
MVT: Multi-Vision Transformer for Event-Based Small Target Detection


Abstract
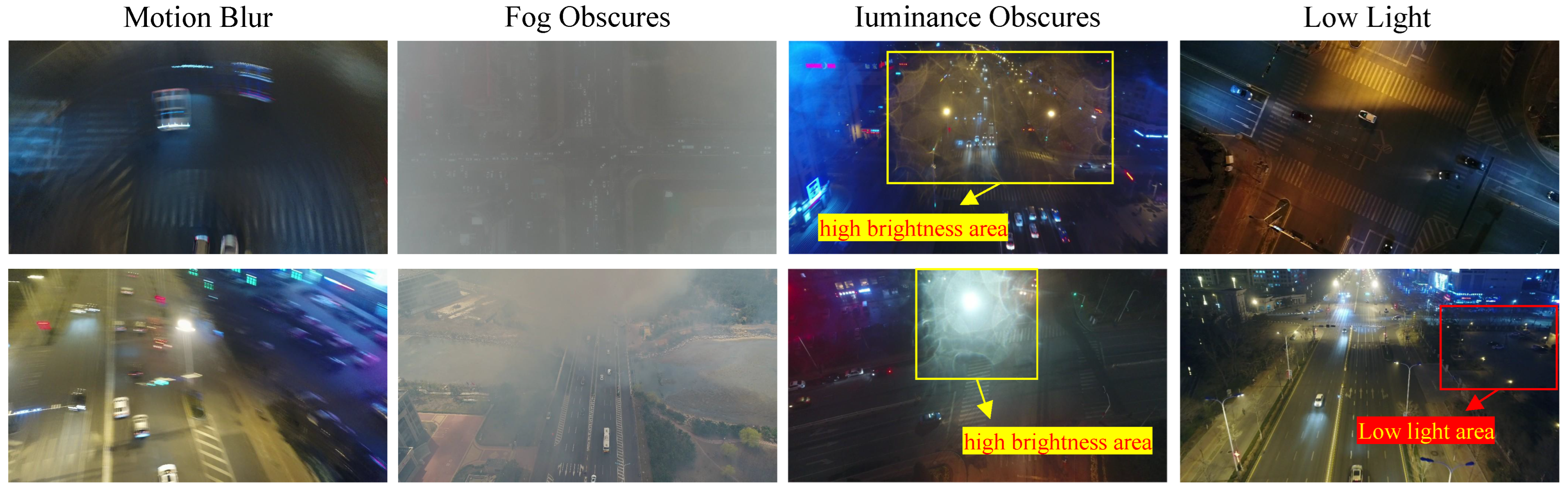
1. Introduction
- The first remote sensing dataset based on event cameras has been proposed, called the Event Object Detection Dataset (EOD Dataset), which consists of over 5000 event streams and includes six categories of objects like car, bus, pedestrian, two-wheel, boat, and ship.
- We propose a novel multi-scale extraction network named Multi-Vision Transformer (MVT), which consists of three efficient modules proposed by us. The downsampling module, the Channel Spatial Attention (CSA) module, and the Global Spatial Attention (GSA) module. Overall, The MVT incorporates efficient modules, achieving a substantial reduction in computational complexity with high performance.
- Considering that extracting information at all scales consumes massive computing resources, we propose a novel cross-scale attention mechanism that progressively fuses high-level features with low-level features, enabling the incorporation of low-level information. The Cross-Deformable-Attention (CDA) reduces the computational complexity of the Transformer Encoder and entire network by approximately 82% and 45% while preserving the original performance.
- As a multi-scale object detection network, MVT achieves state-of-the-art performance trained from scratch without fine-tuning, which trained for 36 epochs, achieving 28.7% mAP@0.5:0.95 and 16.6% on the EOD Dataset, 31.7% mAP@0.5:0.95 and 24.3% on the VisDrone2019 Dataset, 28.2% mAP@0.5:0.95 and 23.7% on the UAVDT Dataset.
