As described in the introduction, the augmented dataset [
16] is the only available one to train identification models at present. However, due to lack of representativeness and the low quality of the augmented dataset, it is difficult to effectively train identification models. Another way to create a new dataset is based on the existing identified skylights. Though there are some identified skylights, the accuracy is very poor. So, the only way to create the dataset is to identify skylights manually in suitable experiment areas and with appropriate data.
2.2. Data Selection and Stretching
Although there are some identified skylights by manual identification (as summarized in the introduction), they had positional offset and low accuracy.
Figure 2 shows some identified examples by Cushing, Sharma & Srivastava, and Tettamanti using MRO-CTX image data. In
Figure 2a,b, there is evident positional offset between the labels made by Cushing et al. and Tettamanti. Meanwhile, in
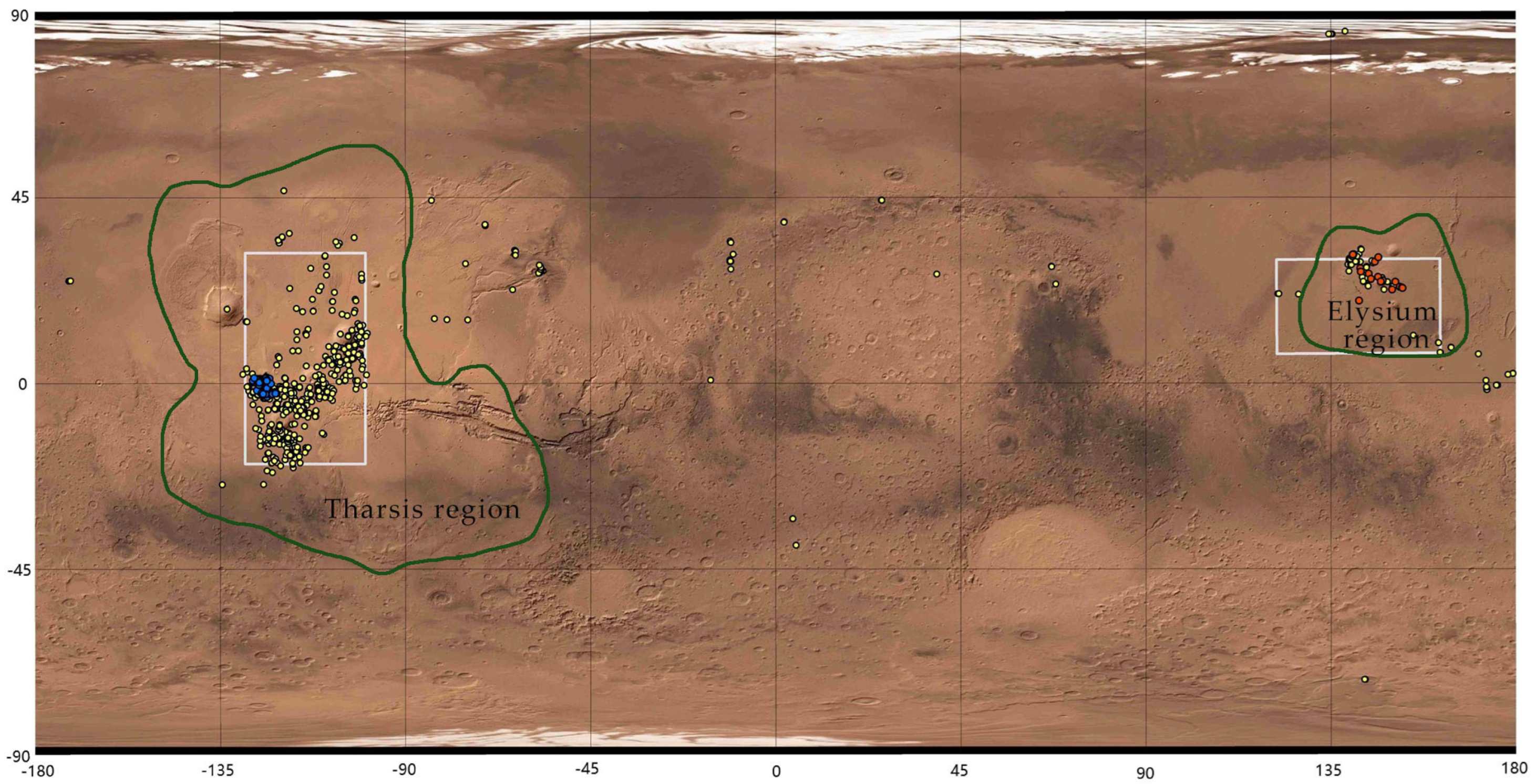
Figure 2c, Sharma & Srivastava misidentified some skylights without overhanging or vertical walls. So, it is impossible to build a skylight dataset based on those existing identification results directly. But the results provide the georeferenced information, which can be used to locate skylights and accelerate labeling samples to create a new sample dataset. So, the skylights identified by Cushing, Sharma & Srivastava and Tettamanti in the experimental areas were selected as the georeferenced data.
