
Ship Detection with Deep Learning in Optical Remote-Sensing Images: A Survey of Challenges and Advances

 , , , ,
, , , ,  , and
, and
Abstract
1. Introduction
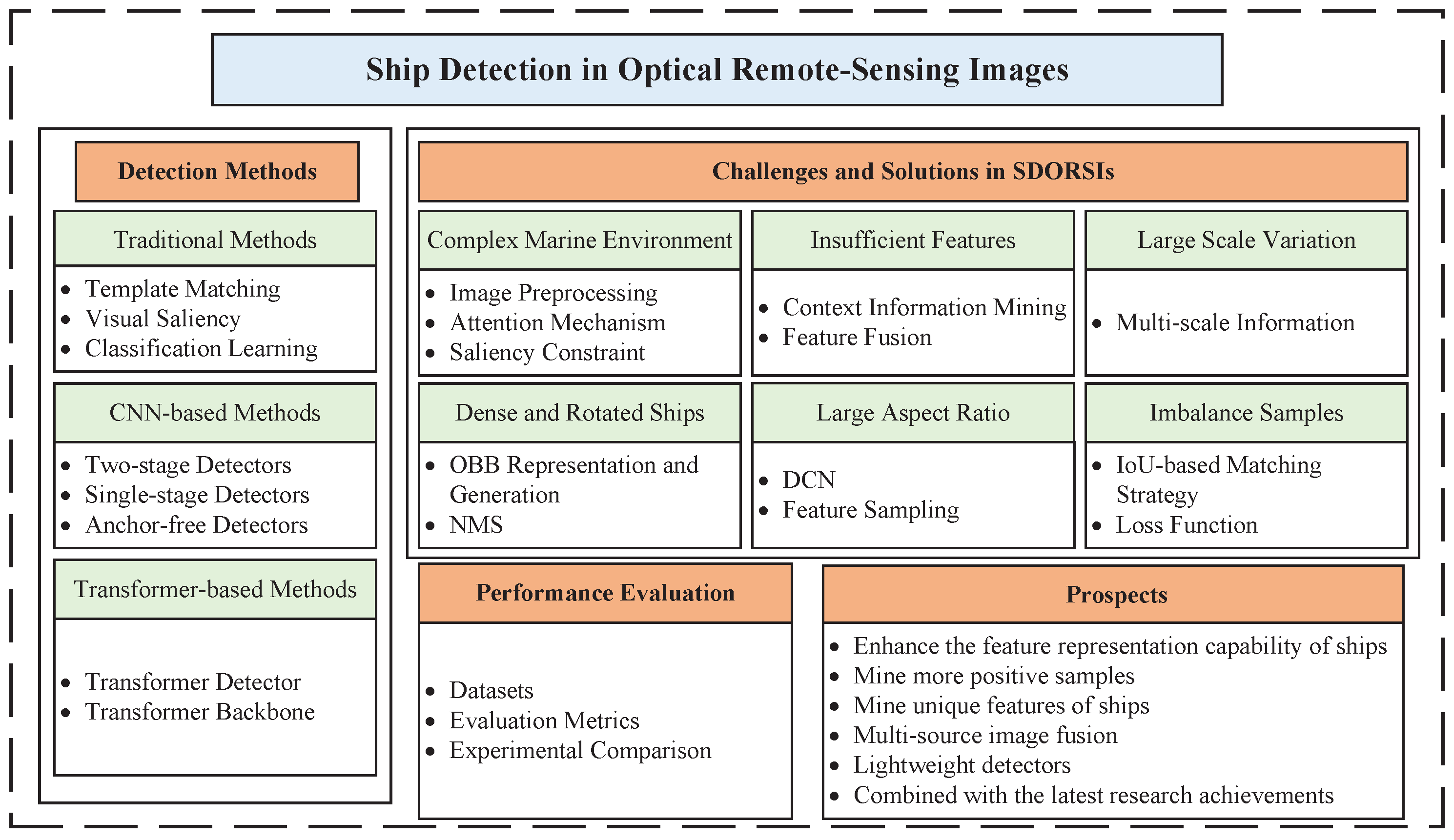
- We systematically review ship-detection technologies in chronological order, including traditional methods, CNN-based methods, and Transformer-based methods.
- Guided by ship characteristics, we classify and outline the existing challenges in SDORSIs. based on CNNs and analyze their advantages and disadvantages.
- We summarize ship datasets and evaluation metrics. Furthermore, we are the first to separate and aggregate ship information from comprehensive datasets. At the same time, we compare and analyze performance improvement of the solutions and the feature extraction abilities of different backbones.
- Prospects of SDORSIs are presented.
2. Methods
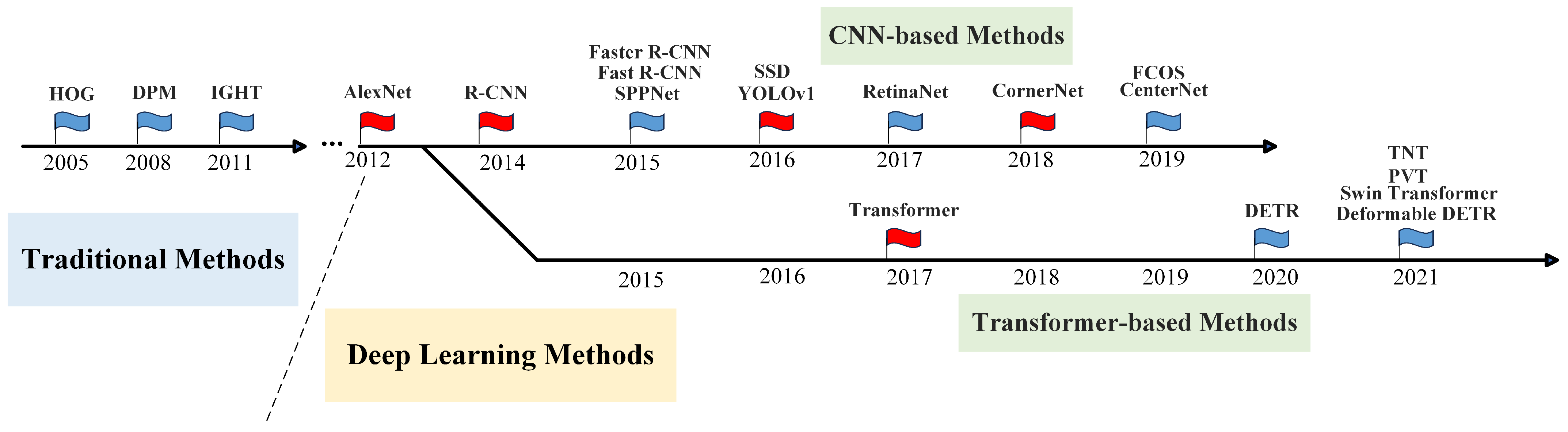
2.1. Traditional Methods
2.1.1. Template-Matching-Based Method
2.1.2. Visual-Saliency-Based Method
2.1.3. Classification-Learning-Based Method
2.1.4. Summary
2.2. CNN-Based Methods
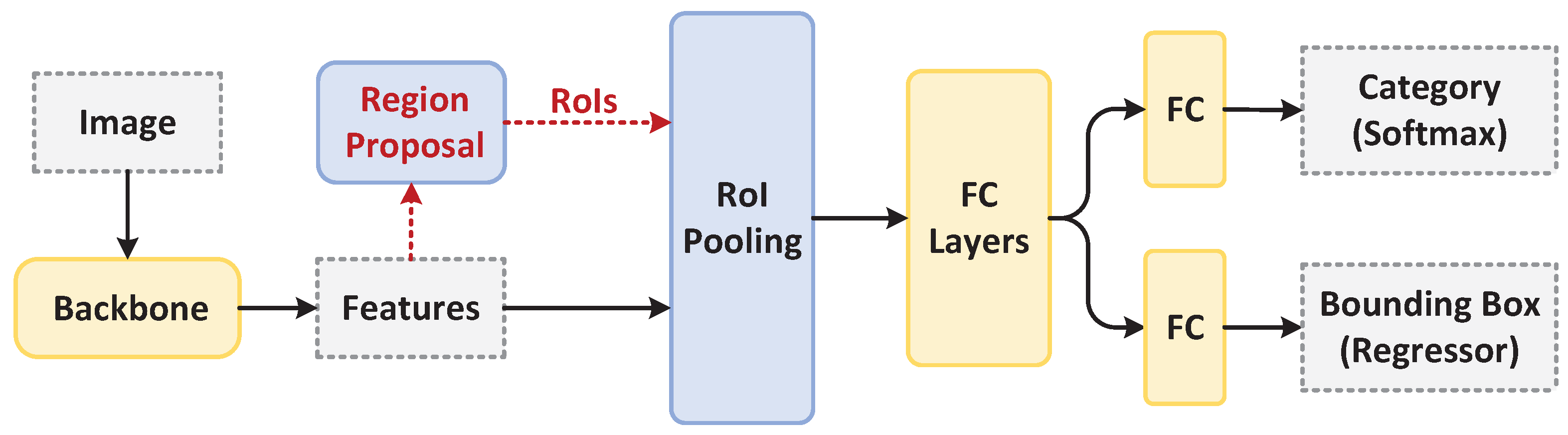
