

Deep Learning Innovations: ResNet Applied to SAR and Sentinel-2 Imagery





Abstract
1. Introduction
1.1. Key Role of GNSS and Microwaves in Remote Sensing
- Georeferencing of Data: A GNSS allows precise geographic coordinates to be associated with collected images and data, facilitating accurate maps and data integration from various sources.
- Time Synchronisation: It provides a highly accurate time reference, accurate to nanoseconds, which is essential for synchronising sensors and platforms in multi-temporal analysis and applications such as SAR.
- Mobile Platform Monitoring: A GNSS enables real-time tracking of drones, planes, and vehicles, ensuring stable and accurate data collection. This is particularly useful in areas such as precision agriculture and infrastructure monitoring.
- Satellite Image Correction: GNSS data correct errors caused by Earth’s rotation, satellite movement, or perspective distortions. Techniques like Differential GNSS (DGNSS) and Real-Time Kinematic (RTK) can enhance accuracy to within a few centimetres.
- Atmospheric Studies and Calibration: GNSS measurements are valuable for analysing atmospheric variations, such as water vapor and electron density, and for calibration and validation campaigns that compare satellite data with ground-based measurements.
1.2. Related Work
2. Materials and Methods
2.1. SAR Applications
2.2. Optical Image Classification
- x is the input to the residual block.
- F(x,Wi) is the transformation learned by the block (with weights Wi).
- The output y is the sum of the input and the learned residual.
- Ability to train networks with hundreds or thousands of layers: This makes it suitable for numerous deep learning applications without performance degradation.
- More efficient signal propagation: ResNet improves signal propagation both forward and backward during training.
- Excellent performance: Produces high-quality results.
- Scalability and robustness: Its modular structure allows for easy expansion to more complex tasks while maintaining robustness and accuracy.
- Flexibility: ResNet can be used in various applications ranging from satellite imagery to facial recognition.
- Streams and reservoirs;
- Marine environment (includes coastal regions);
- Arid regions;
- Verdant places;
- Residential zones;
- Cultivated fields;
- Infrastructure.
- Training set comprised of Kaggle Sentinel-2 data (15,000 records);
- Test set comprised of Kaggle Sentinel-2 data (1000 records);
- Training set comprised of RSI-CB128 data (15,000 records);
- Test set comprised of RSI-CB128 data (1000 records).
- Multi-head self-attention layers, which model global dependencies between patches;
- Feed-forward networks, applied independently to each token;
- Positional embeddings, which preserve spatial information lost during patch flattening.
3. Case Study
3.1. Study Area
3.2. Optical Image: Sentinel-2
3.3. SAR Analysis
3.3.1. Radar Applications: Loss of Vegetation Cover
3.3.2. Loss of Vegetation Cover: Predictions
- Accuracy: 1.00;
- Precision: 1.00;
- Recall: 1.00;
- F1 score: 1.00.
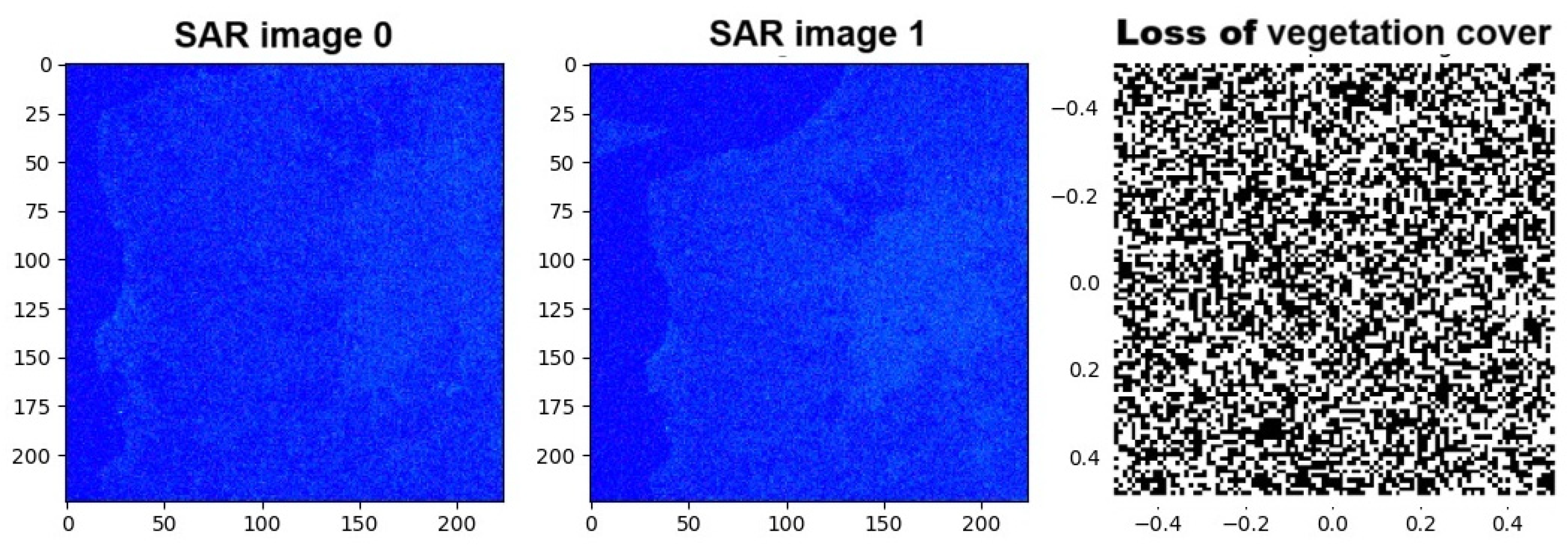
- Image Format:
- Both images have a shape of 224 × 224 × 3, indicating that they are RGB images with three channels.
- 2.
