1. Introduction
As a potent remote sensing technique, hyperspectral imaging might capture high-dimensional data about the Earth’s surface or other objects [
1,
2,
3]. Unlike traditional remote sensing, which captures only a few broad spectral bands, hyperspectral imaging measures the reflectance or emission of light by spanning hundreds of contiguous and narrow spectral bands. These bands come from the shortwave-infrared, near-infrared, and visible sections of the electromagnetic spectrum. The resulting hyperspectral images (HSIs) contain plenty of information about the composition of materials on the surface that can be used in diverse applications, such as vegetation research, ocean exploration, mineral exploration, and disaster response. By analyzing the spectral signatures of various materials, hyperspectral imaging can be used to assist in the identification and mapping of different land cover types, such as forests, wetlands, urban areas, impervious (nonporous) surfaces, and agricultural fields [
4,
5,
6,
7].
In recent decades, many methods relying on artificial features have been developed [
8,
9,
10,
11,
12]. However, artificial feature extraction is often constrained by domain-specific knowledge and expertise, making it challenging to adapt to different datasets and applications, and it lacks sufficient adaptability [
13].
Unlike traditional images, remote sensing image data typically contains more dimensions. With the increase in data dimensionality, classifier performance often shows an initial improvement, because the added dimensions provide more information, enabling the classifier to better distinguish between different categories. However, as dimensionality continues to increase, performance eventually reaches a saturation point, where classification accuracy no longer improves and may even slightly decrease. This suggests that adding dimensions no longer provides useful information after, and may actually introduce noise or redundancy; this is referred to as the Hughes Phenomenon [
14]. Therefore, dimensionality reduction is necessary to mitigate the effects of the dimensionality curse.
For remote sensing images, several dimensionality reduction methods have been presented, which can be broadly classified into two categories: feature extraction [
15] and band selection [
16].
Representative feature extraction methods include principal component analysis (PCA), independent component analysis, and linear discriminant analysis [
17,
18], among others. With the advancement of computer technology, supervised classification methods have evolved in sophistication. Supervised classification utilizes labeled sample data to train classification models or algorithms, such as support vector machines (SVM) [
19] and random forests [
20]. These models and algorithms enable the automatic classification of different land cover categories, and also have achieved significant improvements in accuracy and efficiency.
The rise of deep learning methods signifies a significant advancement in remote sensing image classification. Deep learning methods, particularly convolutional neural networks (CNNs) [
21,
22,
23,
24,
25], exhibit excellent performance in image classification. Notably, they have the ability to automatically extract high-level features from remote sensing images without the need for complex feature engineering. This results in increased accuracy in remote sensing image classification. Furthermore, there are also methods that combine transformers and CNNs for HSI classification [
26,
27,
28,
29,
30,
31]. Deep learning models, especially CNNS, can automatically learn features from raw data. This means that there is no need for manual feature engineering, and that the model itself can discover the most important features. In contrast, SVM typically requires manual feature selection and extraction [
32].
Band selection (BS) can help remove redundant spectral bands, thereby reducing the dimensionality of the HSI data. Furthermore, this can decrease computational costs, accelerate model training speed, and mitigate the risk of overfitting. Feature extraction also allows the model to automatically extract advanced features, while BS assists in selecting spectral bands relevant to the task. By integrating these two approaches, it is possible to achieve comprehensive use of the rich information in the HSI data. This includes various spectral features of the original data, as well as domain knowledge related to the task. This helps improve the model’s representational capacity and performance.
Harnessing the capabilities of these recent advances in technology, we propose a novel lightweight network architecture for HSI classification based on Visual Geometry Group (VGG) networks [
33] and the incorporation of dimensionality reduction and multi-layer perceptron (MLP). In this method, we performed band selection to eliminate duplicate or redundant bands. Prioritizing band selection allowed us to identify the most relevant bands for classification. Furthermore, by using PCA dimensionality reduction, not only was the impact of noise reduced, but the amount of training data was reduced as well. These data preprocessing also improved the efficiency of subsequent network training and increased classification accuracy.
The contributions of this paper can be summarized as follows:
We simultaneously used band selection and whitened PCA to relieve the impact of random seeds on experimental results;
We propose a novel lightweight-VGG (LVGG) network architecture for HSI classification, which aims to maintain high performance while reducing the complexity and computational resource requirements of the network, enabling efficient HSI classification even in resource-constrained environments;
Our proposed method achieved better accuracy in three publicly available HSI datasets as compared to several other existing methods.
The remainder of this paper is organized as follows:
Section 2 describes some related data preprocessing studies. In
Section 3, the proposed LVGG network is introduced in detail.
Section 4 introduces three publicly available HSI datasets and divides them into three parts (i.e., training, validation, and test sets).
Section 5 analyzes comparative experimental results on three HSI datasets, and demonstrates the effectiveness of our method. Finally, some conclusions and discussions are provided in
Section 6.
3. Proposed Method
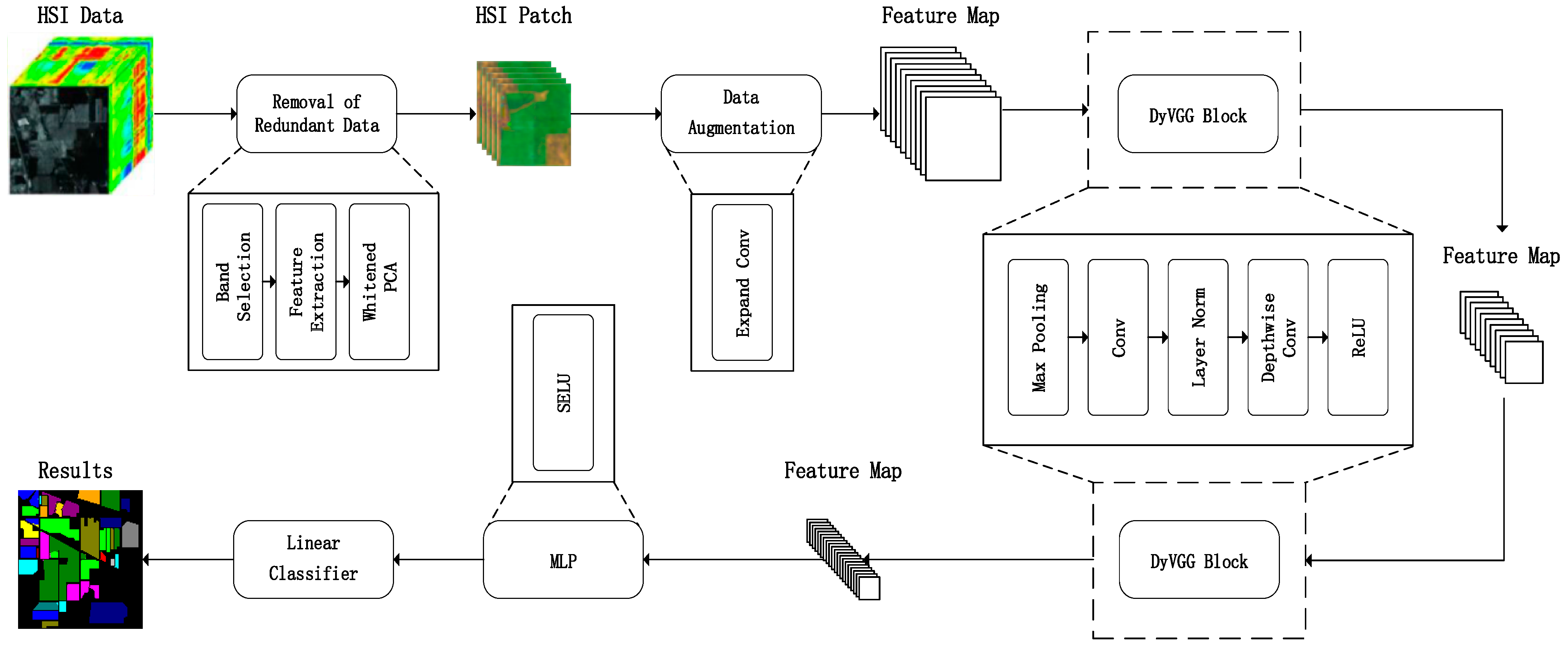
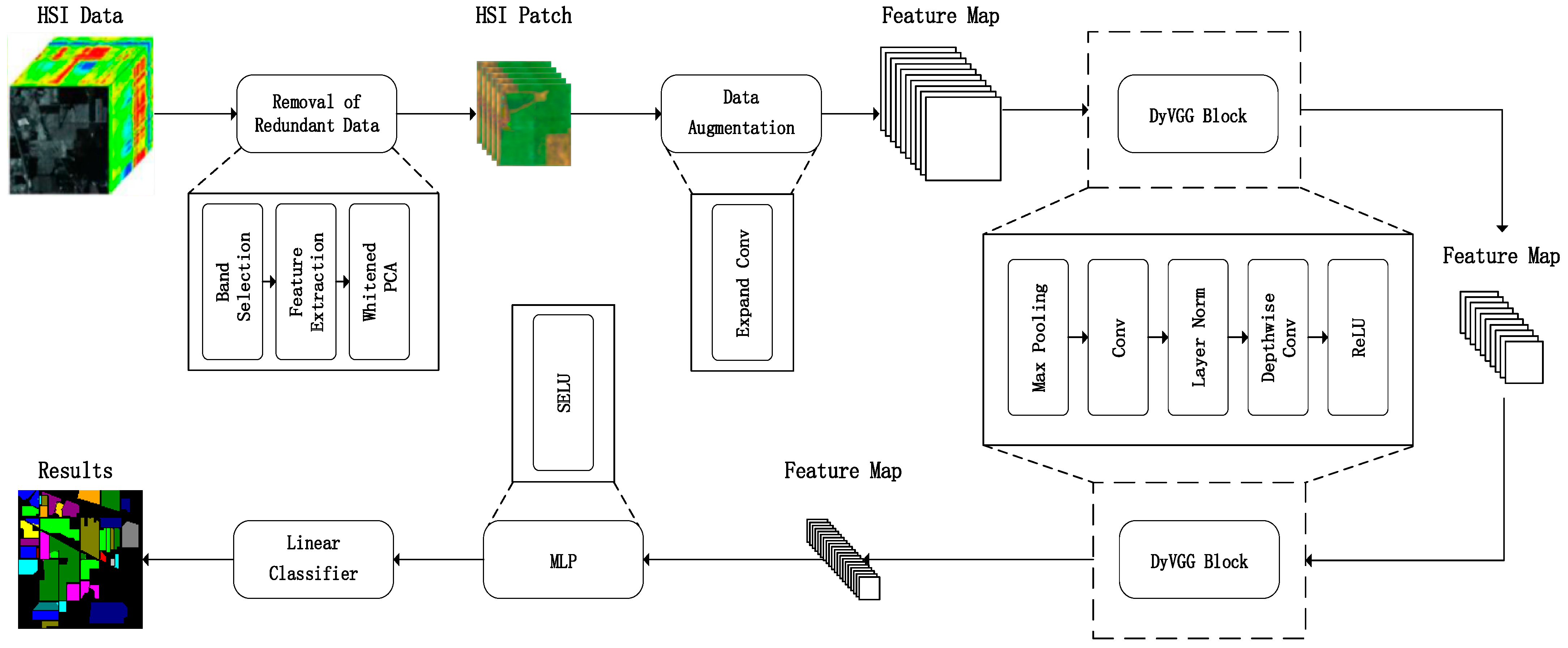
The workflow of the proposed lightweight-VGG method is depicted in