2.2.1. Two-Stage Detector
2.2.2. Single-Stage Detector
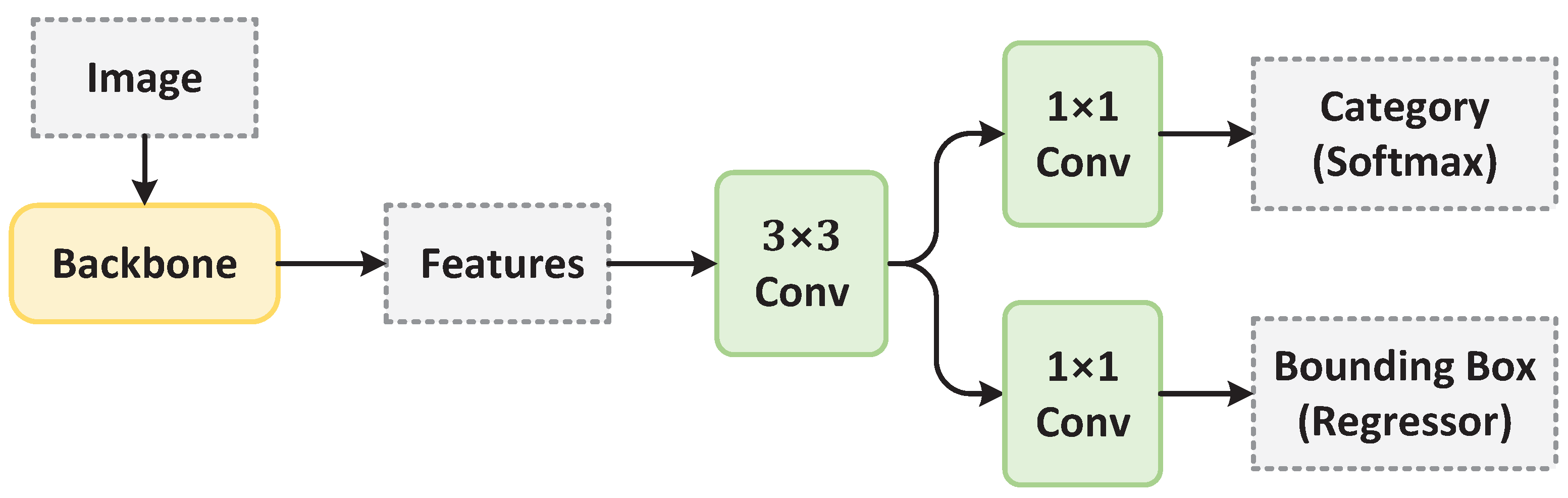
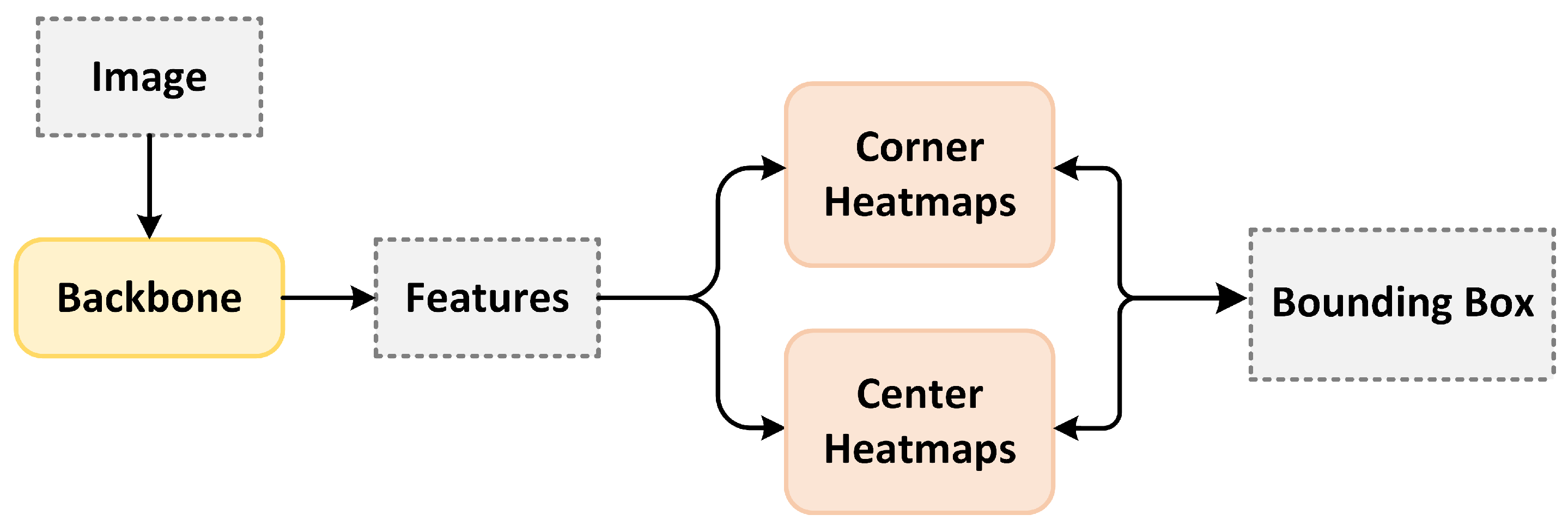
2.2.3. Anchor-Free Detector
2.2.4. Summary
2.3. Transformer-Based Methods
2.3.1. Transformer-Based Detector
2.3.2. Transformer-Based Backbone
2.3.3. Summary
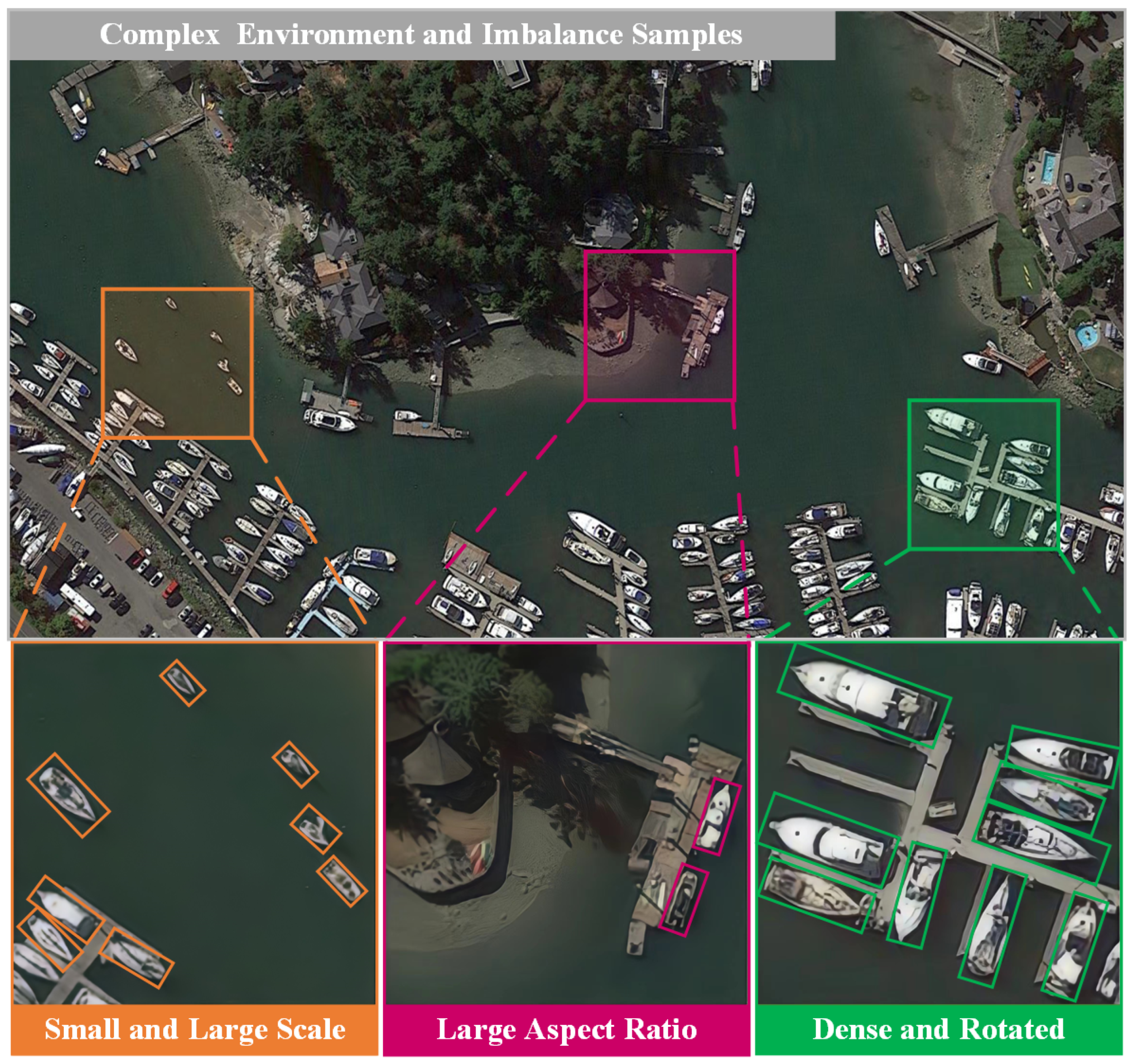
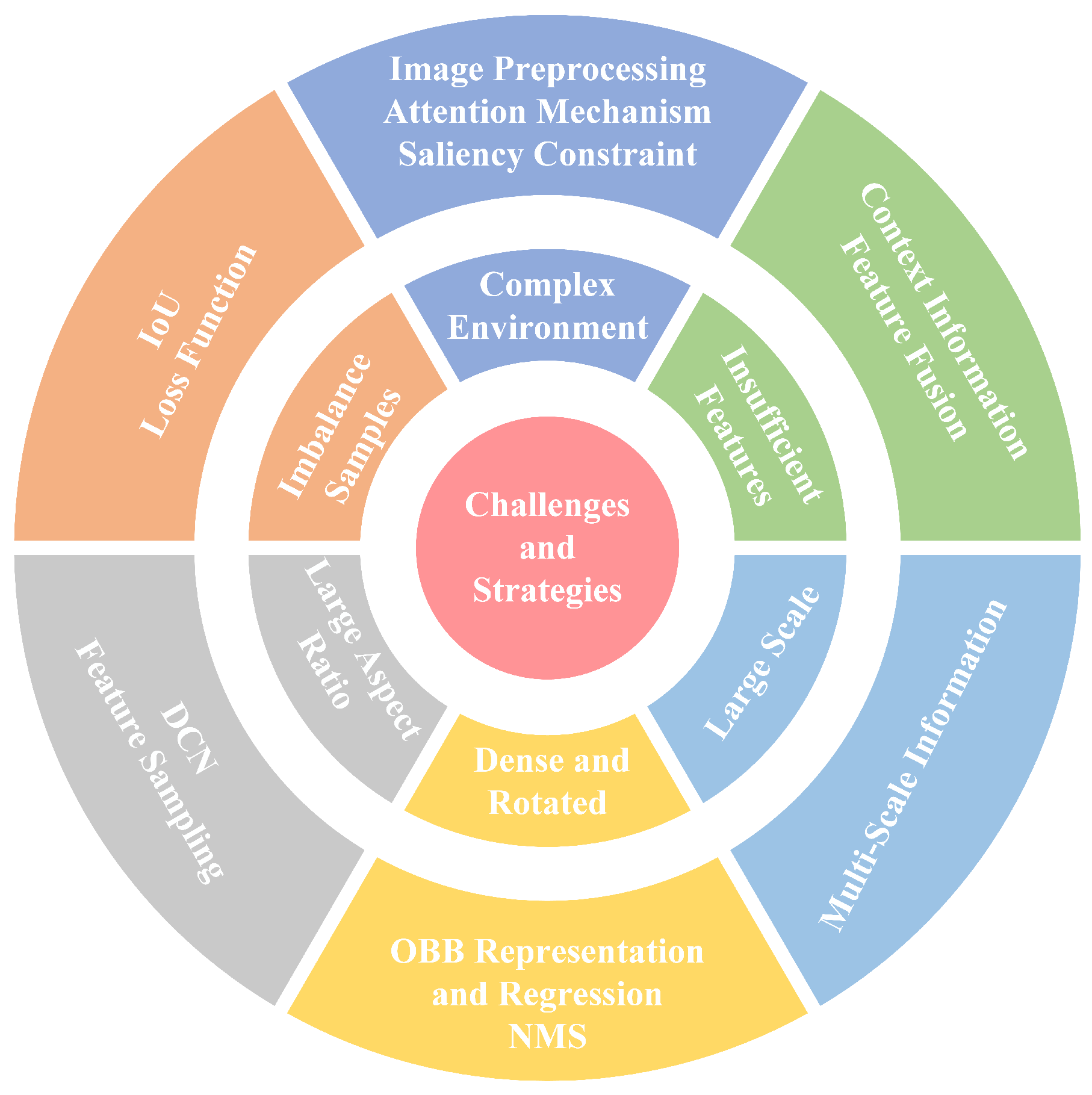
3. Challenges and Solutions in Ship Detection
3.1. Complex Marine Environments
3.1.1. Image-Preprocessing-Based Method
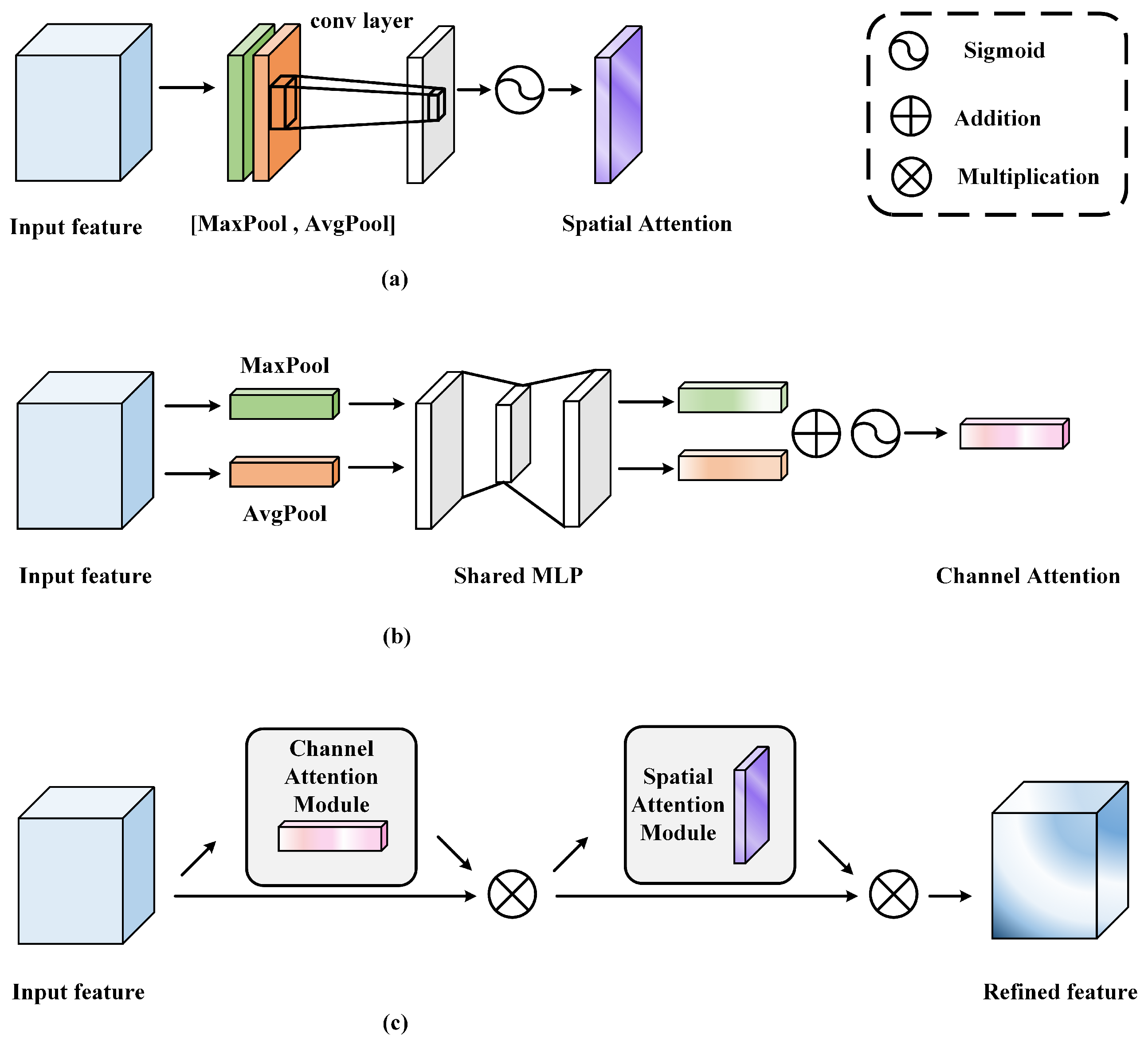
3.1.2. Attention-Mechanism-Based Method
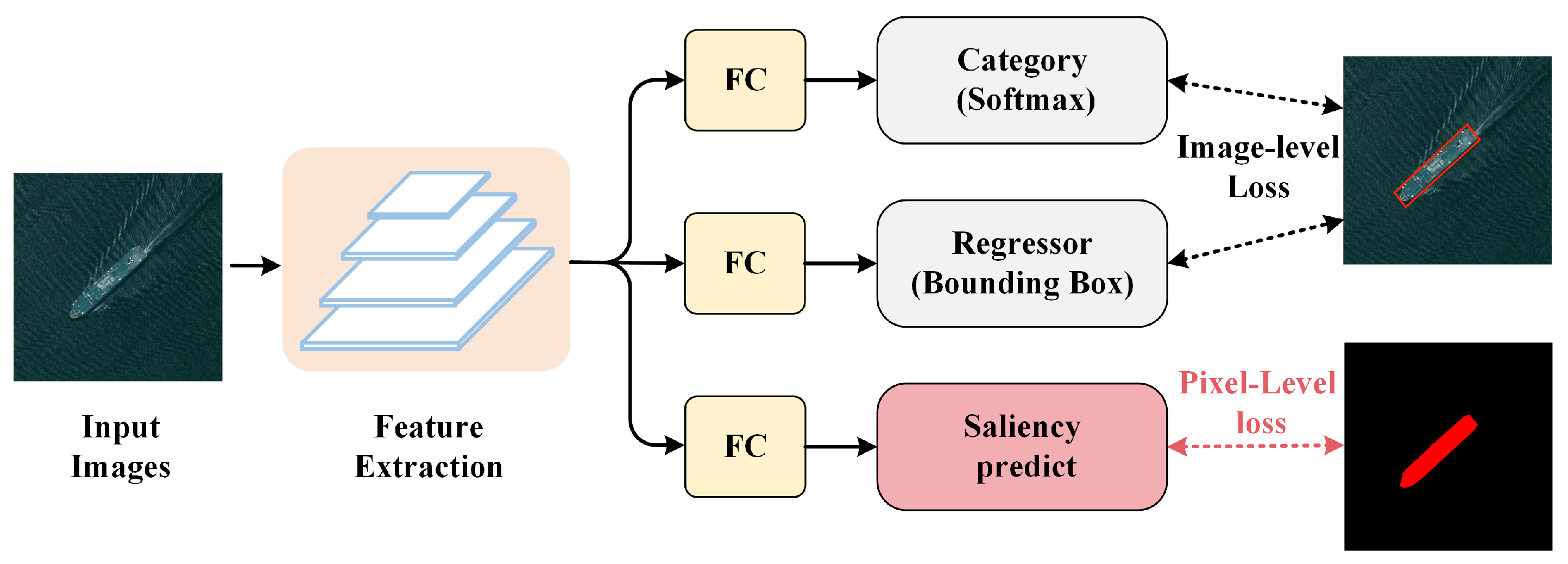
3.1.3. Saliency-Constraint-Based Method
3.1.4. Summary
3.2. Insufficient Discriminative Features
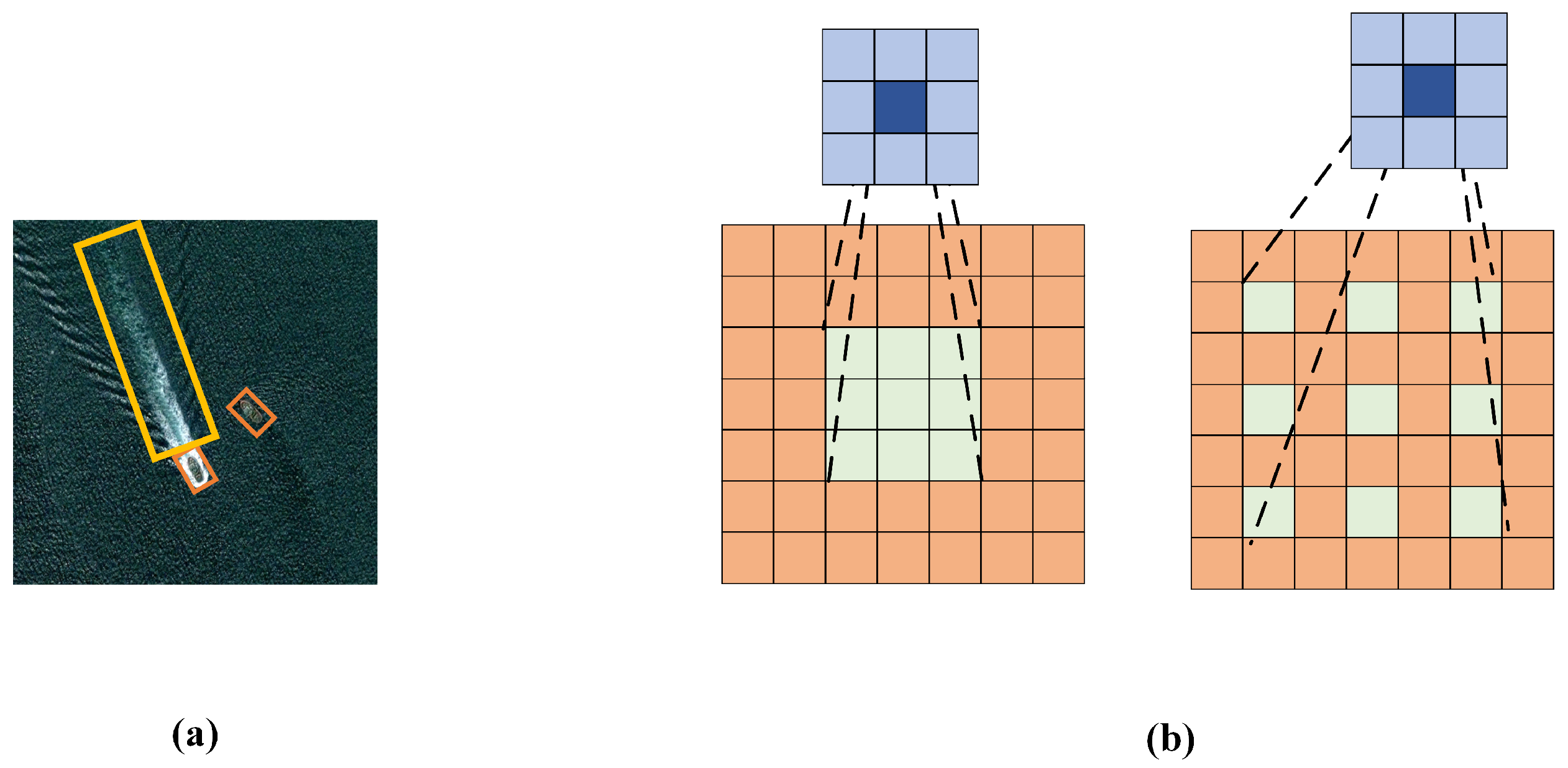
3.2.1. Context Information Mining-Based Method
3.2.2. Feature-Fusion-Based Method
3.2.3. Summary
3.3. Large Scale Variation
3.3.1. Multi-Scale Information-Based Method
3.3.2. Summary
3.4. Dense Distribution and Rotated Ships
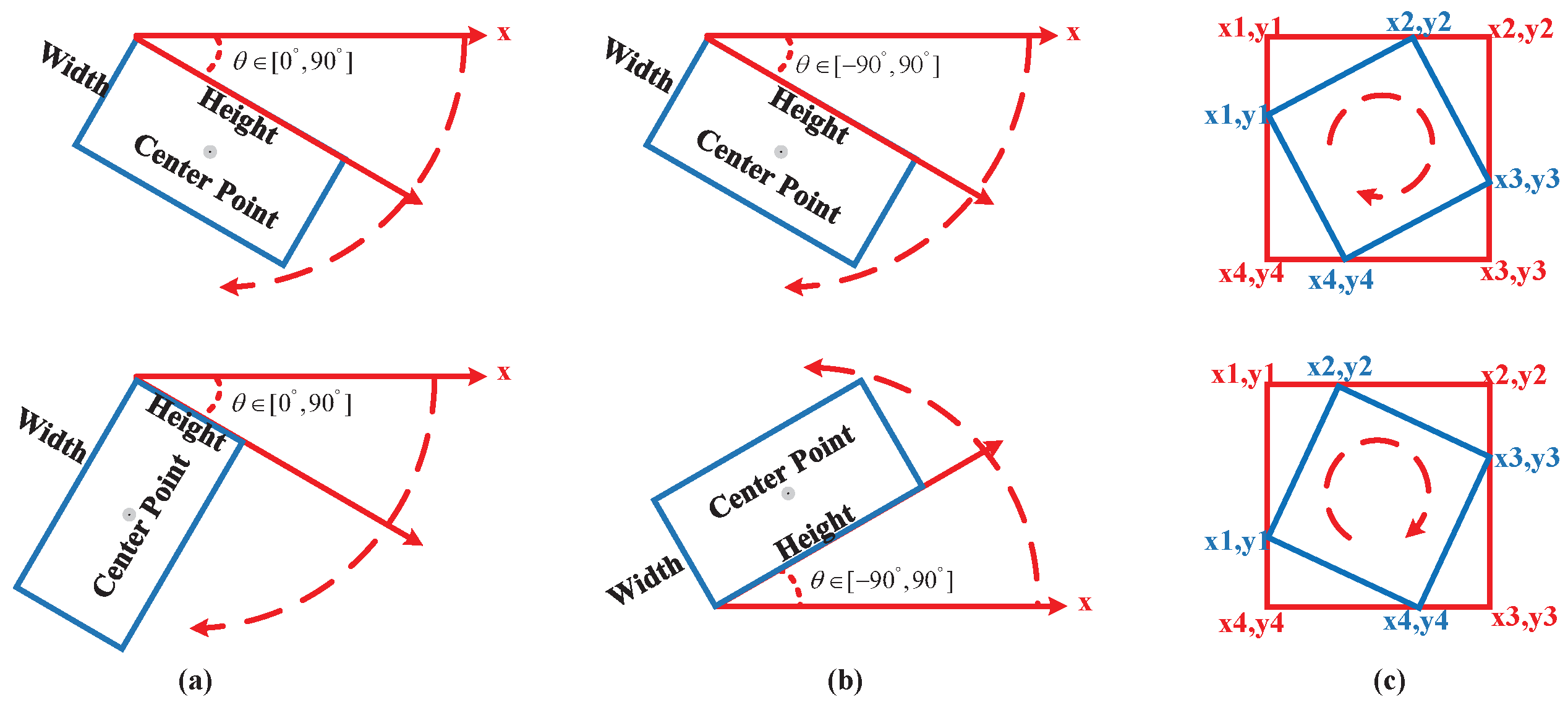
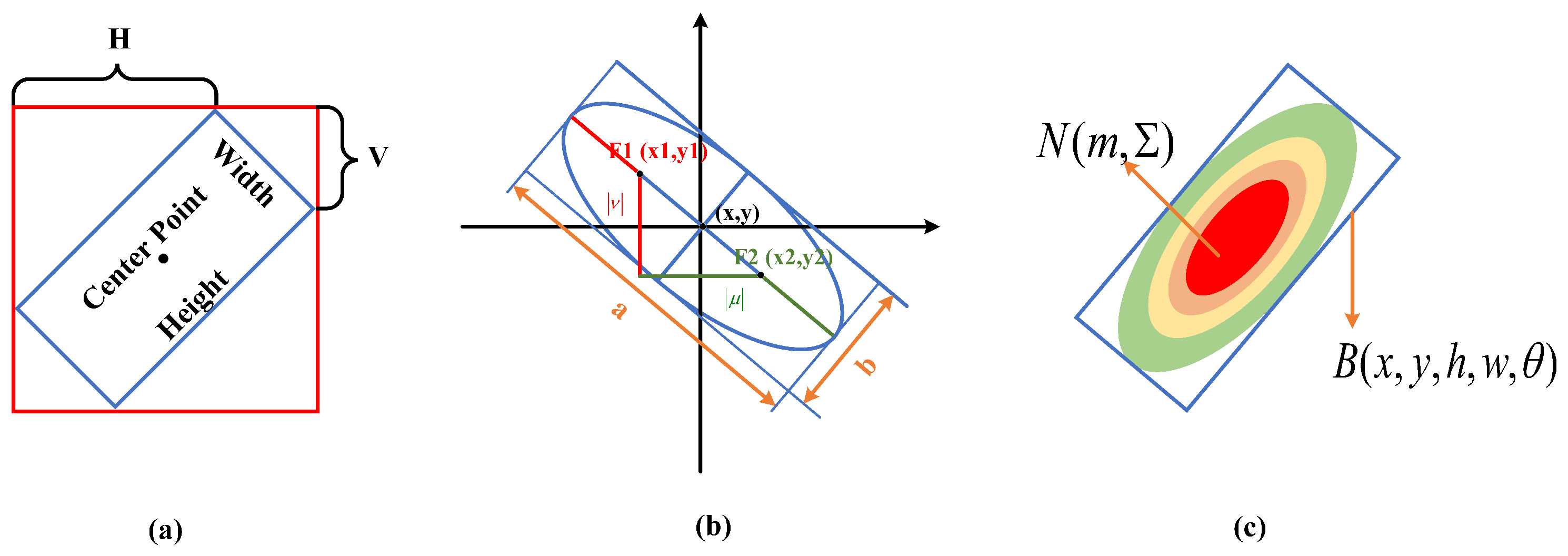
3.4.1. OBB Representation and Regression-Based Method
