


Face Detection Using a Capsule Network for Driver Monitoring Application



Abstract
1. Introduction
2. Methodology
2.1. Capsule Network Theory
| Algorithm 1. Routing algorithm [46] | |
| 1: | procedure) |
| 2: | |
| 3: | for iterations do |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | return |
2.2. Proposed Capsule Routing Mechanism
2.3. Dataset
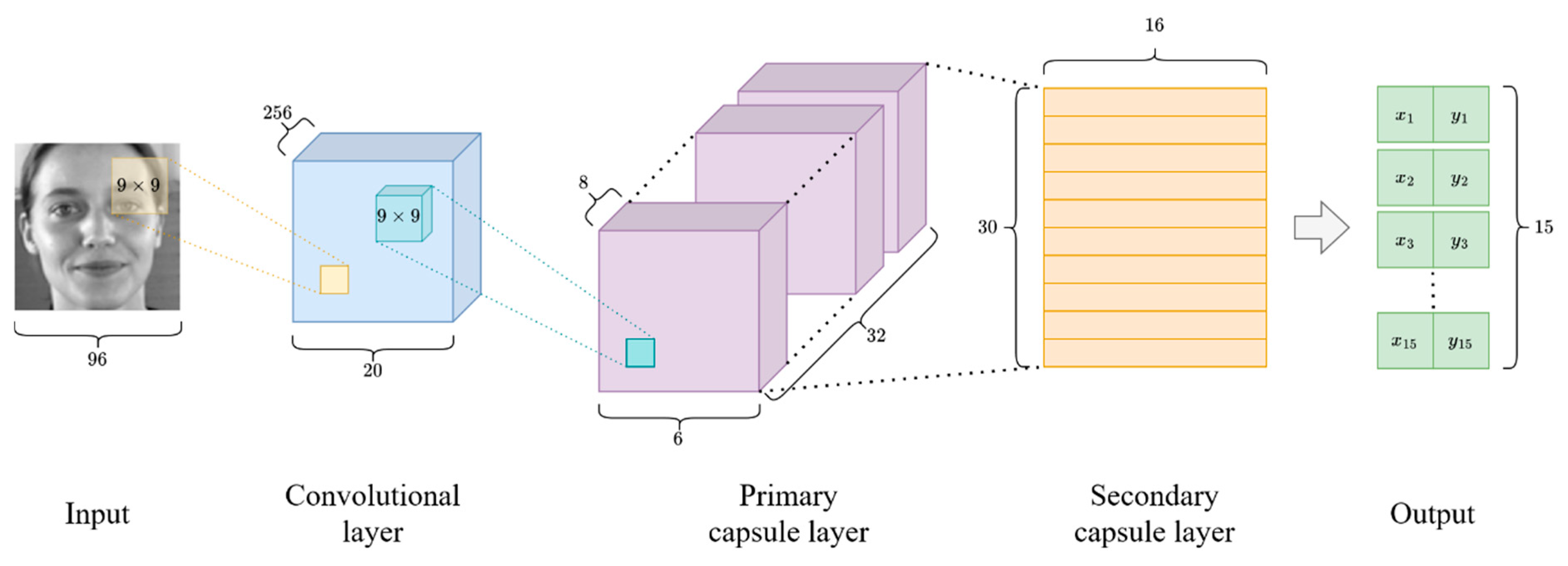
2.4. Network Architectures
3. Training and Results
3.1. Adversarial Attack Methods
3.2. Training Process
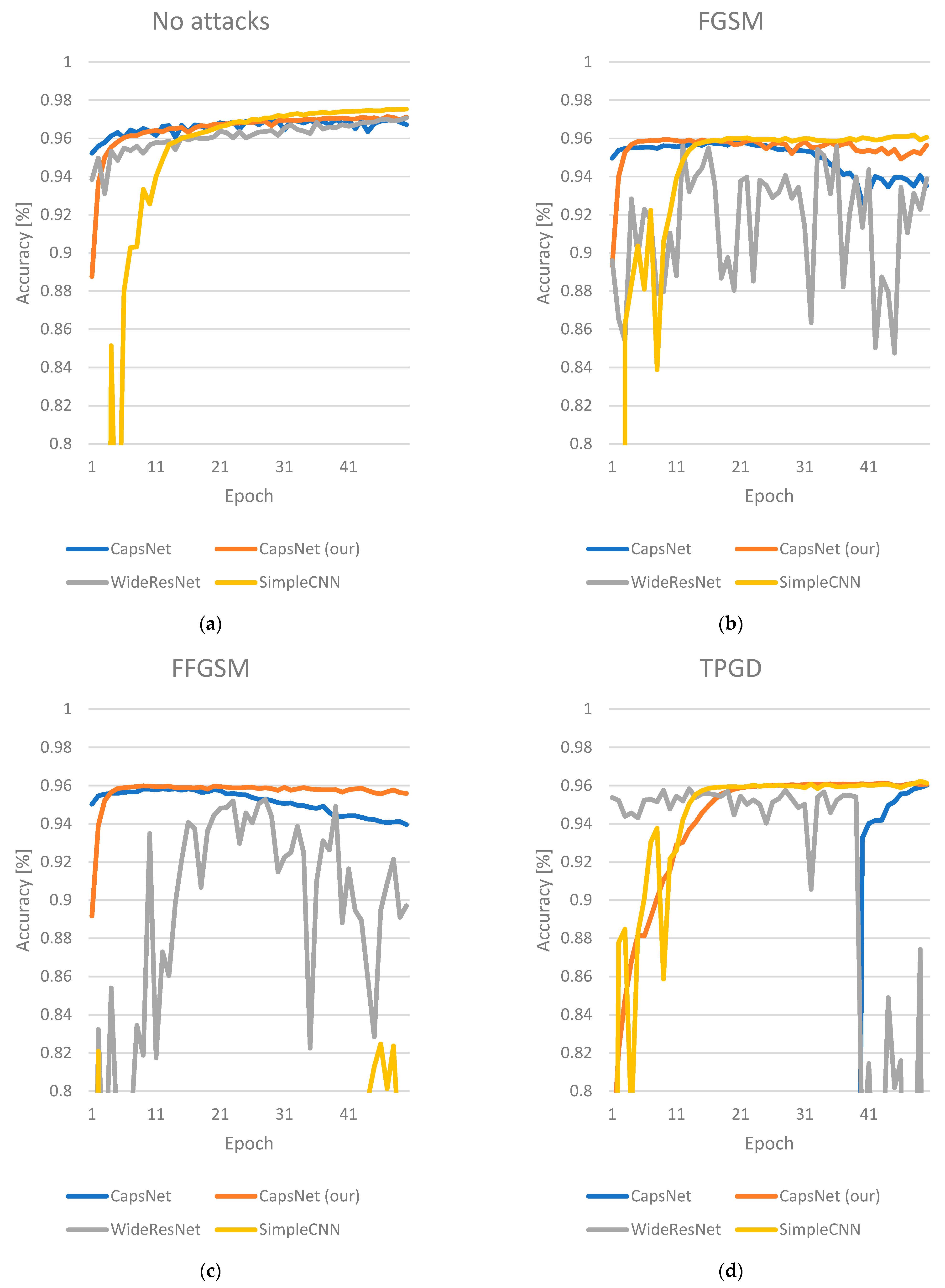
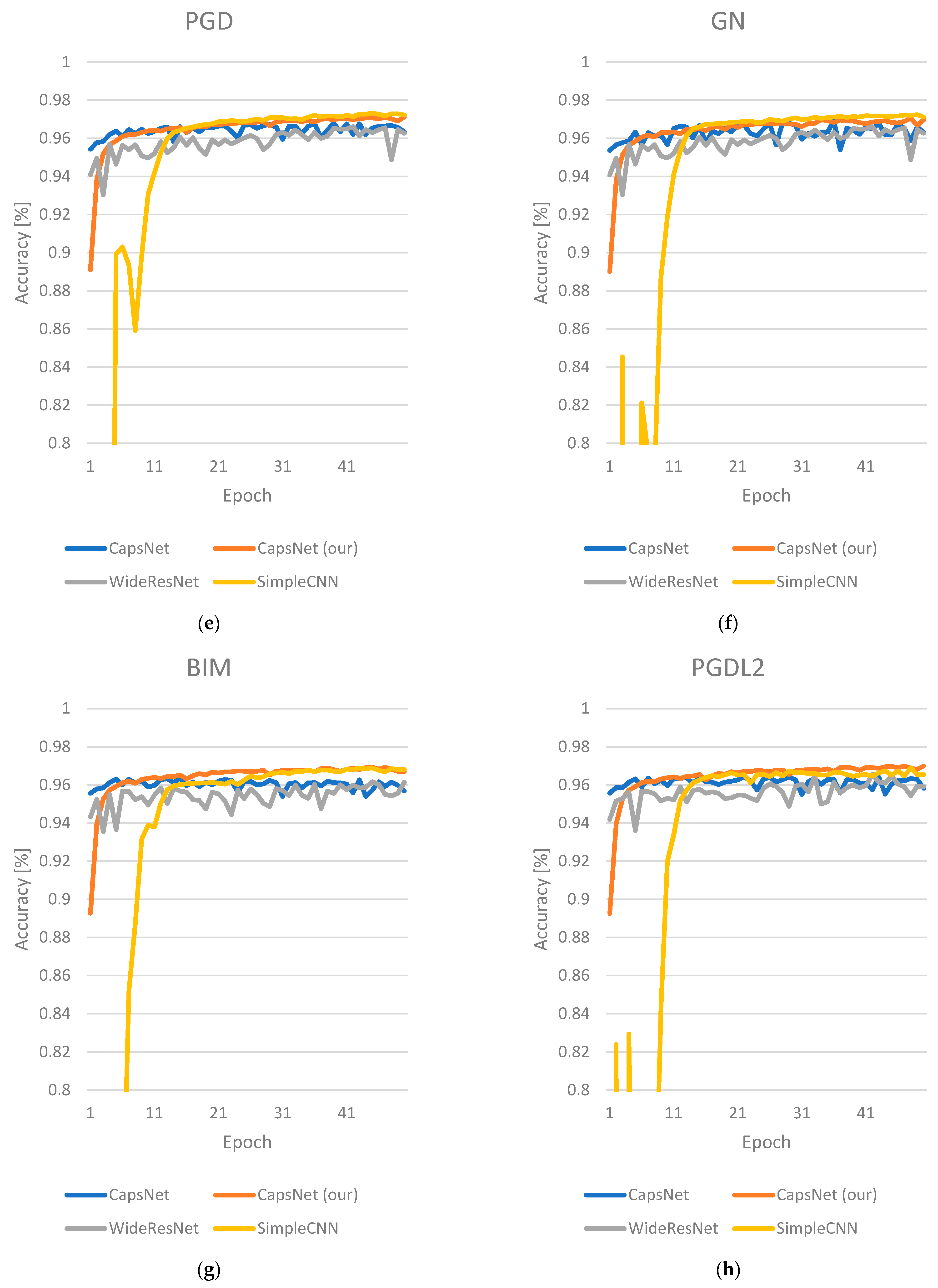
