
Hyperspectral Image Classification on Large-Scale Agricultural Crops: The Heilongjiang Benchmark Dataset, Validation Procedure, and Baseline Results


 , ,
, , 
Abstract
1. Introduction
- (1)
- A large-scale crop classification dataset has been introduced, named the HLJ dataset. Owing to the diversity of land cover types in agricultural regions, this dataset poses several practical challenges, such as uneven distribution of crops, uncertain crop growth stages, mixed planting, etc., and presents an elevated level of complexity in classification.
- (2)
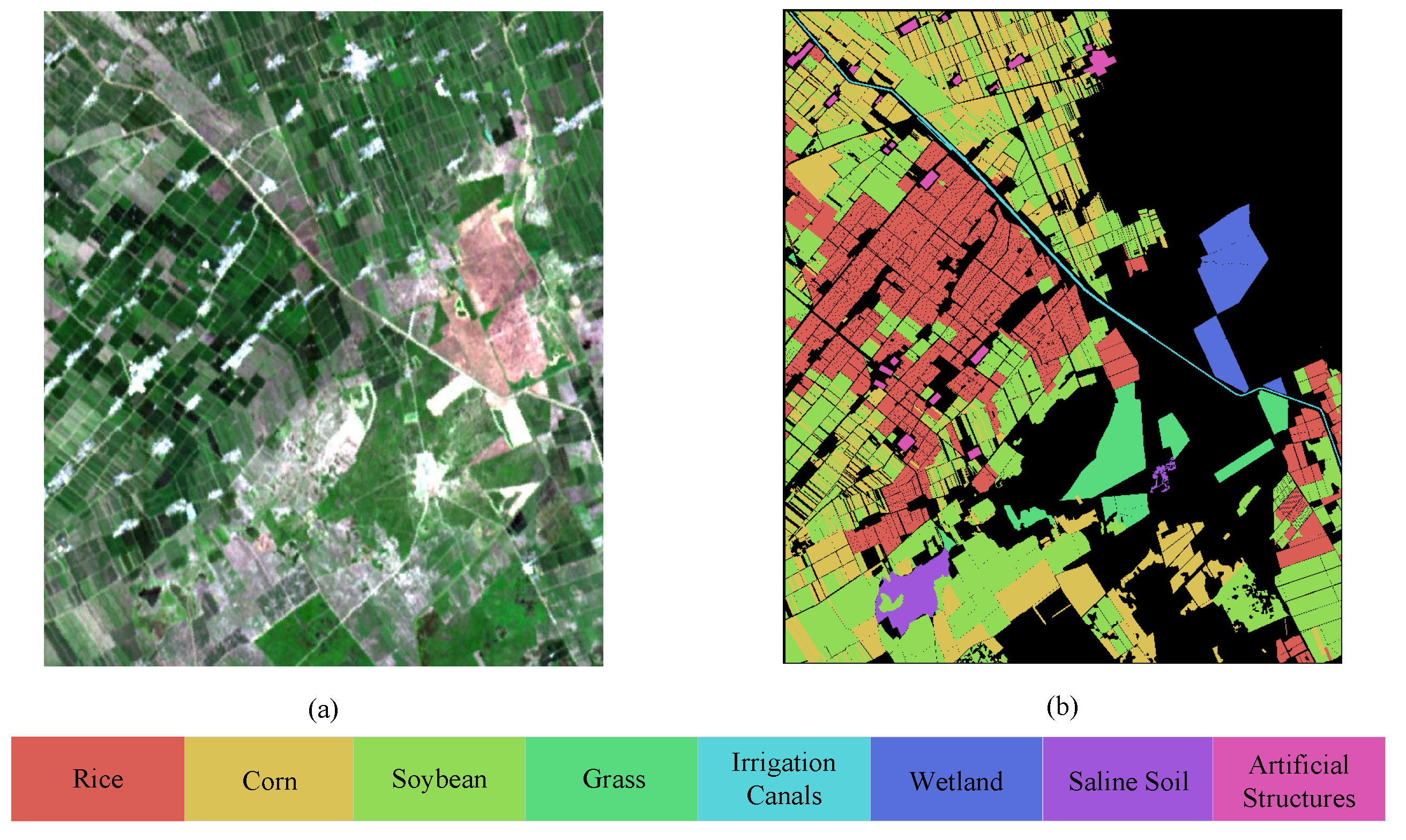
- This is a large-scale dataset that covers a wide range of rural areas, including a sufficiently representative selection of land cover types in the region. These diverse land-cover types contribute to an exceptionally rich set of spectral information. Furthermore, the proposed dataset contains a sufficient and accurate number of labeled samples, with 319685 and 318942 in the two images, respectively. The reliability of these samples stems from on-site surveys and comprehensive analysis of multitemporal images.
- (3)
- The comprehensive validation of the HLJ dataset was conducted by employing several representative methods for basic classification experiments (e.g., SpectralFormer and SSFTT) and comparing the classification results among different datasets using the same methods. This process affirmed the research value inherent in the issues encompassed by the dataset and its suitability as a benchmark dataset for hyperspectral image classification.
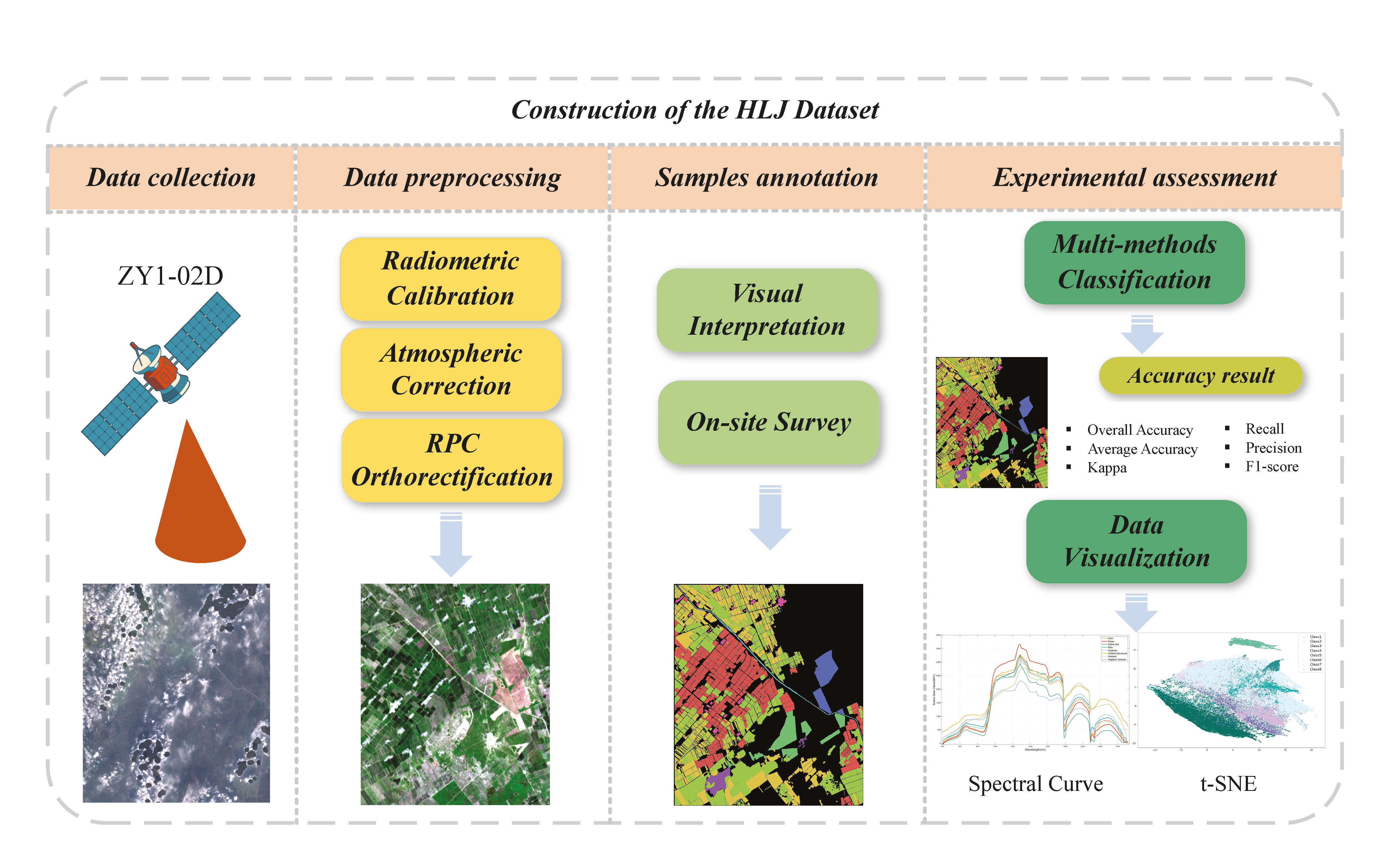
2. Construction of the HLJ Dataset
2.1. The Acquisition of HLJ Dataset
2.2. The Data Preprocessing and Annotation Details of the HLJ Dataset
3. Experimental Settings and Results
3.1. Public Datasets
