


A Lightweight and Adaptive Image Inference Strategy for Earth Observation on LEO Satellites

Abstract
1. Introduction
2. System Models and Mathematical Methods
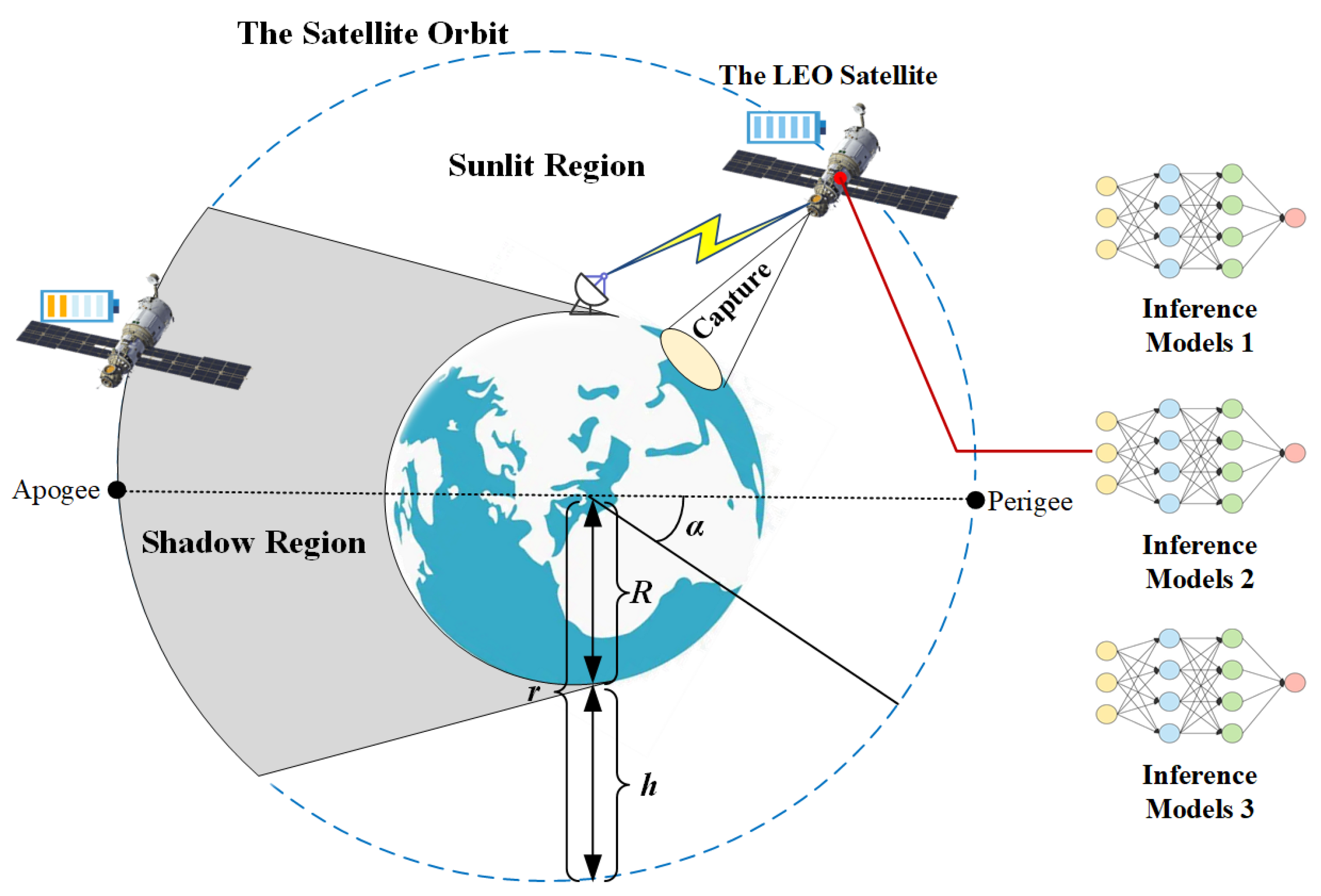
2.1. LEO-IISat Orbital Model
2.2. LEO-IISat Energy Model
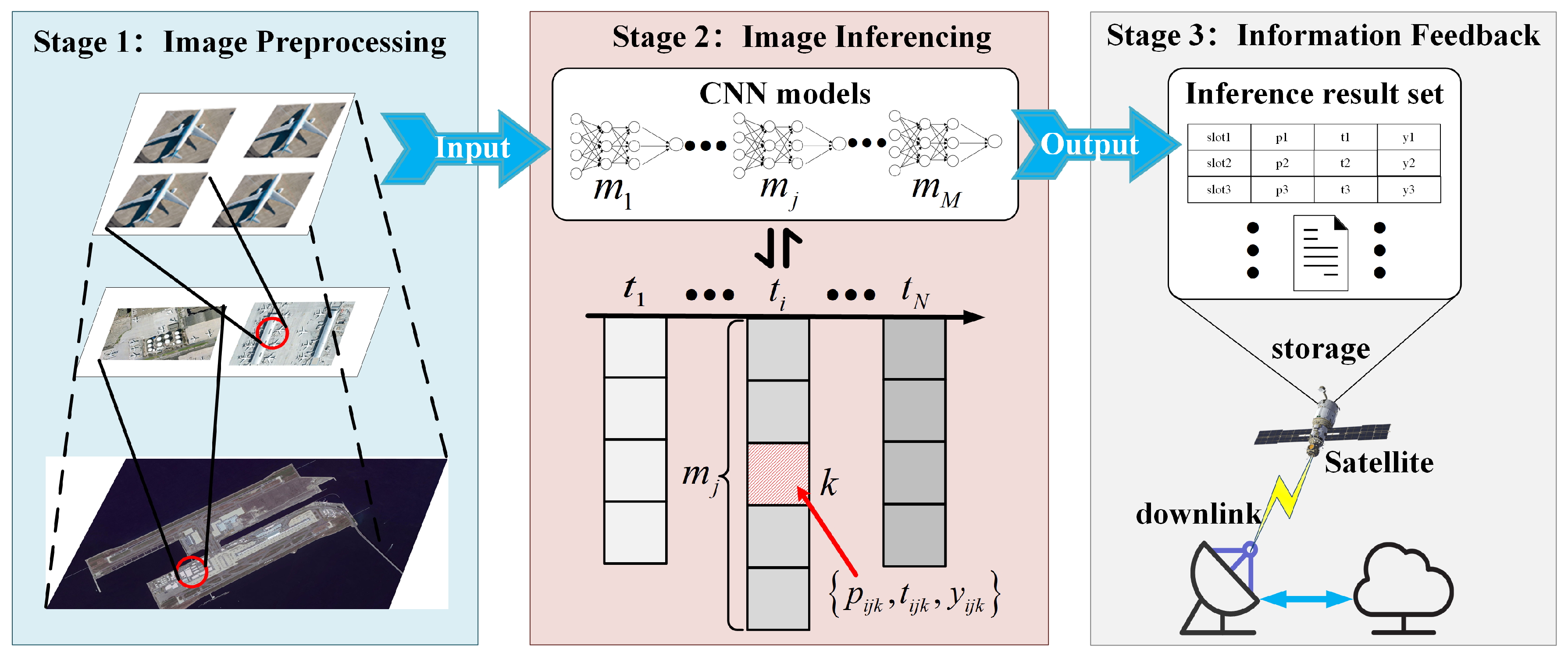
2.3. LEO-IISat Inference Model
2.4. Problem Formulation
2.5. Problem Solving
- is the state space, where the state element represents the available energy for inference in , and the state element represents the task distribution in .
- is the action space, representing the choices for the adaptive strategy, which are the different CNN models.
- is the state transition function, where represents the energy state transition function, and represents the task state transition function.
- is the reward function, representing the reward obtained by selecting CNN model in , as follows:where is the weight coefficient for accuracy-energy efficiency, and is the coefficient for the deviation from the minimum accuracy.
- is the discount factor, determining long-term rewards.