3.3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Blades, L.; Douglas, R.; Early, J.; Lo, C.Y.; Best, R. Advanced Driver-Assistance Systems for City Bus Applications; SAE Technical Papers; Sage: Thousand Oaks, CA, USA, 2020. [Google Scholar] [CrossRef]
- Nylen, A.B.; Reyes, M.L.; Roe, C.A.; McGehee, D.V. Impacts on Driver Perceptions in Initial Exposure to ADAS Technologies. Transp. Res. Rec. 2019, 2673, 354–360. [Google Scholar] [CrossRef]
- Hungund, A.P.; Pai, G.; Pradhan, A.K. Systematic Review of Research on Driver Distraction in the Context of Advanced Driver Assistance Systems. In Transportation Research Record; SAGE Publications Ltd: Thousand Oaks, CA, USA, 2021; Volume 2675, pp. 756–765. [Google Scholar]
- Slootmans, F. European Road Safety Observatory—Facts and Figures—Light Trucks; European Commission: Brussels, Belgiumcon, 2021. [Google Scholar]
- Eurostat. Passenger Transport by Buses and Coaches by Type of—Vehicles Registered in the Reporting Country. Available online: https://ec.europa.eu/eurostat/databrowser/view/ROAD_PA_BUSCOA__custom_1210091/bookmark/table?lang=en&bookmarkId=d8cf5c80-4d26-4dfd-bda5-e94de54b8d49 (accessed on 30 March 2023).