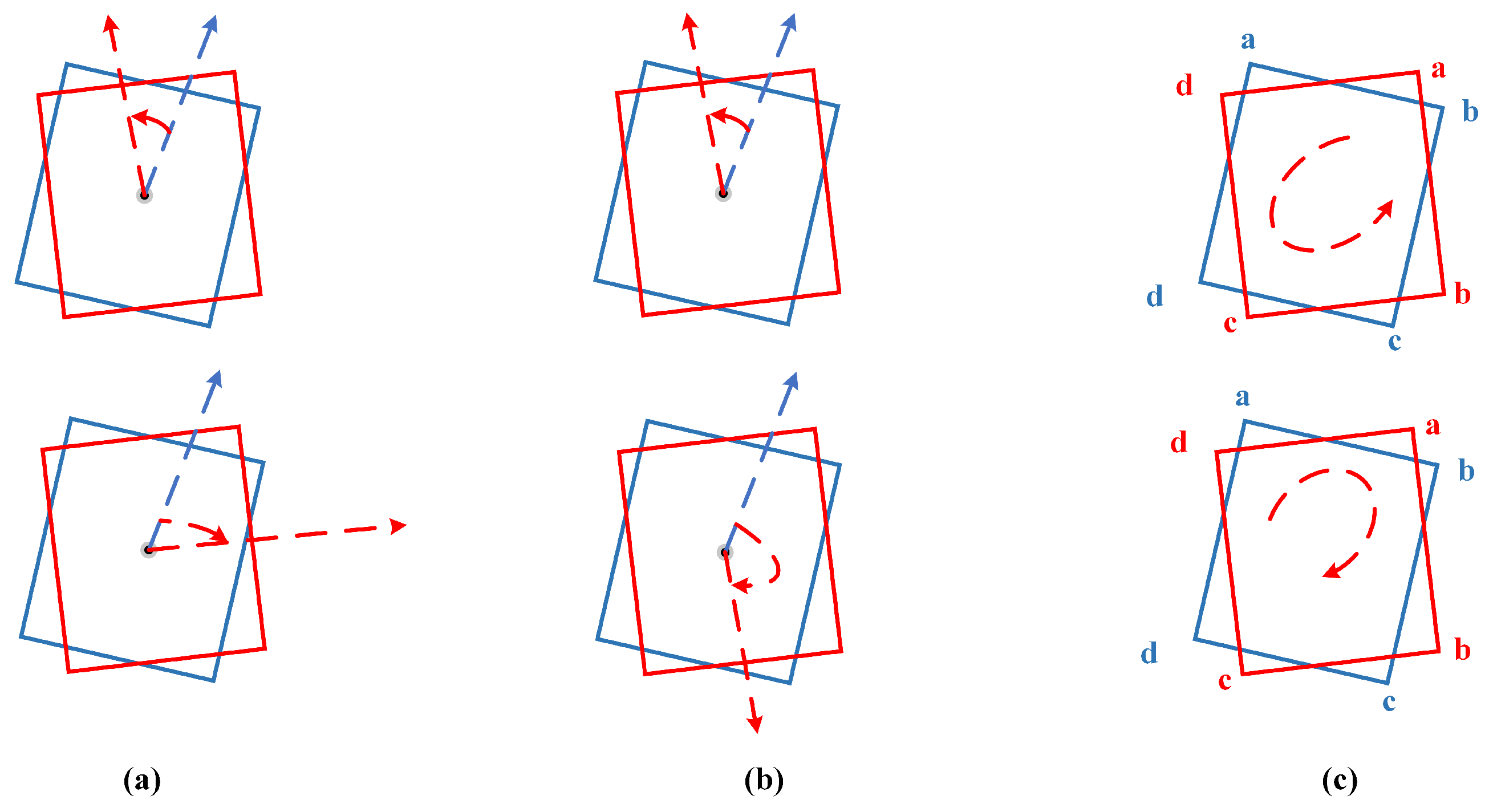
3.4.2. NMS-Based Method
3.4.3. Summary
3.5. Large Aspect Ratio of Ships
3.5.1. DCN-Based Method
3.5.2. Feature Sampling-Based Method
3.5.3. Summary
3.6. Imbalance between Positive and Negative Samples
3.6.1. IoU-Based Matching Methods
3.6.2. Loss-Function-Based Method
3.6.3. Summary
4. Datasets, Evaluation Metrics, and Experiments
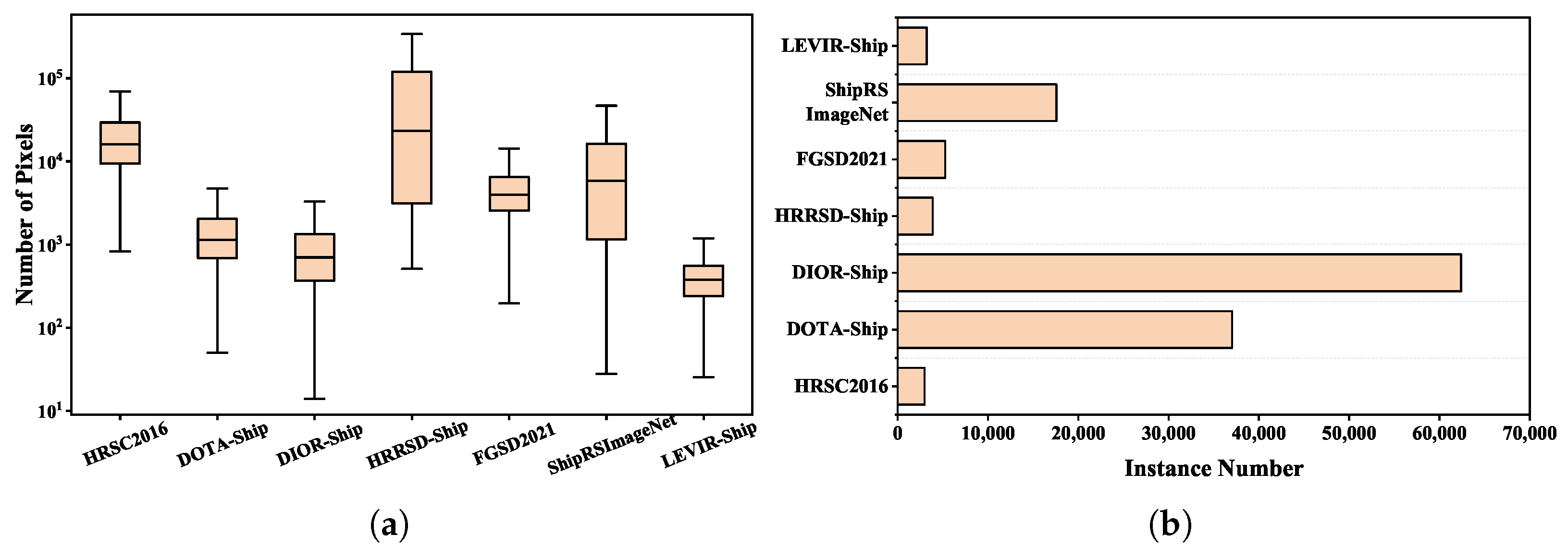
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimentation and Analysis
4.3.1. Algorithm Performance Comparison and Analysis
4.3.2. Performance of Optimization Strategies Comparison and Analysis
4.3.3. Exploration of Transformer Application
5. Discussions and Prospects
- Utilizing super-resolution and other feature enhancement methods to selectively enhance the feature representation ability of small-scale ships, which improve the recall for small ships when the scale variation is extensive. It contributes to further enhancing the overall detection accuracy.
- To address the challenge of imbalance between positive and negative samples, supplementing the quantity of positive samples, such as methods of mining samples from the ignored set and using adaptive IoU thresholds, are helpful to increase the contribution of positive samples during network training.
- Directly transferring common object detection networks to ship detection often fails to produce satisfactory results. Therefore, it is one of the future trends to mine the inherent features of ships, such as the wake of moving ships, large aspect ratios and so on, and design targeted ship detection networks.
- Utilizing image fusion methods of different modalities, such as spatial information and frequency domain information, optical remote-sensing images and SAR images, enables the advantageous complementarity of information. Therefore, It helps to improve the detection accuracy of ships with cloud and fog cover and small-scale ships.
- Designing compact and efficient detection models is more in line with the needs of applications. Therefore, the research on lightweight models, such as knowledge distillation, network pruning, and NAS, is an important strategy for deploying models to embedded devices.
