


Flood Susceptibility Assessment with Random Sampling Strategy in Ensemble Learning (RF and XGBoost)


 ,
,
Abstract
1. Introduction
2. Materials and Methods Description
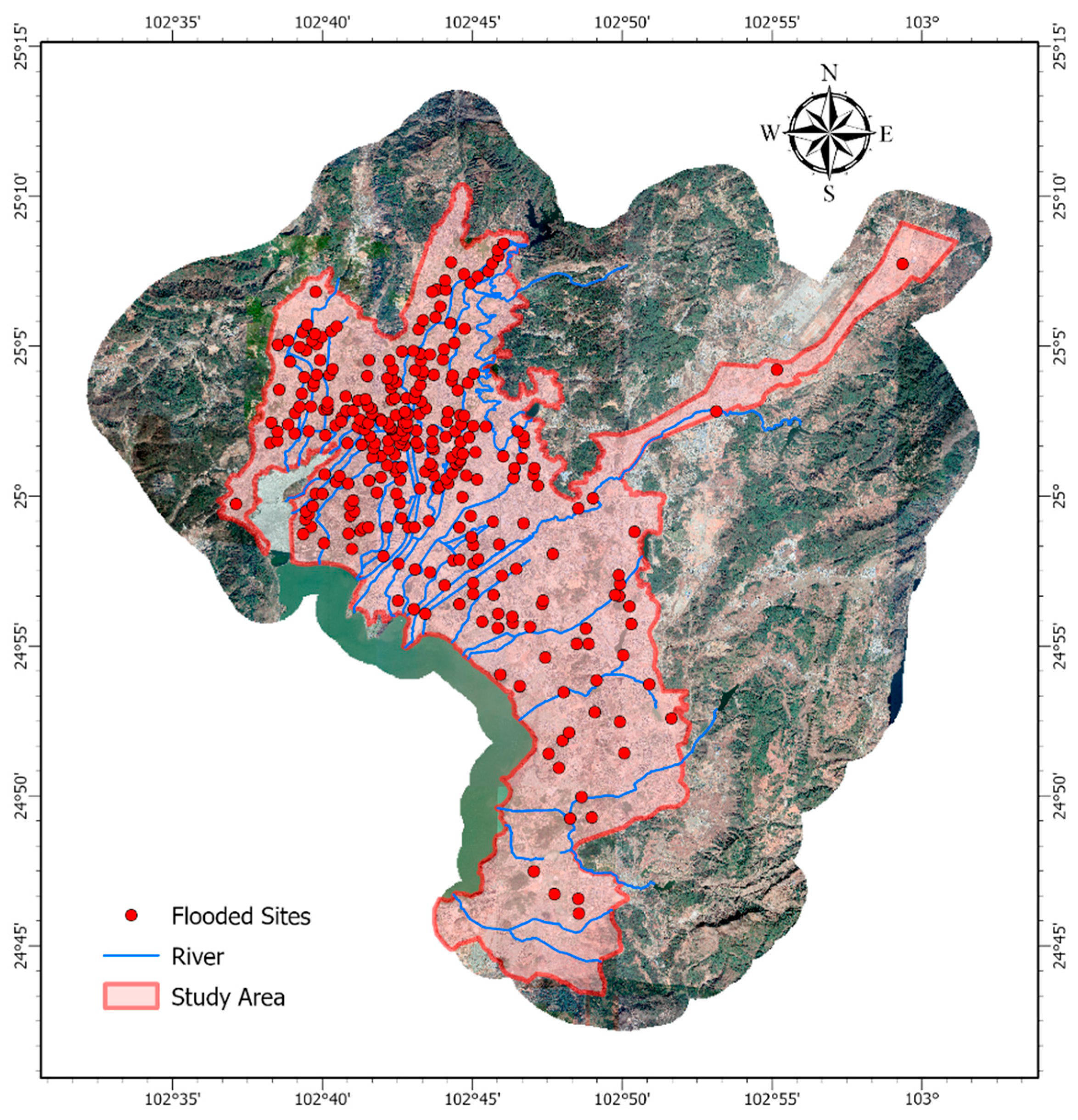
2.1. Study Area
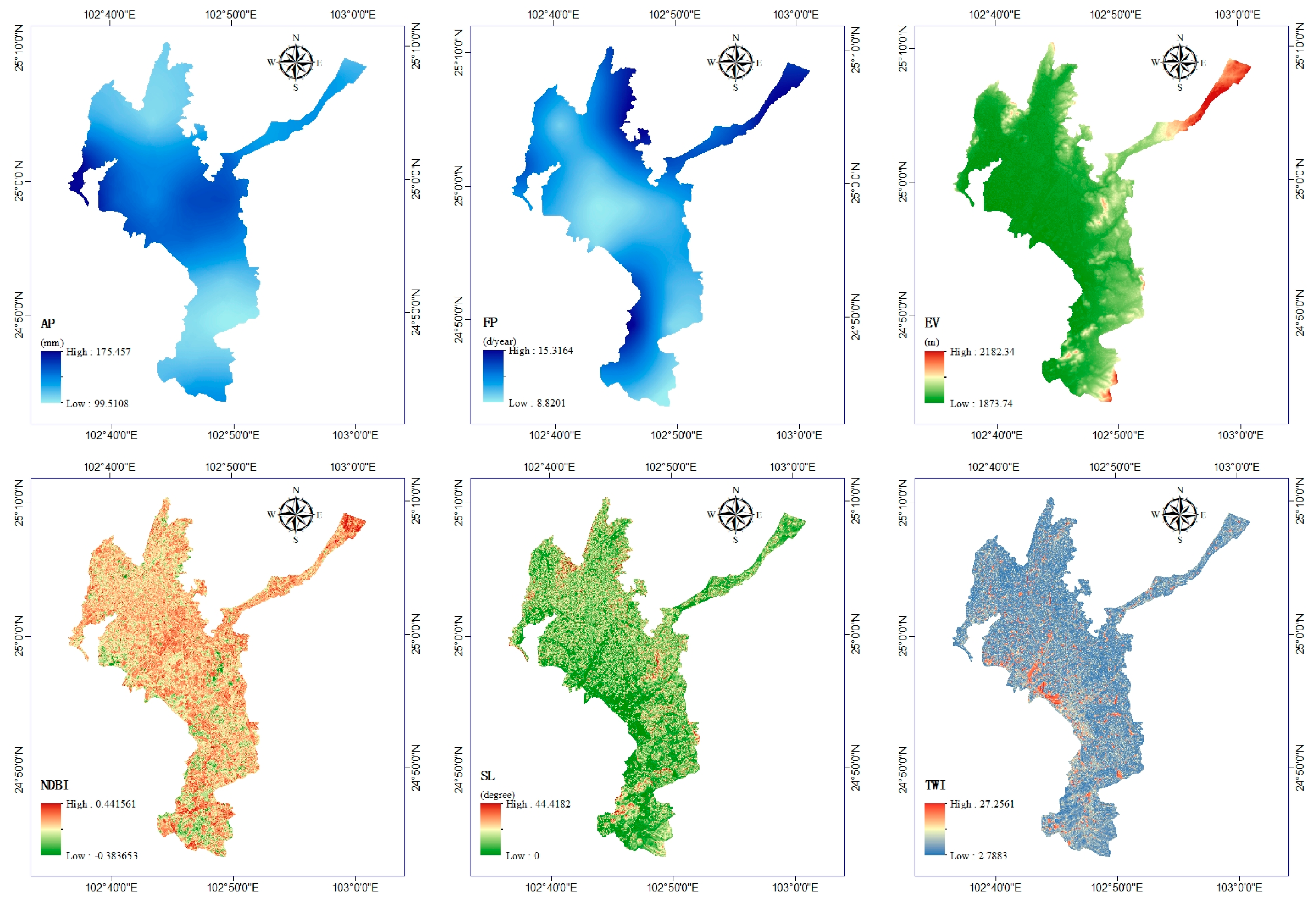
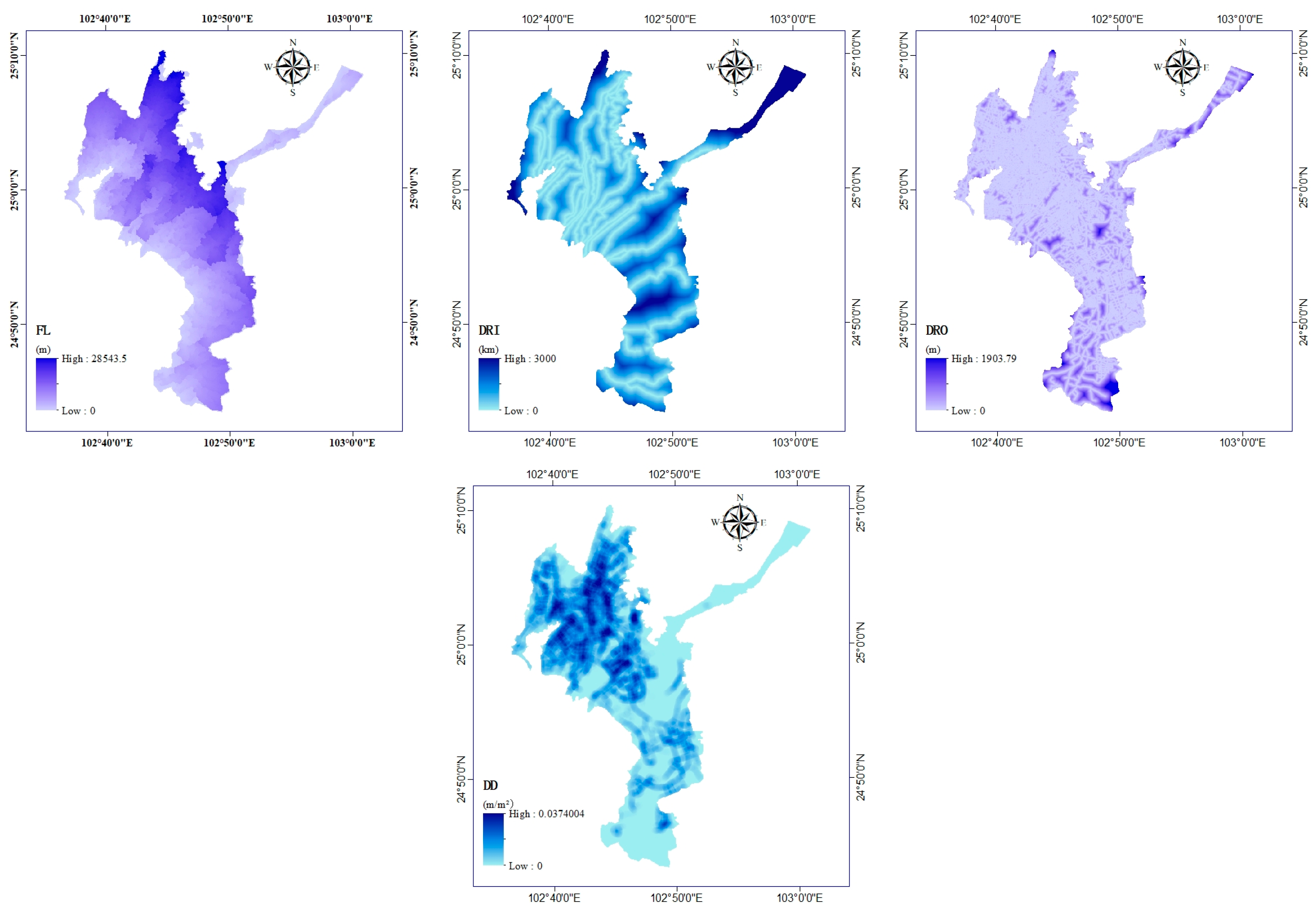
