
DWTMA-Net: Discrete Wavelet Transform and Multi-Dimensional Attention Network for Remote Sensing Image Dehazing


Abstract

1. Introduction
Main Contributions of This Paper
- A novel model is proposed that combines frequency-domain information from the discrete wavelet transform (DWT) with spatial-domain features from convolution. Validation using the complex SateHaze1k [30], HRSD [31], and HazyDet [32] datasets confirms its effectiveness in enhancing detail and visual quality.
- To enhance spatial-domain feature information, a novel multi-dimensional attention module is proposed, applying different attention mechanisms to various features extracted through different convolutions.
- To achieve frequency-domain processing, a novel frequency processing module is proposed, which extracts and refines features from four distinct frequency components generated by the Haar discrete wavelet transform (DWT).
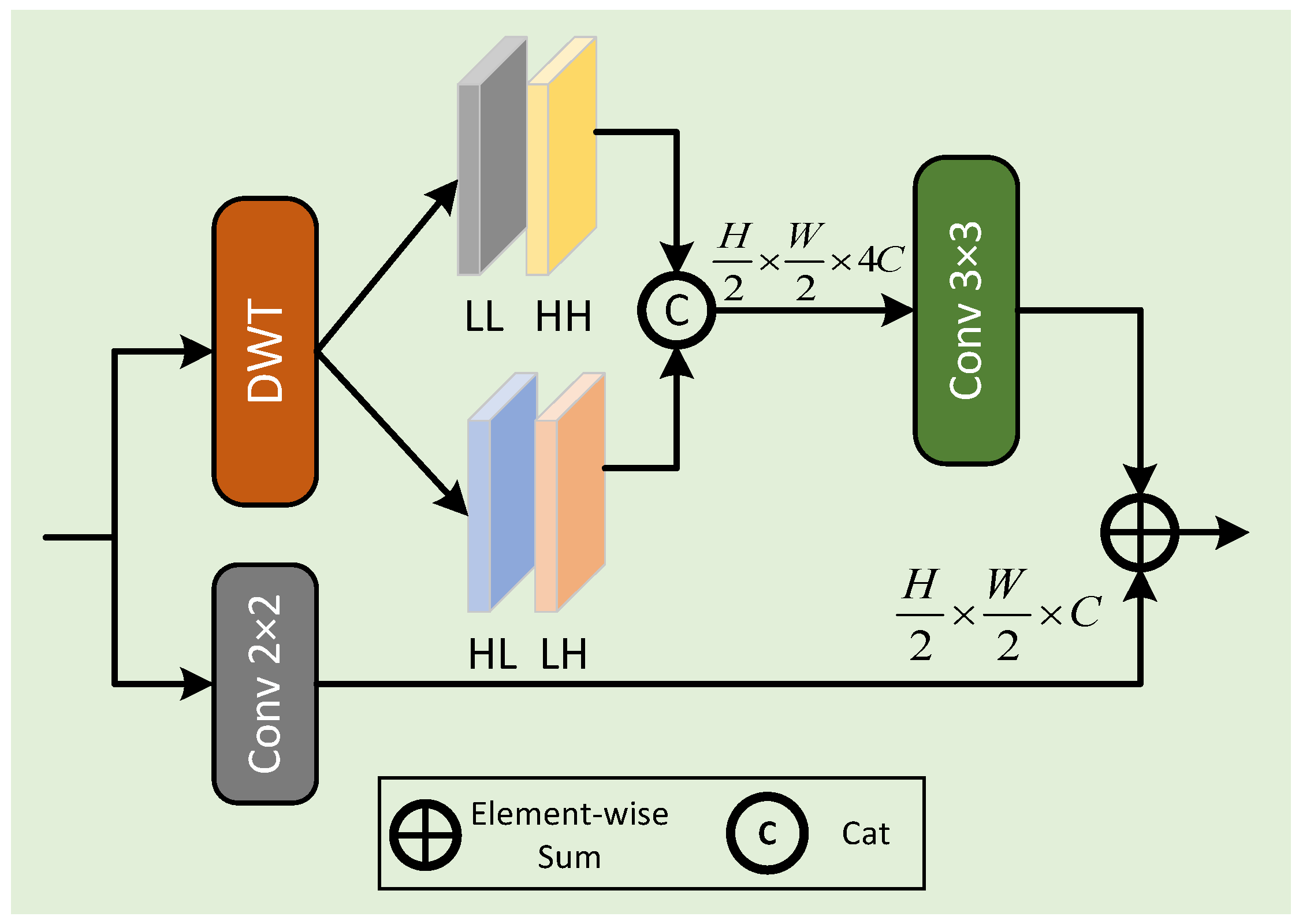
- To capture both frequency- and spatial-domain features, a novel downsampling method is proposed, combining Haar wavelet transform and convolution for effective downsampling.