Figure 1 and encompasses four primary stages. In this method, dimensionality reduction preprocessing is performed on the original HSI data. Next, an expand convolution is introduced to increase the network’s capacity, enabling the network to capture more data features, thus enhancing its performance. The dimension-enhanced data is then fed into a DyVGG block for patch-level feature extraction, and the extracted features are inputted into MLP and linear classifier layers to obtain the predicted labels of the sample data.
3.1. The Removal of Redundant Data
In HSI preprocessing, band selection is an effective way of filtering out redundant bands while retaining important information relevant to the target task. Additionally, PCA is usually used to further reduce the impact of noise and extract key feature information. Hence, we propose a redundant data removal method that integrates band selection and PCA.
3.1.1. Band Selection
This passage describes a process for grouping neighboring bands in a dataset represented by
. The bands in
, denoted as
bands, are initially divided into
equal groups. Each group, labeled
(where
= 1, …,
), is defined as follows:
where
represents the
i-th band image of
and
represents the smallest integer greater than or equal to
.
Next, a fine partition algorithm [
53] is applied to each of the initial band groups
(
= 1, …,
) to create new band groups
(
= 1, …,
). In this new partition, the number of bands may not be the same for different groups, and it is thus designed to group highly correlated spectral bands together, thereby resulting in lower correlation between the different band groups. For simplicity in this description, the new band groups are still marked with
(
= 1, …,
), so the final grouping representation of
is given by:
These highly correlated spectral bands are grouped together, resulting in lower correlation between band groups. Therefore, selecting representative bands from each band group becomes a more reasonable approach. For each band group, we utilize correlation coefficients to find a representative band that is most relevant to other bands in its group. The above process is described in detail as follows:
Step 1: Calculation of Pearson correlation coefficient. For band
x and band
y, the correlation coefficient
can be calculated using the following formula:
where
N represents the number of samples, that is, the number of spatial pixels.
Step 2: Construction of a correlation coefficient matrix. Assuming the number of bands is
for band group
, then the correlation coefficient matrix
(with a size of
×
) is constructed as follows:
where the element
comes from Formula (3).
Step 3: Select the most representative spectral band. For band group
, we sum the correlation coefficient matrix
by column, resulting in a vector
with a size of 1 ×
:
Then, it is easy to find the maximum value in vector
and locate the index of its column:
Hence, the band corresponding to the index is the most representative spectral band of band group .
By selecting the most representative band from each group, a spectral band set
with a dimension of
is formed:
where
represents the chosen band from the
k-th band group.
3.1.2. Whitened PCA
In order to further reduce HSI data dimensionality and eliminate the noise effect in downstream classification, the PCA technique is employed to handle the selected band set ; this preserves most of the information from the original dataset to ensure accuracy in the subsequent training.
Whitened PCA, an extension of PCA, not only reduces data dimensionality, but also eliminates data inter-correlations through linear transformations. Subsequently, whitened data is partitioned into smaller blocks or patches, each of which is centered around a pixel; the label of the central pixel serves as the ground truth label for the patch. To ensure accurate patch extraction, mirror padding is applied to the HSI data. Mirror padding duplicates data values at the boundaries, creating a seamless extension of the original HSI data. Eventually, these patches are inputted into the proposed lightweight-VGG network for the training process.
3.2. Expand Convolution
The proposed method uses 1 × 1 × 128 convolutional kernels to expand the data after dimensionality reduction. This is because the reduced-dimensional data contains too few channels, making it challenging for the network to effectively fit the data. By using more convolutional kernels, features from the reduced dimensional data can be extracted more comprehensively, enabling better learning of critical information within the data. Additionally, this approach enhances the model’s generalization capabilities, ultimately leading to improved classification performance.
Simultaneously increasing the dimensionality can lower the impact of the activation function on the results. If the current activation space has a high degree of integrity for the manifold of interest, passing through the rectified linear unit (ReLU) activation function can cause the activation space to collapse, inevitably resulting in information loss.
3.3. DyVGG Block
The primary characteristic of the previous VGG network is its use of stacked 3 × 3 convolutional layers and 2 × 2 max-pooling layers to create a deep neural network. Using 3 × 3 convolution offers fast computation and a streamlined single-path architecture, while also offering good memory efficiency compared to other structures (such as ResNet’s shortcuts, which do not add to computational load but require double the GPU memory). Additionally, the use of 2 × 2 max-pooling layers effectively reduces the overall number of parameters.
Due to the depth and larger model size of the VGG network, it contains a significant number of parameters, requiring more computational resources and storage space. This can potentially limit its applicability in resource-constrained environments. Additionally, the large number of parameters in the VGG network results in relatively long training times.
To address these above issues, we have introduced a DyVGG block instead of the traditional VGG network, which includes three key points: reduction of network depth, replacement of batch normalization (BN), and use of depthwise convolution.
Point 1: reduction of network depth. We significantly reduced the number of convolutional layers, relying primarily on two sets of 3 × 3 convolutions and two rounds of max-pooling for feature learning. Max-pooling with a stride of 2 is also employed. Max-pooling preserves the maximum value within each pooling window, reducing image resolution and consequently decreasing the number of parameters. This helps alleviate the computational burden on the model, reduces the risk of overfitting, and enhances the network’s generalization capability. Our network structure has 11 fewer CNN layers and 3 fewer max-pool layers than the VGG-16 network.