2. Related Work
2.1. Multi-Scale Feature Learning
2.2. Attention Mechanism
2.3. Remote Sensing Images Object Detection
3. Method
3.1. Overall Architecture
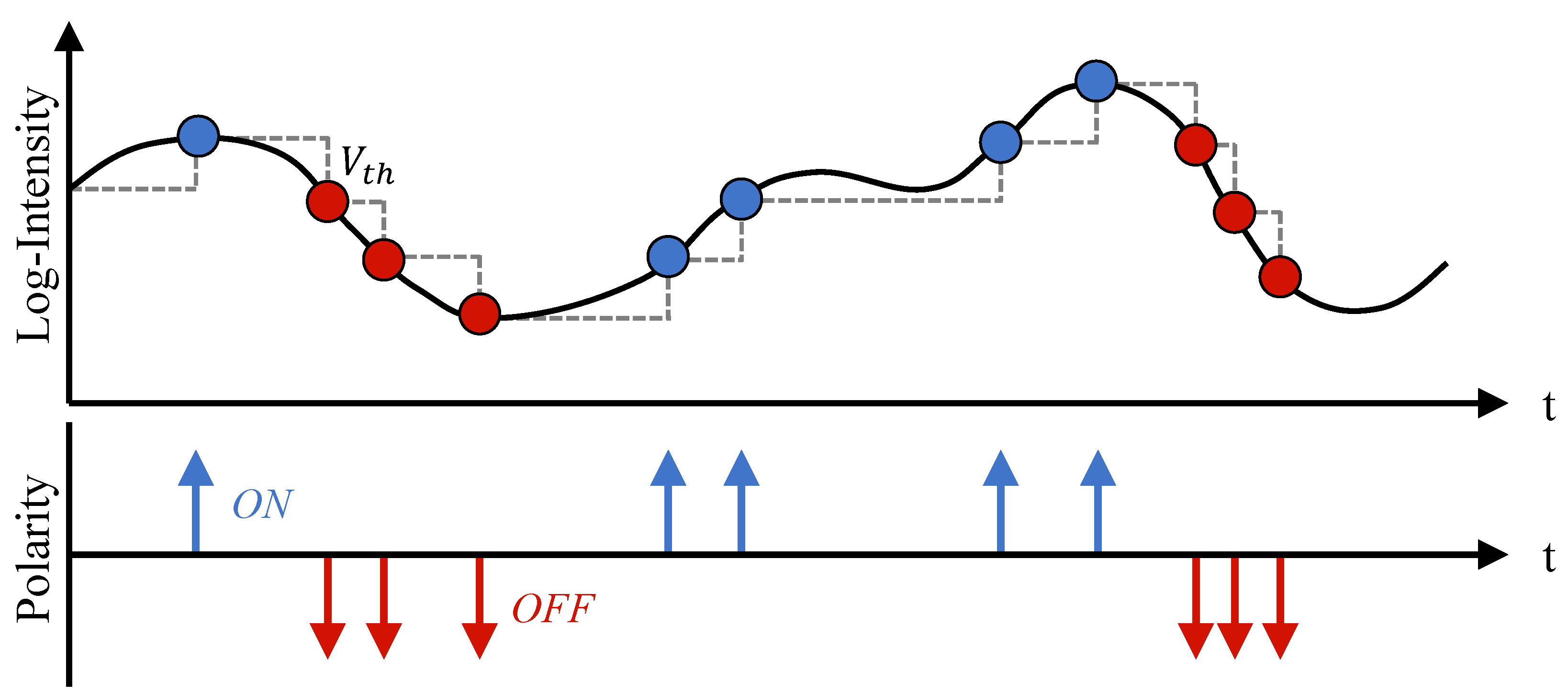
3.2. Event Representation
| Algorithm 1 Voxel grid encoding from event stream |
| Input: Event stream containing N number of events . |
| Output: Voxel grid tensor . |
|
3.3. Multi-Vision Transformer (MVT)
3.3.1. Downsample Module
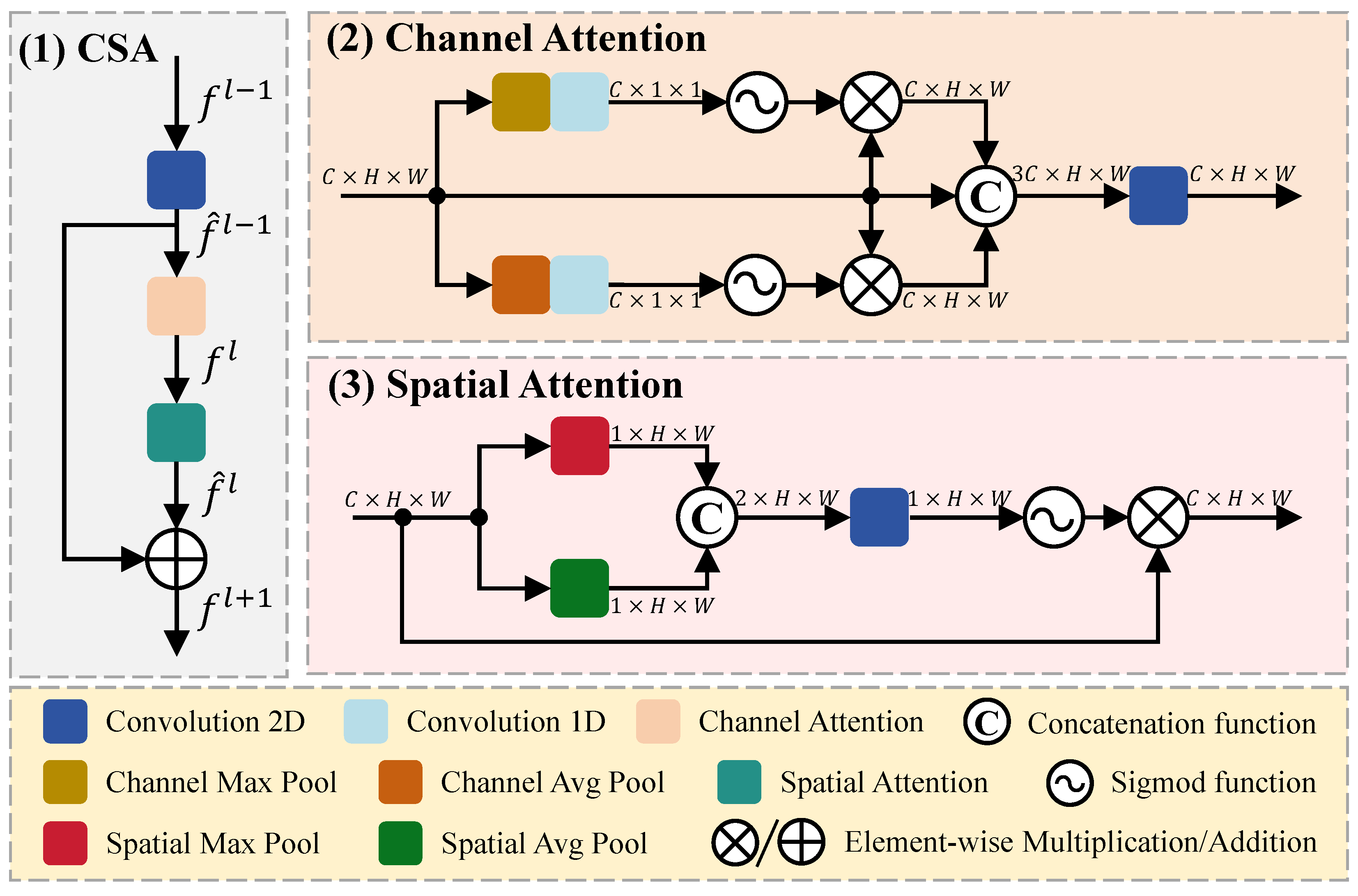
3.3.2. Channel Spatial Attention Module (CSA)
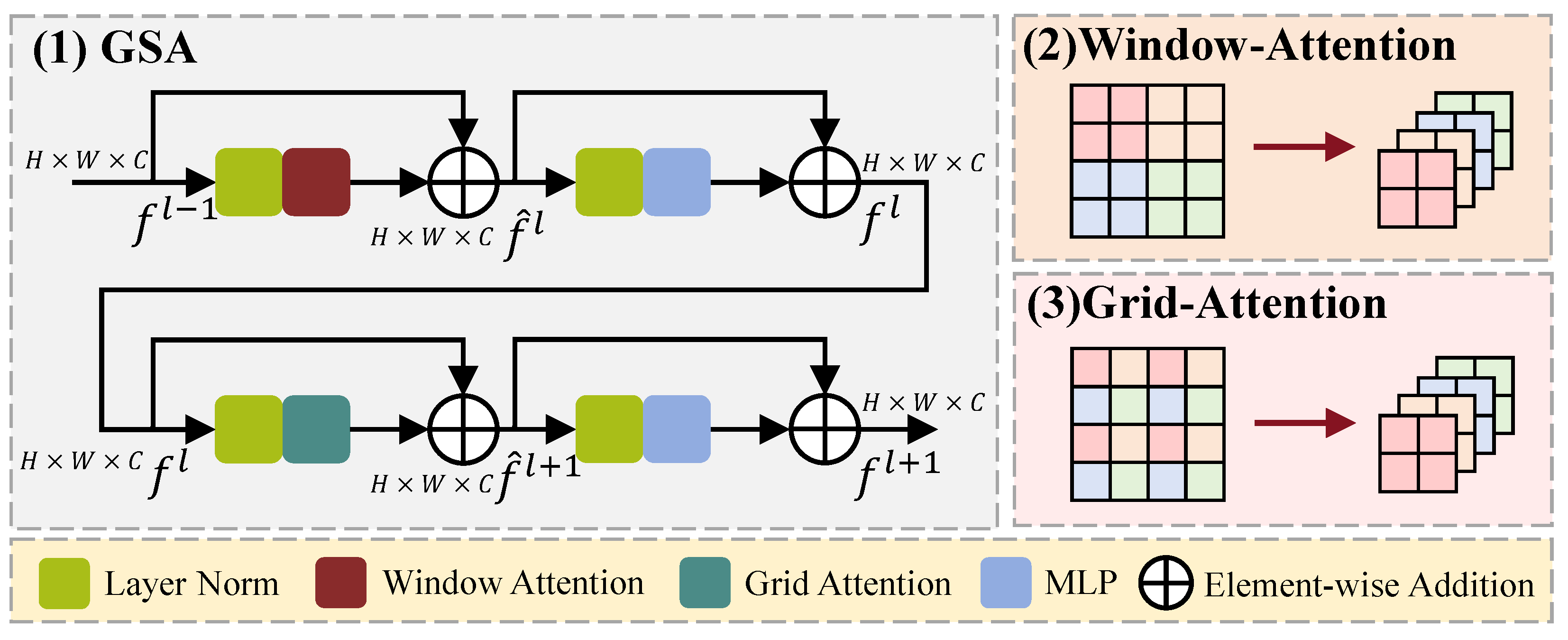
3.3.3. Global Spatial Attention Module (GSA)
3.4. Cross Deformable Attention (CDA)
4. Experiments
4.1. Datasets
4.1.1. EOD Dataset
4.1.2. VisDrone Dataset
4.1.3. UAVDT Dataset
4.2. Implementation Details
4.2.1. Evaluation Metrics
4.2.2. Training Settings
4.2.3. Model Variants
4.3. Ablation Experiments
4.3.1. Ablation of Downsample Module
4.3.2. Ablation of GSA Module
4.3.3. Effect of Multi-Vision Transformer Network
4.4. Benchmark Comparisons
4.4.1. Results on the EOD Dataset
4.4.2. Results on VisDrone2019 Dataset
4.4.3. Results on UAVDT Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brandli, C.; Berner, R.; Yang, M.; Liu, S.C.; Delbruck, T. A 240× 180 130 db 3 μs latency global shutter spatiotemporal vision sensor. IEEE J.-Solid-State Circuits 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Delbruck, T. Frame-free dynamic digital vision. In Proceedings of the International Symposium on Secure-Life Electronics, Advanced Electronics for Quality Life and Society, Tokyo, Japan, 6–7 March 2008; Volume 1, pp. 21–26. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8440–8449. [Google Scholar]
- Mboga, N.; Grippa, T.; Georganos, S.; Vanhuysse, S.; Smets, B.; Dewitte, O.; Wolff, E.; Lennert, M. Fully convolutional networks for land cover classification from historical panchromatic aerial photographs. ISPRS J. Photogramm. Remote Sens. 2020, 167, 385–395. [Google Scholar] [CrossRef]
- Abriha, D.; Szabó, S. Strategies in training deep learning models to extract building from multisource images with small training sample sizes. Int. J. Digit. Earth 2023, 16, 1707–1724. [Google Scholar] [CrossRef]
