


Panoptic Plant Recognition in 3D Point Clouds: A Dual-Representation Learning Approach with the PP3D Dataset


Abstract
1. Introduction
2. Related Work
2.1. Three-Dimensional Plant Datasets
2.2. Three-Dimensional Panoptic Segmentation
3. Materials and Methods
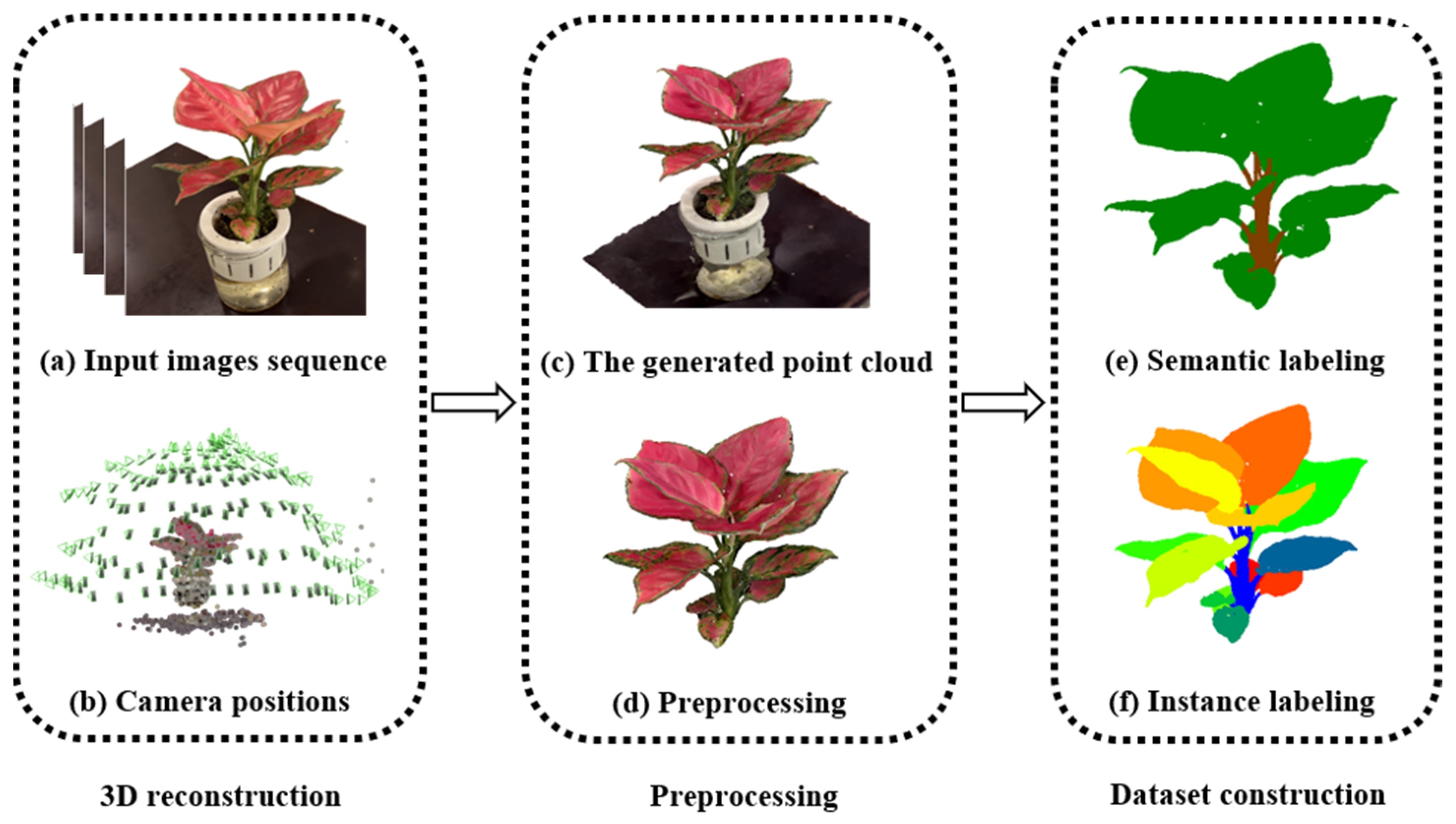
3.1. The PP3D Dataset
3.1.1. Images Acquisition
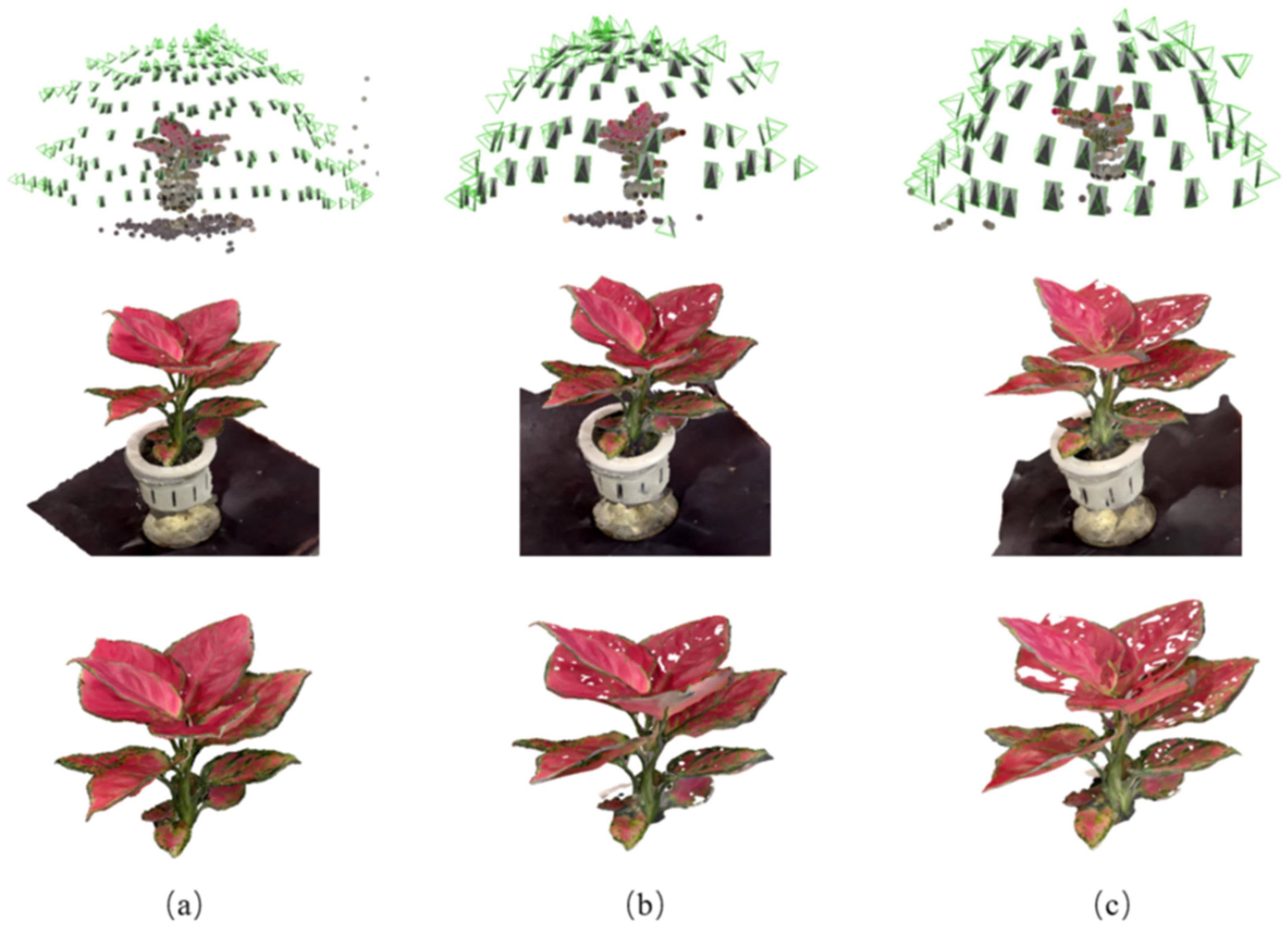
3.1.2. Three-Dimensional Point Cloud Reconstruction
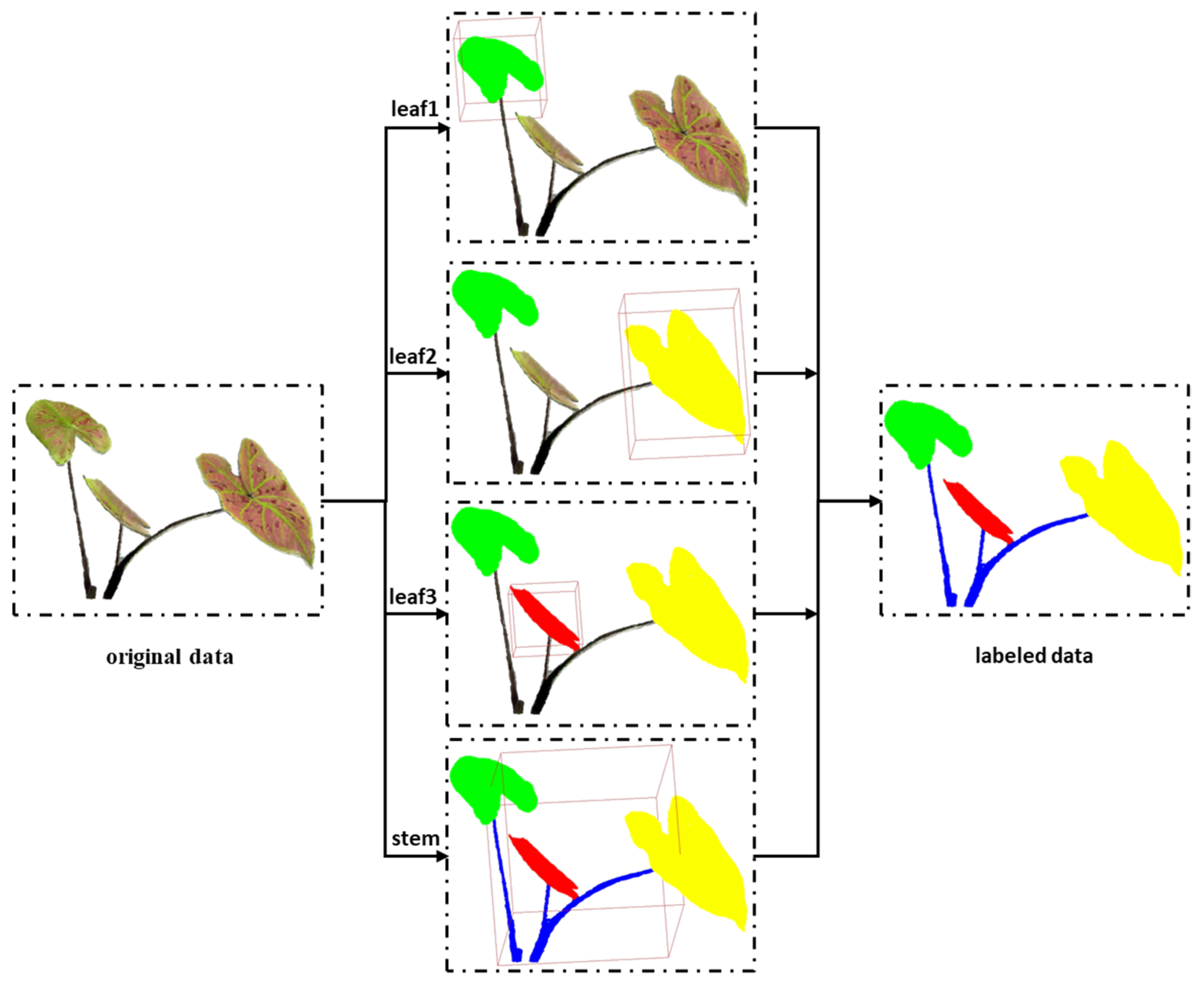
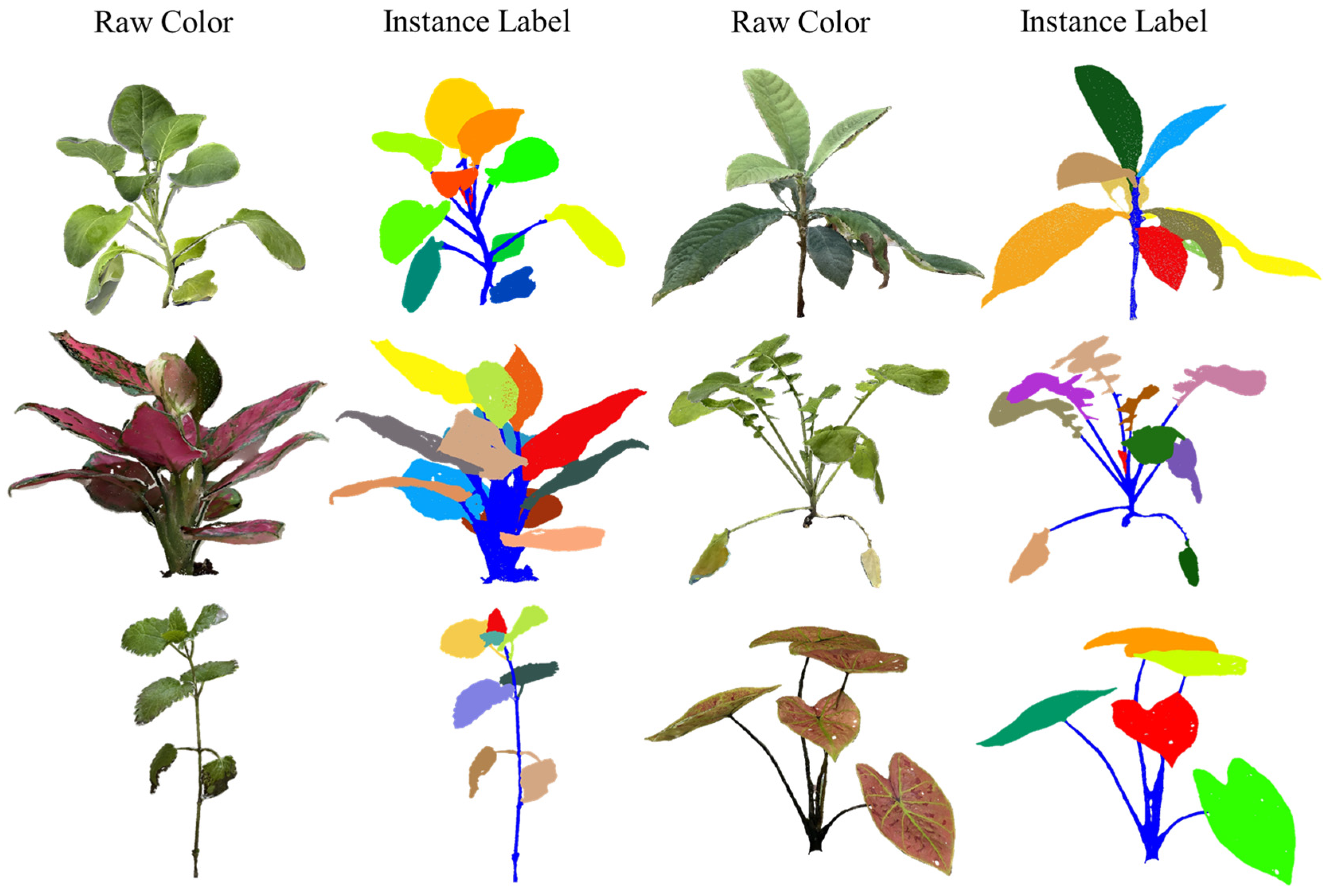
3.1.3. Point Cloud Annotation
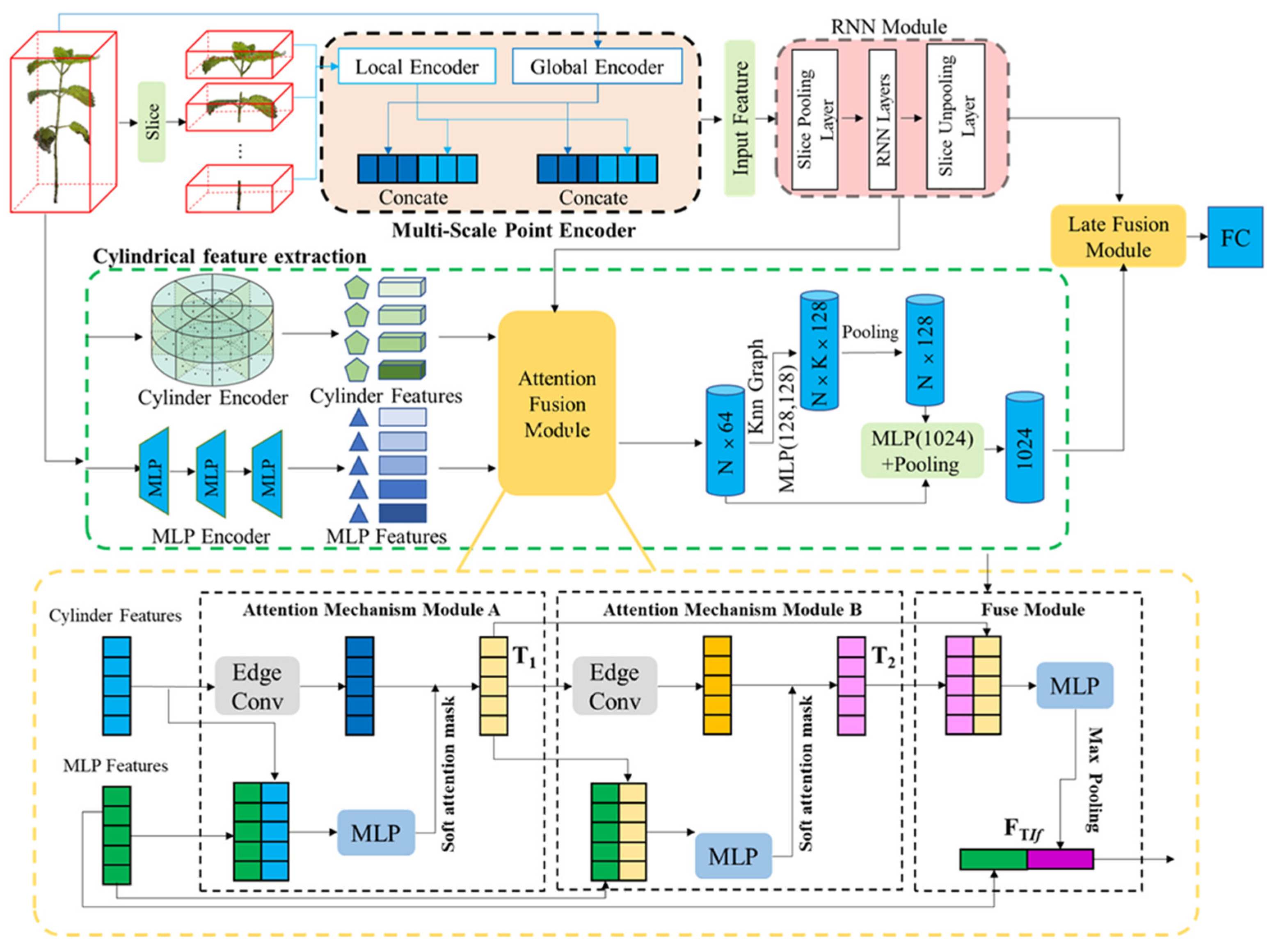
3.2. The Proposed SCNet
3.2.1. Sequential Slice Feature Extraction
3.2.2. Cylindrical Feature Extraction
3.2.3. Feature Fusion Module
4. Results and Discussion
4.1. Representative Baselines and Implementation Details
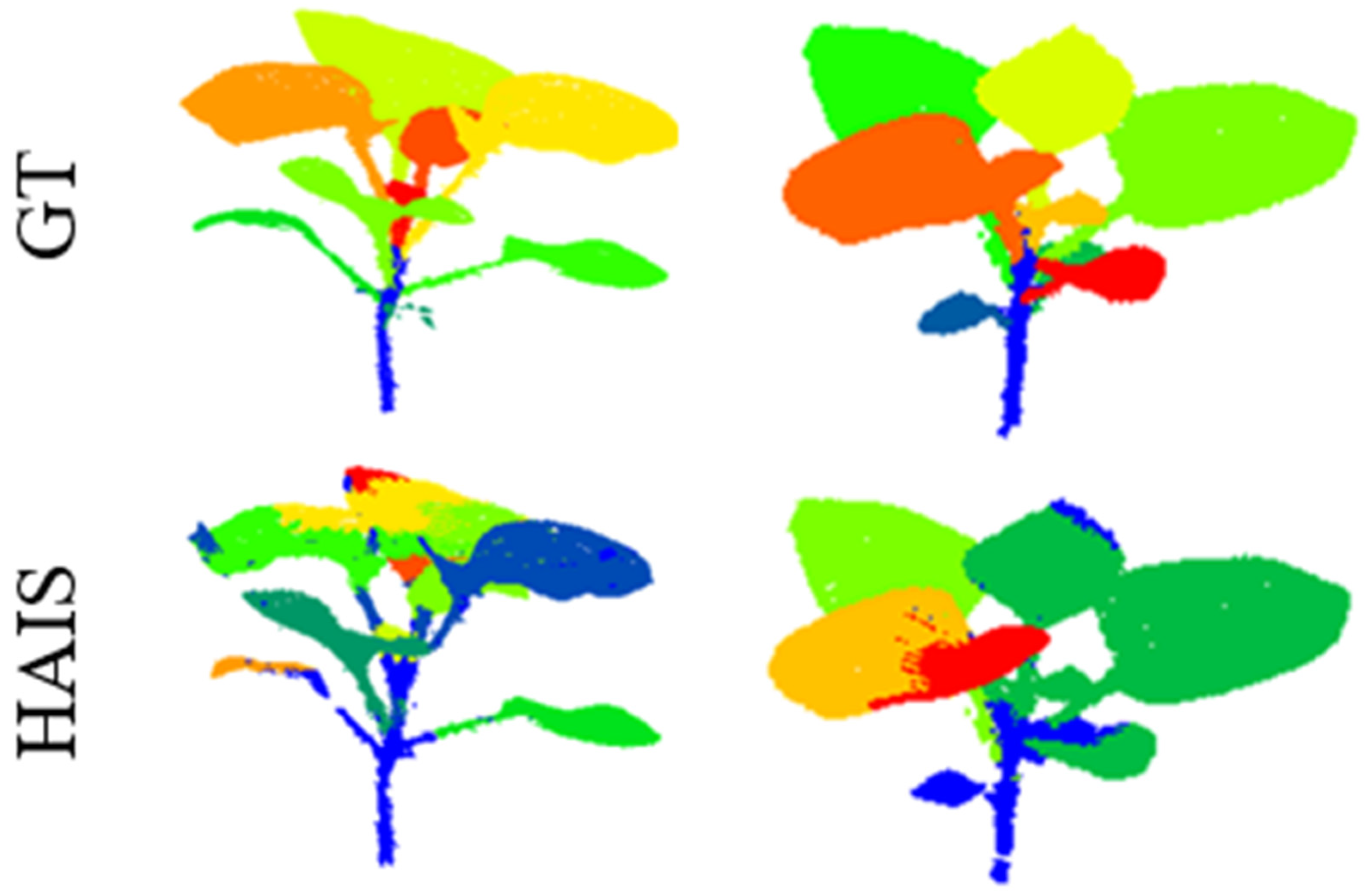
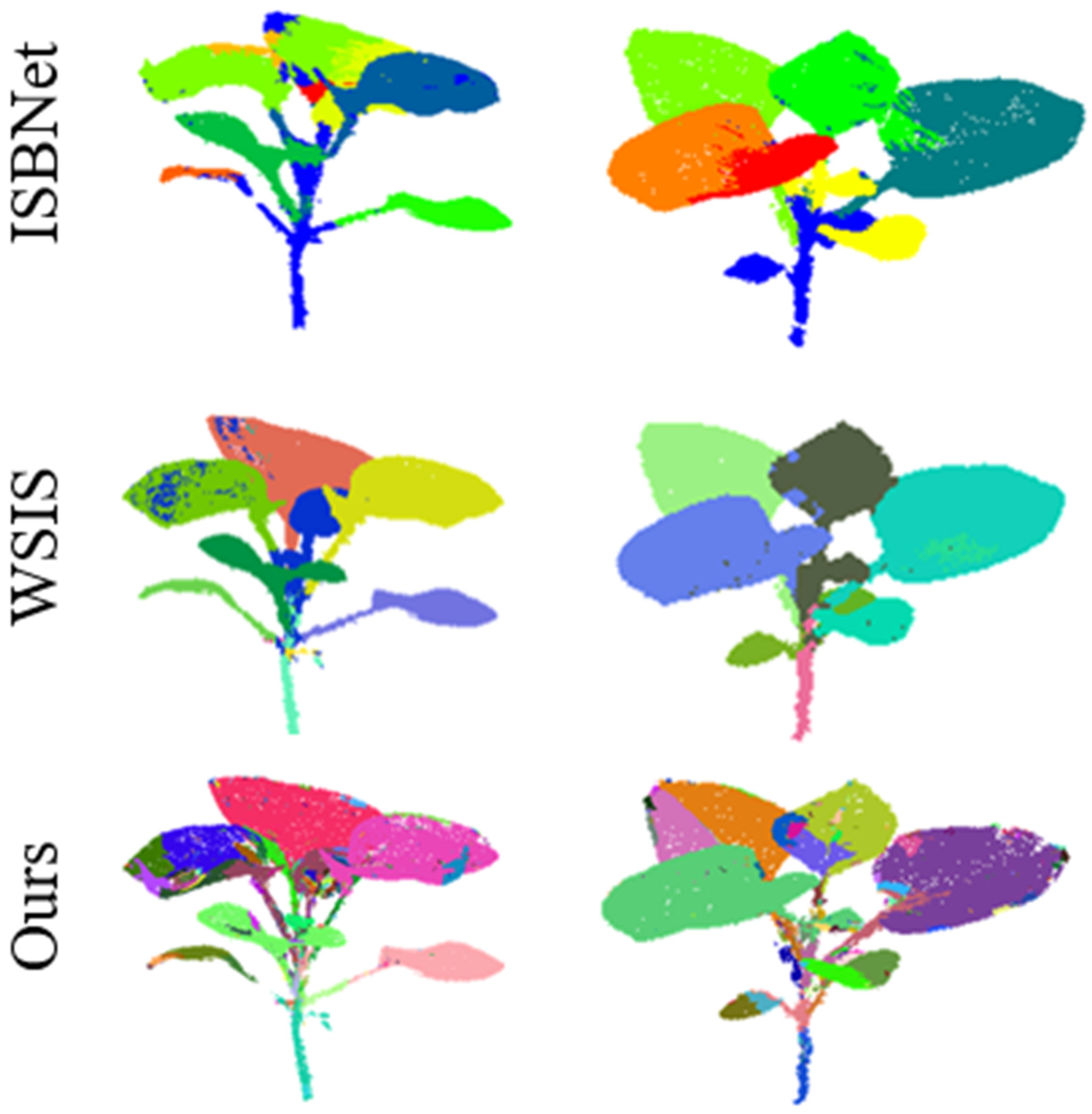
4.2. Qualitative and Quantitative Results
4.3. Experimental Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, H.; Wen, W.; Wu, S.; Guo, X. Comprehensive Review on 3D Point Cloud Segmentation in Plants. Artif. Intell. Agric. 2025, 15, 296–315. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, M.; Liu, Q. A review on multimodal communications for human-robot collaboration in 5G: From visual to tactile. Intell. Robot. 2025, 5, 579–606. [Google Scholar] [CrossRef]
- Jin, S.C.; Su, Y.J.; Wu, F.F.; Pang, S.X.; Gao, S.; Hu, T.Y.; Guo, Q.H. Stem–leaf segmentation and phenotypic trait extraction of individual maize using terrestrial LiDAR data. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1336–1346. [Google Scholar] [CrossRef]
- Hu, H.; Wang, J.; Nie, S.; Zhao, J.; Batley, J.; Edwards, D. Plant pangenomics, current practice and future direction. Agric. Commun. 2024, 2, 100039. [Google Scholar] [CrossRef]