Point 2: replacement of batch normalization. In this method, layer normalization (LN) is used instead of batch normalization. Following the optimization strategy from ConvNeXt [
54], LN is employed after the convolutional layer. The advantages of layer normalization compared to batch normalization include: (1) insensitivity to small batch sizes; LN’s performance is less affected by small batch sizes, making it effective even when dealing with small batches. (2) Lower parameter count; LN generally requires fewer parameters, resulting in more efficient model sizes. (3) No additional computation overhead; BN necessitates the calculation of batch-wise means and variances, while LN avoids these additional computations, leading to lower computational overhead.
Point 3: use of depthwise convolution. For enhancing the flexibility of the model, we improved the activation function, named DyReLU. After convolution, data passes through a 1 × 1 depthwise convolution [
55] before application of the activation function. DyReLU can be formulated as:
where
x represents the input,
represents the 1 × 1 depthwise learned parameters, and
represents the bias associated with these parameters. Additionally, as the network architecture is relatively shallow, residual structures are not used, which also helps reduce computation time.
3.4. Multi-Layer Perceptron
After the processing of the DyVGG block, the extracted features are flattened and inputted into the FC layers. The primary issue with the original VGG network is the excessive number of neurons used in the FC layers, which leads to a large overall parameter count and slow computation. Our approach significantly optimizes the total number of neurons. The FC layer in VGG16 has 4096 neurons, whereas our approach reduces it to 128, resulting in a substantial reduction while maintaining high classification accuracy. This operation also significantly enhances computational speed.
Furthermore, the activation function is switched from ReLU to scaled exponential linear unit (SELU) [
56] in the fully connected layers, which is defined as follows:
where
x is the input, α and
λ (
λ > 1) are hyperparameters, and
e denotes the exponent.
SELU promotes the self-normalization of hidden layer activations, addressing vanishing/exploding gradient issues common in deep neural networks. It also maintains a stable mean and variance of activations, improving generalization and potentially eliminating the need for additional normalization techniques.
5. Experiments
In this section, we describe the experimental setup, including comparative methods, evaluation metrics, and parameter configurations. Subsequently, we conducted quantitative experiments and ablation studies to assess the effectiveness of our proposed method.
5.1. Experimental Settings