- By comparing the feature extraction capabilities of CNNs and Transformer, this paper preliminarily verifies that the global modeling concept of Transformer is helpful to improve the detection accuracy of the network. Therefore, drawing inspiration from the latest research achievements in computer vision is the direction for future development.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abileah, R. Surveying coastal ship traffic with LANDSAT. In Proceedings of the OCEANS 2009, Biloxi, MS, USA, 26–29 October 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z.; Xu, D.; Ben, G.; Gao, Y. Deep Learning-Based Object Detection Techniques for Remote Sensing Images: A Survey. Remote Sens. 2022, 14, 2385. [Google Scholar] [CrossRef]
- Er, M.J.; Zhang, Y.; Chen, J.; Gao, W. Ship detection with deep learning: A survey. Artif. Intell. Rev. 2023, 56, 11825–11865. [Google Scholar] [CrossRef]
- Iwin Thanakumar Joseph, S.; Sasikala, J.; Sujitha Juliet, D. Ship detection and recognition for offshore and inshore applications: A survey. Int. J. Intell. Unmanned Syst. 2019, 7, 177–188. [Google Scholar]
- Bo, L.; Xiaoyang, X.; Xingxing, W.; Wenting, T. Ship detection and classification from optical remote sensing images: A survey. Chin. J. Aeronaut. 2021, 34, 145–163. [Google Scholar]
- Kanjir, U.; Greidanus, H.; Oštir, K. Vessel detection and classification from spaceborne optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for SAR ship detection: Past, present and future. Remote Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- Xu, J.; Fu, K.; Sun, X. An Invariant Generalized Hough Transform Based Method of Inshore Ships Detection. In Proceedings of the 2011 International Symposium on Image and Data Fusion, Tengchong, China, 9–11 August 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Harvey, N.R.; Porter, R.; Theiler, J. Ship detection in satellite imagery using rank-order grayscale hit-or-miss transforms. In Proceedings of the Visual Information Processing XIX; SPIE: Bellingham, WA, USA, 2010; Volume 7701, pp. 9–20. [Google Scholar]
- He, H.; Lin, Y.; Chen, F.; Tai, H.M.; Yin, Z. Inshore Ship Detection in Remote Sensing Images via Weighted Pose Voting. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3091–3107. [Google Scholar] [CrossRef]
- Xu, F.; Liu, J.; Sun, M.; Zeng, D.; Wang, X. A hierarchical maritime target detection method for optical remote sensing imagery. Remote Sens. 2017, 9, 280. [Google Scholar] [CrossRef]
- Nie, T.; He, B.; Bi, G.; Zhang, Y.; Wang, W. A method of ship detection under complex background. ISPRS Int. J. Geo-Inf. 2017, 6, 159. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised Ship Detection Based on Saliency and S-HOG Descriptor from Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar] [CrossRef]
- Bi, F.; Zhu, B.; Gao, L.; Bian, M. A Visual Search Inspired Computational Model for Ship Detection in Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 749–753. [Google Scholar] [CrossRef]
- Lowe, D. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume1; pp. 886–893. [Google Scholar] [CrossRef]
- Corbane, C.; Najman, L.; Pecoul, E.; Demagistri, L.; Petit, M. A complete processing chain for ship detection using optical satellite imagery. Int. J. Remote Sens. 2010, 31, 5837–5854. [Google Scholar] [CrossRef]
- Song, Z.; Sui, H.; Wang, Y. Automatic ship detection for optical satellite images based on visual attention model and LBP. In Proceedings of the 2014 IEEE Workshop on Electronics, Computer and Applications, Ottawa, ON, USA, 8–9 May 2014; pp. 722–725. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A Novel Hierarchical Method of Ship Detection from Spaceborne Optical Image Based on Shape and Texture Features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, Y.; Zheng, X.; Sun, X.; Fu, K.; Wang, H. A New Method on Inshore Ship Detection in High-Resolution Satellite Images Using Shape and Context Information. IEEE Geosci. Remote Sens. Lett. 2014, 11, 617–621. [Google Scholar] [CrossRef]
- Antelo, J.; Ambrosio, G.; Gonzalez, J.; Galindo, C. Ship detection and recognitionin high-resolution satellite images. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 4, pp. IV–514–IV–517. [Google Scholar] [CrossRef]
- Xu, J.; Sun, X.; Zhang, D.; Fu, K. Automatic Detection of Inshore Ships in High-Resolution Remote Sensing Images Using Robust Invariant Generalized Hough Transform. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2070–2074. [Google Scholar] [CrossRef]
- Zhu, L.; Xiong, G.; Guo, D.; Yu, W. Ship target detection and segmentation method based on multi-fractal analysis. J. Eng. 2019, 2019, 7876–7879. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar] [CrossRef]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7355–7364. [Google Scholar] [CrossRef]
- Guo, H.; Yang, X.; Wang, N.; Song, B.; Gao, X. A Rotational Libra R-CNN Method for Ship Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5772–5781. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X.X. HSF-Net: Multiscale Deep Feature Embedding for Ship Detection in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Nie, S.; Jiang, Z.; Zhang, H.; Cai, B.; Yao, Y. Inshore Ship Detection Based on Mask R-CNN. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 693–696. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Patel, K.; Bhatt, C.; Mazzeo, P.L. Deep learning-based automatic detection of ships: An experimental study using satellite images. J. Imaging 2022, 8, 182. [Google Scholar] [CrossRef]
- Gong, W.; Shi, Z.; Wu, Z.; Luo, J. Arbitrary-oriented ship detection via feature fusion and visual attention for high-resolution optical remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2622–2640. [Google Scholar] [CrossRef]
- Wu, J.; Pan, Z.; Lei, B.; Hu, Y. LR-TSDet: Towards tiny ship detection in low-resolution remote sensing images. Remote Sens. 2021, 13, 3890. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Yang, Y.; Pan, Z.; Hu, Y.; Ding, C. CPS-Det: An anchor-free based rotation detector for ship detection. Remote Sens. 2021, 13, 2208. [Google Scholar] [CrossRef]
- Zhuang, Y.; Liu, Y.; Zhang, T.; Chen, H. Contour Modeling Arbitrary-Oriented Ship Detection From Very High-Resolution Optical Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6000805. [Google Scholar] [CrossRef]
- Zhang, Y.; Sheng, W.; Jiang, J.; Jing, N.; Wang, Q.; Mao, Z. Priority branches for ship detection in optical remote sensing images. Remote Sens. 2020, 12, 1196. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neur. In. 2021, 34, 15908–15919. [Google Scholar]
- Yu, Y.; Yang, X.; Li, J.; Gao, X. A Cascade Rotated Anchor-Aided Detector for Ship Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5600514. [Google Scholar] [CrossRef]
- Zheng, Y.; Su, J.; Zhang, S.; Tao, M.; Wang, L. Dehaze-AGGAN: Unpaired Remote Sensing Image Dehazing Using Enhanced Attention-Guide Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5630413. [Google Scholar] [CrossRef]
- Song, R.; Li, T.; Li, T. Ship detection in haze and low-light remote sensing images via colour balance and DCNN. Appl. Ocean Res. 2023, 139, 103702. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, C.; Liu, R.; Zhang, L.; Guo, X.; Tao, D. Self-augmented Unpaired Image Dehazing via Density and Depth Decomposition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Orleans, LA, USA, 18–24 June 2022; pp. 2027–2036. [Google Scholar] [CrossRef]
- Ying, L.; Miao, D.; Zhang, Z. 3WM-AugNet: A Feature Augmentation Network for Remote Sensing Ship Detection Based on Three-Way Decisions and Multigranularity. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1001219. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Z.; Wang, B.; Miao, L.; An, Z.; Xiao, X. Domain adaptive ship detection in optical remote sensing images. Remote Sens. 2021, 13, 3168. [Google Scholar] [CrossRef]
- Wang, Q.; Shen, F.; Cheng, L.; Jiang, J.; He, G.; Sheng, W.; Jing, N.; Mao, Z. Ship detection based on fused features and rebuilt YOLOv3 networks in optical remote-sensing images. Int. J. Remote Sens. 2021, 42, 520–536. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Shi, T.; Zhang, W.; Cui, Y.; Zhao, S. PAG-YOLO: A portable attention-guided YOLO network for small ship detection. Remote Sens. 2021, 13, 3059. [Google Scholar] [CrossRef]
- Qin, C.; Wang, X.; Li, G.; He, Y. An Improved Attention-Guided Network for Arbitrary-Oriented Ship Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6514805. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Zhang, Y.; Liu, Y. Arbitrary-oriented ship detection based on Kullback–Leibler divergence regression in remote sensing images. Earth Sci. Inform. 2023, 16, 3243–3255. [Google Scholar] [CrossRef]
- Qu, Z.; Zhu, F.; Qi, C. Remote sensing image target detection: Improvement of the YOLOv3 model with auxiliary networks. Remote Sens. 2021, 13, 3908. [Google Scholar] [CrossRef]
- Ren, Z.; Tang, Y.; He, Z.; Tian, L.; Yang, Y.; Zhang, W. Ship Detection in High-Resolution Optical Remote Sensing Images Aided by Saliency Information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5623616. [Google Scholar] [CrossRef]
- Chen, J.; Chen, K.; Chen, H.; Zou, Z.; Shi, Z. A Degraded Reconstruction Enhancement-Based Method for Tiny Ship Detection in Remote Sensing Images With a New Large-Scale Dataset. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5625014. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, R.; Deng, R.; Zhao, J. Ship detection and classification based on cascaded detection of hull and wake from optical satellite remote sensing imagery. GIScience Remote Sens. 2023, 60, 2196159. [Google Scholar] [CrossRef]
- Xue, F.; Jin, W.; Qiu, S.; Yang, J. Rethinking Automatic Ship Wake Detection: State-of-the-Art CNN-Based Wake Detection via Optical Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5613622. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, J.; Qin, Y. A novel technique for ship wake detection from optical images. Remote Sens. Environ. 2021, 258, 112375. [Google Scholar] [CrossRef]