- Li, D.; Shi, G.L.; Kong, W.J.; Wang, S.F.; Chen, Y. A leaf segmentation and phenotypic feature extraction framework for multiview stereo plant point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2321–2336. [Google Scholar] [CrossRef]
- Jiang, T.; Liu, S.; Zhang, Q.; Xu, X.; Sun, J.; Wang, Y. Segmentation of individual trees in urban MLS point clouds using a deep learning framework based on cylindrical convolution network. Int. J. Appl. Earth Obs. Geoinf. 2023, 123, 103473. [Google Scholar] [CrossRef]
- Du, R.; Ma, Z.; Xie, P.; He, Y.; Cen, H. PST: Plant segmentation transformer for 3D point clouds of rapeseed plants at the podding stage. ISPRS J. Photogramm. Remote Sens. 2023, 195, 380–392. [Google Scholar] [CrossRef]
- Salve, D.A.; Ferreyra, M.J.; Defacio, R.A.; Maydup, M.L.; Lauff, D.B.; Tambussi, E.A.; Antonietta, M. Andean maize in Argentina: Physiological effects related with altitude, genetic variation, management practices and possible avenues to improve yield. Technol. Agron. 2023, 3, 14. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9297–9307. [Google Scholar]
- Fong, W.K.; Mohan, R.; Hurtado, J.V.; Zhou, L.; Caesar, H.; Beijbom, O.; Valada, A. Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking. IEEE Robot. Autom. Lett. 2022, 7, 3795–3802. [Google Scholar] [CrossRef]
- Xiao, A.; Huang, J.; Xuan, W.; Ren, R.; Liu, K.; Guan, D.; Saddik, A.E.; Lu, S.; Xing, E.P. 3d semantic segmentation in the wild: Learning generalized models for adverse-condition point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 9382–9392. [Google Scholar]