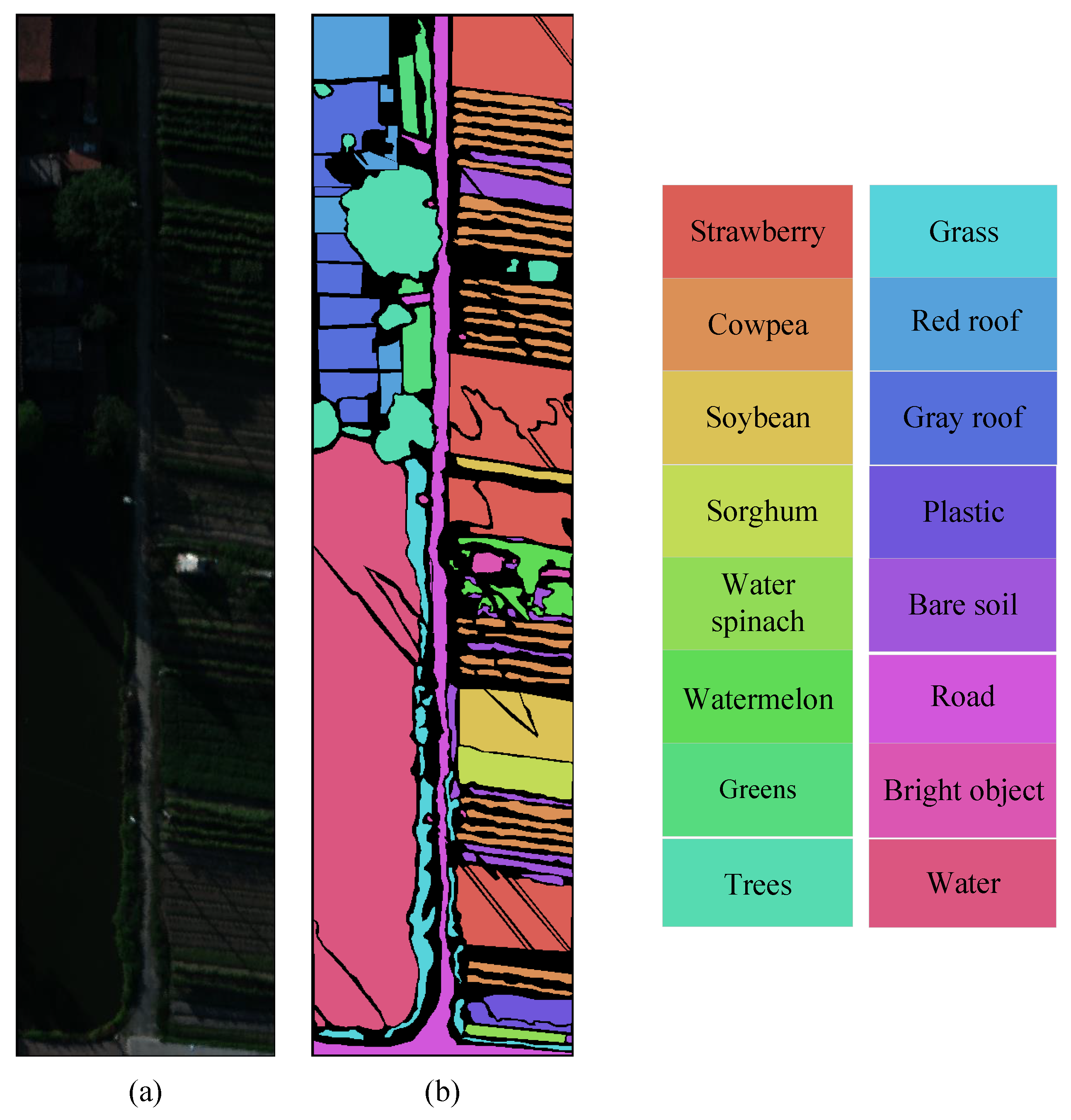
3.1.1. WHU-Hi Dataset
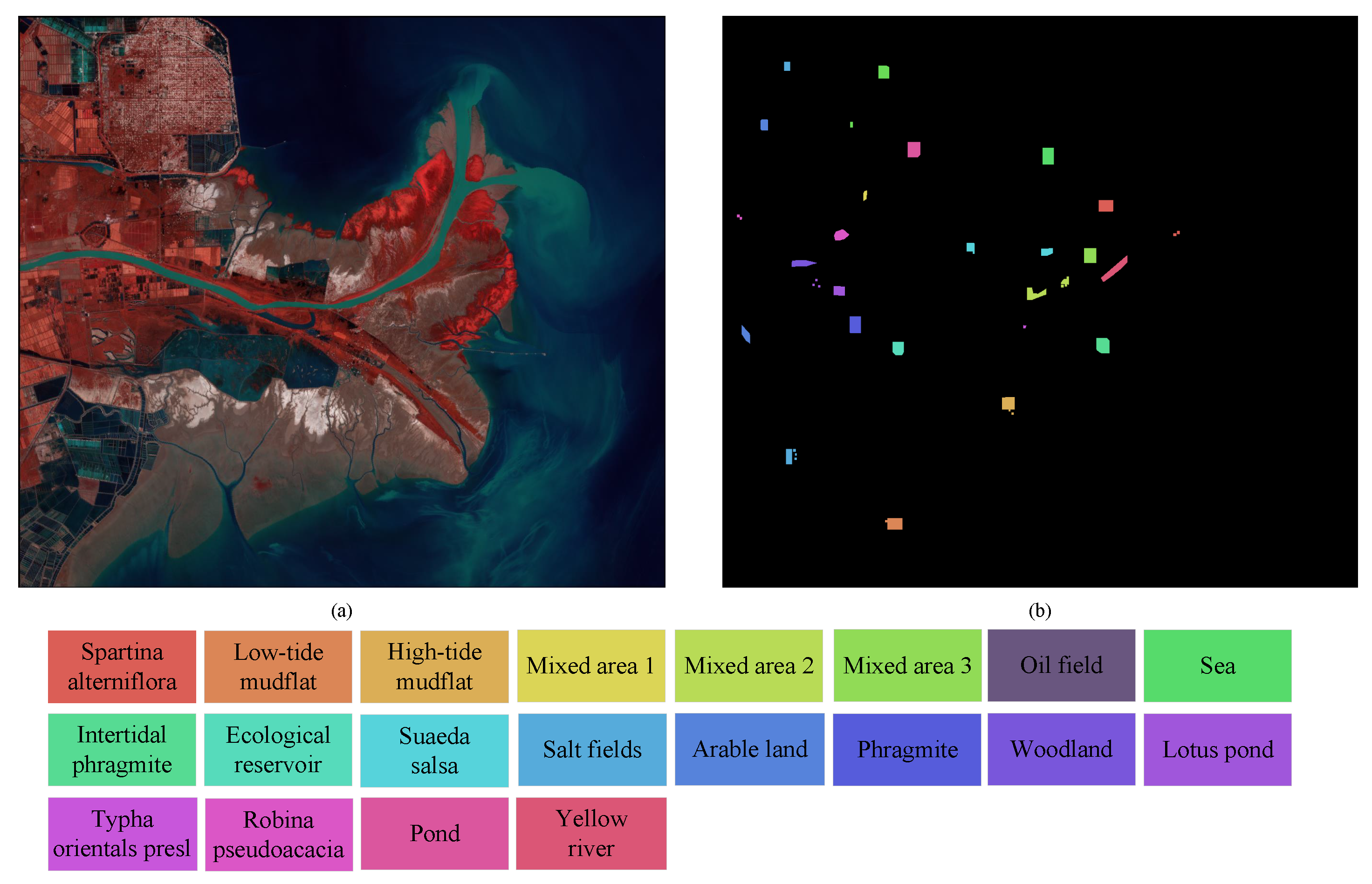
3.1.2. YRE Dataset
3.1.3. Indian Pines Dataset
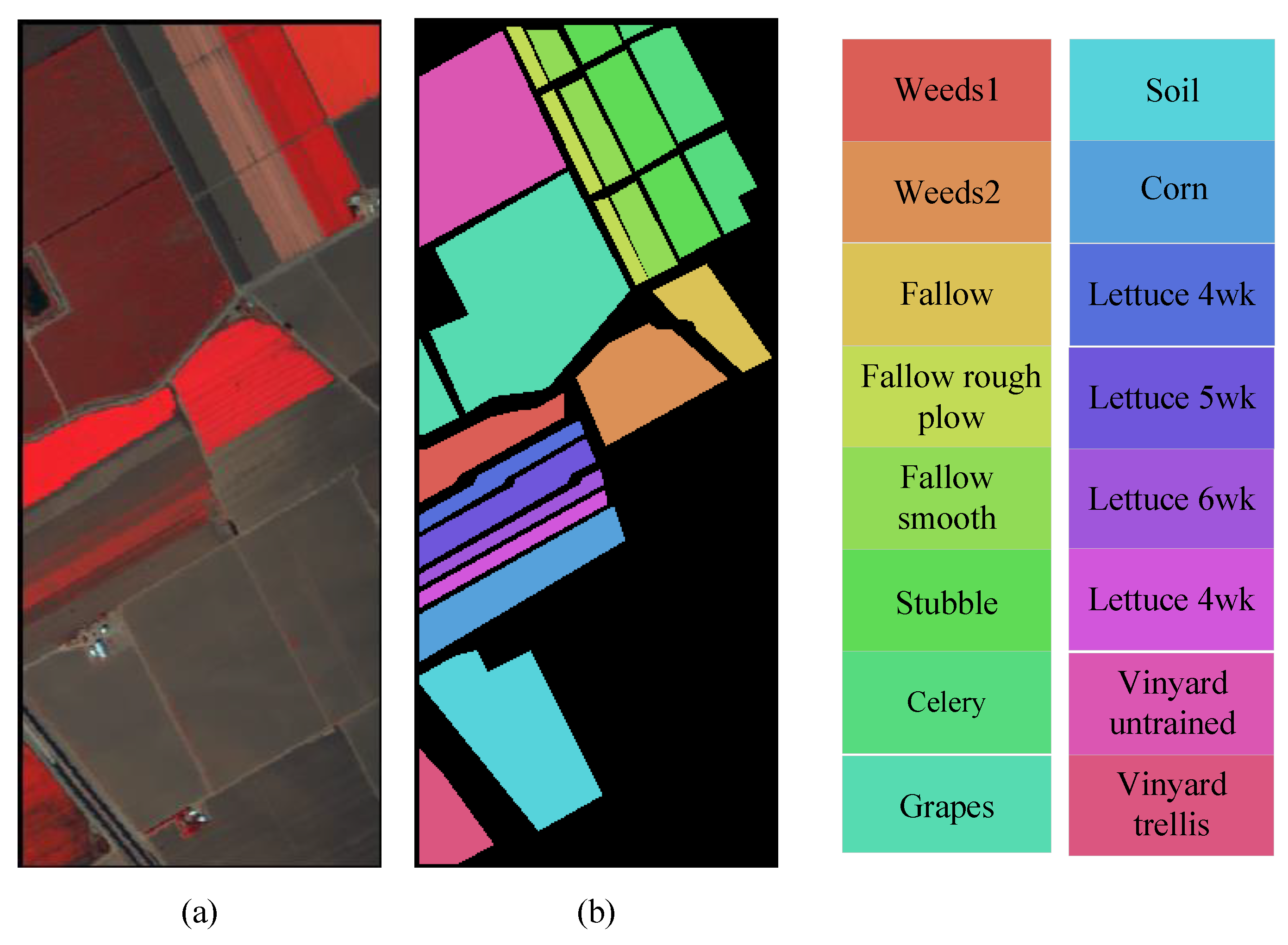
3.1.4. Salinas Dataset
3.2. Classification Experiments of Various Methods on the HLJ Dataset
3.2.1. Experimental Settings
- (a)
- SVM. This serves as the baseline for traditional supervised methods. This method utilizes the machine learning toolkit scikit-learn, maintaining all parameters at their default settings. Using the Radial Basis Function kernel, the penalty parameter C is set to 1.
- (b)
- 2D-Deform. A 2D deformable convolution is chosen as a fundamental convolutional neural network. Stochastic Gradient Descent (SGD) is employed as the optimization approach. The model was trained for 100 epochs with a fixed learning rate of 0.001. After comprehensive consideration of the model parameters, the model’s input is composed of 8 × 8 patches derived from HSI.
- (c)
- SSRN. A modified three-dimensional convolutional neural network with residual connections is used to capture joint spectral and spatial features in the proposed dataset. The method also employs the SGD optimizer with a learning rate of 0.001, trained for 100 epochs. The patch size is 7 × 7.
- (d)
- DBDA. This approach combines attention mechanisms with a convolutional neural network to strengthen the capability of feature extraction and representation through a dual-attention dual-branch structure. This method was trained for 100 epochs, employing a learning rate of 0.001.
- (e)
- DBDA-MISH. In contrast to the DBDA approach, this method incorporates the MISH function as an activation function, aiming to prevent information loss due to the increase in the number of layers in deep neural networks and maintain higher training stability. This method underwent 100 training iterations with a learning rate set at 0.001. Patch size for DBDA and DBDA-MISH is set at 7 × 7.
- (f)
- ViT. This model employs the transformer as the baseline model for image classification. The unique attention mechanism within the transformer allows for capturing global and local features from an overall perspective of the image. For the sake of simplicity in implementation, the ViT method from the open-source project provided in the article is directly utilized. Both the band patch and patch size are set to a default value of 1. The optimizer used is Adaptive Moment Estimation (Adam). The training lasted for 100 epochs.
- (g)
- SpectralFormer. This model focuses on pixel-level HSIC, utilizing the transformer structure for synchronous extraction of spatial–spectral information, rather than employing two separate modules. Distinctive design has enhanced the capability of the transformer-based model to extract local semantic information. Due to memory constraints, this experiment adopts a pixel-wise configuration with a patch size of 1. The band patch is set as 3 to explore the spectral differences among different bands. The model undergoes 100 epochs of training with the Adam optimizer.
- (h)
- SSFTT. This method combines convolutional neural networks and the transformer by utilizing convolutional layers to model low-level spatial–spectral features into tokens. These tokens are then treated as high-level semantic features of HSI, which the transformer excels at handling. In the experiment, PCA is first utilized to reduce the spectral dimensionality to 30. Considering compatibility between the initial and final parts of the model, the patch size is set to 13. The model is trained for 100 epochs.
