1. Introduction
With the advancement of remote sensing technologies, images captured by various crafts and satellites have an enormous quantity and high spatial resolution. These images contain significant information crucial for a wide range of applications, such as land planning, forest protection, traffic monitoring, disaster detection, and personnel rescue. Object detection plays a fundamental yet important role in remote sensing image processing. It can extract valuable information from images by localizing and classifying regions of interest. However, traditional object detection algorithms such as Histogram of Oriented Gradients (HOG) [
1] and Scale-Invariant Feature Transform (SIFT) [
2] rely on handcrafted features tailored to specific scenes, resulting in inferior efficiency, accuracy, and generalization.
In recent years, CNNs have rapidly revolutionized various fields in computer vision (CV), such as image classification, object detection, instance segmentation, and pose estimation. Object detection, as one of the primary tasks, is an indispensable component in industry detection, security surveillance, and autonomous driving. Since the success of AlexNet [
3], scholars and researchers have increasingly focused on the CNN-based detectors. These detectors have gradually surpassed traditional methods and taken a dominant position in object detection.
CNN-based detectors can be broadly categorized into two-stage and one-stage detectors. Two-stage algorithms treat the detection process as region proposal generation and proposal-wise prediction. The R-CNN series are the representative detectors in two-stage algorithms, including R-CNN [
4], Fast R-CNN [
5], Faster R-CNN [
6], Mask R-CNN [
7], and Cascade R-CNN [
8], which have salient performance and wide applications in object detection. On the other hand, one-stage detectors directly produce dense predictions through CNNs, making them more efficient and suitable for various real-time applications. SSD [
9], the YOLO series, and RetinaNet [
10] are the well-known detectors in one-stage algorithms. The YOLO series is a big family of detectors including YOLOv1-v8 [
11,
12,
13,
14,
15,
16,
17,
18] and other variants, with the goal of achieving better and faster performance. RetinaNet employs ResNet [
19] as the backbone and designs focal loss to alleviate the imbalance of hard and easy samples. In addition, to eliminate the limitations of anchor boxes, several anchor-free detectors have been proposed, such as FCOS [
20], CenterNet [
21], and RepPoints [
22]. FCOS leverages the center of grids and down-sample strides to replace anchor boxes and incorporates the center-ness prediction to suppress low-quality boxes. CenterNet detects each object as top-left, bottom-right, and central keypoints and designs cascade corner pooling and center pooling to enrich features. RepPoints utilizes a set of keypoints to represent objects and automatically learns important information.
The models mentioned above are primarily designed for nature images and exhibit excellent performance on datasets like MS COCO [
23]. However, remote sensing images, owing to the top-down view and long capturing distance, possess distinctive characteristics compared with nature images, including complicated backgrounds, limited features, distinct density, and varied scales, as illustrated in
Figure 1. The contextual and comprehensive information in an image is beneficial for recognizing hard targets, which is extremely valuable in remote sensing scenarios. Nevertheless, with the limitation of local computation in the convolution operation, the detectors based on CNNs have local receptive fields and lack interaction among the data of distant positions in an image. To address this problem, researchers in the field of remote sensing have made substantial efforts and innovations. In [
24], CBAM is employed to connect the backbone of YOLOv3 with an auxiliary network. RSADet [
25], a two-stage CNN framework, introduces a scale attention module to fuse spatial and channel information. SRAF-Net [
26] combines deformable convolution and context attention by designing a context-based deformable module. GRS-Det [
27] utilizes Gaussian-Mask to enhance the perception of ships with contextual information. While these models manage to address the problem of lacking contextual information to some extent, there remains a scarcity of long-distance interactions in these CNN-based detectors. Moreover, unsupervised remote sensing image analysis methods such as Spatial-Spectral Masked Auto-encoder [
28] and Nearest Neighbor-Based Contrastive Learning [
29] show promising prospects in object detection.