Experimental Environment: The entire experimental process was conducted on a computer equipped with a GeForce RTX 3070Ti and an Intel i7-12700F 12-core processor, with 32 GB of memory, using Python 3.9 and PyTorch 2.0.1.
Data Acquisition: for the IP, PU, and SA datasets, training sets were randomly sampled at 10%, 5%, and 1%, respectively, using random seeds ranging from 1331 to 1340. The remaining data were used as the test sets.
Evaluation Metrics: three universal indicators were employed, i.e., overall accuracy (OA), average accuracy (AA), and the Kappa coefficient (Kappa).
Comparison Methods: to validate the effectiveness of our proposed method, we compared it with several other classification methods, including methods based on CNN and transformers. We evaluated each method with the most effective configuration. The comparison methods used here were as follows:
The 3D CNN (2016) [
25] contains 3D convolution blocks and a softmax layer;
The SSRN (2017) [
42], built upon 3D CNN by incorporating residual structures for shortcuts;
The HybridSN (2019) [
23], which uses PCA for dimensionality reduction, and for which reduced data is fed into a 3DCNN, followed by a 2DCNN, so as to consider both spectral and spatial information simultaneously;
The SSFTT (2022) [
28], which first learns features through 3DCNN and 2DCNN, and then utilizes a transformer for feature-based classifications;
The GAHT (2022) [
27], a network structure composed of three convolutional layers and the integration of transformers;
The DBDA (2020) [
24], a hyperspectral image classification approach that uses a two-branch CNN architecture with a dual-attention mechanism to effectively capture spectral and spatial features;
The FDSSC (2018) [
22], a fast and efficient hyperspectral image classification framework that utilizes dense spectral–spatial convolutions for accurate classification.
Implementation Details: our LVGG model was implemented using the PyTorch framework. First, we reduced the number of bands to 35 through band selection. The PCA dimension and patch size were set to 7 and 41 × 41, respectively. We then adopted the Adam optimizer, with a batch size of 256 and a learning rate of 1 × 10−4. Then, we used cross-entropy loss in lightweight classifiers. The training schedule involved the use of the Adam optimizer and Cosine Annealing. The original learning rate and minimum learning rate were set to 1 × 10−4 and 5 × 10−6, respectively, and the number of epochs was set to 100 for all datasets. Finally, by repeating this experiment ten times with different training sample selections, we obtained the average values as the final results.
5.2. Classification Results
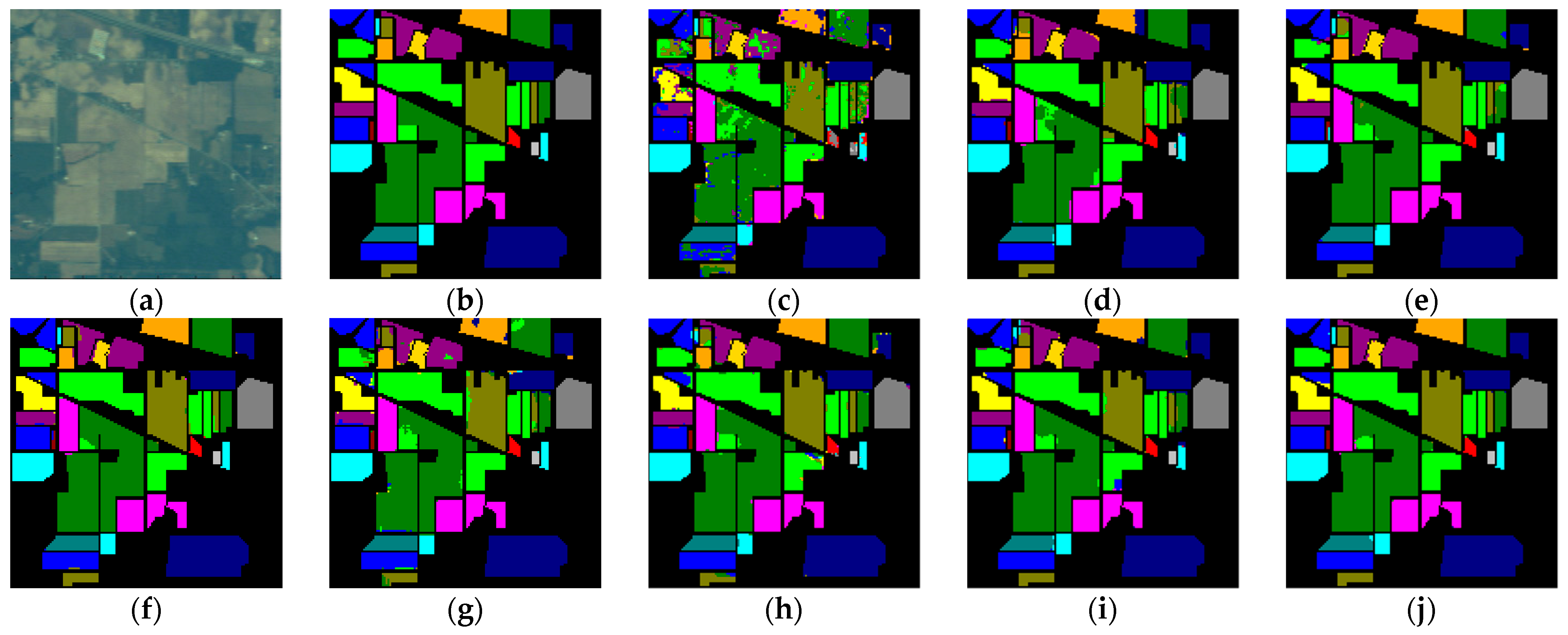
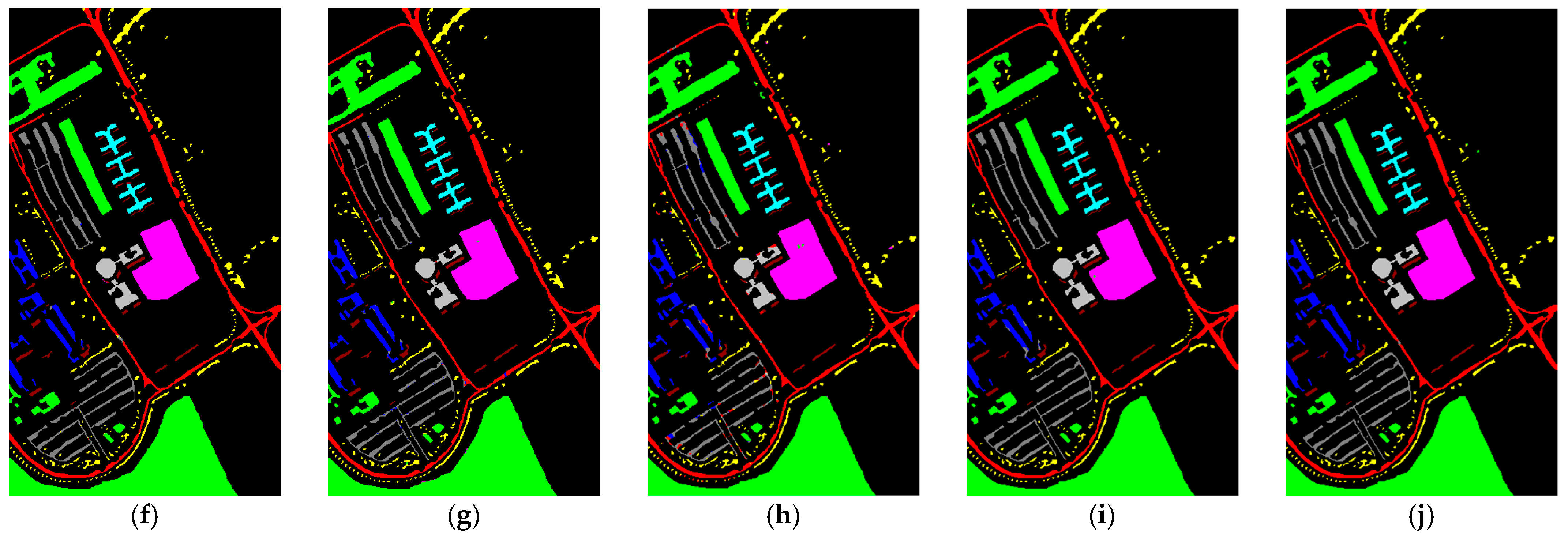
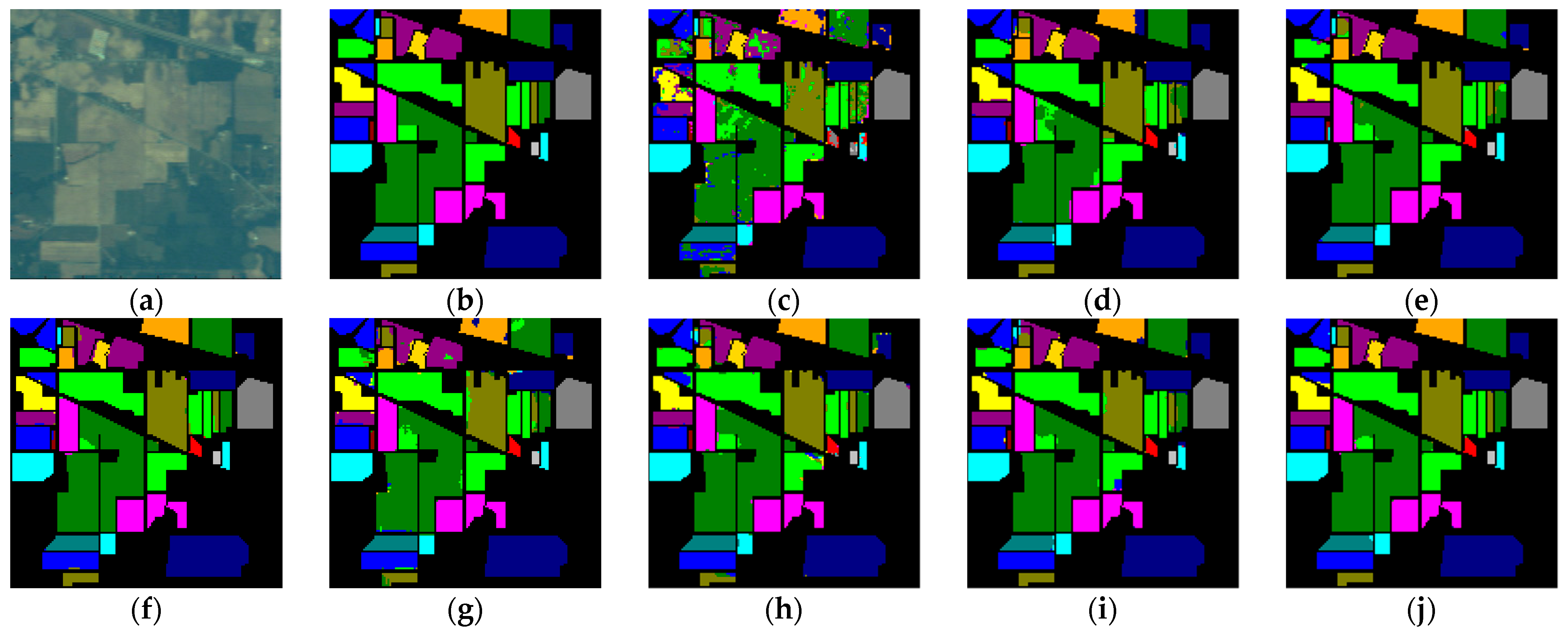
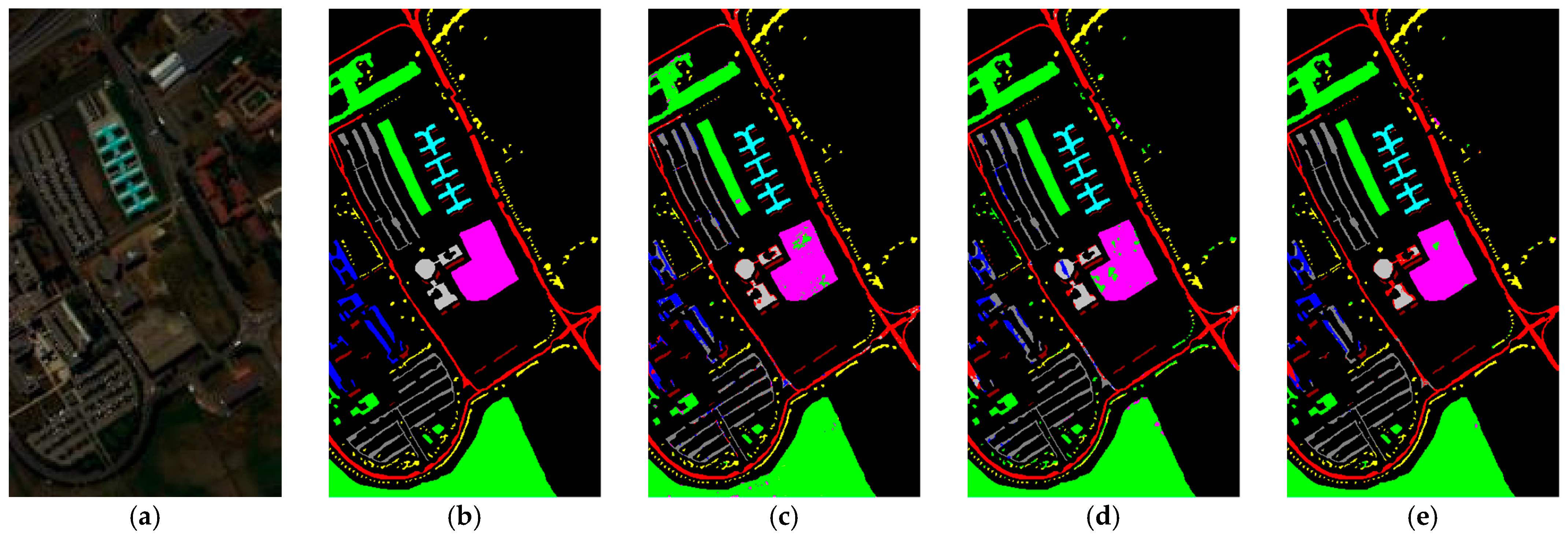
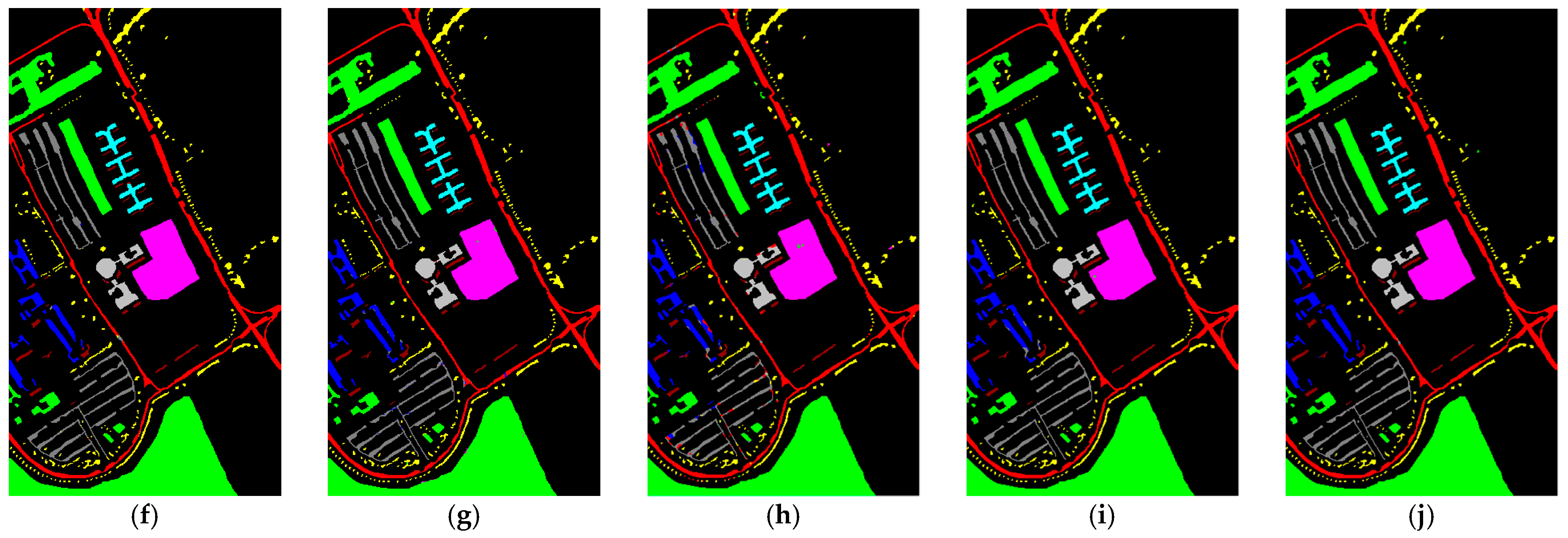
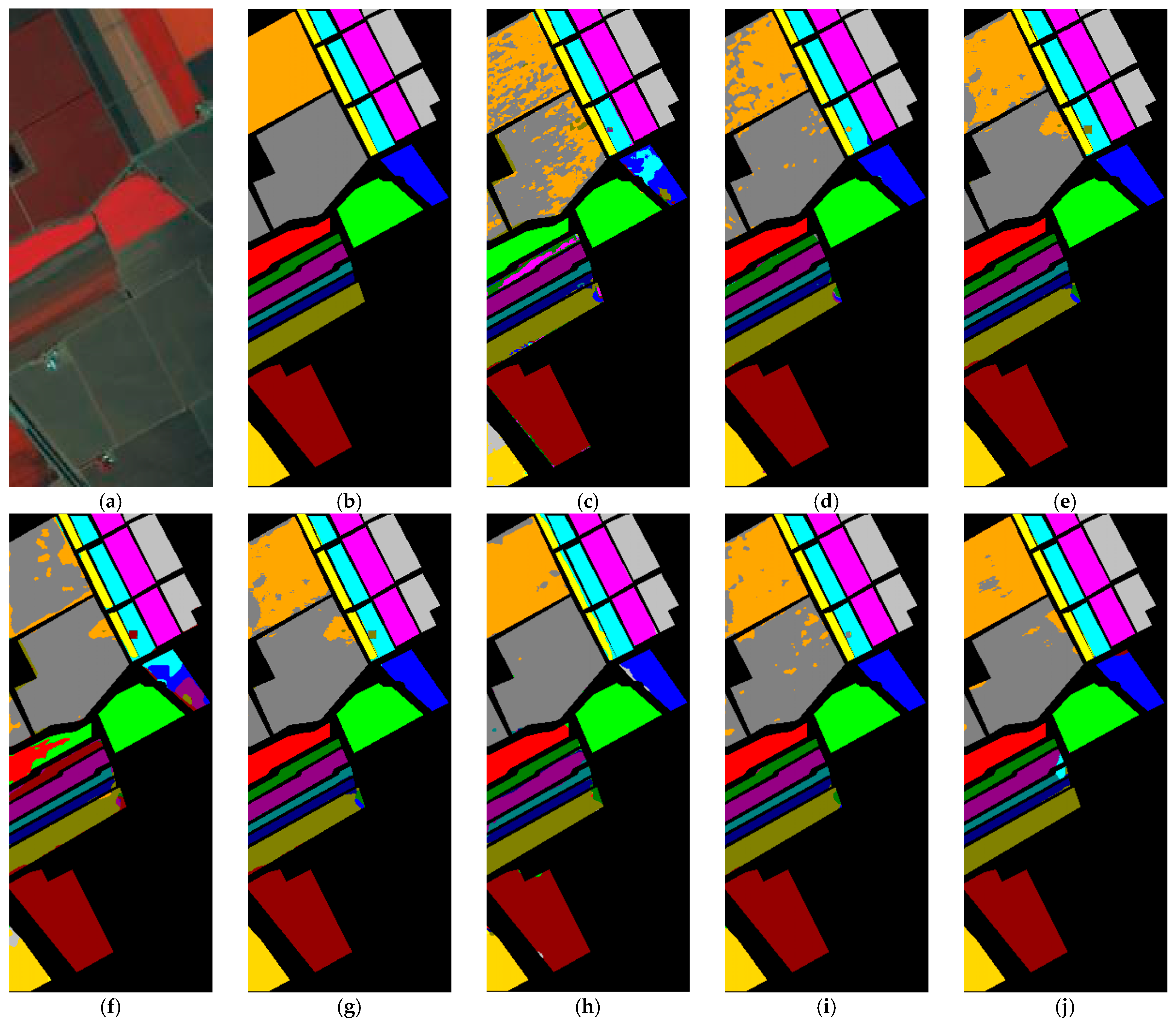