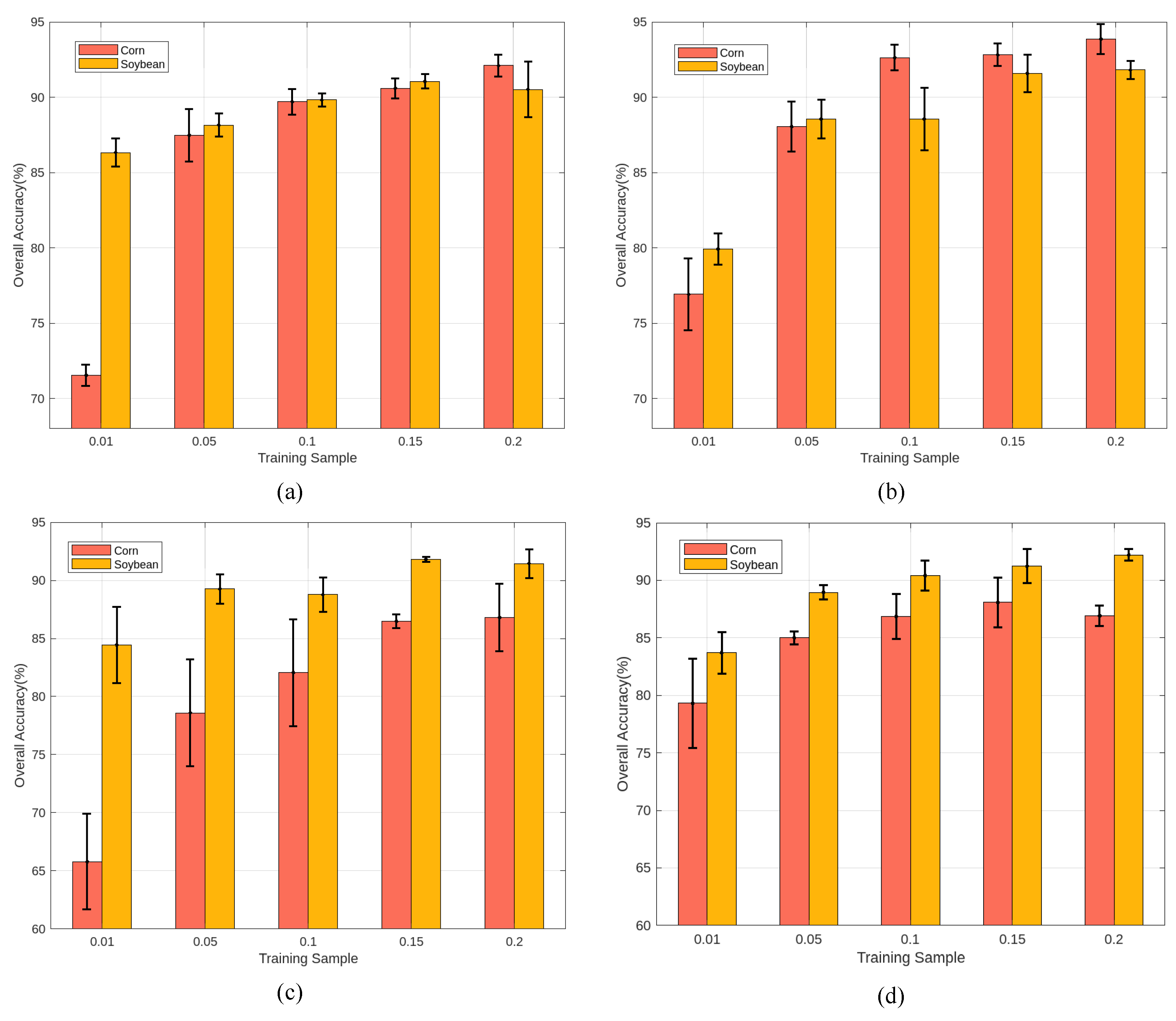
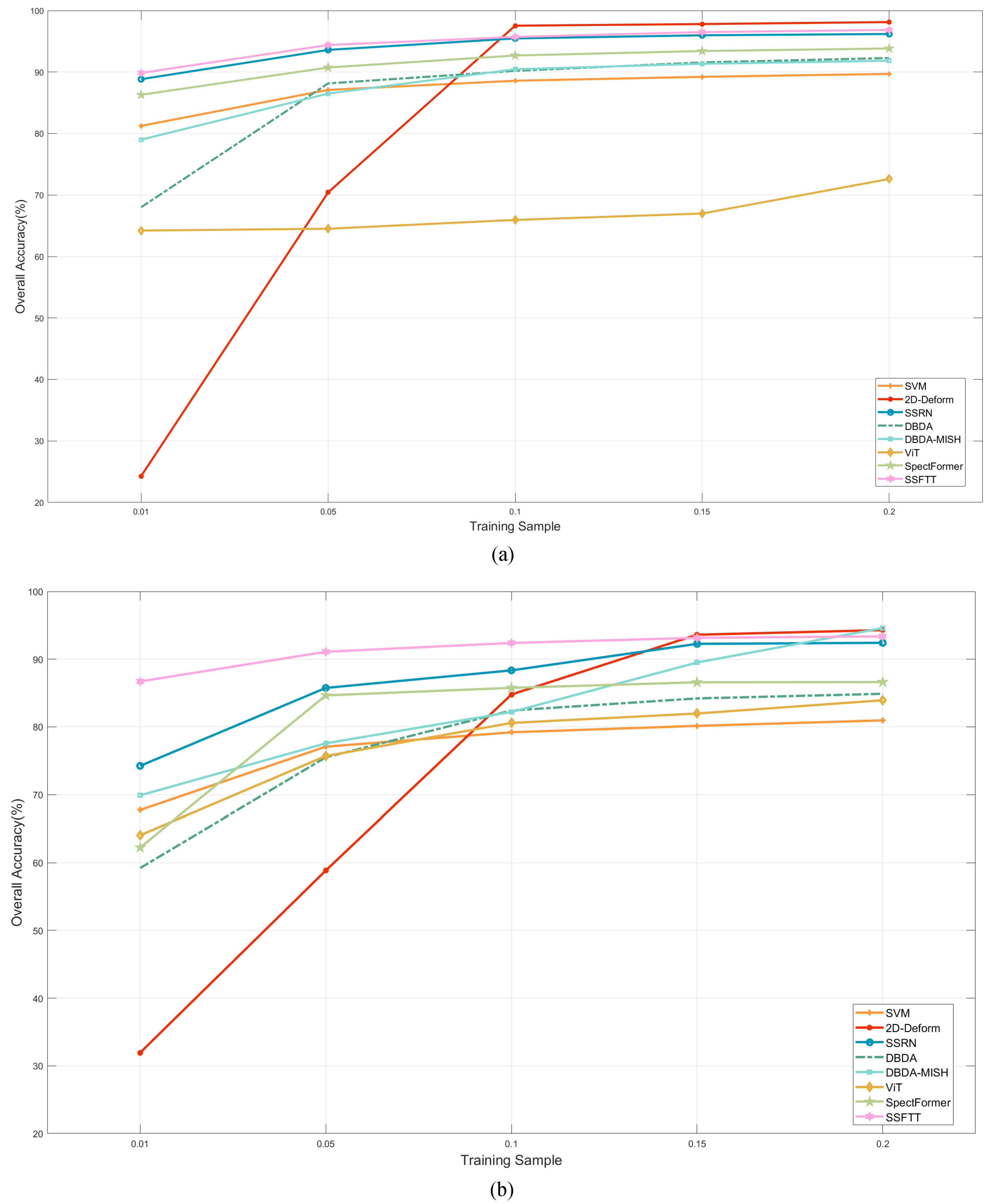
3.2.2. Classification Performance
3.3. Classification Performance on Other Datasets
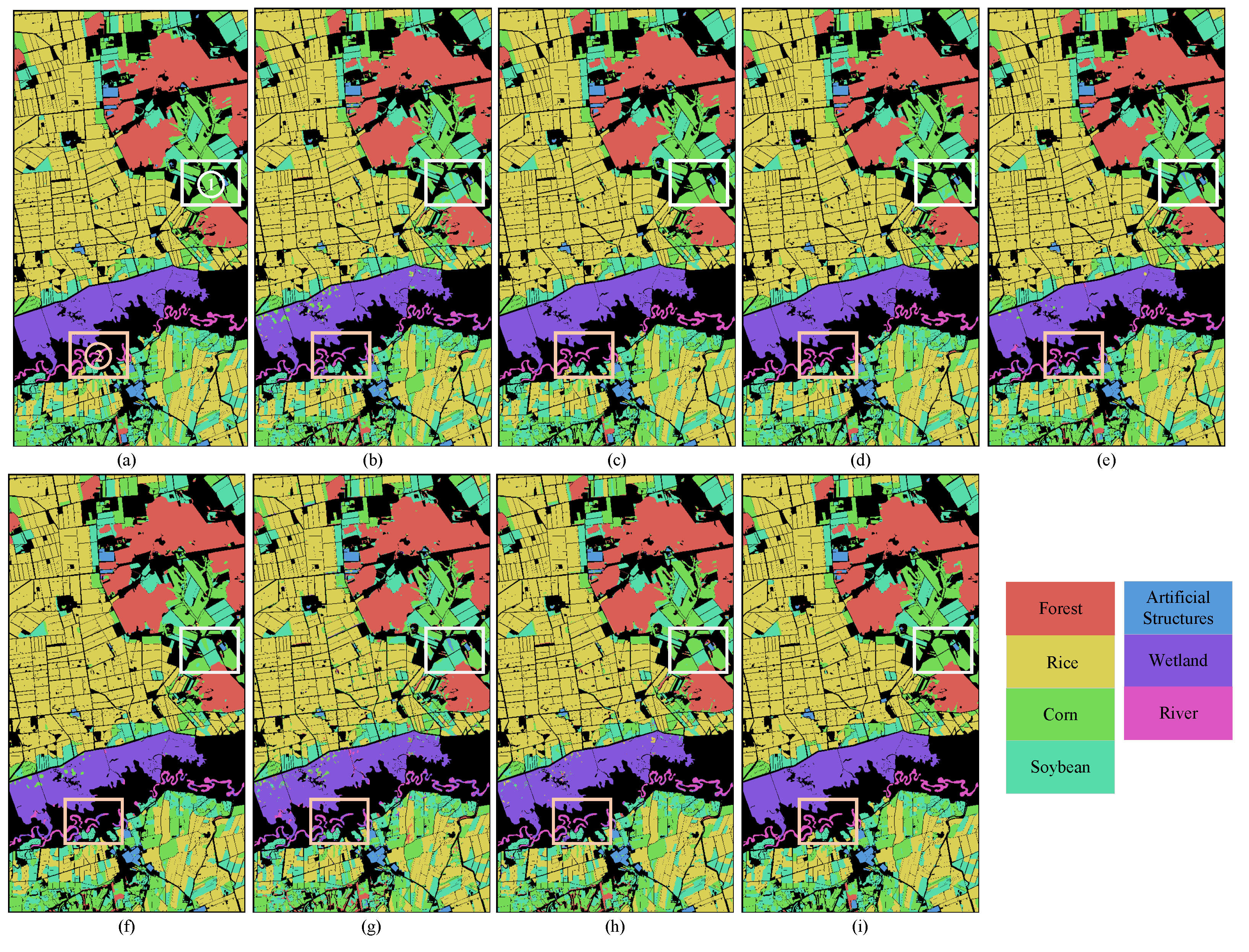
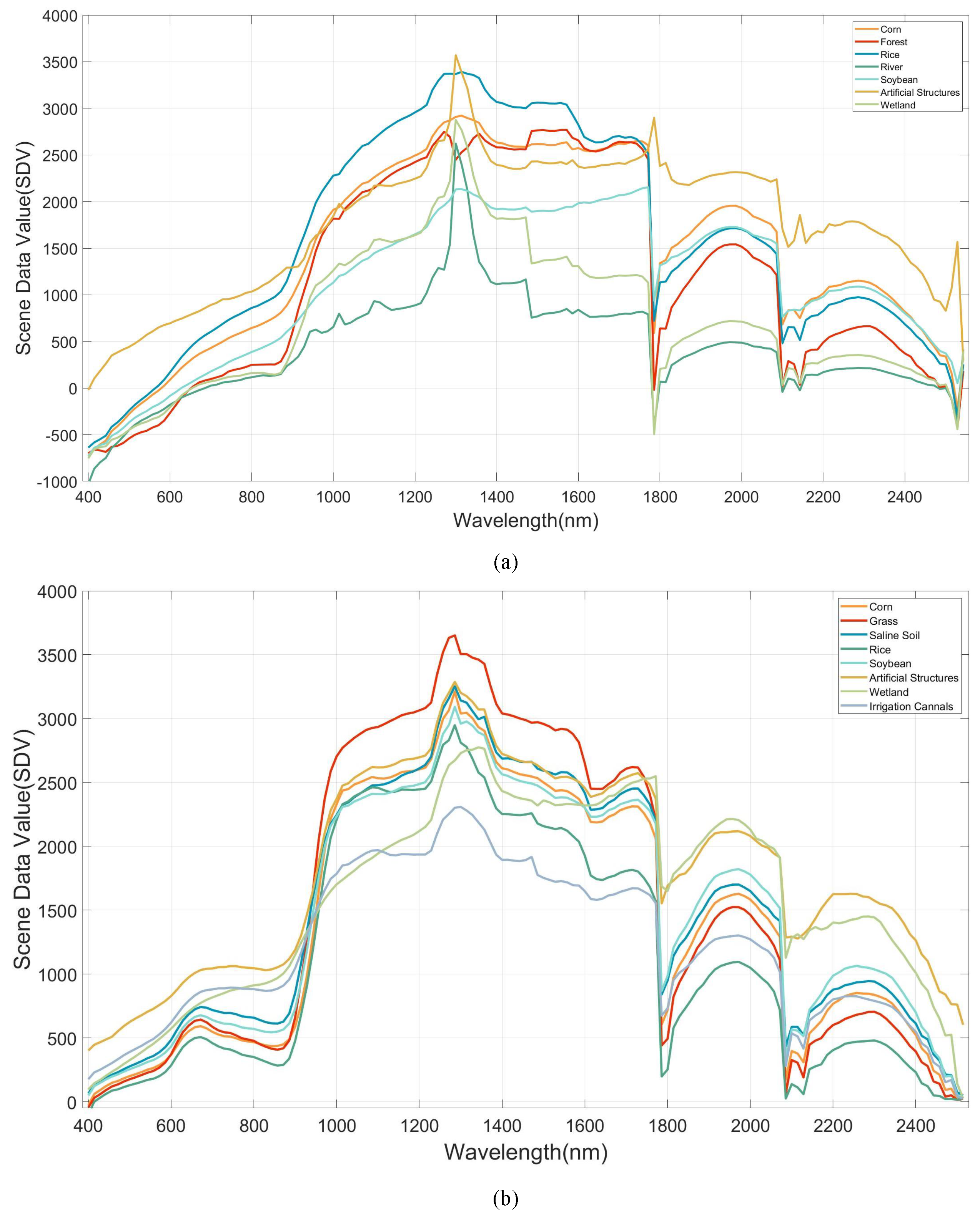
3.4. Visualization of HLJ Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Azzari, G.; Lobell, D.B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar] [CrossRef]
- Guerri, M.F.; Distante, C.; Spagnolo, P.; Bougourzi, F.; Taleb-Ahmed, A. Deep Learning Techniques for Hyperspectral Image Analysis in Agriculture: A Review. arXiv 2023, arXiv:2304.13880. [Google Scholar]
- Ozdogan, M. The spatial distribution of crop types from MODIS data: Temporal unmixing using Independent Component Analysis. Remote Sens. Environ. 2010, 114, 1190–1204. [Google Scholar] [CrossRef]
- Liu, J.; Liu, M.; Tian, H.; Zhuang, D.; Zhang, Z.; Zhang, W.; Tang, X.; Deng, X. Spatial and temporal patterns of China’s cropland during 1990–2000: An analysis based on Landsat TM data. Remote Sens. Environ. 2005, 98, 442–456. [Google Scholar] [CrossRef]
- Sethy, P.K.; Pandey, C.; Sahu, Y.K.; Behera, S.K. Hyperspectral imagery applications for precision agriculture—A systemic survey. Multimed. Tools Appl. 2022, 81, 3005–3038. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, L.; Du, B.; Li, W.; Mark Lai, Y. Band Selection Using Improved Sparse Subspace Clustering for Hyperspectral Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2784–2797. [Google Scholar] [CrossRef]
- Gao, F.; Anderson, M.C.; Zhang, X.; Yang, Z.; Alfieri, J.G.; Kustas, W.P.; Mueller, R.; Johnson, D.M.; Prueger, J.H. Toward mapping crop progress at field scales through fusion of Landsat and MODIS imagery. Remote Sens. Environ. 2017, 188, 9–25. [Google Scholar] [CrossRef]
- Debats, S.R.; Luo, D.; Estes, L.D.; Fuchs, T.J.; Caylor, K.K. A generalized computer vision approach to mapping crop fields in heterogeneous agricultural landscapes. Remote Sens. Environ. 2016, 179, 210–221. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Liu, L.; Xiao, X.; Qin, Y.; Wang, J.; Xu, X.; Hu, Y.; Qiao, Z. Mapping cropping intensity in China using time series Landsat and Sentinel-2 images and Google Earth Engine. Remote Sens. Environ. 2020, 239, 111624. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Yue-Yu, S.; Zhang, X.D.; Kai, M.; Herbert, S. Spatial variability of nutrient properties in black soil of northeast China. Pedosphere 2007, 17, 19–29. [Google Scholar] [CrossRef]
- Shu-hao, T.; Fu-tian, Q.; Heerink, N. Causes and determinants of land fragmentation. China Rural. Surv. 2003, 6, 24–30. [Google Scholar]
- Xiao, L.; Xianjin, H.; Taiyang, Z.; Yuntai, Z.; Yi, L. A review of farmland fragmentation in China. J. Resour. Ecol. 2013, 4, 344–352. [Google Scholar] [CrossRef]
- Yan, S.; Yao, X.; Zhu, D.; Liu, D.; Zhang, L.; Yu, G.; Gao, B.; Yang, J.; Yun, W. Large-scale crop mapping from multi-source optical satellite imageries using machine learning with discrete grids. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102485. [Google Scholar] [CrossRef]
- Zhao, C.; Shen, Y.; Su, N.; Yan, Y.; Liu, Y. Gully Erosion Monitoring Based on Semi-Supervised Semantic Segmentation with Boundary-Guided Pseudo-Label Generation Strategy and Adaptive Loss Function. Remote Sens. 2022, 14, 5110. [Google Scholar] [CrossRef]
