
Adaptive Conditional Reasoning for Remote Sensing Visual Question Answering

Abstract
1. Introduction
- (1)
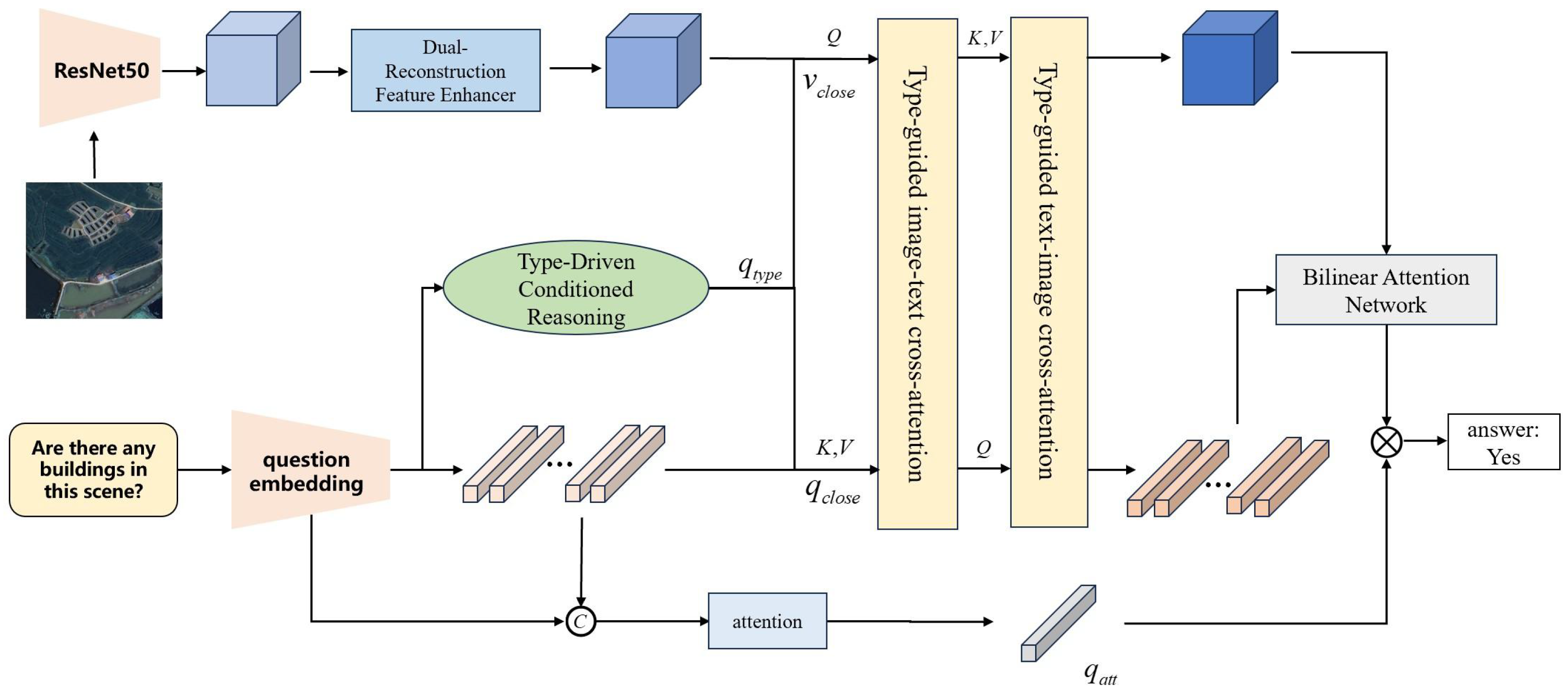
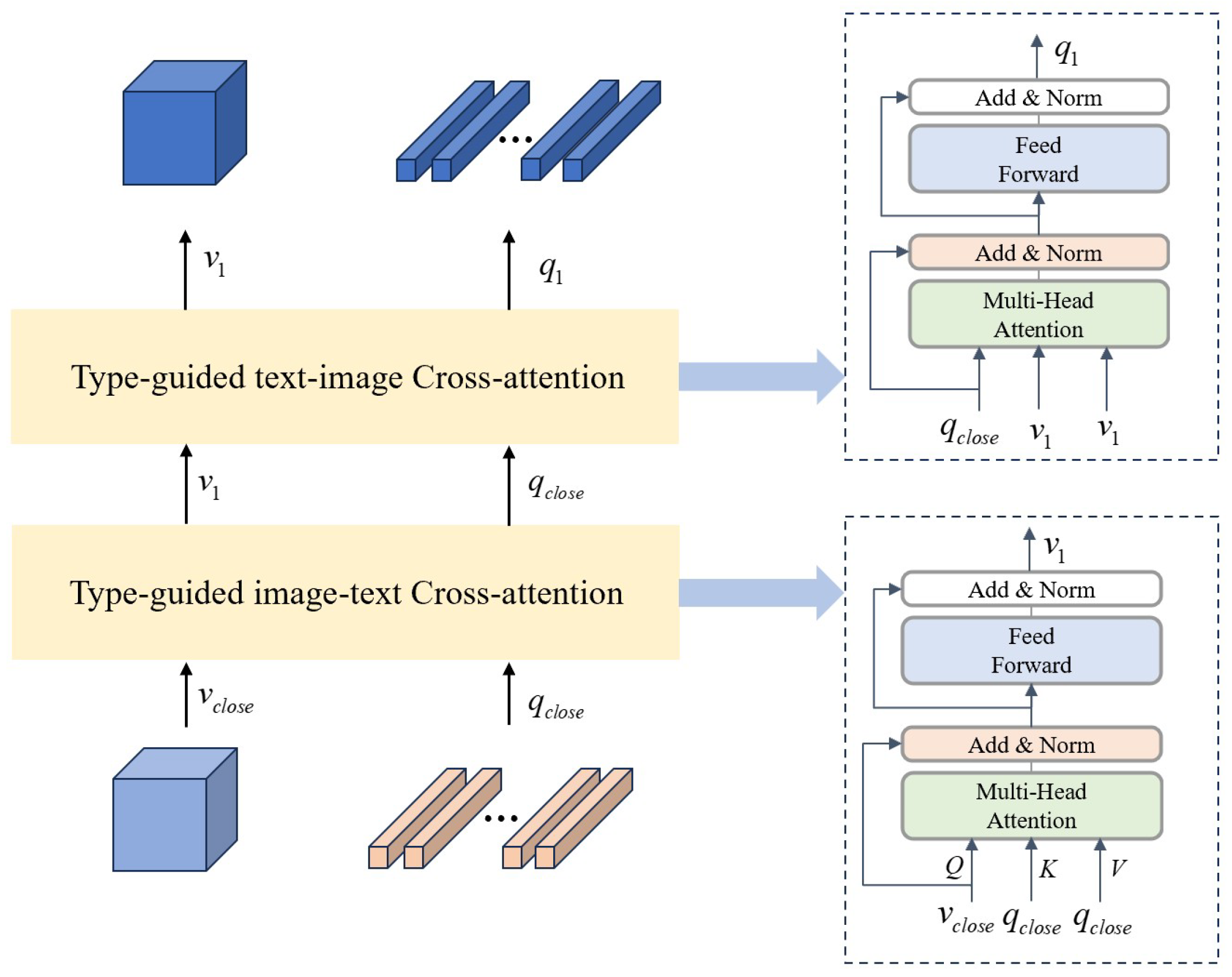
- We propose an Adaptive Conditional Reasoning process which involves a Type-Driven Conditioned Reasoning module and a text–image cross-modal reasoning method based on the type of question. Before the fusion of multimodal features, incorporating a type judgment process enables adaptive selection of reasoning procedures corresponding to different types of questions. By using image–text and text–image attention, the module achieves symmetric interaction between visual and text features.