MO-THEMIS, MRO-CTX, and MRO-HiRISE image data has been used to identify skylights, with resolutions of 100 m/pixel, 6 m/pixel, and 0.25 m/pixel respectively. MO- THEMIS daytime image coverage is global, while the nighttime image coverage spans from 60°S to 60°N, and MRO-CTX and MRO-HiRISE image data covers 99.1% and 1% of the surface of Mars, respectively [
20,
21].
Table 1 shows the spatial resolution and coverage rate of MO-THEMIS, MRO-CTX, and MRO-HiRISE image data. Since the radii of the observed skylights are small (<112.5 m) [
22], some morphological details cannot be imaged in relatively low-resolution image data such as MRO-CTX and MO-THEMIS images. To get more subtle features of the skylight, high-resolution image data is required. Meng et al. [
23] suggested that the detected crater is reliable when the diameter exceeds 10 pixels in the image. According to the above suggestion, the diameter of the identified skylights, as the same negative landform, should be more than 10 pixels. The diameter of the minimal identified skylight is 5 m [
24], so the resolution should be higher than 0.5 m/pixel (5 m ÷ 10 pixel = 0.5 m/pixel). At present, MRO-HiRISE images are the only data whose resolution (0.25 m/pixel) meets the above requirement. Therefore, MRO-HiRISE image data was selected as the data resource (
https://www.uahirise.org/hiwish/browse (accessed on 20 January 2024)) to build the dataset in this article. And 3607 images were downloaded in the experimental areas.
The MRO-HiRISE images were acquired with different levels of illumination, which may make the characteristics of images not obvious. Some experiments have shown that image stretching can highlight the morphological characteristics and enhance the object detection accuracy [
25]. In this article, the max-min stretching method (Equation (1)) was selected to stretch the images.
Figure 3 shows some images before and after stretching. In the stretched images, the characteristics of the skylights are enhanced and become obvious.
2.3. Initial Dataset Building
A skylight identification model should require sufficient skylight samples for effective training, which enables the model to learn enough features and achieve robust identification performance. However, the existing skylight identification results have shown that identified Martian skylight samples are few. If those samples were used to train the identification model, it would affect the identification performance. As described in the introduction, it is necessary to build an initial dataset to augment the dataset. Building an initial dataset includes labeling samples and cropping data.
In addition to skylights, there are also some other similar types of negative landforms on Mars, such as bowl-shaped pits, fracture pits, irregular-shaped pits, and craters, as shown in
Figure 4. The morphological similarities probably pose a challenge in distinguishing skylights from other negative landforms using deep learning models. To address the problem, some researchers have introduced some negative samples into the dataset [
26,
27]. The negative samples provide distracted characteristics distinct from the positive samples, which can enable the model to mitigate overreliance on localized patterns of positive samples and instead learn discriminative global features. Therefore, in this article, skylights are labeled as positive samples and other negative landforms labeled as negative samples. Meanwhile, to enable the model to learn diverse distracted characteristics, negative samples should be labeled as diversely as possible.
During labeling samples, it is necessary to record the boundary of samples. In the experiment, the geographical information system software ArcMap 10.2 was used to label the boundary of sample with the stretched MRO-HiRISE images. Sample labeling includes the following steps:
(1) Create a shapefile and set its coordinate projection system consistent with the corresponding MRO-HiRISE image.
(2) Use the georeferenced skylight to search, locate, and label the corresponding skylight in the stretched image. Because there is a spatial offset between the georeferenced skylight and the corresponding skylight in the enhanced image (due to the spatial offset between MRO-CTX and MRO-HiRISE images), it is necessary to manually identify and confirm the corresponding object. After confirming, a circle was used to label the skylight. For the negative samples, we labeled some classic bowl-shaped pits, fracture pits, irregular-shaped pits, and craters.
