1. Introduction
Artificial intelligence (AI) and classic programming represent two fundamentally different approaches to solving problems with machines [
1,
2]. Classical programming involves explicitly defining a set of rules and instructions for the machine to follow, which are based on the programmer’s understanding of the problem and the desired outcome. While classical programming can be effective for solving well-defined problems, it can quickly become unwieldy for complex tasks that involve a high degree of uncertainty or variability.
In contrast, AI involves training machines to learn from data and adapt their behavior based on experience, making it a more flexible and versatile approach to problem solving (
Figure 1). AI systems can analyze large amounts of data, identify patterns and correlations, and use this information to make predictions or take actions without being explicitly programmed to do so. This makes AI particularly well-suited for tasks that involve complex decision making, such as natural language processing, image recognition, and autonomous driving.
Another key difference between AI and classical programming is the level of human intervention required [
3]. In classical programming, the programmer must carefully design and write the program to achieve the desired outcome, often requiring significant time and effort. In contrast, AI systems can learn and improve on their own, reducing the need for human intervention and empowering machines to perform tasks that were previously thought to be beyond their capabilities [
4,
5].
AI has been a rapidly growing field in recent years, encompassing a range of techniques and approaches to enable machines to perform tasks that typically require human intelligence. With the increasing availability of data and advances in computing power, AI has become an essential tool for businesses and organizations to unlock insights, automate processes, and enhance decision-making capabilities [
6,
7].
The different phases of ML and AI include the following (
Figure 2):
Data collection: This refers to the process of gathering relevant data from various sources such as databases, APIs, or sensors, to use as input for machine learning or AI algorithms. The quality of the data collected will have a significant impact on the results produced by the algorithms.
Data preprocessing: This involves cleaning, organizing, and transforming the raw data collected in the previous step into a format suitable for analysis. This includes tasks such as removing missing values, handling outliers, and scaling the data to ensure that it is normalized and consistent.
Model selection and training: In this phase, a suitable machine learning or AI model is selected based on the specific problem being addressed. The model is then trained on the preprocessed data to learn patterns and make predictions. The training process involves adjusting the model parameters to minimize the error between predicted and actual values.
Model evaluation: Once the model has been trained, it needs to be evaluated to assess its performance. This involves testing the model on a set of data that it has not seen before and comparing the predicted results to the actual values. Various metrics can be used to evaluate the model’s performance, such as accuracy, precision, recall, and F1 score.
Deployment: After the model has been evaluated and validated, it can be deployed to perform the intended task. This involves integrating the model into a larger software system or application and providing a user interface for interaction with the model.
Monitoring and maintenance: Once the model has been deployed, it is important to continuously monitor its performance and make necessary adjustments or updates to ensure that it remains accurate and effective. This includes tasks such as monitoring data input, tracking model behavior, and detecting potential errors or anomalies. Regular maintenance and updates are also required to keep the model up-to-date and relevant to changing conditions or requirements.
As illustrated in
Figure 3, machine learning (ML) is a subset of AI that involves training machines on large datasets to learn patterns and make predictions [
8]. Deep learning (DL) [
9,
10,
11], which involves training neural networks with multiple layers, is a powerful subclass of ML that has shown remarkable success in various applications such as image and speech recognition [
12,
13].
Convolutional neural networks (CNNs) [
14,
15,
16] are a popular type of ML model that have been widely utilized for various tasks, including image recognition [
17,
18,
19,
20], speech recognition [
21,
22,
23,
24,
25], and NLP [
26,
27,
28,
29,
30]. CNNs have been particularly successful in image recognition tasks, achieving state-of-the-art results on several benchmarks. Their success is due to their ability to capture spatial features and patterns in images by using a hierarchical architecture of layers that perform convolution operations and extract features at different levels of abstraction [
31,
32].
This paper provides a comprehensive overview of CNNs, covering their fundamentals, architectures, and recent developments. It also discusses the advantages and limitations of CNNs, provides recommendations for developers and data scientists, examines the existing platforms and libraries for CNNs, and estimates the cost of using CNNs. Our contributions include:
A detailed discussion of the fundamentals of CNNs, including the layers of CNNs, the convolution operation, feature maps, activation functions, and training methods.
A comparison of several popular CNN architectures, including LeNet, AlexNet, VGG, ResNet, and InceptionNet, and a discussion of their strengths and weaknesses.
A review of recent developments in CNNs, including attention mechanisms, capsule networks, transfer learning, adversarial training, quantization and compression, and enhancing the reliability and efficiency of CNNs through formal methods [
33,
34].
Recommendations for developers and data scientists on how to preprocess data, choose appropriate Hyper_Param, use regularization techniques, and evaluate model performance.
A discussion of existing platforms and libraries for CNNs, including TensorFlow, Keras, PyTorch, Caffe, and MXNet, and a comparison of their features and functionalities.
An estimation of the cost of using CNNs, including factors that impact cost such as hardware, dataset size, and model complexity, as well as potential cost-saving strategies.
An examination of when to use CNNs, including tasks suited for CNNs, their computational requirements, and their advantages and limitations.
A review of the security aspects of CNNs, including potential vulnerabilities and strategies for improving the security of CNNs.
A discussion of the future directions of CNN research and development.
The paper is organized as follows:
Section 2 provides an overview of the fundamentals of convolutional neural networks (CNNs), and
Section 3 compares several popular CNN architectures.
Section 4 explains the situations in which it is appropriate to use CNNs, and
Section 5 discusses the advantages and limitations of CNNs.
Section 6 describes some existing platforms and libraries to create CNN models, while
Section 7 compares CNN models with other models. Next,
Section 8 provides recommendations for developers and data scientists, and
Section 9 estimates the cost of using CNNs.
Section 10 reviews recent developments in CNNs, and
Section 11 discusses the use of formal methods for enhancing the reliability and efficiency of CNNs. Finally, the paper concludes in
Section 12.
2. Fundamentals of CNNs
CNNs are a powerful type of neural network that are widely used in image recognition tasks. They consist of a series of convolutional and pooling layers that extract relevant features from the input image, followed by one or more fully connected layers that use these features to make a prediction. To use a CNN for image recognition, it must first be trained on a large dataset of labeled images containing the objects of interest. During training, the CNN learns to associate the extracted features with the correct labels through a process of back propagation and optimization [
35,
36,
37,
38]. Once the CNN has been trained, it can be used to make predictions on new, unseen images by passing the image through the network and selecting the label with the highest predicted probability.
Figure 4 shows a simplified illustration of a CNN used for image classification [
39,
40,
41]. The input of the network is an image of a car, which is fed into the input layer. The input layer passes the image to the first hidden layer, which applies a set of filters to the image. Each filter extracts specific features from the image, such as edges or textures. The output of the first hidden layer is then passed to the next hidden layer, where more filters are applied to extract higher-level features. This process is repeated through several hidden layers until the final hidden layer, which produces a set of features that are passed to the output layer. The output layer produces a probability distribution over the three classes: car, bus, and plane. The network then makes a decision based on the class with the highest probability. The weights of the filters in each layer are learned through a process called back propagation, which adjusts the weights to minimize the error between the predicted output and the actual output.
2.1. Layers of CNNs
A CNN typically consists of multiple layers, each with a specific function in the network:
Convolutional layer: The convolutional layer is the core building block of a CNN [
42,
43]. It performs a convolution operation on the input image with a set of learnable filters. The filters are small matrices that slide over the input image, computing a dot product between the filter and a small region of the input at each step. The output of the convolutional layer is a set of feature maps that represent different features in the input image.
Pooling layer: The pooling layer is used to reduce the spatial dimensions of the feature maps produced by the convolutional layer [
44,
45]. It operates on each feature map independently and downsamples it by taking the maximum or average value of non-overlapping regions. Pooling helps to reduce the computational complexity of the network and also makes the network more robust to small translations in the input image.
Activation layer: The activation layer applies a non-linear activation function to the output of the previous layer [
46,
47,
48]. This introduces non-linearity into the network, allowing it to learn more complex features.
Batch normalization layer: The batch normalization layer normalizes the output of the previous layer by subtracting the mean and dividing by the standard deviation of the batch [
49,
50]. This helps to reduce the internal covariate shift and improves the convergence of the network.
Dropout layer: The dropout layer randomly drops out a percentage of the neurons in the previous layer during training [
51,
52]. This helps to prevent overfitting by forcing the network to learn more robust features.
Fully connected layer: The fully connected layer is a traditional neural network layer that connects every neuron in the previous layer to every neuron in the current layer [
53,
54,
55,
56]. It is typically used at the end of the network to produce the final output.
In addition to these layers, there are also specialized layers that are used in certain types of CNNs. For example, in a recurrent CNN (RCNN), a recurrent layer is added to the network to capture temporal dependencies in the input sequence [
57,
58]. In a long short-term memory (LSTM) CNN, an LSTM layer is used to learn long-term dependencies in the input sequence [
59,
60,
61].
Table 1 presents a summary of the layers commonly used in CNNs and their respective functions in the network. Overall, the different types of layers in a CNN work together to learn and extract features from the input image, and ultimately produce an accurate prediction or classification. By understanding the role of each layer, researchers and practitioners can design more effective CNN architectures for a wide range of computer vision tasks [
62,
63,
64].
2.2. Convolution Operation
The convolution operation (Conv_Op) is a mathematical operation that is commonly used in signal processing, image processing, and computer vision [
65,
66,
67]. It is used to combine two signals or functions to produce a third signal that represents the influence of one signal on the other, weighted by the shape of the other signal. In computer vision, convolution is used to extract features from images using CNNs.
The mathematical definition of the convolution operation is:
Here,
f and
g are two functions that can be discrete or continuous, and
n is the position or time index of the output signal. The convolution operation is denoted by the symbol ∗. When the input signals are discrete, the above equation can be written as:
where
is the sampling interval. When the input signals are continuous, the convolution operation can be defined as:
where
t is the time index of the output signal.
In computer vision, the convolution operation is used to extract features from an image using CNNs. The Conv_Op is a fundamental operation in CNNs that involves sliding a filter or kernel over an input image and computing the dot product at each position to produce an output feature map.
The Conv_Op is applied to each channel of the input image separately, and the resulting feature maps are combined to form the output. The size of the filter is a crucial parameter that determines the size of the receptive field, which is the region of the input that affects the output at a particular position. The stride determines the distance between adjacent filter positions. The amount of zero padding around the input image can also be adjusted to control the size and resolution of the output feature map.
The Conv_Op can be performed using various methods, including the direct method, the Fourier method, and the fast Fourier transform (FFT) method [
68,
69,
70,
71,
72,
73]. The direct method is the most straightforward, but it can be computationally expensive, especially for large input volumes and filters. The Fourier method and the FFT method can significantly speed up the convolution operation by exploiting the convolution theorem, which states that convolution in the spatial domain is equivalent to multiplication in the frequency domain.