- (2)
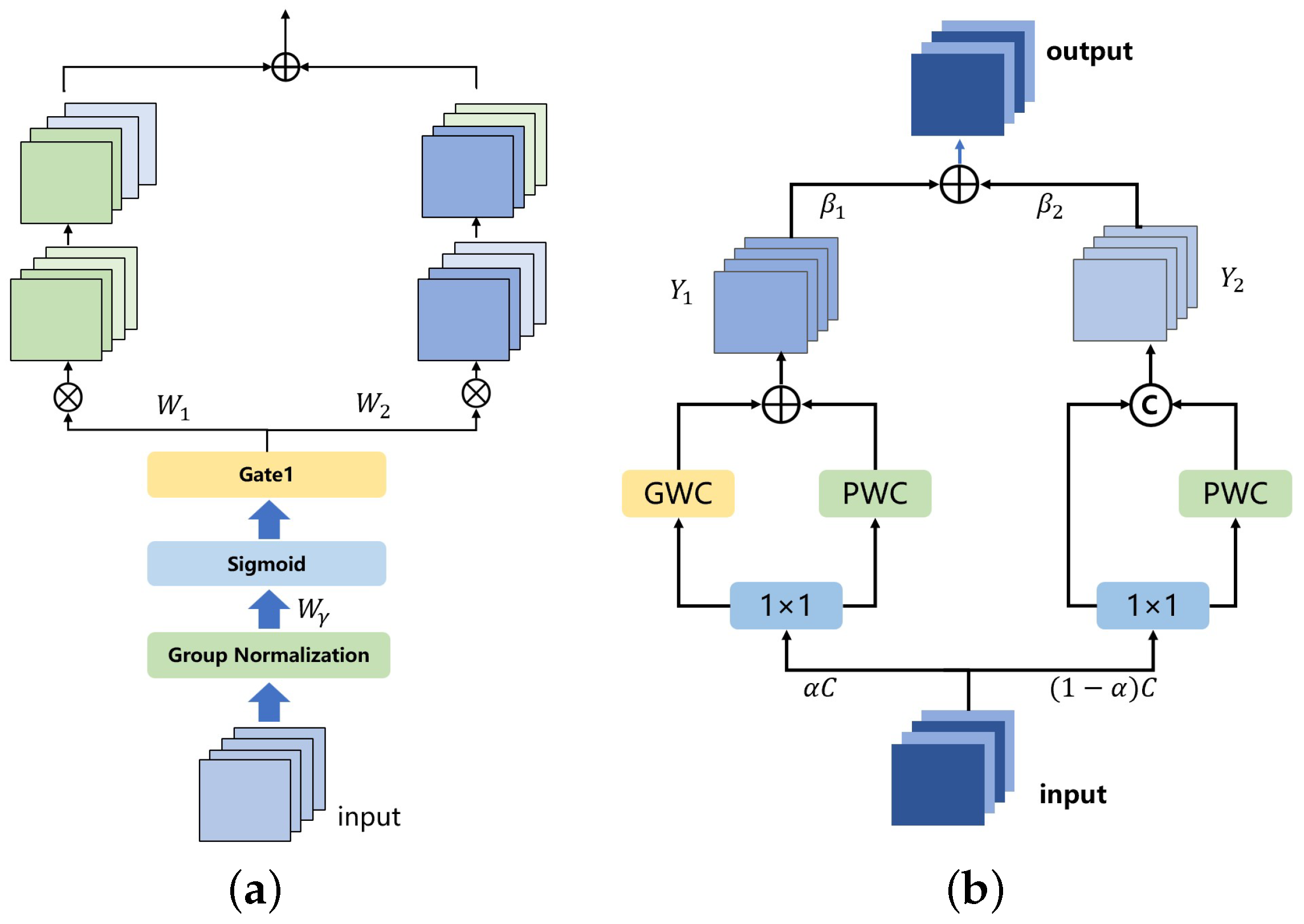
- In order to mitigate spatial redundancy and channel redundancy during image feature extraction, we employ spatial reconstruction convolution and channel reconstruction convolution, which enhance the model’s ability to focus on key areas in remote sensing images.
- (3)
- To demonstrate the superiority of our proposed framework, we conducted an evaluation, comparing it with the other methods on the EarthVQA dataset. The results confirm the substantial improvement and advancement achieved by the Adaptive Conditional Reasoning framework in Remote Sensing Visual Question Answering tasks.