(3) Merge all the labeled samples and output the location and radii. In the ArcMap, we used the Arc Toolbox to merge the identified samples in one file and used the “Calculate Geometry” function to get the radius and coordinate of the center point for each sample.
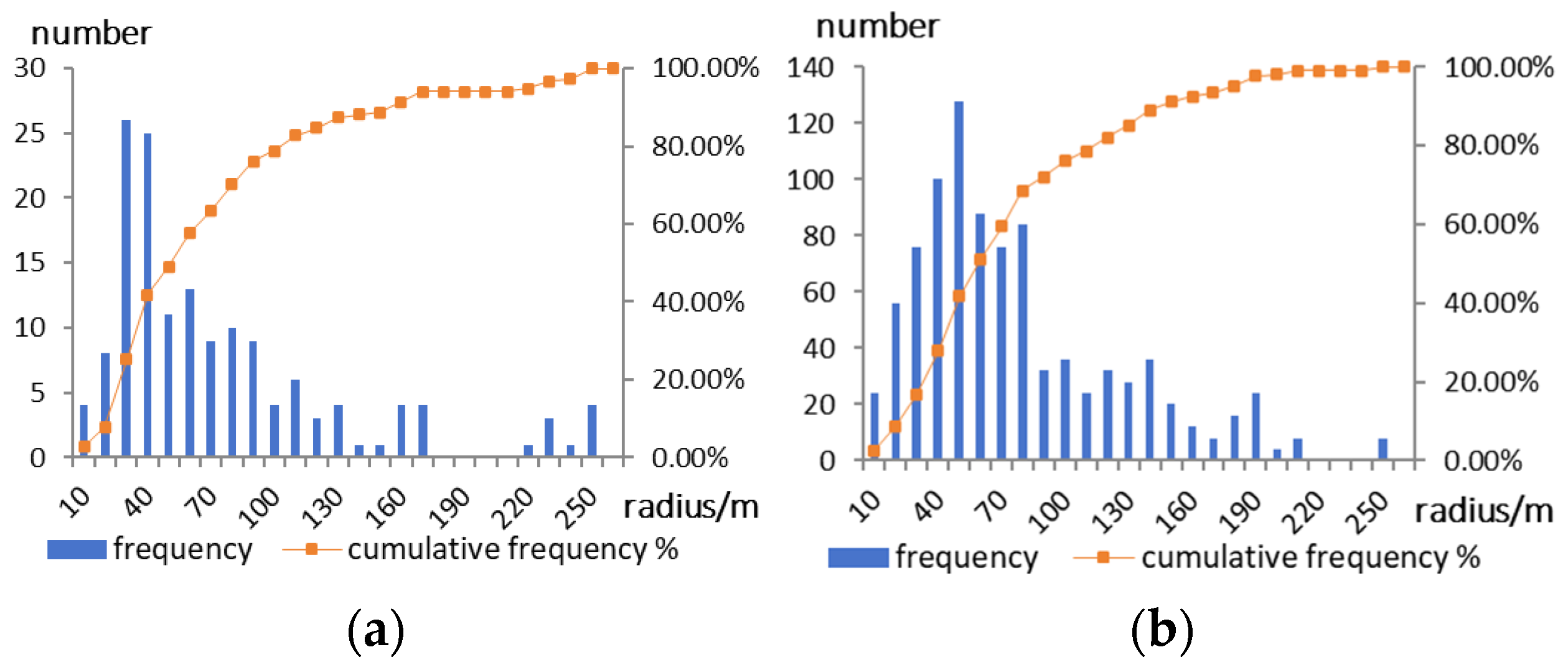
Finally, we labeled 151 skylight samples manually. Most of their radii are less than 100 m, and none exceeds 250 m (see
Figure 5a). Meanwhile, we labeled 920 negative samples with a radius < 250 m (see
Figure 5b).
- 2.
Cropping Data
In the following experiments, about 115 positive samples and 920 negative samples are used for augmenting positive samples for identification model building. To ensure the integrity of the sample, the cropped block must fully cover the range of the sample. As shown in
Figure 5, the largest radius of the sample is about 250 m, so the minimum side length of the image block is about 2048 pixel (2 × 250 m ÷ 0.25 m/pixel = 2000 pixel ≈ 2048 pixel). In this article, the target-centered cropping method was used to crop the HiRISE image. For each sample, the localization was based on the center point. And then, the corresponding image block was cropped by 2048 pixel × 2048 pixel.
