1. Introduction
Sugarcane (
Saccharum officinarum L.) is a crucial economic crop in tropical regions, contributing to approximately 70% of global sugar production [
1] and serving as a primary feedstock for biofuel products such as ethanol. Under limited land resources, the growing demands for both sugar and renewable energy inevitably translate into requirements for higher sugarcane yields. Accurate yield prediction not only reflects the crop’s growth status and supports farm-level management decisions, but also facilitates the planning of harvesting and sugar processing.
Remote sensing technology offers significant advantages over traditional methods by enabling large-area crop monitoring with high spatial and temporal resolution. In recent years, satellite-based remote sensing has emerged as a promising approach for large-scale yield prediction due to its wide coverage, strong spatiotemporal continuity, and cost-effectiveness [
2,
3]. However, satellite remote sensing still faces challenges of cloud obstruction, limited image resolution, and fixed revisit cycles [
4]. Ground-based sensing can provide high-resolution data, but is often limited to point-based monitoring and lacks efficiency for large-scale agricultural applications [
5]. In contrast, unmanned aerial vehicle (UAV) remote sensing combines high spatial resolution, operational flexibility, and cost efficiency, allowing for the real-time acquisition of crop growth information. These advantages have established UAV remote sensing as a primary tool for yield prediction in modern agriculture [
6].
UAVs equipped with multispectral cameras covering visible and near-infrared (NIR) spectral bands can efficiently acquire multiple vegetation indices (VIs) that accurately reflect crop growth status [
7]. When combined with machine learning (ML) models, this approach has been widely applied for yield prediction across various crops [
8,
9]. For instance, Adak et al. [
10] employed Ridge Regression, Lasso Regression, and Elastic Net Regression to predict maize yield based on VIs and Canopy Height Measurements (CHMs) derived from time-series UAV imagery, with Lasso and Elastic Net reaching relatively higher accuracy (R
2 ≈ 0.80) at flowering and silking stages. Peng et al. [
11] evaluated Multiple Linear Regression (MLR), Support Vector Regression (SVR), and Random Forest (RF) to estimate wheat yield based on UAV-derived ear phenotypic features, including ear count, ear size, and ear abnormality index, and RF achieved the best performance (R
2 = 0.86) with all features combined. Tripathi et al. [
12] utilized SVM to estimate rice yield from multispectral VIs, and achieved the best performance (R
2 = 0.62), outperforming RF and Artificial Neural Networks (ANNs). Li et al. [
13] adopted Categorical Boosting (CatBoost), Light Gradient Boosting Machine (LightGBM), RF, Gradient Boosting Decision Tree (GBDT), and Multi-Layer Perceptron (MLP) to predict soybean yield based on RGB imagery, with GBDT achieving the best accuracy (R
2 = 0.82). Variations in model performance across studies are often attributed to the differences in data quality, crop types, study area extent, and feature extraction strategies. Generally, higher prediction accuracies could be achieved under conditions of high-quality data collection, homogeneous study regions, strong correlations between canopy features and yield, and proper model optimization. Conversely, lower accuracy occurred in large-scale heterogeneous areas, challenging data acquisition environments, or when weak relationships existed between canopy characteristics and final yield. Compared to traditional regression methods, ML algorithms such as SVM, RF, and GBDT offer several advantages, including the ability to capture non-linear relationships, handle high-dimensional inputs, and achieve improved accuracy. In recent years, deep learning models such as Long Short-Term Memory (LSTM) networks have also been introduced. Shen et al. [
14] proposed a hybrid model named LSTM-RF which combined Long Short-Term Memory Neural Network (LSTM) and Random Forest (RF) to predict winter wheat yield. The model achieved an R
2 of 0.78 and an RMSE of 684.1 kg/ha. However, the performance heavily depended on large training datasets. In data-limited scenarios, machine learning algorithms often exhibit higher accuracy and better stability than deep learning algorithms, particularly for UAV-based yield predictions which are typically conducted over small, uniform areas. Considering these findings and the specific requirements of our study, we preferred to employ machine learning algorithms for constructing our yield prediction model.