2. Related Work
2.1. Visual Question Answering
2.2. Remote Sensing Visual Question Answering
2.3. Multimodal Fusion and Reasoning
3. Methods
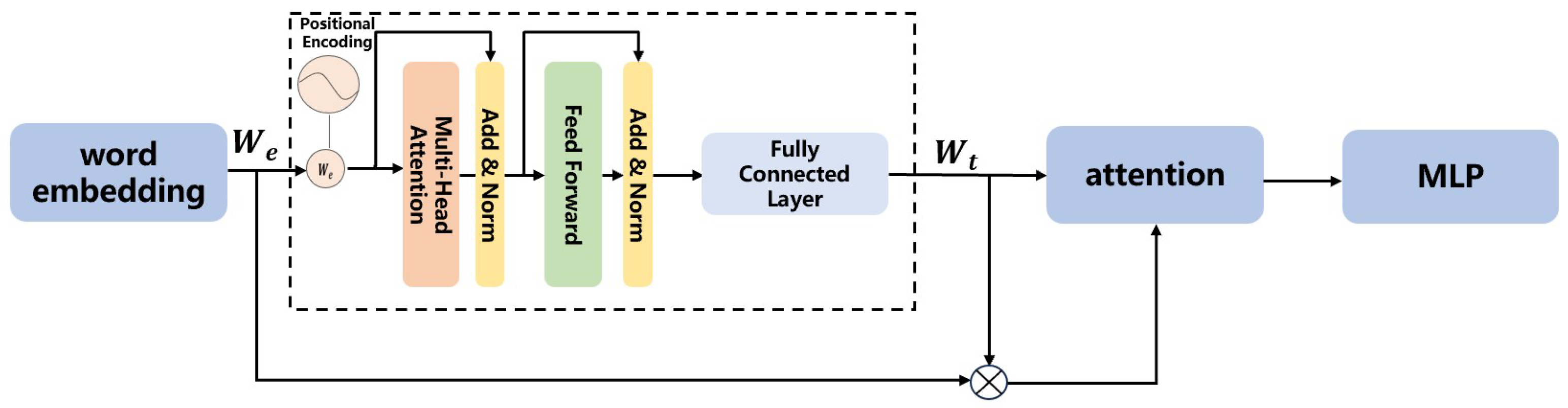
3.1. Type-Driven Conditional Reasoning
3.2. Text–Image Cross-Modal Reasoning Module
3.3. Dual-Reconstruction Feature Enhancer
4. Experiment and Results
4.1. Setting
4.2. Dataset
4.3. Accuracy Evaluation with Other Methods
- (1)
- SAN [34]: SAN processes the input image and question through stacked attention mechanisms, progressively enhancing the model’s focus on different visual information, thereby enabling more accurate reasoning and answering in the given visual scene.
- (2)
- MAC [35]: MAC introduces a memory module, which is used to store and transfer relevant features of the image. The model gradually reads the image features and stores them in the “memory” for subsequent reasoning and answering.
- (3)
- MCAN [36]: MCAN is composed of a series of Modular Co-Attention (MCA) layers. Each MCA layer is capable of modeling the attention between the image and the question.
- (4)
- BUTD [37]: BUTD combines bottom-up and top-down attention mechanisms to compute the salient regions in the image at the object level.
- (5)
- D-VQA [38]: D-VQA constructs branches from questions to answers and from visuals to answers, capturing the biases in language and vision, and applies two unimodal bias detection modules to explicitly identify and remove negative biases.
- (6)
- RSVQA [39]: A baseline model constrained by its shallow CNN feature extractor in capturing high-resolution RS image details.
- (7)
- SOBA [33]: SOBA generates object semantics using a segmentation network and aggregates internal object features through pseudo-masks.
