1. Introduction
Remote sensing object detection (RSOD) plays a critical role in a wide range of applications [
1,
2,
3], including disaster response, urban monitoring, and maritime surveillance. However, the high cost of annotating dense and diverse objects in high-resolution satellite images severely limits the scalability of fully supervised detection models. To address this limitation, semi-supervised object detection (SSOD) has emerged as a promising paradigm that leverages abundant unlabeled data alongside a small set of labeled samples [
4].
Among the recent developments in SSOD, teacher–student frameworks have become the most widely adopted. In these approaches, a teacher model generates pseudo-labels on unlabeled data, which are then used to supervise the student model. The teacher is typically updated via an exponential moving average (EMA) [
5] of the student weights, aiming to provide stable supervision. Despite recent advances, SSOD in remote sensing faces several unique challenges. A major issue is the progressive accumulation of pseudo-label errors during training. In complex scenes with dense targets and varying object scales, pseudo boxes generated by the teacher often contain false positives or localization errors, particularly in early stages. Once accepted, these unreliable boxes influence the student model and are further reinforced through the EMA update cycle, ultimately degrading detection performance.
Although pseudo-labeling has become a central component in SSOD, its quality remains a critical bottleneck. One major limitation lies in how pseudo-labels are selected. Most existing methods, whether based on static thresholds or dynamic strategies, rely solely on classification confidence scores to accept or reject predictions. However, these scores often fail to capture localization quality, especially in dense or cluttered scenes, leading to the inclusion of inaccurate boxes. Another issue arises in the way pseudo-labels are used during optimization. Once selected, all pseudo boxes typically contribute equally to the training loss, regardless of their actual reliability. This uniform weighting introduces gradient noise and weakens model convergence, particularly when teacher and student predictions diverge. Furthermore, some object categories exhibit highly complex visual patterns that make them difficult to learn from noisy pseudo-label supervision. These hard classes tend to be poorly represented in the unsupervised branch, as pseudo-labels for them are often missing or inaccurate. Consequently, they receive limited gradient updates and underperform.
To address these challenges, we propose Error-Mitigation Teacher (EMT), a modular framework designed to reduce pseudo-label noise and suppress error accumulation in semi-supervised remote sensing object detection. EMT introduces a three-stage error control pipeline that jointly considers classification confidence, localization precision, and training dynamics throughout training.
First, the Adaptive Pseudo-Label Filtering (APLF) module mitigates noisy pseudo-label selection by combining class-wise confidence thresholds with geometric verification using a second-stage RCNN head. This dual-criteria filtering ensures that only pseudo boxes with both semantic and spatial reliability are retained. Second, the Confidence-Based Loss Reweighting (CBLR) module addresses label-level unreliability by evaluating how well the teacher model can reconstruct its own pseudo-labels during a secondary forward pass. The resulting regression and classification losses serve as reliability indicators, which are normalized and used to dynamically weight each instance during optimization, reducing the influence of uncertain pseudo-labels. Third, the Enhanced Supervised Learning (ESL) module improves class-level robustness by identifying hard-to-learn categories based on the learning difficulty estimated from pseudo-label in the unsupervised branch. These categories receive increased attention in the supervised branch, enabling joint optimization that balances the learning across all classes.
EMT consistently outperforms state-of-the-art SSOD methods, as demonstrated by extensive experiments on three representative remote sensing benchmarks: DOTA, DIOR, and SSDD. The remainder of this article is organized as follows:
Section 2 provides an overview of related work in object detection for remote sensing images and semi-supervised object detection. The proposed method is detailed in
Section 3.
Section 4 presents a comprehensive account of the experiments and analysis. Finally,
Section 5 concludes our work.
2. Related Work
In this section, we briefly introduce the literature related to our work, encompassing remote sensing object detection and Semi-Supervised Object Detection.
2.1. Remote Sensing Object Detection
Unlike natural image datasets like MS COCO, remote-sensing images typically feature multi-scale and clustered targets. CNN-based detectors have achieved excellent performance in RSOD. Depending on whether candidate regions are generated, these methods can be categorized into single-stage and two-stage detectors. Two-stage detectors generally yield better results, while single-stage detectors offer faster detection speeds.
Single-stage detectors consider detection tasks as regression problems and utilize convolutional layers to efficiently process feature maps, producing localization and classification results. Owing to the advantages of lightweight deployment, single-stage detectors hold broad application potential in the field of remote sensing. Wei et al. [
6] introduced a bilateral attention mechanism in YOLOX to enhance the detection of small-sized objects. S2A-Net [
7] employed deformable ConvNets [
8] to align anchors and features for aerial image object detection. DAFNe [
9] introduced a centrality function for bounding boxes of arbitrary orientations, improving localization performance.
Two-stage detectors segment the process into two steps. The first step generates a range of possible proposals, similar to single-stage detectors, and the second step refines these suggestions. Faster RCNN [
10] has become the most widely used foundational framework in RSOD [
1], which abandoned the Selective Search algorithm in RCNN [
11] and designed the RPN subnet to derive proposals from the anchor mechanism. The multi-scale feature fusion of FPN [
12] and the RoI Align method proposed in Mask RCNN [
13], which reduces the quantization error, have also been applied to recent implementations of Faster RCNN. Additionally, Ding et al.’s RoI Transformer [
14] applies spatial transformations to Regions of Interest (RoIs), enhancing the detection performance of rotating targets in remote sensing imagery. ReDet [
15] offers a rotation-equivariant detector that extracts rotation-invariant features of targets.
While most existing RSOD methods focus on enhancing localization precision through architectural adaptations such as rotation-equivariant modules and anchor refinements, they typically rely on fully supervised training paradigms. However, in remote sensing applications where annotations are scarce and expensive, these methods struggle to maintain performance. In contrast, our EMT framework addresses this challenge by incorporating pseudo-label noise mitigation strategies under a semi-supervised setting, thereby achieving stronger generalization with limited labeled data. In this work, we focus on horizontal bounding box (HBB) detection, which is compatible with a broader range of remote sensing datasets and yields more stable performance under semi-supervised training settings.
2.2. Semi-Supervised Object Detection
Semi-supervised learning has seen remarkable success in object detection by effectively leveraging unlabeled data through mechanisms such as pseudo-labeling [
16], consistency regularization [
17], and transfer learning [
18]. In recent years, the teacher–student paradigm, combined with pseudo-label learning, has become the dominant framework in semi-supervised object detection (SSOD). Under this paradigm, a teacher model generates pseudo-labels for unlabeled images, and a student model is trained using both labeled data and high-confidence pseudo-labeled data. Although conceptually simple, this approach has undergone significant evolution to overcome core challenges such as pseudo-label noise, confirmation bias, and class imbalance. Below, we review representative SSOD methods following this developmental trajectory.
Early works such as STAC [
16] proposed a two-stage training pipeline, where the teacher model, trained on labeled data, generates pseudo-labels for unlabeled images using a fixed confidence threshold. The student model is then trained with both labeled data and pseudo-labeled data under strong augmentation. While effective, this method is prone to confirmation bias and label noise. To alleviate such issues, Unbiased Teacher [
19] introduced an EMA strategy, adapted from Mean Teacher [
5], to update the teacher model dynamically using the student model during training.