- Liu, Z.; Xu, J.; Li, J.; Plaza, A.; Zhang, S.; Wang, L. Moving Ship Optimal Association for Maritime Surveillance: Fusing AIS and Sentinel-2 Data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5635218. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, R.; Zhao, J. Simulation of Kelvin wakes in optical images of rough sea surface. Appl. Ocean Res. 2019, 89, 36–43. [Google Scholar] [CrossRef]
- Xu, Q.; Li, Y.; Shi, Z. LMO-YOLO: A Ship Detection Model for Low-Resolution Optical Satellite Imagery. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 4117–4131. [Google Scholar] [CrossRef]
- Chen, L.; Shi, W.; Deng, D. Improved YOLOv3 based on attention mechanism for fast and accurate ship detection in optical remote sensing images. Remote Sens. 2021, 13, 660. [Google Scholar] [CrossRef]
- Zhou, L.; Li, Y.; Rao, X.; Liu, C.; Zuo, X.; Liu, Y. Ship Target Detection in Optical Remote Sensing Images Based on Multiscale Feature Enhancement. Comput. Intell. Neurosci. 2022, 2022, 2605140. [Google Scholar] [CrossRef]
- Liu, W.; Ma, L.; Chen, H. Arbitrary-Oriented Ship Detection Framework in Optical Remote-Sensing Images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Z.; Wang, B.; Miao, L.; Zong, H. A Novel CNN-Based Method for Accurate Ship Detection in HR Optical Remote Sensing Images via Rotated Bounding Box. IEEE Trans. Geosci. Remote Sens. 2021, 59, 686–699. [Google Scholar] [CrossRef]
- Tian, L.; Cao, Y.; He, B.; Zhang, Y.; He, C.; Li, D. Image enhancement driven by object characteristics and dense feature reuse network for ship target detection in remote sensing imagery. Remote Sens. 2021, 13, 1327. [Google Scholar] [CrossRef]
- Qin, P.; Cai, Y.; Liu, J.; Fan, P.; Sun, M. Multilayer Feature Extraction Network for Military Ship Detection From High-Resolution Optical Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 11058–11069. [Google Scholar] [CrossRef]
- Han, Y.; Yang, X.; Pu, T.; Peng, Z. Fine-Grained Recognition for Oriented Ship Against Complex Scenes in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5612318. [Google Scholar] [CrossRef]
- Wen, G.; Cao, P.; Wang, H.; Chen, H.; Liu, X.; Xu, J.; Zaiane, O. MS-SSD: Multi-scale single shot detector for ship detection in remote sensing images. Appl. Intell. 2023, 53, 1586–1604. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, X.; Zhu, S.; Xu, F.; Liu, J. LMSD-Net: A Lightweight and High-Performance Ship Detection Network for Optical Remote Sensing Images. Remote Sens. 2023, 15, 4358. [Google Scholar] [CrossRef]
- Si, J.; Song, B.; Wu, J.; Lin, W.; Huang, W.; Chen, S. Maritime Ship Detection Method for Satellite Images Based on Multiscale Feature Fusion. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 6642–6655. [Google Scholar] [CrossRef]
- Yan, Z.; Li, Z.; Xie, Y.; Li, C.; Li, S.; Sun, F. ReBiDet: An Enhanced Ship Detection Model Utilizing ReDet and Bi-Directional Feature Fusion. Appl. Sci. 2023, 13, 7080. [Google Scholar] [CrossRef]
- Li, J.; Li, Z.; Chen, M.; Wang, Y.; Luo, Q. A new ship detection algorithm in optical remote sensing images based on improved R3Det. Remote Sens. 2022, 14, 5048. [Google Scholar] [CrossRef]
- Chen, W.; Han, B.; Yang, Z.; Gao, X. MSSDet: Multi-Scale Ship-Detection Framework in Optical Remote-Sensing Images and New Benchmark. Remote Sens. 2022, 14, 5460. [Google Scholar] [CrossRef]
- Xie, X.; Li, L.; An, Z.; Lu, G.; Zhou, Z. Small Ship Detection Based on Hybrid Anchor Structure and Feature Super-Resolution. Remote Sens. 2022, 14, 3530. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, G.; Zhu, P.; Zhang, T.; Li, C.; Jiao, L. GRS-Det: An Anchor-Free Rotation Ship Detector Based on Gaussian-Mask in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3518–3531. [Google Scholar] [CrossRef]
- Guo, H.; Bai, H.; Yuan, Y.; Qin, W. Fully deformable convolutional network for ship detection in remote sensing imagery. Remote Sens. 2022, 14, 1850. [Google Scholar] [CrossRef]
- Liu, Q.; Xiang, X.; Yang, Z.; Hu, Y.; Hong, Y. Arbitrary Direction Ship Detection in Remote-Sensing Images Based on Multitask Learning and Multiregion Feature Fusion. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1553–1564. [Google Scholar] [CrossRef]
- Ouyang, L.; Fang, L.; Ji, X. Multigranularity Self-Attention Network for Fine-Grained Ship Detection in Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 9722–9732. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H.; Wu, F. Ship detection in optical satellite images via directional bounding boxes based on ship center and orientation prediction. Remote Sens. 2019, 11, 2173. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, C.; Fu, Q. OFCOS: An Oriented Anchor-Free Detector for Ship Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6004005. [Google Scholar] [CrossRef]
- Su, N.; Huang, Z.; Yan, Y.; Zhao, C.; Zhou, S. Detect Larger at Once: Large-Area Remote-Sensing Image Arbitrary-Oriented Ship Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6505605. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, M.; Zhao, H.; Tang, R.; Lin, S.; Cheng, X.; Wang, H. Arbitrary-Oriented Ellipse Detector for Ship Detection in Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 7151–7162. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Koo, J.; Seo, J.; Jeon, S.; Choe, J.; Jeon, T. RBox-CNN: Rotated bounding box based CNN for ship detection in remote sensing image. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 420–423. [Google Scholar]
- Chen, J.; Xie, F.; Lu, Y.; Jiang, Z. Finding Arbitrary-Oriented Ships From Remote Sensing Images Using Corner Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1712–1716. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Zhou, S.; Wang, Y.; Hou, Y. Arbitrary-Oriented Ship Detection Through Center-Head Point Extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5612414. [Google Scholar] [CrossRef]
- Cui, Z.; Leng, J.; Liu, Y.; Zhang, T.; Quan, P.; Zhao, W. SKNet: Detecting Rotated Ships as Keypoints in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8826–8840. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Zhang, Y.; Guo, L.; Wang, Z.; Yu, Y.; Liu, X.; Xu, F. Intelligent ship detection in remote sensing images based on multi-layer convolutional feature fusion. Remote Sens. 2020, 12, 3316. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Chai, B.; Nie, X.; Gao, H.; Jia, J.; Qiao, Q. Remote Sensing Images Background Noise Processing Method for Ship Objects in Instance Segmentation. J. Indian Soc. Remote Sens. 2023, 51, 647–659. [Google Scholar] [CrossRef]
- Cui, Z.; Sun, H.M.; Yin, R.N.; Jia, R.S. SDA-Net: A detector for small, densely distributed, and arbitrary-directional ships in remote sensing images. Appl. Intell. 2022, 52, 12516–12532. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, R.; Guo, H.; Yang, W.; Yu, H.; Zhang, P.; Zou, T. Fine-Grained Ship Detection in High-Resolution Satellite Images With Shape-Aware Feature Learning. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 1914–1926. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, R.; Li, Y.; Pan, B. Oriented ship detection based on intersecting circle and deformable RoI in remote sensing images. Remote Sens. 2022, 14, 4749. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Zhang, Y.; Gao, Y.; Zhao, Z.; Feng, H.; Zhao, T. Context Feature Integration and Balanced Sampling Strategy for Small Weak Object Detection in Remote-Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2024, 112, 102966. [Google Scholar] [CrossRef]
- Zhang, C.; Xiong, B.; Li, X.; Kuang, G. Aspect-Ratio-Guided Detection for Oriented Objects in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8024805. [Google Scholar] [CrossRef]
- Li, Y.; Bian, C.; Chen, H. Dynamic Soft Label Assignment for Arbitrary-Oriented Ship Detection. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 1160–1170. [Google Scholar] [CrossRef]
- Song, Z.; Wang, L.; Zhang, G.; Jia, C.; Bi, J.; Wei, H.; Xia, Y.; Zhang, C.; Zhao, L. Fast Detection of Multi-Direction Remote Sensing Ship Object Based on Scale Space Pyramid. In Proceedings of the 2022 18th International Conference on Mobility, Sensing and Networking (MSN), Guangzhou, China, 4–16 December 2022; pp. 1019–1024. [Google Scholar] [CrossRef]
- Liu, M.; Chen, Y.; Ding, D. AureNet: A Real-Time Arbitrary-oriented and Ship-based Object Detection. In Proceedings of the 2023 IEEE 2nd International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 24–26 February 2023; pp. 647–652. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Wang, Y.; Feng, P.; He, R. ShipRSImageNet: A Large-Scale Fine-Grained Dataset for Ship Detection in High-Resolution Optical Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 8458–8472. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimedia 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2844–2853. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Song, Q.; Yang, F.; Yang, L.; Liu, C.; Hu, M.; Xia, L. Learning Point-Guided Localization for Detection in Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 1084–1094. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3500–3509. [Google Scholar] [CrossRef]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrary-oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2021; Volume 35, pp. 2355–2363. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI conference on artificial intelligence, Washington DC, USA, 7–14 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Ming, Q.; Miao, L.; Zhou, Z.; Yang, X.; Dong, Y. Optimization for Arbitrary-Oriented Object Detection via Representation Invariance Loss. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8021505. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605814. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602511. [Google Scholar] [CrossRef]
- Pan, C.; Li, R.; Liu, W.; Lu, W.; Niu, C.; Bao, Q. Remote Sensing Image Ship Detection Based on Dynamic Adjusting Labels Strategy. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4702621. [Google Scholar] [CrossRef]