4.4. Ablation Study
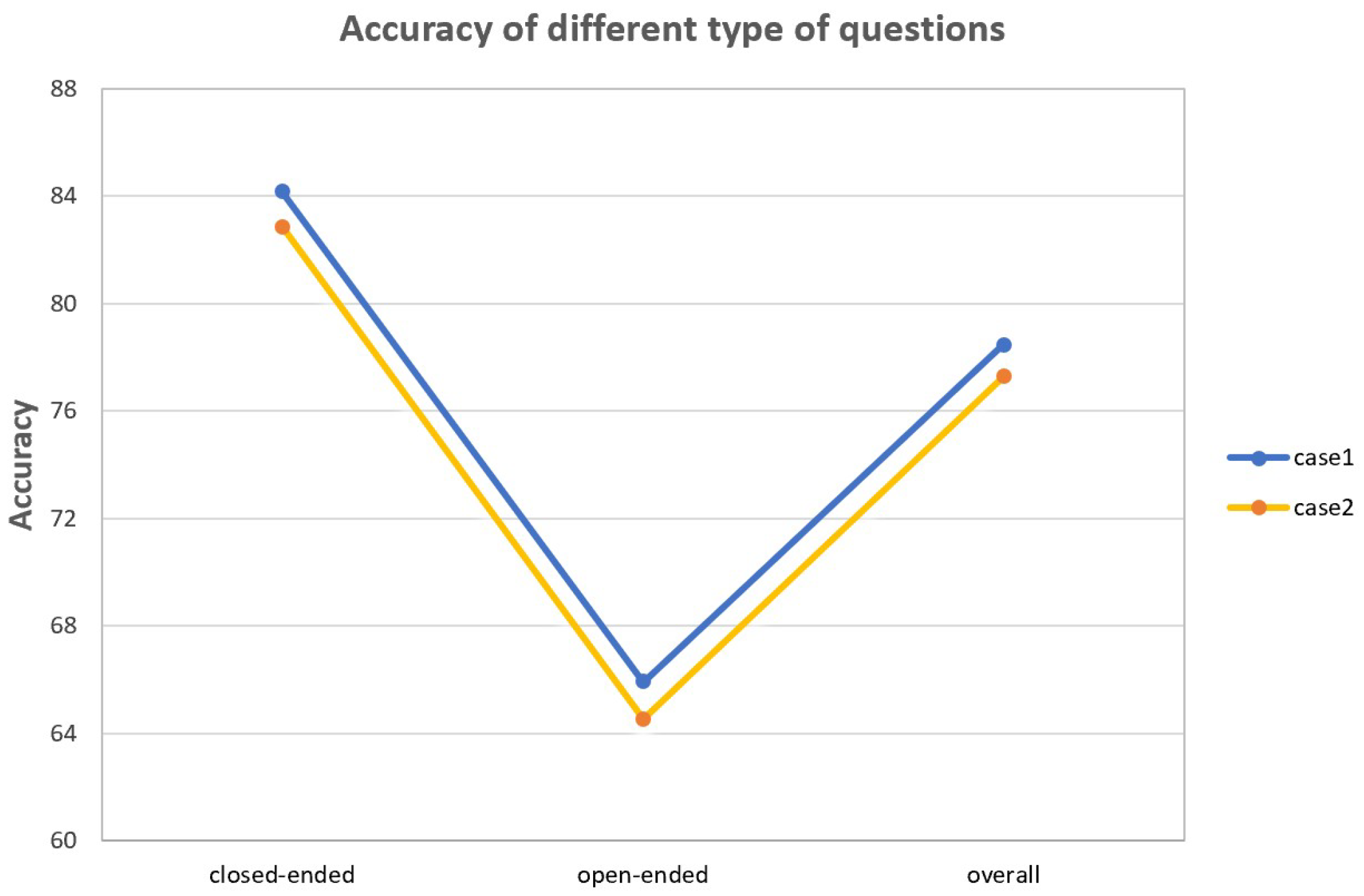
4.5. Accuracy of Different Types of Questions
5. Discussion
5.1. Qualitative Result Visualization
5.2. Attention Visualization on the EarthVQA Dataset
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qing, Y.; Ming, D.; Wen, Q.; Weng, Q.; Xu, L.; Chen, Y.; Zhang, Y.; Zeng, B. Operational earthquake-induced building damage assessment using CNN-based direct remote sensing change detection on superpixel level. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102899. [Google Scholar]
- Lei, T.; Wang, J.; Li, X.; Wang, W.; Shao, C.; Liu, B. Flood disaster monitoring and emergency assessment based on multi-source remote sensing observations. Water 2022, 14, 2207. [Google Scholar] [CrossRef]
- Zhu, Y.; Wu, S.; Qin, M.; Fu, Z.; Gao, Y.; Wang, Y.; Du, Z. A deep learning crop model for adaptive yield estimation in large areas. Int. J. Appl. Earth Obs. Geoinf. 2022, 110, 102828. [Google Scholar]
- Zheng, X.; Wang, B.; Du, X.; Lu, X. Mutual attention inception network for remote sensing visual question answering. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5606514. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Lobry, S.; Tuia, D. Visual question answering on remote sensing images. In Advances in Machine Learning and Image Analysis for GeoAI; Elsevier: Amsterdam, The Netherlands, 2024; pp. 237–254. [Google Scholar]
- Lobry, S.; Demir, B.; Tuia, D. RSVQA meets BigEarthNet: A new, large-scale, visual question answering dataset for remote sensing. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 1218–1221. [Google Scholar]
- Bazi, Y.; Al Rahhal, M.M.; Mekhalfi, M.L.; Al Zuair, M.A.; Melgani, F. Bi-modal transformer-based approach for visual question answering in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4708011. [Google Scholar]
- Siebert, T.; Clasen, K.N.; Ravanbakhsh, M.; Demir, B. Multi-modal fusion transformer for visual question answering in remote sensing. In Image and Signal Processing for Remote Sensing XXVIII; SPIE: Bellingham, WA, USA, 2022; Volume 12267, pp. 162–170. [Google Scholar]
- Zhan, Y.; Xiong, Z.; Yuan, Y. Rsvg: Exploring data and models for visual grounding on remote sensing data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5604513. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiao, L.; Li, L.; Liu, X.; Chen, P.; Liu, F.; Li, Y.; Guo, Z. A spatial hierarchical reasoning network for remote sensing visual question answering. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4400815. [Google Scholar]
- Sarkar, A.; Chowdhury, T.; Murphy, R.R.; Gangopadhyay, A.; Rahnemoonfar, M. Sam-vqa: Supervised attention-based visual question answering model for post-disaster damage assessment on remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4702716. [Google Scholar]