In summary, convolution is a mathematical operation that is used to combine two signals or functions to produce a third signal that represents the influence of one signal on the other, weighted by the shape of the other signal. In computer vision, convolution is used to extract features from images using CNNs. The Conv_Op involves sliding a filter over an input image and computing the dot product at each position to produce an output feature map. The size of the filter, the stride, and the amount of zero padding are adjustable parameters that can be used to control the size and resolution of the output. The convolution operation can be performed using various methods, and the choice of activation function is also an important consideration.
2.3. Feature Maps
In CNNs, a feature map (Feat_Map) is a crucial component that represents the output of a convolutional layer [
74,
75,
76,
77,
78,
79]. The Feat_Map is a two-dimensional array that reflects the degree to which the local regions of the input image match the filters that were applied to them. Each element of the Feat_Map corresponds to the activation of a neuron in the layer and captures some specific aspect of the input image.
The Feat_Map is computed by convolving a set of filters with the input image. Each filter generates a single-channel Feat_Map that highlights a specific feature or pattern in the input image. The Feat_Maps produced by different filters in the same layer can be stacked together to create a multi-channel Feat_Map that captures different aspects of the input image.
Mathematically, the computation of a Feat_Map can be represented as:
where
is the value of the
k-th Feat_Map at position
in the output tensor,
is the weight of the
k-th filter at position
,
is the value of the
n-th input Feat_Map at position
, and
is the bias term for the
k-th Feat_Map.
In this equation, F represents the height and width of the filter, represents the number of channels in the input tensor, and is a scalar bias term that is added to each element of the k-th Feat_Map. The weights are learned during the training process using back propagation and gradient descent, and they determine how each filter responds to the local regions of the input image.
The computation of a Feat_Map involves sliding the filter over the input image and computing the dot product between the filter and the corresponding local region of the input image at each position. The resulting values are then summed and passed through an activation function to obtain the final values of the Feat_Map. This process is repeated for each filter in the layer, resulting in a set of Feat_Maps that collectively capture different aspects of the input image.
Overall, the Feat_Map is a powerful tool in CNNs that allows them to extract and capture important features from the input image, enabling them to perform a wide range of visual recognition tasks.
2.4. Activation Functions
Activation functions (Activ_Funcs) are an essential component in CNNs that introduce non-linearity into the model [
80,
81,
82,
83,
84,
85]. This non-linearity is crucial because many real-world phenomena exhibit complex, non-linear behavior, and a model that only uses linear operations will not be able to capture these phenomena accurately. Thus, Activ_Funcs help to make CNNs more expressive and able to model a wider range of functions.
Commonly used Activ_Funcs in CNNs include the rectified linear unit (ReLU), the sigmoid function, and the hyperbolic tangent (tanh) function (
Figure 5). ReLU is the most widely used Activ_Func in modern CNNs because of its simplicity and effectiveness in reducing the vanishing gradient problem during training.
Mathematically, the ReLU Activ_Func is defined as:
where
x is the input to the neuron. This function returns the maximum of 0 and
x, effectively “turning off” any negative values and leaving positive values unchanged. This simple non-linear function allows for better learning of complex features in CNNs and helps to prevent the saturation of neurons during training.
The sigmoid function, on the other hand, is defined as:
where
x is the input to the neuron. The sigmoid function has a characteristic S-shape and maps any real number to a value between 0 and 1, making it a good choice for binary classification problems. However, it suffers from the vanishing gradient problem when used in deep neural networks due to its saturating nature, which can slow down the training process.
The hyperbolic tangent (tanh) function is similar to the sigmoid function but maps any real number to a value between −1 and 1. It is also a non-linear function that is useful for introducing non-linearity into the model. However, like the sigmoid function, it can suffer from the vanishing gradient problem in deep neural networks.
In addition to these commonly used Activ_Funcs, there are also other functions such as the softmax function, which is used in the output layer of CNNs for multi-class classification problems. The softmax function maps the output of the last layer to a probability distribution over the classes, making it suitable for probability-based classification tasks.
Overall, the choice of Activ_Funcs in CNNs can have a significant impact on the performance and convergence of the model. Different functions have different strengths and weaknesses, and choosing the right function for the task at hand is an important part of designing a successful CNN.
2.5. Padding, Stride, and Filters
Padding, stride, and filters are important parameters in CNNs that determine the size and resolution of the output feature maps (Feat_Maps) [
86,
87,
88,
89,
90,
91,
92,
93]. These parameters play a crucial role in controlling the amount of information that is retained in the Feat_Maps and can greatly impact the performance of the network.
Padding involves adding extra rows and columns of zeros around the input image before applying the filters. This can help to preserve the spatial dimensions of the image as it passes through the convolutional layers. Padding is typically used to ensure that the output Feat_Maps have the same spatial dimensions as the input image or to control the size of the output Feat_Maps.
Stride is another important parameter in CNNs that determines the distance between adjacent filter positions as the filter is slid over the input image. By adjusting the stride, it is possible to control the resolution of the output Feat_Maps. A larger stride results in a lower resolution output Feat_Map, while a smaller stride leads to a higher resolution output Feat_Map.
Filters are the small matrices that are applied to the input image to produce the Feat_Map. The filters are learned during the training process, and their values are updated using back propagation. The size of the filter is an important parameter that determines the size and complexity of the features that the filter can capture. Larger filters can capture more complex features but require more computation and are more prone to overfitting.
The size of the output Feat_Map depends on the size of the input image, the size of the filter, the stride, and the amount of padding. The output Feat_Map size can be calculated using the following formula:
where
W is the width (or height) of the input image,
F is the width (or height) of the filter,
P is the amount of padding, and
S is the stride. This formula gives the number of positions where the filter can be applied to the input image to produce the output Feat_Map.
Adjusting the padding, stride, and filter size is an important part of designing a CNN architecture that can effectively capture the features of the input image and produce high-quality Feat_Maps. These parameters provide a degree of flexibility in the design of convolutional layers, allowing the network to be tailored to the specific task at hand. For example, a network designed for image classification may use larger filters and smaller strides to capture more complex features, while a network designed for object detection may use smaller filters and larger strides to reduce the computation required and speed up the detection process.
Overall, understanding the role of padding, stride, and filters in CNNs is critical for designing effective neural network architectures that can accurately capture and classify complex visual patterns in images and other signals.
2.6. Training CNNs
Training a CNN involves adjusting the weights and biases of the model so that it produces accurate predictions on the training data [
94,
95,
96,
97,
98,
99]. This is achieved using an optimization algorithm that minimizes a loss function (Loss_Func), which measures the difference between the predicted output of the model and the true output. The most commonly utilized optimization algorithm for training CNNs is stochastic gradient descent (SGD), which updates the weights and biases of the model in small steps based on the gradient of the Loss_Func with respect to these parameters. The process of updating the weights and biases using the gradient is called back propagation, and it involves propagating the error from the output layer (Out_Lay) back through the network to update the weights and biases of each layer. This is achieved using the chain rule of calculus to compute the derivative of the Loss_Func with respect to each parameter in the network. The learning rate is a Hyper_Param that controls the size of the updates made to the weights and biases at each iteration of the optimization algorithm. It is important to choose a suitable learning rate, as a value that is too small may cause the optimization algorithm to converge slowly, while a value that is too large may cause the algorithm to overshoot the optimal weights and biases and fail to converge. Other Hyper_Params that can be tuned to improve the performance of the model include the number of layers in the network, the size of the filters, the number of filters in each layer, the type of Activ_Func utilized, and the amount of padding and stride utilized in the convolutional layers and Pool_Lays.
2.7. Back Propagation
Back propagation is an algorithm utilized to efficiently compute the gradients of the Loss_Func with respect to the weights and biases of a neural network [
100,
101,
102,
103]. It works by propagating the error from the Out_Lay back through the network and computing the derivative of the Loss_Func with respect to each parameter in the network using the chain rule of calculus. The back propagation algorithm is utilized in conjunction with an optimization algorithm to update the weights and biases of the network during training. An illustration of this notion is shown in
Figure 6.
Mathematically, the back propagation algorithm can be represented as:
Compute the output of the network for a given input.
Compute the error between the predicted output and the true output.
Compute the gradient of the Loss_Func with respect to the output of the network.
Use the chain rule to compute the gradient of the Loss_Func with respect to the weights and biases of each layer in the network:
where
L is the Loss_Func,
is the weight connecting neuron
i in layer
to neuron
j in layer
l,
is the bias of neuron
i in layer
l, and
is the weighted sum of the inputs to neuron
i in layer
l.
Update the weights and biases of the network using an optimization algorithm.
Repeat steps 1–5 for each training example.
Repeat steps 1–6 for a fixed number of epochs or until convergence.
2.8. Optimization Algorithms
Optimization algorithms are utilized to update the weights and biases of a neural network during training to minimize the Loss_Func [
104,
105]. The most commonly utilized optimization algorithm for training neural networks is stochastic gradient descent (SGD), which updates the weights and biases of the network in small steps based on the gradient of the Loss_Func with respect to these parameters.
Other optimization algorithms that have been developed include the following:
Momentum: This algorithm adds a momentum term to the gradient update, which helps to smooth out the updates and accelerate convergence. The update rule for momentum can be written as:
where
is the momentum at time
t,
is the momentum coefficient,
is the gradient of the Loss_Func with respect to the weights at time
,
is the learning rate, and
is the updated weights.
AdaGrad: This algorithm adapts the learning rate for each weight based on the magnitude of the gradients seen so far, which allows for faster convergence on flat directions and slower convergence on steep directions. The update rule for AdaGrad can be written as:
where
is the diagonal matrix of sums of squares of past gradients up to time
t,
is a small constant to avoid division by zero, and all other variables are as previously defined.
RMSProp: This algorithm uses a moving average of the squared gradients to adapt the learning rate for each weight, which helps to prevent the learning rate from becoming too large. The update rule for RMSProp can be written as:
where
is the moving average of the squared gradients up to time
t,
is the decay rate, and all other variables are as previously defined.
Adam: This algorithm combines ideas from momentum and AdaGrad to create an adaptive learning rate algorithm that works well in practice for a wide range of neural networks. The update rule for Adam can be written as:
where
and
are the first and second moment estimates of the gradients,
and
are the decay rates for the first and second moments,
and
are bias-corrected estimates of the first and second moments,
is a small constant to avoid division by zero, and all other variables are as previously defined.
Table 2 summarizes several optimization algorithms that are commonly used to update the weights and biases of neural networks during training to minimize the Loss_Func, including SGD, momentum, AdaGrad, RMSProp, and Adam, each with their own unique characteristics that can have a significant impact on the performance of the network.
2.9. Regularization Techniques
Regularization techniques are utilized to prevent overfitting in neural networks, which occurs when the model performs well on the training data but poorly on new unseen data [
106,
107,
108,
109,
110]. Regularization techniques work by adding a penalty term to the Loss_Func that encourages the model to have simpler weights or to reduce the magnitude of the weights.
Some commonly utilized regularization techniques include:
L1 regularization: This technique adds a penalty to the Loss_Func proportional to the absolute value of the weights, which encourages the model to have sparse weights and can lead to feature selection [
111,
112,
113,
114]. The regularized Loss_Func for L1 regularization can be written as:
where
is the original Loss_Func,
is the
ith weight in the network,
n is the total number of weights, and
is the regularization strength.