2. Related Works
2.1. Prior-Guided Image Dehazing Methods
2.2. Data-Driven Approaches for Image Dehazing
3. Method
3.1. Wavelet Downsampling Module
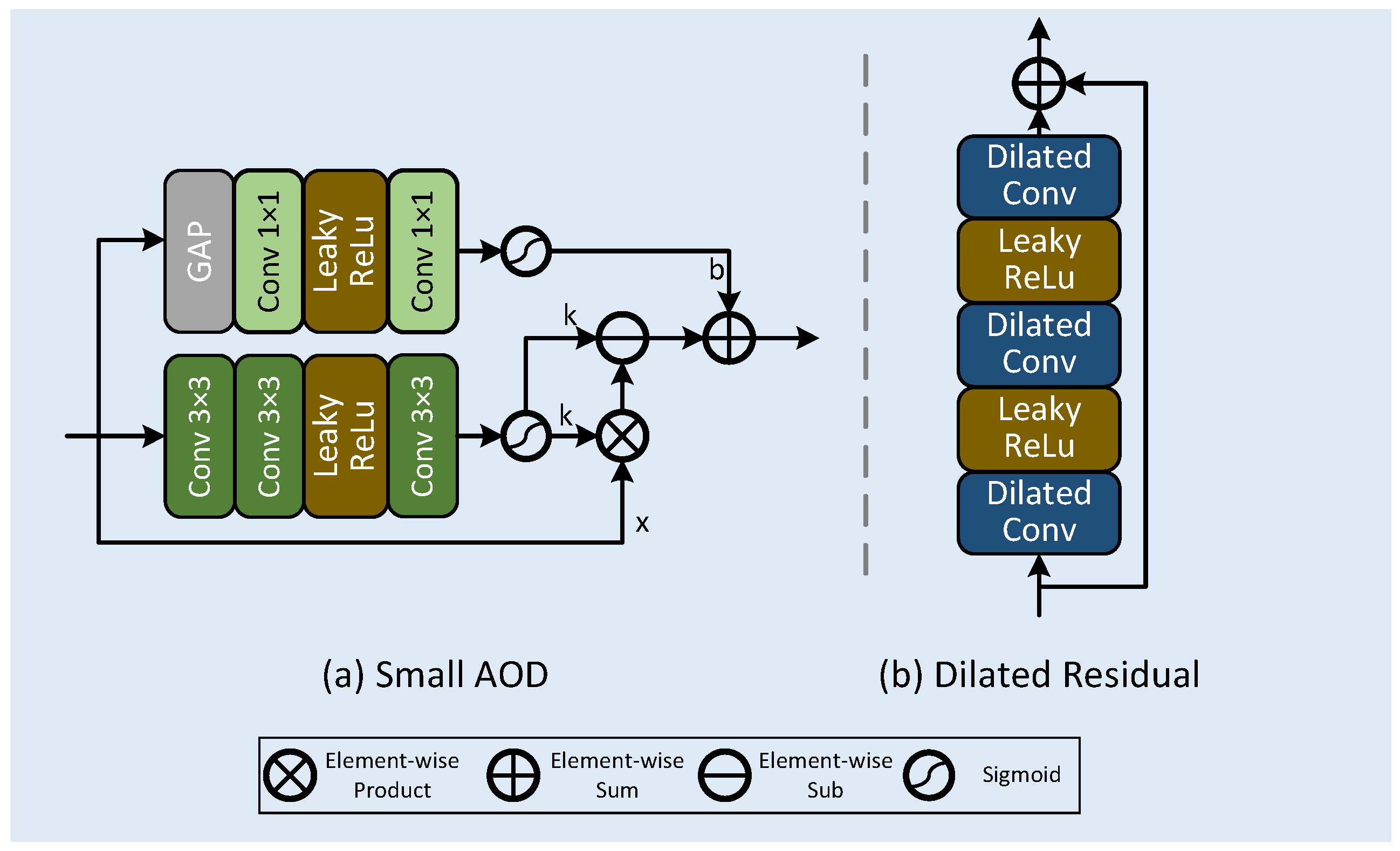
3.2. Discrete Wavelet Block
3.3. Multi-Dimensional Attention Block
3.4. Loss Function
4. Results
4.1. Datasets
4.2. Implementation Details
4.3. Quantitative Evaluations
4.4. Qualitative Evaluations
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kumar, P.; Singh, S.; Pandey, A.; Singh, R.K.; Srivastava, P.K.; Kumar, M.; Dubey, S.K.; Sah, U.; Nandan, R.; Singh, S.K.; et al. Multi-level impacts of the COVID-19 lockdown on agricultural systems in India: The case of Uttar Pradesh. Agric. Syst. 2021, 187, 103027. [Google Scholar] [CrossRef]
- Amaro García, A. Relationship between blue economy, cruise tourism, and urban regeneration: Case study of Olbia, Sardinia. J. Urban Plan. Dev. 2021, 147, 05021029. [Google Scholar] [CrossRef]
- Li, S.; Fang, H.; Zhang, Y. Determination of the leaf inclination angle (LIA) through field and remote sensing methods: Current status and future prospects. Remote Sens. 2023, 15, 946. [Google Scholar] [CrossRef]
- Yan, Q.; Yang, K.; Hu, T.; Chen, G.; Dai, K.; Wu, P.; Ren, W.; Zhang, Y. From dynamic to static: Stepwisely generate HDR image for ghost removal. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 1409–1421. [Google Scholar] [CrossRef]
- McCartney, E. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley & Sons Inc.: Hoboken, NJ, USA, 1976. [Google Scholar]
- Yan, Q.; Zhang, L.; Liu, Y.; Zhu, Y.; Sun, J.; Shi, Q.; Zhang, Y. Deep HDR imaging via a non-local network. IEEE Trans. Image Process. 2020, 29, 4308–4322. [Google Scholar] [CrossRef]
- Kulkarni, A.; Phutke, S.S.; Vipparthi, S.K.; Murala, S. C2AIR: Consolidated Compact Aerial Image Haze Removal. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 749–758. [Google Scholar]
- Ali, A.; Sarkar, R.; Chaudhuri, S.S. Wavelet-based Auto-Encoder for simultaneous haze and rain removal from images. Pattern Recognit. 2024, 150, 110370. [Google Scholar] [CrossRef]
- Wang, T.; Tao, G.; Lu, W.; Zhang, K.; Luo, W.; Zhang, X.; Lu, T. Restoring vision in hazy weather with hierarchical contrastive learning. Pattern Recognit. 2024, 145, 109956. [Google Scholar] [CrossRef]