- Visualisation:
- The images show an intensity map with a colour gradation mainly in shades of blue. This suggests that the HV and HH bands have been combined to create an RGB image.
- The ResNet50 model classified the 2007 and 2023 SAR images, and the predictions are different. This indicates that the model detected significant changes in vegetation cover between the two years.
- The difference between the predictions of the 2007 and 2023 images was calculated to determine the loss of vegetation cover.
- The loss of vegetation cover was normalised to display only two colours (forest/no forest), and the percentage loss was calculated.
- The visualisation of the preprocessed and resized images clearly shows the differences between the 2007 and 2023 SAR images.
- The loss of vegetation cover between the images was quantified and visualised, highlighting the areas where vegetation decreased.
- The percentage loss of vegetation cover was 19%.
- The first two images represent the preprocessed and resized SAR data for the years 2007 and 2023. Both images show an intensity map with a colour gradient mainly in shades of blue (Figure 11). This suggests that the HV and HH bands have been combined to create an RGB image.
- The third image shows the loss of vegetation cover between the 2007 and 2023 SAR images. The map is displayed in greyscale, with a colour bar ranging from −0.4 to 0.4. This indicates the difference in intensity between the two images, where negative values represent a decrease in vegetation cover and positive values represent an increase.
- Differences between SAR images:
- The 2007 and 2023 SAR images show variations in the intensities of the HV and HH bands, indicating changes in vegetation cover (Figure 12).
- The vegetation cover loss map highlights areas where vegetation has decreased between 2007 and 2023. Dark areas represent significant vegetation loss, while light areas represent less loss or an increase in vegetation.
- The preprocessed and resized SAR images clearly show the differences in vegetation cover between the two years.
- The vegetation cover loss map provides a clear visualisation of the areas where vegetation has decreased, helping to identify the most affected areas.
3.3.3. Radar Applications: Urban Footprint
3.3.4. Urban Footprint: Predictions
- Accuracy: 0.95;
- Precision: 0.95;
- Recall: 0.95;
- F1 score: 0.95.
- Shape and Colour:
- The shapes are irregular and red in colour.
- The background is black, which emphasises the red forms.
- 2.
- Progression:
- The shapes seem to change or evolve from left to right, suggesting a possible transformation or variation over time or through different phases.
- Evolution of Images: The progression of shapes could represent a change in the characteristics of SAR images through different preprocessing or classification stages.
- Visualisation of Results: This could be a visualisation of the differences between the urban footprints of 2015 and 2025.
- SAR Image 2015:
- This image represents the 2015 urban footprint. The red areas indicate the urban areas identified in 2015.
- 2.
- SAR Image 2025:
- This image represents the urban footprint of 2025. The red areas indicate the urban areas identified in 2025.