- Hitouri, S.; Varasano, A.; Mohajane, M.; Ijlil, S.; Essahlaoui, N.; Ali, S.A.; Essahlaoui, A.; Pham, Q.B.; Waleed, M.; Palateerdham, S.K.; et al. Hybrid machine learning approach for gully erosion mapping susceptibility at a watershed scale. ISPRS Int. J.-Geo-Inf. 2022, 11, 401. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, S.; Wu, S.; Jin, S.; Reis, S.; Liu, H.; Gu, B. Rebuilding the linkage between livestock and cropland to mitigate agricultural pollution in China. Resour. Conserv. Recycl. 2019, 144, 65–73. [Google Scholar] [CrossRef]
- Wu, W.; Yu, Q.; You, L.; Chen, K.; Tang, H.; Liu, J. Global cropping intensity gaps: Increasing food production without cropland expansion. Land Use Policy 2018, 76, 515–525. [Google Scholar] [CrossRef]
- Wu, B.; Li, Q. Crop planting and type proportion method for crop acreage estimation of complex agricultural landscapes. Int. J. Appl. Earth Obs. Geoinfor. 2012, 16, 101–112. [Google Scholar] [CrossRef]
- Su, Y.; Gao, L.; Jiang, M.; Plaza, A.; Sun, X.; Zhang, B. NSCKL: Normalized Spectral Clustering with Kernel-Based Learning for Semisupervised Hyperspectral Image Classification. IEEE Trans. Cybern. 2023, 53, 6649–6662. [Google Scholar] [CrossRef]
- Su, Y.; Chen, J.; Gao, L.; Plaza, A.; Jiang, M.; Xu, X.; Sun, X.; Li, P. ACGT-Net: Adaptive Cuckoo Refinement-Based Graph Transfer Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5521314. [Google Scholar] [CrossRef]
- Liu, Q.; Peng, J.; Ning, Y.; Chen, N.; Sun, W.; Du, Q.; Zhou, Y. Refined Prototypical Contrastive Learning for Few-Shot Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5506214. [Google Scholar] [CrossRef]
- Liu, Q.; Peng, J.; Chen, N.; Sun, W.; Ning, Y.; Du, Q. Category-Specific Prototype Self-Refinement Contrastive Learning for Few-Shot Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5524416. [Google Scholar] [CrossRef]
- Rao, N.R.; Garg, P.K.; Ghosh, S.K. Development of an agricultural crops spectral library and classification of crops at cultivar level using hyperspectral data. Precis. Agric. 2007, 8, 173–185. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, Y.; Shang, K.; Zhang, L.; Wang, S. Crop classification based on feature band set construction and object-oriented approach using hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4117–4128. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, J.; Sun, W.; Chen, N.; Du, Q.; Ning, Y.; Su, H. Two-Branch Attention Adversarial Domain Adaptation Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5540813. [Google Scholar] [CrossRef]
- Tang, Y.; Feng, S.; Zhao, C.; Fan, Y.; Shi, Q.; Li, W.; Tao, R. An Object Fine-Grained Change Detection Method Based on Frequency Decoupling Interaction for High Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5600213. [Google Scholar] [CrossRef]
- Feng, S.; Feng, R.; Wu, D.; Zhao, C.; Li, W.; Tao, R. A Coarse-to-Fine Hyperspectral Target Detection Method Based on Low-Rank Tensor Decomposition. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5530413. [Google Scholar] [CrossRef]
