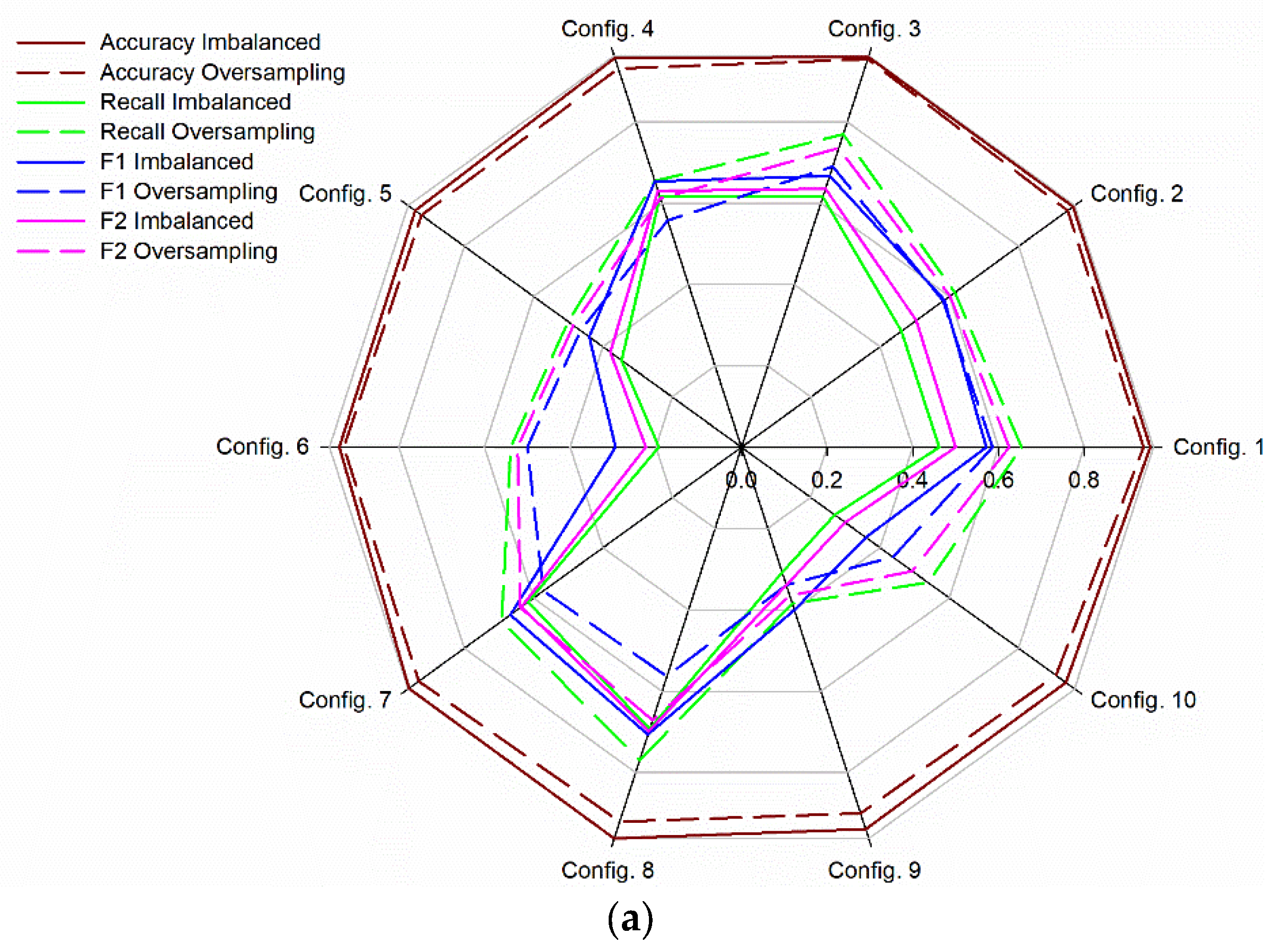
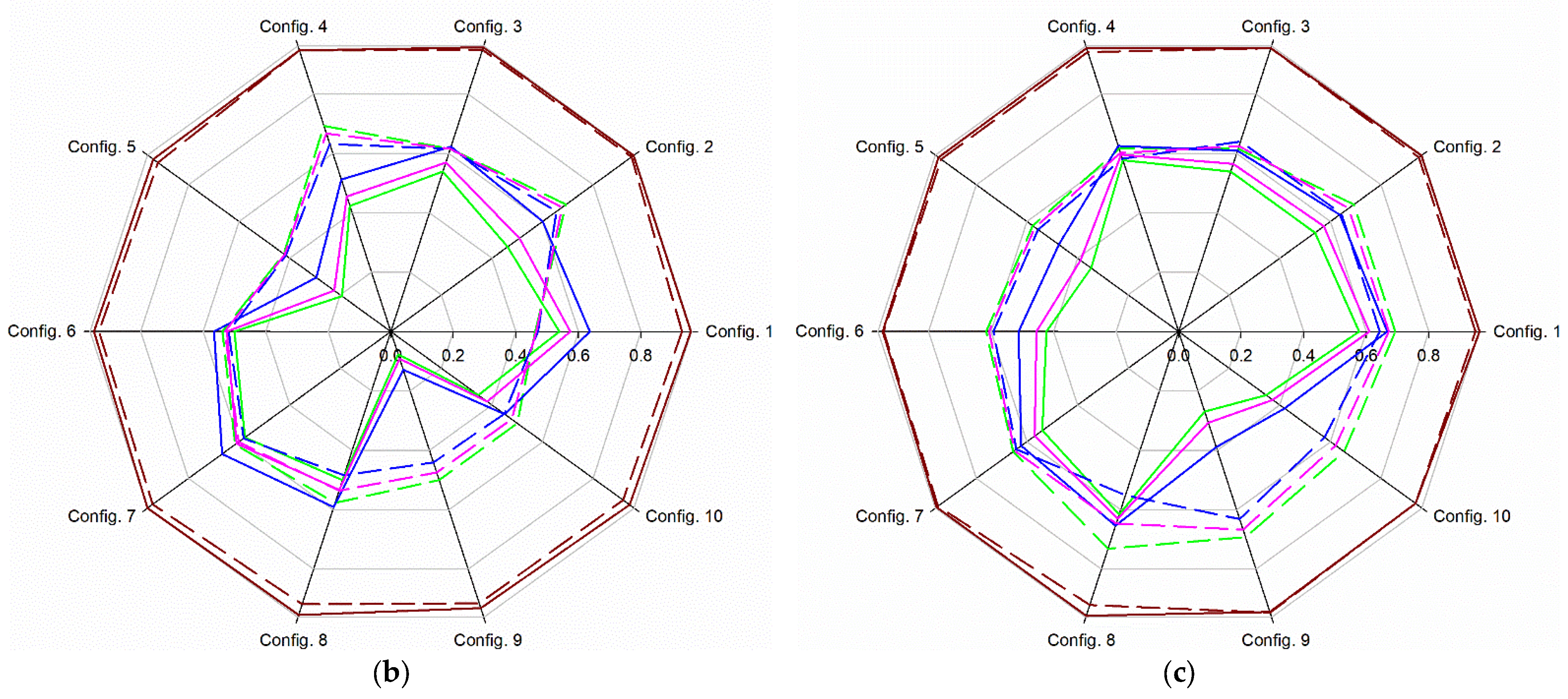
3.1. Binary Supervised Classification Approach
3.1.1. Influence of Soil Matric Potential and Soil Water Content on the Performance of the Models
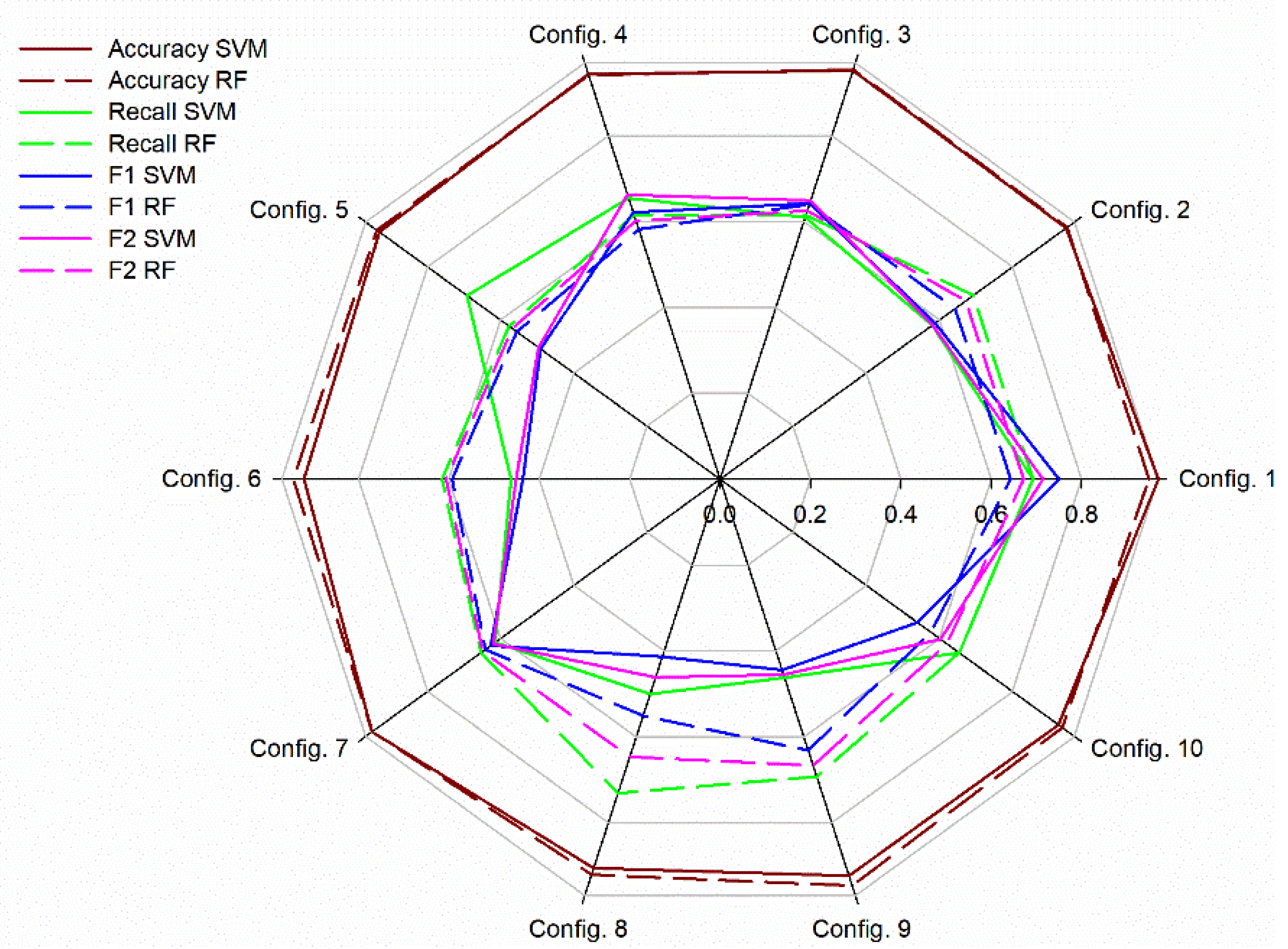
3.1.2. Comparison between RF and SVM Models
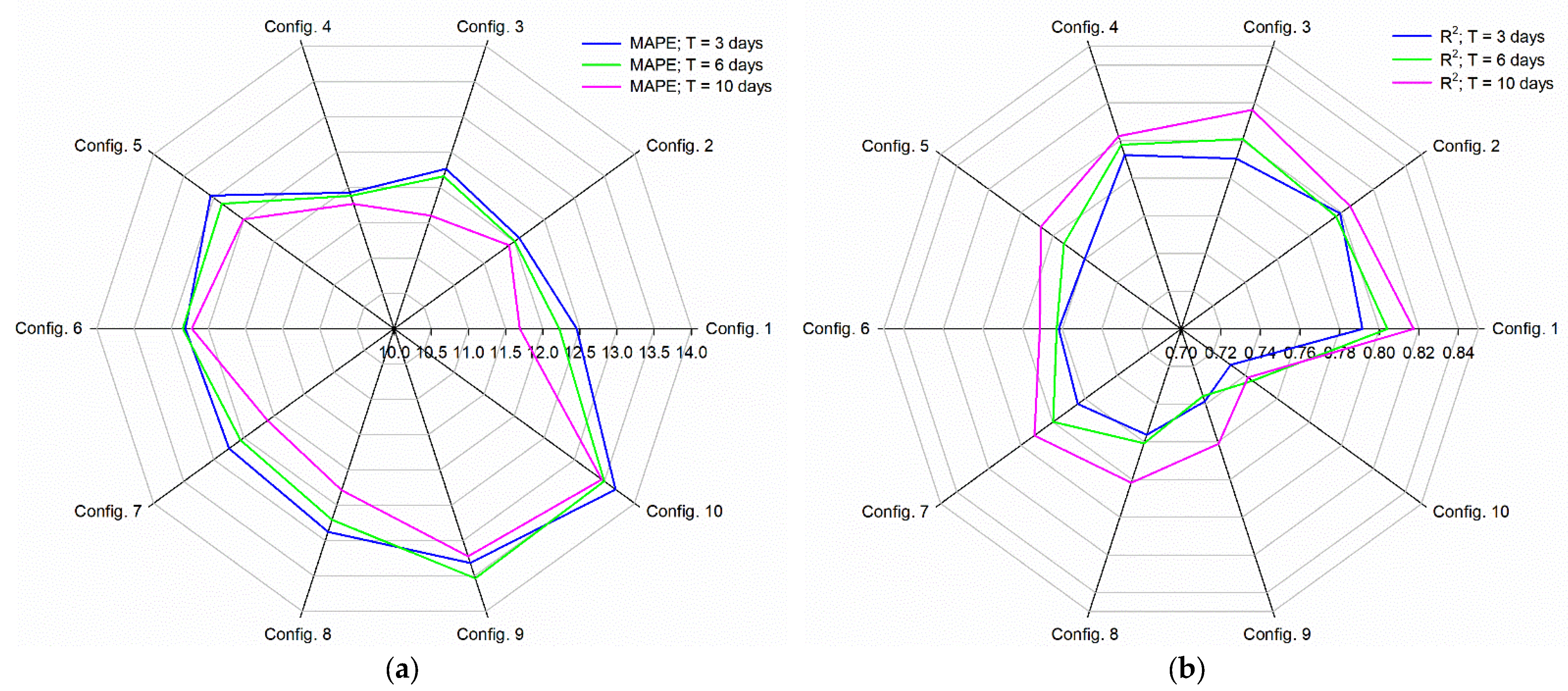
3.2. Regression Approach
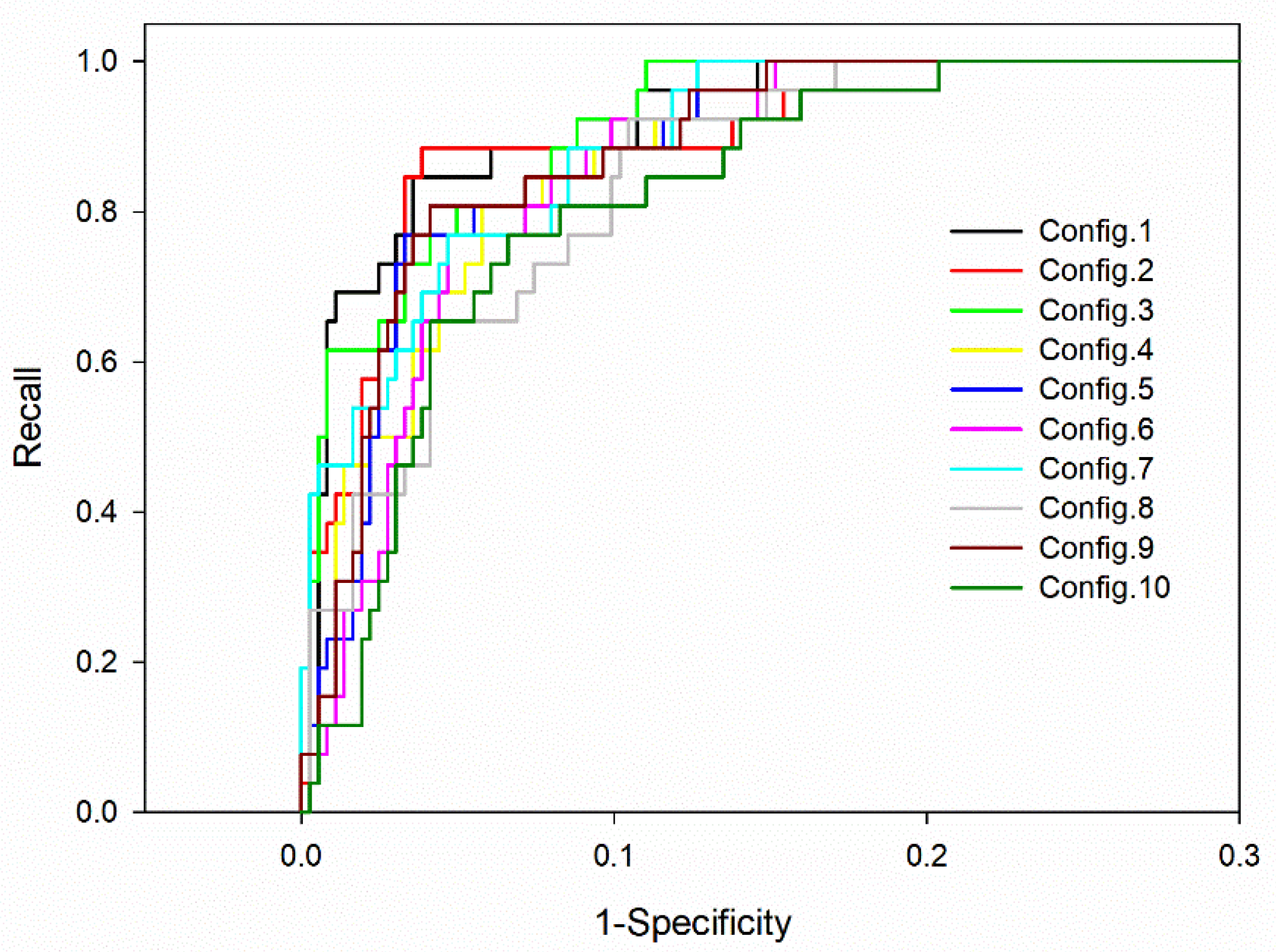
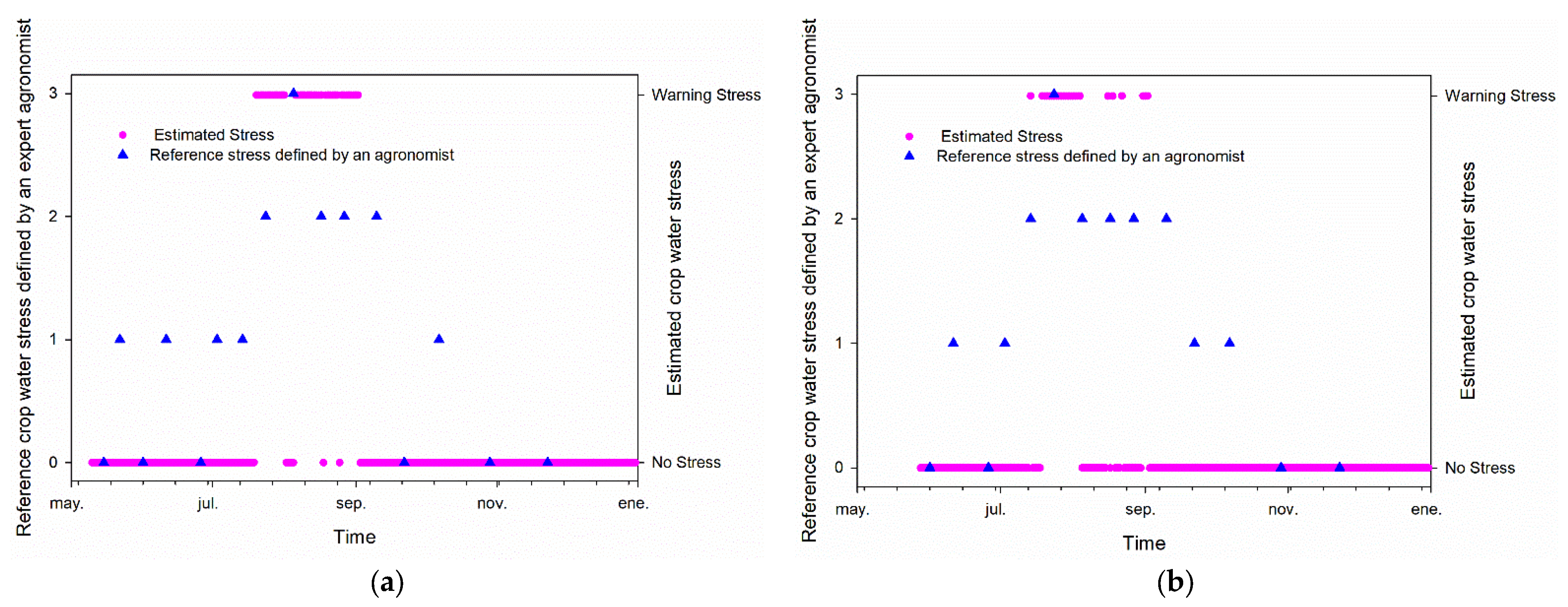
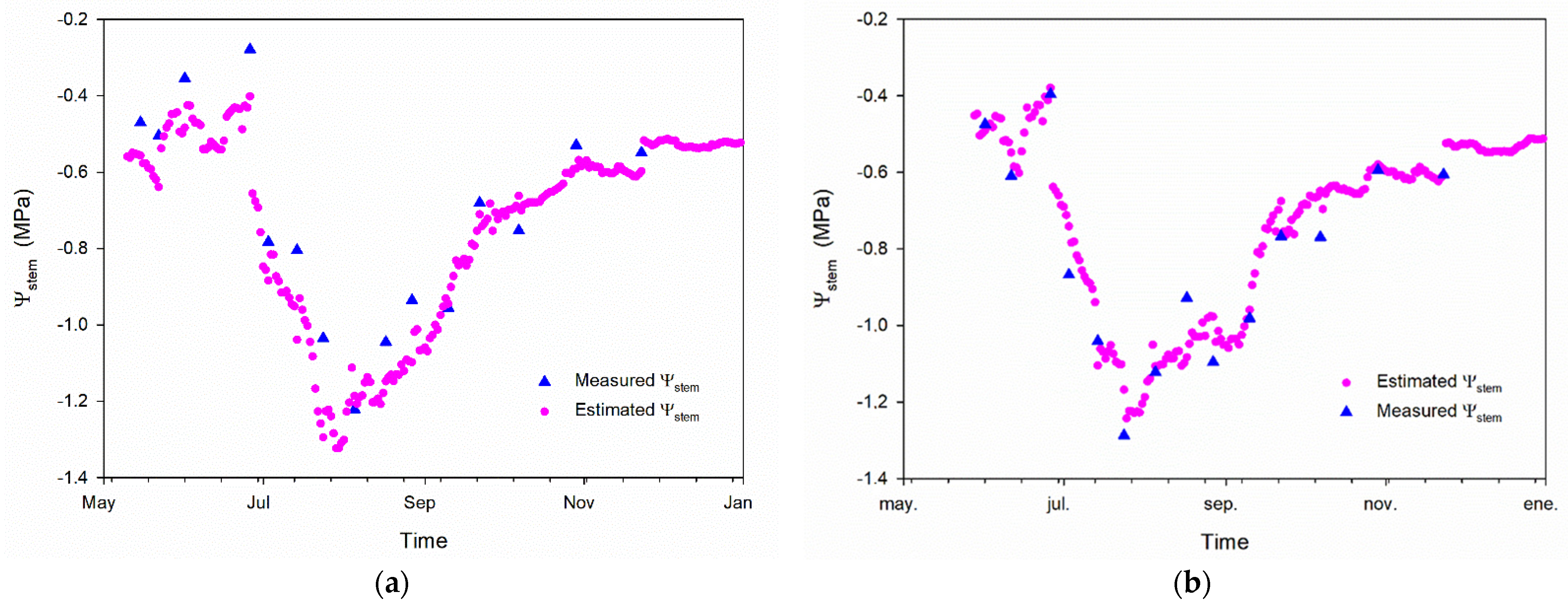
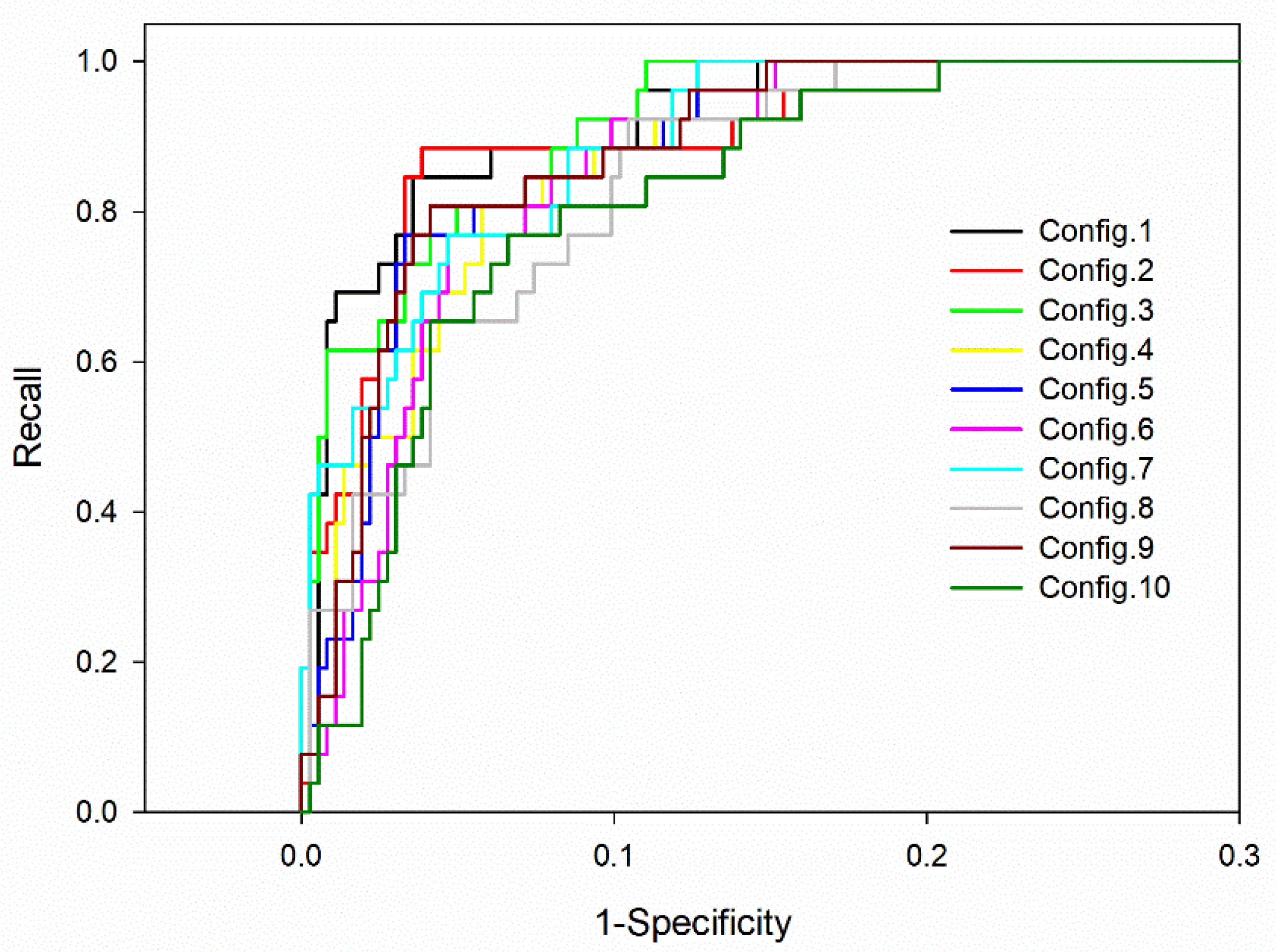
3.3. Classification Model Test
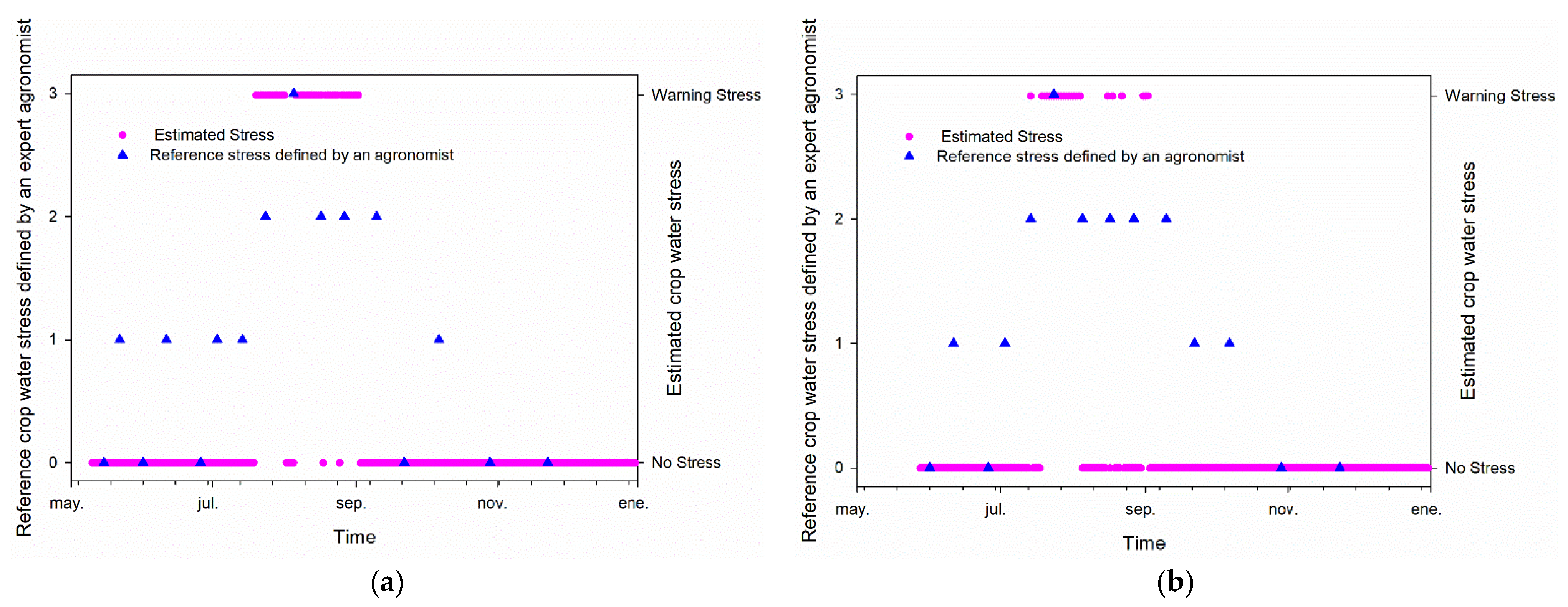
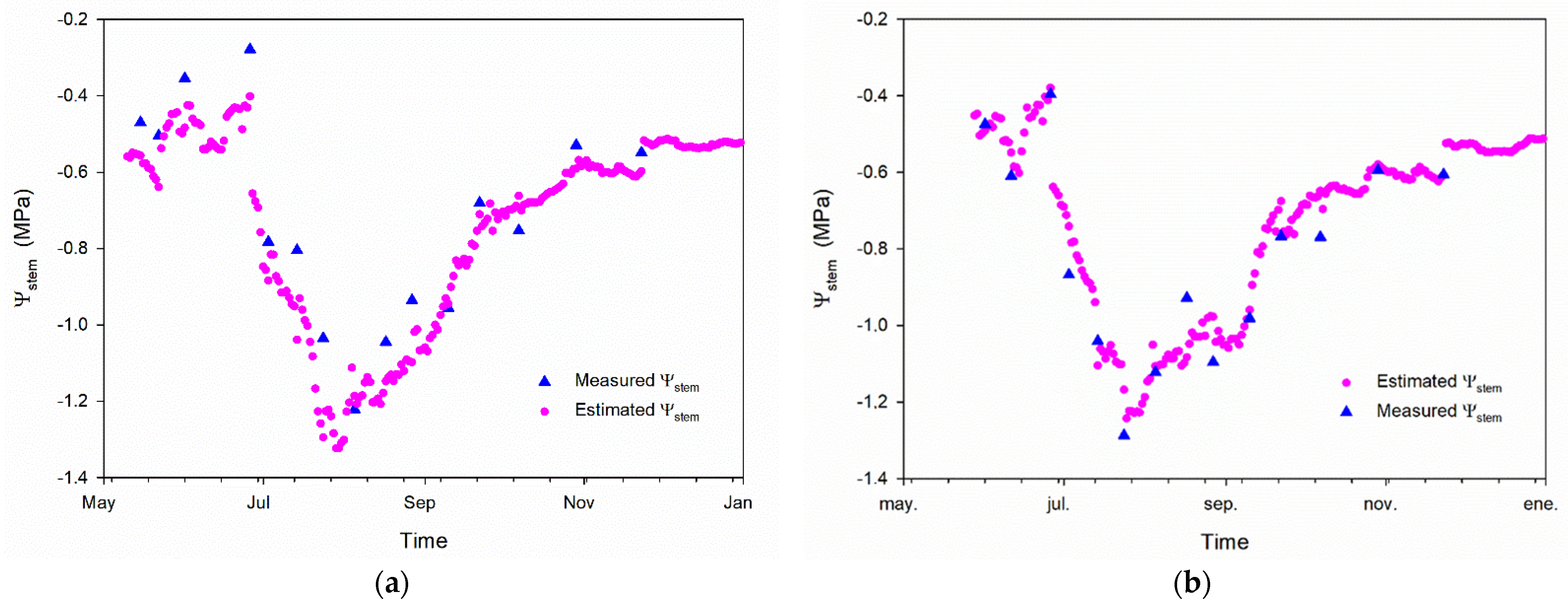
3.4. Regression Model Test
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Faurès, J.M.; Bartley, D.; Bazza, M.; Burke, J.; Hoogeveen, J.; Soto, D.; Steduto, P. Climate-Smart Agriculture Sourcebook; FAO: Rome, Italy, 2013; ISBN 978-92-5-107720-7. [Google Scholar]
- IPCC. Climate Change and Water Technical Paper of the Intergovernmental Panel on Climate Change; IPCC: Geneva, Switzerland, 2008. [Google Scholar]
- Santos Pereira, L.; Cordery, I.; Iacovides, I. Coping with Water Scarcity: Addressing the Challenges; Springer: Dordrecht, The Netherlands, 2009; ISBN 9781402095788. [Google Scholar]