- Xiao, Z.; Qian, L.; Shao, W.; Tan, X.; Wang, K. Axis learning for orientated objects detection in aerial images. Remote Sens. 2020, 12, 908. [Google Scholar] [CrossRef]
- Feng, P.; Lin, Y.; Guan, J.; He, G.; Shi, H.; Chambers, J. TOSO: Student’s-T Distribution Aided One-Stage Orientation Target Detection in Remote Sensing Images. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4057–4061. [Google Scholar] [CrossRef]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2149–2158. [Google Scholar] [CrossRef]
- Deng, G.; Wang, Q.; Jiang, J.; Hong, Q.; Jing, N.; Sheng, W.; Mao, Z. A Low Coupling and Lightweight Algorithm for Ship Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6513505. [Google Scholar] [CrossRef]
- Liang, D.; Geng, Q.; Wei, Z.; Vorontsov, D.A.; Kim, E.L.; Wei, M.; Zhou, H. Anchor Retouching via Model Interaction for Robust Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619213. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. ReDet: A Rotation-equivariant Detector for Aerial Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2785–2794. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 677–694. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense Label Encoding for Boundary Discontinuity Free Rotation Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15814–15824. [Google Scholar] [CrossRef]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning modulated loss for rotated object detection. In Proceedings of the AAAI conference on artificial intelligence, Washington DC, USA, 7–14 February 2021; Volume 35, pp. 2458–2466. [Google Scholar]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented RepPoints for Aerial Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1819–1828. [Google Scholar] [CrossRef]
- Wang, J.; Li, F.; Bi, H. Gaussian Focal Loss: Learning Distribution Polarized Angle Prediction for Rotated Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4707013. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Zhou, S.; Wang, Y. DARDet: A Dense Anchor-Free Rotated Object Detector in Aerial Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8024305. [Google Scholar] [CrossRef]
- Yu, D.; Xu, Q.; Liu, X.; Guo, H.; Lu, J.; Lin, Y.; Lv, L. Dual-Resolution and Deformable Multihead Network for Oriented Object Detection in Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 930–945. [Google Scholar] [CrossRef]
- Hua, Z.; Pan, G.; Gao, K.; Li, H.; Chen, S. AF-OSD: An Anchor-Free Oriented Ship Detector Based on Multi-Scale Dense-Point Rotation Gaussian Heatmap. Remote Sens. 2023, 15, 1120. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Advantages | Disadvantages | References | |
|---|---|---|---|---|
| Traditional Methods | Template Matching | It is simple to operate. | It requires a lot of prior knowledge and is sensitive to the environment. | [8,9,10] |
| Visual Saliency | It calculates the contrast between a certain region and its surrounding areas to extract regions. | It has higher requirements for image quality. | [11,12,13,14] | |
| Classification Learning | It establishes the relationship between ship features and ship categories. | The manually designed features only utilize the low-level visual information and cannot express the complex semantic information. | [17,18] | |
| CNN-based Methods | Two-stage Detector | It divides the ship detection into two stages and has high accuracy and robustness. | Detection efficiency of two-stage detector may be lower than single-stage detector. | [25,26,27,28,29,30,31,32] |
| Single-stage Detector | It is suitable for the applications that require high real-time accuracy and high efficiency. | Detection accuracy of single-stage detector may be lower than two-stage detector. | [36,37,38,39,40,41,42,43] | |
| Anchor-free Detector | It uses keypoints instead of anchor boxes to detect ships which improves the generalization of the model. | It exhibits poor performance for ships with ambiguous keypoints. | [47,48,49] | |
| Transformer Methods | Detector Backbone | It can explore long-range dependencies in targets, and effectively capture global features. | The high data requirements make it challenging to achieve satisfactory results on small datasets. | [54,55,56,57,58] |
| Methods | Advantages | Disadvantages | References | |
|---|---|---|---|---|
| Image Preprocessing | Exclude Background | It filters out untargeted images in advance. | Introducing convolutional layers requires additional training for the network. | [59] |
| Dehazing Algorithm | It improves the quality of the image by eliminating the impact of clouds and fog. | Excessive dehazing may result in information loss. Simple algorithms are not suitable for complex scenes. | [60,61,62,63] | |
| Attention Mechanism | Channel Attention Mechanism | It adjusts channel weights dynamically to focus on ships. | It has limitations in extracting global information. | [64,65,66,67] |
| Spatial Attention Mechanism | It highlights important information in the image to focus on ships. | It may excessively focus on local structures, leading to a decreased ability to generalize. | [66,67] | |
| Convolutional Attention Module | It adjusts convolutional kernel weights dynamically at different positions to focus on ships. | Introducing additional computation. | [68,69] | |
| Saliency Constraint | Saliency Constraint | It uses the concept of multi-task learning and pixel-level supervision to focus on ships. | It has a high requirement for the resolution of the images. The weight needs to be adjusted manually. | [70,71] |
| Methods | Advantages | Disadvantages | References | |
|---|---|---|---|---|
| Context Information Mining | Ship Wake | The wake is closely related to the ship and can provide additional discriminative information. | Excessive context information may compromise detection performance. | [72,73,74,75,76] |
| Dilated Convolution | It enhances the receptive field without introducing additional parameters while maintaining resolution. | There are gaps in the dilated convolution kernel, which leads to information discontinuity. | [77,78,79] | |
| Feature Fusion | Feature Fusion | Integrating information from feature maps with different resolutions can extract rich semantic information and localization information to enhance information interaction capabilities. | Improper fusion methods may result in loss or confusion of information. | [80,81,82,83,84,85] |
| Methods | Advantages | Disadvantages | References | |
|---|---|---|---|---|
| Multi-Scale Information | FPN and Improvements | It enables the model to handle ships of different scales through the pyramid structure and the feature fusion is used to enhance the information interaction ability to improve the detection accuracy. | By introducing the pyramid structure, it increases the computational complexity and training time. | [33,50,70,86,87,88,89,90,91,92,93,94] |
| Methods | Advantages | Disadvantages | References | |
|---|---|---|---|---|
| OBB Representation | Five Parameters | It is represented by (x, y, w, h, ) and more accurately represents the position and orientation information of ships. | At the angle boundary, angle change leads to a sharp increase in loss. | [95,96,97] |
| Eight Parameters | It is represented by (, , , , , , , ) and does not use angles to represent direction. | It produces loss discontinuity and a large number of parameters. | [98] | |
| Others | It can alleviate the problem of loss discontinuity. | Some methods increase the computational complexity and the training time. | [93,99,100,101] | |
| OBB Regression | Anchor-Based | It utilizes predefined anchor boxes for the OBB’s more accurate regression. | The performance is greatly influenced by hyperparameters, which are related to sizes and aspect ratios of predefined anchor boxes. | [64,96,102] |
| Anchor-Free | It is not constrained by sizes and aspect ratios of anchor boxes, reducing hyperparameters. | Due to the absence of prior information provided by anchor boxes, the results are sometimes lower than anchor-based methods. | [93,103,104,105] | |
| NMS | Soft-NMS | It alleviates the problem of missed dense ships by weighting overlapping bounding boxes. | It is not combined with rotated feature of the ship. | [35,106,107] |
| Soft-Rotate -NMS | It combines rotated features with Soft-NMS, making it more suitable for ship detection. | The IoU threshold has a significant impact on NMS. | [105] | |
| Methods | Advantages | Disadvantages | References | |
|---|---|---|---|---|
| DCN | DCN | It can adaptively extract feature information for irregularly shaped ships by randomly sampling. | The offset of sampling points entirely relies on the prediction of network and DCN consumes more memory compared to the standard convolution. | [52,94,99,109,110] |
| Feature Sampling | ROI Pooling ROI Align | It adapts to the ship geometry of the large aspect ratio, and extracts features uniformly in different directions. | It maps multiple feature points to one feature point, which may cause some degree of information loss and computational error. | [81,111,112] |
| Methods | Advantages | Disadvantages | References | |
|---|---|---|---|---|
| IoU | Improved IoU Calculation | It can obtain more positive samples to participate in training by improving the calculation method of IoU. | It introduces additional computation and increases the complexity of the network. | [81,97,116] |
| Dynamical IoU Threshold | It dynamically adjusts the threshold based on the shape of the ship to obtain more positive samples. | It requires designing a suitable threshold mapping function and constraining the range of threshold. Inappropriate mapping ranges may introduce interfering samples. | [114,115] | |
| Loss Function | Improved Loss Function | It assigns more weight to positive samples during loss calculation, and improves their contribution in training. | It relies on hyperparameters tuning, and requires constant manual search for the optimal value. | [43,103,117] |