- Solórzano, J.V.; Mas, J.F.; Gallardo-Cruz, J.A.; Gao, Y.; de Oca, A.F.M. Deforestation detection using a spatio-temporal deep learning approach with synthetic aperture radar and multispectral images. ISPRS J. Photogramm. Remote Sens. 2023, 199, 87–101. [Google Scholar] [CrossRef]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10440–10450. [Google Scholar]
- Xu, H.; Tang, X.; Ai, B.; Yang, F.; Wen, Z.; Yang, X. Feature-selection high-resolution network with hypersphere embedding for semantic segmentation of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4411915. [Google Scholar] [CrossRef]
- Hao, X.; Yin, L.; Li, X.; Zhang, L.; Yang, R. A Multi-Objective Semantic Segmentation Algorithm Based on Improved U-Net Networks. Remote Sens. 2023, 15, 1838. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Li, R.; Shen, Y. YOLOSR-IST: A deep learning method for small target detection in infrared remote sensing images based on super-resolution and YOLO. Signal Process. 2023, 208, 108962. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhang, M.; Zhang, R.; Zhang, J.; Guo, J.; Li, Y.; Gao, X. Dim2Clear network for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5001714. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxvit: Multi-axis vision transformer. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 459–479. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Poznanski, J.; Yu, L.; Rai, P.; Ferriday, R.; et al. ultralytics/yolov5: v3. 0. Zenodo 2020. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Gehrig, M.; Scaramuzza, D. Recurrent vision transformers for object detection with event cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13884–13893. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Iacono, M.; Weber, S.; Glover, A.; Bartolozzi, C. Towards event-driven object detection with off-the-shelf deep learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Jiang, Z.; Xia, P.; Huang, K.; Stechele, W.; Chen, G.; Bing, Z.; Knoll, A. Mixed frame-/event-driven fast pedestrian detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), IEEE, Montreal, QC, Canada, 20–24 May 2019; pp. 8332–8338. [Google Scholar]