Neck Attention Block (NAB) [
30] is an effective block and achieves salient performance in small object detection. However, due to channel attention used in NAB, the improved model lacks sufficient global information for extracting and fusing important features. In this paper, we introduce the Convolution with Transformer Attention Module (CTAM) to enhance contextual and comprehensive information for CNN-based detectors, aiming at improving localization capacity and detection accuracy in remote sensing scenarios. CTAM is a novel plug-and-play attention module composed of two key components: a convolutional bottleneck block and a simplified Transformer layer. The convolutional bottleneck block is a bottleneck structure utilized to extract local features and retain position biases, and the simplified Transformer layer is designed to capture long-range dependency and provide global contextual information.
To demonstrate the effectiveness and efficiency of CTAM, we selected YOLOv8n as the baseline, which achieves better performance while maintaining fast detection speed. We improved YOLOv8n with CTAM and conducted extensive experiments on the DIOR dataset [
31]. YOLOv8n-CTAM surpasses the baseline by 2.8 mAP@50-95, with only a slight increase in detection time (0.2 ms). Notably, YOLOv8n-CTAM exhibits higher superiority with stricter IoU thresholds, such as mAP@70 and mAP@90, indicating CTAM makes the model focus on the central regions of targets and enhances localization capacity by integrating local features with global information. Compared with state-of-the-art detectors, it achieves cutting-edge performance while maintaining extremely fast speed. The results obtained on the TGRS-HRRSD dataset [
32] further demonstrate the excellent generalization ability of CTAM.
The main contributions of this paper are as follows:
- (1)
We construct CTAM, a novel plug-in-play attention module, which effectively addresses the limitations of both CNNs and Transformer. CTAM facilitates the integration of local features and global contextual information and significantly enhances YOLOv8n’s localization capacity.
- (2)
In contrast to the original Transformer applied in CV, we design a simplified Transformer structure by eliminating universal yet unnecessary operations for remote sensing scenarios, resulting in superior performance.
- (3)
We conducted extensive experiments on the DIOR and TGRS-HRRSD datasets, explicitly demonstrating the positive impact of CTAM. It improves localization capacity and exhibits noteworthy effectiveness, efficiency, and generalization ability.
The remainder of this paper is organized as follows: In