L2 regularization: This technique adds a penalty to the Loss_Func proportional to the square of the weights, which encourages the model to have small weights and can help to prevent overfitting [
115,
116,
117,
118]. The regularized Loss_Func for L2 regularization can be written as:
where all variables are as previously defined.
Dropout: This technique randomly drops out some of the neurons in the network during training, which helps to prevent the model from relying too heavily on any one feature and can improve generalization performance [
119,
120,
121]. The dropout regularization can be implemented by randomly setting the output of each neuron to zero with a certain probability
p during training. The dropout regularization can be written as:
where
y is the output of a layer,
is the regularized output,
r is a binary mask that is randomly generated for each training example, and ⊙ denotes element-wise multiplication. During testing, the dropout is turned off and the output is scaled by
to compensate for the effect of dropout.
Early stopping: This technique stops the training process early based on a validation set performance metric, which helps to prevent the model from overfitting to the training data [
122,
123,
124,
125]. The idea is to monitor the validation loss or accuracy during training and stop the training process when the validation
Table 3 summarizes several commonly utilized regularization techniques for preventing overfitting in neural networks, including L1 and L2 regularization, dropout, and early stopping, each with their own unique approach to encouraging simpler weights or preventing over-reliance on any one feature, ultimately improving the generalization performance of the model.
2.10. Evaluation Metrics
One of the most common challenges faced by training algorithms is the need to prevent overfitting, which is addressed in this study through the use of regularization. To assess the learning performance of the CNN model, a confusion matrix is employed as a conventional evaluation technique. In the field of image categorization, the confusion matrix is used to evaluate the predicted results against the actual values and measure the model’s performance. Through the confusion matrix, we can not only identify accurate and inaccurate predictions but also gain insights into the specific types of errors made. To calculate the confusion matrix, a set of test data and validation data containing the obtained results’ values are required. This traditional method can be used to identify six types of welding flaws, and the evaluation measure is depicted in
Figure 7.
The results are divided into four categories:
True positive (): The “true positive” category in the confusion matrix represents the number of instances in which the model accurately predicts the positive class or event out of all the true positive instances in the dataset.
True negative (): In the confusion matrix, “true negative” refers to the number of instances in which the model correctly predicts the negative class out of all the true negative instances in the dataset.
False positive (): The “false positive” represents the model’s error when it incorrectly predicts the presence of a specific condition or event that is not actually present. This type of error is also called a type I error and can lead to incorrect decisions if not properly managed.
False negative (): A “false negative” in the confusion matrix is when the model incorrectly predicts the absence of an event among all actual positive instances in the data. It measures the model’s tendency to miss positive cases or make type II errors.
3. CNN Architectures
Over the years, several different CNN architectures have been developed, each with its own unique features and performance characteristics.
3.1. LeNet
LeNet is one of the earliest CNN architectures, developed by Yann L.C. et al. in 1998 for recognizing handwritten digits. The LeNet architecture consists of two Conv_Lays, followed by two fully connected layers [
126,
127,
128,
129]. The Conv_Lays use small filters and Pool_Lays to extract features from the input image, and the fully connected layers use a softmax activation to output a probability distribution over the possible classes.
Mathematically, the LeNet architecture can be represented as:
Conv_Lay with 6 filters of size 5 × 5, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 16 filters of size 5 × 5, followed by a 2 × 2 max Pool_Lay.
Fully connected layer with 120 units and a sigmoid Activ_Func.
Fully connected layer with 84 units and a sigmoid Activ_Func.
Out_Lay with 10 units and a softmax Activ_Func.
3.2. AlexNet
AlexNet is a CNN architecture developed by Alex Krizhevsky et al. in 2012, which achieved state-of-the-art performance on the ImageNet dataset [
130,
131,
132]. The AlexNet architecture consists of five Conv_Lays, followed by three fully connected layers. The Conv_Lays use larger filters than LeNet and also include local response normalization and overlapping Pool_Lays. The fully connected layers use ReLU activation to introduce non-linearity into the network.
Mathematically, the AlexNet architecture can be represented as:
Conv_Lay with 96 filters of size 11 × 11, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 256 filters of size 5 × 5, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 384 filters of size 3 × 3.
Conv_Lay with 384 filters of size 3 × 3.
Conv_Lay with 256 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Fully connected layer with 4096 units and a ReLU Activ_Func.
Fully connected layer with 4096 units and a ReLU Activ_Func.
Out_Lay with 1000 units and a softmax Activ_Func.
3.3. VGG
VGG is a CNN architecture developed by Karen Simonyan and Andrew Zisserman in 2014, which achieved state-of-the-art performance on the ImageNet dataset [
133,
134,
135,
136,
137]. The VGG architecture consists of multiple layers of small 3 × 3 convolutional filters, followed by max Pool_Lays. The fully connected layers use ReLU activation and dropout regularization to prevent overfitting.
Mathematically, the VGG architecture can be represented as:
Conv_Lay with 64 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 128 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 256 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 512 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 512 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Fully connected layer with 4096 units and a ReLU Activ_Func, followed by dropout regularization.
Fully connected layer with 4096 units and a ReLU Activ_Func, followed by dropout regularization.
Out_Lay with 1000 units and a softmax Activ_Func.
3.4. ResNet
ResNet is a CNN architecture developed by Kaiming He et al. in 2015, which introduced the concept of residual connections to address the problem of vanishing gradients in deep networks [
138,
139,
140,
141,
142,
143]. The ResNet architecture consists of multiple residual blocks, each of which includes multiple Conv_Lays and shortcut connections that bypass the Conv_Lays and add the original input to the output of the block. The fully connected layers use a softmax activation to output a probability distribution over the possible classes.
Mathematically, the ResNet architecture can be represented as:
Conv_Lay with 64 filters of size 7 × 7, followed by a 3 × 3 max Pool_Lay.
Multiple residual blocks, each of which consists of:
Conv_Lay with 64 filters of size 3 × 3.
Conv_Lay with 64 filters of size 3 × 3.
Shortcut connection that adds the original input to the output of the block.
Multiple residual blocks, each of which consists of:
Conv_Lay with 128 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 128 filters of size 3 × 3.
Conv_Lay with 128 filters of size 3 × 3.
Shortcut connection that adds the original input to the output of the block.
Multiple residual blocks, each of which consists of:
Conv_Lay with 256 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 256 filters of size 3 × 3.
Conv_Lay with 256 filters of size 3 × 3.
Shortcut connection that adds the original input to the output of the block.
Multiple residual blocks, each of which consists of:
Conv_Lay with 512 filters of size 3 × 3, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 512 filters of size 3 × 3.
Conv_Lay with 512 filters of size 3 × 3.
Shortcut connection that adds the original input to the output of the block.
Fully connected layer with 1000 units and a softmax Activ_Func.
3.5. InceptionNet
InceptionNet, also known as GoogLeNet, is a CNN architecture developed by Christian Szegedy et al. in 2014, which introduced the concept of inception modules to allow for efficient use of computational resources [
144,
145,
146,
147,
148]. Inception modules consist of multiple convolutional filters of different sizes and Pool_Lays, which are concatenated together to form the output of the module. The InceptionNet architecture also includes auxiliary classifiers to help with training and to regularize the network.
Mathematically, the InceptionNet architecture can be represented as:
Conv_Lay with 64 filters of size 7 × 7, followed by a 2 × 2 max Pool_Lay.
Conv_Lay with 64 filters of size 1 × 1, followed by a Conv_Lay with 192 filters of size 3 × 3, and a 2 × 2 max Pool_Lay.
Multiple inception modules, each of which consists of:
Conv_Lay with 64 filters of size 1 × 1.
Conv_Lay with 96 filters of size 3 × 3.
Conv_Lay with 128 filters of size 5 × 5.
Max Pool_Lay with a 3 × 3 filter and stride 1.
Concatenation of the outputs of the previous layers.
Multiple inception modules, each of which consists of:
Conv_Lay with 192 filters of size 1 × 1.
Conv_Lay with 96 filters of size 3 × 3.
Conv_Lay with 208 filters of size 5 × 5.
Max Pool_Lay with a 3 × 3 filter and stride 1.
Concatenation of the outputs of the previous layers.
Multiple inception modules, each of which consists of:
Conv_Lay with 160 filters of size 1 × 1.
Conv_Lay with 112 filters of size 3 × 3.
Conv_Lay with 224 filters of size 5 × 5.
Max Pool_Lay with a 3 × 3 filter and stride 1.
Concatenation of the outputs of the previous layers.
3.6. Comparison of CNN Architectures
The goal of this section is to provide a comparison of the key details and performance of several popular CNN architectures, including LeNet, AlexNet, VGG, ResNet, and InceptionNet. The details of each architecture, including the number of layers, filters, and top-1 and top-5 error rates, are summarized in
Table 4.
Note that the number of layers and filters is approximate, as it varies depending on the specific implementation of each architecture. The top-1 and top-5 error rates are the percentage of images in the ImageNet dataset that are misclassified by the model, with the top-1 error rate indicating the percentage of images for which the correct class is not in the top predicted class, and the top-5 error rate indicating the percentage of images for which the correct class is not in the top-5 predicted classes.
In terms of performance, ResNet and InceptionNet have achieved the lowest error rates on the ImageNet dataset, with ResNet achieving a top-5 error rate of just 1.6%. VGG also achieved impressive performance, with a top-5 error rate of 8.7%. AlexNet achieved a top-5 error rate of 17.0%, which was a significant improvement over previous state-of-the-art models at the time. LeNet was one of the earliest CNN architectures and was designed for recognizing handwritten digits, so its performance is not directly comparable to the other architectures.
One notable trend in these architectures is the increasing depth of the models over time. LeNet had just 5 layers, while AlexNet had 8 and VGG had 19. ResNet and InceptionNet took this trend to the extreme, with ResNet having 152 layers and InceptionNet having 22 layers. However, these architectures also introduced new techniques to help with training deeper models, such as residual connections and inception modules.
Another trend is the use of smaller filters, which allows for more layers to be added without significantly increasing the number of parameters in the model. LeNet utilized 5 × 5 filters, while AlexNet utilized a mix of 11 × 11 and 5 × 5 filters. VGG utilized only 3 × 3 filters, which allowed for a very deep architecture with relatively few parameters. ResNet and InceptionNet also utilized a mix of small filters, with InceptionNet using a variety of filter sizes in its inception modules.
Overall, each of these architectures has made important contributions to the field of computer vision and deep learning (DL). LeNet was one of the first successful CNN architectures, while AlexNet demonstrated the potential of DL for image classification tasks. VGG showed that very deep architectures could achieve state-of-the-art performance, while ResNet and InceptionNet introduced new techniques for training even deeper models.
