





An Efficient Aerial Image Detection with Variable Receptive Fields

Abstract
1. Introduction
- Aiming at the above challenges in aerial remote sensing images, we design a lightweight real-time object detection framework VRF-DETR with variable receptive fields based on the RT-DETR framework. Compared with some real-time detection benchmark models and state-of-the-art (SOTA) methods, VRF-DETR can provide adaptive receptive fields and achieve better performance while ensuring real-time performance.
- To solve the confusion caused by the difference in height and viewing angle, we propose the MSRF2 module. The module integrates parallel dilated convolution and attention mechanism, which can adaptively adjust the receptive field according to the context information so that the model can dynamically capture multi-scale features and improve the detection accuracy of small targets and occluded targets.
- We design the AGConv module and GMSC block to reconstruct the backbone network, where AGConv uses gated attention to optimize feature extraction, and GMSC combines MSRF2 and AGConv to reduce parameters by 46% while enhancing multi-scale feature representation.
- The CGF module is proposed to optimize the neck network, leveraging dynamic weight allocation to alleviate semantic conflicts in multi-scale feature fusion, thereby improving the complementarity of features across different scales with minimal computational overhead.
2. Related Work
2.1. Receptive Field Enhancement in Remote Sensing
2.2. Lightweight Backbone Networks