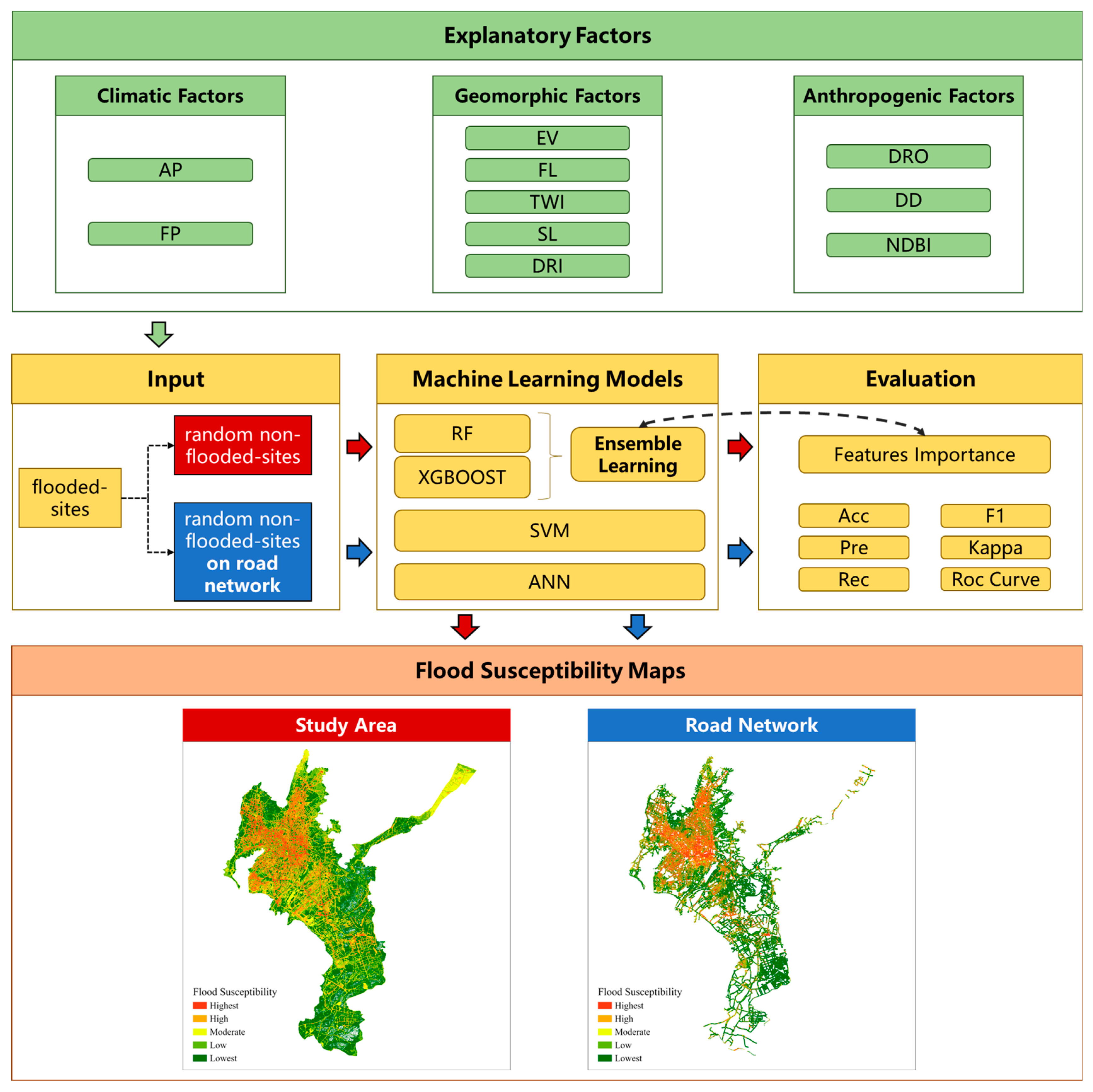
2.2. Explanatory Factors
2.2.1. Climatic Factors
2.2.2. Geomorphic Factors
2.2.3. Anthropogenic Factors
2.3. Flooded and Non-Flooded-Sites
2.4. Method Describe
2.4.1. Random Forest (RF)
2.4.2. XGBoost
2.4.3. Support Vector Machine (SVM)