- Xi, B.; Li, J.; Li, Y.; Song, R.; Xiao, Y.; Du, Q.; Chanussot, J. Semisupervised cross-scale graph prototypical network for hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9337–9351. [Google Scholar] [CrossRef] [PubMed]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Duc, H.N.; Chang, L.Y. A phenology-based classification of time-series MODIS data for rice crop monitoring in Mekong Delta, Vietnam. Remote Sens. 2013, 6, 135–156. [Google Scholar] [CrossRef]
- Tatsumi, K.; Yamashiki, Y.; Torres, M.A.C.; Taipe, C.L.R. Crop classification of upland fields using Random forest of time-series Landsat 7 ETM+ data. Comput. Electron. Agric. 2015, 115, 171–179. [Google Scholar] [CrossRef]
- Zhao, Y.; Feng, D.; Yu, L.; Cheng, Y.; Zhang, M.; Liu, X.; Xu, Y.; Fang, L.; Zhu, Z.; Gong, P. Long-term land cover dynamics (1986–2016) of Northeast China derived from a multi-temporal Landsat archive. Remote Sens. 2019, 11, 599. [Google Scholar] [CrossRef]
- Zhao, C.; Qin, B.; Feng, S.; Zhu, W.; Zhang, L.; Ren, J. An Unsupervised Domain Adaptation Method Towards Multi-Level Features and Decision Boundaries for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5546216. [Google Scholar] [CrossRef]
- Zhao, C.; Qin, B.; Feng, S.; Zhu, W.; Sun, W.; Li, W.; Jia, X. Hyperspectral Image Classification with Multi-Attention Transformer and Adaptive Superpixel Segmentation-Based Active Learning. IEEE Trans. Image Process. 2023, 32, 3606–3621. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, J.; Li, J.; Wang, Y.; Zeng, D. SDFC dataset: A large-scale benchmark dataset for hyperspectral image classification. Opt. Quantum Electron. 2023, 55, 173. [Google Scholar] [CrossRef]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J.J. Hyperspectral imaging: A review on UAV-based sensors, data processing and applications for agriculture and forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef]
- Tu, Y.; Bian, M.; Wan, Y.; Fei, T. Tea cultivar classification and biochemical parameter estimation from hyperspectral imagery obtained by UAV. PeerJ 2018, 6, e4858. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Wang, X.; Xu, Y.; Wang, S.; Jia, T.; Hu, X.; Zhao, J.; Wei, L.; Zhang, L. Mini-UAV-Borne Hyperspectral Remote Sensing: From Observation and Processing to Applications. IEEE Geosci. Remote Sens. Mag. 2018, 6, 46–62. [Google Scholar] [CrossRef]
- Ni, R.; Tian, J.; Li, X.; Yin, D.; Li, J.; Gong, H.; Zhang, J.; Zhu, L.; Wu, D. An enhanced pixel-based phenological feature for accurate paddy rice mapping with Sentinel-2 imagery in Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 178, 282–296. [Google Scholar] [CrossRef]
- Chong, L.; Liu, H.J.; Qiang, F.; Guan, H.X.; Qiang, Y.; Zhang, X.L.; Kong, F.C. Mapping the fallowed area of paddy fields on Sanjiang Plain of Northeast China to assist water security assessments. J. Integr. Agric. 2020, 19, 1885–1896. [Google Scholar]
- Mao, D.; Wang, Z.; Li, L.; Miao, Z.; Ma, W.; Song, C.; Ren, C.; Jia, M. Soil organic carbon in the Sanjiang Plain of China: Storage, distribution and controlling factors. Biogeosciences 2015, 12, 1635–1645. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.; Gao, C.Z.; Tao, R. Central Attention Network for Hyperspectral Imagery Classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8989–9003. [Google Scholar] [CrossRef]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 Indian Pine Test Site 3. 2015. Available online: https://purr.purdue.edu/publications/1947/1 (accessed on 20 December 2023).