2.3. Multi-Scale Feature Fusion
3. Methods
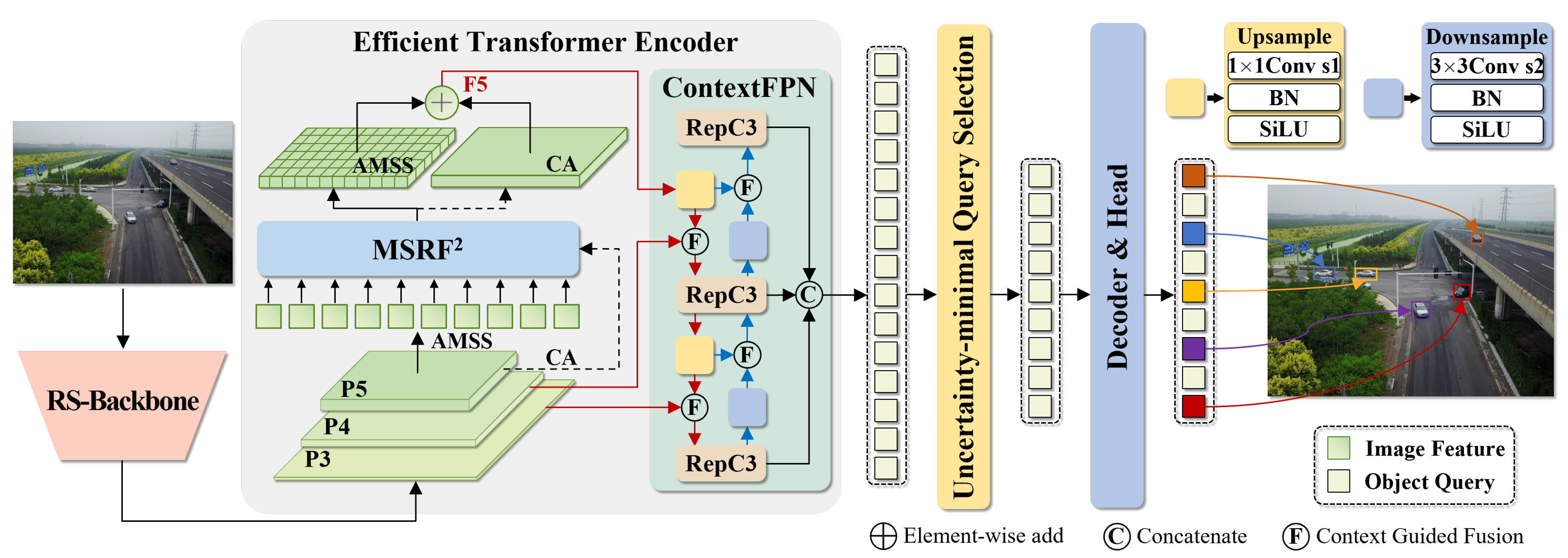
3.1. Overall Architecture
3.2. Encoder for Dynamic Multi-Scale Context Fusion
3.2.1. RT-DETR Encoder
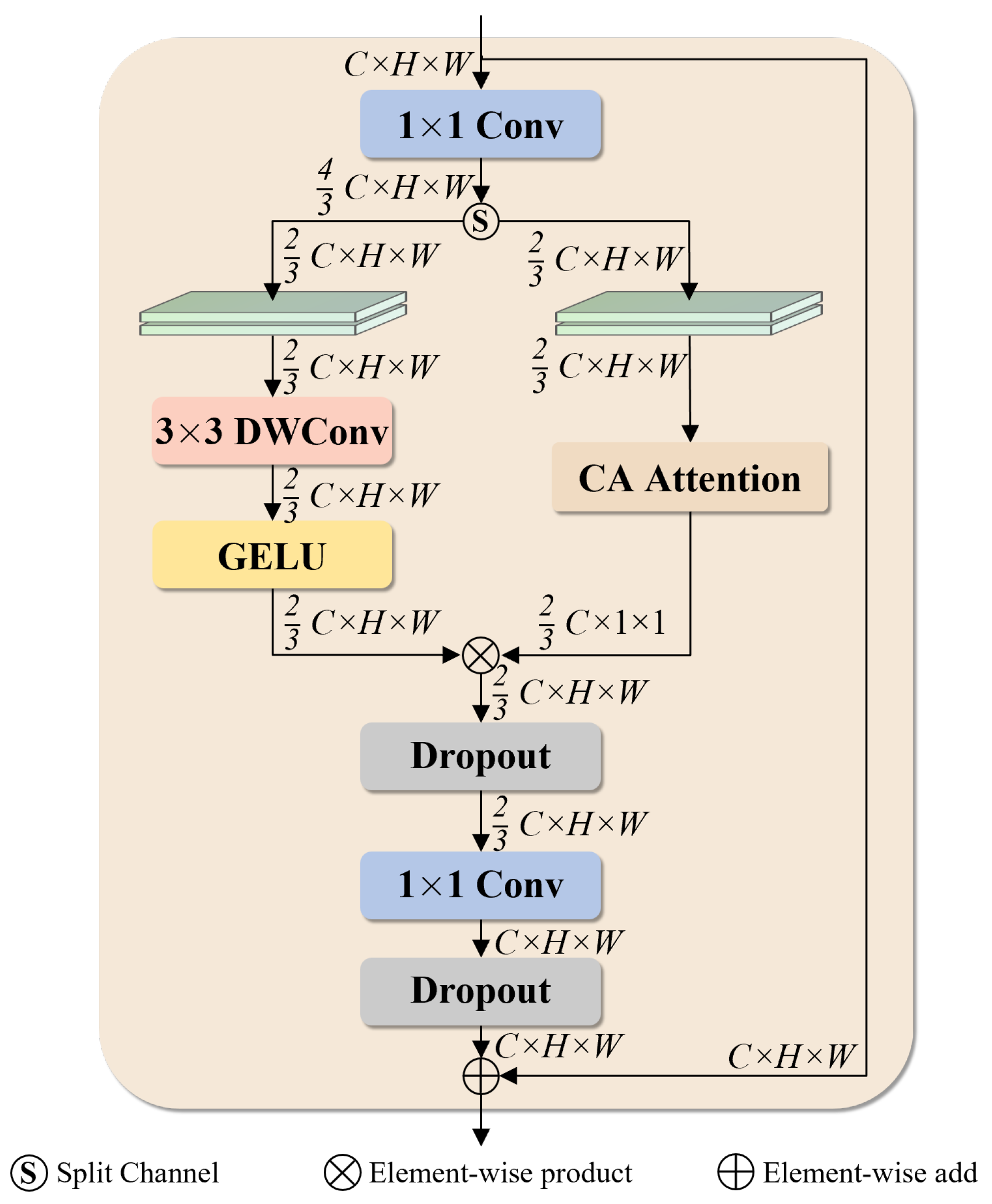
3.2.2. MSRF2 Module
3.3. Lighter and Stronger RS-Backbone
3.3.1. From ResNet to CSPDarknet
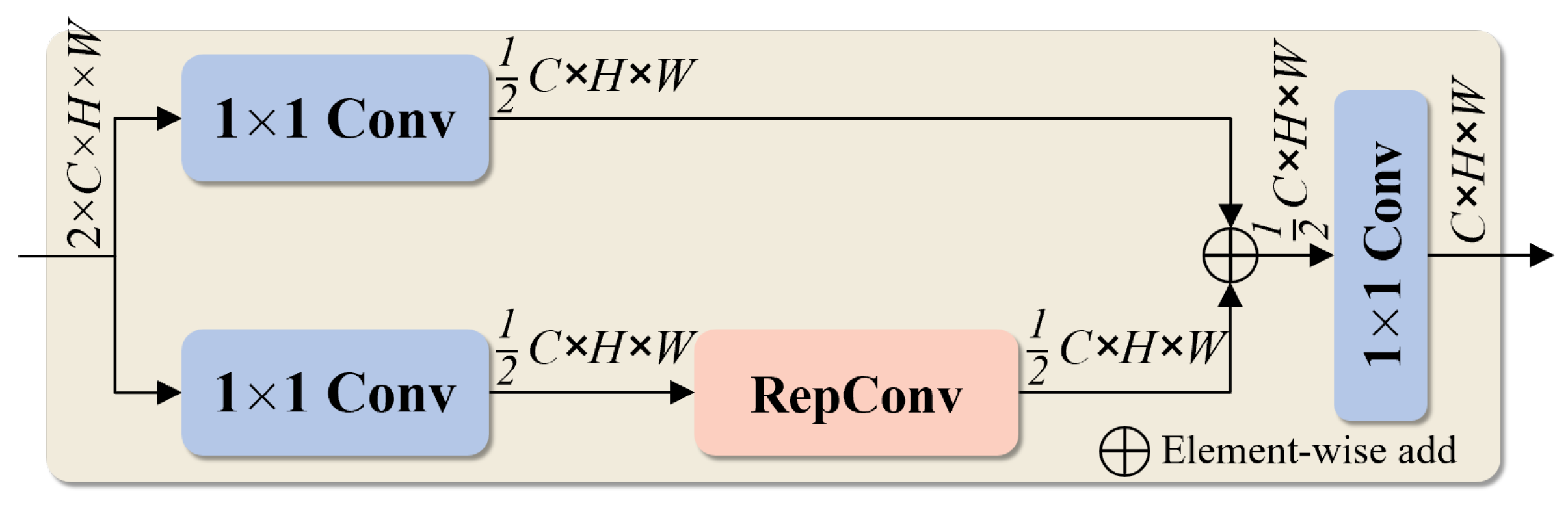
3.3.2. GMSC Block
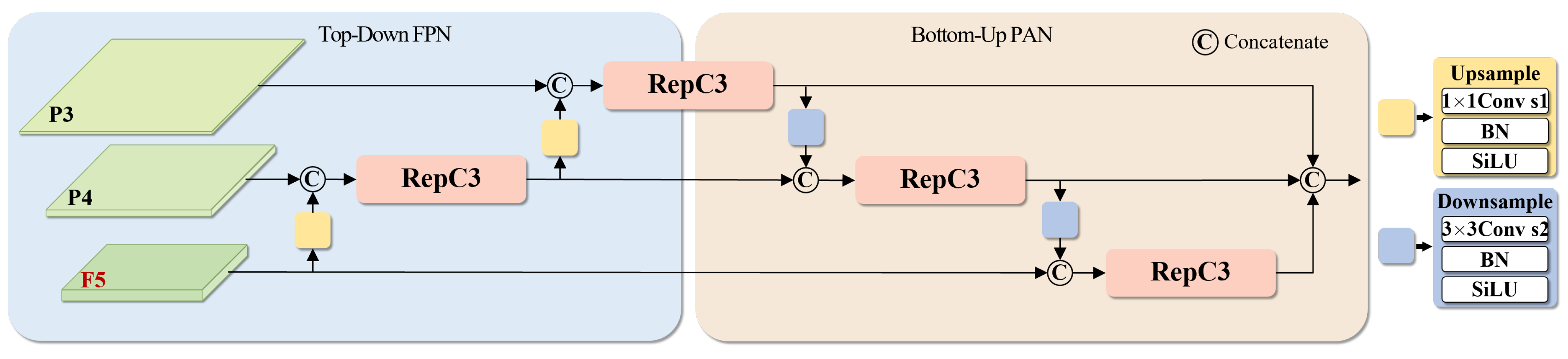
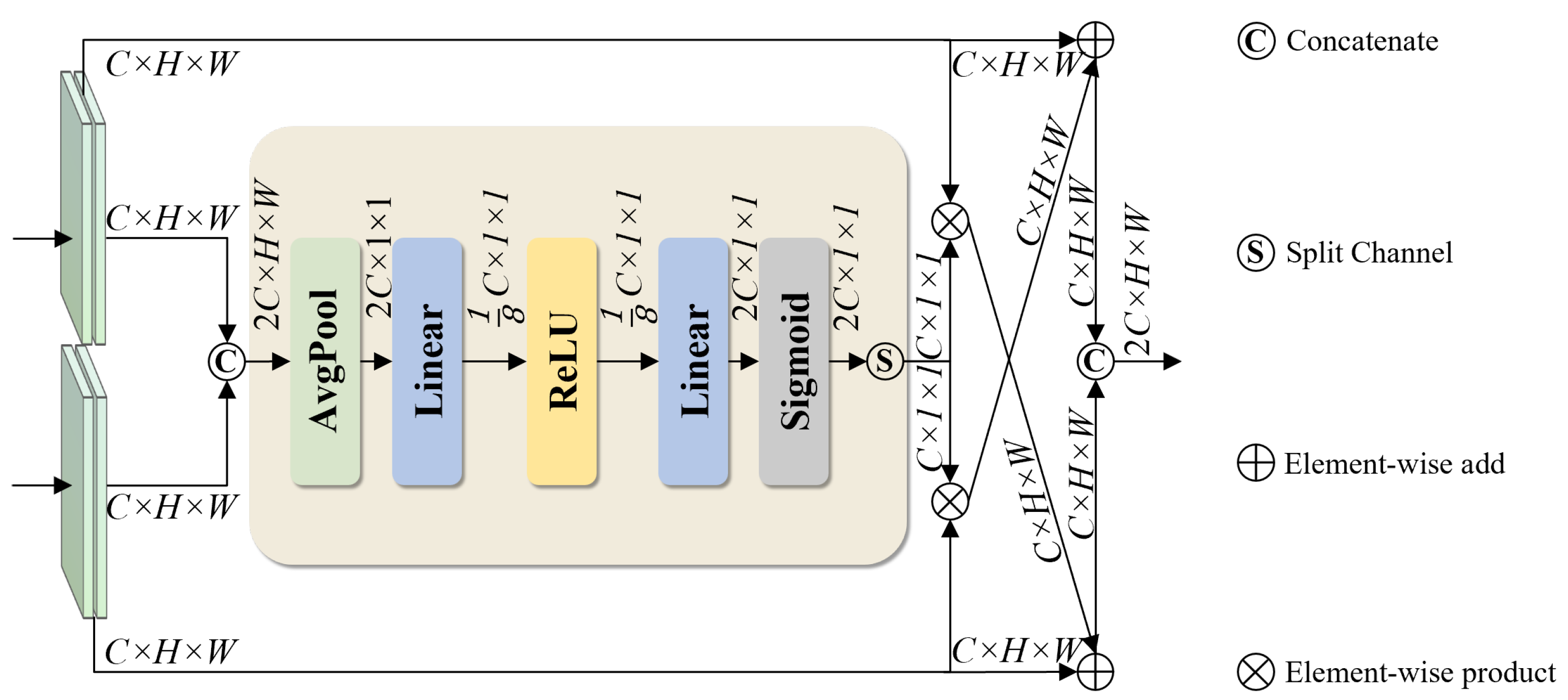
3.4. Context-Guided Feature Fusion Network
3.4.1. RT-DETR Feature Fusion Network
3.4.2. CGF Module
4. Experiments
4.1. Datasets
4.2. Experimental Configuration and Evaluation Metrics
4.2.1. Experimental Configuration
- CPU: 13th Gen Intel® CoreTM i7-13700K @ 3.40 GHz (Intel, Santa Clara, CA, USA).