4. When to Use CNN?
4.1. Some Examples
Table 5 summarizes selected research papers and their key findings related to the use of CNNs, including automated welding fault detection, lip reading, olive leaf disease detection, mask recognition for COVID-19, visual spam classification, and driver sleepiness detection. The table highlights the proposed methods, the accuracy rates achieved, and the potential applications of the developed models. More details about each example are provided next.
The proposed method in [
149] uses a convolutional neural network (CNN) and data augmentation to identify multi-class welding errors in X-ray pictures (see
Figure 8 and
Figure 9). Detecting weld faults with X-rays is expensive and time consuming, requiring experienced specialists who may make mistakes owing to weariness and distraction. Data augmentation techniques such as random rotation, shearing, zooming, brightness adjustment, and horizontal flips are used to train a generalized CNN network to identify welding flaws in a multi-class dataset. The suggested approach is tested using 4479 industrial X-ray images of cavity, cracks, inclusion slag, absence of fusion, shape defects, and normal flaws. The proposed method for automated welding flaw detection and categorization had a 92% accuracy rate. Thus, this work proposes an automated method for detecting multi-class welding faults in X-ray pictures using data augmentation and a CNN, which could reduce manual inspection expenses and errors.
The work reported in [
150] developed a Kannada language dataset and machine-learning-based VSR technique. VSR is a lip-reading method that can help hearing-impaired, laryngeal, and loud people. The authors created a dataset of five random Kannada sentences with an average video time of 1 to 1.2 s. Using a VGG16 CNN and ReLU activation function, they extracted and classified features with 91.90% accuracy. The suggested system outperformed HCNN, ResNet-LSTM, Bi-LSTM, and GLCM-ANN. Thus, this work developed a novel dataset and machine-learning-based VSR technique for Kannada, which may aid hearing-impaired or loud people.
The work discussed in [
151] developed a novel deep ensemble learning technique that uses CNN and vision transformer models to detect and classify olive leaf illnesses. Disease detection algorithms based on deep learning are becoming increasingly essential in agriculture, but the diversity of plant species and regional features of many species make them difficult to build. Due to the range of pathogens that can infect olive groves, olive leaf diseases are difficult to diagnose. The authors built binary and multi-classification methods using deep convolutional models. The proposed deep ensemble learning technique uses CNN and vision transformer models to achieve 96% multi-class classification accuracy and 97% binary classification accuracy, beating other models. This study suggests that the proposed approach could detect and classify olive leaf illnesses, which could assist olive growers by enabling timely disease identification and treatment. Thus, the work developed a novel deep ensemble learning technique for olive leaf disease detection and classification, which could increase olive grove profitability and sustainability.
The work discussed in [
105] developed a strong mask detection model utilizing computer vision to tackle COVID-19. The authors remark that the COVID-19 epidemic has motivated the artificial intelligence community to research new ways to fight the disease, and computer vision, a sub-discipline of AI, has been effective in many sectors. The authors have since contributed a few articles using computer vision for COVID-19 tasks. The suggested mask detection model can identify persons wearing prescribed masks, those not wearing masks, and those not wearing masks properly. Experiments prove the model’s power and robustness. Thus, this work developed a computer vision-based mask recognition algorithm to help battle COVID-19 by detecting those who are not wearing masks or wearing them improperly.
The work discussed in [
152] explores visual spam classification using deep convolutional neural networks (DCNNs) and transfer-learning-based pre-trained CNN models. Image spam, which uses images to bypass text-based spam filters, was classified using two DCNN models and several pre-trained ImageNet architectures on three datasets. Cost-sensitive learning was also tested for data imbalance. In the best situation, several of the presented models approach 99% accuracy with zero false positives, improving picture spam classification. This study proposes employing DCNNs and transfer-learning-based pre-trained CNN models to improve visual spam categorization.
The work discussed in [
153] developed a neural-network-based approach for detecting driver micro-naps and sleepiness. In this work, the authors use facial landmarks detected by a camera as input to a convolutional neural network to categorize tiredness instead of a multi-layer perceptron. The suggested CNN-based model obtains high accuracy rates, with more than 88% for the category without glasses, more than 85% for the category night without glasses, and an overall average accuracy of more than 83% in all categories. The proposed model has a maximum size of 75 KB and is smaller, simpler, and more storage-efficient than the benchmark model. This lightweight and accurate CNN-based model might be used to construct a real-time driver sleepiness detection system for embedded systems and Android devices, according to the authors. Thus, this work proposes a lightweight classification model for driver sleepiness detection that is accurate and easy to use.
4.2. Tasks Suited for CNNs
CNNs are particularly well-suited for tasks that involve analyzing visual data, such as image classification, object detection, and segmentation. This is because CNNs are able to learn hierarchical representations of visual data, where higher-level features are built upon lower-level features, allowing the model to understand complex patterns in the data and make accurate predictions.
CNNs are also well-suited for tasks that involve analyzing sequential data, such as speech recognition and NLP, where the data has a spatial or temporal structure that can be exploited by the Conv_Lays. For example, in speech recognition, the input waveform can be viewed as a sequence of frames, and the Conv_Lays can be utilized to extract features from these frames that capture the phonetic content of the speech. In NLP, the Conv_Lays can be utilized to extract features from the input text that capture the meaning of the words and their relationships to each other.
4.3. Best Utilized with Large Amounts of Training Data
CNNs require a large amount of labeled training data to perform well. This is because the models have millions of parameters that need to be learned from the data, and they require a significant amount of variation in the data to avoid overfitting. In general, the more data that is available for training, the better the performance of the model will be. However, collecting large amounts of labeled training data can be time consuming and expensive, especially for tasks that involve fine-grained classification or segmentation. In such cases, transfer learning can be a useful technique, where a pre-trained model is utilized as a starting point and fine-tuned on a smaller dataset. This can significantly reduce the amount of labeled data required for training and improve the performance of the model.
It is also worth noting that CNNs can be sensitive to the quality of the training data. If the data is noisy or contains biases, the model may learn to recognize these artifacts rather than the underlying patterns in the data. Therefore, it is important to carefully curate and preprocess the training data to ensure that it is representative of the task at hand.
4.4. Computational Requirements
Training CNNs can be computationally expensive, especially for large models with many layers. This is because CNNs typically require a lot of memory and processing power to train. However, recent advances in hardware and software have made it possible to train large CNNs on a single GPU or even multiple GPUs in parallel.
In addition to the computational requirements for training, there are also computational requirements for inference, where the model is utilized to make predictions on new data. The computational requirements for inference depend on the size of the model and the complexity of the task, but they are generally less than the requirements for training. In some cases, it may be necessary to optimize the model architecture or use specialized hardware, such as tensor processing units (TPUs), to achieve real-time performance.
To reduce the computational requirements of training and inference, various techniques have been developed, including model pruning, quantization, and compression. These techniques aim to reduce the size of the model and the number of operations required for inference, without significantly degrading the performance of the model. Additionally, pre-trained models are available for many tasks, which can significantly reduce the computational requirements for training new models. These pre-trained models can be fine-tuned on a smaller dataset, which can lead to improved performance and reduced training time.
Overall, while CNNs can be computationally expensive, they are a powerful tool for analyzing visual and sequential data. They are best suited for tasks that require the analysis of complex patterns in the data and are most effective when trained on large amounts of labeled data. With recent advances in hardware and software, CNNs are becoming increasingly accessible to researchers and practitioners, and are likely to continue to play a significant role in the field of ML and computer vision.
5. Advantages and Limitations of CNNs
5.1. Advantages
CNNs have several advantages that make them a powerful tool for analyzing visual and sequential data. One of the main advantages of CNNs is their ability to learn hierarchical representations of the input data, where higher-level features are built upon lower-level features. This allows the model to understand complex patterns in the data and make accurate predictions.
Another advantage of CNNs is their ability to handle inputs of varying sizes and aspect ratios. This is because the Conv_Lays are able to learn features that are translation-invariant, meaning that they can recognize the same pattern regardless of its location in the input. Additionally, max-pooling layers can be utilized to downsample the input, allowing the model to handle inputs of varying sizes and aspect ratios.
CNNs also have the ability to generalize well to new data, meaning that they are able to make accurate predictions on data that they have not seen before. This is because the models learn features that are relevant to the task, rather than memorizing specific examples from the training data. Additionally, transfer learning can be utilized to transfer knowledge from pre-trained models to new tasks, which can improve the accuracy of the model and reduce the amount of training data required.
5.2. Limitations
While CNNs have several advantages, they also have some limitations that should be considered when using them. One limitation of CNNs is that they require a large amount of labeled training data to perform well. This is because the models have millions of parameters that need to be learned from the data, and they require a significant amount of variation in the data to avoid overfitting. Collecting and labeling large amounts of training data can be time consuming and expensive, especially for tasks that involve fine-grained classification or segmentation.
Another limitation of CNNs is that they can be sensitive to the quality of the training data. If the data is noisy or contains biases, the model may learn to recognize these artifacts rather than the underlying patterns in the data. Therefore, it is important to carefully curate and preprocess the training data to ensure that it is representative of the task at hand.
Additionally, CNNs can be computationally expensive to train and evaluate, especially for large models with many layers. This is because CNNs typically require a lot of memory and processing power to train. However, recent advances in hardware and software have made it possible to train large CNNs on a single GPU or even multiple GPUs in parallel. Additionally, various techniques have been developed to reduce the computational requirements of training and inference, such as model pruning, quantization, and compression.
Finally, CNNs are not always the best choice for every task. For example, if the input data has a different structure, such as a graph or a tree, then other types of neural networks, such as graph neural networks or recursive neural networks, may be more appropriate. Additionally, if the task requires reasoning over symbolic or logical representations, then other types of models, such as rule-based systems or logic-based systems, may be more suitable. Therefore, it is important to carefully consider the specific requirements of the task when choosing a model architecture.
Table 6 summarizes the advantages and limitations of CNNs, highlighting their ability to learn hierarchical representations of input data, handle inputs of varying sizes and aspect ratios, and generalize well to new data, while also noting their requirements for large amounts of labeled training data, sensitivity to the quality of training data, and computational expense.
6. Existing Platforms and Libraries
There are several platforms and libraries available for building CNNs and other types of neural networks. These platforms and libraries provide a wide range of tools and functions for building, training, and deploying models. Here, a more detailed overview of some of the most popular platforms and libraries is provided.
6.1. TensorFlow
TensorFlow is an open-source ML platform developed by Google. It is one of the most widely utilized platforms for building and deploying ML models, including CNNs [
154,
155,
156,
157,
158]. TensorFlow provides a wide range of tools and libraries for building and deploying models, including high-level APIs, such as Keras, and low-level APIs, such as TensorFlow Core, which allow for greater flexibility and control over the model architecture. TensorFlow also includes tools for distributed training, which can be utilized to train large models on multiple machines in parallel.
One of the key benefits of TensorFlow is its compatibility with a wide range of hardware, including CPUs, GPUs, and TPUs. This allows for efficient computation and training of models, which can be especially important for tasks that require large amounts of data and computation. TensorFlow also includes tools for model optimization and deployment, which can help to improve the performance and efficiency of models.