3. Results
3.1. Simulation Parameters
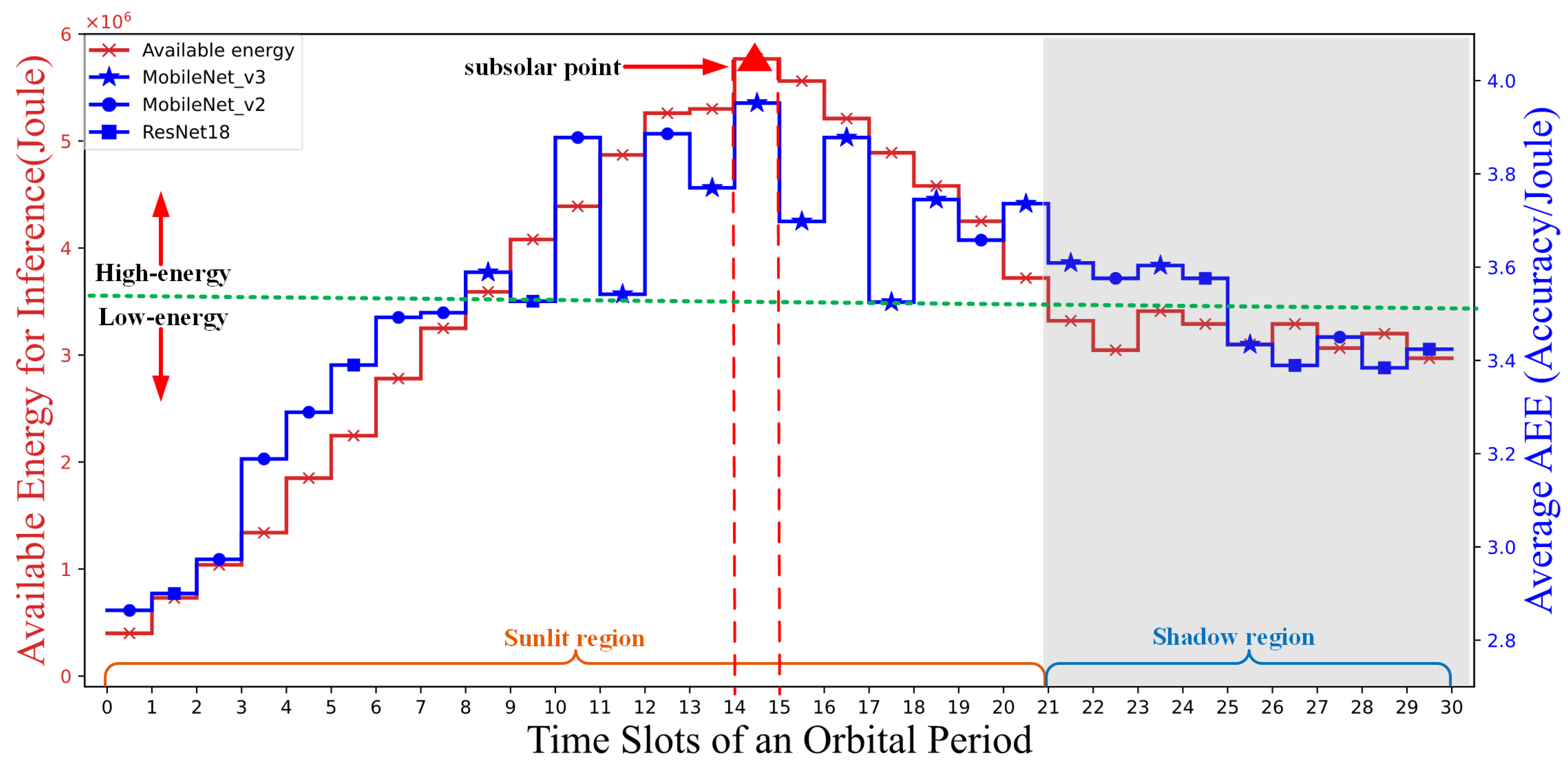
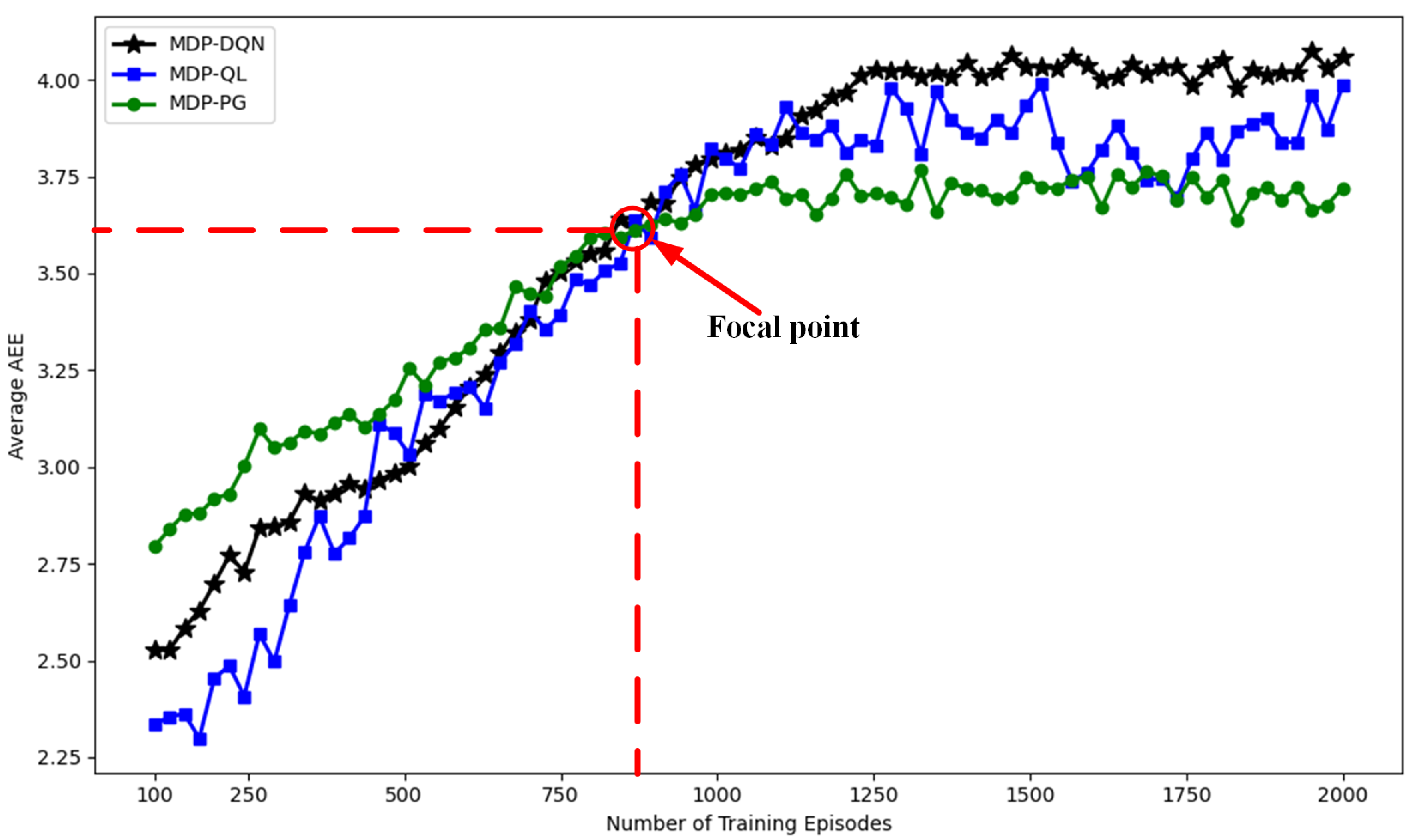
3.2. MDP-DQN Strategy Results
3.3. Comparison Results of Different Strategies
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Banafaa, M.; Shayea, I.; Din, J.; Azmi, M.H.; Alashbi, A.; Daradkeh, Y.I.; Alhammadi, A. 6G Mobile Communication Technology: Requirements, Targets, Applications, Challenges, Advantages, and Opportunities. Alex. Eng. J. 2023, 64, 245–274. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary Perspectives on Emerging Challenges, Opportunities, and Agenda for Research, Practice, and Policy. Int. J. Inf. Manag. 2021, 57, 101994. [Google Scholar] [CrossRef]
- Bedi, R. In-Orbit Artificial Intelligence and Machine Learning On-Board Processing Solutions for Space Applications: Edge-Based and Versal Space Reference Designs: First Design-In Experiences. In Proceedings of the 2023 European Data Handling & Data Processing Conference (EDHPC), Juan Les Pins, France, 2–6 October 2023; pp. 1–4. [Google Scholar] [CrossRef]
- He, C.; Dong, Y.; Li, H.; Liew, Y. Reasoning-Based Scheduling Method for Agile Earth Observation Satellite with Multi-Subsystem Coupling. Remote Sens. 2023, 15, 1577. [Google Scholar] [CrossRef]
- Cui, G.; Duan, P.; Xu, L.; Wang, W. Latency Optimization for Hybrid GEO–LEO Satellite-Assisted IoT Networks. IEEE Internet Things J. 2023, 10, 6286–6297. [Google Scholar] [CrossRef]
- Zhu, X.; Jiang, C. Integrated Satellite-Terrestrial Networks toward 6G: Architectures, Applications, and Challenges. IEEE Internet Things J. 2021, 9, 437–461. [Google Scholar] [CrossRef]
- Wang, W.; Chen, W.; Luo, Y.; Long, Y.; Lin, Z.; Zhang, L.; Lin, B.; Cai, D.; He, X. Model Compression and Efficient Inference for Large Language Models: A Survey. arXiv 2024, arXiv:2402.09748. [Google Scholar] [CrossRef]
- Malaviya, P.; Sarvaiya, V.; Shah, A.; Thakkar, D.; Shah, M. A Comprehensive Review on Space Solar Power Satellite: An Idiosyncratic Approach. Environ. Sci. Pollut. Res. 2022, 29, 42476–42492. [Google Scholar] [CrossRef]
- Miralles, P.; Thangavel, K.; Scannapieco, A.F.; Jagadam, N.; Baranwal, P.; Faldu, B.; Abhang, R.; Bhatia, S.; Bonnart, S.; Bhatnagar, I.; et al. A Critical Review on the State-of-the-Art and Future Prospects of Machine Learning for Earth Observation Operations. Adv. Space Res. 2023, 71, 4959–4986. [Google Scholar] [CrossRef]
