
A Performance Study of CNN Architectures for the Autonomous Detection of COVID-19 Symptoms Using Cough and Breathing

Abstract
1. Introduction
- The first comprehensive performance comparison study of state-of-the-art deep CNN structures (ResNets, VGGs, AlexNet, DenseNet, SqueezeNet) and a custom multimodal CIdeR [3] structure for autonomous COVID-19 detection on the EPFL [18] and Cambridge [19] cough and breathing datasets. We investigate the classification measures of these methods for both unimodal and multimodal detection.
- The investigation of the effect of the dataset size on the COVID-19 detection process.
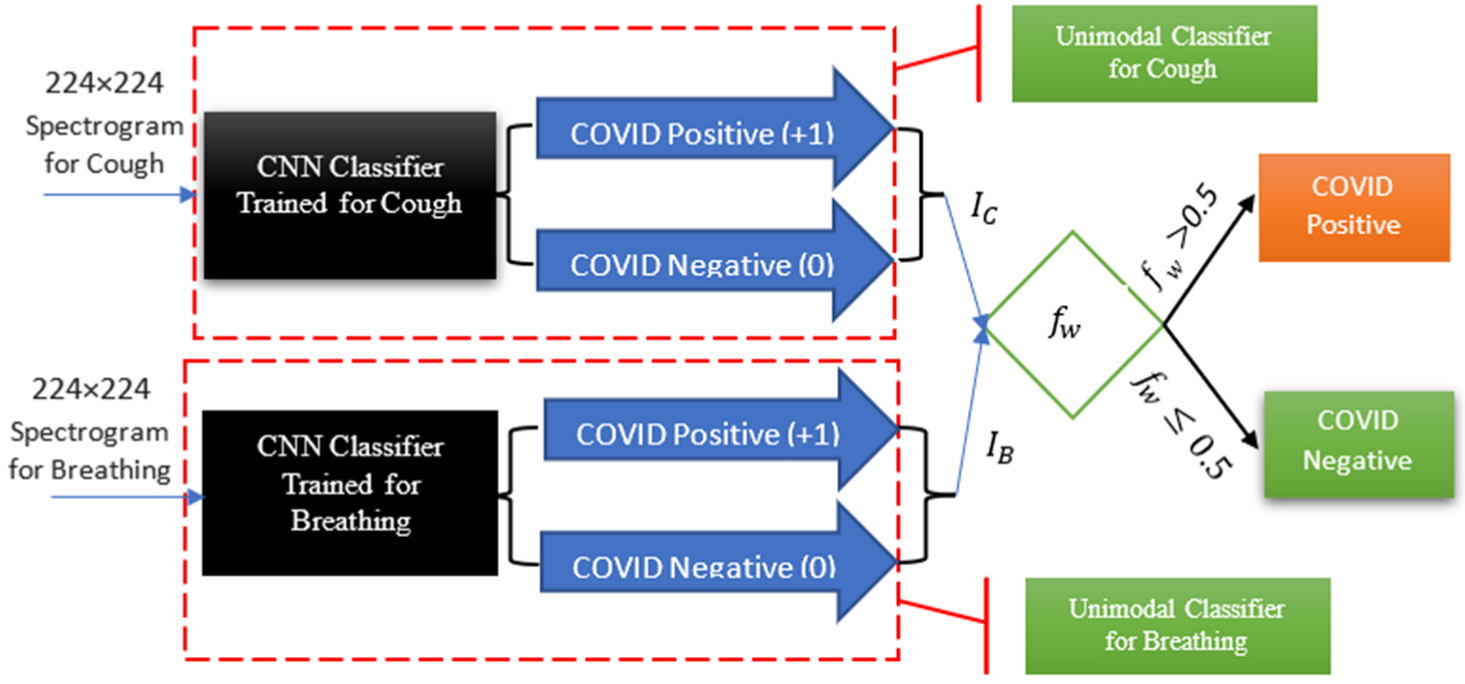
- For the multimodal investigation, explicitly taking into account the impact and prevalence of cough and breathing recordings in detecting COVID-19 through the use of our multimodal weighting function, allowing for more accurate detection of the virus.