6.2. Keras
Keras is a high-level API for building neural networks, including CNNs, that runs on top of TensorFlow. Keras provides a simple and intuitive interface for building and training neural networks, making it an ideal choice for beginners or for rapid prototyping [
159,
160,
161,
162,
163]. Keras supports a wide range of model architectures and includes tools for data preprocessing, model evaluation, and visualization. One of the key benefits of Keras is its ease of use, which allows users to quickly build and train models without needing to have a deep understanding of the underlying mathematics or programming.
Keras also includes a wide range of pre-trained models, such as the VGG16, Inception, and ResNet models, which can be utilized for various computer vision tasks, such as image classification, object detection, and segmentation. These pre-trained models can be fine-tuned for specific tasks, which can help to reduce the amount of data and computation required for training.
6.3. PyTorch
PyTorch is an open-source ML framework developed by Facebook. It provides a dynamic computational graph, which allows for greater flexibility and ease of use when building and training neural networks, including CNNs [
164,
165,
166,
167,
168]. PyTorch also includes tools for distributed training and supports both high-level APIs, such as TorchVision, and low-level APIs, which allow for greater control over the model architecture.
One of the key benefits of PyTorch is its dynamic computational graph, which allows users to define and modify the model architecture on the fly. This can be especially useful for tasks that require experimentation and exploration of different model architectures. PyTorch also includes tools for visualization, model evaluation, and deployment, which can help to simplify the development and deployment process.
6.4. Caffe
Caffe is an open-source DL library developed by Berkeley AI Research (BAIR). It is designed for efficient computation of deep neural networks, including CNNs, and includes a wide range of pre-trained models that can be utilized for various computer vision tasks [
169,
170,
171,
172,
173]. Caffe also includes tools for visualization, model evaluation, and deployment.
One of the key benefits of Caffe is its efficiency, which allows for fast computation and training of models. This can be especially important for tasks that require large amounts of data and computation. Caffe also includes a wide range of pre-trained models, such as the AlexNet, GoogLeNet, and YOLO models, which can be utilized for various computer vision tasks.
6.5. MXNet
MXNet is an open-source DL framework developed by Apache. It provides a wide range of tools and libraries for building and deploying DL models, including CNNs [
174,
175]. MXNet supports both high-level APIs, such as Gluon, and low-level APIs, which allow for greater control over the model architecture. MXNet also includes tools for distributed training and supports a wide range of programming languages, including Python, R, and Scala.
One of the key benefits of MXNet is its flexibility, which allows for customization of the model architecture and computation. MXNet also includes a wide range of pre-trained models, such as the ResNet, SqueezeNet, and SSD models, which can be utilized for various computer vision tasks. MXNet is also known for its scalability, which allows for efficient computation and training of models on large datasets.
6.6. Comparison of Platforms and Libraries
To summarize the differences between these platforms and libraries, a comparison table is provided below. A summary of this comparison is provided in
Table 7From the comparison table, it can be seen that TensorFlow and MXNet are ideal choices for tasks that require high computation efficiency and scalability, while Keras and PyTorch are better suited for tasks that require ease of use and flexibility. Caffe is useful for tasks that require efficient computation and a wide range of pre-trained models, while also being low level and less flexible.
It is important to note that this comparison is not exhaustive and the specific requirements of the task should be considered when choosing a platform or library. For example, if the task requires deploying the model to mobile devices, TensorFlow Lite may be the best choice, while if the task requires integration with other Python libraries, such as NumPy or pandas, then PyTorch may be the better choice.
It is also worth noting that these platforms and libraries are constantly evolving, with new features and updates being released regularly. As such, it is important to stay up-to-date with the latest developments and best practices in the field. Additionally, hybrid approaches, which combine multiple platforms or libraries, can be utilized to take advantage of the strengths of each. For example, TensorFlow and PyTorch can be utilized together to take advantage of the high-level APIs and distributed training capabilities of TensorFlow and the flexibility and ease of use of PyTorch’s dynamic computational graph. Similarly, Keras and Caffe can be utilized together to take advantage of Keras’ simplicity and Caffe’s efficient computation capabilities.
7. Comparison with Other Model Architectures
While CNNs are a powerful tool for analyzing visual and sequential data, they are not always the best choice for every task. There are several alternative model architectures that can be utilized in place of CNNs, depending on the specific requirements of the task. Here, a more detailed comparison between CNNs and some of the alternative model architectures is provided. A summary of this comparison is provided in
Table 8.
CNNs vs. Fully Connected Neural Networks (FCNs): FCNs are similar to traditional feedforward neural networks but can handle inputs of variable size and shape. FCNs have been utilized for tasks such as object detection and segmentation, but they are less effective than CNNs for tasks that involve analyzing images or other visual data. This is because FCNs do not take into account the spatial relationships between pixels in an image, which is a key feature of CNNs. In addition, FCNs are more prone to overfitting than CNNs, especially when dealing with large and complex datasets.
CNNs vs. Recurrent Neural Networks (RNNs): RNNs are designed for processing sequential data, such as speech or text. RNNs have been utilized for tasks such as speech recognition and language translation, but they are less effective than CNNs for tasks that involve analyzing visual data. This is because RNNs are less able to capture the spatial relationships between pixels in an image, which is a key feature of CNNs. In addition, RNNs are more computationally expensive than CNNs, especially when dealing with long sequences, which can make them less practical for some tasks.
CNNs vs. Graph Neural Networks (GNNs): GNNs are designed for processing data that has a graph structure, such as social networks or chemical molecules. GNNs have been utilized for tasks such as node classification and link prediction, but they are less effective than CNNs for tasks that involve analyzing visual data. This is because GNNs are less able to capture the spatial relationships between pixels in an image, which is a key feature of CNNs. In addition, GNNs can be computationally expensive, especially when dealing with large graphs, which can make them less practical for some tasks.
CNNs vs. Rule-based and Logic-based Systems: Rule-based systems and logic-based systems are designed for tasks that require reasoning over symbolic or logical representations. These systems are less effective than CNNs for tasks that involve analyzing visual data, but they are more suitable for tasks such as expert systems, decision making, and knowledge representation. Rule-based systems and logic-based systems can be more interpretable than CNNs, which can be an advantage in some applications. However, they are less able to handle noisy or ambiguous data, which is a key strength of CNNs.
In general, the choice of model architecture depends on the specific requirements of the task. If the task involves analyzing visual or sequential data, then CNNs or RNNs are likely to be the most effective choice. If the data has a graph structure, then GNNs may be the most appropriate choice. If the task involves reasoning over symbolic or logical representations, then rule-based systems or logic-based systems may be the most suitable choice.
It is also worth noting that hybrid architectures, which combine multiple types of models, can be utilized to improve performance on complex tasks. For example, a CNN can be utilized to extract features from an image, which are then fed into an RNN for sequence modeling and prediction. Another example is the use of attention mechanisms, which can be utilized to focus on specific regions of an image or sequence, improving the performance of both CNNs and RNNs. Ultimately, the choice of model architecture should be informed by the specific requirements of the task and the available data, and a careful consideration of the strengths and limitations of each model architecture.
8. Recommendations for Developers and Data Scientists
As summarized in
Table 9, building and training CNNs can be a complex task that requires careful consideration of several factors. Here, some recommendations for developers and data scientists who are building CNNs are provided.
8.1. Preprocessing the Data
Preprocessing the data is an important step in building a CNN. This involves transforming the raw input data into a format that can be utilized by the CNN. Preprocessing can include resizing the images, normalizing the pixel values, and augmenting the data with techniques such as flipping or rotating the images. Proper preprocessing can help to improve the accuracy and generalization of the model. When preprocessing the data, it is important to consider the characteristics of the dataset and the requirements of the model. For example, if the dataset contains images of different sizes, it may be necessary to resize the images to a common size to ensure that they can be processed by the CNN. Similarly, if the pixel values of the images have a large range, it may be necessary to normalize the values to a smaller range to ensure that the model can learn effectively.
8.2. Choosing Appropriate Hyper_Param
Choosing appropriate Hyper_Param such as the learning rate, batch size, and number of epochs can greatly affect the performance of the model. Hyper_Param can be tuned using techniques such as grid search or random search. It is important to avoid overfitting the model by using techniques such as early stopping or reducing the learning rate over time. When choosing Hyper_Param, it is important to consider the characteristics of the dataset and the complexity of the model. For example, if the dataset is large, it may be necessary to use a smaller learning rate to ensure that the model converges effectively. Similarly, if the model is complex, it may be necessary to use a smaller batch size to prevent the model from overfitting on the training data.
8.3. Using Regularization Techniques
Regularization techniques such as L1 or L2 regularization, dropout, or batch normalization can also be utilized to prevent overfitting of the model. Regularization can help to improve the generalization of the model and prevent it from memorizing the training data. When using regularization techniques, it is important to consider the specific requirements of the task and the architecture of the model. For example, if the model is deep, it may be necessary to use dropout to prevent overfitting, while if the model is shallow, L2 regularization may be more appropriate.
8.4. Hardware Considerations
Hardware considerations such as the available GPUs or TPUs, can greatly affect the performance and efficiency of the model. CNNs are computationally intensive and require large amounts of processing power, so it is important to choose hardware that can handle the workload. Distributed training can also be utilized to train large models on multiple machines in parallel. Additionally, choosing appropriate batch sizes and optimizing the memory usage can help to improve the efficiency of the model. When considering hardware constraints, it is important to balance the computational requirements of the model with the available resources. For example, if the model requires a large amount of memory, it may be necessary to use a smaller batch size to ensure that the model can fit into the available memory. Similarly, if the hardware has limited processing power, it may be necessary to use a simpler model architecture or to train the model over a longer period of time. Distributed training can also be utilized to train large models on multiple machines in parallel, which can greatly reduce the time required to train the model. However, distributed training can also introduce additional complexity and require specialized knowledge and infrastructure.
8.5. Evaluating Model Performance
Evaluating the performance of the model is an important step in building a CNN. This involves splitting the data into training, validation, and testing sets, and using metrics such as accuracy, precision, recall, and F1 score to evaluate the performance of the model. It is also important to visualize the results using techniques such as confusion matrices or ROC curves. When evaluating the performance of the model, it is important to consider the specific requirements of the task. For example, if the model is being utilized for a medical diagnosis, it may be more important to maximize the sensitivity of the model to detect true positives, even at the cost of increased false positives. Similarly, if the model is being utilized for a self-driving car, it may be more important to minimize the false positives to ensure the safety of the passengers. It is also important to consider the potential biases and ethical implications of the model. CNNs can be utilized for a wide range of applications, including facial recognition, object detection, and surveillance. It is important to consider the potential biases and ethical implications of these applications and to ensure that the models are transparent, explainable, and fair. For example, facial recognition systems have been shown to exhibit bias against certain groups of people, such as people with darker skin tones or women. It is important to ensure that these biases are identified and addressed to ensure that the model is fair and unbiased.