Compared to other methods, the proposed LVGG model achieved the highest OA and Kappa on three benchmark datasets. The classification plots are shown in
Figure 2,
Figure 3 and
Figure 4, respectively, while
Table 4,
Table 5 and
Table 6 display the algorithms’ classification accuracy regarding the three datasets in detail.
5.2.1. IP
Table 4 shows the classification performance of different models on the IP dataset. Among the compared methods, SSRN, HybridSN, DBDA, and FDSSC employ relatively complex CNN-based frameworks, incorporating elements such as 3D CNN, residual connections, and MLP to enhance classification performance. However, these approaches come at the cost of consumed computational time. In contrast, SSFTT, based on a lightweight transformer architecture, offers a shorter training time but exhibits a slight decrease in accuracy compared to other methods.
GAHT adopts a hybrid approach, combining elements of both transformers and CNNs. This hybrid strategy results in shorter training times while improving accuracy. In comparison to other methods, compared to FDSSC, SSFTT, and GAHT, our LVGG improved 0.22%, 1.06%, and 0.58% in OA and 0.04%, 1.15%, and 0.60% in Kappa, respectively. However, it did show a slightly increased overall training time compared to SSFTT.
5.2.2. PU
For the PU dataset, because we chose a training set percentage of 5%, the training data volume was relatively large. As a result, all methods yielded good results. Among these methods, GAHT and FDSSC were two models that performed well, in addition to our method. The accuracy of Class 3, Class 8, and Class 9 significantly impacted the overall OA. While our method did not perform well in classifying Class 7, it did achieve the highest accuracy in most other classes. Furthermore, the transformer-based SSFTT did not perform as well as the hybrid model GAHT, which combines transformers and CNN. This suggests that convolutional methods still performed effectively on the PU dataset. However, our method still achieved the best OA, AA, and Kappa results while also being the fastest in terms of execution time.
5.2.3. SA
For the SA dataset, we selected only 1% of the data as the training set, which led to lower classification accuracy for the SSFTT method. The low accuracy of SSFTT in classifying Class 8 and Class 15 may be due to the limited number of samples that the transformer learned, coupled with the similarity of features. When dealing with a limited number of HSI samples, there are limitations associated with transformer-based methods; possibly, these methods require a larger amount of data to learn effectively due to weaker inductive biases. In contrast, CNN-based methods tend to perform better under these conditions, and our approach outperformed all others. This could be attributed to the use of a larger patch size, allowing for a broader learning scope that works well with small datasets.