- 3.
- Urban Footprint Difference (2015–2025):
- This image shows the difference between the urban footprints of 2015 and 2025. The changes in colour indicate the areas where the urban footprint has changed over time.
- Accuracy:
- It measures the percentage of correct forecasts out of the total forecasts.
- 2.
- F1 score:
- It is the harmonic mean of precision and recall. It is useful when you need a balance between precision and recall.
- 3.
- Precision:
- It measures the percentage of corrected positive forecasts out of the total positive forecasts.
- 4.
- Recall:
- It measures the percentage of correct positive predictions out of the total of true positives.
- Accuracy: 0.95;
- F1 score: 0.95;
- Precision: 0.95;
- Recall: 0.95.
3.4. Object-Based Image Analysis
4. Results
Processing Phases
- Understanding Sentinel Image Classification: The task involved labelling images taken from satellites (Sentinel) into categories like forest, water, urban area, etc.
- Data collection and image editing in similar sizes.
- Preprocessing the Data: When resizing images, all images were resized to ensure they were of the same size; when normalising pixel values, the pixel values were scaled between 0 and 1 for better model performance; and data transformations, rotations, flips, or zooms were applied to increase the variety in the dataset tag. This step in the process significantly improves the performance of the model. Isaac Corley et al. [36] in their paper explore the importance of image size and normalisation in pre-trained models for remote sensing.
- Choosing a Model: A model like a convolutional neural network (CNN) was selected initially. The retrained models like ResNet were considered for better accuracy, as they already knew how to identify general features.
- Training the Model: The dataset was divided into training and testing sets.
- Network typology: It uses “skip” (residual) connections that simplify training. These connections help mitigate the problem of gradient disappearance, allowing for stronger gradients and better stability during training.
- Performance on images: It shows good performance on image classification datasets. Its residual block architecture allows for better capturing the characteristics of complex images.
- Generalisation: Because of its depth and residual connections, it tends to generalise well to test datasets.
- Dataset: The dataset that maps the image names with the respective tags (labels) is read and modified. Additionally, another column that includes the respective labels as list items is created. Using that column, we extracted the unique labels in the dataset [37].
- Image caption approach with visual attention: The attention mechanism has been applied to improve performance [38]. It is a mechanism that allows deep learning models to focus on specific parts of an image that are most relevant to the task at hand, while ignoring less important information.
5. Discussion
- Cloud Layer (Optical Imagery—Sentinel-2)
- Mitigation Strategy:
- Impact on Prediction:
- Future Integration:
- 2.
- Occlusion and Shadowing Effects
- Mitigation Strategy:
- Impact on Prediction:
- Future Enhancements:
- 3.
- Data Noise (SAR Imagery—Speckle)
- Mitigation Strategy:
- Speckle in SAR: We applied Lee filtering (5 × 5 kernel) to reduce speckle (which is not strictly ‘noise’) while preserving edge information on ALOS PALSAR images (searching areas with loss of vegetation cover); speckle in Sentinel-1 images (SLC IW—Single Look Complex, Interferometric Wide swath) was reduced with Multi-Looking used as a filtering option, also reducing image’s dimensions.
- Radiometric calibration and terrain correction were performed to ensure geometric and radiometric consistency.
- Impact on Prediction:
- Future Enhancements:
- 4.
- Model-Level Robustness
- ResNet Architecture:
- Training Techniques:
6. Conclusions
- -
- Geographical Scope and Generalisation:
- -
- Spectral Band Limitation:
- -
- Temporal generalisation:
- -
- Environmental Interference and Data Quality:
- -
- Computational constraints:
- Generalisation Capability: ResNet is able to learn more complex representations and generalise better to new data than traditional methods such as OBIA, which often require manual segmentation and may be less flexible.
- Automation and Scalability: The use of ResNet allows for high automation in the classification process, reducing the need for manual intervention. This is particularly useful for analysing large volumes of satellite data, where efficiency and scalability are crucial.
- Robustness to Noisy Data: Deep neural networks, including ResNet, tend to be more robust to noisy data and image variations, improving the classification accuracy compared to segmentation-based methods such as OBIA.