2.4.4. Artificial Neural Network (ANN)
2.5. Evaluation Metrics
2.6. Experimental Design and Model Implementation
3. Results
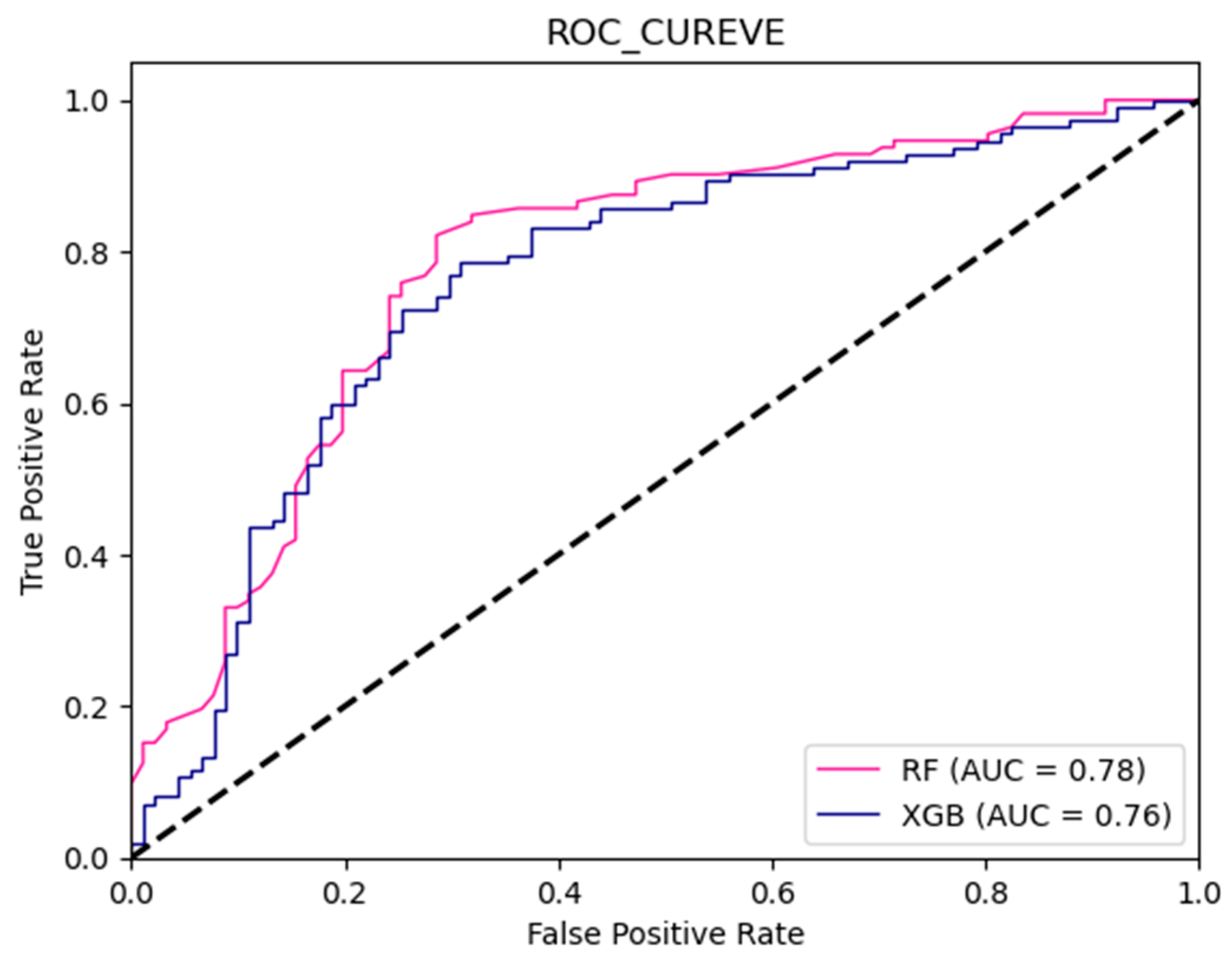
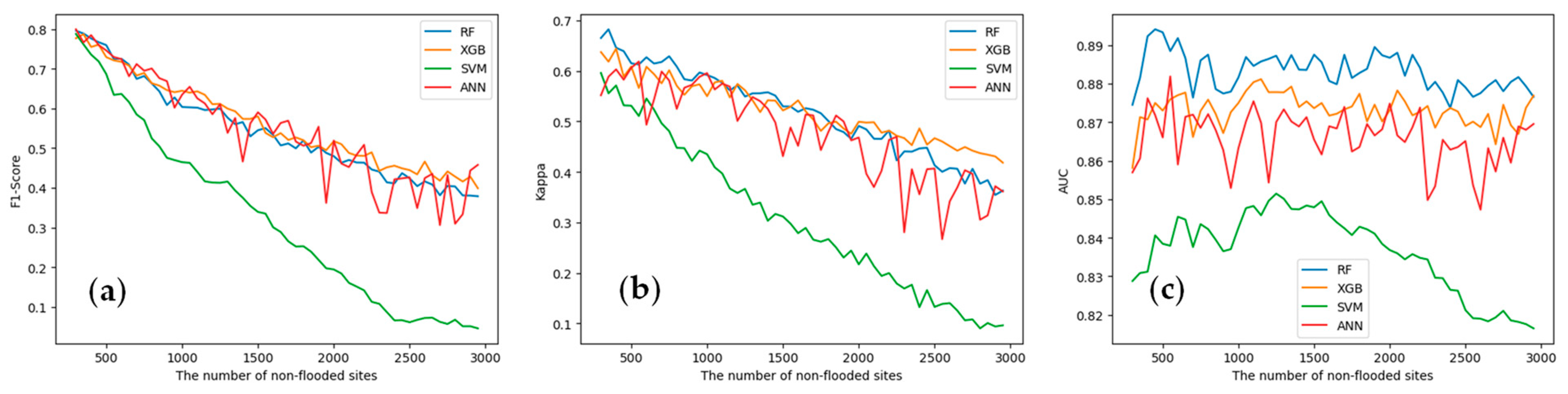
3.1. Model Comparison
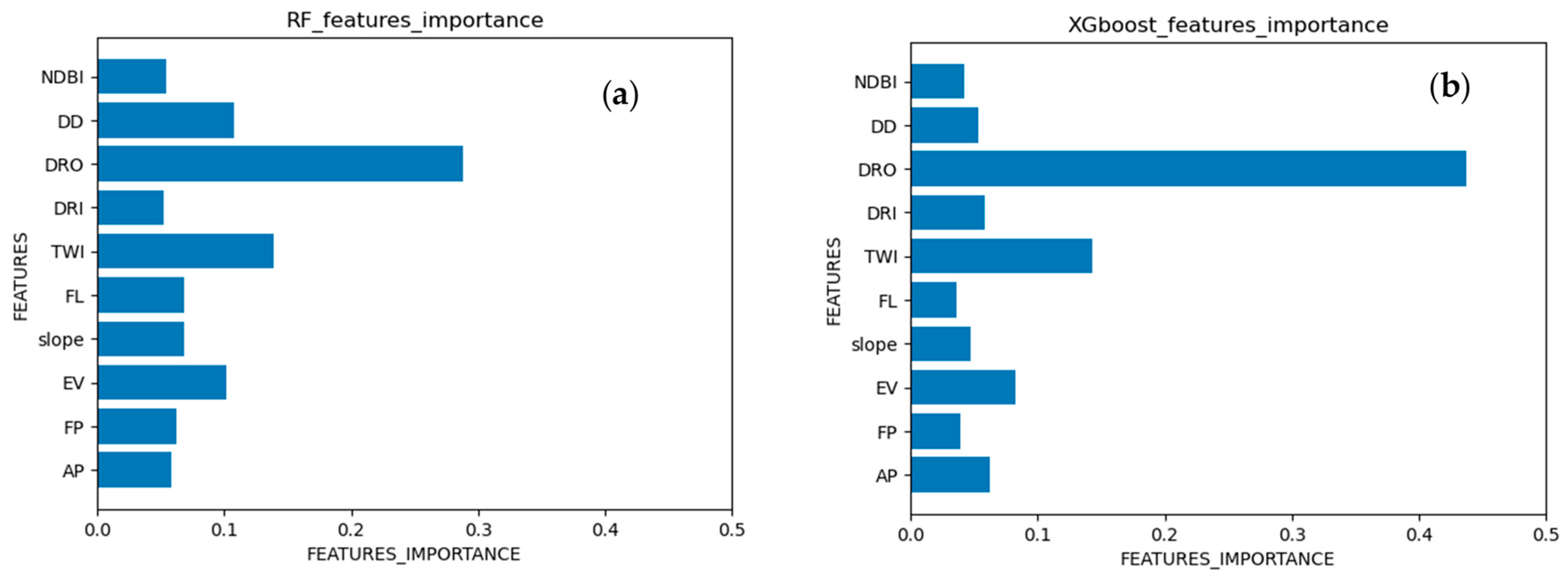
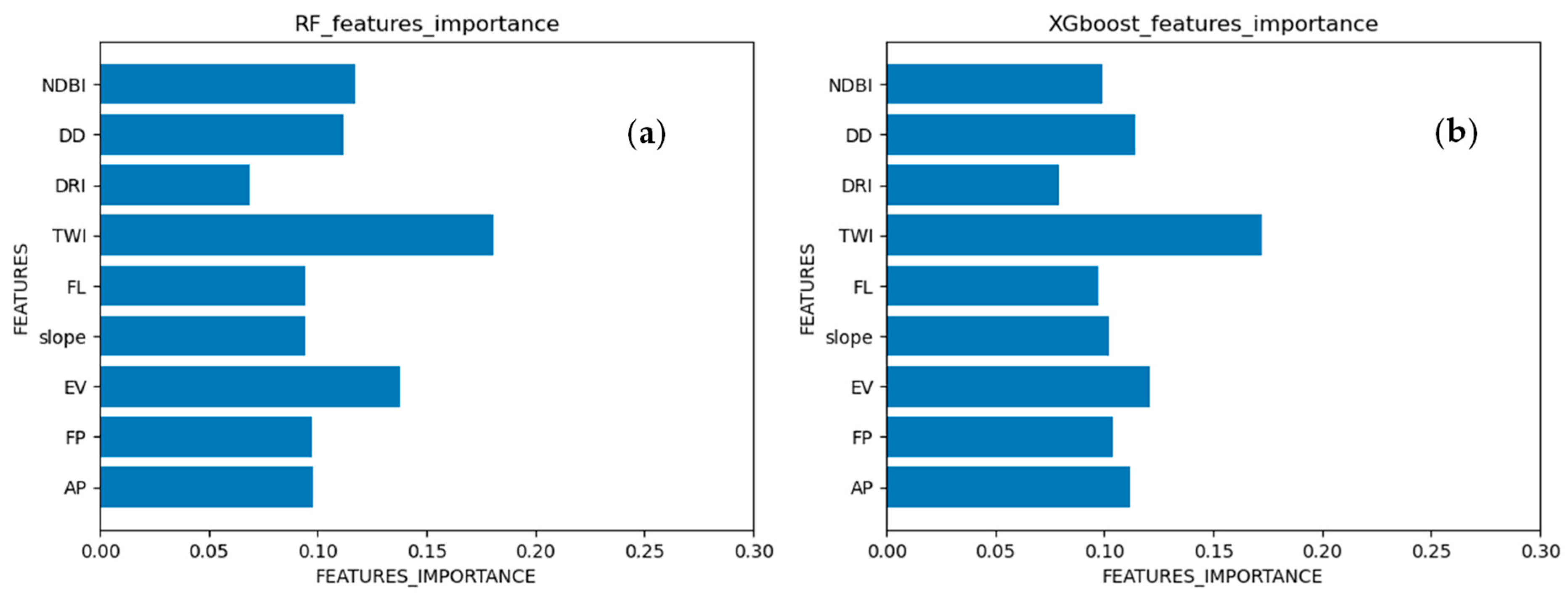
3.2. Feature Importance