- Ran, L.; Wang, L.; Zhuo, T.; Xing, Y.; Zhang, Y. DDF: A Novel Dual-Domain Image Fusion Strategy for Remote Sensing Image Semantic Segmentation with Unsupervised Domain Adaptation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4708113. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Ricci, R.; Melgani, F. Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery. Remote Sens. 2024, 16, 1477. [Google Scholar]
- Jiang, Y.; Li, W.; Hossain, M.S.; Chen, M.; Alelaiwi, A.; Al-Hammadi, M. A snapshot research and implementation of multimodal information fusion for data-driven emotion recognition. Inf. Fusion 2020, 53, 209–221. [Google Scholar]
- Gadzicki, K.; Khamsehashari, R.; Zetzsche, C. Early vs late fusion in multimodal convolutional neural networks. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–6. [Google Scholar]
- Mai, S.; Xing, S.; Hu, H. Locally confined modality fusion network with a global perspective for multimodal human affective computing. IEEE Trans. Multimed. 2019, 22, 122–137. [Google Scholar]
- Huang, J.; Tao, J.; Liu, B.; Lian, Z.; Niu, M. Multimodal transformer fusion for continuous emotion recognition. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3507–3511. [Google Scholar]
- Zhao, Z.; Zhou, C.; Zhang, Y.; Li, C.; Ma, X.; Tang, J. Text-Guided Coarse-to-Fine Fusion Network for Robust Remote Sensing Visual Question Answering. arXiv 2024, arXiv:2411.15770. [Google Scholar]
- Bichindaritz, I.; Kansu, E.; Sullivan, K.M. Case-based reasoning in care-partner: Gathering evidence for evidence-based medical practice. In Proceedings of the European Workshop on Advances in Case-Based Reasoning, Dublin, Ireland, September 23–25 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 334–345. [Google Scholar]
- Marling, C.; Sqalli, M.; Rissland, E.; Muñoz-Avila, H.; Aha, D. Case-based reasoning integrations. AI Mag. 2002, 23, 69. [Google Scholar]
- Nam, H.; Ha, J.W.; Kim, J. Dual attention networks for multimodal reasoning and matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 299–307. [Google Scholar]
- Lippe, P.; Holla, N.; Chandra, S.; Rajamanickam, S.; Antoniou, G.; Shutova, E.; Yannakoudakis, H. A multimodal framework for the detection of hateful memes. arXiv 2020, arXiv:2012.12871. [Google Scholar]
- Zellers, R.; Lu, X.; Hessel, J.; Yu, Y.; Park, J.S.; Cao, J.; Farhadi, A.; Choi, Y. Merlot: Multimodal neural script knowledge models. Adv. Neural Inf. Process. Syst. 2021, 34, 23634–23651. [Google Scholar]
- Yang, Z.; Li, L.; Wang, J.; Lin, K.; Azarnasab, E.; Ahmed, F.; Liu, Z.; Liu, C.; Zeng, M.; Wang, L. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv 2023, arXiv:2303.11381. [Google Scholar]
- Zheng, G.; Yang, B.; Tang, J.; Zhou, H.Y.; Yang, S. Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models. Adv. Neural Inf. Process. Syst. 2023, 36, 5168–5191. [Google Scholar]