Subsequent works have focused on improving the quality of pseudo-labels used to train the student. ISMT [
20] aggregates detection results from multiple historical iterations to stabilize pseudo-labels and reduce temporal noise, while RPL [
21] and PCT [
22] propose a dynamic thresholding mechanism that jointly considers classification and localization confidence to improve label reliability. However, methods that rely solely on classification confidence often fail to account for localization quality, leading to underestimated noise in early training and missed detections in later stages.
Building upon these ideas, more recent methods have employed consistency regularization to further enhance the learning of the unsupervised branch. Soft Teacher [
23] proposes a soft weighting strategy that assigns each unlabeled bounding box a classification loss proportional to the confidence score from the teacher. It also introduced box jittering to refine localization targets. Unbiased Teacher v2 [
24] extended this framework to anchor-free detectors like FCOS and introduced the Listen2Student mechanism to enhance the learning of localization signals. Consistent-Teacher [
25] redesigned the sample allocation strategy and detection head to improve pseudo-label stability and reduce oscillation noise in one-stage detectors.
Some studies have explored the adaptation of the teacher–student framework to transformer-based architectures. For example, Semi-DETR [
26] extends SSOD to DETR-style detectors by employing hybrid matching strategies and introducing cross-view query consistency as well as cost-based pseudo-label mining. In the context of remote sensing, SSOD-QCTR [
27] further customizes the semi-supervised transformer framework by designing dedicated loss functions for remote sensing.
While prior SSOD methods have made notable progress, they often rely on classification confidence alone for pseudo-label selection, apply uniform loss weighting regardless of label quality, and offer limited support for learning under-represented categories. In contrast, our EMT framework introduces a unified strategy that jointly considers semantic and geometric cues during label selection, modulates supervision strength based on prediction reliability, and enhances learning for hard classes through adaptive supervision. These innovations help mitigate error accumulation and promote more stable and balanced training in semi-supervised remote sensing detection.
3. Materials and Methods
3.1. Overview
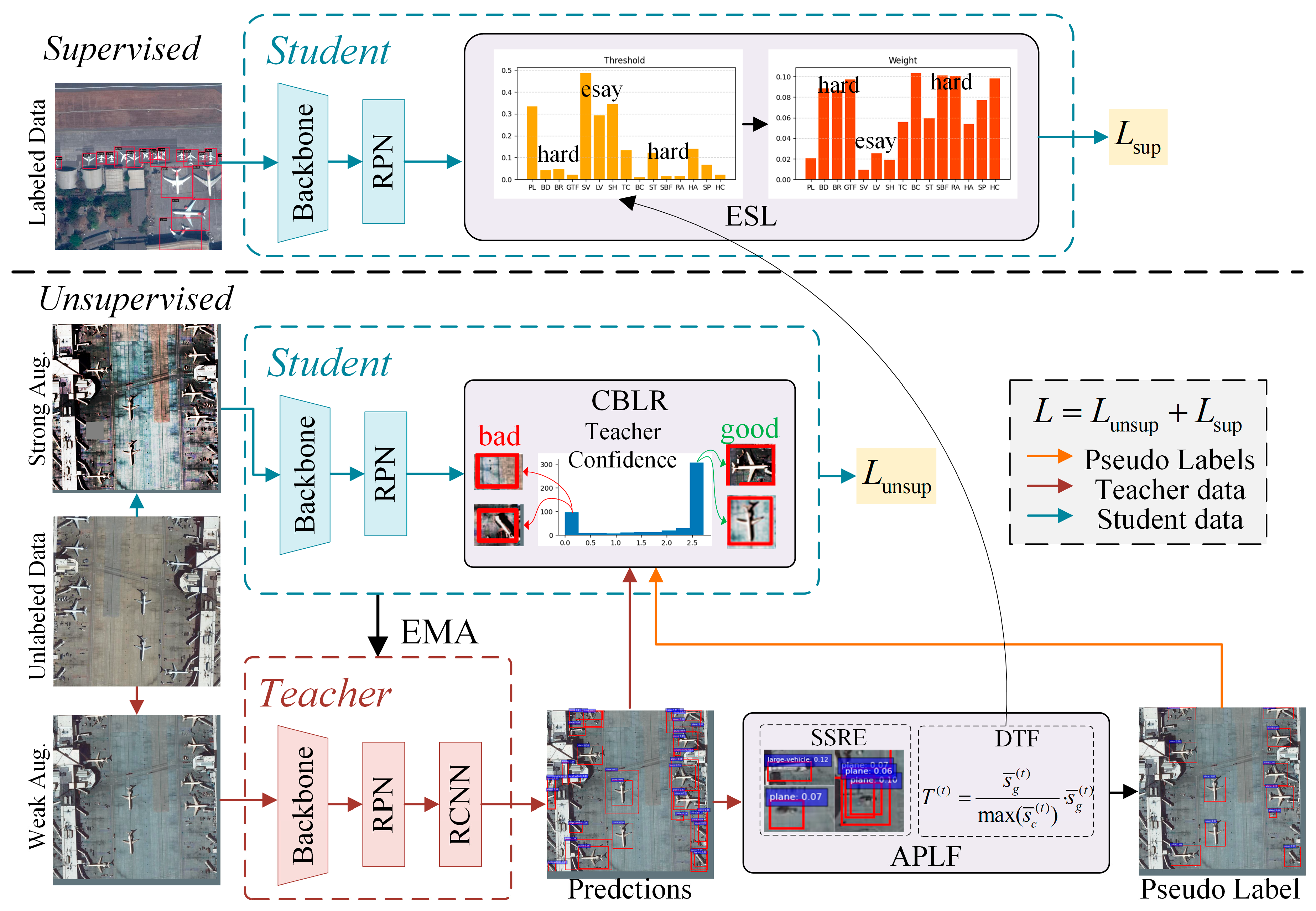
As illustrated in
Figure 1, the proposed Error-Mitigation Teacher (EMT) framework adopts a teacher–student architecture composed of supervised and unsupervised branches, allowing the model to fully leverage both labeled and unlabeled data. Each branch uses a Faster RCNN detector with an FPN backbone to support robust multi-scale feature extraction. The teacher network is updated via an exponential moving average (EMA) of the student model, ensuring stability during pseudo-label generation.
In the supervised branch, we introduce Enhanced Supervised Learning (ESL), which adjusts class-wise loss weights based on learning difficulty inferred from the pseudo-label distribution. Specifically, ESL identifies underperforming classes based on the confidence thresholds estimated by APLF and increases their supervised loss contributions. This strategy directs the model’s focus toward hard-to-learn categories in the labeled data, thereby improving class-level detection robustness.
In the unsupervised branch, unlabeled images undergo both weak and strong augmentations [
22]. The teacher network generates pseudo-labels from weakly augmented views, which are refined by the proposed Adaptive Pseudo-Label Filtering (APLF) module before being treated as targets for the student’s training on strongly augmented samples. APLF re-evaluates pseudo-labels using a second-stage RCNN head and dynamically adjusts confidence thresholds to suppress low-quality predictions. During loss computation on these samples, the Confidence-Based Loss Reweighting (CBLR) module evaluates the reliability of each pseudo-labeled region by performing a secondary forward pass in the teacher network. Specifically, the teacher attempts to reconstruct its own pseudo-labels, and the resulting classification and regression losses are used as reliability indicators. These values are then used to apply a soft weighting function, reducing the impact of unreliable supervision.