- Zheng, Z.; Zhong, Y.; Ma, A.; Zhang, L. FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5612–5626. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of hyperspectral image based on double-branch dual-attention mechanism network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Name | Number of Samples | Ratio |
|---|---|---|---|
| 1 | Forest | 46,222 | 0.1445 |
| 2 | Rice | 139,383 | 0.4360 |
| 3 | Corn | 50,941 | 0.1593 |
| 4 | Soybean | 46,382 | 0.1451 |
| 5 | Artificial Structures | 3467 | 0.0108 |
| 6 | Wetland | 28,835 | 0.0901 |
| 7 | River | 4455 | 0.0139 |
| Total | 319,685 | ||
| Class | Name | Number of Samples | Ratio |
|---|---|---|---|
| 1 | Rice | 82,711 | 0.2593 |
| 2 | Corn | 79,158 | 0.2482 |
| 3 | Soybean | 119,710 | 0.3753 |
| 4 | Grass | 14,478 | 0.0453 |
| 5 | Irrigation Canals | 2710 | 0.0085 |
| 6 | Wetland | 11,180 | 0.0351 |
| 7 | Saline Soil | 5448 | 0.0171 |
| 8 | Artificial Structures | 3547 | 0.0111 |
| Total | 318,942 | ||
| Class | SVM | 2D-Deform | SSRN | DBDA | DBDA-MISH | ViT | SpectralFormer | SSFTT |
|---|---|---|---|---|---|---|---|---|
| 1 | 92.94 ± 0.047 | 98.26 ± 0.22 | 97.26 ± 0.41 | 92.79 ± 3.36 | 96.18 ± 0.26 | 96.60 ± 0.68 | 95.52 ± 0.45 | 96.97 ± 0.71 |
| 2 | 95.90 ± 0.01 | 99.09 ± 0.12 | 98.63 ± 0.25 | 96.36 ± 1.50 | 97.75 ± 0.19 | 95.26 ± 0.91 | 97.31 ± 0.72 | 98.08 ± 0.17 |
| 3 | 75.16 ± 0.09 | 94.67 ± 0.43 | 89.70 ± 0.85 | 79.68 ± 6.32 | 78.63 ± 1.17 | 75.42 ± 0.91 | 83.14 ± 2.84 | 92.63 ± 0.83 |
| 4 | 82.55 ± 0.11 | 93.96 ± 0.36 | 89.82 ± 0.44 | 82.52 ± 3.96 | 82.61 ± 0.72 | 83.20 ± 1.16 | 85.68 ± 1.40 | 88.55 ± 1.28 |
| 5 | 64.91 ± 1.08 | 95.23 ± 0.31 | 84.32 ± 0.57 | 70.22 ± 2.07 | 44.98 ± 8.53 | 79.31 ± 1.69 | 84.52 ± 2.81 | 93.21 ± 1.66 |
| 6 | 88.52 ± 0.08 | 99.84 ± 0.03 | 98.75 ± 0.79 | 93.24 ± 1.17 | 95.13 ± 0.50 | 93.63 ± 2.02 | 96.88 ± 1.43 | 99.67 ± 0.13 |
| 7 | 9.165 ± 1.43 | 98.63 ± 0.57 | 90.32 ± 3.19 | 66.42 ± 9.02 | 25.81 ± 6.84 | 57.14 ± 10.34 | 79.76 ± 5.13 | 95.74 ± 1.69 |
| OA | 88.59 ± 0.03 | 97.54 ± 0.10 | 95.47 ± 0.15 | 90.19 ± 0.51 | 90.46 ± 0.26 | 89.69 ± 0.72 | 92.69 ± 0.34 | 95.72 ± 0.12 |
| AA | 72.74 ± 0.35 | 97.10 ± 0.10 | 92.69 ± 0.38 | 83.03 ± 0.87 | 74.44 ± 1.48 | 82.94 ± 1.79 | 88.97 ± 1.07 | 94.98 ± 0.29 |
| Precision | 79.96 ± 0.05 | 84.47 ± 0.45 | 83.81 ± 0.22 | 79.66 ± 0.78 | 79.08 ± 1.50 | 85.44 ± 0.77 | 90.70 ± 0.26 | 94.84 ± 0.27 |
| Recall | 75.62 ± 0.12 | 84.86 ± 0.19 | 82.23 ± 0.49 | 77.72 ± 0.89 | 76.03 ± 0.73 | 82.93 ± 1.79 | 88.05 ± 0.65 | 94.81 ± 0.41 |
| F1 | 77.52 ± 0.06 | 84.66 ± 0.31 | 82.98 ± 0.29 | 78.62 ± 0.82 | 77.77 ± 0.62 | 83.71 ± 1.16 | 89.14 ± 0.25 | 94.81 ± 0.29 |
| Kappa | 84.43 ± 0.04 | 96.65 ± 0.14 | 93.82 ± 0.21 | 86.63 ± 0.67 | 86.95 ± 0.35 | 85.99 ± 1.02 | 90.03 ± 0.46 | 94.18 ± 0.16 |
| Class | SVM | 2D-Deform | SSRN | DBDA | DBDA-MISH | ViT | SpectralFormer | SSFTT |
|---|---|---|---|---|---|---|---|---|
| 1 | 88.93 ± 0.13 | 96.27 ± 1.32 | 96.48 ± 0.94 | 92.41 ± 1.22 | 93.35 ± 1.15 | 89.36 ± 0.71 | 93.26 ± 0.53 | 97.92 ± 0.56 |
| 2 | 66.96 ± 0.19 | 73.07 ± 13.9 | 82.06 ± 4.60 | 63.94 ± 10.9 | 67.22 ± 5.94 | 70.19 ± 3.26 | 71.56 ± 5.63 | 86.88 ± 1.97 |
| 3 | 80.15 ± 0.07 | 81.28 ± 8.49 | 88.77 ± 1.46 | 87.39 ± 5.11 | 80.16 ± 2.28 | 81.35 ± 3.08 | 88.60 ± 2.82 | 90.41 ± 1.31 |
| 4 | 81.23 ± 0.21 | 95.60 ± 1.48 | 97.18 ± 1.15 | 92.18 ± 0.69 | 94.10 ± 1.42 | 89.22 ± 3.59 | 95.05 ± 1.71 | 98.58 ± 0.37 |
| 5 | 24.12 ± 11.54 | 93.40 ± 4.31 | 56.66 ± 20.3 | 52.28 ± 6.39 | 86.95 ± 5.47 | 82.17 ± 2.38 | 79.45 ± 2.37 | 97.52 ± 0.96 |
| 6 | 97.40 ± 0.17 | 99.21 ± 0.48 | 99.09 ± 0.29 | 96.15 ± 0.81 | 98.22 ± 2.03 | 96.01 ± 1.78 | 98.72 ± 0.59 | 99.92 ± 0.05 |
| 7 | 0.87 ± 0.48 | 92.79 ± 3.14 | 38.21 ± 37.51 | 58.13 ± 6.89 | 75.39 ± 16.87 | 42.17 ± 7.65 | 73.17 ± 8.41 | 95.71 ± 1.81 |
| 8 | 78.35 ± 0.12 | 88.96 ± 2.94 | 55.78 ± 44.24 | 71.20 ± 4.53 | 83.28 ± 8.34 | 86.92 ± 2.14 | 79.06 ± 10.91 | 98.57 ± 1.60 |
| OA | 79.16 ± 0.09 | 84.79 ± 2.99 | 88.35 ± 0.88 | 82.43 ± 1.31 | 82.22 ± 1.85 | 80.93 ± 0.89 | 85.77 ± 0.79 | 92.41 ± 0.16 |