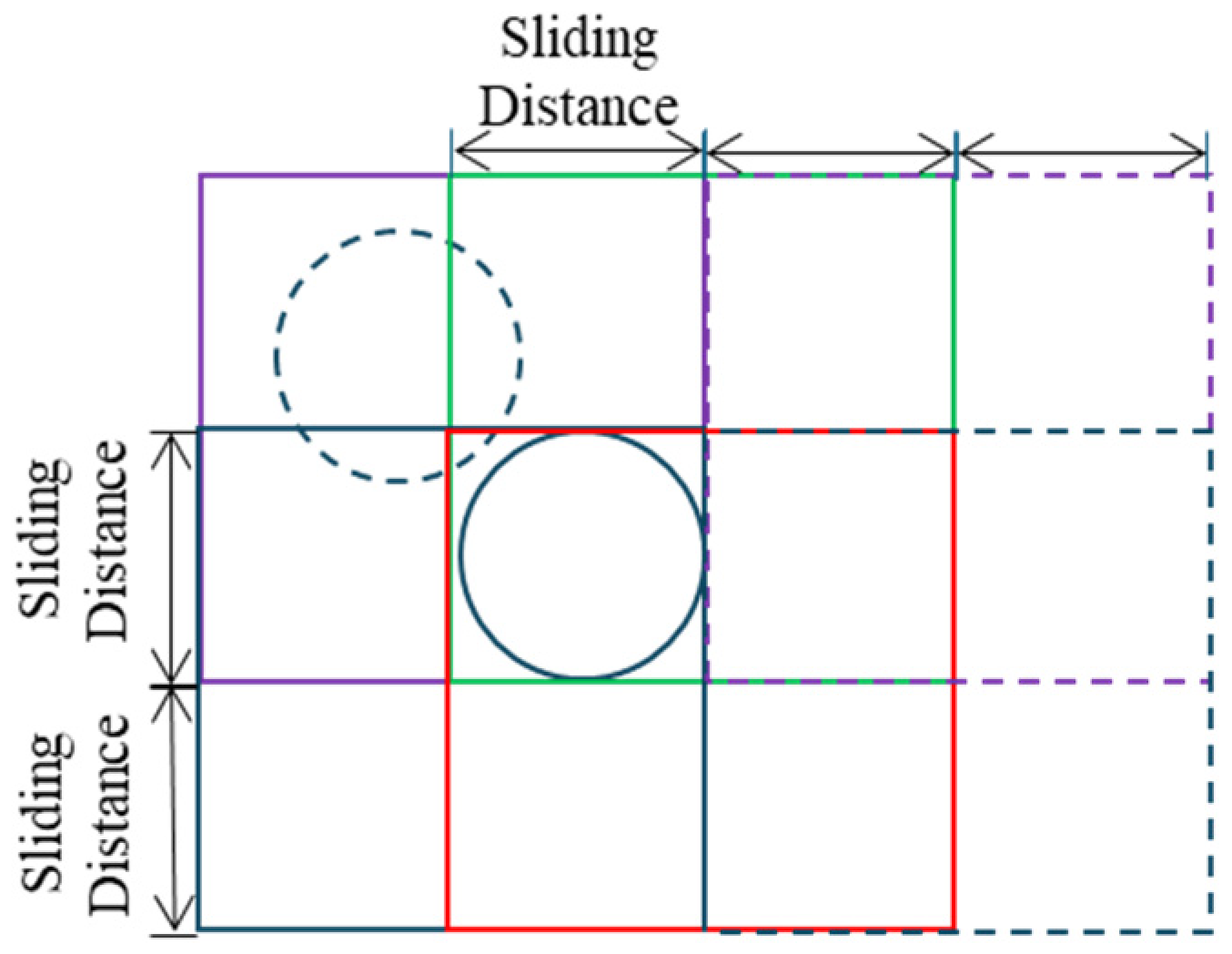
To evaluate the performance of identification model, the other 36 positive samples in 36 MRO-HiRISE images were selected to create a test dataset. In addition, to test the model’s robustness in filtering out false positives within real-world scenarios, the test dataset should introduce distractors (other negative landforms and backgrounds). To reserve the above information for the test samples, the sliding window method was used to crop the 36 MRO-HiRISE images. During the cropping process, the minimum side length of sample is 2048 pixels (calculation process as described above) and the sliding distance is the same as the minimum side length. In the test dataset, the largest sample should be covered by at least an image block. So, the image block is defined as 4096 pixel × 4096 pixel (see
Figure 6). For each MRO-HiRISE image file, the image was cropped by 4096 pixel × 4096 pixel, with a 2048 pixel sliding distance from left to right and top to bottom.