- Damjanović, M.; Stević, Ž.; Stanimirović, D.; Tanackov, I.; Marinković, D. Impact of the Number of Vehicles on Traffic Safety: Multiphase Modeling. Facta Univ. Ser. Mech. Eng. 2022, 20, 177–197. [Google Scholar] [CrossRef]
- Goh, K.; Currie, G.; Sarvi, M.; Logan, D. Factors Affecting the Probability of Bus Drivers Being At-Fault in Bus-Involved Accidents. Accid. Anal. Prev. 2014, 66, 20–26. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, S.; Kokkinogenis, Z.; Couto, A. Using Real-Life Alert-Based Data to Analyse Drowsiness and Distraction of Commercial Drivers. Transp. Res. Part F Traffic Psychol. Behav. 2019, 60, 25–36. [Google Scholar] [CrossRef]
- Young, K.; Regan, M.; Hammer, M. Driver Distraction: A Review of the Literature (Report); Monash University Accident Research Centre: Clayton, Australia, 2003; p. 66. [Google Scholar]
- National Highway Traffic Safety Administration. Distracted Driving; National Highway Traffic Safety Administration (NHTSA): Washington, DC, USA, 2021. [Google Scholar]
- Otmani, S.; Rogé, J.; Muzet, A. Sleepiness in Professional Drivers: Effect of Age and Time of Day. Accid. Anal. Prev. 2005, 37, 930–937. [Google Scholar] [CrossRef]
- Huhta, R.; Hirvonen, K.; Partinen, M. Prevalence of Sleep Apnea and Daytime Sleepiness in Professional Truck Drivers. Sleep Med. 2021, 81, 136–143. [Google Scholar] [CrossRef]
- Felix, M.; Intriago Alvarez, M.B.; Vanegas, E.; Farfán Bajaña, M.J.; Sarfraz, Z.; Sarfraz, A.; Michel, J.; Cherrez-Ojeda, I. Risk of Obstructive Sleep Apnea and Traffic Accidents among Male Bus Drivers in Ecuador: Is There a Significant Relationship? Ann. Med. Surg. 2022, 74, 103296. [Google Scholar] [CrossRef]
- Thiffault, P.; Bergeron, J. Monotony of Road Environment and Driver Fatigue: A Simulator Study. Accid. Anal. Prev. 2003, 35, 381–391. [Google Scholar] [CrossRef]
- Sahayadhas, A.; Sundaraj, K.; Murugappan, M. Detecting Driver Drowsiness Based on Sensors: A Review. Sensors 2012, 12, 16937–16953. [Google Scholar] [CrossRef]
- Hallac, D.; Sharang, A.; Stahlmann, R.; Lamprecht, A.; Huber, M.; Roehder, M.; Sosič, R.; Leskovec, J. Driver Identification Using Automobile Sensor Data from a Single Turn. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Rio de Janeiro, Brazil, 1–4 November 2016; pp. 953–958. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, Y.; Zhao, S.; Zhang, X. Real-Time Surface EMG Pattern Recognition for Hand Gestures Based on Support Vector Machine. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, ROBIO, Dali, China, 6–8 December 2019; pp. 1258–1262. [Google Scholar] [CrossRef]
- Campos-Ferreira, A.E.; Lozoya-Santos, J.d.J.; Tudon-Martinez, J.C.; Mendoza, R.A.R.; Vargas-Martínez, A.; Morales-Menendez, R.; Lozano, D. Vehicle and Driver Monitoring System Using On-Board and Remote Sensors. Sensors 2023, 23, 814. [Google Scholar] [CrossRef]
- Fischer, S.; Szürke, S.K. Detection Process Of Energy Loss In Electric Railway Vehicles. Facta Univ. Ser. Mech. Eng. 2023, 21, 81–99. [Google Scholar] [CrossRef]
- Maslać, M.; Antić, B.; Lipovac, K.; Pešić, D.; Milutinović, N. Behaviours of Drivers in Serbia: Non-Professional versus Professional Drivers. Transp. Res. Part F Traffic Psychol. Behav. 2018, 52, 101–111. [Google Scholar] [CrossRef]