- Su, Q.; Chou, Y.; Hu, Y.; Li, J.; Mei, S.; Zhang, Z.; Li, G. Deep directly-trained spiking neural networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6555–6565. [Google Scholar]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 989–997. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. Detecting tiny objects in aerial images: A normalized Wasserstein distance and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2022, 190, 79–93. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density map guided object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 190–191. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14454–14463. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, H.; Zhou, J.; Gan, Y.; Vong, C.M.; Liu, Q. Novel up-scale feature aggregation for object detection in aerial images. Neurocomputing 2020, 411, 364–374. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8514–8523. [Google Scholar]
- Ma, Y.; Chai, L.; Jin, L. Scale decoupled pyramid for object detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4704314. [Google Scholar] [CrossRef]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A global-local self-adaptive network for drone-view object detection. IEEE Trans. Image Process. 2020, 30, 1556–1569. [Google Scholar] [CrossRef]
- Xu, J.; Li, Y.; Wang, S. Adazoom: Adaptive zoom network for multi-scale object detection in large scenes. arXiv 2021, arXiv:2106.10409. [Google Scholar]
- Ge, Z.; Qi, L.; Wang, Y.; Sun, Y. Zoom-and-reasoning: Joint foreground zoom and visual-semantic reasoning detection network for aerial images. IEEE Signal Process. Lett. 2022, 29, 2572–2576. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, X.; He, W.; Ren, J.; Zhang, Q.; Zhao, T.; Bai, R.; He, X.; Liu, J. Scale Optimization Using Evolutionary Reinforcement Learning for Object Detection on Drone Imagery. arXiv 2023, arXiv:2312.15219. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Size | Kernel | Stride | Channels | ||