After cropping the data, we obtained the initial dataset, which contained 115 positive sample image blocks and 920 negative sample image blocks for data augmentation, and 6394 image blocks (including 36 positive samples along with other negative landforms and background regions) for identification model testing.







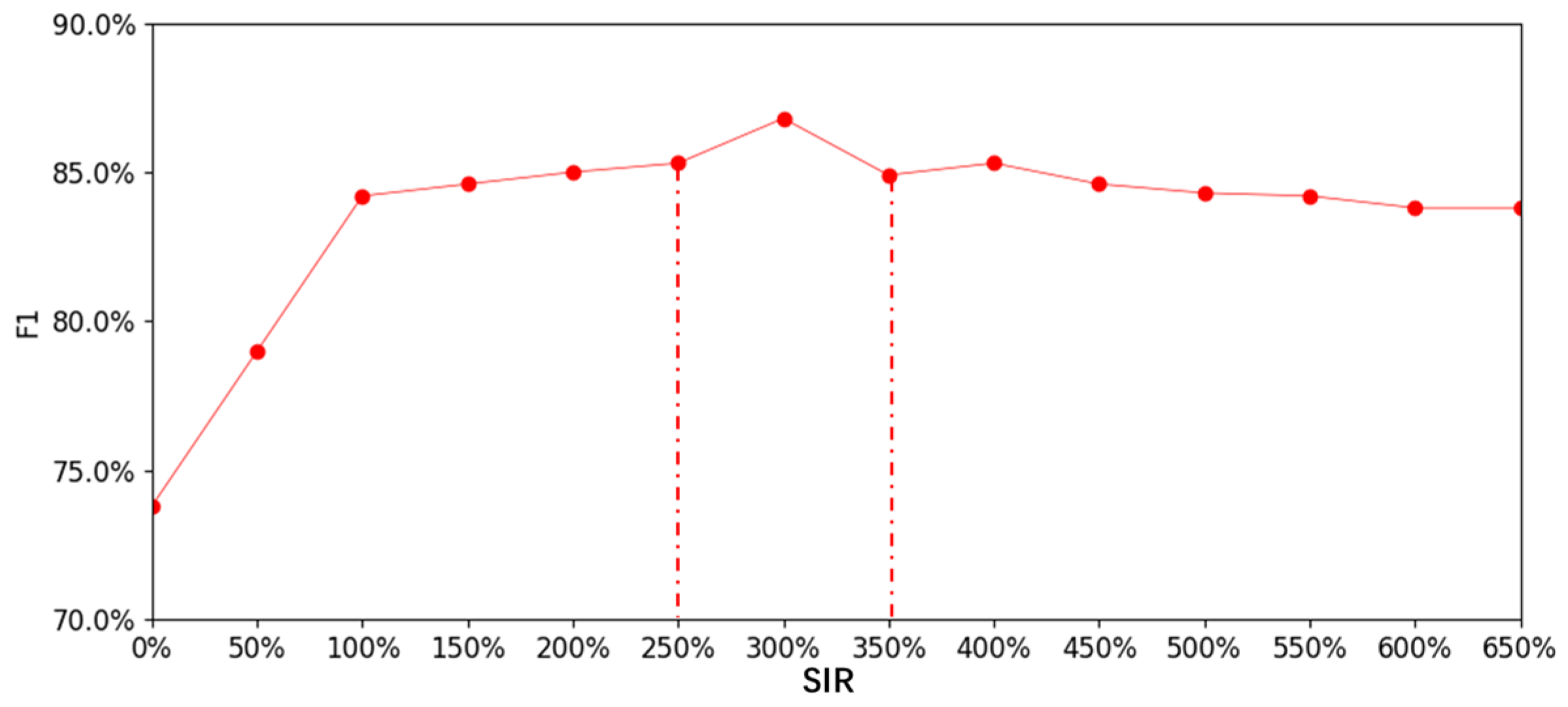