Together, these three components form a unified and lightweight error-mitigation pipeline. APLF provides high-quality pseudo-labels, CBLR suppresses noise during optimization, and ESL adaptively enhances class-level supervision. This design systematically reduces error accumulation and improves generalization in complex remote sensing scenarios.
3.2. Adaptive Pseudo-Label Filtering
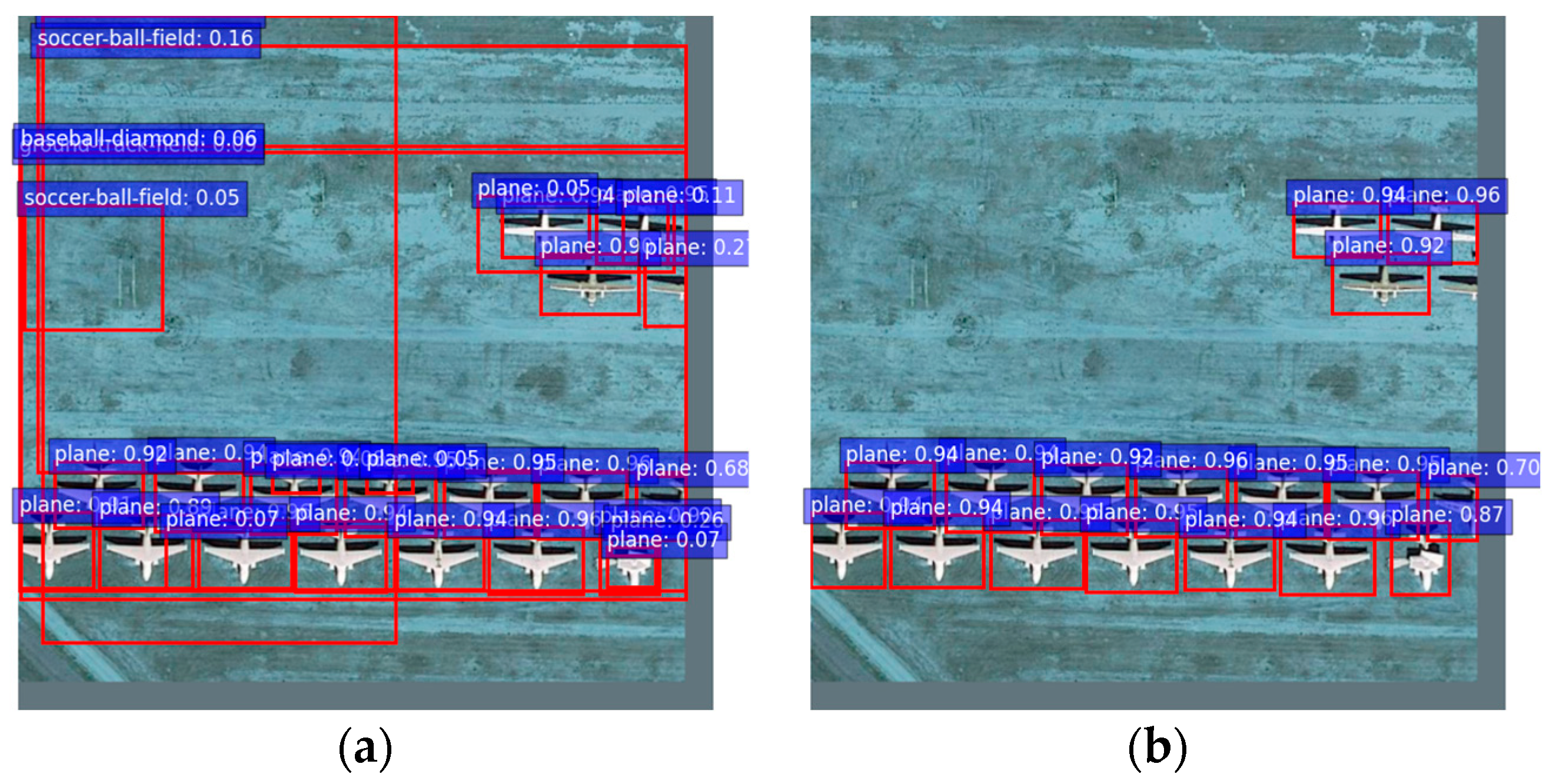
In semi-supervised object detection (SSOD), the quality of pseudo-labels generated by the teacher network critically influences the training stability and overall performance of the student model. However, remote sensing imagery typically presents greater complexity and diversity compared to natural scenes, exhibiting significant intra-class variability, densely packed objects, and cluttered backgrounds. Such conditions commonly result in numerous false positives and unstable predictions in pseudo-labels, especially during the initial training phases. As illustrated in
Figure 2a, naively accepting pseudo-labels from early-stage teacher predictions can significantly degrade detection performance due to the propagation of noisy supervision signals.
To mitigate these issues, we introduce Adaptive Pseudo-Label Filtering (APLF), a robust and adaptive filtering module that selectively retains high-quality pseudo-labels based on both classification consistency and class-specific confidence dynamics. The APLF module comprises two key components: Second-Stage RCNN Evaluation (SSRE) and Dynamic Threshold Filtering (DTF).
3.2.1. Second-Stage RCNN Evaluation
The design of the SSRE component is motivated by a structural limitation in the standard Faster RCNN detection pipeline. In most implementations, the RCNN head predicts classification scores and per-class bounding box regressions for each region proposal generated by the Region Proposal Network (RPN). Following this stage, Non-Maximum Suppression (NMS) is applied independently for each class, which helps balance category-wise detections. However, this per-class NMS mechanism also leads to an unintended consequence: a large number of low-confidence or ambiguous bounding boxes may survive, especially for frequent or spatially overlapping categories.
These surviving boxes, although structurally allowed by the NMS step, may include clearly erroneous predictions. If used as pseudo-labels, they can contaminate the training signal and interfere with the adaptive threshold estimation of downstream components such as DTF. To mitigate this, we propose Second-Stage RCNN Evaluation (SSRE) as a lightweight verification strategy that reuses the RCNN head to filter out the most unreliable detections based on label consistency.
Notably, SSRE does not attempt to comprehensively denoise the pseudo-label set, but instead aims to remove only the most obviously unstable predictions. This is achieved by re-evaluating each bounding box through the RCNN head a second time, using the same features. If the predicted class label changes between the two evaluations, the detection is considered inconsistent and is discarded. Although our SSRE is not derived from cascaded architectures, it adopts a similar intuition to multi-stage refinement strategies used in fully supervised detectors such as Cascade R-CNN [
28] and Deformable DETR [
29], where iterative prediction improves localization quality. In our case, this principle is applied in a novel semi-supervised context to identify noisy pseudo-labels via internal consistency checks, with minimal computational overhead.
Formally, let be a bounding box retained after per-class NMS. Let denote the predicted class label from the first RCNN pass in teacher’s prediction process. The same box is then re-evaluated to obtain a second label . Candidate boxes for which are considered unstable and thus removed from the pseudo-label set.
This label consistency check provides an efficient approximation of prediction stability. Compared with threshold-based heuristics, SSRE leverages the model’s own classification behavior to identify unreliable detections. It avoids additional network branches or confidence calibration components, thereby preserving computational efficiency while improving pseudo-label reliability in complex remote sensing scenarios.