|---|---|---|---|---|---|---|
| MVT-B | MVT-S | MVT-T | ||||
| S1 | 1/4 | 7 | 4 | 96 ✔ | 64 | 32 |
| S2 | 1/8 | 3 | 2 | 192 ✔ | 128 ✔ | 64 |
| S3 | 1/16 | 3 | 2 | 384 ✔ | 256 ✔ | 128 ✔ |
| S4 | 1/32 | 3 | 2 | 768 ✔ | 512 ✔ | 256 ✔ |
| Model | Structure | mAP | mAP | Entire | Encoder | Params | ||
|---|---|---|---|---|---|---|---|---|
| CSA | GSA | CDA | @0.5:0.95 | @0.5 | GFLOPs | GFLOPs | ||
| Baseline | - | - | - | 0.214 | 0.403 | 67.6 | 47.6 | 25.6 M |
| MVT-B | ✔ | - | - | 0.238 | 0.474 | 69.7 | 47.6 | 34.5 M |
| - | ✔ | - | 0.265 | 0.527 | 84.7 | 47.6 | 97.3 M | |
| - | - | ✔ | 0.212 | 0.401 | 28.4 | 8.4 | 25.7 M | |
| ✔ | ✔ | - | 0.288 | 0.569 | 86.8 | 47.6 | 106.3 M | |
| ✔ | ✔ | ✔ | 0.287 | 0.565 | 47.6 | 8.4 | 106.4 M | |
| Downsampling Type | mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 | Params | |||
|---|---|---|---|---|---|---|---|
| Patch Merging | 0.281 | 0.557 | 0.254 | 0.159 | 0.336 | 0.566 | 6.21 M |
| Conv. non-overlapping | 0.283 | 0.559 | 0.257 | 0.160 | 0.337 | 0.565 | 6.20 M |
| Conv. overlapping | 0.290 | 0.573 | 0.264 | 0.166 | 0.358 | 0.582 | 13.94 M |
| Attention Type | mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 | Params | |||
|---|---|---|---|---|---|---|---|
| Swin-Attn | 0.280 | 0.558 | 0.251 | 0.162 | 0.347 | 0.545 | 99.5 M |
| Grid-Attn | 0.287 | 0.565 | 0.263 | 0.166 | 0.353 | 0.580 | 66.9 M |
| Model | Backbone | mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 | Params | |||
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [34] | ResNet 50 | 0.183 | 0.392 | 0.122 | 0.089 | 0.202 | 0.371 | 42.0 M |
| DetectoRS [40] | ResNet 101 | 0.194 | 0.433 | 0.154 | 0.103 | 0.235 | 0.389 | 540.1 M |
| YOLOv5 [27] | CSPDarkNet 53 | 0.232 | 0.469 | 0.190 | 0.113 | 0.263 | 0.466 | 93.0 M |
| Cascade R-CNN [28] | Transformer | 0.234 | 0.445 | 0.208 | 0.122 | 0.276 | 0.485 | 335.0 M |
| YOLOv7 [41] | CSPDarkNet 53 | 0.237 | 0.480 | 0.197 | 0.118 | 0.286 | 0.479 | 135.8 M |