5.3. Ablation Studies
We analyzed the proposed LVGG framework by transitioning from the VGG block to the lightweight-VGG block, and conducted experiments on the IP dataset with the corresponding results summarized in
Table 7. First, the activation function of the FC layers was modified from ReLU to SELU, as SELU has self-normalizing properties and performs well in FC layers. Using SELU as the activation function for FC layers improved performance compared to the basic VGG structure.
We also improved the activation function for regular convolutions. While VGG uses ReLU as the activation function, we introduced DyReLU as an alternative to enhance the non-linearity of shallow networks. Using DyReLU as the activation function also resulted in improved accuracy.
Regarding normalization, for the IP dataset, using a large batch size with batch normalization decreased the classification accuracy, while using layer normalization improved the accuracy. Therefore, layer normalization was adopted for normalization in this proposed network.
Activation functions and normalization have an impact on network classification accuracy. Additionally, the expand convolution also contributes to improved accuracy. As we had seven channels after the whitened PCA, using only seven channels for the classification limited the overall convolutional features. Therefore, expanding the convolution before regular the convolution enhances the network’s learning ability and achieves better classification accuracy.
5.4. Parameter Analysis
We analyzed the effect of various parameters on the classification performance of our proposed lightweight-VGG method by conducting experiments using different parameter settings in the same experimental setting as described in
Section 5.1.
5.4.1. The Effectiveness of Band Selection
The criteria for determining the number of bands is to minimize it as much as possible while ensuring the accuracy of SVM. As shown in
Table 8, the highest accuracy appears when the number of selected bands is 35 on the IP dataset. In addition, when taken as 35, the number of bands and accuracy achieve a certain degree of balance on the other two HSI datasets. Therefore, 35 bands were chosen in this study.
5.4.2. The Effectiveness of PCA Size Selection
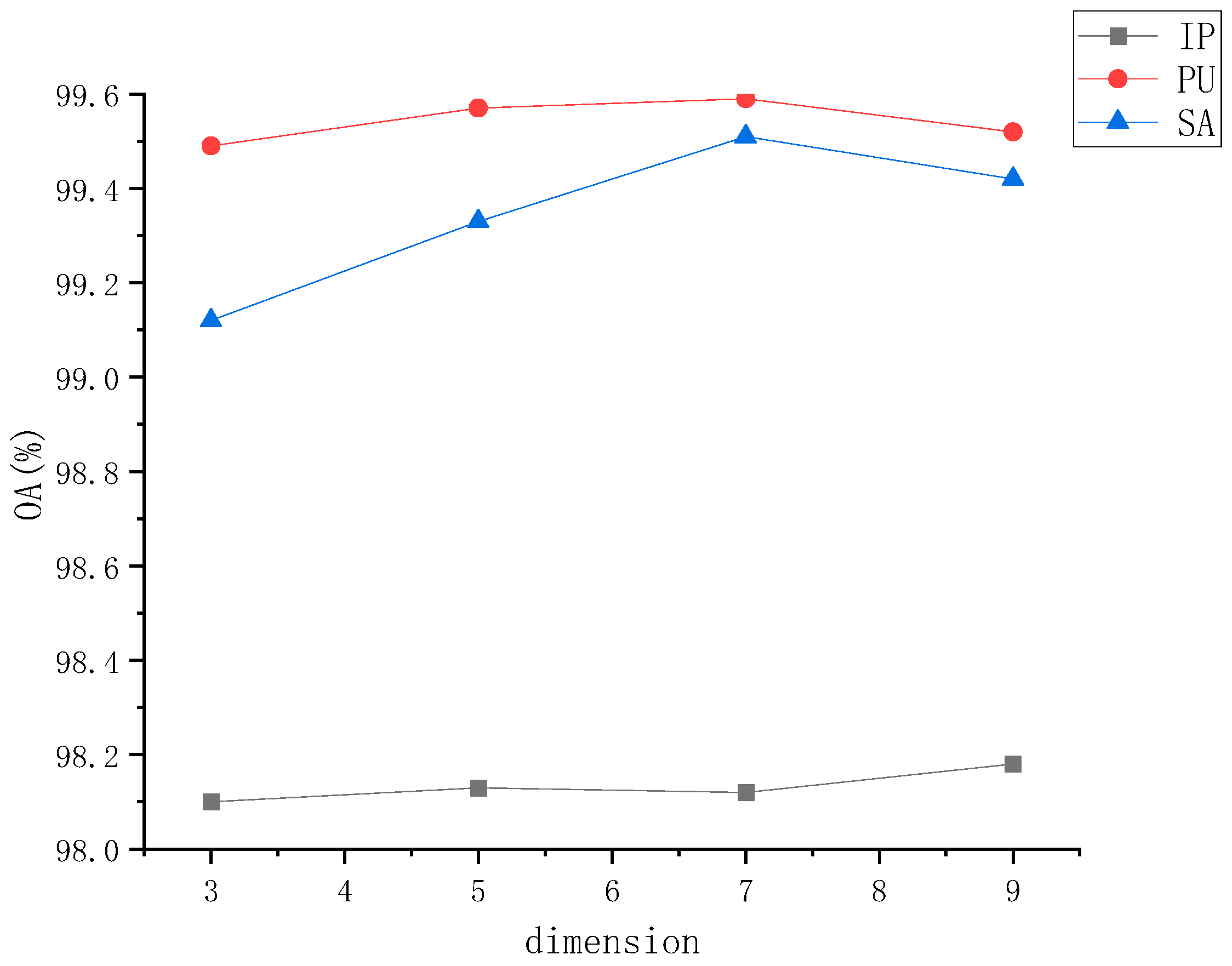
We investigated the impact of different PCA dimensions on classification performance, evaluated using overall accuracy. The purpose of PCA dimensionality reduction is to reduce the data’s dimensions, lowering computational cost and noise. By selecting an appropriate PCA dimension, noise or less significant variations can be filtered out. Lower PCA dimensions may filter out important information, while higher PCA dimensions may retain noise. Lower PCA dimensions result in higher data compression but may lead to information loss. Higher PCA dimensions retain more information but increase data dimensionality. Lower PCA dimensions typically enhance computational efficiency, as processing low-dimensional data is faster. However, in our case, we performed PCA after band selection, so setting the PCA dimensions to seven achieved outstanding performances.
As shown in
Figure 5, the results with PCA dimensions set to seven were comparable to those retaining more dimensions, indicating that band selection filtered out most of the noise, and that PCA dimensions of seven were sufficient to achieve good performance.