- Hu, Q.Y.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Towards semantic segmentation of urban-scale 3D point clouds: A dataset, benchmarks and challenges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4977–4987. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2d-3d-semantic data for indoor scene understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Mo, K.; Zhu, S.; Chang, A.X.; Yi, L.; Tripathi, S.; Guibas, L.J.; Su, H. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2–8 July 2019; pp. 909–918. [Google Scholar]
- Zhu, R.; Sun, K.; Yan, Z.; Yan, X.; Yu, J.; Shi, J.; Hu, Z.; Jiang, H.; Xin, D.; Zhang, Z.; et al. Analysing the phenotype development of soybean plants using low-cost 3D reconstruction. Sci. Rep. 2020, 10, 7055. [Google Scholar] [CrossRef] [PubMed]
- Jiang, T.; Wang, Y.; Liu, S.; Zhang, Q.; Zhao, L.; Sun, J. Instance recognition of street trees from urban point clouds using a three-stage neural network. ISPRS J. Photogramm. Remote Sens. 2023, 199, 305–334. [Google Scholar] [CrossRef]
- Li, D.; Shi, G.L.; Li, J.S.; Chen, Y.L.; Zhang, S.Y.; Xiang, S.Y.; Jin, S.C. PlantNet: A dual-function point cloud segmentation network for multiple plant species. ISPRS J. Photogramm. Remote Sens. 2022, 184, 243–263. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, Z.; Sun, K.; Li, S.; Yu, J.; Miao, L.; Zhang, Z.; Li, Y.; Zhao, H.; Hu, Z.; et al. Soybean-MVS: Annotated three-dimensional model dataset of whole growth period soybeans for 3D plant organ segmentation. Agriculture 2023, 13, 1321. [Google Scholar] [CrossRef]
- Mertoğlu, K.; Şalk, Y.; Sarıkaya, S.K.; Turgut, K.; Evrenosoğlu, Y.; Çevikalp, H.; Gerek, Ö.N.; Dutagaci, H.; Rousseau, D. PLANesT-3D: A New Annotated Data Set of 3D Color Point Clouds of Plants. In Proceedings of the Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 2–8 July 2023; pp. 1–4. [Google Scholar]