- Yan, Q.; Wang, H.; Ma, Y.; Liu, Y.; Dong, W.; Woźniak, M.; Zhang, Y. Uncertainty estimation in HDR imaging with Bayesian neural networks. Pattern Recognit. 2024, 156, 110802. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, Z.; Liu, Y.; Sheng, Y.; Ren, W.; Xiong, H. Physical-priors-guided DehazeFormer. Knowl.-Based Syst. 2023, 266, 110410. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Hu, E.; Wang, A.; Shiri, B.; Lin, W. VNDHR: Variational single nighttime image dehazing for enhancing visibility in intelligent transportation systems via hybrid regularization. IEEE Trans. Intell. Transp. Syst. 2025; early access. [Google Scholar]
- Liu, Y.; Yan, Z.; Tan, J.; Li, Y. Multi-purpose oriented single nighttime image haze removal based on unified variational retinex model. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1643–1657. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Chen, S.; Ye, T.; Ren, W.; Chen, E. Nighthazeformer: Single nighttime haze removal using prior query transformer. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 4119–4128. [Google Scholar]
- Li, C.; Hu, E.; Zhang, X.; Zhou, H.; Xiong, H.; Liu, Y. Visibility restoration for real-world hazy images via improved physical model and Gaussian total variation. Front. Comput. Sci. 2024, 18, 181708. [Google Scholar] [CrossRef]
- Li, T.; Liu, Y.; Ren, W.; Shiri, B.; Lin, W. Single Image Dehazing Using Fuzzy Region Segmentation and Haze Density Decomposition. IEEE Trans. Circuits Syst. Video Technol. 2025; early access. [Google Scholar]
- Chen, G.; Jia, Y.; Yin, Y.; Fu, S.; Liu, D.; Wang, T. Remote sensing image dehazing using a wavelet-based generative adversarial networks. Sci. Rep. 2025, 15, 3634. [Google Scholar] [CrossRef] [PubMed]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Pang, Y.; Xie, J.; Li, X. Visual haze removal by a unified generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3211–3221. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October– 2 November 2019; pp. 7314–7323. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef]
- Nie, J.; Xie, J.; Sun, H. Remote Sensing Image Dehazing via a Local Context-Enriched Transformer. Remote Sens. 2024, 16, 1422. [Google Scholar] [CrossRef]
- Shi, Y.; Xia, B.; Jin, X.; Wang, X.; Zhao, T.; Xia, X.; Xiao, X.; Yang, W. Vmambair: Visual state space model for image restoration. arXiv 2024, arXiv:2403.11423. [Google Scholar] [CrossRef]
- Wang, J.; Wu, S.; Yuan, Z.; Tong, Q.; Xu, K. Frequency compensated diffusion model for real-scene dehazing. Neural Netw. 2024, 175, 106281. [Google Scholar] [CrossRef]
- Huang, Y.; Xiong, S. Remote sensing image dehazing using adaptive region-based diffusion models. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 8001805. [Google Scholar] [CrossRef]