- Confederación Hidrográfica del Segura. Plan Hidrológico de la Demarcación del Segura 2015/2021; Ministerio de Agricultura, Alimentación y Medio Ambiente, 2015. Available online: https://www.chsegura.es/export/descargas/planificacionydma/planificacion15-21/docsdescarga/DIE_PHC_2015-21.pdf (accessed on 12 April 2022).
- Ruiz-Sanchez, M.C.; Domingo, R.; Castel, J.R. Deficit irrigation in fruit trees and vines in Spain. Span. J. Agric. Res. 2010, 8, 5–20. [Google Scholar] [CrossRef] [Green Version]
- Vera, J.; Abrisqueta, I.; Conejero, W.; Ruiz-Sánchez, M.C. Precise sustainable irrigation: A review of soil-plant-atmosphere monitoring. Acta Hortic. 2017, 1150, 195–202. [Google Scholar] [CrossRef]
- Fereres, E.; Soriano, M.A. Deficit irrigation for reducing agricultural water use. J. Exp. Bot. 2007, 58, 147–159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Katerji, N.; Mastrorilli, M.; Rana, G. Water use efficiency of crops cultivated in the Mediterranean region: Review and analysis. Eur. J. Agron. 2008, 28, 493–507. [Google Scholar] [CrossRef]
- Evans, R.G.; Sadler, E.J. Methods and technologies to improve efficiency of water use. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Blaya-Ros, P.J.; Blanco, V.; Torres-Sánchez, R.; Domingo, R. Drought-Adaptive Mechanisms of Young Sweet Cherry Trees in Response to Withholding and Resuming Irrigation Cycles. Agronomy 2021, 11, 1812. [Google Scholar] [CrossRef]