- Shang, S.; Zhang, J.; Wang, X.; Wang, X.; Li, Y.; Li, Y. Faster and Lighter Meteorological Satellite Image Classification by a Lightweight Channel-Dilation-Concatenation Net. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2301–2317. [Google Scholar] [CrossRef]
- Leyva-Mayorga, I.; Martinez-Gost, M.; Moretti, M.; Pérez-Neira, A.; Vázquez, M.Á; Popovski, P.; Soret, B. Satellite Edge Computing for Real-Time and Very-High Resolution Earth Observation. IEEE Trans. Commun. 2023, 71, 6180–6194. [Google Scholar] [CrossRef]
- Gost, M.M.; Leyva-Mayorga, I.; Pérez-Neira, A.; Vázquez, M.Á.; Soret, B.; Moretti, M. Edge Computing and Communication for Energy-Efficient Earth Surveillance with LEO Satellites. In Proceedings of the 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, Republic of Korea, 16–20 May 2022; pp. 556–561. [Google Scholar] [CrossRef]
- Khalek, N.A.; Tashman, D.H.; Hamouda, W. Advances in machine learning-driven cognitive radio for wireless networks: A survey. IEEE Commun. Surv. Tutor. 2024, 26, 1201–1237. [Google Scholar] [CrossRef]
- Yin, L.; Cao, X. Inspired lightweight robust quantum Q-learning for smart generation control of power systems. Appl. Soft Comput. 2022, 131, 109804. [Google Scholar] [CrossRef]
- Bhandari, J.; Russo, D. Global optimality guarantees for policy gradient methods. Oper. Res. 2024, 72, 1906–1927. [Google Scholar] [CrossRef]
- Ali, Y.A.; Awwad, E.M.; Al-Razgan, M.; Maarouf, A. Hyperparameter search for machine learning algorithms for optimizing the computational complexity. Processes 2023, 11, 349. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, W.; Zhai, A.; He, P.; Wang, D. DQN based single-pixel imaging. Opt. Express 2021, 29, 15463–15477. [Google Scholar] [CrossRef]
- Luo, J.; Li, F.; Jiao, J. A dynamic multiobjective recommendation method based on soft actor-critic with discrete actions. J. King Saud Univ. Comput. Inf. Sci. 2025, 37, 1. [Google Scholar] [CrossRef]
- Alavipanah, S.K.; Karimi Firozjaei, M.; Sedighi, A.; Fathololoumi, S.; Zare Naghadehi, S.; Saleh, S.; Naghdizadegan, M.; Gomeh, Z.; Arsanjani, J.J.; Makki, M.; et al. The Shadow Effect on Surface Biophysical Variables Derived from Remote Sensing: A Review. Land 2022, 11, 2025. [Google Scholar] [CrossRef]