Section 2, we provide an overview of related works concerning Transformer and the YOLO series.
Section 3 offers a detailed description of CTAM and the improved model.
Section 4 presents the specific datasets used in our study and the experiments and analysis of CTAM. Finally, the conclusion is drawn in
Section 5.
3. Materials and Methods
3.1. CTAM
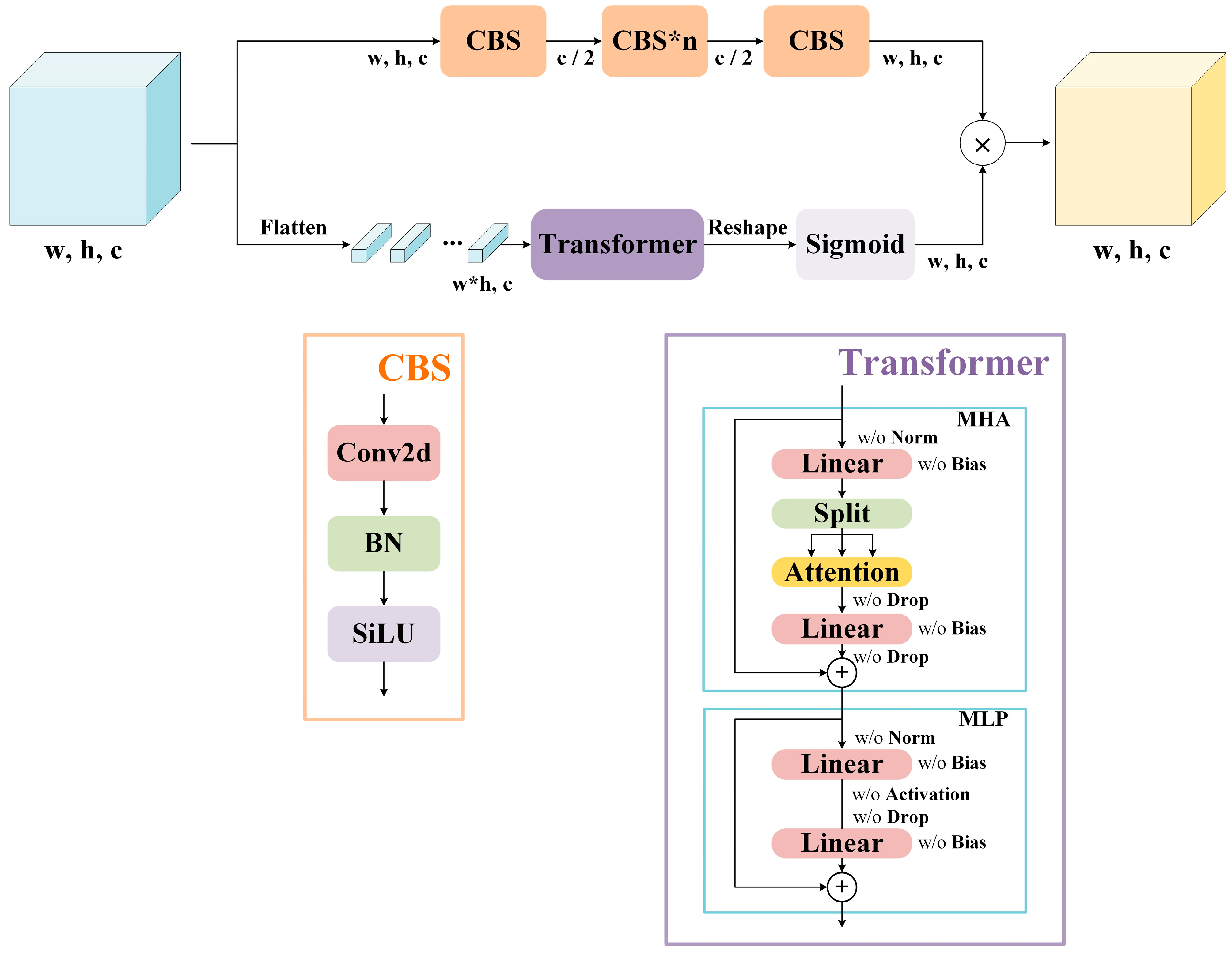
With the limitations of the top-down view, long capturing distance, and complex interference, remote sensing images exhibit some characteristics that differ from nature images, including complicated backgrounds, limited features, distinct density, and varied scales. Global contextual and comprehensive information can help detectors recognize targets, which is exceptionally valuable for object detection in remote sensing scenarios. Nevertheless, typical CNN-based detectors, restricted by the nature of convolution operation, severely lack global interaction. To address this pivotal problem, we construct a novel plug-and-play module named CTAM, aiming at integrating global contextual information with local features. It is composed of two primary components: a simplified Transformer layer, responsible for capturing long-range dependency, and a convolutional bottleneck block, responsible for extracting local features and providing inductive biases for the other component.
As depicted in
Figure 2, the simplified Transformer layer contains two reshape operations and an easier Transformer variant. Although many models in CV, such as ViT, apply a standard Transformer to various tasks, we assume that it could not be the optimal form for object detection in remote sensing. The experiments described in
Section 4 indicate that, at least for CTAM, the original Transformer is not a suitable form. For this paper, the simplified Transformer removes LayerNorm [
54], Dropout, and GeLU [
55] and utilizes single-head attention to compute self-attention. It can be broadly divided into two parts: multi-head attention (MHA) and multi-layer perception (MLP). To process 2D feature maps, we flatten the map
into
to serve as the input for the simplified Transformer, where
represents the resolution of the feature map. The matrices of Query, Key, and Value are computed as
‘Linear’ refers to a fully connected layer, and ‘Split’ is an operation that segments a matrix into chunks along the channel dimension.
maintain the same sizes as
. Then, the computation of self-attention is as follows:
The final output of MHA with a residual connection, denoted as
, can be expressed as
MLP is composed of two fully connected layers without GeLU in the first layer. The entire process can be defined as
where
represents the output of MLP.