2. Related Works
2.1. Unimodal Detection of COVID-19
2.2. Multimodal Detection of COVID-19
3. Deep Learning Networks for COVID-19 Symptom Detection
3.1. Deep CNN Structures
- (1)
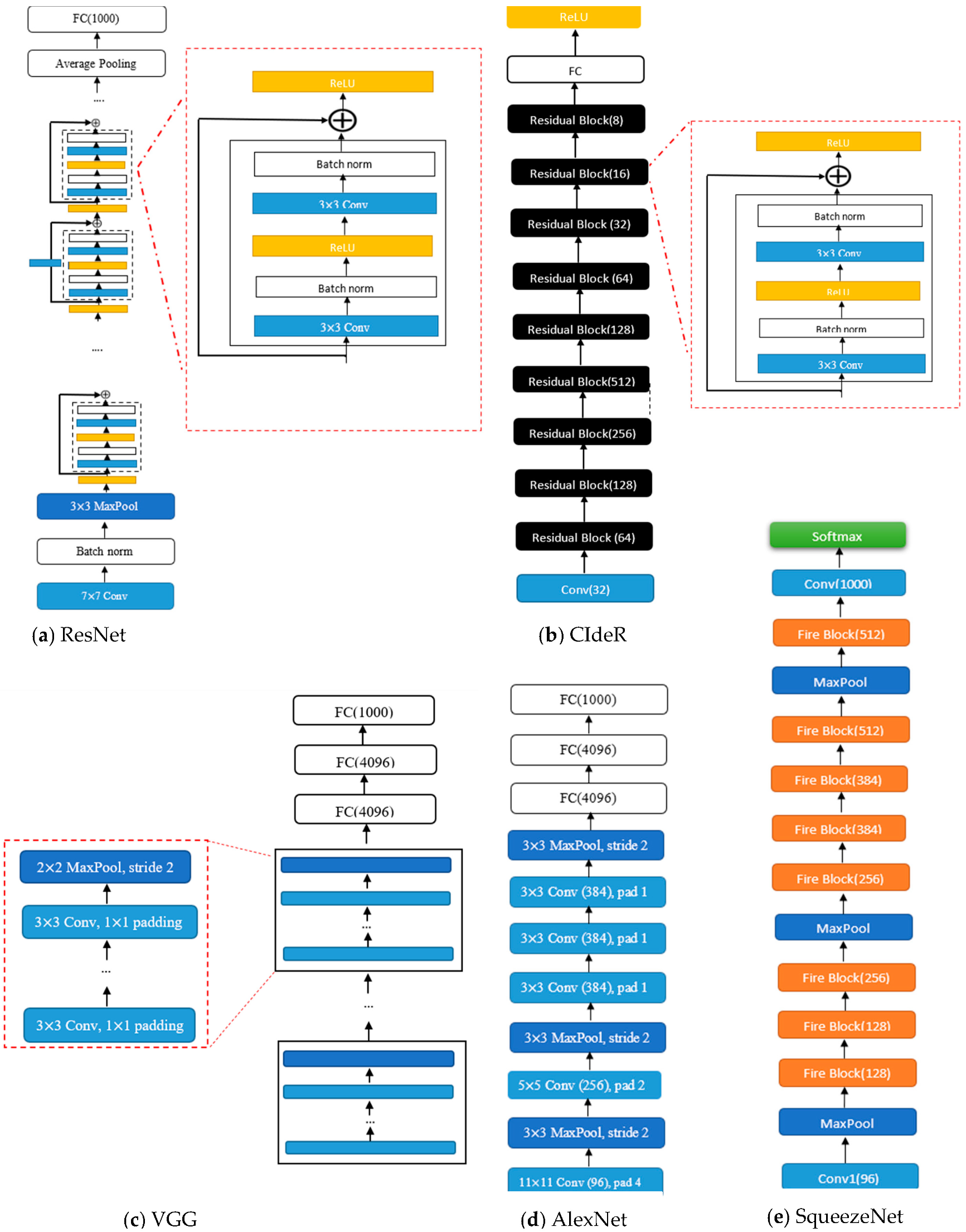
- ResNet: ResNet (see Figure 1) structures [29] are designed using residual blocks. Each residual block has two 3 × 3 convolutional layers with the same number of output channels. Each layer is followed by a batch normalization layer and a rectified linear activation unit (ReLU) activation function. The first two layers of ResNets are a 7 × 7 convolutional layer followed by a 3 × 3 maximum pooling layer. In ResNet, there are also residual skips for the blocks [29]. This structure has one average pooling layer and a fully connected layer. There are two main reasons that these skips are added to the network. They help to address the vanishing gradient or degradation (accuracy saturation) problem that exists in other deep CNN structures. Namely, when more layers are added to the structure, higher training errors will be obtained. However, ResNet structures have solved this issue by skipping several layers [29].