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, J.; Zheng, Z.; Chen, Z.; Ma, A.; Zhong, Y. Earthvqa: Towards queryable earth via relational reasoning-based remote sensing visual question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5481–5489. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 21–29. [Google Scholar]
- Hudson, D.A.; Manning, C.D. Compositional Attention Networks for Machine Reasoning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6281–6290. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wen, Z.; Xu, G.; Tan, M.; Wu, Q.; Wu, Q. Debiased Visual Question Answering from Feature and Sample Perspectives. In Advances in Neural Information Processing Systems; Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; MIT Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Lobry, S.; Marcos, D.; Murray, J.; Tuia, D. RSVQA: Visual Question Answering for Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8555–8566. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Bas Co | Bas Ju | Rel Co | Rel Ju | Obj An | Com An | Overall | Param. (M) |
|---|---|---|---|---|---|---|---|---|
| BAN | 77.6 | 89.8 | 63.7 | 81.9 | 55.7 | 45.1 | 76.7 | 58.7 |
| SAN | 76.2 | 87.6 | 59.2 | 81.8 | 55.0 | 43.3 | 75.7 | 32.3 |
| MAC | 72.5 | 82.9 | 55.9 | 79.5 | 46.3 | 40.5 | 72.0 | 38.6 |
| MCAN | 79.8 | 89.6 | 63.8 | 81.8 | 55.6 | 45.0 | 77.0 | 55.2 |
| D-VQA | 77.3 | 89.7 | 64.0 | 82.1 | 55.1 | 43.2 | 76.6 | 37.8 |
| SOBA | 80.1 | 89.6 | 67.8 | 82.6 | 61.4 | 49.3 | 78.1 | 40.5 |
| RSVQA | 70.7 | 82.4 | 55.5 | 79.3 | 42.5 | 35.5 | 70.7 | 30.2 |
| BUTD | 77.2 | 90.0 | 60.9 | 82.0 | 56.3 | 42.3 | 76.5 | 34.9 |
| ACR (ours) | 79.7 | 89.8 | 68.0 | 83.6 | 61.6 | 49.2 | 78.5 | 47.9 |
| DRE | TCR | Bas Co | Bas Ju | Rel Co | Rel Ju | Obj An | Com An | Overall |
|---|---|---|---|---|---|---|---|---|
| 78.9 | 89.0 | 64.2 | 82.7 | 57.4 | 47.6 | 77.3 | ||
| ✓ | 79.2 | 89.3 | 64.6 | 81.7 | 57.5 | 48.3 | 77.4 | |
| ✓ | 80.4 | 90.2 | 67.5 | 82.8 | 60.3 | 48.5 | 78.4 | |
| ✓ | ✓ | 79.7 | 89.8 | 68.0 | 83.6 | 61.6 | 49.2 | 78.5 |
| Types | Open-Ended | Closed-Ended | Overall Accuracy |
|---|---|---|---|
| case1 | 84.1 | 65.9 | 78.5 |
| case2 | 82.8 | 64.5 | 77.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Bai, Z.; Zhou, M.; Jia, B.; Gao, P.; Zhu, R. Adaptive Conditional Reasoning for Remote Sensing Visual Question Answering. Remote Sens. 2025, 17, 1338. https://doi.org/10.3390/rs17081338
Gao Y, Bai Z, Zhou M, Jia B, Gao P, Zhu R. Adaptive Conditional Reasoning for Remote Sensing Visual Question Answering. Remote Sensing. 2025; 17(8):1338. https://doi.org/10.3390/rs17081338
Chicago/Turabian StyleGao, Yiqun, Zongwen Bai, Meili Zhou, Bolin Jia, Peiqi Gao, and Rui Zhu. 2025. "Adaptive Conditional Reasoning for Remote Sensing Visual Question Answering" Remote Sensing 17, no. 8: 1338. https://doi.org/10.3390/rs17081338
APA StyleGao, Y., Bai, Z., Zhou, M., Jia, B., Gao, P., & Zhu, R. (2025). Adaptive Conditional Reasoning for Remote Sensing Visual Question Answering. Remote Sensing, 17(8), 1338. https://doi.org/10.3390/rs17081338