In summary, we express the output of the simplified Transformer layer
as
Regarding the convolutional bottleneck block, it contains a stack of ‘CBSs’ (Conv-BN-SiLU), composed of one convolutional layer, Batch Normalization [
56], and SiLU [
57], as shown in
Figure 2. The first and final ‘CBSs’ are used for channel compression and expansion. Those in between are employed for feature extraction and fusion. To balance the performance and computational cost of CTAM, we introduce the hyperparameter n to control the quantity of the middle ‘CBS’. The result of the convolutional bottleneck block
can be computed as
Inspired by NAB using traditional attention mechanisms to regulate the feature map after convolutional layers instead of the original map, we employ element-wise multiplication to fuse the features generated by the convolutional bottleneck block and the simplified Transformer layer. In this manner, we can acquire the features of each grid, guided by both global contextual and local information. CTAM is a complementary integration that introduces local concentration for Transformer and long-range dependency for the CNN. With the improvement of CTAM, YOLOv8n exhibits stronger localization capacity and better performance, as detailed in
Section 4. Ultimately, the whole CTAM can be formally expressed as
where
and ‘
’ refer to the output of CTAM and element-wise multiplication, respectively.
3.2. YOLOv8n-CTAM
YOLOv8, as one of the most cutting-edge models in the YOLO series, further boosts performance and flexibility across various tasks and applications. Like other common detectors, YOLOv8 can be divided into three components, backbone, path aggregation structure [
58], and detection head.
Figure 3 explicitly depicts the architecture of YOLOv8n-CTAM.
A preprocessed remote sensing image with the resolution of (800, 800, 3) serves as the input image and is fed into the backbone. Note that YOLOv8 proposes ‘C2F’ as the basic unit instead of ‘C3’ in YOLOv5, featuring more gradient paths. Through a sequence of ‘Stage’, we can obtain three feature maps with 8, 16, and 32 downsampling rates, respectively. Subsequently, these maps are sent into the path aggregation structure, composed of top-down and bottom-up paths. This structure aims to enhance localization information for the coarse maps and contextual information for the fine-grained maps. Finally, the detection head utilizes the augmented feature maps to predict the category and bounding box for each grid. To mitigate the conflict between classification and regression, YOLOv8 designs a decoupled head and adopts the general distribution to model bounding box representation.
YOLOv8 develops some variants with different widths and depths for various applications. YOLOv8n acquires the fastest detection speed and the smallest memory usage by decreasing its width and depth. Therefore, we select YOLOv8n as the baseline to satisfy the requirement of real-time detection. CTAM is inserted between the path aggregation structure and the detection head to integrate global contextual information with local features for object detection in remote sensing scenarios. The visualization results in
Section 4 adequately demonstrate the effectiveness of CTAM.
4. Results
4.1. Experimental Environment and Settings
All experiments were carried out on a Linux operating system (Ubuntu 20.04) with an Intel(R) Core (TM) i9-10940X CPU and two Nvidia RTX-3090 GPUs for distributed training. The deep learning framework was Pytorch 1.13 based on Python 3.9.16, CUDA 11.7, and Torchvision 0.14.1.
Hyperparameter settings play a significant role in the training process and greatly impact the final detection accuracy. To ensure a fair comparison, each model in this paper adopted the same hyperparameters outlined in
Table 1. ‘Image size’ is the resolution of input images, restricting the sizes of targets and computational cost. ‘Epoch’ represents the number of iterations that a detector is trained on a dataset. Appropriate epochs make a model achieve excellent performance while saving computational resources. ‘Learning rate’, ‘Momentum’, and ‘Weight decay’ regulate the convergence rate and training stability. ‘Mosaic’ is a valuable measure for alleviating data overfitting. In addition, ‘n (#CBS)’, utilized to control local feature extraction, is introduced into the convolutional bottleneck block of CTAM. According to the experiments in
Section 4.5, YOLOv8n is improved with CTAM (n = 2) to integrate long-range dependency with local features.
4.2. Evaluation Metrics
To evaluate the effectiveness and efficiency of CTAM, we adopt common metrics in object detection, including precision, recall, average precision (AP), mean average precision (mAP), model parameters, FLOPs, and detection time. Precision denotes the proportion of true positive samples among the total positive samples, and recall measures the proportion of true positive samples among the total true samples. The AP value for each category is obtained by calculating the area under the precision–recall curve, and mAP denotes the mean of AP values across all categories. The AP and mAP can be expressed as
where ‘P(R)’ denotes the precision–recall curve and ‘nc’ represents the number of categories.