- (2)
- DenseNet: The DenseNet architecture [30] focuses on making the deep learning networks deeper and, at the same time, more efficient to train. The DenseNet structure simplifies the connectivity between the layers by eliminating the need to learn redundant feature maps. Hence, the structure needs fewer parameters compared to the equivalent traditional CNNs, which results in higher computational and memory efficiency. DenseNet-201 has 98 dense blocks, followed by a global average pool and a fully connected layer [30]. Each dense block includes both 1 × 1 and 3 × 3 convolutional layers. Due to the intricate nature of these structures, it is advisable to see the primary reference [30] to obtain a comprehensive and accurate visual representation of the DenseNet architecture.
- (3)
- VGG: The visual geometry group (VGG) (see Figure 1) structures [33] are built by blocks. One block for VGG consists of a sequence of convolutions with 3 × 3 kernels with 1 × 1 padding and 2 × 2 maximum pooling with a stride of 2. After the final pooling layer, there are fully connected (FC) layers [33].
- (4)
- (5)
- SqueezeNet: The SqueezeNet (see Figure 1) architecture [32] is comprised of “squeeze” and “expand” layers. The structure consists of a convolutional layer [32], followed by eight fire blocks and, finally, a final convolutional layer. A fire module consists of a squeeze convolutional layer (which has a 1 × 1 filter) and an expand layer that includes 1 × 1 and 3 × 3 convolutional filters [32].
- (6)
- CIdeR: CIdeR (see Figure 1) [3] is based on the ResNet-50 structure. It has one input layer and nine residual blocks (each consisting of a convolutional layer followed by a batch normalization and ReLU). This structure has an output fully connected layer followed by a ReLU. CIdeR can be used for unimodal detection by training on only one input mode (i.e., breathing or cough).