- Yan, Q.; Hu, T.; Wu, P.; Dai, D.; Gu, S.; Dong, W.; Zhang, Y. Efficient Image Enhancement with A Diffusion-Based Frequency Prior. IEEE Trans. Circuits Syst. Video Technol. 2025; early access. [Google Scholar]
- Huang, B.; Zhi, L.; Yang, C.; Sun, F.; Song, Y. Single satellite optical imagery dehazing using SAR image prior based on conditional generative adversarial networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1806–1813. [Google Scholar]
- Zhang, L.; Wang, S. Dense haze removal based on dynamic collaborative inference learning for remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 5631016. [Google Scholar] [CrossRef]
- Feng, C.; Chen, Z.; Kou, R.; Gao, G.; Wang, C.; Li, X.; Shu, X.; Dai, Y.; Fu, Q.; Yang, J. HazyDet: Open-source Benchmark for Drone-view Object Detection with Depth-cues in Hazy Scenes. arXiv 2024, arXiv:2409.19833. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Fattal, R. Dehazing using color-lines. Acm Trans. Graph. (TOG) 2014, 34, 1–14. [Google Scholar] [CrossRef]
- Tang, K.; Yang, J.; Wang, J. Investigating haze-relevant features in a learning framework for image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2995–3000. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22 –29 October 2017; pp. 4770–4778. [Google Scholar]
- Lu, L.; Xiong, Q.; Xu, B.; Chu, D. Mixdehazenet: Mix structure block for image dehazing network. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–10. [Google Scholar]
- Cui, Y.; Ren, W.; Knoll, A. Omni-Kernel Network for Image Restoration. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, 20–27 February 2024; Volume 38, pp. 1426–1434. [Google Scholar]
- Sui, T.; Xiang, G.; Chen, F.; Li, Y.; Tao, X.; Zhou, J.; Hong, J.; Qiu, Z. U-Shaped Dual Attention Vision Mamba Network for Satellite Remote Sensing Single-Image Dehazing. Remote Sens. 2025, 17, 1055. [Google Scholar] [CrossRef]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5694–5703. [Google Scholar]
- Li, Y.; Chen, X. A coarse-to-fine two-stage attentive network for haze removal of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1751–1755. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, L.; Li, Q.; Guan, X.; Tao, T. Multi-Dimensional and Multi-Scale Physical Dehazing Network for Remote Sensing Images. Remote Sens. 2024, 16, 4780. [Google Scholar] [CrossRef]