- GPU: NVIDIA GeForce RTX 4090 with 24 GB GDDR6X memory (NVIDIA, Santa Clara, CA, USA).
4.2.2. Evaluation Metrics
4.3. Experimental Evaluation of Encoder
4.3.1. The Optimal Configuration of the MSRF2 Module
4.3.2. Comparison Between MSRF2 and Other Encoders
4.4. Experimental Evaluation of Backbone
4.4.1. The Optimal Configuration of the GMSC Block
4.4.2. Comparison Between GMSC-Based RS-Backbone and Other Backbone
4.5. Experimental Evaluation of Neck
4.5.1. The Optimal Configuration of the CGF Module
4.5.2. Comparison Between CGF-Based ContextFPN and Other FPN
4.6. Ablation Experiment
4.7. Comparison Experiment
4.8. Visualization Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khelifi, L.; Mignotte, M. Deep learning for change detection in remote sensing images: Comprehensive review and meta-analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, T.; Wang, G.; Zhu, P.; Tang, X.; Jia, X.; Jiao, L. Remote sensing object detection meets deep learning: A metareview of challenges and advances. IEEE Geosci. Remote Sens. Mag. 2023, 11, 8–44. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the 2020 European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: DETR with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Cheng, R. A survey: Comparison between Convolutional Neural Network and YOLO in image identification. In Proceedings of the 2020 Journal of Physics: Conference Series, Virtual, 3–5 September 2020; p. 012139. [Google Scholar]
- Li, Y.; Miao, N.; Ma, L.; Shuang, F.; Huang, X. Transformer for object detection: Review and benchmark. Eng. Appl. Artif. Intell. 2023, 126, 107021. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Zhang, H.; Liu, K.; Gan, Z.; Zhu, G.N. UAV-DETR: Efficient End-to-End Object Detection for Unmanned Aerial Vehicle Imagery. arXiv 2025, arXiv:2501.01855. [Google Scholar]
- Min, L.; Dou, F.; Zhang, Y.; Shao, D.; Li, L.; Wang, B. CM-YOLO: Context Modulated Representation Learning for Ship Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4202414. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 431–435. [Google Scholar] [CrossRef]
- Yi, H.; Liu, B.; Zhao, B.; Liu, E. Small object detection algorithm based on improved YOLOv8 for remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1734–1747. [Google Scholar] [CrossRef]
- Gao, T.; Li, Z.; Wen, Y.; Chen, T.; Niu, Q.; Liu, Z. Attention-free global multiscale fusion network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5603214. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef]
- Sun, H.; Bai, J.; Yang, F.; Bai, X. Receptive-field and direction induced attention network for infrared dim small target detection with a large-scale dataset IRDST. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5000513. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-guided pyramid context networks for detecting infrared small target under complex background. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 11963–11975. [Google Scholar]
- Liu, S.; Chen, T.; Chen, X.; Chen, X.; Xiao, Q.; Wu, B.; Kärkkäinen, T.; Pechenizkiy, M.; Mocanu, D.; Wang, Z. More convnets in the 2020s: Scaling up kernels beyond 51 × 51 using sparsity. arXiv 2022, arXiv:2207.03620. [Google Scholar]
- Chen, H.; Chu, X.; Ren, Y.; Zhao, X.; Huang, K. PeLk: Parameter-efficient large kernel convnets with peripheral convolution. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 5557–5567. [Google Scholar]
- Gao, R. Rethinking dilated convolution for real-time semantic segmentation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 4675–4684. [Google Scholar]
- Munir, M.; Rahman, M.M.; Marculescu, R. RapidNet: Multi-Level Dilated Convolution Based Mobile Backbone. In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2025; pp. 8302–8312. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 16794–16805. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the 2017 International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 11976–11986. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Hu, Y.; Tian, S.; Ge, J. Hybrid convolutional network combining multiscale 3D depthwise separable convolution and CBAM residual dilated convolution for hyperspectral image classification. Remote Sens. 2023, 15, 4796. [Google Scholar] [CrossRef]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, Z.; Wang, C.; Zhao, J.; Huang, L. RCCT-ASPPNet: Dual-encoder remote image segmentation based on transformer and ASPP. Remote Sens. 2023, 15, 379. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and multiscale transformer fusion network for remote-sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 13906–13915. [Google Scholar]