3.2. Datasets
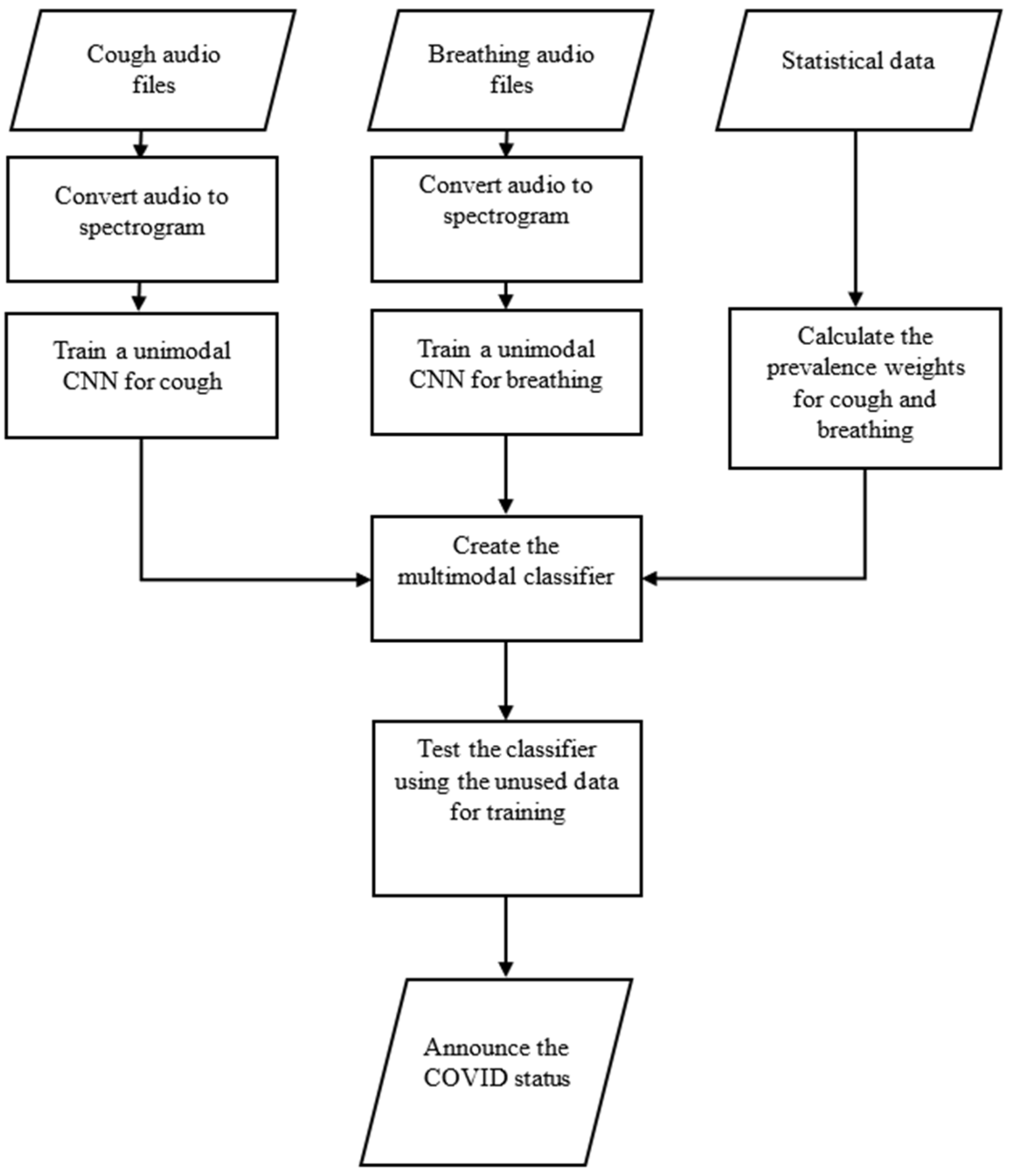
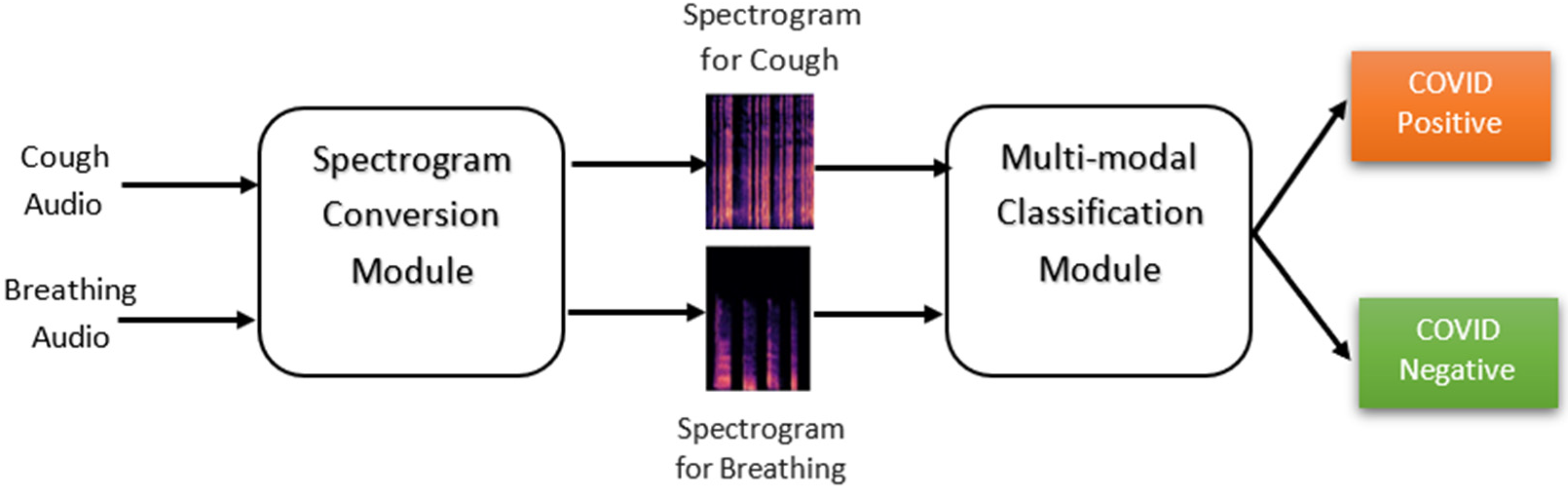
4. CNN-Based COVID-19 Classification Methodology
5. Training
6. Comparison of Deep CNN Structures for Multimodal Detection: Experiments and Results
6.1. Unimodal Detection of COVID-19
6.2. Multimodal Detection of COVID-19
6.3. Statistical Significance between CNN Structures
6.4. Precision, Recall, and F1 Scores
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Albes, M.; Ren, Z.; Schuller, B.W.; Cummins, N. Squeeze for Sneeze: Compact Neural Networks for Cold and Flu Recognition. INTERSPEECH 41 2020, 4546–4550. [Google Scholar]
- Nallanthighal, V.S.; Strik, H. Deep sensing of breathing signal during conversational speech. INTERSPEECH 2019, 4110–4114. [Google Scholar] [CrossRef]
- Coppock, H.; Gaskell, A.; Tzirakis, P.; Baird, A.; Jones, L.; Schuller, B. End-to-end convolutional neural network enables COVID-19 detection from breath and cough audio: A pilot study. BMJ Innov. 2021, 7, 356–362. [Google Scholar] [CrossRef] [PubMed]
- Effati, M.; Nejat, G. Deep Learning-Based Multi-modal COVID-19 Screening by Socially Assistive Robots Using Cough and Breathing Symptoms. In Proceedings of the Social Robotics: 14th International Conference, ICSR 2022, Florence, Italy, 13–16 December 2022; Springer: Berlin/Heidelberg, Germany, 2023. Part II. pp. 217–227. [Google Scholar]