- Integration of Multispectral Information: ResNet can easily integrate information from different spectral bands, further improving the classification accuracy of satellite images.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Woodhouse, I.H. Introduction to Microwave Remote Sensing, 3rd ed.; CRC Press: Leiden, The Netherlands, 2006. [Google Scholar]
- Woodhouse, I.; Nichol, C.; Patenaude, G.; Malthus, T. Remote Sensing System. Patent No. International Application Number PCT/GB2009/050490, 11 December 2009. [Google Scholar]
- Soria-Ruiz, J.; Fernandez-Ordoñez, Y.; Woodhouse, I.H. Land-cover classification using radar and optical images: A case study in Central Mexico. Int. J. Remote Sens. 2010, 31, 3291–3305. [Google Scholar] [CrossRef]
- Buontempo, C.; Hutjes, R.; Beavis, P.; Berckmans, J.; Cagnazzo, C.; Vamborg, F.; Thépaut, T.; Bergeron, C.; Almond, S.; Dee, D.; et al. Fostering the development of climate services through Copernicus Climate Change Service (C3S) for agriculture applications. Weather Clim. Extrem. 2020, 27, 100226. [Google Scholar] [CrossRef]
- Ajmar, A.; Boccardo, P.; Broglia, M.; Kucera, J.; Giulio-Tonolo, F.; Wania, A. Response to flood events: The role of satellite-based emergency mapping and the experience of the Copernicus emergency management service. Flood Damage Surv. Assess. New Insights Res. Pract. 2017, 14, 211–228. [Google Scholar]
- Pace, R.; Chiocchini, F.; Sarti, M.; Endreny, T.A.; Calfapietra, C.; Ciolfi, M. Integrating Copernicus land cover data into the i-Tree Cool Air model to evaluate and map urban heat mitigation by tree cover. Eur. J. Remote Sens. 2023, 56, 2125833. [Google Scholar] [CrossRef]
- Soulie, A.; Granier, C.; Darras, S.; Zilbermann, N.; Doumbia, T.; Guevara, M.; Jalkanen, J.-P.; Keita, S.; Liousse, C.; Crippa, M.; et al. Global anthropogenic emissions (CAMS-GLOB-ANT) for the Copernicus Atmosphere Monitoring Service simulations of air quality forecasts and reanalyses. Earth Syst. Sci. Data Discuss. 2023, 16, 1–45. [Google Scholar] [CrossRef]
- Chrysoulakis, N.; Ludlow, D.; Mitraka, Z.; Somarakis, G.; Khan, Z.; Lauwaet, D.; Hooyberghs, H.; Feliu, E.; Navarro, D.; Feigenwinter, C.; et al. Copernicus for urban resilience in Europe. Sci. Rep. 2023, 13, 16251. [Google Scholar] [CrossRef]
- Salgueiro, L.; Marcello, J.; Vilaplana, V. Single-Image Super-Resolution of Sentinel-2 Low Resolution Bands with Residual Dense Convolutional Neural Networks. Remote Sens. 2021, 13, 5007. [Google Scholar] [CrossRef]
- Fotso Kamga, G.A.; Bitjoka, L.; Akram, T.; Mengue Mbom, A.; Rameez Naqvi, S.; Bouroubi, Y. Advancements in satellite image classification: Methodologies, techniques, approaches and applications. Int. J. Remote Sens. 2021, 42, 7662–7722. [Google Scholar] [CrossRef]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef]
- Ren, Y.; Zhang, B.; Chen, X.; Liu, X. Analysis of spatial-temporal patterns and driving mechanisms of land desertification in China. Sci. Total Environ. 2024, 909, 168429. [Google Scholar] [CrossRef]
- Aruna Sri, P.; Santhi, V. Enhanced land use and land cover classification using modified CNN in Uppal Earth Region. Multimed. Tools Appl. 2025, 84, 14941–14964. [Google Scholar] [CrossRef]
- Samaei, S.R.; Ghahfarrokhi, M.A. AI-Enhanced GIS Solutions for Sustainable Coastal Management: Navigating Erosion Prediction and Infrastructure Resilience. In Proceedings of the 2nd International Conference on Creative Achievements of Architecture, Urban Planning, Civil Engineering and Environment in the Sustainable Development of the Middle East, Mashhad, Iran, 1 December 2023. [Google Scholar]
- Kamyab, H.; Khademi, T.; Chelliapan, S.; SaberiKamarposhti, M.; Rezania, S.; Yusuf, M.; Farajnezhad, M.; Abbas, M.; Jeon, B.H.; Ahn, Y. The latest innovative avenues for the utilization of artificial Intelligence and big data analytics in water resource management. Results Eng. 2023, 20, 101566. [Google Scholar] [CrossRef]