- Liu, B.; Chen, S.B.; Wang, J.X.; Tang, J.; Luo, B. An Oriented Object Detector for Hazy Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1001711. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Thin Haze | Moderate Haze | Thick Haze | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | NIQE | PSNR | SSIM | NIQE | PSNR | SSIM | NIQE | PSNR | SSIM | NIQE | |
| DCP [34] | 20.15 | 0.8645 | 17.98 | 20.51 | 0.8932 | 17.09 | 15.77 | 0.7117 | 17.73 | 18.81 | 0.8241 | 17.60 |
| AOD-Net [39] | 15.97 | 0.8169 | 18.66 | 15.39 | 0.7442 | 17.28 | 14.44 | 0.7013 | 17.91 | 15.27 | 0.7541 | 17.95 |
| FCTF-Net [44] | 19.13 | 0.8532 | 18.77 | 22.32 | 0.9107 | 17.75 | 17.78 | 0.7617 | 18.14 | 19.74 | 0.8419 | 18.22 |
| GridDehaze-Net [20] | 19.81 | 0.8556 | 18.77 | 22.75 | 0.9085 | 16.35 | 17.94 | 0.7551 | 18.69 | 20.17 | 0.8397 | 17.94 |
| FFA-Net [22] | 24.04 | 0.9130 | 17.09 | 25.62 | 0.9336 | 16.80 | 21.70 | 0.8422 | 17.35 | 23.79 | 0.8963 | 17.08 |
| MixDehaze-Net [40] | 22.12 | 0.8822 | 18.04 | 23.92 | 0.9040 | 16.08 | 19.96 | 0.7950 | 17.94 | 22.00 | 0.8604 | 17.35 |
| OK-Net [41] | 20.68 | 0.8860 | 17.78 | 25.39 | 0.9406 | 17.47 | 20.21 | 0.8186 | 18.57 | 22.09 | 0.8817 | 17.94 |
| Dehazeformer [24] | 24.90 | 0.9104 | 16.88 | 27.13 | 0.9431 | 16.70 | 22.68 | 0.8497 | 17.64 | 24.90 | 0.9011 | 17.07 |
| VmambaIR [26] | 20.81 | 0.8753 | 18.28 | 24.34 | 0.9132 | 16.61 | 20.04 | 0.8045 | 17.96 | 21.73 | 0.8643 | 17.62 |
| FCDM [27] | 18.94 | 0.8486 | 18.08 | 17.36 | 0.8753 | 16.81 | 16.97 | 0.7530 | 18.09 | 17.76 | 0.8256 | 17.66 |
| MMPD-Net [45] | 25.16 | 0.9227 | 16.76 | 27.30 | 0.9454 | 16.76 | 22.85 | 0.8571 | 17.96 | 25.10 | 0.9084 | 17.16 |
| DWTMA-Net | 25.59 | 0.9229 | 16.71 | 27.53 | 0.9459 | 16.80 | 22.88 | 0.8576 | 17.33 | 25.33 | 0.9088 | 16.95 |
| Method | LHID | DHID | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | NIQE | PSNR | SSIM | NIQE | PSNR | SSIM | NIQE | |
| DCP [34] | 21.34 | 0.7976 | 19.84 | 19.15 | 0.8195 | 18.99 | 20.25 | 0.8086 | 19.42 |
| AOD-Net [39] | 21.91 | 0.8144 | 19.53 | 16.03 | 0.7291 | 18.91 | 18.97 | 0.7718 | 19.22 |
| FCTF-Net [44] | 28.55 | 0.8727 | 19.27 | 22.43 | 0.8482 | 18.61 | 25.49 | 0.8605 | 18.94 |
| GridDehaze-Net [20] | 25.80 | 0.8584 | 19.54 | 26.77 | 0.8851 | 18.93 | 26.29 | 0.8718 | 19.24 |
| FFA-Net [22] | 29.33 | 0.8755 | 19.02 | 24.62 | 0.8657 | 18.50 | 26.98 | 0.8706 | 18.76 |
| MixDehaze-Net [40] | 29.47 | 0.8631 | 19.26 | 27.36 | 0.8864 | 18.89 | 28.42 | 0.8748 | 19.08 |
| OK-Net [41] | 29.03 | 0.8766 | 18.73 | 27.80 | 0.8973 | 18.17 | 28.42 | 0.8870 | 18.45 |