- Khalifa, N.E.M.; Taha, M.H.N.; Hassanien, A.E.; Elghamrawy, S. Detection of coronavirus (COVID-19) associated pneumonia based on generative adversarial networks and a fine-tuned deep transfer learning model using chest X-ray dataset. arXiv 2020, arXiv:2004.01184. [Google Scholar]
- Motamed, S.; Rogalla, P.; Khalvati, F. RANDGAN: Randomized generative adversarial network for detection of COVID-19 in chest X-ray. Sci. Rep. 2021, 11, 1–10. [Google Scholar] [CrossRef]
- Soldati, G.; Smargiassi, A.; Inchingolo, R.; Buonsenso, D.; Perrone, T.; Briganti, D.F.; Perlini, S.; Torri, E.; Mariani, A.; Mossolani, E.E. Is there a role for lung ultrasound during the COVID-19 pandemic? J. Ultrasound Med. 2020, 37, 1459–1462. [Google Scholar] [CrossRef]
- Yuki, K.; Fujiogi, M.; Koutsogiannaki, S. COVID-19 pathophysiology: A review. Clin. Immunol. 2020, 215, 108427. [Google Scholar] [CrossRef]
- Bertsimas, D.; Bandi, H.; Boussioux, L.; Cory-Wright, R.; Delarue, A.; Digalakis, V.; Gilmour, S.; Graham, J.; Kim, A.; Kitane, D.L. An Aggregated Dataset of Clinical Outcomes for COVID-19 Patients. 2020. Available online: http://www.covidanalytics.io/datasetdocumentation (accessed on 1 December 2022).