Multispectral imagery contains multiple spectral bands from which various VIs are typically derived to enhance the characterization of crop canopy features by mitigating errors caused by variations in illumination and ground cover conditions. As a result, numerous variables are involved in model development. Feature selection thus plays a critical role, particularly in machine learning-based yield modeling, as it directly affects model performance and computational efficiency. Accurate identification of the most relevant features can simplify the model structure, reduce training time, enhance generalization ability, and prevent overfitting. Current variable selection approaches include Principal Component Analysis (PCA) [
15], Pearson correlation analysis [
16], gray relational analysis (GRA) [
17], etc. Gómez et al. [
18] carried out Pearson correlation between wheat yield and satellite imagery spectral features/climate data in Mexico from 2004 to 2018, and selected the featured variables by certain thresholds. The result showed that the RF model using features with correlation coefficients above 0.5 achieved the best performance (R
2 = 0.84). However, Pearson correlation has limitations—it only captures linear relationships, is sensitive to outliers, and cannot account for feature interactions or multicollinearity. Ahmad et al. [
19] employed PCA to relate NDVI and Land Surface Temperature (LST) from Landsat 8 with maize yield in Pakistan, and constructed yield prediction models using LASSO and SVM, achieving high accuracy (R
2 = 0.94). Nevertheless, PCA may obscure key information, relies on linear assumptions, and suffers from interpretability issues. Chu et al. [
20] applied GRA to map rice distribution and analyze its driving factors in central China, finding cumulative temperature, slope, and proximity to water to be key influencers. Fei et al. [
21] used GRA to select the important multispectral VIs and normalized relative canopy temperature (NRCT) which were derived from UAV-based multispectral and thermal images at each growth stage for in-season grain yield prediction. In this context, GRA has been shown to offer strong adaptability for multi-attribute decision-making, allowing the accurate quantification of relationships among variables while minimizing subjective interference [
22].
Sugarcane has a long growing period, lasting up to 12 months, and its yield is influenced by a wide range of factors. Several researchers have conducted in-depth studies on sugarcane yield prediction, employing various methods and technologies to improve prediction accuracy. Some researchers investigated sugarcane yield prediction methods only based on meteorological data or large-scale (state-scale) statistical data such as area, area under irrigation, production attributes, etc. For example, Kumar et al. [
23] constructed a Multiple Linear Regression (MLR) model for sugarcane yield prediction based on meteorological data, while Satpathi et al. [
24] compared MLR with penalized regression methods (LASSO, Ridge, Elastic Net), and a range of machine learning algorithms including Extreme Gradient Boosting (XGB), RF, SVM, and ANN based on meteorological data. Saini et al. [
25] proposed a deep learning-based hybrid model, CNN-Bi-LSTM_CYP, which integrated Convolutional Neural Networks (CNNs) and a Bidirectional Long Short-Term Memory (Bi-LSTM) for sugarcane yield prediction in India based on state-scale statistical data from 1990 to 2019. Akbarian et al. [
26] explored the use of high-resolution UAV-based multispectral imagery to improve early-stage, row-level sugarcane yield prediction in Bundaberg, Australia, where Pearson correlation analysis and stepwise feature selection were conducted and a Generalized Linear Model (GLM) was then developed. Results indicated that the mid-growth stage (from mid-March to early May) was the optimal UAV data acquisition window, and the combination of Normalized Difference Red Edge Index (NDRE) and Green–Red Normalized Difference Vegetation Index (GRNDVI) in March achieved the highest accuracy (R
2 = 0.74), enabling accurate yield prediction up to six months before harvest and providing ample time for decision-making in field management. Canata et al. [
27] built RF and MLR models based on Sentinel-2 images for a commercial sugarcane site with two consecutive cropping seasons, and reached an R
2 of 0.70 for the testing dataset.