- Deng, L.; Yang, M.; Li, T.; He, Y.; Wang, C. RFBNet: Deep multimodal networks with residual fusion blocks for RGB-D semantic segmentation. arXiv 2019, arXiv:1907.00135. [Google Scholar]
- Wang, J.; Li, X.; Zhou, L.; Chen, J.; He, Z.; Guo, L.; Liu, J. Adaptive receptive field enhancement network based on attention mechanism for detecting the small target in the aerial image. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–18. [Google Scholar] [CrossRef]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density map guided object detection in aerial images. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 190–191. [Google Scholar]
- Duan, C.; Wei, Z.; Zhang, C.; Qu, S.; Wang, H. Coarse-grained density map guided object detection in aerial images. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2789–2798. [Google Scholar]
- Huang, Y.; Chen, J.; Huang, D. UFPMP-Det: Toward accurate and efficient object detection on drone imagery. In Proceedings of the 2022 AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 1026–1033. [Google Scholar]
- Li, Z.; Lian, S.; Pan, D.; Wang, Y.; Liu, W. AD-Det: Boosting Object Detection in UAV Images with Focused Small Objects and Balanced Tail Classes. Remote Sens. 2025, 17, 1556. [Google Scholar] [CrossRef]
- Liu, C.; Gao, G.; Huang, Z.; Hu, Z.; Liu, Q.; Wang, Y. YOLC: You only look clusters for tiny object detection in aerial images. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13863–13875. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. Squeezenext: Hardware-aware neural network design. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1638–1647. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNetv2: Practical guidelines for efficient cnn architecture design. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 2019 International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Tan, M.; Le, Q. EfficientNetv2: Smaller models and faster training. In Proceedings of the 2021 International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Virtual, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Tang, S.; Zhang, S.; Fang, Y. HIC-YOLOv5: Improved YOLOv5 for small object detection. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 6614–6619. [Google Scholar]
- Xiao, Y.; Xu, T.; Xin, Y.; Li, J. FBRT-YOLO: Faster and Better for Real-Time Aerial Image Detection. In Proceedings of the 2025 AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 25–27 February 2025; pp. 8673–8681. [Google Scholar]
- Li, C.; Zhao, R.; Wang, Z.; Xu, H.; Zhu, X. RemDet: Rethinking Efficient Model Design for UAV Object Detection. In Proceedings of the 2025 AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 25–27 February 2025; pp. 4643–4651. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Qi, S.; Song, X.; Shang, T.; Hu, X.; Han, K. MSFE-YOLO: An improved yolov8 network for object detection on drone view. IEEE Geosci. Remote. Sens. Lett. 2024, 21, 6013605. [Google Scholar] [CrossRef]
- Min, L.; Fan, Z.; Lv, Q.; Reda, M.; Shen, L.; Wang, B. YOLO-DCTI: Small object detection in remote sensing base on contextual transformer enhancement. Remote Sens. 2023, 15, 3970. [Google Scholar] [CrossRef]
- Zhang, Z. Drone-YOLO: An efficient neural network method for target detection in drone images. Drones 2023, 7, 526. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 13668–13677. [Google Scholar]
- Yin, N.; Liu, C.; Tian, R.; Qian, X. SDPDet: Learning scale-separated dynamic proposals for end-to-end drone-view detection. IEEE Trans. Multimed. 2024, 26, 7812–7822. [Google Scholar] [CrossRef]
- Wang, M.; Yang, W.; Wang, L.; Chen, D.; Wei, F.; KeZiErBieKe, H.; Liao, Y. FE-YOLOv5: Feature enhancement network based on YOLOv5 for small object detection. J. Vis. Commun. Image Represent. 2023, 90, 103752. [Google Scholar] [CrossRef]