- Fancello, G.; Daga, M.; Serra, P.; Fadda, P.; Pau, M.; Arippa, F.; Medda, A. An Experimental Analysis on Driving Behaviour for Professional Bus Drivers. Transp. Res. Procedia 2020, 45, 779–786. [Google Scholar] [CrossRef]
- Karimi, S.; Aghabayk, K.; Moridpour, S. Impact of Driving Style, Behaviour and Anger on Crash Involvement among Iranian Intercity Bus Drivers. IATSS Res. 2022, 46, 457–466. [Google Scholar] [CrossRef]
- Bonfati, L.V.; Mendes Junior, J.J.A.; Siqueira, H.V.; Stevan, S.L. Correlation Analysis of In-Vehicle Sensors Data and Driver Signals in Identifying Driving and Driver Behaviors. Sensors 2023, 23, 263. [Google Scholar] [CrossRef] [PubMed]
- Biondi, F.N.; Saberi, B.; Graf, F.; Cort, J.; Pillai, P.; Balasingam, B. Distracted Worker: Using Pupil Size and Blink Rate to Detect Cognitive Load during Manufacturing Tasks. Appl. Ergon. 2023, 106, 103867. [Google Scholar] [CrossRef]
- Underwood, G.; Chapman, P.; Brocklehurst, N.; Underwood, J.; Crundall, D. Visual Attention While Driving: Sequences of Eye Fixations Made by Experienced and Novice Drivers. Ergonomics 2003, 46, 629–646. [Google Scholar] [CrossRef]
- Underwood, G.; Chapman, P.; Bowden, K.; Crundall, D. Visual Search While Driving: Skill and Awareness during Inspection of the Scene. Transp. Res. Part F Traffic Psychol. Behav. 2002, 5, 87–97. [Google Scholar] [CrossRef]
- Nagy, V.; Kovács, G.; Földesi, P.; Kurhan, D.; Sysyn, M.; Szalai, S.; Fischer, S. Testing Road Vehicle User Interfaces Concerning the Driver’s Cognitive Load. Infrastructures 2023, 8, 49. [Google Scholar] [CrossRef]
- Shi, Y.; Xu, Y.; Ferraioli, A.; Piga, B.; Mussone, L.; Caruso, G. A Method of Processing Eye-Tracking Data to Study Driver’s Visual Perception in Simulated Driving Scenarios. In Proceedings of the European Transport Conference, Online, 8–11 September 2020. [Google Scholar]
- Reilly, J.; Zuckerman, B.; Kelly, A.E. A Primer on Design and Data Analysis for Cognitive Pupillometry. Mod. Pupillometry 2021, 9–25. [Google Scholar] [CrossRef]
- Sigari, M.-H.; Pourshahabi, M.-R.; Soryani, M.; Fathy, M. A Review on Driver Face Monitoring Systems for Fatigue and Distraction Detection. Int. J. Adv. Sci. Technol. 2014, 64, 73–100. [Google Scholar] [CrossRef]
- Biondi, F.; Coleman, J.R.; Cooper, J.M.; Strayer, D.L. Average Heart Rate for Driver Monitoring Systems. Int. J. Hum. Factors Ergon. 2016, 4, 282–291. [Google Scholar] [CrossRef]
- Fujiwara, K.; Abe, E.; Kamata, K.; Nakayama, C.; Suzuki, Y.; Yamakawa, T.; Hiraoka, T.; Kano, M.; Sumi, Y.; Masuda, F.; et al. Heart Rate Variability-Based Driver Drowsiness Detection and Its Validation with EEG. IEEE Trans. Biomed. Eng. 2019, 66, 1769–1778. [Google Scholar] [CrossRef]
- Dehzangi, O.; Rajendra, V.; Taherisadr, M. Wearable Driver Distraction Identification On-the-Road via Continuous Decomposition of Galvanic Skin Responses. Sensors 2018, 18, 503. [Google Scholar] [CrossRef]
- Li, G.; Chung, W.Y. A Context-Aware EEG Headset System for Early Detection of Driver Drowsiness. Sensors 2015, 15, 20873–20893. [Google Scholar] [CrossRef] [PubMed]