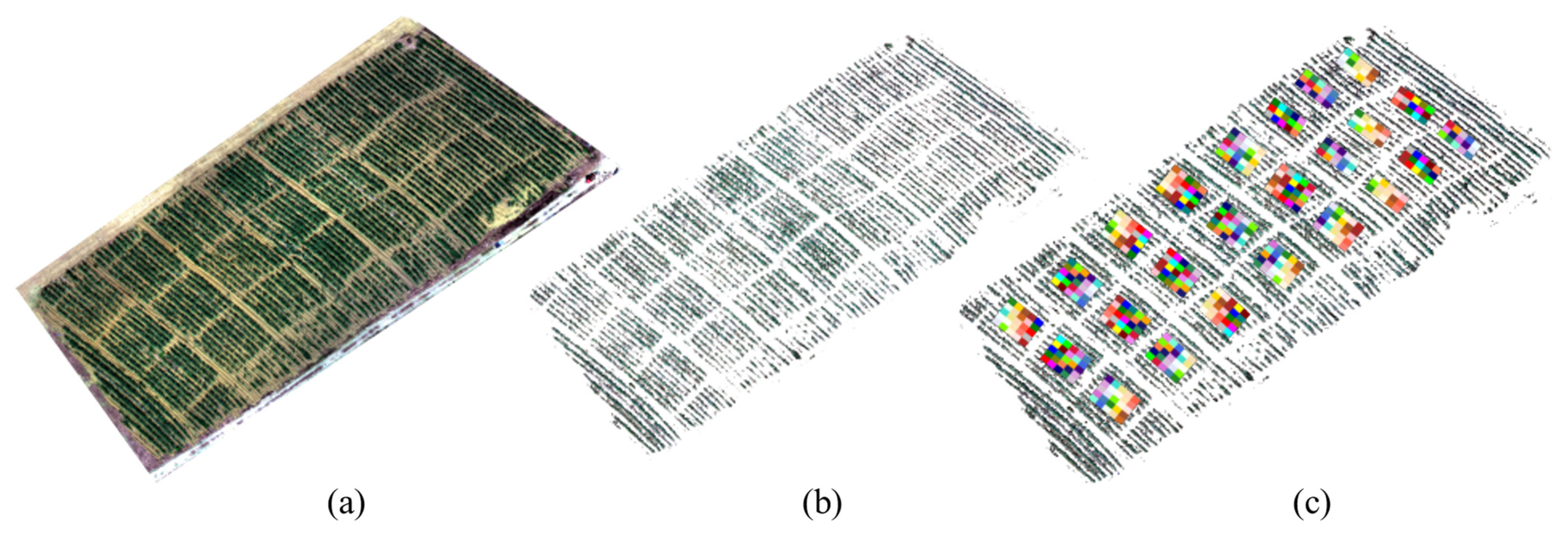
While many studies have applied remote sensing for crop yield prediction, relatively few have focused on sugarcane yield estimation, especially with full-season spectral data. Sugarcane’s long growth cycle and the yield of the stalk part which is totally beneath the canopy make it difficult for imagery from a single stage to fully capture the yield potential. Thus, identifying sugarcane-specific sensitive spectral features and developing dedicated models is of significant importance. To address this gap, this study utilizes UAV-based multispectral imagery across key growth stages to explore