- Effati, M.; Sun, Y.-C.; Naguib, H.E.; Nejat, G. Multimodal Detection of COVID-19 Symptoms using Deep Learning & Probability-based Weighting of Modes. In Proceedings of 2021 17th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Bologna, Italy, 11–13 October 2021; pp. 151–156. [Google Scholar]
- Fakhry, A.; Jiang, X.; Xiao, J.; Chaudhari, G.; Han, A.; Khanzada, A. Virufy: A Multi-Branch Deep Learning Network for Automated Detection of COVID-19. arXiv 2021, arXiv:2103.01806. [Google Scholar]
- Banerjee, A.; Nilhani, A. A Residual Network based Deep Learning Model for Detection of COVID-19 from Cough Sounds. arXiv 2021, arXiv:2106.02348. [Google Scholar]
- Laguarta, J.; Hueto, F.; Subirana, B. COVID-19 artificial intelligence diagnosis using only cough recordings. IEEE Open J. Eng. Med. Biol. 2020, 1, 275–281. [Google Scholar] [CrossRef]
- Rao, S.; Narayanaswamy, V.; Esposito, M.; Thiagarajan, J.J.; Spanias, A. COVID-19 detection using cough sound analysis and deep learning algorithms. Intell. Decis. Technol. 2021, 15, 655–665. [Google Scholar] [CrossRef]
- Rao, S.; Narayanaswamy, V.; Esposito, M.; Thiagarajan, J.; Spanias, A. Deep Learning with hyper-parameter tuning for COVID-19 Cough Detection. In Proceedings of 2021 12th International Conference on Information, Intelligence, Systems & Applications (IISA), Chania Crete, Greece, 12–14 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Tsalera, E.; Papadakis, A.; Samarakou, M. Comparison of Pre-Trained CNNs for Audio Classification Using Transfer Learning. J. Sens. Actuator Netw. 2021, 10, 72. [Google Scholar] [CrossRef]
- Luo, C.; Li, X.; Wang, L.; He, J.; Li, D.; Zhou, J. How does the data set affect cnn-based image classification performance? In Proceedings of 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 361–366. [Google Scholar] [CrossRef]
- Orlandic, L.; Teijeiro, T.; Atienza, D. The COUGHVID crowdsourcing dataset, a corpus for the study of large-scale cough analysis algorithms. Sci. Data 2021, 8, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Spathis, D.; Xia, T.; Cicuta, P.; Mascolo, C. Exploring automatic diagnosis of covid-19 from crowdsourced respiratory sound data. arXiv 2020, arXiv:2006.05919. [Google Scholar]
- Imran, A.; Posokhova, I.; Qureshi, H.N.; Masood, U.; Riaz, M.S.; Ali, K.; John, C.N.; Hussain, M.I.; Nabeel, M. AI4COVID-19: AI enabled preliminary diagnosis for COVID-19 from cough samples via an app. Inform. Med. Unlocked 2020, 20, 100378. [Google Scholar] [CrossRef]
- Alkhodari, M.; Khandoker, A.H. Detection of COVID-19 in smartphone-based breathing recordings: A pre-screening deep learning tool. PLoS ONE 2022, 17, e0262448. [Google Scholar] [CrossRef]
- Sharma, N.; Krishnan, P.; Kumar, R.; Ramoji, S.; Chetupalli, S.R.; Ghosh, P.K.; Ganapathy, S. Coswara--A Database of Breathing, Cough, and Voice Sounds for COVID-19 Diagnosis. arXiv 2020, arXiv:2005.10548. [Google Scholar]