- Blanco, V.; Martínez-Hernández, G.B.; Artés-Hernández, F.; Blaya-Ros, P.J.; Torres-Sánchez, R.; Domingo, R. Water relations and quality changes throughout fruit development and shelf life of sweet cherry grown under regulated deficit irrigation. Agric. Water Manag. 2019, 217, 243–254. [Google Scholar] [CrossRef]
- Blanco, V.; Torres-Sánchez, R.; Blaya-Ros, P.J.; Pérez-Pastor, A.; Domingo, R. Vegetative and reproductive response of ‘Prime Giant’ sweet cherry trees to regulated deficit irrigation. Sci. Hortic. 2019, 249, 478–489. [Google Scholar] [CrossRef]
- Blanco, V.; Blaya-Ros, P.J.; Torres-Sánchez, R.; Domingo, R. Influence of Regulated Deficit Irrigation and Environmental Conditions on Reproductive Response of Sweet Cherry Trees. Plants 2020, 9, 94. [Google Scholar] [CrossRef] [Green Version]
- Marsal, J. FAO irrigation and drainage paper 66. In Crop Yield Response Water. Sweet Cherry; FAO: Rome, Italy, 2012; pp. 449–457. [Google Scholar]
- Shackel, K.A.; Ahmadi, H.; Biasi, W.; Buchner, R.; Goldhamer, D.; Gurusinghe, S.; Hasey, J.; Kester, D.; Krueger, B.; Lampinen, B.; et al. Plant water status as an index of irrigation need in deciduous fruit trees. Horttechnology 1997, 7, 23–29. [Google Scholar] [CrossRef] [Green Version]
- Intrigliolo, D.S.; Castel, J.R. Continuous measurement of plant and soil water status for irrigation scheduling in plum. Irrig. Sci. 2004, 23, 93–102. [Google Scholar] [CrossRef]