- Persello, C.; Wegner, J.D.; Hänsch, R.; Tuia, D.; Ghamisi, P.; Koeva, M.; Camps-Valls, G. Deep Learning and Earth Observation to Support the Sustainable Development Goals: Current Approaches, Open Challenges, and Future Opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 172–200. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Z.; Wang, L.; Wang, N.; Yang, Y.; Li, R.; Zhang, Y.; Liu, A.; Yuan, H.; Hoque, M. Comparison of the Real-Time Precise Orbit Determination for LEO between Kinematic and Reduced-Dynamic Modes. Measurement 2022, 187, 110224. [Google Scholar] [CrossRef]
- Prol, F.S.; Ferre, R.M.; Saleem, Z.; Välisuo, P.; Pinell, C.; Lohan, E.S.; Elsanhoury, M.; Elmusrati, M.; Islam, S.; Çelikbilek, K.; et al. Position, Navigation, and Timing (PNT) through Low Earth Orbit (LEO) Satellites: A Survey on Current Status, Challenges, and Opportunities. IEEE Access 2022, 10, 83971–84002. [Google Scholar] [CrossRef]
- Liu, W.; Lai, Z.; Wu, Q.; Li, H.; Zhang, Q.; Li, Z.; Li, Y.; Liu, J. In-Orbit Processing or Not? Sunlight-Aware Task Scheduling for Energy-Efficient Space Edge Computing Networks. In Proceedings of the IEEE INFOCOM 2024—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 20–23 May 2024; pp. 881–890. [Google Scholar] [CrossRef]
- Pathak, A.D.; Saha, S.; Bharti, V.K.; Gaikwad, M.M.; Sharma, C.S. A Review on Battery Technology for Space Application. J. Energy Storage 2023, 61, 106792. [Google Scholar] [CrossRef]
- Hong, D.; Hu, J.; Yao, J.; Chanussot, J.; Zhu, X.X. Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model. ISPRS J. Photogramm. Remote Sens. 2021, 178, 107–122. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Jiang, Y.; Zhang, X.; Zheng, R.; Qiu, R.; Sun, Y.; Zhao, C.; Shang, H. ResNet18DNN: Prediction Approach of Drug-Induced Liver Injury by Deep Neural Network with ResNet18. Brief. Bioinform. 2022, 23, bbab503. [Google Scholar] [CrossRef]
- Kazmi Policht, N.F.; Brooks, T.N.; North, P. Characterization and Classification of Low-Resolution LEO and GEO Satellites with Electro-Optical Fiducial Markers. In Proceedings of the AIAA SCITECH 2024 Forum, Orlando, FL, USA, 8–12 January 2024; p. 2267. [Google Scholar] [CrossRef]
- Abraham, K.; Abdelwahab, M.; Abo-Zahhad, M. Classification and Detection of Natural Disasters Using Machine Learning and Deep Learning Techniques: A Review. Earth Sci. Inform. 2024, 17, 869–891. [Google Scholar] [CrossRef]