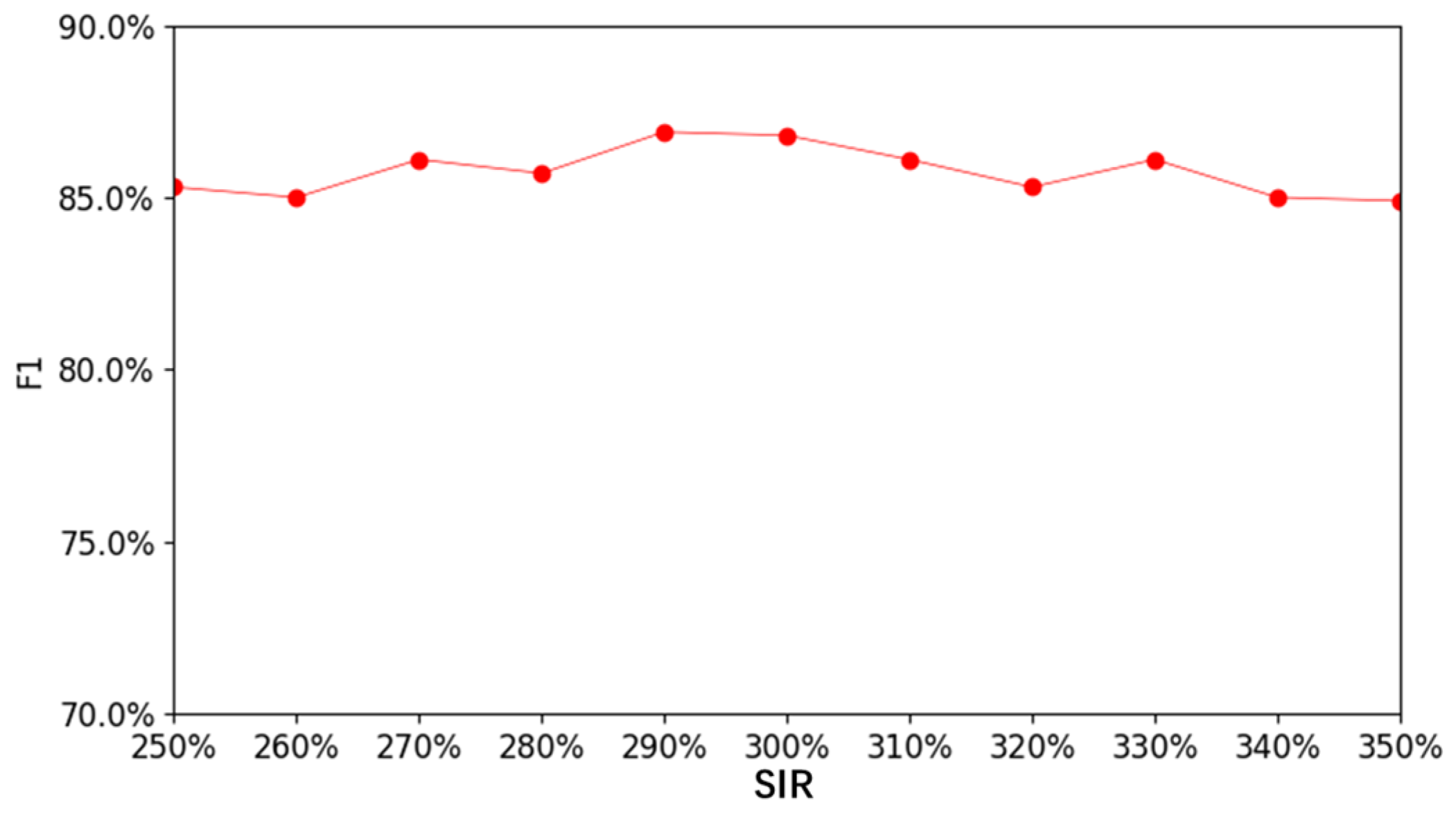


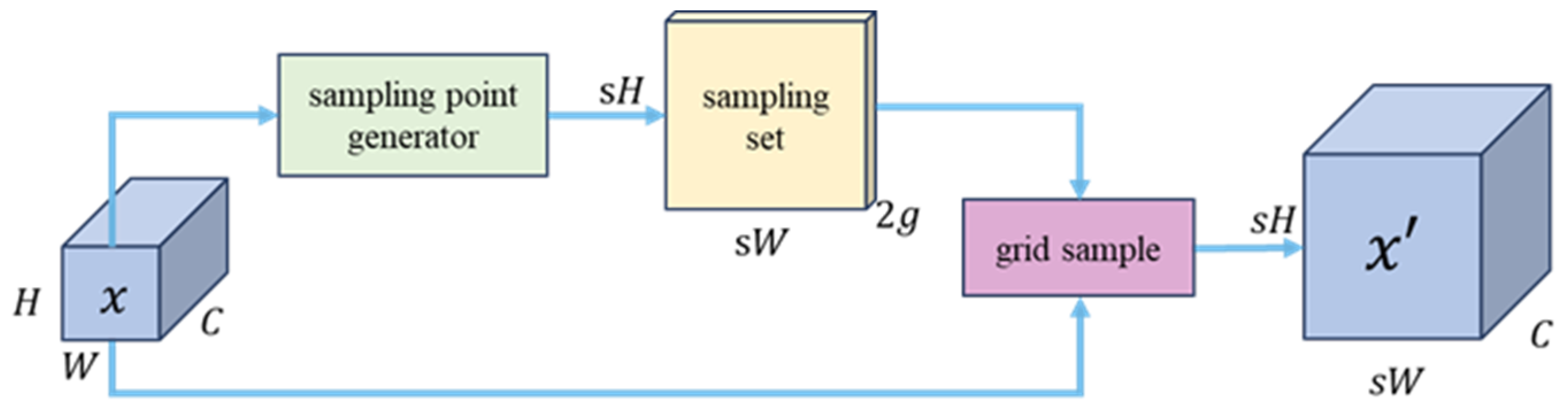
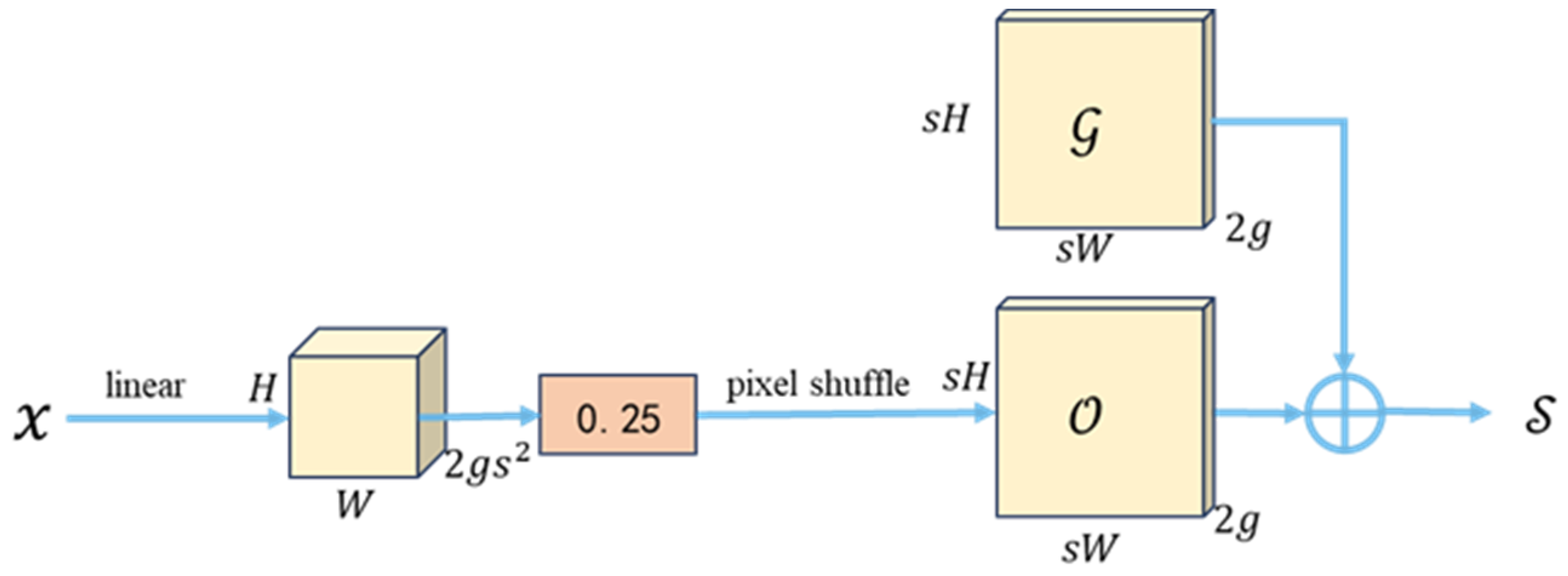



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}