- Xiao, Y.; Xu, T.; Yu, X.; Fang, Y.; Li, J. A Lightweight Fusion Strategy with Enhanced Inter-layer Feature Correlation for Small Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4708011. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Du, S.; Liang, X.; Wu, K.; Tian, Y.; Liu, Y.; Jian, L. Multiple scales fusion and query matching stabilization for detection with transformer. Eng. Appl. Artif. Intell. 2025, 144, 110047. [Google Scholar] [CrossRef]
- Dong, Y.; Cordonnier, J.B.; Loukas, A. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. In Proceedings of the 2021 International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 2793–2803. [Google Scholar]
- Liu, S.; Cao, J.; Yang, R.; Wen, Z. Key phrase aware transformer for abstractive summarization. Inf. Process. Manag. 2022, 59, 102913. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 4905–4913. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, H.; Yoo, Y.; Seo, G.; Han, D.; Yun, S.; Kwak, N. C3: Concentrated-comprehensive convolution and its application to semantic segmentation. arXiv 2018, arXiv:1812.04920. [Google Scholar]
- Shi, D. TransNext: Robust foveal visual perception for vision transformers. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 17773–17783. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making vgg-style convnets great again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 14420–14430. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 4794–4803. [Google Scholar]
- Pan, Z.; Cai, J.; Zhuang, B. Fast vision transformers with hilo attention. Adv. Neural Inf. Process. Syst. 2022, 35, 14541–14554. [Google Scholar]
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.H.; Khan, F.S. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 17425–17436. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal models for the mobile ecosystem. In Proceedings of the 2024 European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–3 October 2024; pp. 78–96. [Google Scholar]
- Yang, Z.; Guan, Q.; Zhao, K.; Yang, J.; Xu, X.; Long, H.; Tang, Y. Multi-branch Auxiliary Fusion YOLO with Re-parameterization Heterogeneous Convolutional for Accurate Object Detection. In Proceedings of the 2024 Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Urumqi, China, 18–20 October 2024; pp. 492–505. [Google Scholar]
- Chen, Y.; Zhang, C.; Chen, B.; Huang, Y.; Sun, Y.; Wang, C.; Fu, X.; Dai, Y.; Qin, F.; Peng, Y.; et al. Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases. Comput. Biol. Med. 2024, 170, 107917. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wang, J.; Yu, J.; He, Z. ARFP: A novel adaptive recursive feature pyramid for object detection in aerial images. Appl. Intell. 2022, 52, 12844–12859. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Ma, Y.; Chai, L.; Jin, L. Scale decoupled pyramid for object detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4704314. [Google Scholar] [CrossRef]
- Zeng, W.; Wu, P.; Wang, J.; Hu, G.; Zhao, J. C4D-YOLOv8: Improved YOLOv8 for object detection on drone-captured images. Signal Image Video Process. 2025, 19, 862. [Google Scholar] [CrossRef]
- Luo, W.; Yuan, S. Enhanced YOLOv8 for small-object detection in multiscale UAV imagery: Innovations in detection accuracy and efficiency. Digit. Signal Process. 2025, 158, 104964. [Google Scholar] [CrossRef]
- Lv, W.; Zhao, Y.; Chang, Q.; Huang, K.; Wang, G.; Liu, Y. RT-DETRv2: Improved baseline with bag-of-freebies for real-time detection transformer. arXiv 2024, arXiv:2407.17140. [Google Scholar]
- Peng, Y.; Li, H.; Wu, P.; Zhang, Y.; Sun, X.; Wu, F. D-FINE: Redefine regression Task in DETRs as Fine-grained distribution refinement. arXiv 2024, arXiv:2410.13842. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A global-local self-adaptive network for drone-view object detection. IEEE Trans. Image Process. 2020, 30, 1556–1569. [Google Scholar] [CrossRef]
- Liao, H.; Tang, Y.; Liu, Y.; Luo, X. ViDroneNet: An efficient detector specialized for Target Detection in Aerial Images. Digit. Signal Process. 2025, 164, 105270. [Google Scholar] [CrossRef]
- Alqahtani, D.K.; Cheema, M.A.; Toosi, A.N. Benchmarking deep learning models for object detection on edge computing devices. In Proceedings of the 2024 International Conference on Service-Oriented Computing, Berlin, Germany, 4–8 November 2024; pp. 142–150. [Google Scholar]
- Bi, H.; Feng, Y.; Tong, B.; Wang, M.; Yu, H.; Mao, Y.; Chang, H.; Diao, W.; Wang, P.; Yu, Y.; et al. RingMoE: Mixture-of-Modality-Experts Multi-Modal Foundation Models for Universal Remote Sensing Image Interpretation. arXiv 2025, arXiv:2504.03166. [Google Scholar]