| Dataset | Year | Image | Category | Instance | Resolution | Image Size | Label |
|---|---|---|---|---|---|---|---|
| HRSC2016 [118] | 2016 | 1070 | 4 | 2976 | 0.4–2 m | 300 × 300–1500 × 900 | HBB, OBB |
| DOTA-ship [119] | 2017 | 434 | 1 | 37,028 | 0.5 m | 800 × 800–4000 × 4000 | HBB, OBB |
| DIOR-ship [120] | 2018 | 2702 | 1 | 62,400 | 0.5–30 m | 800 × 800 | HBB |
| HRRSD-ship [121] | 2019 | 2165 | 1 | 3886 | 0.5–1.2m | 270 × 370–4000 × 5500 | HBB |
| FGSD2021 [104] | 2021 | 636 | 20 | 5274 | 1 m | 1202 × 1205 | OBB |
| ShipRSImageNet [122] | 2021 | 3435 | 50 | 17,573 | 0.12–6 m | 930 × 930 | HBB, OBB |
| LEVIR-ship [71] | 2021 | 3896 | 1 | 3119 | 16m | 512 × 512 | HBB |
| Method | Year | Publication | Backbone | Input_Size | mAP |
|---|---|---|---|---|---|
| Anchor-based (Two-stage) | |||||
| CNN [126] | 2017 | ICPR | ResNet-101 | 800 × 800 | 73.07 |
| RRPN [127] | 2018 | TMM | ResNet-101 | 800 × 800 | 79.08 |
| RoI_Trans [128] | 2019 | CVPR | ResNet-101 | 512 × 800 | 86.20 |
| Gliding Vertex [129] | 2021 | TPAMI | ResNet-101 | 512 × 800 | 88.20 |
| OPLD [130] | 2021 | JSTAR | ResNet-50 | 1024 × 1333 | 88.44 |
| Oriented R-CNN [131] | 2021 | ICCV | ResNet-101 | 1333 × 800 | 90.50 |
| Anchor-based (One-stage) | |||||
| DAL [132] | 2021 | AAAI | ResNet-101 | 416 × 416 | 88.95 |
| Det [133] | 2021 | AAAI | ResNet-101 | 800 × 800 | 89.26 |
| DLAO [99] | 2022 | GRSL | DCNDarknet25 | 800 × 800 | 88.28 |
| RIDet-Q [134] | 2022 | GRSL | ResNet-101 | 800 × 800 | 89.10 |
| CFC-Net [135] | 2022 | TGRS | ResNet-101 | 800 × 800 | 89.70 |
| A-Net [136] | 2022 | TGRS | ResNet-101 | 512 × 800 | 90.17 |
| DSA-Net [67] | 2022 | GRSL | CSPDarknet-53 | 608 × 608 | 90.41 |
| DAL-BCL [137] | 2023 | TGRS | CSPDarknet-53 | 800 × 800 | 89.70 |
| 3WM-AugNet [63] | 2023 | TGRS | ResNet-101 | 512 × 512 | 90.69 |
| Anchor-free | |||||
| Axis Learning [138] | 2020 | RS | ResNet-101 | 800 × 800 | 78.15 |
| TOSO [139] | 2020 | ICASSP | ResNet-101 | 800 × 800 | 79.29 |
| SKNet [105] | 2021 | TGRS | Hourglass-104 | 511 × 511 | 88.30 |
| BBAVectors [140] | 2021 | WACV | ResNet-101 | 608 × 608 | 88.60 |
| CHPDet [104] | 2022 | TGRS | DLA-34 | 512 × 512 | 88.81 |
| LCNet [141] | 2022 | GRSL | RepVGG-A1 | 416 × 416 | 89.50 |
| CMDet [51] | 2023 | GRSL | ResNet-50 | 640 × 640 | 90.20 |
| AEDet [100] | 2023 | JSTAR | CSPDarknet-53 | 800 × 800 | 90.45 |
| Method | Backbone | Air | Was | Tar | Aus | Whi | San | New | Tic | Bur | Per | Lew | Sup | Kai | Hop | Mer | Fre | Ind | Ave | Sub | Oth | mAP | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Anchor-based (Two-stage) | |||||||||||||||||||||||
| CNN [126] | Resnet50 | 89.9 | 80.9 | 80.5 | 79.4 | 87.0 | 87.8 | 44.2 | 89.0 | 89.6 | 79.5 | 80.4 | 47.7 | 81.5 | 87.4 | 100 | 82.4 | 100 | 66.4 | 50.9 | 57.2 | 78.1 | 10.3 |
| RoI_Trans [128] | Resnet50 | 90.9 | 88.6 | 87.2 | 89.5 | 78.5 | 88.8 | 81.8 | 89.6 | 89.8 | 90.4 | 71.7 | 74.7 | 73.7 | 81.6 | 78.6 | 100 | 75.6 | 78.4 | 68.0 | 66.9 | 83.5 | 19.2 |
| Oriented R-CNN [131] | Resnet50 | 90.9 | 89.7 | 81.5 | 81.1 | 79.6 | 88.2 | 98.9 | 89.8 | 90.6 | 87.8 | 60.4 | 73.9 | 81.8 | 86.7 | 100 | 60.0 | 100 | 79.4 | 66.9 | 63.7 | 82.5 | 27.4 |
| DEA-Net [142] | Resnet50 | 90.4 | 91.4 | 84.6 | 93.5 | 88.7 | 94.5 | 92.1 | 90.7 | 92.4 | 88.9 | 60.6 | 81.6 | 85.4 | 90.3 | 99.7 | 83.1 | 98.5 | 76.6 | 68.5 | 69.2 | 86.0 | 12.1 |
| SCRDet [143] | Resnet50 | 77.3 | 90.4 | 87.4 | 89.8 | 78.8 | 90.9 | 54.5 | 88.3 | 89.6 | 74.9 | 68.4 | 59.2 | 90.4 | 77.2 | 81.8 | 73.9 | 100 | 43.9 | 43.8 | 57.1 | 75.9 | 9.2 |
| ReDet [144] | ReResnet50 | 90.9 | 90.6 | 80.3 | 81.5 | 89.3 | 88.4 | 81.8 | 88.8 | 90.3 | 90.5 | 78.1 | 76.0 | 90.7 | 87.0 | 98.2 | 84.4 | 90.9 | 74.6 | 85.3 | 71.2 | 85.4 | 13.8 |
| Anchor-based (One-stage) | |||||||||||||||||||||||
| Retinanet [43] | Resnet50 | 89.7 | 89.2 | 78.2 | 87.3 | 77.0 | 86.9 | 62.7 | 81.5 | 83.3 | 70.6 | 46.8 | 69.9 | 80.2 | 83.1 | 100 | 80.6 | 89.7 | 61.5 | 42.5 | 9.1 | 73.5 | 35.6 |
| CSL [145] | Resnet50 | 89.7 | 81.3 | 77.2 | 80.2 | 71.4 | 77.2 | 52.7 | 87.7 | 87.7 | 74.2 | 57.1 | 97.2 | 77.6 | 80.5 | 100 | 72.7 | 100 | 32.6 | 37.0 | 40.7 | 73.7 | 10.4 |
| Det [133] | Resnet50 | 90.9 | 80.9 | 81.5 | 90.1 | 79.3 | 87.5 | 29.5 | 77.4 | 89.4 | 69.7 | 59.9 | 67.3 | 80.7 | 76.8 | 72.7 | 83.3 | 90.9 | 38.4 | 23.1 | 40.0 | 70.5 | 14.0 |
| DCL [146] | Resnet50 | 89.9 | 81.4 | 78.6 | 80.7 | 78.0 | 87.9 | 49.8 | 78.7 | 87.2 | 76.1 | 60.6 | 76.9 | 90.4 | 80.0 | 78.8 | 77.9 | 100 | 37.1 | 31.2 | 45.6 | 73.3 | 10.0 |
| RSDet [147] | Resnet50 | 89.8 | 80.4 | 75.8 | 77.3 | 78.6 | 88.8 | 26.1 | 84.7 | 87.6 | 75.2 | 55.1 | 74.4 | 89.7 | 89.3 | 100 | 86.4 | 100 | 27.6 | 37.6 | 50.6 | 73.7 | 15.4 |
| A-Net [136] | Resnet50 | 90.9 | 81.4 | 73.3 | 89.1 | 80.9 | 89.9 | 81.2 | 89.2 | 90.7 | 88.9 | 60.5 | 75.9 | 81.6 | 89.2 | 100 | 68.6 | 90.9 | 61.3 | 55.7 | 64.7 | 80.2 | 33.1 |
| Anchor-free | |||||||||||||||||||||||
| BBAVectors [140] | Resnet50 | 99.5 | 90.9 | 75.9 | 94.3 | 90.9 | 52.9 | 88.5 | 90.0 | 80.4 | 72.2 | 76.9 | 88.2 | 99.6 | 100 | 94.0 | 100 | 74.5 | 58.9 | 63.1 | 81.1 | 83.6 | 18.5 |
| CHPDet [104] | DLA34 | 90.9 | 90.4 | 89.6 | 89.3 | 89.6 | 99.1 | 99.4 | 90.2 | 90.2 | 90.3 | 70.7 | 87.9 | 89.2 | 96.5 | 100 | 85.1 | 100 | 84.4 | 68.5 | 56.9 | 87.9 | 41.7 |
| CenterNet [48] | DLA34 | 67.2 | 77.9 | 79.2 | 75.5 | 66.8 | 79.8 | 76.8 | 83.1 | 89.0 | 77.7 | 54.5 | 72.6 | 77.4 | 100 | 100 | 60.8 | 74.8 | 46.5 | 44.1 | 6.8 | 70.5 | 48.5 |
| RepPoint [148] | Resnet50 | 91.2 | 89.2 | 85.6 | 89.3 | 87.6 | 93.1 | 94.2 | 91.5 | 88.7 | 83.3 | 71.4 | 81.1 | 89.4 | 91.5 | 95.6 | 82.6 | 100 | 86.6 | 64.7 | 57.5 | 85.7 | 36.7 |
| GF-CSL [149] | Resnet50 | 92.6 | 90.3 | 86.6 | 90.5 | 88.2 | 95.3 | 97.9 | 89.8 | 91.2 | 86.9 | 69.7 | 85.6 | 92.7 | 92.5 | 99.7 | 85.1 | 98.6 | 86.7 | 79.4 | 70.4 | 88.5 | 40.3 |
| DARDet [150] | Resnet50 | 90.9 | 89.2 | 69.7 | 89.6 | 88.0 | 81.4 | 90.3 | 89.5 | 90.5 | 79.7 | 62.5 | 87.9 | 90.2 | 89.2 | 100 | 68.9 | 81.8 | 66.3 | 44.3 | 56.2 | 80.3 | 31.9 |
| DDMNet [151] | DDRNet39 | 98.2 | 89.8 | 92.5 | 97.1 | 91.6 | 94.9 | 90.9 | 90.0 | 90.5 | 79.0 | 80.2 | 91.7 | 90.0 | 93.6 | 100 | 93.2 | 100 | 74.8 | 48.7 | 69.4 | 87.3 | 43.8 |
| Challenges | Strategies | Methods | Year | mAP |
|---|---|---|---|---|
| Complex environment | Attention Mechanism | AM [45] | 2021 | 82.67 (+1.81) |
| CDA [64] | 2021 | 87.20 (+0.70) | ||
| CLM [67] | 2022 | 86.18 (+1.13) | ||
| GCM [67] | 2022 | 87.75 (+2.70) | ||
| DFAM [84] | 2022 | 78.65 (+3.70) | ||
| Image Preprocessing | De_haze [61] | 2023 | 95.27 (+1.59) | |
| Saliency Constraint | SPB * [70] | 2022 | 86.51 (+0.99) | |
| Large Aspect Ratio | Feature Sampling | AP [81] | 2021 | 89.20 (+0.80) |
| OP [105] | 2021 | 88.30 (+1.80) | ||
| DCN | DCN [99] | 2022 | 86.42 (+8.46) | |
| DRoI [67] | 2022 | 89.21 (+0.61) | ||
| Dense and Rotated ship | OBB Representation | Gaussian-Mask [93] | 2021 | 88.38 (+0.87) |
| Six Parameters [99] | 2022 | 88.28 (+3.55) | ||
| ICR-Head [67] | 2022 | 89.17 (+0.57) | ||
| MDP-RGH [152] | 2023 | 89.69 (+4.75) | ||
| DAL [137] | 2023 | 89.70 (+0.20) | ||
| OBB Regression | EL [50] | 2021 | 87.70 (+1.92) | |
| BR [64] | 2021 | 87.40 (+2.00) | ||
| OAC [98] | 2023 | 91.07 (+6.89) | ||
| KLD [68] | 2023 | 89.87 (+3.94) | ||
| Large Scale Variation | Multi-scale Information | SCM [93] | 2021 | 88.43 (+0.92) |
| FFM [45] | 2021 | 83.34 (+2.48) | ||
| NASFCOS-FPN [50] | 2021 | 88.20 (+2.42) | ||
| FES * [70] | 2022 | 87.01 (+1.49) | ||
| DFF [84] | 2022 | 74.95 (+2.63) | ||
| FE-FPN [98] | 2023 | 84.11 (+6.05) | ||
| AF-OSD [152] | 2023 | 89.69 (+1.80) | ||
| RFF-Net [68] | 2023 | 83.91 (+3.96) |
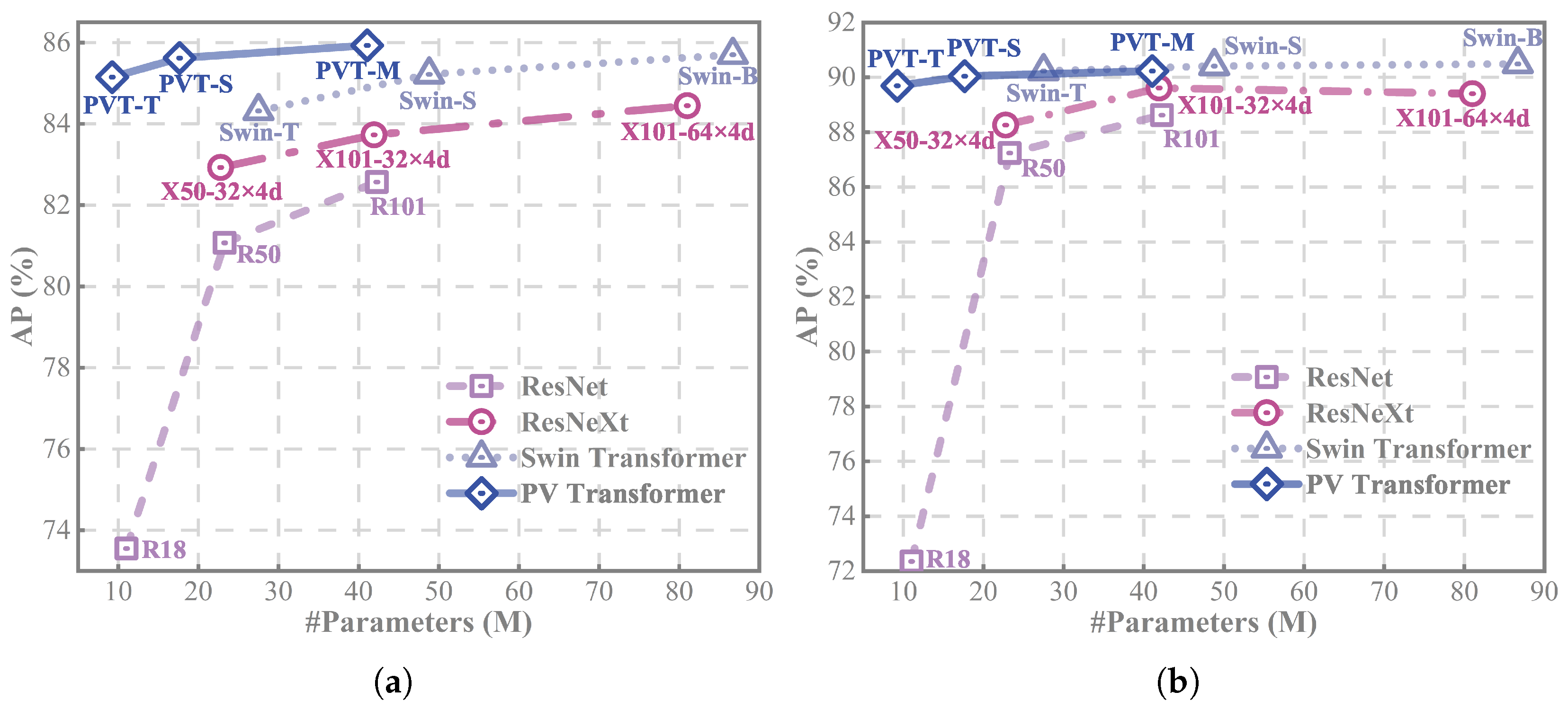
| Backbones | Params(M) | GFLOPs(G) | mAP |
|---|---|---|---|
| ResNet-18 [153] | 11.02 | 38.07 | 73.55 |
| ResNet-50 [153] | 23.28 | 86.10 | 81.07 |
| ResNet-101 [153] | 42.28 | 163.99 | 82.57 |
| ResNext-50-32 × 4d [154] | 22.77 | 89.25 | 82.93 |
| ResNext-101-32 × 4d [154] | 41.91 | 167.83 | 83.73 |
| ResNext-101-64 × 4d [154] | 81.00 | 324.99 | 84.45 |
| Swin-tiny [56] | 27.50 | 95.36 | 84.32 |
| Swin-small [56] | 48.79 | 188.10 | 85.22 |
| Swin-base [56] | 86.68 | 334.16 | 85.70 |
| PVT-tiny [57] | 9.24 | 32.40 | 85.15 |
| PVT-small [57] | 17.65 | 63.51 | 85.62 |
| PVT-Medium [57] | 41.07 | 108.96 | 85.93 |
| Backbones | Params(M) | GFLOPs(G) | mAP |
|---|---|---|---|
| ResNet-18 [153] | 11.02 | 38.07 | 72.35 |
| ResNet-50 [153] | 23.28 | 86.10 | 87.24 |
| ResNet-101 [153] | 42.28 | 163.99 | 88.62 |
| ResNext-50-32 × 4d [154] | 22.77 | 89.25 | 88.26 |
| ResNext-101-32 × 4d [154] | 41.91 | 167.83 | 89.61 |
| ResNext-101-64 × 4d [154] | 81.00 | 324.99 | 89.40 |
| Swin-tiny [56] | 27.50 | 95.36 | 90.23 |
| Swin-small [56] | 48.79 | 188.10 | 90.41 |
| Swin-base [56] | 86.68 | 334.16 | 90.49 |
| PVT-tiny [57] | 9.24 | 32.40 | 89.69 |
| PVT-small [57] | 17.65 | 63.51 | 90.04 |
| PVT-Medium [57] | 41.07 | 108.96 | 90.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, T.; Wang, Y.; Li, Z.; Gao, Y.; Chen, C.; Feng, H.; Zhao, Z. Ship Detection with Deep Learning in Optical Remote-Sensing Images: A Survey of Challenges and Advances. Remote Sens. 2024, 16, 1145. https://doi.org/10.3390/rs16071145
Zhao T, Wang Y, Li Z, Gao Y, Chen C, Feng H, Zhao Z. Ship Detection with Deep Learning in Optical Remote-Sensing Images: A Survey of Challenges and Advances. Remote Sensing. 2024; 16(7):1145. https://doi.org/10.3390/rs16071145
Chicago/Turabian StyleZhao, Tianqi, Yongcheng Wang, Zheng Li, Yunxiao Gao, Chi Chen, Hao Feng, and Zhikang Zhao. 2024. "Ship Detection with Deep Learning in Optical Remote-Sensing Images: A Survey of Challenges and Advances" Remote Sensing 16, no. 7: 1145. https://doi.org/10.3390/rs16071145
APA StyleZhao, T., Wang, Y., Li, Z., Gao, Y., Chen, C., Feng, H., & Zhao, Z. (2024). Ship Detection with Deep Learning in Optical Remote-Sensing Images: A Survey of Challenges and Advances. Remote Sensing, 16(7), 1145. https://doi.org/10.3390/rs16071145