- Meimetis, D.; Papaioannou, S.; Katsoni, P.; Lappas, V. An Architecture for Early Wildfire Detection and Spread Estimation Using Unmanned Aerial Vehicles, Base Stations, and Space Assets. Drones Auton. Veh. 2024, 1, 10006. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A Benchmark Dataset for Fine-Grained Object Recognition in High-Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Turkoglu, M.O.; D’Aronco, S.; Perich, G.; Liebisch, F.; Streit, C.; Schindler, K.; Wegner, J.D. Crop Mapping from Image Time Series: Deep Learning with Multi-Scale Label Hierarchies. Remote Sens. Environ. 2021, 264, 112603. [Google Scholar] [CrossRef]
- Yousif, M.J. Enhancing the accuracy of image classification using deep learning and preprocessing methods. Artif. Intell. Robot. Dev. J. 2023, 3, 348. [Google Scholar] [CrossRef]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xView: Objects in Context in Overhead Imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar] [CrossRef]
- Qiao, Y.; Teng, S.; Luo, J.; Sun, P.; Li, F.; Tang, F. On-Orbit DNN Distributed Inference for Remote Sensing Images in Satellite Internet of Things. IEEE Internet Things J. 2024, 12, 5687–5703. [Google Scholar] [CrossRef]
- He, Z.; Tran, K.P.; Thomassey, S.; Zeng, X.; Xu, J.; Yi, C. Multi-Objective Optimization of the Textile Manufacturing Process Using Deep-Q-Network Based Multi-Agent Reinforcement Learning. J. Manuf. Syst. 2022, 62, 939–949. [Google Scholar] [CrossRef]
- Park, S.; Yoo, Y.; Pyo, C.W. Applying DQN Solutions in Fog-Based Vehicular Networks: Scheduling, Caching, and Collision Control. Veh. Commun. 2022, 33, 100397. [Google Scholar] [CrossRef]
- Edwards, M.R.; Holloway, T.; Pierce, R.B.; Blank, L.; Broddle, M.; Choi, E.; Duncan, B.N.; Esparza, Á.; Falchetta, G.; Fritz, M.; et al. Satellite Data Applications for Sustainable Energy Transitions. Front. Sustain. 2022, 3, 910924. [Google Scholar] [CrossRef]
- Myyas, R.E.N.; Al-Dabbasa, M.; Tostado-Véliz, M.; Jurado, F. A Novel Solar Panel Cleaning Mechanism to Improve Performance and Harvesting Rainwater. Solar Energy 2022, 237, 19–28. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, X.; Wang, L.; Xing, L.; Pedrycz, W. Resource-Constrained Self-Organized Optimization for Near-Real-Time Offloading Satellite Earth Observation Big Data. Knowl.-Based Syst. 2022, 253, 109496. [Google Scholar] [CrossRef]