3.2.2. Dynamic Threshold Filtering
After filtering unstable predictions via SSRE, the remaining pseudo-labels are further refined using DTF. Unlike conventional fixed-score thresholds that apply a uniform confidence cutoff across all classes, DTF adaptively adjusts thresholds on a per-class basis, based on the evolving prediction quality over training.
This design is motivated by the observation that pseudo-label confidence scores can differ significantly across classes due to factors such as object size, class frequency, and visual ambiguity. Rigid thresholds tend to unfairly penalize rare or difficult classes, leading to excessive false negatives. DTF addresses this by computing a class-wise threshold T that dynamically adapts using EMA of softmax scores.
Let
be the matrix of softmax classification probabilities output by the second RCNN pass, where
N is the number of retained boxes and
C is the number of object classes. Define the global confidence
as the EMA of the maximum scores per box:
Similarly, the local per-class confidence vector
is updated using:
where
controls the momentum.
Finally, the adaptive threshold vector
This normalization ensures that each class threshold is scaled relative to its own average confidence, while remaining anchored to the global detection quality. Pseudo-labels whose confidence scores fall below their class-specific threshold are discarded.
Together, SSRE and DTF constitute a coherent pseudo-label filtering strategy. SSRE eliminates clearly unstable predictions via classification consistency, while DTF adjusts selection strictness based on class-specific learning dynamics. By combining these two complementary components, APLF significantly improves the quality and balance of pseudo-labels used for training, enhancing both convergence stability and final detection accuracy in remote sensing scenarios.
3.3. Confidence-Based Loss Reweighting
Unlike ground-truth annotations, pseudo-labels inherently contain noise due to imperfect localization and class ambiguity. Even with filtering mechanisms such as APLF, these labels cannot match the precision of human annotations. When such imperfect labels are used to guide sample assignment, especially under IoU-based anchor assignment schemes, they may lead to incorrect positive or negative assignments for region proposals. For instance, slightly inaccurate bounding boxes may still be accepted as positives, resulting in suboptimal regression targets and unstable gradients, as also observed in Consistent Teacher [
25].
To mitigate this issue, we introduce the Confidence-Based Loss Reweighting (CBLR) module, which assigns soft, sample-wise weights to pseudo-labeled instances based on their estimated reliability. In contrast to prior works that rely on hard filtering or modify the sample assignment process, CBLR retains the original assignments and instead modulates each sample’s influence during loss optimization. This design allows the model to learn from uncertain labels in a more stable and graded manner, improving robustness while preserving valuable supervision signals.
Specifically, we reuse the RoIs generated in the student branch and feed them into the teacher model’s RCNN head (no gradients) for evaluation. During this secondary forward pass, the teacher treats its own pseudo-labels, originally predicted under weak augmentation on the same image, as ground-truth targets and attempts to re-predict them. The classification and regression losses from this pass indicate how well the teacher can recover its own predictions. Since loss magnitude reflects the ease of fitting a label, it serves as a proxy for label reliability: low loss implies a self-consistent and likely correct pseudo-label, whereas high loss suggests inconsistency or noise. These per-sample loss values are normalized within each mini-batch and used to scale the corresponding student loss. This dynamic weighting strategy ensures that noisy labels contribute less to gradient updates, while reliable ones retain full influence.
Let
and
denote the class probability vectors output by the teacher and student models, respectively, for the
i-th pseudo-labeled RoI. Let
and
denote the bounding box predictions, and let
and
be the pseudo-label targets. We define the classification and regression confidence weights as:
Here, and are the RCNN loss functions for classification and regression, respectively. The softmax operation is computed over all pseudo-labels in the mini-batch, ensuring normalized weights and stabilizing learning dynamics. High-loss samples receive lower weights, reducing their impact on the loss calculation.
For the regression branch, each pseudo-label corresponds to a group of positively assigned anchors. We compute the loss at the pseudo-label level:
Here,
is the number of pseudo-labels and
the number of assigned anchors for the
k-th box. For the classification branch, we apply confidence weights to each labeled anchor directly:
To ensure stability, all weights are detached from the computation graph. The teacher model does not participate in gradient updates, and its loss values are used solely to guide student training through differentiable, static reweighting.
Overall, CBLR serves as the second stage of error mitigation: while APLF removes clearly erroneous pseudo-labels, CBLR dynamically suppresses the impact of remaining uncertainty. Because loss-based reliability is grounded in the model’s own predictive certainty, it adapts dynamically to varying levels of label noise, class imbalance, and sample complexity, thereby enhancing stability across heterogeneous domains.
3.4. Enhanced Supervised Learning
Although the focus of semi-supervised learning lies in exploiting unlabeled data, the effective use of the limited labeled set remains equally crucial, especially in remote sensing scenarios where annotations are expensive and typically class-imbalanced. Conventional supervised training treats all categories equally, which may cause the model to overfit frequent classes while under-learning rare or difficult ones. Moreover, in a multi-class detection context, uniform treatment can further exacerbate the long-tail nature of remote sensing datasets.
To address this issue, we propose Enhanced Supervised Learning (ESL), which dynamically reweights the supervised classification loss to emphasize classes with higher learning difficulty. The core idea is to use the class-wise pseudo-label quality, derived from the DTF module (
Section 3.2), to guide how much weight should be given to each class during supervised training.
Let be the vector of adaptive class-specific thresholds computed in DTF. These thresholds represent the average pseudo-label confidence for each class. A lower value indicates that pseudo-labels for class c tend to have lower confidence, suggesting that the model is struggling to learn or generalize to that class.
To encourage the model to focus more on such difficult classes, we apply an exponential inverse transformation:
This ensures that classes with low-confidence pseudo-labels receive higher weight. To maintain training stability and ensure balanced optimization, we normalize the total supervised classification loss using the following formulation:
Here, is the predicted classification probability vector for the i-th labeled RoI, and is its assigned ground-truth class label. The exponential term dynamically scales the loss according to the current difficulty of class , inferred from the pseudo-label statistics of the unlabeled branch.
This design offers three advantages. First, ESL adaptively emphasizes classes with lower pseudo-label confidence, mitigating the under-learning of rare or hard-to-detect categories. Second, by reusing pseudo-label statistics from the unsupervised branch, ESL aligns the supervised learning process with the evolving difficulty of each class. Third, the use of normalized exponential weights ensures training stability and avoids distorting the overall loss scale. In combination with APLF and CBLR, ESL completes a coherent error mitigation framework that jointly improves pseudo-label quality, suppresses residual errors, and enhances class-wise learning balance.
3.5. Overall Training Objective
EMT is trained with the proposed unsupervised losses for unlabeled data as well as the supervised loss for labeled data. The overall loss
L is defined as:
and represent the total supervised and unsupervised losses, respectively. are the losses from the RPN for supervised and unsupervised data, respectively. are the RCNN losses, further divided into regression and components. is a balancing parameter that determines the relative importance of the unsupervised loss compared to supervised loss. We also set an additional 5000 iterations for model warming-up to ensure meaningful pseudo-labels, during which is not calculated. The teacher network is updated using the EMA of the student’s parameters and is not involved in gradient computation. During inference, only the teacher detector is used, and none of the error mitigation modules introduce additional runtime overhead.