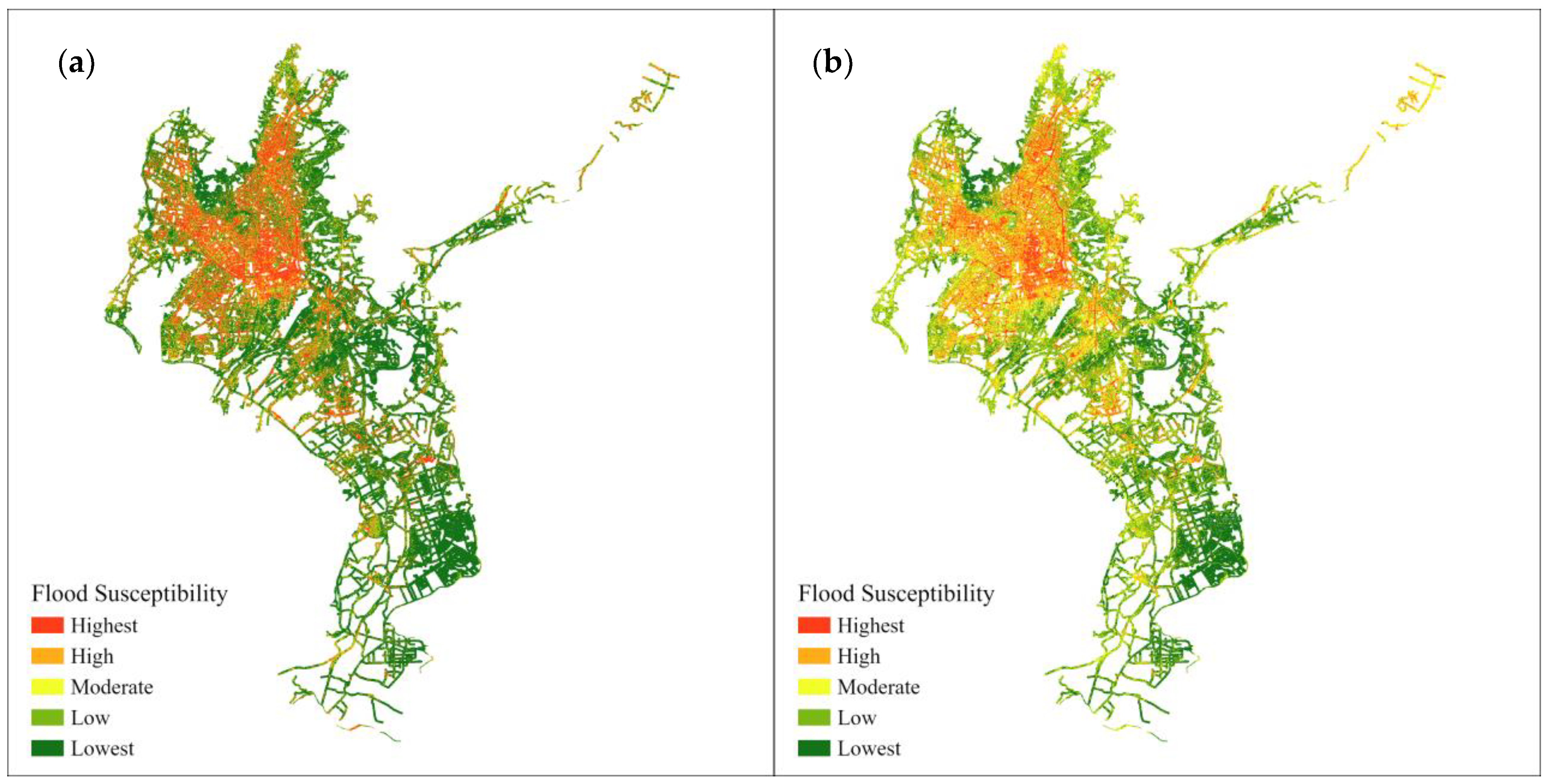
3.3. Flood Susceptibility Map
3.4. Flood Susceptibility in Road Network
4. Discussion
5. Conclusions
- (1)
- Both ensemble learning models, RF and XGBoost, demonstrate high accuracy in assessing flood susceptibility in mountainous urban areas. RF exhibits the best performance among all models, achieving an Acc of 0.81, Pre of 0.80, Rec of 0.81, and Kappa score of 0.89. XGBoost closely follows, with an accuracy of 0.80, precision of 0.78, recall of 0.81, and a Kappa score of 0.88. Their performances are significantly superior to those of ANN and SVM.