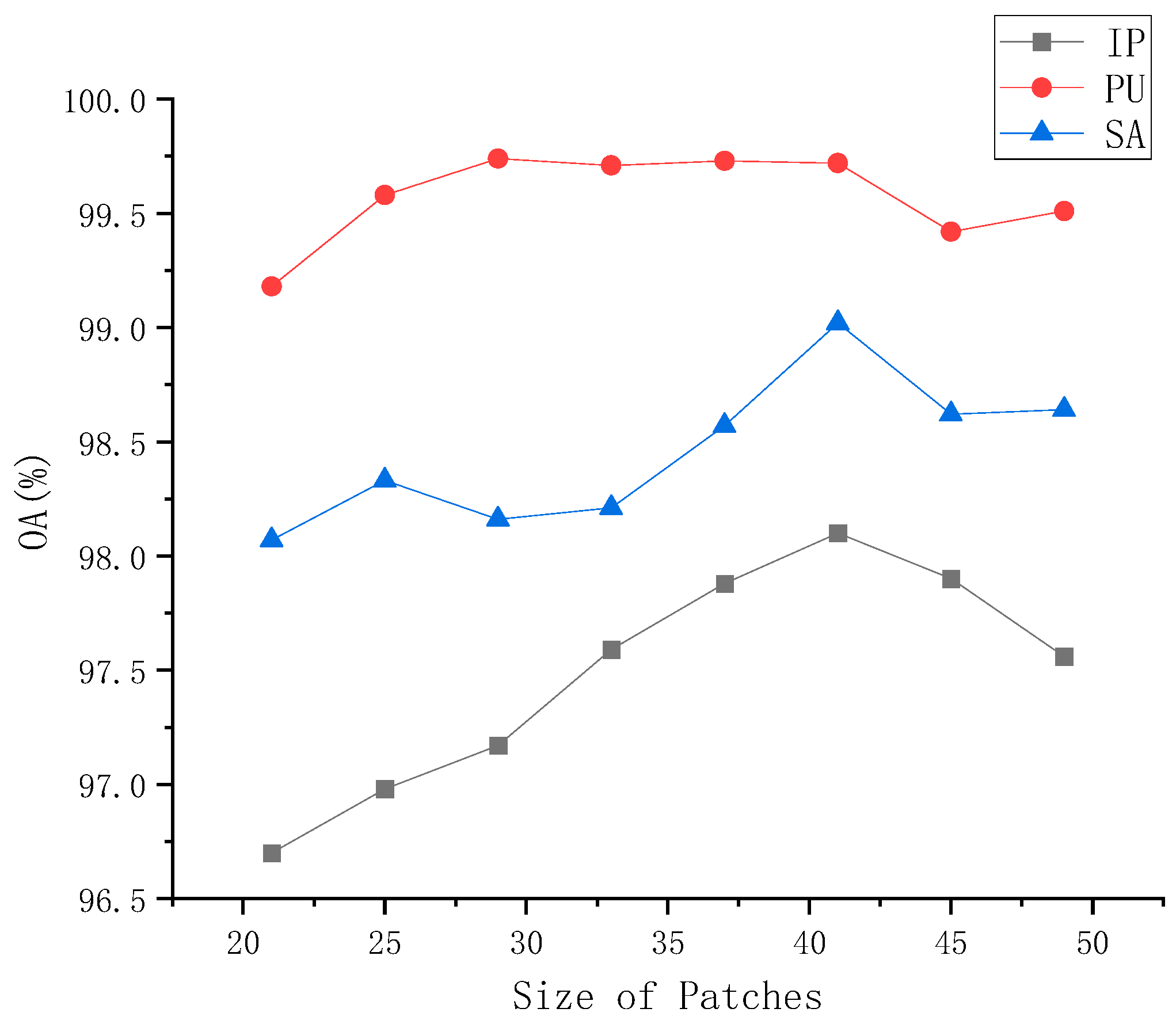
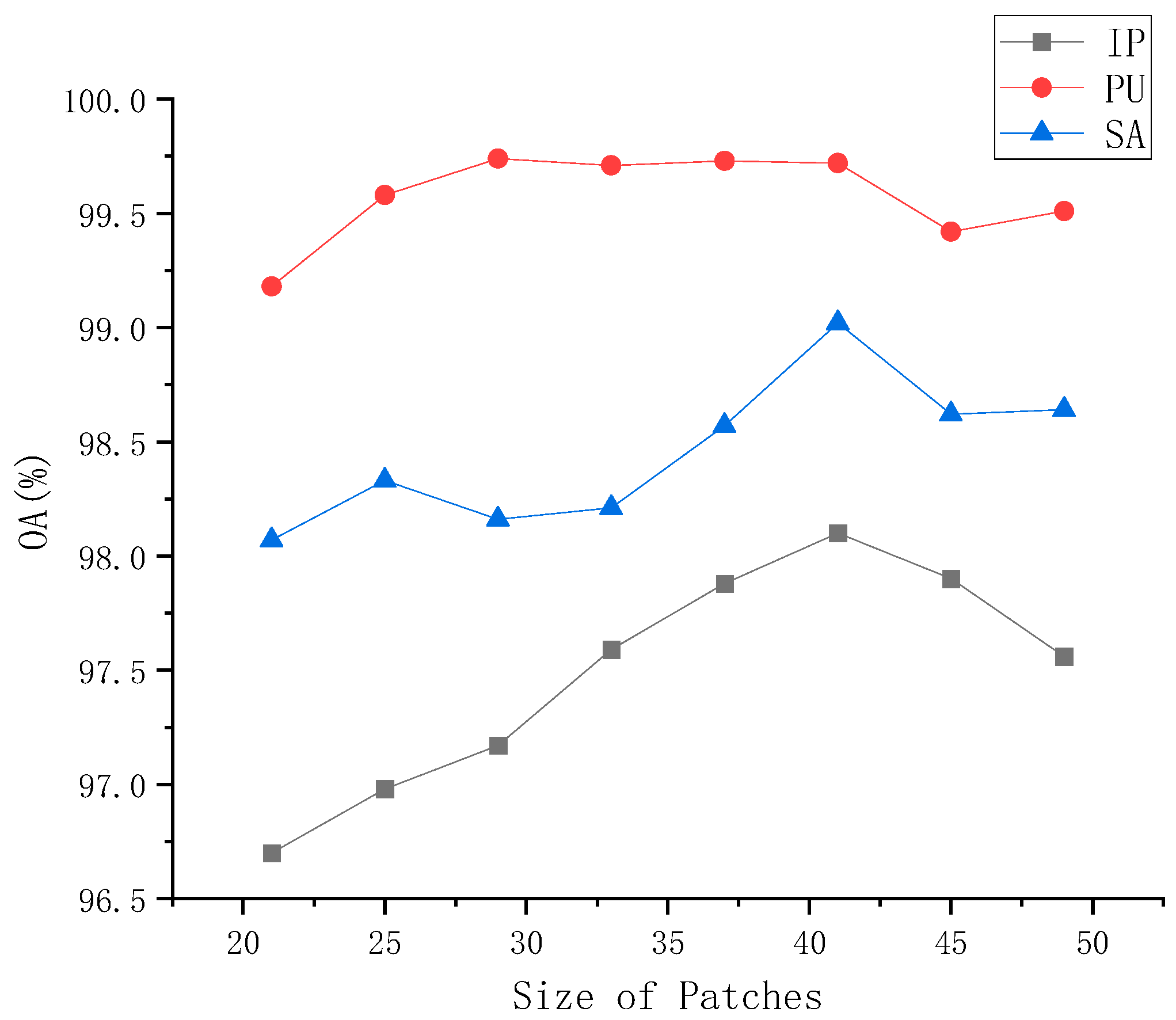
5.4.3. The Effectiveness of Patch Size Selection
We investigated the impact of different patch sizes on classification performance, which we evaluated based on overall accuracy. The patch sizes varied from 21 × 21 to 49 × 49, as shown in
Figure 6. As the patch size increased, performance initially improved and then started to decline. When the patch size was set to 41 × 41, we obtained the best performance for the IP, PU, and SA datasets, with OAs of 98.10%, 99.72%, and 99.02%, respectively. The performance of the PU dataset remained relatively stable from 21 × 21 to 49 × 49, possibly due to the high training rate of the PU dataset. However, the IP and SA datasets showed variations in performance. This may be attributed to the use of max-pooling in our method, where smaller image patches did not have sufficient representation, and overly large patches could make the overall structure too complex. Therefore, we chose a patch size of 41 × 41.