| AA | 64.75 ± 1.49 | 90.07 ± 1.16 | 76.78 ± 9.46 | 76.71 ± 1.96 | 84.83 ± 3.98 | 79.67 ± 2.09 | 84.87 ± 2.68 | 95.35 ± 0.55 |
| Precision | 77.32 ± 0.18 | 85.72 ± 0.21 | 84.26 ± 0.26 | 77.76 ± 0.60 | 79.49 ± 0.43 | 76.83 ± 2.51 | 85.64 ± 0.83 | 95.36 ± 0.48 |
| Recall | 71.82 ± 0.21 | 85.85 ± 0.08 | 83.15 ± 0.72 | 76.06 ± 0.86 | 69.79 ± 1.78 | 79.68 ± 1.16 | 84.53 ± 0.59 | 95.22 ± 0.52 |
| F1 | 74.09 ± 0.12 | 85.78 ± 0.12 | 83.69 ± 0.47 | 76.8 ± 0.62 | 72.70 ± 1.67 | 76.12 ± 1.92 | 84.86 ± 0.38 | 95.27 ± 0.17 |
| Kappa | 70.54 ± 0.13 | 79.15 ± 4.07 | 83.86 ± 1.25 | 75.48 ± 2.01 | 75.01 ± 2.69 | 73.75 ± 1.24 | 80.26 ± 1.17 | 89.54 ± 0.23 |
| Class | WHU-LK | HLJ-Yan | HLJ-Raohe |
|---|---|---|---|
| 1 | 99.99 ± 0.01 | 97.92 ± 0.56 | 96.97 ± 0.71 |
| 2 | 100.00 ± 0.00 | 86.88 ± 1.97 | 98.08 ± 0.17 |
| 3 | 100.00 ± 0.00 | 90.41 ± 1.31 | 92.63 ± 0.83 |
| 4 | 99.96 ± 0.01 | 98.58 ± 0.37 | 88.55 ± 1.28 |
| 5 | 99.60 ± 0.05 | 97.52 ± 0.96 | 93.21 ± 1.66 |
| 6 | 99.95 ± 0.04 | 99.92 ± 0.05 | 99.67 ± 0.13 |
| 7 | 99.97 ± 0.01 | 95.71 ± 1.81 | 95.74 ± 1.69 |
| 8 | 98.98 ± 0.05 | 98.57 ± 1.60 | |
| 9 | 98.74 ± 0.16 | ||
| OA | 99.90 ± 0.01 | 92.41 ± 0.16 | 95.72 ± 0.12 |
| AA | 99.69 ± 0.02 | 95.35 ± 0.55 | 94.98 ± 0.29 |
| Kappa | 99.86 ± 0.01 | 89.54 ± 0.23 | 94.18 ± 0.16 |
| Class | YRE | SA | IP | WH-HC |
|---|---|---|---|---|
| 1 | 100.00 ± 0.00 | 100.00 ± 0.00 | 96.10 ± 5.48 | 99.64 ± 0.13 |
| 2 | 100.00 ± 0.00 | 100.00 ± 0.00 | 95.89 ± 0.41 | 99.34 ± 0.47 |
| 3 | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.73 ± 0.35 | 98.39 ± 2.25 |
| 4 | 100.00 ± 0.00 | 99.92 ± 0.12 | 99.81 ± 0.38 | 99.68 ± 0.16 |
| 5 | 100.00 ± 0.00 | 99.68 ± 0.16 | 99.40 ± 0.87 | 98.80 ± 1.35 |
| 6 | 100.00 ± 0.00 | 99.97 ± 0.03 | 99.63 ± 0.34 | 95.59 ± 1.17 |
| 7 | 99.61 ± 0.78 | 99.97 ± 0.03 | 100.00 ± 0.003 | 99.20 ± 0.40 |
| 8 | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.91 ± 0.19 | 99.22 ± 0.27 |
| 9 | 100.00 ± 0.00 | 100.00 ± 0.00 | 83.33 ± 11.65 | 98.82 ± 0.82 |
| 10 | 100.00 ± 0.00 | 99.79 ± 0.09 | 98.17 ± 0.75 | 99.65 ± 0.11 |
| 11 | 100.00 ± 0.00 | 99.94 ± 0.05 | 99.61 ± 0.15 | 99.66 ± 0.27 |
| 12 | 100.00 ± 0.00 | 100.00 ± 0.00 | 97.53 ± 0.72 | 98.81 ± 1.65 |
| 13 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 95.81 ± 1.62 |
| 14 | 100.00 ± 0.00 | 99.96 ± 0.08 | 99.91 ± 0.14 | 99.07 ± 0.82 |
| 15 | 100.00 ± 0.00 | 99.92 ± 0.04 | 99.31 ± 0.742 | 97.99 ± 1.15 |
| 16 | 100.00 ± 0.00 | 100.00 ± 0.00 | 90.48 ± 4.94 | 99.93 ± 0.08 |
| 17 | 100.00 ± 0.00 | |||
| 18 | 100.00 ± 0.00 | |||
| 19 | 100.00 ± 0.00 | |||
| 20 | 100.00 ± 0.00 | |||
| OA | 99.98 ± 0.04 | 99.95 ± 0.01 | 98.76 ± 0.22 | 98.88 ± 1.78 |
| AA | 99.98 ± 0.04 | 99.95 ± 0.01 | 97.43 ± 0.92 | 98.69 ± 1.70 |
| Kappa | 99.97 ± 0.04 | 99.94 ± 0.01 | 98.58 ± 0.25 | 98.69 ± 2.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Feng, S.; Wu, D.; Zhao, C.; Liu, X.; Zhou, Y.; Wang, S.; Deng, H.; Zheng, S. Hyperspectral Image Classification on Large-Scale Agricultural Crops: The Heilongjiang Benchmark Dataset, Validation Procedure, and Baseline Results. Remote Sens. 2024, 16, 478. https://doi.org/10.3390/rs16030478
Zhang H, Feng S, Wu D, Zhao C, Liu X, Zhou Y, Wang S, Deng H, Zheng S. Hyperspectral Image Classification on Large-Scale Agricultural Crops: The Heilongjiang Benchmark Dataset, Validation Procedure, and Baseline Results. Remote Sensing. 2024; 16(3):478. https://doi.org/10.3390/rs16030478
Chicago/Turabian StyleZhang, Hongzhe, Shou Feng, Di Wu, Chunhui Zhao, Xi Liu, Yuan Zhou, Shengnan Wang, Hongtao Deng, and Shuang Zheng. 2024. "Hyperspectral Image Classification on Large-Scale Agricultural Crops: The Heilongjiang Benchmark Dataset, Validation Procedure, and Baseline Results" Remote Sensing 16, no. 3: 478. https://doi.org/10.3390/rs16030478
APA StyleZhang, H., Feng, S., Wu, D., Zhao, C., Liu, X., Zhou, Y., Wang, S., Deng, H., & Zheng, S. (2024). Hyperspectral Image Classification on Large-Scale Agricultural Crops: The Heilongjiang Benchmark Dataset, Validation Procedure, and Baseline Results. Remote Sensing, 16(3), 478. https://doi.org/10.3390/rs16030478