- (2)
- The selection of negative samples significantly impacts the assessment of flood susceptibility. Using different negative samples yields flood susceptibility maps with varying features. The feature importance in ensemble learning algorithms reveals the differences in the potential distribution of positive and negative samples in the training data. Feature importance in ensemble learning can be utilized to minimize human bias in the collection of flooded-site samples.
- (3)
- The strategy of randomly sampling negative samples demands greater robustness from machine learning algorithms. Ensemble learning algorithms are reliable and robust in handling the uncertainty of negative samples. With an increase in the number of negative samples, ensemble learning demonstrates strong generalization and noise resistance capabilities.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jayawardena, A.W. Hydro-Meteorological Disasters: Causes, Effects and Mitigation Measures with Special Reference to Early Warning with Data Driven Approaches of Forecasting. Procedia IUTAM 2015, 17, 3–12. [Google Scholar] [CrossRef]
- Hammond, M.J.; Chen, A.S.; Djordjević, S.; Butler, D.; Mark, O. Urban Flood Impact Assessment: A State-of-the-Art Review. Urban Water J. 2015, 12, 14–29. [Google Scholar] [CrossRef]
- Nkwunonwo, U.C.; Whitworth, M.; Baily, B. A Review of the Current Status of Flood Modelling for Urban Flood Risk Management in the Developing Countries. Sci. Afr. 2020, 7, e00269. [Google Scholar] [CrossRef]
- O’Donnell, E.C.; Thorne, C.R. Drivers of Future Urban Flood Risk. Philos. Trans. R. Soc. A 2020, 378, 20190216. [Google Scholar] [CrossRef] [PubMed]
- Miller, J.D.; Hutchins, M. The Impacts of Urbanisation and Climate Change on Urban Flooding and Urban Water Quality: A Review of the Evidence Concerning the United Kingdom. J. Hydrol. Reg. Stud. 2017, 12, 345–362. [Google Scholar] [CrossRef]
- Stoffel, M.; Wyżga, B.; Marston, R.A. Floods in Mountain Environments: A Synthesis. Geomorphology 2016, 272, 1–9. [Google Scholar] [CrossRef]
- Qi, W.; Ma, C.; Xu, H.; Chen, Z.; Zhao, K.; Han, H. A Review on Applications of Urban Flood Models in Flood Mitigation Strategies. Nat. Hazards 2021, 108, 31–62. [Google Scholar] [CrossRef]
- Recanatesi, F.; Petroselli, A. Land Cover Change and Flood Risk in a Peri-Urban Environment of the Metropolitan Area of Rome (Italy). Water Resour. Manag. 2020, 34, 4399–4413. [Google Scholar] [CrossRef]
- Nardi, F.; Annis, A.; Di Baldassarre, G.; Vivoni, E.R.; Grimaldi, S. GFPLAIN250m, a Global High-Resolution Dataset of Earth’s Floodplains. Sci. Data 2019, 6, 180309. [Google Scholar] [CrossRef]
- Petroselli, A. LIDAR Data and Hydrological Applications at the Basin Scale. GIScience Remote Sens. 2012, 49, 139–162. [Google Scholar] [CrossRef]
- Blöschl, G.; Ardoin-Bardin, S.; Bonell, M.; Dorninger, M.; Goodrich, D.; Gutknecht, D.; Matamoros, D.; Merz, B.; Shand, P.; Szolgay, J. At What Scales Do Climate Variability and Land Cover Change Impact on Flooding and Low Flows? Hydrol. Process. 2007, 21, 1241–1247. [Google Scholar] [CrossRef]
- Pinos, J.; Timbe, L. Performance Assessment of Two-Dimensional Hydraulic Models for Generation of Flood Inundation Maps in Mountain River Basins. Water Sci. Eng. 2019, 12, 11–18. [Google Scholar] [CrossRef]
- Cao, F.; Tao, Q.; Dong, S.; Li, X. Influence of Rain Pattern on Flood Control in Mountain Creek Areas: A Case Study of Northern Zhejiang. Appl. Water Sci. 2020, 10, 224. [Google Scholar] [CrossRef]
- Jiang, W.; Yu, J. Impact of Rainstorm Patterns on the Urban Flood Process Superimposed by Flash Floods and Urban Waterlogging Based on a Coupled Hydrologic–Hydraulic Model: A Case Study in a Coastal Mountainous River Basin within Southeastern China. Nat. Hazards 2022, 112, 301–326. [Google Scholar] [CrossRef]
- Moghim, S.; Gharehtoragh, M.A.; Safaie, A. Performance of the Flood Models in Different Topographies. J. Hydrol. 2023, 620, 129446. [Google Scholar] [CrossRef]
- Zhao, Y.; Xia, J.; Xu, Z.; Qiao, Y.; Zhao, G.; Zhang, H. An Urban Hydrological Model for Flood Simulation in Piedmont Cities: Case Study of Jinan City, China. J. Hydrol. 2023, 625, 130040. [Google Scholar] [CrossRef]
- Costabile, P.; Costanzo, C.; Kalogiros, J.; Bellos, V. Toward Street-Level Nowcasting of Flash Floods Impacts Based on HPC Hydrodynamic Modeling at the Watershed Scale and High-Resolution Weather Radar Data. Water Resour. Res. 2023, 59, e2023WR034599. [Google Scholar] [CrossRef]
- Pham, B.T.; Avand, M.; Janizadeh, S.; Phong, T.V.; Al-Ansari, N.; Ho, L.S.; Das, S.; Le, H.V.; Amini, A.; Bozchaloei, S.K. GIS Based Hybrid Computational Approaches for Flash Flood Susceptibility Assessment. Water 2020, 12, 683. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A Novel Hybrid Artificial Intelligence Approach for Flood Susceptibility Assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Kanani-Sadat, Y.; Arabsheibani, R.; Karimipour, F.; Nasseri, M. A New Approach to Flood Susceptibility Assessment in Data-Scarce and Ungauged Regions Based on GIS-Based Hybrid Multi Criteria Decision-Making Method. J. Hydrol. 2019, 572, 17–31. [Google Scholar] [CrossRef]
- Hu, S.; Cheng, X.; Zhou, D.; Zhang, H. GIS-Based Flood Risk Assessment in Suburban Areas: A Case Study of the Fangshan District, Beijing. Nat. Hazards 2017, 87, 1525–1543. [Google Scholar] [CrossRef]