8.6. Security Aspects
Data privacy and security should also be considered when building and deploying CNNs, as these models may be trained on sensitive data or utilized to make decisions that affect people’s lives. It is important to ensure that the data utilized to train the model is anonymized and that proper measures are taken to protect the privacy and security of the data. Additionally, it is important to ensure that the model is deployed in a secure environment and that appropriate measures are taken to protect against attacks such as adversarial examples or model poisoning attacks. Adversarial examples are inputs that are specifically crafted to cause the model to misclassify them, and they can be created by adding small perturbations to the inputs. Adversarial attacks can have serious consequences, such as causing self-driving cars to misidentify traffic signs or causing facial recognition systems to misidentify people. To prevent adversarial attacks, it is important to use techniques such as adversarial training or defensive distillation, which involve training the model with adversarial examples to improve its robustness. Model poisoning attacks involve an attacker intentionally injecting malicious data into the training dataset to compromise the model’s performance or introduce backdoors that can be exploited later. To prevent model poisoning attacks, it is important to ensure that the training data is properly sanitized and that only trusted sources are utilized to collect the data.
In addition to these technical measures, it is important to ensure that appropriate policies and regulations are in place to govern the use of CNNs. This includes ensuring that the models are utilized ethically and responsibly, and that they do not violate the rights of individuals or groups. By following these recommendations and staying up-to-date with the latest developments in the field, developers and data scientists can build models that are accurate, efficient, and secure.
9. Estimation of the Cost of Using CNNs
Building and training CNNs can be a computationally intensive process that requires significant resources. Estimating the cost of using CNNs can help developers and data scientists to plan and budget for the necessary resources.
9.1. Factors Impacting Cost (Hardware, Dataset Size, Model Complexity)
Several factors can impact the cost of using CNNs, including the hardware utilized to train the models, the size of the dataset, and the complexity of the model architecture. Hardware requirements can vary depending on the size and complexity of the model, as well as the size of the dataset. Larger models and datasets may require more powerful hardware, such as graphics processing units (GPUs) or tensor processing units (TPUs), to achieve reasonable training times. The cost of these hardware components can vary depending on the manufacturer, model, and specifications. The size of the dataset can also impact the cost of using CNNs. Larger datasets may require more storage space and may take longer to preprocess before training. This can increase the cost of storage and computing resources. Finally, the complexity of the model architecture can impact the cost of using CNNs. More complex models may require more training time, more hardware resources, and more data preprocessing. This can increase the cost of using CNNs.
9.2. Cloud-Based Services and Renting Hardware to Reduce Costs
One way to reduce the cost of using CNNs is to leverage cloud-based services or to rent hardware. Cloud-based services offer the advantage of on-demand access to computing resources, which can be scaled up or down as needed. This can help to reduce the upfront costs of hardware and infrastructure, as well as the ongoing costs of maintaining and upgrading the hardware. Cloud-based services also offer the advantage of flexibility and scalability. Developers and data scientists can choose to use the cloud for specific tasks, such as data preprocessing or model training, and then scale back the resources when the task is completed. This can help to reduce the overall cost of using CNNs. Another option for reducing the cost of using CNNs is to rent hardware from cloud providers or third-party vendors. This can be a cost-effective solution for developers and data scientists who need access to high-performance computing resources but cannot afford to invest in the hardware themselves. Renting hardware can also offer the advantage of flexibility and scalability. Developers and data scientists can choose to rent hardware for specific tasks or projects, and then return the hardware when the task is completed. This can help to reduce the overall cost of using CNNs and provide access to the latest hardware technologies.
9.3. Considering Potential Benefits of Using CNNs
While the cost of using CNNs can be significant, it is important to consider the potential benefits of using these models. CNNs can offer significant improvements in accuracy and efficiency compared to traditional ML algorithms, particularly for tasks such as image classification, object detection, and natural language processing [
176,
177]. By accurately classifying and detecting objects in images and videos, CNNs can help to improve a wide range of applications, from self-driving cars to medical diagnosis. In NLP, CNNs can be utilized for sentiment analysis, language translation, and speech recognition. The potential benefits of using CNNs can also extend beyond improving accuracy and efficiency. CNNs can offer insights into complex data and help to identify patterns and relationships that may not be apparent through traditional data analysis. This can lead to new discoveries and innovations in fields such as healthcare, finance, and engineering. Moreover, the use of CNNs can also lead to cost savings and increased productivity in the long run. By automating tasks that would otherwise require significant human effort, such as image and speech recognition, CNNs can help to reduce labor costs and improve efficiency. In summary, while the cost of using CNNs can be significant, it is important to consider the potential benefits of using these models. By leveraging cloud-based services or renting hardware, developers and data scientists can reduce the upfront costs associated with using CNNs. Additionally, the potential benefits of using CNNs, such as improved accuracy, insights into complex data, and cost savings, can make them a worthwhile investment for a wide range of applications.
10. Recent Developments
As summarized in
Table 10, CNNs have been the subject of extensive research and development in recent years, leading to several innovative approaches to improve performance and efficiency.
10.1. Attention Mechanisms
Attention mechanisms are a powerful tool for improving the performance of CNNs [
178,
179,
180,
181,
182]. They allow the model to selectively focus on specific regions of an image or sequence of data, rather than processing the entire input at once. This can help improve accuracy and reduce computational requirements, making attention mechanisms particularly useful for tasks such as image captioning and machine translation. In CNNs, attention mechanisms can be integrated at various levels of the network architecture, such as within individual Conv_Lays or across multiple layers. Recent research has shown that attention mechanisms can significantly improve the performance of CNNs, particularly for tasks that require understanding of long-range dependencies or complex relationships between the input data.
10.2. Capsule Networks
Capsule networks are a recent development in CNNs that aim to improve the ability of the model to represent hierarchical relationships between objects in an image [
183,
184,
185,
186,
187]. In traditional CNNs, the model learns to identify objects by detecting specific patterns of pixels in the input image. However, this approach can be limited in its ability to capture the relationships between objects in the image. Capsule networks address this limitation by representing objects as capsules, which are vectors that capture the properties of the object, such as its position, orientation, and texture. Capsules can then be combined to represent higher-level objects and relationships between objects in the image, resulting in a more robust representation of the input data. Recent research has shown that capsule networks can achieve state-of-the-art performance on several image classification tasks, particularly when the training dataset is small or noisy.
10.3. Transfer Learning
Transfer learning is a technique that allows CNNs to leverage the knowledge learned from one task to improve performance on a second, related task [
188,
189,
190,
191,
192]. This can be particularly useful when training data for the second task is limited or unavailable. In transfer learning, the CNN is first trained on a large, labeled dataset, such as ImageNet, and then the learned features are transferred to a second, related task. This can significantly reduce the amount of training data required for the second task and improve the accuracy of the model. Recent research has shown that transfer learning can be particularly effective for tasks such as object detection and image segmentation, where the model needs to identify specific objects in an image.
10.4. Adversarial Training
Adversarial training is a technique that improves the robustness of CNNs to adversarial attacks. Adversarial attacks are a type of attack where an attacker adds small, imperceptible perturbations to the input data, causing the model to misclassify the input [
193,
194,
195,
196,
197]. In adversarial training, the CNN is trained on both the original, clean dataset and a modified version of the dataset that includes adversarial examples. This helps the model to learn to be robust to these attacks and improve its overall performance. Recent research has shown that adversarial training can significantly improve the robustness of CNNs to adversarial attacks, particularly for tasks such as image classification and object detection.
10.5. Quantization and Compression
Quantization and compression are techniques that reduce the memory and computational requirements of CNNs [
198,
199,
200,
201]. In quantization, the weights and activations of the CNN are represented using fewer bits, reducing the amount of memory required to store the model. In compression, the CNN is pruned to remove unnecessary weights or neurons, resulting in a smaller and more efficient model. Recent research has shown that these techniques can significantly reduce the memory and computational requirements of CNNs without sacrificing performance. This can be particularly useful for deploying CNNs on resource-constrained devices, such as mobile phones or embedded systems.
In summary, recent developments in CNNs have led to several innovative approaches to improve performance, efficiency, and robustness. Attention mechanisms, capsule networks, transfer learning, adversarial training, and quantization and compression are just a few examples of these recent developments. By incorporating these techniques into their CNN models, developers and data scientists can achieve state-of-the-art performance while reducing the computational and memory requirements of their models.
11. Enhancing Reliability and Efficiency of CNNs through Formal Methods
As already mentioned in previous sections, CNNs are a powerful tool for a wide range of applications, including image and speech recognition, NLP, and autonomous vehicles. However, designing and verifying CNNs can be a complex and error-prone process, particularly as the size and complexity of the model increases. Formal methods can help to address these challenges by providing a rigorous approach to designing and verifying CNNs. Formal methods are a set of mathematical techniques for specifying, modeling, and verifying systems [
202,
203,
204,
205,
206]. They are particularly useful for systems that require high levels of reliability, safety, and security, such as those utilized in aerospace, defense, and medical applications. Formal methods can provide a high degree of confidence in the correctness of a system by proving that it meets a set of formal specifications and requirements [
207,
208,
209,
210].
In the context of CNNs, formal methods can be utilized to verify that the model meets certain specifications, such as accuracy, efficiency, or robustness. This can help to identify potential errors or weaknesses in the model architecture or training process before deployment, reducing the risk of errors or failures in the field. Formal methods can also be utilized to generate adversarial examples, which are inputs that are designed to cause the model to misclassify the input. Adversarial examples can be utilized to evaluate the robustness of the model and identify potential vulnerabilities that could be exploited by attackers. By using formal methods to generate adversarial examples, developers and data scientists can ensure that the model is robust to a wide range of potential attacks and improve the overall security of the system. Moreover, formal methods can help to improve the efficiency and scalability of CNN models. As CNNs become more complex and larger, finding optimal configurations for the model Hyper_Param can become increasingly challenging. Formal methods can be utilized to systematically explore the search space of Hyper_Param and identify the optimal configuration that meets the desired specifications and requirements. In addition, formal methods can also be utilized to develop automated tools for designing and verifying CNNs. These tools can help to reduce the time and effort required for designing and verifying CNNs, while also improving the reliability and quality of the models.
Table 11 summarizes the various benefits of using formal methods to enhance the reliability and efficiency of CNNs, including verification of model specifications, generation of adversarial examples, optimization of Hyper_Param configurations, and development of automated tools, each contributing to the overall quality and robustness of the models. In summary, the use of formal methods can provide a rigorous approach to designing and verifying CNNs, improving the reliability, safety, and security of the models. Formal methods can help to identify potential errors or vulnerabilities in the model architecture and training process, while also improving the efficiency and scalability of the models. By incorporating formal methods into the CNN design and verification process, developers and data scientists can achieve a high degree of confidence in the correctness and robustness of their models, making them suitable for a wide range of applications in diverse industries.