- Schunck, D.; Magistri, F.; Rosu, R.A.; Cornelißen, A.; Chebrolu, N.; Paulus, S.; Léon, J.; Klingbeil, L. Pheno4D: A spatio-temporal dataset of maize and tomato plant point clouds for phenotyping and advanced plant analysis. PLoS ONE 2021, 16, e0256340. [Google Scholar] [CrossRef]
- Dutagaci, H.; Rasti, P.; Galopin, G.; Rousseau, D. ROSE-X: An annotated data set for evaluation of 3D plant organ segmentation methods. Plant Methods 2020, 16, 28. [Google Scholar] [CrossRef]
- Conn, A.; Pedmale, U.V.; Chory, J.; Navlakha, S. High-resolution laser scanning reveals plant architectures that reflect universal network design principles. Cell Syst. 2017, 5, 53–62. [Google Scholar] [CrossRef]
- Behley, J.; Milioto, A.; Stachniss, C. A benchmark for LiDAR-based panoptic segmentation based on KITTI. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13596–13603. [Google Scholar]
- Sirohi, K.; Mohan, R.; Büscher, D.; Burgard, W.; Valada, A. Efficientlps: Efficient lidar panoptic segmentation. IEEE Trans. Robot. 2021, 38, 1894–1914. [Google Scholar] [CrossRef]
- Hurtado, J.V.; Mohan, R.; Burgard, W.; Valada, A. Mopt: Multi-object panoptic tracking. arXiv 2020, arXiv:2004.08189. [Google Scholar]
- Mohan, R.; Valada, A. Efficientps: Efficient panoptic segmentation. Int. J. Comput. Vis. 2021, 129, 1551–1579. [Google Scholar] [CrossRef]
- Gasperini, S.; Mahani, M.A.N.; Marcos-Ramiro, A.; Navab, N.; Tombari, F. Panoster: End-to-end panoptic segmentation of lidar point clouds. IEEE Robot. Autom. Lett. 2021, 6, 3216–3223. [Google Scholar] [CrossRef]
- Milioto, A.; Behley, J.; McCool, C.; Stachniss, C. Lidar panoptic segmentation for autonomous driving. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 8505–8512. [Google Scholar]
- Razani, R.; Cheng, R.; Li, E.; Taghavi, E.; Ren, Y.; Bingbing, L. Gp-s3net: Graph-based panoptic sparse semantic segmentation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 16076–16085. [Google Scholar]