- Farkas, J.Z.; Hoyk, E.; de Morais, M.B.; Csomós, G. A systematic review of urban green space research over the last 30 years: A bibliometric analysis. Heliyon 2023, 9, e13406. [Google Scholar] [CrossRef] [PubMed]
- Adegun, A.A.; Viriri, S.; Tapamo, J.R. Review of deep learning methods for remote sensing satellite images classification: Experimental survey and comparative analysis. J. Big Data 2023, 10, 93. [Google Scholar] [CrossRef]
- Ding, Y.; Cheng, Y.; Cheng, X.; Li, B.; You, X.; Yuan, X. Noise-resistant network: A deep-learning method for face recognition under noise. J. Image Video Proc. 2017, 2017, 43. [Google Scholar] [CrossRef]
- Li, H.; Dou, X.; Tao, C.; Wu, Z.; Chen, J.; Peng, J.; Deng, M.; Zhao, L. RSI-CB: A Large-Scale Remote Sensing Image Classification Benchmark Using Crowdsourced Data. Sensors 2020, 20, 1594. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large Scale Visual Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Benediktsson, J.A.; Pesaresi, M.; Arnason, K. Classification and Feature Extraction for Remote Sensing Images from Urban Areas Based on Morphological Transformations. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1940–1949. [Google Scholar] [CrossRef]
- Baatz, M.; Benz, U.; Dehgani, S.; Heynen, M.; Höltje, A.; Hofmann, P.; Lingenfelder, I.; Mimler, M.; Sohlbach, M.; Weber, M.; et al. eCognition 4.0 Professional User Guide; Definiens Imaging GmbH: München, Germany, 2004. [Google Scholar]
- Köppen, M.; Ruiz-del-Solar, J.; Soille, P. Texture Segmentation by biologically-inspired use of Neural Networks and Mathematical Morphology. In Proceedings of the International ICSC/IFAC Symposium on Neural Computation (NC’98), Vienna, Austria, 23–25 September 1998; pp. 23–25. [Google Scholar]
- Pesaresi, M.; Kanellopoulos, J. Morphological Based Segmentation and Very High Resolution Remotely Sensed Data. In Detection of Urban Features Using Morphological Based Segmentation, Proceedings of the MAVIRIC Workshop; Kingston University: Kingston upon Thames, UK, 1998; pp. 271–284. [Google Scholar]
- Serra, J. Image Analysis and Mathematical Morphology, 2: Theoretical Advances; Academic Press: New York, NY, USA, 1998. [Google Scholar]
- Shackelford, A.K.; Davis, C.H. A Hierarchical Fuzzy Classification Approach for High Resolution Multispectral Data Over Urban Areas. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1920–1932. [Google Scholar] [CrossRef]
- Small, C. Multiresolution Analysis of Urban Reflectance. In Proceedings of the IEEE/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas, Rome, Italy, 8–9 November 2001. [Google Scholar]
- Soille, P.; Pesaresi, M. Advances in Mathematical Morphology Applied to Geoscience and Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2002, 41, 2042–2055. [Google Scholar] [CrossRef]
- Tzeng, Y.C.; Chen, K.S. A Fuzzy Neural Network to SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 1998, 36, 301–307. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy Sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Addabbo, P.; Focareta, M.; Marcuccio, S.; Votto, S.; Ullo, S.L. Contribution of Sentinel-2 data for applications in vegetation monitoring. Acta Imeko 2016, 5, 44–54. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.K.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bilotta, G. OBIA to Detect Asbestos-Containing Roofs. In International Symposium New Metropolitan Perspectives; Springer: Cham, Switzerland, 2022; pp. 2054–2064. [Google Scholar] [CrossRef]
- Corley, I.; Robinson, C.; Dodhia, R.; Lavista Ferres, J.M.; Najafirad, P. Revisiting Pre-Trained Remote Sensing Model Benchmarks: Resizing and Normalization Matters. 2023. Available online: https://www.tensorflow.org/tutorials/text/image_captioning (accessed on 28 February 2025).