- Balam, V.P.; Chinara, S. Development of Single-Channel Electroencephalography Signal Analysis Model for Real-Time Drowsiness Detection: SEEGDD. Phys. Eng. Sci. Med. 2021, 44, 713–726. [Google Scholar] [CrossRef]
- Rahman, N.A.A.; Mustafa, M.; Sulaiman, N.; Samad, R.; Abdullah, N.R.H. EMG Signal Segmentation to Predict Driver’s Vigilance State: Notes in Mechanical Engineering; Springer: Berlin/Heidelberg, Germany, 2022; pp. 29–42. [Google Scholar] [CrossRef]
- Bulagang, A.F.; Weng, N.G.; Mountstephens, J.; Teo, J. A Review of Recent Approaches for Emotion Classification Using Electrocardiography and Electrodermography Signals. Inform. Med. Unlocked 2020, 20, 100363. [Google Scholar] [CrossRef]
- European Parliament Regulation (EU) 2019/2144 of the European Parliament and of the Council. Off. J. Eur. Union 2019, L325, 32019R2144.
- Koay, H.V.; Chuah, J.H.; Chow, C.O.; Chang, Y.L. Detecting and Recognizing Driver Distraction through Various Data Modality Using Machine Learning: A Review, Recent Advances, Simplified Framework and Open Challenges (2014–2021). Eng. Appl. Artif. Intell. 2022, 115, 105309. [Google Scholar] [CrossRef]
- Liu, W.; Wang, X. Researches Advanced in Face Recognition. Highlights Sci. Eng. Technol. AMMSAC 2023, 49, 41. [Google Scholar] [CrossRef]
- Chaves, D.; Fidalgo, E.; Alegre, E.; Alaiz-Rodríguez, R.; Jáñez-Martino, F.; Azzopardi, G. Assessment and Estimation of Face Detection Performance Based on Deep Learning for Forensic Applications. Sensors 2020, 20, 4491. [Google Scholar] [CrossRef] [PubMed]
- Verma, B.; Choudhary, A. Deep Learning Based Real-Time Driver Emotion Monitoring. In Proceedings of the 2018 IEEE International Conference on Vehicular Electronics and Safety, ICVES 2018, Madrid, Spain, 12–14 September 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Jain, D.K.; Jain, R.; Lan, X.; Upadhyay, Y.; Thareja, A. Driver Distraction Detection Using Capsule Network. Neural Comput. Appl. 2021, 33, 6183–6196. [Google Scholar] [CrossRef]
- Ali, S.F.; Hassan, M.T. Feature Based Techniques for a Driver’s Distraction Detection Using Supervised Learning Algorithms Based on Fixed Monocular Video Camera. KSII Trans. Internet Inf. Syst. 2018, 12, 3820–3841. [Google Scholar] [CrossRef]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming Auto-Encoders; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules Sara. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- James, P.; Cukierski, W. Facial Keypoints Detection; Kaggle: San Francisco, CA, USA, 2017. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference 2016 (BMVC 2016), York, UK, 19–22 September 2016; pp. 1–12. [Google Scholar] [CrossRef]
- An, S.; Lee, M.; Park, S.; Yang, H.; So, J. An Ensemble of Simple Convolutional Neural Network Models for MNIST Digit Recognition. arXiv 2020, arXiv:2008.10400v2. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011, Granada, Spain, 16 December 2011; pp. 1–9. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); 8693 LNCS; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C.; Christopher, J.C. Burges. The MNIST Database of Handwritten Digits. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 30 June 2023).