- Khoirunisa, N.; Ku, C.-Y.; Liu, C.-Y. A GIS-Based Artificial Neural Network Model for Flood Susceptibility Assessment. Int. J. Environ. Res. Public Health 2021, 18, 1072. [Google Scholar] [CrossRef] [PubMed]
- Al-Abadi, A.M. Mapping Flood Susceptibility in an Arid Region of Southern Iraq Using Ensemble Machine Learning Classifiers: A Comparative Study. Arab. J. Geosci. 2018, 11, 218. [Google Scholar] [CrossRef]
- Rahman, M.; Ningsheng, C.; Islam, M.M.; Dewan, A.; Iqbal, J.; Washakh, R.M.A.; Shufeng, T. Flood Susceptibility Assessment in Bangladesh Using Machine Learning and Multi-Criteria Decision Analysis. Earth Syst. Environ. 2019, 3, 585–601. [Google Scholar] [CrossRef]
- Bui, D.T.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A Novel Deep Learning Neural Network Approach for Predicting Flash Flood Susceptibility: A Case Study at a High Frequency Tropical Storm Area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of Urban Flood Susceptibility Using Semi-Supervised Machine Learning Model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef] [PubMed]
- Madhuri, R.; Sistla, S.; Srinivasa Raju, K. Application of Machine Learning Algorithms for Flood Susceptibility Assessment and Risk Management. J. Water Clim. Chang. 2021, 12, 2608–2623. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Zuo, D. Urban Flood Susceptibility Assessment Based on Convolutional Neural Networks. J. Hydrol. 2020, 590, 125235. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood Susceptibility Assessment Using GIS-Based Support Vector Machine Model with Different Kernel Types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Costache, R. Flood Susceptibility Assessment by Using Bivariate Statistics and Machine Learning Models-a Useful Tool for Flood Risk Management. Water Resour. Manag. 2019, 33, 3239–3256. [Google Scholar] [CrossRef]
- Abedi, R.; Costache, R.; Shafizadeh-Moghadam, H.; Pham, Q.B. Flash-Flood Susceptibility Mapping Based on XGBoost, Random Forest and Boosted Regression Trees. Geocarto Int. 2022, 37, 5479–5496. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L.; et al. A Comparative Assessment of Flood Susceptibility Modeling Using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- MacInnes, J.; Santosa, S.; Wright, W. Visual Classification: Expert Knowledge Guides Machine Learning. IEEE Comput. Graph. Appl. 2010, 30, 8–14. [Google Scholar] [CrossRef] [PubMed]
- Belton, V.; Stewart, T. Multiple Criteria Decision Analysis: An Integrated Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002; ISBN 0-7923-7505-X. [Google Scholar]
- Chen, J.; Huang, G.; Chen, W. Towards Better Flood Risk Management: Assessing Flood Risk and Investigating the Potential Mechanism Based on Machine Learning Models. J. Environ. Manag. 2021, 293, 112810. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Wang, J.; Abbas, Z.; Yang, Y.; Zhao, Y. Ensemble Learning Analysis of Influencing Factors on the Distribution of Urban Flood Risk Points: A Case Study of Guangzhou, China. Front. Earth Sci. 2023, 11. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Zhou, Z.-H. Ensemble Learning; Springer: Berlin/Heidelberg, Germany, 2021; ISBN 9811519668. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble Learning: A Survey. WIREs Data Min. Knowl. Discov. 2018, 8. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A Survey on Ensemble Learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Guan, D.; Yuan, W.; Lee, Y.-K.; Najeebullah, K.; Rasel, M.K. A Review of Ensemble Learning Based Feature Selection. IETE Tech. Rev. 2014, 31, 190–198. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for Feature Selection: A Review and Future Trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Van Ootegem, L.; Verhofstadt, E.; Van Herck, K.; Creten, T. Multivariate Pluvial Flood Damage Models. Environ. Impact Assess. Rev. 2015, 54, 91–100. [Google Scholar] [CrossRef]
- Zhang, D.; Shi, X.; Xu, H.; Jing, Q.; Pan, X.; Liu, T.; Wang, H.; Hou, H. A GIS-Based Spatial Multi-Index Model for Flood Risk Assessment in the Yangtze River Basin, China. Environ. Impact Assess. Rev. 2020, 83, 106397. [Google Scholar] [CrossRef]
- Zhao, X.; Huang, G. Urban Watershed Ecosystem Health Assessment and Ecological Management Zoning Based on Landscape Pattern and SWMM Simulation: A Case Study of Yangmei River Basin. Environ. Impact Assess. Rev. 2022, 95, 106794. [Google Scholar] [CrossRef]
- Meyer, F. Topographic Distance and Watershed Lines. Signal Process. 1994, 38, 113–125. [Google Scholar] [CrossRef]
- Sørensen, R.; Zinko, U.; Seibert, J. On the Calculation of the Topographic Wetness Index: Evaluation of Different Methods Based on Field Observations. Hydrol. Earth Syst. Sci. 2006, 10, 101–112. [Google Scholar] [CrossRef]
- BEVEN, K.J.; KIRKBY, M.J. A Physically Based, Variable Contributing Area Model of Basin Hydrology / Un Modèle à Base Physique de Zone d’appel Variable de l’hydrologie Du Bassin Versant. Hydrol. Sci. Bull. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- O’Neill, E.; Brereton, F.; Shahumyan, H.; Clinch, J.P. The Impact of Perceived Flood Exposure on Flood-Risk Perception: The Role of Distance: Flood-Risk Perception: The Role of Distance. Risk Anal. 2016, 36, 2158–2186. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping Flood Susceptibility in Mountainous Areas on a National Scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Horton, R.E. Erosional Development of Streams and Their Drainage Basins. Hydrophysical Approach To Quantitative Morphology. GSA Bull. 1945, 56, 275–370. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of Normalized Difference Built-up Index in Automatically Mapping Urban Areas from TM Imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Varshney, A. Improved NDBI Differencing Algorithm for Built-up Regions Change Detection from Remote-Sensing Data: An Automated Approach. Remote Sens. Lett. 2013, 4, 504–512. [Google Scholar] [CrossRef]