- Chen, B.; Liu, L.; Zou, Z.; Shi, Z. Target Detection in Hyperspectral Remote Sensing Image: Current Status and Challenges. Remote Sens. 2023, 15, 3223. [Google Scholar] [CrossRef]
- Ferreira, B.; Silva, R.G.; Iten, M. Earth Observation Satellite Imagery Information-Based Decision Support Using Machine Learning. Remote Sens. 2022, 14, 3776. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Yan, K.; Li, W.; Wang, K.I.K.; Ma, J.; Jin, Q. Edge-Enabled Two-Stage Scheduling Based on Deep Reinforcement Learning for Internet of Everything. IEEE Internet Things J. 2022, 10, 3295–3304. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, T.; Lin, Y.; Chen, Y.; Zeng, H.; Pei, J.; Wang, J.; Liu, X.; Zhou, Y.; Zhang, J.; et al. A Vision Chip with Complementary Pathways for Open-World Sensing. Nature 2024, 629, 1027–1033. [Google Scholar] [CrossRef]
- Yang, X.; Shi, Y.; Liu, W.; Ye, H.; Zhong, W.; Xiang, Z. Global Path Planning Algorithm Based on Double DQN for Multi-Tasks Amphibious Unmanned Surface Vehicle. Ocean Eng. 2022, 266, 112809. [Google Scholar] [CrossRef]
- Tan, T.; Xie, H.; Xia, Y.; Shi, X.; Shang, M. Adaptive Moving Average Q-Learning. Knowl. Inf. Syst. 2024, 66, 7389–7417. [Google Scholar] [CrossRef]
- Huang, C.; Wang, G.; Zhou, Z.; Zhang, R.; Lin, L. Reward-Adaptive Reinforcement Learning: Dynamic Policy Gradient Optimization for Bipedal Locomotion. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7686–7695. [Google Scholar] [CrossRef]
- Shakya, A.K.; Pillai, G.; Chakrabarty, S. Reinforcement Learning Algorithms: A Brief Survey. Expert Syst. Appl. 2023, 231, 120495. [Google Scholar] [CrossRef]
- Li, D.; Yang, Q.; Ma, L.; Wang, Y.; Zhang, Y.; Liao, X. An Electrical Vehicle-Assisted Demand Response Management System: A Reinforcement Learning Method. Front. Energy Res. 2023, 10, 1071948. [Google Scholar] [CrossRef]
- Vashist, A.; Shanmugham, S.V.V.; Ganguly, A.; Manoj, S. DQN Based Exit Selection in Multi-Exit Deep Neural Networks for Applications Targeting Situation Awareness. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–9 January 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Rodrigues, F.F.C. Supergame, A System with Data Collection to Support Game Recommendation: Creating a Recommender System for Casual Games. Master’s Thesis, Universidade de Evora, Évora, Portugal, 2023. [Google Scholar]