- Diao, W.; Yu, H.; Kang, K.; Ling, T.; Liu, D.; Feng, Y.; Bi, H.; Ren, L.; Li, X.; Mao, Y.; et al. RingMo-Aerial: An Aerial Remote Sensing Foundation Model with Affine Transformation Contrastive Learning. arXiv 2024, arXiv:2409.13366. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | YOLO Series | RT-DETR Series |
|---|---|---|
| Input size | 640 × 640 | 640 × 640 |
| Batch size | 8 | 8 |
| Training epochs | 300 | 300 |
| Optimizer | SGD | AdamW |
| Initial learning rate | 0.01 | 0.0001 |
| Learning rate factor | 0.01 | 0.01 |
| Momentum | 0.937 | 0.9 |
| Warmup steps | 2000 | 2000 |
| Dilated Rates | mAPs (%↑) | mAP50 (%↑) | mAP50-95 (%↑) |
|---|---|---|---|
| (1, 3, 5) | 21.4 | 50.3 | 31.1 |
| (3, 5, 7) | 21.6 | 52.1 | 32.2 |
| (5, 7, 9) | 19.9 | 50.6 | 31.2 |
| Module | mAP50 (%↑) | mAP50-95 (%↑) | Params (M↓) | FLOPs (G↓) |
|---|---|---|---|---|
| Baseline (AIFI) | 47.2 | 28.7 | 20.2 | 57.0 |
| CGA [84] | 44.7 | 26.7 | 19.8 | 57.4 |
| DAT [85] | 46.5 | 28.1 | 20.0 | 57.5 |
| HiLo [86] | 47.5 | 29.1 | 19.9 | 57.4 |
| EAA [87] | 48.2 | 29.4 | 20.0 | 57.5 |
| MSRF2 (Ours) | 49.3 | 29.9 | 20.0 | 57.5 |
| Model Combination | mAP50 (%↑) | mAP50-95 (%↑) | Params (M↓) | FLOPs (G↓) |
|---|---|---|---|---|
| A | 49.3 | 30.2 | 15.7 | 53.1 |
| B | 51.0 | 31.5 | 15.3 | 49.0 |
| C | 50.1 | 30.7 | 15.3 | 48.7 |
| D | 52.1 | 32.2 | 13.8 | 44.6 |
| Module | mAP50 (%↑) | mAP50-95 (%↑) | Params (M↓) | FLOPs (G↓) |
|---|---|---|---|---|
| Baseline (ResNet-18) | 49.3 | 29.9 | 20.0 | 57.5 |
| SwinTransformer-T [88] | 39.7 | 22.7 | 36.5 | 97.5 |
| EfficientVit-M0 [84] | 43.1 | 24.1 | 10.7 | 28.0 |
| LSKNet-T [27] | 44.7 | 26.8 | 12.6 | 37.7 |
| Mobilenetv4-S [89] | 46.5 | 27.9 | 11.4 | 48.8 |
| YOLOv8-S-Backbone | 48.9 | 29.8 | 15.5 | 53.1 |
| RS-Backbone (Ours) | 51.4 | 31.8 | 13.6 | 44.6 |
| Fusion Mode | mAP50 (%↑) | mAP50-95 (%↑) | Params (M↓) | FLOPs (G↓) |
|---|---|---|---|---|
| A | 51.4 | 31.8 | 13.6 | 44.6 |
| B | 48.4 | 29.4 | 13.4 | 43.3 |
| C | 51.2 | 31.5 | 13.8 | 44.6 |
| D | 50.3 | 31.0 | 13.8 | 44.6 |
| E | 52.1 | 32.2 | 13.8 | 44.6 |
| Module | mAP50 (%↑) | mAP50-95 (%↑) | Params (M↓) | FLOPs (G↓) |
|---|---|---|---|---|
| Baseline (CCFF) | 51.4 | 31.8 | 13.6 | 44.6 |
| BiFPN [61] | 46.6 | 27.9 | 14.2 | 53.8 |
| MAFPN [90] | 46.9 | 27.8 | 17.2 | 44.9 |
| HSFPN [91] | 50.0 | 30.6 | 11.9 | 44.0 |
| ContextFPN (Ours) | 52.1 | 32.2 | 13.8 | 44.6 |
| MSRF2 | GMSC | CGF | mAP50 | mAP50-95 | Params | FLOPs | |
|---|---|---|---|---|---|---|---|
| MSRF2 | AGConv | (%↑) | (%↑) | (M↓) | (G↓) | ||
| - | - | - | - | 47.2 | 28.7 | 20.2 | 57.0 |
| ✓ | - | - | - | 49.3 | 29.9 | 20.0 | 57.5 |
| - | ✓ | - | - | 47.4 | 28.7 | 15.1 | 48.8 |
| - | - | ✓ | - | 47.0 | 28.6 | 15.1 | 48.6 |
| - | ✓ | ✓ | - | 49.5 | 30.2 | 13.6 | 44.4 |
| - | - | - | ✓ | 47.9 | 29.6 | 20.1 | 57.3 |
| ✓ | ✓ | - | - | 50.4 | 31.1 | 15.2 | 48.9 |
| ✓ | - | ✓ | - | 49.6 | 30.3 | 15.2 | 48.7 |
| ✓ | ✓ | ✓ | - | 51.4 | 31.8 | 13.6 | 44.6 |
| ✓ | - | - | ✓ | 49.5 | 30.5 | 20.1 | 57.5 |
| - | - | ✓ | ✓ | 47.7 | 29.1 | 15.2 | 48.6 |
| - | ✓ | ✓ | ✓ | 50.0 | 30.7 | 13.7 | 44.4 |
| ✓ | ✓ | ✓ | ✓ | 52.1 | 32.2 | 13.8 | 44.6 |
| Model | Publication | Imgsize | Detection Precision | Model Complexity | ||
|---|---|---|---|---|---|---|
| mAP50 | mAP50-95 | Params | FLOPs | |||
| (%)↑ | (%)↑ | (M)↓ | (G)↓ | |||
| Two-stage methods | ||||||
| Faster R-CNN [92] | NeurIPS 2015 | 640 × 640 | 31.0 | 18.2 | 41.2 | 127.0 |
| ARFP [93] | Appl Intell | 1333 × 800 | 33.9 | 20.4 | 42.7 | 193.8 |
| EMA [94] | ICASSP 2023 | 640 × 640 | 49.7 | 30.4 | 91.2 | 246.7 |
| SDP [95] | TGRS | 800 × 800 | 52.5 | 30.2 | 96.7 | - |
| One-stage methods | ||||||
| YOLOv8-M | - | 640 × 640 | 35.8 | 20.6 | 25.9 | 78.9 |
| YOLOv10-M [4] | NeurIPS 2024 | 640 × 640 | 44.1 | 26.4 | 15.4 | 59.1 |
| YOLOv11-M [5] | arXiv 2024 | 640 × 640 | 44.6 | 26.6 | 20.1 | 68.0 |
| YOLOv12-M [6] | arXiv 2025 | 640 × 640 | 43.1 | 26.3 | 20.2 | 67.5 |
| HIC-YOLOv5 [55] | ICRA 2024 | 640 × 640 | 44.3 | 26.0 | 10.5 | 31.2 |
| MSFE-YOLO-L [62] | GRSL 2024 | 640 × 640 | 46.8 | 29.0 | 41.6 | 160.2 |
| YOLO-DCTI [63] | Remote Sensing | 1024 × 1024 | 49.8 | 27.4 | 37.7 | 280.0 |
| Drone-YOLO-L [64] | Drones | 640 × 640 | 51.3 | 31.1 | 76.2 | - |
| C4D-YOLOv8 [96] | SIVP | 640 × 640 | 45.8 | 27.9 | 16.5 | 66.3 |