- Ortuño, M.F.; García-Orellana, Y.; Conejero, W.; Ruiz-Sánchez, M.C.; Mounzer, O.; Alarcón, J.J.; Torrecillas, A. Relationships between climatic variables and sap flow, stem water potential and maximum daily trunk shrinkage in lemon trees. Plant Soil 2006, 279, 229–242. [Google Scholar] [CrossRef]
- Navarro-Hellín, H.; Martínez-del-Rincon, J.; Domingo-Miguel, R.; Soto-Valles, F.; Torres-Sánchez, R. A decision support system for managing irrigation in agriculture. Comput. Electron. Agric. 2016, 124, 121–131. [Google Scholar] [CrossRef] [Green Version]
- Torres-Sanchez, R.; Navarro-Hellin, H.; Guillamon-Frutos, A.; San-Segundo, R.; Ruiz-Abellón, M.C.; Domingo-Miguel, R. A Decision Support System for Irrigation Management: Analysis and Implementation of Different Learning Techniques. Water 2020, 12, 548. [Google Scholar] [CrossRef] [Green Version]
- Martí, P.; Gasque, M.; González-Altozano, P. An artificial neural network approach to the estimation of stem water potential from frequency domain reflectometry soil moisture measurements and meteorological data. Comput. Electron. Agric. 2013, 91, 75–86. [Google Scholar] [CrossRef]
- Valdés-Vela, M.; Abrisqueta, I.; Conejero, W.; Vera, J.; Ruiz-Sánchez, M.C. Soft computing applied to stem water potential estimation: A fuzzy rule based approach. Comput. Electron. Agric. 2015, 115, 150–160. [Google Scholar] [CrossRef]