To evaluate the performance of the detector more comprehensively and accurately, we utilized different IoU thresholds to acquire corresponding mAP values. A higher threshold signifies a more rigorous criterion for the overlaps between bounding boxes and ground truth boxes. Specifically, mAP@50 represents an mAP value computed with an IoU threshold of 0.5. mAP@50-95 is the average of the mAP values under the IoU thresholds between 0.5 and 0.95, with a step of 0.05. To explicitly verify the localization capacity of CTAM, mAP@50, mAP@70, mAP@90, and mAP@50-95 were adopted as the evaluation criteria in the next experiments.
4.3. Datasets
DIOR is a large-scale, diverse, and publicly available remote sensing dataset containing 23,463 images and 192,472 instances. It is divided into three subsets: a training set (5862 images), a validation set (5863 images), and a test set (11,738 images). It has 20 categories: airplane, airport, baseball field, basketball court, bridge, chimney, dam, expressway service area, expressway toll station, harbor, golf course, ground track field, overpass, ship, stadium, storage tank, tennis court, train station, vehicle, and windmill. Each image in DIOR is standardized to the resolution of (800, 800, 3). The sizes of bounding boxes range from 2 to 764 pixels, posing a considerable challenge for object detection on the DIOR dataset. Each object in DIOR is annotated with a horizontal bounding box. In comparison to VEDAI, HRSC2016, and COWC, DIOR has more images and instances, which is beneficial for the robustness and generalization of detectors. For this paper, we conducted extensive experiments on the DIOR dataset to demonstrate the efficiency and effectiveness of CTAM.
Aiming at validating the generalization ability of CTAM, experiments were conducted on the TGRS-HRRSD dataset, another large-scale remote sensing dataset. This dataset possesses 21,761 images categorized into 13 classes, and the mean scale per class ranges from 42 to 277 pixels. Furthermore, it elaborately balances the number of each category. The comprehensive results are detailed in the next section.
4.4. Experiments on the DIOR Dataset
To testify to the efficiency and effectiveness of CTAM, we initially trained YOLOv8n on the training and validation sets of the DIOR dataset with 100 epochs and evaluated its performance on the test set. For a fair comparison, we improved YOLOv8n with CTAM (n = 2) using the same settings and strategies. The experimental results for all categories are documented in
Table 2. YOLOv8n-CTAM achieves 84.6 precision, 68.5 recall, and 54.2 mAP@50-95. It outperforms the baseline by a large margin, indicating the effectiveness of CTAM. ‘Time’ represents the total time, including preprocessing, inference, and postprocessing time on an NVIDIA RTX 3090 with a batch size of 16. Due to the calculation of global contextual information occurring in the feature maps with 8
, 16
, and 32
strides, YOLOv8n-CTAM has a slight growth in ‘FLOPs’, ‘Param’, and ‘Time’. It remains an extremely lightweight detector meeting the real-time requirement. Furthermore, with an increasing IoU threshold, YOLOv8n-CTAM achieves progressively better performance, surpassing the baseline by 1.8 mAP@50, 2.7 mAP@70, and 4.4 mAP@90. These results provide substantial evidence that CTAM can enhance localization capacity and detection performance by introducing global contextual information.