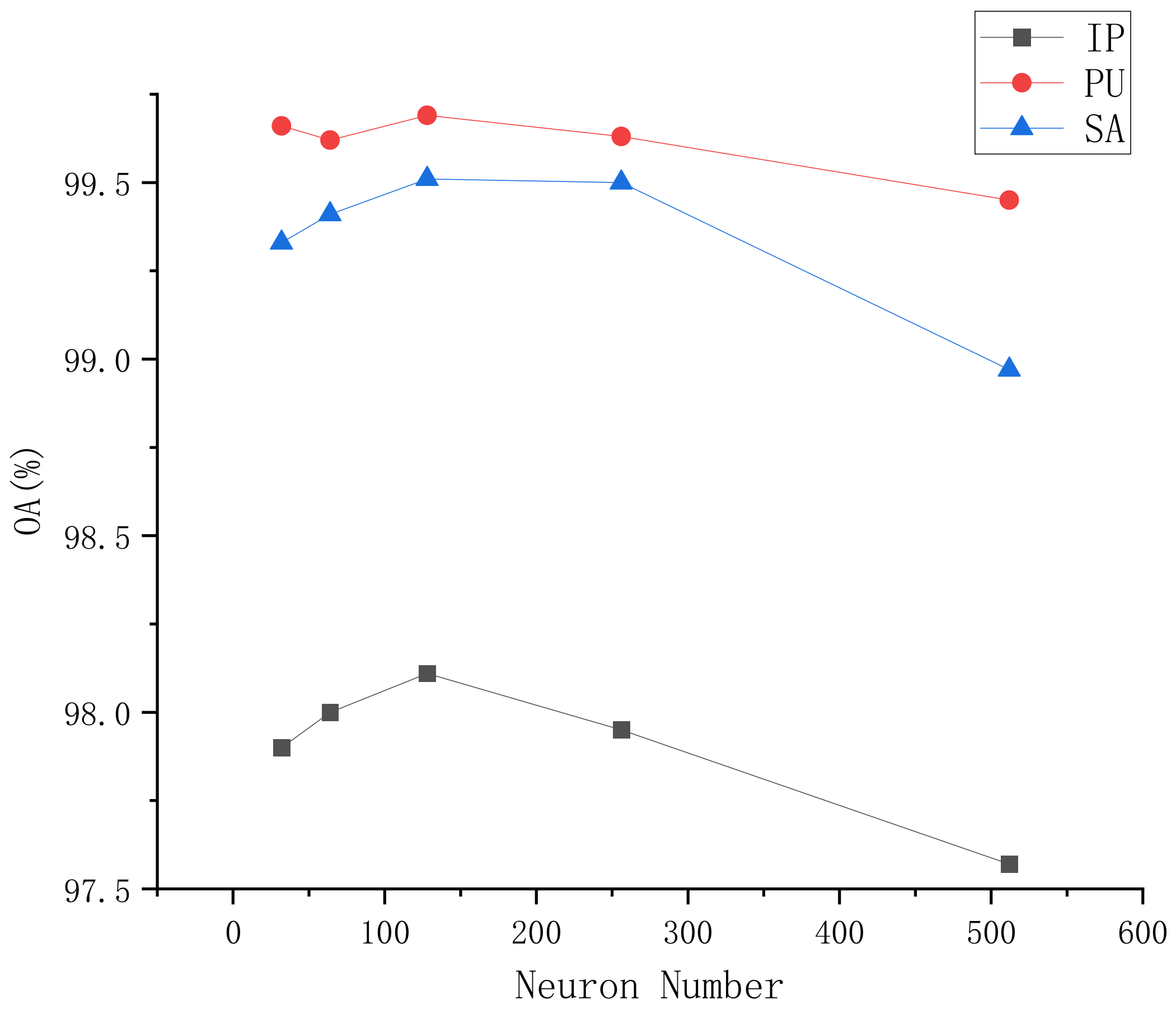
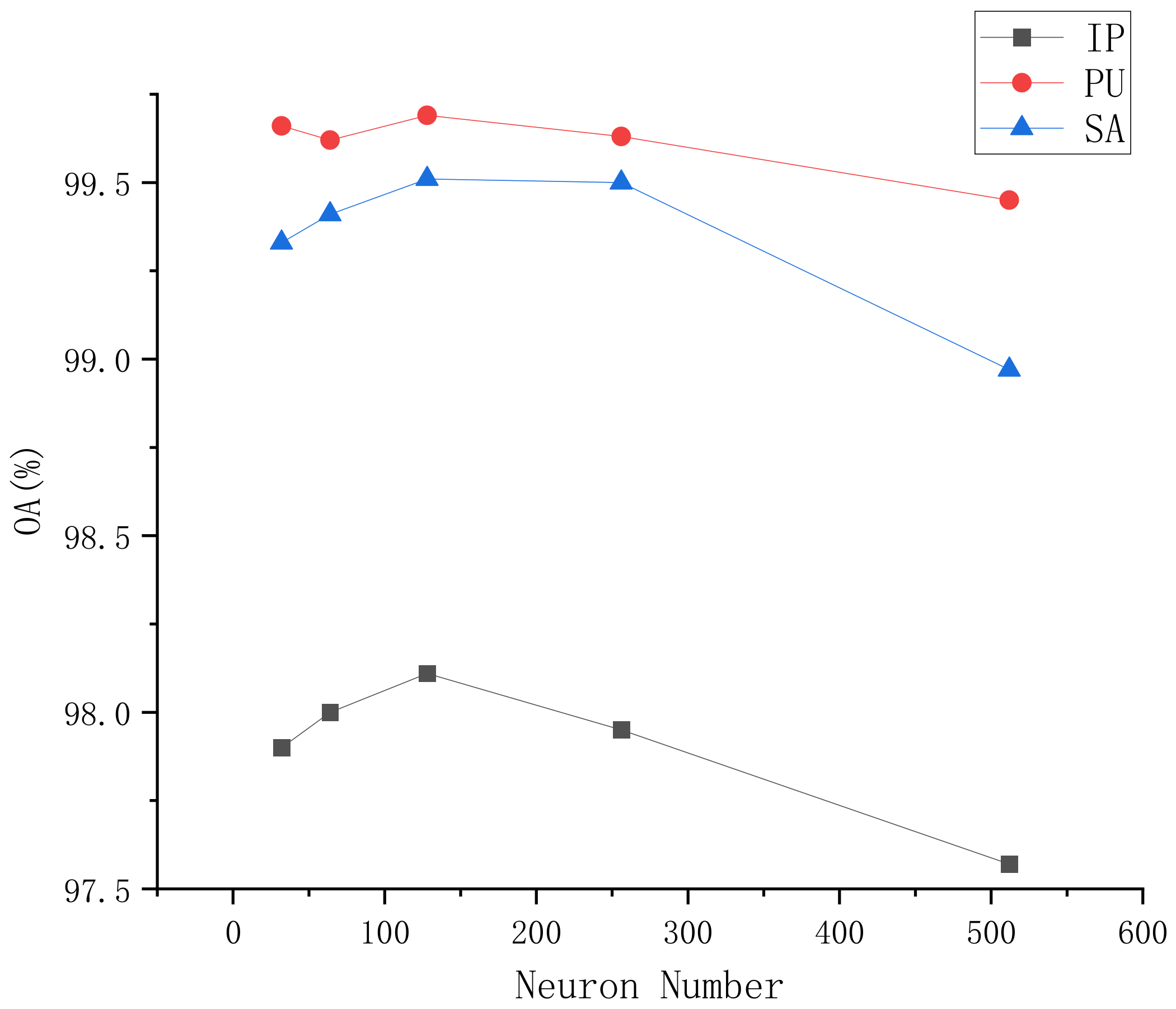
5.4.4. The Effectiveness of Neuron Number in the FC Layer
We investigated the impact of different neuron numbers in the FC layer on classification performance, evaluating based on overall accuracy. Neuron numbers ranged from 32 to 512, as shown in
Figure 7. Performance improved with an increase in neurons but began to decline thereafter. On all three datasets, the best performance was generally achieved with 128 neurons, although 64 neurons also showed good results in the SA and PU datasets.
5.5. Computational Efficiency
We also verified computational efficiency by observing the performance of these methods in terms of execution time, number of parameters, and the number of floating-point operations (FLOPs) on three HSI datasets. The statistical results are shown in
Table 9.
SSRN is a combination of 3D CNN with a ResNet structure short-circuit.
HybridSN is a network that combines 3D CNN and 2D CNN, resulting in shorter execution times. Because it uses PCA for dimensionality reduction, followed by two rounds of 3D convolution for feature extraction, and because it uses a 2D convolutional network, it results in shorter execution times compared to SSRN.
SSFTT is the fastest model in terms of execution time because it consists of only one layer of 3D CNN and one layer of 2D CNN, followed by the tokenization of features through the transformer. Due to the limited data, the transformer learns quickly. The model has the shortest training time and the least number of parameters. However, the overall accuracy is moderate.
GAHT is a method that combines transformers with CNN, so the overall execution time is similar as well. Although it has the lowest FLOPs, its execution time is not very short due to the involvement of group convolutions.
FDSSC is the most time-consuming CNN network because it involves reconstruction and feature extraction using complex 3D CNN. The high time complexity of 3D CNN results in the longest overall execution time.
DBDA employs dense 3D CNN for learning, much like FDSSC. However, it does not have the reconstruction step that FDSSC has, which significantly reduces its execution time.
In comparison to these methods, our proposed LVGG method has a short execution time because it only utilizes 1 × 1 and 3 × 3 2D convolutions. Its FLOPs are relatively low, but due to a relatively larger number of parameters compared to transformer methods, its runtime is somewhat longer than those of transformer-based approaches.
6. Conclusions
This study proposes a lightweight-VGG approach to improve HSI classification speed and accuracy. In this context, we introduce a method that performs PCA after selecting bands for classification. Most existing works either directly use raw images or apply PCA with a large number of retained dimensions, which can introduce noise and be sensitive to random seeds. Additionally, many transformer-based classification methods involve complex and computationally expensive operations, yet they do not achieve high accuracy in HSI classification. In contrast, our proposed LVGG approach reduces the number of parameters in the fully connected layers, resulting in a faster processing speed while maintaining high classification accuracy.
By performing PCA on the data after selecting the bands, and then conducting network classification, our proposed method provides improved stability and speed. Moreover, its smaller parameter size allows for faster processing, making it suitable for deployment on lightweight devices. Quantitative experiments using three HSI datasets showed that our LVGG approach outperformed existing methods in both performance and speed.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}