- Zhou, Z.; Zhang, Y.; Foroosh, H. Panoptic-polarnet: Proposal-free lidar point cloud panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13194–13203. [Google Scholar]
- Li, J.K.; He, X.; Wen, Y.; Gao, Y.; Cheng, X.Q.; Zhang, D. Panoptic-phnet: Towards real-time and high-precision lidar panoptic segmentation via clustering pseudo heatmap. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11799–11808. [Google Scholar]
- Hong, F.Z.; Zhou, H.; Zhu, X.; Li, H.S.; Liu, Z.W. Lidar-based panoptic segmentation via dynamic shifting network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13090–13099. [Google Scholar]
- Li, D.; Li, J.S.; Xiang, S.Y.; Pan, A.Q. PSegNet: Simultaneous semantic and instance segmentation for point clouds of plants. Plant Phenomics 2022, 2022, 9787643. [Google Scholar] [CrossRef] [PubMed]
- Luo, L.Y.; Jiang, X.T.; Yang, Y.; Samy, E.R.A.; Lefsrud, M.G.; Hoyos-villegas, V.; Sun, S.P. Eff-3dpseg: 3d organ-level plant shoot segmentation using annotation-efficient deep learning. Plant Phenomics 2023, 5, 0080. [Google Scholar] [CrossRef] [PubMed]
- Mirande, K.; Godin, C.; Tisserand, M.; Charlaix, J.; Besnard, F.; Hétroy-Wheeler, F. A graph-based approach for simultaneous semantic and instance segmentation of plant 3D point clouds. Front. Plant Sci. 2022, 13, 1012669. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wu, W.; Qi, Z.; Li, F. PointConv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Ibrahim, M.; Akhtar, N.; Anwar, S.; Mian, A. SAT3D: Slot attention transformer for 3D point cloud semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5456–5466. [Google Scholar] [CrossRef]