- Aslam, A.; Rana, I.A.; Bhatti, S.S. The Spatiotemporal Dynamics of Urbanisation and Local Climate: A Case Study of Islamabad, Pakistan. Environ. Impact Assess. Rev. 2021, 91, 106666. [Google Scholar] [CrossRef]
- Breiman Random Forests. Mach. Learn. 2001, 45, 5–32. [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Li, L.; Du, Y.; Ma, S.; Ma, X.; Zheng, Y.; Han, X. Environmental Disaster and Public Rescue: A Social Media Perspective. Environ. Impact Assess. Rev. 2023, 100, 107093. [Google Scholar] [CrossRef]
- Chen, X.; Shuai, C.; Zhao, B.; Zhang, Y.; Li, K. Imputing Environmental Impact Missing Data of the Industrial Sector for Chinese Cities: A Machine Learning Approach. Environ. Impact Assess. Rev. 2023, 100, 107050. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Singh, V.P.; Woolhiser, D.A. Mathematical Modeling of Watershed Hydrology. J. Hydrol. Eng. 2002, 7, 270–292. [Google Scholar] [CrossRef]
- Gonçalves, L.; Subtil, A.; Oliveira, M.R.; de Zea Bermudez, P. ROC Curve Estimation: An Overview. REVSTAT-Stat. J. 2014, 12, 1–20. [Google Scholar] [CrossRef]
- Chen, J.; Yang, S.T.; Li, H.W.; Zhang, B.; Lv, J.R. Research on Geographical Environment Unit Division Based on the Method of Natural Breaks (Jenks). Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-4/W3, 47–50. [Google Scholar] [CrossRef]
- Chen, A.S.; Evans, B.; Djordjević, S.; Savić, D.A. A Coarse-Grid Approach to Representing Building Blockage Effects in 2D Urban Flood Modelling. J. Hydrol. 2012, 426–427, 1–16. [Google Scholar] [CrossRef]
- Schubert, J.E.; Sanders, B.F. Building Treatments for Urban Flood Inundation Models and Implications for Predictive Skill and Modeling Efficiency. Adv. Water Resour. 2012, 41, 49–64. [Google Scholar] [CrossRef]
- Mallick, R.B.; Tao, M.; MK, N. Impact of Flooding on Roadways. Geotech. Nat. Eng. Sustain. Technol. GeoNEst 2018, 385–397. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Data Source | Format | |
|---|---|---|---|
| Climatic | AP | CHIRPS | 5 km × 5 km Raster |
| FP | CHIRPS | 5 km × 5 km Raster | |
| Geomorphic | EV | Kunming Natural Resources and Planning Bureau. | 20 m × 20 m Raster |
| FL | From DEM | 20 m × 20 m Raster | |
| TWI | From DEM | 20 m × 20 m Raster | |
| SL | From DEM | 20 m × 20 m Raster | |
| DRI | Kunming Flood Control and Drought Relief Headquarters Office | GIS Polyline Shape | |
| Anthropogenic | DRO | Kunming Natural Resources and Planning Bureau. | GIS Polyline Shape |
| DD | Kunming Flood Control and Drought Relief Headquarters Office | GIS Polyline Shape | |
| NDBI | Landsat 8 satellite | 30 m × 30 m Raster | |
| RF | XGBoost | SVM | ANN | |
| Acc | 0.81 | 0.80 | 0.78 | 0.76 |
| Pre | 0.80 | 0.78 | 0.82 | 0.69 |
| Rec | 0.81 | 0.81 | 0.76 | 0.81 |
| F1 | 0.80 | 0.79 | 0.78 | 0.73 |
| Kappa | 0.89 | 0.88 | 0.85 | 0.85 |
| RF | XGBoost | SVM | BPNN | |||||
|---|---|---|---|---|---|---|---|---|
| Number | Proportion | Number | Proportion | Number | Proportion | Number | Proportion | |
| Highest | 254 | 74.7% | 285 | 83.8% | 217 | 63.8% | 260 | 76.5% |
| High | 51 | 15.0% | 18 | 5.3% | 70 | 20.6% | 44 | 12.9% |
| Moderate | 19 | 5.6% | 9 | 2.6% | 28 | 8.2% | 15 | 4.4% |
| Low | 11 | 3.2% | 9 | 2.6% | 16 | 4.7% | 12 | 3.5% |
| Lowest | 2 | 0.6% | 16 | 4.7% | 6 | 1.8% | 6 | 1.8% |
| RF | XGBoost | SVM | BPNN | |
| Highest | 118,350 | 214,492 | 172,260 | 197,711 |
| High | 149,583 | 82,366 | 187,810 | 162,711 |
| Moderate | 243,332 | 79,758 | 216,815 | 175,000 |
| Low | 348,563 | 124,056 | 325,784 | 247,556 |
| Lowest | 580,254 | 939,410 | 537,413 | 657,104 |
| RF | XGBoost | |||
|---|---|---|---|---|
| Number | Proportion | Number | Proportion | |
| Highest | 264 | 83.8% | 275 | 87.3% |
| High | 31 | 9.8% | 17 | 5.4% |
| Moderate | 10 | 3.2% | 4 | 1.3% |
| Low | 6 | 1.9% | 7 | 2.2% |
| Lowest | 4 | 1.3% | 12 | 3.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, H.; Pang, B.; Bai, P.; Zhao, G.; Liu, S.; Liu, Y.; Li, M. Flood Susceptibility Assessment with Random Sampling Strategy in Ensemble Learning (RF and XGBoost). Remote Sens. 2024, 16, 320. https://doi.org/10.3390/rs16020320
Ren H, Pang B, Bai P, Zhao G, Liu S, Liu Y, Li M. Flood Susceptibility Assessment with Random Sampling Strategy in Ensemble Learning (RF and XGBoost). Remote Sensing. 2024; 16(2):320. https://doi.org/10.3390/rs16020320
Chicago/Turabian StyleRen, Hancheng, Bo Pang, Ping Bai, Gang Zhao, Shu Liu, Yuanyuan Liu, and Min Li. 2024. "Flood Susceptibility Assessment with Random Sampling Strategy in Ensemble Learning (RF and XGBoost)" Remote Sensing 16, no. 2: 320. https://doi.org/10.3390/rs16020320
APA StyleRen, H., Pang, B., Bai, P., Zhao, G., Liu, S., Liu, Y., & Li, M. (2024). Flood Susceptibility Assessment with Random Sampling Strategy in Ensemble Learning (RF and XGBoost). Remote Sensing, 16(2), 320. https://doi.org/10.3390/rs16020320