4. Experimental Results
4.1. Datasets
DOTA: We perform experiments on the DOTA1.0 [
30] dataset, a comprehensive and widely-employed collection for object detection in remote sensing. Encompassing a substantial variety of 15 common categories: plane (PL), baseball diamond (BD), bridge (BR), ground track field (GTF), small vehicle (SV), large vehicle (LV), ship (SH), tennis court (TC), basketball court (BC), storage tank (ST), soccer ball field (SBF), roundabout (RA), harbor (HA), swimming pool (SP) and helicopter (HC). This large dataset has become a benchmark in the field. It features images sourced from diverse sensors and platforms, ranging in size from 800 × 800 to an expansive 20,000 × 20,000 pixels. Its breadth and diversity have established DOTA as a standard for assessing object detection algorithms in remote sensing applications.
DIOR: Another prevalent dataset in the remote sensing object detection domain, DIOR [
31] includes 23,463 images with a total of 190,288 instances. Uniformly sized at 800 × 800 pixels, the dataset spans 20 distinct categories: airplane (PL), airport (PO), baseball field (BD), basketball court (BC), bridge (BR), chimney (CH), dam (DM), expressway service areas (ESA), expressway toll station (ETS), golf field (GF), ground track field (GTF), harbor (HA), overpass (OP), ship (SH), stadium (SD), storage tank (ST), tennis court (TC), train station (TS), vehicle (V), and windmill (WM). Like DOTA, DIOR is utilized for its variety and representativeness of the remote sensing object detection challenges, providing a rich resource for validating the robustness and effectiveness of detection models.
SSDD: The SAR Ship Detection Dataset (SSDD) [
32] is a publicly available dataset specifically created for ship detection in SAR images. It comprises a total of 1160 images containing 2456 annotated ships, and it captures diverse variations in sea state, image resolution, and sensor. We use the officially provided training and test sets for model training and evaluation. Moreover, due to the inherent challenges in annotating SAR images, such as low contrast and high noise levels, there is a heightened need for effective SSOD methods to alleviate the annotation burden and improve detection performance.
4.2. Training Protocol
For our experiments on the DOTA and DIOR datasets, we adhere to a structured partitioning methodology to effectively evaluate the performance of our SSOD framework. Specifically, for DOTA dataset, we first partition the images into 640 × 640 patches following the approach outlined in PCT [
22]. This preprocessing step ensures that even the smallest labeled subset (1%) contains a sufficient number of labeled images, facilitating robust training despite the reduced labeled data. For the DIOR dataset, we do not perform image partitioning.
Subsequently, we divide the training sets of both the DOTA and DIOR datasets into subsets comprising 1%, 5%, and 10% of images with ground truth annotations. The remaining portions of each training set consist exclusively of unlabeled images, rigorously testing the network’s capability to leverage unlabeled data for improved detection performance. Each dataset’s validation set is reserved for assessing the performance of the trained models.
Contrary to the training regimen established in PCT and Soft Teacher, which involves 180,000 iterations for the 1% protocol and 360,000 iterations for both the 5% and 10% protocols, our approach emphasizes training efficiency. We employ a reduced number of training iterations: 90,000 iterations for the 1% protocol and 180,000 iterations for both the 5% and 10% protocols. This adjustment demonstrates the efficacy of our method in achieving comparable or superior performance with fewer computational resources.
For SSDD, since the training set contains only 928 images, applying a 1% protocol would result in merely 9 labeled images, leading to unstable training. To ensure more reliable learning while testing the model’s generalization at different labeled data proportions, we adopt 5%, 10%, and 20% protocols instead. All SSDD protocols are trained for 18,000 iterations.
4.3. Evaluation Metrics
In this work, we adopt horizontal bounding box (HBOX) detection across all datasets. This choice aligns with the annotation format of most RSOD benchmarks (e.g., DIOR, SSDD), and avoids the additional complexity and instability introduced by angle regression in Rotated Bounding Boxes (RBOX). Moreover, HBOX enables more efficient training and fairer comparison with recent SSOD methods, many of which are limited to horizontal annotations.
To effectively evaluate the performance of our model, we employ the widely recognized mean Average Precision (mAP) metrics, specifically mAP50 and mAP50:95. The mAP50 metric applies an Intersection over Union (IoU) threshold of 0.5 to classify detections as true positives, which is particularly favored in the RSOD community for its relevance in scenarios where moderate localization accuracy is sufficient. On the other hand, the mAP50:95 metric, as proposed by the MS-COCO benchmark, provides a more comprehensive assessment by averaging the model’s performance across ten IoU thresholds ranging from 0.5 to 0.95 in increments of 0.05. This broader measure captures the model’s localization accuracy across various levels of precision, making it essential for a thorough performance analysis. By utilizing both mAP50 and mAP50:95, we ensure a balanced evaluation of our model’s detection capabilities, accounting for both general and fine-grained localization performance.
4.4. Implementation Details
All experiments described in this paper were conducted on one NVIDIA RTX4090. To ensure a fair comparison, our method employs the same training and testing strategies as PCT and Soft Teacher. We train the model with a batch size of 5, maintaining a labeled to unlabeled image ratio of 1:4. The weak data augmentations include two operations: random resize and random flip. The strong data augmentations are more comprehensive, comprising five operations: random resize, random flip, random color space transformation, random geometric transformation, and erasing. Both types of augmentations are applied to the same unlabeled image.
Our optimizer of choice is SGD, initialized with a learning rate of 0.004, a momentum of 0.9, and a weight decay rate of 0.0001. In line with prevalent SSOD methodology, like PCT, we utilize the Faster RCNN framework with FPN for both student and teacher networks, maintaining separate weights. ResNet50 [
33] serves as the backbone for all experiments. We employ the EMA, widely used in semi-supervised object detection, to update the teacher model parameters based on the student’s parameters, adhering to the same momentum decay settings used in APLF.
4.5. Comparison with the State-of-the-Art Methods
To comprehensively evaluate the effectiveness of our proposed EMT framework, we compare it against several state-of-the-art SSOD methods, which represent the current leading approaches in both general and remote sensing domains. These include Consistent Teacher [
25], a single-stage detector-based method that improves pseudo-label stability via enhanced feature alignment; Soft Teacher [
23], which builds upon the Faster RCNN framework and employs soft labels and jittering strategies to reduce label noise; MixPL [
34], which mitigates pseudo-label imbalance across quantity, scale, and class via mixup and mosaic augmentations; and Semi-DETR [
26], a transformer-based method incorporating deformable attention and hybrid bipartite matching to improve detection in complex scenes. These methods are consistently ranked among the top-performing SSOD approaches under standard benchmarks such as COCO 10% labeled data.
We also include PCT [
22], which is one of the most advanced SSOD methods specifically tailored for remote sensing object detection. PCT enhances pseudo-label quality via contrastive learning and introduces scale-sensitive learning mechanisms, making it especially suitable for remote sensing scenarios with multi-scale, dense objects.
For fair evaluation, all methods are tested on DOTA, DIOR, and SSDD under consistent protocols, using mAP50 and mAP50:95 as performance metrics. Our results show that EMT outperforms all compared baselines across datasets and protocols, demonstrating its superior ability to mitigate pseudo-label errors and enhance detection robustness in challenging remote sensing environments. We re-implemented all methods with publicly available code; for methods without released code (e.g., PCT), we report the results directly from their original publications.