- Wang, X.; Liu, S.; Shen, X.; Shen, C.; Jia, J. Associatively segmenting instances and semantics in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4096–4105. [Google Scholar]
- Chen, S.; Fang, J.; Zhang, Q.; Liu, W.; Wang, X.G. Hierarchical aggregation for 3d instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 15467–15476. [Google Scholar]
- Ngo, T.D.; Hua, B.S.; Nguyen, K. ISBNet: A 3D point cloud instance segmentation network with instance-aware sampling and box-aware dynamic convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–19 June 2023; pp. 13550–13559. [Google Scholar]
- Zhao, L.; Tao, W. JSNet: Joint instance and semantic segmentation of 3d point clouds. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 12951–12958. [Google Scholar]
- Chen, M.; Hu, Q.; Yu, Z.; Thomas, H.; Feng, A.; Hou, Y.; McCullough, K.; Ren, F.; Soibelman, L. STPLS3D: A large-scale synthetic and real aerial photogrammetry 3D point cloud dataset. arXiv 2022, arXiv:2203.09065. [Google Scholar]
- Tao, A.; Duan, Y.; Wei, Y.; Lu, J.; Zhou, J. Seg-group: Seg-level supervision for 3d instance and semantic segmentation. IEEE Trans. Image Process 2020, 31, 4952–4965. [Google Scholar] [CrossRef]
- Tang, L.; Hui, L.; Xie, J. Learning inter-superpoint affinity for weakly supervised 3d instance segmentation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Macao, China, 4–8 December 2022; pp. 1282–1297. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Soybean-MVS | PLANesT-3D | Pheno-4D | ROSE-X | Plant3D | PP3D (Ours) |
|---|---|---|---|---|---|---|
| Year | 2023 | 2023 | 2021 | 2020 | 2017 | 2025 |
| Plant Species | soybean | pepper, rosebush, and ribes | maize and tomato | rosebush | tomato, tobacco and sorghum | 20 species |