- Blanco, V.; Domingo, R.; Pérez-Pastor, A.; Blaya-Ros, P.J.; Torres-Sánchez, R. Soil and plant water indicators for deficit irrigation management of field-grown sweet cherry trees. Agric. Water Manag. 2018, 208, 83–94. [Google Scholar] [CrossRef]
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M. Crop evapotranspiration—Guidelines for computing crop water requirements. In FAO Irrigation and Drainage Paper 56; Food and Agriculture Organization: Rome, Italy, 1998; ISBN 92-5-104219-5. [Google Scholar]
- Fereres, E.; Martinich, D.A.; Aldrich, T.M.; Castel, J.R.; Holzapfel, E.; Schulbach, H. Drip irrigation saves money in young almond orchards. Calif. Agric. 1982, 36, 12–13. [Google Scholar]
- Blanco, V.; Blaya-Ros, P.J.; Castillo, C.; Soto-Vallés, F.; Torres-Sánchez, R.; Domingo, R. Potential of UAS-Based Remote Sensing for Estimating Tree Water Status and Yield in Sweet Cherry Trees. Remote Sens. 2020, 12, 2359. [Google Scholar] [CrossRef]
- McCutchan, H.; Shackel, K.A. Stem-water Potential as a Sensitive Indicator of Water Stress in Prune Trees (Prunus domestica L. cv. French). J. Am. Soc. Hortic. Sci. 1992, 117, 607–611. [Google Scholar] [CrossRef] [Green Version]
- SIAR. SIAR—Servicio Integral de Asesoramiento al Regante de Castilla-La Mancha. Available online: https://crea.uclm.es/siar/datosMeteorologicos (accessed on 23 February 2022).