| DMNet [42] | CSPDarkNet 53 | 0.255 | 0.503 | 0.228 | 0.142 | 0.311 | 0.529 | 96.7 M |
| Sparse R-CNN [43] | Transformer | 0.259 | 0.510 | 0.215 | 0.133 | 0.312 | 0.521 | 352.0 M |
| Deformable DETR [3] | ResNet 50 | 0.262 | 0.521 | 0.238 | 0.145 | 0.317 | 0.536 | 41.0 M |
| CLusDet [44] | ResNeXt 101 | 0.266 | 0.543 | 0.244 | 0.127 | 0.332 | 0.547 | - |
| MVT-B (ours) | Transformer | 0.287 | 0.565 | 0.263 | 0.166 | 0.353 | 0.580 | 106.4 M |
| MVT-S (ours) | Transformer | 0.273 | 0.557 | 0.255 | 0.159 | 0.341 | 0.551 | 56.6 M |
| MVT-T (ours) | Transformer | 0.258 | 0.525 | 0.230 | 0.144 | 0.315 | 0.542 | 26.1 M |
| Model | Backbone | mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 | Params | |||
|---|---|---|---|---|---|---|---|---|
| Cascade R-CNN [28] | ResNet 50 | 0.232 | 0.399 | 0.234 | 0.165 | 0.368 | 0.394 | 273.2 M |
| YOLOv5 [27] | CSPDarknet 53 | 0.241 | 0.441 | 0.247 | 0.153 | 0.356 | 0.384 | 93.0 M |
| RetinaNet [45] | ResNet 101 | 0.243 | 0.443 | 0.187 | 0.187 | 0.352 | 0.378 | 251.7 M |
| Libra RCNN [29] | ResNet 50 | 0.243 | 0.412 | 0.249 | 0.168 | 0.340 | 0.368 | 185.4 M |
| Cascade R-CNN [28] | Transformer | 0.247 | 0.424 | 0.265 | 0.177 | 0.372 | 0.403 | 335.0 M |
| HawkNet [46] | ResNet 50 | 0.256 | 0.443 | 0.258 | 0.199 | 0.360 | 0.391 | 130.9 M |
| VFNet [47] | ResNet 50 | 0.259 | 0.421 | 0.270 | 0.168 | 0.373 | 0.414 | 296.2 M |
| DetectoRS [40] | ResNet 101 | 0.268 | 0.432 | 0.280 | 0.175 | 0.382 | 0.417 | 540.1 M |
| Sparse R-CNN [43] | Transformer | 0.276 | 0.463 | 0.282 | 0.188 | 0.392 | 0.433 | 352.0 M |
| DMNet [42] | CSPDarknet 53 | 0.282 | 0.476 | 0.289 | 0.199 | 0.396 | 0.558 | 96.7 M |
| ClusDet [44] | ResNeXt 101 | 0.284 | 0.532 | 0.264 | 0.191 | 0.408 | 0.544 | - |
| SDMNet [48] | CSPDarknet 53 | 0.302 | 0.525 | 0.306 | 0.226 | 0.396 | 0.398 | 96.6 M |
| MVT-B (ours) | Transformer | 0.317 | 0.522 | 0.342 | 0.243 | 0.421 | 0.552 | 106.4 M |
| MVT-S (ours) | Transformer | 0.296 | 0.497 | 0.321 | 0.225 | 0.405 | 0.533 | 56.6 M |
| MVT-T (ours) | Transformer | 0.277 | 0.465 | 0.303 | 0.202 | 0.388 | 0.502 | 26.1 M |