4.5.1. Analysis Across All Categories
Table 1 demonstrates that under both mAP
50 and mAP
50:95 evaluation standards, EMT effectively learns from unlabeled data even with a small fraction of annotated training data. Specifically, on the DOTA dataset, EMT outperforms all compared methods, including the transformer-based Semi-DETR, in both mAP
50 and mAP
50:95. This performance gain is attributed to EMT’s ability to reduce error accumulation in SSOD for remote sensing, allowing for more efficient utilization of data that surpasses the performance improvements seen in more complex detector models. Notably, for the commonly used mAP
50 metric in RSOD, EMT achieves improvements of 1.3, 1.8, and 1.1 points over the best competing methods under 1%, 5%, and 10% labeled data protocols, respectively. For the more localization-sensitive mAP
50:95 metric, EMT records enhancements of 0.5, 2.2, and 2.6 points, respectively.
On DIOR, EMT also achieves comprehensive leading performance on the mAP50 metric, particularly breaking through the 70 mAP50 threshold under the 10% labeled data protocol, being the only method to do so. For mAP50:95, although Consistent Teacher with its more complex detection head shows advantages in localization, EMT maintains a leading position among Faster RCNN based methods, such as PCT and Soft Teacher.
We further evaluate the generalization of EMT on the SSDD dataset, which focuses on ship detection in SAR. Since SSDD contains only one class (ship), the mAP
50 reported corresponds to the average precision of ship detection. As shown in
Table 1, EMT achieves state-of-the-art performance across all labeling ratios in mAP
50. Under the 20% labeled protocol, EMT attains an mAP
50 of 91.2, outperforming Soft Teacher and Semi-DETR by 2.5 and 1.9 mAP
50, respectively. Even with only 5% labeled data, EMT achieves an mAP
50 of 81.3, maintaining a strong advantage over prior works. From the perspective of localization accuracy, EMT also excels on the mAP
50:95 metric, with values of 50.5, 51.5, and 60.1 for 5%, 10%, and 20% protocols, respectively. These results demonstrate that EMT’s improvements are not solely derived from better classification, but also from superior bounding box precision, which is critical in maritime surveillance tasks.
4.5.2. Analysis with Specific Categories
Table 2 presents detailed category-wise evaluations on the DOTA dataset, demonstrating the consistent superiority of our proposed method compared to existing semi-supervised object detection frameworks. Across varying annotation rates (1%, 5%, and 10%), our approach achieves either leading or second-best performance in most categories, highlighting robust generalization capabilities. Specifically, our method notably excels in complex and structurally distinctive categories. For instance, at the 10% annotation level, our model achieves the highest mAP
50 of 85.4 in plane and 93.4 in tennis court, significantly surpassing competing methods.
Although our model demonstrates strong overall performance, categories like Basketball Court exhibits comparatively limited results at the 1% annotation rate for all methods. The challenges are likely due to limited training samples and indistinct object boundaries. Despite these inherent difficulties, our method frequently remains among the top two performers, underscoring its robustness. Notably, our semi-supervised model surpasses the fully supervised Oracle Faster RCNN in certain categories such as plane and large vehicle. This superior performance is partly attributed to the EMA mechanism, which effectively enlarges the equivalent training batch size, thus enhancing feature representation and generalization.
An additional observation is found in the helicopter category, where performance at the 10% supervision level declines across all methods compared to lower supervision rates. This decline likely arises from visual confusion with similar categories such as plane, commonly encountered in airport contexts. This underscores the importance of precise pseudo-label refinement strategies to mitigate class confusion.
Table 3 further validates the robustness and effectiveness of our method on the DIOR dataset. Our model consistently demonstrates superior or highly competitive performance across various annotation scenarios, particularly excelling in semantically challenging categories like storage tank, expressway service area and vehicle.
However, the model’s performance in train station indicates persistent challenges due to inherent visual ambiguities and sparse annotations at the 1% annotation rate. Despite these challenges, our method consistently ranks among the top-performing approaches. Additionally, increasing annotation rates to 10% further enhances performance, achieving notable mAP50 scores of 44.0 in both vehicle and dam, and an impressive 83.1 in ground track field, matching or slightly exceeding the fully supervised Oracle Faster RCNN. Compared with representative baselines under the same protocols, our method maintains clear advantages across most categories, including recent strong methods like Soft Teacher, Semi DETR and MixPL. This further underscores the robustness and generalization ability of EMT across diverse object types.
Analyzing cross-dataset performances reveals that competing approaches such as MixPL and Semi-DETR exhibit strengths primarily within certain categories. In contrast, our method demonstrates more consistent advantages across diverse categories and datasets. This consistent cross-dataset performance indicates our model’s capability to capture generalizable semantic representations, reinforcing its effectiveness in varied remote sensing scenarios.
4.6. Ablation Studies
4.6.1. Ablation Studies of Each Component in the EMT
In this section, we thoroughly investigate the DOTA dataset to assess the effectiveness and robustness of the EMT. We employed the same training strategies and testing settings as previous standard SSOD methods to ensure a fair comparison. Specifically, we randomly divided the DOTA training set into three subsets containing 1%, 5%, and 10% of labeled images, while treating the remainder of the training set as unlabeled data.
Table 4 presents the ablation studies of each component within EMT, evaluating their contributions under different labeled data protocols. The baseline method represents the original teacher–student network without the inclusion of APLF, CBLR, or ESL.
APLF corresponds to the pseudo-label threshold filtering mechanism in the teacher–student framework. In the ablation study, we replaced APLF with a fixed high threshold of 0.9, following existing methodologies. Removing APLF resulted in a significant decline in performance, especially under the 1% labeled data protocol, where mAP50 dropped by 5.3 points. This substantial decrease is attributed to the model’s increased reliance on pseudo-labels due to limited labeled data, highlighting APLF’s critical role in balancing true positive retention and false positive elimination. In higher labeled data protocols (5% and 10%), the performance drops were around 2 points of mAP50, demonstrating APLF’s effectiveness in more data-rich scenarios as well.
CBLR is responsible for mitigating error accumulation in the unsupervised learning branch by weighting the loss based on pseudo-label confidence. The ablation involved resetting the sample loss weights to 1, reverting to the original Faster RCNN loss computation. This removal led to performance decline of approximately 3 points in mAP50 across all protocols. Notably, the degradation was more pronounced for CBLR compared to APLF in the 5% and 10% protocols, underscoring CBLR’s crucial role in managing noise and enhancing robustness These findings indicate that traditional supervised loss calculation methods are inadequate for SSOD in the unsupervised branch, even when pseudo-label quality is high.
ESL is responsible for mitigating error accumulation by reweighting the supervised classification loss based on information from the unsupervised branch. Specifically, ESL leverages class-specific adaptive thresholds in APLF to assess the learning difficulty of each class and adjusts the loss weights accordingly. In the ablation study, we reset the loss weights to 1, reverting to the original Faster RCNN loss functions. This removal caused decreases in both mAP50 and mAP50:95 across all protocols, with more significant drops observed in the 5% and 10% protocols (from 43.8 to 43.6 at 1%, from 62.0 to 60.9 at 5%, and from 62.8 to 61.5 at 10%). The greater impact in higher protocols is due to ESL’s enhanced ability to exploit the increased labeled data, effectively suppressing error accumulation and ensuring balanced learning across classes. When ESL is used in isolation, the performance gains are limited. This is because the removal of APLF and CBLR leads to accumulated errors in the unsupervised branch, resulting in inaccurate class difficulty estimations that ESL relies on for loss reweighting.