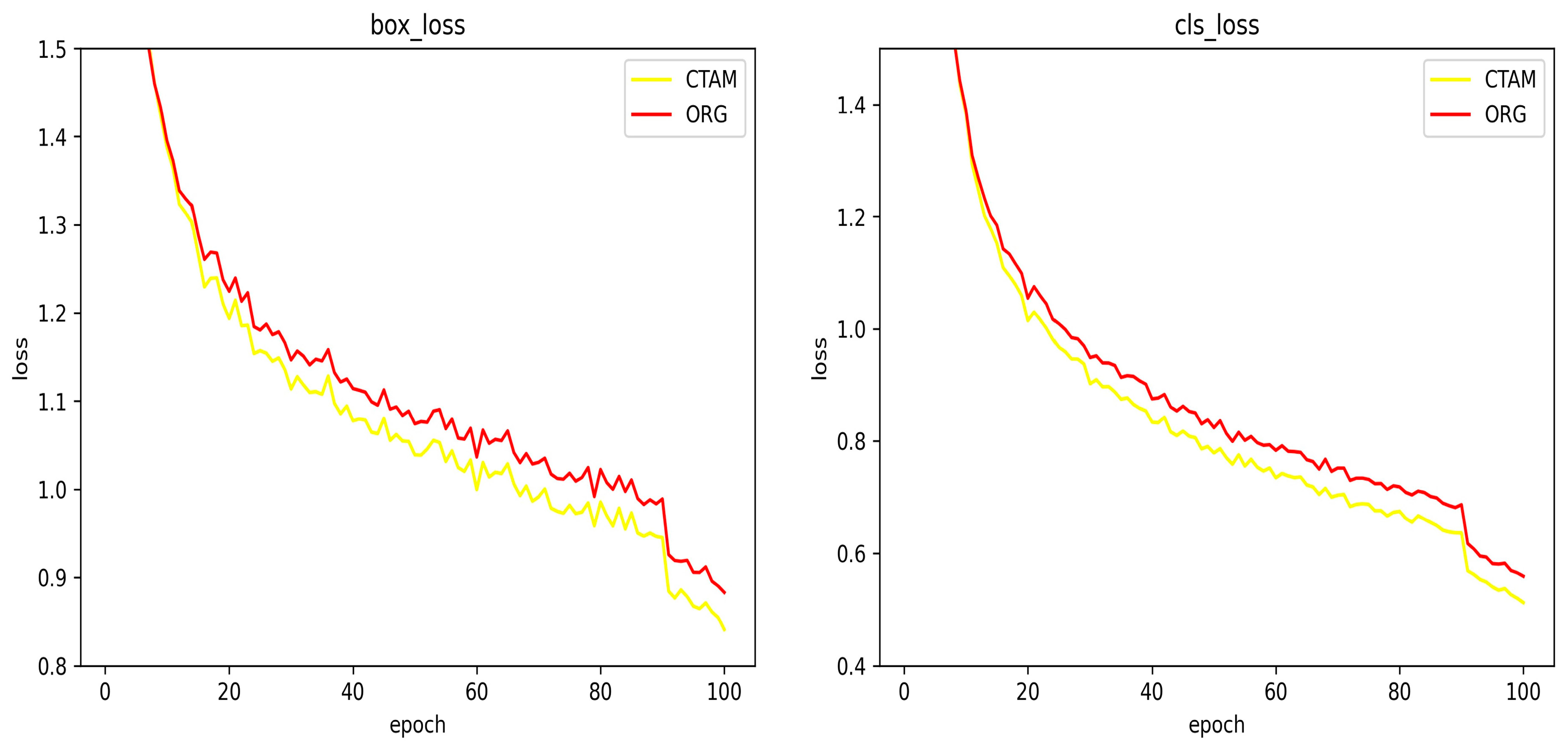
Table 3 presents the performance of the baseline and YOLOv8n-CTAM across each category. In almost all classes, YOLOv8-CTAM displays higher accuracy, recall, and mAP@50-95 compared with the baseline, especially in golf field detection, where it exceeds the baseline by 5.0 precision, 4.4 recall, and 11.4 mAP@50-95. Apparently, we can confirm that CTAM is beneficial for multi-scale target detection in remote sensing scenarios. Furthermore, we analyze the training processes of both detectors, as shown in
Figure 4. YOLOv8n-CTAM exhibits a faster convergence rate in both regression and classification loss. Notably, the loss curves of both models show a rapid decline in the last 10 epochs, indicating that closing Mosaic in the last 10 epochs can lead to an enhancement in the final performance.