effective sugarcane yield prediction strategies. The main research objectives of this research are as follows:
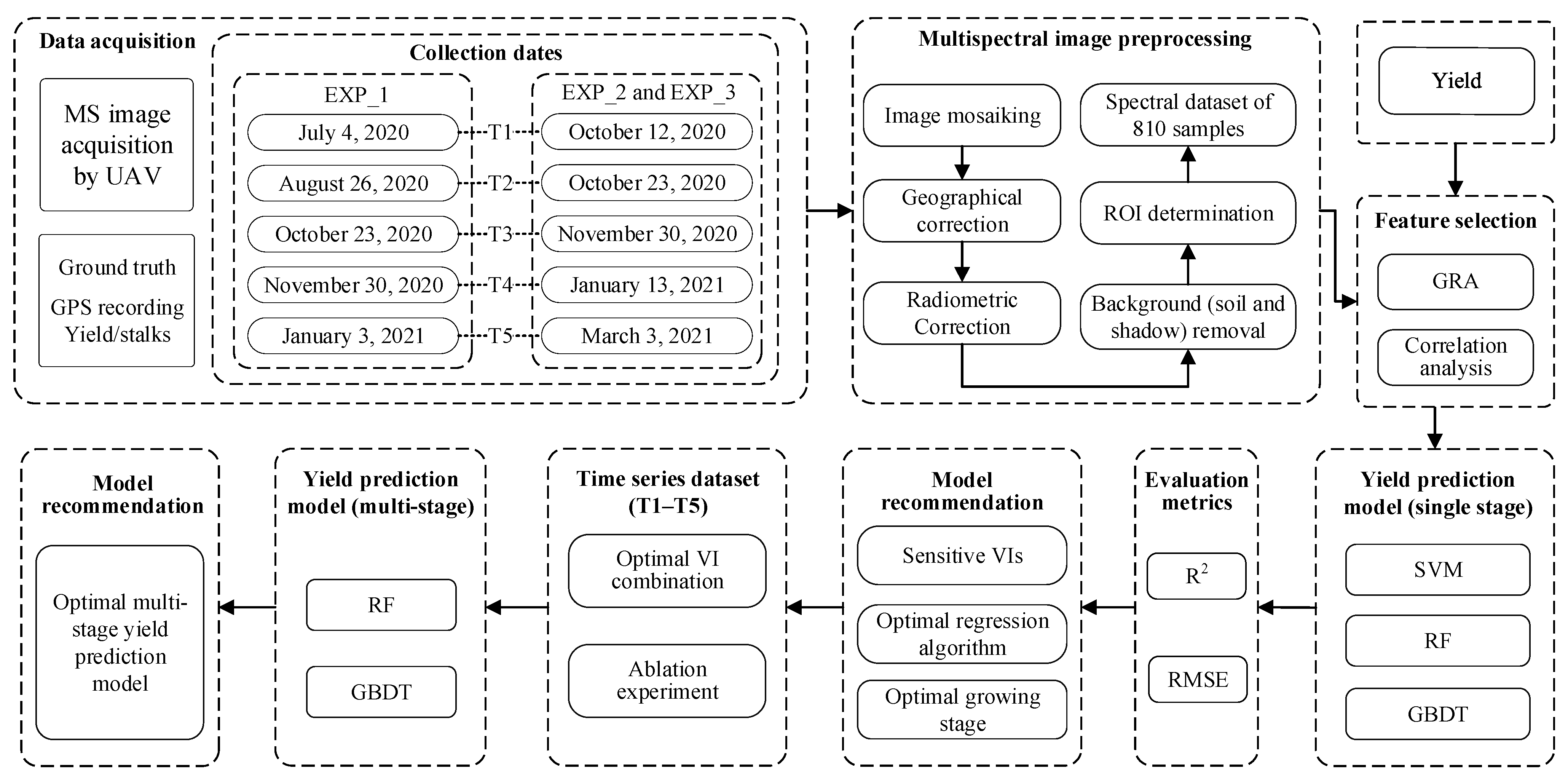
(1) To develop a hybrid feature selection method based on gray relational degree and correlation analysis (GRD-r) for extracting yield-sensitive VIs;
(2) To systematically evaluate the performance of prediction models constructed with different growth stage data and feature combinations using ensemble learning algorithms (GBDT, RF) and SVM;
(3) To determine optimal feature sets and establish robust regression models for both single-stage and multi-stage yield prediction scenarios.