Overall, the ablation studies demonstrate that APLF, CBLR, and ESL collectively play essential roles in mitigating error accumulation within SSOD for remote sensing. Each component contributes uniquely to enhancing pseudo-label quality, reducing the influence of noisy data, and ensuring balanced learning across diverse and challenging object categories. Moreover, when used in combination, these modules exhibit clear synergistic effects. The full configuration, which incorporates all three modules, consistently achieves the best performance across all labeled data protocols. This highlights the complementary nature of APLF, CBLR, and ESL in addressing different aspects of pseudo-label reliability and class imbalance, thereby significantly boosting the overall effectiveness and robustness of the EMT framework.
4.6.2. Ablation Studies of Each Component in the APLF
APLF is designed to improve the quality of pseudo-labels in remote sensing SSOD by balancing the retention of true positives with the removal of false positives under challenging conditions. It achieves this by the cooperation of two internal modules: SSRE, and DTF. To further verify the effectiveness of each component within APLF, we conducted additional experiments focusing on the 1% training protocol of the DOTA dataset. As indicated by
Table 3, the 1% protocol was chosen because it contains the smallest amount of labeled data, making the model’s performance more dependent on the pseudo-label filter.
APLF comprises two sequential sub-modules: SSRE and DTF. In our ablation experiments, disabling SSRE means that the corresponding module is removed from the filtering process, while ablating DTF is achieved by replacing the dynamic threshold with a fixed threshold of 0.9 (as used in many previous implementations).
Table 5 presents the ablation results of each sub-module within APLF under the 1% training protocol on DOTA.
Ablating the SSRE module results in a decrease in mAP50 from 43.8 to 41.3, a drop of 2.5 points. This indicates that SSRE plays a role in refining pseudo-labels. By evaluating the classification results from two RCNN stages, SSRE effectively removes a significant number of low-quality predictions, preventing the dynamic threshold in DTF from being estimated too low. This effect is particularly notable in categories such as small vehicle (SV), where mAP50 drops significantly from 47.5 to 16.2, highlighting SSRE’s importance in scenarios involving densely distributed, small-sized objects commonly found in urban environments.
Ablating the DTF module causes a substantial decrease in mAP50 from 43.8 to 40.1, a drop of 3.7 points. This highlights the critical role of dynamic thresholding in balancing the retention of true positives and the elimination of false positives based on the model’s evolving confidence levels. The most significant declines occur in categories like storage tank (ST), where mAP50 drops drastically from 58.6 to 30.6. This clearly indicates that categories with variable confidence distributions rely heavily on dynamic threshold adjustments to maintain accurate pseudo-label filtering.
Overall, the ablation studies of APLF’s sub-components confirm that each module contributes uniquely to enhancing pseudo-label quality. SSRE is crucial for refining and ensuring the precision of pseudo-labels, particularly in medium and small objects, while DTF dynamically adjusts thresholds to adapt to varying data distributions, thereby preventing error accumulation and improving the model’s robustness and performance, especially for large objects.
4.7. Analysis of Transformer Backbone
Given that the recent Semi-DETR [
26] method employs a Transformer-based detector, we extend the backbone of our EMT framework to compare the performance differences between CNN-based and Transformer-based architectures.
ResNet [
33] is a widely used CNN model for object detection tasks, while Transformers have emerged as a powerful alternative framework for image classification and detection. In recent years, Transformer-based backbones such as Swin Transformer [
35] and Pyramid Vision Transformer (PVT) [
36] have demonstrated strong performance across various dense prediction tasks. To evaluate the robustness and generalizability of our EMT framework, we replace the ResNet backbone with these two representative Transformer-based architectures while keeping all other components unchanged. This allows us to assess EMT’s compatibility with different types of backbone paradigms under semi-supervised settings.
The results in
Table 6 demonstrate that our EMT framework consistently improves detection performance across all tested backbones and supervision levels. Notably, when using Swin Transformer, EMT achieves the highest mAP scores among all configurations, with particularly large gains in the 1% and 10% settings. This suggests that Swin’s ability to model long-range dependencies and hierarchical features is especially beneficial when labeled data is scarce or object appearances vary significantly.
In contrast, the Pyramid Vision Transformer (PVT), although less complex than Swin, still shows clear performance improvements when combined with EMT. Compared to its supervised-only baseline, EMT with PVT improves mAP50:95 by 6.2, 4.7, and 4.2 under the 1%, 5%, and 10% settings, respectively. This confirms that EMT remains effective even with more lightweight Transformer architectures.
Furthermore, across all backbones (ResNet50, Swin, and PVT), EMT consistently outperforms both the fully supervised baseline and the strong PCT baseline. This highlights EMT’s backbone-agnostic design and its robustness in mitigating pseudo-label noise and class imbalance under varying architectural choices. These findings validate the generality and practical adaptability of EMT in real-world remote sensing SSOD.
4.8. Visualization of Predictions in Test Set
To intuitively demonstrate the effectiveness of our proposed model, we visualize the prediction results on the test sets of DOTA, DIOR, and SSDD, as shown in
Figure 3,
Figure 4, and
Figure 5, respectively. These visualizations correspond to EMT models trained with only 10% of labeled data from each dataset.
Despite challenges such as diverse object scales, SAR noise patterns, and cluttered or complex backgrounds, the proposed EMT accurately detects and localizes objects across various scenes and categories. Notably, in
Figure 5, the model effectively identifies ships in noisy SAR imagery from the SSDD dataset, demonstrating robustness to low contrast and low SNR conditions.
These results highlight that EMT maintains strong generalization and high detection quality even in semi-supervised settings, validating its applicability to real-world remote sensing tasks with limited annotation budgets.
4.9. Visualization of Pseudo-Labels
To further illustrate the effectiveness of APLF, we visualize the pseudo-labels in
Figure 6. Specifically, ground truth annotations are marked with green boxes, while pseudo-labels are indicated by red boxes. The selected images are sampled from the unlabeled training data on 10% labeled DOTA and SSDD with weak augmentation, representing the input data processed by the teacher model during SSOD training. By comparing the visualization results before and after applying APLF, we observe that the teacher model’s predictions contain a significant number of false positives, including high-confidence erroneous pseudo-labels. However, APLF effectively reduces the number of false positives while preserving true positives as much as possible, thereby providing the student model with a more reliable supervisory signal.
4.10. Inference Cost Analysis
To assess the computational efficiency and deployment feasibility of the proposed EMT framework, a comprehensive inference cost evaluation was conducted. The analysis includes inference speed (measured in frames per second, FPS) and GPU memory usage under various labeling regimes.
All evaluations were performed on the DIOR dataset, which consists of images that have been uniformly cropped to a fixed size of 800 × 800 pixels. This characteristic eliminates the need for additional resizing or padding operations during inference, ensuring consistent and reproducible measurement conditions. The experiments were conducted on a single NVIDIA RTX 3060 GPU with 12 GB of memory to simulate realistic deployment scenarios on resource-constrained or embedded platforms, rather than relying on high-performance server-class GPUs.
Inference performance was evaluated for three model categories under different labeled data regimes: (1) supervised models trained with 1%, 5%, and 10% labeled data, (2) EMT models trained under identical labeling ratios, and (3) an Oracle model trained using 100% labeled data. For each model, inference throughput and memory usage were measured with and without automatic mixed precision (AMP) enabled. A total of 2000 test images were used per configuration, and the reported values represent the average across all samples after removing warm-up iterations. All models were tested with consistent settings, including a batch size of 1 without gradient computation.