In comparison with the state-of-the-art detectors, YOLOv8n-CTAM achieves the most cutting-edge performance, as listed in
Table 4. Specifically, the improved detector outperforms the well-known detectors in natural scenes by a large margin. In the field of remote sensing, it also surpasses SCRDet++ with ResNet-101 and CANet by 1.4 and 2.2 mAP@50, respectively. Above all, YOLOv8n-CTAM is a lightweight detector with an impressive 435 frames per second (FPS) on a single NVIDIA RTX 3090. YOLOv8n-CTAM demonstrates considerable potential for various applications and deployments in diverse remote sensing scenarios.
Some detection results obtained by YOLOv8n-CTAM are displayed in
Figure 5. YOLOv8n-CTAM successfully overcomes the challenges posed by remote sensing images, including complicated backgrounds, limited features, distinct density, and varied scales. It achieves salient performance across various scenes and multi-scale categories. Although it may miss some targets or yield incorrect results in extremely hard situations, the acceptable detection accuracy with the remarkably low computational burden renders YOLOv8n-CTAM flexible and robust for deployment on real-time hardware platforms. In conclusion, the integration of global and local information within CTAM can compensate for inherent drawbacks in CNN and Transformer, leading to excellent localization capacity and detection accuracy in remote sensing images.
4.5. Ablation Study
4.5.1. The Simplified Transformer in CTAM
Transformer is a powerful structure that can acquire long-range dependency by calculating scaled dot-product attention among all positions. To address the critical limitation of CNNs lacking global contextual information, we incorporate Transformer into CTAM to integrate local features with contextual and comprehensive information. Although the standard Transformer derived from NLP has been widely applied in CV, we assume that sequences and images have essential differences, and the standard Transformer can be optimized to achieve better performance for object detection in remote sensing scenarios. In this paper, we delve into a detailed analysis of the Transformer structure and construct a simplified Transformer layer in CTAM to accommodate the task of remote sensing object detection.
Extensive experiments for the optimal Transformer encoder structure were conducted on the DIOR dataset, as documented in
Table 5. At first, ‘Initial’ has the worst mAP@50-95 among all Transformer variants. The absence of LayerNorm in ‘A’ results in an improvement of 0.5 mAP@50-95 compared with ‘Initial’, indicating that LayerNorm, widely applied in NLP, may hinder detection performance in remote sensing scenarios. Subsequently, the variants with different numbers of heads, specifically two and four, exhibit identical performance to the variant with ‘#Heads’ = 1. Hence, we removed this hyperparameter and viewed it as a constant. Similarly, ‘Dropout’ has a negative impact on the detection accuracy, so it was set to 0. Finally, we eliminated the activation function ‘GeLU’ from MLP and constructed the simplified Transformer layer for CTAM. Moreover, the investigation of the influence of biases in MHA and MLP illustrates that the simplified Transformer encoder with both biases achieves the most salient performance on the DIOR dataset.
4.5.2. The Number of ‘CBSs’
In the convolutional bottleneck block of CTAM, the number of ‘CBSs’ serves as a hyperparameter introduced to regulate the extraction of local features and restrict computational complexity, as depicted in
Figure 2. We varied the value of ‘n’ within the range [0, 1, 2, 3], and the corresponding experimental results are listed in
Table 6. YOLOv8n with CTAM (n = 2) achieves the best precision, recall, mAP@50, and mAP@50-95, illustrating that it adequately extracts and fuses local features while increasing negligible computational burden. Consequently, CTAM (n = 2) is considered as the default module for YOLOv8n due to its optimal performance.
4.5.3. Comparison with Traditional Attention Modules
Traditional attention modules in CV such as SE [
61], CBAM [
62], and ECA [
63] have widespread applications in CV. To enhance features and suppress noises, these modules utilize the information extracted from the feature map to recalibrate themselves. However, like NAB, we claim this way is inflexible and harmful for feature extraction. In contrast, CTAM utilizes the global information generated by the simplified Transformer layer to integrate with the local features of the convolutional bottleneck block. For a fair comparison, we replaced CTAM with SE, CBAM, and ECA in the same positions, and the corresponding experimental results are displayed in
Table 7. Compared with the original model, SE, CBAM, and ECA are nearly useless in performance, but CTAM brings an obvious improvement.