| Acquisition Method | reconstructed using MVS technology | reconstructed from 2D color images of real plants through MVS | measured with a highly accurate 3D laser scanning system with a spatial precision of less than a tenth of a millimeter | acquired through X-ray scanning | mapped using high-precision 3D laser scanning | partly collected by MVS and partly by photogrammetry |
| Sensor | SLR digital camera | MVS system | Laser scanning | X-ray tomography | Laser scanning | MVS and photogrammetry system |
| Color | Yes | Yes | No | No | No | Yes |
| Number of Point Clouds | 102 | 34 | 126 | 11 | 505 | ~500 |
| Labeled Classes | leaf, main stem and stem | leaf and stem | soil, stem and leaf | leaf, stem, flower and pot | - | leaf and stem |
| Organ-level Label | No | Yes | Yes | No | - | Yes |
| Methods | AP(%) | AP50(%) | AP25(%) | |||
|---|---|---|---|---|---|---|
| Stem | Leaf | Stem | Leaf | Stem | Leaf | |
| ASIS [40] | 16.7 | 14.1 | 34.8 | 28.2 | 42.5 | 39.9 |
| HAIS [41] | 54.4 | 53.0 | 70.2 | 62.6 | 74.0 | 71.5 |
| ISBNet [42] | 0.4 | 7.1 | 1.2 | 9.5 | 2.2 | 1.3 |
| JSNet [43] | 16.3 | 13.2 | 33.7 | 27.2 | 40.9 | 35.7 |
| SCNet (ours) | 60.0 | 56.1 | 71.3 | 64.5 | 75.4 | 72.2 |
| Methods | AP(%) | AP50(%) | AP25(%) | |||
|---|---|---|---|---|---|---|
| Stem | Leaf | Stem | Leaf | Stem | Leaf | |
| ASIS [40] | 16.7 | 14.1 | 34.8 | 28.2 | 42.5 | 39.9 |
| ASIS # | 16.8 | 13.8 | 33.9 | 27.4 | 40.1 | 36.5 |
| 0.1 | −0.3 | −0.9 | −0.8 | −2.4 | −3.4 | |
| HAIS [41] | 54.4 | 53.0 | 70.2 | 62.6 | 74.0 | 71.5 |
| HAIS # | 50.2 | 49.6 | 63.8 | 55.2 | 69.1 | 63.2 |
| −4.2 | −3.4 | −6.4 | −7.4 | −4.9 | −8.3 | |
| ISBNet [42] | 0.4 | 7.1 | 1.2 | 9.5 | 2.2 | 1.3 |
| ISBNet # | 0.4 | 7.0 | 1.1 | 8.8 | 2.0 | 1.3 |
| 0.0 | −0.1 | −0.1 | −0.7 | −0.2 | 0.0 | |
| JSNet [43] | 16.3 | 13.2 | 33.7 | 27.2 | 40.9 | 35.7 |
| JSNet # | 18.9 | 14.2 | 33.8 | 27.0 | 39.2 | 35.6 |