5. Conclusions
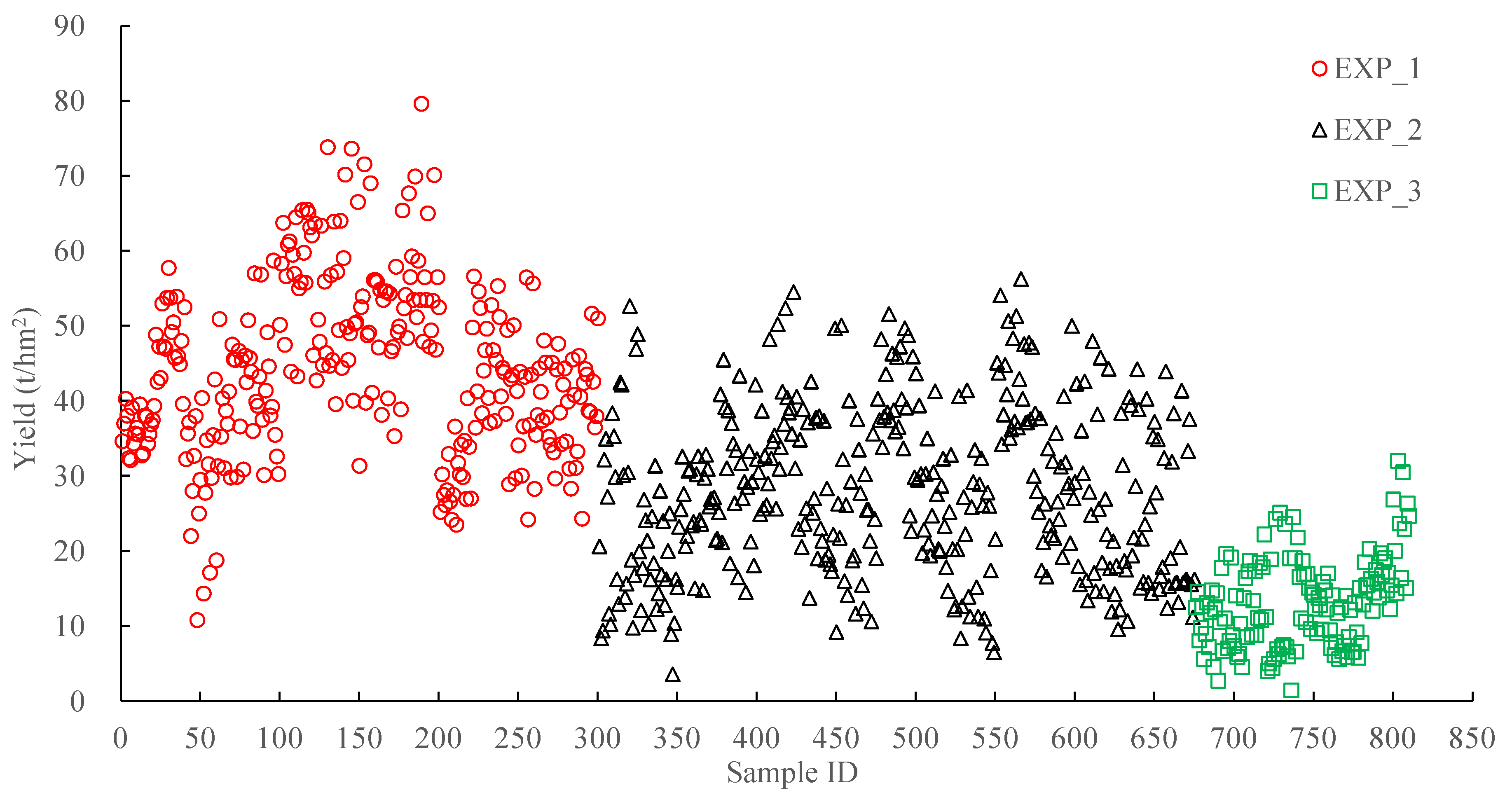
This study collected multi-temporal multispectral imagery from three sugarcane experimental fields under different fertilization treatments to analyze the relationship between spectral features and yield. A feature selection criterion of sensitive VIs for yield prediction was proposed. Sugarcane yield prediction models with the least variables were built both for a single-growth-stage scenario and a multi-growth-stage scenario. The main conclusions were as follows:
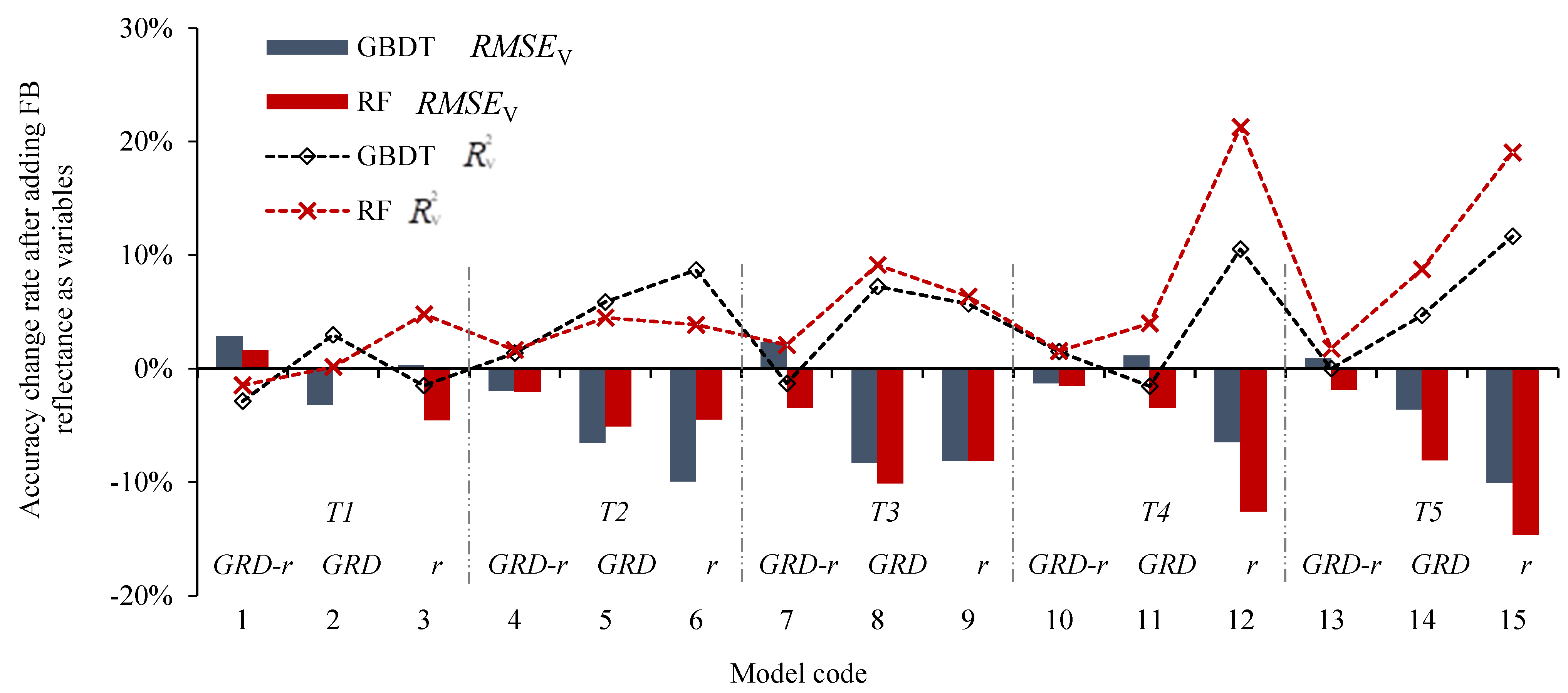
(1) A variable selection criterion named “GRD-r” was proposed, which integrated both GRA and correlation analysis among variables. The core idea was that when selecting yield prediction variables, both the GRD and |r| values with respect to yield should be considered. The selected VIs should exhibit a high GRD or |r| with yield, while maintaining relatively low inter-correlations (|r|) among themselves.
(2) Yield prediction models constructed using sensitive VIs selected based on the “GRD-r” criterion achieved the best performance.