Moreover, YOLOv8n-CTAM (Local) and YOLOv8n-CTAM (Global) represent YOLOv8n-CTAM only with the convolutional bottleneck block and the simplified Transformer layer, respectively. Their results in
Table 7 demonstrate that the integration of local features and global attention is indispensable and significant.
4.6. Visualization
To further comprehend the influence of employing CTAM between the path aggregation structure and the detection head in YOLOv8n, we visualize the feature maps before and after the employment of CTAM, as depicted in
Figure 6. The raw image contains two small-size vehicles and two medium-size airplanes. The detection results generated by YOLOv8n-CTAM exhibit highly accurate bounding boxes and reliable probabilities, demonstrating the effectiveness of CTAM. YOLOv8n is structured with three branches for multi-scale prediction, where the feature maps with 8
, 16
, and 32
downsampling rates are responsible for small-size, medium-size, and large-size targets, respectively. In the small-scale branch, the feature map behind CTAM exhibits higher and more centralized attention towards the two vehicles, compared with the map before CTAM. Meanwhile, in the medium-scale branch, the former feature map focuses on multiple parts surrounding the two airplanes, while the attention of the latter map converges on the centers of the airplanes. Since the responses mainly concentrate on the first two feature maps for these targets, the visualization and discussion of the large-scale branch are omitted.
This visualization provides valuable insights into how CTAM influences the feature extraction and fusion in YOLOv8n. The detailed comparison illustrates that CTAM enables YOLOv8n to focus on the central regions of targets and generate extremely accurate bounding boxes by integrating local features with global contextual information. This visualization corresponds with the conclusion that CTAM can significantly improve the localization capacity according to the mAP values with different IoU thresholds.
4.7. Experiments on the TGRS-HRRSD Dataset
To validate the generalization ability of CTAM, we also conducted experiments on the TGRS-HRRSD dataset, a multi-scale remote sensing dataset containing 55,740 instances and 13 categories. For a fair comparison, we adopted the consistent hyperparameters and strategies used in the DIOR dataset and trained detectors on the train–validate set. As listed in
Table 8, YOLOv8n-CTAM outperforms the baseline by 0.9 mAP@50 and 2.1 mAP@50-95. Compared to typical detectors, YOLOv8n-CTAM achieves a superior performance on the TGRS-HRRSD dataset while maintaining a rapid detection time. Compared with lightweight models, YOLOv8n-CTAM exceeds YOLOv4-Tiny and YOLOv4-Tiny-NAB by a large margin. Hence, these experiments indicate that CTAM is not limited to a specific dataset and exhibits excellent generation ability in various remote sensing scenarios.
5. Conclusions
Remote sensing images have complicated backgrounds, limited features, distinct densities, and varied scales, rendering global contextual information extremely significant and valuable for object detection. However, CNN-based detectors with the limitation of local receptive fields have difficulty in capturing long-range dependency, resulting in inferior performance. To eliminate this inherent deficiency, we make the following contributions in this paper:
- (1)
We construct a novel plug-in-play attention module called CTAM, composed of a convolutional bottleneck block and a simplified Transformer layer. It can integrate local features with global contextual information through the interaction between the two components.
- (2)
We design a simplified Transformer in CTAM that is unlike the standard Transformer encoder widely applied in CV, and we demonstrate its validity in various remote sensing scenarios.
- (3)
For real-time object detection in remote sensing, we adopt YOLOv8n as the baseline and introduce CTAM to build YOLOv8n-CTAM. Extensive experiments demonstrate that YOLOv8n-CTAM achieves cutting-edge performance and generalization ability while maintaining an extremely rapid inference speed.
- (4)
The visualization of CTAM explicitly explains why CTAM can enhance localization capacity and improve detection accuracy by incorporating global information into local features.
Despite the remarkable performance and efficiency displayed by CTAM, it also brings unacceptable computational complexity and memory usage due to the defect of self-attention. In the future, we will optimize the computation of self-attention in CTAM and further explore the feasibility and flexibility of designing a backbone based on CTAM for object detection in remote sensing.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}