| 2.6 | 1.0 | 0.1 | −0.2 | −1.7 | −0.1 | |
| SCNet (ours) | 60.0 | 56.1 | 71.3 | 64.5 | 75.4 | 72.2 |
| SCNet # | 56.3 | 56.0 | 69.5 | 63.4 | 74.2 | 69.9 |
| −3.7 | −0.1 | −1.8 | −1.1 | −1.2 | −2.3 | |
| Methods | Annotation | AP(%) | AP50(%) | AP25(%) | |||
|---|---|---|---|---|---|---|---|
| Stem | Leaf | Stem | Leaf | Stem | Leaf | ||
| HAIS [41] | 100% | 54.4 | 53.0 | 70.2 | 62.6 | 74.0 | 71.5 |
| HAIS [41] | 0.10% | 22.0 | 21.5 | 33.8 | 31.2 | 45.6 | 44.7 |
| ISBNet [42] | 100% | 0.4 | 7.1 | 1.2 | 9.5 | 2.2 | 1.3 |
| ISBNet [42] | 0.10% | 1.3 | 6.8 | 0.9 | 7.6 | 2.5 | 1.0 |
| SCNet (ours) | 100% | 60.0 | 56.1 | 71.3 | 64.5 | 75.4 | 72.2 |
| SCNet (ours) | 0.10% | 20.5 | 11.9 | 38.3 | 31.8 | 46.2 | 46.8 |
| WSIS [46] | 0.10% | 30.5 | 26.5 | 46.7 | 41.2 | 50.1 | 45.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Wu, S.; Fu, J.; Fang, S.; Liu, S.; Jiang, T. Panoptic Plant Recognition in 3D Point Clouds: A Dual-Representation Learning Approach with the PP3D Dataset. Remote Sens. 2025, 17, 2673. https://doi.org/10.3390/rs17152673
Zhao L, Wu S, Fu J, Fang S, Liu S, Jiang T. Panoptic Plant Recognition in 3D Point Clouds: A Dual-Representation Learning Approach with the PP3D Dataset. Remote Sensing. 2025; 17(15):2673. https://doi.org/10.3390/rs17152673
Chicago/Turabian StyleZhao, Lin, Sheng Wu, Jiahao Fu, Shilin Fang, Shan Liu, and Tengping Jiang. 2025. "Panoptic Plant Recognition in 3D Point Clouds: A Dual-Representation Learning Approach with the PP3D Dataset" Remote Sensing 17, no. 15: 2673. https://doi.org/10.3390/rs17152673
APA StyleZhao, L., Wu, S., Fu, J., Fang, S., Liu, S., & Jiang, T. (2025). Panoptic Plant Recognition in 3D Point Clouds: A Dual-Representation Learning Approach with the PP3D Dataset. Remote Sensing, 17(15), 2673. https://doi.org/10.3390/rs17152673