- Muguli, A.; Pinto, L.; Sharma, N.; Krishnan, P.; Ghosh, P.K.; Kumar, R.; Bhat, S.; Chetupalli, S.R.; Ganapathy, S.; Ramoji, S. DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics. arXiv 2021, arXiv:2103.09148. [Google Scholar]
- Pahar, M.; Klopper, M.; Warren, R.; Niesler, T. COVID-19 detection in cough, breath and speech using deep transfer learning and bottleneck features. Comput. Biol. Med. 2022, 141, 105153. [Google Scholar] [CrossRef]
- Chetupalli, S.R.; Krishnan, P.; Sharma, N.; Muguli, A.; Kumar, R.; Nanda, V.; Pinto, L.M.; Ghosh, P.K.; Ganapathy, S. Multi-modal Point-of-Care Diagnostics for COVID-19 Based On Acoustics and Symptoms. arXiv 2021, arXiv:2106.00639. [Google Scholar]
- Schuller, B.W.; Batliner, A.; Bergler, C.; Mascolo, C.; Han, J.; Lefter, I.; Kaya, H.; Amiriparian, S.; Baird, A.; Stappen, L. The INTERSPEECH 2021 computational paralinguistics challenge: COVID-19 cough, COVID-19 speech, escalation & primates. arXiv 2021, arXiv:2102.13468. [Google Scholar]
- Hemdan, E.E.-D.; El-Shafai, W.; Sayed, A. CR19: A framework for preliminary detection of COVID-19 in cough audio signals using machine learning algorithms for automated medical diagnosis applications. J. Ambient Intell. Humaniz. Comput. 2022, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Vinod, D.N.; Prabaharan, S. COVID-19-The Role of Artificial Intelligence, Machine Learning, and Deep Learning: A Newfangled. Arch. Comput. Methods Eng. 2023, 1–16. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Honolulu, HI, USA, 21–26 July 2017, pp. 4700–4708. [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar] [CrossRef]
- Akman, A.; Coppock, H.; Gaskell, A.; Tzirakis, P.; Jones, L.; Schuller, B.W. Evaluating the covid-19 identification resnet (cider) on the interspeech covid-19 from audio challenges. Front. Digit. Health 2022, 4, 789980. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | DL Structure | Unimodal Approach | Multimodal Approach | Considering the Prevalence of Symptoms | Comprehensive Comparison to Other Unimodal Approaches | Comparison to Other Multimodal Approaches |
|---|---|---|---|---|---|---|
| [11,19] | ResNet-50 | ✔ | ✗ | N/A | ✗ | N/A |
| [13,14,25] | VGGs | ✔ | ✗ | N/A | ✗ | N/A |
| [26] | DenseNet | ✔ | ✗ | N/A | ✗ | N/A |
| [3] | CIdeR | ✗ | ✔ | ✗ | ✗ | ✗ |
| [28] | GRU | ✗ | ✔ | ✗ | ✗ | ✗ |
| Our Work | ResNets, VGGs, DenseNet, AlexNet, SqueezeNet, CIdeR | ✔ | ✔ | ✔ | ✔ | ✔ |
| Cough | Breathing | Cough and Breathing | ||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Cambridge | EPFL | Cambridge | Cambridge | ||||
| CNN Structure | ||||||||
| CIdeR | 81% | 83% | 84% | 82% | ||||
| ResNet-18 | 76% | 92% | 76% | 76% | ||||
| ResNet-34 | 75% | 93% | 41% | 80% | ||||