- Goriparthi, R.G. Deep Learning Architectures for Real-Time Image Recognition: Innovations and Applications. Rev. Intel. Artif. Med. 2024, 15, 880–907. Available online: https://redcrevistas.com/index.php/Revista/article/view/219 (accessed on 14 February 2025).
- Zhang, Y.; Cheng, Y.; Zheng, H.; Tao, F. Long-/Short-Term Preference Based Dynamic Pricing and Manufacturing Service Collaboration Optimization. IEEE Trans. Ind. Inform. 2022, 18, 8948–8956. [Google Scholar] [CrossRef]
- Nabi, A.; Baidya, T.; Moh, S. Comprehensive Survey on Reinforcement Learning-Based Task Offloading Techniques in Aerial Edge Computing. Internet Things 2024, 28, 101342. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| h | 25% | ||
| N | 30 | ||
| D |
| Parameter Name | Parameter Value |
|---|---|
| Candidate CNN models | MobileNet_v3; MobileNet_v2; ResNet18 |
| Onboard computing device | NVIDIA Jetson AGX Orin |
| Raw image dataset | xView Dataset |
| Number of images processed per | ∼ |
| CNN Models | Accuracy (%) | Energy (J) | Delay (ms) | EDP/A (J · ms/%) |
|---|---|---|---|---|
| MobileNet_v3 | ∼ | ∼ | ∼ | ∼ |
| MobileNet_v2 | ∼ | ∼ | 4∼5 | ∼ |
| ResNet18 | ∼ | ∼ | 6∼8 | ∼ |
| Parameter | Value | Parameter | Value | Parameter | Value |
|---|---|---|---|---|---|
| 1.5 | 2000 | 0.99 | |||
| 10 | 0.001 | 0.9 |
| Strategies | MDP-DQN | MDP-QL | MDP-PG |
|---|---|---|---|
| Variance | 0.023 | 0.061 | 0.032 |
| Algorithms | DQN | QL | PG |
|---|---|---|---|
| Time complexity |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Fang, Y.; Huang, D.; Lu, Z.; Lv, J. A Lightweight and Adaptive Image Inference Strategy for Earth Observation on LEO Satellites. Remote Sens. 2025, 17, 1175. https://doi.org/10.3390/rs17071175
Wang B, Fang Y, Huang D, Lu Z, Lv J. A Lightweight and Adaptive Image Inference Strategy for Earth Observation on LEO Satellites. Remote Sensing. 2025; 17(7):1175. https://doi.org/10.3390/rs17071175
Chicago/Turabian StyleWang, Bo, Yuhang Fang, Dongyan Huang, Zelin Lu, and Jiaqi Lv. 2025. "A Lightweight and Adaptive Image Inference Strategy for Earth Observation on LEO Satellites" Remote Sensing 17, no. 7: 1175. https://doi.org/10.3390/rs17071175
APA StyleWang, B., Fang, Y., Huang, D., Lu, Z., & Lv, J. (2025). A Lightweight and Adaptive Image Inference Strategy for Earth Observation on LEO Satellites. Remote Sensing, 17(7), 1175. https://doi.org/10.3390/rs17071175