- Ghaffarian, S.; Valente, J.; van der Voort, M.; Tekinerdogan, B. Effect of Attention Mechanism in Deep Learning-Based Remote Sensing Image Processing: A Systematic Literature Review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Ide, H.; Kurita, T. Improvement of learning for CNN with ReLU activation by sparse regularization. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2684–2691. [Google Scholar]
- Rasamoelina, A.D.; Adjailia, F.; Sinčák, P. A Review of Activation Function for Artificial Neural Network. In Proceedings of the 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 23–25 January 2020; pp. 281–286. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | GPS | GLONASS | Galileo | BeiDou |
|---|---|---|---|---|
| Country | USA | Russia | European Union | China |
| Operational satellites | ~31 | ~24 | ~24 | ~35 |
| Orbit | MEO (20,200 km) | MEO (19,100 km) | MEO (23,222 km) | MEO, GEO, IGSO |
| Accuracy (civil) | 3–5 m | 5–10 m | <1 m | 2–5 m |
| Accuracy (military) | <1 m | 1–2 m | 20 cm | <1 m |
| Operational year | 1995 | 1996 (2011 relaunch) | 2016 (complete in 2027) | 2000 (global in 2020) |
| Global coverage | Yes | Yes | Yes | Yes |
| Main frequencies | L1, L2, L5 | Frequencies~GPS | E1, E5, E6 | B1, B2, B3 |
| Characteristics | CLC 1990 | CLC 2000 | CLC 2006 | CLC 2012 | CLC 2018 |
|---|---|---|---|---|---|
| Satellite data | Landsat-5 MSS/TM, single date | Landsat-7 ETM, single date | SPOT-4/5 and IRS P6 LISS III, dual date | IRS P6 LISS III and Rapid Eye, dual date | Sentinel-2 and Landsat-8 for gap filling |
| Temporal extent | 1986–1998 | 2000 ± 1 year | 2006 ± 1 year | 2011–2012 | 2017–2018 |
| Geometric accuracy, satellite data | ≤50 m | ≤25 m | ≤25 m | ≤25 m | ≤10 m (Sentinel-2) |
| Min. mapping unit/width | 25 ha/100 m | 25 ha/100 m | 25 ha/100 m | 25 ha/100 m | 25 ha/100 m |
| Geometric accuracy, CLC | 100 m | better than 100 m | better than 100 m | better than 100 m | better than 100 m |
| Production time | 10 years | 4 years | 3 years | 2 years | 1.5 years |
| Number of participating countries | 27 | 39 | 39 | 39 | 39 |
| Model | Accuracy | Precision | Recall | F1 Score | AUC |
|---|---|---|---|---|---|
| ResNet | 0.96 | 0.92 | 0.85 | 0.82 | 0.89 |
| Vision Transformer | 0.91 | 0.88 | 0.84 | 0.85 | 0.87 |
| U-Net | 0.83 | 0.71 | 0.79 | 0.70 | 0.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bilotta, G.; Bibbò, L.; Meduri, G.M.; Genovese, E.; Barrile, V. Deep Learning Innovations: ResNet Applied to SAR and Sentinel-2 Imagery. Remote Sens. 2025, 17, 1961. https://doi.org/10.3390/rs17121961
Bilotta G, Bibbò L, Meduri GM, Genovese E, Barrile V. Deep Learning Innovations: ResNet Applied to SAR and Sentinel-2 Imagery. Remote Sensing. 2025; 17(12):1961. https://doi.org/10.3390/rs17121961
Chicago/Turabian StyleBilotta, Giuliana, Luigi Bibbò, Giuseppe M. Meduri, Emanuela Genovese, and Vincenzo Barrile. 2025. "Deep Learning Innovations: ResNet Applied to SAR and Sentinel-2 Imagery" Remote Sensing 17, no. 12: 1961. https://doi.org/10.3390/rs17121961
APA StyleBilotta, G., Bibbò, L., Meduri, G. M., Genovese, E., & Barrile, V. (2025). Deep Learning Innovations: ResNet Applied to SAR and Sentinel-2 Imagery. Remote Sensing, 17(12), 1961. https://doi.org/10.3390/rs17121961