| DyHead-SODL [97] | Digit Signal Process | 640 × 640 | 50.1 | 30.4 | 25.1 | 44.7 |
| End-to-end methods | ||||||
| DETR [7] | ECCV 2020 | 1333 × 750 | 40.1 | 24.1 | 40.0 | 187.1 |
| Deformable DETR [8] | ICLR 2020 | 1333 × 800 | 43.1 | 27.1 | 40.2 | 172.5 |
| RT-DETR-R18 [13] | CVPR 2024 | 640 × 640 | 47.2 | 28.7 | 20.2 | 57.0 |
| RT-DETR-R50 [13] | CVPR 2024 | 640 × 640 | 50.7 | 30.9 | 41.8 | 133.2 |
| UAV-DETR-R50 [14] | arXiv 2025 | 640 × 640 | 51.1 | 31.5 | 42.0 | 170 |
| Ours | ||||||
| VRF-DETR | - | 640 × 640 | 52.1 | 32.2 | 13.8 | 44.6 |
| Model | Detection Precision | Model Complexity | |||
|---|---|---|---|---|---|
| mAPs | mAP50 | mAP50-95 | Params | FLOPs | |
| (%)↑ | (%)↑ | (%)↑ | (M)↓ | (G)↓ | |
| One-stage methods | |||||
| YOLOv8-M | 9.0 | 33.2 | 19.0 | 25.9 | 78.9 |
| YOLOv10-M [4] | 9.7 | 34.5 | 19.5 | 15.4 | 59.1 |
| YOLOv11-M [5] | 9.8 | 35.0 | 20.3 | 20.1 | 68.0 |
| YOLOv12-M [6] | 9.4 | 33.6 | 19.2 | 20.2 | 67.5 |
| YOLOX-M [3] | 9.9 | 34.2 | 21.1 | 25.3 | 73.8 |
| FBRT-YOLO-M [56] | 9.4 | 34.4 | 19.6 | 7.36 | 58.7 |
| End-to-end methods | |||||
| RT-DETR-R18 [13] | 13.9 | 33.3 | 18.5 | 20.2 | 57.0 |
| RT-DETRv2-R18 [98] | 12.7 | 39.1 | 22.2 | 20.0 | 60.0 |
| D-Fine-M [99] | 13.0 | 39.6 | 22.1 | 19.2 | 56.4 |
| Ours | |||||
| VRF-DETR | 15.5 | 39.9 | 23.3 | 13.8 | 44.6 |
| Model | Publication | Imgsize | Detection Precision | Model Complexity | ||
|---|---|---|---|---|---|---|
| mAP50 | mAP50-95 | Params | FLOPs | |||
| (%)↑ | (%)↑ | (M)↓ | (G)↓ | |||
| Two-stage methods | ||||||
| Faster R-CNN [92] | NeurIPS 2015 | 1024 × 540 | 30.7 | 16.9 | 41.2 | 171.3 |
| Cascade R-CNN [100] | CVPR 2018 | 1024 × 540 | 30.5 | 17.1 | 69.3 | 193.1 |
| ClusDet [40] | ICCV 2019 | 1000 × 600 | 26.5 | 13.7 | 181.0 | 1647.3 |
| DMNet [41] | CVPRW 2020 | 1000 × 600 | 24.6 | 14.7 | 228.4 | 4492.2 |
| GLSAN [101] | TIP 2020 | 1000 × 600 | 28.1 | 17.0 | 590.9 | 2186.8 |
| CDMNet [42] | ICCV 2021 | 1000 × 600 | 29.1 | 16.8 | - | - |
| UFPMP-Det [43] | AAAI 2022 | 1000 × 600 | 38.7 | 24.6 | 32.6 | 132.0 |
| AD-Det [44] | Remote Sensing | 1024 × 540 | 34.2 | 20.1 | 64.1 | 1072.1 |
| RemDet-L [57] | AAAI 2025 | 640 × 640 | 34.5 | 20.6 | 35.3 | 67.4 |
| One-stage methods | ||||||
| YOLOv5-M | - | 640 × 640 | 29.8 | 17.2 | 25.1 | 64.2 |
| YOLOv8-M | - | 640 × 640 | 31.0 | 18.8 | 25.9 | 78.9 |
| QueryDet [65] | CVPR 2022 | 640 × 640 | 27.2 | 14.3 | 32.3 | 125.4 |
| SDPDet [66] | TMM | 1024 × 540 | 32.0 | 20.0 | - | 139.7 |
| YOLC [45] | TITS | 1024 × 640 | 30.9 | 19.3 | 38.9 | 151 |
| FBRT-YOLO-L [56] | AAAI 2025 | - | 31.1 | 18.4 | 14.6 | 119.2 |
| ViDroneNet [102] | Digit Signal Process | 1080 × 540 | 39.2 | 23.6 | 41.98 | 100.21 |
| End-to-end methods | ||||||
| DETR [7] | ECCV 2020 | 1333 × 750 | 36.5 | 22.1 | 40.0 | 187.1 |
| Deformable DETR [8] | ICLR 2020 | 1333 × 800 | 28.4 | 17.1 | 40.2 | 172.5 |
| RT-DETR-R18 [13] | CVPR 2024 | 640 × 640 | 38.1 | 23.3 | 20.2 | 57.0 |
| Ours | ||||||
| VRF-DETR | - | 640 × 640 | 40.3 | 25.9 | 13.8 | 44.6 |
| Batch Size | Model | VisDrone2019 | UAVDT | ||
|---|---|---|---|---|---|
|
Inference Time (ms)↓ | FPS↑ |
Inference Time (ms)↓ | FPS↑ | ||
| 1 | RT-DETR-R18 [13] | 12.6 | 79.4 | 13.1 | 76.3 |
| RT-DETR-R50 [13] | 18.6 | 53.8 | 18.2 | 54.9 | |
| VRF-DETR (Ours) | 16.1 | 62.1 | 16.6 | 60.2 | |
| 8 | RT-DETR-R18 [13] | 3.3 | 303.0 | 3.5 | 285.7 |
| RT-DETR-R50 [13] | 7.1 | 140.8 | 7.1 | 140.8 | |
| VRF-DETR (Ours) | 5.7 | 175.4 | 5.4 | 185.2 | |
| 16 | RT-DETR-R18 [13] | 3.3 | 303.0 | 2.8 | 357.1 |
| RT-DETR-R50 [13] | 6.5 | 153.8 | 6.2 | 161.3 | |
| VRF-DETR (Ours) | 6.3 | 158.7 | 5.3 | 188.7 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Shi, L.; An, G. An Efficient Aerial Image Detection with Variable Receptive Fields. Remote Sens. 2025, 17, 2672. https://doi.org/10.3390/rs17152672
Liu W, Shi L, An G. An Efficient Aerial Image Detection with Variable Receptive Fields. Remote Sensing. 2025; 17(15):2672. https://doi.org/10.3390/rs17152672
Chicago/Turabian StyleLiu, Wenbin, Liangren Shi, and Guocheng An. 2025. "An Efficient Aerial Image Detection with Variable Receptive Fields" Remote Sensing 17, no. 15: 2672. https://doi.org/10.3390/rs17152672
APA StyleLiu, W., Shi, L., & An, G. (2025). An Efficient Aerial Image Detection with Variable Receptive Fields. Remote Sensing, 17(15), 2672. https://doi.org/10.3390/rs17152672