12. Conclusions
In conclusion, CNNs have become a powerful tool for image recognition tasks, achieving state-of-the-art results on several benchmarks. In this paper, a comprehensive overview of CNNs was provided, covering their fundamentals, architectures, and recent developments. The article also discussed the advantages and limitations of CNNs, provided recommendations for developers and data scientists, examined the existing platforms and libraries for CNNs, and estimated the cost of using CNNs. It started by discussing the fundamentals of CNNs, including the layers of CNNs, Conv_Op, Feat_Maps, Activ_Funcs, and training methods. It then compared several popular CNN architectures, including LeNet, AlexNet, VGG, ResNet, and InceptionNet, and examined when to use CNNs. It also discussed the advantages and limitations of CNNs, highlighting their ability to learn complex patterns from large datasets, but also noting their computational requirements and potential vulnerabilities to adversarial attacks. We provided recommendations for developers and data scientists on how to preprocess data, choose appropriate Hyper_Param, use regularization techniques, and evaluate model performance. It also examined the existing platforms and libraries for CNNs, including TensorFlow, Keras, PyTorch, Caffe, and MXNet, and compared their features and functionalities. It estimated the cost of using CNNs, including factors that impact cost, such as hardware, dataset size, and model complexity, as well as potential cost-saving strategies. We reviewed recent developments in CNNs, including attention mechanisms, capsule networks, transfer learning, adversarial training, quantization and compression, and enhancing the reliability and efficiency of CNNs through formal methods. It highlighted the potential benefits of these techniques for improving the accuracy, efficiency, and robustness of CNN models. It also discussed the security aspects of CNNs, including potential vulnerabilities and strategies for improving the security of CNNs.
In summary, CNNs have revolutionized the field of image recognition, but their applications extend far beyond that. With the increasing availability of data and computing resources, CNNs have the potential to transform a wide range of industries, from healthcare and finance to transportation and entertainment. However, developing and deploying CNNs can be a complex and error-prone process, requiring careful consideration of the model architecture, training process, and performance evaluation. Our paper provides a comprehensive guide to CNNs, covering their fundamentals, architectures, recent developments, advantages and limitations, recommendations for developers and data scientists, existing platforms and libraries, cost estimation, and security aspects. By incorporating these insights into their CNN models, developers and data scientists can improve the accuracy, efficiency, and robustness of their models and achieve state-of-the-art performance. As CNN research and development continue to evolve, it is quite probable that CNNs will become even more powerful and versatile, driving advances in AI and ML and transforming the way people live, work, and interact with technology.