| MMPD-Net [45] | 29.76 | 0.8771 | 18.98 | 28.23 | 0.8977 | 18.29 | 29.00 | 0.8874 | 18.64 |
| FCDM [27] | 15.16 | 0.6459 | 18.79 | 17.13 | 0.6978 | 20.43 | 16.15 | 0.6719 | 19.61 |
| DWTMA-Net | 29.86 | 0.8828 | 18.70 | 28.34 | 0.8981 | 18.15 | 29.10 | 0.8905 | 18.43 |
| Method | HazyDet | ||
|---|---|---|---|
| PSNR | SSIM | NIQE | |
| DCP [34] | 17.03 | 0.8024 | 12.30 |
| AOD-Net [39] | 18.99 | 0.7808 | 12.27 |
| FCTF-Net [44] | 24.89 | 0.8552 | 12.23 |
| GridDehaze-Net [20] | 26.66 | 0.8801 | 11.33 |
| FFA-Net [22] | 27.12 | 0.8782 | 11.31 |
| MixDehaze-Net [40] | 28.75 | 0.9068 | 11.30 |
| OK-Net [41] | 27.76 | 0.8875 | 11.36 |
| DWTMA-Net | 29.02 | 0.9108 | 11.23 |
| Method | FLOPs | Parameters |
|---|---|---|
| DCP | - | - |
| AOD-Net | 457.70 (M) | 1.76 (K) |
| FCTF-Net | 40.19 (G) | 163.48 (K) |
| GridDehaze-Net | 85.72 (G) | 955.75 (K) |
| FFA-Net | 624.20 (G) | 4.68 (M) |
| MixDehaze-Net | 114.30 (G) | 3.17 (M) |
| OK-Net | 158.20 (G) | 4.43 (M) |
| MMPD-Net | 298.19 (G) | 8.66 (M) |
| DWTMA-Net | 188.72 (G) | 8.34 (M) |
| Method | Thin Haze | |
|---|---|---|
| PSNR | SSIM | |
| Base(DM) | 18.47 | 0.8547 |
| Base(DM) + DWB | 20.53 | 0.8896 |
| Base(DM) + MAB | 21.84 | 0.8838 |
| Base(DM) + DWB + MAB | 22.87 | 0.8940 |
| Base + MAB + WDM | 21.64 | 0.8860 |
| Base + DWB + MAB + WDM | 23.69 | 0.9043 |
| Method | Thin Haze | |
|---|---|---|
| PSNR | SSIM | |
| DWTMA-Net - CA | 23.16 | 0.8966 |
| DWTMA-Net - PA | 20.04 | 0.8905 |
| DWTMA-Net - FA | 22.66 | 0.8910 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, X.; He, R.; Wang, L.; Zhou, H.; Liu, Y.; Xiong, H. DWTMA-Net: Discrete Wavelet Transform and Multi-Dimensional Attention Network for Remote Sensing Image Dehazing. Remote Sens. 2025, 17, 2033. https://doi.org/10.3390/rs17122033
Guan X, He R, Wang L, Zhou H, Liu Y, Xiong H. DWTMA-Net: Discrete Wavelet Transform and Multi-Dimensional Attention Network for Remote Sensing Image Dehazing. Remote Sensing. 2025; 17(12):2033. https://doi.org/10.3390/rs17122033
Chicago/Turabian StyleGuan, Xin, Runxu He, Le Wang, Hao Zhou, Yun Liu, and Hailing Xiong. 2025. "DWTMA-Net: Discrete Wavelet Transform and Multi-Dimensional Attention Network for Remote Sensing Image Dehazing" Remote Sensing 17, no. 12: 2033. https://doi.org/10.3390/rs17122033
APA StyleGuan, X., He, R., Wang, L., Zhou, H., Liu, Y., & Xiong, H. (2025). DWTMA-Net: Discrete Wavelet Transform and Multi-Dimensional Attention Network for Remote Sensing Image Dehazing. Remote Sensing, 17(12), 2033. https://doi.org/10.3390/rs17122033