(3) For the single-stage prediction, the GBDT model built at the T3 stage using WDRVI, NGBDI, and TDVI achieved the highest accuracy ( = 0.77 and RMSEV = 7.63 t/hm2).
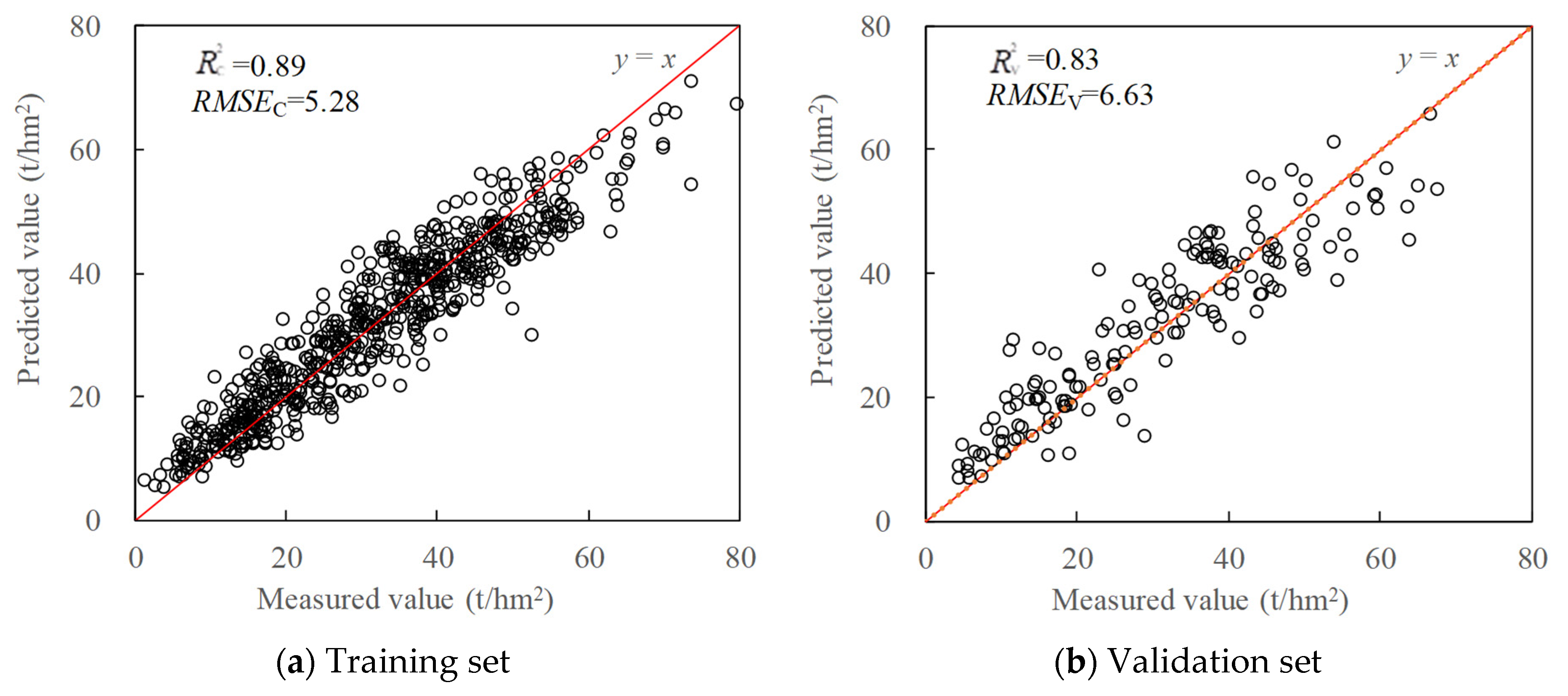
(4) For the multi-stage prediction, the GBDT model built from DVI (T1), NDVI (T2), TDVI (T3), NDVI (T4), and SRPI (T5) achieved the best overall performance (= 0.83 and RMSEV = 6.63 t/hm2).


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}