| ResNet-50 | 76% | 92% | 76% | 69% | ||||
| ResNet-101 | 82% | 92% | 77% | 85% | ||||
| ResNet-152 | 77% | 93% | 76% | 74% | ||||
| VGG16 | 86% | 91% | 86% | 74% | ||||
| VGG19 | 91% | 92% | 84% | 89% | ||||
| AlexNet | 69% | 92% | 84% | 60% | ||||
| DenseNet-201 | 90% | 91% | 81% | 88% | ||||
| SqueezeNet1_0 | 79% | 90% | 76% | 84% | ||||
| Average | 80% | 91% | 76% | 76% | ||||
| Dataset/Data Type | H | p-Value |
|---|---|---|
| Cambridge/Cough | 12.64 | 0.24 |
| EPFL/Cough | 2.11 | 0.99 |
| Cambridge/Breathing | 56.32 | <0.001 |
| Cambridge/Cough and Breathing | 15.46 | 0.12 |
| EPFL | Cambridge | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Measure | Accuracy | Recall | Precision | F1 | Accuracy | Recall | Precision | F1 | |
| Structure | |||||||||
| ResNet-34 | 0.93 | 0.98 | 0.93 | 0.95 | 0.75 | 0.84 | 0.74 | 0.79 | |
| ResNet-152 | 0.93 | 0.98 | 0.92 | 0.95 | 0.77 | 0.83 | 0.76 | 0.79 | |
| VGG19 | 0.92 | 0.97 | 0.92 | 0.94 | 0.91 | 0.96 | 0.91 | 0.94 | |
| DenseNet-201 | 0.91 | 0.99 | 0.91 | 0.94 | 0.90 | 0.95 | 0.90 | 0.92 | |
| Measure | Accuracy | Recall | Precision | F1 | |
|---|---|---|---|---|---|
| Structure | |||||
| CIdeR | 0.84 | 0.88 | 0.89 | 0.88 | |
| VGG16 | 0.86 | 0.83 | 0.99 | 0.90 | |
| VGG19 | 0.84 | 0.90 | 0.88 | 0.89 | |
| AlexNet | 0.84 | 0.88 | 0.9 | 0.89 | |
| DenseNet-201 | 0.81 | 0.88 | 0.8 | 0.84 | |
| Measure | Accuracy | Recall | Precision | F1 | |
|---|---|---|---|---|---|
| Structure | |||||
| CIdeR | 0.82 | 0.85 | 0.81 | 0.83 | |
| ResNet-34 | 0.80 | 0.87 | 0.80 | 0.83 | |
| ResNet-101 | 0.85 | 0.91 | 0.82 | 0.86 | |
| SqueezeNet1_0 | 0.84 | 0.83 | 0.98 | 0.90 | |
| VGG19 | 0.89 | 0.93 | 0.90 | 0.91 | |
| DenseNet-201 | 0.88 | 0.91 | 0.92 | 0.91 | |
| Cough | Breathing | Cough and Breathing | ||
|---|---|---|---|---|
| Dataset | ASBLab | ASBLab | ASBLab | |
| Structure | ||||
| VGG19 | 97% | 92% | 61% | |
| DenseNet-201 | 95% | 89% | 83% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Effati, M.; Nejat, G. A Performance Study of CNN Architectures for the Autonomous Detection of COVID-19 Symptoms Using Cough and Breathing. Computers 2023, 12, 44. https://doi.org/10.3390/computers12020044
Effati M, Nejat G. A Performance Study of CNN Architectures for the Autonomous Detection of COVID-19 Symptoms Using Cough and Breathing. Computers. 2023; 12(2):44. https://doi.org/10.3390/computers12020044
Chicago/Turabian StyleEffati, Meysam, and Goldie Nejat. 2023. "A Performance Study of CNN Architectures for the Autonomous Detection of COVID-19 Symptoms Using Cough and Breathing" Computers 12, no. 2: 44. https://doi.org/10.3390/computers12020044
APA StyleEffati, M., & Nejat, G. (2023). A Performance Study of CNN Architectures for the Autonomous Detection of COVID-19 Symptoms Using Cough and Breathing. Computers, 12(2), 44. https://doi.org/10.3390/computers12020044