The results are summarized in
Table 7. Across all configurations, the EMT framework achieves inference speed and GPU memory usage comparable to the supervised and Oracle models, confirming that the proposed modules (APLF, CBLR, and ESL) do not introduce any computational overhead at inference time. The model deployed during inference maintains the standard structure of the Faster RCNN detector, ensuring architectural consistency.
A consistent improvement in inference speed is observed when AMP is enabled, with an average FPS increase of approximately 10 FPS and a reduction of around 50 MB in memory consumption across all models. This demonstrates the effectiveness of AMP in accelerating inference and reducing resource requirements, particularly beneficial for low-power or embedded environments. It is also noted that a slight variation in FPS between the EMT and supervised models under identical label ratios. This difference may be partially attributed to minor system-level resource fluctuations during benchmarking. In addition, the supervised models, trained with highly limited labeled data, tend to produce more false positives, potentially leading to a marginally longer NMS stage.
These observations further confirm that EMT not only enhances detection performance in low-label regimes, but also preserves inference efficiency, making it well-suited for deployment in real-time or resource-constrained remote sensing applications.
5. Discussion
5.1. Computational Efficiency and Complexity
Computational efficiency is a critical aspect in deploying object detection frameworks. The EMT framework introduces additional modules such as APLF and CBLR, raising potential concerns about computational overhead. To address these concerns, we provide a detailed analysis of the computational complexity introduced by EMT.
During the pseudo-label generation phase in standard SSOD, the teacher model typically processes approximately 1000 region proposals generated by the RPN through the RCNN head. In contrast, the proposed SSRE module within APLF reassesses only pseudo-labels identified by the teacher as potential positives. Given that the number of these pseudo-labels typically does not exceed 100, the additional computational cost introduced by the SSRE is minimal (less than 10% of the computational burden associated with processing standard RPN proposals). Furthermore, the pseudo-label reassessment does not require gradient computation, significantly reducing memory and computational time.
Similarly, the CBLR module introduces minor additional computations by requiring the teacher network to perform an extra forward pass and loss computation for RoIs generated by the student. However, since these operations do not involve gradient calculations, the associated computational cost is substantially lower than a standard forward-backward pass of the student model.
Overall, the primary computational cost in Faster RCNN-based object detection arises from its ResNet50 backbone. Therefore, the incremental computation introduced by EMT is negligible compared to the backbone’s computational requirements. Importantly, during inference, the EMT framework does not alter the computational complexity or memory usage compared to the underlying detector, ensuring that deployment efficiency remains unaffected.
5.2. Comparison Between CNN-Based and Transformer-Based Detectors
Transformer-based object detectors, such as Semi-DETR, have garnered attention due to their ability to capture global context through self-attention mechanisms, inherently modeling the interactions between multiple objects. Such global contextual understanding could potentially enhance detection performance in remote sensing scenarios, especially those involving dense and multi-scale targets. However, transformer-based models typically require substantial amounts of training data and computational resources to converge effectively. In scenarios with extremely limited labeled data, transformer models may exhibit suboptimal performance due to insufficient training signals.
In contrast, EMT, built upon the CNN-based Faster RCNN architecture, offers significant advantages in terms of data efficiency and computational practicality, particularly under low-labeling conditions. The convolutional architecture inherently requires fewer training samples to achieve robust performance, making EMT especially suitable for remote sensing tasks where labeled data is scarce or expensive to obtain.
Importantly, the error mitigation strategies incorporated in EMT, such as pseudo-label filtering and consistency-based reweighting, are fundamentally model-agnostic. These strategies can theoretically be integrated into transformer-based detectors to similarly reduce error accumulation and enhance detection accuracy. As future work, we intend to explore hybrid architectures that leverage both the global context modeling strengths of transformer detectors and the effective error mitigation strategies developed in EMT. Such integrations hold promise for further advancing semi-supervised object detection in remote sensing applications.
6. Limitations and Future Work
Despite the demonstrated effectiveness of EMT, several challenging yet important aspects remain to be addressed. Firstly, although EMT has been evaluated extensively on optical and SAR datasets separately, its robustness and generalization capabilities in extremely complex scenarios remain to be fully verified, such as disaster-affected regions with drastic appearance changes, strong interference, or unusual imaging angles. Such conditions typically introduce significant domain shifts, thus posing considerable challenges to the model’s current design.
Secondly, EMT’s practical deployability on truly resource-constrained embedded platforms has not been empirically validated. Although our inference efficiency experiments simulated resource-constrained scenarios using an NVIDIA RTX 3060 GPU (12 GB), constraints prevented us from implementing and evaluating EMT directly on embedded hardware. Future work should therefore involve deploying and testing EMT on actual embedded devices or edge-computing platforms to further verify and improve its applicability in real-world remote sensing systems.
Thirdly, although we visually demonstrated the effectiveness of pseudo-label refinement through the APLF module, the interpretability of the model itself remains inherently limited. This limitation partly stems from the historical difficulty and complexity of interpretability in deep learning itself, a longstanding open research problem. Consequently, future studies should explore advanced visualization and attribution methods to enhance transparency and deepen our understanding of model behavior across different training stages.
Fourth, while our framework focuses explicitly on semi-supervised training methodologies, its compatibility with multi-modal data (e.g., optical and SAR imagery fusion) was not experimentally investigated. In principle, EMT’s architecture can inherently accommodate multi-modal input, but it is also important to recognize that multi-modal fusion introduces additional complexities, including modality alignment and complementary information integration. Investigating EMT’s effectiveness and required adaptations for multi-modal remote sensing data thus presents an interesting and valuable direction for future research.
Finally, our current method does not explicitly model prediction uncertainty. Nevertheless, EMT incorporates implicit uncertainty-aware mechanisms through modules such as APLF which dynamically filters low-confidence pseudo-labels and CBLR which downweights noisy samples based on reconstruction loss. These strategies have been shown to improve robustness, as evidenced in our ablation studies and pseudo-label visualizations. In future work, we plan to explore more principled uncertainty modeling approaches, such as entropy-based filtering or agreement-aware selection, which may further enhance the reliability of pseudo-label supervision under severe domain shifts.
7. Conclusions
In this paper, we proposed EMT, a novel framework designed to improve SSOD performance in remote sensing. EMT addresses the common issue of error accumulation from noisy pseudo-labels, which is particularly severe in remote sensing scenarios due to complex backgrounds, class imbalance, and dense object distributions.
Our framework integrates three complementary components. First, APLF enhances pseudo-label quality through second-pass consistency checks and class-aware dynamic thresholds. Second, CBLR down-weights unreliable pseudo-labels using teacher–student consistency, suppressing residual error propagation during training. Third, ESL dynamically adjusts class-wise loss weights based on pseudo-label confidence, ensuring better use of limited labeled data.
Extensive experiments on three widely-used remote sensing datasets (DOTA, DIOR, and SSDD) demonstrate that EMT achieves consistent improvements over state-of-the-art SSOD baselines, including both convolutional and transformer-based methods. Notably, EMT maintains high detection performance even with only 5–10% labeled data and introduces negligible additional inference cost.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}