- Barua, S.; Islam, M.M.; Yao, X.; Murase, K. MWMOTE—Majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans. Knowl. Data Eng. 2014, 26, 405–425. [Google Scholar] [CrossRef]
- Cordón, I.; García, S.; Fernández, A.; Herrera, F. Preprocessing Algorithms for Imbalanced Datasets Version 1.0.2.1; Institute for Statistics and Mathematics of WU (Wirtschaftsuniversität Wien): Vienna, Austria, 2020. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2011, 16, 321–357. [Google Scholar] [CrossRef]
- Giménez-Gallego, J.; González-Teruel, J.D.; Jiménez-Buendía, M.; Toledo-Moreo, A.B.; Soto-Valles, F.; Torres-Sánchez, R. Segmentation of Multiple Tree Leaves Pictures with Natural Backgrounds using Deep Learning for Image-Based Agriculture Applications. Appl. Sci. 2019, 10, 202. [Google Scholar] [CrossRef] [Green Version]
- Oates, M.J.; González-Teruel, J.D.; Ruiz-Abellon, M.C.; Guillamon-Frutos, A.; Ramos, J.; Torres-Sánchez, R. Using a low-cost Components e-nose for Basic Detection of Different Foodstuffs. IEEE Sens. J. 2022, accepted (unpublished). [Google Scholar]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: Boston, MA, USA, 2012; pp. 157–175. ISBN 978-1-4419-9326-7. [Google Scholar]
- Pisner, D.A.; Schnyer, D.M. Chapter 6—Support vector machine. In Machine Learning: Methods and Applications to Brain Disorders; Academic Press: Cambridge, MA, USA, 2020; pp. 101–121. ISBN 9780128157398. [Google Scholar]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; R Core Team; et al. caret: Classification and Regression Training. R Package Version 6.0-86; Institute for Statistics and Mathematics of WU (Wirtschaftsuniversität Wien): Vienna, Austria, 2020. [Google Scholar]
- Liaw, A.; Wiener, M. randomForest: Breiman and Cutler’s Random Forests for Classification and Regression. R Package Version 4.6-14. Available online: https://www.stat.berkeley.edu/~breiman/RandomForests/ (accessed on 1 February 2022).
- Karatzoglou, A.; Smola, A.; Hornik, K.; National ICT Australia (NICTA); Maniscalco, M.A.; Teo, C.H. kernlab: Kernel-Based Machine Learning Lab version 0.9-29; Institute for Statistics and Mathematics of WU (Wirtschaftsuniversität Wien): Vienna, Austria, 2019.
- Shung, K.P. Accuracy, Precision, Recall or F1? Available online: https://towardsdatascience.com/accuracy-precision-recall-or-f1-331fb37c5cb9 (accessed on 3 March 2022).
- Brownlee, J. A Gentle Introduction to the Fbeta-Measure for Machine Learning. Available online: https://machinelearningmastery.com/fbeta-measure-for-machine-learning/ (accessed on 3 March 2022).
- González-Teruel, J.D.; Jones, S.B.; Soto-Valles, F.; Torres-Sánchez, R.; Lebron, I.; Friedman, S.P.; Robinson, D.A. Dielectric Spectroscopy and Application of Mixing Models Describing Dielectric Dispersion in Clay Minerals and Clayey Soils. Sensors 2020, 20, 6678. [Google Scholar] [CrossRef] [PubMed]
- González-Teruel, J.D.; Robinson, D.A.; Jones, S.B.; Skierucha, W.; Szyplowska, A. Impact of Effective Electromagnetic Frequency on Soil Moisture Sensor Calibration. In Proceedings of the ASA-CSSA-SSSA 2019 International Annual Meeting, San Antonio, TX, USA, 10–13 November 2019. [Google Scholar]
- González-Teruel, J.D.; Torres-Sánchez, R.; Blaya-Ros, P.J.; Toledo-Moreo, A.B.; Jiménez-Buendía, M.; Soto-Valles, F. Design and Calibration of a Low-Cost SDI-12 Soil Moisture Sensor. Sensors 2019, 19, 491. [Google Scholar] [CrossRef] [Green Version]
- González-Teruel, J.D.; Blanco, V.; Blaya-Ros, P.J.; Domingo, R.; Soto-Valles, F.; Torres-Sánchez, R. Estimación del Nivel de Estrés Hídrico en Frutales Mediante Técnicas Machine Learning para Aplicación en Sistemas de Riego Inteligentes. In Proceedings of the XLII Jornadas de Automática, Castellón de la Plana, Spain, 1–3 September 2021; Alonso Muñoz, A., Cabrera Santana, P.J., Chaos García, D., Déniz Suárez, Ó., Estévez Estévez, E., Guzmán Sánchez, J.L., Marín Prades, R., Muñoz de la Peña Sequedo, D., Peñarrocha Alós, I., Pitarch Pérez, J.L., et al., Eds.; Servizo de Publicacións da Universidade da Coruña: A Coruña, Spain; Comité Español de Automática: Barcelona, Spain; Universitat Jaume I: Castellón, Spain, 2021; pp. 477–484. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Harvest Period | Rule | Category |
|---|---|---|
| Pre-harvest | Ψstem > −0.9 MPa | ‘no stress’ |
| Ψstem < −0.9 MPa | ‘warning stress’ | |
| Post-harvest | Ψstem > −1.2 MPa | ‘no stress’ |
| Ψstem < −1.2 MPa | ‘warning stress’ |
| Soil Variables | Weather Variables | Calendar Variables |
|---|---|---|
| θv20_Di, i = 1, …, T | air_RHDi, i = 1, …, T | DOY |
| θv20_ACCUM(T) | air_RHACCUM(T) | |
| θv40_Di, i = 1, …, T | ϕDi, i = 1, …, T | Harvest period |
| θv40_ACCUM(T) | ϕACCUM(T) | |
| Ψm25_Di, i = 1, …, T | air_TempDi, i = 1, …, T | |
| Ψm25_ACCUM(T) | air_TempACCUM(T) | |
| Ψm50_Di, i = 1, …, T | WSDi, i = 1, …, T | |
| Ψm50_ACCUM(T) | WSACCUM(T) | |
| VPDDi, i = 1, …, T | ||
| VPDACCUM(T) | ||
| rainfallDi, i = 1, …, T | ||
| rainfallACCUM(T) |
| Configuration | Input Variables | N. of Inputs |
|---|---|---|
| 1 | All the inputs | 22 |
| 2 | All inputs but the daily dynamics | 12 |