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–11. [Google Scholar]
- Wong, E.; Rice, L.; Kolter, J.Z. Fast Is Better than Free: Revisiting Adversarial Training. arXiv 2020, arXiv:2001.03994. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–28. [Google Scholar]
- Zhang, H.; Yu, Y.; Jiao, J.; Xing, E.P.; El Ghaoui, L.; Jordan, M.I. Theoretically Principled Trade-off between Robustness and Accuracy. In Proceedings of the 36th International Conference on Machine Learning, ICML, Long Beach, CA, USA, 10–15 June 2019; pp. 12907–12929. [Google Scholar]
- Joyce, J.M. Kullback-Leibler Divergence. International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial Examples in the Physical World. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Workshop Track Proceedings, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|
| Percentage (%) | 10.4 | 10.0 | 10.0 | 10.0 | 9.6 | 9.5 | 9.5 | 7.4 | N/D |
| Passenger-kilometers (million km) | 238,368 | 230,616 | 246,661 | 240,574 | 224,813 | 225,958 | 231,099 | 135,427 | 138,262 |
| Capsule | Neuron | |
|---|---|---|
| Input | ) | ) |
| Affine transform | - | |
| Weighting | ||
| Nonlinear activation | ||
| Output | ) | ) |
| No Attack | FGSM | FFGSM | TPGD | PGD | GN | BIM | PGDL2 | |
|---|---|---|---|---|---|---|---|---|
| Wide-ResNet | 0.9707 | 0.9561 | 0.9528 | 0.9584 | 0.9661 | 0.9661 | 0.9616 | 0.9655 |
| SimpleCNN | 0.9753 | 0.9618 | 0.8248 | 0.9623 | 0.9732 | 0.9724 | 0.9689 | 0.9689 |
| CapsNet | 0.9703 | 0.9582 | 0.9583 | 0.9602 | 0.9678 | 0.9691 | 0.9635 | 0.9643 |
| CapsNet (own, current) | 0.9714 | 0.9593 | 0.9599 | 0.9613 | 0.9712 | 0.9706 | 0.9693 | 0.9698 |
| FGSM | FFGSM | TPGD | PGD | GN | BIM | PGDL2 | |
|---|---|---|---|---|---|---|---|
| Wide-ResNet | 1.50% | 1.84% | 1.27% | 0.47% | 0.47% | 0.93% | 0.53% |
| SimpleCNN | 1.39% | 15.43% | 1.34% | 0.22% | 0.30% | 0.66% | 0.66% |
| CapsNet | 1.24% | 1.24% | 1.04% | 0.25% | 0.12% | 0.70% | 0.61% |
| CapsNet (own, current) | 1.25% | 1.19% | 1.04% | 0.03% | 0.09% | 0.23% | 0.16% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hollósi, J.; Ballagi, Á.; Kovács, G.; Fischer, S.; Nagy, V. Face Detection Using a Capsule Network for Driver Monitoring Application. Computers 2023, 12, 161. https://doi.org/10.3390/computers12080161
Hollósi J, Ballagi Á, Kovács G, Fischer S, Nagy V. Face Detection Using a Capsule Network for Driver Monitoring Application. Computers. 2023; 12(8):161. https://doi.org/10.3390/computers12080161
Chicago/Turabian StyleHollósi, János, Áron Ballagi, Gábor Kovács, Szabolcs Fischer, and Viktor Nagy. 2023. "Face Detection Using a Capsule Network for Driver Monitoring Application" Computers 12, no. 8: 161. https://doi.org/10.3390/computers12080161
APA StyleHollósi, J., Ballagi, Á., Kovács, G., Fischer, S., & Nagy, V. (2023). Face Detection Using a Capsule Network for Driver Monitoring Application. Computers, 12(8), 161. https://doi.org/10.3390/computers12080161