There are still several areas where CNNs can be improved and further developed. One of the future directions of CNN research is to improve their interpretability and explainability. Currently, CNNs are often treated as black-box models, and it can be challenging to understand how they make decisions. Therefore, future research can focus on developing methods to interpret and explain the decisions made by CNNs, such as feature visualization, saliency maps, and attention mechanisms. Another area of future research is to enhance the robustness and security of CNNs. CNNs are susceptible to adversarial attacks, where subtle changes to the input can cause the model to make incorrect predictions. Therefore, future research can explore ways to make CNNs more robust and secure, such as adversarial training, robust optimization, and model-based verification. Finally, CNNs can be further developed to deal with more complex tasks, such as video recognition, 3D object recognition, and natural language processing. This requires the development of new CNN architectures and training methods that can handle the temporal and spatial complexities of these tasks. Overall, future research can focus on improving the interpretability, robustness, and versatility of CNNs to enable their use in a wider range of applications and domains.
One potential limitation of this survey paper is that it mainly focuses on convolutional neural networks (CNNs) and may not provide a comprehensive overview of other types of machine learning models and techniques that are relevant to various applications. To overcome this limitation, future research can explore other types of machine learning models, such as recurrent neural networks (RNNs), decision trees, support vector machines (SVMs), and Gaussian mixture models (GMMs), and compare their strengths and weaknesses with CNNs. Additionally, since CNNs are often used in conjunction with other techniques, future research can also investigate the integration of CNNs with other models, such as generative adversarial networks (GANs), reinforcement learning (RL), and transfer learning. This would provide a more comprehensive understanding of the different approaches to machine learning and their potential applications.















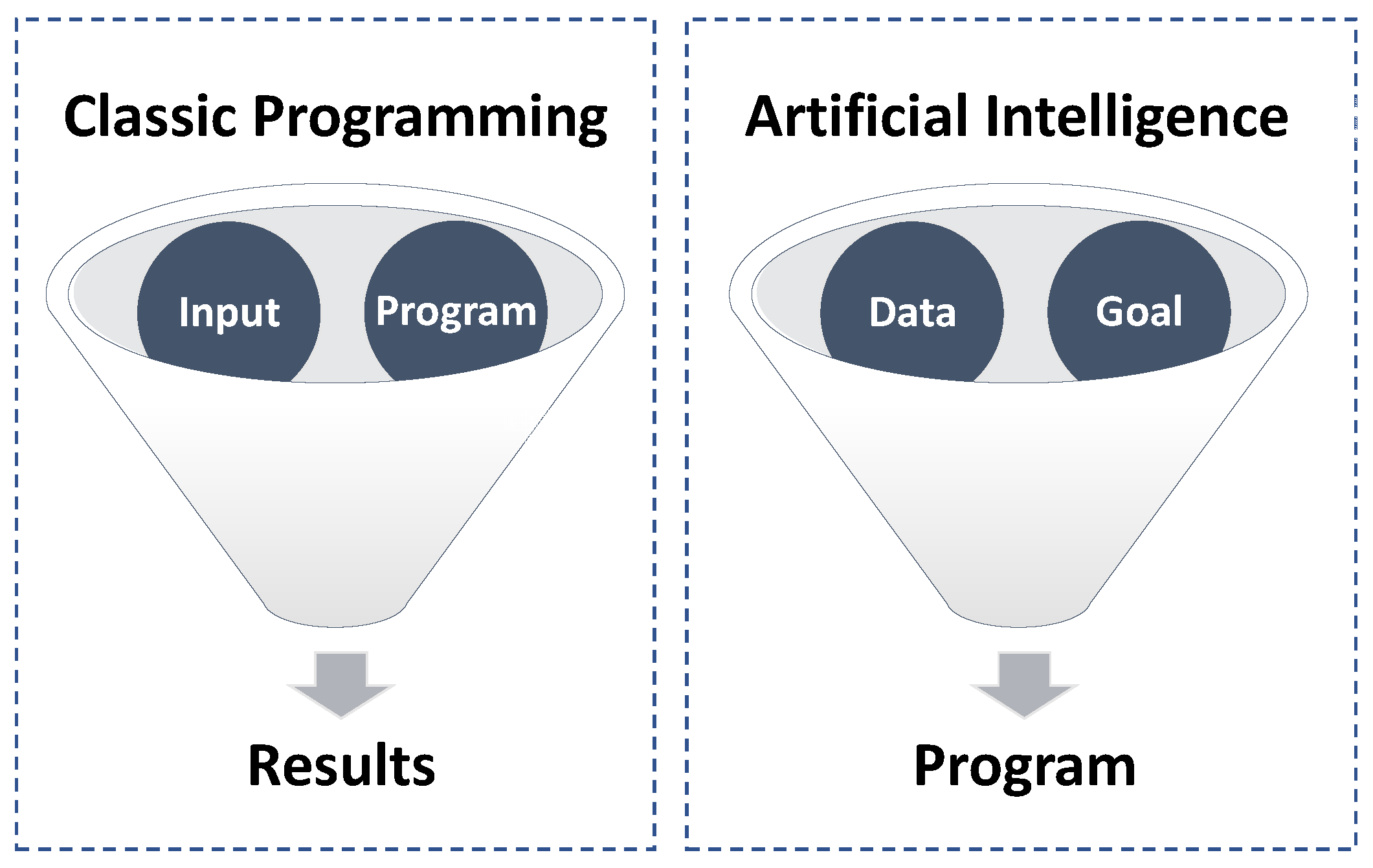{kind=link}
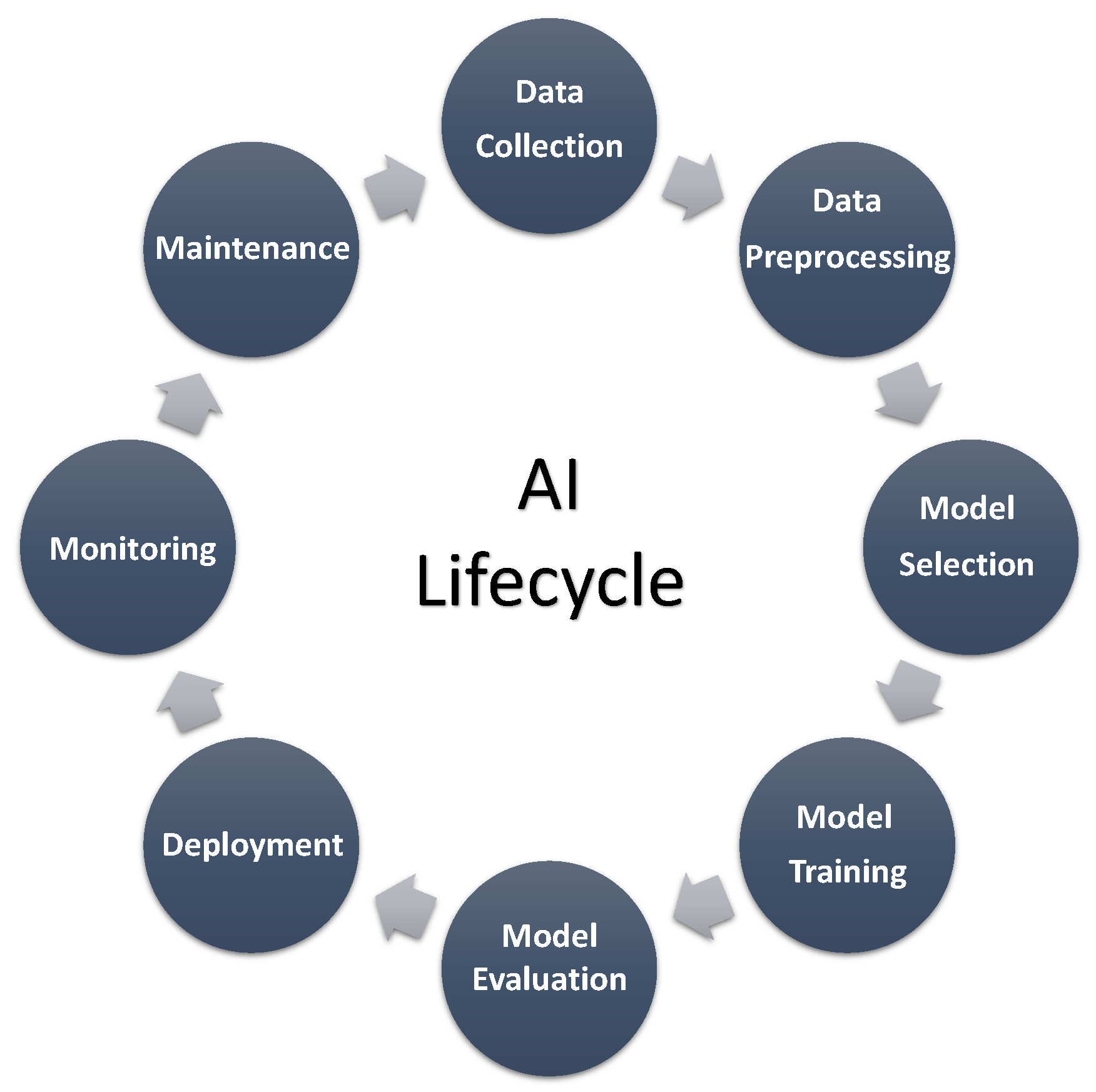{kind=link}
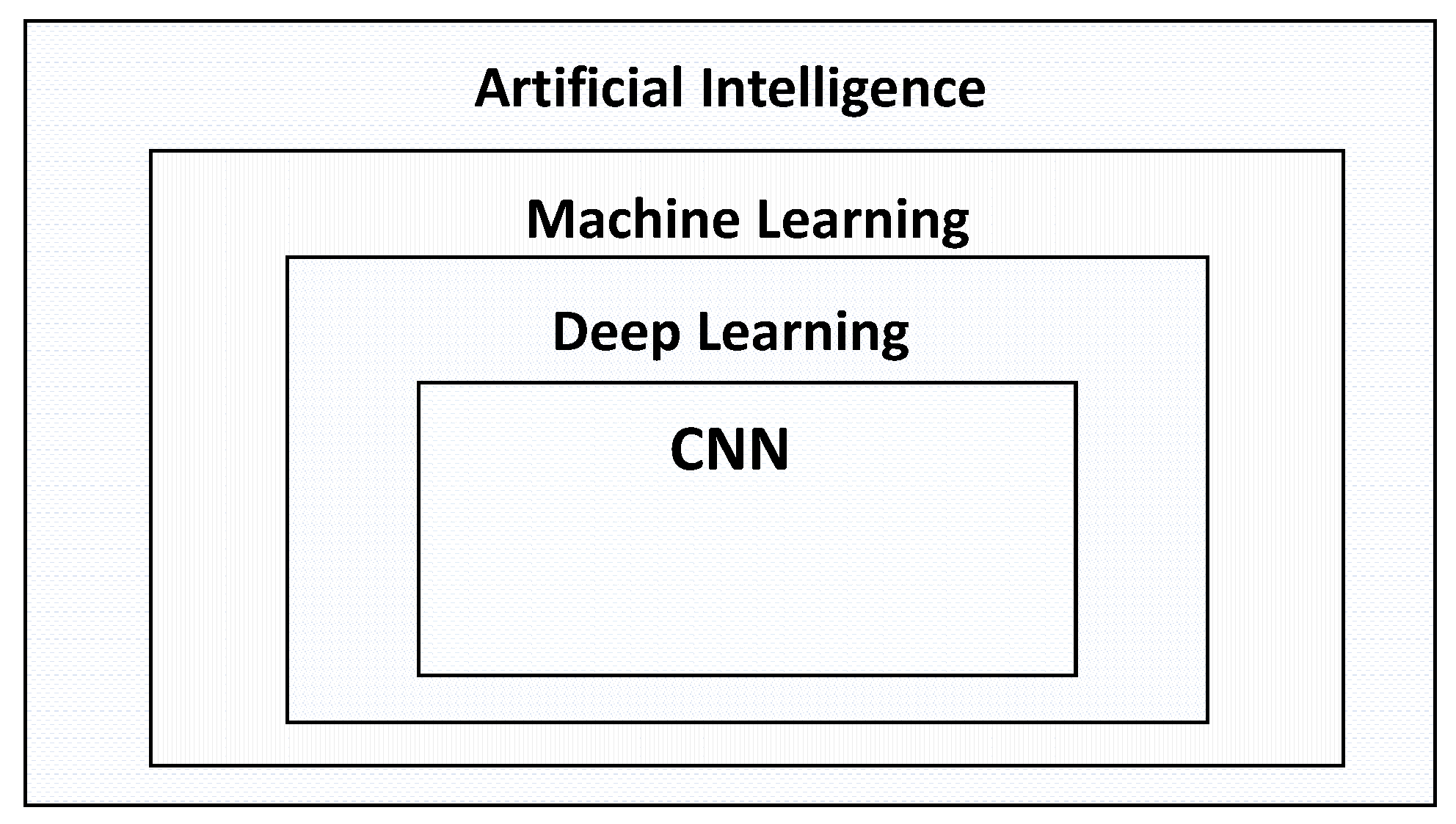{kind=link}
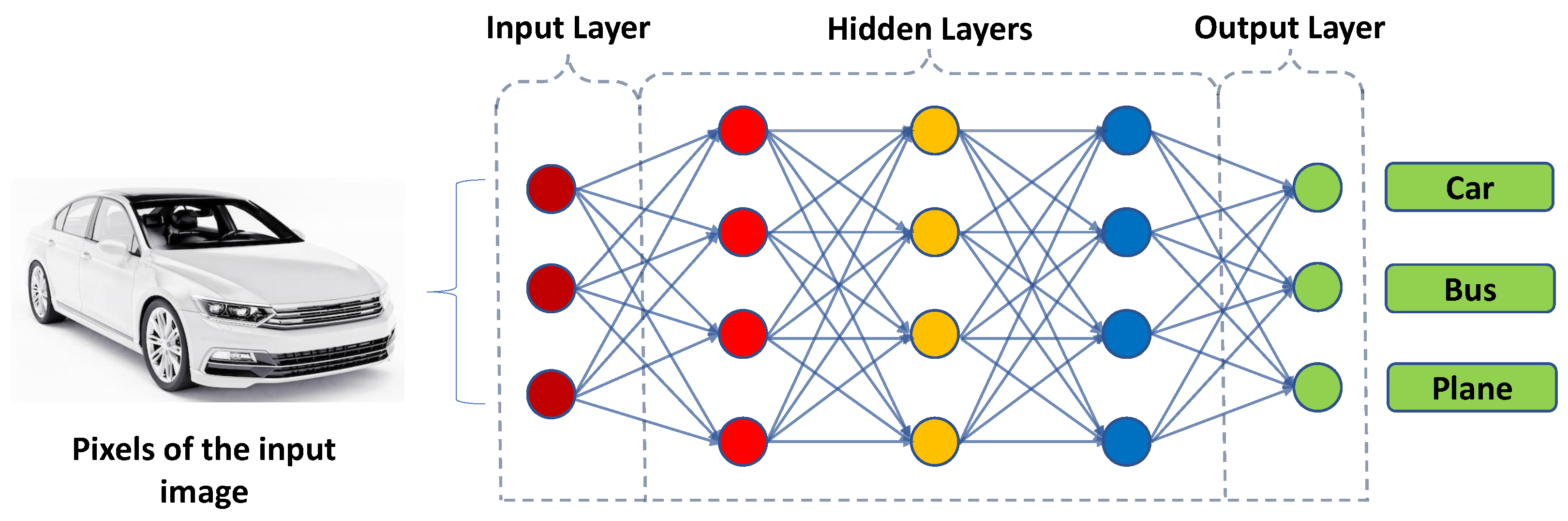{kind=link}
{kind=link}
{kind=link}
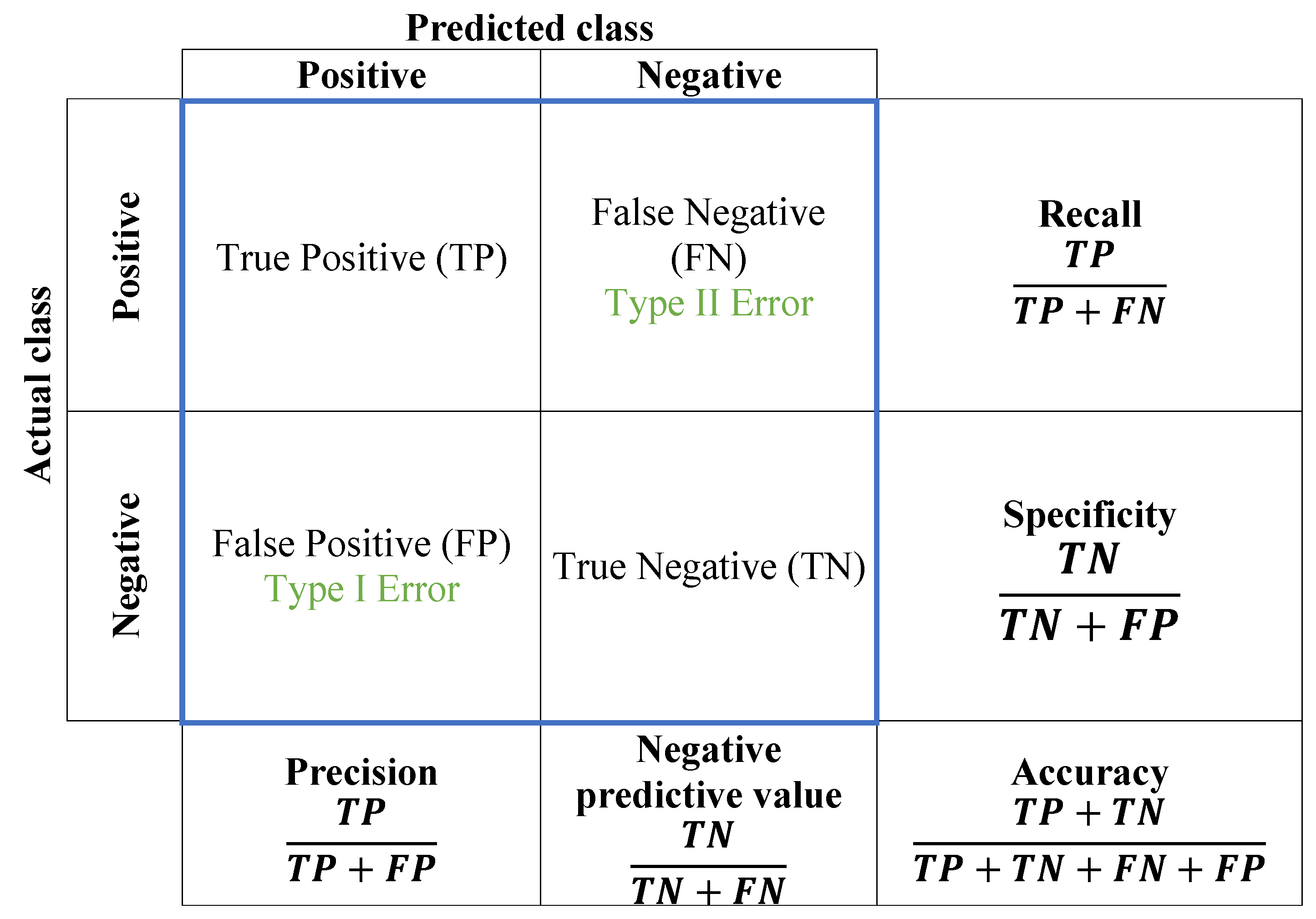{kind=link}
{kind=link}
{kind=link}