| 3 | All inputs but θv dynamics | 18 |
| 4 | All inputs but the daily dynamics and θv dynamics | 10 |
| 5 | All inputs but Ψm dynamics | 18 |
| 6 | All inputs but the daily dynamics and Ψm dynamics | 10 |
| 7 | DOY, harvest period and Ψm and VPD dynamics | 8 |
| 8 | DOY, harvest period and Ψm and VPD accumulated dynamics | 5 |
| 9 | DOY, harvest period and θv and VPD dynamics | 8 |
| 10 | DOY, harvest period and θv and VPD accumulated dynamics | 5 |
| T | Metric | Input Configuration | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 3 days | Accuracy | 0.954 | 0.956 | 0.959 | 0.956 | 0.941 | 0.938 | 0.959 | 0.961 | 0.938 | 0.936 |
| Precision | 0.750 | 0.800 | 0.727 | 0.696 | 0.600 | 0.625 | 0.727 | 0.720 | 0.571 | 0.538 | |
| Recall | 0.462 | 0.462 | 0.615 | 0.615 | 0.346 | 0.192 | 0.615 | 0.692 | 0.308 | 0.269 | |
| Specificity | 0.989 | 0.992 | 0.983 | 0.981 | 0.983 | 0.992 | 0.983 | 0.981 | 0.983 | 0.983 | |
| F1 | 0.571 | 0.585 | 0.667 | 0.653 | 0.439 | 0.294 | 0.667 | 0.706 | 0.400 | 0.359 | |
| F2 | 0.500 | 0.504 | 0.635 | 0.630 | 0.378 | 0.223 | 0.635 | 0.698 | 0.339 | 0.299 | |
| TP | 12 | 12 | 16 | 16 | 9 | 5 | 16 | 18 | 8 | 7 | |
| FP | 4 | 3 | 6 | 7 | 6 | 3 | 6 | 7 | 6 | 6 | |
| TN | 359 | 360 | 357 | 356 | 357 | 360 | 357 | 356 | 357 | 357 | |
| FN | 14 | 14 | 10 | 10 | 17 | 21 | 10 | 8 | 18 | 19 | |
| 6 days | Accuracy | 0.959 | 0.959 | 0.956 | 0.946 | 0.938 | 0.949 | 0.961 | 0.954 | 0.931 | 0.943 |
| Precision | 0.778 | 0.857 | 0.737 | 0.647 | 0.625 | 0.650 | 0.789 | 0.722 | 0.400 | 0.643 | |
| Recall | 0.538 | 0.462 | 0.538 | 0.423 | 0.192 | 0.500 | 0.577 | 0.500 | 0.077 | 0.346 | |
| Specificity | 0.989 | 0.994 | 0.986 | 0.983 | 0.992 | 0.981 | 0.989 | 0.986 | 0.992 | 0.986 | |
| F1 | 0.636 | 0.600 | 0.622 | 0.512 | 0.294 | 0.565 | 0.667 | 0.591 | 0.129 | 0.450 | |
| F2 | 0.574 | 0.508 | 0.569 | 0.455 | 0.223 | 0.524 | 0.610 | 0.533 | 0.092 | 0.381 | |
| TP | 14 | 12 | 14 | 11 | 5 | 13 | 15 | 13 | 2 | 9 | |
| FP | 4 | 2 | 5 | 6 | 3 | 7 | 4 | 5 | 3 | 5 | |
| TN | 359 | 361 | 358 | 357 | 360 | 356 | 359 | 358 | 360 | 358 | |
| FN | 12 | 14 | 12 | 15 | 21 | 13 | 11 | 13 | 24 | 17 | |
| 10 days | Accuracy | 0.961 | 0.959 | 0.954 | 0.954 | 0.949 | 0.946 | 0.956 | 0.956 | 0.943 | 0.936 |
| Precision | 0.789 | 0.778 | 0.700 | 0.682 | 0.750 | 0.647 | 0.737 | 0.696 | 0.700 | 0.529 | |
| Recall | 0.577 | 0.538 | 0.538 | 0.577 | 0.346 | 0.423 | 0.538 | 0.615 | 0.269 | 0.346 | |
| Specificity | 0.989 | 0.989 | 0.983 | 0.981 | 0.992 | 0.983 | 0.986 | 0.981 | 0.992 | 0.978 | |
| F1 | 0.667 | 0.636 | 0.609 | 0.625 | 0.474 | 0.512 | 0.622 | 0.653 | 0.389 | 0.419 | |
| F2 | 0.610 | 0.574 | 0.565 | 0.595 | 0.388 | 0.455 | 0.569 | 0.630 | 0.307 | 0.372 | |
| TP | 15 | 14 | 14 | 15 | 9 | 11 | 14 | 16 | 7 | 9 | |
| FP | 4 | 4 | 6 | 7 | 3 | 6 | 5 | 7 | 3 | 8 | |
| TN | 359 | 359 | 357 | 356 | 360 | 357 | 358 | 356 | 360 | 355 | |
| FN | 11 | 12 | 12 | 11 | 17 | 15 | 12 | 10 | 19 | 17 | |
| T | Metric | Input Configuration | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 3 days | Accuracy | 0.938 | 0.941 | 0.954 | 0.931 | 0.923 | 0.928 | 0.931 | 0.920 | 0.900 | 0.907 |
| Precision | 0.531 | 0.552 | 0.625 | 0.486 | 0.433 | 0.467 | 0.486 | 0.444 | 0.303 | 0.368 | |
| Recall | 0.654 | 0.615 | 0.769 | 0.654 | 0.500 | 0.538 | 0.692 | 0.769 | 0.385 | 0.538 | |
| Specificity | 0.959 | 0.964 | 0.967 | 0.950 | 0.953 | 0.956 | 0.948 | 0.931 | 0.937 | 0.934 | |
| F1 | 0.586 | 0.582 | 0.690 | 0.557 | 0.464 | 0.500 | 0.571 | 0.563 | 0.339 | 0.438 | |
| F2 | 0.625 | 0.602 | 0.735 | 0.612 | 0.485 | 0.522 | 0.638 | 0.671 | 0.365 | 0.493 | |
| TP | 17 | 16 | 20 | 17 | 13 | 14 | 18 | 20 | 10 | 14 | |
| FP | 15 | 13 | 12 | 18 | 17 | 16 | 19 | 25 | 23 | 24 | |
| TN | 348 | 350 | 351 | 345 | 346 | 347 | 344 | 338 | 340 | 339 | |
| FN | 9 | 10 | 6 | 9 | 13 | 12 | 8 | 6 | 16 | 12 | |
| 6 days | Accuracy | 0.931 | 0.951 | 0.949 | 0.946 | 0.920 | 0.933 | 0.941 | 0.918 | 0.915 | 0.918 |
| Precision | 0.480 | 0.621 | 0.615 | 0.581 | 0.407 | 0.500 | 0.552 | 0.417 | 0.394 | 0.406 | |
| Recall | 0.462 | 0.692 | 0.615 | 0.692 | 0.423 | 0.538 | 0.615 | 0.577 | 0.500 | 0.500 | |
| Specificity | 0.964 | 0.970 | 0.972 | 0.964 | 0.956 | 0.961 | 0.964 | 0.942 | 0.945 | 0.948 | |
| F1 | 0.471 | 0.655 | 0.615 | 0.632 | 0.415 | 0.519 | 0.582 | 0.484 | 0.441 | 0.448 | |
| F2 | 0.465 | 0.677 | 0.615 | 0.667 | 0.420 | 0.530 | 0.602 | 0.536 | 0.474 | 0.478 | |
| TP | 12 | 18 | 16 | 18 | 11 | 14 | 16 | 15 | 13 | 13 | |
| FP | 13 | 11 | 10 | 13 | 16 | 14 | 13 | 21 | 20 | 19 | |
| TN | 350 | 352 | 353 | 350 | 347 | 349 | 350 | 342 | 343 | 344 | |
| FN | 14 | 8 | 10 | 8 | 15 | 12 | 10 | 11 | 13 | 13 | |
| 10 days | Accuracy | 0.949 | 0.949 | 0.954 | 0.941 | 0.938 | 0.943 | 0.951 | 0.920 | 0.946 | 0.936 |
| Precision | 0.600 | 0.600 | 0.667 | 0.552 | 0.536 | 0.571 | 0.630 | 0.442 | 0.581 | 0.515 | |
| Recall | 0.692 | 0.692 | 0.615 | 0.615 | 0.577 | 0.615 | 0.654 | 0.731 | 0.692 | 0.654 | |
| Specificity | 0.967 | 0.967 | 0.978 | 0.964 | 0.964 | 0.967 | 0.972 | 0.934 | 0.964 | 0.956 | |
| F1 | 0.643 | 0.643 | 0.640 | 0.582 | 0.556 | 0.593 | 0.642 | 0.551 | 0.632 | 0.576 | |