| Model | Backbone | mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 | Params | |||
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [34] | ResNet 50 | 0.110 | 0.234 | 0.084 | 0.081 | 0.202 | 0.265 | 42.0 M |
| Cascade R-CNN [28] | ResNet 50 | 0.121 | 0.235 | 0.108 | 0.084 | 0.215 | 0.147 | 273.2 M |
| ClusDet [44] | ResNet 101 | 0.137 | 0.265 | 0.125 | 0.091 | 0.251 | 0.312 | - |
| Cascade R-CNN [28] | Transformer | 0.138 | 0.244 | 0.117 | 0.090 | 0.232 | 0.268 | 335.0 M |
| DMNet [42] | CSPDarkNet 53 | 0.147 | 0.246 | 0.163 | 0.093 | 0.262 | 0.352 | 96.7 M |
| Sparse R-CNN [43] | Transformer | 0.153 | 0.266 | 0.171 | 0.118 | 0.253 | 0.288 | 352.0 M |
| GLSAN [49] | CSPDarkNet 53 | 0.170 | 0.281 | 0.188 | - | - | - | - |
| AdaZoom [50] | CSPDarkNet 53 | 0.201 | 0.345 | 0.215 | 0.142 | 0.292 | 0.284 | - |
| ReasDet [51] | CSPDarkNet 53 | 0.218 | 0.349 | 0.248 | 0.153 | 0.327 | 0.308 | - |
| EVORL [52] | ResNet 50 | 0.280 | 0.438 | 0.315 | 0.218 | 0.404 | 0.359 | - |
| MVT-B (ours) | Transformer | 0.282 | 0.421 | 0.322 | 0.237 | 0.397 | 0.368 | 106.4 M |
| MVT-S (ours) | Transformer | 0.267 | 0.405 | 0.297 | 0.206 | 0.373 | 0.350 | 56.6M |
| MVT-T (ours) | Transformer | 0.238 | 0.367 | 0.271 | 0.162 | 0.356 | 0.322 | 26.1M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, S.; Lv, H.; Zhao, Y.; Liu, H.; Sun, M. MVT: Multi-Vision Transformer for Event-Based Small Target Detection. Remote Sens. 2024, 16, 1641. https://doi.org/10.3390/rs16091641
Jing S, Lv H, Zhao Y, Liu H, Sun M. MVT: Multi-Vision Transformer for Event-Based Small Target Detection. Remote Sensing. 2024; 16(9):1641. https://doi.org/10.3390/rs16091641
Chicago/Turabian StyleJing, Shilong, Hengyi Lv, Yuchen Zhao, Hailong Liu, and Ming Sun. 2024. "MVT: Multi-Vision Transformer for Event-Based Small Target Detection" Remote Sensing 16, no. 9: 1641. https://doi.org/10.3390/rs16091641
APA StyleJing, S., Lv, H., Zhao, Y., Liu, H., & Sun, M. (2024). MVT: Multi-Vision Transformer for Event-Based Small Target Detection. Remote Sensing, 16(9), 1641. https://doi.org/10.3390/rs16091641