| F2 | 0.672 | 0.672 | 0.625 | 0.602 | 0.568 | 0.606 | 0.649 | 0.646 | 0.667 | 0.620 | |
| TP | 18 | 18 | 16 | 16 | 15 | 16 | 17 | 19 | 18 | 17 | |
| FP | 12 | 12 | 8 | 13 | 13 | 12 | 10 | 24 | 13 | 16 | |
| TN | 351 | 351 | 355 | 350 | 350 | 351 | 353 | 339 | 350 | 347 | |
| FN | 8 | 8 | 10 | 10 | 11 | 10 | 9 | 7 | 8 | 9 | |
| T | Metric | Input Configuration | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 10 days | Accuracy | 0.969 | 0.946 | 0.951 | 0.943 | 0.931 | 0.920 | 0.951 | 0.905 | 0.923 | 0.925 |
| Precision | 0.818 | 0.600 | 0.630 | 0.563 | 0.481 | 0.414 | 0.640 | 0.351 | 0.430 | 0.459 | |
| Recall | 0.692 | 0.580 | 0.61 | 0.654 | 0.692 | 0.462 | 0.615 | 0.500 | 0.462 | 0.654 | |
| Specificity | 0.989 | 0.972 | 0.972 | 0.961 | 0.961 | 0.953 | 0.975 | 0.934 | 0.956 | 0.945 | |
| F1 | 0.750 | 0.588 | 0.642 | 0.621 | 0.491 | 0.436 | 0.627 | 0.413 | 0.444 | 0.540 | |
| F2 | 0.714 | 0.581 | 0.649 | 0.662 | 0.496 | 0.451 | 0.620 | 0.461 | 0.455 | 0.603 | |
| T | Metric | Input Configuration | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 3 days | ME | −0.004 | −0.002 | −0.004 | −0.002 | −0.002 | −0.001 | −0.005 | −0.002 | −0.002 | −0.002 |
| RMSE | 0.122 | 0.120 | 0.123 | 0.122 | 0.131 | 0.131 | 0.130 | 0.132 | 0.137 | 0.139 | |
| R2 | 0.791 | 0.799 | 0.790 | 0.792 | 0.760 | 0.762 | 0.765 | 0.756 | 0.738 | 0.731 | |
| MAPE | 12.458 | 12.080 | 12.265 | 11.928 | 13.052 | 12.808 | 12.745 | 12.876 | 13.317 | 13.683 | |
| 6 days | ME | −0.004 | −0.002 | −0.003 | −0.001 | −0.001 | −0.002 | −0.003 | −0.002 | −0.001 | −0.002 |
| RMSE | 0.118 | 0.121 | 0.119 | 0.120 | 0.127 | 0.130 | 0.126 | 0.131 | 0.138 | 0.135 | |
| R2 | 0.804 | 0.797 | 0.801 | 0.798 | 0.773 | 0.763 | 0.780 | 0.761 | 0.736 | 0.745 | |
| MAPE | 12.223 | 12.005 | 12.159 | 11.883 | 12.865 | 12.843 | 12.554 | 12.705 | 13.533 | 13.493 | |
| 10 days | ME | −0.003 | −0.001 | −0.003 | −0.002 | −0.002 | 0.000 | −0.006 | −0.002 | −0.001 | −0.001 |
| RMSE | 0.114 | 0.118 | 0.115 | 0.119 | 0.123 | 0.128 | 0.122 | 0.125 | 0.131 | 0.136 | |
| R2 | 0.817 | 0.805 | 0.816 | 0.802 | 0.788 | 0.771 | 0.792 | 0.782 | 0.761 | 0.742 | |
| MAPE | 11.691 | 11.914 | 11.600 | 11.768 | 12.507 | 12.722 | 12.105 | 12.287 | 13.222 | 13.454 | |
| T | Metric | Input Configuration | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| 3 days | AUC | 0.974 | 0.971 | 0.970 | 0.966 | 0.952 | 0.951 | 0.964 | 0.958 | 0.938 | 0.937 | |
| Deviation error 1 | 0.008 | 0.009 | 0.009 | 0.010 | 0.012 | 0.013 | 0.010 | 0.011 | 0.014 | 0.013 | ||
| Asymptotic signification 2 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | ||
| 95% asymptotic confidence interval | Lower bound | 0.958 | 0.954 | 0.952 | 0.947 | 0.928 | 0.926 | 0.944 | 0.936 | 0.910 | 0.910 | |
| Upper bound | 0.990 | 0.988 | 0.988 | 0.985 | 0.976 | 0.976 | 0.985 | 0.980 | 0.965 | 0.963 | ||
| 6 days | AUC | 0.972 | 0.965 | 0.970 | 0.960 | 0.955 | 0.952 | 0.964 | 0.954 | 0.936 | 0.945 | |
| Deviation error 1 | 0.009 | 0.010 | 0.009 | 0.010 | 0.012 | 0.012 | 0.011 | 0.012 | 0.014 | 0.013 | ||
| Asymptotic signification 2 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | ||
| 95% asymptotic confidence interval | Lower bound | 0.954 | 0.944 | 0.953 | 0.940 | 0.932 | 0.928 | 0.943 | 0.931 | 0.908 | 0.918 | |
| Upper bound | 0.990 | 0.985 | 0.988 | 0.981 | 0.978 | 0.976 | 0.985 | 0.978 | 0.964 | 0.971 | ||
| 10 days | AUC | 0.974 | 0.968 | 0.972 | 0.960 | 0.962 | 0.956 | 0.966 | 0.951 | 0.963 | 0.944 | |
| Deviation error 1 | 0.009 | 0.011 | 0.009 | 0.010 | 0.010 | 0.011 | 0.010 | 0.012 | 0.010 | 0.013 | ||
| Asymptotic signification 2 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | ||
| 95% asymptotic confidence interval | Lower bound | 0.957 | 0.947 | 0.955 | 0.940 | 0.941 | 0.934 | 0.946 | 0.927 | 0.943 | 0.918 | |
| Upper bound | 0.992 | 0.989 | 0.989 | 0.981 | 0.983 | 0.978 | 0.985 | 0.975 | 0.984 | 0.970 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
González-Teruel, J.D.; Ruiz-Abellon, M.C.; Blanco, V.; Blaya-Ros, P.J.; Domingo, R.; Torres-Sánchez, R. Prediction of Water Stress Episodes in Fruit Trees Based on Soil and Weather Time Series Data. Agronomy 2022, 12, 1422. https://doi.org/10.3390/agronomy12061422
González-Teruel JD, Ruiz-Abellon MC, Blanco V, Blaya-Ros PJ, Domingo R, Torres-Sánchez R. Prediction of Water Stress Episodes in Fruit Trees Based on Soil and Weather Time Series Data. Agronomy. 2022; 12(6):1422. https://doi.org/10.3390/agronomy12061422
Chicago/Turabian StyleGonzález-Teruel, Juan D., Maria Carmen Ruiz-Abellon, Víctor Blanco, Pedro José Blaya-Ros, Rafael Domingo, and Roque Torres-Sánchez. 2022. "Prediction of Water Stress Episodes in Fruit Trees Based on Soil and Weather Time Series Data" Agronomy 12, no. 6: 1422. https://doi.org/10.3390/agronomy12061422
APA StyleGonzález-Teruel, J. D., Ruiz-Abellon, M. C., Blanco, V., Blaya-Ros, P. J., Domingo, R., & Torres-Sánchez, R. (2022). Prediction of Water Stress Episodes in Fruit Trees Based on Soil and Weather Time Series Data. Agronomy, 12(6), 1422. https://doi.org/10.3390/agronomy12061422